Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
核心问题是什么?
NVIDIA,不开源
目的
图像到视频合成 (I2V)
输入:参考图像 I 和控制条件
输出:生成一系列后续视频帧,且确保生成的视频剪辑不仅表现出合理的运动,而且忠实地保留了参考图像的视觉外观。
✅ 区别于类似link 这种的“图像生成 → 视频生成”的任务。
现有方法及存在的问题
通过利用扩散模型强大的生成先验,最近的方法显示出有前途的开放域 I2V 泛化能力。
- 现有方法很难维持时间一致性。
- 现有方法对生成结果提供有限的控制。
本文方法
Motion-I2V 通过显式运动建模将 I2V 分解为两个阶段。
对于第一阶段,我们提出了一种基于扩散的运动场预测器,其重点是推导参考图像像素的轨迹。
对于第二阶段,我们提出运动增强时间注意力来增强 VDM 中有限的一维时间注意力。该模块可以在第一阶段预测轨迹的指导下有效地将参考图像的特征传播到合成帧。
效果
[❓] 光流擅长描述视角不变的物体平移,本文以光流为条件为什么能支持较大运动和视点变化,稀疏轨迹和区域注释零镜头视频到视频的转换?
与现有方法相比,即使存在较大运动和视点变化,Motion-I2V 也可以生成更一致的视频。
通过第一阶段训练稀疏轨迹ControlNet,Motion-I2V可以支持用户通过稀疏轨迹和区域注释精确控制运动轨迹和运动区域。与仅依赖文本指令相比,这为 I2V 过程提供了更多的可控性。
此外,Motion-I2V 的第二阶段自然支持零镜头视频到视频的转换。
✅ 优点是精确控制。
缺点是,当用户控制与图像内容存在矛盾时该如何调和?
核心贡献是什么?
-
双阶段图像到视频生成:Motion-I2V将图像到视频的生成分解为两个阶段。第一阶段专注于预测像素级的运动轨迹,第二阶段则利用这些预测轨迹来指导视频帧的生成。
-
显式运动建模:与以往直接学习复杂图像到视频映射的方法不同,Motion-I2V通过显式建模运动来增强生成视频的一致性和可控性。
-
基于扩散的运动场预测:在第一阶段,提出了一种基于扩散模型的运动场预测器,该预测器接收参考图像和文本指令作为条件,并预测参考图像中所有像素的轨迹。
-
运动增强的时间注意力:在第二阶段,提出了一种新颖的运动增强时间注意力模块,用于增强视频潜在扩散模型中有限的一维时间注意力。
-
稀疏轨迹控制:Motion-I2V支持使用稀疏轨迹ControlNet进行训练,允许用户通过稀疏的轨迹和区域注释精确控制运动轨迹和运动区域。
-
区域特定动画(Motion Brush):框架还支持区域特定的I2V生成,用户可以通过自定义的运动遮罩来指定要动画化的图像区域。
-
零样本视频到视频翻译:Motion-I2V的第二阶段自然支持零样本视频到视频翻译,可以使用源视频的运动信息来指导转换后的第一帧。
大致方法是什么?
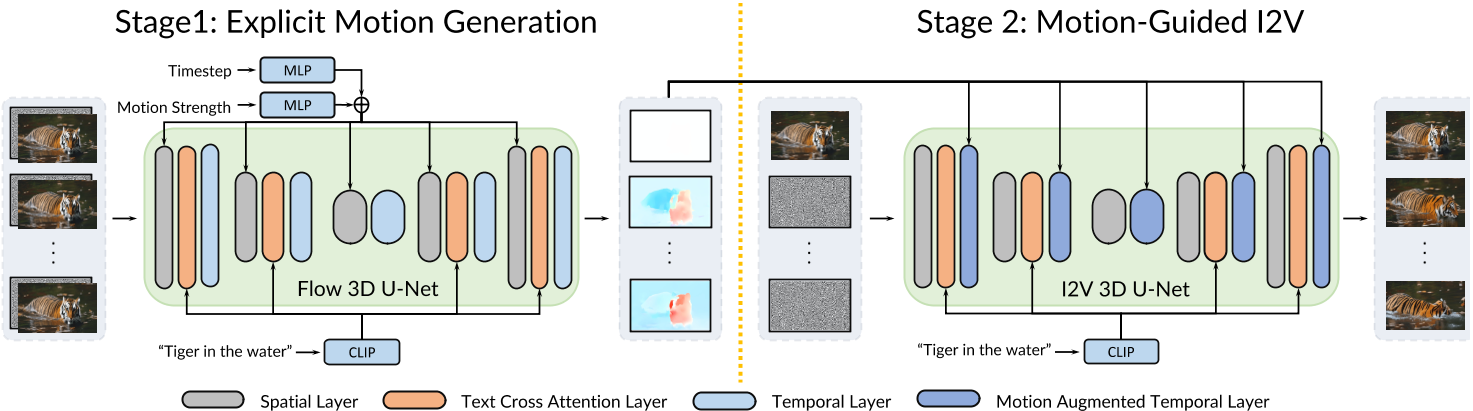
