DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning
DeepLoco:使用分层深度强化学习的动态移动技能
论文详解文档
目录
1. 基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning |
| 中文译名 | DeepLoco:使用分层深度强化学习的动态移动技能 |
| 发表会议 | ACM Transactions on Graphics (TOG) 2017 (SIGGRAPH) |
| 作者单位 | 英属哥伦比亚大学、新加坡国立大学 |
| 主要作者 | Xue Bin Peng, Glen Berseth, KangKang Yin, Michiel van de Panne |
2. 核心问题:这篇论文要解决什么问题?
2.1 背景故事
想象一下你想让一个 3D 虚拟角色(比如游戏里的人物)在复杂的环境中行走:
- 需要沿着一条弯弯曲曲的小路走
- 需要绕过障碍物
- 需要一边走路一边踢足球
- 需要在有移动障碍物的环境中穿行
问题:如何让角色学会这些复杂的移动技能?
2.2 现有方法的局限性
方法 A:有限状态机 (FSM) + 反馈控制
传统方法:人工设计状态机
- 状态 1:抬腿
- 状态 2:向前迈步
- 状态 3:放下腿
- ...
局限性:
- 需要大量人工设计
- 不够灵活,遇到新情况就失效
- 动作看起来比较僵硬
方法 B:纯强化学习(端到端)
让 AI 自己从零开始学
局限性:
- 3D 双足行走本身就很难学
- 直接学复杂任务(如绕障碍 + 踢球)几乎不可能
- 学习速度慢,容易失败
2.3 DeepLoco 的解决方案
核心思想:分层控制
┌─────────────────────────────────────┐
│ 高层控制器 (HLC) │
│ High-Level Controller │
│ 频率:2Hz(每 0.5 秒决策一次) │
│ 任务:规划步法、导航 │
└──────────────┬──────────────────────┘
│ 输出:步法计划
▼
┌─────────────────────────────────────┐
│ 低层控制器 (LLC) │
│ Low-Level Controller │
│ 频率:30Hz(每 0.033 秒执行一次) │
│ 任务:保持平衡、执行动作 │
└──────────────┬──────────────────────┘
│ 输出:关节角度
▼
┌─────────────┐
│ 角色模型 │
└─────────────┘
为什么分层?
- 高层:像人的"大脑",负责想"我要往哪走"
- 低层:像人的"小脑",负责想"怎么保持平衡迈腿"
2.4 这篇论文的贡献
- 环境感知的 3D 双足行走:角色可以看着地形图来决定怎么走
- 多种行走风格:可以学习正常走、高抬腿走、弯腿走等多种风格
- 强大的鲁棒性:可以承受一定的外力推挤、上下坡
- 复杂任务能力:学会踢足球、绕障碍等复杂技能
3. 基础知识铺垫
强化学习基础:如需了解强化学习的完整数学框架(MDP、贝尔曼方程、价值函数等),请参考 DeepLearningNotes - 强化学习基础
3.1 强化学习 (Reinforcement Learning) 基础
强化学习就像训练小狗:
状态 (State) → 动作 (Action) → 奖励 (Reward)
比如训练小狗捡球:
- 状态:球在哪里,小狗在哪里
- 动作:跑、跳、咬
- 奖励:捡到球 +1 分,摔倒 -1 分
目标:学会最大化奖励的动作
3.2 策略梯度 (Policy Gradient)
策略 π:状态 → 动作的映射规则
策略梯度方法:
- 让角色尝试各种动作
- 如果某个动作带来好结果,就增加这种动作的概率
- 如果带来坏结果,就减少这种动作的概率
3.3 Actor-Critic 方法
Actor (演员):负责做动作
Critic (评论家):负责评价动作好不好
工作流程:
1. Actor 做一个动作
2. Critic 评价这个动作值多少分
3. 如果评价好,强化这个动作;否则弱化
3.4 CACLA 算法
论文用的是 CACLA 算法的改进版本:
CACLA (Continuous Actor-Critic Learning Automaton)
核心思想:
- 只有当动作带来"比预期更好"的结果时,才学习
- 用"时间差分"来评估好坏
公式:
δ = r + γV(s') - V(s)
如果 δ > 0:说明动作比预期好,学习它!
