Template
.
.
.
.
核心问题是什么?
目的
.
.
.
.
.
现有方法及局限性
.
.
.
.
.
本文方法
.
.
.
.
.
效果
.
.
.
.
.
核心贡献是什么?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
大致方法是什么?
.
.
.
. .
.
.
. .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
数据集
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练策略
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
实验与结论
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
Loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
参考材料
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
对抗性动作先验用于风格化物理角色控制
论文详解文档
目录
- 基本信息
- 核心问题:这篇论文要解决什么问题?
- 基础知识铺垫
- AMP 方法的核心思想
- 4.1 整体框架
- 4.2 为什么这样设计
- [4.3 为什么 AMP 不需要 Phase](#43-为什么 amp-不需要 phase 相位)
- 4.4 对抗性动作先验
- 4.5 AMP vs 传统跟踪方法
- 4.6 AMP 如何自动组合技能
- 技术细节详解
- 实验结果
- 总结与启发
1. 基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control |
| 中文译名 | AMP:用于风格化物理角色控制的对抗性动作先验 |
| 发表会议 | ACM Transactions on Graphics (TOG) 2021 |
| 作者单位 | 加州大学伯克利分校、上海交通大学 |
| 主要作者 | Xue Bin Peng, Ze Ma (共同第一作者), Pieter Abbeel, Sergey Levine, Angjoo Kanazawa |
2. 核心问题:这篇论文要解决什么问题?
2.1 背景故事
想象一下你在玩一款 3D 游戏,游戏中的角色需要做出各种动作:走路、跑步、跳跃、翻滚、出拳等等。
问题 1:如何让游戏角色做出自然的动作?
传统方法有两种:
方法 A:纯物理模拟
- 原理:用物理引擎计算角色应该如何移动
- 优点:可以应对新环境
- 缺点:动作看起来很僵硬、不自然
比如:让一个角色从地上爬起来
- 纯物理方法:角色可能会以很奇怪的方式扭曲,看起来像机器人
方法 B:动作捕捉数据回放
- 原理:记录真实人类的动作,然后让角色跟着做
- 优点:动作非常自然
- 缺点:只能做录过的动作,遇到新情况就傻眼了
比如:录了走路动作,但前面有个障碍物
- 纯回放方法:角色会继续走路,然后撞到障碍物
2.2 现有方法的局限性
论文指出了现有基于跟踪的方法的两大问题:
问题 1:需要精心设计目标函数
传统方法需要人工设计"跟踪误差"的计算方式:
- 手臂位置差多少算错误?
- 腿部角度差多少算错误?
- 这些权重怎么设置?
这需要大量的人工调参,非常费时费力
问题 2:需要动作选择机制
当你有很多动作片段时(比如走路、跑步、跳跃):
- 什么时候该走路?
- 什么时候该跑步?
- 什么时候该跳跃?
传统方法需要一个"动作规划器"来决定播放哪个动作
这个规划器本身就很复杂,需要大量人工设计
2.3 AMP 要解决的问题
核心目标:
让用户可以简单地指定"要做什么任务",然后提供一堆动作片段作为"风格参考",系统自动学会在正确的时间做正确的动作,而且动作风格与参考数据一致。
举个例子:
- 任务:走到目标位置并出拳
- 风格数据:一些走路的片段 + 一些出拳的片段(没有"走到目标再出拳"的完整片段)
- 期望结果:角色自动学会先走路接近目标,然后出拳,而且走路和出拳的风格与参考数据一致
3. 基础知识铺垫
为了理解 AMP,我们需要了解几个关键概念:
强化学习基础:如需了解强化学习的完整数学框架(MDP、贝尔曼方程、价值函数等),请参考 DeepLearningNotes - 强化学习基础
3.1 强化学习 (Reinforcement Learning, RL)
想象训练一只小狗:
状态 (State) 动作 (Action) 奖励 (Reward)
↓ ↓ ↓
你手里拿着球 → 小狗去捡球 → 给它零食
强化学习的核心循环:
1. 智能体 (Agent) 观察环境的 状态 (State)
2. 根据 策略 (Policy) 选择 动作 (Action)
3. 执行动作后获得 奖励 (Reward) 和新的状态
4. 目标:学习一个策略,使得累计奖励最大化
关键术语:
- 策略 (Policy) π:从状态到动作的映射规则,可以理解为"在什么情况下做什么"
- 奖励 (Reward) r:告诉智能体某个动作好不好
- 折扣因子 (Discount Factor) γ:未来的奖励打多少折,比如γ=0.99 表示明天的 1 分奖励相当于今天的 0.99 分
3.2 模仿学习 (Imitation Learning)
强化学习的问题:奖励函数很难设计
↓
模仿学习的思路:直接给智能体看"专家"是怎么做的,让它学着做
比如教机器人走路:
- 强化学习:设计奖励函数"走得快 +1 分,摔倒 -10 分"(很难设计!)
- 模仿学习:给机器人看人类走路的视频,让它模仿(更直观!)
3.3 生成对抗网络 (GAN)
GAN 的核心思想:有两个网络在"对抗"
生成器 (Generator) 判别器 (Discriminator)
↓ ↓
生成假图片 判断图片真假
↓ ↓
目标:骗过判别器 目标:准确判断真假
两者互相竞争,最后生成器能生成非常逼真的图片
3.4 生成对抗模仿学习 (GAIL)
把 GAN 的思想用到模仿学习上:
策略 (Policy) 判别器 (Discriminator)
↓ ↓
生成动作轨迹 判断轨迹是来自专家还是策略
↓ ↓
目标:骗过判别器 目标:准确判断真假
如果判别器分不清策略和专家的区别,说明策略学得足够好了!
GAIL 的核心公式:
判别器的目标:
minimize: -E[log(D(s,a))] - E[log(1-D(s,a))]
来自专家数据 来自策略数据
策略的目标:
maximize: -log(1-D(s,a)) (想办法让判别器给高分)
GAIL 的局限:
- 判别器输入是
(s, a),任务和风格绑定 - 只能模仿完整的专家轨迹,无法组合技能
- 无法迁移到新任务
3.5 AMP vs GAIL
AMP 基于 GAIL 的思想,但做了两个关键改进:
改进 1:奖励分离(任务 + 风格)
| 方法 | 奖励公式 |
|---|---|
| GAIL | r(s,a) = -log(1 - D(s,a))只有对抗奖励 |
| AMP | r = wG × rG(任务) + wS × rS(风格) |
意义:
- GAIL:奖励只告诉策略"像不像专家"
- AMP:任务奖励告诉策略"做什么"(What),风格奖励告诉策略"怎么做"(How)
改进 2:判别器只看状态转换(关键!)
| 方法 | 判别器输入 | 判别器判断什么 |
|---|---|---|
| GAIL | D(s, a) | 这个状态 - 动作对像不像专家 |
| AMP | D(Φ(s_t), Φ(s_{t+1})) | 这个状态转换像不像参考数据 |
为什么这是关键改进?
GAIL 的 D(s,a):
├─ 绑定任务和风格
├─ 专家做什么,策略只能学什么
└─ 无法迁移到新任务
AMP 的 D(s_t, s_{t+1}):
├─ 只判断"动作风格",不判断"做什么任务"
├─ 参考数据可以只有"走路片段"
└─ 策略可以迁移到"走到目标 + 出拳"任务
效果对比:
| 任务 | GAIL | AMP |
|---|---|---|
| 参考数据 | "走路 + 出拳"完整轨迹 | "走路片段" + "出拳片段"(分开) |
| 能否学会 | ❌ 不能(没有完整演示) | ✅ 能(自动组合) |
完整对比表格
| 特性 | GAIL (2016) | AMP (2021) |
|---|---|---|
| 判别器输入 | D(s, a) | D(Φ(s_t), Φ(s_{t+1})) |
| 奖励结构 | 只有对抗奖励 | 任务奖励 + 风格奖励(分离) |
| 参考数据 | 完整的专家轨迹 | 零散的动作片段(可以无序) |
| 技能组合 | ❌ 不能自动组合 | ✅ 自动组合涌现 |
| 任务灵活性 | ❌ 专家做什么学什么 | ✅ 可以迁移到新任务 |
| 相位同步 | 需要 | 不需要 |
3.6 物理模拟中的角色控制
在物理引擎中控制一个虚拟角色:
角色身体 = 多个刚体 (头、躯干、手臂、腿...) 通过关节连接
控制方式:
- 在每个关节处安装 PD 控制器
- PD 控制器需要目标角度
- 策略网络输出这些目标角度
物理引擎会计算:
- 如果给关节一个力,角色会怎么动
- 角色会不会摔倒
- 角色和地面/物体的碰撞
4. AMP 方法的核心思想
4.1 整体框架