图1:Motion-I2V 概述。 Motion-I2V 的第一阶段的目标是推导能够合理地为参考图像设置动画的运动。它以参考图像和文本提示为条件,预测参考帧和所有未来帧之间的运动场图。第二阶段传播参考图像的内容以合成帧。一种新颖的运动增强时间层通过扭曲特征增强一维时间注意力。该操作扩大了时间感受野并减轻了直接学习复杂时空模式的复杂性。
Stage 1: 使用VDM进行运动预测
我们选择采用预先训练的稳定扩散模型进行视频运动场预测,以利用强大的生成先验。
运动场建模
将第一阶段的预测目标(使参考图像动画化的运动场)表示为一系列 2D 位移图{\(f_{0→i}|i = 1,..., N \)},其中每个 f0→i 是参考帧与时间步 i 处未来帧之间的光流。通过这样的运动场表示,对于参考图像 I0 的每个源像素 p ∈ I2,我们可以轻松地确定其在时间步 i 处目标图像 Ii 上对应的坐标 p′i = p + f0→i(p)。
✅ 根据视频数据生成运动场。
训练运动场预测器
| 模型结构 | 预训练参数 | 训练模块 | 学习目标 |
|---|---|---|---|
| 同LDM | LDM | Spatial 层 | 条件下未来第i帧的光流 |
| VLDM(LDM1) | 上一步 | vanilla 时间模块 | 运动场 |
| VLDM | 上一步 | 全部 | 运动场 |
- 调整预训练的 LDM 来预测以参考图像和文本提示为条件的单个位移场。
- 冻结调整后的 LDM 参数,并集成vanilla 时间模块以创建用于训练的 VLDM。
- 继续微调整个 VLDM 模型以获得最终的运动场预测器。
[❓] 任务的输入是稀疏轨迹和区域注释,为什么训练输入是文本注释?
答:先训一个 text-based 光流生成的基模型,然后以 ControlNet 形式注入控制条件,得到条件控制的光流生成模型。
[❓] 为什么不直接注入控制条件,而是分两步?
答:基模型通常都是 text-based 生成模型,然后以不同的方式注入条件。如果以 ControlNet 方式注入,通常会 fix 原模型。
编码运动场和条件图像
考虑到扩散模型的计算效率时,我们使用optical flow encoder 把 motion field map 编码为 latent representation。optical flow encoder 的结构与 LDM 的图像自动编码器相同,不同之处在于它接收和输出2通道光流图而不是3通道RGB图像。
[❓] 光流 encoder 是预训练的吗?
为了引入reference image condition,我们沿着通道维度把reference image latent representation 与 noise concat到一起。
✅ 有三种注入 reference Image 的方法
- 使用 SD encoder 编码后,以 conctext 的形式注入到 conv 3D 中
- 使用 CLIP encoder 编码后,与 UNet feature 做 cross attention
- 使用 SD encoder 编码后,与noise 在 channel 维度 concat.
- 使用 SD encoder 编码后,与noise 在 time 维度 concat.