如果 δ ≤ 0:说明动作不如预期,不学习
4. DeepLoco 方法的核心思想
4.1 整体架构
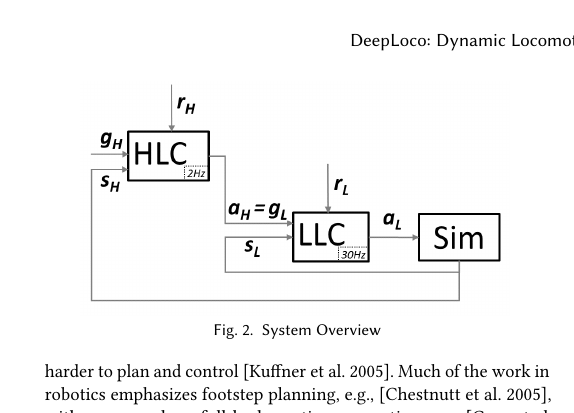
Figure 1. DeepLoco 系统概述:高层控制器 (HLC) 以 2Hz 频率规划步法,低层控制器 (LLC) 以 30Hz 频率执行关节控制,物理模拟以 3kHz 频率运行。
图示说明:DeepLoco 系统分为两层 — HLC(2Hz)看地形、做决策、规划步法;LLC(30Hz)看状态、执行动作、控制关节;物理模拟(3000Hz)计算碰撞、受力。
┌──────────────────────────────────────────────────────┐
│ DeepLoco 系统 │
├──────────────────────────────────────────────────────┤
│ │
│ 输入:地形图 + 角色状态 + 任务目标 │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 高层控制器 │ 2Hz │
│ │ (HLC) │ 输出:下一步踩哪里 │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 低层控制器 │ 30Hz │
│ │ (LLC) │ 输出:关节角度 │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 物理模拟 │ 3000Hz │
│ └─────────────────┘ │
│ │
└──────────────────────────────────────────────────────┘
4.2 为什么这样设计?
时间尺度分离
| 控制器 | 频率 | 时间尺度 | 负责什么 |
|---|---|---|---|
| HLC | 2Hz | 0.5 秒 | 规划步法(像下棋,一步一想) |
| LLC | 30Hz | 0.033 秒 | 执行动作(像反射,快速响应) |
| 物理 | 3000Hz | 0.00033 秒 | 物理计算(保证稳定性) |
好处
1. 高层可以专注"大局":往哪走、绕什么路
2. 低层可以专注"细节":怎么迈步、怎么平衡
3. 同一个低层控制器可以被多个高层任务复用
4. 学习更高效:高低层分开学,比一起学容易
5. 技术细节详解
5.1 低层控制器 (LLC) 详解
LLC 的职责
协调关节运动,模仿参考动作的风格,同时满足步法目标并保持平衡
LLC 的输入(状态空间,110 维)
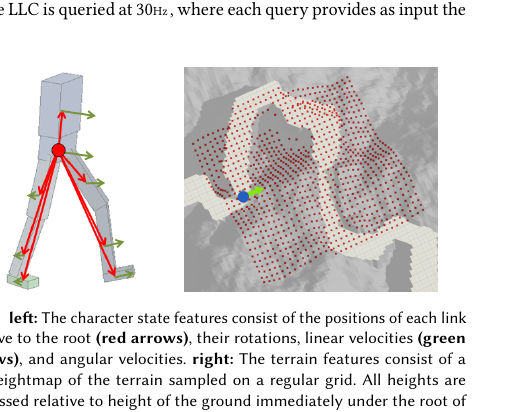
Figure 2. 角色状态特征(左):每个连杆相对于根节点的位置(红箭头)、旋转、线速度(绿箭头)和角速度。地形特征(右):32x32 规则网格采样的高度图。
图示说明:LLC 输入状态包括角色各部位的位置、旋转、线速度、角速度,以及地形高度图。
┌────────────────────────────────────────┐
│ LLC 输入状态 s_L │
├────────────────────────────────────────┤
│ • 身体各部位位置(相对于骨盆) │
│ • 身体各部位旋转(四元数) │
│ • 身体各部位线速度 │
│ • 身体各部位角速度 │
│ • 双脚接触地面标志(1=接触,0=悬空) │
│ • 相位变量 φ ∈ [0,1](表示步态周期) │
└────────────────────────────────────────┘
总维度:110 维
相位变量是什么?
相位变量 φ 用来跟踪"现在走到哪一步了"
一个完整的步态周期 = 1 秒
- φ = 0.0:左脚刚落地
- φ = 0.25:左脚支撑中期
- φ = 0.5:右脚刚落地
- φ = 0.75:右脚支撑中期
- φ = 1.0:回到左脚落地
作用:让控制器知道"现在应该做什么"
LLC 的目标(步法计划)
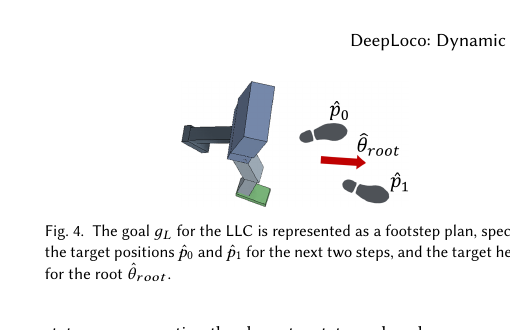
Figure 3. LLC 的目标 g_L 表示为步法计划,指定下一步和下下一步的目标位置 p̂₀, p̂₁,以及根节点的目标朝向 θ̂_root。
图示说明:LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root) — 下一步位置、下下一步位置、身体朝向。研究证明"两步就够了"。
LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root)
p̂₀:下一步的目标位置(2D)
p̂₁:下下一步的目标位置(2D)
θ̂_root:身体的目标朝向
为什么是两个步子?