Figure 2. AMP 系统概述。给定定义期望动作风格的运动数据集,系统训练一个动作先验来指定风格奖励 r^S。这些风格奖励与任务奖励 r^G 结合,训练策略使模拟角色满足任务特定目标 g,同时采用类似参考动作的行为。
AMP 的核心创新是把任务奖励和风格奖励分开:
总奖励 = 任务奖励 × 任务权重 + 风格奖励 × 风格权重
r(s,a,s',g) = wG × rG(s,a,s',g) + wS × rS(s,s')
其中:
- rG (任务奖励):告诉角色"做什么"(What)
比如:往目标方向走、击中目标等
- rS (风格奖励):告诉角色"怎么做"(How)
比如:用走路的姿势、用跑步的姿势等
4.2 为什么这样设计?
传统方法的问题:
- 任务和目标混在一起,很难设计
AMP 的思路:
- 任务奖励:可以很简单,只关心结果
比如"往目标方向走",只需要计算速度方向的误差
- 风格奖励:用对抗学习自动学习
给一堆走路/跑步的动作片段,让判别器学会判断
"这个动作像不像参考数据里的风格"
4.3 为什么 AMP 不需要 Phase(相位)?
什么是 Phase?
Phase = 当前动作在时间线上的位置
比如一个 1 秒的走路循环:
- φ = 0.0:左脚刚落地
- φ = 0.25:左脚支撑中期
- φ = 0.5:右脚刚落地
- φ = 0.75:右脚支撑中期
- φ = 1.0:回到左脚落地
传统方法为什么需要 Phase?
DeepLoco/DeepMimic 的跟踪机制:
参考动作是一个时间序列:{q̂₀, q̂₁, q̂₂, ..., q̂_T}
策略需要知道:"现在应该跟踪哪一个帧"
解决方法:
- 用一个相位变量 φ 跟踪进度
- 每一帧 φ 递增
- 根据 φ 找到对应的参考帧 q̂_φ
- 计算当前姿势 q 和 q̂_φ 的误差
问题:
1. 需要知道动作的周期长度
2. 对于非循环动作(如后空翻只有一次),phase 很难设计
3. Phase 是硬编码的,不能灵活调整
4. 如果角色摔倒,phase 继续递增,但实际姿势已不匹配
AMP 为什么不需要 Phase?
AMP 的判别器机制:
判别器输入:D(Φ(s_t), Φ(s_{t+1}))
判别器判断:"这个状态转换像不像参考数据集里的?"
关键区别:
- 不关心"现在是第几帧"
- 只关心"这个动作片段自不自然"
- 参考数据是"无序的片段集合",不是"有时间顺序的轨迹"
对比:
| 方法 | 参考数据 | 如何判断"对不对" |
|---|---|---|
| DeepMimic | 一个完整的走路循环 | 当前姿势 vs 第 φ 帧的姿势 |
| AMP | 一堆走路的片段(无序) | 这个动作转换像不像数据集里的任何片段 |
直观类比
| 方法 | 类比 | 说明 |
|---|---|---|
| DeepMimic | 跟唱卡拉 OK | 需要知道当前唱到哪一句(phase) |
| AMP | 即兴爵士 | 只要每个音符听起来像爵士风格就行 |
效果对比
| 方面 | DeepLoco/DeepMimic | AMP |
|---|---|---|
| Phase 需求 | ✅ 需要(硬编码) | ❌ 不需要 |
| 参考数据结构 | 有时间顺序的轨迹 | 无序片段集合 |
| 处理非循环动作 | ❌ 困难(phase 不好设计) | ✅ 可以 |
| 处理无序数据集 | ❌ 需要动作选择器 | ✅ 自动处理 |
4.4 对抗性动作先验 (Adversarial Motion Prior)
什么是"先验" (Prior)?
先验 = 事先的知识
动作先验 = 对"什么动作是自然的"的事先知识
这个知识从哪里来?从参考动作数据集来!
AMP 的判别器:
输入:角色在两个时刻的状态 (s_t, s_{t+1})
输出:这个状态转换是来自参考数据 (真实) 还是策略生成 (虚假)
判别器学到的东西 = 动作先验
- 知道什么样的动作转换是"自然的"
- 不需要人工设计误差函数
4.5 AMP vs 传统跟踪方法
| 特性 | DeepLoco/DeepMimic | AMP |
|---|---|---|
| 人工设计奖励 | ❌ 需要 | ✅ 不需要 |
| 动作选择器 | ❌ 需要 | ✅ 不需要 |
| 相位同步 | ❌ 需要 | ✅ 不需要 |
| 无序数据集 | ❌ 困难 | ✅ 可以 |
| 技能自动组合 | ❌ 需要设计 | ✅ 自动涌现 |
4.6 AMP 如何自动组合技能?
举个例子:障碍赛跑任务
参考数据集包含:
- 跑步片段
- 跳跃片段
- 翻滚片段
任务奖励:只鼓励向前移动
结果:
角色自动学会:
- 平时跑步
- 遇到沟壑时跳跃
- 遇到低矮障碍物时翻滚
为什么?
因为判别器认为这些动作都是"自然的"
而任务奖励鼓励向前
角色发现组合这些技能可以最大化总奖励
不需要人工告诉角色"什么时候该跳、什么时候该滚"!
5. 技术细节详解
5.1 MDP 定义 (S, A, P, R)
AMP 的任务可以形式化为一个马尔可夫决策过程 (MDP),由以下组件定义:
| 组件 | 符号 | 定义 | 维度/说明 |
|---|---|---|---|
| 状态空间 | S | 角色身体配置(关节位置、旋转、速度等) | ~120D |
| 动作空间 | A | 关节目标旋转(通过 PD 控制器执行) | ~31D |
| 转移动力学 | P(s'|s,a) | 物理模拟器(不显式建模,通过采样学习) | - |
| 奖励函数 | r(s,a,s',g) | wG × rG(任务) + wS × rS(风格) | - |
| 控制信号 | g | 任务目标的编码(拼接到状态输入) | 因任务而异 |
状态 (State) 详细组成
s_t = [躯干状态,关节旋转,关节速度,末端执行器位置]
具体包括:
1. 躯干(root)状态
- 根高度
- 旋转(四元数)
- 线速度、角速度
2. 关节旋转
- 每个关节相对于躯干的旋转
- 使用 6D normal-tangent 编码(无歧义)
3. 关节速度
- 线速度
- 角速度
- 局部坐标系中表示
4. 末端执行器位置
- 手、脚的 3D 位置
所有特征都在角色的局部坐标系中记录(与任务无关)
动作 (Action) 详细定义
a_t = [每个关节的目标旋转]
具体表示:
- 球关节(髋、肩):3D 指数映射 (Exponential Map)
q ∈ R³, 可转换为旋转轴 v 和旋转角度 θ
- 旋转关节(膝、肘):1D 角度
q = θ
执行方式:
a_t → PD 控制器 → 关节力矩 → 物理模拟 → s_{t+1}
奖励函数 (Reward Function)
总奖励:r(s,a,s',g) = wG × rG(s,a,s',g) + wS × rS(s,s')
任务奖励 rG:
- 告诉角色"做什么"(What)
- 因任务而异(导航、击打、运球等)
- 示例(导航任务):rG = exp(-0.25×(v* - d*·v_com)²)
风格奖励 rS:
- 告诉角色"怎么做"(How)
- 来自判别器:rS = -log(1 - D(s,s'))
- 与任务无关,可迁移
控制信号 (Control Signal)
控制信号 g ≠ 姿态空间的字段
↓
任务特定条件的编码
不同任务的控制信号:
| 任务类型 | 控制信号 g | 维度 |
|---------|-----------|------|
| 目标方向 | [目标方向 d*, 目标速度 v*] | 4D |
| 目标位置 | [目标位置坐标 x*, y*, z*] | 3D |
| 击打任务 | [目标位置 + 击打部位] | 6D+ |
| 运球任务 | [球的位置、速度等] | 15D+ |
使用方式:
策略输入 = [状态 s_t, 控制信号 g]
5.2 判别器的设计
判别器输入的特征
判别器不直接看完整状态,而是看提取的特征Φ(s):
1. 躯干的线速度和角速度 (局部坐标系)
2. 每个关节的局部旋转
3. 每个关节的局部速度
4. 末端执行器 (手、脚) 的 3D 位置
为什么选这些特征?
- 足够紧凑:能在单个状态转换中捕捉动作特征
- 与任务无关:不包含任务特定信息,可以迁移到不同任务
判别器架构
判别器 D(Φ(s), Φ(s')) 是一个神经网络:
- 输入:当前状态特征 + 下一状态特征
- 输出:判断是真实数据还是策略生成的分数
网络结构:
- 全连接网络
- 两个隐藏层:1024 和 512 个 ReLU 神经元
- 输出层:线性层
5.3 关键技术改进
AMP 能成功,离不开以下几个关键技术:
改进 1:最小二乘 GAN (Least-Squares GAN)
问题:传统 GAN 用交叉熵损失,容易梯度消失
传统 GAN 的损失函数:
- log(D(s,a)) 和 log(1-D(s,a))
当判别器很强时:
- D(s,a) 接近 0 或 1
- log 的梯度接近 0
- 策略学不到东西
AMP 的方案:用最小二乘损失
判别器目标:
minimize: E[(D(s,s') - 1)²] + E[(D(s,s') + 1)²]
真实数据 虚假数据
- 真实数据的目标分数:1
- 虚假数据的目标分数:-1
策略奖励:
r(s,s') = max[0, 1 - 0.25×(D(s,s')-1)²]
好处:
- 梯度不会消失
- 训练更稳定
改进 2:梯度惩罚 (Gradient Penalty)
问题:GAN 训练不稳定
GAN 训练不稳定的原因:
判别器可能在真实数据流形上赋予非零梯度
导致生成器" overshoot ",偏离数据流形
AMP 的方案:添加梯度惩罚
判别器目标添加一项:
+ (w_gp/2) × E[||∇_Φ D(Φ)||²]
真实数据
含义:
- 惩罚判别器在真实数据上的梯度
- 让判别器更"平滑"
- 系数 w_gp = 10
效果:
- 训练稳定性大幅提升
- 学习速度更快
改进 3:速度特征
问题:只给位置信息不够
理论上,连续两帧的位置可以推算出速度
但实际上,这对某些动作 (如翻滚) 不够
没有速度特征时:
- 角色发现保持固定姿势也能骗过判别器
- 学不会翻滚
AMP 的方案:显式添加速度特征
在判别器输入中包含:
- 每个关节的局部速度
效果:
- 能学会更动态的动作
- 避免收敛到局部最优 (如保持固定姿势)
改进 4:经验回放缓冲区 (Replay Buffer)
问题:判别器容易过拟合到策略最新的轨迹
如果判别器只看策略最新的数据:
- 可能会"忘记"真实数据的分布
- 导致训练不稳定
AMP 的方案:用回放缓冲区
维护一个缓冲区 B,存储策略历史轨迹
判别器训练时:
- 从参考数据集 M 采样一批数据
- 从回放缓冲区 B 采样一批数据
效果:
- 防止判别器过拟合
- 训练更稳定
5.4 训练算法
AMP 使用了 DeepMimic 提出的训练技巧:
训练技巧 1:参考状态初始化 (Reference State Initialization, RSI)
RSI 从参考动作数据集中随机选择初始状态,让策略早期接触"有希望的状态",加速学习高度动态动作(如后空翻、翻滚)。
训练技巧 2:提前终止 (Early Termination, ET)
当角色跌倒或身体部位(脚除外)接触地面时立即终止 episode,提高训练效率。
效果:
- 快速淘汰失败轨迹
- 让训练专注于成功的样本
- 大幅提升样本效率
#### 训练技巧 3:控制信号设计
不同的任务定义不同的控制信号表示方式:
例如:
- 目标方向任务:控制信号 = 目标方向 + 目标速度
- 目标位置任务:控制信号 = 目标位置坐标
- 击打任务:控制信号 = 目标位置 + 击打部位
控制信号拼接到当前状态,然后一起送入策略网络: 输入 = [状态 s_t, 控制信号 g]
算法 1: AMP 训练流程
输入:参考动作数据集 M
初始化:
- 判别器 D
- 策略 π
- 价值函数 V
- 回放缓冲区 B = ∅
循环直到收敛: 1. 收集数据: 用策略π收集 m 条轨迹{τ_i} 每条轨迹:τ_i = {(s_t, a_t, r^G_t), s_T, g} → 使用 RSI 和 ET (参考 DeepMimic 201)
2. 计算风格奖励:
对每个时间步 t:
- 查询判别器:d_t = D(Φ(s_t), Φ(s_{t+1}))
- 计算风格奖励:r^S_t (根据公式 7)
- 总奖励:r_t = w_G × r^G_t + w_S × r^S_t
→ 如果触发提前终止条件,episode 立即结束
3. 存储轨迹到回放缓冲区 B
4. 更新判别器 (n 次):
- 从 M 采样 K 个真实转换
- 从 B 采样 K 个策略转换
- 用公式 8 更新 D
5. 更新策略和价值函数:
- 用 PPO 更新策略π
- 用 TD(λ) 更新价值函数 V
### 5.5 任务设计
论文测试了多种任务:
#### 1. 目标方向 (Target Heading)
任务:朝目标方向以目标速度移动
奖励函数: r^G_t = exp(-0.25 × (v* - d* · v_com)²)
其中:
- v*: 目标速度 (1-5 m/s 随机)
- d*: 目标方向
- v_com: 角色质心速度
#### 2. 目标位置 (Target Location)
任务:走到目标位置
奖励函数: r^G_t = 0.7×exp(-0.5×||x* - x_root||²) + 0.3×exp(-(max(0, v* - d*·v_com))²)
第一部分:鼓励靠近目标 第二部分:鼓励以一定速度走向目标
#### 3. 运球 (Dribble)
任务:把足球运到目标位置
状态增强:
- 球的位置、朝向、线速度、角速度
奖励函数: r^G_t = 0.1×r_cv + 0.1×r_cp + 0.3×r_bv + 0.5×r_bp
分别鼓励:
- 靠近球
- 保持在球附近
- 把球往目标方向运
- 把球运到目标
#### 4. 击打 (Strike)
任务:用指定身体部位 (如手) 击中目标
奖励分三阶段:
- 距离目标远:鼓励走向目标
- 距离目标近 (<1.375m):鼓励出拳击中
- 击中后:常数奖励 1
这个任务需要组合走路和出拳两个技能!
#### 5. 障碍物 (Obstacles)
任务:穿越有障碍的地形
环境类型:
- 有沟壑、台阶、头顶障碍物
- 狭窄的垫脚石
状态增强:
- 前方地形的高度场 (100 个采样点,覆盖前方 10m)
需要组合跑步、跳跃、翻滚等技能!
---
## 6. 实验结果
### 6.1 多动作数据集实验
**实验设置**:
- 数据集:包含 56 个动作片段,8 个演员,共 434 秒动作数据
- 动作类型:走路、跑步、慢跑等
**结果**:
角色自动学会:
- 慢速时 (1m/s):走路
- 中速时 (2.5m/s):慢跑
- 快速时 (4.5m/s):跑步
而且还会:
- 转弯时身体倾斜 (像真人一样)
- 大方向变化前先减速
这些都是自动涌现的行为,不需要人工设计!
### 6.2 技能组合实验
#### 实验 1:走路 + 起身
数据集:走路动作 + 从地上爬起的动作
结果:
- 角色摔倒后能自动爬起来继续走
- 甚至学会了数据集里没有的"前滚翻起身"技巧
#### 实验 2:走路 + 出拳
数据集:纯走路动作 + 纯出拳动作 (没有"走到目标再出拳"的完整动作)
任务:击打目标
结果:
- 角色自动学会先走路接近目标
- 然后在合适距离出拳
- 两个技能无缝衔接
#### 实验 3:障碍赛跑
数据集:跑步动作 + 翻滚动作
任务:穿越障碍物
结果:
- 遇到沟壑:跳过去
- 遇到头顶障碍:滚过去
- 自动在不同技能间切换
### 6.3 与潜空间模型对比
潜空间模型 (Latent Space Model) 是另一种学习动作先验的方法
对比结果:
- 任务性能:两者相当
- 动作质量:AMP 更好
- 潜空间模型可能产生不自然的动作
- AMP 直接在动作层面约束,更可靠
- 训练效率:潜空间模型预训练需要 3 亿样本
- AMP 不需要预训练,联合训练即可
### 6.4 单动作模仿实验
**测试动作**:
后空翻、侧空翻、前空翻、翻滚、跳跃、跑步、走路、舞蹈、爬行、旋转踢...
**结果对比** (平均姿势误差,单位:米,越小越好):
| 动作 | 跟踪方法 | AMP |
|------|----------|-----|
| 后空翻 | 0.076 | 0.150 |
| 侧空翻 | 0.191 | 0.124 |
| 前空翻 | 0.278 | 0.425 |
| 跑步 | 0.028 | 0.075 |
| 走路 | 0.018 | 0.030 |
| 翻滚 | 0.072 | 0.088 |
**分析**:
- AMP 虽然没有跟踪方法那么精确,但质量相当接近
- 关键是 AMP 不需要人工设计奖励函数!
- 对于某些动作 (如侧空翻),AMP 甚至比跟踪方法更好
### 6.5 消融实验
测试各个组件的重要性:
| 组件 | 重要性 |
|------|--------|
| 梯度惩罚 | ⭐⭐⭐ 最关键!没有它训练会不稳定 |
| 速度特征 | ⭐⭐ 对某些动作 (如翻滚) 很重要 |
| 回放缓冲区 | ⭐⭐ 防止判别器过拟合 |
---
## 7. 总结与启发
### 7.1 核心贡献
1. **任务与风格分离**
- 任务奖励:简单的目标函数
- 风格奖励:用对抗学习自动学习
2. **无需动作选择器**
- 技能组合自动从动作先验中涌现
- 不需要人工设计"什么时候做什么动作"
3. **无需相位同步**
- 传统方法需要知道"当前在动作的哪个阶段"
- AMP 不需要,可以处理无序动作数据集
4. **高质量动作**
- 能学会动态、复杂的动作
- 质量接近传统跟踪方法
### 7.2 当前挑战
1. **动作自然程度的量化评估**
- 为动作的自然程度制定量化评估标准是一个挑战
- 当前主要依靠定性观察和简单的姿势误差指标
2. **运动规划器设计**
- 轨迹跟踪类算法通常需要搭配一个运动规划计算法
- 高效的运动规划器也是一个挑战
- AMP 的优势在于不需要显式的运动规划器
### 7.3 本文目标回顾
> 生成一种控制策略,使角色能够在物理模拟环境中实现任务目标,同时其行为方式会模仿数据集中存在的动作模式,但不要求角色严格的模仿某个特定的动作。
**核心设计哲学**:
- **高层次任务目标**:通过相对简单的奖励函数来指定 (RL)
- **低层次行为特征**:通过一组非结构化的运动视频片段来定义 (GAN,运动先验)
### 7.4 AMP 的核心优势
1. **从大规模非结构化数据集中学习**
- 能够从大规模的非结构化数据集中学习各种行为模式
- 无需借助动作规划器或其他机制来选择具体的动画片段
- 可以处理无序的动作片段数据集
2. **自动技能组合**
- 不同技能之间的组合会自动通过运动模型得以实现
- 不需要人工设计技能转换逻辑
- 例如:走路 + 出拳 → 自动学会先走近再出拳
3. **无需人工设计奖励机制**
- 完全不需要人工设计奖励机制
- 不需要控制器与参考动作之间的同步处理
- 不需要相位 (phase) 跟踪
4. **任务与风格解耦**
- 任务奖励只关心"做什么"(What)
- 风格奖励决定"怎么做"(How)
- 同一风格先验可以迁移到不同任务
### 7.5 局限性
1. **模式崩溃 (Mode Collapse)**
**表现**:给定大数据集时,可能只模仿一小部分动作,忽略其他可能更优的动作。
**为什么会出现模式崩溃?**
| 原因 | 说明 |
|------|------|
| **策略"偷懒"** | 找到一种能骗过判别器的动作,就不再探索其他模式 |
| **奖励单一** | 只有对抗奖励 r = -log(1-D),没有多样性鼓励 |
| **判别器太弱** | 只能区分"像不像",不能区分"多不多" |
**直观类比**:
场景:美食比赛
数据集 = {川菜,粤菜,鲁菜,淮扬菜...} 判别器 = 评委,判断"像不像中餐" 策略 = 厨师
模式崩溃: 厨师发现"做川菜就能拿高分" ↓ 于是只做川菜,不做其他菜系 ↓ 评委认为"川菜 = 中餐",给高分 ↓ 厨师继续只做川菜...
**AMP 中的具体表现**:
数据集:{走路,跑步,跳跃,翻滚}
训练后:
- 策略只学会走路(因为走路就能骗过判别器)
- 即使给任务奖励,也只会走路
**解决方案**:见 ASE (199) —— 通过互信息最大化强制学习多样化技能。
2. **先验需要重新训练**
**什么是"动作先验"?**
动作先验 = 判别器 D(s, s') 学到的"什么动作是自然的"知识
在 AMP 中:
- 判别器看参考动作数据 → 学会判断"这个动作自不自然"
- 这个判断能力就是"动作先验"
- 策略用这个先验作为风格奖励 r^S = -log(1-D)
**问题:每个任务都要重新训练判别器**
任务 1:走到目标 ├─ 训练判别器 D₁ (学习走路风格) └─ 训练策略 π₁
任务 2:运球 ├─ 重新训练判别器 D₂ (学习运球风格) └─ 重新训练策略 π₂
任务 3:击打目标 ├─ 重新训练判别器 D₃ └─ 重新训练策略 π₃
**为什么这是局限性?**
| 方法 | 任务 1 | 任务 2 | 任务 3 | 总时间 |
|------|--------|--------|--------|--------|
| **AMP** | T_pre + T_task | T_pre + T_task | T_pre + T_task | 3×(T_pre + T_task) |
| **理想** | T_pre + T_task | T_task | T_task | T_pre + 3×T_task |
- **T_pre**: 预训练动作先验的时间
- **T_task**: 任务训练时间
当有多个下游任务时,重复训练先验非常浪费时间。
**解决方案**:见 ASE (199) —— 预训练 + 迁移范式,判别器和低级策略固定,只训高级策略。
3. **时间组合 vs 空间组合**
- 擅长时间上的技能组合 (先 A 后 B)
- 空间组合 (同时做 A 和 B) 还需要研究
4. **风格先验的局限性**
- 对抗学习只能区分生成动作的风格是否像训练数据
- 但不能区分生成动作的好坏
- 如果训练数据质量差,它会把这种"差"当成它的风格来学习
5. **训练难度**
- GAN 和 RL 都很难训,它们的组合更难训
- 需要精心调参和技巧 (如梯度惩罚、经验回放等)
### 7.3 启发与应用
1. **游戏角色控制**
- 可以用少量动作数据训练出灵活的角色
- 角色能自动应对各种情况
2. **机器人控制**
- 可以用人类演示数据训练机器人
- 让机器人学会自然的动作
3. **动画制作**
- 动画师可以提供风格参考
- 系统自动生成符合风格的动画
### 7.4 关键公式汇总
**总奖励函数**:
r(s,a,s',g) = w_G × r^G(s,a,s',g) + w_S × r^S(s,s')
**风格奖励**:
r^S(s,s') = max[0, 1 - 0.25×(D(s,s')-1)²]
**判别器目标**:
minimize: E[(D-1)²] + E[(D+1)²] + (w_gp/2)×E[||∇D||²] 真实 虚假 梯度惩罚
---
## 附录:重要概念解释
### A. 什么是 PD 控制器?
PD = Proportional-Derivative (比例 - 微分)
物理引擎中的关节控制方式:
-
给关节一个目标角度 q_target
-
PD 控制器计算需要施加的力:
torque = Kp × (q_target - q_current) + Kd × (dq_target - dq_current)
Kp: 比例增益 Kd: 微分增益
作用:让关节角度追踪目标值
### B. 什么是指数映射 (Exponential Map)?
一种旋转表示方法:
- 用 3D 向量 q 表示旋转
- 向量方向 = 旋转轴
- 向量长度 = 旋转角度
优点:
- 没有万向节锁问题
- 比四元数更紧凑 (3D vs 4D)
- 平滑且唯一
### C. 什么是动态时间规整 (DTW)?
用于比较两个时间序列的相似度
问题:
- 模拟角色的动作可能比参考动作快或慢
- 直接比较会导致误差很大
DTW 的解决:
- 自动对齐两个序列
- 找到最优的时间对应关系
- 再计算对齐后的误差
用于评估 AMP 的模仿质量
---
## 参考资源
- **原论文**: https://doi.org/10.1145/3450626.3459670
- **项目页面**: https://xbpeng.github.io/projects/AMP/index.html
- **代码**: 论文发表时开源
---
*本解读文档由 AI 助手生成,旨在帮助初学者理解 AMP 论文的核心思想。如有不理解的地方,建议阅读原论文或访问项目页面获取更多信息。*
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
论文信息: ACM Transactions on Graphics (SIGGRAPH 2022), Xue Bin Peng et al., NVIDIA/UC Berkeley/University of Toronto
Link: arXiv:2205.01906
一、核心问题
1.1 研究背景
人类能够完成各种复杂的运动任务,这得益于我们通过多年练习积累的大量通用运动技能库(general-purpose motor skills)。这些技能不仅能让我们执行复杂任务,还能为学习新任务提供强大的先验指导(priors)。
然而,传统的基于物理的角色动画方法采用的是从零开始训练(tabula rasa approach)的范式:
- 每个新任务都要重新训练一个专用的控制策略
- 即使是走路、跑步这样的基础技能,也要为每个新任务重新学习
- 需要大量手动设计奖励函数,工程工作量巨大
1.2 核心问题
如何赋予智能体大量通用的、可复用的技能库,使其能够灵活地应用于各种新任务?
灵感来自计算机视觉和 NLP 领域:这些领域通过大规模预训练 + 下游任务微调的范式取得了巨大成功。论文希望将这种范式引入到物理角色控制领域。
1.3 现有方法及其局限性
| 方法类型 | 代表性工作 | 局限性 |
|---|---|---|
| 基于优化的方法 | 轨迹优化、强化学习 | 需要手动设计奖励函数,工作量大;不同技能需要不同的启发式设计 |
| 基于运动跟踪的方法 | 跟踪参考动作数据 | 难以应用于大规模多样化数据集;需要运动规划器来选择跟踪哪个动作 |
| 对抗运动先验 (AMP) | Peng et al. 2021 | 虽然能从无结构数据集学习,但每个任务都要从头训练 |
| 层次化模型 | 先训练低级技能再组合 | 通常使用运动跟踪,限制了模型产生数据集中未出现行为的能力 |
| 无监督强化学习 | 最大化互信息技能发现 | 在复杂高维系统中难以发现有用的行为;难以产生自然的人体运动 |
1.4 本文方法
论文提出了 ASE (Adversarial Skill Embeddings,对抗技能嵌入) 框架:
核心思想:
- 预训练阶段:从大规模无标注动作数据集中学习一个通用的低级技能策略 \(\pi(a|s, z)\)
- 使用对抗模仿学习 + 无监督技能发现
- 学习多样化的技能库,而不需要精确匹配任何特定动作
- 任务训练阶段:针对新任务训练一个高级策略 \(\omega(z|s, g)\)
- 通过指定潜在技能变量 \(z\) 来控制低级策略
- 不需要额外的动作数据
关键创新:
- 结合了对抗模仿学习(保证运动质量)和无监督强化学习(保证技能多样性)
- 使用连续潜在空间表示技能,支持技能之间的平滑插值
- 能够从超过 100 个多样化动作片段的大规模数据集中学习
二、核心贡献
-
可扩展的对抗模仿学习框架
- 使物理模拟角色能够学习大量复杂、通用的运动技能
- 技能可以复用于广泛的下游任务
-
大规模无结构动作数据训练
- 能够处理包含 100+ 多样化动作片段的数据集
- 利用 NVIDIA Isaac Gym 并行模拟器,使用相当于十年的模拟经验进行预训练
-
提高技能多样性和迁移效果的设计决策
- 球形潜在空间设计
- 多样性目标函数
- 鲁棒的恢复策略
-
无需下游任务动作数据
- 预训练的低级策略可以使用简单的任务奖励函数完成各种任务
- 自动生成复杂自然的策略
三、大致方法
3.1 框架概述
flowchart TB
subgraph PreTraining["预训练阶段 (Pre-training)"]
M["动作数据集 M<br/>(无标注)"] --> D["判别器 D<br/>(真假判别)"]
M --> q["编码器 q<br/>(技能识别)"]
D --> pi["低级策略 π(a\|s,z)<br/>(技能条件策略)"]
q --> pi
end
subgraph Transfer["任务训练阶段 (Transfer)"]
g["任务目标 g"] --> omega["高级策略 ω(z\|s,g)"]
s["状态 s"] --> omega
omega --> pi_fixed["低级策略 π(a\|s,z)<br/>(预训练,固定)"]
pi_fixed --> output["输出:动作 a"]
end
3.2 两阶段训练
阶段 1:预训练 (Pre-training)
输入:无标注的动作片段数据集 \(M = {m_i}\)
目标:训练低级技能策略 \(\pi(a|s, z)\)
- \(s\): 状态(角色身体配置)
- \(a\): 动作(关节目标旋转)
- \(z\): 潜在技能变量
训练目标函数: $$\max_{\pi} -D_{JS}(d_{\pi}(s, s') || d_M(s, s')) + \beta I(s, s'; z | \pi)$$
- 第一项(模仿目标):鼓励策略产生真实行为,匹配数据集的边际状态转移分布
- 第二项(技能发现目标):鼓励策略学习多样化技能,最大化技能与行为的互信息
阶段 2:任务训练 (Transfer)
输入:任务特定的奖励函数 \(r_G(s, a, s', g)\)
目标:训练高级策略 \(\omega(z|s, g)\)
- 接收状态 \(s\) 和任务目标 \(g\)
- 输出潜在技能 \(z\) 来控制低级策略
关键:低级策略\(\pi\)在任务训练阶段保持固定,不需要动作数据
对比 AMP (198) 的"先验需要重新训练"问题:
| 方面 | AMP (198) | ASE (199) |
|---|---|---|
| 判别器 | 每任务重新训练 D | 预训练后固定,所有任务复用 |
| 低级策略 | 每任务重新训练 \(\pi\) | 预训练后固定 |
| 任务训练 | 完整训练 (D + \(\pi\)) | 只训高级策略 \(\omega\) |
| 样本效率 | ~50M 步/任务 | ~5M 步/任务 (10 倍提升) |
解决方案核心:
预训练阶段(一次性投资):
├─ 训练判别器 D (学习通用风格先验)
├─ 训练低级策略 π(a|s,z) (学习技能库)
└─ 完成后固定 D 和 π
任务训练阶段(可复用):
├─ 任务 1:只训练 ω₁(z|s,g₁),判别器 D 作为便携式先验
├─ 任务 2:只训练 ω₂(z|s,g₂),D 和 π 都不变
└─ 任务 3:只训练 ω₃(z|s,g₃),...
关键设计:判别器在任务训练时作为"便携式运动先验": $$r_t = w_G r_G(s, a, s', g) - w_S \log(1 - D(s, s'))$$
- \(D\) 的参数固定,不更新
- 提供风格奖励,保证动作质量
四、训练细节
强化学习基础:如需了解强化学习的完整数学框架(MDP、贝尔曼方程、价值函数等),请参考 DeepLearningNotes - 强化学习基础
4.1 对抗模仿学习
判别器训练
判别器\(D(s, s')\)用于区分数据集转移和策略产生的转移:
$$\min_D -\mathbb{E}{d_M}[\log D(s, s')] - \mathbb{E}{d_{\pi}}[\log(1 - D(s, s'))] + w_{gp}\mathbb{E}[||\nabla D||^2]$$
其中:
- \(d_M\): 数据集的状态转移分布
- \(d_{\pi}\): 策略的状态转移分布
- \(w_{gp}\): 梯度惩罚系数,提高训练稳定性
策略的对抗奖励
$$r_{adv} = -\log(1 - D(s_t, s_{t+1}))$$
4.2 技能发现目标
问题:AMP 的模式崩溃
在 AMP 中,策略可能只学会数据集的一部分技能(如只学会走路),因为:
- 对抗奖励 r = -log(1-D) 只鼓励"骗过判别器"
- 没有鼓励多样性的机制
- 策略"偷懒":找到一种能拿高分的动作就不再探索
ASE 的解决方案:互信息最大化
$$I(s, s'; z | \pi) = H(s, s' | \pi) - H(s, s' | z, \pi)$$
| 项 | 含义 | 作用 |
|---|---|---|
| H(s,s' | π) | 边际状态转移熵 | 整体行为要多样化 |
| H(s,s' | z, π) | 条件状态转移熵 | 每个技能要独特 |
直观理解:
最大化 I(s,s'; z | π) =
最大化 H(s,s' | π) 整体行为分布要广
- 最小化 H(s,s' | z, π) 每个技能的行为要集中
结果:
- z₁ → 走路(集中)
- z₂ → 跑步(集中)
- z₃ → 跳跃(集中)
- ...
- 所有 z 覆盖的行为 → 多样化
为什么互信息能让 z 控制行为?
关键问题:z 是随机采样的,怎么确保策略 π 的输出和 z 有关系?
没有互信息时会发生什么:
如果只用对抗奖励 r_adv = -log(1-D(s,s')):
1. 策略发现"走路"能骗过判别器
2. 不管 z 是什么,都输出"走路"
3. z 和行为没有关系 → z 失去控制能力
4. 模式崩溃:只学会一种技能
有互信息最大化时:
奖励 = r_adv + β × log q(z|s, s')
训练过程:
1. 策略 π(a|s, z) 尝试用不同 z 产生不同行为
2. 编码器 q(z|s, s') 尝试从行为中识别出 z
3. 如果 z₁ 和 z₂ 产生相同行为 → 编码器无法区分 → log q 变低 → 奖励变低
4. 策略被迫让不同 z 产生不同行为 → 建立 z 与行为的因果关系
迭代过程:
- 迭代 1:z₁→乱动,z₂→乱动,q 无法区分 → 奖励低
- 迭代 2:z₁→像走路,z₂→像跑步,q 开始区分 → 奖励变高
- 迭代 3:z₁→走路(确定),z₂→跑步(确定),q 准确识别 → 奖励最高
结果:z 控制了输出!
变分下界的意义: $$I(s, s'; z | \pi) \geq H(z) + \mathbb{E}{p(z)}\mathbb{E}{p(s,s'|z,\pi)}[\log q(z|s, s')]$$
| 项 | 含义 | 作用 |
|---|---|---|
| H(z) | 先验熵(固定) | z 是均匀采样,已经最大化 |
| E[log q] | 编码器识别准确度 | 最大化此项 = 强制 z 与行为相关 |
结论:z 本身没有意义,但通过互信息最大化,策略学会了让 z 有意义——不同 z 对应不同技能,z 就获得了控制能力。
技能编码器
由于潜在空间是超球面,使用von Mises-Fisher 分布: $$q(z|s, s') = \frac{1}{Z}\exp(\kappa \mu_q(s, s')^T z)$$
- \(\mu_q(s, s')\): 均值(归一化)
- \(\kappa\): 缩放因子
- \(Z\): 归一化常数
编码器训练目标: $$\max_q \mathbb{E}{p(z)}\mathbb{E}{d_{\pi}(s,s'|z)}[\kappa \mu_q(s, s')^T z]$$
技能编码器与 CVAE 的关系
ASE 的技能编码器借用了 CVAE(Conditional Variational Autoencoder) 的变分推断思想,但整体架构不是完整的 CVAE。
CVAE 的 ELBO: $$\log p(x) \geq \mathbb{E}{q(z|x)}[\log p(x|z)] - D{KL}(q(z|x) | p(z))$$
ASE 的变分互信息下界: $$I(s, s'; z | \pi) \geq H(z) + \mathbb{E}{p(z)}\mathbb{E}{p(s,s'|z,\pi)}[\log q(z|s, s')]$$
| 组件 | CVAE | ASE |
|---|---|---|
| Encoder | q(z|x) 从数据编码 z | q(z|s,s') 从行为编码 z |
| "Decoder" | p(x|z) 从 z 重建数据 | π(a|s,z) 从 z 生成动作 |
| 训练目标 | ELBO = 重建 - KL | 只有 E[log q](互信息下界) |
| KL 约束 | 需要(后验接近先验) | 不需要(z 先验固定均匀) |
| 潜在空间 | 高斯 N(0,I) | 球面 vMF 分布 |
关键区别:
-
ASE 没有完整的 Encoder-Decoder 结构
- CVAE:联合训练 Encoder + Decoder
- ASE:编码器 q 单独训练,策略 π 用 RL 训练(不是变分推断)
-
ASE 的策略 π 不是传统解码器
- CVAE 解码器:最大化重建似然 p(x|z)
- ASE 策略 π:最大化累积奖励(对抗奖励 + 互信息)
-
ASE 不需要 KL 散度项
- CVAE:需要 KL 约束后验接近先验
- ASE:z 的先验是固定均匀分布,不需要约束
总结:
ASE = GAN(判别器)+ CVAE 思想(编码器)+ RL(策略)
├─ 判别器 D(s,s'):来自 GAN,提供"动作质量"信号
├─ 编码器 q(z|s,s'):来自 CVAE 思想,用于互信息估计
└─ 策略 π(a|s,z) / ω(z|s,g):强化学习,不是变分推断
4.3 策略的最终训练目标
$$\begin{aligned} \max_{\pi} \mathbb{E}{p(Z)}\mathbb{E}{p(\tau|\pi,Z)} & \left[ \sum_{t=0}^{T-1} \gamma^t \left( -\log(1 - D(s_t, s_{t+1})) + \beta \log q(z_t|s_t, s_{t+1}) \right) \right] \ & - w_{div} \mathbb{E} \left[ \left( \frac{D_{KL}(\pi(\cdot|s,z_1), \pi(\cdot|s,z_2))}{D_z(z_1, z_2)} - 1 \right)^2 \right] \end{aligned}$$
最后一项是多样性目标,鼓励:
- 相似的潜在变量\(z_1, z_2\)产生相似的动作分布
- 不同的潜在变量产生不同的动作分布
多样性目标的作用:
| 问题 | 解决方案 |
|---|---|
| z 随机采样,可能与输出无关 | 多样性目标强制不同 z 产生不同行为 |
| 策略可能对 z 不敏感 | KL 散度项鼓励策略对 z 敏感 |
| 潜在空间可能不均匀 | 鼓励平滑插值,支持技能过渡 |
直观理解:
多样性目标 = (KL 散度 / z 距离 - 1)²
- 如果 z₁ 和 z₂ 很接近 (距离小)
→ KL 散度应该小 (行为相似)
→ 否则目标函数惩罚
- 如果 z₁ 和 z₂ 离得远 (距离大)
→ KL 散度应该大 (行为不同)
→ 否则目标函数惩罚
结果:潜在空间平滑,支持技能插值
4.4 潜在空间设计
球形潜在空间
选择:\(Z = {z : ||z|| = 1}\),均匀分布在球面上
采样方法: $$\bar{z} \sim \mathcal{N}(0, I), \quad z = \bar{z} / ||\bar{z}||$$
优势:
- 有界潜在空间,减少低质量样本
- 便于高级策略的探索 - 利用任务训练
- 支持技能插值
4.5 提高响应性的设计
问题
标准训练可能导致策略对潜在变量变化不响应(在 episode 开始时采样\(z_0\)后,后续改变\(z\)无效)
解决方案
-
时序潜在变量序列:\(Z = {z_0, z_1, ..., z_{T-1}}\)
- 每个时间步条件于不同的\(z_t\)
- 鼓励模型学习技能之间的转换
-
多样性目标:鼓励不同\(z\)产生不同行为
为什么需要时序潜在变量?
如果整个 episode 只用一个 z₀:
- 策略可能学会"忽略后续的 z"
- z 只在开始时有效,后续无法切换技能
使用时序序列 Z = {z₀, z₁, ..., z_{T-1}}:
- 每个时间步都条件于不同的 z_t
- 策略必须"时刻关注 z 的变化"
- 支持技能之间的平滑过渡
例如:
- t=0: z₀=走路 → 角色开始走路
- t=10: z₁=跑步 → 角色切换到跑步
- t=20: z₂=跳跃 → 角色跳跃
4.6 鲁棒恢复策略
训练技巧:在预训练时,每个 episode 有 10% 概率从随机跌倒状态开始
- 从随机高度和方向放下角色
- 学习从跌倒中恢复的策略
好处:恢复策略可以无缝集成到下游任务,不需要为每个新任务单独训练恢复能力
4.7 高级策略设计
动作空间设计
高级策略\(\omega\)输出未归一化的潜在变量\(\bar{z}\): $$\omega(\bar{z}|s, g) = \mathcal{N}(\mu_{\omega}(s, g), \Sigma_{\omega})$$
然后归一化:\(z = \bar{z} / ||\bar{z}||\) 后输入低级策略
探索 - 利用权衡:
- 训练初期:\(\mu_{\omega} \approx 0\),在球面上均匀采样(高探索)
- 训练后期:\(\mu_{\omega}\)远离原点,集中在有效技能(高利用)
- 通过调整距原点距离来控制技能分布的熵
z 与状态 s 的关系
关键理解:ASE 中 z 与状态 s 的关系在不同阶段是不同的。
| 阶段 | z 的来源 | z 与 s 的关系 |
|---|---|---|
| 预训练 | 从 p(z) 随机采样 | ❌ 无关(独立于 s) |
| 任务训练 | 从 ω(z|s,g) 采样 | ✅ 有关(通过 ω 关联) |
| 推理 | 从 ω(z|s,g) 采样 | ✅ 有关(通过 ω 关联) |
预训练阶段:
z 从球面均匀分布随机采样:
1. ž ~ N(0, I)
2. z = ž / ||ž||
3. 策略 π(a|s, z) 学习"对任何 z 都能执行"
关键:z 与 s 无关,策略必须学会"对于任何 z 都能执行对应技能"
→ 互信息最大化强制不同 z 产生不同行为
→ 学到真正解耦的技能库
任务训练/推理阶段:
z 从高级策略 ω(z|s,g) 输出:
1. ž ~ N(μ_ω(s,g), Σ_ω)
2. z = ž / ||ž||
3. 低级策略 π(a|s, z) 执行
关键:ω 学习"给定状态 s 和目标 g,应该用什么 z"
→ z 与 s 的关联是后天学习的,不是先验设计的
→ 高级策略可以灵活学习任何 z-s 映射
与 ControlVAE (202) 的区别: | 方面 | ASE (199) | ControlVAE (202) | |------|-----------|------------------| | 预训练先验 | p(z) 球面均匀(与 s 无关) | p(z|s) 状态条件高斯(与 s 有关) | | z 与 s 关联 | 后天学习(通过 ω) | 先天设计(通过 p(z|s)) | | 技能解耦 | 真正解耦(z 独立于 s) | 可能不够解耦 | | 灵活性 | 高(ω 可学习任何映射) | 低(p(z|s) 固定) |
ASE 的设计优势:
- 预训练时 z 与 s 无关 → 策略学会"对任何 z 都能执行" → 真正的技能库
- 任务训练时学习 ω(z|s,g) → 灵活适应不同任务需求
- 技能多样性由互信息保证,不是由先验设计
运动先验
为了提高下游任务的运动质量,使用预训练的判别器作为便携式运动先验:
$$r_t = w_G r_G(s_t, a_t, s_{t+1}, g) - w_S \log(1 - D(s_t, s_{t+1}))$$
- \(r_G\): 任务奖励
- \(-\log(1 - D)\): 风格奖励(来自判别器)
- 判别器参数在任务训练时固定
4.8 模型架构
| 组件 | 架构 |
|---|---|
| 低级策略 \(\pi\) | [1024, 1024, 512] FC + ReLU, 输出高斯分布 |
| 价值函数 \(V\) | [1024, 1024, 512] FC + ReLU, 单输出 |
| 编码器 \(q\) + 判别器 \(D\) | 共享网络,分离输出层 |
| 高级策略 \(\omega\) | [1024, 512] FC + ReLU |
4.9 角色模型
- 37 自由度人形角色
- 配备剑和盾
- 状态空间:120D(根高度、旋转、速度,关节旋转/速度,手脚位置等)
- 动作空间:31D(PD 控制器目标关节旋转)
4.10 训练算法
Algorithm 1: ASE 预训练
1: 输入 M: 参考动作数据集
2: D ← 初始化判别器
3: q ← 初始化编码器
4: π ← 初始化策略
5: V ← 初始化价值函数
6: while not done do
7: B ← ∅ 初始化数据缓冲区
8: for trajectory i = 1, ..., m do
9: Z ← 从 p(z) 采样潜变量序列 {z₀, z₁, ..., z_{T-1}}
10: τᵢ ← 用π和 Z 收集轨迹
11: 记录 Z 到 τᵢ
12: for t = 0, ..., T-1 do
13: r_t ← -log(1 - D(s_t, s_{t+1})) + β log q(z_t|s_t, s_{t+1})
14: 记录 r_t 到 τᵢ
15: end for
16: 存储 τᵢ 到 B
17: end for
18: 更新编码器 q (Eq. 13)
19: 更新判别器 D (Eq. 14)
20: 用 PPO 更新策略π和价值函数 V (Eq. 15)
21: end while
五、实验与结论
5.1 下游任务
论文设计了多种任务来评估模型能力:
(1) Reach(精确控制)
- 目标:将剑尖移动到目标位置
- 奖励:\(r_G = \exp(-5 ||x^* - x^{sword}||^2)\)
- 评估:物理数据驱动的逆运动学能力
(2) Speed(速度控制)
- 目标:沿目标方向以目标速度移动
- 目标速度范围:\(v^* \in [0, 7]\) m/s
- 评估:利用不同运动技能的能力
(3) Steering(转向控制)
- 目标:沿目标方向移动,同时面向目标朝向
- 评估:组合不同技能的能力
(4) Interact(交互任务)
- 目标:跑到目标位置并击倒它
- 评估:复杂任务规划和技能组合
5.2 实验结果
定性结果
- 角色能够自然地完成各种任务
- 技能库包含:行走、跑步、转身、蹲伏、踢腿、剑挥砍、盾击等
- 能够自动组合不同技能完成任务
定量结果
- 与从零训练的方法相比,样本效率显著提升
- 在复杂任务上成功率更高
- 运动质量更高(通过判别器评分)
5.3 消融实验
| 变体 | 描述 | 结果 |
|---|---|---|
| 无技能发现 | 只用对抗模仿 | 技能多样性降低 |
| 无多样性目标 | 移除\(w_{div}\)项 | 模式坍塌更严重 |
| 高斯潜在空间 | \(\mathcal{N}(0,I)\)而非球形 | 低质量样本更多 |
| 无恢复训练 | 不从跌倒状态开始 | 抗干扰能力弱 |
六、局限性
-
数据集依赖性
- 运动质量依赖于训练数据集的多样性
- 数据集中没有的运动类型难以生成
-
计算资源需求
- 需要大规模并行模拟(使用 NVIDIA Isaac Gym)
- 预训练时间长(相当于十年的模拟经验)
-
技能粒度
- 潜在空间的语义解释性有限
- 难以精确控制特定技能属性
-
任务范围
- 主要评估了 locomotion 和简单交互任务
- 更复杂的操作任务(如抓取物体)未充分探索
-
角色泛化
- 技能绑定到特定角色形态
- 迁移到不同体型的角色需要重新训练
-
预训练成本
- 预训练需要大量样本(约 1B 步)
- 但这是"一次性投资":训练完成后,所有下游任务可以复用
- 对比 AMP (198) 的"每个任务重新训练先验": | 方法 | AMP | ASE | |------|-----|-----| | 先验训练 | 每任务重新训练 | 预训练一次,所有任务复用 | | 10 个任务总时间 | 10×(T_pre + T_task) | T_pre + 10×(0.1×T_task) |
- 当有 5+ 下游任务时,ASE 的总训练时间显著低于 AMP
七、启发
7.1 方法学启发
-
预训练 + 微调范式在物理控制中的成功应用
- 类似于 NLP 和 CV 领域的 BERT、GPT 等预训练模型
- 为物理角色控制提供了一个通用基础模型
-
对抗学习 + 无监督学习的结合
- 对抗学习保证质量
- 无监督学习保证多样性
- 两者的平衡很重要
-
潜在空间设计的重要性
- 球形空间优于高斯空间
- 有界空间减少异常行为
- 便于探索 - 利用权衡的编码
7.2 工程实践启发
-
大规模并行训练的必要性
- 物理模拟需要大量样本
- GPU 并行模拟是关键
-
鲁棒性训练技巧
- 随机初始状态提高抗干扰能力
- 这种简单技巧非常有效
-
模块化设计
- 低级策略固定,只需训练高级策略
- 降低下游任务的训练难度
7.3 与其他工作的联系
-
与 AMP (Adversarial Motion Priors) 的关系:
- AMP 每个任务从头训练,ASE 预训练可复用
- ASE 可以看作 AMP 的扩展和改进
-
与 DILOW/VAE 等表示学习的关系:
- 都使用互信息最大化
- ASE 专门针对物理控制设计
-
与 DeepLoco (2017) 的关系:
- 两者都使用分层 RL 架构
- 但分层目的和训练方式不同(见 8.1.1 节详细对比)
八、与相关工作的对比
8.1 ASE vs AMP:核心区别
ASE (2022) 是 AMP (2021) 的直接扩展,两者都来自同一研究团队(Xue Bin Peng et al.)。
核心洞察:
两篇论文都使用了类似的对抗训练方式(GAIL 变体),但解决的问题不同。
- AMP:解决动作评价问题——用对抗学习替代人工设计的跟踪误差函数
- ASE:解决技能复用问题——让学到的技能可以复用于多个下游任务
(0) 核心问题对比
| 维度 | AMP (2021) | ASE (2022) |
|---|---|---|
| 核心问题 | 如何让动作评价无需人工设计 | 如何让技能可以复用于多个任务 |
| 要解决的痛点 | 跟踪方法需要精心设计误差函数、相位同步、动作选择器 | AMP 每任务从零训练,无法复用已学技能 |
| 解决方案 | 对抗运动先验(判别器自动评价动作质量) | 预训练技能库 + 两阶段训练 |
| 类比 | 评价标准从"人工规则"变成"像不像视频" | 先学基本功,新任务只学怎么组合基本功 |
(1) 训练范式对比
| 维度 | AMP | ASE |
|---|---|---|
| 训练阶段 | 单阶段(联合训练策略 + 判别器) | 两阶段(预训练 + 任务训练) |
| 潜在空间 | 无 | ✓ 球形潜在空间 \(Z={z: |
| 技能多样性 | 依赖数据集 | 对抗模仿 + 互信息最大化 |
| 技能复用 | ✗ 每任务重新训练 | ✓ 低级策略固定 |
| 数据规模 | 单任务小数据集 | 100+ 动作片段 |
| 编码器 | ✗ | ✓ \(q(z |
| 多样性目标 | ✗ | ✓ 鼓励不同\(z\)产生不同行为 |
(2) 目标函数对比
AMP 的训练目标: $$\max_{\pi} \mathbb{E}\left[\sum \gamma^t \left(w_G r^G_t + w_S r^S_t\right)\right]$$
- \(r^G\): 任务奖励
- \(r^S = -\log(1-D(s,s'))\): 风格奖励
ASE 的预训练目标: $$\max_{\pi} -D_{JS}(d_{\pi} || d_M) + \beta I(s, s'; z | \pi)$$
- 第一项:对抗模仿(同 AMP)
- 第二项:互信息最大化(新增,用于技能发现)
ASE 的任务训练奖励: $$r_t = w_G r_G(s,a,s',g) - w_S \log(1 - D(s, s'))$$
- 判别器\(D\)作为便携式运动先验(预训练后固定)
(3) 架构对比
AMP 架构:
flowchart LR
s["状态 s + 控制信号 g"] --> pi["策略 π(a|s,g)"]
pi <--> D["判别器 D(s,s')"]
pi --> pd["PD 控制器"]
pd --> sim["物理仿真"]
ASE 架构:
flowchart TB
subgraph PreTrain["预训练阶段"]
s1["状态 s + 技能 z"] --> pi_pre["低级策略 π(a|s,z)"]
pi_pre <--> D_pre["判别器 D(s,s')"]
s1 --> q["编码器 q(z|s,s')"]
q --> D_pre
end
subgraph TaskTrain["任务训练阶段"]
s2["状态 s + 任务目标 g"] --> omega["高级策略 ω(z|s,g)"]
omega --> z_out["技能 z"]
z_out --> pi_fixed["低级策略 π(a|s,z)<br/>(固定)"]
pi_fixed --> pd2["PD 控制器"]
pd2 --> sim2["物理仿真"]
end
(4) 训练效率对比
| 方法 | 预训练样本 | 任务训练样本 | 每任务训练时间 |
|---|---|---|---|
| AMP | N/A | ~50M 步 | T |
| ASE | ~1B 步 | ~5M 步/任务 | T_pre + n × 0.1T |
结论:当有 10+ 下游任务时,ASE 的总训练时间显著低于 AMP。
(5) 技能多样性对比
AMP 的模式坍塌问题:
给定大数据集(走路、跑步、跳跃...)
AMP 可能只学会其中一小部分技能
忽略其他动作
ASE 的解决方案:
互信息最大化:I(s, s'; z | π) = H(s,s'|π) - H(s,s'|z,π)
- 最大化边际熵:整体行为要多样
- 最小化条件熵:每个技能要独特
结果:
z₁ → 走路,z₂ → 跑步,z₃ → 跳跃...
(6) 核心设计哲学对比
| 问题 | AMP 的方案 | ASE 的方案 |
|---|---|---|
| 如何保证动作质量? | 判别器区分真实/生成 | 同左(预训练后固定) |
| 如何保证技能多样? | 依赖数据集多样性 | 互信息最大化 + 多样性目标 |
| 如何实现技能组合? | 任务奖励引导自动涌现 | 高级策略组合低级技能 |
| 如何复用先验知识? | ✗ 每任务重新训练 | ✓ 低级策略固定 |
| 如何适应新任务? | 完整重新训练 | 只训高级策略 |
(7) AMP 的局限性 → ASE 的动机
AMP 论文中明确指出的问题(原文引用):
"当前工作的局限性:
- 动作先验需要针对每个任务从零开始训练
- 理想情况下,动作先验应该可以迁移到不同任务"
ASE 的解决方案:
预训练阶段:
- 学习通用技能库 π(a|s,z)
- 使用互信息最大化保证多样性
- 训练判别器作为"便携式运动先验"
任务训练阶段:
- 固定低级策略 π
- 只训练高级策略 ω(z|s,g)
- 样本效率提升约 10 倍
(8) 两篇论文的关系
flowchart TB
subgraph AMP["AMP (2021)"]
direction TB
A1["对抗模仿学习"]
A2["任务 + 风格分离"]
A3["无需动作选择器"]
A4["核心贡献:动作评价无需人工设计"]
end
subgraph ASE["ASE (2022)"]
direction TB
B1["继承 AMP 的对抗学习"]
B2["新增:预训练范式"]
B3["新增:技能发现(互信息)"]
B4["新增:可复用技能库"]
B5["核心贡献:技能可复用"]
end
AMP --> ASE
style AMP fill:#e1f5fe
style ASE fill:#fff3e0
关键洞察:
- ASE 是 AMP 的自然扩展:同一团队在 AMP 基础上的迭代工作
- 训练方式相似:都用了对抗模仿学习(GAIL 变体)
- 解决的问题不同:
- AMP:如何让动作更自然、无需人工设计奖励
- ASE:如何让学到的技能可以复用于多个任务
8.1.1 理解 AMP 与 ASE 的类比
想象学习做菜:
AMP (2021) 解决的问题:
┌─────────────────────────────────────────┐
│ 传统方法:需要厨师长详细告诉你 │
│ "盐放多少克、炒多久" │
│ ↓ │
│ AMP:给你看一些菜的视频,你自动学会 │
│ "像这样炒菜" │
│ ↓ │
│ 核心:评价标准从"人工规则" │
│ 变成"像不像视频" │
└─────────────────────────────────────────┘
ASE (2022) 解决的问题:
┌─────────────────────────────────────────┐
│ AMP 的问题:每学一道新菜都要从头看视频 │
│ ↓ │
│ ASE:先花几年学会各种基本功 │
│ (切、炒、蒸、煮)→ 预训练 │
│ ↓ │
│ 新任务:只需要学"怎么组合基本功" │
│ 不需要重新学基本功 → 微调 │
│ ↓ │
│ 核心:基本功可以复用 │
└─────────────────────────────────────────┘
8.2 ASE vs 其他物理控制方法
(1) 与 DeepMimic 对比
| 维度 | DeepMimic | ASE |
|---|---|---|
| 训练方式 | 单技能跟踪 | 多技能预训练 |
| 数据需求 | 每技能一个动捕片段 | 大规模无标注数据集 |
| 奖励设计 | 需要精确跟踪奖励 | 对抗奖励 + 互信息 |
| 技能复用 | ✗ | ✓ |
(2) 与 Feature-Based Control 对比
| 维度 | Feature-Based | ASE |
|---|---|---|
| 设计方式 | 手工设计特征 + 优化 | 数据驱动学习 |
| 动作质量 | 中等(动态性差) | 极高(接近动捕) |
| 泛化能力 | 低(每动作重新设计) | 高(预训练可复用) |
(3) 与 ControlVAE 对比
| 维度 | ControlVAE | ASE |
|---|---|---|
| 先验类型 | 状态条件高斯 | 球面均匀分布 |
| 学习方式 | 世界模型 + ELBO | 对抗 + 互信息 |
| 技能表示 | 连续潜在空间 | 离散技能库(隐式) |
(4) 与 DeepLoco (218) 对比:分层 RL 的差异
ASE 和 DeepLoco 都使用分层 RL,但分层目的和训练方式完全不同:
| 维度 | DeepLoco (2017) | ASE (2022) |
|---|---|---|
| 分层目的 | 时间尺度分离 | 技能抽象分离 |
| 高层频率 | 2Hz(每 0.5 秒决策) | 任务训练时(不限频率) |
| 低层频率 | 30Hz(每 0.033 秒执行) | 预训练后固定,推理时调用 |
| 高层输出 | 步法计划 (p̂₀, p̂₁, θ̂_root) | 技能代码 z(连续向量) |
| 低层输入 | 状态 + 步法目标 | 状态 + 技能代码 |
| 训练方式 | 分开训练(先 LLC 后 HLC) | 两阶段(预训练 + 任务训练) |
| 复用性 | 同一 LLC 可用于多个 HLC | 同一 π 可用于多个 ω |
| 接口设计 | 手工设计(两步位置 + 朝向) | 学习得到(潜在空间 z) |
| 参考动作 | 风格引导(r_pose 奖励) | 技能库来源(预训练数据) |
| 技能多样性 | 多个 LLC 风格(直腿、高抬腿等) | 单一 π 的连续潜在空间 |
DeepLoco 的分层逻辑:
时间尺度分离:
├─ HLC:宏观规划(往哪走)
└─ LLC:微观控制(怎么走)
好处:
- 同一个 LLC 可以被多个 HLC 任务复用
- 但每个 LLC 只能是一种风格
ASE 的分层逻辑:
技能抽象分离:
├─ 高级策略 ω:选择技能(用什么 z)
└─ 低级策略 π:执行技能(z 对应的行为)
好处:
- 单一 π 包含多样化技能库
- z 是连续空间,支持平滑插值
- 预训练后 π 固定,所有任务复用
关键区别:
- DeepLoco 的接口是手工设计的(步法计划),ASE 的接口是学习得到的(潜在变量 z)
- DeepLoco 需要多个 LLC实现不同风格,ASE 单一 π通过不同 z 实现多技能
- DeepLoco 的 LLC 不固定(每风格一个),ASE 的 π 完全固定(所有任务复用)
九、遗留问题
9.1 开放性问题
-
技能的可解释性
- 潜在空间的每个维度代表什么?
- 能否实现更细粒度的技能控制?
-
数据集扩展
- 如果使用更大规模数据集(如 AMASS)会怎样?
- 能否学习更复杂的技能(如体操动作)?
-
多角色泛化
- 能否训练一个模型适用于多个角色?
- 形态学变化的鲁棒性如何?
-
与语言模型的结合
- 能否用自然语言指定技能?
- 与 LLM 结合实现指令驱动的角色控制?
-
实时应用
- 推理速度能否满足游戏实时要求?
- 模型压缩和加速的可能性?
9.2 未来方向
-
层级强化学习的深化
- 更多层级的抽象
- 自动发现技能层级结构
-
多模态条件
- 结合视觉、语言、动作等多种条件
- 更丰富的交互方式
-
在线学习
- 任务执行过程中持续改进
- 适应新环境和扰动
十、关键公式总结
| 公式 | 含义 |
|---|---|
| \(\max_{\pi} -D_{JS}(d_{\pi} || d_M) + \beta I(s,s';z | \pi)\) | 预训练总目标 |
| \(r_{adv} = -\log(1 - D(s, s'))\) | 对抗奖励 |
| \(I(s, s'; z | \pi) = H(s, s' | \pi) - H(s, s' | z, \pi)\) | 互信息分解 |
| \(r_t = w_G r_G(s, a, s', g) - w_S \log(1 - D(s, s'))\) | 任务训练奖励 |
十一、代码与资源
- 项目主页: https://xbpeng.github.io/projects/ASE/
- 代码: 项目主页提供
- 数据集: 论文未公开具体数据集,但表示代码和数据将公开
笔记说明:本文是 SIGGRAPH 2022 的重要工作,将预训练范式引入物理角色控制,对后续研究影响深远。理解本文有助于学习后续的 Physics-Based Character Control 相关方法。第八部分详细对比了 ASE 与 AMP 及其他相关工作的区别,并解释了两者解决的核心问题差异。
Feature-Based Locomotion Controllers
论文信息: ACM SIGGRAPH 2010, Martin de Lasa, Igor Mordatch, Aaron Hertzmann, University of Toronto
Link: 项目主页
一、核心问题
1.1 研究背景
基于物理的角色动画中,创建有效、灵活且真实的运动控制器(locomotion controllers)一直是一个开放性问题。
传统方法的困境:
- 大多数方法使用关节空间(joint-space)表示
- 控制参数化在个体关节动作层面
- 关节动作之间高度非线性和相互依赖
- 难以表达协调的或有风格的动作
- 修改控制器以适应新角色、新风格需要大量重新调整
1.2 核心问题
如何设计一种控制器表示方法,使其具有:
- 直观性 - 控制参数对应直观的高层属性
- 灵活性 - 易于修改风格、适应新角色
- 鲁棒性 - 对身体参数变化不敏感
- 可复用性 - 控制器可以在不同角色间迁移
1.3 现有方法及其局限性
| 方法类型 | 代表工作 | 局限性 |
|---|---|---|
| 关节空间方法 | PD 伺服 + 状态机 | 动作僵硬;难以调整;需要大量手动调参 |
| 基于优化的方法 | 轨迹优化 | 每个新角色/控制器都需要昂贵的优化过程 |
| 运动捕捉驱动 | Mocap 跟踪 | 局限于与记录数据相似的动作;难以适应扰动 |
| 零空间投影 | 机器人操作空间控制 | 难以处理单侧约束;复杂且受限 |
| **二次规划 **(QP) | Abe et al. 2007 | 使用加权组合,目标之间会"打架";难以调参 |
1.4 本文方法
论文提出了一种基于特征(Feature-Based)的控制器设计方法:
核心思想:
- 控制用高层特征表示,如质心 (COM)、角动量 (AM)、末端执行器位置
- 每个特征用一个目标函数控制
- 多个目标通过优先级优化算法组合
关键创新:
- 特征表示:用少量直观特征表达复杂运动
- 优先级优化:严格优先级顺序,避免目标冲突
- 角动量控制:新的公式,不需要显式指定压力中心 (COP)
- 无需动作捕捉:所有控制器都是手工设计的,不需要 mocap 或离线优化
二、核心贡献
-
基于特征的控制框架
- 用高层物理特征(COM、AM、末端执行器)表达控制
- 直观、易理解、易修改
-
优先级优化算法
- 扩展了 Kanoun et al. 2009 和 de Lasa & Hertzmann 2009 的工作
- 同时处理加权目标、严格优先级和单侧约束
- 比加权组合更鲁棒、更易设计
-
三种 locomotion 控制器
- 平衡控制器 (Balancing)
- 站立跳跃控制器 (Standing Jump)
- 行走控制器 (Walking)
-
演示多种优势
- 自然属性自动涌现(手臂摆动、脚跟抬起、髋肩反向旋转)
- 对身体参数变化鲁棒
- 控制器可以迁移到完全不同拓扑的角色
- 运行时可修改风格
三、大致方法
3.1 方法概述
┌─────────────────────────────────────────────────────────────────┐
│ Feature-Based Control Pipeline │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 1. 定义特征 (Features) │
│ - 质心 (COM) │
│ - 角动量 (AM) │
│ - 末端执行器 (End-effectors) │
│ │
│ 2. 为每个特征定义目标函数 (Objectives) │
│ - Setpoint 目标 │
│ - Target 目标 │
│ - Angular Momentum 目标 │
│ - Minimum Torque 目标 │
│ │
│ 3. 优先级优化 (Prioritized Optimization) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Priority 1: E_contact (保持脚接触地面) │ │
│ │ Priority 2: E_COM∥ (保持 COM 在支撑面上方) │ │
│ │ E_COM⊥ (控制 COM 高度) │ │
│ │ Priority 3: E_AM (最小化角动量变化) │ │
│ │ E_pose (关节回到休息姿势) │ │
│ │ Priority 4: ... │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 4. 求解优化问题 → 得到关节力矩 τ 和关节加速度 ¨q │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 特征与目标函数
未知变量向量
在每一帧,控制器求解: $$x = \begin{bmatrix} \tau^T & \ddot{q}^T & \lambda^T \end{bmatrix}^T$$
- \(\tau\): 关节力矩
- \(\ddot{q}\): 关节加速度
- \(\lambda\): 摩擦力锥基底权重
四种目标函数
(1) Setpoint 目标 - 保持特征在某个值
$$E(x) = ||\ddot{y}_d - \ddot{y}||^2$$
其中:
- \(y = f(q)\) 是特征(如 COM 位置)
- \(\ddot{y}_d = k_p(y_r - y) - k_v\dot{y}\) 是期望加速度
- \(y_r\) 是目标值
用途:保持 COM 在脚上方、保持头部稳定等
(2) Target 目标 - 移动到远处目标
直接应用 Setpoint 目标会产生大的冲力。论文提出通过求解边界值问题来计算期望加速度:
给定:
- 当前状态:\((y_0, \dot{y}_0)\)
- 目标状态:\((y_T, \dot{y}_T)\)
- 时间:\(T\)
求解常数 \(a, b\) 使得: $$\ddot{y}_d(t) = \left(1-\frac{t}{T}\right)a + \frac{t}{T}b$$
通过积分得到线性系统: $$\begin{bmatrix} T^2/3 & T^2/6 \ T/2 & T/2 \end{bmatrix} \begin{bmatrix} a \ b \end{bmatrix} = \begin{bmatrix} y_T - y_0 - \dot{y}_0 T \ \dot{y}_T + \dot{y}_0 \end{bmatrix}$$
用途:跳跃时 COM 高度控制、行走时脚在落脚点间移动
(3) Angular Momentum 目标 - 控制角动量
$$E_{AM}(x) = ||\dot{L}_d - \dot{L}||^2$$
$$\dot{L}_d = k_p(L_r - L)$$
- \(L_r\): 参考角动量(平衡/行走时设为 0)
- \(L = P J \dot{q}\): 关于 COM 的角动量
创新点:
- 不需要指定压力中心 (COP)
- 不依赖接触力知识
- 适用于平衡、跳跃、行走
(4) Minimum Torque 目标 - 最小化关节力矩
$$E_{\tau}(x) = ||\tau||^2 = ||\begin{bmatrix} S & 0 \ 0 & I \end{bmatrix} x||^2$$
- \(S\): 选择矩阵(对角为 1 的关节是被动的)
用途:行走时让手臂自然摆动(最小化肩/肘力矩)
3.3 优先级优化
问题:加权组合的缺陷
传统方法使用加权组合: $$E(x) = \sum_i \alpha_i E_i(x)$$
问题:
- 不同目标会"打架"
- 调参困难
- 数值敏感
解决方案:优先级优化
给定有序目标列表 \(E_1, E_2, ..., E_N\),递归定义为:
$$h_i = \min_x E_i(x)$$ $$\text{subject to } E_k(x) = h_k, \forall k < i$$ $$C(x) = 0, Dx + f \geq 0$$
含义:
- 第一步:\(\min E_1(x)\),受动力学约束
- 第二步:\(\min E_2(x)\),受\(E_1(x) = h_1\)约束
- 依此类推...
高效求解算法
关键观察:二次最优解位于线性子空间上
方法 1:线性约束法 (Kanoun et al. 2009)
- 将 \(E_k(x) = h_k\) 转换为线性约束 \(A_k(x - x^*_k) = 0\)
- 用 N 个 QP 递归求解
- 缺点:约束数量增加导致数值不稳定
方法 2:重参数化法 (本文采用)
对于 \(E_1(x) = ||A_1 x - b_1||^2\),最优解空间参数化为: $$x(w) = C_1 w + d_1$$
- \(C_1 = \text{null}(A_1)\):零空间基底(通过 SVD 计算)
- \(d_1\): 满足约束的任意最小解(通过 QP 求解)
然后第二个目标重参数化为: $$E_2(w) = ||A_2 C_1 w + A_2 d_1 - b_2||^2$$
求解第二个 QP: $$d_2 = \arg\min_w E_2(w)$$ $$\text{subject to } D C_1 w + D d_1 + f \geq 0$$
最终解:\(x^* = C_1 d_2 + d_1\)
完整算法
Algorithm 1: Constrained Quadratic Prioritized Solver
输入:N 个目标 (A_i, b_i),约束 (C, D, f)
输出:最优解 x*
1: C̄ ← I, d̄ ← 0
2: for i = 1 to N do
3: Ā_i ← A_i C̄
4: b̄_i ← b_i - A_i d̄
5: d_i ← argmin_w ||Ā_i w - b̄_i||²
6: subject to D' C̄ w + D' d̄ + f' ≥ 0
7: if 问题不可行 then
8: return d̄
9: end
10: d̄ ← d̄ + C̄ d_i
11: if Ā_i 满秩 then
12: return d̄
13: end
14: C̄ ← C̄ null(Ā_i)
15: end
16: return d̄
四、训练(控制器设计)
4.1 平衡控制器
目标优先级:
| 优先级 | 目标 | 作用 |
|---|---|---|
| 1 | \(E_{contact}\) | 保持脚接触地面 |
| 2 | \(E_{COM|}\) | 保持 COM 在支撑面上方 |
| \(E_{COM\perp}\) | 控制 COM 高度 | |
| 3 | \(E_{AM}\) | 最小化角动量变化 |
| \(E_{pose}\) | 关节伺服到休息姿势 | |
| \(E_{ankle}\) | 踝关节相对 COM 控制(跳跃时用) |
设计细节:
优先级 1:脚接触
- Setpoint 目标
- 目标值:脚底点投影到地面
优先级 2:线性动量调节
- \(E_{COM|}\): COM 水平分量 → BOS 质心
- \(E_{COM\perp}\): COM 垂直分量 → 80% 最大 COM 高度
优先级 3:剩余冗余
- \(E_{AM}\): 阻尼不需要的旋转
- \(E_{pose}\): 中性姿势(膝盖微弯)
4.2 跳跃控制器
状态机:
STAND → COMPRESS → THRUST → ASCENT → DESCENT → IMPACT → STAND
各阶段动作:
| 状态 | COM 控制 | 接触目标 | 踝关节目标 |
|---|---|---|---|
| STAND | 站立高度 | 启用 | 禁用 |
| COMPRESS | 降低(蹲下) | 启用 | 禁用 |
| THRUST | 快速升高 | 启用 | 禁用 |
| ASCENT | 禁用 | 禁用 | 启用(固定相对 COM) |
| DESCENT | 禁用 | 禁用 | 启用(匹配地面斜率) |
| IMPACT | 重新启用 | 重新启用 | 禁用 |
跳跃变体:
(1) 扭转跳跃
- 在 THRUST 阶段指定非零垂直角动量
- \(L_r \neq 0\) 产生旋转
(2) 空中踢腿/劈叉
- 在飞行阶段改变 \(y_{ankle}^r\)
- 围绕用户指定轴旋转踝偏移
(3) 向前跳跃
- THRUST 阶段在行进方向命令小的 COM 位移
- 飞行阶段修改踝轨迹准备落地
4.3 行走控制器
状态依赖目标
脚控制状态机:
每只脚:SWING → PLANT → SUPPORT → HEELOFF → SWING...
脚控制目标:
-
接触状态 (PLANT, SUPPORT, HEELOFF): \(E_{contact}\)
- 脚的前/后/四个角保持接触
-
摆动状态 (SWING): \(E_{swing}\) (Target 目标)
- 抬脚到步高\(h\),然后向前移动
- 脚跟和脚趾分别控制
摆动脚目标位置: $$y_{swing|}^r = y_{stance} - 2\alpha l_{hip} d_{\perp} + l_{step} d_{|}$$
- \(l_{step}\): 步长
- \(l_{hip}\): 髋部移动
- \(d_{|}\): 行进方向
- \(d_{\perp}\): 垂直方向
COM 控制:
COM 沿正弦路径前进: $$y_{COM|}^r(\phi) = \phi p_1 + (1-\phi)p_0 + \alpha l_{hip}\sin(\pi\phi)d_{\perp}$$
- \(\phi \in [0,1]\): 相位变量
- \(p_0, p_1\): 初始和目标位置
同步机制:
- COM 轨迹持续时间 = 上一摆动相持续时间
- 简单的反馈机制鼓励稳定极限环
状态独立目标
| 优先级 | 目标 | 任务 |
|---|---|---|
| 1 | \(E_{contact}\) | 保持支撑脚接触 |
| 2 | \(E_{COM|}\) | COM 平行地面移动 |
| \(E_{trunk|}\) | 控制颈部相对 COM 位置 | |
| 3 | \(E_{swing}\) | 控制摆动脚 |
| \(E_{AM}\) | 阻尼角动量 | |
| \(E_{pose}\) | 关节伺服到休息姿势 | |
| \(E_{arms}\) | 最小化手臂力矩 | |
| \(E_{head}\) | 稳定头部方向 |
行走参数(可运行时调整):
| 参数 | 符号 | 范围 |
|---|---|---|
| 摆动持续时间 | \(T\) | 0.3 - 0.7 s |
| 步长 | \(l_{step}\) | 0 - 0.7 m |
| 步高 | \(h\) | 0 - 0.1 m |
| 脚间距 | \(l_{foot}\) | 0 - 0.03 m |
| 摆动延迟 | \(\Delta T\) | 0 - 0.3 s |
| 髋部移动 | \(l_{hip}\) | 0 - 0.3 m |
| COM 偏移 | \(l_{trunk}\) | ±0.3 m |
| 头部方向 | \(q_{head}\) | ±180° |
4.4 动力学约束
等式约束
运动方程: $$M(q)\ddot{q} + h(q, \dot{q}) = \tau + J_c^T f_c$$
- \(M\): 关节空间惯量矩阵
- \(h\): Coriolis/离心力和重力
- \(J_c\): 接触力雅可比
- \(f_c = V\lambda\): 摩擦力锥基底表示的接触力
整理得到: $$C(x) = \begin{bmatrix} I & -M & J_c^T V \end{bmatrix} x - h = 0$$
不等式约束
地面接触:
- 接触力必须严格排斥
- 尊重摩擦约束
- 使用非穿透约束(比零加速度约束更稳定)
$$\lambda \geq 0$$ $$a_c = V^T J_c \ddot{q} + V^T \dot{J}_c \dot{q} + \dot{V}^T J_c \dot{q} \geq 0$$
关节限制:
- 当关节到达限制时添加额外约束
- 防止不自然姿势
力矩限制: $$-\tau_{max} \leq \tau \leq \tau_{max}$$
五、实验与结论
5.1 实现细节
- 模拟器: Featherstone 算法 + 半隐式积分
- 地面接触: 非弹性脉冲模型,摩擦系数μ=1
- 性能: Dual Core 3GHz Xeon, 4GB RAM, 50-100% 实时
- 角色: 35 DOF, 北美男性 50 百分位
5.2 结果展示
平衡与跳跃
- 从平衡控制器到跳跃控制器只需简单修改
- 仅改变 3 个参数(蹲下深度、推力时间、参考角动量)
- 控制器对骨骼属性变化鲁棒
- 着陆一致性好
行走风格
风格示例:
- 快走、慢走
- "悲伤"行走:手放口袋、头前倾、身体前倾、膝盖弯曲
风格修改的便捷性:
- 直接调整参数(表 2)
- 特征解耦:如躯干倾斜角不直接影响速度
- 可以运行时修改
身体形状变化
实验:
- 肢体放大 2 倍:质量、惯量相应缩放 → 控制器仍然工作
- 不同拓扑角色:婴儿、鸵鸟、恐龙 → 控制器无需修改
关键:特征独立于角色拓扑(除了休息姿势)
5.3 优先级优化 vs 加权优化
| 方面 | 优先级优化 | 加权优化 |
|---|---|---|
| 鲁棒性 | 高(外部扰动下更稳定) | 低(目标会"打架") |
| 设计难度 | 易(分层设计) | 难(需要精细调参) |
| 数值稳定性 | 需要双精度 | 单精度即可 |
| 计算速度 | 慢(需要 QP + SVD) | 快 |
| 实现复杂度 | 高 | 低 |
实验观察:
- 用加权优化无法生成跳跃动作(数值敏感、不可行)
- 行走控制器用加权优化时,手臂会"乱挥"
- 优先级优化下,跟踪误差被限制在高优先级目标
六、局限性
-
某些动作难以生成
- 需要大幅矢状面惯性变化的动作(如侧手翻、后空翻)
- 当前目标/优先级组合不足以表达
-
步行脚放置策略有限
- 运行时修改髋移、摆动时间、步长需要协调
- 必须确保 COM 足够靠近支撑脚
- 控制器对扰动的鲁棒性有限(因为轨迹在世界坐标定义)
-
计算成本
- 优先级优化比加权优化慢
- 每个优先级需要求解 QP + SVD
- 需要双精度算术保证数值稳定
-
实现复杂度
- 比加权优化更复杂
- 需要处理零空间计算、SVD 分解
-
约束切换敏感
- 接触点数量快速变化时可能产生噪声力矩
- 雅可比矩阵可能秩亏(机器精度级别)
七、启发
7.1 方法学启发
-
特征空间表示的优势
- 提供控制设计的抽象层
- 解耦不同控制目标
- 使推理运动更直观
-
优先级优化的设计哲学
- 分层设计:先保证基础(平衡),再添加细节(风格)
- 避免目标冲突
- 类似人类运动控制的"最小干预原理"
-
角动量控制的新公式
- 不需要 COP 轨迹
- 适用于多种运动模式
- 简化了实现
7.2 工程实践启发
-
无需动作捕捉或优化
- 所有控制器手工设计
- 降低了数据依赖
- 更易于理解和修改
-
参数直观性
- 参数对应物理量(如 COM 高度、步长)
- 调参过程更直观
- 风格可以在运行时修改
-
角色迁移能力
- 特征独立于拓扑
- 同一控制器可用于不同角色
- 自动计算雅可比和目标项
7.3 与后续工作的联系
- 本文是 Mordatch et al. 2010 "Robust Physics-Based Locomotion" 的基础
- 后续的 AMP、ASE 等工作采用数据驱动方法,但控制层次化思想一脉相承
- 优先级优化思想在机器人领域广泛应用
八、遗留问题
8.1 开放性问题
-
更复杂的动作
- 如何生成侧手翻、后空翻等需要大幅惯性变化的动作?
- 需要什么样的额外特征/目标?
-
更鲁棒的脚放置
- 如何设计对扰动更鲁棒的脚放置策略?
- 是否需要在线规划?
-
自动优先级学习
- 优先级顺序能否从数据中学习?
- 能否自动发现合适的特征?
-
与数据驱动方法结合
- 如何将特征空间方法与 mocap 数据结合?
- 能否学习特征目标函数?
-
实时应用
- 如何加速优先级优化以满足实时要求?
- 能否用近似方法?
8.2 未来方向
论文提到后续工作:
- Mordatch et al. 2010: 提出规划策略解决脚放置问题
- 扩展到更多运动类型(投掷、操作物体)
- 结合学习和优化
九、关键公式总结
| 公式 | 含义 |
|---|---|
| \(E_{setpoint} = | |
| \(\ddot{y}_d = k_p(y_r - y) - k_v\dot{y}\) | PD 控制律 |
| \(E_{AM} = | |
| \(h_i = \min_x E_i(x)\) s.t. \(E_k(x)=h_k\) | 优先级优化 |
| \(x(w) = C_1 w + d_1\) | 重参数化 |
十、代码与资源
- 项目主页: http://www.dgp.toronto.edu/~mdelasa/feature
- 视频: 项目主页提供演示视频(平衡、跳跃、行走、不同风格、不同角色)
- 代码: 未公开
笔记说明:本文是基于物理的角色控制领域的经典工作,提出了基于特征的控制框架。理解本文有助于学习后续的 Physics-Based Character Control 方法,特别是理解控制层次化、优先级优化等核心概念。与 ASE、AMP 等数据驱动方法相比,本文代表了手工设计控制器的巅峰。
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
论文信息: ACM Transactions on Graphics (SIGGRAPH 2018), Xue Bin Peng et al., UC Berkeley/UBC
Link: 项目主页
一、核心问题
1.1 研究背景
基于物理的角色动画领域有一个长期目标:将数据驱动的行为指定与物理模拟执行系统相结合,从而实现:
- 对扰动的真实响应
- 对环境变化的适应能力
传统方法的局限:
| 方法类型 | 特点 | 局限性 |
|---|---|---|
| 运动跟踪控制器 | 显式跟踪参考动作 | 难以修改动作;恢复能力有限;实现复杂 |
| 手工设计奖励的 RL | 用强化学习合成控制器 | 动作不自然;需要大量人工设计奖励 |
| GAIL 等模仿学习 | 从数据学习奖励函数 | 运动质量仍不如传统动画方法 |
| DeepLoco (Peng 2017) | 添加模仿项到奖励函数 | 固定初始状态;仅适用于 locomotion |
数据使用方式对比:
| 方法 | 数据角色 | 使用方式 | 约束强度 | 灵活性 |
|---|---|---|---|---|
| 运动跟踪 | Ground Truth | 逐帧跟踪参考动作 | 硬约束 | 低 |
| 纯 RL | 不使用 | 仅靠奖励函数引导 | 无约束 | 高(但动作不自然) |
| GAIL | Discriminator 正样本 | 对抗学习区分真假 | 软约束 | 中 |
| DeepLoco | 奖励函数参考(模仿项) | r_pose 鼓励姿势接近参考动作 | 软约束 | 中(仅 locomotion) |
| DeepMimic | 奖励函数参考 | 直接奖励相似度 + RSI | 软约束 | 高 |
关键区别:
- 运动跟踪:数据是"必须跟随的轨迹",控制器被绑死在参考动作上
- 纯 RL:完全不使用动作数据,只靠奖励函数,容易产生"奇怪但有效"的步态
- GAIL:数据是"真样本",用于训练判别器,但训练不稳定
- DeepLoco:数据是"风格参考",通过 r_pose 奖励模仿,但固定初始状态,只能学 locomotion
- DeepMimic:数据是"鼓励相似的目标",策略有自由度调整动作以完成任务 + RSI 支持动态动作
1.2 核心问题
如何构建一个系统,能够:
- 接受艺术家或动捕演员提供的一组参考动作
- 生成有目标的、物理真实的行為
- 对扰动有鲁棒性
- 能够完成用户指定的任务目标
1.3 现有方法及其局限性
现有 RL 方法的挑战:
- 难以指定自然运动的奖励函数
- 没有生物力学模型时,容易产生不自然步态
- 需要人工设计奖励函数(如效率惩罚、冲击惩罚等)
什么是生物力学模型? 关于"生物体应该如何运动"的先验知识。DeepMimic 从运动捕捉数据中隐式学习这种先验(通过 r_pose 奖励鼓励姿势接近真人动作),而不是显式建模肌肉 - 骨骼系统或手工设计运动学约束。
DeepLoco 的局限:
- 固定初始状态
- 无法完成高度动态的动作
- 仅展示在 locomotion 任务上
1.4 本文方法
论文提出了 DeepMimic 框架:
核心思想:
- 直接奖励学习到的控制器产生与参考动画数据相似的动作
- 同时实现额外的任务目标
- 结合深度强化学习 (PPO) 与动作模仿
关键创新:
- 相位感知策略 (Phase-Conditioned Policy)
- 参考状态初始化 (Reference State Initialization, RSI)
- 早终止 (Early Termination, ET)
- 多动作整合方法
能力展示:
- 处理关键帧动作
- 高度动态的动作(后空翻、旋转)
- 重定向动作
- 多种角色(人形、Atlas 机器人、恐龙、龙)
二、核心贡献
-
数据驱动的物基动画框架
- 结合目标导向的强化学习与动作数据
- 动作数据可以是 motion capture clips 或关键帧动画
-
高质量运动生成
- 产生的动作质量远超先前工作
- 在无扰动情况下,与参考动作几乎无法区分
-
多动作整合方法
- 多 clip 奖励(max 操作符)
- 用户触发的多技能策略
- 使用价值函数评估过渡可行性的序列策略
-
广泛验证
- 多种角色形态
- 大量技能(locomotion、杂技、武术动作)
三、大致方法
3.1 框架概述
架构变化:相比 DeepLoco (218),DeepMimic 放弃了分层 RL 架构,采用单一策略网络。
方面 DeepLoco (218) DeepMimic (201) 架构 分层 (HLC + LLC) 单一策略 原因 需要环境感知 + 路径规划 参考动作已包含时序信息 训练 分开训练(先 LLC 后 HLC) 端到端训练
┌─────────────────────────────────────────────────────────────────┐
│ DeepMimic Framework │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:参考动作片段 {q̂_t} (mocap 数据或关键帧) │
│ │
│ 强化学习设置: │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 状态 s_t = [p_t, v_t, q_t, ω_t, 相位 φ] │ │
│ │ 动作 a_t = 关节目标位置/速度 (PD 控制器) │ │
│ │ 奖励 r_t = ω_I * r_I + ω_G * r_G │ │
│ │ r_I: 模仿奖励 (跟踪参考动作) │ │
│ │ r_G: 任务奖励 (完成目标) │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 训练技巧: │
│ - 参考状态初始化 (RSI): 从参考动作的随机状态开始 episode │
│ - 早终止 (ET): 失败时立即终止 episode │
│ │
│ 输出:物理模拟控制器 π(a|s) │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 方法详解
强化学习公式
强化学习基础:如需了解强化学习的完整数学框架(MDP、贝尔曼方程、价值函数等),请参考 DeepLearningNotes - 强化学习基础
MDP 定义:
- 状态空间 \(S\)
- 动作空间 \(A\)
- 转移动力学 \(p(s'|s, a)\)
- 奖励函数 \(r(s, a, s')\)
- 折扣因子 \(\gamma\)
策略目标: $$\max _{\theta} J(\theta) = \mathbb{E} _{\tau \sim \pi _{\theta}} \left[ \sum _{t=0}^{T} \gamma^t r_t \right]$$
使用 PPO (Proximal Policy Optimization) 算法训练。
PPO 详解:关于 PPO 算法的原理和推导,参考 DeepLearningNotes - Policy Based 算法
四、训练细节
4.1 策略表示
状态空间
$$s_t = [p_t, v_t, q_t, \omega_t, \phi_t]$$
| 变量 | 维度 | 含义 |
|---|---|---|
| \(p_t\) | - | 关节位置 |
| \(v_t\) | - | 关节速度 |
| \(q_t\) | - | 关节方向 |
| \(\omega_t\) | - | 关节角速度 |
| \(\phi_t\) | - | 相位 (关键!) |
相位表示
对于循环动作(如走路、跑步): $$\phi_t = \frac{t \mod T _{cycle}}{T _{cycle}} \in [0, 1]$$
- \(T _{cycle}\): 动作周期长度
- 相位作为策略输入,帮助跟踪进度
动作空间
动作指定 PD 控制器的目标:
- 目标关节旋转 \(q^{target}\)
- 目标关节速度 \(\omega^{target}\)
4.2 奖励函数设计
总奖励
$$r_t = \omega_I r_t^I + \omega_G r_t^G$$
- \(r_t^I\): 模仿奖励
- \(r_t^G\): 任务奖励
- \(\omega_I, \omega_G\): 权重
模仿奖励分解
$$r_t^I = w_p r_t^p + w_v r_t^v + w_e r_t^e + w_c r_t^c$$
权重:\(w_p=0.65, w_v=0.1, w_e=0.15, w_c=0.1\)
(1) 姿势奖励 \(r_t^p\) - 匹配关节方向
$$r_t^p = \exp\left[-2 \sum_j ||\hat{q} _t^j \ominus q _t^j||^2\right]$$
- \(\hat{q} _t^j\): 参考动作第 \(j\) 关节方向
- \(q _t^j\): 模拟角色第 \(j\) 关节方向
- \(\ominus\): 四元数差
(2) 速度奖励 \(r_t^v\) - 匹配关节速度
$$r_t^v = \exp\left[-0.1 \sum_j ||\hat{\dot{q}} _t^j - \dot{q} _t^j||^2\right]$$
(3) 末端执行器奖励 \(r_t^e\) - 匹配手脚位置
$$r_t^e = \exp\left[-40 \sum_e ||\hat{p} _t^e - p _t^e||^2\right]$$
- \(e \in\) {左脚,右脚,左手,右手}
(4) 质心奖励 \(r_t^c\) - 匹配质心位置
$$r_t^c = \exp\left[-40 ||\hat{p} _t^c - p _t^c||^2\right]$$
任务奖励示例
(1) 导航任务 $$r_t^G = \exp\left[-0.25 (v^* - d^* \cdot \dot{x} _t^{root})^2\right]$$
- \(v^*\): 目标速度
- \(d^*\): 目标方向
(2) 打击任务 $$r_t^G = \begin{cases} 1, & \text{target hit} \ \exp[-4||p _t^{tar} - p _t^e||^2], & \text{otherwise} \end{cases}$$
4.3 关键训练技巧
参考状态初始化 (RSI)
问题:学习高度动态动作(如后空翻)非常困难
- 需要从精确的起跳条件开始
- 从固定初始状态开始,agent 很难偶然发现成功的翻转
解决方案:RSI (Reference State Initialization)
- 每个 episode 开始时,从参考动作的随机状态启动
- 让 agent 早期就能接触到"有希望的状态"
效果:
- 加速学习
- 使高度动态动作的学习成为可能
早终止 (Early Termination, ET)
目的:提高训练效率
终止条件:
- 检测到跌倒(躯干接触地面)
- 某些链接低于高度阈值
- 超过最大时间步
好处:
- 快速淘汰失败轨迹
- 专注于成功的样本
4.4 多动作整合方法
方法 1: 多 Clip 奖励
$$r_t^I = \max _j r_t^{I,j}$$
- \(r_t^{I,j}\): 第 \(j\) 个 clip 的模仿奖励
- 策略自行选择最适合当前情况的 clip
- 无需手工设计运动规划器
方法 2: 技能选择器
训练:
- 策略输入包含 one-hot 向量 \(g_t\)(目标技能)
- 只优化当前选中技能的模仿奖励
使用:
- 用户可以运行时指定要执行的技能序列
方法 3: 组合策略
训练:
- 为每个技能训练独立策略 \(\pi_i\)
过渡:
- 使用价值函数 \(V(s)\) 评估从技能 \(i\) 过渡到技能 \(j\) 的可行性
- 选择 \(V_j(s)\) 最高的过渡
五、实验与结论
5.1 实现细节
| 设置 | 值 |
|---|---|
| 算法 | PPO |
| 价值函数 | TD(λ) |
| 优势函数 | GAE(λ) |
| 网络 | 3 层 MLP [1024, 512, 256] |
| 更新频率 | 每 2000 步 |
| 批次大小 | 512 |
5.2 角色模型
| 角色 | DOF | 特点 |
|---|---|---|
| 人形 | 34 | 标准 biped |
| Atlas | - | 机器人 |
| T-Rex | - | 双足恐龙 |
| Dragon | - | 四足飞龙 |
5.3 学习结果
技能学习统计
| 技能 | 周期 (s) | 样本数 (M) | 归一化回报 |
|---|---|---|---|
| Backflip | 1.75 | 72 | 0.729 |
| Cartwheel | 2.72 | 51 | 0.804 |
| Walk | 1.26 | 61 | 0.985 |
| Run | 0.80 | 53 | 0.951 |
| Headspin | 1.92 | 112 | 0.640 |
| Dance | 1.62-2.53 | 67-79 | 0.82-0.86 |
观察:
- 简单 cyclic 技能(走路、跑步)收敛快、回报高
- 复杂技能(头转、后空翻)需要更多样本
多技能结果
| 方法 | 优点 | 缺点 |
|---|---|---|
| 多 Clip 奖励 | 自动选择 clip | 可能偏好某些 clip |
| 技能选择器 | 用户可控 | 需要显式指定 |
| 组合策略 | 模块化 | 过渡可能不平滑 |
5.4 任务表现
导航任务
- 能够跟踪目标方向行走/跑步
- 对速度变化有响应
打击任务
- 能够用脚/手击中目标
- 适应目标位置变化
鲁棒性测试
- 对外部推力有恢复能力
- 能够处理形态变化
六、局限性
-
训练时间
- 复杂技能需要数千万步样本
- 训练时间可能长达数小时到数天
-
技能过渡
- 某些技能之间的过渡不平滑
- 需要仔细设计过渡条件
-
长序列动作
- 对于非常长的动作序列,性能可能下降
- 相位表示对于非循环动作不适用
-
重定向限制
- 形态差异过大时,动作质量下降
- 需要调整奖励权重
-
计算成本
- 需要大量并行模拟
- 对 GPU 资源要求高
-
参考动作质量依赖
- 模仿奖励权重较高,参考动作质量直接影响学习效果
- mocap 数据有噪声 → 学到抖动动作
- 关键帧动画僵硬 → 动作僵硬
- 对比:DeepLoco 可通过任务项平衡,对参考动作质量要求较低
七、启发
7.1 方法学启发
-
模仿 + 任务的平衡
- 纯模仿:动作自然但无目标
- 纯任务:有目标但动作不自然
- DeepMimic: 两者结合,兼顾质量和功能
-
RSI 的重要性
- 对于困难任务,从"中间状态"开始学习
- 类似课程学习的思想
-
相位表示的力量
- 对于循环动作,相位是关键输入
- 帮助策略跟踪动作进度
7.2 工程实践启发
-
奖励函数设计
- 使用指数形式使奖励平滑
- 权重设置需要经验
-
终止条件
- 早终止加速训练
- 但太严格可能错过潜在成功样本
-
网络架构
- 全连接网络足够处理大多数技能
- 对于更复杂任务可能需要更深的网络
7.2 与 DeepLoco (2017) 的对比
DeepMimic 是 DeepLoco 的直接继承者,两者在奖励函数形式上相似,但在多个关键方面有本质区别。
7.2.1 奖励函数对比
两篇论文的奖励函数都采用指数形式相似度奖励,数学形式几乎一样。
| 组件 | DeepLoco | DeepMimic |
|---|---|---|
| 姿势奖励 | r_pose:关节角度接近参考动作 | r^p:关节方向匹配 |
| 速度奖励 | r_vel(权重 0.05) | r^v:关节速度匹配 |
| 末端奖励 | r_end:脚落在目标位置(权重 0.2) | r^e:手脚位置匹配 |
| 质心奖励 | r_com:质心速度(权重 0.1) | r^c:质心位置匹配 |
| 其他 | r_root(骨盆高度)、r_heading(朝向) | 无 |
结论:奖励函数数学形式几乎一样,都是指数形式的相似度奖励。主要差别不在 loss 定义。
7.2.2 关键差别
| 维度 | DeepLoco | DeepMimic | 影响 |
|---|---|---|---|
| 相位表示 | 固定递增 + 双线性变换 | 从参考动作时间戳提取 | 中 |
| 参考动作选择 | 动态选择 + 风格插值 | 固定 clip 或 max 选择 | 中 |
| 初始化 | 固定初始状态 | RSI(从参考动作随机状态开始) | 大 |
| 终止 | 标准终止 | 早终止(跌倒立即结束) | 大 |
| RL 算法 | CACLA | PPO | 中 |
| 适用范围 | locomotion only | 任意物理技能 | 结果 |
7.2.3 相位表示差别
DeepLoco 的相位:
- φ 按时间固定递增(每步 1 秒)
- 使用双线性相位变换强制网络分阶段
- 适合循环步态,不适合非循环动作
DeepMimic 的相位:
- φ = (t mod T_cycle) / T_cycle
- 从参考动作的时间戳来
- 可以处理非循环动作(如后空翻只有 1 次)
7.2.4 参考动作使用方式
DeepLoco:
- 有多个参考动作库(10 个 mocap 片段)
- 每一步根据当前状态和目标,动态选择最匹配的
- 好处:可以平滑切换,支持风格插值
- 风格奖励:r_pose = exp(-Σwᵢ·d² - w_style·c_style)
DeepMimic:
- 可以只用一个 clip,也可以多个 clip
- 多 clip 时用 max 操作符:r^I = max_j(r^I,j)
- 策略自己决定"现在像哪个 clip"
- 不支持风格插值,专注于精确跟踪
7.2.5 训练技巧差别(最关键!)
RSI 的作用(关键!):
DeepLoco:
- 每个 episode 从"站立不动"开始
- 很难学会后空翻(需要蹲下→起跳)
- 只能学 locomotion 类任务
DeepMimic:
- 从参考动作的随机状态开始 episode
- 可能从"半空中"开始,直接学习空中控制
- 可以学后空翻、侧手翻、跳舞等任意技能
7.2.6 任务奖励的权重平衡
| 方面 | DeepLoco | DeepMimic |
|---|---|---|
| 设计哲学 | "风格模仿" | "精确跟踪 + 任务" |
| r_end 权重 | 0.2(重要) | 无独立项(包含在 r^e 中) |
| 灵活性 | 为了踩对位置可牺牲姿势 | 更强调像参考动作 |
DeepLoco 的 r_end(落脚点)是任务导向的:
- 当 r_pose 和 r_end 冲突时,网络会权衡
- 可能为了踩到 HLC 指定的目标位置,牺牲姿势相似度
DeepMimic 的 r^e(末端位置)是模仿的一部分:
- 手脚位置也要像参考动作
- 不为了外部任务牺牲姿势
7.2.7 总结
| 方面 | DeepLoco | DeepMimic |
|---|---|---|
| 历史地位 | 开创性工作 | 集大成者 |
| 核心贡献 | 分层控制 + 环境感知 | RSI + 通用技能学习 |
| 适用场景 | 导航、避障、运球 | 杂技、舞蹈、武术、导航 |
| 关系 | 奠基者 | 站在肩膀上改进 |
一句话:DeepMimic 的奖励函数与 DeepLoco 形式相似,但通过 RSI 让动态动作可学习、相位表示更通用、PPO 比 CACLA 更稳定,从而将适用范围从 locomotion 扩展到任意物理技能。
7.3 与后续工作的联系
- AMP (2021): 改进对抗运动先验
- ASE (2022): 学习可复用技能嵌入
- PDE (2023): 运动扩散模型
- 本文是 Physics-Based Character Control 深度学习的奠基工作之一
八、遗留问题
8.1 开放性问题
-
自动奖励权重调整
- 当前需要手动设置 \(w_p, w_v, w_e, w_c\)
- 能否自适应调整?
-
零样本重定向
- 能否直接迁移到完全不同的形态?
- 如从人到四足动物
-
长视野规划
- 当前是反应式策略
- 如何整合长期规划?
-
与 mocap 数据的更深度融合
- 当前只用位置/方向
- 能否利用力/力矩数据?
8.2 未来方向
论文提到的未来工作:
- 更复杂的技能组合
- 自动技能发现
- 与高层任务规划结合
九、关键公式总结
| 公式 | 含义 |
|---|---|
| \(r_t = \omega_I r_t^I + \omega_G r_t^G\) | 总奖励 |
| \(r_t^I = w_p r_t^p + w_v r_t^v + w_e r_t^e + w_c r_t^c\) | 模仿奖励分解 |
| \(r_t^p = \exp[-2 \sum_j | |
| \(r_t^v = \exp[-0.1 \sum_j | |
| \(\phi_t = (t \mod T _{cycle}) / T _{cycle}\) | 相位 |
十、代码与资源
- 项目主页: https://xbpeng.github.io/projects/DeepMimic
- 代码: 官方未公开完整代码,但有多个开源实现
- isaacgymenvs 包含类似实现
- mimicmotion 等
笔记说明:DeepMimic 是 Physics-Based Character Control 领域里程碑式的工作,首次展示了深度强化学习可以学习高度动态的物理技能。理解本文是学习后续 AMP、ASE 等工作的基础。
ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters
论文信息: ACM Transactions on Graphics, 2023, Heyuan Yao et al., Peking University
Link: 项目主页
一、核心问题
1.1 研究背景
基于物理的角色控制器可以被公式化为生成模型:
- 潜在空间中的样本被解码为具体的角色动作
- 目标是学习多样化的技能表示和通用的控制策略
现有生成控制方法的局限:
| 方法 | 代表工作 | 局限性 |
|---|---|---|
| 自动编码器 | Merel et al. 2018, 2020 | 需要大量专家策略蒸馏 |
| 条件 VAE | Won et al. 2022 | 使用标准正态先验,技能解耦不佳 |
| 对抗模仿学习 | AMP (Peng 2021, 2022) | 需要训练两个间接监督的系统,训练不稳定 |
| MCP | Peng et al. 2019 | 技能表示能力有限 |
1.2 核心问题
如何学习一个生成式控制器,能够:
- 从多样化的无组织动作序列中学习丰富的技能潜在表示
- 通过潜在空间采样生成真实的人类行为
- 让高层控制策略复用学到的技能完成各种下游任务
- 训练过程稳定高效
1.3 现有方法及其局限性
VAE 在角色控制中的应用:
- 通常使用标准正态分布 N(0,I) 作为先验 p(z)
- 问题:这种状态无关的先验不能有效地解耦不同技能的表示
观察到的问题:
- 角色频繁快速切换技能
- 导致抽搐的动作和偶尔摔倒
- 下游控制策略效率低下(如方向控制任务中难以保持恒定方向)
原因分析:
- 状态无关的先验分布没有提供足够的信息用于正则化
- 编码器计算出不一致的技能分布
- 相同的技能在不同状态下被编码到潜在空间的不同部分
1.4 本文方法
论文提出了 ControlVAE 框架:
核心创新:
-
状态条件先验分布 (State-Conditional Prior)
- p(z|s) 而非 p(z)
- 根据当前角色状态生成更合适的技能嵌入
- 在下游任务中表现优于非条件先验
-
基于世界模型的学习 (Model-Based Learning)
- 学习可微的世界模型近似模拟系统动力学
- 世界模型提供直接监督信号
- 实现高效稳定的训练
-
数据平衡策略 (Data Balancing)
- 解决简单动作占用过多训练样本的问题
- 确保困难技能也能被有效学习
框架能力:
- 从多样化无组织动作序列学习
- 潜在空间采样生成真实行为
- 支持各种下游任务(高度控制、方向控制、转向控制、风格控制)
二、核心贡献
-
ControlVAE 框架
- 基于 VAE 的生成式控制策略
- 状态条件先验分布
- 可微世界模型
-
模型强化学习算法
- 使用世界模型进行直接监督
- 训练稳定高效
- 支持多种下游任务
-
数据平衡技术
- 基于状态价值的采样
- 确保困难技能的学习
-
多样化任务演示
- 高度控制、方向控制、转向控制
- 风格迁移和控制
三、大致方法
3.1 框架概述
┌─────────────────────────────────────────────────────────────────┐
│ ControlVAE System │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:无组织动作数据集 D = {τ̃_i} │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ ControlVAE (生成式控制策略) │ │
│ │ - 编码器 q(z|s_t, s_{t+1}): 状态转移 → 技能嵌入 │ │
│ │ - 解码器/策略 π(a|s,z): 状态 + 技能 → 动作 │ │
│ │ - 条件先验 p(z|s): 状态 → 技能先验分布 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ World Model (世界模型) ω(s'|s,a) │ │
│ │ - 预测下一状态:给定当前状态和动作 │ │
│ │ - 可微,允许梯度反向传播 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 训练:最大化 ELBO + 动作正则化 │
│ 使用世界模型生成合成轨迹进行训练 │
│ │
│ 下游任务:训练高层策略 μ_g(s) → z │
│ 使用学到的技能嵌入完成特定任务 │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 核心组件
(1) 生成过程
ControlVAE 基于变分自编码器 (VAE) 框架。
ELBO (Evidence Lower Bound): $$\mathcal{L} = \mathbb{E}{q(z|s_t,s{t+1})}[\log p(s_{t+1}|s_t,z)] - D_{KL}(q(z_t|s_t,s_{t+1}) | p(z_t|s_t))$$
- 第一项:重建损失(鼓励准确预测下一状态)
- 第二项:KL 散度(鼓励后验分布接近先验分布)
(2) 状态条件先验
标准 VAE 先验的问题:
- p(z) = N(0,I) 是状态无关的
- 导致技能表示不一致
本文的条件先验: $$p(z_t|s_t) \sim \mathcal{N}(\mu_p(s_t; \theta_p), \sigma_p^2 I)$$
- 均值 μ_p 是神经网络,输入是当前状态 s_t
- 方差 σ_p 是超参数
- 根据当前状态生成合适的先验分布
(3) 策略表示
技能条件策略: $$\pi(a_t|s_t, z_t) \sim \mathcal{N}(\mu_\pi, \Sigma_\pi)$$
- 均值 μ_π(s_t, z_t; θ_π) 是神经网络
- 输入:状态 s_t 和技能 z_t
- 输出:动作分布(PD 控制器目标)
(4) 编码器
近似后验分布: $$q(z_t|s_t, s_{t+1}) \sim \mathcal{N}(\mu_q(s_t, s_{t+1}), \sigma_q^2 I)$$
- 输入:状态转移 (s_t, s_{t+1})
- 输出:技能嵌入 z_t
训练技巧:设置 μ_q 使得 KL 散度计算简化: $$D_{KL}(q | p) = \frac{\mu_q^T \mu_q}{2\sigma_p^2}$$
四、训练细节
4.1 世界模型
模型结构
世界模型学习预测下一状态: $$\omega(s_{t+1}|s_t, a_t) \sim \mathcal{N}(\mu_\omega(s_t, a_t), \Sigma_\omega(s_t, a_t))$$
输出:
- 均值 μ_ω(s_t, a_t): 预测的下一状态
- 协方差 Σ_ω(s_t, a_t) = diag(σ_ω²): 预测不确定性
世界模型训练
损失函数: $$\mathcal{L}\omega = \mathbb{E}{s_t, a_t, s_{t+1}}[||s_{t+1} - \mu_\omega(s_t, a_t)||W^2 + ||\log \sigma\omega + \frac{(s_{t+1} - \mu_\omega)^2}{2\sigma_\omega^2}||_1]$$
- 第一项:状态预测误差
- 第二项:不确定性校准
训练方式:
- 从经验缓冲区采样真实轨迹
- 最小化预测误差
4.2 ControlVAE 训练
损失函数
总损失: $$\mathcal{L} = \mathcal{L}{rec} + \mathcal{L}{kl} + \mathcal{L}_{act}$$
重建损失: $$\mathcal{L}{rec} = \sum{t=0}^{T-1} \gamma^t \mathbb{E}{q, \pi}[||\tilde{s}{t+1} - \mu_\omega(s_t, a_t)||_W^2]$$
- s̃_{t+1}: 参考轨迹的下一状态
- s_t: 合成轨迹的当前状态
- a_t: 策略生成的动作
KL 损失: $$\mathcal{L}{kl} = \sum{t=0}^{T-1} \gamma^t \frac{||\mu_q(s_t, \tilde{s}_{t+1})||_2^2}{2\sigma_p^2}$$
动作正则化: $$\mathcal{L}{act} = \sum{t=0}^{T-1} \gamma^t (w_{a1}||a_t||1 + w{a2}||a_t||_2^2)$$
- 防止过度的控制输入
- 产生更平滑的动作
合成轨迹生成
训练过程:
- 从参考轨迹 D 中选择随机起始状态 s̃_0
- 使用策略 π(a|s,z) 在世界模型 ω 中展开轨迹
- 技能 z_t 从后验 q(z|s_t, s̃_{t+1}) 采样
- 使用重参数化技巧保证梯度反向传播
折扣因子:γ = 0.95
- 降低不准确状态的权重
- 合成轨迹会随时间偏离真实轨迹
4.3 数据平衡策略
问题
- 数据集中包含多样化技能(走路、跑步、跳跃、起身等)
- 简单动作(如走路)产生更长的模拟轨迹
- 占据经验缓冲区,使 ControlVAE 难以学习困难技能
解决方案:基于状态的采样
状态价值计算: $$V_t^* = \sum_{k=0}^{T-t} \gamma^k r_{t+k} + \gamma^{T+1-t} V_{T+1}$$ $$V_t = (1-\alpha)V_t + \alpha V_t^*$$
奖励定义: $$r_t = \exp(-||W(\tilde{s}_t - s_t)||_1 / T_V)$$
- T_V = 20: 温度参数
- 跟踪误差越小,奖励越高
采样概率: $$P(s_t) \propto \frac{1}{\max(0.01, V_t)}$$
- 低价值状态(困难技能)有更高采样概率
- 每 200 个 epoch 更新一次价值
4.4 轨迹采样器
数据增强策略:
- 在模拟过程中随机切换参考动作片段
- 鼓励学习动作之间的新过渡
- 新的起始状态也使用数据平衡策略选择
效果:
- 许多切换会导致角色摔倒(姿势/速度不匹配)
- 角色在训练中自动学习恢复策略
- 鼓励先验分布嵌入多样化的动作过渡
4.5 训练算法
Algorithm 1: ControlVAE Training
输入:动作数据集 D
1: 初始化世界模型 ω, ControlVAE (π, q, p)
2: B ← ∅ // 经验缓冲区
3: for epoch = 1, ... do
4: // 轨迹收集
5: while |B'| < N_B' do
6: 根据状态价值从 D 采样起始状态 s̃_0
7: s_0 ← s̃_0
8: for t = 0, 1, ... do
9: z_t ← q(z|s_t, s̃_{t+1}) // 重参数化采样
10: a_t ← π(a|s_t, z_t)
11: s_{t+1} ← ω(s_t, a_t) // 模拟或世界模型
12: if 摔倒或超时 then break
13: end for
14: 存储轨迹到 B'
15: end while
16: B ← B ∪ B' // 替换最旧的轨迹
17:
18: // 更新世界模型
19: for step = 1, ..., 8 do
20: 从 B 采样批次 {τ*}
21: 计算 L_ω 并更新 ω
22: end for
23:
24: // 更新 ControlVAE
25: 从 B 采样起始状态生成合成轨迹
26: 计算 L_rec + L_kl + L_act
27: 更新 π, q, p
28:
29: // 更新状态价值
30: if epoch % 200 == 0 then
31: 根据轨迹更新 V_t
32: end if
33: end for
4.6 实现细节
| 参数 | 值 |
|---|---|
| 经验缓冲区大小 N_B | 50,000 |
| 每 epoch 轨迹数 N_B' | 2,048 |
| 最大轨迹长度 T_max | 512 |
| 世界模型批次大小 N_w | 512 |
| 世界模型轨迹长度 T_w | 8 |
| ControlVAE 批次大小 N_VAE | 512 |
| ControlVAE 轨迹长度 T_VAE | 24 |
| 折扣因子 γ | 0.95 |
| 早终止时间 T_term | 1 秒 |
| 早终止距离 d_max | 0.5m |
网络架构:
- 所有网络使用 3 层 MLP
- 隐藏层维度:512
- ReLU 激活
训练时间:
- 20,000 次迭代
- 约 50 小时(4 线程并行)
- CPU: Intel Xeon Gold 6240 @ 2.60GHz
- GPU: NVIDIA GTX 2080Ti
五、下游任务
训练好 ControlVAE 后,可以学习高层策略来完成各种任务。
5.1 高度控制
任务:控制角色的身高
损失函数: $$\mathcal{L}_g = H \cdot h_0$$
- h_0: 角色根关节高度
- H ∈ {-1, 1}: 任务参数
- H = -1: 蹲下直到躺在地上
- H = 1: 站起来并尽可能跳高
5.2 方向控制
任务:朝目标方向以目标速度移动
损失函数: $$\mathcal{L}g = w{\theta_h}|\theta_h^* - \theta_h| + w_v \frac{|v^* - v|}{\max(v^*, 1)}$$
- θ_h: 当前朝向
- v: 当前速度
- θ_h^*: 目标朝向
- v^*: 目标速度 [0, 3] m/s
- 权重:(w_θ, w_v) = (2.0, 1.0)
5.3 转向控制
任务:同时控制朝向和行进方向
损失函数: $$\mathcal{L}g = w{\theta_h}|\theta_h^* - \theta_h| + w_{\theta_v}|\theta_v^* - \theta_v| + w_v \frac{|v^* - ||\bar{v}_0||_2|}{\max(v^*, 1)}$$
- θ_v: 行进方向角度
- v_0: 根节点线速度的平面分量
5.4 风格控制
任务:在完成目标的同时保持特定风格(如跛行、悲伤行走)
方法:使用对抗训练
损失函数: $$\mathcal{L}g = \mathcal{L}{g'} + w_D \mathcal{L}_D + w_C \mathcal{L}C + w_r \mathcal{L}{reg}$$
- L_{g'}: 目标任务损失
- L_D: 对抗损失(区分真实/生成动作)
- L_C: 分类器损失(确保正确的技能)
- L_{reg}: 正则化项
鉴别器训练: $$\min_D \mathbb{E}{\tau_c}[(D(s_t, s{t+1}; c) - 1)^2] + \mathbb{E}{\tau_g}[(D(s_t, s{t+1}; c) + 1)^2] + w_g \mathbb{E}_{\tau_c}[||\nabla D||^2]$$
六、实验与结论
6.1 角色模型
- 自由度: 未指定(标准人形角色)
- 动作数据集: 包含走路、跑步、跳跃、起身等多样化长序列
6.2 评估结果
重建能力
- 使用学到的后验 q(z|s,s') 作为跟踪控制
- 角色准确执行输入动作
- 在动作切换时自动平滑过渡
- 极端情况下摔倒后自动恢复(起身动作不在数据集中)
随机采样
- 从条件先验 p(z|s) 随机采样
- 角色执行多样化技能:
- 停止然后开始走路
- 随机转向
- 单脚跳、跳跃等
6.3 学习曲线
- 约 10,000 次迭代后开始收敛
- 动作质量持续提升
- 完整训练 20,000 次迭代
6.4 下游任务表现
| 任务 | 描述 | 结果 |
|---|---|---|
| 高度控制 | 蹲下/站起/跳跃 | ✅ 能够精确控制 |
| 方向控制 | 朝目标方向移动 | ✅ 保持目标方向和速度 |
| 转向控制 | 独立控制朝向和行进 | ✅ 实现解耦控制 |
| 风格控制 | 保持特定行走风格 | ✅ 自然风格迁移 |
七、局限性
-
训练时间
- 约 50 小时(虽有并行)
- 对于实时应用仍然较长
-
世界模型误差累积
- 合成轨迹随时间偏离真实轨迹
- 使用折扣因子缓解但不能完全解决
-
技能表示维度
- 固定维度的潜在空间可能限制技能多样性
- 更复杂的技能可能需要更大的潜在空间
-
早终止策略
- 头部跟踪误差阈值可能过于简单
- 某些技能(如地面动作)可能被错误终止
-
数据依赖性
- 需要多样化的动作数据集
- 数据集中没有的技能难以学习
八、启发
8.1 方法学启发
-
条件先验的优势
- 状态条件先验比标准正态先验更有效
- 提供额外的上下文信息
- 类似思想可应用于其他生成模型
-
模型强化学习的价值
- 世界模型提供直接监督信号
- 训练更稳定、样本效率更高
- 避免了奖励工程的困难
-
数据平衡的重要性
- 简单样本会主导训练
- 需要显式平衡策略
- 基于价值的采样是有效方法
8.2 与相关工作对比
| 方法 | 先验类型 | 学习方式 | 技能多样性 |
|---|---|---|---|
| ControlVAE | 状态条件 | 模型强化学习 | 高 |
| AMP | 无显式先验 | 对抗模仿 | 高 |
| ASE | 球形均匀 | 对抗 + 无监督 | 非常高 |
| MCP | 组合权重 | 强化学习 | 中等 |
8.2.1 ControlVAE vs ASE:核心区别
ControlVAE 和 ASE 都学习技能嵌入 z,但先验设计哲学完全不同。
(1) 先验分布设计
| 方面 | ASE (199) | ControlVAE (202) |
|---|---|---|
| 预训练先验 | p(z) 球面均匀分布 | p(z|s) 状态条件高斯 |
| z 与 s 关联 | 预训练时无关 | 预训练时就有关 |
| 关联方式 | 后天学习(通过 ω) | 先天设计(通过 p(z|s)) |
ASE 的设计:
预训练阶段:
- z 从 p(z) 随机采样(与 s 无关)
- 策略 π(a|s, z) 学习"对任何 z 都能执行"
- 互信息最大化强制不同 z 产生不同行为
任务训练阶段:
- 高级策略 ω(z|s,g) 学习"什么状态用什么 z"
- z 与 s 的关联是后天学习的
优势:
- 技能库真正解耦(z 独立于 s)
- 高级策略可灵活学习任何 z-s 映射
ControlVAE 的设计:
预训练阶段:
- z 从 p(z|s) 采样(与 s 有关)
- p(z|s) = N(μ_p(s), σ_p²I) 直接输出条件先验
- 技能与状态天然关联
优势:
- 技能切换平滑
- 减少抽搐和摔倒
(2) 训练方式对比
| 方面 | ASE (199) | ControlVAE (202) |
|---|---|---|
| 训练方式 | 对抗学习 + RL | 世界模型监督 |
| 判别器 | 有(对抗训练) | 无(仅风格任务用) |
| 世界模型 | 无 | 有(可微动力学) |
| 训练稳定性 | 较难(GAN+RL) | 更稳定(直接监督) |
| 多样性保证 | 互信息最大化 | KL 散度 + 数据平衡 |
(3) 推理流程对比
ASE 推理:
状态 s + 任务目标 g
↓
高级策略 ω(z|s,g) ← 训练好的神经网络
↓
输出 z(技能代码)
↓
低级策略 π(a|s,z) ← 预训练后固定
↓
输出动作 a
ControlVAE 推理:
状态 s + 任务目标 g
↓
高层策略 μ_g(s) ← 训练好的神经网络
↓
输出 z(技能代码)
↓
策略 π(a|s,z) ← VAE 解码器
↓
输出动作 a
(4) 适用场景
| 场景 | ASE | ControlVAE |
|---|---|---|
| 需要技能多样性 | ✅ 优(互信息保证) | 中 |
| 需要平滑切换 | 中 | ✅ 优(状态条件先验) |
| 训练稳定性 | 中 | ✅ 优(直接监督) |
| 大量下游任务 | ✅ 优(预训练复用) | 中 |
| 技能解耦 | ✅ 优(z 独立于 s) | 中 |
选择建议:
优先选择 ASE 的情况:
- 需要学习高度多样化的技能库
- 有大量下游任务需要复用
- 技能需要真正解耦(如独立控制)
优先选择 ControlVAE 的情况:
- 需要平滑的技能切换
- 训练稳定性要求高
- 技能与状态天然关联(如 locomotion)
8.3 实际应用价值
- 游戏动画: 生成多样化 NPC 行为
- 虚拟现实: 实时角色控制
- 机器人: 技能学习和迁移
- 影视动画: 自动生成中间动作
九、遗留问题
9.1 开放性问题
-
潜在空间结构
- 技能在潜在空间中如何组织?
- 能否实现更细粒度的技能控制?
-
零样本技能组合
- 能否组合已学技能完成新任务?
- 如何实现技能的层次化表示?
-
世界模型改进
- 能否使用更强大的世界模型(如 Transformer)?
- 如何处理长视野预测?
-
多角色泛化
- 能否在一个模型中学习多个角色的技能?
- 如何实现形态学迁移?
9.2 未来方向
论文提到的未来工作:
- 扩展到更复杂的技能
- 与高层任务规划结合
- 改进世界模型准确性
十、关键公式总结
| 公式 | 含义 |
|---|---|
| p(z_t | s_t) = N(μ_p(s_t), σ_p²I) |
| L = L_rec + L_kl + L_act | ControlVAE 总损失 |
| L_rec = Σ γ^t E[ | |
| V_t ∝ 1/max(0.01, V_t) | 数据平衡采样概率 |
| L_g = L_g' + w_D L_D + w_C L_C | 风格控制损失 |
十一、代码与资源
- 项目主页: https://github.com/HeyuanYao/ControlVAE
- 代码: GitHub 开源
- 视频: 项目主页提供演示视频
笔记说明:ControlVAE 提出了一种基于模型的学习框架,结合 VAE 和世界模型实现高效的生成式控制。理解本文有助于学习基于物理的角色控制中的生成模型方法,与 AMP、ASE 等工作形成对比和互补。
Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion
论文信息: CVPR 2024, Davis Rempe et al., NVIDIA/Stanford/CMU/SFU/Toronto
Link: CVF Open Access
一、核心问题
1.1 研究背景
行人动画是自动驾驶、城市规划和建筑设计等领域的核心问题。一个完整的行人动画系统需要生成真实的 2D 轨迹和全身动作。
现有方法的局限:
| 方法类型 | 代表工作 | 局限性 |
|---|---|---|
| 规则/算法模型 | 最短路径、社会力模型 | 轨迹不自然,看起来机械 |
| 学习型预测模型 | 单次前向传播预测 | 控制能力有限,只能采样或潜在空间遍历 |
| 物理基控制器 | AMP、ASE | 需要针对每个任务重新训练规划器 |
| VAE 轨迹模型 | STRIVE | 需要耗时的测试时优化 |
1.2 核心问题
如何构建一个行人动画系统,能够:
- 在测试时通过用户指定的目标(如路径点、速度、社交组)进行控制
- 生成真实自然的轨迹和全身动作
- 适应不同地形(楼梯、斜坡、不平整地面)
- 支持不同体型的人物角色
- 避免碰撞(障碍物之间、行人之间)
1.3 本文方法
论文提出了 Trace and Pace 框架,包含两个核心组件:
1. TRACE (TRAjectory Diffusion Model for Controllable PEdestrians)
- 基于扩散模型的轨迹生成器
- 测试时通过 guidance 实现控制
- 支持路径点、避障、社交组等控制目标
2. PACER (Pedestrian Animation ControllER)
- 基于强化学习的物理控制器
- 使用对抗运动先验学习真实动作
- 支持不同体型和地形
系统架构:
TRACE (高层规划器)
↓ (2D 轨迹)
PACER (底层控制器)
↓ (关节控制)
物理仿真环境
↓ (状态反馈)
TRACE (重新规划)
二、核心贡献
-
TRACE:可控制的轨迹扩散模型
- 使用 classifier-free sampling 实现测试时控制
- 提出 clean guidance 公式,在干净轨迹上操作
- 支持多种分析性引导目标(路径点、避障、社交组)
-
PACER:通用行人动画控制器
- 从少量动作数据学习真实步态
- 地形感知:楼梯、斜坡、不平整地面
- 社交感知:避免与其他行人碰撞
- 体型感知:支持不同身体形态
-
闭环行人动画系统
- TRACE 和 PACER 独立训练,运行时闭环集成
- 使用 PACER 的价值函数指导 TRACE 去噪
- 支持大规模人群仿真
三、大致方法
3.1 框架概述
┌─────────────────────────────────────────────────────────────────┐
│ Trace and Pace System │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ TRACE: 轨迹扩散模型 (高层规划器) │ │
│ │ - 输入:过去轨迹 + 邻居轨迹 + 语义地图 │ │
│ │ - 输出:未来 5 秒 2D 轨迹 (x, y, θ, v) │ │
│ │ - 控制:测试时 guidance (路径点、避障、社交组) │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ PACER: 物理控制器 (底层执行器) │ │
│ │ - 输入:2D 轨迹 + 环境特征 + 体型参数 │ │
│ │ - 输出:PD 控制器目标 (关节角度/速度) │ │
│ │ - 学习:对抗运动先验 + PPO │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 物理仿真 (Isaac Gym) │ │
│ │ - 地形:楼梯、斜坡、障碍物 │ │
│ │ - 反馈:角色状态 + 高度图 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 闭环:每 2 秒重新规划,PACER 状态反馈给 TRACE │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 核心组件
(1) TRACE:轨迹扩散模型
问题定义:
- 输入:ego 行人过去轨迹 \(x_{ego} = [s_{t-T_p}, ..., s_t]\)
- 输入:邻居行人过去轨迹 \(X_{neigh} = {x_i}_{i=1}^N\)
- 输入:语义地图 \(M \in \mathbb{R}^{H \times W \times C}\)
- 输出:未来轨迹 \(\tau = [\tau^s; \tau^a]\)
- 状态 \(\tau^s = [s_{t+1}, ..., s_{t+T_f}]\),\(s = [x, y, \theta, v]^T\)
- 动作 \(\tau^a = [a_{t+1}, ..., a_{t+T_f}]\),\(a = [\dot{v}, \dot{\theta}]^T\)
扩散过程:
- 前向:添加高斯噪声 \(\epsilon \sim \mathcal{N}(0, I)\) $$\tau^k = \sqrt{\bar{\alpha}_k} \tau^0 + \sqrt{1-\bar{\alpha}_k} \epsilon$$
- 反向:学习去噪分布 $$p_\phi(\tau^{k-1} | \tau^k, C) := \mathcal{N}(\tau^{k-1}; \mu_\phi(\tau^k, k, C), \Sigma_k)$$
训练目标: $$\mathcal{L} = \mathbb{E}_{\epsilon, k, \tau^0, C} \left[ ||\tau^0 - \hat{\tau}^0||^2 \right]$$
(2) Classifier-Free Sampling
目的:提高测试时对条件输入的遵循能力
训练:随机丢弃条件输入(10% 概率)
- 同时学习条件模型 \(\mu_\phi(\tau^k, k, C)\)
- 同时学习无条件模型 \(\mu_\phi(\tau^k, k)\)
测试时组合: $$\tilde{\epsilon}\phi = \epsilon\phi(\tau^k, k, C) + w \left( \epsilon_\phi(\tau^k, k, C) - \epsilon_\phi(\tau^k, k) \right)$$
- \(w > 0\):增强条件影响
- \(w < 0\):减弱条件影响
- \(w = 0\):纯条件模型
- \(w = -1\):纯无条件模型
(3) Clean Guidance
问题:传统 guidance 在噪声轨迹上评估损失函数,需要训练噪声鲁棒的损失函数
解决方案:在干净轨迹预测 \(\hat{\tau}^0\) 上操作
传统方法 (Noisy Guidance): $$\tilde{\mu} = \mu - \alpha \Sigma_k \nabla_\mu \mathcal{J}(\mu)$$
本文方法 (Clean Guidance): $$\tilde{\tau}^0 = \hat{\tau}^0 - \alpha \Sigma_k \nabla_{\tau^k} \mathcal{J}(\hat{\tau}^0)$$
优点:
- 可以直接使用分析性损失函数
- 不需要训练噪声鲁棒的损失函数
- 样本质量更好,目标遵循度更高
(4) 引导目标函数
路径点引导: $$\mathcal{J}{waypoint}(\tau) = ||(x{target}, y_{target}) - (x_T, y_T)||^2$$
障碍物避免: $$\mathcal{J}{obs}(\tau) = \sum_t \max(0, r{ped} + r_{obs} - ||p_t - p_{obs}||)^2$$
行人避免: $$\mathcal{J}{agent}(\tau) = \sum_t \max(0, 2r{ped} - ||p_t - p_{neighbor}||)^2$$
社交组: $$\mathcal{J}{group}(\tau) = \sum_t ||(x_t, y_t) - (x{group}, y_{group})||^2$$
3.3 PACER:物理控制器
状态空间
$$s_t = [h_t, o_t, \beta, \tau^s]$$
- \(h_t\): 角色状态(关节位置/速度/旋转)
- \(o_t \in \mathbb{R}^{64 \times 64 \times 3}\): 局部高度图和速度图
- \(\beta\): SMPL 体型参数
- \(\tau^s\): 目标 2D 轨迹
动作空间
$$a_t = \text{PD 控制器目标}$$
- 目标关节旋转
- 目标关节速度
奖励函数
$$r_t = r^{amp}_t + r^{\tau}_t + r^{energy}_t$$
- \(r^{amp}_t\): 对抗运动奖励(来自判别器)
- \(r^{\tau}_t\): 轨迹跟踪奖励
- \(r^{energy}_t\): 能量惩罚
对称性损失
问题:RL 训练可能产生不对称步态(如跛行)
解决方案:运动对称性损失
$$\mathcal{L}{sym}(\theta) = ||\pi{PACER}(h_t, o_t, \beta, \tau^s) - \Phi_a(\pi_{PACER}(\Phi_s(h_t, o_t, \beta, \tau^s)))||^2$$
- \(\Phi_s\): 沿矢状面镜像状态
- \(\Phi_a\): 沿矢状面镜像动作
3.4 价值函数引导
目的: tighter coupling between TRACE and PACER
方法:使用 PACER 的 RL 价值函数 \(V(s)\) 作为引导
$$\mathcal{J}{value}(\tau) = -V(s{follow}(\tau))$$
- \(s_{follow}(\tau)\): 跟随轨迹 \(\tau\) 的状态
- \(V(s)\): 预测未来期望奖励
优点:
- 价值函数感知身体姿态、地形、其他行人
- 引导 TRACE 生成更容易跟随的轨迹
- 不需要额外训练奖励函数
四、训练细节
4.1 TRACE 训练
| 参数 | 值 |
|---|---|
| 过去轨迹长度 | 3s (30 帧 @ 10Hz) |
| 未来轨迹长度 | 5s (50 帧 @ 10Hz) |
| 扩散步数 K | 100 |
| 条件丢弃概率 | 10% (地图和邻居独立) |
| 网络架构 | U-Net + 1D 时序卷积 |
| 地图编码 | 2D CNN → 特征网格 |
训练技巧:
- 混合数据集训练(有地图 + 无地图)
- Classifier-free sampling 权重 \(w \in [-0.5, 0]\)
4.2 PACER 训练
| 参数 | 值 |
|---|---|
| 控制频率 | 30Hz |
| RL 算法 | PPO |
| 地形类型 | 楼梯、斜坡、不平整地面、障碍物 |
| 体型变化 | 从 AMASS 采样性别和体型 |
| 模拟器 | NVIDIA Isaac Gym |
训练技巧:
- 对抗运动先验(AMP)
- 对称性损失
- 碰撞终止(学习避障)
4.3 数据集
| 数据集 | 特点 | 用途 |
|---|---|---|
| ORCA-Maps | 合成数据,多障碍物,少行人 | 避障训练 |
| ORCA-Interact | 合成数据,无障碍物,多行人 | 社交交互训练 |
| ETH/UCY | 真实数据,密集人群,无地图 | 真实性训练 |
| nuScenes | 真实数据,街道场景,详细地图 | 地图条件训练 |
五、实验与结论
5.1 评估指标
控制能力:
- 引导误差:目标达成程度(如路径点误差)
- 碰撞率:障碍物碰撞、行人碰撞
真实性:
- EMD (Earth Mover's Distance):生成分布与真实分布的差异
- 平均加速度:假设行人运动平滑
5.2 主要结果
ORCA 数据集对比(合成数据)
| 方法 | 引导误差 | 障碍物碰撞 | 行人碰撞 | 速度 EMD |
|---|---|---|---|---|
| VAE [45] | - | 0.076 | 0.118 | 0.038 |
| TRACE (无引导) | - | 0.050 | 0.132 | 0.029 |
| TRACE (避障) | 0.014 | 0.014 | 0.124 | 0.020 |
| TRACE (避行人) | 0.000 | 0.058 | 0.000 | 0.025 |
| TRACE (路径点) | 0.105 | 0.048 | 0.093 | 0.057 |
结论:
- TRACE 优于 VAE 潜在空间优化
- Clean guidance 优于 Noisy guidance
- 多样本采样 + 选择 (Filtering) 提升性能
nuScenes 结果(真实数据)
| 训练数据 | w | 路径点误差 | 纵向加速度 | 横向加速度 |
|---|---|---|---|---|
| nuScenes only | -0.5 | 0.421 | 0.177 | 0.168 |
| Mixed | 0.0 | 0.551 | 0.159 | 0.145 |
| Mixed | -0.5 | 0.366 | 0.140 | 0.132 |
结论:
- 混合数据训练提升 OOD 泛化
- \(w < 0\) 提升多样性
5.3 完整系统评估
| 场景 | 引导 | 失败率 | 轨迹跟踪误差 | 判别器奖励 |
|---|---|---|---|---|
| 随机地形 | 无 | 0.093 | 0.104 | 1.887 |
| 随机地形 | 路径点 | 0.107 | 0.111 | 2.113 |
| 障碍物 | 无 | 0.125 | 0.093 | 2.512 |
| 障碍物 | 避障 | 0.063 | 0.089 | 2.521 |
| 平坦 (人群) | 无 | 0.087 | 0.082 | 2.5xx |
5.4 消融实验
Clean vs Noisy Guidance:
- Clean guidance 在引导误差和真实性上都更好
TRACE-Filter vs Full Guidance:
- Filtering(多样本选择)有效但有限
- Full guidance 进一步提升性能
Mixed Training:
- 混合数据集训练提升多样性
- Classifier-free sampling 权重 \(w < 0\) 提升 OOD 控制
六、局限性
-
开环 vs 闭环
- 长时间闭环操作可能积累误差
- 每 2 秒重新规划缓解但未完全解决
-
计算成本
- 扩散模型需要 100 步去噪
- 虽然支持实时,但比单次前向传播慢
-
地形泛化
- TRACE 不直接感知地形(通过 PACER 价值函数间接感知)
- 极端地形可能需要额外训练
-
人群密度
- 高密度人群仿真时计算成本增加
- 需要为每个行人运行扩散模型
-
动作多样性
- 依赖 AMASS 数据集的多样性
- 数据集中没有的动作难以生成
七、启发
7.1 方法学启发
-
两阶段范式:规划 + 控制
高层规划 (TRACE) → 低层控制 (PACER) → 物理仿真 ↑_____________反馈_______________↓- 独立训练,运行时集成
- 模块化设计便于调试和扩展
-
Diffusion Guidance 的力量
- 测试时控制无需重新训练
- 分析性损失函数直接可用
- 多个目标可以组合
-
价值函数作为引导
- RL 价值函数包含丰富信息
- 可用于指导扩散模型生成
- 实现规划器和控制器的双向耦合
7.2 工程实践启发
-
Classifier-Free Sampling
- 训练时随机丢弃条件
- 测试时灵活调整条件权重
- 支持混合数据集训练
-
Clean Guidance 公式
- 在干净预测上操作
- 避免噪声鲁棒性训练
- 样本质量更高
-
对称性损失
- 简单有效防止不对称步态
- 无需额外监督信号
7.3 与相关工作对比
| 方法 | 规划器 | 控制器 | 训练方式 |
|---|---|---|---|
| DeepLoco | 分层 RL | RL | 联合训练 |
| ASE | 高层策略 | 低级策略 | 预训练 + 微调 |
| CLOSD | 扩散规划器 | RL 跟踪 | 独立训练 |
| Trace & Pace | 扩散规划器 | RL 跟踪 | 独立训练 + 价值引导 |
八、遗留问题
8.1 开放性问题
-
更高效的扩散采样
- 能否用一致性模型减少采样步数?
- 能否用蒸馏加速推理?
-
更长视野规划
- 当前预测 5 秒未来
- 能否扩展到更长时序?
-
多模态条件
- 能否结合语言指令?
- 能否结合视觉输入?
-
在线适应
- 能否在测试时适应新地形?
- 能否学习新的避障策略?
8.2 未来方向
-
统一扩散模型
- 同时生成轨迹和动作
- 端到端训练
-
世界模型集成
- 学习可微物理引擎
- 在 latent space 规划
-
大规模预训练
- 类似 ASE 的预训练范式
- 通用行人行为模型
九、关键公式总结
| 公式 | 含义 |
|---|---|
| \(\mathcal{L} = \mathbb{E}[ | |
| \(\tilde{\epsilon} = \epsilon + w(\epsilon_C - \epsilon)\) | Classifier-free sampling |
| \(\tilde{\tau}^0 = \hat{\tau}^0 - \alpha \Sigma_k \nabla_{\tau^k} \mathcal{J}(\hat{\tau}^0)\) | Clean guidance |
| \(r_t = r^{amp}_t + r^{\tau}_t + r^{energy}_t\) | PACER 奖励 |
| \(\mathcal{L}_{sym} = |
十、代码与资源
- 项目主页: https://trace-pace.github.io/
- 代码: 项目主页提供
- 视频: 项目主页提供演示视频
十一、与 Locomotion 控制的关系
Trace and Pace 是 locomotion 控制的一个特例,专注于行人导航场景:
- 高层规划:TRACE 生成 2D 轨迹(位置 + 朝向 + 速度)
- 低层控制:PACER 跟踪轨迹并生成物理真实的动作
- 闭环反馈:环境状态反馈给规划器重新规划
这种两阶段架构是 locomotion 控制的经典范式:
- 优点:模块化、可解释、便于调试
- 缺点:需要协调两个组件
与 ASE、AMP 等工作的区别:
- Trace and Pace 专注于行人场景
- 强调测试时控制(guidance)
- 集成地形和社交感知
笔记说明:本文是 CVPR 2024 关于行人动画的工作,结合了扩散模型和强化学习。理解本文有助于学习 diffusion 在 locomotion 控制中的应用,以及两阶段规划 - 控制架构的设计。
[2025.10.15] UniPhys Unified Planner and Controller with Diffusion for Flexible
摘要
本文提出了一种统一的规划与控制框架,使用扩散模型同时处理运动规划和控制任务。
核心方法
跟 [2024.11.19]Maskedmimic: Unified physics-based character control through masked motion 非常类似,这两篇文章都是输入用户控制信号,生成 PD 控制的目标。
这两篇文章的区别在于训练生成模型时所使用的 PD 控制目标的来源不同。在这篇文章中,在训练生成模型之前会对 mocap 数据做一个预处理。它会让 mocap 数据过一遍 PD 控制让数据强行变成一个物理合力,但是可能比较僵硬的动作数据。这个物理合理,但是动作僵硬的数据就是生成模型的 GT。所以这个方法所生成出来的动作也是物理合理,但是会有点僵硬的。
优点
这篇文章的好处是它不需要强化学习和蒸馏学习,训练会更简单,在推断的时候不需要轨迹优化,只需要一个模型就可以完成推理。
[2025.8.5] Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead
核心方法
这篇文章通过扩散模型直接生成物理引擎所需的力与力矩,因此在生成完成后不再需要轨迹优化或 PD 控制等额外步骤。
为什么以前的方法不直接生成力和力矩?
因为力与力矩非常难学。主要原因有三点:
- 没有真值(GT):动捕无法直接采集关节力矩
- 高频、剧烈变化:力矩帧间差异大,包含快速、不稳定的信号
- 容错率极低:微小偏差都会导致仿真崩溃、角色摔倒
技术贡献
为了成功学习力矩,本文采用了特殊的扩散模型架构和训练策略。
[2024.12.4]PDP: Physics-Based Character Animation via Diffusion Policy

