A Recipe for Scaling up Text-to-Video Generation
Ali,开源,VGen
核心问题是什么?
目的
基于diffusion model的文生视频
现有方法
文本视频的pair data规模有限。但是无标注的视频剪辑有很多。
本文方法
TF-T2V:一种新颖的文本到视频生成框架。它可以直接使用无文本视频进行学习。其背后的基本原理是将文本解码过程与时间建模过程分开。 为此,我们采用内容分支和运动分支,它们通过共享权重进行联合优化。
效果
通过实验,论文展示了TF-T2V在不同规模的数据集上的性能提升,证明了其扩展性。此外,TF-T2V还能够生成高分辨率的视频,并且可以轻松地应用于不同的视频生成任务。
核心贡献是什么?
-
文本到视频的生成框架(TF-T2V):提出了一个新的框架,它利用无文本的视频(text-free videos)来学习生成视频,从而克服了视频字幕的高成本和公开可用数据集规模有限的问题。
-
双分支结构:TF-T2V包含两个分支:内容分支(content branch)和运动分支(motion branch)。内容分支利用图像-文本数据集学习空间外观生成,而运动分支则使用无文本视频数据学习时间动态合成。
-
时间一致性损失(Temporal Coherence Loss):为了增强生成视频的时间连贯性,提出了一个新的损失函数,它通过比较预测帧与真实帧之间的差异来显式地约束学习相邻帧之间的相关性。
-
半监督学习:TF-T2V支持半监督学习设置,即结合有标签的视频-文本数据和无标签的视频数据进行训练,这有助于提高模型的性能。
大致方法是什么?
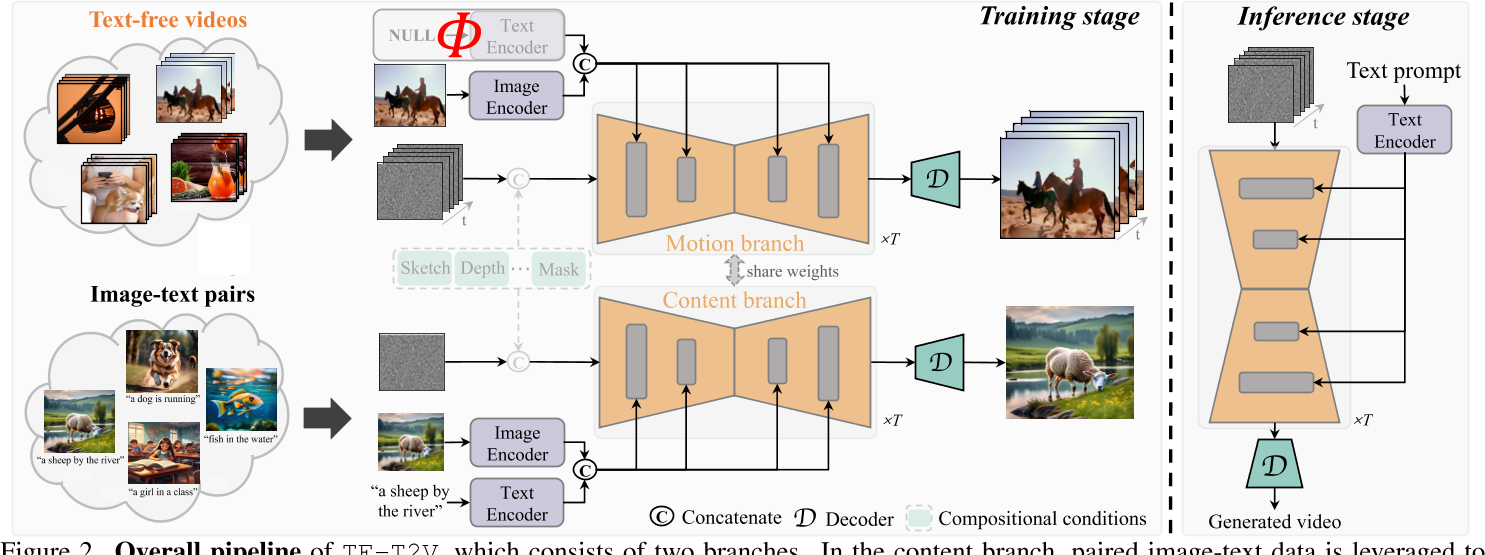
—— 在内容分支中,利用成对的图像文本数据来学习文本条件和图像条件的空间外观生成。
—— 运动分支通过提供无文本视频(或部分配对的视频文本数据,如果可用)来支持运动动态合成的训练。
—— 在训练阶段,两个分支联合优化。值得注意的是,TF-T2V 可以通过合并可组合条件无缝集成到组合视频合成框架中。
—— 在推理中,TF-T2V 通过将文本提示和随机噪声序列作为输入来实现文本引导视频生成。
运动分支