- 研究证明"两步就够了"(Zaytsev et al. 2015)
- 只看一步:太短视
- 看三步以上:计算太复杂,收益不大
LLC 的输出(动作空间,22 维)
LLC 动作 a_L = 每个关节的 PD 目标角度
角色模型:
- 每条腿:3 个关节(髋、膝、踝)
- 髋关节:3 自由度(球窝关节)
- 膝关节:1 自由度
- 踝关节:3 自由度
- 腰部:3 自由度
总关节自由度:22 个
输出:每个关节的目标角度(轴角表示,4 维)
5.2 参考动作 (Reference Motion)
什么是参考动作?
参考动作是"样本动作",告诉 LLC"应该是什么风格"
可以是:
1. 手工 keyframe 动画(一个简单的走路循环)
2. 动作捕捉数据(真人走路的录像)
DeepLoco 用了:
- 1 个手工制作的平面走路循环
- 10 个动作捕捉片段(约 7 秒的走路和转身数据)
如何使用参考动作?
LLC 不需要精确跟踪参考动作,只需要"模仿风格"
比如参考动作是"军人走路":
- LLC 学会"抬头挺胸、步伐有力"的风格
- 但可以根据需要调整步幅、方向
这样做的好处:
- 灵活:可以适应不同的步法目标
- 鲁棒:参考动作不完美也没关系
动作选择机制
当有多个参考动作时(比如左转、右转、直行):
1. 提取每个动作的特征:
ψ(q̂ⱼ) = (支撑脚位置,摆动脚位置,身体朝向)
2. 根据当前目标和状态,选择最匹配的动作:
K(s, g_L) = argmin ||ψ(s, g_L) - ψ(q̂ⱼ)||
3. 选中的动作用来指导这一步的奖励函数
参考动作的使用方式(重要)
参考动作 不直接作为网络输入,而是通过 奖励函数 间接引导学习。
- 根据状态 s 和目标 g_L,从参考动作库选择一个动作 q̂
- 用 q̂ 计算奖励:
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)²)
r_vel = exp(-Σᵢ wᵢ·d(q̂̇ᵢ(t), q̇ᵢ)²) - 网络通过最大化奖励,间接学会模仿参考动作的风格
为什么这样设计?
- 灵活:可以适应不同的步法目标,不必精确跟踪
- 鲁棒:参考动作不完美也没关系,只需提供"风格参考"
- "风格模仿"而非"动作复制"
参考动作质量的影响
DeepLoco 对参考动作质量要求较低,具有较好的鲁棒性:
| 参考动作问题 | DeepLoco 的影响 | 原因 |
|---|---|---|
| mocap 数据有噪声 | 较小 | r_end、r_com 等任务项可以平衡 |
| 关键帧动画僵硬 | 较小 | 可自适应调整,牺牲姿势相似度 |
| 片段较短 | 中 | 需要足够覆盖步态周期 |
| 风格不适合任务 | 中 | 可优先完成任务 |
| 完全无参考动作 | 完全学不会走路 | 没有引导信号 |
实验结果(论文 Section 6.1):
- 10 个 mocap 片段:学习最快,最终性能最好
- 1 个 hand-authored 片段:可以学会走路,但转弯较差
- 没有参考动作:完全学不会走路
核心原因:
r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading
↑ ↑ ↑
模仿项 任务项 任务项
r_pose 只占 0.5,当与任务冲突时可以牺牲
→ 参考动作只是"风格参考",不是"必须遵循的轨迹"
工程建议:
- 参考动作质量不高时,DeepLoco 仍能学到功能正常的步态
- 但"风格"可能带有参考动作的痕迹
- 建议至少使用 1 个合理的走路循环作为参考
为什么是"风格模仿"而非"动作复制"?