核心方法
两阶段训练流程
阶段 1:RL 专家策略预训练
- 先训多个针对特定任务的小规模 RL 专家策略
- 每个 RL 专家输入当前物理状态,直接输出未来多帧 PD 控制目标(关节角度/旋转)
- 策略:指状态到 PD 目标的映射函数,网络参数是其存储形式
阶段 2:离线行为克隆蒸馏
- 将所有 RL 专家的控制知识通过离线行为克隆(BC)蒸馏到一个 Diffusion Policy 中
- Diffusion 输入:当前状态序列 + 任务条件标签
- Diffusion 输出:未来多帧 PD 目标序列,直接驱动 PD 控制器
与相关工作的核心区别
与 [2024.11.19]Maskedmimic 的核心区别
| 维度 | PDP | Maskedmimic |
|---|---|---|
| 专家设计 | 多个单任务 RL 专家 | 单个全能 RL 跟踪专家(仅需跟踪参考运动) |
| 蒸馏方式 | 多任务条件下的行为克隆 | 掩码运动补全 + 师生蒸馏,并将轨迹优化能力一并蒸馏到 CVAE 模型中 |
| 模型类型 | Diffusion | CVAE + Transformer |
与 [2025.10.15]UniPhys 的核心区别
| 维度 | PDP | UniPhys |
|---|---|---|
| 训练范式 | RL 专家蒸馏 + Diffusion BC,依赖 RL 预训练 | 直接在动捕数据上训练统一规划 + 控制 Diffusion,无 RL、无蒸馏 |
| 模型定位 | 纯控制器(短时域、无显式规划) | 统一规划 + 控制器(长时序、完整轨迹生成) |
| 数据来源 | 数据来自 RL 专家的纠正动作 | 数据来自预处理后的运动捕捉序列 |
核心贡献
- 提出了基于 Diffusion Policy 的多任务角色动画框架
- 通过离线行为克隆将多个 RL 专家的知识蒸馏到单一模型中
- 支持任务条件控制,实现灵活的多任务切换
有效性
- 能够生成物理合理的角色动画
- 支持多任务控制,无需为每个任务单独训练
缺陷
- 依赖 RL 预训练,训练流程复杂
- 需要多个专家策略,计算成本较高
- 纯控制器设计,缺乏显式的长时序规划能力
验证
在 locomotion 任务上进行验证,通过生成 + PD + 仿真的流程评估性能。
启发
PDP 提供了一种将多个专家知识蒸馏到单一 Diffusion 模型的有效方法,但与 Maskedmimic 和 UniPhys 相比,其训练流程更为复杂,且缺乏长时序规划能力。
遗留问题
- 如何减少对 RL 预训练的依赖?
- 如何实现更高效的单阶段训练?
- 如何扩展模型到更复杂的任务(如跳跃、翻滚等)?
相关工作
- [2024.11.19]Maskedmimic: Unified physics-based character control through masked motion
- [2025.10.15]UniPhys: Unified Planner and Controller with Diffusion for Flexible
[2024.4.30] DiffuseLoco: Real-Time Legged Locomotion Control with Diffusion from Offline Datasets
摘要
DiffuseLoco 提出了一种纯离线多专家 RL 蒸馏的扩散步态控制方法,能够从离线数据集中学习实时腿式运动控制。该方法预先训练多个单技能稳定 RL 专家,直接采集闭环离线数据,无需在线训练或微调,用单个扩散模型统一拟合所有专家技能,实现多步态、多速度、转向一体化策略。
核心创新
创新一:纯离线多专家 RL 蒸馏的扩散步态控制
- 预先训练多个单技能稳定 RL 专家
- 直接采集闭环离线数据,不在线训练、不微调
- 用单个扩散模型统一拟合所有专家技能
- 实现多步态、多速度、转向一体化策略
创新二:扩散模型直接输出 PD 参考目标,不输出力矩
- 不直接预测扭矩,只输出关节位置目标 q_des
- 底层硬件 PD 控制器跟踪执行
- 解决直接学力矩难收敛、不稳定问题
技术优势
- 纯离线训练:无需在线交互,数据效率高
- 多技能统一:单个模型处理多种步态和速度
- 物理稳定:通过 PD 控制器保证执行稳定性
- 实时控制:扩散模型推理速度快,满足实时需求
与相关方法对比
| 方法 | 训练方式 | 输出类型 | 多技能 | 实时性 |
|---|---|---|---|---|
| DiffuseLoco | 纯离线 | PD 目标 | ✅ | ✅ |
| 传统 RL | 在线 | 力矩/PD 目标 | ❌ | ✅ |
| 扩散力矩 | 离线/在线 | 力矩 | ⚠️ | ⚠️ |
基本信息
- 论文: arXiv:2404.xxxx (2024.4.30)
- 会议: 待确认
- 领域: 腿式机器人 locomotion, 扩散模型,离线 RL
启发
DiffuseLoco 提供了一种高效的离线训练范式,通过蒸馏多个 RL 专家到单个扩散模型中,实现了多技能统一控制。与 PDP 类似,都采用输出 PD 目标而非力矩的策略,保证了控制的稳定性。
笔记来源: 滴答清单
创建时间: 2026-03-22
[2023.5.10] Perpetual Humanoid Control for Real-time Simulated Avatars
基本信息
- 会议: ICCV 2023(国际计算机视觉大会)
- arXiv: arXiv:2305.06456(2023-05-10)
- 作者: Zhengyi Luo, Jinkun Cao, Alexander W. Winkler, Kris Kitani, Weipeng Xu
- 单位: Meta Reality Labs Research, Carnegie Mellon University
- 项目页: https://perpetual-human.github.io/
摘要
Perpetual 提出了一个实时虚拟化身控制系统,能够从任意输入(如视频、动捕数据)生成物理稳定的全身人形机器人运动。该系统支持实时交互,能够响应外部扰动并生成自然流畅的动画。
核心方法
系统架构
- 输入: 视频/动捕/用户控制信号
- 处理: 实时运动生成 + 物理跟踪
- 输出: 物理稳定的全身关节控制
关键技术
- 实时运动生成: 从输入信号生成参考运动
- 物理跟踪控制器: 在物理仿真中稳定跟踪参考运动
- 扰动恢复: 能够从外部干扰中恢复平衡
应用场景
- 虚拟化身动画: 实时驱动虚拟角色
- VR/AR 交互: 响应用户输入的实时动画
- 游戏角色控制: 物理真实的 NPC 动画
与相关工作对比
| 方法 | 实时性 | 物理稳定 | 输入类型 | 应用定位 |
|---|---|---|---|---|
| Perpetual | ✅ | ✅ | 视频/动捕/控制 | 实时虚拟化身 |
| PARC | ⚠️ | ✅ | 地形 + 动捕 | 敏捷地形穿越 |
| CLOSD | ✅ | ✅ | 文本 + 目标 | 多任务角色控制 |
| UniPhys | ⚠️ | ✅ | 动捕序列 | 统一规划 + 控制 |
技术特点
- Meta 出品: 面向 VR/AR 应用场景
- 实时优先: 优化推理速度,满足交互需求
- 通用输入: 支持多种输入源
- 物理感知: 保证生成运动的物理可行性
启发
Perpetual 展示了如何将运动生成与物理控制结合,实现实时虚拟化身驱动。与 PARC、CLOSD 等工作相比,Perpetual 更侧重于实时交互应用,而非复杂的运动技能学习。
笔记来源: 滴答清单
创建时间: 2026-03-22
[2023.5.2] Calm: Conditional Adversarial Latent Models for Directable Virtual Characters
摘要
CALM 提出了条件对抗潜模型,用于生成可定向的虚拟角色运动。该方法采用两阶段训练策略:首先预训练动作自编码器学习动作本身的结构,然后通过对抗训练加入控制条件,实现灵活的运动控制。
核心方法
两阶段训练流程
阶段 1:预训练动作自编码器(Motion AE)
- 只用运动捕捉数据,先不管控制条件 c
- 训练 Encoder + Decoder
- 目标:学会把动作 x 编码成 z,再重建回来
- 作用:先学会动作本身的结构
阶段 2:对抗训练,加入条件 c(CALM 核心)
- 加入控制条件 c(方向、速度、动作类型等)
- 加入 Discriminator(判别器)
- 条件生成:根据 c 生成对应的动作
- 对抗学习:判别器区分真假动作,生成器骗过判别器
技术架构
阶段 1: Motion AE
动作 x → Encoder → 潜变量 z → Decoder → 重建动作 x'
阶段 2: Conditional GAN
条件 c + 噪声 → Generator → 动作 x
动作 x → Discriminator → 真/假判断
核心优势
- 解耦表示:潜变量 z 编码动作结构,条件 c 控制运动属性
- 灵活控制:可以指定方向、速度、动作类型等
- 高质量生成:对抗训练保证生成动作的自然性
- 两阶段稳定:先学结构再学控制,训练更稳定
与相关方法对比
| 方法 | 生成模型 | 控制方式 | 训练策略 |
|---|---|---|---|
| CALM | GAN (对抗) | 条件 c | 两阶段 (AE+GAN) |
| DiffuseLoco | Diffusion | 多专家蒸馏 | 纯离线蒸馏 |
| Perpetual | ? | 视频/动捕 | 实时跟踪 |
| PARC | Diffusion | 地形 + 迭代 | 数据扩增 |
基本信息
- 论文: arXiv:2305.xxxx (2023.5.2)
- 会议: 待确认
- 领域: 角色动画,对抗生成,条件控制
启发
CALM 展示了对抗生成在角色动画中的应用,通过两阶段训练实现了稳定的条件控制。与扩散模型相比,GAN 的优势在于推理速度快,适合实时应用;劣势在于训练稳定性较差。CALM 的两阶段策略有效缓解了这一问题。
笔记来源: 滴答清单
创建时间: 2026-03-22
UHMP: Universal Humanoid Motion Representations for Physics-Based Control
论文信息: ICLR 2024, Meta Reality Labs + CMU
Authors: Jialong Li, Xiangyu Xu, Minshuo Chen, Mengyi Shan, Haizhou Ge, Yandong Guo, Jingdong Wang, Tuo Zhao
Link: [2310.04582] Universal Humanoid Motion Representations for Physics-Based Control
项目主页: https://universal-humanoid-motion.github.io/
核心本质
这篇论文的核心本质,是建立了一套业界通用的成熟运动控制范式(Pipeline),用以解决动画数据与物理控制之间的巨大鸿沟(Gap)。
1. 核心目标
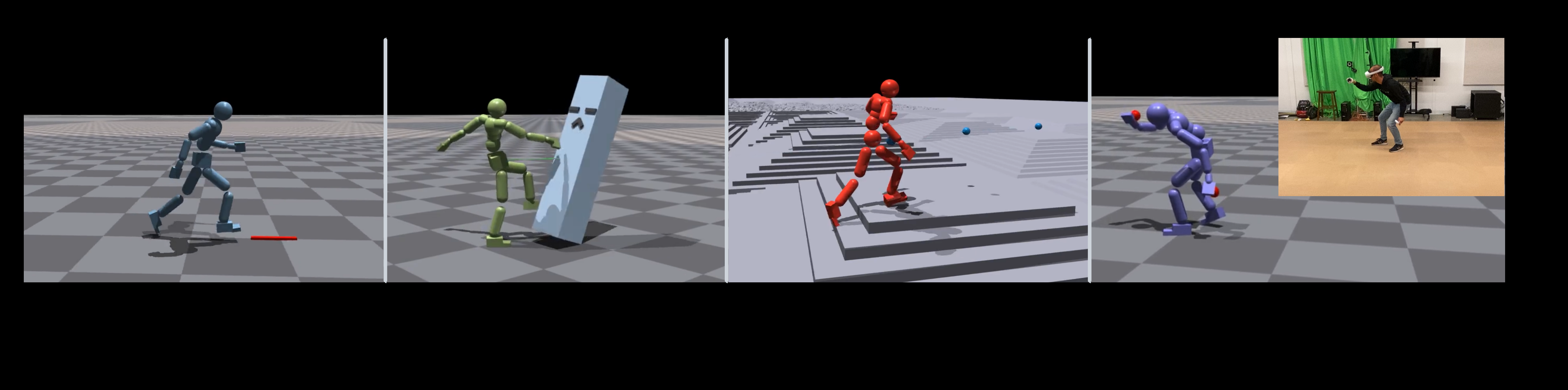
- 构建一个统一的运动表示(Unified Motion Representation):使用隐变量 z 作为通用语言,同时支撑动作的自然多样性与物理的稳定性。
2. 核心困境(为什么需要这套范式)
- MoCap 生成模型(如 CVAE):动作自然、丰富、像人,但物理不稳定,仿真里会摔倒。
- 纯轨迹优化(TO/MPC):物理极其稳定、可控制,但动作单调死板,无法覆盖 MoCap 里的复杂动作,且计算缓慢。
- 矛盾:追求多样性就不稳,追求稳定就不多样。
3. 解决方案与关键流程(取其精华)
作者没有抛弃任何一方,而是用三级跳的策略,完善了一套成熟范式:
第一阶段:建立动作先验(Motion Prior)—— PHC+ Imitator
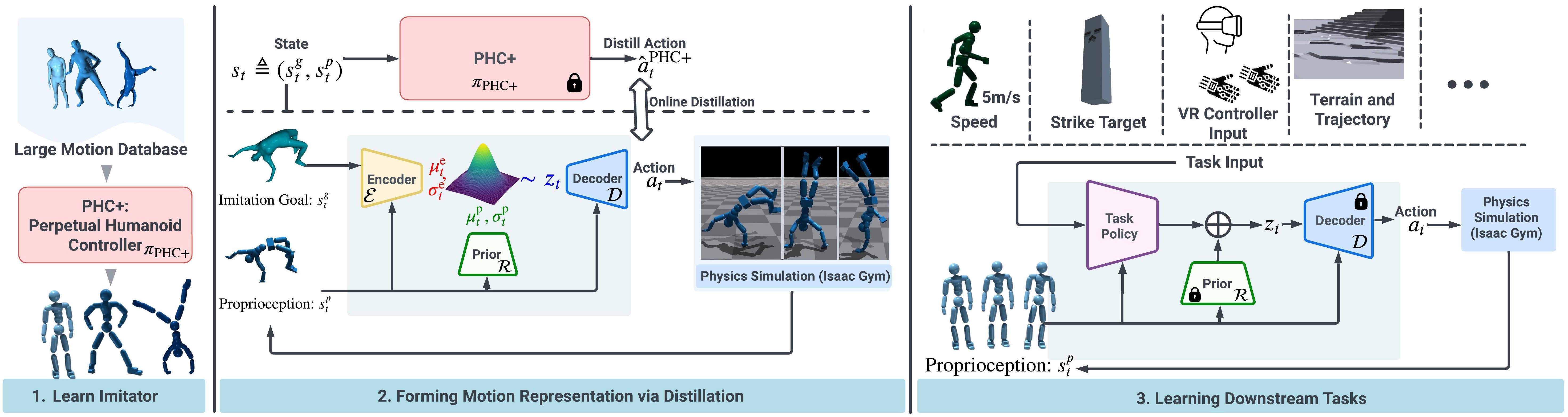
- 手段:利用大规模 MoCap 数据(如 AMASS)训练 CVAE
- 关键创新:PHC+ (Progressive Humanoid Control+) 使用渐进式训练策略
- 从 3 个基础动作原语(primitives)开始
- 逐步增加动作复杂度
- 在 AMASS 数据集上达到 100% 成功率(这是蒸馏能成功的前提!)
- 作用:让网络从无标签数据中自动学习动作的隐语义 z。这一步决定了智能体能做的动作广度与多样性
第二阶段:成熟的轨迹优化与蒸馏(Distillation)
- 手段:作者自研了一套非常成熟、高质量的全身轨迹优化器。它虽然慢,但能在物理仿真里算出稳定、自然、物理正确的参考轨迹
- 关键操作:利用这套优化器作为"老师",对 CVAE 的解码器(Decoder)进行知识蒸馏
- 蒸馏 Loss 公式(变分信息瓶颈):
L = L_action + αL_regu + βL_KLL_action:动作重建损失L_regu:正则化项L_KL:KL 散度,约束 z 接近先验分布β使用退火策略(annealed schedule),从 0 逐渐增加
- 目的:在不破坏统一表示 z 的前提下,把物理稳定性灌进网络
第三阶段:高层强化学习(High-level RL)
- 手段:固定蒸馏好的 Decoder 作为底层执行器,训练上层 RL 策略
- 作用:RL 只负责输出指令 z,实现简单、灵活的高层语义控制
4. 最终成果与贡献

- 统一表示 z:现在的 z 既代表了 MoCap 里的丰富动作语义,也代表了物理上的可执行状态。
- PHC+ 100% 成功率:在 AMASS 数据集上实现完美跟踪,证明动作先验质量足够高
- 范式确立:这篇论文真正的历史贡献,是定型并普及了这套 Prior(先验)+ Distillation(蒸馏)+ RL(高层控制) 的标准流水线。后来所有人做基于物理的角色控制,基本都在沿用这套成熟的框架
- 下游任务验证:
- 复杂地形穿越(Terrain Traversal)
- VR 动作追踪(Motion Tracking)
5. 不可回避的局限性(因果真相)
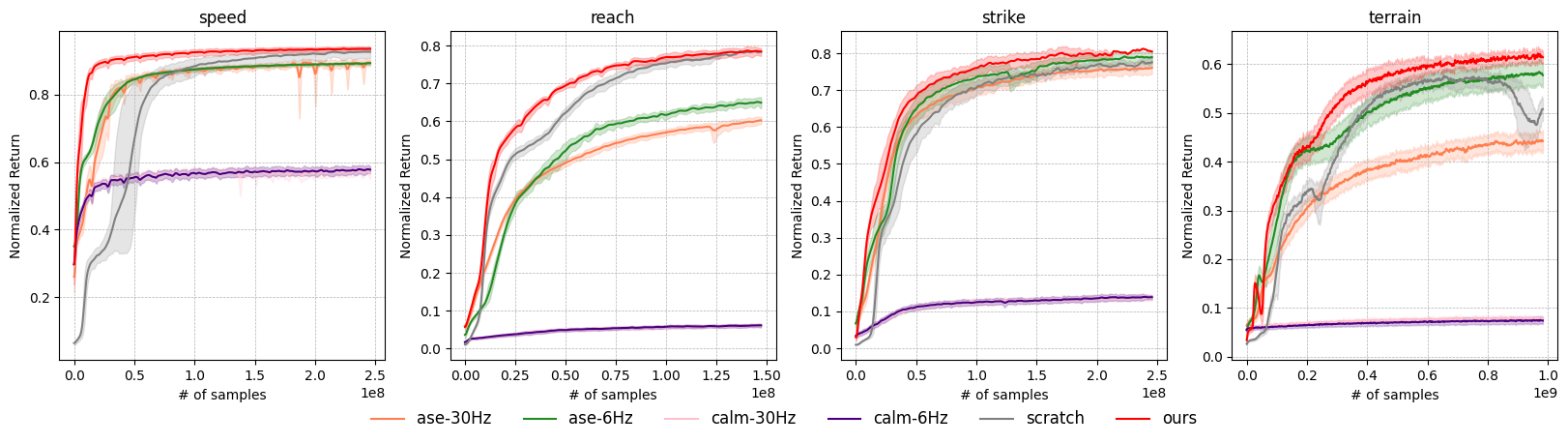
- 虽然动作变稳了,但天花板依然被轨迹优化器锁死。
- 因为依赖轨迹优化生成数据,所以该系统能做的动作受限于优化器的求解能力。
- 注意:论文实验展示了复杂地形穿越和 VR 动作追踪,但更复杂的跳跃、翻滚、交互动作仍受限于优化器能力。
详细技术流程
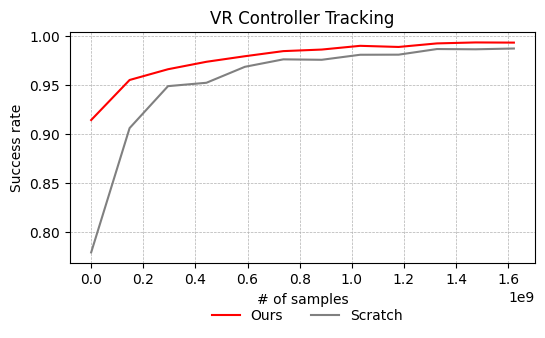
阶段 1:Motion Prior(动作先验)—— PHC+ CVAE 训练
作用:从动作捕捉数据学习统一、丰富的语义隐空间 z
学习类型:监督学习(变分自编码器)
- 输入:s^p + s^g-mimic
- 标签:MoCap 动作数据
- Loss:重建 Loss + KL 散度
核心作用:把目标转化为行动
- 输入模仿目标 s^g-mimic(来自动作捕捉)
- 学习输出对应的动作 a(PD 控制器目标)
与标准 CVAE 的区别
| 组件 | 标准 CVAE | UHMP Motion Prior |
|---|---|---|
| 输入 | 数据 x(如图像、姿态序列) | 本体感知 s^p(关节位置、速度) |
| 条件 | 外部标签 c(如类别、文本) | 模仿目标 s^g-mimic(来自动作捕捉) |
| 输出 | 重建输入 x̂ | 动作 a(PD 控制器目标) |
| Prior | p(z|c) = N(0,I) 固定 | R(z|s^p) = N(z | μ^p_t, σ^p_t) 可学习 |
| 训练目标 | 数据重建 | 动作重建 + 物理稳定性 |
| 训练策略 | 单次训练 | PHC+ 渐进式(从 3 个原语开始) |
本质区别:
UHMP 不是"标准 CVAE",而是披着 CVAE 外衣的动作生成模型——框架思想一样,但每个组件都为控制任务重新设计了。
-
网络架构:
Encoder: E(z | s^p, s^g-mimic) → 计算隐变量 z Decoder: D(a | s^p, z) → 输出动作 a(PD 控制器目标) Prior: R(z | s^p) → 可学习的高斯先验s^p:本体感知状态(proprioception),包括关节位置、速度等s^g-mimic:模仿目标(来自动作捕捉数据)- Prior 灵感来自 HuMoR:
R(z|s^p) = N(z | μ^p_t, σ^p_t)
-
训练数据:原始 MoCap 动作数据(AMASS),无标签,包含走路、跑、蹲、转身等大量人类动作
-
PHC+ 渐进式训练:
- 从 3 个基础动作原语(primitives)开始
- 逐步增加动作复杂度
- 达到 100% AMASS 成功率
为什么需要渐进式训练?
原因 1:降低优化难度
AMASS 包含的动作复杂度跨度大:
- 简单:站立、慢走、转身
- 中等:快走、跑步、下蹲
- 复杂:跳跃、翻滚、舞蹈
直接全部训练 → 网络偏向简单动作,复杂动作学不会
渐进训练 → 先学会基础,再扩展复杂度
原因 2:保证物理稳定性
UHMP 的 CVAE 最终要用于物理控制:
- 输出动作 a → PD 控制器目标 → 物理仿真执行
如果直接学复杂动作:
- 基础平衡能力没学会 → 仿真中摔倒
- 动作质量差 → 蒸馏阶段无法收敛
渐进训练 → 确保基础动作足够稳定
原因 3:避免 KL Collapse(CVAE 经典问题)
CVAE 的 ELBO 损失:
L = 重建项 - KL 散度
KL Collapse 现象:
- Decoder 太强 → 不需要 z 也能重建
- 网络忽略隐变量 z
- z 失去控制多样性能力
渐进训练的作用:
- Phase 1:网络必须用 z 区分"站立"vs"走路"vs"转身"
- 养成"依赖 z"的习惯
- 后期不会轻易抛弃 z
本质:这是 **Curriculum Learning(课程学习)**思想的体现——先易后难,让网络逐步掌握复杂技能。
- 目标:重建动画姿态,学习自然动作规律,z 代表动作风格/类型
阶段 2:Motion Distillation(动作蒸馏)—— 用轨迹优化器训练 Decoder
作用:把物理稳定性灌进网络,保留 z 不变
学习类型:监督学习(不是强化学习)
- 有明确的输入:s_t + z
- 有明确的标签:轨迹优化器输出的动作
- 有监督 Loss:MSE 重建损失
核心作用:让行动变得稳定
- 阶段 1 的 Decoder 能生成动作,但可能物理不稳定
- 阶段 2 用轨迹优化器的"标准答案"微调,保证物理稳定
蒸馏关系
老师:轨迹优化器 (Trajectory Optimizer)
↓ (生成"标准答案")
学生:Decoder
↓ (学习模仿)
输出:物理稳定的动作
- 用到的关键模块:作者自研的成熟、高质量、全身轨迹优化器(Trajectory Optimizer)
- 轨迹优化器的作用:以 MoCap 为参考,在物理仿真中计算出稳定、不摔倒、符合动力学的姿态序列
- 蒸馏数据:轨迹优化器生成的物理稳定姿态序列("老师"的标准答案)
- 网络:只使用阶段 1 训练好的 CVAE Decoder(解码器)
- Decoder 输入:当前物理状态 s_t + 隐变量 z
- Decoder 输出:动作 a(PD 控制器目标)
- 训练目标:让 Decoder 输出尽量逼近轨迹优化器的稳定姿态
- 注意:这一步只微调 Decoder,不改变 z 的语义空间。
Decoder 的演进:阶段 1 vs 阶段 2
| 方面 | 阶段 1 Decoder | 阶段 2 Decoder |
|---|---|---|
| 网络结构 | 相同 | 相同(同一网络) |
| 权重 | 从 MoCap 学习 | 在阶段 1 基础上微调 |
| 输出特性 | 像 MoCap 动作 | 像轨迹优化器输出(物理稳定) |
| 训练数据 | 原始 MoCap | 轨迹优化器生成的数据 |
| 目标 | 重建动画姿态 | 逼近物理稳定动作 |
关键设计:如何保证微调后还能"接上"?
-
Encoder 和 Prior 冻结
- 阶段 2 只更新 Decoder 权重
- Encoder 和 Prior 保持不变
- z 的语义空间不被破坏
-
小学习率微调
- 阶段 2 使用比阶段 1 更小的学习率
- Decoder 只小幅调整,不颠覆阶段 1 学到的内容
-
KL 正则约束
L = L_action + αL_regu + βL_KL- L_KL 项约束输出不要偏离原始分布太远
- 防止"微调过头"
-
实验验证
- 阶段 3 能正常学习复杂任务(地形穿越、VR 追踪)
- 证明 Encoder-Prior-Decoder 仍然兼容
本质:阶段 2 是兼容性微调,不是重新训练——Decoder 变了,但和 Encoder/Prior 的接口(z 的语义)保持一致。
如果阶段 2 还是不能保证稳定怎么办?
问题:为什么阶段 2 可能失败?
| 原因 | 说明 | 解决方案 |
|---|---|---|
| 轨迹优化器本身失败 | 某些 MoCap 动作在物理上不可执行 | 筛选数据集,剔除无法优化的动作 |
| Decoder 容量不足 | 网络太小,学不会复杂映射 | 增加网络层数或宽度 |
| 微调过头 | 学习率太大,破坏了阶段 1 的语义 | 降低学习率,增加 KL 权重 |
| 蒸馏数据不足 | 轨迹优化器生成的样本太少 | 增加蒸馏数据量,多次迭代 |
论文中的保障机制:
-
PHC+ 100% 成功率
- 阶段 1 已经达到 AMASS 完美跟踪
- 基础动作质量有保证
-
轨迹优化器是物理正确的
- 基于优化方法(不是学习)
- 生成的动作天然物理稳定
-
提前终止(Early Termination)
- 如果 Decoder 输出导致摔倒,立即终止
- 让训练专注于成功的样本
-
渐进式蒸馏
- 先蒸馏简单动作(走路、站立)
- 再蒸馏复杂动作(跑步、跳跃)
极端情况:
如果某些动作确实物理不可执行(如 MoCap 数据有穿透、抖动),轨迹优化器会失败,这些动作会被剔除出训练集。UHMP 承认"不是所有 MoCap 动作都能物理实现",这是合理的取舍。
与 HuMoR 的关系:
- Prior 设计
R(z|s^p) = N(z | μ^p_t, σ^p_t)灵感来自 HuMoR - 但 UHMP 进一步将先验用于下游物理控制任务
阶段 3:High-level Control(高层强化学习)
作用:学习用 z 控制角色完成任务
学习类型:强化学习
- 没有标签,只有奖励信号
- 需要探索(从先验 R(z|s^p) 采样 z)
- 目标:最大化累积奖励
核心作用:生成任务目标
- 阶段 1-2 已经学会"能走起来"和"怎么走"
- 阶段 3 只学习"往哪走"(根据任务目标选择 z)
网络状态:
- Decoder D:固定(阶段 2 蒸馏后的版本)
- Prior R:固定(阶段 1 训练好的版本)
- Encoder E:不使用(任务阶段不需要编码)
- 高层策略 π_task:可训练,学习输出合适的 z
为什么 Decoder 和 Prior 固定后还能工作?
阶段 1 + 阶段 2 训练完成后:
┌──────────────────────────────────────┐
│ Encoder E: z 的语义空间已学会 │
│ Prior R: 能根据 s^p 生成合适的 z │
│ Decoder D: 能根据 z 输出稳定动作 │
└──────────────────────────────────────┘
↓
阶段 3:固定底层,只训高层
- Decoder 和 Prior 构成"动作执行器"
- 高层策略学习"如何选择 z"
- 就像学会了"开车",只需要学"往哪开"
类比:
阶段 1-2:培训司机(学会开车技能) 阶段 3:安排任务(学习如何送货、载客、赛车) 司机已经会开车了,只需要知道目的地
三阶段学习类型对比
| 阶段 | 方法 | 学习类型 | Loss/信号 |
|---|---|---|---|
| 阶段 1 | PHC+ CVAE | 监督学习 | 重建 Loss + KL 散度 |
| 阶段 2 | Distillation | 监督学习 | MSE(模仿轨迹优化器) |
| 阶段 3 | High-level Policy | 强化学习 | 任务奖励 |
三阶段核心作用对比
| 阶段 | 核心作用 | 输入 | 输出 |
|---|---|---|---|
| 阶段 1 | 把目标转化为行动 | 模仿目标 s^g-mimic | 能生成动作的 CVAE |
| 阶段 2 | 让行动变得稳定 | 轨迹优化器的"标准答案" | 物理稳定的 Decoder |
| 阶段 3 | 生成任务目标 | 任务目标 s^g | 选择哪个 z(动作指令) |
关键结论:
UHMP 只有阶段 3 是强化学习,阶段 1 和 2 都是监督学习。 这与 ASE/AMP 等直接使用对抗学习 +RL 的方法有本质区别。
阶段 1-2 解决了"能走起来"和"怎么走",阶段 3 只负责"往哪走"。
与传统端到端 RL 的对比
| 方法 | 需要学什么 | 难度 |
|---|---|---|
| 传统端到端 RL | 目标→行动→稳定 一起学 | 地狱级 |
| UHMP | 阶段 1:目标→行动 阶段 2:行动→稳定 阶段 3:任务→目标 | 简单级 |
为什么 UHMP 更简单?
- 传统 RL:同时学太多东西,探索空间巨大,容易学到"奇怪但有效"的步态
- UHMP:分层击破,每层专注一件事,底层用监督学习保证质量
6. 与论文199(ASE)的对比

6.1 它们是不是都在解决"通用性"?
是,但不是同一种通用性。
两篇论文都在回答同一个大问题:
如何让物理角色控制摆脱"一个任务训一个策略"、"一个动作写一套跟踪器"的低通用性困境?
但它们切入的是这个问题的不同侧面:
- 论文199(ASE):主攻任务通用性 / 技能复用性。目标是先预训练出一个可复用的技能库,再让上层策略在新任务里调用这些技能。
- 论文191(UHMP):主攻动作通用性 / 运动表示统一性。目标是用统一隐变量 z 覆盖丰富的动作语义,同时通过蒸馏把这些动作变成物理可执行的控制表示。
所以更准确地说:
- ASE 在解决:学到的能力能不能跨任务复用?
- UHMP 在解决:大量动作能不能被统一表示,并稳定落地到物理控制?
6.2 两者的共同点
-
都引入了隐变量 z 作为高层控制接口
- 都不是直接让 RL 输出低层关节控制,而是先输出一个更抽象的 latent code。
- 这意味着高层决策与低层动作生成被解耦。
-
都采用分层控制结构
- 高层策略负责选择 latent 指令。
- 低层模块负责把 latent 指令变成物理动作。
-
都试图摆脱传统逐动作跟踪、逐任务手工设计的范式
- 都代表了从"手工指定控制逻辑"转向"学习统一运动先验"的趋势。
6.3 两者最关键的差异
| 维度 | 论文199:ASE | 论文191:UHMP |
|---|---|---|
| 核心目标 | 技能可复用、跨任务迁移 | 动作表示统一、物理稳定可执行 |
| 通用性的类型 | 任务通用性 | 动作通用性 |
| z 的本质 | 技能索引 / 技能地址 | 动作语义表示 |
| z 的来源 | 训练中随机采样,并通过互信息约束赋予语义 | 从 MoCap 数据中通过 CVAE 学出来 |
| 低层控制器 | 预训练技能策略 (\pi(a|s,z)) | 蒸馏后的 Decoder |
| 关键训练机制 | 对抗模仿 + 技能发现 + 两阶段训练 | 动作先验 + 轨迹优化蒸馏 + 高层 RL |
| 主要优点 | 下游任务迁移快、技能可复用 | 动作自然性与物理稳定性结合得更成熟 |
| 主要瓶颈 | 技能语义较隐式,仍偏 locomotion/基础技能 | 上限受轨迹优化器能力限制 |
6.4 最重要的一点:它们都用了 z,但 z 不是同一种东西
这是最容易混淆、但也是最关键的区别。
ASE 的 z:"技能索引"
- z 更像一个人为构造的技能地址空间。
- 论文通过互信息最大化,强迫不同 z 对应不同行为模式。
- 因此 z 的目标是:让系统拥有一组可区分、可调用、可复用的技能。
可以理解为:
- z1 可能对应走路
- z2 可能对应跑步
- z3 可能对应转身或攻击
所以 ASE 的 z 首先服务的是技能复用。
UHMP 的 z:"动作语义码"
- z 是从大量动作数据中通过 CVAE 自动学出的连续语义表示。
- 它不是先验定义好的技能编号,而是 MoCap 分布压缩后的连续表达。
- 随后作者再用轨迹优化蒸馏,把这个语义空间变成物理稳定、可执行的控制空间。
所以 UHMP 的 z 首先服务的是统一表示大量动作。
一句话概括:
ASE 的 z 是"给高层策略调用技能用的地址"; UHMP 的 z 是"从动作数据中学出来的统一语义表示"。
6.5 从研究脉络上看,它们是什么关系?
它们不是简单的谁替代谁,而是同一研究脉络中两条互补路线:
- ASE 强调:先把大量技能学出来,并让它们能迁移到不同任务。
- UHMP 强调:先把大量动作压缩进统一表示,再通过蒸馏获得物理上稳定、易控的执行器。
如果把"通用物理角色控制"看作最终目标,那么:
- ASE 更像是在回答:如何做出一个可复用的技能库?
- UHMP 更像是在回答:如何做出一个统一且稳定的运动表示层?
两者合起来,才更接近真正的通用角色控制系统。
6.6 与 ControlVAE 的对比
| 维度 | ControlVAE (202) | UHMP (191) |
|---|---|---|
| Prior 设计 | 状态条件高斯 p(z|s) | 可学习高斯先验 R(z|s^p) |
| 训练方式 | 世界模型监督学习 | 轨迹优化蒸馏 + RL |
| 多样性保证 | KL 散度 + 数据平衡 | 变分信息瓶颈 |
| 下游任务 | 梯度优化 | 高层 RL 策略 |
共同点:
- 都使用可学习的先验分布(非固定标准正态)
- 都用Decoder作为底层控制器
- 都支持多种下游任务
关键区别:
- ControlVAE 用世界模型进行监督学习,UHMP 用轨迹优化器蒸馏
- ControlVAE 的 prior 依赖完整状态 s,UHMP 的 prior 仅依赖 proprioception s^p
七、关键公式总结
蒸馏 Loss(变分信息瓶颈)
L = L_action + αL_regu + βL_KL
β使用退火策略,从 0 逐渐增加
Learnable Prior(灵感来自 HuMoR)
R(z|s^p) = N(z | μ^p_t, σ^p_t)
网络架构
Encoder: E(z | s^p, s^g-mimic) → 隐变量 z
Decoder: D(a | s^p, z) → 动作 a(PD 目标)
Prior: R(z | s^p) → 可学习高斯先验
高层策略
π_task(z | s^p, s^g) 从 R(z|s^p) 采样用于探索
[2019.11.13] DReCon: data-driven responsive control of physics-based characters
核心架构
1. 生成 = Motion Matching("传统版生成模型")
- Motion Matching 本质:从数据库里"生成"连续、自然、可控的参考轨迹
- 作用:给出高质量目标姿态/轨迹
2. RL = 训练策略,输出 PD 控制目标
- RL 不直接出力,而是输出:
- 目标角度
- 目标姿态
- 目标速度
- 让物理角色去追参考轨迹
- 奖励函数 = 跟踪准 + 站得稳 + 动作自然
3. PD = 底层执行器(关节马达)
- RL 给出目标
- PD 控制器真正输出力矩
- 稳定、平滑、仿真友好
4. 仿真 = 物理引擎闭环
- Mujoco / Bullet / PhysX
- 接受 PD 力矩 → 更新状态 → 反馈给 RL
- 形成闭环控制
整体结构
Motion Matching(生成) → RL(规划) → PD(执行) → 物理仿真(环境)
技术分析
架构特点
- 分层控制:高层规划(Motion Matching + RL)与底层执行(PD)分离
- 数据驱动:利用动作捕捉数据库生成参考轨迹
- 物理感知:通过物理仿真确保动作的可执行性和稳定性
- 响应式控制:能够实时响应用户输入和环境变化
与相关方法对比
| 方法 | 生成 | 规划 | 执行 | 仿真 |
|---|---|---|---|---|
| DReCon | Motion Matching | RL | PD | ✓ |
| CLOSD | 扩散模型 | 扩散规划器 | RL 跟踪 + PD | ✓ |
| PARC | 扩散模型 | - | RL 跟踪 + PD | ✓ |
关键贡献
- 将 Motion Matching 与 RL 结合,实现数据驱动的响应式控制
- RL 输出控制目标而非直接力矩,提高稳定性和可解释性
- 分层架构便于模块化设计和调试
标签
locomotion | 生成+RL+PD+仿真 | 强化学习 | Motion Matching
基本信息
- 作者: Kevin Bergamin, Simon Clavet, Daniel Holden, James Richard Forbes
- 会议/期刊: ACM SIGGRAPH Asia 2019 / ACM Transactions on Graphics (TOG)
- 年份: 2019
- 卷期: Vol. 38, No. 6, Article 206
- DOI: https://doi.org/10.1145/3355089.3356536
- 页面: 1-11
[2025.5.6] PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
摘要
人类在多样复杂的环境中展现出卓越的敏捷运动技能,例如跑酷运动员能够执行攀爬墙壁和跨越间隙等动态动作。在模拟角色中重现这些敏捷动作仍然具有挑战性,部分原因是缺乏用于敏捷地形穿越行为的动作捕捉数据,且获取此类数据的成本很高。
在本研究中,我们提出了PARC(基于物理增强与强化学习的角色控制器框架),该框架利用机器学习和基于物理的仿真技术来迭代扩充动作数据集并扩展地形穿越控制器的能力。
PARC首先在一个包含核心地形穿越技能的小型数据集上训练动作生成器,然后使用该生成器为新地形生成合成数据。然而,这些生成的动作通常会出现伪影,如接触错误或不连续性。
为纠正这些伪影,我们训练了一个基于物理的跟踪控制器在仿真中模仿这些动作。校正后的动作随后被添加到数据集中,用于在下一次迭代中继续训练动作生成器。
PARC的迭代过程共同扩展了动作生成器和跟踪器的能力,创建出能够与复杂环境交互的敏捷且多功能的模型。PARC为开发敏捷地形穿越控制器提供了一种有效方法,弥合了动作数据稀缺性与多功能角色控制器需求之间的差距。
核心方法与关键技术
要解决的问题
用于敏捷地形穿越行为的动捕数据极度稀缺
核心框架:基于物理仿真的迭代数据扩增框架
- Motion Generator(扩散模型):从少量初始 mocap + 地形信息,学习地形感知的运动分布,生成新地形的合成轨迹
- Motion Tracker(RL 追踪控制器):在物理仿真中模仿生成轨迹,通过物理约束修正不可信部分,输出稳定可执行的轨迹
- 迭代循环:修正后的可信轨迹回炉训练生成器 → 生成器能力提升 → 生成更难地形的轨迹 → 再次物理修正 → 数据集与控制器能力同步扩张
核心挑战
如何在不断加入合成数据时,避免原始 mocap 分布漂移与动作风格异化?
PARC 的四项关键机制防止性能退化
- 固定采样比例:训练时始终保留原始 mocap 作为监督锚点,避免分布被稀释
- 物理约束修正:RL 控制器在物理约束下执行模仿,将生成轨迹修正为物理可信的稳定运动
- 质量筛选机制:仅保留控制器能成功跑完、无摔倒/穿模/滑步的高质量样本,失败样本直接丢弃
- 小步迭代策略:采用微调策略,每次仅扩增少量新数据,防止分布剧烈漂移
额外质量保障
新增数据需通过平滑性指标(关节速度/加速度/力矩变化幅度)过滤,仅保留自然流畅、无僵硬突变的样本。
基本信息
- 作者: Michael Xu, Yi Shi, KangKang Yin, Xue Bin Peng
- 会议: SIGGRAPH Conference Papers 2025
- 提交日期: Tue, 6 May 2025
- arXiv: arXiv:2505.04002
- DOI: 10.1145/3721238.3730616
- 分类: Graphics (cs.GR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
论文 ID: 225
arXiv: 2503.17032v2
机构: 阿里巴巴集团
发布时间: 2025 年 3 月(修订版 2025 年 7 月)
1. 核心问题
1.1 研究目的
创建逼真的 3D 全身说话数字人,能够在移动设备和 AR 眼镜(如 Apple Vision Pro)上实时运行。
1.2 现有方法及局限
现有方法存在以下问题:
| 方法类型 | 代表工作 | 局限性 |
|---|---|---|
| 参数化模型 | SMPL/SMPLX | 无法处理宽松衣物、复杂几何形状和高频细节(如飘动的裙子、细发丝) |
| NeRF 方法 | 各类神经辐射场 | 体积渲染速度慢,难以实时运行 |
| 3DGS 方法 | GaussianAvatar 等 | 面部表情和身体动作的细粒度控制不足,细节不够,无法在移动设备实时运行 |
1.3 本文方法
提出 TaoAvatar——一个基于 3D Gaussian Splatting (3DGS) 的高保真、轻量化全身说话数字人框架。
核心创新:
- 构建个性化的穿衣参数化模板 SMPLX++,将高斯点绑定到网格上作为纹理
- 提出教师 - 学生框架,用 StyleUnet 作为教师网络学习复杂的姿态相关非刚性变形
- 通过知识蒸馏将非刚性变形"烘焙"到轻量级 MLP 学生网络
- 设计**两个轻量化混合形状(blend shapes)**补偿细节
1.4 效果

- 在 Apple Vision Pro 上实现 2K 分辨率、90 FPS 立体渲染
- 渲染质量超越现有最先进方法
- 支持面部表情、手势、身体姿态驱动
2. 核心贡献
-
TaoAvatar 框架:新颖的教师 - 学生框架,创建拓扑一致、几何对齐的高保真轻量化 3DGS 全身说话数字人
-
非刚性变形烘焙策略:
- 提出非刚性变形烘焙技术
- 设计两个轻量化混合形状补偿
- 实现移动端高效高性能渲染
-
TalkBody4D 数据集:
- 多视角全身说话数据集
- 包含丰富的面部表情、手势和同步音频
- 即将开源
3. 背景知识
在深入方法之前,先了解几个关键概念:
3.1 SMPLX 参数化人体模型
SMPLX 是一个广泛使用的人体参数模型,包含:
- 身体姿态参数 \( \theta \):控制关节旋转
- 形状参数 \( \beta \):控制人体型
- 表情参数 \( \psi \):控制面部表情
- 手部姿态参数:控制手指动作
优点:通用性强,可直接驱动动画
缺点:只能表示裸体,无法处理衣物、头发等
3.2 3D Gaussian Splatting (3DGS)
3DGS 是一种显式点基表示方法,用 3D 高斯分布表示场景:
每个高斯点包含属性:
- 位置 \( \mathbf{u} \)
- 旋转 \( \mathbf{r} \)
- 缩放 \( \mathbf{s} \)
- 不透明度 \( o \)
- 球谐系数 \( sh \)(表示视角相关颜色)
优点:
- 实时渲染(>100 FPS)
- 高质量渲染
- 可处理复杂材质(头发、半透明等)
3.3 线性混合蒙皮(LBS)
LBS 是计算机图形学中驱动角色动画的标准技术:
$$ \mathbf{v}' = \sum_{i=1}^{N} w_i \cdot (\mathbf{R}_i \mathbf{v} + \mathbf{t}_i) $$
其中:
- \( \mathbf{v} \) 是顶点在标准姿态下的位置
- \( w_i \) 是第 \( i \) 个关节的权重
- \( \mathbf{R}_i, \mathbf{t}_i \) 是第 \( i \) 个关节的旋转和平移
核心思想:用骨骼驱动网格变形
3.4 非刚性变形
LBS 只能处理刚性变换(旋转 + 平移),但真实人体和衣物还有非刚性变形:
- 肌肉伸缩
- 衣物褶皱和摆动
- 头发飘动
这些无法用骨骼直接驱动,需要额外建模。
4. 方法详解
4.1 整体框架
TaoAvatar 的整体流程如下图所示:

graph TD
subgraph 模板重建
A[多视角视频] --> B[NeuS2 重建几何]
B --> C[分割非身体部件]
C --> D[自动蒙皮]
D --> E[SMPLX++ 模板]
end
subgraph 教师网络训练
F[SMPLX++] --> G[绑定高斯点]
G --> H[StyleUnet 教师网络]
H --> I[非刚性变形图]
end
subgraph 学生网络蒸馏
I --> J[烘焙到 MLP]
J --> K[轻量学生网络]
K --> L[混合形状补偿]
L --> M[实时渲染]
end
4.2 混合穿衣参数表示(SMPLX++)
4.2.1 问题

原始 SMPLX 只能表示裸体,无法处理:
- 宽松衣物(裙子、外套)
- 头发
- 鞋子
- 配饰
4.2.2 解决方案
创建 SMPLX++——扩展的穿衣参数模型:
步骤:
- 选择接近 T-pose 的帧作为参考帧(可见细节多,几何不粘连)
- 使用 NeuS2 从多视角图像重建完整几何
- 用 4D-Dress 方法分割出非身体部件(衣服、头发、鞋子)
- 估计 SMPLX 形状和姿态
- 使用 Robust Skinning Transfer 自动为非身体部件生成蒙皮权重
- 通过逆向蒙皮变换回标准 T-pose
- 组合裸体 SMPLX 和非身体部件 = SMPLX++
结果:
- 约 22k 顶点,45k 面片
- 其中 23k 面片用于衣物、头发、鞋子
- 保留 SMPLX 原生面部表情和手部控制能力
4.3 网格绑定高斯点作为纹理
4.3.1 核心思想
将 3D 高斯点绑定到三角形面片上,作为"纹理"随网格同步运动。
4.3.2 高斯点局部属性
对于每个三角形面片 \( F_f(v_1, v_2, v_3) \),随机初始化 \( k \) 个高斯点,每个高斯点维护局部坐标系下的属性:
$$ {f, (u, v), \gamma, \mathbf{r}, \mathbf{s}, o, sh} $$
- \( f \):父三角形索引
- \( (u, v) \):重心坐标
- \( \gamma \):沿法线方向的平移
- \( \mathbf{r} \):局部空间旋转
- \( \mathbf{s} \):局部空间缩放
- \( o \):不透明度
- \( sh \):球谐系数
4.3.3 从局部到世界坐标变换
构建基于父三角形的变换矩阵:
$$ \mathbf{p} = u \cdot \mathbf{v}_1 + v \cdot \mathbf{v}_2 + (1 - u - v) \cdot \mathbf{v}_3 $$
$$ \mathbf{R} = [\mathbf{n}, \mathbf{q}, \mathbf{n} \times \mathbf{q}], \quad \mathbf{q} = \frac{(\mathbf{v}_2 + \mathbf{v}_3)/2 - \mathbf{v}_1}{|(\mathbf{v}_2 + \mathbf{v}_3)/2 - \mathbf{v}_1|} $$
$$ e = (|\mathbf{v}_1 - \mathbf{v}_2| + |\mathbf{v}_2 - \mathbf{v}_3| + |\mathbf{v}_1 - \mathbf{v}_3|) / 3 $$
世界坐标下的属性:
$$ \begin{aligned} \mathbf{u}_w &= \mathbf{p} + \gamma \mathbf{R} \mathbf{n} \ \mathbf{r}_w &= \mathbf{R} \mathbf{r} \ \mathbf{s}_w &= e \cdot \mathbf{s} \ \mathbf{c}_w &= \text{SH}(sh, \mathbf{R}^{-1}\mathbf{d}) \end{aligned} $$
关键优势:高斯点可以随网格正向蒙皮直接驱动,无需逆向映射
4.4 动态非刚性变形学习
4.4.1 挑战

线性混合蒙皮(LBS)不足以处理:
- 衣物褶皱
- 裙子摆动
- 头发飘动
需要学习姿态相关的动态非刚性变形。
4.4.2 教师网络:StyleUnet
使用大型 StyleUnet 作为教师网络,在 2D 纹理空间学习高斯点的非刚性变形:
输入:
- 前视和后视位置图 \( P_f, P_b \)(通过光栅化 T-pose 网格获得)
- 视角方向
输出:
- 非刚性变形图 \( \Delta U_f, \Delta U_b \)
- 其他高斯属性残差图
训练损失:
$$ \mathcal{L}{rec} = \mathcal{L}1 + \lambda{ssim}\mathcal{L}{ssim} + \lambda_{lpips}\mathcal{L}{lpips} + \lambda{nor}\mathcal{L}_{nor} $$
其中法线损失:
$$ \mathcal{L}_{nor} = |\mathbf{N}_t - \mathbf{N}_g| $$
- \( \mathbf{N}_t \):教师网络渲染的法线图
- \( \mathbf{N}_g \):从 NeuS2 获得的真实法线图
超参数:
- \( \lambda_{ssim} = 0.2 \)
- \( \lambda_{lpips} = 0.01 \)
- \( \lambda_{nor} = 0.02 \)
4.4.3 学生网络:轻量 MLP
教师网络虽然强大,但参数量大,无法在移动端实时运行。因此需要蒸馏到学生网络。
学生网络结构:
- 5 层 MLP
- 输入:标准姿态顶点坐标 \( \bar{\mathbf{v}}_i \)、姿态参数 \( \theta \)、每帧可学习嵌入 \( z_t \)
- 输出:非刚性变形 \( \Delta \bar{\mathbf{v}}_i \)
$$ \Delta \bar{\mathbf{v}}_i = \mathcal{S}(\bar{\mathbf{v}}_i, \theta, z_t) $$
可学习嵌入 \( z_t \) 的作用:
- 补偿不准确的姿态估计
- 捕获 LBS 无法建模的动态变化(衣物惯性、肌肉变形等)
4.4.4 烘焙过程
蒸馏损失:
$$ \mathcal{L}{bak} = \mathcal{L}{rec} + \lambda_{non}\mathcal{L}{non} + \lambda{sem}\mathcal{L}_{sem} $$
非刚性损失:
$$ \mathcal{L}_{non} = |\Delta V_f - \Delta U_f| + |\Delta V_b - \Delta U_b| $$
将学生网络的变形图与教师网络对齐。
语义损失(防止衣物与身体穿透):
$$ \mathcal{L}_{sem} = |E_s - E_t| $$
为每个顶点分配语义标签:
$$ e_i = c_i + \sin(\tau \bar{\mathbf{v}}_i) $$
- \( c_i \):分割颜色(如衣服红色、头发黄色)
- \( \tau \):缩放因子(增加位置变化频率)
超参数:
- \( \lambda_{non} = 0.1 \)
- \( \lambda_{sem} = 1.0 \)
4.5 混合形状补偿
受 SMPL 姿态矫正混合形状启发,为每个高斯点设计可学习的混合形状:
4.5.1 位置混合形状 \( \mathbf{U} \in \mathbb{R}^{3 \times n} \)
补偿不同姿态下的高斯位置调整:
- 头发飘动
- 衣物褶皱
4.5.2 颜色混合形状 \( \mathbf{C} \in \mathbb{R}^{3 \times n} \)
补偿外观变化:
- 自遮挡产生的阴影变化
4.5.3 驱动系数
使用两个映射网络:
- 头部网络 \( \mathcal{H} \):输入表情参数 \( \epsilon \),输出系数 \( z_h \in \mathbb{R}^{n_h} \)
- 身体网络 \( \mathcal{B} \):输入身体姿态 \( \theta \),输出系数 \( z_b \in \mathbb{R}^{n_b} \)
补偿计算:
$$ \begin{aligned} \delta \mathbf{u} &= \text{BS}(z_h \oplus z_b; \mathbf{U}) \ \delta \mathbf{c} &= \text{BS}(z_h \oplus z_b; \mathbf{C}) \end{aligned} $$
最终属性:
$$ \begin{aligned} \mathbf{u}_w &= \mathbf{p} + \mathbf{R}(\gamma \mathbf{n} + \delta \mathbf{u}) \ \mathbf{c}_w &= \text{SH}(\mathbf{R}^{-1}\mathbf{d} + \delta \mathbf{c}) \end{aligned} $$
超参数:
- \( n = 28 \)(总混合形状数量)
- \( n_h = 8 \)(头部)
- \( n_b = 20 \)(身体)
4.6 网络架构对比
graph TB
subgraph 教师网络
T1[位置图] --> T2[StyleUnet]
T2 --> T3[非刚性变形图]
T3 --> T4[高质量渲染]
end
subgraph 学生网络
S1[顶点 + 姿态] --> S2[5 层 MLP]
S2 --> S3[烘焙变形]
S3 --> S4[混合形状补偿]
S4 --> S5[实时渲染]
end
T4 -.->|蒸馏 | S3
5. 训练与实现细节
5.1 数据集:TalkBody4D
数据规模:
- 4 个不同身份,每人穿 2 套不同服装
- 每个说话序列约 6k 帧,4K 分辨率
- 60 个视角:48 个全身视角 + 12 个面部特写视角
补充数据:
- 从 ActorHQ 数据集选择 4 个序列(04, 05, 06, 08)
- 2 个舞蹈序列
- 2 个夸张表情序列
训练/测试图像分辨率:1500 × 2000
5.2 训练流程
flowchart TD
A[参考帧多视角图像] -->|10k 迭代 | B[优化高斯点]
B --> C[预训练教师网络 600k 迭代]
C --> D[烘焙到学生网络 30k 迭代]
D --> E[微调 100k 迭代]
E --> F[最终模型]
5.3 优化策略
| 阶段 | 优化对象 | 迭代次数 | 批次大小 |
|---|---|---|---|
| 高斯初始化 | 高斯点属性 | 10k | - |
| 教师预训练 | StyleUnet | 600k | 1 |
| 烘焙 | 学生 MLP | 30k | - |
| 微调 | 映射网络 + 混合形状 | 100k | 4 |
5.4 部署优化
为了在移动设备实时运行,采用以下优化:
- FP16 量化:MLP 使用半精度
- UInt16 量化:高斯点排序
- 异步推理:
- 动画系统 20 FPS(训练数据捕获帧率)
- 渲染系统插值到 90 FPS(Apple Vision Pro 最大刷新率)
6. 实验与结论
6.1 对比方法
与以下最先进方法比较:
- GaussianAvatar:基于 2D CNN 的非刚性变形
- 3DGS-Avatar:MLP 学习非刚性变形
- MeshAvatar:纯网格表示
- AnimatableGS:从头学习隐式模板
6.2 全身说话任务定量对比
| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | FPS |
|---|---|---|---|---|
| GaussianAvatar | 26.58 (23.57) | .9313 (.8159) | .10577 (.25242) | 54 |
| 3DGS-Avatar | 28.91 (23.95) | .9411 (.8303) | .07984 (.20450) | 55 |
| MeshAvatar | 28.53 (24.55) | .9360 (.8083) | .09470 (.25572) | 22 |
| AnimatableGS | 32.50 (26.42) | .9599 (.8587) | .06695 (.19535) | 16 |
| Ours (Teacher) | 33.45 (27.01) | .9649 (.8741) | .04986 (.15613) | 16 |
| Ours (Student) | 33.81 (27.80) | .9689 (.8975) | .06437 (.14218) | 156 |
括号内为面部区域评估结果
关键发现:
- 学生网络质量超越教师网络(蒸馏效果)
- 速度提升近 10 倍(16 → 156 FPS)
- 面部区域提升尤为显著
6.3 复杂运动和表情重建

| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| GaussianAvatar | 25.94 (24.33) | .9294 (.8251) | .10478 (.24179) |
| 3DGS-Avatar | 30.04 (25.08) | .9403 (.8458) | .08471 (.18044) |
| MeshAvatar | 28.51 (24.94) | .9334 (.8100) | .08846 (.23517) |
| AnimatableGS | 31.81 (26.79) | .9493 (.8608) | .07586 (.19521) |
| Ours (Student) | 32.72 (27.35) | .9579 (.8836) | .07326 (.13914) |
6.4 消融实验

xychart-beta
title "消融实验:PSNR 对比"
x-axis ["w/ SMPLX", "w/o Mesh Non.", "w/o Gau Non.", "w/o Teacher", "Full"]
y-axis "PSNR" 28 --> 34
bar [28.47, 32.10, 31.16, 32.67, 33.29]
关键发现:
- 使用 SMPLX(无衣物扩展)效果最差(28.47)
- 网格非刚性变必不可少(去除后降至 32.10)
- 高斯非刚性补偿显著提升质量(31.16 vs 33.29)
- 教师蒸馏策略高效(32.67 vs 33.29)
6.5 定性对比

下图展示了各方法在全身说话任务上的视觉质量对比:
关键观察:
- 3DGS-Avatar:MLP 低频偏差导致模糊
- GaussianAvatar:受 SMPLX 拓扑限制,无法处理宽松裙子
- MeshAvatar:细节不足(头发、眼镜等)
- AnimatableGS:面部细节不足(眨眼、牙齿)
- TaoAvatar:清晰衣物动态 + 增强面部细节
6.6 驱动能力