使用 SD 1.5 预训练模型初始化的 LDM 权重,并将新添加的 4 个输入通道的权重设置为零。
帧步长 i 使用两层 M LP 进行嵌入,并添加到时间嵌入中,作为运动强度条件。
帧步长 i 的作用:表明要生成的是未来第几帧的光流
帧步长 i 的注入方式: MLP(time embdding) + MLP(step embdding), 见图1
Stage 2: 运动预测和视频渲染
运动增强的时间注意力
通过motion-augmented temporal attention,增强了 vanilla VLDM 的1-D temporal attention的同时,保持其他模块不变。
定义z为第 l 个时间层的 latent feature。简化batch size的情况下,z的维度为 (1+N )×Cl ×hl ×wl,其中 cl、hl、wl 分别表示特征的通道维度、高度和宽度。其中 z[0] 为参考帧对应的特征图,用 z[1 : N ]为后续帧。
✅ reference image 和 noise 在时间维度 concat。其结果再与光流 embdding 在 channel 维度 concat。
| flow emb\(_0\) | flow emb\(_1\) | flow emb\(_2\) | ...... | flow emb\(_n\) |
|---|---|---|---|---|
| ref image emb | noise\(_1\) | noise\(_2\) | ...... | noise\(_n\) |
根据第一阶段预测的运动场 {f0→i|i = 1, ..., N } (假设调整大小以对齐空间形状)对z[0]作warp,得到z[i]'
$$ z[i]' = \mathcal W(z[0], f_{i\rightarrow 0}) $$
z[i]'与z[i]在时间维度上交错(intealeaved),得到
$$ z_{aug} = [[z[0], z[1]', z[1], ..., z[N]', z[N]] $$
调整z和\(z_{aug}\)的维度顺序,使得在后面做时间维度上的attention。
时间维度上的attention为cross attention,其中K和V来自\(z_{aug}\),Q来自z。
✅ 该操作通过引入第一阶段的预测运动场引导,扩大了的时间模块的感受野。
因为 motion field 描述的是当前帧与 reference 帧之间的光流,相当于额外获得了这一段时间的运动信息,所以说有更大的感受野。
有选择地加噪
在去噪过程的每个时间步 t,总是将reference image latent code与noise latent code在时间维度上concat,以保证reference image的内容在生成过程中被忠实地保留。
✅ 实际上是用 ref image emb 代替了 noise\(_0\) 而不是在 noise\(_0\) 前加一帧 ref image.用这种方式,可以实现“预置指定帧的内容”的目的。
应用:Motion-I2V生成的细粒度控制
稀疏轨迹控制
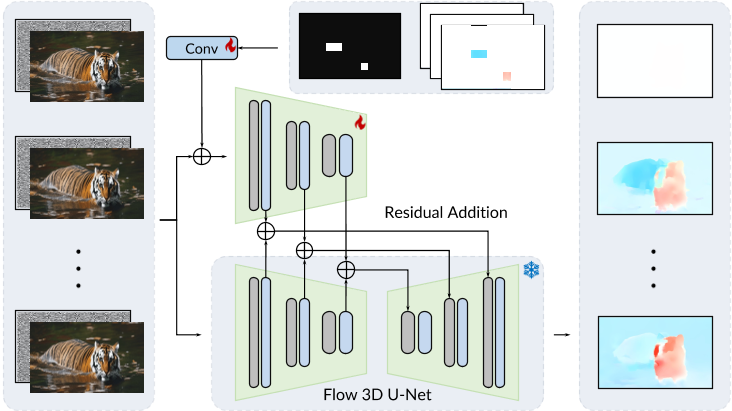
第一阶段中,通过ControlNet把人工绘制的轨迹图作为控制信号进行motion field map的生成。
第二阶段不变。
区域控制
第一阶段中,通过ControlNet把人工绘制的区域图作为控制信号进行motion field map的生成。
第二阶段不变。
视频风格转换
- 使用 image-to-image 第一帧进行图像风格转换
- 使用dense point tracker 计算dispacement space。
- 使用2和1计算motion field
- 使用motion field驱动1
训练
预训练模型
第一阶段:Stable Diffusion v1.5
第二阶段:AnimateDiff v2
数据集
WebVid-10M [1], a large scale text-video dataset
[❓] 3个细粒度控制的应用场中的 ControlNet,如何构造数据
答:根据视频可以直接生成光流,即 pair data 中的 y, 通过生成关键点及关键点追踪的方法生成稀疏轨迹,即pair date 中的x.