虽然 r_pose 确实在鼓励关节角度接近参考动作,但 DeepLoco 与后续的 DeepMimic(2018)有本质区别:
| 对比维度 | DeepLoco(风格模仿) | DeepMimic(动作复制) |
|---|---|---|
| 目标 | 模仿风格 + 完成步法任务 | 精确复现动作轨迹 |
| r_pose 权重 | 0.5 | 更高(主要目标) |
| r_end 权重 | 0.2(重要) | 很低或没有 |
| 参考动作作用 | 提供姿势参考 | 提供完整轨迹 |
| 灵活性 | 高(可修改落脚点) | 低(必须踩对位置) |
关键原因:
-
r_pose 只是总奖励的一部分
- r_end(落脚点)占 0.2 — 为了踩到 HLC 指定的目标位置,可以牺牲姿势相似度
- 当 r_pose 和 r_end 冲突时,网络会权衡取舍
-
相位变量 φ 是独立递增的
- φ 按时间递增(每步 1 秒),不从参考动作中提取
- 角色可以走得快或慢,只要姿势"像"就行
-
参考动作可以动态切换
- 每一步都可以从多个参考动作中选一个最匹配的
- 不是固定跟踪某一个完整序列
设计效果:
- 角色可以用"军人走路"的风格,但走到任意目标位置
- 可以用"高抬腿"风格,同时绕过障碍物
- 学的是"怎么走的样子",不是"具体怎么走"
5.3 LLC 奖励函数
奖励函数告诉 LLC"什么是好的行为":
r_L = w_pose·r_pose + w_vel·r_vel + w_root·r_root
+ w_com·r_com + w_end·r_end + w_heading·r_heading
权重:(0.5, 0.05, 0.1, 0.1, 0.2, 0.1)
各项奖励含义
| 奖励项 | 含义 | 作用 |
|---|---|---|
| r_pose | 姿势奖励 | 关节角度接近参考动作 |
| r_vel | 速度奖励 | 关节速度接近参考动作 |
| r_root | 骨盆高度奖励 | 保持合适的身体高度 |
| r_com | 质心速度奖励 | 保持合适的移动速度 |
| r_end | 落脚点奖励 | 脚落在目标位置 |
| r_heading | 朝向奖励 | 身体朝向正确方向 |
姿势奖励公式
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)²)
d(·,·):计算两个四元数的距离
wᵢ:每个关节的权重
含义:
- 实际姿势 qᵢ 越接近参考姿势 q̂ᵢ,奖励越高
- exp 函数确保奖励在 [0,1] 范围内
- 距离为 0 时,奖励 = 1(完美)
- 距离越大,奖励越接近 0
5.4 双线性相位变换 (Bilinear Phase Transform)
问题
只用一个标量相位 φ 有什么问题?
实验发现:
- 网络不能很好地区分不同的相位
- 导致"拖脚"现象(脚没有抬够高)
为什么?
- 单个数值 φ 对神经网络来说不够明显
- 网络不容易学会"不同相位做不同事"
解决方案:双线性相位变换
1. 把相位 φ 分成 4 个区间:
Φ₀ = 1 当 0 ≤ φ < 0.25
Φ₁ = 1 当 0.25 ≤ φ < 0.5
Φ₂ = 1 当 0.5 ≤ φ < 0.75
Φ₃ = 1 当 0.75 ≤ φ < 1
2. 计算外积:
[s_L] [s_L] [s_L] [s_L] [s_L]
[g_L] × Φ = [Φ₀·g_L], [Φ₁·g_L], [Φ₂·g_L], [Φ₃·g_L]
效果
变换后的特征:
- 只有当前相位对应的特征块是"激活"的
- 其他特征块都是 0
好处:
- 强制网络在不同相位使用不同的"子网络"
- 相当于给网络植入了"不同阶段做不同事"的先验
- 显著改善步态质量,减少拖脚现象
5.5 LLC 网络结构
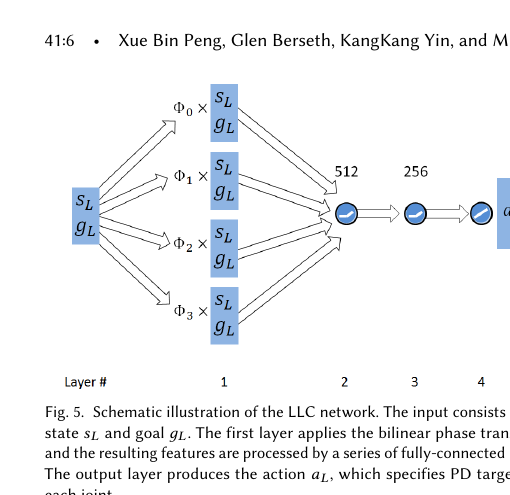
Figure 4. LLC 网络结构示意图。输入为状态 s_L 和目标 g_L。第一层应用双线性相位变换,所得特征经全连接层处理。输出层产生动作 a_L,指定每个关节的 PD 目标。
图示说明:LLC 网络结构 — 输入层应用双线性相位变换,经 FC(512)→FC(256) 处理,输出动作均值。参数量约 50 万。
LLC 神经网络:
输入层:s_L + g_L (状态 + 目标)
↓
第 1 层:双线性相位变换 → 特征维度扩展
↓
第 2 层:全连接层,512 单元,ReLU 激活
↓
第 3 层:全连接层,256 单元,ReLU 激活