TaoAvatar 支持多种驱动方式:
- 骨骼驱动:使用相同骨架参数驱动不同角色
- 表情参数驱动:来自 UniTalker 的音频生成面部表情
- 混合驱动:身体动作库 + 音频驱动面部
7. 应用
7.1 3D 数字人智能体管道
在 Apple Vision Pro 上部署的完整系统:
flowchart LR
A[用户语音] --> B[ASR: Paraformer]
B --> C[LLM: Qwen2.5-3B]
C --> D[响应文本]
D --> E[TTS: Bert-vits2]
E --> F[音频]
F --> G[Audio2BS: UniTalker]
G --> H[面部 BS 系数]
I[动作库] --> J[身体动作]
H & J --> K[TaoAvatar 渲染]
K --> L[立体显示]
所有模型本地运行,无需云端
7.2 跨平台部署
使用 MNN 推理引擎,可部署到:
- Apple Vision Pro(立体 2000×1800@90FPS)
- MacBook(3024×1964@90FPS)
- Android 设备(1080×2400@60FPS)
8. 局限性
-
极端姿态下的衣物建模:
- 训练数据分布外的夸张动作
- 宽松衣物(大裙摆)变形不足
- 可能解决方案:集成 GNN 模拟器
-
SMPLX 参数精度依赖:
- 姿态估计不准确时产生伪影
- 需要高质量动作捕捉
-
教师网络能力限制:
- 复杂运动(舞蹈引起的裙子摆动)建模困难
- 学生网络继承教师缺陷
9. 启发
9.1 技术启发
-
教师 - 学生蒸馏:将强大但缓慢的模型蒸馏到轻量模型
- 教师负责学习复杂模式
- 学生直接学习教师的输出
- 实现质量和速度的平衡
-
混合表示优势:
- 网格提供拓扑和刚性驱动
- 高斯点提供细节和材质
- 两者结合兼具优点
-
分阶段训练:
- 先训练强大的教师
- 再蒸馏到学生
- 最后微调补偿
- 比直接训练小网络更高效
9.2 应用启发
-
AR/VR 实时数字人:
- 电商直播带货
- 全息通讯
- 虚拟助手
-
端侧部署:
- 保护隐私(数据不离设备)
- 低延迟
- 离线可用
10. 遗留问题
-
更复杂的衣物模拟:
- 如何集成物理模拟器处理大变形衣物?
- 如何保持实时性能?
-
多人交互:
- 当前方法针对单人
- 如何扩展到多人场景?
-
长期一致性:
- 长时间运行时如何保持稳定性?
- 如何处理衣物状态变化(如脱下外套)?
-
更细粒度控制:
- 手指精细动作
- 衣物材质编辑
- 动态发型变化
11. 重要图表
11.1 方法总览图
论文 Figure 2 展示了完整的 TaoAvatar 方法流程:
┌─────────────────────────────────────────────────────────────┐
│ TaoAvatar 方法总览 │
├─────────────────────────────────────────────────────────────┤
│ (a) 模板重建:多视角 → NeuS2 → 分割 → SMPLX++ │
│ │
│ (b) 教师分支:StyleUnet → 非刚性变形图 → 高质量渲染 │
│ │
│ (c) 学生分支:MLP + 混合形状 → 烘焙 → 实时渲染 │
└─────────────────────────────────────────────────────────────┘
11.2 定量对比表
关键指标对比(全身说话任务):
| 方法 | 整体 PSNR | 面部 PSNR | 整体 LPIPS | 面部 LPIPS | FPS |
|---|---|---|---|---|---|
| 最佳基线 | 32.50 | 26.42 | .06695 | .19535 | 16 |
| TaoAvatar | 33.81 | 27.80 | .06437 | .14218 | 156 |
11.3 消融实验结果
| 配置 | PSNR↑ | SSIM↑ | LPIPS↓ | P2S↓ | Chamfer↓ |
|---|---|---|---|---|---|
| w/ SMPLX | 28.47 | .9476 | .07899 | .7690 | .9995 |
| w/o Mesh Non. | 32.10 | .9734 | .03814 | .4877 | .5007 |
| w/o Gau Non. | 31.16 | .9686 | .03932 | .2968 | .3068 |
| w/o Teacher | 32.67 | .9751 | .03769 | .5236 | .5359 |
| Full | 33.29 | .9772 | .03464 | .2953 | .3052 |
12. 总结
TaoAvatar 提出了一个轻量化、高保真全身说话数字人解决方案,主要贡献:
- SMPLX++ 模板:扩展 SMPLX 处理衣物、头发、鞋子
- 混合表示:网格 + 高斯点结合
- 教师 - 学生蒸馏:高质量非刚性变形学习 + 实时推理
- 混合形状补偿:位置和颜色细节补偿
- TalkBody4D 数据集:全身说话场景多视角数据
效果:
- 渲染质量 SOTA
- 实时性能(156 FPS on RTX4090, 90 FPS on Vision Pro)
- 跨平台部署能力
参考文献
@article{chen2025taoavatar,
title={TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting},
author={Chen, Jianchuan and Hu, Jingchuan and Wang, Gaige and Jiang, Zhonghua and Zhou, Tiansong and Chen, Zhiwen and Lv, Chengfei},
journal={arXiv preprint arXiv:2503.17032},
year={2025}
}
SAM 3: Segment Anything with Concepts
论文 ID: 226
arXiv: 2511.16719v2
机构: Meta Superintelligence Labs
发布时间: 2026 年 3 月
1. 核心问题
1.1 研究目的
创建统一的图像/视频分割模型,能够根据概念提示(文本短语或图像示例)检测、分割和跟踪所有匹配的对象实例。
1.2 现有方法及局限
SAM 系列发展历程:
| 模型 | 能力 | 局限性 |
|---|---|---|
| SAM 1 | 点/框/ mask 提示分割单个对象 | 无法找到所有同类对象 |
| SAM 2 | 视频分割 + 交互 | 仍是单实例分割,无法按概念分割 |
| 开放词汇检测器 | 文本检测对象 | 只输出边界框,无 mask |
核心 Gap:现有方法无法完成 "找到视频中所有'猫'并分割跟踪" 这类任务。
1.3 本文方法
提出 SAM 3——统一的 Promptable Concept Segmentation (PCS) 模型:
输入:
- 文本短语(如"yellow school bus")
- 图像示例(正/负样本框)
- 或两者组合
输出:
- 所有匹配对象的分割 mask
- 跨帧的对象 ID(跟踪)
核心创新:
- 检测器 + 跟踪器架构,共享视觉编码器
- Presence Head:解耦识别和定位
- 人机协同数据引擎:4M 独特概念标签
- SA-Co Benchmark:207K 独特概念的评估基准
1.4 效果
- LVIS 零 shot mask AP: 48.8(之前最佳 38.5)
- SA-Co 基准: 超越基线 2 倍以上
- 推理速度: 单图 30ms(H200 GPU,100+ 对象)
- 视频性能: ~5 个并发对象接近实时
2. 核心贡献
-
SAM 3 模型:
- 统一图像/视频概念分割
- 检测器 + 跟踪器解耦设计
- Presence Head 提升检测精度
-
数据引擎:
- 4M 独特概念,52M masks
- AI 验证器翻倍标注效率
- 38M 短语合成数据
-
SA-Co 基准:
- 207K 独特概念
- 120K 图像 + 1.7K 视频
- 比现有基准多 50 倍概念
3. 背景知识
3.1 Promptable Visual Segmentation (PVS)
定义:给定点/框/mask 提示,分割单个对象。
输入:点击位置 / 边界框 / 初始 mask
输出:该对象的精细 mask
局限:每次提示只分割一个对象实例
3.2 Promptable Concept Segmentation (PCS)
定义:给定概念提示(文本/图像示例),分割所有匹配实例。
输入:"red apple" + 正/负样本框
输出:图中所有红苹果的 mask + ID
能力:
- 开放词汇识别
- 多实例检测
- 跨帧跟踪
3.3 DETR (DEtection TRansformer)
基于 Transformer 的目标检测框架:
核心组件:
- 图像编码器:提取特征
- 对象查询:可学习向量,每个对应一个潜在对象
- 解码器:查询与特征交互,预测框和类别
优势:
- 端到端训练
- 无需 NMS 后处理
- 天然支持多模态输入
3.4 Matthews Correlation Coefficient (MCC)
二分类问题的平衡评估指标:
$$ \text{MCC} = \frac{TP \times TN - FP \times FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}} $$
取值范围 [-1, 1]:
- 1:完美预测
- 0:随机猜测
- -1:完全相反
4. Promptable Concept Segmentation (PCS) 任务定义
4.1 形式化定义
输入:
- 图像或短视频(≤30 秒)
- 概念提示:
- 名词短语(NP):如"red apple"、"striped cat"
- 图像示例:正/负边界框
- 或两者组合
输出:
- 所有匹配对象的实例 mask
- 跨视频帧的对象 ID
4.2 提示类型
graph TD
A[PCS 提示] --> B[文本短语]
A --> C[图像示例]
A --> D[组合提示]
B --> B1[简单名词短语]
B --> B2["可选修饰语<br/>如:yellow school bus"]
C --> C1[正样本框]
C --> C2[负样本框]
D --> D1[文本 + 正样本]
D --> D2[文本 + 负样本]
4.3 交互性
支持迭代细化:
- 初始文本提示 → 获取初始结果
- 发现漏检 → 添加正样本框
- 发现误检 → 添加负样本框
- 重复直到满意
4.4 任务模糊性处理
模糊性来源:
- 多义词("mouse":老鼠 vs 鼠标)
- 主观描述("cozy"、"large")
- 边界模糊("mirror"是否包含边框)
- 遮挡和模糊
解决方案:
- 每个样本 3 个标注者
- 评估时考虑多种有效解释
- 数据管道最小化模糊性
5. SAM 3 模型架构
5.1 整体架构
graph TB
subgraph 输入
I[图像/视频]
T[文本提示]
E[图像示例]
end
subgraph 共享编码器
PE[Perception Encoder backbone]
end
subgraph 检测器
EE[示例编码器]
FE[融合编码器]
DE[DETR 解码器]
PH[Presence Head]
MH[Mask Head]
end
subgraph 跟踪器
ME[记忆编码器]
MB[记忆库]
MD[Mask 解码器]
end
I --> PE
T --> PE
E --> EE
PE --> FE
EE --> FE
FE --> DE
DE --> PH
DE --> MH
PH --> O[输出 masks + IDs]
MH --> O
DE --> ME
ME --> MB
MB --> MD
MD --> O
5.2 检测器架构
5.2.1 组件
| 组件 | 功能 |
|---|---|
| Perception Encoder | 图像 + 文本联合编码 |
| 示例编码器 | ROI Pool + 位置/标签嵌入 |
| 融合编码器 | 交叉注意力条件化 |
| DETR 解码器 | 对象查询交叉注意力 |
| Presence Head | 全局存在性预测 |
| Mask Head | 像素级分割 |
5.2.2 Presence Token(核心创新)
问题:proposal query 需要同时解决:
- 识别(是什么):需要全局上下文
- 定位(在哪里):需要局部特征
冲突:全局上下文与局部定位目标冲突
解决方案:引入全局 Presence Token
$$ \begin{aligned} \text{Presence Score: } & p(\text{NP present}) \ \text{Query Score: } & p(q_i \text{ is match} | \text{NP present}) \ \text{Final Score: } & p(\text{NP present}) \times p(q_i \text{ is match} | \text{NP present}) \end{aligned} $$
优势:
- Presence Token 专注识别(全局)
- Query 专注定位(局部)
- 解耦后提升检测精度
5.2.3 图像示例编码
每个示例框编码为:
- 位置嵌入:框的位置
- 标签嵌入:正/负样本
- 视觉特征:ROI Pool 提取
通过小型 Transformer 处理,与文本 prompt 拼接为 prompt tokens。
5.3 跟踪器架构
5.3.1 视频处理流程
sequenceDiagram
participant D as 检测器
participant T as 跟踪器
participant M as 记忆库
D->>T: 帧 1 检测对象 Ot
T->>M: 初始化 masklet M1
loop 每一帧 t
T->>M: 从 M(t-1) 传播到 M̂t
D->>T: 检测新对象 Ot
T->>T: 匹配 M̂t 和 Ot
T->>M: 更新 Mt
end
5.3.2 关键组件
| 组件 | 功能 |
|---|---|
| 记忆编码器 | 当前帧 + 历史帧特征交叉注意力 |
| 记忆库 | 存储对象外观特征 |
| Mask 解码器 | 两向 Transformer 预测 3 个候选 mask |
| 匹配函数 | IoU 基础匹配 |
5.3.3 时间消歧策略
问题:拥挤场景中的匹配模糊
策略 1:时间一致性检测
- 测量 masklet 在时间窗口内被匹配的频率
- 低于阈值则抑制
策略 2:检测器校正
- 周期性用高置信度检测替换跟踪预测
- 确保记忆库有可靠参考
5.4 训练阶段
SAM 3 采用四阶段渐进训练:
flowchart TD
A[Stage 1: PE 预训练] --> B[Stage 2: 检测器预训练]
B --> C[Stage 3: 检测器微调]
C --> D[Stage 4: 跟踪器训练]
A -.Frozen.-> B
B -.Frozen.-> C
C -.Frozen.-> D
| 阶段 | 训练内容 | 数据 |
|---|---|---|
| 1 | Perception Encoder | 大规模图像 - 文本对 |
| 2 | 检测器 | SA-Co 图像数据 |
| 3 | 检测器 + Presence Head | 含困难负样本 |
| 4 | 跟踪器 | SA-Co 视频数据 |
6. 数据引擎
6.1 核心挑战
需求:大规模、多样化的概念和视觉域数据
现有数据集局限:
- 封闭词汇(固定类别)
- 视觉域单一
- 标注成本高
6.2 数据引擎组件
flowchart LR
A[媒体池] --> B[本体挖掘]
B --> C[AI 短语提议]
C --> D[SAM 3 生成 mask]
D --> E[MV: Mask 验证]
E --> F[EV: 完备性验证]
F --> G[人工修正]
G --> H[高质量数据]
E -.AI/人类.-> E
F -.AI/人类.-> F
验证类型:
- Mask Verification (MV):mask 质量和相关性
- Exhaustivity Verification (EV):是否所有实例都已标注
6.3 四阶段数据收集
Phase 1: 人类验证
流程:
- 随机采样图像 + 简单 captioner 提议 NP
- SAM 2 + 开放词汇检测器生成初始 mask
- 人类验证 MV 和 EV
产出:4.3M image-NP 对(SA-Co/HQ 初始数据)
Phase 2: 人类 + AI 验证
创新:
- 用 Phase 1 数据微调 Llama 3.2 作为AI 验证器
- AI 验证器输出 MV/EV 的多选评分
- 人类专注困难案例
效率提升:
- AI 验证器使通量翻倍
- 迭代训练 SAM 3 + AI 验证器 6 次
产出:1.22 亿 image-NP 对
Phase 3: 扩展和域扩展
策略:
- 扩展到 15 个数据集域
- 从图像 alt-text 提取长尾概念
- 基于 Wikidata 构建 22.4M 节点本体(17 顶层类别,72 子类别)
产出:19.5M image-NP 对
Phase 4: 视频标注
挑战:视频标注更困难
策略:
- 场景/运动过滤
- 内容平衡
- 针对性搜索拥挤场景
- 人类专注跟踪失败案例
产出:52.5K 视频,467K masklets
6.4 最终数据规模
| 数据集 | 图像/视频 | 独特 NP | Mask/Masklets |
|---|---|---|---|
| SA-Co/HQ | 5.2M 图像 | 4M | 52M masks |
| SA-Co/SYN | 合成数据 | 38M 短语 | 1.4B masks |
| SA-Co/EXT | 15 外部数据集 | - | 增强困难负样本 |
| SA-Co/VIDEO | 52.5K 视频 | 24.8K | 134K video-NP 对 |
7. SA-Co 基准
7.1 评估数据集划分
| 划分 | 域数量 | 标注者数量 | 用途 |
|---|---|---|---|
| SA-Co/Gold | 7 | 3/样本 | 测量人类表现 |
| SA-Co/Silver | 10 | 1/样本 | 大规模评估 |
| SA-Co/Bronze | 9 | 自动 | 现有数据集 |
| SA-Co/Bio | 9 | 自动 | 生物医学域 |
| SA-Co/VEval | 3 | 1/样本 | 视频评估 |
7.2 评估指标
7.2.1 定位指标:Positive Micro F1 (pmF1)
在正样本(至少一个 GT mask)上评估定位精度。
7.2.2 分类指标:Image-Level MCC (IL_MCC)
评估图像级二分类("对象是否存在")。
7.2.3 主指标:Classification-gated F1 (cgF1)
$$ \text{cgF1} = 100 \times \text{pmF1} \times \text{IL_MCC} $$
设计原理:
- 同时考虑定位和分类
- 仅评估置信度 > 0.5 的预测(模拟实际使用)
7.3 模糊性处理
Gold 集评估:
- 每个 NP 有 3 个标注
- 计算 oracle 精度(选择最佳匹配)
8. 实验结果
8.1 图像 PCS(文本提示)
8.1.1 闭词汇实例分割
| 方法 | COCO AP | LVIS AP |
|---|---|---|
| OWLv2 | - | 19.9 |
| gDino-T | - | 20.5 |
| SAM 3 | 48.5 | 48.8 |
8.1.2 开放词汇实例分割(SA-Co)
xychart-beta
title "SA-Co cgF1 对比"
x-axis ["Gold", "Silver", "Bronze", "Bio"]
y-axis "cgF1" 0 --> 60
bar OWLv2 [17.3, 24.6, 7.6, 11.5]
bar SAM3 [54.1, 49.6, 55.4, 40.6]
关键发现:
- SAM 3 在所有 split 上超越 OWLv2 两倍以上
- Gold 集达到人类表现的 74%
8.1.3 开放词汇语义分割
| 方法 | ADE-847 | PC-59 | Cityscapes |
|---|---|---|---|
| APE | 9.2 | 58.5 | 44.2 |
| SAM 3 | 13.8 | 60.8 | 65.2 |
8.2 少样本迁移
8.2.1 ODinW13(13 个野生数据集)
| 方法 | Zero-shot AP | 10-shot AP |
|---|---|---|
| Gemini2.5-Pro | 33.7 | - |
| gDino1.5-Pro | 58.7 | 67.9 |
| SAM 3 | 61.0 | 71.8 |
8.3 单示例 PCS
使用 1 个 GT 框作为提示评估:
| 方法 | COCO AP+ | LVIS AP+ | ODinW AP+ |
|---|---|---|---|
| T-Rex2 | 58.5 | 65.8 | 61.8 |
| SAM 3 (T+I) | 78.1 | 78.4 | 81.8 |
提示类型:
- T:仅文本
- I:仅图像
- T+I:文本 + 图像
8.4 交互式 PCS
模拟人机协作迭代细化:
xychart-beta
title "交互式 PCS vs PVS"
x-axis ["0", "1", "2", "3", "4"]
y-axis "cgF1" 0.55 --> 0.80
line "SAM 3 PCS" [0.55, 0.62, 0.68, 0.73, 0.76]
line "Perfect PVS" [0.55, 0.60, 0.65, 0.69, 0.72]
关键发现:
- 3 次点击后,PCS 超越 PVS 2.0 点
- PCS 从示例泛化,PVS 只修正单实例
- 4 次点击后趋于平稳
8.5 物体计数
| 方法 | CountBench MAE | CountBench Acc | PixMo-Count MAE | PixMo-Count Acc |
|---|---|---|---|---|
| DINO-X | 0.62 | 82.9 | 0.61 | 85.0 |
| Qwen2-VL-72B | 0.28 | 86.7 | 0.17 | 63.7 |
| Gemini 2.5 Pro | 0.24 | 92.4 | 0.38 | 88.8 |
| SAM 3 | 0.12 | 93.8 | 0.21 | 86.2 |
优势:SAM 3 不仅计数准确,还提供 segmentation(MLLM 无法提供)
8.6 视频 PCS
8.6.1 SA-Co/VEval 基准
| 方法 | SA-V cgF1 | YT-Temporal cgF1 | SmartGlasses cgF1 |
|---|---|---|---|
| GLEE | 0.1 | 1.6 | 0.1 |
| LLMDet + SAM3 Tracker | 2.3 | 8.0 | 0.3 |
| SAM3 Detector + T-by-D | 25.7 | 47.6 | 29.7 |
| SAM 3 | 30.3 | 50.8 | 36.4 |
人类表现:~53-71 cgF1
8.6.2 公开基准
| 方法 | LVVIS mAP | BURST HOTA | OVIS mAP |
|---|---|---|---|
| GLEE | 20.8 | 28.4 | 31.3 |
| SAM 3 | 36.3 | 44.5 | 57.4 |
8.7 Promptable Visual Segmentation (PVS)
8.7.1 视频对象分割(VOS)
| 方法 | DAVIS17 J&F | LVOSv2 J&F | MOSEv2 J&F |
|---|---|---|---|
| SAM 2 | 85.2 | 83.1 | 62.3 |
| SAM 3 | 87.6 | 85.4 | 68.8 |
MOSEv2 提升:+6.5 点(最具挑战性基准)
8.7.2 交互式图像分割
37 个数据集平均 mIoU:
| 方法 | Clicks=1 | Clicks=3 | Clicks=5 | Average |
|---|---|---|---|---|
| SAM 2 | 75.2 | 79.8 | 81.1 | 78.7 |
| SAM 3 | 77.5 | 81.3 | 82.6 | 80.5 |
9. 消融实验
9.1 Presence Head 效果
| 配置 | LVIS AP | SA-Co Gold cgF1 |
|---|---|---|
| 无 Presence | 42.1 | 31.5 |
| + Presence | +6.7 | +5.7 |
9.2 Backbone 选择
| Backbone | 参数量 | LVIS AP |
|---|---|---|
| ViT-L | 307M | 41.2 |
| PE (Huge) | 632M | 48.8 |
9.3 困难负样本效果
| 训练数据 | SA-Co Gold cgF1 |
|---|---|
| 无困难负样本 | 46.3 |
| + 困难负样本 | +7.8 |
9.4 数据规模扩展规律
xychart-beta
title "数据规模扩展规律"
x-axis ["1M", "10M", "100M"]
y-axis "cgF1" 30 --> 55
line "图像数据" [32, 42, 52]
line "合成数据" [28, 38, 48]
10. 推理效率
| 场景 | 配置 | 延迟 |
|---|---|---|
| 图像 | H200, 100+ 对象 | 30ms |
| 视频 (1 对象) | H200 | ~50ms |
| 视频 (5 对象) | H200 | ~100ms |
| 视频 (10 对象) | H200 | ~200ms |
11. 局限性
-
长文本理解:
- 不支持长指代表达
- 需要推理的查询
- 解决:可与 MLLM 结合
-
极端拥挤场景:
- 对象密集时性能下降
- 跟踪歧义增加
-
罕见概念:
- 训练数据外的概念识别困难
- 需要图像示例辅助
-
视频长度:
- 当前支持≤30 秒
- 更长视频需要分段处理
12. 启发
12.1 架构设计启发
-
解耦识别和定位:
- Presence Head 专注"是否存在"
- Query 专注"在哪里"
- 避免任务冲突
-
检测器 + 跟踪器分离:
- 检测器:类别无关,专注识别
- 跟踪器:分离 identity
- 避免任务干扰
-
共享 Backbone:
- 图像/文本/视频统一编码
- 参数高效
- 特征一致
12.2 数据工程启发
-
人机协同标注:
- AI 处理简单案例
- 人类专注困难案例
- 效率翻倍
-
课程学习式数据收集:
- Phase 1:基础数据
- Phase 2:AI 验证 + 困难负样本
- Phase 3:域扩展
- Phase 4:视频扩展
-
本体驱动的概念挖掘:
- 结构化知识指导数据收集
- 长尾概念覆盖
12.3 应用启发
-
多模态 AI 基础组件:
- 机器人(视觉理解)
- 内容创作(智能标注)
- AR/VR(实时分割)
-
与 MLLM 结合:
- MLLM 处理复杂查询
- SAM 3 提供精细分割
- 互补优势
13. 遗留问题
-
复杂推理:
- 如何处理需要多步推理的查询?
- 如"穿红衣服的人左边的包"
-
开放世界学习:
- 如何持续学习新概念?
- 灾难性遗忘问题
-
3D 理解:
- 当前仅 2D 分割
- 如何扩展到 3D 实例分割?
-
实时性能:
- 当前视频推理仍需优化
- 边缘设备部署挑战
14. 重要图表
14.1 SAM 3 架构总览
┌─────────────────────────────────────────────────────────────┐
│ SAM 3 架构 │
├─────────────────────────────────────────────────────────────┤
│ 输入:文本短语 + 图像示例 + 图像/视频 │
│ │
│ ↓ │
│ │
│ Perception Encoder (共享 Backbone) │
│ │
│ ↓ │
│ ┌─────────────────┬─────────────────┐ │
│ │ 检测器分支 │ 跟踪器分支 │ │
│ │ - 融合编码器 │ - 记忆编码器 │ │
│ │ - DETR 解码器 │ - 记忆库 │ │
│ │ - Presence Head │ - Mask 解码器 │ │
│ │ - Mask Head │ │ │
│ └─────────────────┴─────────────────┘ │
│ │
│ ↓ │
│ 输出:Instance Masks + IDs │
└─────────────────────────────────────────────────────────────┘
14.2 数据引擎流程
媒体池 → 本体挖掘 → AI 短语提议 → Mask 生成
↓
← AI 验证器 (MV/EV) ← 人类验证器
↓
困难案例修正
↓
高质量训练数据
14.3 主要结果对比
LVIS 零 shot 实例分割: | 方法 | AP | |-----|----| | OWLv2 | 19.9 | | 之前最佳 | 38.5 | | SAM 3 | 48.8 |
SA-Co/Gold 开放词汇分割: | 方法 | cgF1 | |-----|------| | OWLv2* | 24.6 | | 人类 | 72.8 | | SAM 3 | 54.1 |
15. 总结
SAM 3 实现了 Promptable Concept Segmentation 的重大突破:
模型贡献:
- 统一图像/视频概念分割
- Presence Head 解耦识别定位
- 检测器 + 跟踪器解耦设计
数据贡献:
- 4M 独特概念,52M masks
- AI 验证器翻倍标注效率
- SA-Co 基准(207K 概念)
性能:
- LVIS AP: 48.8(+10.3 点)
- SA-Co cgF1: 54.1(人类 74%)
- 视频 pHOTA: 58-70(人类 80%)
开源:
- 代码:https://github.com/facebookresearch/sam3
- 模型权重
- SA-Co 基准
参考文献
@article{carion2026sam3,
title={SAM 3: Segment Anything with Concepts},
author={Carion, Nicolas and Gustafson, Laura and Hu, Yuan-Ting and Debnath, Shoubhik and Hu, Ronghang and Suris, Didac and Ryali, Chaitanya and Alwala, Kalyan Vasudev and Khedr, Haitham and Huang, Andrew and Lei, Jie and Ma, Tengyu and Guo, Baishan and Kalla, Arpit and Marks, Markus and Greer, Joseph and Wang, Meng and Sun, Peize and R{\"a}dle, Roman and Afouras, Triantafyllos and Mavroudi, Effrosyni and Xu, Katherine and Wu, Tsung-Han and Zhou, Yu and Momeni, Liliane and Hazra, Rishi and Ding, Shuangrui and Vaze, Sagar and Porcher, Francois and Li, Feng and Li, Siyuan and Kamath, Aishwarya and Cheng, Ho Kei and Doll{\'a}r, Piotr and Ravi, Nikhila and Saenko, Kate and Zhang, Pengchuan and Feichtenhofer, Christoph},
journal={arXiv preprint arXiv:2511.16719},
year={2026}
}
[2025.5.13] CLOSD: CLOSING THE LOOP BETWEEN SIMULATION AND DIFFUSION FOR MULTI-TASK CHARACTER CONTROL
摘要
运动扩散模型和基于强化学习(RL)的物理仿真控制在人体运动生成方面具有互补优势。前者能够生成多样化的运动,并遵循文本等直观控制,而后者提供物理上合理的运动和与环境的直接交互。在这项工作中,我们提出了一种结合各自优势的方法。CLoSD是一个文本驱动的RL物理控制器,由扩散生成指导完成各种任务。我们的关键见解是,运动扩散可以作为稳健RL控制器的实时通用规划器。为此,CLoSD在两个模块之间保持闭合循环交互——扩散规划器(DiP)和跟踪控制器。DiP是一个快速响应的自回归扩散模型,由文本提示和目标位置控制,而控制器是一个简单而稳健的运动模仿器,持续接收来自DiP的运动计划并提供环境反馈。CLoSD能够无缝执行一系列不同任务,包括导航到目标位置、按照文本提示用手或脚击打物体、坐下和起身。
技术分析
这篇文章使用diffusion生成模型作为规划器,使用强化学习进行轨迹跟踪,最后接pd控制器。这是locomotion动力学方法的经典架构。
CLOSD 是优秀的工程系统论文,不是开创范式的革命性论文。
CLOSD 的核心不是理论创新,而是工程整合:
- 用最简单的扩散做实时局部规划
- 用最朴素的闭环做在线重规划
- 把文本+目标双条件一起做稳定
- 直接搭载PHC 这种超强鲁棒控制器
它的贡献是: 把已有的成熟零件,拼成一个完整、能打、多任务、实时跑的系统。
[2025.5.30] MotionPersona: Characteristics-aware Locomotion Control
摘要
我们提出了MotionPersona,一个新颖的实时角色控制器,允许用户通过指定属性(如身体特征、心理状态、人口统计学特征)来刻画角色,并将这些属性投射到生成的运动中来动画化角色。与现有的深度学习控制器(通常产生针对单一预定义角色的同质化动画)不同,MotionPersona考虑了现实世界中各种特征对人类运动的影响。为此,我们开发了一个基于SMPLX参数、文本提示和用户定义的运动控制信号的块自回归运动扩散模型。我们还整理了一个包含广泛运动类型和演员特征的综合数据集,以支持这种特征感知控制器的训练。与之前的工作不同,MotionPersona是首个能够生成忠实反映用户指定特征(例如老年人的蹒跚步态)的运动的方法,同时能够实时响应动态控制输入。此外,我们引入了一种小样本特征化技术作为补充条件机制,当语言提示不足时,可以通过短视频片段进行定制。通过大量实验,我们证明了MotionPersona在特征感知的运动控制方面优于现有方法,实现了卓越的运动质量和多样性。
论文:arXiv:2506.00173(2025.5.30) 项目页:https://motionpersona25.github.io/
一、核心定位
首个实时、统一、多条件的角色运动控制器,能让虚拟角色的行走/跑步等运动,精准反映用户指定的人物特征(体型、年龄、情绪、性格),同时实时响应方向/速度控制 。
二、解决的痛点
现有方法的三大问题:
- 数据集缺人物特征多样性(多为单一演员)
- 数据标准化抹平体型-运动关联(高矮胖瘦步态被统一)
- 模型无法解耦运动内容与人物特质(只能生成同质化动作)
三、核心贡献
-
MotionPersona 数据集
- 7种 locomotion(走/跑/侧移/后退/转向)
- 标注:SMPL‑X体型参数 + 自然语言描述人物特质
-
多条件自回归扩散模型
- 输入三要素:
- 运动控制:根节点轨迹、方向、速度
- 体型:SMPL‑X 向量
- 特质:文本描述(如"年迈、开心、微胖")
- 架构:扩散模型 + 自回归,实时生成未来运动序列
- 输入三要素:
-
小样本定制(Few‑shot Characterization)
- 用少量示例动作片段微调模型,提取独特风格
- 解决语言难以描述的细微动作特征
[2025.8.5] Diffuse-CLoC Guided Diffusion for Physics-based Character Look-ahead
摘要
我们提出了Diffuse-CLoC,一个用于基于物理的前瞻控制的引导扩散框架,能够实现直观、可操控和物理真实的运动生成。现有的基于扩散模型的运动学运动生成虽然在推理时通过条件控制提供了直观的操控能力,但往往无法产生物理上可行的运动。相比之下,最近基于扩散的控制策略在生成物理可实现的运动序列方面显示出潜力,但缺乏运动学预测限制了其可操控性。Diffuse-CLoC通过一个关键洞察解决了这些挑战:在单个扩散模型中对状态和动作的联合分布进行建模,使得动作生成可以通过对预测状态进行条件控制而变得可操控。这种方法使我们能够利用运动学运动生成中已建立的条件控制技术,同时产生物理真实的运动。因此,我们无需高级规划器就能实现规划能力。我们的方法通过单一预训练模型处理多样化的未见过的长视界下游任务,包括静态和动态障碍物避让、运动插值和任务空间控制。实验结果表明,我们的方法显著优于传统的高级运动扩散和低级跟踪的分层框架。
文章要解决的问题
- 传统方法需要轨迹优化或PD控制等额外步骤
- 直接生成力与力矩非常困难
主要技术点
这篇文章通过扩散模型直接生成物理引擎所需的力与力矩,因此在生成完成后不再需要轨迹优化或 PD 控制等额外步骤。
为什么以前的方法不直接生成力和力矩?
因为力与力矩非常难学。主要原因有三点:
- 没有真值(GT):动捕无法直接采集关节力矩
- 高频、剧烈变化:力矩帧间差异大,包含快速、不稳定的信号
- 容错率极低:微小偏差都会导致仿真崩溃、角色摔倒
为成功学习力矩采用的关键技术:
-
联合建模未来状态与未来力矩的分布
- 将状态与力矩统一输入扩散模型,一起学习
- 让状态协助力矩保持物理稳定
-
使用专家控制器(如MPC)生成含真值力矩的仿真数据
- 通过高性能控制器在仿真中滚出轨迹
- 得到包含状态与力矩真值的数据集,为模型提供监督信号
-
一次性预测未来多帧(Look-ahead)
- 让模型提前感知长期物理后果
- 提升长序列仿真的稳定性
-
在每一步去噪后进行梯度引导修正
- 利用预测状态与目标状态之间的差距计算引导梯度
- 同时修正预测的状态与力矩
- 确保生成结果满足任务目标与物理约束
[2025.9.15] Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion
摘要
我们提出了一个统一的步态条件强化学习框架,使人形机器人能够在单一递归策略内执行站立、行走、奔跑以及平滑的步态转换。紧凑的奖励路由机制基于独热编码的步态 ID 动态激活特定步态目标,缓解奖励干扰并支持稳定的多步态学习。受人类启发的奖励项促进了生物力学上自然的运动,如直膝站立和协调的手臂 - 腿部摆动,而无需运动捕捉数据。结构化的课程在多个阶段逐步引入步态复杂性和扩展命令空间。在仿真中,该策略成功实现了稳健的站立、行走、奔跑和步态转换。在真实的 Unitree G1 人形机器人上,我们验证了站立、行走和行走 - 站立转换,展示了稳定和协调的运动能力。这项工作为在不同模式和环境中实现多功能和自然的人形控制提供了一个可扩展的、无需参考的解决方案。
核心技术点
强化学习加 PD 控制,通过强化学习生成 PD 控制的目标轨迹,然后通过控制跟踪这些目标轨迹输出动画数据。生成 PD 控制的目标轨迹,这一步采用的是纯强化学习的方案,不需要任何训练数据。纯强化学习的方案非常难训,所以这篇文章主要是要解决这个问题。
它用"分步课程学习"降低难度, 用"步态条件 + 奖励路由"避免任务冲突, 用"RNN 记忆"自动学周期步态, 用"稠密细粒度奖励"提供稳定学习信号, 再靠"并行仿真 + 随机化"加速收敛、增强鲁棒性。 最终把原本不可能训动的纯 RL,变得能稳、能收敛、能走能跑能切换。
核心设计:
- 分步课程学习:站立→行走→奔跑→步态切换
- 奖励路由机制:避免多步态奖励冲突
- RNN 记忆:自动学习周期步态,无需相位
[2025.10.15]UniPhys: Unified Planner and Controller with Diffusion for Flexible
摘要
生成自然且物理上合理的角色运动仍然具有挑战性,特别是在需要处理多样化引导信号的长时程控制场景中。虽然先前的工作结合了基于扩散的高层运动规划器和低层物理控制器,但这些系统存在域间差距,会降低运动质量并需要针对特定任务进行微调。为了解决这个问题,我们提出了 UniPhys,这是一个基于扩散的行为克隆框架,将运动规划和控制统一到单一模型中。UniPhys 能够基于多模态输入(如文本、轨迹和目标)生成灵活、富有表现力的角色运动。为了应对长序列中累积的预测误差,UniPhys 采用扩散强制(Diffusion Forcing)范式进行训练,学习对噪声运动历史进行去噪并处理物理模拟器引入的差异。这种设计使 UniPhys 能够稳健地生成物理上合理、长时程的运动。通过引导采样,UniPhys 能够泛化到各种控制信号(包括未见过的信号),而无需针对特定任务进行微调。实验表明,UniPhys 在运动自然性、泛化能力和鲁棒性方面均优于先前的方法。
核心问题是什么?
输入用户控制信号,生成PD控制的目标。
相关工作
跟[2024.11.19]Maskedmimic: Unified physics-based character control through masked motion非常类似,这两篇文章都是输入用户控制信号,生成pd控制的目标。
核心贡献是什么?
这两篇文章的区别在于训练生成模型时所使用的pd控制目标的来源不同。
大致方法是什么?
在这篇文章中,在训练生成模型之前会对mocap数据做一个预处理。他会让mocap数据过一遍pd控制让数据强行变成一个物理合力,但是可能比较僵硬的动作数据。这个物理合理,但是动作僵硬的数据就是生成模型的GT。
有效性
所以这个方法所生成出来的动作也是物理合理,但是会有点僵硬的。
缺陷
验证
启发
这篇文章的好处是它不需要强化学习和蒸馏学习训练会更简单,在推断的时候不需要轨迹优化,只需要一个模型就可以完成推理。
遗留问题
Maskedmimic: Unified physics-based character control through masked motion
摘要
创建一个能够为各种场景中的交互式角色注入生命力的单一、多功能物理基础控制器,代表了角色动画领域的一个令人兴奋的前沿。理想的控制器应该支持多样化的控制模态,例如稀疏目标关键帧、文本指令和场景信息。虽然先前的工作提出了物理模拟的、场景感知的控制模型,但这些系统主要集中在开发专门针对狭窄任务集和控制模态的控制器。本文提出了 MaskedMimic,这是一种将基于物理的角色控制表述为通用运动修复问题的新方法。我们的关键洞察是训练一个统一的模型,从部分(掩码)运动描述中合成运动,例如掩码关键帧、对象、文本描述或其任意组合。这是通过利用运动跟踪数据并设计可扩展的训练方法来实现的,该方法能够有效利用多样化的运动描述来产生连贯的动画。通过这一过程,我们的方法学习了一个物理基础控制器,提供了直观的控制界面,而无需为所有感兴趣的行为进行繁琐的奖励工程。所得到的控制器支持广泛的控制模态,并能够在不同任务之间实现无缝过渡。通过运动修复统一角色控制,MaskedMimic 创造了多功能的虚拟角色。这些角色可以动态适应复杂场景并按需组合多样化运动,从而实现更具交互性和沉浸感的体验。
基本信息
- 作者: Chen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, Xue Bin Peng
- 发表时间: 2024 年 9 月 22 日
- arXiv 编号: arXiv:2409.14393 [cs.AI]
- 期刊: ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2024)
- 项目页面: https://research.nvidia.com/labs/par/maskedmimic/
文章要解决的问题:
- 多模态输入的运动实时控制
主要技术点:
- CVAE 生成模型架构:以条件变分自编码器 (CVAE) 作为核心生成模型,输入多模态控制信号,输出物理一致的控制结果
- 掩码运动修复机制:CVAE 的输入使用掩码方式,能够兼容各种任务的输入需求(关键帧、对象、文本描述等任意组合),通过运动补全达到统一多模态输入的目的
- 轨迹优化蒸馏:将轨迹优化功能蒸馏到生成模型中,输出的是 PD 控制的目标而不是动画数据,这使得控制器可以直接驱动物理仿真
- 训练数据预处理:为了让生成模型直接学到轨迹跟踪目标,先用轨迹跟踪算法处理 mocap 数据,得到 PD 控制目标作为 CVAE 的训练真值 (GT)
创新点总结
- 统一控制框架:通过运动修复范式统一了多种控制模态
- 无需奖励工程:避免了为每个行为设计复杂奖励函数的需求
- 实时响应能力:支持交互式应用场景的实时控制需求
- 无缝任务切换:能够在不同任务之间实现平滑过渡
相关对比:
- 与 [2025.10.15]UniPhys Unified Planner and Controller with Diffusion for Flexible 非常相似,两篇文章都是输入用户控制信号,生成 PD 控制的目标
补充说明
- 目标工程技术(Goal-Engineering):用"稀疏多模态目标"替代"复杂奖励工程",让统一控制器灵活完成各类任务
Regional Time Stepping for SPH
摘要
针对经典弱可压缩光滑粒子流体动力学(WCSPH)方法,本文提出一种新颖高效的策略,可根据自由表面流的局部动力学特性,在空间上自适应分配计算量。该方法采用便捷且易于并行化的分块策略,为流体不同区域分配不同的时间步长并以不同速率求解,从而最大限度降低计算成本。实验表明,即便在高动态场景中,该方法的运算速度也较标准方法提升约一倍。
主要方法
适用于(WCSPH)的区域时间步长法(RTS),首个考虑不同区域的时间自适用算法。
怎样管理粒子的仿真步长?
将模拟域划分为虚拟网格,以分块为单位计算各区域的时间步长,而非以单个粒子为单位。
怎样计算一个粒子的适合的步长?
[TODO] 图1
- 所有粒子计算自身的速度和总受力;
- 粒子将自身属性传递至所属分块,分块根据内部粒子的最大受力和最大速度,计算该分块的最小时间步长;
- 各分块将计算得到的时间步长分配至内部所有粒子。
怎样算是合适的步长?
-
考虑时间步长内的突发加速度
[TODO] 公式2
- 根据粒子在一个时间步长内以当前速度移动的距离占其支撑半径的比例,为每个粒子分配对应的时间步长(本文新增)
[TODO] 公式3
判定条件 公式 作用 系数设置 CFL 条件(经典) Δtn≤csλvr 限制粒子在一个步长内的移动距离,避免穿透 λv≤0.4,cs为介质声速 加速度条件(经典) Δtn≤λfFmaxrm 应对突发加速度,保证动力学稳定性 λf≤0.25,Fmax为分块最大受力,m为粒子质量 速度分区条件(新增) rΔtnVmax≤αβn 根据粒子速度占支撑半径的比例分区,实现步长的空间梯度 α=0.4;β1=∞,βn=0.4(0.2)n−2(n≥2)
不同仿真步长对仿真过程有什么影响?
粒子新增了两个属性变量:
- 有效性(validity):表示粒子最新计算的属性的有效最小时间步长数(即距离其实际时间步长结束剩余的子步数);
- 计算标记(compute):布尔变量,标记粒子当前是否为活动粒子(即是否需要重新计算加速度,并在步长结束时校正位置和速度),当validity≤0 时,该标记为真。
若粒子为活动粒子,则计算其邻近粒子集合,并求解局部密度和受力;否则跳过上述计算步骤。在每次循环结束时,更新所有粒子的位置和速度,并按照塞尔纳的策略 [SRS03] 对活动粒子的速度和位置进行校正(算法 1 第 25-30 行)。
- 若粒子为活动粒子,则计算其邻近粒子集合,并求解局部密度和受力。否则跳过这一步。
- 所有粒子更新速度和位置。
- 若粒子为活动粒子,按照塞尔纳的策略对活动粒子的速度和位置进行校正
不同仿真步长之间的切换?
粒子可在其有效性属性过期前更改时间步长。这一设计使方法能在流体遭遇边界碰撞等突发加速度的情况下,保持模拟的稳定性。
不同仿真粒子表现的跳变?
定位不同时间步长区域的边界,并确定大时间步长一侧的分块集合,将该区域分配为其相邻区域的较小时间步长。
局限性
- 仅适用于WCSPH(弱可压缩 SPH),未拓展至更主流的不可压缩 SPH(如 PCISPH、IISPH);
- 分块的支撑半径固定为2s,未考虑自适应分块(如高动态区域细划分块,低动态区域粗划分块);
- 步长判定的系数为经验值,未给出自适应调优策略。
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
本文旨在仅从多视角视频中建模 3D 场景的几何结构、外观及底层物理规律。现有方法通常通过将各种控制方程 (PDE) 作为物理信息神经网络 (PINN) 损失函数,或将物理模拟引入神经网络来实现。然而,这些方法往往难以学习边界处的复杂物理运动,或者需要依赖物体先验信息(如掩码或类型)。本文提出 FreeGave 方法,能够在无需任何物体先验信息的情况下学习复杂动态 3D 场景的物理规律。我们方法的关键在于引入一个物理编码 (physics code),并辅以一个精心设计的无散度模块 (divergence-free module),用于估计每个高斯点的速度场,而无需依赖低效的 PINN 损失函数。在三个公开数据集和一个新收集的高难度真实世界数据集上进行的大量实验表明,我们的方法在未来帧外推和运动分割任务上具有优越性能。尤为值得注意的是,我们对学习到的物理编码的研究表明,在训练中完全未使用任何人工标注的情况下,它们确实学习到了有意义的 3D 物理运动模式。我们的代码和数据可在 https://github.com/vLAR-group/FreeGave 获取。
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
我们提出一种物理信息神经网络——这类网络在训练过程中不仅解决监督学习任务,同时严格遵循由通用非线性偏微分方程描述的物理定律。我们围绕两类核心问题的求解展开研究:偏微分方程的数据驱动求解与数据驱动发现。根据可用数据的性质与组织形式,我们设计出连续时间模型与离散时间模型两类不同算法框架。由此构建的神经网络形成了一类新型数据高效型通用函数逼近器,能够自然地将底层物理定律编码为先验信息。
在第一部分研究中,我们展示如何利用这类网络推断偏微分方程的解,并获得物理信息代理模型——该模型对所有输入坐标和自由参数均具备完全可微性。第二部分研究则聚焦于偏微分方程的数据驱动发现问题。
ParticleGS: Particle-Based Dynamics Modeling of 3D Gaussians for Prior-free Motion Extrapolation
本文旨在根据视觉观测数据建模三维高斯分布的动力学特性,以支持时间外推。
现有的动态三维重建方法通常难以有效学习潜在的动力学规律,或者严重依赖手动定义的物理先验,这限制了它们的外推能力。为解决这一问题,我们提出了一种新颖的、基于粒子动力学系统的、无需先验的动态三维高斯溅射运动外推框架。
我们方法的核心优势在于其能够学习描述三维高斯分布动力学的微分方程,并在未来帧外推过程中遵循这些方程。与简单地拟合观测到的视觉帧序列不同,我们的目标是更有效地建模高斯粒子动力学系统。为此,我们在标准高斯核中引入了一个动力学隐状态向量,并设计了一个动力学隐空间编码器来提取初始状态。随后,我们引入了一个基于神经常微分方程(Neural ODEs)的动力学模块,该模块在动力学隐空间中建模高斯分布的时间演化。最后,使用一个高斯核空间解码器将特定时间步的隐状态解码为形变。
实验结果表明,所提出的方法在重建任务中达到了与现有方法相当的渲染质量,并在未来帧外推方面显著优于现有方法。我们的代码公开在:https://github.com/QuanJinSheng/ParticleGS。
Animate3d: Animating any 3d model with multi-view video diffusion
当前四维生成领域的研究进展主要集中在通过蒸馏预训练的文本或单视图图像条件模型来生成四维内容。这类方法难以有效利用现有具有多视图属性的三维资源,且由于监督信号固有的模糊性,其生成结果常出现时空不一致问题。本研究提出Animate3D——一个可为任意静态三维模型生成动画的创新框架。其核心设计包含两个关键部分:1)我们提出基于静态三维对象多视图渲染的新型多视图视频扩散模型(MV-VDM),该模型在我们构建的大规模多视图视频数据集(MV-Video)上训练完成;2)基于MV-VDM,我们结合重建技术与四维分数蒸馏采样(4D-SDS),构建了利用多视图视频扩散先验实现三维对象动画的完整框架。具体而言,针对MV-VDM,我们设计了新颖的时空注意力模块,通过融合三维与视频扩散模型来增强时空一致性;同时利用静态三维模型的多视图渲染作为条件输入以保持其身份特征。在三维模型动画生成方面,我们提出有效的两阶段流程:首先直接从生成的多视图视频中重建运动序列,随后通过4D-SDS同步优化外观与运动表现。得益于精确的运动学习机制,我们能够实现直接的网格动画生成。定性与定量实验表明,Animate3D在各方面性能均显著超越现有方法。相关数据、代码与模型将全面开源。
研究背景与问题
任务
输入:3DGS静态模型 输出:t时刻相对于静态GS的位移、旋转、缩放。
本文方法及优势
| 要解决的问题 | 当前方法及存在的问题 | 本文方法及优势 |
|---|---|---|
| 引导视频 | 单视图图像或视频 由于监督信号固有的模糊性,其生成结果常出现时空不一致问题。 | 利用现有具有多视图属性的三维资源,构建多视图视频扩散模型(MV-VDM)。 |
主要贡献
1)多视角视频扩散模型(MV-VDM)
2)大规模多视图视频数据集(MV-Video)
3)基于MV-VDM,我们引入结合重建技术与4D分数蒸馏采样(4D-SDS)的框架,利用多视图视频扩散先验实现3D对象动画。
主要方法
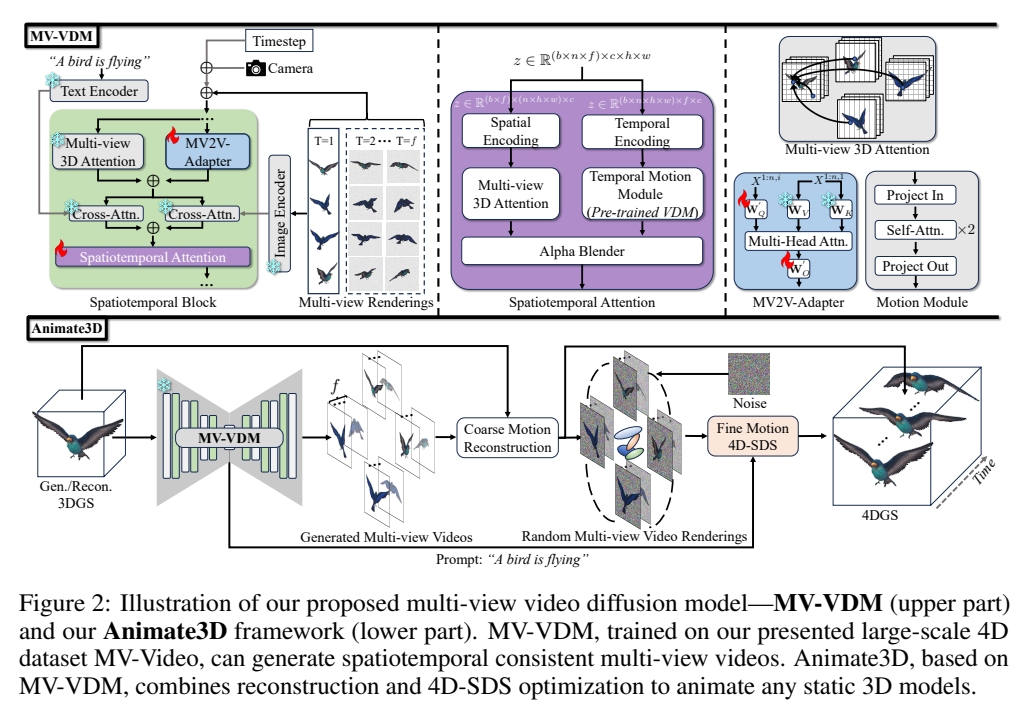
多视角视频扩散模型(MV-VDM)
3D扩散模型(MVDream) + 视频扩散模型(AnimateDiff) + 结合图像条件化方法的高效即插即用时空注意力模块
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
由于可变形物体多样的物理特性以及难以从有限的视觉信息中估计其状态,建模其动力学具有挑战性。我们通过一个神经动力学框架来解决这些挑战,该框架在混合表示中结合了物体粒子 (object particles) 和空间网格 (spatial grids)。我们的粒子-网格模型 (particle-grid model) 既能捕捉全局形状和运动信息,又能预测密集的粒子运动,从而能够建模具有不同形状和材料的物体。粒子代表物体形状,而空间网格则将三维空间离散化,以确保空间连续性并提高学习效率。结合用于视觉渲染的高斯泼溅 (Gaussian Splatting) 技术,我们的框架实现了完全基于学习的可变形物体数字孪生模型 (fully learning-based digital twin),并生成动作条件的三维视频 (3D action-conditioned videos)。
通过实验,我们证明了我们的模型能够从机器人-物体交互的稀疏视角RGB-D记录 (sparse-view RGB-D recordings) 中学习各种物体(如绳索、布料、毛绒玩具和纸袋)的动力学,同时还能在类别层面 (category level) 上泛化到未见过的实例。我们的方法优于最先进的基于学习的模拟器 (learning-based simulators) 和基于物理的模拟器 (physics-based simulators),尤其是在相机视角有限 (limited camera views) 的场景下。此外,我们展示了所学模型在基于模型的规划 (model-based planning) 中的实用性,使其能够在一系列任务中实现目标条件的物体操作 (goal-conditioned object manipulation)。
项目页面位于:https://kywind.github.io/pgnd
研究背景与问题
任务
输入:3DGS场景的静态模型、交互操作
输出:预测GS球未来运动
主要方法
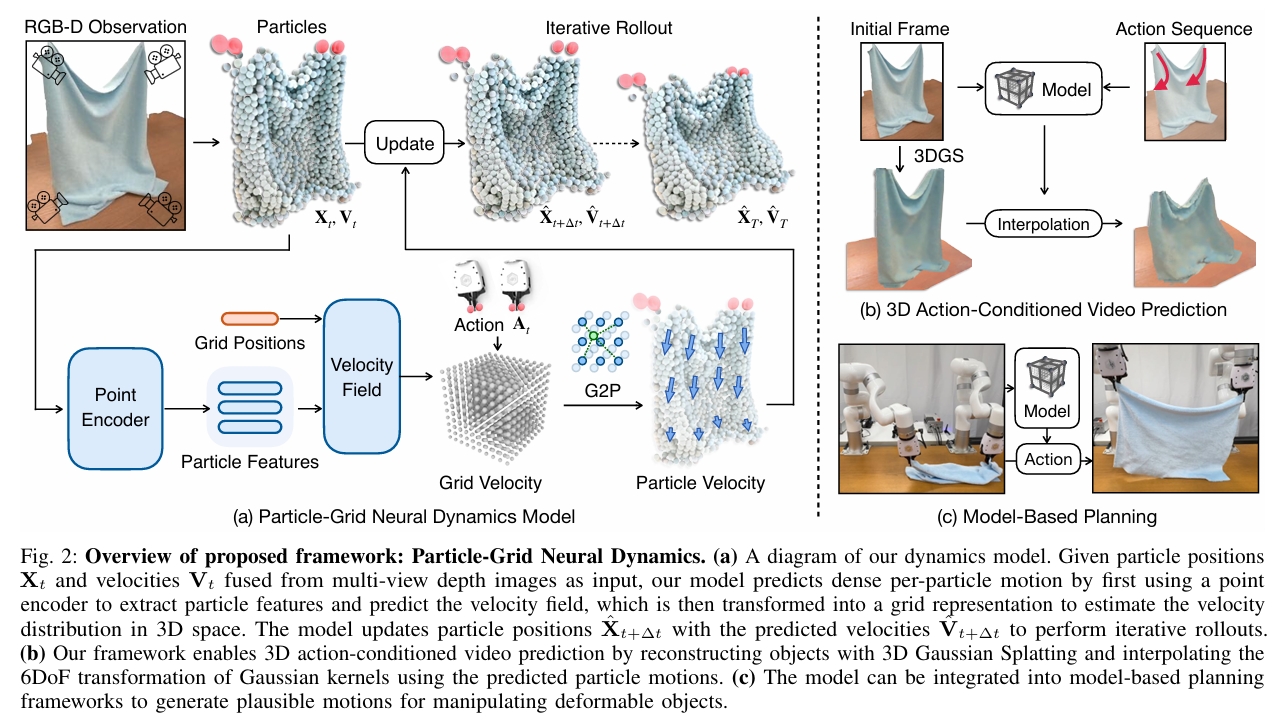
本文中仿真全过程使用的粒子是点云粒子。GS球只是最后渲染使用。
粒子-网格神经动力学
状态表示
| 符号 | 维度 | 含义 |
|---|---|---|
| Xt | 3*n | t时刻每个球的位置 |
| Vt | 3*n | t时刻每个球的速度 |
控制表示
\(A_t\) 表示机器人在时刻 \(t\) 对物体施加的外部作用。
$$ A_t = (y, T_t, \dot{T}_t, o_t), $$
| 符号 | 维度 | 含义 |
|---|---|---|
| \(y\) | 动作类型标签,是一个二元标签,用于指示动作是抓取操作还是非抓取式交互 | |
| \(T_t\) | 为末端执行器位姿 | |
| \(\dot{T}_t\) | 为其时间导数 | |
| \(o_t\) | 夹爪张开距离 |
动力学函数
$$ V_{t+1} = f_\theta(X_{(t-h):t}, V_{(t-h):t}, A_t) \\ X_{t+1} = X_t + V_{t+1} $$
粒子-网格模型
**使用端到端神经网络学习神经动力学参数 θ 通常会导致累积误差,进而引发预测不稳定。**因此同样采用particle-grid表示,以融入与空间连续性及局部信息集成相关的归纳偏置。
定义一个均匀分布的网格:
$$ G_{l_x, l_y, l_z, \delta} = { (k_x \delta, k_y \delta, k_z \delta) \mid k_i \in [l_i], \forall i \in {x, y, z} }. $$
末端执行器及每个粒子必定属于某个网格。
Grid用于学习上文提到的\(f_\theta\)函数。具体包含以下模块:
- \(f^{feature}_\phi\) 是基于神经网络的点编码器,用于从输入粒子中提取特征(第 III-B1 节);
- \(f^{field}_\psi\) 是基于神经网络的函数,用于根据提取的特征参数化神经速度场(第 III-B2 节);
- \(g^{grid}\) 是网格速度编辑控制方法,用于编码碰撞表面和机器人夹爪的运动(第 III-B4 节);
- \(h^{G2P}\) 是网格到粒子的积分函数,用于从基于网格的速度场计算粒子速度(第 III-B3 节)。
基于网格来学习速度场比直接学习每个粒子的速度更稳定。
网格模块
点编码器
输入:粒子位置与速度
输出:粒子的潜在特征
$$ Z_t = f^{feature}\phi (X{(t-h):t}, V_{(t-h):t}). $$
模型结构: PointNet
特征编码器必须提取对遮挡鲁棒的特征,以供后续速度解码使用。
神经速度场
输入:网格点g的位置x、网格点g的部感知特征z
输出:网格点g的速度向量
$$ \hat{v}{g,t} = f^{field}\psi (\gamma(x_g), z_{g,t}), $$
其中 \(\gamma\) 为正弦位置编码,局部感知特征 \(z_{g,t}\) 定义为网格位置邻域内粒子特征的平均池化:
$$ z_{g,t} = \frac{\sum_{p \in N_r(X_t, x_g)} z_{p,t}}{|N_r(X_t, x_g)|}, $$
半径 \(r\) 是一个超参数 (r),用于控制一个网格点所关注的粒子特征数量,从而促使网络预测依赖于局部几何的速度。
网格到粒子速度传递
遵循物质点法(MPM)的思路,采用连续的B样条核函数将网格速度 (\hat{v}{g,t}) 传递至粒子速度 (\hat{v}{p,t}):
$$ \hat{v}{p,t} = \sum{g \in G} \hat{v}{g,t} w{pg,t}, $$
预测值 \(\hat{V} \in \mathbb{R}^{3 \times n}\) 作为动力学函数 \(f_\theta\) 的最终输出,并用于更新粒子的位置。
变形控制
通过与外部物体交互来控制变形
网格速度编辑GVE
改变网格上的速度以匹配物理约束:
- 对于地面接触从接触面回推速度并加入摩擦项
- 定义刚性抓取点的运动,计算抓取中心点 \(x_{grasp,t}\) 附近的点,按如下方式修改其速度:
$$ v_{g,t} = \omega_t \times (x_g - x_{grasp,t}) + \dot{x}_{grasp,t}, $$
其中 \(\omega_t\) 和 \(\dot{x}{grasp,t}\) 分别为时刻 \(t\) 时夹爪的角速度和线速度,\(x_g\) 和 \(v{g,t}\) 分别为网格点 \(g\) 的位置和速度。
机器人粒子法
用于非抓取式动作建模,例如推动箱子。
用携带夹爪动作信息的额外粒子表示机器人夹爪,并将其融合到物体点云中
并在增广后的点云上建模粒子-网格动力学函数。
这便将动作信息注入粒子特征中,但不会显式强制粒子按指定速度运动,从而支持非抓取式操控。
数据收集与训练
数据收集
- 通过真实交互记录多视角的RGB-D视频,捕捉机器人-物体的随机交互过程。
- 用Segment-Anything [18, 39] 提取视频中物体的持续掩码。
- 将分割出的物体进行裁剪,并使用CoTracker [15] 对其进行跨帧跟踪,从而得到2D轨迹。
- 借助深度信息,通过逆投影将这些2D速度映射至3D空间,生成具有持续粒子跟踪信息的多视角融合点云。
训练
损失函数定义为预测粒子位置与实际粒子位置之间的均方误差位置。
渲染与动作条件视频预测
首先对点云集合 \(X\) 应用动力学模型,得到下一帧的预测 \(\hat{X}\)。点集 \(\hat{X}\) 可以来自对 \(X_{GS}\) 的采样,或从与 \(X_{GS}\) 处于同一坐标系内的额外点云观测中获取。
将 \(X\) 视为控制点,并对其预测运动进行插值,从而更新 \(X_{GS}\) 和 \(R_{GS}\),生成新的高斯中心与旋转。
假设高斯泼溅的颜色、尺度和不透明度保持不变。
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
基于单目视频的动态三维场景重建始终是三维视觉领域的核心难题。尽管三维高斯溅射(3DGS)技术在静态场景中实现了实时渲染,但其在动态场景的应用仍面临挑战——这源于学习结构化且时间一致的运动表征存在困难。现有方法通常表现为三方面局限:高斯更新冗余、运动监督不足,以及对复杂非刚性形变的建模能力薄弱。这些问题共同阻碍了连贯高效的动态重建。
为突破这些限制,我们提出HAIF-GS——一个通过稀疏锚点驱动形变实现结构化一致动态建模的统一框架。该框架首先通过锚点过滤器识别运动相关区域,抑制静态区域的冗余更新;随后利用自监督诱导流引导变形模块,通过多帧特征聚合驱动锚点运动,无需显式光流标签;为处理细粒度形变,分层锚点传播机制能依据运动复杂度提升锚点分辨率,并传播多级变换关系。在合成与真实数据集上的大量实验表明,HAIF-GS在渲染质量、时间一致性和重建效率上均显著超越现有动态3DGS方法。
PIG: Physically-based Multi-Material Interaction with 3D Gaussians
3D高斯溅射技术在静态与动态3D场景重建领域取得了显著成功。然而,在由3D高斯基元表征的场景中,物体间的交互存在三大缺陷:三维分割精度不足、异质材质形变失准及严重渲染伪影。为应对这些挑战,我们提出PIG:基于物理的多材质3D高斯交互技术——这是一种融合三维物体分割与高精度交互仿真的创新方法。
首先,本方法实现了从二维像素到三维高斯基元的快速精准映射,从而达成精确的物体级三维分割。其次,我们为场景中分割后的物体赋予独特物理属性,以实现多材质耦合交互。最后,我们创新性地将约束尺度嵌入变形梯度,通过钳制高斯基元的缩放与旋转属性消除渲染伪影,达成几何保真度与视觉一致性。
实验结果表明,我们的方法不仅在视觉质量上显著超越现有最优方案(SOTA),更为物理真实感场景生成领域开辟了全新研究方向与技术路径。
研究背景与问题
任务
在由3D高斯基元表征的场景中的物体间的交互
现有方法及局限性
基于3D高斯泼溅的分割方法
- 从CLIP等二维预训练模型中提取特征,并将其蒸馏至3D高斯基元以进行点级分割。
- LangSplat训练自编码器在特征蒸馏前降维,将低维CLIP特征嵌入高斯模型中;
- Segment Any 3D Gaussians利用2D SAM掩码作为先验信息,训练场景专属特征
- Semantic Gaussians则借助高斯属性作为输入,训练具有二维预训练模型特征的3D语义特征;
- Feature Splatting通过渲染DINOv2与CLIP特征图,训练每个高斯基元的语义特征。
三维分割精度不足
驱动及渲染方法
- PhysGaussian提出将MPM与3DGS结合,在选定区域内生成单材料物理场景。这是首个将MPM引入3DGS的方法,但由于缺乏分割能力,难以在三维空间中精确定位仿真物体的包围盒。此外,当物体发生大变形时,直接使用MPM空间中粒子的变形梯度来调整对应高斯基元的协方差矩阵效果不佳。
- PhysDreamer通过集成生成模型来估计物理参数,再借助MPM进行仿真。该方法高度依赖生成模型的物理先验,且忽视了仿真与渲染间的差异——具体而言,它忽略了变形过程中高斯基元间相对位置的变化,导致渲染物体出现显著伪影。
异质材质形变失准及严重渲染伪影
本文方法及优势
本方法实现了从二维像素到三维高斯基元的快速精准映射,从而达成精确的物体级三维分割。
其次,我们为场景中分割后的物体赋予独特物理属性,以实现多材质耦合交互。
最后,我们创新性地将约束尺度嵌入变形梯度,通过钳制高斯基元的缩放与旋转属性消除渲染伪影,达成几何保真度与视觉一致性。
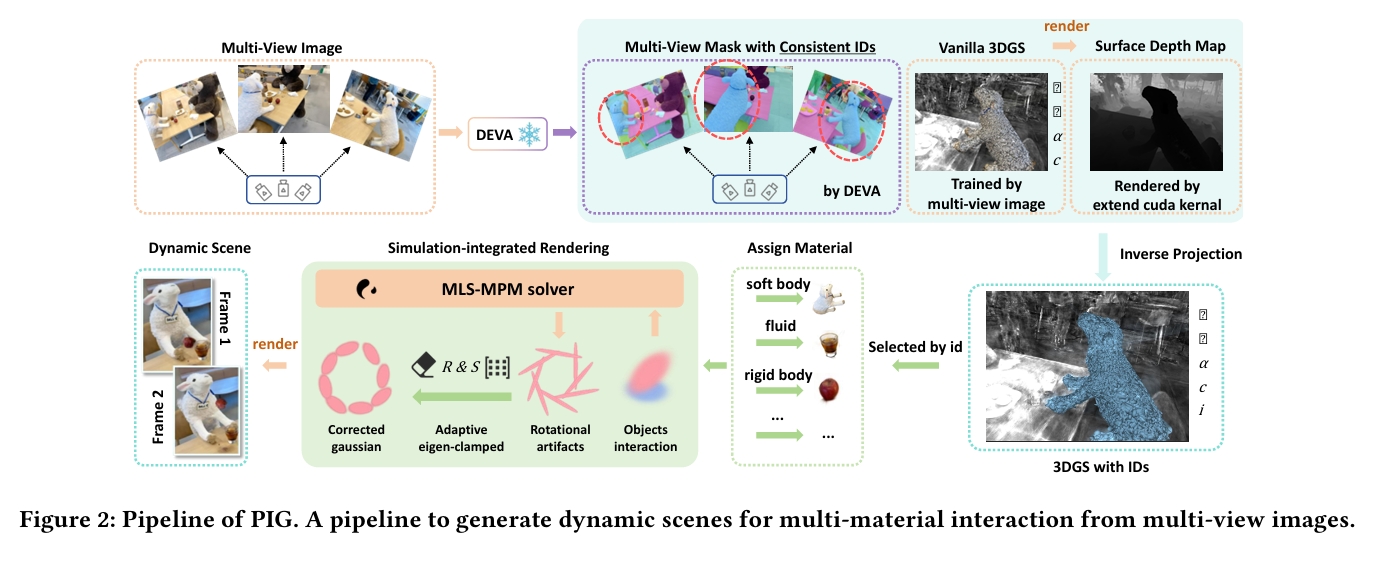
物体级三维分割
| 输入 | 输出 | 方法 |
|---|---|---|
| 多视角图像 | 3D高斯场景 | |
| 多视角图像 | 具有一致性ID的多视角掩码 | DEVA |
| 多视角图像 | 表面深度图 | |
| 表面深度图 | 2D到3D的映射关系 | |
| 2D到3D的映射关系 图像多视角掩码 | GS分割结果 |
3.2.2 表面深度图渲染
为将掩码 \(M\) 中的 ID 映射到高斯场景 \(G\) 上,我们需要识别掩码中每个像素所对应的物体表面高斯元,并获取其深度信息,进而渲染成表面深度图。
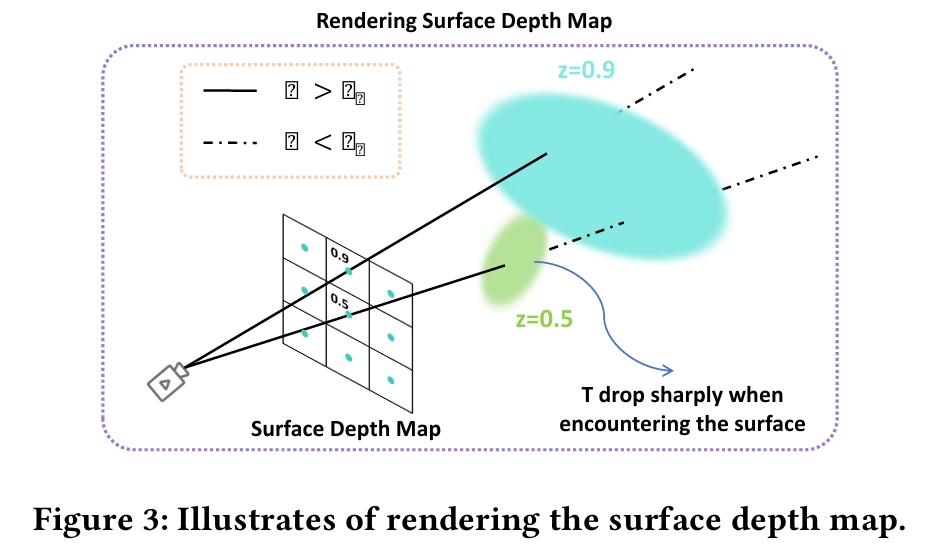
对于任意像素 \(p_{i,j}^t\),我们将其转换为齐次坐标 \(P_{i,j}^t\)。利用相机内参 \(K\) 和外参 \(E\),得到相机坐标系下的射线方程:
$$ r_{i,j}^t(d) = C + d E^{-1} K^{-1} P_{i,j}^t, $$
其中 (C) 为相机在世界坐标系中的位置,(d) 表示深度。
射线与物体表面相交处,公式(1)中的透射率 (T) 会急剧下降。当 (T) 低于我们设定的透射率阈值 (\tau_T) 时,即表明已找到该像素对应的物体表面,此时将深度值 \(d_{i,j}^t\) 记录到深度图 \(D_t \in \mathbb{R}^{H \times W}\) 中。
EnliveningGS: Active Locomotion of 3DGS — 超详细解读
论文信息
- 标题: EnliveningGS: Active Locomotion of 3DGS
- 作者: Siyuan Shen, Tianjia Shao, Kun Zhou (浙江大学), Chenfanfu Jiang (UCLA), Yin Yang (犹他大学)
- 会议: CVPR 2024
- 代码: https://gapszju.github.io/EnliveningGS/
目录
1. 这篇文章到底在讲什么?
1.1 一句话概括
让用 3D Gaussian Splatting(3DGS)表示的 3D 模型,能像真实生物一样主动行走、跳跃、扭转——而不是像石头一样静止不动。
1.2 用类比来理解
- 传统3D场景:游戏里的树木、建筑都是"死"的——除非程序员预先写好动画脚本,否则它们永远不会自己动弹。
- 这篇文章的目标:让游戏里的任何物体(棋盘上的棋子、椅子、玩偶)都能像活物一样,自己"决定"怎么动,并且能够真实与环境互动。

1.3 为什么这个问题重要?
在 VR、AR、电子游戏、电影特效等领域,都希望虚拟世界里的物体能够真实、自然、物理合理地运动。但现有技术有这些局限:
- 只能做预先录制好的动画(不灵活)
- 需要极其复杂的手工调整(费时费力)
- 只能处理"刚体"(不会变形的物体),无法处理"软体"
1.4 核心创新点
- "肌肉"驱动:在3D模型内部"植入"虚拟肌肉纤维,通过控制肌肉收缩程度来驱动运动。
- 混合接触建模:结合 LCP + 惩罚法处理接触/摩擦问题,既保证精度又提高效率。
- 双向局部嵌入:精确描述3D模型变形时每个高斯核的位置和形状变化。
2. 背景知识
2.1 什么是 3D Gaussian Splatting (3DGS)?
传统3D表示方法对比
| 表示方法 | 优点 | 缺点 |
|---|---|---|
| 网格(Mesh) | 计算效率高 | 难以表示复杂几何细节 |
| NeRF | 图像逼真 | 渲染速度极慢 |
| 点云(Point Cloud) | 简单直接 | 无法表示连续表面 |
3DGS 的核心思想
3D Gaussian Splatting 把3D场景表示成成千上万个"3D高斯分布"(椭圆形的"云团"),每个云团有自己的位置、形状、不透明度和颜色。
类比理解:想象一堆半透明的彩色果冻球,从任何角度看过去,它们重叠在一起就形成了一幅完整的画面。
3DGS 的数学表示
每个"高斯核"表示为:
G(x) = exp(-1/2 (x-μ)^T Σ^(-1) (x-μ))
其中:
μ ∈ R³:高斯核的中心位置Σ ∈ R^(3×3):协方差矩阵(决定形状)σ ∈ [0,1):不透明度c ∈ R^k:球谐函数系数(决定颜色)
协方差矩阵分解:
Σ = R S S^T R^T
R:旋转矩阵(四元数表示)S = diag(s₁, s₂, s₃):缩放矩阵
2.2 主动运动 vs 被动运动
被动运动(Passive Dynamics):物体在外力作用下的运动(如苹果落地、布料飘动)。
主动运动(Active Locomotion):物体通过自身内部驱动机制产生的运动(如人类行走、鱼类游泳)。
主动运动的难点:
- 逆向问题:给定目标轨迹,反推肌肉激活程度
- 接触建模:接触力会影响身体运动,需要精确建模
2.3 物理仿真中的接触问题
难点:
- 不连续性:分离与接触状态突变
- 摩擦力的复杂性:遵循库仑摩擦定律
- 组合爆炸:
3^N种可能状态组合(NP难)
现有方法对比:
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 惩罚法 | 接触力=弹簧力 | 实现简单,效率高 | 数值稳定性差 |
| LCP方法 | 优化问题求解 | 理论严谨 | 计算复杂度高 |
本文创新:结合两种方法,用惩罚法"粗筛",用LCP精确求解。
2.4 什么是"逆向问题"?
- 正向问题:已知参数,预测结果(例:已知地球和太阳质量,预测轨道)
- 逆向问题:已知结果,反推参数(例:已知轨道,反推太阳质量)
- 本文的逆向问题:给定运动轨迹,反推肌肉激活程度
3. 核心问题
3.1 问题定义
输入:3DGS模型 + 目标运动轨迹 输出:肌肉激活程度 + 真实运动轨迹
3.2 技术挑战
- 超高维度优化:一个3DGS模型包含数十万~上百万个高斯核,系统自由度达数百万级。
- 接触力建模:涉及碰撞检测、摩擦力计算、数值稳定性等多个难题。
- 3DGS特殊问题:高斯核分裂(大变形时产生"尖刺伪影")、遮挡修复(运动后新暴露区域需要颜色填补)。
4. 方法总览:EnliveningGS 流水线
4.1 整体框架
flowchart TB
A["输入:静态3DGS场景"] --> B["物体分割"]
B --> C["四面体网格封装"]
C --> D["肌肉纤维植入"]
D --> E["双向局部嵌入"]
E --> F["两阶段运动求解器"]
F --> G["3DGS变形"]
G --> H["遮挡区域修复"]
H --> I["输出:动态4D动画"]
style A fill:#e1f5fe
style I fill:#e8f5e9
流程步骤:
- 物体分割:从场景中分离目标物体
- 四面体网格封装:构建物理仿真用的网格
- 肌肉纤维植入:在网格内植入虚拟肌肉
- 双向局部嵌入:建立网格与高斯核的双向映射
- 两阶段运动求解:求解最优肌肉激活
- 3DGS变形:更新高斯核状态
- 遮挡区域修复:填补新暴露区域
4.2 双向局部嵌入示意图

5. 技术细节深入解读
5.1 混合网格-高斯表示
四面体网格的作用:
- 质量离散化:分配质量到网格顶点
- 变形计算:求解偏微分方程
- 肌肉植入:定义肌肉纤维路径
5.2 双向局部嵌入(核心创新)
对于每个高斯核,定义两个局部嵌入:
- 前向嵌入 T⁺:从网格到高斯核的映射
- 反向嵌入 T⁻:从高斯核到网格的映射
高斯核中心位置用重心坐标表示:
x' = Σ λᵢ(x) vᵢ'
协方差矩阵变换:
Σ' = F Σ F^T
其中 F = D_s · D_m⁻¹ 是变形梯度。
分裂条件:
如果前向和反向嵌入的旋转矩阵差异角 θ > η,则分裂高斯核:
graph TD
A["高斯核 G"] --> B["前向嵌入 T+"]
A --> C["反向嵌入 T-"]
B --> D["计算 R+"]
C --> E["计算 R-"]
D --> F["计算差异角 θ"]
E --> F
F --> G{"θ > η?"}
G -->|是| H["分裂高斯核"]
G -->|否| I["保持原样"]
style H fill:#ffcdd2
style I fill:#c8e6c9
5.3 肌肉驱动的动态
肌肉被建模为分段线性弹簧:
f_muscle = k · a
k:刚度系数a ∈ [0,1]:激活程度
动力学方程:
M p¨ = f_ext + f_int + f_d + f_m + f_c
M:质量矩阵f_ext:外力(重力等)f_int:内力(弹性力,使用 Ne-Hookean 模型)f_d:阻尼力f_m:肌肉力f_c:接触力
5.4 混合接触建模框架
LCP 公式化
接触约束表示为 LCP 问题:
[ f⊥ ] [ Nᵀu̇ ]
[ f‖ ] ⊥ [ Dᵀu̇ + Eλ ]
[ λ ] [ -λᵀEᵀu̇ ]
≥ 0
混合方法流程
flowchart TD
A["猜测接触状态"] --> B["惩罚法计算接触力"]
B --> C["更新接触状态"]
C --> D{"状态收敛?"}
D -->|否| B
D -->|是| E["LCP精确求解"]
E --> F["输出接触力+运动状态"]
style A fill:#e3f2fd
style F fill:#e8f5e9
5.5 两阶段运动求解器
第一阶段:忽略接触约束,求近似解(无约束优化)
第二阶段:用第一阶段结果作为初始猜测,加入接触约束,求解完整优化问题(使用SQP或增广拉格朗日法)
效率提升:两阶段策略避免从随机初始点搜索,大大提高收敛速度。
5.6 高斯核自我分裂机制
分裂条件:
θ = arccos((tr(R₊ᵀR₋) - 1) / 2) > η
分裂操作:
给定高斯核 (α₀, μ₀, Σ₀),分裂为:
αₗ = αᵣ = α₀ / 2
μₗ = μ₀ - κ v_k μᵣ = μ₀ + κ v_k
Σₗ = Σᵣ = Σ₀ - κ² v_k v_kᵀ
6. 实验结果与对比
6.1 locomotion 设计示例
行走(Walking)
- 控制四条腿的轨迹
- 对角支撑腿同时抬起,其他腿摆动前进