数据集: 纯视频、视频 - 文本 Pair data
输入: 视频的中间帧并使用 CLIP 编码。与生成视频同维度的噪声。
✅ 3个数据集,2个分支,组全出4种训练策略。
—— 输入文本,生成图像。
—— 输入图像,生成图像。
—— 输入图像(视频中间帧),生成视频。
—— 输入图像(视频中间帧)+ 文本,生成视频。
❓ 如何平衡这4种训练策略的训练顺序、训练次数、数据量?
❓ 不同训练数据及预训练数据的图像分辨都不相同,如何处理这其中的 GAP?
训练参数: 同时训练 Spatial Layer 和 Temporal Layer.
训练方式: CFG
空间外观分支
数据集: 图 - 文 Pair data
训练参数: 仅 Spatial 模块,且不引入 Temporal 模块
输入: 随机使用文或图作为控制条件,目的是任意一种条件都能引导生成。噪声与生成图像同维度。文本和图像都使用 CLIP 编码。
✅ 这里的 reference Image 是以CLIP Embedding 的形式送进去的,是一种比较弱的约束关系。但这里 reference Image 的作用只是提供一种外观先验,并不是照片续写,所以这样也够用了。
训练模块: 只训 Spatial 部分,不引入 temporal 部分。
[❓] 文本和图像是 Concat 的关系,但一次只提供一个,没有提供的部分填什么?
训练与验证
数据集
LAION-400M, LAION:大规模、高质量的图文数据集
WebVid10M:小规模、低分辨率的文本-视频数据集
YouTube, TikTok:大量无标注视频
loss
新增coherence loss用于计算帧间的连续性。
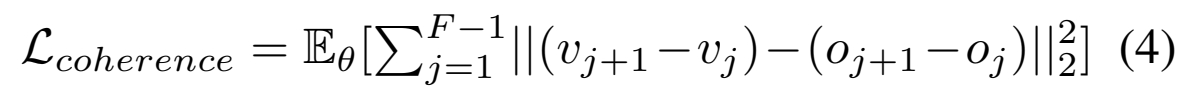
根据公式3可知 V 是 noise GT,因此 coherence loss 监督 noise 的时序特征。
训练策略
Base Mode:
Model Scipe T2V[54]
VideoComposer[58]
训练所有的视频片断为:4FPS,16 frames
❓ 这里提到 WebVid10M 是作为 text-free 数据集业用的,那么视频一文本 pair ddfa 的训练,用的是什么数据集?