↓
输出层:线性层 → 动作均值 μ(s_L, g_L)
参数量:约 50 万
5.6 风格修改 (Style Modification)
通过在奖励函数中添加风格项,可以让 LLC 学会不同的行走风格:
风格奖励通用公式
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)² - w_style·c_style)
c_style:风格项(人工设计的规则)
w_style:风格权重(训练超参数,控制"像参考动作"vs"满足风格"的平衡)
注意:
- c_style 是人工设计的规则,不是从数据中学的
- 每个风格项针对特定关节或特定变量
- 风格奖励只在训练特殊风格时使用,基础 LLC(正常行走)不使用
- 风格 loss 是可选项:训练正常行走时 w_style = 0,训练特殊风格时 w_style > 0
支持的风格
| 风格 | 风格项 c_style | 效果 |
|---|---|---|
| 前倾行走 | d(q̂_waist, q_waist)² | 身体向前倾斜 |
| 侧倾行走 | d(q̂_waist, q_waist)² | 身体向侧面倾斜 |
| 直腿行走 | d(q_I, q_knee)² | 膝盖不弯曲 |
| 高抬腿 | (ĥ_knee - h_knee)² | 抬腿更高 |
| 原地行走 | 使用原地点参考动作 | 在原地踏步 |
风格插值
如果有两个风格的 LLC:π_La 和 π_Lb
可以线性插值得到新风格:
π_Lc(s, g) = (1-u)·π_La(s, g) + u·π_Lb(s, g)
u ∈ [0, 1]:插值系数
- u = 0:纯风格 a
- u = 0.5:a 和 b 的中间风格
- u = 1:纯风格 b
效果:可以在不同风格之间平滑过渡
关键理解:
- 一个 LLC = 一种确定的风格(训练时由 w_style + c_style 决定)
- 风格是在训练时确定的,推理时无法改变
- 想换风格:要么重新训练新 LLC,要么对已有 LLC 进行插值
5.7 高层控制器 (HLC) 详解
HLC 的职责
提供中间目标给 LLC,以实现高层任务目标(如导航、避障、踢球)
HLC 的输入(状态空间,1129 维)
┌────────────────────────────────────────┐
│ HLC 输入状态 s_H │
├────────────────────────────────────────┤
│ 身体特征 C (类似 LLC 状态,但没有相位和接触标志) │
│ 地形特征 T (32×32 高度图) │
│ 任务目标 g_H │
└────────────────────────────────────────┘
地形图:
- 分辨率:32×32
- 覆盖范围:约 11m×11m
- 向前延伸 10m,向后延伸 1m
- 高度值相对于角色当前位置
地形图示例
角色看到的"高度图"就像这样(俯视):
← 11m →
┌─────────┐ ↑
│ ░░░▓▓░░░│ │
│ ░░▓▓▓▓░░│ 11m
│ ░░░▓▓░░░│ │
│ ░░░░▒░░░│ ↓
└─────────┘
图例:
░ = 平地
▓ = 障碍物(高)
▒ = 路径(目标方向)
HLC 的输出
HLC 动作 a_H = LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root)
即:HLC 决定"下一步踩哪里",LLC 负责"怎么走到那里"
5.8 HLC 网络结构
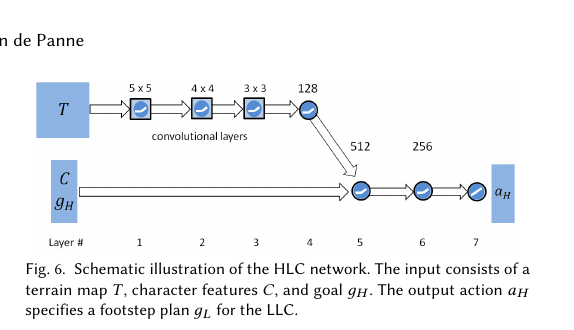
Figure 5. HLC 网络结构示意图。输入包括地形图 T、角色特征 C 和目标 g_H。输出动作 a_H 指定给 LLC 的步法计划 g_L。
图示说明:HLC 使用 CNN 处理地形图(32×32),经三层卷积(16→32→32 滤波器)和 FC(128) 后,与身体特征、任务目标拼接,再经 FC(512)→FC(256) 输出动作。参数量约 250 万。

Figure 6. 32×32 高度图示例,覆盖 11×11 米区域。左:路径;中:柱子障碍;右:方块障碍。
图示说明:HLC 输入的地形图是 32×32 高度图,覆盖 11×11 米区域,向前延伸 10m,向后延伸 1m。
HLC 卷积神经网络:
输入:
- 地形图 T:32×32
- 身体特征 C
- 任务目标 g_H
↓
卷积层 1:16 个 5×5 滤波器
↓