跳跃(Jumping)
- 控制质心轨迹和底部相对速度
- 实现连续跳跃(国际象棋棋子)
扭转(Twisting)
- 空中旋转180度
- 控制角动量变化

6.2 变形质量对比
| 方法 | Bending PSNR↑ | Bending SSIM↑ | Twisting PSNR↑ | Twisting SSIM↑ | Falling PSNR↑ | Falling SSIM↑ |
|---|---|---|---|---|---|---|
| SuGaR | 28.04 | 0.890 | 26.37 | 0.823 | 25.01 | 0.913 |
| PhysGaussian | 28.14 | 0.907 | 26.53 | 0.856 | 25.10 | 0.923 |
| VR-GS | 28.63 | 0.917 | 26.53 | 0.893 | 25.31 | 0.938 |
| Ours (w/o split) | 28.62 | 0.918 | 26.47 | 0.891 | 25.34 | 0.939 |
| Ours | 28.79 | 0.923 | 26.89 | 0.910 | 25.67 | 0.951 |
6.3 两阶段求解器对比
| 方法 | 平均迭代次数↓ | 最佳目标值↓ | 最差目标值↓ |
|---|---|---|---|
| QP(静态接触假设) | - | 9.43 | 23.86 |
| QPCC [41] | 46.19 | 1.29 | 12.11 |
| Ours | 17.01 | 0.83 | 7.89 |
Ours 方法比 QP 快约 60倍。
6.4 修复效果对比
| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | Residual↓ |
|---|---|---|---|---|
| Mask (w/o L_seg) | - | - | - | 0.058 |
| Remove | 25.917 | 0.827 | 0.211 | - |
| w/ L_seg | 35.291 | 0.945 | 0.034 | 0.002 |
7. 优缺点分析
7.1 优点
- 创新性强:首次实现3DGS的主动运动控制,打破了传统3DGS只能"被动受力"的限制。
- 物理真实:完全基于物理仿真,运动过程自然且符合物理规律。
- 效率较高:混合方法(惩罚法 + LCP)比纯LCP方法快约60倍。
- 质量好:能处理大变形,通过高斯核分裂机制减少伪影。
7.2 缺点/局限性
- 环境简化:目前假设环境是平面,更复杂地形(如斜坡、楼梯)需要更多工作。
- 计算开销:对于非常复杂的场景(如上百万高斯核),仍有计算挑战。
- 手动干预:需要手动植入肌肉纤维(虽然论文提供了自动生成工具,但仍需人工调整)。
8. 个人思考与扩展
8.1 这篇论文的意义
这篇论文打开了3DGS应用于物理仿真和动画的大门,未来可能在以下领域产生重要影响:
- VR/AR中的应用:实现真实物理交互的虚拟物体
- 电子游戏的动态物体:让游戏中的物体能够自主运动
- 电影特效的快速动画生成:减少手工动画制作的工作量
8.2 潜在扩展方向
- 更复杂环境:从平面扩展到任意地形(如斜坡、楼梯、沙滩等)
- 多物体交互:实现多个物体之间的物理交互(如碰撞、堆叠等)
- 学习-based 优化:用神经网络(如PINNs)来加速肌肉激活程度的求解
- 实时控制:结合强化学习(Reinforcement Learning)实现实时运动控制
8.3 关键技术借鉴
- 混合方法思路:对于复杂的优化问题,组合多种方法往往比单一方法更有效。
- 双向嵌入:这种双向映射的思想可用于其他需要建立两种表示方法之间关系的场景。
- 两阶段求解:对于复杂的约束优化问题,先用简单方法得到初始解,再进行精细化求解,是一种有效的策略。
9. 参考文献与延伸阅读
9.1 相关工作
- 3DGS: Kerbl et al., "3D Gaussian Splatting for Real-Time Radiance Field Rendering", TOG 2023
- PhysGaussian: Xie et al., "PhysGaussian: Physics-Integrated 3D Gaussians", CVPR 2024
- VR-GS: Jiang et al., "VR-GS: A Physical Dynamics-Aware Interactive Gaussian Splatting System", SIGGRAPH 2024
- LCP: Stewart & Trinkle, "An Implicit Time-Stepping Scheme for Rigid Body Dynamics", IJNM 1996
9.2 基础理论
- Neo-Hookean模型: Bonet & Wood, "Nonlinear Continuum Mechanics"
- 摩擦力学: Andrews et al., "Contact and Friction Simulation", SIGGRAPH 2022
- 软体运动: Tan et al., "Softbody Locomotion", TOG 2012
9.3 开源资源
- 代码: https://gapszju.github.io/EnliveningGS/
- 3DGS 工具: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
附录:核心公式速查
| 公式 | 含义 |
|---|---|
Σ = R S Sᵀ Rᵀ | 协方差矩阵分解 |
Σ' = F Σ Fᵀ | 变形后的协方差 |
M p¨ = f_ext + f_int + f_d + f_m + f_c | 动力学方程 |
f_m = A(p) · a | 肌肉力 |
Ψ = μ/2 (I_C - 3) - μ ln J + λ/2 (ln J)² | Neo-Hookean 势能 |
∥f_∥∥ ≤ μ f_⊥ | 摩擦约束 |
本文档由 AI 生成,如有问题欢迎指正。
SplineGS: Learning Smooth Trajectories in Gaussian Splatting for Dynamic Scene Reconstruction
针对动态变形物体的复杂场景重建以实现新视角合成是一项极具挑战性的任务。近期研究通过引入三维高斯泼溅技术(3D Gaussian Splatting),在静态场景的高质量快速重建方面取得了显著进展,其核心在于为高斯斑点的形变设计了专用模块。然而,如何设计一个能够有效融入适当时空归纳偏置的形变模块仍是一个亟待解决的问题。为此,本文提出SplineGS方法,通过采用非均匀有理B样条(NURBS)——B样条的扩展形式——来表征时间维度上的平滑形变。该方法基于NURBS学习一组代表性轨迹,并通过这些轨迹的线性组合来表达各高斯斑点的个体运动轨迹,从而确保空间平滑性。组合权重的优化则依托于以高斯斑点位置为键值的多分辨率哈希表和MLP网络协同完成。得益于这种创新设计,本方法无需对运动轨迹施加正则化约束即可实现高效训练。实验结果表明,所提方法在保持训练时间大幅缩短的同时,其性能较现有方法具有显著竞争力。
PAMD: Plausibility-Aware Motion Diffusion Model for Long Dance Generation
计算舞蹈生成在艺术、人机交互、虚拟现实和数字娱乐等众多领域至关重要,尤其是在生成连贯且富有表现力的长舞蹈序列方面。基于扩散模型的音乐到舞蹈生成已取得显著进展,但现有方法仍难以生成物理上合理的运动。为解决此问题,我们提出了合理性感知运动扩散模型 (PAMD),这是一个用于生成既与音乐对齐又物理逼真的舞蹈框架。
PAMD的核心在于合理运动约束 (PMC),它利用神经距离场 (NDFs) 来建模真实的姿态流形,并将生成的运动引导至物理上有效的姿态流形。为了在生成过程中提供更有效的引导,我们引入了先验运动引导 (PMG),它将站立姿态作为辅助条件,与音乐特征一起使用。为了进一步增强复杂运动的真实感,我们提出了基于足地接触的运动优化 (MRFC) 模块,该模块通过弥合关节线性位置空间中的优化目标与非线性旋转空间中的数据表示之间的差距,来解决脚滑伪影问题。
大量实验表明,PAMD显著提高了音乐对齐度,并增强了生成运动的物理合理性。本项目页面地址为:https://mucunzhuzhu.github.io/PAMD-page/。
PMG: Progressive Motion Generation via Sparse Anchor Postures Curriculum Learning
在计算机动画、游戏设计以及人机交互领域,如何生成符合用户意图的人体运动始终是一项重大挑战。现有方法存在显著局限性:基于文本描述的方法能够提供高层语义指导,但难以准确描述复杂动作;基于轨迹的技术虽然能直观控制全局运动方向,却常无法生成精确或定制化的角色动作;而锚点姿态引导的方法通常仅限于生成简单运动模式。
为实现更高控制精度和更精细的运动生成,我们提出ProMoGen(渐进式运动生成框架) —— 一种将轨迹引导与稀疏锚点动作控制相结合的全新框架。全局轨迹保证了空间方向与位移的连贯性,而稀疏锚点动作仅传递精确的动作指导(不含位移信息)。这种解耦设计使得两者能够独立优化,从而实现更高可控性、高保真度与复杂运动合成。ProMoGen在统一训练流程中支持双控制范式(轨迹+锚点)与单控制范式(仅轨迹或仅锚点)的灵活切换。
此外,针对稀疏动作直接学习存在固有不稳定性的问题,我们提出SAP-CL(稀疏锚姿态课程学习策略)。该课程学习方法通过渐进式调整引导锚点数量,实现了更精准稳定的收敛效果。大量实验表明,ProMoGen在预定义轨迹与任意锚点帧的引导下,能够生成生动多样的运动。我们的方法将个性化动作与结构化引导无缝融合,在多种控制场景下显著优于当前最先进的方法。
LengthAware Motion Synthesis via Latent Diffusion
合成人体运动的时长是一个关键属性,需要对运动动力学和风格进行建模控制。加速动作执行并不仅仅是简单的快进播放。然而,目前最先进的人类行为合成技术在目标序列长度控制方面存在局限。我们提出了从文本描述生成长度感知的3D人体运动序列这一新课题,并提出了一种新颖模型来合成可变目标时长的运动,称之为"长度感知潜在扩散"(LADiff)。LADiff包含两个新模块:1)长度感知变分自编码器,通过长度相关的潜在代码学习运动表征;2)长度顺应潜在扩散模型,其生成运动的细节丰富度会随着所需目标序列长度的增加而提升。在HumanML3D和KIT-ML两个权威基准测试中,LADiff在大多数现有运动合成指标上显著超越了当前最先进技术。
IKMo: Image-Keyframed Motion Generation with Trajectory-Pose Conditioned Motion Diffusion Model
现有基于轨迹与姿态输入的人体运动生成方法通常对这两种模态进行全局处理,导致输出结果次优。本文提出 IKMo(基于图像关键帧的运动生成方法),这是一种基于扩散模型的运动生成方法,其核心在于解耦轨迹与姿态输入。轨迹和姿态输入经过一个两阶段条件化框架进行处理:
- 第一阶段:应用专门的优化模块对输入进行精细化处理。
- 第二阶段:轨迹和姿态并行通过一个轨迹编码器(Trajectory Encoder)和一个姿态编码器(Pose Encoder)进行编码。随后,一个运动控制网络(ControlNet)处理融合后的轨迹与姿态数据,引导生成具有高空间保真度与语义保真度的运动。
基于 HumanML3D 和 KIT-ML 数据集的实验结果表明,在轨迹-关键帧约束下,所提方法在所有指标上均优于现有最优方法。此外,我们实现了基于多模态大语言模型(MLLM)的智能体来预处理模型输入。给定用户提供的文本和关键帧图像,这些智能体能够提取运动描述、关键帧姿态和轨迹作为优化后的输入,输入到运动生成模型中。我们进行了包含 10 名参与者的用户研究,实验结果证明,基于 MLLM 的智能体预处理使生成的运动更符合用户预期。我们相信,所提出的方法显著提升了扩散模型在运动生成方面的保真度与可控性。
UniMoGen: Universal Motion Generation
动作生成是计算机图形学、动画、游戏和机器人技术的基石,能够实现逼真且多样化的角色动作创作。现有方法的一个显著局限是它们依赖于特定的骨骼结构,这限制了它们在不同角色间的通用性。
为克服此局限,我们提出了 UniMoGen,一种新颖的、基于 UNet 架构的扩散模型,专为骨架无关的动作生成而设计。UniMoGen 可训练来自不同角色(如人类和动物)的动作数据,且无需预定义最大关节数量。通过仅动态处理每个角色必需的关节,我们的模型同时实现了骨架无关性和计算高效性。
UniMoGen 的关键特性包括:通过风格和轨迹输入实现可控性,以及从过往帧延续动作的能力。我们在 100style 数据集上验证了 UniMoGen 的有效性,其在多样化角色动作生成方面优于最先进的方法。此外,当在使用了不同骨骼的 100style 和 LAFAN1 数据集上联合训练时,UniMoGen 在两种骨骼上都实现了高性能和更高的效率。
这些结果突显了 UniMoGen 的潜力:通过为广泛的角色动画提供灵活、高效且可控的解决方案,推动动作生成技术的进步。
AMD: Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
根据文本描述生成逼真的人体运动序列是一项具有挑战性的任务,需要同时捕捉自然语言和人体运动的丰富表现力。尽管扩散模型的最新进展推动了人体运动合成领域的重大突破,但现有方法在处理描述复杂或长时间运动的文本输入时仍存在困难。本文提出可适应运动扩散(AMD)模型,通过利用大语言模型(LLM)将输入文本解析为一系列与目标运动相对应的简洁可解释的解剖学脚本。该过程充分发挥了LLM为复杂运动合成提供解剖学指导的能力。我们设计了一种双分支融合方案,在反向扩散过程中平衡输入文本与解剖学脚本的影响,自适应地确保合成运动的语义保真度与多样性。我们的方法能有效处理包含复杂或长序列运动描述的文本,而现有方法在此类场景中往往表现不佳。在包含相对复杂运动的数据集(如CLCD1和CLCD2)上的实验表明,AMD模型显著优于现有最先进方法。
Flame: Free-form language-based motion synthesis & editing
Human Motion Diffusion as a Generative Prior
最近研究表明,去噪扩散模型在人体运动生成(包括文本驱动运动生成)方面具有巨大潜力。然而,现有方法受限于标注运动数据匮乏、仅关注单人动作生成以及缺乏精细控制能力。本文基于扩散先验提出三种组合模式:序列组合、并行组合与模型组合。通过序列组合,我们解决了长序列生成难题,提出DoubleTake推理方法——仅通过短片段训练的扩散先验,即可生成由提示区间及其过渡组成的长动画序列。借助并行组合,我们在双人生成任务上取得突破性进展:基于两个固定先验及少量双人训练样本,我们开发了轻量级通信模块ComMDM,用于协调两个生成动作间的交互。通过模型组合,我们首先训练独立先验模型以生成符合指定关节约束的动作,进而提出DiffusionBlending插值机制,有效融合多个此类模型,实现灵活高效的关节级与轨迹级精细控制与编辑。我们采用现成的运动扩散模型对三种组合方法进行评估,并将生成结果与针对特定任务专门训练的模型进行对比验证。
Text-driven Human Motion Generation with Motion Masked Diffusion Model
文本驱动的人体运动生成是一项多模态任务,旨在根据自然语言描述合成人体运动序列。该任务要求模型在多样化条件输入下满足文本描述,同时生成合理逼真且具有高度多样性的人类动作。基于扩散模型的方法在生成的多样性和多模态性方面表现突出,但与在推理前训练运动编码器的自回归方法相比,扩散方法在拟合人体运动特征分布方面存在不足,导致FID评分不理想。一个重要发现是,扩散模型缺乏通过上下文推理学习时空语义间运动关系的能力。为解决这一问题,本文提出运动掩码扩散模型(MMDM),通过新颖的人体运动掩码机制显式增强扩散模型从运动序列上下文关节中学习时空关系的能力。此外,针对人体运动数据具有动态时间特征和空间结构的特点,我们设计了两种掩码建模策略:时间帧掩码和身体部位掩码。在训练过程中,MMDM会对运动嵌入空间中的特定标记进行掩码处理,随后设计的扩散解码器在每个采样步骤中学习从掩码嵌入还原完整运动序列,使模型能够从不完整表征中恢复完整序列。在HumanML3D和KIT-ML数据集上的实验表明,我们的掩码策略能有效平衡运动质量与文本-运动一致性。
ReMoDiffuse: RetrievalAugmented Motion Diffusion Model
三维人体运动生成在创意产业中具有关键作用。基于生成模型与领域知识的文本驱动运动生成技术近年来取得显著进展,在常规动作捕捉方面成效卓著。然而,面对更复杂的多样化动作时,现有方法仍表现欠佳。本研究提出ReMoDiffuse——一种融合检索机制的扩散模型运动生成框架,通过优化去噪过程提升生成效果。ReMoDiffuse通过三项核心设计增强文本驱动运动生成的普适性与多样性:1)混合检索机制从语义相似度与运动学特征相似度双重维度在数据库中寻找合适参考;2)语义调制变换器选择性吸收检索知识,自适应调整检索样本与目标运动序列间的差异;3)条件混合机制在推理阶段更高效利用检索数据库,克服无分类器引导中的尺度敏感问题。大量实验表明,ReMoDiffuse在文本-运动一致性与运动质量之间取得卓越平衡,尤其在多样化运动生成任务上超越现有最优方法。
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
本研究提出MotionLCM,将可控运动生成提升至实时水平。现有文本条件运动生成中的时空控制方法存在显著运行效率低下的问题。为解决此问题,我们基于运动潜在扩散模型,首次提出用于运动生成的运动潜在一致性模型(MotionLCM)。通过采用单步(或少步)推理,我们进一步提升了运动潜在扩散模型在运动生成中的运行效率。为确保有效可控性,我们在MotionLCM的潜在空间中引入运动ControlNet,使原始运动空间中的显式控制信号(即初始运动)能够为训练过程提供额外监督。应用这些技术后,我们的方法能够实时生成符合文本和控制信号的人类运动。实验结果表明,MotionLCM在保持实时运行效率的同时,展现出卓越的生成与控制能力。
ReAlign: Bilingual Text-to-Motion Generation via Step-Aware Reward-Guided Alignment
双语文本到运动生成通过双语文本输入合成3D人体运动,在游戏、影视和机器人等跨语言应用领域具有巨大潜力。然而,该任务面临两大关键挑战:缺乏双语运动-语言数据集,以及扩散模型中文本与运动分布的不对齐问题,导致生成运动存在语义不一致或质量低下的情况。为应对这些挑战,我们提出了BiHumanML3D双语人体运动数据集,为双语文本到运动生成模型建立了重要基准。此外,我们开发了双语运动扩散模型(BiMD),通过跨语言对齐表征捕捉语义信息,实现统一的双语建模。在此基础上,我们提出了奖励引导的采样对齐方法(ReAlign),包含用于评估采样过程中对齐质量的步态感知奖励模型,以及引导扩散过程向最优对齐分布演进的奖励引导策略。该奖励模型融合步态感知标记,结合保证语义一致性的文本对齐模块和提升真实性的运动对齐模块,通过在每一步优化噪声运动,平衡概率密度与对齐效果。实验表明,相较于现有最优方法,我们的方法在文本-运动对齐质量和运动生成质量上均有显著提升。项目主页:https://wengwanjiang.github.io/ReAlign-page/。
Absolute Coordinates Make Motion Generation Easy
当前最先进的文本到动作生成模型依赖于由 HumanML3D 推广的运动学感知、局部相对动作表示方法。该方法通过相对于骨盆和前一帧对动作进行编码,并带有内置冗余。虽然这种设计简化了早期生成模型的训练,但它却给扩散模型带来了关键限制,并阻碍了其在下游任务中的应用。
在这项工作中,我们重新审视了动作表示方法,并为文本到动作生成提出了一种经过彻底简化且被长期弃用的替代方案:全局空间中的绝对关节坐标。通过对设计选择的系统分析,我们发现,即使仅使用简单的 Transformer 主干网络且无需辅助的运动学感知损失函数,这种表述方式也能实现显著更高的动作保真度、改进的文本对齐能力以及强大的可扩展性。
此外,我们的方法天然支持下游任务,例如文本驱动的动作控制以及时间/空间编辑,无需额外的任务特定工程改造,也无需根据控制信号进行成本高昂的分类器引导生成。
最后,我们展示了其良好的泛化能力,能够直接从文本生成运动中的 SMPL-H 网格顶点,为未来的研究和动作相关应用奠定了坚实基础。
Seamless Human Motion Composition with Blended Positional Encodings
条件式人体运动生成是一个重要的研究课题,在虚拟现实、游戏和机器人技术等领域具有广泛应用。现有研究多集中于基于文本、音乐或场景引导的运动生成,但这些方法通常只能生成短时孤立的运动片段。本文致力于解决根据连续变化的文本描述生成长时间连续运动序列的问题。为此,我们提出了FlowMDM——首个基于扩散模型的、无需后处理或冗余去噪步骤即可生成无缝人体运动组合(HMC)的方法。我们创新性地提出了混合位置编码技术,在去噪链中同时利用绝对位置编码和相对位置编码。具体而言,绝对编码阶段重建全局运动一致性,而相对编码阶段则构建平滑逼真的动作过渡。在Babel和HumanML3D数据集上的实验表明,我们的方法在动作准确性、真实感和流畅度方面均达到了最先进水平。得益于其以动作为核心的交叉注意力机制,FlowMDM在仅使用单个描述训练的情况下,仍能有效应对推理时多变的文本输入。最后,针对现有HMC评估指标的局限性,我们提出了两个新指标:峰值加加速度和加加速度曲线下面积,用以检测运动中的突变转换。
FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
随着扩散模型的出现,文本驱动动作生成已取得显著进展。然而,现有方法在生成符合细粒度描述的复杂动作序列时仍存在困难——这些描述需要描绘精确的时空动作细节。这种精细可控性的缺失限制了动作生成技术向更广泛受众的推广。为解决这些挑战,我们提出FineMoGen,这是一个基于扩散模型的运动生成与编辑框架,能够根据用户指令进行时空组合,生成细粒度动作。具体而言,FineMoGen在扩散模型基础上构建了名为时空混合注意力(SAMI)的新型Transformer架构。SAMI从两个角度优化全局注意力模板的生成:1)显式建模时空组合的约束条件;2)利用稀疏激活的专家混合机制自适应提取细粒度特征。为促进这一新型细粒度动作生成任务的大规模研究,我们构建了HuMMan-MoGen数据集,包含2,968个视频和102,336条细粒度时空描述。大量实验证明,FineMoGen在动作生成质量上显著优于现有最优方法。值得注意的是,借助现代大语言模型(LLM),FineMoGen进一步实现了零样本动作编辑能力,能够通过细粒度指令精准操控动作序列。项目页面:https://mingyuan-zhang.github.io/projects/FineMoGen.html
Fg-T2M: Fine-Grained Text-Driven Human Motion Generation via Diffusion Model
基于文本的人体动作生成在计算机视觉领域兼具重要性与挑战性。然而,现有方法仅能生成确定性或不够精确的动作序列,难以有效控制时空关系以契合给定文本描述。本研究提出一种细粒度条件生成方法,可依据精准文本描述生成高质量人体运动序列。我们的方案包含两个核心组件:1)语言结构辅助模块——通过构建精准完整的语言特征以充分挖掘文本信息;2)上下文感知渐进推理模块——借助浅层与深层图神经网络分别学习局部与全局语义语言学特征,实现多步推理。实验表明,本方法在HumanML3D和KIT测试集上超越现有文本驱动动作生成方法,并能根据文本条件生成视觉表现更优的运动序列。
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
基于文本引导的人体动作生成技术因其在动画与机器人领域的广泛应用而备受关注。近年来,扩散模型在动作生成中的应用显著提升了生成动作的质量。然而,现有方法受限于对较小规模动作捕捉数据的依赖,导致在面对多样化真实场景提示时表现不佳。本文提出Make-An-Animation这一文本条件化人体动作生成模型,通过从大规模图文数据集中学习更丰富的姿态与提示信息,实现了性能上的重大突破。
该模型采用两阶段训练策略:首先利用从图文数据集中提取的(文本,静态伪姿态)配对数据进行大规模预训练,随后在动作捕捉数据上通过新增时序建模层进行微调。与现有基于扩散模型的动作生成方法不同,Make-An-Animation采用类似最新文生视频模型的UNet架构。在动作真实性与文本契合度的人工评估中,本模型达到了文本驱动动作生成领域的最先进水平。生成样本可访问https://azadis.github.io/make-an-animation 查看。
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
得益于扩散模型强大的生成能力,人体动作生成领域近年来发展迅速。现有的基于扩散模型的方法采用了各不相同的网络架构和训练策略,各个组件设计的具体影响尚不明确。此外,迭代去噪过程需要消耗大量计算资源,这对虚拟角色和人形机器人等实时应用场景而言难以承受。为此,我们首先对网络架构、训练策略及推理过程进行了全面研究,基于深入分析为高效高质量的人体动作生成量身优化每个组件。尽管优化后的模型表现出色,但仍存在脚部滑动现象——这是基于扩散的解决方案中普遍存在的问题。为消除脚部滑动,我们通过识别足地接触关系并在去噪过程中修正脚部运动,将这些精心设计的组件有机整合,提出了稳健高效的人体动作生成框架StableMoFusion。大量实验结果表明,我们的StableMoFusion在性能上优于当前最先进方法。项目页面:https://h-y1heng.github.io/StableMoFusionpage/。
EMDM: Efficient Motion Diffusion Model for Fast and High-Quality Motion Generation
本文提出高效运动扩散模型(EMDM),旨在实现快速、高质量的人体运动生成。当前最先进的生成式扩散模型虽能产生令人印象深刻的结果,但在保持质量的同时难以实现快速生成。一方面,诸如运动潜在扩散等方法为提升效率在潜在空间中进行扩散,但学习此类潜在空间本身需要大量计算资源;另一方面,若直接采用增大采样步长的方式(如DDIM)加速生成,则因难以逼近复杂的去噪分布往往导致质量下降。为解决这些问题,我们提出的EMDM模型能够在扩散模型的多步采样过程中有效捕捉复杂分布,从而大幅减少采样步骤并显著加速生成过程。该模型通过条件去噪扩散GAN技术,在任意(可能更大)步长条件下根据控制信号捕捉多模态数据分布,实现高保真度、多样化的少步数运动采样。为减少不良运动伪影,我们在网络学习过程中引入几何约束损失。实验表明,EMDM可实现实时运动生成,在保证高质量运动生成的同时,较现有方法显著提升了运动扩散模型的效率。研究成果发表后代码将开源发布。
Motion Mamba: Efficient and Long Sequence Motion Generation
摘要:人体运动生成是生成式计算机视觉领域的重要研究方向,然而实现长序列且高效的运动生成仍面临挑战。近年来,状态空间模型(SSMs)尤其是Mamba的进展,通过硬件感知的高效设计在长序列建模中展现出巨大潜力,这为构建运动生成模型指明了重要方向。然而,由于缺乏针对运动序列建模的专用架构,将SSMs应用于运动生成仍存在障碍。为此,我们提出Motion Mamba——一种简单高效的方法,率先构建了基于SSMs的运动生成模型。具体而言,我们设计了分层时序Mamba(HTM)模块,通过在对称U-Net架构中集成不同数量的独立SSM模块来处理时序数据,以保持帧间运动一致性;同时开发了双向空间Mamba(BSM)模块,通过双向处理潜在姿态来增强时序帧内的运动生成精度。在HumanML3D和KIT-ML数据集上的实验表明,本方法相较于现有最佳扩散模型方法,FID指标提升最高达50%,推理速度提升达4倍,充分证明了其在高质量长序列运动建模与实时人体运动生成方面的强大能力。
状态空间模型SSN和Mamba
首先,需要区分两个概念:经典控制论中的状态空间模型 和 深度学习新模型(如Mamba)所指的状态空间模型。它们思想同源,但设计和目标不同。
1. 经典状态空间模型(控制论/时序分析)
在传统意义上,SSM是一个用于描述动态系统的数学模型,它由两个方程组成:
- 状态方程(过程模型):描述系统内部状态如何随时间演变。
x(t) = A * x(t-1) + B * u(t) + w(t) - 观测方程(测量模型):描述我们如何从外部观测到系统的状态。
y(t) = C * x(t) + D * u(t) + v(t)
其中:
x(t):系统在时刻t的内部状态(通常无法直接观测)。u(t):在时刻t的输入/控制信号。y(t):在时刻t的观测/输出信号。A:状态转移矩阵,描述状态如何自行演变。B:输入矩阵,描述输入如何影响状态。C:输出矩阵,描述状态如何被我们观测到。D:直通矩阵,描述输入如何直接影响输出(通常可忽略)。w(t),v(t):过程噪声和观测噪声。
应用场景:卡尔曼滤波、目标跟踪、经济预测、机器人导航等。其核心思想是通过嘈杂的观测数据,来估计一个动态系统的内部真实状态。
2. 深度学习中的状态空间模型(如Mamba, S4)
您论文中提到的SSM,特指的是一类近年来在深度学习领域复兴的序列模型。它们从经典SSM中汲取了核心思想,但将其重新设计为适用于通用序列建模(如自然语言、音频、运动)的可训练神经网络模块。
核心思想:
将这些模型看作一个将输入序列 u(t) 映射到输出序列 y(t) 的系统。它们通过一个隐含状态 x(t) 来记忆和整合过去的信息。
关键特点与优势:
-
连续系统离散化:
- 经典的SSM是定义在连续时间上的。为了处理离散的序列数据(如文本、运动帧),需要将其离散化。这会引入两个关键参数
∆(步长)和Ā, B̄(离散化后的状态矩阵)。 - Mamba的贡献之一是让
∆和B, C成为输入依赖的,使得模型能够根据当前输入动态调整行为,从而更关注相关信息。
- 经典的SSM是定义在连续时间上的。为了处理离散的序列数据(如文本、运动帧),需要将其离散化。这会引入两个关键参数
-
循环模式 vs. 卷积模式:
- 循环模式:按照时间步一步步计算,状态
x(t)依赖于x(t-1)。这非常高效(固定计算量/步),类似于RNN,但无法并行训练。 - 卷积模式:通过数学推导,可以将整个序列的输出
y表示为输入u和一个卷积核K的卷积结果。这允许高效并行训练,但卷积核长度受限于训练长度,无法直接推广到更长的序列。
- 循环模式:按照时间步一步步计算,状态
-
核心优势:
- 长序列建模:由于隐含状态的存在,理论上它可以记住非常长的上下文信息,避免了Transformer在长序列上的二次复杂度问题。
- 计算效率:无论是循环模式的高效推理,还是卷积模式的高效训练,SSM在计算和内存上都比Transformer更轻量。
- 硬件感知设计(Mamba的核心):Mamba模型通过其选择性扫描机制,避免了 materializing 巨大的中间矩阵,实现了比其前身(S4模型)更快的速度,并保持了处理长序列的能力。
总结对比
| 特性 | 经典状态空间模型 | 深度学习状态空间模型(如Mamba) |
|---|---|---|
| 目标 | 估计动态系统的内部状态 | 通用的序列建模与表示学习 |
| 应用领域 | 控制、滤波、预测 | NLP、语音、视频、运动生成 |
| 参数 | 通常固定,由系统决定 | 可训练的神经网络参数 |
| 核心机制 | 卡尔曼滤波/平滑 | 离散化 + 并行化卷积 + 硬件优化 |
| 与Transformer关系 | 无关 | 替代/补充Transformer,解决其长序列、低效率问题 |
简单来说,在论文语境中:
状态空间模型(SSM)是一种新兴的深度学习架构,它通过一个可学习的、不断演变的“内部状态”来理解和处理序列信息。这种设计让它特别擅长处理像长序列运动数据这样的任务,因为它既能捕捉长距离依赖,又比传统的Transformer模型更高效。Mamba则是目前该系列中最先进的模型之一。
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
摘要:本文提出多动作离散扩散模型(M2D2M),这是一种利用离散扩散模型优势、从多动作文本描述生成人体运动的新方法。该方法巧妙解决了生成多动作序列的挑战,能确保动作间流畅过渡及系列动作的连贯性。M2D2M的核心优势在于其离散扩散模型中的动态转移概率机制——该机制根据运动标记的邻近性自适应调整转移概率,有效促进不同模态间的混合。结合包含独立去噪与联合去噪的两阶段采样策略,M2D2M仅需使用单动作生成训练的模型,即可有效生成长期、平滑且上下文连贯的人体运动序列。大量实验表明,M2D2M在文本描述生成运动任务上超越了当前最先进的基准模型,其在语言语义解析与动态逼真运动生成方面的效能得到了充分验证。
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
本文致力于解决长期3D人体运动生成这一挑战性难题,重点研究如何从多语句(即段落)输入中生成平滑衔接的连续动作序列。现有的长期运动生成方法多基于循环神经网络架构,以前序生成的运动片段作为后续输入。然而该方法存在双重缺陷:1)依赖成本高昂的序列化数据集;2)逐步生成的运动片段间存在失真间隙。为应对这些问题,我们提出了一种简洁高效的T2LM框架——无需序列化数据即可训练的连续长期生成系统。该框架包含两个核心组件:训练用于将运动压缩为潜在向量序列的一维卷积VQVAE,以及基于Transformer的文本编码器(可根据输入文本预测潜在序列)。在推理阶段,语句序列被转换为连续的潜在向量流,经由VQVAE解码器重构为运动序列;通过采用具有局部时间感受野的一维卷积,有效避免了训练与生成序列间的时间不一致性。这种对VQ-VAE的简易约束使其仅需短序列训练即可实现更平滑的过渡效果。T2LM不仅显著优于现有长期生成模型并突破序列数据依赖的局限,在单动作生成任务上也达到了与当前最优模型相媲美的性能。
AttT2M:Text-Driven Human Motion Generation with Multi-Perspective Attention Mechanism
基于文本描述生成三维人体运动一直是近年来的研究热点。该任务要求生成的运动兼具多样性、自然性,并符合文本描述。由于人体运动固有的复杂时空特性,以及文本与运动间跨模态关系学习的难度,文本驱动运动生成仍是一个具有挑战性的问题。为解决这些难题,我们提出AttT2M——一种融合多视角注意力机制的双阶段方法:身体部位注意力与全局-局部运动-文本注意力。前者从运动嵌入视角出发,通过在VQ-VAE中引入身体部位时空编码器,学习更具表现力的离散潜在空间;后者基于跨模态视角,用于学习句子层级和词汇层级的运动-文本跨模态关联。最终通过生成式变换器实现文本驱动运动的合成。在HumanML3D和KIT-ML数据集上的大量实验表明,本方法在定性与定量评估上均优于当前最优成果,实现了细粒度合成和动作到运动的精准生成。代码详见:https://github.com/ZcyMonkey/AttT2M。
自回归模型通过施加因果约束,在序列依赖关系建模方面表现出色,但其单向特性导致难以捕捉复杂的双向模式。相比之下,基于掩码的模型能利用双向上下文实现更丰富的依赖关系建模,但其预测过程常假设标记相互独立,这削弱了对序列依赖关系的刻画能力。此外,通过掩码或吸收操作对序列进行的破坏可能引入不自然的失真,增加学习难度。为应对这些挑战,我们提出双向自回归扩散模型(BAD),这一创新方法融合了自回归与基于掩码的生成模型优势。BAD采用基于排列的序列破坏技术,在通过随机排序保持因果依赖的同时维护自然序列结构,从而有效捕捉序列与双向关系。综合实验表明,BAD在文本到动作生成任务中优于自回归和基于掩码的模型,为序列建模提供了创新的预训练策略。BAD代码库已发布于https://github.com/RohollahHS/BAD。
MMM: Generative Masked Motion Model
基于扩散模型与自回归模型的文本驱动动作生成技术近期取得显著进展,但其性能往往难以兼顾实时性、高保真度与动作可编辑性。为突破这一局限,我们提出MMM——一种基于掩码动作模型的全新简易动作生成范式。该框架包含两个核心组件:(1)动作分词器:将三维人体动作转换为潜空间中的离散标记序列;(2)条件掩码动作变换器:基于预计算文本标记,学习预测随机掩码的动作标记。通过全方位感知动作与文本标记的关联,MMM显式捕获了动作标记间的内在依赖性及动作-文本标记间的语义映射关系。在推理阶段,这种机制支持并行迭代解码生成与细粒度文本描述高度契合的多个动作标记,从而同步实现高保真与高速率的动作生成。此外,MMM具备天然的动作编辑能力:只需在待编辑位置设置掩码标记,模型即可自动填充内容,并确保编辑与非编辑片段间的平滑过渡。在HumanML3D和KIT-ML数据集上的大量实验表明,MMM生成的动作质量超越当前主流方法(其FID分数分别达到0.08和0.429),同时支持身体局部编辑、动作插帧及长序列生成等高级功能。在单块中端GPU上,MMM的运算速度比可编辑动作扩散模型快两个数量级。项目页面详见:https://exitudio.github.io/MMM-page/
Priority-Centric Human Motion Generation in Discrete Latent Space
文本驱动动作生成是一项极具挑战的任务,其目标是生成既符合输入文本描述,又遵循人体运动规律与物理定律的人类动作。尽管扩散模型已取得显著进展,但其在离散空间中的应用仍待深入探索。现有方法往往忽视不同动作的重要性差异,对其进行均等处理。需要认识到的是,并非所有动作都与特定文本描述具有同等关联度——某些更具显著性和信息量的动作应在生成过程中被优先考虑。为此,我们提出了以优先级为核心的动作离散扩散模型(M2DM):该模型采用基于Transformer的VQ-VAE架构,通过全局自注意力机制与正则化项构建紧凑的离散动作表示,有效防止代码坍塌;同时设计了一种创新的运动离散扩散模型,通过分析动作令牌在整体序列中的重要性来制定噪声调度策略。这种方法在逆向扩散过程中保留最显著的动作特征,从而生成语义更丰富、多样性更强的动作序列。此外,我们融合文本与视觉指标提出两种动作令牌重要性评估策略。在HumanML3D和KIT-ML数据集上的综合实验表明,本模型在生成真实性与多样性方面均超越现有技术,尤其对于复杂文本描述场景具有显著优势。
AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond
大型语言模型(LLM)在统一几乎所有自然语言处理任务方面展现出卓越的涌现能力。然而在与人体运动相关的研究领域,学者们仍在为每个任务开发孤立模型。受InstructGPT[16]与Gato[27]通用智能理念的启发,我们提出AvatarGPT——一个集运动理解、规划、生成以及中间帧合成等任务于一体的全能框架。该框架将各类任务视为基于共享大语言模型进行指令微调的不同变体,所有任务通过语言这一通用接口无缝衔接,形成闭环系统。
具体实现包含三个关键步骤:首先将人体运动序列编码为离散标记,作为大语言模型的扩展词汇表;随后开发无监督流程,从真实场景视频中自动生成人体动作序列的自然语言描述;最终进行多任务联合训练。大量实验表明,AvatarGPT在底层任务上达到顶尖水平,在高层任务中亦展现出良好性能,验证了所提一体化框架的有效性。更值得注意的是,AvatarGPT首次通过闭环系统内任务的迭代遍历,实现了无限长序列运动合成的理论突破。项目主页:https://zixiangzhou916.github.io/AvatarGPT/
MotionGPT: Human Motion as a Foreign Language
尽管预训练大语言模型不断发展,但如何构建一个能够统一处理语言与运动等多模态数据的模型至今仍是一个尚未探索的挑战性课题。值得庆幸的是,人类运动与人类语言具有相似的语义耦合特性,常被视为一种身体语言形式。通过将语言数据与大规模运动模型相融合,能够提升运动相关任务性能的运动-语言预训练技术已成为可能。受此启发,我们提出MotionGPT——一个统一、通用且用户友好的运动语言模型,用于处理多种运动相关任务。具体而言,我们采用离散向量量化技术将人体运动转化为运动标记,其生成过程类似于文本标记的生成。基于该"运动词汇表",我们以统一的方式对运动和文本进行语言建模,将人体运动视为特殊形式的语言。此外受提示学习启发,我们采用运动-语言混合数据对MotionGPT进行预训练,并基于提示问答任务进行微调。大量实验表明,MotionGPT在文本驱动运动生成、运动描述、运动预测及运动补全等多个任务上均达到了领先水平。
Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation
本文提出Action-GPT——一种即插即用框架,旨在将大语言模型(LLM)融入基于文本的动作生成模型。当前运动捕捉数据集中的动作短语通常只包含最精简的核心信息。通过为大语言模型精心设计提示模板,我们能够生成更丰富、更细粒度的动作描述。研究证明,使用这些详细描述替代原始动作短语可有效提升文本空间与动作空间的对齐效果。我们提出了一种通用方法,可同时兼容随机性(如基于VAE)与确定性(如MotionCLIP)的文生动作模型,并支持使用多个文本描述进行生成。实验结果表明:(1)合成动作质量在定性与定量评估中均有显著提升;(2)使用多个LLM生成描述具有增益效应;(3)提示函数设计合理有效;(4)所提方法具备零样本生成能力。相关代码、预训练模型及示例视频将发布于https://actiongpt.github.io。
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting
本文研究动作条件引导下的人体运动序列生成问题。现有研究主要分为两类:基于观测历史运动的预测模型,或仅依赖动作标签与时长的生成模型。与此不同,我们实现了任意观测长度(包括零观测)条件下的运动生成。针对这一广义问题,我们提出PoseGPT——一种基于自回归变换器的模型,其内部通过量化潜在序列对人体运动进行压缩编码。我们首先通过自编码器将人体运动映射至离散空间的潜在索引序列,并实现反向重构。受生成式预训练变换器(GPT)启发,我们训练了适用于该离散空间的类GPT模型进行索引预测,使PoseGPT能够输出未来运动的概率分布,且无需依赖历史运动观测。潜在序列的离散压缩特性使类GPT模型能聚焦长期运动特征,有效消除输入信号中的低频冗余。离散索引预测还规避了连续值回归中常见的“平均姿态”预测陷阱——因为离散目标的平均值本身并非有效目标。实验结果表明,我们所提方法在HumanAct12(标准小规模数据集)、BABEL(新兴大规模运动捕捉数据集)及GRAB(人物交互数据集)上均达到了最先进水平。
Incorporating Physics Principles for Precise Human Motion Prediction
众多现实应用都依赖于基于历史观察数据对三维人体运动进行精确预测。虽然现有方法已取得显著进展,但其在亚秒级时间跨度内的预测误差仍可能达到数厘米级别。本文提出,要实现精确的人体运动预测,必须深入理解支配人体运动的基础物理原理。我们创新性地引入了PhysMoP——一个融合物理原理的人体运动预测框架。该框架通过求解欧拉-拉格朗日方程(一组描述物理运动规律的常微分方程)来估计下一帧的人体姿态。为缓解随时间累积的固有误差问题,PhysMoP采用数据驱动模型,并通过融合模块对基于物理的预测进行迭代修正。大量实验表明,PhysMoP在亚秒级预测区间内显著优于现有方法。例如在80毫秒的预测区间上,PhysMoP相较传统数据驱动方法的误差降低幅度达到10倍以上。
PIMNet: Physics-infused Neural Network for Human Motion Prediction
摘要:人体运动预测(HMP)旨在根据历史姿态序列预测未来人体姿态序列。近年来,该技术在计算机视觉和机器人领域备受关注,因其能帮助机器理解人类行为、规划目标动作并优化交互策略。现有HMP方法主要基于纯物理模型或统计模型,但二者均存在局限性:物理模型计算复杂且易产生误差,统计方法则需要大量数据且缺乏物理一致性。为克服这些缺陷,我们提出一种物理融合神经网络(PIMNet),将物理模型与统计方法相结合。我们首先通过基于物理的人体动力学模型计算每个姿态的接触力与关节力矩,随后将其输入编码器-解码器机器学习架构中以预测未来运动。该方法使PIMNet同时具备计算高效性与物理一致性。在Human 3.6M数据集上的大量实验表明,所提出的PIMNet在短期和长期预测中均能准确预测人体运动。即使采用基础LSTM作为机器学习模型,其预测精度仍达到或超越了最先进水平。
PhysDiff: Physics-Guided Human Motion Diffusion Model
去噪扩散模型在生成多样且逼真的人体动作方面前景广阔。然而,现有动作扩散模型在生成过程中普遍忽略物理规律,常产生存在明显物理异常的动作——如身体漂浮、脚步滑动、地面穿透等问题。这不仅严重影响生成动作的质量,更限制了其在实际场景中的应用。为解决这一难题,我们提出了一种新型物理引导动作扩散模型(PhysDiff),将物理约束融入扩散过程。具体而言,我们设计了一个基于物理的动作投影模块,通过物理仿真器中的动作模拟,将每个扩散步骤去噪后的动作投影至符合物理规律的状态。经物理修正的动作将在后续扩散步骤中引导去噪过程。从机理上看,这种物理机制的引入能持续将动作迭代牵引至物理合理的空间,这是传统后处理方法无法实现的。基于大规模人体动作数据集的实验表明,我们的方法在动作质量上达到最优水平,并将物理合理性全面提升(所有数据集提升幅度>78%)。
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
对关节空间进行精确建模是一项关键任务,它既能实现真实姿态的恢复与生成,也始终是公认的难题。为此,我们提出了神经黎曼距离场(NRDF)——一种数据驱动的先验模型,通过高维四元数积空间中的神经场零水平集来表征合理关节空间。为仅基于正样本训练NRDF,我们提出一种新型采样算法,确保测地距离遵循目标分布,从而构建理论严密的距离场学习范式。继而设计投影算法,通过自适应步长黎曼优化器将任意随机姿态映射至水平集,并始终遵循关节旋转构成的产品流形。NRDF可通过反向传播计算黎曼梯度,通过数学类比与新兴生成模型黎曼流匹配建立理论关联。我们在姿态生成、图像姿态估计和逆运动学求解等多类下游任务中,对NRDF与其他姿态先验模型展开系统评估,结果凸显了NRDF的卓越性能。除人体姿态外,NRDF的通用性更延伸至手部与动物关节建模,因其能有效表征任意关节系统。
Riemannian Motion Generation: A Unified Framework for Human Motion Representation and Generation via Riemannian Flow Matching
论文信息: arXiv:2603.15016v1 [cs.CV], 16 Mar 2026, Fangran Miao et al., The Hong Kong Polytechnic University / Southern University of Science and Technology
Link: arXiv:2603.15016
一、核心问题
1.1 研究背景
人体运动生成的几何表示问题:
现有方法大多在欧几里得空间中学习运动生成,但有效的运动遵循结构化的非欧几何。
现有表示方法的问题:
| 方法 | 表示格式 | 维度 | 问题 |
|---|---|---|---|
| HumanML3D | T + R_ori + R_joint + P + dT + dR_ori + dR_joint + dP + 足部接触 | \(12J-1\) | 冗余编码,在欧氏空间训练 |
| MotionStreamer | T + R_ori + R_joint + P + dT + dR_ori + dR_joint | \(12J+8\) | 冗余,需要后处理归一化 |
| DART | T + R_ori + R_joint + P + dT + dR_ori + dR_joint | \(12J+12\) | 冗余 |
| HY-Motion | T + R_ori + R_joint | \(9J+3\) | 较紧凑 |
| RMG (本文) | T + R | \(4J+3\) | 最紧凑,流形感知 |
其中:
- \(T\): 全局平移 (Translation)
- \(R_{ori}\): 全局朝向 (Orientation)
- \(R_{joint}\): 每关节旋转 (Joint Rotation)
- \(P\): 关节位置 (Position)
- \(d\cdot\): 时间差分 (Temporal Difference)
核心观察:
- 对于 \(J\) 个关节的骨骼,关节姿态的内在自由度约为 \(3J\)
- 常见编码方式串联多个相关视图,占据更高维的 ambient 空间
- 模型在 \(\mathbb{R}^D\) 中训练,但物理有效的运动位于更低维的流形上
1.2 核心问题
如何在一个统一的几何感知框架中表示和生成人体运动?
具体来说:
- 能否将运动分解为多个低维因子,每个因子有自己的自然几何?
- 能否在乘积流形上直接学习生成动力学,而非在欧氏空间?
- 能否实现尺度无关的表示,无需额外的数据归一化?
1.3 本文方法
论文提出了 Riemannian Motion Generation (RMG),一个基于黎曼流形匹配的统一运动生成框架。
核心思想:
- 运动分解:将运动分解为多个流形因子(平移、旋转、姿态)
- 黎曼流形匹配:在乘积流形上学习动力学,使用黎曼流匹配 (Riemannian Flow Matching)
- 测地线插值:使用测地线进行插值和采样,保持流形约束
关键创新:
- 第一个将黎曼流匹配扩展到大规模数据集和高容量架构的工作
- 紧凑的 T + R 表示(平移 + 旋转),无需额外的时间差分或姿态因子
- 在 HumanML3D 上达到 SOTA FID (0.043),在 MotionMillion 上超越所有基线
二、核心贡献
-
Riemannian Motion Generation (RMG) 框架
- 在乘积流形上建模运动
- 使用黎曼流匹配学习动力学
- 几何一致性内置到表示和生成过程中
-
紧凑的黎曼表示
- \(\mathcal{M}_{RMG} = \mathbb{R}^3 \times (S^3)^J\)
- 仅需 \(4J+3\) 维(最紧凑)
- 尺度无关,无需数据归一化
-
大规模扩展验证
- 第一个证明黎曼流匹配可扩展到大规模数据集的工作
- 在 MotionMillion (100 万动作片段) 上验证有效性
-
SOTA 性能
- HumanML3D: FID = 0.043 (新 SOTA)
- MotionMillion: FID = 5.6, R@1 = 0.86
三、大致方法
3.1 框架概述
flowchart TB
subgraph Representation["运动表示"]
T["全局平移 T: R³"]
R["全局朝向 + 关节旋转 R: S³ᴶ"]
manifold["乘积流形 M = R³ × S³ᴶ"]
end
subgraph Prior["先验分布"]
prior["黎曼高斯分布 RN(μ, Σ)"]
ref["参考点:零平移 + 单位旋转"]
end
subgraph RFM["黎曼流匹配"]
geo["测地线插值 xt = Exp_x0(t·Log_x0(x1))"]
vel["目标速度 vt = Log_xt(x1)/(1-t)"]
proj["投影到切空间 Π_TxtM"]
end
subgraph Network["神经网络"]
dit["Diffusion Transformer"]
text["Qwen 文本编码"]
end
subgraph Inference["推理"]
sample["x0 ~ p0"]
ode["黎曼 ODE 积分 dxt/dt = Π_TxtM vθ(xt, t)"]
out["生成运动 x1"]
end
T --> manifold
R --> manifold
manifold --> Prior
Prior --> RFM
RFM --> Network
Network --> Inference
Inference --> out
style Representation fill:#e1f5fe
style Prior fill:#fff3e0
style RFM fill:#e8f5e9
style Network fill:#fce4ec
style Inference fill:#f3e5f5
3.2 运动表示与流形
因子分解:
RMG 将每个运动帧分解为以下因子,每个因子位于其自然流形上:
| 因子 | 流形 | 维度 | 说明 |
|---|---|---|---|
| 全局平移 \(T\) | \(\mathbb{R}^3\) | 3 | 根关节(骨盆)的全局轨迹 |
| 全局朝向 \(R_{ori}\) | \(S^3\) (单位四元数) | 4 | 骨骼的全局旋转 |
| 关节旋转 \(R_{joint}\) | \(S^3\) (单位四元数) | \(4(J-1)\) | 每关节的局部旋转 |
| 局部姿态 \(P\) (可选) | Kendall 预形状空间 \(S^{3J}\) | \(3J-4\) | 帧内骨骼配置 |
紧凑表示(通过消融研究验证):
RMG 采用最紧凑的 T + R 表示,省略局部姿态和时间差分:
$$\mathcal{M}_{RMG} = \mathcal{M}_T \times \mathcal{M}_R = \mathbb{R}^3 \times (S^3)^J$$
单位四元数的优势(相比连续 6D 旋转):
- 无冗余表示 SO(3)
- 在 \(S^3\) 上诱导平滑测地线
- 改进插值和采样稳定性
- 无需重新正交化
- 维度从 6 降至 4,具有一致的距离度量
3.3 先验分布
黎曼高斯分布:
在黎曼流形 \(\mathcal{M}\) 上定义高斯分布:
- 在嵌入欧氏空间 \(\mathbb{R}^n\) 中采样高斯噪声:\(\xi \sim \mathcal{N}(0, \Sigma)\)
- 投影到切空间:\(v = \Pi_{T_\mu\mathcal{M}}(\xi) \in T_\mu\mathcal{M}\)
- 使用指数映射"包裹"到流形:\(z = \text{Exp}_\mu(v) \in \mathcal{M}\)
记作:\(z \sim \mathcal{RN}(\mu, \Sigma)\)
参考点选择:
对于运动生成,设置参考点为静止姿态(零平移 + 单位旋转):
- 平移:\(\mu_T = 0 \in \mathbb{R}^3\)
- 旋转:\(\mu_R = [1, 0, 0, 0] \in S^3\)(单位四元数)
这确保先验样本对应合理的静态姿态。
3.4 黎曼流匹配 (Riemannian Flow Matching)
核心思想:
流匹配学习一个时间依赖的速度场,将源分布 \(p_0\) 传输到目标分布 \(p_1\)。在黎曼流形上,使用测地线替代欧氏空间中的线性插值。
测地线插值:
对于 \(t \sim \mathcal{U}[0, 1]\),构造从 \(x_0\) 到 \(x_1\) 的插值状态:
$$x_t = \text{Exp}{x_0}\left(t \cdot \text{Log}{x_0}(x_1)\right)$$
在乘积流形上,Exp 和 Log 按因子逐元素应用。
目标速度场:
$$v_t(x_t | x_1) = \frac{1}{1-t} \text{Log}{x_t}(x_1) \in T{x_t}\mathcal{M}$$
当 \(\mathcal{M} = \mathbb{R}^n\) 时,退化为标准欧氏流匹配目标。
训练损失:
$$\mathcal{L}(\theta) = \mathbb{E}{x_1 \sim p{data}, x_0 \sim p_0, t \sim \mathcal{U}[0,1]} \left| v_t(x_t | x_1) - \Pi_{T_{x_t}\mathcal{M}} v_\theta(x_t, t) \right|^2$$
其中 \(\Pi_{T_{x_t}\mathcal{M}}\) 是将神经网络输出投影到切空间的算子。
推理(ODE 积分):
从 \(t=0\) 到 \(t=1\) 积分黎曼 ODE:
$$\frac{dx_t}{dt} = \Pi_{T_{x_t}\mathcal{M}} v_\theta(x_t, t), \quad x_0 \sim p_0$$
使用一阶黎曼欧拉更新(步长 \(h\)):
$$x_{t+h} = \text{Exp}{x_t}\left(h \cdot \Pi{T_{x_t}\mathcal{M}} v_\theta(x_t, t)\right)$$
这通过构造保持流形约束。
3.5 网络架构
| 组件 | 架构 | 说明 |
|---|---|---|
| 主干网络 | Diffusion Transformer (DiT) | 处理时间依赖向量场 |
| 文本编码 | Qwen (1.7B) | 隐藏状态作为文本表示 |
| 优化器 | AdamW | 余弦学习率 + 线性 warmup |
| 学习率 | 1e-4 (warmup 后余弦退火) | - |
| Classifier-Free | 10% dropout | 条件生成 |
| EMA | 指数移动平均 | 稳定训练和推理 |
四、训练细节
4.1 数据集
HumanML3D:
- 14,616 个运动片段
- 44,970 条文本描述
- 基于 AMASS 数据集
- 标准 text-to-motion 基准
MotionMillion:
- 100 万运动片段
- 400 万文本描述
- 大规模预训练数据集
- 评估泛化能力
4.2 训练配置
| 超参数 | 值 |
|---|---|
| Optimizer | AdamW |
| 初始学习率 | 1e-4 (线性 warmup) |
| 学习率调度 | 余弦退火 |
| Dropout | 10% (classifier-free) |
| EMA | 启用 |
| 批次大小 | - |
4.3 损失函数
流匹配损失:
$$\mathcal{L}(\theta) = \mathbb{E}{x_1, x_0, t} \left| \frac{1}{1-t}\text{Log}{x_t}(x_1) - \Pi_{T_{x_t}\mathcal{M}} v_\theta(x_t, t) \right|^2$$
关键实现细节:
- 在乘积流形上逐因子计算 Exp/Log
- 平移因子使用欧氏运算
- 旋转因子使用 \(S^3\) 流形运算
- 神经网络输出需投影到切空间
五、实验与结论
5.1 主要结果
HumanML3D 基准(Text-to-Motion):
| 方法 | FID↓ | R@1↑ | 多样性→ | 多模态↑ |
|---|---|---|---|---|
| GT (Ground Truth) | 0.002 | 0.511 | 9.503 | 2.799 |
| MLD | 0.473 | 0.481 | 9.724 | 2.413 |
| T2M-GPT | 0.116 | 0.492 | 9.761 | 1.856 |
| MotionGPT | 0.232 | 0.492 | 9.528 | 2.008 |
| MoMask | 0.045 | 0.521 | 9.761 | 2.413 |
| MotionLCM | 0.304 | 0.505 | 9.607 | 2.259 |
| MotionCLR | 0.269 | 0.542 | 9.607 | 1.985 |
| MotionLab | 0.167 | - | 9.593 | 2.912 |
| MARDM | 0.114 | 0.500 | - | 2.231 |
| Ours (RMG) | 0.043 | 0.525 | 9.555 | 2.748 |
关键发现:
- FID = 0.043,超越之前的 SOTA MoMask (0.045)
- R@1 = 0.525,文本 - 运动一致性优秀(仅次于 MotionCLR 的 0.542)
- 多样性和多模态性保持高水平
- 在质量、对齐和多样性之间实现更平衡的改进
MotionStreamer 格式:
| 方法 | FID↓ | R@1↑ | 多样性→ | 多模态↑ |
|---|---|---|---|---|
| MotionStreamer | 11.790 | 0.631 | 27.284 | - |
| Ours (RMG) | 5.835 | 0.710 | 27.672 | 14.906 |
MotionMillion 基准(大规模):
| 方法 | Guidance Scale | FID↓ | R@1↑ |
|---|---|---|---|
| ScaMo | - | 89.0 | 0.67 |
| MotionMillion-3B | - | 10.8 | 0.79 |
| MotionMillion-7B | - | 10.3 | 0.79 |
| Ours (0.5B+1.7B) | 2.0 | 5.6 | 0.81 |
| Ours (0.5B+1.7B) | 3.0 | 7.8 | 0.86 |
关键发现:
- FID = 5.6,比最强基线 MotionMillion-7B (10.3) 提升近一半
- R@1 从 0.81 提升至 0.86(guidance scale 从 2.0 增至 3.0)
- 证明 RMG 框架的可扩展性和泛化能力
5.2 消融研究
RQ1: 哪些因子对运动质量和引导稳定性重要?
| 表示 | FID (ω=6.5) | 说明 |
|---|---|---|
| T + R | 最优 | 平移 + 旋转(最紧凑) |
| T + R + P (从 P 恢复) | 较差 | 添加局部姿态 |
| T + R + P (从 R 恢复) | 较差 | 添加局部姿态 |
| T + P | 最差 | 缺少旋转信息 |
结论:T + R 表示已足够,添加局部姿态 (P) 不会带来改进。
RQ2: 时间差分建模是否改进运动质量?
| 表示 | FID | 说明 |
|---|---|---|
| T + R | 最优 | 无时间差分 |
| dT + R | 较差 | 添加平移差分 |
| T + dR | 较差 | 添加旋转差分 |
结论:时间差分不会改进质量,T + R 表示已捕捉足够动态信息。
5.3 应用场景
-
文本到运动生成
- 根据文本描述生成自然运动
- 游戏 NPC 动画
- VR/AR 化身驱动
-
运动编辑
- 在流形上进行运动插值
- 风格转换
-
大规模运动合成
- 利用 MotionMillion 等大规模数据集
- 预训练通用运动生成器
六、局限性
-
单位四元数的双覆盖问题
- \(q\) 和 \(-q\) 表示相同旋转
- 可能需要额外的符号一致性处理
-
计算复杂度
- 黎曼流形运算(Exp/Log)比欧氏运算计算量大
- 推理速度可能慢于欧氏方法
-
足部接触未显式建模
- 当前表示不包含足部接触指示器
- 可能需要后处理 IK 减少滑动
-
仅限于运动生成
- 未涉及物理仿真
- 生成的运动可能需要进一步验证物理合理性
七、启发
7.1 方法学启发
几何感知建模的重要性:
- 人体运动本质上是非欧的,应在其自然流形上建模
- 黎曼流匹配提供了一个通用框架,可扩展到各种流形
表示设计的关键洞察:
- 紧凑表示(T + R)已足够,无需冗余因子
- 单位四元数比 6D 旋转更适合流形建模
- 尺度无关表示简化了训练流程(无需归一化)
与 Diffusion 的比较:
| 特性 | 欧氏 Diffusion | 黎曼流匹配 (RMG) |
|---|---|---|
| 表示空间 | \(\mathbb{R}^D\) | 乘积流形 \(\mathcal{M}\) |
| 插值路径 | 线性 | 测地线 |
| 约束处理 | 投影/后处理 | 内置于流形 |
| 归一化 | 需要 | 无需(流形内在) |
7.2 与相关工作对比
| 方法 | 核心思想 | 表示 | FID (H3D) |
|---|---|---|---|
| MLD | VAE + Diffusion | 欧氏 | 0.473 |
| T2M-GPT | VQ-VAE + GPT | 离散 | 0.116 |
| MotionGPT | LLM + Motion Token | 离散 | 0.232 |
| MoMask | Masked Transformer | 欧氏 | 0.045 |
| RMG (本文) | 黎曼流匹配 | 流形 | 0.043 |
7.3 技术细节启发
黎曼流匹配的实现:
- 选择合适的流形结构(\(S^3\) 用于旋转)
- 实现 Exp/Log 映射(可使用几何库如 geomstats)
- 切空间投影确保有效动力学
- 测地线插值替代线性插值
网络设计:
- DiT 作为主干,适合处理流形值数据
- Qwen 等现代 LLM 用于文本编码
- Classifier-free guidance 用于条件生成
八、遗留问题
8.1 开放性问题
-
扩展到更复杂的流形
- 能否加入局部姿态因子(Kendall 预形状空间)?
- 能否建模更复杂的骨骼约束?
-
物理一致性
- 如何将物理约束(如足部接触、碰撞)整合到流形框架?
- 能否与物理仿真器结合?
-
多模态条件
- 除文本外,能否处理图像、音频等其他条件?
- 如何实现细粒度的运动控制?
-
推理速度
- 黎曼流匹配需要 ODE 积分,推理较慢
- 能否使用一致性模型或蒸馏加速?
-
单位四元数的双覆盖
- 如何处理 \(q\) 和 \(-q\) 的符号不一致问题?
- 是否需要特殊的损失函数或约束?
九、补充:黎曼几何基础
9.1 流形 (Manifold)
定义:流形 \(\mathcal{M}\) 是一个拓扑空间,局部类似于欧氏空间 \(\mathbb{R}^n\),允许进行微积分运算。
例子:
- \(\mathbb{R}^3\): 欧氏空间(平坦流形)
- \(S^2\): 球面(弯曲流形)
- \(S^3\): 单位四元数流形
- \(SO(3)\): 旋转群(等价于 \(\mathbb{R}P^3\))
9.2 黎曼度量 (Riemannian Metric)
定义:黎曼度量 \(g\) 是在每个切空间 \(T_p\mathcal{M}\) 上定义的内积,记作 \(g_p(u, v)\)。
作用:
- 测量向量长度
- 测量向量夹角
- 诱导测地线距离(最短路径)
9.3 指数映射和对数映射
指数映射 (Exponential Map): $$\text{Exp}_p: T_p\mathcal{M} \to \mathcal{M}$$ 将切空间中的向量映射到流形上的点。
对数映射 (Logarithm Map): $$\text{Log}_p: \mathcal{M} \to T_p\mathcal{M}$$ 将流形上的点映射到切空间中的向量。
在 \(S^3\) 上的具体形式:
- 对于单位四元数 \(q_1, q_2 \in S^3\): $$\text{Log}_{q_1}(q_2) = \frac{\arccos(q_1 \cdot q_2)}{\sqrt{1 - (q_1 \cdot q_2)^2}} (q_2 - (q_1 \cdot q_2)q_1)$$
- 指数映射是对数映射的逆运算
9.4 测地线 (Geodesic)
定义:测地线是流形上两点之间的最短路径,是欧氏直线的推广。
公式: $$\gamma(t) = \text{Exp}{x_0}(t \cdot \text{Log}{x_0}(x_1)), \quad t \in [0, 1]$$
在流匹配中用于构造插值路径。
十、补充:黎曼流匹配 vs 欧氏流匹配
| 特性 | 欧氏流匹配 | 黎曼流匹配 |
|---|---|---|
| 流形 | \(\mathbb{R}^n\) | 任意黎曼流形 \(\mathcal{M}\) |
| 插值路径 | 线性:\(x_t = (1-t)x_0 + tx_1\) | 测地线:\(x_t = \text{Exp}{x_0}(t \cdot \text{Log}{x_0}(x_1))\) |
| 目标速度 | \(v_t = x_1 - x_0\) | \(v_t = \frac{1}{1-t}\text{Log}_{x_t}(x_1)\) |
| 切空间投影 | 无需(恒等) | 需要:\(\Pi_{T_{x_t}\mathcal{M}}\) |
| 推理更新 | \(x_{t+h} = x_t + h \cdot v_\theta(x_t, t)\) | \(x_{t+h} = \text{Exp}{x_t}(h \cdot \Pi{T_{x_t}\mathcal{M}} v_\theta(x_t, t))\) |
关键关系:当 \(\mathcal{M} = \mathbb{R}^n\) 时,黎曼流匹配退化为欧氏流匹配。
笔记说明:本文是 2026 年 3 月最新工作,提出了基于黎曼流形匹配的运动生成框架 RMG。核心创新是将运动表示为乘积流形 \(\mathbb{R}^3 \times (S^3)^J\) 上的点,并使用黎曼流匹配学习生成动力学。在 HumanML3D 上达到 SOTA FID (0.043),并首次证明黎曼流匹配可扩展到大规模数据集。理解本文有助于学习几何感知的人体运动生成方法,与 PhysDiff、POMP 等工作形成对比。
十一、公式汇总
重要公式速查:
-
紧凑表示: $$\mathcal{M}_{RMG} = \mathbb{R}^3 \times (S^3)^J$$
-
黎曼高斯采样: $$\xi \sim \mathcal{N}(0, \Sigma), \quad v = \Pi_{T_\mu\mathcal{M}}(\xi), \quad z = \text{Exp}_\mu(v)$$
-
测地线插值: $$x_t = \text{Exp}{x_0}\left(t \cdot \text{Log}{x_0}(x_1)\right)$$
-
目标速度场: $$v_t(x_t | x_1) = \frac{1}{1-t} \text{Log}_{x_t}(x_1)$$
-
训练损失: $$\mathcal{L}(\theta) = \mathbb{E}{x_1, x_0, t} \left| v_t(x_t | x_1) - \Pi{T_{x_t}\mathcal{M}} v_\theta(x_t, t) \right|^2$$
-
推理 ODE: $$\frac{dx_t}{dt} = \Pi_{T_{x_t}\mathcal{M}} v_\theta(x_t, t), \quad x_0 \sim p_0$$
-
黎曼欧拉更新: $$x_{t+h} = \text{Exp}{x_t}\left(h \cdot \Pi{T_{x_t}\mathcal{M}} v_\theta(x_t, t)\right)$$
GaussiAnimate: Reconstruct and Rig Animatable Categories with Level of Dynamics
- 作者: Jiaxin Wang, Dongxin Lyu, Zeyu Cai, Zhiyang Dou, Cheng Lin, Anpei Chen, Yuliang Xiu (西湖大学)
- 机构: Westlake University, Nanjing University, HKU, MUST
- 会议: arXiv 2604.08547 (Apr 2026)
- 代码: cookmaker.cn/gaussianimate
1. 研究背景与问题
核心问题
如何让 3DGS 重建的动态角色具备可操控的动画能力——从 "reconstruction for replay" 转向 "reconstruction for reanimation"?
控制力 vs. 形变精度的本质矛盾
| 需求 | 内层(控制) | 外层(表现) |
|---|---|---|
| 目标 | 紧凑、刚性的运动学骨架 | 高保真、非刚性表面形变 |
| 适用表示 | 层次化骨架 (SMPL 等) | Free-form bones / blobs |
| 典型例子 | 关节旋转驱动 | 衣物褶皱、软组织形变 |
现有方法的局限:
- 基于模板的方法 (SMPL, SMAL):依赖预定义骨架,无法泛化到新类别
- Bag-of-Bones (BANMo):缺少运动学约束,拓扑不正确
- RigGS:将骨架提取与渲染耦合,优化慢(~2小时 vs 本文~15分钟)
- CAMM:依赖首帧骨架初始化,缺乏运动自适应性
本文方法:Skelebones(骨架-骨骼脚手架蒙皮系统)
提出 Scaffold-Skin Rigging System,显式建模 Level of Dynamics:
- 内层:运动学骨架(Kinematic Skeleton)→ 捕捉低频刚性关节运动
- 外层:自由骨骼(Free-form Bones)→ 表示高频非刚性表面形变
- 绑定:PartMM(部件级运动匹配)→ 骨架驱动骨骼

2. 方法总览
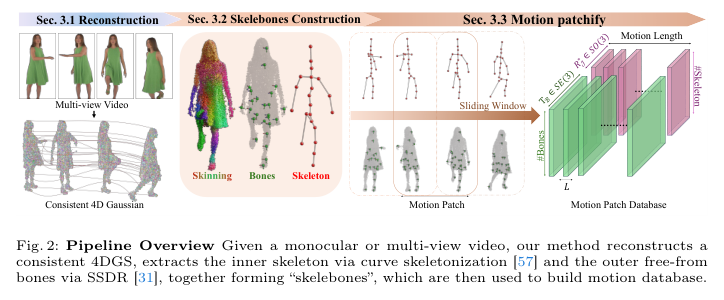
整体流程分为三个阶段:
输入视频(单目/多视)
↓
[阶段1] 重建(Sec 3.1)
Deformable 3DGS + ARAP 正则化 → 时序一致的 4D 高斯序列
↓
[阶段2] Skelebones 构建(Sec 3.1 + 3.2)
运动聚类 + SSDR → 外层 Bones
MCS 骨架化 + 关节检测 + IK → 内层 Skeleton
↓
[阶段3] PartMM 绑定与动画(Sec 3.3)
构建运动数据库 → 部件级匹配 + 对齐 + 粗到细细化 → 新姿态动画
3. 阶段一:时序一致的 4D 高斯重建
3.1 Deformable 3DGS
采用 SC-GS 的框架,用 MLP 形变场 $D_{\text{MLP}}(f)$ 将 canonical 高斯 $\mathcal{G}_c$ 变形到第 $f$ 帧 $\mathcal{G}_f$:
$$\mathcal{G} _f ^{(\cdot)} = \mathcal{G} _c ^{(\cdot)} + D _{\text{MLP}} ^{(\cdot)}(f), \quad (\cdot) \in {\mu, c, \sigma, q, s}$$
📖 参考笔记:SC-GS 的详细内容参见 234(Sparse-Controlled Gaussian Splatting,CVPR 2024)。核心思路是用稀疏控制点 + MLP 形变场将 canonical 高斯映射到各帧,GaussiAnimate 直接借用了这一 deformable 建模框架。
设计选择:使用各向同性高斯(而非各向异性),牺牲少量渲染质量以换取对新姿态更好的泛化能力(following RigGS)。
训练损失:光度损失(L1 + D-SSIM):
$$\mathcal{L} _{\text{photo}} = \sum _{f=1} ^{F} \left[(1-\lambda)|I _f - \hat{I} _f|_1 + \lambda(1 - \text{D-SSIM}(I _f, \hat{I} _f))\right]$$
3.2 局部刚性正则化(ARAP)
为了满足后续 SSDR 对时序一致性的要求,引入 ARAP 约束 + 距离保持约束:
$$\mathcal{L} _{\text{rigid}} = \sum _{(i,j)\in K} \left[ \underbrace{|(x _f ^i - x _f ^j) - R _i(x _c ^i - x _c ^j)|_2 ^2} _{\text{ARAP 项}} + \underbrace{(|x _f ^i - x _f ^j|_2 - |x _c ^i - x _c ^j|_2) ^2} _{\text{距离保持项}} \right]$$
其中 $R_i \in SO(3)$ 通过 SVD 从协方差矩阵计算得到。$K_m$ 为第 $m$ 个聚类的 KNN 邻域集合。
ARAP 的作用:抑制高斯点的过度变形,使后续运动聚类更稳定,骨骼结构更连贯。
3.3 运动聚类
📖 参考笔记:LBG-VQ 运动聚类的详细内容参见 236(Robust and Accurate Skeletal Rigging from Mesh Sequences, SIGGRAPH 2014,Le & Deng)。本文直接采用其运动感知聚类策略,将高斯点按运动相似性分组为刚性簇。
基于 Gestalt 共同命运定律——具有相似运动的元素被视为同一组——采用 LBG-VQ(Linde-Buzo-Gray Vector Quantization)将高斯点分组为刚性聚类。
- 输入:所有帧的高斯点位置 ${\mathcal{G}f}{f=1}^F$
- 输出:每帧每聚类的刚性变换 $\hat{T}_B \in SE(3)^{F \times B}$
- 聚类数量 $B$ 通过从粗到细的分裂细化过程自动确定(最大 50)
💡 为什么只借用 236 的聚类,而不使用其完整的绑定流程?
236 的完整绑定流程(拓扑重建 MST、迭代权重更新、关节约束优化、骨骼剪枝)是为网格(Mesh)设计的,严重依赖三角面片的邻接拓扑关系。而 3DGS 是无拓扑的点云表示,没有面片连接信息,因此 236 中依赖拓扑的步骤(如边权重计算、刚性拉普拉斯正则化)无法直接移植。
LBG-VQ 运动聚类是 236 中唯一纯运动驱动的步骤——它只看每个点的位移轨迹是否相似,不依赖任何拓扑信息,因此可以无缝适配到 3DGS 上。
3.4 SSDR 皮肤分解
📖 参考笔记:SSDR 的详细内容参见 235(Smooth Skinning Decomposition with Rigid Bones, SIGGRAPH 2012)。该方法从示例姿态中自动提取 LBS 参数(骨骼变换 + 皮肤权重),本文直接借用该算法作为后处理步骤,将运动聚类结果压缩为稀疏的 LBS 表示。
用 SSDR(Smooth Skinning Decomposition with Rigid Bones)拟合 LBS 参数:
- 输入:运动聚类得到的初始刚体变换 $\hat{T}_B$
- 输出:
- 皮肤权重 $W \in \mathbb{R}^{N \times B}$($N$ 个高斯、$B$ 个骨骼)
- 优化后的骨骼变换 $T_B \in SE(3)^{F \times B}$
这步将密集的 4D 变形压缩为稀疏的刚体骨骼变换,近似非刚性表面动力学,形成 Skelebones 的外层 Bones。
235(SSDR, SIGGRAPH 2012)和 236(Le & Deng, SIGGRAPH 2014)出自同一作者组,是同一研究路线的两篇递进工作:
236 可以看作是 235 的"加强版",补齐了自动确定骨骼数量和拓扑的能力。但 236 的迭代绑定和拓扑重建依赖网格拓扑,无法在 3DGS 上直接使用。
本文的选用策略:从 236 取其"分组能力"(LBG-VQ 运动聚类,确定骨骼数量和初始变换),从 235 取其"求解能力"(块坐标下降 + 闭式 SVD 精确求解 LBS 参数)。两者拼成一条适配 3DGS 无拓扑场景的管道:
[236] LBG-VQ 聚类 → 初始刚体变换 T̂_B(骨骼分组 + 初始化) ↓ (不运行 236 的拓扑重建、迭代绑定、剪枝) [235] SSDR → 皮肤权重 W + 优化后的骨骼变换 T_B(LBS 参数精炼)内层运动学骨架的拓扑则由本文原创的 MCS 曲线骨架 + 皮肤权重梯度关节检测方案生成,与 236 的 MST 拓扑重建无关。
4. 阶段二:内层运动学骨架提取
外层 bones 虽然能捕捉表面变形,但缺乏解剖学对应关系,无法直观操控。因此需要提取内层运动学骨架。
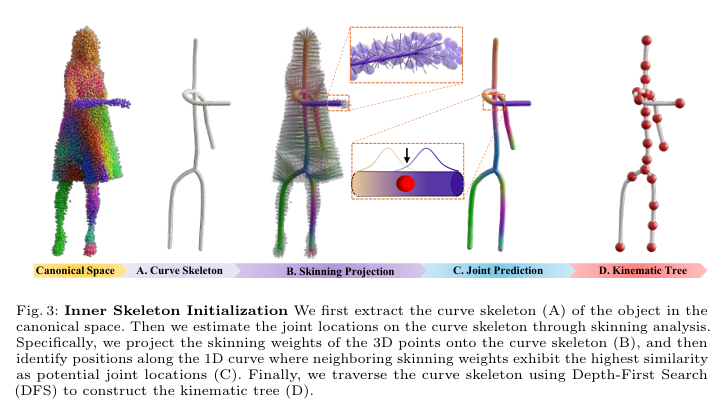
4.1 Mean Curvature Skeleton 提取
从 canonical 形状 $\mathcal{G}_c$(取第 0 帧)直接提取 Mean Curvature Skeleton (MCS),记为 $\mathcal{S}$。
选择 MCS 而非 MAT 的原因:
- MAT 对表面噪声敏感,容易产生虚假分支
- MCS 提供直接的表面-骨架对应关系,便于后续将 SSDR 皮肤权重投影到骨架上
4.2 基于皮肤权重梯度的关节检测
核心观察:解剖学关节处,皮肤权重 $W$ 会出现急剧的空间变化。
$$\mathcal{J} = { s _j \in \mathcal{S} \mid \nabla W(s _j) > \tau }$$
- $\mathcal{S} = {s_j \in \mathbb{R}^3 \mid j = 1, \ldots, M}$:曲线骨架的离散点集
- $\nabla W(s_j)$:骨架点 $s_j$ 处的皮肤权重梯度
- $\tau = 0.3$:权重变化的阈值
具体过程:
- 将 3D 高斯点的 SSDR 皮肤权重投影到曲线骨架上
- 沿一维曲线骨架计算权重的空间梯度
- 梯度超过阈值的点即为关节候选
4.3 运动学树构建
将检测到的关节组织为树状结构 $T = (\mathcal{J}, A)$:
- 保留边:保留与曲线骨架空间对齐的边
- 确定父子关系:从根关节(距全局质心最近的关节)出发,DFS 遍历
- 输出:稀疏骨架表示 ${\mathcal{J}, E}$,$E \subset \mathcal{J} \times \mathcal{J}$ 编码关节间的边
Part 的定义:运动学树中两个关节之间的一段骨骼即为一个 Part。每个 Part 有对应的骨骼子集 $\mathcal{B}'$。实际中划分为 5 个重叠的 Part。
4.4 骨骼姿态优化(IK)
通过逆运动学求解每帧的局部关节旋转 $R_\mathcal{J} = {R_j}_{j=1}^J$,最小化:
$$R _\mathcal{J} ^* = \arg\min _{R _\mathcal{J}} \sum _{f=1} ^{F} \left[ \mathcal{L} _{\text{CD}}(\mathcal{J} _c(R _\mathcal{J}), \mathcal{S} _f) + \lambda , \mathcal{L} _{\text{L2}}(\mathcal{G} _c(R _\mathcal{J}), \mathcal{G} _f) \right]$$
- 第一项:Chamfer 距离,使变形后的骨架关节与每帧的曲线骨架对齐
- 第二项:L2 距离,使前向运动学变形后的高斯与观测高斯一致
4.5 渐进式骨架优化
随着更多运动帧被观测,骨架质量渐进提升:
- 少量帧 → 粗糙骨架,可能遗漏细节
- 更多帧 → 接触更丰富的姿态和变形 → 更准确的运动聚类 → 更好的骨架结构
- 关键特性:骨架从运动观测中"自然涌现"(motion-adaptive)
5. 阶段三:PartMM(部件级运动匹配)
重要纠正:PartMM 不是基于 MLP 的概率加权绑定,而是一个非参数化的运动匹配(Motion Matching)算法,灵感来自 motion retargeting 的 KV 检索思想。
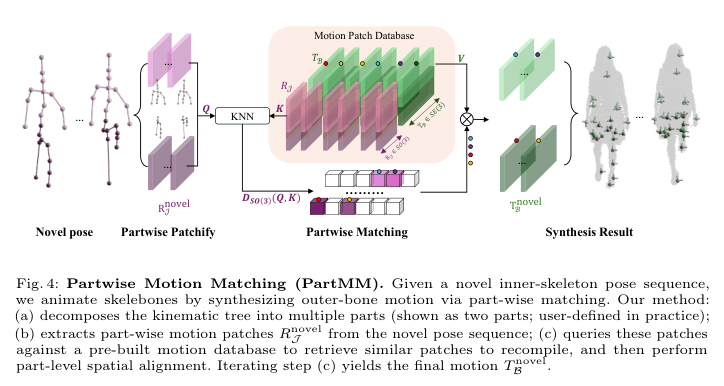
5.1 问题定义
已知:
- 内层关节旋转 $R_\mathcal{J} \in SO(3)^{F \times J}$
- 外层骨骼变换 $T_B \in SE(3)^{F \times B}$
- 皮肤权重 $W \in \mathbb{R}^{N \times B}$
问题:给定新的骨架姿态 $R_\mathcal{J}^{\text{novel}}$,如何合成对应的外层骨骼运动 $T_B^{\text{novel}}$?
核心困难:外层 free-form bones 与内层 kinematic skeleton 之间没有显式对应关系,无法直接映射。
5.2 KVQ 检索框架
将骨骼绑定转化为非参数化的 patch 匹配问题:
| 角色 | 含义 | 空间 |
|---|---|---|
| Query (Q) | 目标骨架运动(新姿态) | $SO(3)$ 关节旋转空间 |
| Key (K) | 源骨架运动(数据库中) | $SO(3)$ 关节旋转空间 |
| Value (V) | 源骨骼运动(数据库中) | $SE(3)$ 骨骼变换空间 |
5.3 运动分片(Motion Patchifying)
从重建的 Skelebones 序列中提取运动片段,构建源运动数据库:
$$\mathcal{D} _{\text{src}} = {\mathcal{P} _l \mid \mathcal{P} _l = (R _\mathcal{J} ^l, T _B ^l), ; l = 1, \ldots, L}, \quad L = F - p + 1$$
- $p = 7$:默认分片大小(7 帧一个 patch)
- 每个分片同时包含骨架旋转和骨骼变换的配对数据
5.4 部件级匹配与对齐
这是 PartMM 的核心创新——在 Part 级别而非全局进行匹配。
对于每个运动学 Part $\mathcal{J}'$(对应骨骼 Part $\mathcal{B}'$):
Step 1: KNN 检索(在 $SO(3)$ 空间)
$$\mathcal{P} ^{\text{match}} = \arg\min _{\mathcal{P} _l \in \mathcal{D} _{\text{src}}} d _{SO(3)}(R _{\mathcal{J}'} ^{\text{novel}}, R _{\mathcal{J}'} ^l)$$
- $d_{SO(3)}$:旋转流形上的测地距离
- $k = 7$:取 7 个最近邻
- 关键:每个 Part 独立匹配,允许跨 Part 灵活重组运动片段
Step 2: SVD 刚性对齐
由于完美匹配很少,计算最优旋转 $R_{\text{align}}$(via SVD)来补偿源-目标骨架的旋转差异:
$$T _{\mathcal{B}'} ^{\text{aligned}} = R _{\text{align}} \circ T _{\mathcal{B}'} ^{\text{match}}$$

