Learning Transferable Visual Models From Natural Language Supervision
CLIP:Encoders bridge vision and language
- CLIP text-/image-embeddings are commonly used in diffusion models for conditional generation
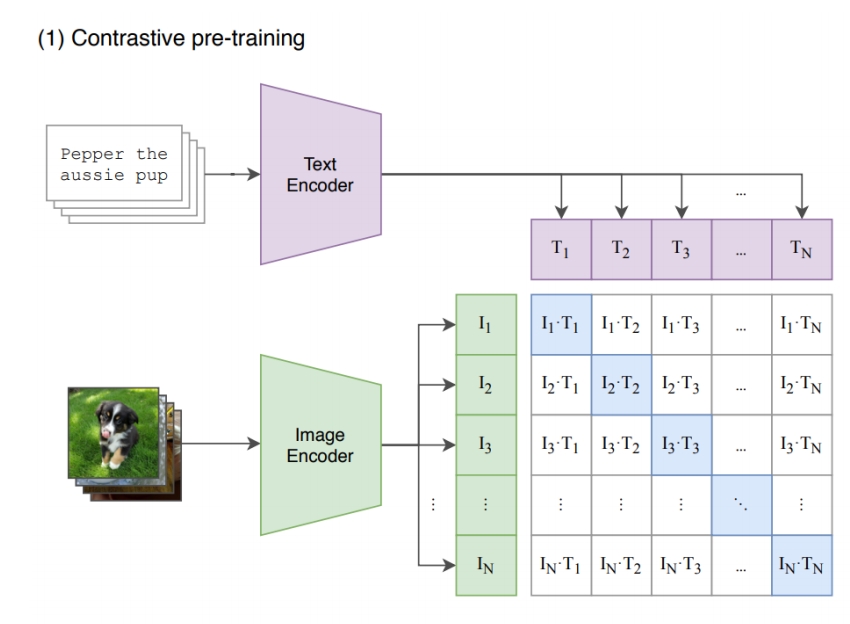
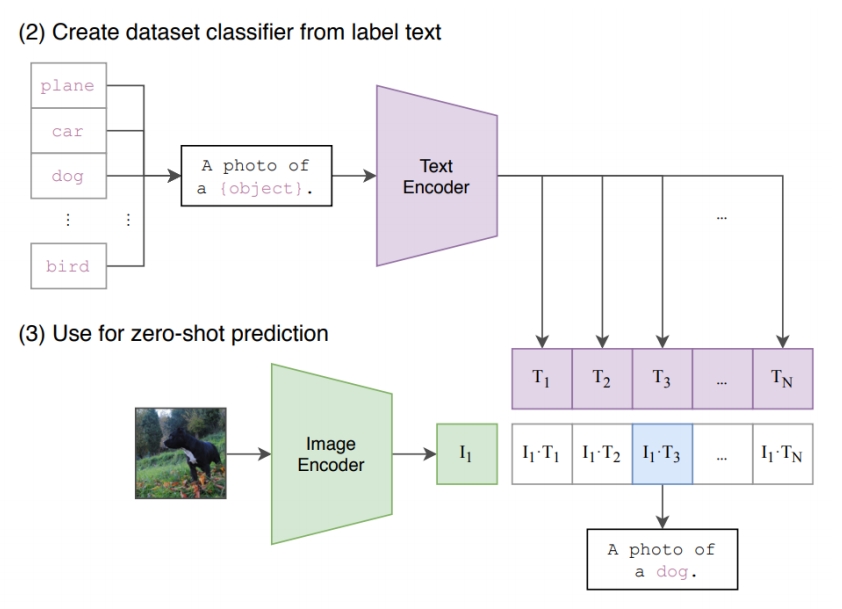
❓ 文本条件怎么输入到 denoiser?
✅ CLIP embedding:202 openai,图文配对训练用 CLIP 把文本转为 feature.