卷积层 2:32 个 4×4 滤波器
↓
卷积层 3:32 个 3×3 滤波器
↓
全连接层:128 单元
↓
拼接:[地形特征,C, g_H]
↓
全连接层 1:512 单元,ReLU
↓
全连接层 2:256 单元,ReLU
↓
输出层:线性层 → 动作 a_H
参数量:约 250 万
5.9 HLC 任务
任务 1:路径跟随 (Path Following)
目标:沿着岩石地形上的狭窄路径行走
环境:
- 路径宽度:1-2 米
- 地形用 Perlin 噪声生成
- 目标点随机出现在路径上
输入:
- 地形图(可以看到路径)
- 到目标的方向和距离
奖励:
r_H = exp(-min(0, u_tar·v_com - v̂_com)²)
含义:鼓励角色以至少 1m/s 的速度向目标移动
任务 2:足球运球 (Soccer Dribbling)
目标:把足球带到目标位置
挑战:
- 需要先走到球旁边
- 然后用脚控制球向目标移动
- 到达目标后要"停球"
输入(15 维):
- 目标方向/距离
- 球的方向/距离/高度/速度/角速度
- (没有地形图,因为是平地)
奖励:
r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp
各项含义:
- r_cv:角色走向球
- r_cp:角色靠近球
- r_bv:球向目标移动
- r_bp:球靠近目标
任务 3:柱子障碍 (Pillar Obstacles)
目标:穿过密集的柱子障碍物到达目标
环境:
- 障碍物:0.75m×0.75m 底座,高 2-8 米
- 随机放置
- 有很多可能的路径
奖励:同路径跟随
任务 4:方块障碍 (Block Obstacles)
目标:绕过大方块障碍物到达目标
环境:
- 障碍物:0.5m-7m 的方块
- 需要找到可行的路径
奖励:同路径跟随
任务 5:动态障碍 (Dynamic Obstacles)
目标:在移动障碍物中穿行到达目标
环境:
- 障碍物以 0.2-1.3 m/s 的速度来回移动
- 角色最大速度约 1 m/s
- 环境动态变化
输入:
- 速度图(而不是高度图)
- 每个点记录障碍物的 2D 速度
奖励:同路径跟随
5.10 MDP 定义总结(S、A、P、R)
LLC(低层控制器,30Hz)
| 要素 | 定义 | 维度 |
|---|---|---|
| S_L (状态) | • 身体各部位位置/旋转/线速度/角速度(相对于骨盆) • 双脚接触地面标志 • 相位变量 φ ∈ [0,1] | 110 维 |
| A_L (动作) | 每个关节的 PD 目标角度(轴角表示) | 22 维 |
| R_L (奖励) | r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading | - |
| P (动力学) | 物理模拟器(3000Hz),未显式建模,通过采样学习 | - |
奖励各项含义:
- r_pose:关节角度接近参考动作
- r_vel:关节速度接近参考动作
- r_root:骨盆高度奖励
- r_com:质心速度奖励
- r_end:脚落在目标位置
- r_heading:身体朝向正确方向
HLC(高层控制器,2Hz)
| 要素 | 定义 | 维度 |
|---|---|---|
| S_H (状态) | • 身体特征 C(类似 LLC 状态,无相位和接触标志) • 地形特征 T(32×32 高度图) • 任务目标 g_H | 1129 维 |
| A_H (动作) | LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root) — 下一步位置、下下一步位置、身体朝向 | 5 维 (2+2+1) |
| R_H (奖励) | 路径跟随:r_H = exp(-min(0, u_tar·v_com - v̂_com)²) 运球:r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp | - |
| P (动力学) | 物理模拟器 + LLC 的动态响应,未显式建模 | - |
5.11 训练策略
分层训练流程
Step 1:训练 LLC
- 固定步法目标(随机生成)
- 学习走路和保持平衡
- 训练约 600 万次迭代(2 天,16 核 CPU)
Step 2:训练 HLC
- 冻结 LLC 权重(不再更新)
- 学习给 LLC 下达正确的步法指令
- 训练约 100 万次迭代(7 天,CPU)
为什么分开训练?