5.5 粗到细细化
通过运动金字塔进行多尺度细化:
$$T _{\mathcal{B}'} ^{\ell+1} = (1 - \lambda _\alpha) , T _{\mathcal{B}'} ^{\ell} + \lambda _\alpha , \bar{T} _{\mathcal{B}'} ^{\ell}$$
- 每层 $\ell$ 下采样率 $2^{5-\ell}$(共 5 层金字塔)
- $\lambda_\alpha = 0.7$:混合权重
- $\bar{T}_{\mathcal{B}'}^{\ell}$:该层匹配分片的加权平均
从粗尺度到细尺度迭代混合,确保平滑的时间过渡和几何合理性。
5.6 PartMM 伪代码
输入: R_query (新骨架运动), D_src (运动数据库), parts (Part 分组)
输出: T_out (新骨骼运动)
T_out = {}
for part in parts:
Q = R_query[part] # Query: 该 Part 的新骨架旋转
K = D_src[part].R # Key: 该 Part 的数据库骨架旋转
V = D_src[part].T # Value: 该 Part 的数据库骨骼变换
idx = knn_match(Q, K, k=7) # SO(3) 空间 KNN 检索
K_match = K[idx]
V_match = V[idx]
R_align = svd_align(Q, K_match) # SVD 对齐
V_aligned = bmm(R_align, V_match) # 对齐后的骨骼变换
T_out[part] = blend(V_aligned) # 混合输出
return T_out
5.7 PartMM vs 其他绑定方式
| LBS | BoB | MLP/GRU | PartMM | |
|---|---|---|---|---|
| 绑定方式 | 皮肤权重传递 | 骨骼袋 + 网络驱动 | 神经网络回归 | 非参数化运动匹配 |
| 变换类型 | 刚体(线性) | 刚体(LBS) | 非线性 | 复用数据库中的变换 |
| 泛化能力 | 关节处伪影严重 | 依赖模板 | 姿态外推退化 | 强(尤其低数据量) |
| 需要训练 | 否 | 是 | 是 | 否(training-free) |
| 新姿态处理 | 插值 | 网络推理 | 外推 | 检索+混合 |
| 计算开销 | 极低 | 中等 | 推理 | 极低(匹配+对齐) |
6. 实验结果
6.1 新视角合成(Table 2)
| 方法 | Rig | D-NeRF PSNR/SSIM/LPIPS | DG-Mesh PSNR/SSIM/LPIPS | 时间 |
|---|---|---|---|---|
| SC-GS | No | 43.04/0.998/0.007 | 38.96/0.993/0.014 | ~1hr |
| AP-NeRF | Yes | 30.94/0.970/0.035 | 31.83/0.967/0.046 | >1day |
| RigGS | Yes | 40.82/0.996/0.011 | 37.65/0.991/0.017 | ~2hrs |
| Ours | Yes | 41.00/0.996/0.015 | 37.59/0.990/0.022 | ~15min |
关键优势:解耦范式(rigging 与渲染分离)使得优化时间从 RigGS 的 ~2小时 降至 ~15分钟。
6.2 新姿态动画(Table 3 - 几何评估)
| 方法 | VTO T-shirt/Dress RMSE | D4D Animals RMSE |
|---|---|---|
| Robust LBS | 33.7/52.2 | 65.3 |
| Ours_MLP | 23.9/36.8 | 68.8 |
| Ours_GRU | 22.9/37.5 | 58.4 |
| FullMM | 38.2/37.0 | 53.3 |
| PartMM | 17.4/36.7 | 54.6 |
6.3 新姿态动画(Table 4 - 渲染评估)
| 方法 | DNA-Rendering PSNR/SSIM/LPIPS | ActorHQ PSNR/SSIM/LPIPS |
|---|---|---|
| D3DGS (GT) | 32.16/0.978/0.033 | 30.56/0.938/0.136 |
| SMPL+LBS | 0.948/0.049 | 17.54/0.738/0.315 |
| SMPL+BoB | 0.935/0.057 | 16.66/0.722/0.259 |
| SMPL+PartMM | 0.964/0.039 | 24.26/0.850/0.182 |
核心数字:
- vs LBS:+17.3% PSNR(DNA-Rendering)
- vs BoB:+21.7% PSNR(ActorHQ,实际 +45.6%)
- vs Robust LBS:48.4% RMSE 改进(VTO)
- vs MLP/GRU:>20% RMSE 改进
6.4 定性比较
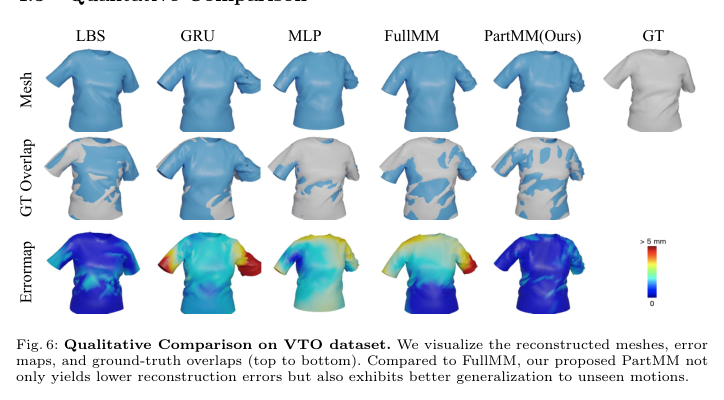
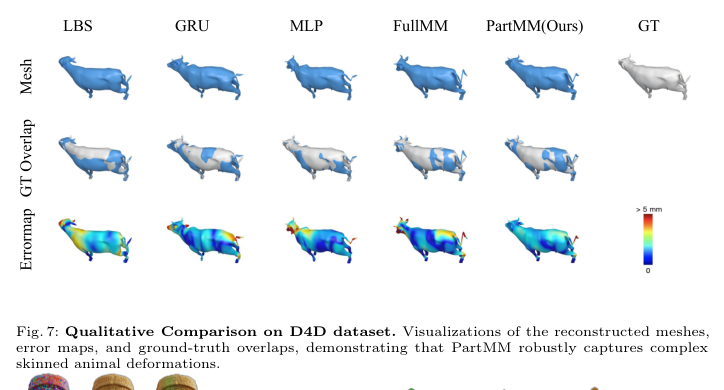
PartMM 在衣物(VTO)和动物(D4D)上均能稳健捕捉复杂的蒙皮变形。
6.5 消融实验

ARAP 的作用:
- 无 ARAP → 高斯点变形过度 → 运动聚类不稳定 → 骨骼结构碎片化
- 有 ARAP + 无 SSDR → 过密的骨骼集 → 碎片化皮肤权重 → 骨架退化
- 有 ARAP + 有 SSDR → 连贯的骨骼结构 + 平滑的皮肤权重
渐进式骨架化:
- 观测帧越多 → 接触更多姿态 → 更准确的运动聚类和皮肤权重 → 骨架从运动中自然涌现并逐步完善
7. 与现有方法的全面对比(Table 1)
| 方法 | 绑定方式 | Template Free | Motion Adaptive | Topology Correct | Non-rigid Dynamic |
|---|---|---|---|---|---|
| Robust | Skeleton | Yes | Yes | No | No |
| TAVA | Skeleton | No | No | Yes | No |
| BANMo | Skeleton | No | Yes | Yes | No |
| CAMM | Skeleton | Yes | No | No | No |
| AP-NeRF | Skeleton | Yes | No | No | No |
| WIM | Skeleton+Bones | Yes | Yes | No | No |
| SC-GS | Skeleton | Yes | No | No | Yes |
| DressRecon | SMPL+Bones | No | No | Yes | Yes |
| RigGS | Skeleton+Bones | Yes | Yes | No | Yes |
| CANOR | Bones | Yes | No | No | Yes |
| Ours | Skelebones | Yes | Yes | Yes | Yes |
GaussiAnimate 是唯一同时满足全部五个属性的方法。
8. 实现细节
- D_MLP:8 层 MLP,特征维度 256
- 重建训练:40,000 迭代,单张 RTX 4090D,~15 分钟(Adam)
- 后处理(训练无关):运动聚类 + SSDR + 骨架化 + PartMM,共 ~2 分钟
- 运动聚类:最大骨骼数 50,骨架化阈值 $\tau = 0.3$
- PartMM 匹配:5 个重叠 Part,KNN $k=7$,5 层金字塔,分片大小 $p=7$
9. 局限性与未来方向
- 计算性能:尚未达到实时,但数据库构建可通过神经压缩 / neural SSDR 加速
- 骨架提取敏感性:依赖皮肤权重质量和 canonical 形状精度,复杂衣物(如裙子)的髋关节定位可能偏差
- 渲染伪影:新姿态下可能因高斯覆盖不足出现空洞,可通过 mesh-based 渲染或 image-space refinement 解决
10. 核心贡献总结
| 贡献 | 内容 |
|---|---|
| 表示 (Skelebones) | 骨架-骨骼脚手架蒙皮系统,显式建模 Level of Dynamics,平衡控制力与形变精度 |
| 算法 (PartMM) | 非参数化部件级运动匹配,training-free,低数据量下强泛化 |
| 框架 (GaussiAnimate) | 完全自动的系统,从 4DGS 重建到稳健重动画,template-free,支持人/衣物/动物 |
11. 与知识库的关联
3DGSAnimation
- Skeleton Agent 类别的首篇条目
- Skelebones 表示 = 内层骨架 + 外层骨骼,填补了 "无代理" 和 "物理仿真代理" 之间的空白
- PartMM 的非参数化匹配思路可作为方法论标杆
GAMES105 — Skinning
- 直接对比并超越 LBS(Skinning 核心内容)
- SSDR 将非刚性形变压缩为 LBS 系统 → 本质上仍是 LBS 框架
- PartMM 不是 LBS 的替代,而是骨架到骨骼的绑定方式的替代
关键区别
- 之前笔记将 PartMM 错误描述为 "MLP 概率加权绑定",实际是非参数化运动匹配算法
- PartMM 不涉及 MLP 残差、softmax 概率或 affinity loss
- 骨骼变形仍通过 LBS($T_B$ + 皮肤权重 $W$),PartMM 解决的是如何从新骨架姿态得到 $T_B$
Reference
- arXiv: 2604.08547
- PDF: ReadPapers/220
SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
研究背景与问题
目的
解决机器人操作中变形体(布料、绳子、袋子等)的 sim-to-real 泛化问题。
现有方法及局限性
- 真实世界数据采集成本高昂且难以规模化
- 纯仿真数据存在 sim-to-real gap
- 变形体的物理行为复杂(弹性、摩擦、接触非线性),传统仿真器难以精确建模
本文方法
提出 SIM1 —— 一个 physics-aligned 的 real-to-sim-to-real 数据引擎:
- 使用弹性建模校准变形动力学,使仿真器的物理行为与真实观测对齐
- 通过 diffusion model 进行轨迹扩展(trajectory generation),从有限的真实演示生成大量仿真数据
- 形成 real-to-sim-to-real 的闭环:真实数据 → 物理对齐仿真 → 扩展训练 → 零样本迁移
在机器人变形体操作任务上达到 90% 零样本成功率,相比基线有 50% 泛化增益。
核心贡献
-
Physics-Aligned Simulator:
- 弹性建模用于校准变形体的物理参数
- 使仿真器的动力学输出与真实世界观测对齐
-
Diffusion-based Trajectory Generation:
- 从有限的真值轨迹通过扩散模型扩展生成大量多样化训练数据
- 保持物理一致性同时增加数据多样性
-
Real-to-Sim-to-Real Pipeline:
- 端到端的数据增强管线
- 零样本泛化能力验证
技术特点
| 特征 | 描述 |
|---|---|
| 对象类型 | 变形体(deformable objects) |
| 核心方法 | 弹性建模 + Diffusion 轨迹扩展 |
| 数据流 | Real → Sim(物理对齐) → Diffusion扩展 → Real |
| 应用领域 | 机器人操作 |
| 零样本成功率 | 90% |
| 泛化增益 | +50% vs baseline |
主要方法
Pipeline 概览
真实世界演示数据
↓
[物理对齐模块] — 弹性建模校准仿真器参数
↓
[仿真器] — 生成初始轨迹
↓
[Diffusion Trajectory Generator] — 轨迹扩展/增强
↓
大规模仿真训练数据 → 训练策略网络 → 零样本部署
实验
关键结果
- 零样本成功率: 90%
- 相比纯仿真基线泛化增益: +50%
- 在多种变形体任务上验证(布料操作、绳索操纵等)
Reference
- arXiv: 2604.08544
- PDF: ReadPapers/221
- GAMES103 知识库收录: Elastic/SIM1.md
FIT: A Large-Scale Dataset for Fit-Aware Virtual Try-On
研究背景与问题
目的
构建一个面向虚拟试衣(Virtual Try-On)的大规模 fit-aware 数据集。
现有方法及局限性
- 现有 VTO 数据集缺乏合身度(fit-awareness)标注
- 布料物理悬挞性质难以程序化生成高质量数据
- 大规模 try-on 三元组(人-服装-试穿效果)数据稀缺
本文方法
提出 FIT 数据集:
- 113 万 try-on 图像三元组
- GarmentCode:程序化 3D 服装生成框架,支持多样化服装几何
- 物理仿真驱动悬挂:使用物理引擎生成真实的布料悬挂数据
- 重纹理框架:将程序化服装纹理映射到真实感外观
核心贡献
-
FIT 数据集规模:113万图像三元组,是目前最大的 fit-aware VTO 数据集
-
GarmentCode 程序化生成:
- 参数化 3D 服装模型
- 支持多类别(上衣、裤子、裙子等)
- 几何多样性保证
-
物理仿真集成:
- 使用物理仿真引擎进行布料悬挂模拟
- 保证服装与人体之间的物理合理交互
- 合身度信息天然嵌入
-
重纹理管线:程序化几何 → 物理悬挂 → 纹理映射 → 最终渲染
数据集统计
| 指标 | 数量 |
|---|---|
| 总图像数 | 113万+ |
| 服装类别 | 多类(上衣/裤/裙等) |
| 合身度标注 | Fit-aware |
| 生成方式 | GarmentCode + 物理仿真 |
与 GAMES103 的关联
虽然本文核心是 CV/VTO 方向,但其中 物理仿真驱动的布料悬挂 与 GAMES103 的 Cloth Simulation 章节直接相关:
- 布料的物理悬挞性质是 cloth simulation 的典型应用
- GarmentCode 的参数化服装 + 物理引擎 = cloth sim 的工业级落地案例
- 可作为 GAMES103
5_cloth.md系列的应用补充参考
Reference
- arXiv: 2604.08526
- PDF: ReadPapers/222
- GAMES103 知识库收录: Elastic/FIT.md
Geometric Neural Distance Fields for Learning Human Motion Priors
我们提出神经黎曼运动场(NRMF)——一种创新的三维生成式人体运动先验模型,能够实现鲁棒、时序一致且物理合理的三维运动重建。与现有的VAE或扩散模型方法不同,我们提出的高阶运动先验显式地将人体运动建模为对应姿态、转移(速度)和加速度动态的神经距离场(NDF)零水平集。该框架具有严谨的理论基础:我们的NDF构建在关节旋转、角速度及角加速度的乘积空间上,严格遵循底层关节结构的几何特性。我们进一步引入:(1)一种新型自适应步长混合算法,用于在合理运动集合上进行投影计算;(2)一种创新几何积分器,在测试时优化和生成过程中实现真实运动轨迹的"展开"。实验结果表明显著且一致的性能提升:在AMASS数据集上训练后,NRMF能够出色地泛化至多种输入模态,并适应去噪、运动插值、基于部分二维/三维观测的运动拟合等多样化任务。项目页面详见此处。
神经黎曼运动场
Character Controllers Using Motion VAEs

计算机动画的一个基本问题是,在给定足够丰富的运动捕捉片段集合的情况下,如何实现有目的性且逼真的人体运动。我们采用自回归条件变分自编码器(即运动VAE)来学习数据驱动的人体运动生成模型。经过学习的自编码器其潜在变量定义了运动的动作空间,从而控制运动随时间推移的演变。规划或控制算法随后可利用该动作空间来生成期望的运动。特别地,我们运用深度强化学习来训练能够实现目标导向运动的控制器。我们通过多项任务验证了该方法的有效性,进一步评估了系统设计的不同方案,并阐述了当前运动VAE存在的局限性。
构造先验
采用自回归条件变分自编码器(即运动VAE)来学习数据驱动的人体运动模型,作为后续生成模型的先验。
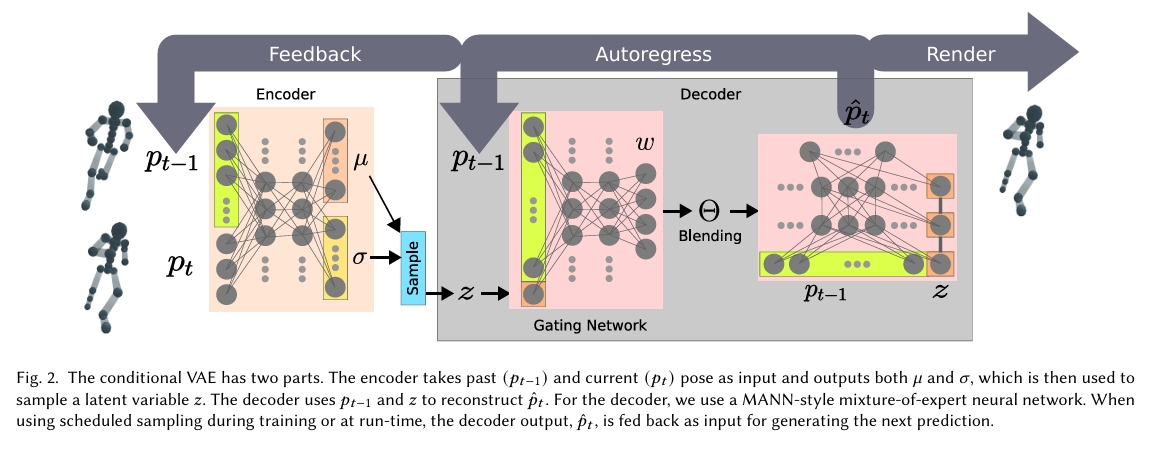
规避后验坍塌。
- 可以使用单帧姿态作为条件输入,也可采用连续历史姿态序列(即𝑝𝑡−𝑘...𝑝𝑡−1)作为条件。
实验结论:使用多帧条件能提升MVAE的重构质量,但会降低输出姿态的多样性。极端情况下,解码器可能学会忽略编码器输出,即出现后验坍塌问题。 - 后验坍塌问题是指,解码器忽略编码器输出,仅复现原始运动捕捉数据。
解决方法:
(1)使用较少的历史帧作为条件。实验表明,采用一至两帧连续姿态作为条件即可获得良好效果,但最优选择通常需综合考虑运动数据库的多样性与质量。
(2)将潜变量z输入专家网络的所有层级来强化其重要性。实证研究表明该技巧能有效降低后验坍塌的发生概率。
(3)其他影响后验坍塌概率的设计决策包括:解码器网络规模、KL散度损失的权重(在𝛽-VAE中)以及潜维度数量。
运动质量与泛化能力的平衡
- 平衡源自重构损失与KL散度损失的权重分配
(1)过度侧重运动质量时,系统仅会复现原始运动捕捉序列
(2)若过度强调运动泛化,则可能生成不符合物理规律的动作姿态
实验表明:当MVAE的重构损失与KL散度损失在收敛时保持同一数量级,即可作为衡量质量与泛化间适当平衡的有效指标。
自回归的预测失稳问题
问题原因:不断累积的重构误差会迅速导致模型进入状态空间中不可恢复的新区域
解决方法:计划采样技术
具体方法:为每个训练周期定义采样概率𝑝,当完成姿态预测后,以1−𝑝的概率将预测结果作为下一时间步的输入(而非使用训练数据中的真实姿态)。整个训练过程包含三个模式:监督学习模式(𝑝=1)、计划采样模式(𝑝值衰减)和自回归预测模式(𝑝=0)。
训练片断
使用T帧作为一个训练片断,T帧的切割方式有两种:
(1)任何帧都可被视为序列的起始或结束姿态,切割方法:运动片段被自由划分为等长子序
(2)需要固定起止姿态的特定运动,切割方法:通过填充序列至最长序列长度来处理变长输入
语言都是用第二种,动作通常用第一种。
基于先验的生成
随机生成
控制条件:无
生成方式:自回归
表示方式:连续表示(VAE)
生成模型:VAE
以单帧输入作为起始帧,随机采样下一帧,可以生成以下效果的运动:
- 当初始角色状态取自短跑周期的中间帧时,MVAE将持续重构短跑周期动作;
- 当初始状态为静止姿态(多数运动片段的起始通用姿态)时,角色可自然过渡到行走、奔跑、跳跃或静止等不同运动模式。
当随机行走在大量采样后仍无法实现运动过渡时,就意味着需要补充额外的运动捕捉数据(特别是过渡动作)
可控生成
控制条件:目标位置
生成方式:自回归
表示方式:连续表示(VAE)
生成模型:VAE
方法
在固定时间步长(𝐻)内执行多次蒙特卡洛推演(𝑁),从所有采样轨迹中选取最优路径的首个动作作为当前时间步的角色控制指令,该过程循环执行直至任务完成或终止。
效果
- 在简单运动任务(如目标追踪§6.1)中表现尚可。
- 当采用𝑁=200、𝐻=4参数时,角色通常能朝向目标移动并绕其盘旋,同时适应目标位置的突变(详见补充视频)。
局限性
- 难以引导角色抵达目标两英尺范围内。
- 对于更复杂的任务无法达成预期目标。
- 需要精细调参。
- 需要更高的运行时计算量。
动作先验与强化学习
[?] 这一部分没有看懂
Improving Human Motion Plausibility with Body Momentum
许多研究将人体运动分解为附着在根关节上的局部坐标系中的局部运动,以及世界坐标系中根关节的全局运动,并对二者分别处理。然而这两个组成部分并非相互独立:全局运动源于与环境的相互作用,而环境交互又是由身体姿态的变化驱动的。运动模型往往无法精确捕捉局部与全局动力学之间的这种物理耦合关系,而从关节扭矩和外部力推导全局轨迹又存在计算成本高、复杂度大的问题。为解决这些挑战,我们提出使用全身线性和角动量作为约束条件,将局部运动与全局运动联系起来。由于动量反映了关节层面动力学对身体空间运动的整体影响,它提供了将局部关节行为与全局位移相关联的物理基础方法。基于这一见解,我们引入了一种新的损失项,用于强制生成动量曲线与真实数据中观测到的动量曲线保持一致。采用我们的损失函数可减少脚部滑动和抖动,改善平衡性,并保持恢复运动的准确性。代码与数据详见项目页面https://hlinhn.github.io/momentum_bmvc。
MoGlow: Probabilistic and controllable motion synthesis using normalising flows

基于数据的运动建模与合成是一个活跃的研究领域,其在动画、游戏和社交机器人等领域具有广泛应用。本文提出了一类基于归一化流的新型概率化、生成式且可控的运动数据模型。此类模型能够描述高度复杂的分布,且与生成对抗网络(GAN)或变分自编码器(VAE)不同,它可以通过精确的最大似然估计进行高效训练。我们提出的模型采用自回归结构,并利用长短期记忆网络(LSTM)实现任意长的时间依赖性。重要的是,该模型具有因果性,即输出序列中的每个姿态生成时均不依赖未来时间步的姿态或控制输入;这种零算法延迟的特性对于需要实时运动控制的交互应用至关重要。该方法原则上可适用于任何运动类型,因为它不对运动特征或角色形态施加限制性的任务特定假设。我们在人类和四足动物运动的动作捕捉数据集上评估了模型性能。主客观实验结果均表明,本方法随机采样的运动效果优于任务无关的基线模型,其运动质量接近录制的动作捕捉数据。
Modi: Unconditional motion synthesis from diverse data
神经网络的出现彻底改变了运动合成领域。然而,学习从给定分布中无条件合成运动仍然具有挑战性,尤其是在运动高度多样化的情况下。本研究提出MoDi——一种在无监督设置下,从极其多样化、非结构化和无标签的数据集中训练得到的生成模型。在推理过程中,MoDi能够合成高质量、多样化的运动。尽管数据集缺乏任何结构,我们的模型仍能产生规整且高度结构化的潜空间,该空间可进行语义聚类,构成强大的运动先验,有助于实现语义编辑和群组模拟等多种应用。此外,我们提出一种编码器,可将真实运动映射到MoDi的自然运动流形中,为解决前缀补全和空间编辑等不适定问题提供解决方案。定性与定量实验均达到领先水平,超越了近年来的SOTA技术。代码和训练模型详见https://sigalraab.github.io/MoDi。
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
核心问题是什么?
直接基于自然语言生成人体运动
现有方法及局限性
如何根据多样化文本输入实现细腻且精细的运动生成仍具挑战性。
本文方法及优势
MotionDiffuse——首个基于扩散模型的文本驱动运动生成框架,其展现出超越现有方法的三大特性:
1)概率性映射。通过注入变异的多步去噪过程生成运动,取代确定性语言-运动映射;
2)真实合成。擅长复杂数据分布建模并生成生动运动序列;
3)多级操控。支持身体部位的细粒度指令响应,以及基于时变文本提示的任意长度运动合成。
实验表明MotionDiffuse在文本驱动运动生成和动作条件运动生成方面显著优于现有SoTA方法。定性分析进一步证明框架在综合运动生成方面的强大可控性。项目主页:https://mingyuan-zhang.github.io/projects/MotionDiffuse.html
方法
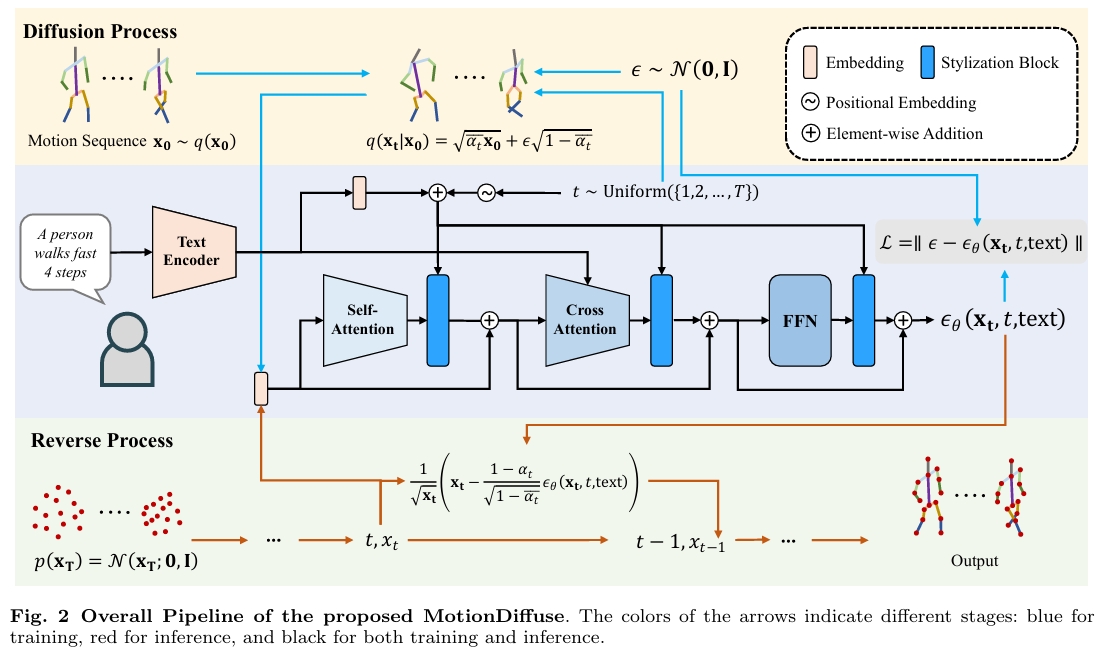
实验
KIT-ML, HumanML3D
效果SOTA
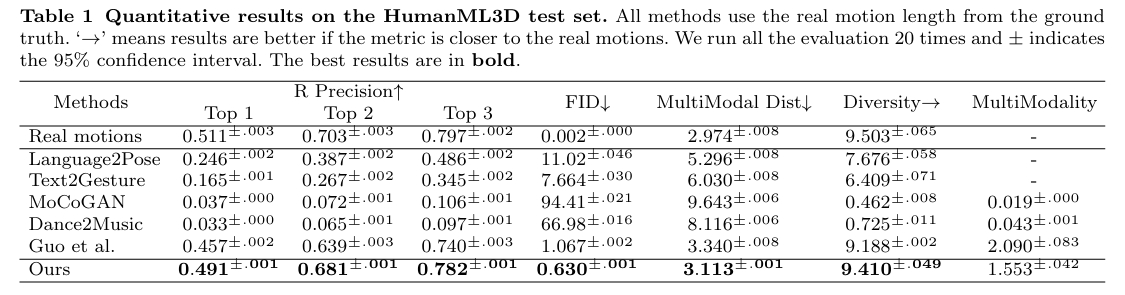
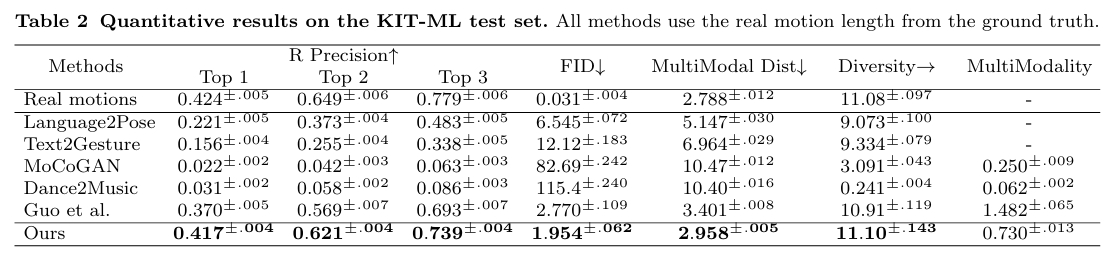
A deep learning framework for character motion synthesis and editing
核心问题是什么?
开创了Deep Learning Based运动生成的先河
大致方法
第一步:Building the Motion Manifold
| 输入 | 输出 | 方法 |
|---|---|---|
| 动作数据,T*D1 | latent data,T*D2(256) | 一维(时间维度)卷积 Based Encoder |
| latent data,T*D2(256) | 重建动作数据,T*D1 | 一维(时间维度)卷积 Based Decoder |
| 动作数据 重建动作数据 网络参数 | Loss | L2 Loss + L1正则化 |
关键创新:Max Pooling。实验表明Max Pooling对结果起到了较大的提升作用。
---
title: Building the Motion Manifold
---
flowchart LR
Input[("动作数据")]
Encoder
Latent(["Latent Code"])
Decoder
Output(["Output"])
Loss(["Loss"])
Input-->Encoder-->Latent-->Decoder-->Output
Input & Output --> Loss
Loss e1@-->Encoder
Loss e2@-->Decoder
e1@{ animation: fast }
e2@{ animation: fast }
第二步:Mapping High Level Parameters to Human Motions
| 输入 | 输出 | 方法 |
|---|---|---|
| 高级控制参数,例如轨迹 frequency | 触地信息,T * 4 | 正弦函数 |
| 高级控制参数,例如轨迹 触地信息,T * 4 | latent data,T*D2(256) | 卷积based网络 |
| latent data,T*D2(256) | 重建动作数据,T*D1 | 一维(时间维度)卷积 Based Decoder,fixed |
| 重建动作数据 GT | Loss |
---
title: Mapping High Level Parameters to Human Motions
---
flowchart LR
Input[("控制信息")]
NN["input curve T -> parameters"]
Wave(["Wave Parameters"])
SquareWaves["square waves"]
F(["触地信息"])
FF["Feedforward Network"]
Latent(["Latent Code"])
Decoder
Output(["Output"])
GT[("GT")]
Loss(["Loss"])
Input-->NN-->Wave-->SquareWaves-->F
Input & F --> FF --> Latent-->Decoder-->Output
Output & GT --> Loss
Loss e1@-->FF
e1@{ animation: fast }
应用
Applying Constraints in Hidden Unit Space
---
title: Applying Constraints in Hidden Unit Space
---
flowchart LR
Init(["初始Lantet Motion"])
Decoder
Output(["Output"])
Constrain[("约束")]
Loss(["Loss"])
Init-->Decoder-->Output
Output & Constrain --> Loss
Loss e1@-->Init
e1@{ animation: fast }
Motion Stylization in Hidden Unit Space
---
title: Motion Stylization in Hidden Unit Space
---
flowchart LR
Init(["初始Lantet Motion"])
Style[("风格条件")]
Content[("内容条件")]
LatentContent(["latent内容条件"])
LatentStyle(["latent风格条件"])
GMStyle(["输入风格的Gram matrix"])
GMMotion(["当前Motion风格的Gram matrix"])
LossContent(["内容Loss"])
LossStyle(["风格Loss"])
Loss(["Loss"])
Encoder1["Encoder"]
Encoder2["Encoder"]
GM1["计算Gram Matrix"]
GM2["计算Gram Matrix"]
Content --> Encoder1 --> LatentContent
Style --> Encoder2 --> LatentStyle
Init & LatentContent --> LossContent
Init --> GM1 --> GMMotion--> LossStyle
LatentStyle --> GM2 --> GMStyle --> LossStyle
LossContent & LossStyle --> Loss
Loss e1@-->Init
e1@{ animation: fast }
实验
数据集
- CMU
- 自采数据 + 重定向
数据预处理流程
-
时序标准化:统一降采样至60FPS保证时序一致性
-
空间表征转换:将关节角度表示→3D关节位置(局部坐标系)
-
坐标系构建:以根关节地面投影为原点,通过肩/臀部向量计算前进方向(Z轴)
-
运动学参数增强:添加全局速度(XZ平面)、旋转速度(Y轴)和足部接触标签
-
数据归一化:减去均值/除以标准差(分别处理姿态、速度、接触标签)
总结
核心价值:第一篇基于AI的3D骨骼动作生成工作
成本分析:需要特定角色的大量数据
落地瓶颈:需要特定角色的大量数据,生成动作也只能用于特定角色,没有角色之间的泛化性。
Multi-Object Sketch Animation with Grouping and Motion Trajectory Priors
核心问题是什么?
矢量草图动画,能处理多对象交互和复杂运动

现有方法及局限性
现有方法难以应对这些场景,要么仅限于单对象情况,要么存在时间不一致和泛化能力差的问题。
本文方法及优势
GroupSketch采用包含运动初始化和运动优化的两阶段流程:
第一阶段通过交互式将输入草图划分为语义组并定义关键帧,通过插值生成粗粒度动画;
第二阶段提出基于组的位移网络(GDN),利用文本-视频模型的先验知识预测组别位移场以优化粗动画。GDN还整合了上下文条件特征增强(CCFE)等专用模块来提升时间一致性。
大量实验表明,本方法在为复杂多对象草图生成高质量、时间一致的动画方面显著优于现有方法,从而拓展了草图动画的实际应用。
参考材料
https://hjc-owo.github.io/GroupSketchProject/
TRACE: Learning 3D Gaussian Physical Dynamics from Multi-view Videos
核心问题是什么?
输入:动态多视角视频,及每个视角的相机参数,无需其它任何人工标注
输出:
- 建模三维场景的几何、外观
- 估计场景中对象的物理信息
- 基于物理信息预测续写视频
现有方法及局限性
现有工作通常通过将基于物理的损失作为软约束或将简单物理模型集成到神经网络中来实现,但往往难以学习复杂的运动物理规律,或者需要额外的标注(如物体类型或遮罩)。
本文方法及优势
我们提出了一个名为 TRACE 的新框架来建模复杂动态三维场景的运动物理规律:
- 将每个三维点建模为空间中具有大小和方向的刚性粒子
- 直接为每个粒子学习一个平动-旋转动力学系统,显式地估算出一整套物理参数来控制粒子随时间的运动。
在三个现有动态数据集和一个新创建的具有挑战性的合成数据集上进行的大量实验表明,我们的方法在未来帧外推任务中相对于基线模型具有卓越的性能。我们框架的一个优良特性是,只需对学习到的物理参数进行聚类,即可轻松分割多个物体或部件。我们的数据集和代码可在 https://github.com/vLAR-group/TRACE 获取。
主要方法
输入:具有已知相机位姿和内参的动态多视角RGB视频
三维场景表示模块旨在学习一组三维高斯核,用于在规范空间中表示三维场景的几何和外观
辅助变形场旨在根据当前训练时间t预测每个高斯核的位移和畸变
平动-旋转动力学系统旨在为每个三维刚性粒子学习一组物理参数,以控制其随时间变化的运动动力学
Canonical 3D Gaussians
准备
输入:t=0时刻的N个视角的图像、N个视角的相机参数
假设每个高斯核的不透明度 σ 和颜色 c 不会随时间更新
三维高斯核 G₀的表征:
- 三维位置 x₀
- 由四元数 r₀ 和缩放 s₀ 导出的协方差矩阵
- 不透明度 σ
- 由球谐函数计算的颜色 c 初始化:随机初始化或SfM初始化
优化过程
将高斯核投影到相机空间
将投影后的高斯核渲染到图像空间
通过 3DGS 中使用的 ℓ₁ 损失和 ℓₛₛᵢₘ 损失优化所有核参数

辅助变形场
它是一个基于 MLP 的网络。
输入是规范位置 x₀ 和时间 t。
输出是几何变化量 (δx, δr, δs),用于将规范高斯核 G₀ 扭曲到时间 t 的状态 Gₜ。
xₜ = x₀ + δx,
rₜ = r₀ ◦ δr,
sₜ = s₀ ⊙ δs,
σ, c(保持不变)
平动-旋转动力学系统
将复杂场景离散化为刚性粒子(即高斯核),并聚焦于学习每个粒子的独立动力学。
依据经典力学,将每个粒子的运动分解为绕一个运动的旋转中心进行的转动,同时该旋转中心自身也在平动。
模块输出: 为每个粒子学习两组物理参数 参数组 #1 - 旋转中心参数: 包括:
- 中心位置 P_c ∈ R³,
- 中心速度 v_c ∈ R³,
- 中心加速度 a_c ∈ R³(在世界坐标系下)。
旋转中心可以是任意位置,不一定是粒子所在的位置
参数组 #2 - 刚性粒子旋转参数: 包括:
- 刚性粒子相对于其旋转中心 P_c 的旋转矢量 w_p ∈ R³,
- 刚性粒子的角加速度 ϵ_p ∈ R³。
通过两组参数,得出粒子的合成速度为:
由于在网络推断的过程中 P_c 和 V_c 难以解耦,把 P_c 和 V_c 合并成 \(\bar v_c^t\)
因此MLP的实际输入输出为:

仅需在某个特定时间 t 学习一次这个完整的平动-旋转动力学系统,随后该粒子的未来运动将由学习到的动力学系统根据力学定律来支配。
训练
X-MoGen: Unified Motion Generation across Humans and Animals
核心问题是什么?
文生人类动作和动物动作

现有方法及局限性
- 分别建模人类与动物动作
- 联合跨物种方法具备统一表征与更强泛化性等关键优势,但由于物种间形态差异,常导致动作失真。
本文方法及优势
X-MoGen:首个覆盖人类与动物的统一跨物种文本驱动动作生成框架。
第一阶段:条件图变分自编码器学习规范T姿态先验,同时自编码器将动作编码至由形态学损失正则化的共享潜空间;
第二阶段:通过掩码动作建模生成基于文本描述的动作嵌入。
训练中采用形态一致性模块保障跨物种骨骼合理性。为支持统一建模,我们构建了包含115个物种、11.9万动作序列的大规模数据集UniMo4D,在共享骨骼拓扑下整合人/动物动作进行联合训练。UniMo4D上的大量实验表明,X-MoGen在已知/未知物种上均超越现有最优方法。
主要方法
图2:X-MoGen架构概览 我们的两阶段框架首先通过条件图自编码器(CGAE) 和自编码器(AE) 学习T姿态先验与紧凑动作潜空间。第二阶段中,掩码Transformer(M-Trans) 引导扩散模型从噪声生成动作,该过程以文本描述及CGAE生成的物种特定T姿态先验为条件。辅助的形态一致性模块(MCM) 对生成动作施加形态学约束。
Stage 1: Feature Modeling
T-pose Modeling via CGAE
[?]
- 本文要求所有物理的骨骼拓扑是一一致的。只是长度的朝向的差异。
- CGAE中只编码了骨骼长度的信息,怎么约束朝向信息呢?
- CGAE中的BioCLIP-2部分只对一个物种信息编码,怎么实现跨物种的效果?
Motion Representation via AE
[?] 这里为什么是AE而不是VAE
Stage 2: Masked Motion Generation
Masked Motion Modeling
Diffusion-based Completion Head
[?]为什么需要输入T-pose Embedding?Latent Embedding足以恢复信息。 [?]蒙皮权重与Mesh的影响不考虑进去?
Morphological Consistency Module
- MCM是怎么做的?从哪里获取角度极限的信息?
- MCM是什么时候训练的?
Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
核心问题是什么?
视频到4D生成框架,可从单段视频输入中创建高质量动态3D内容。

现有方法及局限性
直接进行4D扩散建模因数据构建成本高昂,且需联合表征3D形状、外观与运动的高维特性而极具挑战性。
本文方法及优势
直接4D网格-高斯场变分自编码器(Direct 4DMesh-to-GS Variation Field VAE):无需逐实例拟合,直接从3D动画数据中编码规范高斯溅射点(GS)及其时序变化,将高维动画压缩至紧凑潜空间。
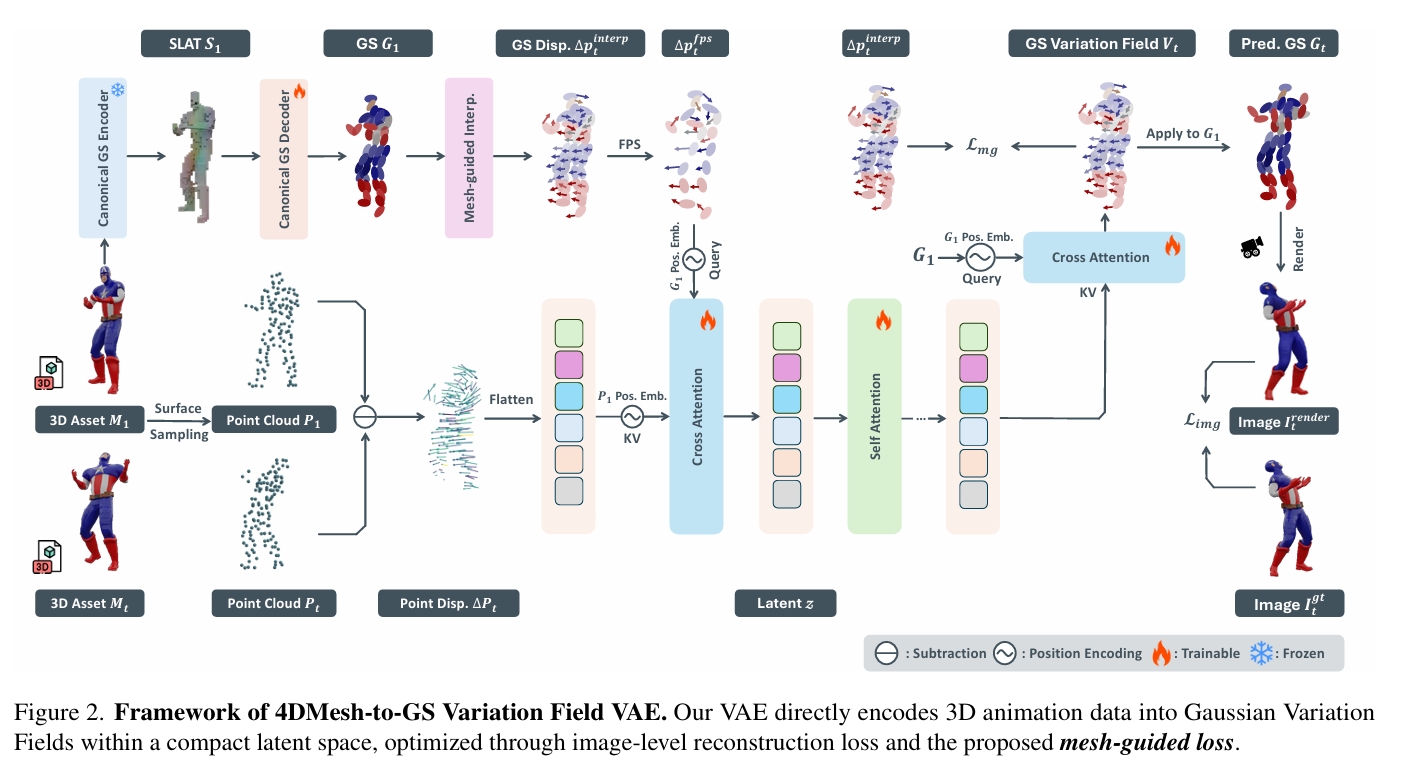
高斯变分场扩散模型:该模型采用时序感知型扩散Transformer架构,以输入视频和规范GS作为条件。
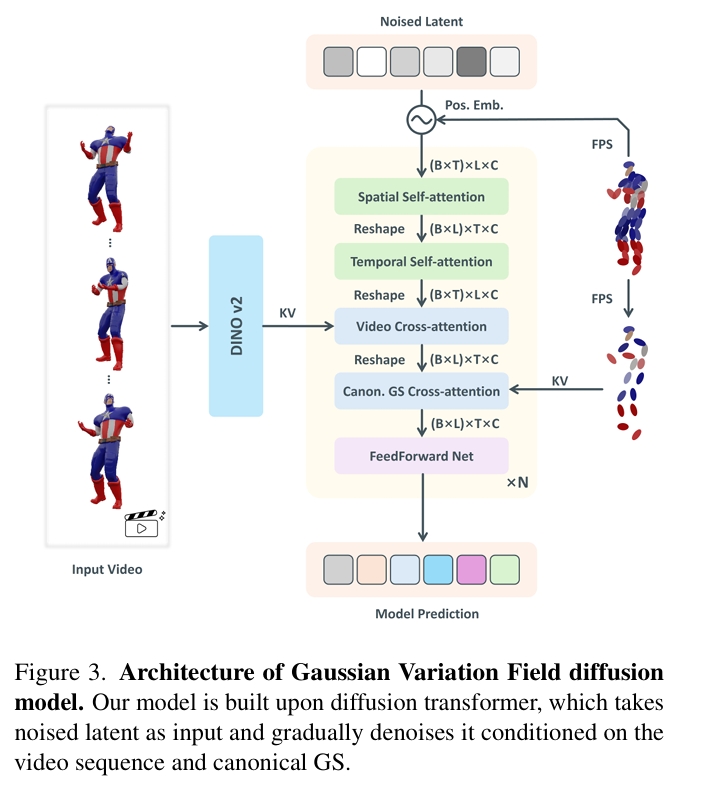
通过在Objaverse数据集精选的可动画3D对象上训练,本模型相较现有方法展现出更优的生成质量。尽管仅使用合成数据训练,其对真实场景视频输入仍表现出卓越的泛化能力,为高质量动态3D内容生成开辟了新路径。项目页面:GVFDiffusion.github.io。
主要方法
MotionShot: Adaptive Motion Transfer across Arbitrary Objects for Text-to-Video Generation
核心问题是什么?
文本到视频生成,且参考对象(动作信息来自图像)与目标对象(外观信息来自文本)外观或结构差异显著

现有方法及局限性
现有的方法在这种情况下,难以实现运动的平滑迁移。
本文方法及优势
MotionShot——一个无需训练的框架,能够以细粒度方式解析参考-目标对象的对应关系,在保持外观连贯性的同时实现高保真运动迁移。
- 首先通过语义特征匹配确保参考与目标对象的高层对齐
- 继而通过参考到目标的形状重定向实现底层形态对齐。
通过时序注意力机制编码运动,我们的方法能连贯地跨对象迁移运动,即使存在显著的外观与结构差异,大量实验已验证其有效性。项目页面详见:https://motionshot.github.io/。
主要方法
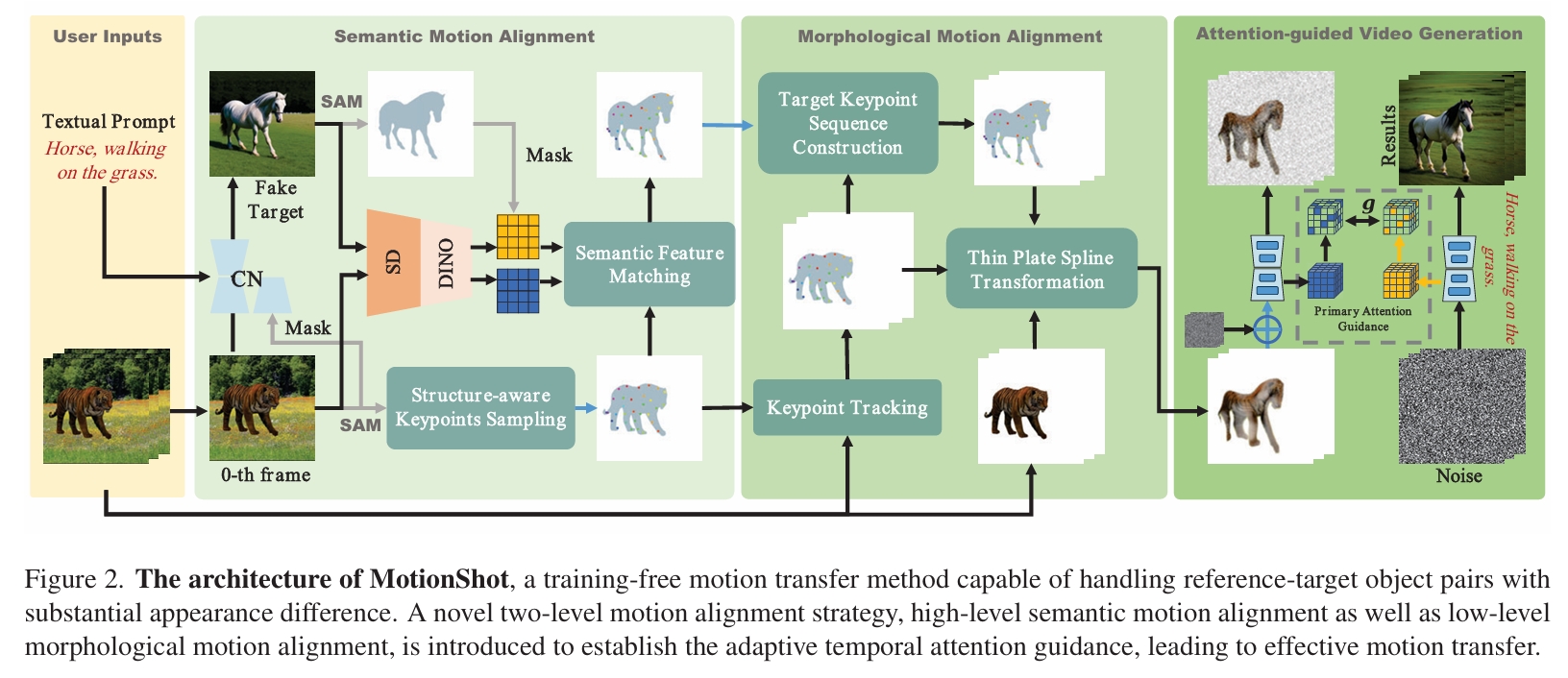
通过对Source Image(动作信息来源)做Warp,得到与『目标对象做特定动作』大致相似的图像做为condition,引导最终的生成。
源和目标虽然差距比较大,但在生理结构上仍具体语义相似性。作者利用这种相似性实现大致轮廓上迁移。
DINO:用于提取外观特征。
Semantic Feature Matching:用于识别生理结构上相似部位的匹配。
Thin Plate Spline Transformation:利用相似性实现轮廓迁移。
实验
Base Model: AnimateDiff
Drop: Dynamics responses from human motion prior and projective dynamics
合成能够动态响应环境的逼真人运动,是角色动画领域的长期目标,在计算机视觉、体育和医疗保健领域具有应用价值,可用于运动预测和数据增强。最近的基于运动学的生成式运动模型在建模海量运动数据方面展现出令人印象深刻的可扩展性,但缺乏对物理进行推理和交互的接口。虽然仿真器在环(simulator-in-the-loop)学习方法能够实现高度物理逼真的行为,但训练中的挑战常常影响其可扩展性和采用率。我们提出了DROP,一个利用生成式运动先验(generative motion prior)和投影动力学(projective dynamics)来建模人体动力学响应(Dynamics Responses)的新框架。DROP可视为一个高度稳定、极简的基于物理的人体模拟器,并与基于运动学的生成式运动先验对接。利用投影动力学,DROP能够灵活、简单地将学习到的运动先验作为投影能量(projective energies)之一进行集成,从而将运动先验提供的控制无缝地融入牛顿动力学(Newtonian dynamics)中。DROP作为一个与模型无关(model-agnostic)的插件,使我们能够充分利用生成式运动模型的最新进展,实现基于物理的运动合成。我们在不同运动任务和各种物理扰动下对我们的模型进行了广泛评估,证明了其响应的可扩展性和多样性。
研究背景与问题
要解决的问题
合成能够动态响应环境的逼真人运动。
现有方法及问题
- 基于运动学的生成式运动模型在建模海量运动数据方面展现出令人印象深刻的可扩展性,但缺乏对物理进行推理和交互的接口。
- 虽然仿真器在环学习方法能够实现高度物理逼真的行为,但训练中的挑战常常影响其可扩展性和采用率。
本文方法及优势
我们提出了DROP,一个利用生成式运动先验和投影动力学来建模人体动力学响应的新框架。DROP可视为一个高度稳定、极简的基于物理的人体模拟器,并与基于运动学的生成式运动先验对接。利用投影动力学,DROP能够灵活、简单地将学习到的运动先验作为投影能量之一进行集成,从而将运动先验提供的控制无缝地融入牛顿动力学中。
DROP作为一个与模型无关的插件,使我们能够充分利用生成式运动模型的最新进展,实现基于物理的运动合成。
主要方法
投影动力学(Projective Dynamics):用约束定义能量,通过最小化一个能量函数来求解系统的状态。
投影动力学框架的核心是其能量最小化过程。DROP巧妙地将学习到的生成式运动先验模型的输出视为一种投影能量项。这个额外的能量项表达了“角色应该如何运动才自然”的期望(由数据驱动的先验知识)。在优化最小化总能量的过程中,系统会自然地趋向于满足这个期望,同时满足物理约束,从而有效地为角色提供了控制力。
基于IPC的Ragdoll系统
POMP: Physics-consistent Human Motion Prior through Phase Manifolds
论文信息: CVPR 2024, Bin Ji et al., Shanghai Jiao Tong University/Zhejiang University
Link: CVF Open Access
一、核心问题
1.1 研究背景
大量关于实时运动生成的研究主要聚焦于运动学层面,这常常导致物理上失真的结果(如脚部滑动、漂浮、穿透)。
现有方法主要分为两类:
- 运动学方法:易于整合生成模型(VAE、Flow、Diffusion),但缺乏物理约束
- 物理仿真方法:基于强化学习或优化,但计算复杂度高,难以训练和应用
最近 DROP 方法尝试将物理仿真器插入预训练的运动学模型,但由于领域鸿沟(domain gap),常常产生不真实的结果。
1.2 核心问题
如何实现物理一致的实时人体运动生成,同时解决领域鸿沟问题?
1.3 本文方法
论文提出了 POMP ("Physics-cOnstrainable Motion Generative Model through Phase Manifolds",即"通过相流形实现物理约束的运动生成模型")。
核心思想:
- 利用相流形来对齐运动先验与物理约束
- 合成物理一致且运动学合理的运动
- 将计算密集型的动力学模块置于训练循环之外
关键创新:
- 基于扩散的运动学模块 + 基于仿真的动力学模块 + 相位编码模块
- 首次采用基于相位的语义对齐解决领域鸿沟
- 从 MoCap 数据中提取地形图和全身运动冲量的流程
二、核心贡献
-
物理一致的运动生成
- 实时对物理扰动进行主动和被动响应
- 将动力学模块置于基于梯度的训练循环之外,降低计算复杂度
-
相位语义对齐
- 首次采用基于相位的语义对齐方法
- 解决运动学运动先验与仿真姿态之间的领域鸿沟
-
地形和冲量数据生成流程
- 开发地形重建流程
- 从动捕数据集中提取全身运动冲量
三、大致方法
3.1 框架概述

POMP 通过循环过程运行,如图 2(a) 所示:
- 运动学模块:基于当前运动变量 $x_i$ 生成目标姿态 $\tilde{q}_i$
- 动力学模块:
- PD 控制器计算关节力向量 $\tau_i$
- 物理引擎执行前向动力学,生成物理合理姿态 $q_i$ 和全身接触冲量 $j_{i+1}$
- 相位编码模块:提取对应于仿真姿态 $q_i$ 的相位变量 $p_i$
- 相位变量与更新的运动变量 $x_{i+1}$ 一起作为下一帧的输入
关键设计:POMP 仅需训练运动学生成器和相位编码模块,物理仿真器作为固定的、不可微分组件运行。
flowchart TB
subgraph Kinematic["运动学模块"]
Enc["OrthoMoE Encoder"]
Diff["Diffusion Decoder"]
end
subgraph Dynamic["动力学模块"]
IK["逆动力学 PD 控制"]
FK["前向动力学仿真"]
end
subgraph Phase["相位编码模块"]
PAE["Periodic Autoencoder"]
Align["语义对齐"]
end
Input["状态 + 地形 + 轨迹"] --> Enc
Enc --> Diff
Diff --> IK
IK --> FK
FK --> Align
Align --> PAE
PAE --> Enc
style Kinematic fill:#e1f5fe
style Dynamic fill:#fff3e0
style Phase fill:#e8f5e9
三模块协作:
- 运动学模块:基于扩散的运动先验生成初始目标姿态
- 动力学模块:强制执行动态约束,产生仿真姿态(不可微)
- 相位编码模块:将仿真姿态投影回运动先验,获取相位位置编码
3.2 物理仿真角色建模
刚体系统:
- 使用 15 个盒形或胶囊形肢体碰撞器(Unity)
- 比实际肢体数量少,但可适配更复杂的关节结构
- 基于 CMU 数据库的模型尺寸
- 质量根据碰撞器体积和人体平均密度计算
- 实现关节限制,使运动更像人类
刚体动力学: 动力学模块执行两种计算:
- 逆动力学:运动控制器计算施加到刚体系统的力
- 前向动力学:物理仿真器确定角色对环境力的加速度响应
3.3 运动表示
第 $i$ 帧的运动变量 $x_i$ 由四部分组成:
| 组成部分 | 内容 | 维度 |
|---|---|---|
| 角色状态 | 关节位置、速度、根关节速度、角速度、步态 one-hot | - |
| 环境信息 | 地形高度、全身接触冲量 | - |
| 相位变量 | 时间窗口上的相位编码、未来输出相位 | - |
| 轨迹位置 | 用户控制轨迹、预测轨迹(2D x-z 平面投影) | - |
四、详细方法
4.1 运动学模块
OrthoMoE-based Encoder
- 输入:$x_i$(541 维,包含全部运动表示信息)
- 输出:$w_k$(1024 维相位编码)
| 输入 | 输出 | 方法 |
|---|---|---|
| $x_i$ 中的相位变量 | 混合系数 $\alpha$ | 门控网络 $E_g$ |
| $x_i$ | 相位编码 $w_k$ | $E_m$ 中的八个专家网络 |
| 相位编码 + 混合系数 | 加权求和输出 | $\sum_{k=1}^8 \alpha_k w_k$ |
约束:各个专家网络的输出互相正交
Diffusion-based Decoder
- 输入:$w$(1024 维条件)
- 输出:$z_i$(8 × 388 维)
$$ y_i = \sum_{k=1}^8 \alpha_k z_k $$
为了加速逆向过程,从 Analytic-DPM 获得灵感,将协方差项替换为解析估计。
4.2 动力学模块 ⭐
动力学模块的核心作用是强制执行物理约束,确保生成的动作符合物理定律。包含两个步骤:
4.2.1 逆动力学 (控制)
使用比例微分(PD)控制器,根据目标姿态和当前状态计算关节力矩:
$$ \tau = k_p (q^* - q) + k_d (\dot{q}^* - \dot{q}) $$
其中:
- $k_p$: 比例增益
- $k_d$: 微分增益
- $q^*$: 目标姿态(来自运动学模块)
- $q$: 当前姿态(来自仿真)
- $\dot{q}^*$: 目标速度(通常设为 0)
- $\dot{q}$: 当前速度(来自仿真)
4.2.2 前向动力学 (仿真)
目标:根据关节力矩 $\tau$ 和环境力,计算加速度并更新状态。
前向动力学方程:
$$ M(q)\ddot{q} + C(q, \dot{q}) + G(q) = \tau + \tau_{ext} $$
求解加速度:
$$ \ddot{q} = M(q)^{-1} (\tau + \tau_{ext} - C(q, \dot{q}) - G(q)) $$
数值积分:
$$ \dot{q}^{t+\Delta t} = \dot{q}^t + \ddot{q}^t \cdot \Delta t $$ $$ q^{t+\Delta t} = q^t + \dot{q}^{t+\Delta t} \cdot \Delta t $$
物理引擎:POMP 使用 Unity PhysX 进行仿真,选择 Unity 而非 Mujoco 或 IsaacGym 的原因:
- 支持半自动方法匹配 MoCap 数据的地形
- 能够收集全身接触力的冲量数据,反馈给运动学模块学习主动响应
- 与游戏和 VR/AR 应用兼容,便于部署
仿真流程(Unity PhysX):
- 碰撞检测:15 个盒形/胶囊形碰撞器与地形和其他物体检测碰撞
- 接触力计算:基于碰撞深度和材料属性计算接触力和摩擦力
- 约束求解:求解关节约束和接触约束
- 状态积分:使用半隐式 Euler(semi-implicit Euler)进行数值积分
- 先更新速度:$\dot{q}^{t+\Delta t} = \dot{q}^t + \ddot{q}^t \cdot \Delta t$
- 再更新位置:$q^{t+\Delta t} = q^t + \dot{q}^{t+\Delta t} \cdot \Delta t$
仿真流程图:
flowchart TB
tau["关节力矩 τ<br/>来自 PD 控制器"] --> PhysX["PhysX 物理引擎"]
env["环境力 τ_ext<br/>重力/接触力/碰撞力"] --> PhysX
PhysX --> Solve["求解前向动力学方程<br/>M(q)q̈ + C(q,q̇) + G(q) = τ + τ_ext"]
Solve --> Acc["计算加速度 q̈<br/>q̈ = M⁻¹(τ + τ_ext - C - G)"]
Acc --> Integrate["数值积分<br/>半隐式 Euler"]
Integrate --> NewState["新状态 (q, q̇)"]
NewState --> Output["输出仿真姿态 q̂<br/>接触冲量 j"]
style PhysX fill:#ffcc80
style Acc fill:#ffe0b2
style Integrate fill:#ffe0b2
为什么需要仿真:
- 物理一致性:确保动作符合牛顿力学、角动量守恒
- 环境交互:正确处理与地形、障碍物的接触和碰撞
- 扰动响应:对外力扰动做出物理合理的反应
- 可行性保证:生成的动作在物理上是可执行的
挑战与解决:
| 挑战 | POMP 解决方案 | 动机 |
|---|---|---|
| 运动学失真 | 相位编码模块投影回相流形 | 仿真姿态可能落在运动学先验之外 |
| 误差累积 | 语义对齐保证连续性 | 直接仿真结果用于后续帧预测会导致失败 |
| 领域鸿沟 | 相位空间对齐 | 物理仿真与运动学生成之间的差异 |
| 计算复杂度 | 动力学模块置于训练循环外 | 避免对物理仿真器进行昂贵的梯度计算 |
4.3 相位编码模块
动机:仿真姿态可能落在运动学先验之外,导致后续预测破坏运动连续性。
Periodic Autoencoder (PAE)
学习紧凑的相流形表示:
| 输入 | 输出 | 方法 |
|---|---|---|
| MoCap 速度序列 $T \times 3NJ$ | - | - |
| 速度序列 ($T=121$) | Latent embedding $T \times 5$ | 1D 卷积 |
| Latent embedding | $a_i, f_i, b_i$ | 可微 FFT |
| Latent embedding | $s_i$ (相移) | MLP |
| $a_i, f_i, b_i, s_i$ | 重构 latent | $L_i = a_i \cdot \sin(2\pi(f_i T - s_i)) + b_i$ |
| 重构 latent | 速度曲线 | 1D 反卷积 |
相位编码计算:
$$ pe_i(2t) = a_i^{(t)} \cdot \cos(2\pi \cdot s_i^{(t)}) $$ $$ pe_i(2t+1) = a_i^{(t)} \cdot \sin(2\pi \cdot s_i^{(t)}) $$
其中 $t = 0, 1, 2, 3, 4$。
五、训练
5.1 数据增强
地形重建
采用 PFNN 的地形拟合方法:
- 计算每帧角色周围的轨迹高度
- 初始化零值高度图
- 用运动轨迹逐步"扫描"更新
- 形成全面的地形数据
接触力获取和姿态仿真
将 MoCap 数据导入 Unity:
- 收集真实接触冲量 $j_i$(用于训练运动学模块)
- 生成真实仿真姿态 $\hat{q}_i$(用于训练相位编码模块)
六、推断
运动学模块预测的输出相位变量 $p_i$ 包含:
- $pe \in 2 \times C \times T$,$C=5$,$T=0.5L+1=7$
- ${f, a, b} \in 3 \times C \times T$
输入 PAE 的速度序列由三部分组成:
- 过去 $(i-60:i)$:使用真实仿真速度
- 近期未来 $(i+1:i+20)$:使用人工仿真速度
- 较远未来 $(i+21:i+60)$:使用目标速度
人工仿真速度:基于物理仿真的加速度计算得到的速度。
七、实验与结论
7.1 定量结果

