P37
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
通过优化文本嵌入(text embeddings)来实现对复杂视觉概念的精准捕捉和复用。

1. 核心思想
目标:在预训练的文本到图像生成模型(如Stable Diffusion)中,仅通过少量示例图像(通常3-5张)学习一个新的视觉概念(如特定物体、艺术风格等),并将其表示为可复用的文本嵌入向量(即伪词,pseudo-word)。
关键创新:
- 不修改模型权重,而是通过优化文本嵌入空间中的一个新的嵌入向量来表示目标概念。
- 该向量可以像普通词汇一样被插入到自然语言描述中(例如“A photo of
<S*>”),指导模型生成包含该概念的图像。
✅ 用一个 word 来 Encode 源,因此称为 Textual Inversion.
2. 方法细节
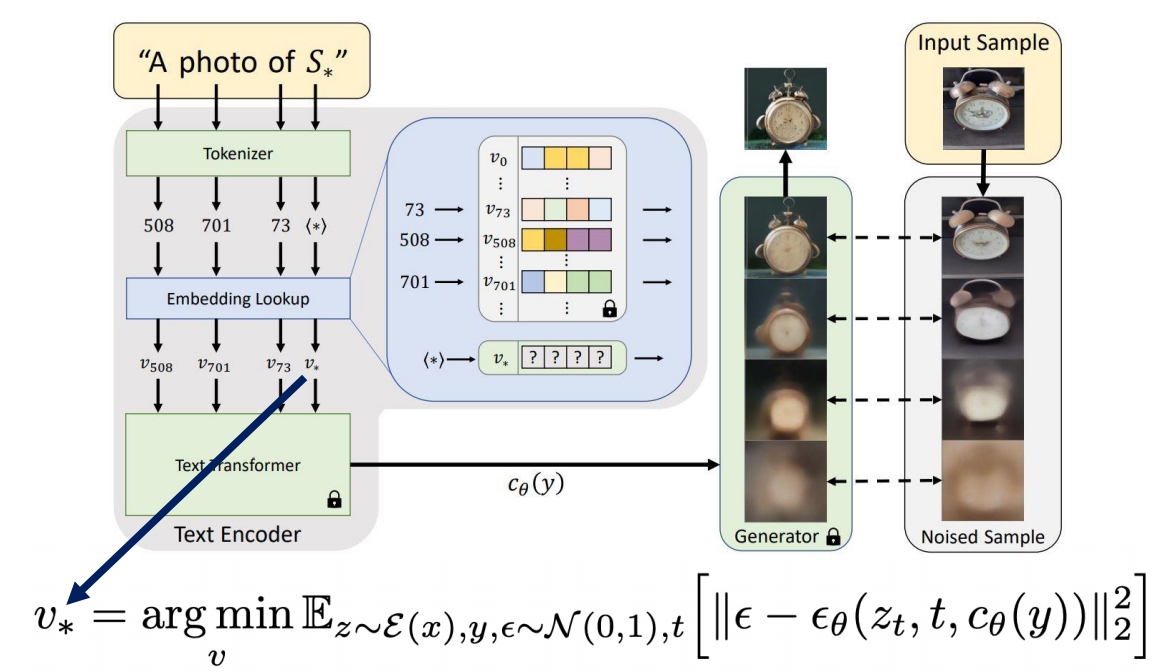
2.1 问题定义
- 预训练的文本到图像模型使用文本编码器(如CLIP的文本编码器)将输入文本映射为嵌入向量 \( E \)。
- 传统方法中,所有词汇的嵌入是固定的;而Textual Inversion通过优化一个新的嵌入向量 \( v_* \) 来表示目标概念。
2.2 优化过程
- 输入:少量(3-5张)同一概念的图像集合 \( {x_i} \) 和对应的文本描述模板(如“A photo of
<>”)。文本描述转为token编码。 - 目标:找到一个嵌入向量(embedding) \( v_* \),使得用该向量(embedding)替换模板中的占位符
<>后,能作为condition引导模型重建输入图像。 - 损失函数:基于扩散模型的噪声预测损失(Denoising Loss),最小化生成图像与输入图像之间的差异。
2.3 伪词(Pseudo-Word)的引入
- 将 \( v_* \) 绑定到一个新的“伪词”(如
<S*>),并将其添加到模型的词汇表中。 - 此后,用户只需在提示词中使用该伪词(如“A
<S*>in the style of Van Gogh”),即可调用学到的概念。
3. 优势与特点
- 轻量化:仅需优化一个嵌入向量,无需微调整个模型。
- 可组合性:学到的概念可以与其他词汇自由组合(如风格迁移、场景插入)。
- 高保真:能够捕捉细粒度视觉特征(如物体形状、纹理、艺术风格)。
- 低数据需求:仅需少量图像即可训练。
4. 实验结果
- 任务:
- 物体重建(如特定玩具、雕塑)。

- 风格迁移(如特定艺术家的画风)。

- 属性组合(如“
<S*>with sunglasses”)。
- 物体重建(如特定玩具、雕塑)。
- 对比基线:优于直接微调模型(Fine-tuning)和基于检索的方法。
- 用户研究:生成的图像在概念保真度和语义可控性上表现优异。
5. 应用场景
- 个性化生成:快速学习用户自定义的概念(如个人宠物、家具)。
- 艺术创作:复用特定风格或物体。
- 数据增强:为稀有物体生成训练数据。
6. 局限性
- 泛化性:对极端视角或复杂概念的捕捉有限。
- 多模态性:一个嵌入可能无法覆盖同一概念的所有变体(如不同姿态的物体)。
- 计算成本:优化过程仍需迭代训练(每概念约1小时GPU)。
7. 后续影响
Textual Inversion启发了后续工作(如DreamBooth、Custom Diffusion),推动了文本到图像模型中轻量化定制方向的发展。其核心思想也被扩展至视频生成、3D生成等领域。
总结
该论文提出了一种高效的方法,通过优化文本嵌入空间中的向量来实现视觉概念的复用,平衡了生成质量与计算效率,为个性化图像生成提供了重要工具。