- LLC 先学会"怎么走"
- HLC 再学会"往哪走"
- 同一个 LLC 可以被多个 HLC 复用
训练超参数
| 参数 | LLC | HLC |
|---|---|---|
| 批次大小 m | 32 | 32 |
| 经验回放大小 | 50k | 50k |
| 学习率(Critic) | 0.01 | 0.01 |
| 学习率(Actor) | 0.001 | 0.001 |
| 折扣因子 γ | 0.95 | 0.95 |
| 探索率 ε | 1→0.2 | 1→0.5 |
| 探索衰减 | 1M 迭代 | 200k 迭代 |
经验回放 (Experience Replay)
记录角色经历过的每一步:
τ = (s, g, a, r, s', λ)
s:开始状态
g:目标
a:动作
r:奖励
s':结束状态
λ:是否加了探索噪声
训练时:
- 从回放内存中随机采样 32 个经验
- 用这些经验更新网络
- 好处:打破数据相关性,提高样本效率
5.12 鲁棒性分析
抗干扰能力
| LLC 风格 | 向前推 | 向侧推 | 上坡 | 下坡 |
|---|---|---|---|---|
| 正常行走 | 200N | 210N | 16% (9.1°) | 11% (6.3°) |
| 高抬腿 | 140N | 190N | 9% (5.1°) | 5% (2.9°) |
| 直腿 | 150N | 180N | 12% (6.8°) | 6% (3.4°) |
| 双腿直 | 90N | 130N | 9% (5.1°) | 5% (2.9°) |
| 前倾 | 180N | 290N | 10% (5.7°) | 16% (9.1°) |
| 侧倾 | 160N | 220N | 7% (4.0°) | 16% (9.1°) |
测试方法:
- 角色走路时,在躯干中点施加 0.25 秒的推力
- 逐渐增加推力直到角色摔倒
观察:
- 正常行走最鲁棒
- 直腿行走较不稳定(符合直觉)
- 前倾/侧倾对侧推有更好的抵抗力
为什么有鲁棒性?
原因:训练时的探索噪声
训练时:
- 给动作加高斯噪声(约关节范围的 10%)
- 相当于不断"推搡"角色
- 角色必须学会从扰动中恢复
结果:
- 自然学会平衡策略
- 不需要专门训练抗干扰
5.13 迁移学习
分层结构的好处:组件可以 interchangeably 使用
场景 1:同一个 LLC,不同的 HLC
- 正常行走 LLC 可以用于:路径跟随、运球、避障等
场景 2:同一个 HLC,不同的 LLC
- 路径跟随 HLC 可以配合:正常行走、高抬腿、前倾等
场景 3:迁移 + 微调
- 用正常行走训练的 HLC
- 直接用于高抬腿 LLC(性能下降)
- 微调 200k 次迭代(性能恢复)
- 比从零训练(1M 次)快得多
6. 实验结果
6.1 LLC 学习曲线
比较三种设置:
1. 10 个动作捕捉片段
2. 1 个手工制作片段
3. 没有参考动作
结果:
- 10 个 mocap 片段:学习最快,最终性能最好
- 1 个 hand-authored 片段:可以学会走路,但转弯较差
- 没有参考动作:完全学不会走路
结论:参考动作对引导学习非常重要
6.2 HLC 学习曲线
| 任务 | 归一化累积奖励 (NCR) |
|---|---|
| 路径跟随 | 0.55 |
| 足球运球 | 0.77 |
| 柱子障碍 | 0.56 |
| 方块障碍 | 0.70 |
| 动态障碍 | 0.18 |
观察:
- 静态环境任务(路径、柱子、方块)学得较好
- 动态障碍物最难,因为 LLC 没有学过"停止"
NCR 解释:
- NCR = 1:完美表现
- 但有些任务理论上达不到 1(如运球需要时间)
- 0.5-0.7 已经表示相当不错的性能
6.3 分层 vs 端到端
对比实验:
- 分层:HLC + LLC(分开训练)
- 端到端:单个网络直接输出关节命令
结果:
- 端到端方法:两种任务都完全失败
- 分层方法:成功学会所有任务
为什么分层赢了?