具体参考51
loss
训练策略
实验与结论
实验1: 横向对比
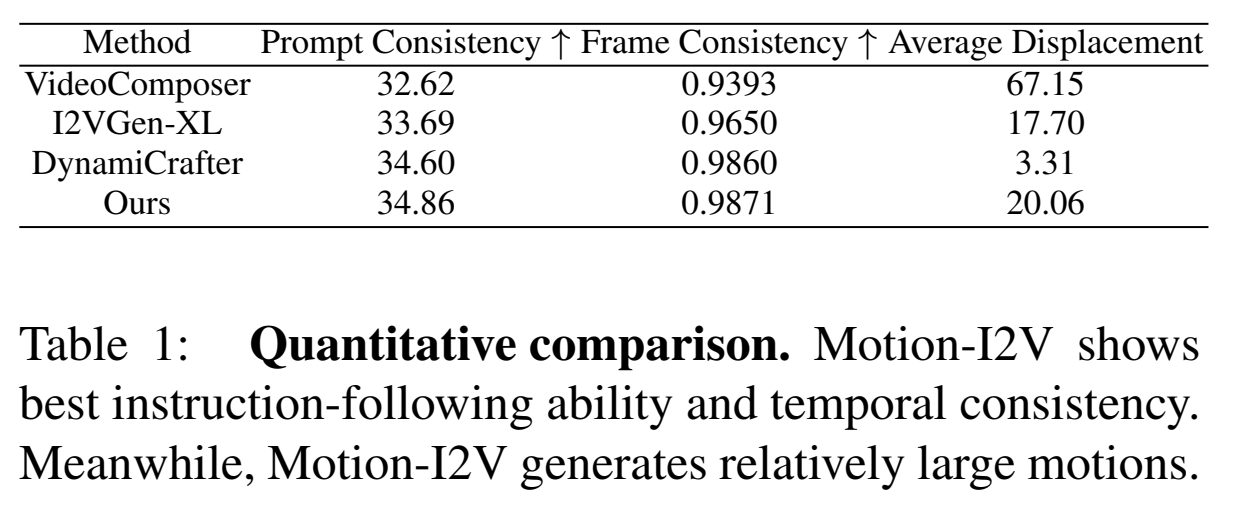
效果: Dynami Crafter 运动幅度较小。Pika 1.0生成的动作类型较少,但质量较高,Gen2的运动幅度大,但有变形。
实验2: Ablation
- 不使用 Stage 1
- 使用 Stage 1 但用普通 attention 进行信息注入。
- 使用 Stage 1 和 motion-augmented temporal attention.
效果:
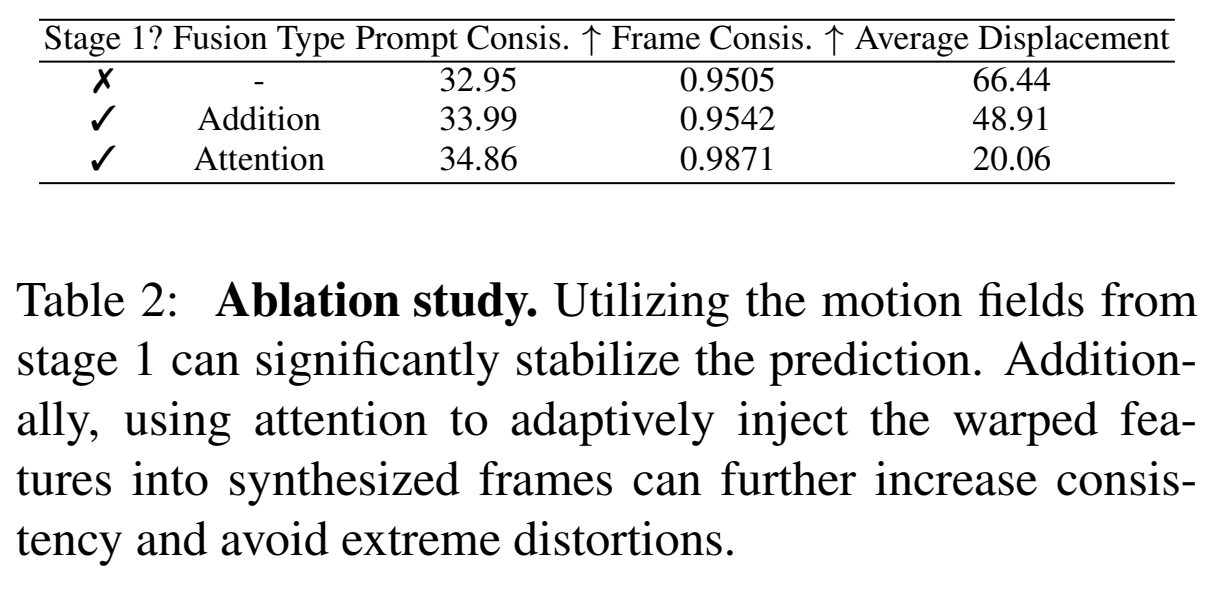
结论:相对于稀疏轨迹控制,使用光流控制的生成结果更稳定。
有效
- 一致性和可控性的比较优势:通过定量和定性比较,Motion-I2V在一致性和可控性方面优于现有方法,尤其是在存在大运动和视角变化的情况下。
局限性
- 生成视频的亮度倾向于中等水平。
这可能是因为noise scedule不强制最后一个时间步具有零信噪比(SNR),这会导致训练测试差异并限制模型的泛化性。使用最新的Zero-SNR noise schedulers可以缓解这个问题。
启发
motion field 的注入方式
遗留问题
参考材料
- 项目页面:https://xiaoyushi97.github.io/Motion-I2V/