实验与结论
实验一: 同期效果横向对比
效果:
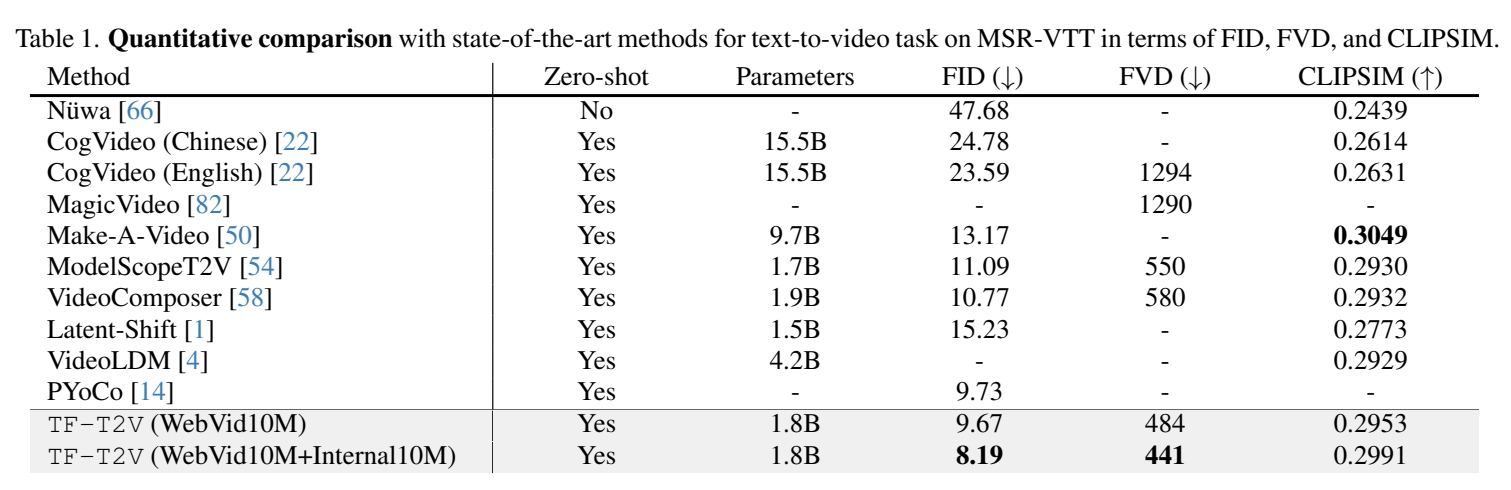
结论: 本文方法生成视频在单帧质和时序连续性上均优于同期模型。
实验二:
- 不使用 coherence loss
- 使用 coherence loss
效果: 生成视频的帧间 CLIP 相似度,2优于1。
给论: coherence loss 有时序一致性有效。
实验三:
- depth/sketch/motion-Image Pair data + 纯视频数,联合训练。
效果: 可以在没有“条件 - 视频” pair data 的情况下,训练出条件视频生成模型。
给论: 内容 / 运动 = 分支训练框加可以有效解决缺少条件 - 视频数据对的问题。
实验四:
- 不使用 coherence loss
- 使用 coherence loss
效果: 比较生成视频连续两帧的 CLIP 相似度,2优于1
结论: temporal coherence loss 可以缓解时序不连续问题(例如 color shift)
实验五:
- 不使用“文本-视频”数据训练
- 使用“文本-视频”数据训练
效果: 2优于1
有效
-
扩展性和多样性:通过实验,论文展示了TF-T2V在不同规模的数据集上的性能提升,证明了其扩展性。此外,TF-T2V还能够生成高分辨率的视频,并且可以轻松地应用于不同的视频生成任务。
-
无需复杂的级联步骤:与以往需要复杂级联步骤的方法不同,TF-T2V通过统一的模型组装内容和运动,简化了文本到视频的生成过程。
❓ 复杂级联步骤是指什么方法?
-
插拔式框架:TF-T2V是一个即插即用(plug-and-play)的框架,可以集成到现有的文本到视频生成和组合视频合成框架中。
-
实验结果:论文通过广泛的定量和定性实验,展示了TF-T2V在合成连贯性、保真度和可控性方面的优势。
局限性
启发
遗留问题
参考材料
- 项目地址:https://github.com/ali-vilab/VGen