- 端到端需要同时学会"怎么走"和"往哪走"
- 任务太复杂,探索空间太大
- 分层把问题分解成两个较简单的子问题
6.4 风格插值演示
让角色在"正常行走"和"高抬腿"之间插值:
u = 0.0 → 正常行走
u = 0.25 → 稍微抬腿
u = 0.5 → 中等抬腿
u = 0.75 → 较高抬腿
u = 1.0 → 高抬腿
效果:可以平滑过渡,没有明显跳跃
6.5 迁移学习结果
场景:用正常行走 LLC 训练的 HLC,直接用于其他风格 LLC
| 任务 + LLC | 不微调 | 微调 | 重新训练 |
|------------|--------|------|----------|
| 运球 + 高抬腿 | 0.19 | 0.56 | 0.51 |
| 运球 + 直腿 | 0.51 | 0.64 | 0.45 |
| 路径 + 高抬腿 | 0.10 | 0.39 | - |
| 路径 + 前倾 | 0.43 | 0.44 | - |
结论:
- 直接迁移会有性能损失(特别是敏感任务如运球)
- 微调可以快速恢复性能(200k vs 1M 次)
- 简单任务(路径)迁移效果更好
7. 总结与启发
7.1 核心创新点
1. 分层深度强化学习框架
- 高层规划(HLC)+ 低层执行(LLC)
- 不同时间尺度,各司其职
2. 环境感知能力
- 输入:32×32 地形高度图
- 可以"看到"地形并做出决策
3. 风格多样化
- 通过奖励函数修改实现不同风格
- 风格之间可以平滑插值
4. 迁移学习能力
- 组件可以 interchangeably 使用
- 微调可以快速适应新组合
7.2 与后续工作的关系
DeepLoco (2017) → 后续工作:
├→ DeepMimic (2018): 更精确的动作跟踪
├→ AMP (2021): 对抗性动作先验,更灵活的风格学习
├→ ASE (2022): 大规模可重用技能嵌入
└→ 本文作者团队的后续工作
- PDP (2023): 用扩散模型做物理角色控制
- DiffuseLoco (2023): 离线数据集的扩散控制
7.3 局限性
论文自己提到的局限
1. 相位变量仍需手动设计
- 未来可以用 RNN/LSTM 内部记忆
2. HLC-LLC 接口是手工指定的
- 两步位置 + 身体朝向
- 未来可以学习自动表示
3. 分开训练,不是端到端
- 联合训练困难(LLC 动态变化影响 HLC 学习)
4. 采样效率不高
- LLC:600 万次迭代
- HLC:100 万次迭代
- 未来可以用学习到的动态模型改进
5. **固定初始状态**
- 每个 episode 从固定的站立姿势开始
- 难以学习高度动态的动作(如后空翻、跳跃)
- 对比:DeepMimic (2018) 提出 RSI(从参考动作的随机状态开始)
从现代视角看局限
1. 训练时间长
- LLC:2 天(16 核)
- HLC:7 天(CPU)
- 现代方法可能更快
2. 角色模型简单
- 只有 8 个连杆(腿 + 躯干)
- 没有手臂(运球任务除外)
3. 任务相对简单
- 主要是导航类任务
- 没有更复杂的交互(如抓取、操作)
7.4 对后续研究的启发
1. 分层是处理复杂任务的有效策略
- 把大问题分解成小问题
- 不同层次可以独立训练
2. 参考动作是引导学习的好方法
- 不需要精确跟踪
- "风格模仿"比"动作复制"更灵活
3. 环境感知很重要
- 地形图输入让角色可以"看路"
- 为后续工作(如 DiffuseLoco)奠定基础
4. 迁移学习可以大大提高效率
- 组件可以复用
- 微调比重新训练快得多
7.5 关键技术总结
┌────────────────────────────────────────┐
│ DeepLoco 技术栈 │
├────────────────────────────────────────┤
│ • 分层强化学习(HLC + LLC) │
│ • Actor-Critic + CACLA 更新 │
│ • 经验回放(Experience Replay) │
│ • 双线性相位变换 │
│ • CNN 处理地形图 │
│ • 参考动作引导学习 │
│ • 风格插值 │
│ • 迁移学习 + 微调 │
└────────────────────────────────────────┘
8. 公式汇总
8.1 策略表示
随机策略:
a = μ(s, g) + λN, N ∼ G(0, Σ)
λ ~ Ber(ε):探索概率
训练时 λ = 1(加噪声)
推理时 λ = 0(确定性)
8.2 累积奖励
J(π) = E[r₀ + γr₁ + ... + γ^T r_T | π]
γ = 0.95:折扣因子
8.3 CACLA 更新
价值函数更新:
yᵢ = rᵢ + γV(sᵢ', gᵢ)
θ_v ← θ_v + α_v · Oθ_v V(sᵢ, gᵢ) · (yᵢ - V(sᵢ, gᵢ))
策略更新(仅当 δ > 0):
δⱼ = rⱼ + γV(sⱼ', gⱼ) - V(sⱼ, gⱼ)
θ_μ ← θ_μ + α_μ · Oθ_μ μ(sⱼ, gⱼ) · Σ⁻¹ · (aⱼ - μ(sⱼ, gⱼ))
8.4 奖励函数
LLC 奖励:
r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading
HLC 奖励(运球):
r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp
文档完成时间:2026 年 4 月 3 日