HuMoR: 3D Human Motion Model for Robust Pose Estimation
| 缩写 | 英文 | 中文 |
|---|---|---|
| CVAE | conditional variational autoencoder | 条件变分自动编码器 |
| GMM | Gaussian mixture model | 高斯混合模型 |
核心问题是什么?
解决了什么痛点
在存在噪声和遮挡的情况下恢复合理的姿势序列
本文主要贡献是什么
- 一种通过创新的 条件VAE 建模的生成 3D 人体运动先验,可用于多种下游任务。
- 基于运动先验的动作生成
- 基于运动先验的动作优化,可以产生『准确且合理的运动和接触』的动作。
项目页面:geometry.stanford.edu/projects/humor。
主要方法
HuMoR:3D 人体运动先验
定义运动先验
本文将运动先验表达为\(x_{t-1}\)与\(x_{t}\)的动作转移关系。
不同的\(x_{t-1}\)能得到不同的动作转移关系分布。
用于动作生成时,可以取概率最大的转移关系,也可以根据概率函数采样一个分布关系。
用于动作优化时,目的是让实际的转移关系在它的所属分布中的概率尽量大。
同一个\(x_{t-1}\)结合不同的转移关系,能得到不同的\(x_{t}\)。
当输入x0与每一步转换z是确定的时候,第T帧的输出也是确定的。
本文运动先验的理论依据:Latent Variable Dynamics Model 潜变量动力学模型
假设:当前状态只与上一帧状态有关。
目标:\(p_\theta(x_t|x_{t-1})\),描述the plausibility of a transition.
CVAE:引入一个潜变量z,分别求\(p_\theta(z_t|x_{t-1})\)和\(p_\theta(x_t|z_t, x_{t-1})\),结合求出\(p_\theta(x_t|x_{t-1})\)
$$ p_\theta(x_t|x_{t-1}) = \int_{z_t} p_\theta(z_t|x_{t-1}) p_\theta(x_t|z_t, x_{t-1}) $$
这样把问题分解为两部分,其中第一项为Encoder,第二项为Decoder。
由于\(x_t\)和\(x_{t-1}\)差别不大。作者发现学习\(x_t\)与\(x_{t-1}\)之间的差,比直接学习\(x_t\)效果好。
学习运动先验
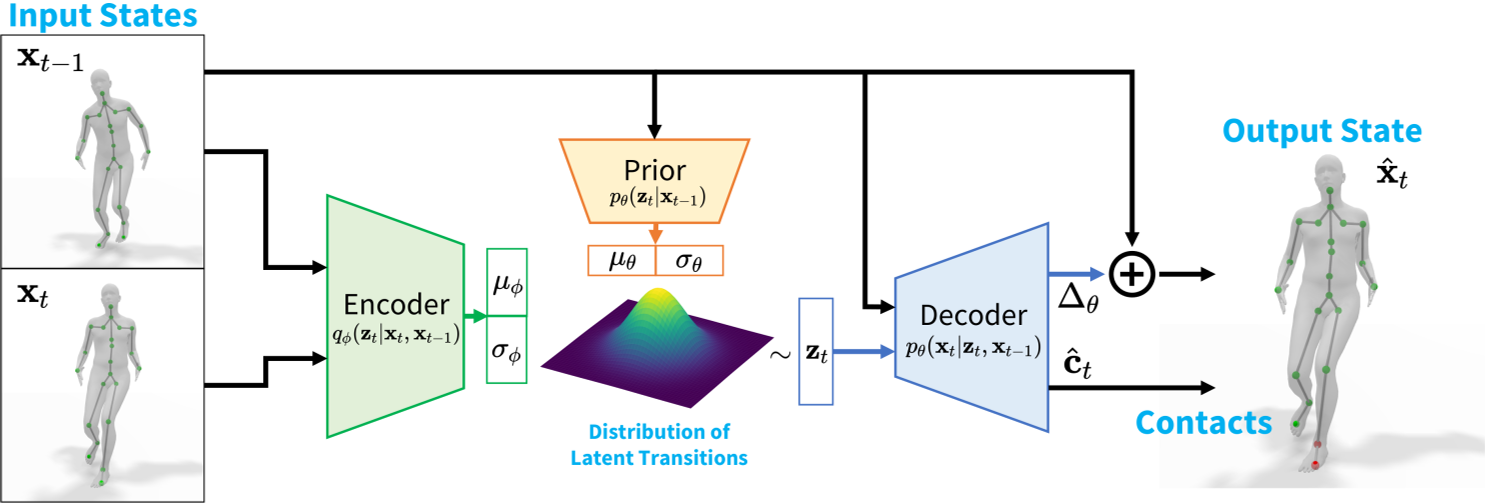
构建转移关系z的先验模型和后验模型。其中先验概率为橙色模块,后验概率为绿色模块。
后验模型从根据的数据对\(x_{t-1}, x_{t}\)中提取转移关系分布,因此能得到比较准确的运动先验。
先验模型是根据\(x_{t-1}\)预测转移关系分布,是在生成任务中会遇到的场景。
| 阶段 | 流程 | Loss | 目的 |
|---|---|---|---|
| 第一阶段 | Encoder(基于后验概率得到的转移关系) + Decoder(基于转移关系得到当前帧)的联合训练 | KL(转移关系分布,0/1分布) 重建Loss(xt, output) | 1. 从数据集中提取较准确的转移关系 2. 得到一个比较准确的动作恢复模型Decoder |
| 第二阶段(第一阶段和第二阶段可以同时进行) | 分布用Encoder和Prior预测转移关系分布 | KL(后验转移分布, 先验转移分布) | 让先验分布逼近后验分布,可以得到一个比较准确的先验转移分布。 |
基于运动先验的动作生成
控制条件:无
生成方式:自回归
表示方式:VAE
生成模型:状态转移
Homor用于动作生成时,可以取概率最大的转移关系,也可以根据概率函数采样一个分布关系。
---
title: Building the Motion Manifold
---
flowchart LR
Input[("Init Frame")]
Past(["Past"])
Prior["Humor Prior"]
Dist(["转移分布"])
Latent(["Latent Code"])
Decoder
Next(["Next"])
Input-->Past-->Prior-->Dist-->Sample-->Latent
Past & Latent --> Decoder-->Next-->Past
基于运动先验的动作优化
输入:观察序列y,为需要被优化的动作序列的特征
优化变量:使用 HuMoR 作为强运动先验,联合求解姿势、身体形状和地平面/接触,以及初始状态x0,转移序列z,形状参数beta,地面高度g
本文用所有运动数据的首帧,基于GMM模型,学习了运动数据的首帧\(p_\theta(x_0)\)的分布
优化目标:通过rollout函数,使得第T帧的输出与观察序列y的第T帧接近
第一步:initialization optimization
优化参数:SMPL参数初值
优化目标:data, shape, additional
第二步:计算z序列的初值
计算方法:CVAE Encoder
实验细节
逐帧的表示
| 符号 | 维度 | 信息 |
|---|---|---|
| \(r\) | 3 | root位移 |
| \(\dot r\) | 3 | root的线速度 |
| \(\Phi\) | 3 | root的朝向 |
| \(\dot \Phi\) | 3 | root的角速度 |
| \(\Theta\) | \(3 \times 21\) | 关节的local rotation,轴角形式 |
| \(J\) | \(3 \times 22\) | 关节的位置 没有提到特殊处理,应该就是指全局位置 |
| \(\dot J\) | \(3 \times 22\) | 关节的线速度 |
触地标签
Decoder会同时输出触地标签,这个标签会在test时使用。
对比Motion VAE
Motion VAE也使用了以上CVAE的原理。本文的改进在于:
通过额外学习条件先验、对状态和接触的变化进行建模以及鼓励关节位置和角度预测之间的一致性来克服这个问题。
训练
训练数据:pair data \((x_{t-1}, x_t)\)
并使用scheduled sampling,使模型对自身错误的长期积累具有鲁棒性。
| 重建loss | 重建出的xt应与训练数据是的xt接近 | 1. 由Encoder\((x_{t-1}, x_t)\)得到潜变量z 2. 由z和\(x_{t-1}\)Decoder出xt |
| KL散度 | z的先验分布与z的后验分布应该接近 | z的先验分布为\(p_\theta(z\mid x_{t-1})\) z的后验分布为\(q_\phi(z\mid x_{t-1},x_{t-1})\) 这个loss的权重在训练时会逐步减小,以避免posterior collapse。 |
| SMPL关节一致性 | 预测出的关节位置应该与GT一致 | [?]这个是不是有点多余?x里面已经包含关节位置、速度和旋转信息了。 |
| 触地标签 | 触地标签应与GT一致 | |
| 触地时脚的速度 | 触地是脚的速度应该较小 |
优化
| 优化目标 | ||
|---|---|---|
| mot | CVAE | z产生的先验概率尽量大,即根据x0和序列z生成每一帧xt之后,再计算每一帧会产生这个z序列的先验概率 |
| mot | init | 第一帧的概率尽量大 |
| data | data | 所产生的序列应与观察序列y相似 |
| reg | skel | 所生成的关节位置应与beta对应的SMPL体型一致 每一帧的骨长应保持不变 |
| reg | env | 当检测到脚步触地时,脚应该不动,且脚的高度为0 |
| reg | gnd | 地面高度接近初值 |
| reg | shape | 正常人的体型的shape参数不会太大 |
| additional | pose | \(z^{poset}\)不要太大 |
| additional | smooth | 前后两帧的关节位置不能发生突变 |
缺陷
- 训练和使用比较麻烦,训练包含2个阶段(训练Encoder&Decoder,训练Prior),使用包含3个阶段(根据初始化序列预测z、优化z、生成输出序列)
- 用于动作优化时一次性对整个序列优化,不能用于流式场景
- 由于运动模型是从室内mocap数据中学习的,因此不能推广到现实世界的复杂性
验证
数据集
AMASS, i3DB, PROX
启发
模型与传统的随机物理模型类似。条件先验可以被视为一个控制器,产生的“力”zt是一个关于状态 xt−1 的函数的输出,而解码器的作用就像方程中广义位置和速度的组合物理动力学模型和欧拉积分器。