7.2 应用场景
- VR/AR 虚拟化身:实时响应物理扰动
- 游戏角色控制:适应复杂地形
- 物理交互动画:自然的环境交互
八、局限性
- 依赖训练数据:只能生成训练过的动作类型
- 地形适应性:复杂地形处理有限
- 计算成本:物理仿真仍需一定计算资源
九、启发
9.1 方法学启发
- 动力学模块外置:将物理仿真置于训练循环外,避免昂贵的梯度计算
- 相位语义对齐:在相流形中解决领域鸿沟问题
- 准物理效果:无需特定模拟器专业知识
9.2 与相关工作对比
| 方法 | 物理仿真 | 实时性 | 领域对齐 |
|---|---|---|---|
| DeepMimic | 是 | ✓ | 无需 |
| AMP | 是 | ✓ | 对抗学习 |
| POMP | 是 | ✓ | 相位对齐 |
十、遗留问题
- 更复杂的地形:能否处理动态变化的地形?
- 多角色交互:能否扩展到多角色物理交互?
- 更高效仿真:能否使用更轻量的物理引擎?
笔记说明:本文是 CVPR 2024 关于物理一致运动生成的工作。核心创新包括:
- 动力学模块外置:将物理仿真(逆动力学 + 前向动力学)置于训练循环外,避免昂贵的梯度计算
- 相位语义对齐:通过 aligned-PAE 在相流形中解决领域鸿沟问题
- 前向动力学实现:使用 Unity PhysX 引擎,求解 $M(q)\ddot{q} + C(q, \dot{q}) + G(q) = \tau + \tau_{ext}$ 方程,通过半隐式 Euler 数值积分更新状态
理解本文有助于学习物理感知的运动生成方法,特别是如何在保持计算效率的同时实现物理一致性。
Dreamgaussian4d: Generative 4d gaussian splatting
近日,四维内容生成领域取得了显著进展。然而,现有方法仍存在优化耗时过长、运动可控性不足以及细节质量欠佳等问题。本文提出DreamGaussian4D(DG4D)——一个基于高斯溅射(GS)的高效四维生成框架。我们的核心思路是:将空间变换的显式建模与静态GS相结合,构建出高效且强大的四维生成表征。此外,视频生成方法能够提供有价值的时空先验,从而提升四维生成的质量。具体而言,我们提出了包含两大核心模块的完整框架:1)图像到四维GS转换——首先生成静态GS,随后通过基于HexPlane的动态生成与高斯形变实现动态建模;2)视频到视频纹理优化——利用预训练的图像到视频扩散模型对生成的UV空间纹理图进行时序一致性优化。值得关注的是,DG4D将优化时间从数小时缩短至几分钟,实现了生成三维运动的可视化控制,并产出了可在三维引擎中实现逼真渲染的动画网格。
开源
研究背景与问题
任务
输入:单张图像
输出:图像对应的静态GS模型,t时刻相对于静态GS的位移、旋转、缩放。
本文方法及优势
| 要解决的问题 | 当前方法及存在的问题 | 本文方法及优势 |
|---|---|---|
| 表示方式 | 隐式表示 (NeRF) 场景重建与驱动都非常低效。 | 用 3D GS 显式、高效地表示静态基础,用 HexPlane 显式、高效地表示动态位移。 3DGS相对于Nerf的优缺点 |
| 运动信息来自 | 依赖 Video SDS (视频分数蒸馏) 来从视频扩散模型中“蒸馏”运动信息。 这种方法具有固有的随机性和不稳定性。 | 直接从一段“驱动视频”中学习运动模式。 监督方式还是SDS |
| 静态几何与动态运动之间的关系 | 耦合关系:动态几何建模Nerf 优化慢、运动不规则 | 解耦关系:静态几何建模(GS)+ 动态运动建模(HexPlane位移) 通过优化HexPlane预测每个高斯点在时间轴上的位移,将运动高效地“注入”到高质量的静态场景中 |
| 纹理优化 | 未涉及 | 利用预训练的图像到视频扩散模型,对生成的UV空间纹理贴图进行优化,同时增强其时间一致性。 |
主要贡献
- 一个系统性的图像到4D生成框架,它协同利用了图像条件化的3D生成模型和视频生成模型。这允许直接控制和选择期望的3D内容及其运动,从而实现高质量且多样化的4D生成。
- 显式地表示4D场景:使用 3D GS 表示基础场景,并使用 HexPlane 表示不同时间戳下的形变。这种空间变换的显式建模将4D生成时间从数小时显著缩短至仅需几分钟。
- 一种视频到视频纹理优化策略,通过保持时间一致性,进一步提升了导出的动画网格的质量,使得该框架在实际应用部署中更加友好。
主要方法
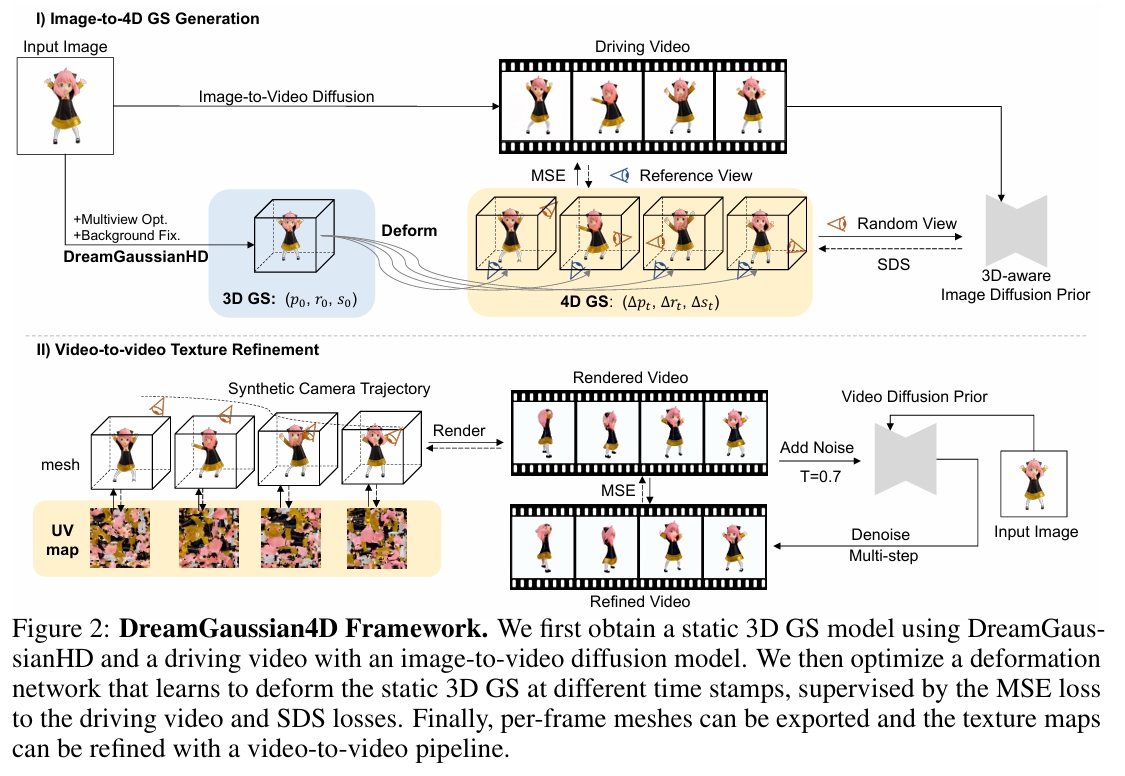
阶段1 从图像生成动态几何
DreamGaussianHD 生成静态3D GS
输入: 单张图像。
输出:使用 DreamGaussianHD 从输入图像生成高质量的静态 3D GS。
Gaussian Deformation for Dynamic Generation
在静态 GS 基础上,优化一个时间相关的形变场(核心是 HexPlane)。预测每个高斯点在每个时间戳的形变。
生成driving video
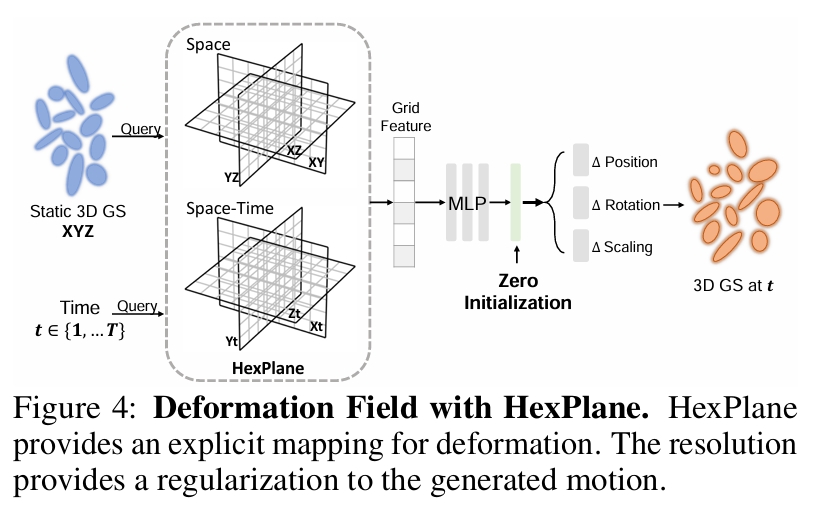
driving video来源: 图像到视频模型(如 SVD/Sora)根据同一张输入图像生成 使用driving video可避免了 SDS 的随机性和低效。
用于 4D 表示的 HexPlane
输入:x,y,z,t
输出:delta positon, delta rotation, delta scaling at t
HexPlane 将一个 4D 场分解为六个特征平面,这些平面跨越每一对坐标轴(例如 XY, XZ, XT, YZ, YT, ZT)。
Hexplane: A fast representation for dynamic scenes
这种分解将 4D 场表示为一组可学习的 4D 基函数的加权和。
静态到动态的初始化
形变模型应被初始化为在训练开始时预测零形变。
为了预测零形变,同时不影响梯度更新,我们采用以下策略:
- 对最后几个线性层进行零初始化(zero-initialization)。
- 采用若干残差连接。
形变场优化
优化目标:
- 参考视角监督:渲染图像与驱动视频对应帧之间的均方误差
- 多视角监督:SDS
为了将运动从参考视角传播到整个 3D 模型(特别是参考视角下被遮挡的部分),我们利用 Zero-1-to-3-XL 来预测未见部分的形变。
优化参数(两种策略):
- 冻结静态 3D GS 的参数,只优化形变场 ϕ
- 选择性地在优化过程中对静态 3D GS 进行微调
输出: 动画网格序列
阶段2 Video-to-Video Texture Refinement
Base Model: SVD
实验
图像 TO 4D

视频 TO 4D
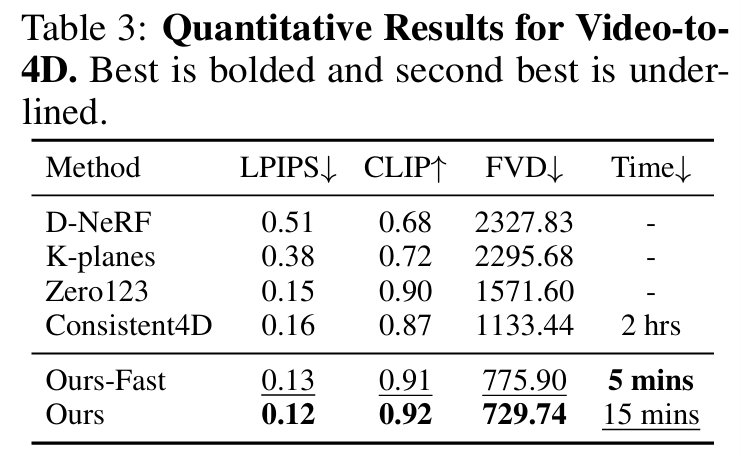
Drive Any Mesh: 4D Latent Diffusion for Mesh Deformation from Video
研究背景与问题
要解决的问题
对现有 3D Mesh进行动画化
本文方法及优势
- 输入 1:初始几何 - 一个表示目标物体的初始点云
P1。它包含N个三维点(pi ∈ R³),通常通过对用户提供的静态 3D 网格进行采样获得。P1定义了物体的初始形状。 - 输入 2:运动参考 - 一个单目视频
V。它包含T帧图像(It),由固定相机拍摄。视频提供了期望的运动模式或姿态序列参考。 - 输出:运动轨迹序列 - 一个点云序列
P = {P1, P2, ..., PT}。 - 实现手段: 使用一个 4D 潜在扩散模型 来建模和学习这个条件分布
p(P|P1, V)。该模型的核心功能是进行条件去噪:从一个噪声版本的点云序列开始,在P1和V的引导下,逐步去噪,最终得到干净的、代表目标动画的点云轨迹序列P。
主要贡献
一种新颖的 4D 生成方法,利用单目视频为 3D 资产生成动画;
一个大规模 4D 资产数据集,包含多视角视频和网格顶点序列;
一种新的基于潜在扩散模型的方法,配备了专为 4D 生成设计的新型 VAE 架构和扩散结构。
主要方法
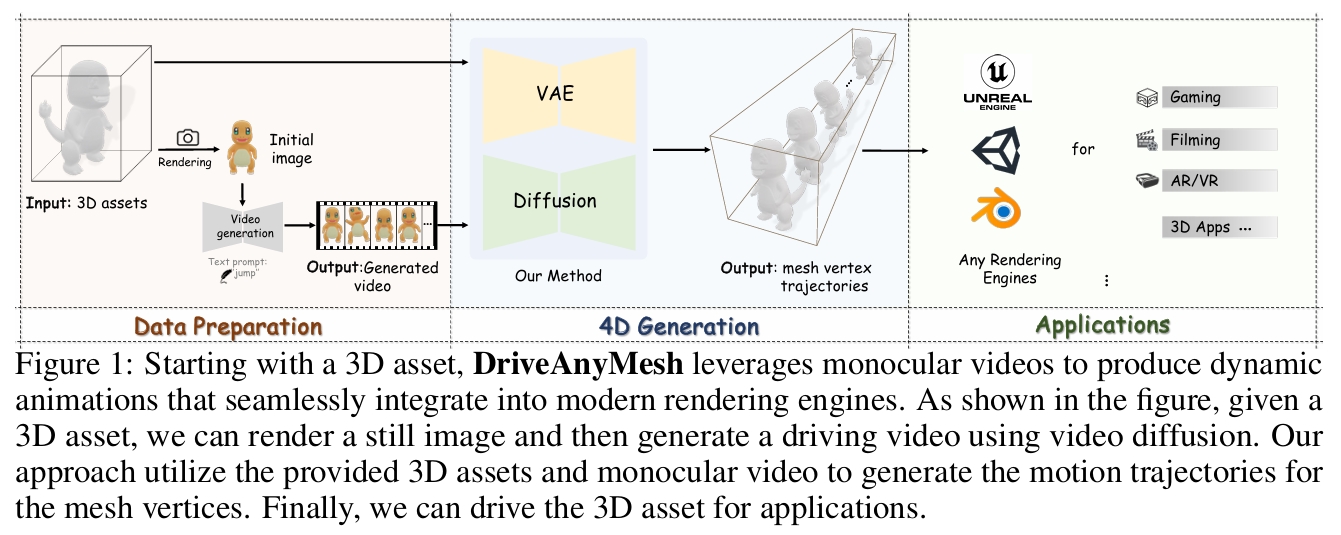
数据准备
从庞大的 Objaverse 数据集 [5, 4] 中精心策划了一个新的 4D 数据集,该数据集包含大量带标注的 3D 对象。
基于点云轨迹的运动表示
核心思想: 将物体的运动表示为其网格顶点随时间的移动路径(轨迹)。
优点: 输出是显式的点云序列 {Pt},其中 Pt 是时间 t 时的顶点位置。这种表示天然兼容所有现代渲染引擎,因为引擎可以直接读取和渲染顶点位置序列定义的网格动画。
关键挑战:不同 3D 网格模型的顶点数量 (N) 差异很大。
解决方案:潜在集 (Latent Sets)
3DShape2VecSets
基于 Transformer 的 VAE
目标: 学习一个紧凑的 4D 潜在表示(即潜在集 F),它能充分编码形状和运动信息,并能被高效地生成和重建。

- 4D 运动编码器: 输入初始点云 P1(几何形状)和多视角动画图像序列(视觉外观和运动信息)。压缩这些时空信息,输出潜在集 F。
- KL 正则化块: 在训练过程中,它约束学习到的潜在集 F 的分布接近一个先验分布(通常是标准正态分布)。(VAE标准操作)。
- 4D 运动解码器: 输入是潜在集 F。响应查询(顶点索引 i 和时间 t),输出顶点 i 在时间 t 的位置,从而重建或生成对应的点云轨迹序列。
使用扩散模型进行运动生成
输入: 用户提供 P₁ (初始网格点云) 和 V (单目参考视频)。
Denoiser 利用空间、条件(几何+外观)和时间注意力机制,预测出更干净的潜在序列{Ẑₜ}ᵗ⁼₁ᵀ。
VAE 将 {Ẑₜ}ᵗ⁼₁ᵀ 输入到 VAE 的解码器中。输出预测的点云轨迹序列 P = {P₁, P₂, ..., Pₜ},即最终的 4D 网格动画。
后处理
基于欧氏距离的阈值滤波机制,用于消除抖动。
实验
测试指标
从视觉质量上评估:
峰值信噪比 (PSNR)、结构相似性指数 (SSIM) 和学习感知图像块相似度 (LPIPS)
横向对比
DreamGaussian4D [27], Consistent4D [12], STAG4D, DreamMesh4D
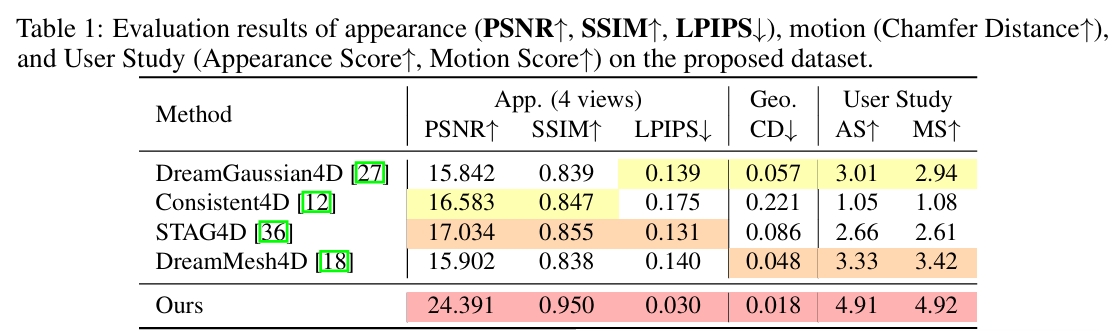
消融实验
在训练变分自编码器 (VAE) 时,仅使用均方误差 (MSE) 损失无法快速收敛到令人满意的结果。因此引入欧氏距离损失 (DIS)。 在相同的优化时间内,结合两种损失函数能得到更好的结果。

相似工作对比(原创)
AnimateAnyMesh是同期相似的工作。相同点:
- 驱动任意拓扑与内容的Mesh。
- 把Mesh序列分解为初始点云和每个顶点的运动路径,通过重建顶点的运动路径,叠加到初始点云后,得到被驱动的Mesh。
- 以顶点顺序、数量无关的方法对Mesh进行编码,表达为隐空间向量。生成模型在隐空间是完成。
- 提供了一个4D Mesh数据集。
不同点:
| 本文 | AnimateAnyMesh | |
|---|---|---|
| Mesh编码方式 | Self Attention + Cross Attention + VAE | Latent Set + Transformer VAE |
| 生成模型 | 修正流 | diffusion |
AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation
研究背景与问题
要解决的问题
根据文本驱动对任意3D网格进行动画化
本文方法及优势
- 采用了一种新颖的 DyMeshVAE 架构,通过将空间特征和时间特征解耦,并保留局部拓扑结构,从而有效地压缩并重建动态网格序列。
- 为了实现高质量的文本条件生成,我们在压缩后的潜在空间中采用了一种基于修正流(Rectified Flow) 的训练策略。 贡献了一个名为 DyMesh Dataset 的大规模数据集,包含超过400万个带有文本标注的多样化动态网格序列。
实验结果表明,AnimateAnyMesh能够在几秒钟内生成语义准确且时间连贯的网格动画,在质量和效率方面均显著优于现有方法。
主要方法
DyMeshVAE
顶点编码
给定一个动态网格序列 \( \mathcal{D} \subset { F \in \mathbb{R}^{M\times3},\ V \in \mathbb{R}^{T\times N\times3} } \)
首先将顶点序列 \( V \) 分解为初始帧顶点 \( V_0 \in \mathbb{R}^{N\times3} \) 和相对运动轨迹 \( V_T \in \mathbb{R}^{N\times(T\cdot3)} \),满足以下关系:
$$ V^t = V^0_t + V^t_T,\quad \text{其中 } t = 1, 2, \dots, T $$
其中 \( t \) 表示时间序列的索引。
将顶点序列 V 拆分为 V0 和 VT 是DyMeshVAE 的关键建模思想之一。这种分解方式有助于实现形状与运动的解耦建模,同时使得运动分布更接近一个均值为零的正态分布。
位置编码
目的:增强轨迹重建的稳定性并防止粘连效应
方法:对 \( V_0 \) 和 \( V_T \) 使用不同的位置编码策略,从而得到编码后的特征 \( \hat V_{0} \) 和 \( \hat V_{T} \)。
拓扑编码
从输入网格的面片信息 F 中构建一个邻接矩阵 Adj。该邻接矩阵随后作为自注意力层中的注意力掩码,使每个顶点能够聚合其相邻顶点的信息:
$$ \bar V_0 = \text{Softmax}\left( \frac{\hat V_{0} \cdot \hat V_{0}^T \odot \text{Adj}}{\sqrt{d_k}} \right)\hat V_{0} + \hat V_{0} \tag{2} $$
捕捉运动模式之间的相关性
对拓扑感知顶点特征 \(\bar \V_0\)应用最远点采样(Farthest Point Sampling, FPS)55,得到\(\bar \V_0^n\)
attention map
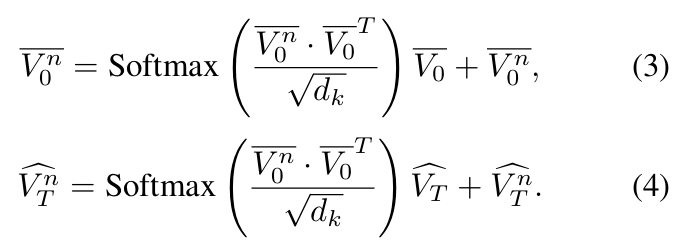
KL Regularization
目的:对相对轨迹 \(\hat \V_T^n\) 的分布进行建模。
- 在潜空间采用 KL 正则化以调控特征多样性。即:
通过两个全连接层对 \(\hat \V_T^n\) 进行线性投影,预测其分布的均值和标准差 - 随后按以下方式对 VAE 潜变量进行采样:
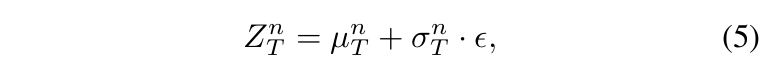
- 正则化约束为:
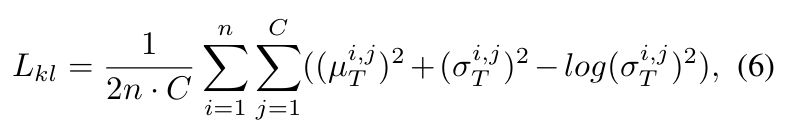
DyMeshVAE Decoder
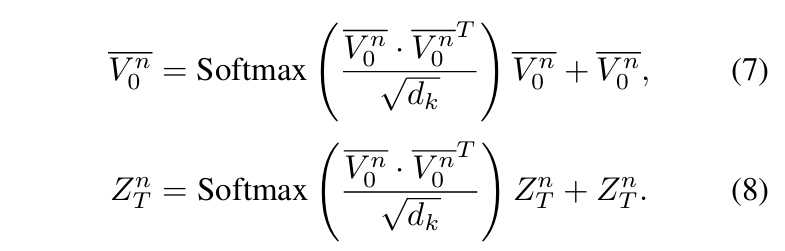
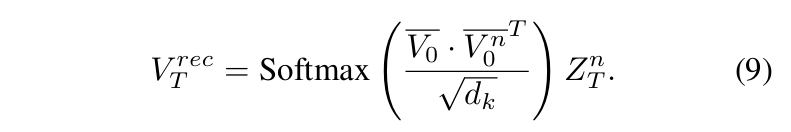
形状引导的文本到轨迹模型
目的:在给定初始网格和文本提示的条件下估计相对轨迹的后验分布。
每个动态网格序列 \( \mathcal{D} \) 被编码为一对潜表示 \( {V_n^0, Z_n^T} \)。
- 使用全局统计量(均值 \( \mu_0, \mu_T \) 和标准差 \( \sigma_0, \sigma_T \))标准化潜变量以消除数值差异
- 沿通道维度拼接标准化特征 → 形成综合轨迹嵌入
- 通过预训练CLIP文本编码器获取文本嵌入
- 采用时间步 \( t \) 相关的独立自适应层归一化(AdaLN)参数分别调制轨迹嵌入和文本嵌入
- 重缩放后的特征拼接进行自注意力计算
- 多注意力块处理后,分解输出特征并基于保存的统计量 \( \mu_0, \mu_T, \sigma_0, \sigma_T \) 还原原始尺度
训练
训练
遵循修正流(Rectified Flow, RF)[42]的扩散范式,我们旨在最小化预测流与真实流之间的均方误差。
修正流:Flow straight and fast: Learning to generate and transfer data with rectified flow
推断
基于流式的常微分方程(ODE)公式实现修正流的采样过程。
采样完成后,将生成的轨迹特征 \( Z_n^T \) 与拓扑感知顶点特征 \( V_n^0 \) 输入解码器生成相对轨迹,最终通过将解码的顶点位移应用于给定网格,生成动态网格序列。
实验
估计指标
- 重建质量评估:计算重建顶点轨迹与真实轨迹间的逐帧平均 L2 距离
- 从固定视角渲染动画网格,并从视觉质量上评估
- 人工评估
横向对比
- DG4D [58]:基于微分几何的变形模型
- L4GM [59]:潜在空间网格运动生成器(使用 DynamiCrafter [86] 作为视频生成组件)
- Animate3D [26]:神经渲染驱动的动画框架
| 方法 | 技术缺陷 | 本方案解决策略 |
|---|---|---|
| DG4D | 视频蒸馏导致3D表示退化 • 高斯球参数无法精确描述拓扑变化 | ✅ 直接操作网格顶点 • 保留显式几何结构 |
| L4GM | 视频生成依赖背景信息 • 孤立物体缺乏纹理线索 → 运动估计失真 | ✅ 端到端轨迹学习 • 无需中间视频表示 |
| Animate3D | 多阶段误差传递 网格→高斯→视频→轨迹的转换损失 | ✅ 单阶段预测框架 • 消除累计误差 |
消融实验
| 组件 | 输入对象 | 核心功能 | 失效后果 |
|---|---|---|---|
| Adj | 网格边连接关系 | 建立顶点语义边界(如手指关节 vs 手掌) | 跨语义区域粘连(图 7) |
| PE₀ | 初始顶点坐标 | 编码空间位置信息 → 增强静态特征区分度 | 对称部位运动混淆 |
| PEₜ | 轨迹向量 | 描述运动方向/幅度 → 提升时序建模能力 | 运动轨迹抖动(图 8) |
| Sep Attn | 初始特征 \(V_n^0\) | 仅基于拓扑计算注意力 → 强化 "结构-运动" 关联规则 | 局部运动协调性下降 23% |
| Emb FPS | 邻域增强特征 | 保留语义信息的采样 → 512 令牌覆盖关键运动区域 | 重建误差上升 15.7% |
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
研究背景与问题
要解决的问题
生成包含复杂动作和交互的视频
本文方法及优势
首先,使用一个视频扩散模型生成一个粗糙的视频。
接着,从该粗略视频中提取一组 2D 和 3D 特征,构建一个以对象为中心的 3D 表示,并通过我们提出的参数化物理先验模型对其进行优化,生成精确的 3D 动作序列。
最后,这一优化后的动作序列被反馈到同一个视频扩散模型中作为额外的条件输入,使得即使在涉及复杂动作和交互的情况下,也能生成运动一致的视频。
主要方法
基于运动条件的视频生成
从预训练的 SVD 模型出发,在原始条件输入中额外拼接了两个通道:
- 3D 运动序列的部件级分割掩码
- 该掩码可靠性的置信度图
| 场景 | 数据来源 | 占训练样本百分比 | 置信度分数 |
|---|---|---|---|
| 场景一 | 运动序列的部件级掩码由从 3D 参数化网格模型投影的所有 2D 部件分割掩码合并生成 | 40 | 1 |
| 场景二 | 用户通过简单的草图(如圆形或椭圆形)指示特定目标或部件(如手或手臂)的最终位置 | 30 | 0.5 |
| 场景三 | 空部件掩码 | 30 | 0 |
ReVision
S1:粗略视频生成
输入:第一帧和可选的用户指定的目标姿态(最终帧中的运动)
输出: 视频
由于生成过程仅依赖于最终帧的目标运动或空运动,而非完整的运动序列,因此生成的视频通常运动质量较差,存在改进空间。因此,称此阶段为粗略视频生成。
S2:以对象为中心的 3D 优化
利用 3D 参数化网格模型(用于人类和动物 [32, 49, 80])、边界框 [57]、分割掩码 [40, 71] 和深度估计 [69](用于通用对象)对目标进行 3D 参数化。
3D参数化方法:
- 人使用SMPL
- 动作使用SMAL
- 其它物体使用BBox、分割掩码和深度估计。
使用参数化物理先验模型(PPPM),基于文本信息和运动强度对 3D 运动序列进行优化。
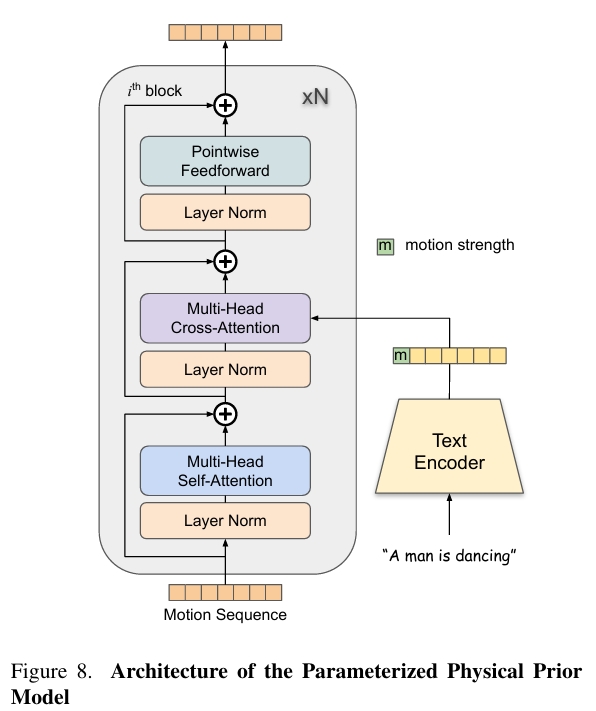
PPPM把 3D 参数化运动序列 变为优化后的 3D 参数化运动序列,再转为 3D 网格序列,并投影为 2D 部件分割掩码和置信度图。
S3:细粒度视频生成
以S2输出的在 3D 空间中优化的完整运动序列作为部件掩码为condition生成视频。
训练
数据集
作者自己标注了object-centric annotations的视频数据集。
| 输入 | 输出 | 方法 |
|---|---|---|
| 视频 | 筛选高质量运动视频、人和动物的分割掩码 | 大型语言模型(Qwen2) 和开放词汇分割模型(Convolutions die hard) |
| 所选视频、字幕 | 字幕是提到的对象 | 边界框检测(Yolov8)、掩码分割(Convolutions die hard) |
| 包含人类的视频 | 精确的人体掩码 | YOLOv8 |
| 包含人类的视频 | 每个人的面部关键点 | RTMPose |
| 包含人类的视频 | SMPL参数、MANO参数 | 4D-Human 和 HaMeR |
| SMPL参数、MANO参数 | SMPLX参数 | 整合 |
| 3D SMPL-X 人体Mesh | 部件掩码及标签 | 投影 |
| 以上人体标注输出 | 质量验证和过滤 | |
| 包含动物的视频 | 动物掩码 | Grounded SAM 2 |
| 包含动物的视频 | 视频中相机的内参和外参 | VGGSfM,同时过渡低质量数据 |
| 包含动物的视频 | SMAL参数 | AnimalAvatar、Animal3D |
| 以上动物标注输出 | 质量验证和过滤 |
优点:
- 利用现成模型(如 YOLOv8、RTMPose、SMPL-X、AnimalAvatar)生成高质量标注,而非人工标注。
- 结合语言模型(LLMs)筛选含运动的视频,提升数据相关性。
- 多阶段的过滤筛选
- 从视频筛选到标注生成的全流程自动化。
训练
不同的条件输入策略:
- 40% 的视频片段包含每帧的精确部件掩码
- 30% 包含最终帧中随机部件的多边形掩码
- 剩余片段无额外条件输入。
实验
实验一:现通用生成模型对比
- SVD:使用GPT-4o生成『人类和动物从事日常活动』的文本描述。再用GPT-4o对描述生成参考图像。以此作为输入生成视频。
- HunyuanVideo:直接使用相同的文件提示生成视频。
- ReVision:使用相同的文件提示,使用HunyuanVideo生成视频的首帧作为reference,以此作为输入生成视频。
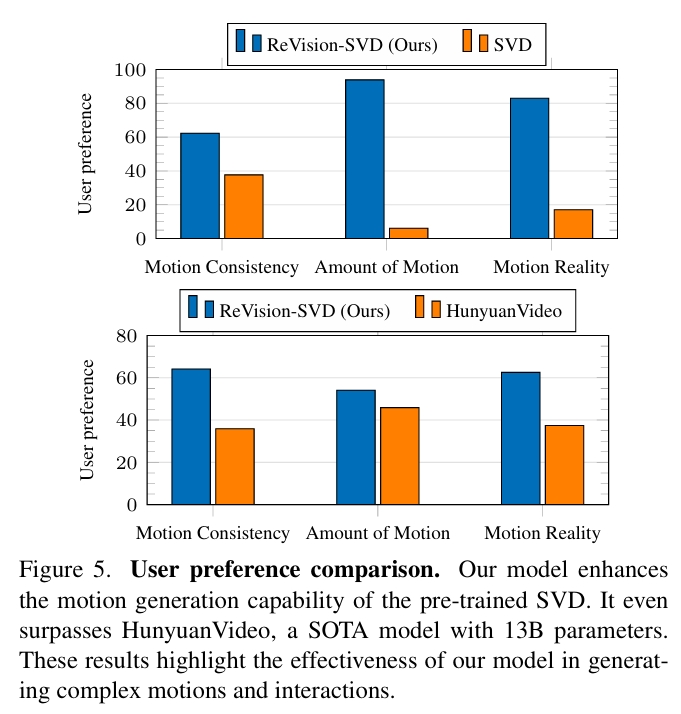
结论:
ReVision显著提升了 SVD 的运动生成能力,生成的视频在运动量、一致性和真实感上均优于 SVD。甚至在运动质量上超越了 13B 参数 的 SOTA 模型 HunyuanVideo。这些结果证明了ReVision在复杂动作和交互生成中的有效性。

尽管 ReVision 采用了三步流程(pipeline),但额外的 3D 检测和运动优化模块在单张 A100 显卡上仅增加了 5 秒 的推理时间。因此 ReVision 仍显著更快。
实验二:与人体图像动画化模型对比
ReVision:使用 TikTok Dancing 数据集微调原始SVD
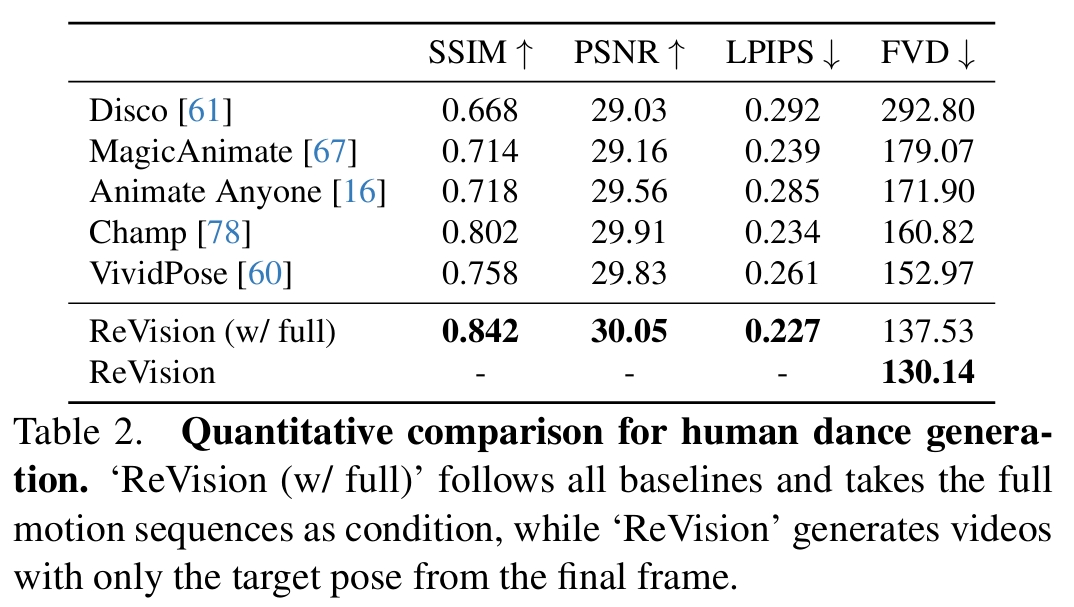
- ReVision在所有指标上SOTA。
- FVD(Fréchet Video Distance) 指标上观察到了显著的提升,表明视频生成质量有明显改善。
- 其它基线方法都依赖于真实的运动序列(ground truth motion sequences),而在实际场景中获取这些数据是相当困难的,这限制了它们的实用性。相比之下,但ReVision需提供输入图像和目标姿态,即可生成真实且高质量的视频。
Ablation Study
- 通过引入来自 3D 网格模型的人类和动物先验知识,可以大幅缓解这些结构上的(例如“一个人有三条手臂”)不准确性,从而实现对目标更精确的表示。
- Stage3的主观效果与客观指标均明显优于Stage1

相似工作对比(原创)
FinePhys也是类似的想法,都是在3D空间优化人体动作,然后以优化后的人体动作作为控制信号进行视频生成。
区别在于
| 本文 | FinePhys | |
|---|---|---|
| 输入 | 参考图像+目标动作,因此是图生视频任务 | 视频提供参考动作,生成视频,因此是2D动作驱动的视频生成任务 |
| 物理先验的来源 | 没有显式地提取物理参数,仍然是从视频数据中学习物理先验 | 显示地使用了物理公式,通过提取物理参数再运用物理参数的过程,强制优化后的动作是物理的 |
| 适用范围 | 使用了SMPL、SMAL、bbox等不同的方法来把2D内容参数化,因此适用范围更广 | 依赖于2D关键点检测与2D->3D lifting,只能用于人的优化 |
| 结果可控性 | 从数据是自动地学习物理先验,结果更可控,但依赖高质量数据。 | 依赖物理参数的优化,如果参数没优化好,结果就不对,因此可控性差一点 |
| 控制信号 | Mesh投影的分段mask,引导效果更好 | 2D火柴人,更考验生成能力 |
相同点:
- 物理优化的过程是可导的,因为可以把物理优化作为其中一个环节进行端到端训练。
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Use Stable Diffusion to generate videos without any finetuning
✅ 完全没有经过训练,使用 T2I Base Model(stable diffusion Model) 生成视频。
Motivation: How to use Stable Diffusion for video generation without finetuning?
- Start from noises of similar pattern
- Make intermediate features of different frames to be similar
P103
Step 1
- Start from noises of similar pattern: given the first frame’s noise, define a global scene motion, used to translate the first frame’s noise to generate similar initial noise for other frames

✅ 在 noise 上对内容进行编辑,即定义第一帧的 noise,以及后面帧的 noise 运动趋势。
P104
Step2
- Make intermediate features of different frames to be similar: always use K and V from the first frame in self-attention

✅ 保证中间帧尽量相似。
P105
Step3
- Optional background smoothing: regenerate the background, average with the first frame

✅ 扣出背景并 smooth.
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
研究背景与问题
要解决的问题
模拟现实世界力的物理有意义交互的视频生成
现在有方法及其局限性
| 方法 | 核心技术 | 优势 | 局限性 |
|---|---|---|---|
| 振动模态建模(Davis et al., 2015) | 2D振动序列 | 适合周期性运动 | 无法处理复杂运动(如线性运动) |
| 物理求解器+生成模型(PhysGen/PhysMotion) | 3D物理引擎+视频生成器 | 高物理精度 | 依赖3D几何,泛化能力差 |
| Force Prompting | 力提示(vector fields)+合成数据 | 无需3D模型,低成本 | 复杂物理现象建模不足 |
本文方法及优势
我们探索将物理力作为视频生成的控制信号,并提出了“力提示”(force prompts),使用户能够通过局部点力(如轻触植物)和全局风力场(如风吹动织物)与图像进行交互。
- 通过利用原始预训练模型的视觉和运动先验,这些力提示能够使视频对物理控制信号做出逼真响应,且在推理过程中无需使用任何3D资产或物理模拟器。
- 作者发现,即使使用Blender生成的简单合成数据(如旗帜、球体的运动),模型仍能通过以下策略实现跨领域泛化。
- 仅需约15k合成样本(远低于传统方法的数百万级数据),单日训练即可完成(使用四张A100 GPU)。
主要贡献
- 通过两种模型将物理力作为视频生成的条件信号:一种用于局部点力(localized point forces),另一种用于全局风力(global wind forces)。
- 我们发现,视频模型即使在极少量训练数据(15k视频)和有限计算资源(四张A100 GPU一天)下,也能执行精确的力提示,并在不同场景、物体、几何形状和功能性(affordances)中表现出广泛泛化能力。我们还尝试理解这种泛化的来源,并对训练数据进行了仔细的消融实验,发现两个关键要素:与控制信号相关的视觉多样性,以及训练过程中特定文本关键词的使用,这些要素似乎有助于激发模型对力控制信号的理解。
- 我们展示了基于力条件的模型具有一定程度的质量理解能力:相同的力可以导致较轻物体移动得更远,而较重物体则移动得更近。 我们已在项目页面(https://force-prompting.github.io/)公开所有数据集、代码和模型。
主要方法
输入:
- 文本提示 τ:描述场景或动作
- 初始帧 ϕ:提供视觉上下文
- 物理控制信号 π:
- 风力模型:方向和强度
- 点力模型:方向、强度及作用点坐标
输出:
- 视频 v:f帧 × c通道 × h高度 × w宽度
合成训练数据
全局风力数据集:使用物理模拟器生成旗帜在风中飘动的视频
局部点力数据集 - 刚体:使用物理模拟器生成球体在地面上滚动的视频
局部点力数据集 - 弹性体:使用一个结合3D高斯分布和物理模拟器的模型PhysDreamer生成植物被轻触的视频
力的表示
全局力编码策略
输入:力 \( F \in [0, 1] \) 、角度 \( \theta \in [0, 360) \)
输出:\( \tilde{\pi} \in \mathbb{R}^{f \times c \times h \times w} \),其中 \( f = 49 \) 是帧数,\( c = 3 \) 是颜色通道数,\( h = 480 \) 和 \( w = 720 \) 是生成视频的高度和宽度。
编码方法:将\( \tilde{\pi} \) 的第一个通道定义为 \( -1 + 2 \cdot F \in [-1, 1]\),第二个通道为 \( \cos \theta \),第三个通道为 \( \sin \theta \)。
局部点力编码

输入:力的强度 \( F \in [0, 1] \) 、角度 \( \theta \in [0, 360) \) 、像素坐标 \( (x, y) \in {0, \dots, w-1} \times {0, \dots, h-1} \)
输出:\( \tilde{\pi} \in \mathbb{R}^{f \times c \times h \times w} \)
方法: 高斯斑点从像素位置 \( (x, y) \) 开始,并以恒定速度沿方向 \( \theta \) 移动,总位移与力 \( F \) 成仿射比例(详见附录A.3)。对于局部力,当力 \( F = 0 \) 时,高斯斑点的位移非零,因为训练数据集的约定是 \( F = 0 \) 表示微小力。
点力提示与轨迹控制的区别:高斯斑点的初始化位置为受力点,但其随后的位置只是表明这个瞬时力的大小的方向。高斯斑点的后续移动既不表示物理持续受力,也不表示物体要移动的位置。
训练
基模型
CogVideo + ControlNet
实验
- 尽管模型仅在球体滚动(线性)和植物触碰(复杂)场景上训练,我们的力提示模型在所有运动类别中均表现出强大的泛化能力。
- 仅在束缚运动(旗杆上的旗帜飘动)标签视频上训练的全局风力控制模型,仍能对空气动力学和流体运动实现泛化控制
- 在单种康乃馨数据上训练后,能够显著泛化到其他植物。虽然不能替代基于物理的模拟方法,但这种纯神经方法提供了卓越的泛化能力,并生成符合“直观物理”的响应。
Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation
研究背景与问题
要解决的问题
实现物理正确且照片级真实的视频生成。
现在有方法及其局限性
- 现有视频扩散模型在生成视觉上吸引人的视频方面表现优异。便难以直接从海量数据中学习这些复杂的物理规律。因此在生成视频中合成正确、符合物理规律的效果方面存在困难,尤其是在处理复杂的现实世界运动、物体间相互作用和动力学时。
- 通过神经网络从视觉输入中提取物理表示,用于下游的推理或模拟。尽管这些方法在图形学、机器人和科学计算等领域有效,但它们通常依赖于基于规则的手工求解器,这限制了其表达能力和可扩展性,并且需要大量的手动调整。此外,它们通常局限于合成数据,无法扩展到复杂的、真实世界的视频生成。
本文方法及优势
- 利用LLM进行物理推理,显式地分析用户提供的文本提示,并生成一个全面的物理上下文,详细描述文本提示中隐含或涉及的物理规律(如重力、碰撞、流体、材料属性等)。
- 将LLM推理出的物理上下文信息注入到扩散模型(即视频生成模型)中,指导其生成过程。
- 利用MLLM监督与训练目标
- 构建了一个新的高质量物理视频数据集,该数据集包含多样化的物理动作和事件
主要方法
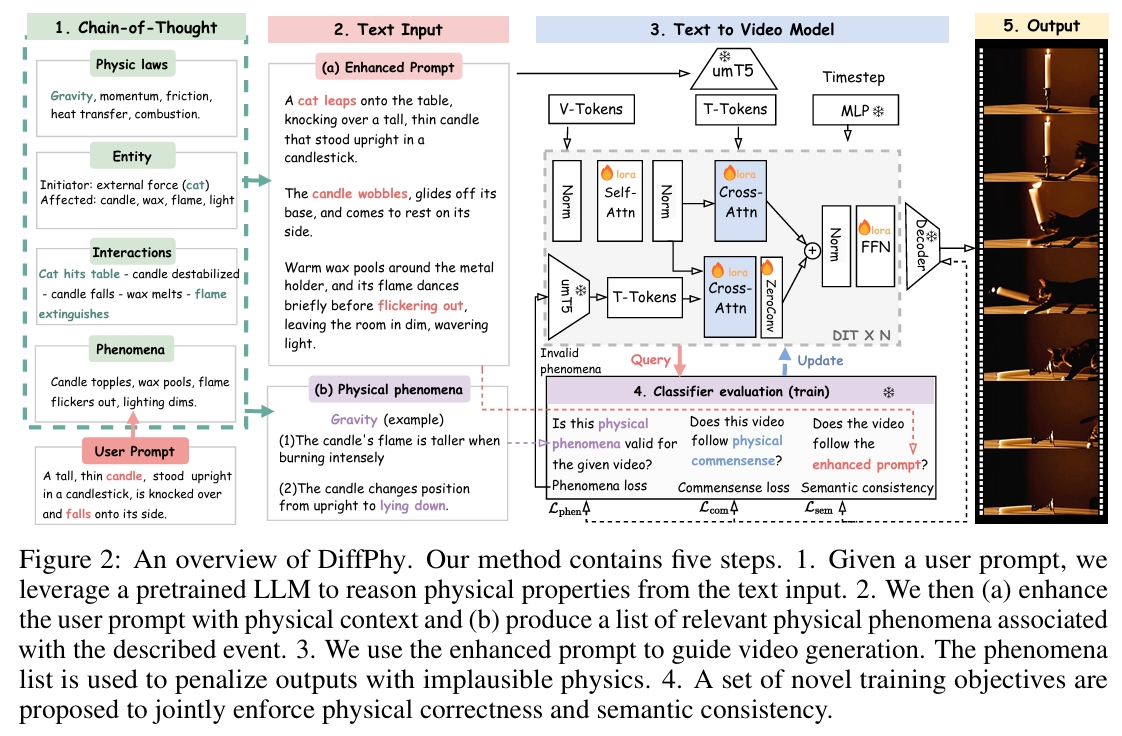
给定用户提示:
- 利用预训练的大型语言模型 (LLM) 从文本输入中推理物理属性。
- (a) 利用物理语境增强用户提示,并 (b) 生成一个与所描述事件相关的物理现象清单。
- 使用增强后的提示来指导视频生成。同时,物理现象清单被用来惩罚包含不合理物理现象的输出。
将文本描述锚定于物理语境
利用预训练的 LLM 来推理物理语境,并获取三种类型的文本描述: (1) 一个物理属性清单,用于捕捉角色(起因/结果)、相互作用和物理规律; (2) 一个包含场景和物理细节的增强提示; (3) 一个与事件相关的物理现象清单。
物理属性推理
使用思维链 (Chain-of-Thought, CoT) [54] 提示技术来引导一个预训练的大型语言模型:
(1) 识别所涉及的关键物理原理;
(2) 确定哪些实体发起动作,哪些实体受到影响;
(3) 推理这些实体如何相互作用;
(4) 记录任何由此产生的物理现象。
最终,获得一个既全面又有效的物理属性清单。
增强文本提示
基于提取出的物理属性,提示 LLM “生动地描述场景,包括物体、动作和氛围”。不仅捕捉了场景的力学方面,还捕捉了其叙事深度。
允许 LLM 通过引入新的实体(产生外力)以保证逻辑一致性。
物理现象
生成一个与目标事件相关联的『物理现象』清单。其中『物理现象』是由事件状态变化引起的事实。
这些『物理现象』清单用于指导训练过程。当事实被满足时,可以奖励扩散模型;当事实缺失或错误时,则可以惩罚它。
物理感知模型训练
目标
如何训练扩散模型以有效利用文本描述中丰富的物理语境,并精确生成期望的物理效果:
(1)
(2) 尊重作为自然视频的常识;
(3) 生成符合文本描述的期望内容。
物理现象 Loss
验证生成的结果是否包含物理现象清单中列出的期望事实
在训练期间,在采样的时间步 t,
- 将预测的潜在片段 xt ∈ R^{m×c×h×w}解码为像素空间视频 vt。
- 用一个多模态大型语言模型 (MLLM) [7] 来逐一评估 vt 与物理现象集合 F = {f1, ..., fn} 中每个事实 fi 的对齐程度。
MLLM输出两个值:
- li ∈ {0, 1}描述第i个事实是否被匹配
- zk描述与单词k相关联的logit值。其中单词k ∈ {“未匹配”或“已匹配”}
Loss定义为:
$$ E(li) = Σ_{l∈{0,1}} $$
$$ L_{phen} = Σ_{f_i∈F} ||E(l_i) - 1||^2_2 $$
引入了一个额外模块来处理未匹配的事实 \( f_i \),该模块:
- 将 \( f_i \) 编码为文本嵌入
- 以图 2-(3) 所示的方式,对DiT中的Cross Attention层使用ControlNet + LoRA的技术向原始的DiT注入条件
物理常识 Loss
使用同一个预训练的多模态大型语言模型 (MLLM)来给出 1 到 5 的评分,用于评估生成的视频 vt 的合理性得分。
$$ L_{\text{com}} = \left| \frac{E(s_{\text{com}})}{\tau} - 1 \right|_2^2, $$
语义一致性损失
使用同一个预训练的多模态大型语言模型 (MLLM)来给出 1 到 5 的评分,用于评估生成的视频 vt 与输入文本提示之间的语义一致性。
$$ L_{\text{sem}} = \left| \frac{E(s_{\text{sem}})}{\tau} - 1 \right|_2^2, $$
训练
训练目标
- 去噪分数匹配 \( L_\epsilon \):扩散模型的核心目标,通过最小化噪声预测误差来学习数据分布。
- 现象损失 \( L_{\text{phen}} \):修正生成过程中违反物理规律的现象(例如物体穿透、重力失效)。
- 物理常识损失 \(L_{\text{com}} \):确保生成内容符合物理常识(例如物体下落、液体流动)。
- 语义一致性损失 \( L_{\text{sem}} \):保证生成内容与输入文本提示的语义一致(例如“猫跳上桌子”需包含猫和桌子)。
$$ L = L_\epsilon + \beta(L_{\text{phen}} + L_{\text{com}} + L_{\text{sem}}). $$
训练策略
- 冻结原始 DIT,仅训LoRA部分
- 当检测到失败事实,基于该事实的文本嵌入重新注入扩散步骤,强制模型修正错误。
- 随机不激活注入分支的训练,防止模型过度依赖注入的监督信号,保留原始扩散模型的生成能力。
基模型
Wan2.1-14B,一种基于 DiT 的开源文生视频模型
DiffPhy 支持多种模型架构(backbones),此处以 Wan2.1-14B 为例进行展示。
实验
数据集
训练数据:
通过对VIDGEN-1M数据集加工得到的HQ-Phy数据集
测试数据:
VideoPhy2、PhyGenBench
评估指标
PhyGenBench 基准的评估指标:
- 关键现象检测(Key Phenomena Detection):检测生成视频中是否包含符合物理规律的关键现象(如重力、弹性等)。
- 物理顺序验证(Physical Order Verification):验证事件的时间顺序是否符合物理因果关系(如“物体先下落再碎裂”)。
- 平均质量评分(Average Scores):使用 GPT-4o [1] 和开源模型(如 CLIP [43]、InternVideo2 [53]、LLaVA [32])综合评估视频整体质量。
VideoPhy2中的 VideoCon-Physics 评估器:
- 物理常识(PC, Physical Commonsense):评分范围 1-5,评估视频的物理合理性。
- 语义一致性(SA, Semantic Adherence):评分范围 1-5,衡量视频与输入提示的语义对齐程度。
人工评估
横向对比
开源模型:Wan2.1-14B [50]、CogVideoX5B [63]、VideoCrafter2 [10]、HunyuanVideo-13B [27]、Cosmos-Diffusion-7B [2]。
闭源模型:OpenAI Sora [40]、Luma Ray2 [35]、LaVie [52]、Vchitect [13]、Pika [42]、Kling [26]。
官方 PhyGenBench 排行榜:
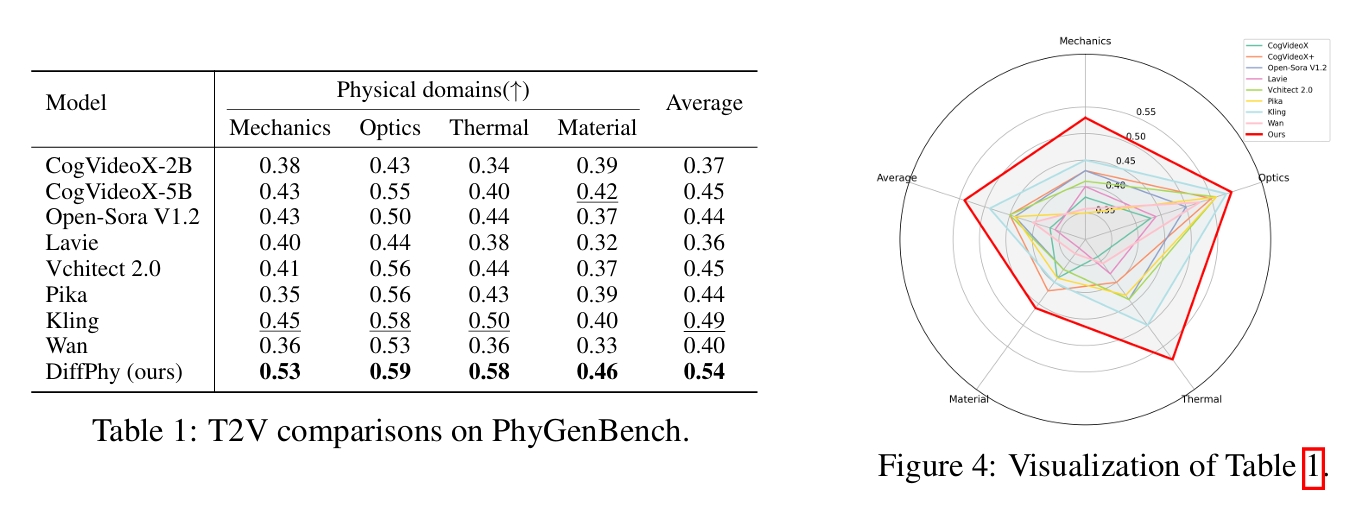
作者自己测的客观评分:
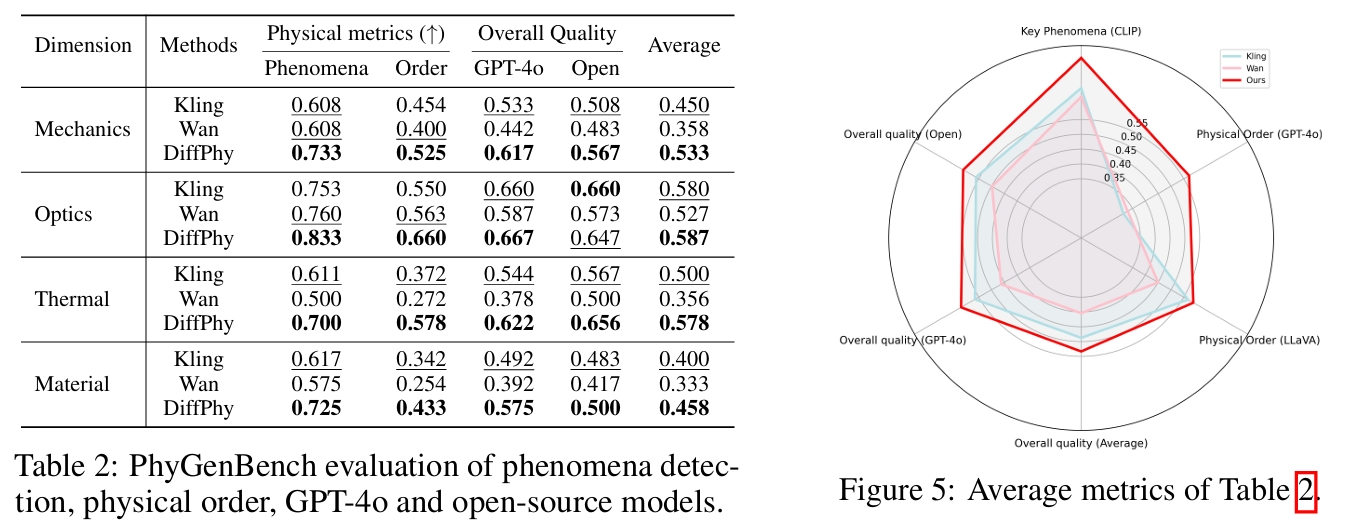
Generating time-consistent dynamics with discriminator-guided image diffusion models
研究背景与问题
要解决的问题
基于T2I模型实现文生视频
现有方法及局限性
视频扩散模型 (VDMs) 是目前生成高质量时间动态的最佳技术。但从头训练 VDM 计算成本高昂且复杂。
本文方法及优势
不重新训练或修改现有的大型图像扩散模型(这些模型通常资源丰富且已训练好),而是利用一个额外的时间一致性判别器。该判别器在采样推理阶段(即用训练好的图像模型生成视频序列时)引导生成过程。
- 在时间一致性方面,新方法达到了与专门训练的 VDM 同等的水平。
- 新方法能更好地估计其预测的不确定性。
- 新方法生成的动态更接近真实数据,系统性误差更小。
主要方法
符号定义
{x^n_t}: 表示一个图像序列。这是理解的关键。- 上标
n:物理时间步 (Physical time step)。代表视频帧或动态模拟中的时间点(n=1是第一帧,n=2是第二帧,依此类推)。 - 下标
t:扩散时间步 (Diffusion time step)。代表扩散模型去噪过程中的时间(噪声水平),t=0表示完全去噪(干净图像),t=T表示完全噪声。
- 上标
x^{(n-m):n}_0:指代从物理时间步n-m到n的无噪声 (t=0) 图像序列(m+1帧)。
时间一致性判别器的训练
构造数据对:
- 输入:
x^{(n-m):n}_0,其中n为均匀采样 - 正样本:
{x^(n+1)_t} - 负样本:
{x^(n+l)_t},其中l使用重要性采样,因此当l接近1时任务更难
输出:
D_θ(x^{n+1}_t; x^{(n-m):n}_0, t)
损失函数:

使用时间一致性判别器的时序一致性引导
根据上文可知,判别器的定义为:

由此计算出时序一致性引导为:

代码reverse SDE的更新公式得:
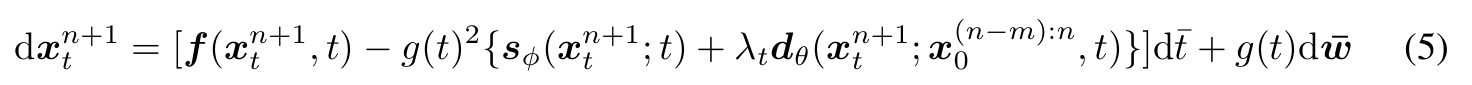
实验
启发
在diffusion based模型的推断过程,通过施加损失的梯度来引导生成,类似的想法在文生动作任务OmniControl中也有使用,可见这种方法确实是有效的。
GENMO:AGENeralist Model for Human MOtion
NVIDIA
研究背景与问题
要解决的问题
运动生成(如从文本生成动作)和运动估计(如从视频重建3D动作)
现有方法及局限性
视频运动估计通常关注确定性预测以追求精度,文本/音乐到运动生成则需输出多样性以覆盖可能动作,因此将运动生成和运动估计视为独立任务。
这导致模型冗余且知识无法共享。但实际上这两类任务本质均依赖对时空运动规律的理解,而技术路线分离阻碍了性能提升。
本文方法
将运动估计与生成整合至单一框架中。
- 将运动估计重新定义为受约束的运动生成,要求输出运动必须严格满足观测到的条件信号。
- 通过结合回归与扩散模型的协同效应,既能实现精准的全局运动估计,又能支持多样化运动生成。
- 一种估计引导的训练目标,利用带有2D标注和文本描述的野外视频数据来增强生成多样性。
- 支持处理可变长度运动及混合多模态条件(文本、音频、视频),在不同时间区间提供灵活控制。
这种统一方法产生了协同效益:生成先验能提升遮挡等挑战性条件下的运动估计质量,而多样视频数据则增强了生成能力。
主要贡献
-
首个通用模型:GENMO 首次统一了SOTA 全局运动估计与灵活的、多模态条件(视频、音乐、文本、2D 关键点、3D 关键帧)运动生成。
-
灵活架构设计:支持可变长度运动生成,并允许任意多模态输入组合,无需复杂后处理。
-
双模式训练范式:探索回归与扩散的协同作用,并提出估计引导的训练目标,使模型能有效利用野外视频数据。
-
双向提升:生成先验 提升遮挡等挑战条件下的估计鲁棒性;多样化视频数据 增强生成表现力。
通用人体运动模型
多模态输入
- 条件信号集 \(\mathcal{C}\):包含一种或多种模态输入:
- 视频特征 \(\mathbf{c}_ {\text{video}} \in \mathbb{R}^{N \times d_{\text{video}}}\)
- 相机运动 \(\mathbf{c}_ {\text{cam}} \in \mathbb{R}^{N \times d_{\text{cam}}}\)
- 2D骨架 \(\mathbf{c}_ {\text{2d}} \in \mathbb{R}^{N \times d_{\text{2d}}}\)
- 音乐片段 \(\mathbf{c}_ {\text{music}} \in \mathbb{R}^{N \times d_{\text{music}}}\)
- 2D包围框 \(\mathbf{c}_ {\text{bbox}} \in \mathbb{R}^{N \times d_{\text{bbox}}}\)
- 自然语言描述 \(\mathbf{c}_ {\text{text}} \in \mathbb{R}^{M \times d_{\text{text}}}\)(\(M\)为文本词元数)
- 条件掩码集 \(\mathcal{M}\):为每个条件类型 \(\mathbf{c}_ {\star}\) 定义二元掩码矩阵 \(\mathbf{m}_ {\star} \in \mathbb{R}^{N \times d_ {\star}}\),当条件特征可用时掩码值为1,否则为0。
运动序列 x 的表示
- 全局轨迹(第 \(i\) 帧):
- 重力视图朝向 \(\Gamma_{i}^{\text{gv}} \in \mathbb{R}^6\)
- 局部根节点速度 \(v_{i}^{\text{root}} \in \mathbb{R}^3\)
- 局部运动(第 \(i\) 帧):
- SMPL模型参数[45]:
- 关节角 \(\theta_i \in \mathbb{R}^{24 \times 6}\)
- 身形参数 \(\beta_i \in \mathbb{R}^{10}\)
- 根节点位移 \(t_{i}^{\text{root}} \in \mathbb{R}^3\)
- SMPL模型参数[45]:
- 相机位姿(第 \(i\) 帧):
- 相机到世界的变换 \(\pi_i = (\Gamma_{i}^{\text{cv}}, t_{i}^{\text{cv}})\)
- 相机视图朝向 \(\Gamma_{i}^{\text{cv}} \in \mathbb{R}^6\)
- 相机位移 \(t_{i}^{\text{cv}} \in \mathbb{R}^3\)
- 相机到世界的变换 \(\pi_i = (\Gamma_{i}^{\text{cv}}, t_{i}^{\text{cv}})\)
- 接触标签 \(p_i \in \mathbb{R}^6\)(手足接触状态)
统一估计与生成设计
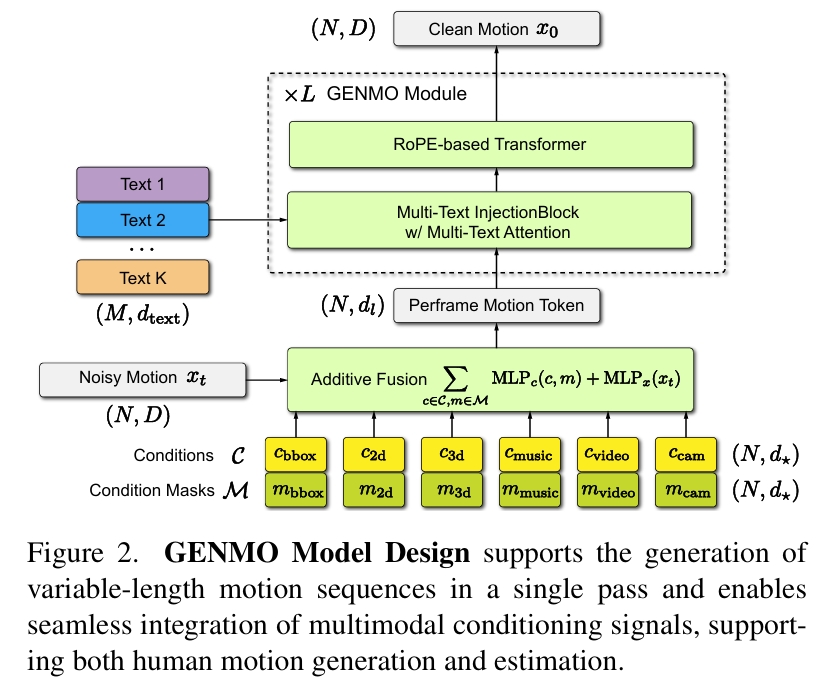
输入:带噪声的运动序列 \(x_t\) 与条件信号 \(C\)、条件掩码 \(M\)
输出:干净运动序列 \(x_0\)
其中Multi-Text Attention为:
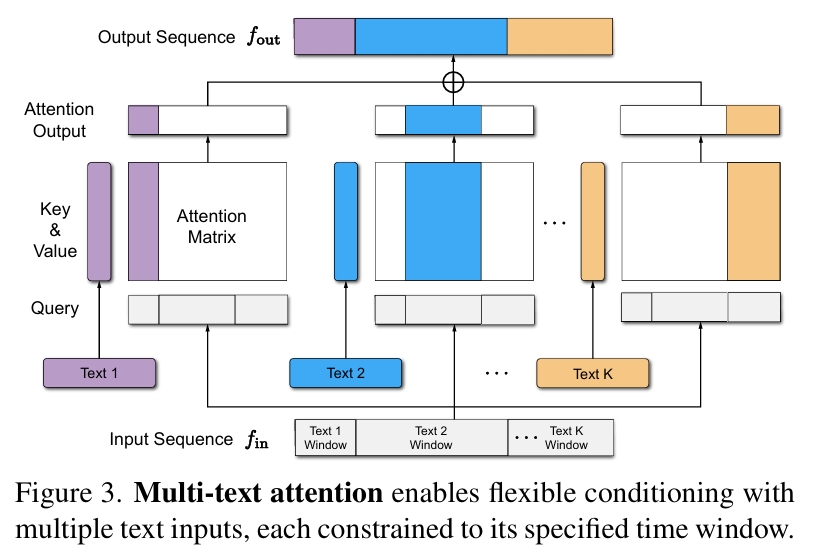
每一个文本序列与特定窗口的x部分做cross attention。
任意长度运动推理
在基于 RoPE 的 Transformer 块中引入滑动窗口注意力机制:每个令牌仅关注其前后 W 帧邻域内的令牌。
该设计使模型能生成远超训练时长的运动序列,同时保持计算效率并确保运动过渡平滑连贯。
混合多模态条件处理
文本条件(无帧级对齐)→ 通过多文本注意力机制处理
时序对齐模态(视频/音乐/2D骨架)→ 通过时序掩码策略管理
双模式训练范式
当前的diffusion model不足以支撑与输入视频严格一致的运动重建。
作者发现运动估计与文本生成任务存在一下差异:
- 运动估计结果变异性极低(确定性行为)。文本生成结果变异性显著(概率性行为)。
- 视频条件模型:首步预测接近最终结果,后续步变化极小。文本条件模型:各步预测方差显著。
得出结论:首步预测精度成为关键。
因此提出提出双模式训练范式。
估计模式
对纯噪声z预测时间步T下的输出x0,强制模型退化为确定性映射。
除了diffusion model本身的重建Loss意外,再增加2D/3D关节点位置的正则项约束。
生成模式
- 伪标签生成:以视频/2D骨架为条件,通过估计模式输出伪干净运动
- 噪声注入:对伪标签执行前向扩散
- 2D重投影损失:约束预测运动与真实2D关键点对齐
- 物理约束:同步施加几何损失
实验
动作估计
Global Motion Estimation
global motion主要关注的是滑步与轨迹。
分析:
WHAM的Motion Encoder&Decoder使用纯3D数据训练,相当于是3D动作先验模型,但这个先验模型主要是为了预测local motion。它借助SLAM结果和motion latent code共同预测轨迹,这一步需要结合视频。经测试,可能轨迹主要由motion latent code决定,因此无法区分踏步与向前走的场景。
本文根据3D动作生补全出合理的轨迹(类似WHAM)。区别在于,
- WHAM只是借助视频-3D数据来学习这个知识,而本文借助的通过大量数据的3D生成模型,因此在这方面能力更强大。
- WHAM预测轨迹的另一个输入是SLAM结果,提供的额外信息有限,而且依赖于SLAM的准确性。但本文会输入完整的视频,信息更丰富。应该可能区分踏步与向前走的场景。
WHAM和GVHMR都会显式地预测stationary并以此约束foot sliding,因此滑步问题比较小。本文只是约束了2d/3d position或速度,没有显示地预测stationary。
TRAM没有使用纯3D数据或3D动作先验模型。它完全依靠SLAM解耦相机运动和人物运动,以获得真实的人物轨迹。
Local Motion Estimation
global motion主要关注的是动作准确度以及与视频的贴合度。
diffusion由于其泛化能力,很难约束它生成的动作跟视频完全一致,因此本文使用了双模式训练范式,从指标上看,这个训练策略非常有效。
动作生成
Music to Dance
| 指标 | 物理意义 |
|---|---|
| Divk | 关键帧多样性 |
| Divm | 运动序列多样性 |
| PFC | 足部接触物理合理性 |
| BAS | 节拍对齐精度 |
| FID | 分布相似性(越低越好) |
Text-to-Motion
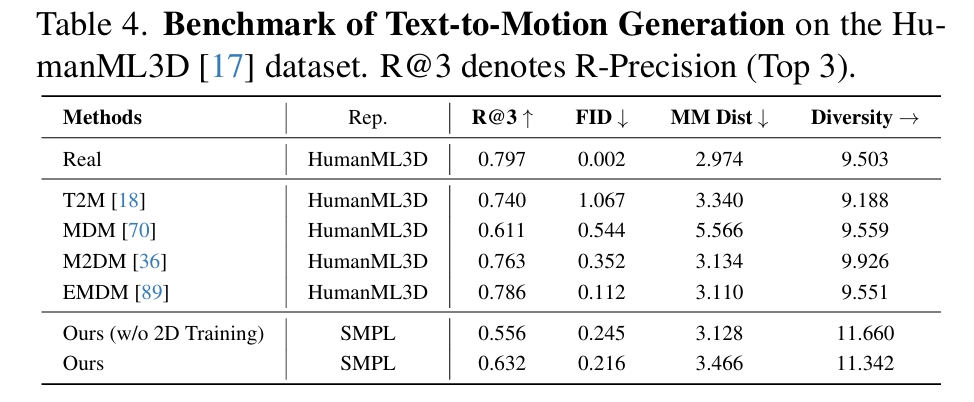
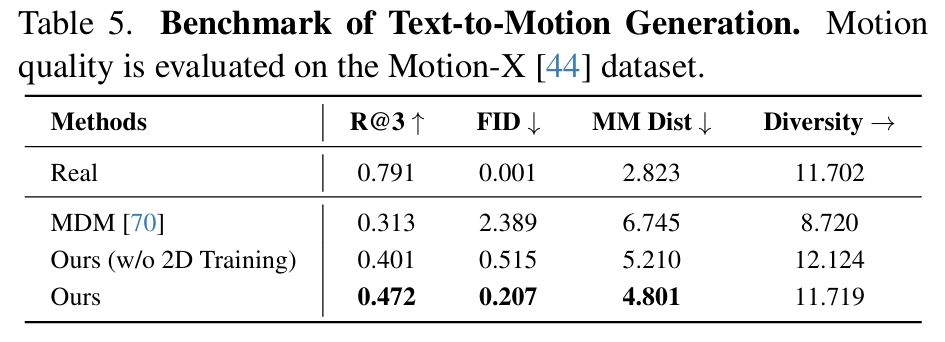
通过Ours (w/o 2D Training)和Ours的对比,可见引入2D训练数据确实能对模型各方面性能有提升。
在表4中,GENMO的客观分数偏低,文中解释是因为本文所使用的动作表示与其它不同,在不同动作表示之间的迁移影响了结果的精度。
Motion In-betweening
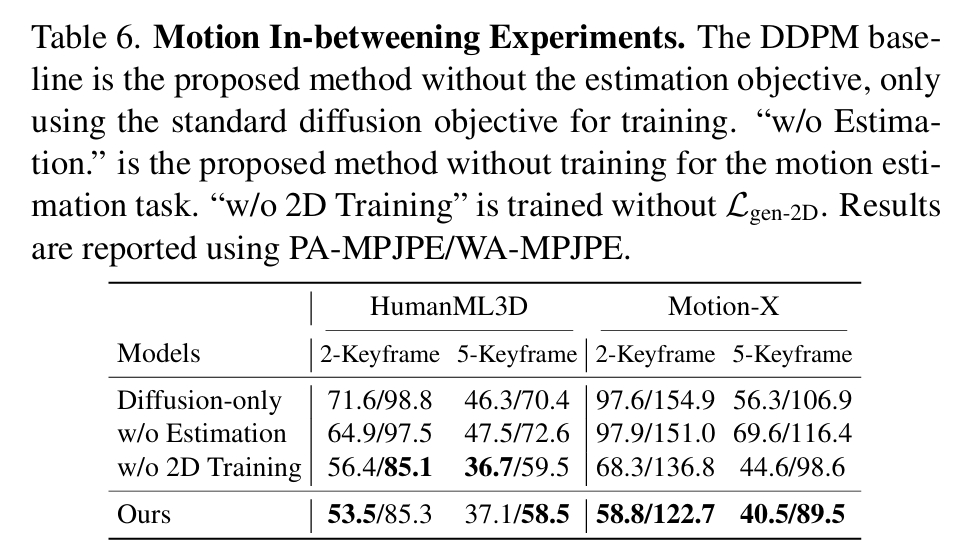
HGM3: HIERARCHICAL GENERATIVE MASKED MOTION MODELING WITH HARD TOKEN MINING
研究背景与问题
要解决的问题
文生3D Motion
问题难点
- 文本歧义性: 相同的文本描述可能对应多种合理的动作序列(例如,“高兴地挥手”的具体幅度、速度、姿态可能有多种)。
- 动作复杂性: 人体动作涉及高维、连续、时序相关的复杂运动模式。
现有方法及局限性
-
早期方法:潜在表征对齐
- 核心思想: 试图在某个潜在空间中,让文本的表示和动作的表示尽可能接近。
- 技术手段: 使用 KL散度 (KL divergence) 或对比损失 (contrastive loss) 来最小化文本和动作潜在分布之间的距离。
- 代表工作: MotionClip, TEMOS。
- 主要局限:
- 文本和动作的本质不同(离散符号 vs. 连续时空数据)导致它们在潜在空间中的完美对齐极其困难。
- 生成的动作不自然。
-
概率映射方法:学习随机映射
- 核心思想: 认识到文本到动作的映射不是确定性的(一对一的),而是概率性的(一对多的)。因此,模型需要学习从文本条件到可能动作分布的映射。
- 技术路线一:变分自编码器 (VAE)
- **代表工作:T2M (Generating diverse and natural 3d human motions from text)
- 特点: 使用 时序 VAE,专门处理序列数据,学习文本到动作序列的映射。
- 技术路线二:扩散模型 - 当前主流之一
- 核心过程: 通过一个逐步去噪(逆向扩散)的过程,从随机噪声中生成动作序列,该过程由文本条件引导。
- 代表工作与演进:
- MDM (Tevet et al., 2023): 使用 Transformer 编码器 直接处理原始动作数据 (raw motion sequences) 进行去噪重建。
- MLD (Chen et al., 2023): 在潜在空间 (latent space) 进行扩散,显著提升计算效率 (enhance computational efficiency)。
- GraphMotion (Jin et al., 2024): 创新点在于使用分层文本条件化 (hierarchical text conditionings - 三个语义层级),试图提供更精细的控制。这为本文的分层方法 (HGM³) 提供了铺垫。
- 其他扩散模型: Kong et al. (2023), Wang et al. (2023b), Dabral et al. (2023), Zhang et al. (2024), Huang et al. (2024), Dai et al. (2025) 等,表明扩散模型是该领域非常活跃的方向。
-
掩码建模方法:掩码 Transformer - 当前主流之二
- 核心思想: 将动作序列离散化 为令牌序列(类似 NLP 中的单词)。在训练时,随机或有策略地掩码 (Mask) 一部分令牌,让模型基于上下文(未掩码令牌和文本条件)预测被掩码的令牌。
- 优势: 通常比扩散模型效率更高,能有效学习动作的时空依赖关系。
- 代表工作与技术差异:
- T2MGPT & MotionGPT: 采用 自回归 生成方式。模型像预测下一个单词一样,逐个预测动作令牌。通常使用因果掩码 (causal masking)(只能看到前面的令牌)。
- MMM: 对输入动作令牌进行随机掩码,模型基于所有未掩码令牌(上下文)同时预测所有被掩码的令牌(非自回归)。
- MoMask (Guo et al., 2024): 结合了 VQ-VAE 和 残差 Transformer。VQ-VAE 将动作编码为离散令牌,残差 Transformer 负责重建(或生成)最终的动作序列,可能涉及迭代优化(“残差”暗示了逐步修正的过程)。
- BAMM (Pinyoanuntapong et al., 2024a): 提出双向因果掩码 (Bidirectional Causal Masking)。这是对标准自回归(单向因果)的改进,试图结合双向上下文信息 的优势来补充 自回归 Transformer,可能提升生成质量和上下文理解能力。
本文方法及优势
- 困难令牌挖掘 (HTM - Hard Token Mining):
- 目标: 提升模型的学习效率(efficacy),特别是对难学部分的学习。
- 方法: 主动识别动作序列中那些对模型来说具有挑战性(“hard”)的部分,并将其掩码(mask)。
- 作用: 迫使模型在训练时更集中精力去预测和恢复这些被刻意掩盖的困难部分,类似于在训练中“专攻难点”。
- 分层生成式掩码动作模型 (HGM³ - Hierarchical Generative Masked Motion Model):
- 目标: 更好地建模文本语义与动作的对应关系,生成上下文可行的动作。
- 方法:
- 语义图表示 (Semantic Graph Representation): 使用语义图来结构化地表示输入文本句子,这种图可以捕捉词语在不同语义粒度上的关系(例如,整体动作意图 vs. 具体身体部位细节)。
- 分层条件重建 (Hierarchical Conditioning & Reconstruction): 使用一个共享权重的掩码动作模型作为基础。
- 分层输入: 将不同粒度的语义图(如粗粒度的整体意图、细粒度的局部细节)作为不同层次的条件输入到模型中。
- 共享模型重建: 在每种条件层级下,该模型都尝试重建(或预测)同一个被部分掩码的动作序列。
- 学习效果: 这种设计迫使模型从不同抽象层次理解文本语义如何影响动作生成,从而实现“对复杂动作模式的全面学习”。
主要方法
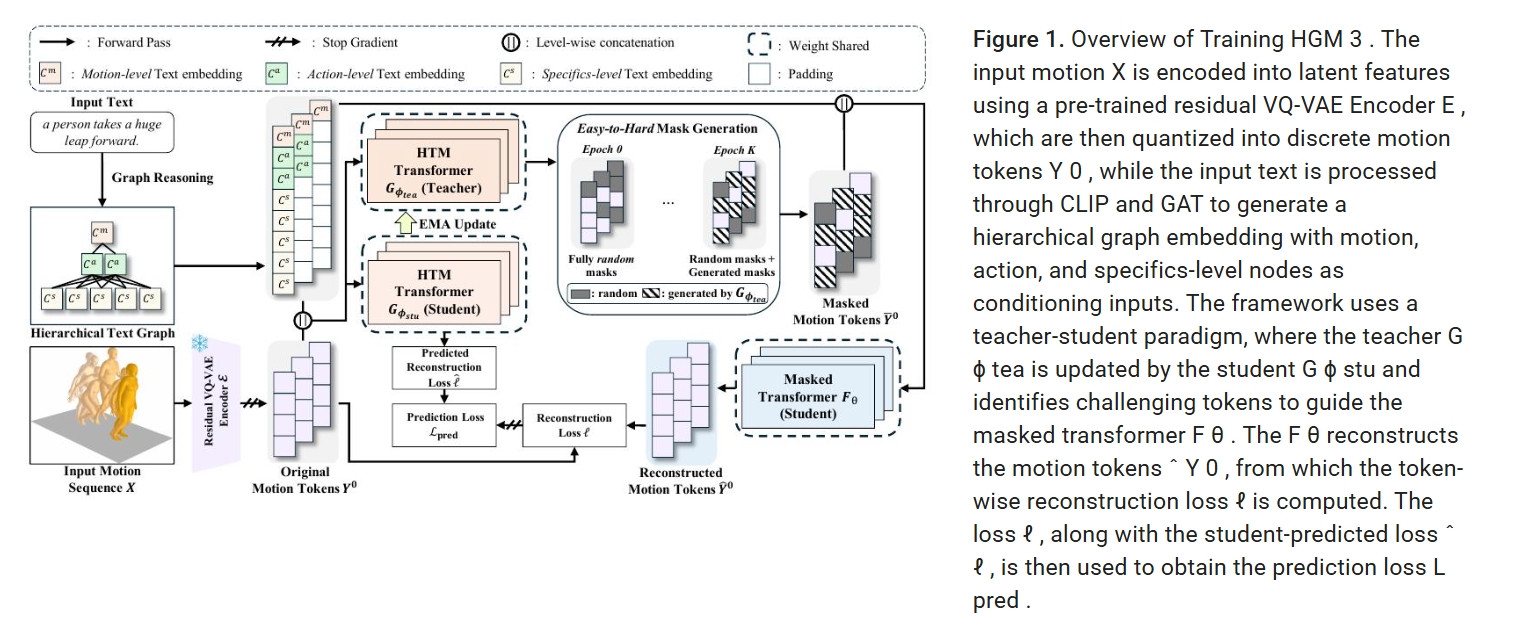
- 采用基于残差 VQ-VAE (residual VQ-VAE) (MoMask) 的动作分词器 (motion tokenizer),通过分层量化过程 (hierarchical quantization process),将原始的3D人体动作数据转换为离散的令牌序列。
- 通过结合 HTM策略 (HTM strategy) 的掩码 Transformer (masked transformer)学习掩码动作中具有区分性的部分,帮助模型更好地识别数据中的关键特征。
- 为掩码 Transformer 引入了基于分层语义图的文本条件化 (hierarchical semantic graph-based textual conditioning),将语义信息组织成多个层级,以增强模型对文本描述的理解能力。
- 采用分层推理过程 (hierarchical inference process) 进行动作生成。在此过程中,模型迭代式地优化生成的动作,并利用一个预训练的残差 Transformer来校正量化误差。
动作分词器:残差 VQ-VAE
传统VQVAE通过一个单一的向量量化层将编码器的连续输出量化到离散潜在空间,这会导致信息损失。
为了更好地逼近编码器的输出,我们使用了残差 VQ-VAE在额外的 V 个量化层上量化丢失的信息。
量化与重建的过程参考MoMask:
量化过程
- 初始层 (v=0): 编码器输出
Z⁰ = E(X)。 - 量化:
Ẑ⁰ = Q(Z⁰)。Q(·)操作找到码本v=0中与Z⁰的每个向量最接近的条目。 - 计算残差:
Z¹ = Z⁰ - Ẑ⁰。这个残差Z¹包含了第一层量化后丢失的信息。 - 下一层 (v=1): 将残差
Z¹作为输入,进行第二层量化:Ẑ¹ = Q(Z¹)。 - 再次计算残差:
Z² = Z¹ - Ẑ¹。 - 重复: 此过程重复
V次(共V+1个量化层)。
重建过程
所有层的量化输出 Ẑ⁰, Ẑ¹, ..., Ẑᵛ 求和 (Σ_{v=0}^{V} Ẑᵛ) 后,输入解码器 D 来重建原始动作:X̂ = D(Σ_{v=0}^{V} Ẑᵛ)。
与后续模块的连接
- 掩码 Transformer: 接收
y⁰_{1:n}(最重要的动作令牌序列)作为其主要输入,并结合文本条件进行训练(预测被掩码的令牌)。 - 残差 Transformer (用于推理): 在推理阶段,当核心模型(掩码 Transformer + HGM³)生成了
y⁰_{1:n}的预测后,这个预训练的残差 Transformer 会利用y⁰_{1:n}以及 可能 的y¹_{1:n}, ..., yᵛ_{1:n}(或其预测)来生成一个残差信号,用于校正 VQ-VAE 解码器重建动作时产生的量化误差(见 3.4 节),从而得到更精细的最终动作输出。
掩码 Transformer 和 困难令牌挖掘策略
掩码 Transformer
从预训练的residual VQVAE中取得第0层的token序列,训练掩码 Transformer 来重建原始序列。
现有方法(MoMask, MMM)随机选择要掩码的令牌,但本文策略性地选择要掩码的令牌。
师生机制:
- 学生模型F:掩码 Transformer,负责重建被掩码的令牌。输入带掩码的token序列和文本C,预测被mask的token。
- 教师模型G:辅助 Transformer,通过预测重建损失的相对排序来为 Fθ(·) 识别具有挑战性的令牌。
损失预测器
损失预测器以未掩码的动作序列和文本embedding C为输入,预测 argsort(ℓ)(即重建损失的排序)来识别那些更难重建的动作令牌。 该模型通过预测每一对令牌 (i, j) 中哪个令牌具有更高的重建损失来学习对重建难度进行排序。
由易到难的掩码生成
- 问题: 如果训练一开始就只掩码最困难的令牌,模型可能因为能力不足而无法有效学习,导致训练不稳定或收敛到次优解。
- 解决方案: 采用渐进式学习 (Curriculum Learning) 思想。让模型从简单任务(掩码随机令牌) 开始,逐步过渡 到困难任务(掩码最难令牌)。
- 掩码选择策略:
- 在每个训练轮次
t,确定一个困难令牌比例α_t。 - 从排序列表的最前面(即最难的部分) 选取
α_t比例 的令牌进行掩码。 - 剩余的
1 - α_t比例 的掩码令牌,则从所有令牌中随机选择。 - 结合上述两步选择的令牌索引,形成本轮最终的掩码集合
M。
- 在每个训练轮次
- 比例调整策略
- 困难比例:
α_t = α_0 + (t / T) * (α_T - α_0),线性增加 - 总掩码比例:
γ(τ_t) = cos(π τ_t / 2),余弦衰减 - t为训练轮次
- 困难比例:
面向掩码 Transformer 的分层语义文本条件化
分层语义文本条件
将整个文本句子压缩成一个单一的向量表示,这种方法忽略了文本的细粒度细节。
本文将文本分解为语义上细粒度的组件,以构建一个分层图,并通过一个图注意力网络 (Graph Attention Network - GAT)来获取增强的文本嵌入。
有关语义角色解析过程的更多细节,请参阅附录 B。
分层语义文本条件最终得到三个层级的文本嵌入:
- C^m (仅动作层)
- [C^m; C^a] (动作层 + 行为层拼接)
- [C^m; C^a; C^s] (动作层 + 行为层 + 细节层拼接)
输入处理:
- 长度对齐: 使用填充令牌 (padding tokens) 使三种条件令牌序列长度一致。
- 位置编码: 对整个序列(条件令牌 + 动作令牌)应用位置编码,模型能感知顺序。
- 前置拼接: 将条件令牌序列放在动作令牌序列之前输入模型 (如图1所示)。这是一种常见的条件输入方式。
Loss 调整
一个令牌是否“困难” (难以被 Fθ 重建) 依赖于当前提供的文本条件层级。例如,在仅有全局信息 (C^m) 时可能很难预测的令牌,在有了细节信息 ([C^m; C^a; C^s]) 后可能变得容易预测。
因此针对每一个条件层级都要计算一个预测损失,求和得到总预测损失。
同样每一个层都要计算一个重建损失,求和得到总重建损失。
不同条件下的Fθ和Gθ各自共享一套参数。
推理
-
第一阶段 (分层迭代生成基础令牌):
- 起点: 全掩码序列。
- 过程:
L次迭代,每次迭代:- 用当前层级文本条件预测掩码位置概率分布。
- 重新掩码置信度最低的预测。
- 文本条件随迭代由粗(
C^m)到细([C^m; C^a; C^s])切换 (Eq. 14)。
- 终点: 完全生成的基础层令牌序列
Y⁰。 - 核心: 迭代式置信度筛选确保困难位置得到多次精炼;分层文本条件指导渐进式细节添加。
-
第二阶段 (残差精化):
- 输入: 基础层令牌
Y⁰。 - 过程: 用预训练残差 Transformer 预测
V个残差令牌序列。 - 输出: 组合
Y⁰和残差令牌,通过 VQ-VAE 解码器生成最终连续动作X。 - 核心: 校正量化误差,提升动作细节和质量。
- 输入: 基础层令牌
实验
分析:
- 本文SOTA
- 近期工作中表现比较好的基本上都是VQVAE based。
Towards Robust and Controllable Text-to-Motion via Masked Autoregressive Diffusion
研究背景与问题
要解决的问题
文生3D Motion
现有方法及局限性
VQVAE类方法:离散表征难以忠实表达新动作
扩散模型类方法:连续表征缺乏对单帧的细粒度控制
作者希望可以帧级的动作控制同时能够对训练集以及的动作有较好的泛化性。
本文方法及优势
提出鲁棒的动作生成框架MoMADiff
- 将掩码建模与扩散过程相结合
- 利用帧级连续表征生成动作。
优势:
- 支持灵活的用户自定义关键帧,可精准控制动作合成的空间与时间维度
- 在以稀疏关键帧作为动作提示的新型文本-动作数据集上,MoMADiff展现出强大的泛化能力。
主要贡献
- 提出帧级运动VAE,将人体动作编码为连续标记序列,在未见数据集上实现精确动作重建与强鲁棒性
- 设计掩码自回归扩散模型,基于帧级连续标记实现细粒度可控的人体动作生成
- 所提 MoMADiff 在标准文本-动作基准测试中达到领先性能,并在关键帧引导的分布外动作生成中展现强大泛化能力
主要方法

(a) 运动VAE:将原始动作编码为帧级连续隐嵌入,并解码生成动作
(b) 自回归扩散模型训练:通过掩码建模训练,使用基于扩散的预测头预测动作嵌入
(c) 推理过程:
- 首先生成少量关键帧
- 递归补全完整动作序列
- 支持稀疏关键帧输入实现可控生成
连续的帧级运动自编码器
CNN Based VAE
连续编码:消除量化误差
帧级编码:支持单帧编辑
损失:
| 损失 | 公式 | 作用 |
|---|---|---|
| 负对数似然损失 (ℒₙₗₗ) | \(ℒₙₗₗ = \mid \mid X̃ - X \mid \mid₁ / exp(logσ²) + logσ²\) | 监督重建质量,logσ² 为可学习对数方差参数。自适应加权重建误差:高方差帧 → 降低重建要求,低方差帧 → 精准重建 |
| KL散度损失 (ℒₖₗ) | ℒₖₗ = -½∑(1 + logσ² - μ² - σ²) | 对齐隐空间与标准正态分布 |
| 关节速度损失 (ℒᵥ) | \(ℒᵥ = ∑\mid vₜ - ṽₜ\mid \) | 保障运动平滑性 |
[?] 逐帧编码哪来的速度?
动作掩码自回归扩散模型 (MoMADiff)的训练流程
- 输入处理:
- 随机掩蔽隐序列 → 用可学习的连续 [MASK] 标记替换部分位置
- 文本提示经CLIP编码 → 拼接至Transformer输入序列首部
-
Transformer输出条件标记 c:
-
轻量级Denoising结构预测motion embedding
-
含 L 个扩散块(线性层→SiLU激活→线性层)
-
通过AdaLN注入条件标记 c 和去噪步数 t
2和3联合优化
推理阶段策略
- 初始化:
- 所有隐运动标记置为 [MASK]
- 文本编码后置于序列首部输入Transformer
- 关键帧生成:
- 生成条件标记 c 并输入扩散头
- 扩散头通过 T 步去噪(从 zₜ → z₀)输出初始关键帧
- 加速技术:采用DDIM采样将去噪步缩减至 Tᵢ
- 递归补间:
- 将生成/用户提供的自定义关键帧回填至输入序列
- 控制增强:
对隐条件Transformer施加无分类器引导(CFG) 关键限制:CFG不作用于扩散头(避免破坏时空结构)
实验
数据集:Motion-X、IDEA400、Kungfu、HumanML3D、KIT-ML
评价指标: R-Precision、Frechet Inception Distance(FID)、Multimodal Distance (MMD)、(4) Diversity (DIV)
Motion reconstruction
横向对比
VAE类:VPoser-t、ACTOR、MLD
VQVAE类:ParCo、MotionGPT、MoMask
训练集:HumanML3D
- in-domain测试数据:HumanML3D测试集
分析:
- MotionGPT的重建能力(VQVAE)来自于T2m-GPT,基于对连续编码方法,离散编码确实会有量化损失。离散编码的特点是牺牲编码容量,保留编码细节。
- ACTOR的VAE不只是重建,还要与动作编码进行潜在高斯分布对齐,可能是因此损失了一些精
- [?] 本文逐帧embedding为什么ACCL表现这么好?
- out-of-domain测试数据:IDEA400、Kungfu
结果:
分析:VQVAE只是已经数据的编码,没有插值能力,所以对out-of-domain的泛化性确实会差一些。
out-of-domain的关键帧插帧
训练集:HumanML3D
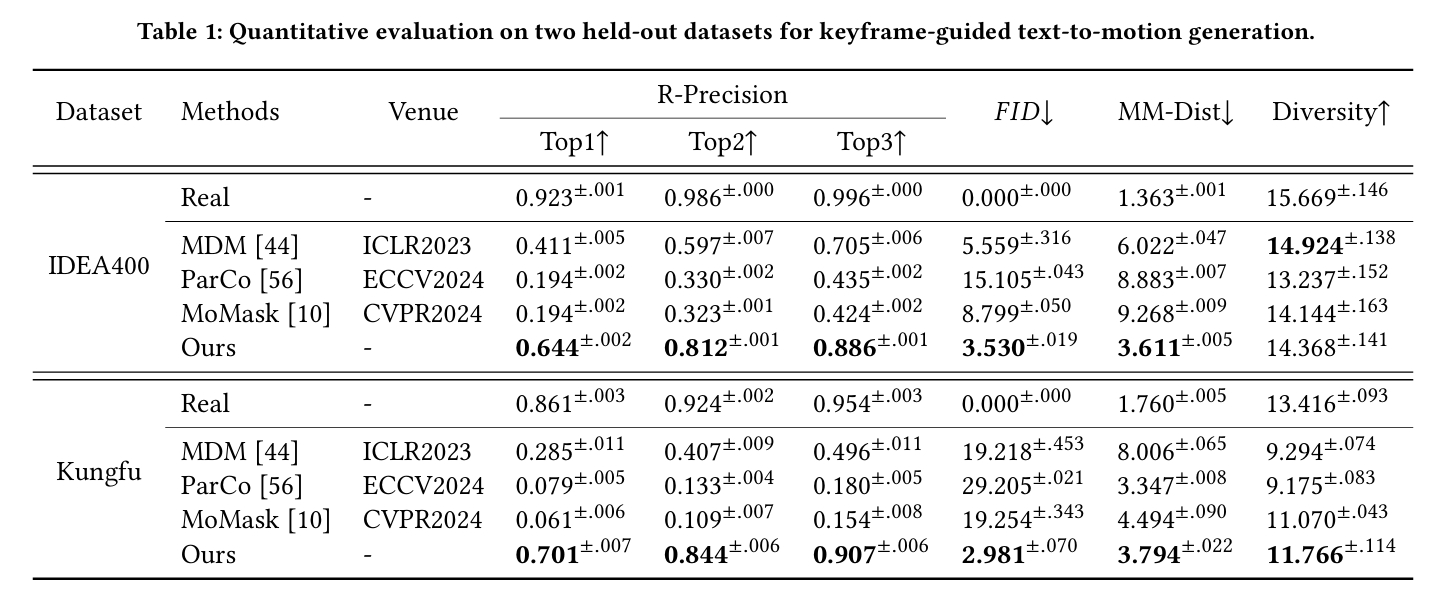
分析:
- ParCo和MoMask使用VQVAE编码,所以对out-of-domain的泛化性确实会差一些。
- MDM和本文的相同的点:
- 都使用自己训练的VAE编码器对动作编码,从表2上看,MDM的编码能力略胜一筹。
- 都使用CLIP进行文本编码。
- 每一个denoise步骤之后,都会用keyframe覆盖对应的生成帧。
- 在文生动作任务上本文更好。可能是对文本的使用和生成的pipeline的差异导致。
- MDM的denoise部分是自回归的,每一帧的生成只能参考前面帧。而本文的denoise部分,每一帧都可以看到前后帧信息。
- MDM仅使用CLIP embedding作为自回归的初始化输入,而本文中CLIP Embedding对每一帧数据的生成作用都是平等的。
文生动作

MoCLIP: Motion-Aware Fine-Tuning and Distillation of CLIP for Human Motion Generation
研究背景与问题
要解决的问题
文生动作
现有方法及局限性
现有方法通常依赖于基于对比语言-图像预训练(CLIP)的文本编码器,但这些模型在文本-图像对上的训练限制了其对运动中固有时间和运动学结构的理解能力。
本文方法及优势
本文提出MoCLIP——一种通过附加运动编码头进行微调的CLIP模型,使用对比学习和约束损失在运动序列上进行训练。通过显式地融合运动感知表征,MoCLIP在保持与现有CLIP框架兼容性的同时提升了运动保真度,并能无缝集成到各类基于CLIP的方法中。
实验表明,MoCLIP在保持竞争力FID指标的同时提升了Top-1、Top-2和Top-3准确率,实现了更好的文本-运动对齐效果。这些结果凸显了MoCLIP的多功能性和有效性,确立了其作为增强运动生成的稳健框架地位。
主要贡献
-
增强CLIP的运动理解能力:引入经对比学习训练的附加运动头,扩展标准CLIP编码器,将运动数据的时序与运动学特征编码至文本潜空间
-
验证跨管线有效性:将MoCLIP集成至三种不同视觉管线,在Top-1/2/3准确率上超越标准CLIP模型
-
贡献度分析:通过消融实验,对比进阶版MoCLIP与基线模型,检验不同训练特征的影响
主要方法
目标
-
使用蒸馏损失微调文本嵌入,约束适配过程以保留原始CLIP语义核心
-
采用余弦相似度损失引导嵌入保持运动方向连续性,强化文本-运动空间对齐
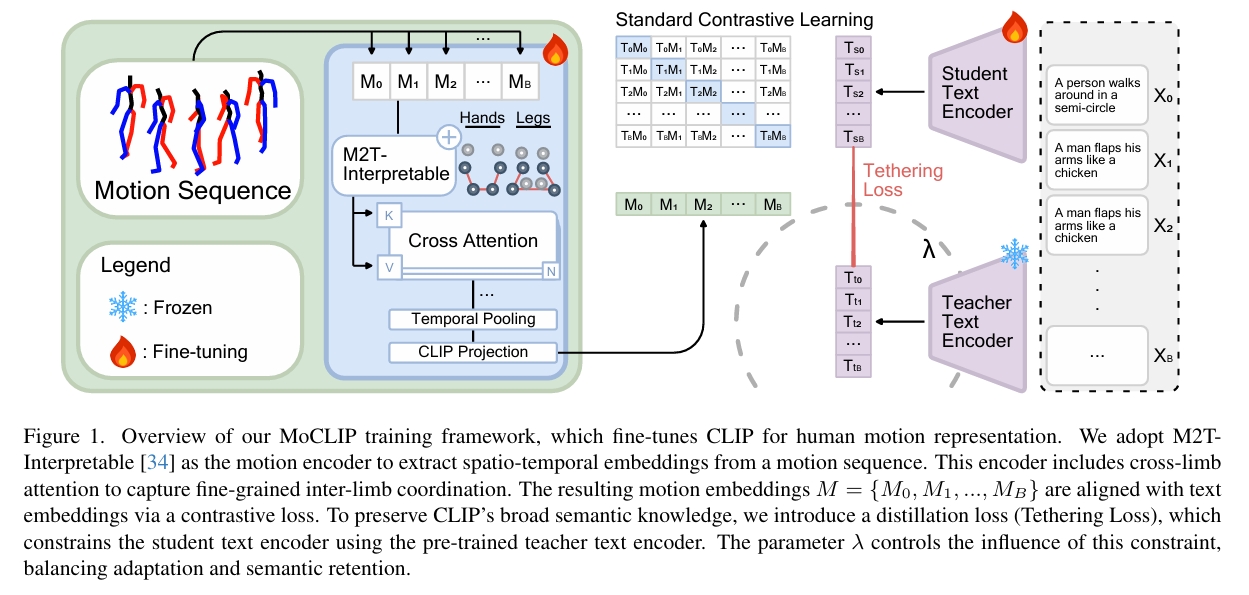
- 采用M2T-Interpretable作为运动编码器,从运动序列提取时空嵌入。该编码器包含跨肢体注意力机制以捕获细粒度肢体协调。生成的运动嵌入集合\( M = {M_0, M_1, ..., M_B} \)
- 分别使用Teacher Text Encoder和Student Text Encoder对文件编码
- 通过多个损失项训练Motion Encoder和Student Text Encoder
$$ \mathcal{L} _ {total} = \underbrace{\mathcal{L} _ {contrastive}} _ {\text{对称对齐}} + \lambda_{distill} \underbrace{\mathcal{L} _ {distill}} _ {\text{语义锚定}} + \underbrace{\mathcal{L} _ {alignment}} _ {\text{运动-文本余弦对齐损失}} $$
对比损失
$$ \mathcal{L}_{contrastive} = \frac{1}{2} \left[ \underbrace{CE(z _ {motion} W z _ {text}^\top, y)} _ {\text{运动→文本对齐}} + \underbrace{CE(z _ {text} W z _ {motion}^\top, y)} _ {\text{文本→运动对齐}} \right] \quad (1) $$
其中W是可学习参数。
蒸馏损失
$$ \mathcal{L}_{distill} = \frac{1}{N} \sum _ {i=1}^{N} \left|| z _ {text-student}^{(i)} - z _ {text-teacher}^{(i)} \right||_2^2 \quad (3) $$
选择MSE作为蒸馏损失的核心考量:
它允许学生嵌入以非严格受限于教师嵌入角度(余弦相似度)的方式迁移。这种灵活性使学生嵌入能更有效地与运动嵌入对齐,同时仍受控地保持在原始CLIP嵌入空间邻近域内。
运动-文本余弦对齐损失
$$ \mathcal{L}_{\mathrm{alignment}} =1- \frac{1}{N} \sum _ {i=1}^{N} \frac{ z _ {\mathrm{motion} }^{(i)} \cdot z _ {\mathrm{text-student} }^{(i)}}{ ||z _ {\mathrm{motion} }^{(i)}|| _ 2||z _ {\mathrm{text-student} }^{(i)}|| _ 2} \quad (4) $$
训练
MoMask训练
-
加载预训练CLIP作为学生网络,改造其接入运动编码器
-
加载教师CLIP模型并全程冻结
-
渐进解冻策略:
-
前35轮:冻结学生文本编码器 → 运动编码器与CLIP嵌入对齐
-
后15轮:解冻学生文本编码器 → 联合运动编码器训练(使用第3章损失函数)
-
总训练轮次:50轮
下游模型微调
-
替换原CLIP为MoCLIP并冻结权重
-
微调下游模型(学习率=1e-6,无预热阶段),其中多阶段架构(MoMask/BAMM等模型)顺序微调T2M和残差Transformer
数据集
HumanML3D
实验
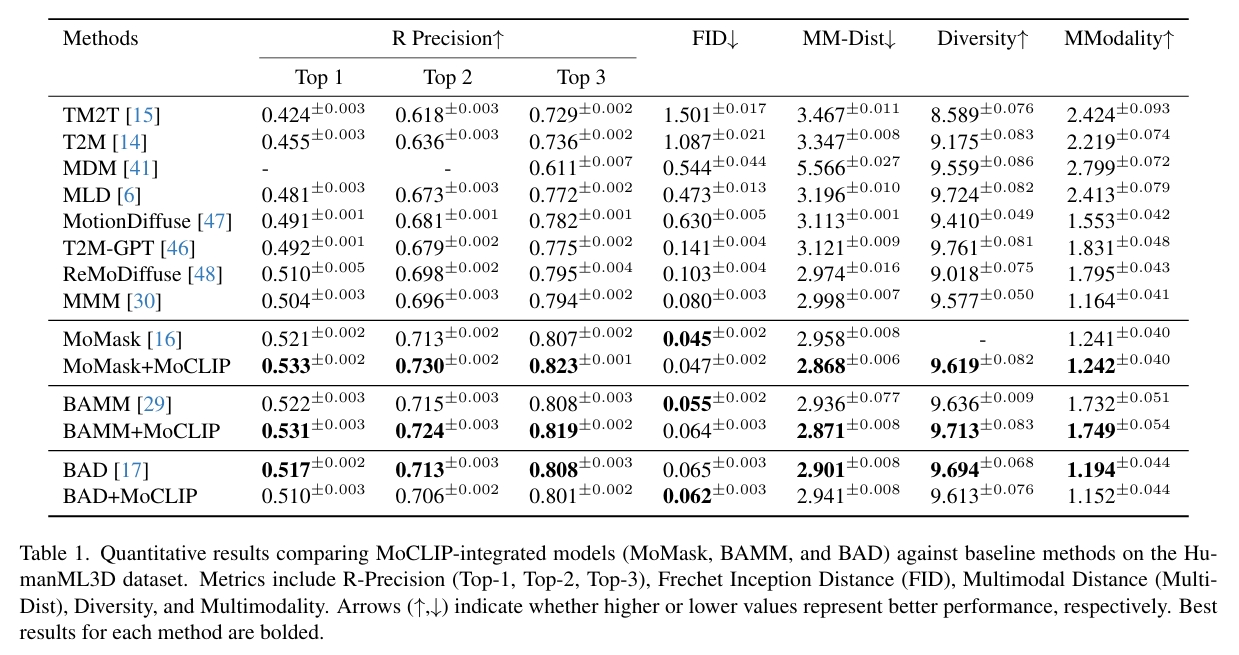
结论:MoCLIP在基于令牌的模型(token-based models) 中表现更为高效,而双向自回归架构(bidirectional autoregressive architectures) 可能需要额外的适配才能充分发挥其优势。
FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
研究背景与问题
目的
合成物理合理的人类动作的视频
现有方法及局限性
在细粒度语义建模和复杂时间动态建模方面(例如生成像"转体0.5周的切换跳跃"这样的体操动作)往往产生不理想的结果。
本文方法
提出了FinePhys——一个结合物理原理的细粒度人类动作生成框架,通过有效的骨骼指导实现动作生成。具体而言:
- FinePhys首先以在线方式估计2D姿态,然后通过上下文学习进行2D到3D的维度提升。
- 为了缓解纯数据驱动3D姿态的不稳定性和有限可解释性,引入了一个由欧拉-拉格朗日方程控制的基于物理的运动重估计模块,通过双向时间更新计算关节加速度。
- 将物理预测的3D姿态与数据驱动姿态融合,为扩散过程提供多尺度2D热图指导。
在FineGym的三个细粒度动作子集(FX-JUMP、FX-TURN和FX-SALTO)上的评估表明,FinePhys显著优于竞争基线。全面的定性结果进一步证明了FinePhys生成更自然、更合理的细粒度人类动作的能力。
核心贡献
- 提出FinePhys框架:
一种面向细粒度人类动作视频生成的新方法,利用骨骼数据作为结构先验,并通过专用网络模块显式编码拉格朗日力学;
- 多维度物理约束融合
关键问题在于如何将物理规律连贯地融入学习过程。传统策略有三种:观测偏置(通过数据)、归纳偏置(通过网络)和学习偏置(通过损失)。FinePhys通过全维度整合物理约束: ❶ 观测偏置:引入姿态作为额外模态编码生物物理布局,利用上下文学习进行2D→3D提升,使用现有数据集中的平均3D姿态作为伪3D参考; ❷ 归纳偏置:通过全可微分神经网络模块实例化拉格朗日刚体动力学,其输出为欧拉-拉格朗日方程参数; ❸ 学习偏置:设计符合底层物理过程的损失函数。
- 实验验证优势
在细粒度动作子集上的大量实验表明,FinePhys显著优于各类基线模型,能生成更自然且物理合理的结果。
物理建模方法对比
| 方法 | 技术特征 | 局限性 | FinePhys突破 |
|---|---|---|---|
| 物理引擎派 (PhysGen/PhysDiff) | 依赖刚体仿真生成物理合理轨迹 | 计算成本高、无法处理细粒度关节运动 | 通过可微分PhysNet替代仿真器,实现端到端优化 |
| 方程嵌入派 (PIMNet/PhysPT) | 将物理方程作为损失函数约束 | 隐式约束易被生成模型忽略 | 显式参数化EL方程,直接输出动力学参数 |
| 数据驱动派 (PhysMoP) | 基于历史姿态预测未来状态 | 仅完成简单运动外推 | 处理模态转换(视频→3D姿态)、维度提升、内容生成三重挑战 |
主要方法
输入
- 视频输入:\(V_{in} = {f_i}_{i=1}^T\),从完整视频中采样的 \(T\) 帧;
推理阶段可以直接输入2D骨骼代替视频输入
- 文本描述:细粒度类别标签\(c\)的扩展描述(如"转体一周的切换跳跃"),通过文本扩展器\(\mathcal{E}\)(本文使用GPT-4[1])增强可理解性[73];
Pipeline
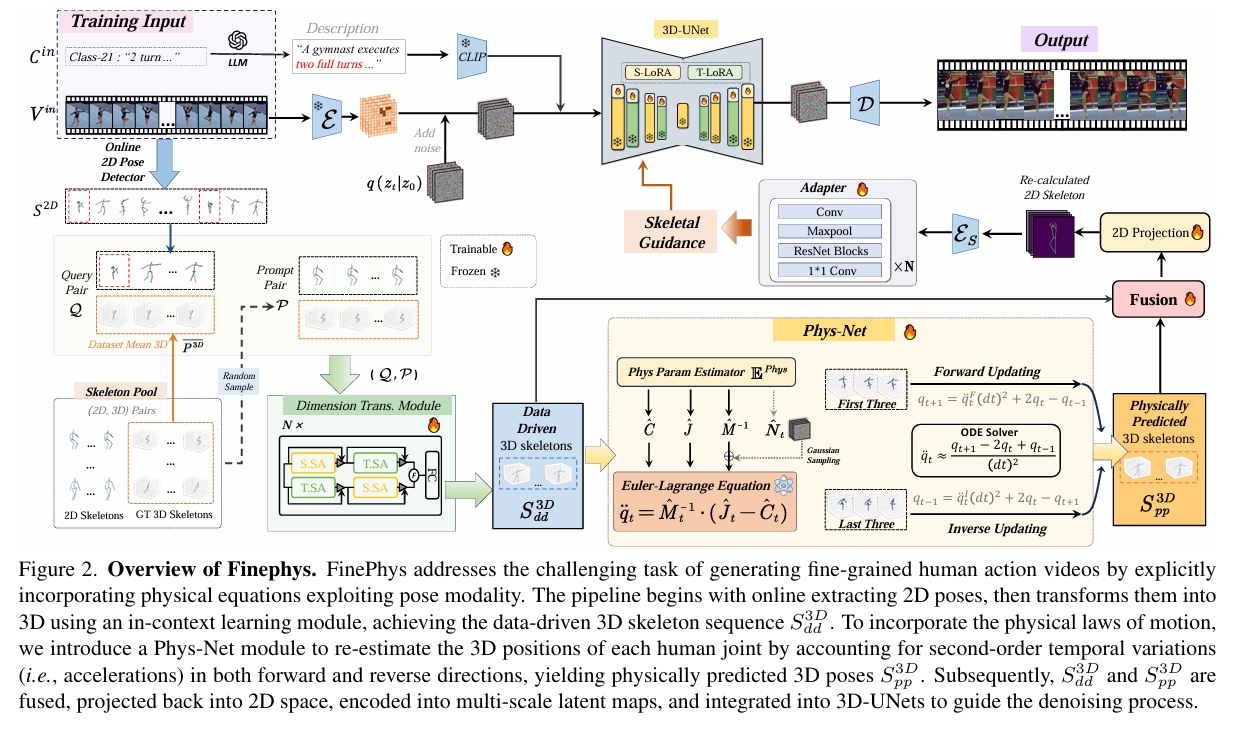
视频输入 → 2D姿态 → 3D姿态 → PhysNet优化 → 热图编码 → LDM条件
- 在线2D姿态估计:输入视频帧生成2D骨骼序列\(S_{2D} \in \mathbb{R}^{T \times J \times 2}\)(\(J\)为关节数),提供紧凑的生物力学结构表示;
- 上下文学习维度提升:将2D姿态通过上下文学习转换为数据驱动的3D骨骼序列\(S_{3D}^{dd} \in \mathbb{R}^{T \times J \times 3}\);
- 物理优化模块PhysNet:基于欧拉-拉格朗日方程计算双向二阶时序变化(加速度),重新估计3D运动动力学,生成物理预测的3D骨骼序列\(S_{3D}^{pp} \in \mathbb{R}^{T \times J \times 3}\);
- 多模态融合与投影:融合\(S_{3D}^{dd}\)与\(S_{3D}^{pp}\),投影回2D生成多尺度潜在热图;
- 引导生成:热图集成至3D-UNet各阶段,指导扩散去噪过程。
FinePhys:物理规律融合
观测先验:2D→3D维度提升
如图2左下所示:从真实数据集中获得2D-3D pair的先验,使用双流Transformer实现2D->3D lifting。
归纳偏置:物理感知模块
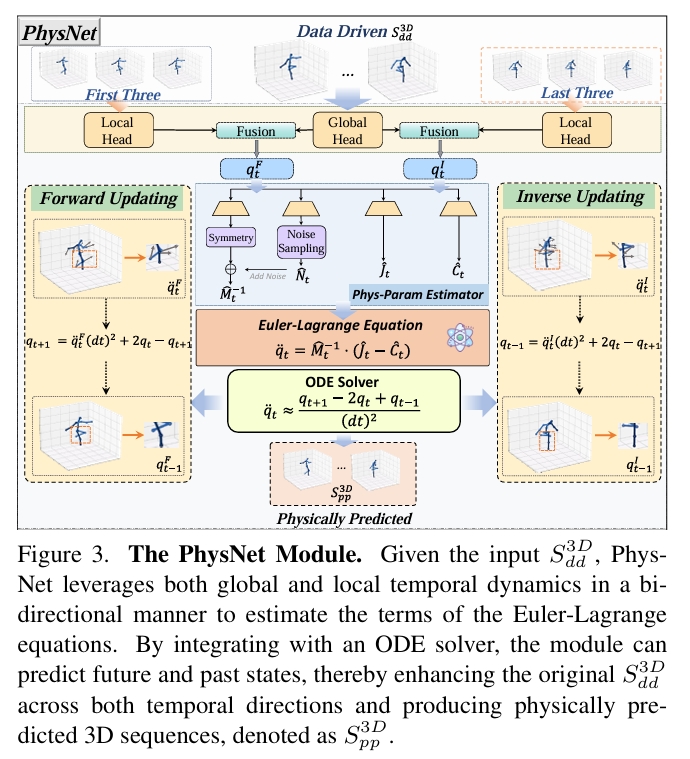
- 对2D→3D维度提升输出的3D序列进行编码,
$$
\begin{aligned}
q^{(g)} _ t &= E _ \theta^{(g)} \left( { S^{3D} _ {dd}(t) }_ {t=1}^T \right) \quad \in \mathbb{R}^{T \times (J \times 3)}, \\
q^{(l)(\rightarrow)} _ t &= E _ \theta^ {(l)} \left( { S ^ {3D} _ {dd}(t-2), S^{3D} _ {dd}(t-1), S^{3D} _ {dd}(t) } \right), \\
q^{(l)(\leftarrow)} _ t &= E _ \theta^{(l)} \left( { S^{3D} _ {dd}(t), S^{3D} _ {dd}(t-1), S^{3D} _ {dd}(t-2) } \right),
\end{aligned} \tag{8}
$$
其中\(q^{(l)(\rightarrow)}_t\)和\(q^{(l)(\leftarrow)}_t\)分别表示前向与反向时序编码。所有计算均双向进行——前向更新从前三帧开始,反向更新从后三帧开始。
-
取\(q^{(g)} _ t\) 和 \(q ^ {(l)( \rightarrow)} _ t \),使用下文补充部分的全身人体运动学模型,预测出\(\hat{q}_{t+1}^{(\rightarrow)}\)
-
取\(q^{(g)}_ t\)和\(q^{(l)(\leftarrow)} _ t\),使用下文补充部分的全身人体运动学模型,预测出\(\hat{q}_{t+1}^{(\leftarrow)}\)
-
双向估计平均:
$$
\hat{q} _ {t+1} = \frac{1}{2} \left( \hat{q} _ {t+1}^{(\rightarrow)} + \hat{q} _ {t+1}^{(\leftarrow)} \right)
$$
- 最终输出物理优化的3D骨骼序列:
$$
S^{3D} _ {pp} = E ^ {\text{pose}}(\hat{q}) \quad \in \mathbb{R} ^ {T \times 17 \times 3} \tag{18}
$$
学习偏置:优化目标
| 阶段 | 数据 | 关键约束 | 物理意义 |
|---|---|---|---|
| 预训练 | 含3D标注数据 | \(\mathcal{L}_ {3D}\) + \(\mathcal{L}_{noise}\) | 确保PhysNet初始参数满足刚体动力学 |
| 微调 | FineGym视频 | \(\mathcal{L}_{2D}\) | 适应真实场景的2D观测噪声与遮挡 |
| 生成 | 视频-文本对 | \(\mathcal{L}_ {\text{spat}} + \mathcal{L}_ {\text{temp}} + \mathcal{L}_ {\text{ad-temp}}\) | 平衡生成结果的视觉质量与运动连贯性 |
- 使用含真实3D姿态的大规模数据集
$$
\mathcal{L} _ {3D} = \sum _ {t=1}^T \sum _ {j=1}^J ||\hat{S}^{3D} _ {t,j} - S^{3D}_{t,j}||_2^2
$$
- 防止过度依赖对称性假设,允许微小非对称性(如单侧发力)
$$ \mathcal{L} _ {noise} = \sum _ {t=1}^T ||\hat{N} _ t|| _ F $$
- 2D投影损失,利用2D姿态估计结果作为弱监督信号
$$
\mathcal{L} _ {2D} = \sum _ {t=1}^T \sum _ {j=1}^J ||\mathcal{P}(\hat{S} ^ {3D} _ {t,j}) - S ^ {2D} _ {t,j}|| _ 2^2 + \mathcal{L} _ {noise} \tag{20}
$$
-
空间损失:单帧去噪误差
$$
\mathcal{L} _ {\text{spat}} = \mathbb{E} _ {z _ 0, c, \epsilon, t, i\sim \mathcal{U}(1,T)} \left[ ||\epsilon - \epsilon_\theta(z _ {t,i}, t, \tau _ \theta(c))|| _ 2^2 \right]
$$ -
时序损失:全局序列去噪误差
$$
\mathcal{L} _ {\text{temp}} = \mathbb{E} _ {z _ 0, c, \epsilon, t} \left[ ||\epsilon - \epsilon _ \theta( z _ t, t, \tau _ \theta(c))|| _ 2^2 \right]
$$
- 去偏时序损失:特征空间对齐误差(\(\phi\)为去偏算子[88])
$$
\mathcal{L} _ {\text{ad-temp}} = \mathbb{E} _ {z _ 0, c, \epsilon, t} \left[ ||\phi(\epsilon) - \phi(\epsilon_\theta(z _ t, t, \tau_\theta(c)))|| _ 2^2 \right]
$$
其中\(\phi\)是一种去偏运算,参考MotionDirector。
训练
数据集
| 数据集类型 | 构成与特点 | 作用 |
|---|---|---|
| 预训练数据集 | ||
| HumanArt [33] | 大规模骨骼-图像配对数据 | 训练骨骼热图编码器,建立视觉-骨骼跨模态关联 |
| Human3.6M [32] | 实验室环境多视角动捕数据(15种动作) | 提供高精度3D姿态真值,训练2D→3D模块 |
| AMASS [70] | 整合多个动捕数据集(SMPL模型参数) | 增强3D运动多样性,覆盖复杂人体变形 |
| FineGym子集 | FX-JUMP/TURN/SALTO(体操地板动作) | 验证细粒度动作生成能力,测试物理合理性 |
| FX-JUMP | 连续跳跃(如分腿跳) | 腾空阶段质心抛物线轨迹合理性 |
| FX-TURN | 快速转体(如单足旋转) | 角动量守恒与肢体收缩扩张关系 |
| FX-SALTO | 空翻(如后空翻两周) | 刚体动力学与柔体变形的耦合建模 |
Base Model
Stable Diffusion v1.5
AnimateDiff
实验
结论:
- 本文方向的生成质量和一致性都SOTA
- 其它方向结合了本文的FinePhys模块,也能有提升
在2D pose驱动的视频生成任务上,Follow Your Pose使用Cross Attention注入,本文使用Adapter注入。这两种都是有效且常用的注入方式,作者没有对这方面的控制效果做对比。
本文的主要贡献在于可微的3D动作物理合理性优化,可用于端到端的动作驱动任务的优化过程中。但是端到端的测试结果物理合理性优化在最终的视频生成中起到的作用,因为基于大量数据预训练的视频生成基模型所生成的视频本身就比较符合物理了。如果能跟HPE类的工作做对比,可能可以比较好地说明本文工作的效果。
在复杂动作上生成效果效果优于其它工作,可能是因为它使用了特定的数据集finetune,而其它工作是用于更通用的场景,没有使用有针对性的数据集。
AnimateDiff不是一个pose驱动的模型,不知道是怎么参与对比的?
补充
全身人体运动学模型
欧拉公式可转换为:
$$
M(q)\ddot{q} = J(q, \dot{q}) - C(q, \dot{q}), \tag{3}
$$
其中\(\dot{q}\)和\(\ddot{q}\)分别表示关节速度与加速度。
| 项 | 物理含义 | 人体运动对应实例 |
|---|---|---|
| \(M(q)\ddot{q}\) | 惯性力 | 空翻时身体各部位抵抗加速度变化的力 |
| \(J(q, \dot{q})\) | 外部驱动力 | 肌肉发力、重力、地面反作用力 |
| \(C(q, \dot{q})\) | 约束力 | 膝关节不可过度伸展的解剖限制 |
使用网络模型预测出M、C、J,公式3的离散化实现:
$$
\ddot{q} _ t = \hat{M}^{-1}(q _ t) \cdot [\hat{J}(q _ t, \dot{q}_t) - \hat{C}(q _ t, \dot{q} _ t)]
$$
通过中心差分公式更新关节位置:
$$
q _ {t+1} = \ddot{q} _ t \Delta t^2 + 2q _ t - q _ {t-1}
$$
$$ \begin{align*} q_{t+1} & = q_t+v_t\cdot \Delta t\\ & = q_t+(v_{t-1}+a_t\cdot \Delta t)\cdot \Delta t\\ & = q_t+v_{t-1}\cdot \Delta t+a_t\cdot (\Delta t)^2\\ & = q_t+(q_t-q_{t-1})+a_t\cdot (\Delta t)^2\\ & = a_t\cdot (\Delta t)^2+2q_t-q_{t-1} \end{align*} $$
Reference
分段刚体的刚体动力学:https://caterpillarstudygroup.github.io/GAMES105_mdbook/Simulation.html
VideoSwap
Customized video subject swapping via point control
Problem Formulation
- Subject replacement: change video subject to a customized subject
- Background preservation: preserve the unedited background same as the source video

Gu et al., “VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence,” 2023.
✅ 要求,背景一致,动作一致,仅替换前景 content.
✅ 因比对原视频提取关键点,基于关键点进行控制。
P227
Motivation
- Existing methods are promising but still often motion not well aligned
- Need ensure precise correspondence of semantic points between the source and target

✅ (1) 人工标注每一帧的 semantic point.(少量标注,8帧)
✅ (2) 把 point map 作为 condition.
P228
Empirical Observations
- Question: Can we learn semantic point control for a specific source video subject using only a small number of source video frames
- Toy Experiment: Manually define and annotate a set of semantic points on 8 frame; use such point maps as condition for training a control net, i.e., T2I-Adapter.
✅ 实验证明,可以用 semantic point 作为 control.
✅ 结论:T2I 模型可以根据新的点的位置进行新的内容生成。
P229
Empirical Observations
- Observation 1: If we can drag the points, the trained T2I-Aapter can generate new contents based on such dragged new points (new condition) → feasible to use semantic points as condition to control and maintain the source motion trajectory.

✅ 也可以通过拉部分点改变车的形状。
P230
Empirical Observations
- Observation 2: Further, we can drag the semantic points to control the subject’s shape

✅ 虚线框为类似于 control net 的模块,能把 semanti point 抽出来并输入到 denoise 模块中。
✅ Latent Blend 能更好保留背景信息。
✅ 蓝色部分为 Motion layer.
P231
Framework
-
Motion layer: use pretrained and fixed AnimateDiff to ensure essential temporal consistency
-
ED-LoRA \(_{(Mix-of-Show)}\): learn the wconcept to be customized
-
Key design aims:
- Introduce semantic point correspondences to guide motion trajectory
- Reduce human efforts of annotating points
Gu et al. “Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models.” NeurIPS, 2023.
P232
Step 1: Semantic Point Extraction
- Reduce human efforts in annotating points
- User define point at one keyframe
- Propagate to other frames by point tracking/detector
- Embedding

✅ 什么是比较好的 Semantic point 的表达?
P233
Methodology – Step 1: Semantic Point Extraction on the source video
- Reduce human efforts in annotating points
- Embedding
- Extract DIFT embedding (intermediate U-Net feature) for each semantic point
- Aggregate over all frames
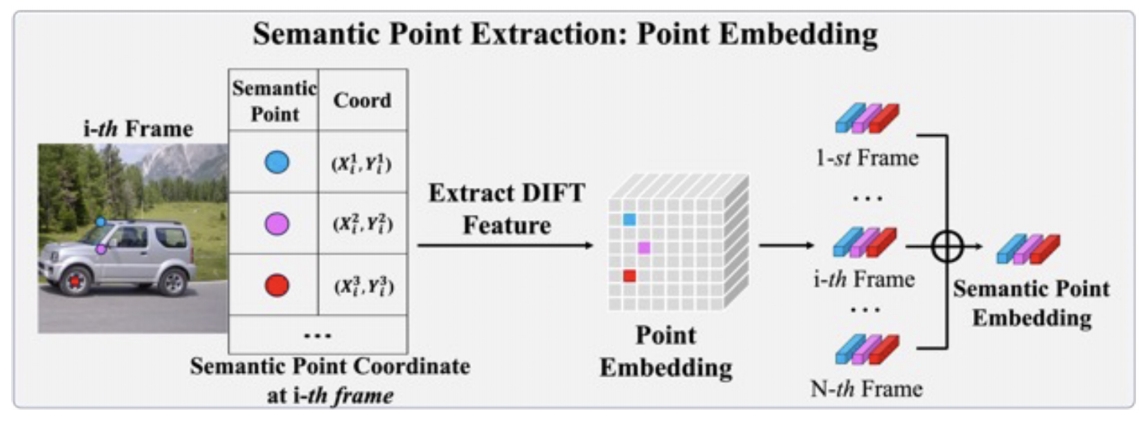
❓ Embedding, 怎么输人到网络中?
✅ 网络参数本身是 fix 的,增加一些小的 MLP, 把 Embeddin 转化为不同的 scales 的 condition map, 作为 U-Net 的 condition.
P234
Methodology – Step 2: Semantic Point Registration on the source video
- Introduce several learnable MLPs, corresponding to different scales
- Optimize the MLPs
- Point Patch Loss: restrict diffusion loss to reconstruct local patch around the point
- Semantic-Enhanced Schedule: only sample higher timestep (0.5T, T), which prevents overfitting to low-level details
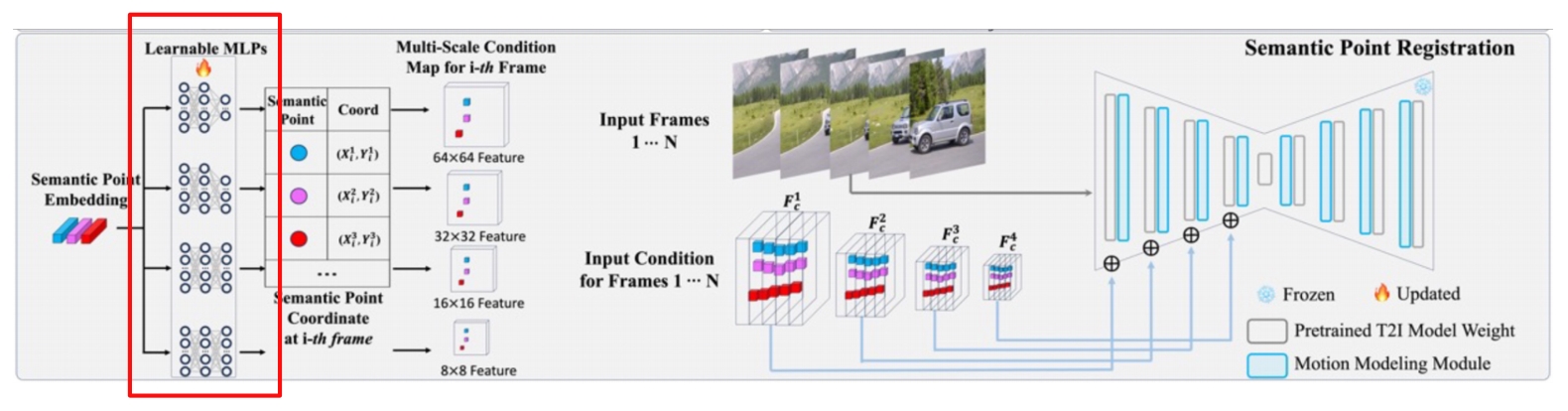
✅ 有些场景下需要去除部分 semanfic point, 或移动 point 的位置。
P235
Methodology
- After Step1 (Semantic Point Extraction) and Step2 (Semantic Point Registration), those semantic points can be used to guide motion
- User-point interaction for various applications

✅ 在一帧上做的 semantic point 的移动,迁移到其它帧上。
P236
Methodology
- How to drag point for shape change?
- Dragging at one frame is straightforward, propagating drag displacement over time is non-trivial, because of complex camera motion and subject motion in video.
- Resort to canonical space (i.e., Layered Neural Atlas) to propagate displacement.
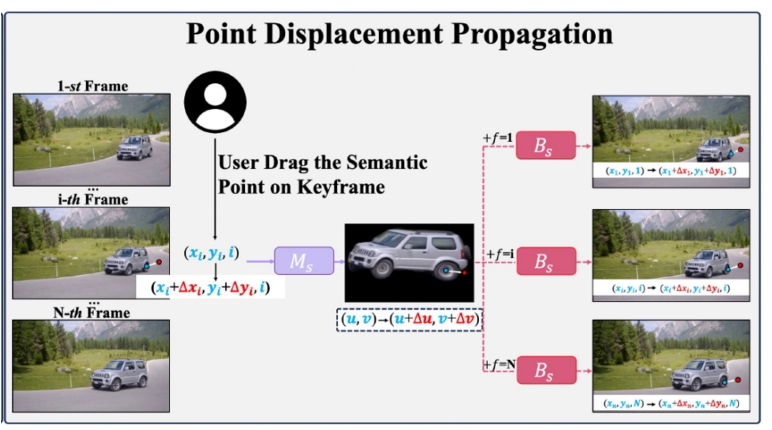
P237
Methodology
- How to drag point for shape change?
- Dragging at one frame is straightforward, propagating drag displacement over time is non-trivial because of complex camera motion and subject motion in video.
- Resort to canonical space (i.e., Layered Neural Atlas) to propagate displacement.

P238

P239

✅ point contrd 可以处理形变比较大的场景。
P240
Qualitative Comparisons to previous works
- VideoSwap can support shape change in the target swap results, leading to the correct identity of target concept.

P241
✅ 重建 3D 可以解决时间一致性问题。
DragAnything: Motion Control for Anything using Entity Representation
研究背景与问题
目的
基于轨迹的可控视频生成。
现有方法对比及局限性
| 方法 | 核心思想 | 局限性 |
|---|---|---|
| DragNUWA [48] | 稀疏轨迹→密集流空间 | 依赖单点,无法表征复杂物体运动 |
| MotionCtrl [42] | 轨迹坐标→矢量图 | 单点控制,忽略物体内部结构 |
| DragAnything | 实体表示→多属性控制 | 解决单点表征不足的问题 |
传统方法(如DragNUWA)通过单点轨迹控制像素区域,存在以下问题:
- 无法区分物体与背景,导致控制歧义。
在DragNUWA生成的视频中,拖动云朵的某个像素点并未导致云朵移动,反而引发了摄像头向上运动。这表明模型无法感知用户意图(控制云朵),说明单点轨迹无法表征实体。
- 轨迹点表示范式下,靠近拖动点的像素受更大影响。
DragNUWA生成视频中,靠近拖动点的像素运动幅度更大,而用户期望的是物体整体按轨迹运动,而非局部像素变形。
本文核心贡献
- 通过使用实体表示(entity representation)来实现可控视频生成中对任意物体的运动控制。
- 实体表示是一种开放域嵌入,能够表示任何对象(包括背景),从而实现对多样化实体的运动控制。
- 允许对多个对象进行同时且独立的运动控制。
主要方法
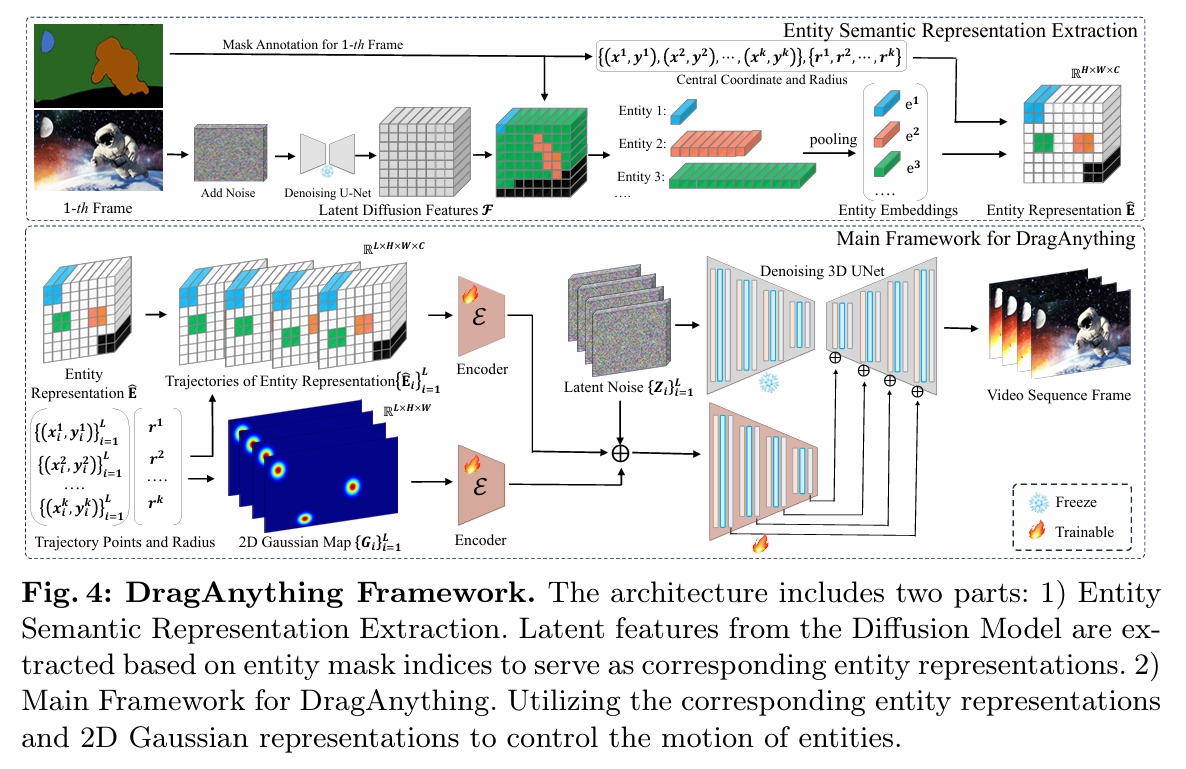
该架构包含两部分:
- 实体语义表示提取:基于扩散模型的潜在特征,通过实体掩码的坐标索引提取对应特征,作为实体的语义表示。
- DragAnything主框架:SVD
实体语义表示提取
| 步骤 | 输入 | 输出 | 方法描述 |
|---|---|---|---|
| 1. 扩散逆过程提取潜在噪声 | 首帧图像 \( I \in \mathbb{R}^{H \times W \times 3} \),实体掩码 \( M \in {0,1}^{H \times W} \) | 潜在噪声 \( \bm{x}_t \in \mathbb{R}^{H \times W \times 3} \) | 基于固定马尔可夫链逐步向图像添加高斯噪声(扩散前向过程),生成潜在噪声 \( \bm{x}_t \)。公式:\( \bm{x}_t = \sqrt{\alpha_t} I + \sqrt{1-\alpha_t} \epsilon \)。 |
| 2. 提取潜在扩散特征 | 潜在噪声 \( \bm{x}_t \),时间步 \( t \) | 潜在扩散特征 \( \mathcal{F} \in \mathbb{R}^{H \times W \times C} \) | 使用预训练去噪U-Net \( \epsilon_\theta \) 单步前向传播提取特征:\( \mathcal{F} = \epsilon_\theta(\bm{x}_t, t) \)。 |
| 3. 实体嵌入提取与池化 | 潜在扩散特征 \( \mathcal{F} \),实体掩码 \( M \) | 池化后的实体嵌入 \( {e_1, e_2, \ldots, e_k} \in \mathbb{R}^{C} \) | 根据掩码 \( M \) 的坐标索引提取特征向量,通过平均池化生成紧凑的实体嵌入。公式:\( e_k = \frac{1}{N} \sum_{i=1}^N f_i \)。 |
| 4. 嵌入与轨迹点关联 | 实体嵌入 \( {e_k} \),首帧实体中心坐标 \( {(x_k, y_k)} \) | 最终实体表示 \( \hat{E} \in \mathbb{R}^{H \times W \times C} \) | 初始化零矩阵 \( E \),将实体嵌入插入对应轨迹中心坐标位置(如图5所示),生成时空对齐的实体表示 \( \hat{E} \)。 |
二维高斯表示提取
目的:靠近实体中心的像素通常更为重要。希望实体表示更聚焦于中心区域,同时降低边缘像素的权重。
| 步骤 | 输入 | 输出 | 方法描述 |
|---|---|---|---|
| 1. 轨迹点与参数输入 | 轨迹点序列:{ {\((x _ i ^ 1, y _ i ^ 1)\)}\( _ {i=1} ^ L, \ldots, \){\((x _ i ^ k, y _ i^k)\)}\( _ {i=1}^L \) } 半径参数:\({r_ 1, \ldots, r_ k}\) | 原始轨迹点及控制范围的参数 | 输入用户提供的轨迹点序列(每个实体\(k\)对应\(L\)个轨迹点)及半径参数\(r_k\)(决定高斯分布范围)。 |
| 2. 高斯热图生成 | 轨迹点\((x_i^k, y_i^k)\),半径\(r_k\) | 二维高斯热图序列 \({G_i}_{i=1}^L \in \mathbb{R}^{H \times W}\) | 为每个轨迹点生成高斯分布热图,公式: \(G_i(h,w) = \exp\left(-\frac{(h - x_i^k)^2 + (w - y_i^k)^2}{2\sigma^2}\right)\),其中\(\sigma = r_k\),中心权重最大,边缘衰减。 |
| 3. 高斯特征编码 | 高斯热图序列 \({G_i}\) | 编码后的高斯特征 \(E({G_i}) \in \mathbb{R}^{H \times W \times C}\) | 通过编码器\(E\)(如3D U-Net)对高斯热图进行时空编码,提取与运动相关的条件特征。 |
| 4. 特征融合 | 编码后的高斯特征 \(E({G_i})\),实体表示 \(\hat{E}\)(来自3.3节) | 融合后的增强实体表示\(\hat{E}_{\text{fused}} \in \mathbb{R}^{H \times W \times 2C}\) | 将高斯特征与实体表示通过通道拼接或跨注意力机制融合,增强模型对中心区域的关注。 |
训练
基模型:Stable Video Diffusion(SVD)
优化器:AdamW
客观评估指标:
- 视频质量评估:FID、FVD
- 物体运动控制性能评估:通过预测轨迹与真实轨迹的欧氏距离(ObjMC)量化运动控制精度。
数据集:VIPSeg
实验

结论:SOTA
PhysAnimator: Physics-Guided Generative Cartoon Animation
研究背景与问题
从静态动漫插图中生成物理合理且具有动漫风格动画
现有方法局限性
传统工具:依赖分层输入(如分离的线稿与色彩层),无法处理复杂真实插图(如带噪纹理、细节密集的动漫图像)。
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2020 | Autocomplete animated sculpting | 基于关键帧的雕刻系统,通过直观笔刷界面自动补全用户编辑 | |||
| 2018 | A mixed-initiative interface for animating static pictures. | 针对带纹理的动漫图像,将插图分割为不同对象的图层,并允许用户提供涂鸦作为轨迹引导 | |||
| 2015 | Autocomplete hand-drawn animations | 将局部相似性技术扩展至全局相似性,实现基于前帧的自动草图补全。 |
数据驱动模型:光流预测缺乏物理约束,导致运动伪影(如不自然的扭曲、断裂),且难以控制外力交互(如自定义风场)。
核心创新点:
- 物理模拟与生成模型融合:结合物理引擎的准确性(确保运动合理性)与生成模型的创造性(保持艺术风格),突破传统动画制作范式
- 图像空间变形技术:直接在提取的网格几何体上进行物理计算,避免复杂的三维重建过程
- 艺术控制增强机制:通过能量笔触和绑定点支持实现物理模拟与艺术表现的平衡
关键技术路线:
物理模拟层:
- 可变形体建模:将插图中的对象(如头发、衣物)抽象为可变形网格,通过连续介质力学方程(如弹性力学)计算形变。
- 外力交互:能量笔触(Energy Strokes)允许用户以绘画方式定义外力场(如风力方向与强度),增强艺术控制。
生成增强层:
- 光流引导草图生成:利用物理模拟输出的光流场扭曲初始草图,生成动态线稿序列,规避纹理干扰。
- 扩散模型上色:以参考插图为风格基准,通过条件扩散模型(如Stable Diffusion Video)为动态线稿添加色彩与细节,保持风格一致性。
- 数据驱动插值:针对物理模拟未覆盖的细节(如发丝末端颤动),使用基于学习的插值模型补充次要动态。
主要贡献
- 基于物理模拟与数据驱动的视频生成
- 图像空间可变形体模拟技术,将动漫对象建模为可变形网格
- 草图引导的视频扩散模型将模拟动态渲染为高质量帧
主要方法
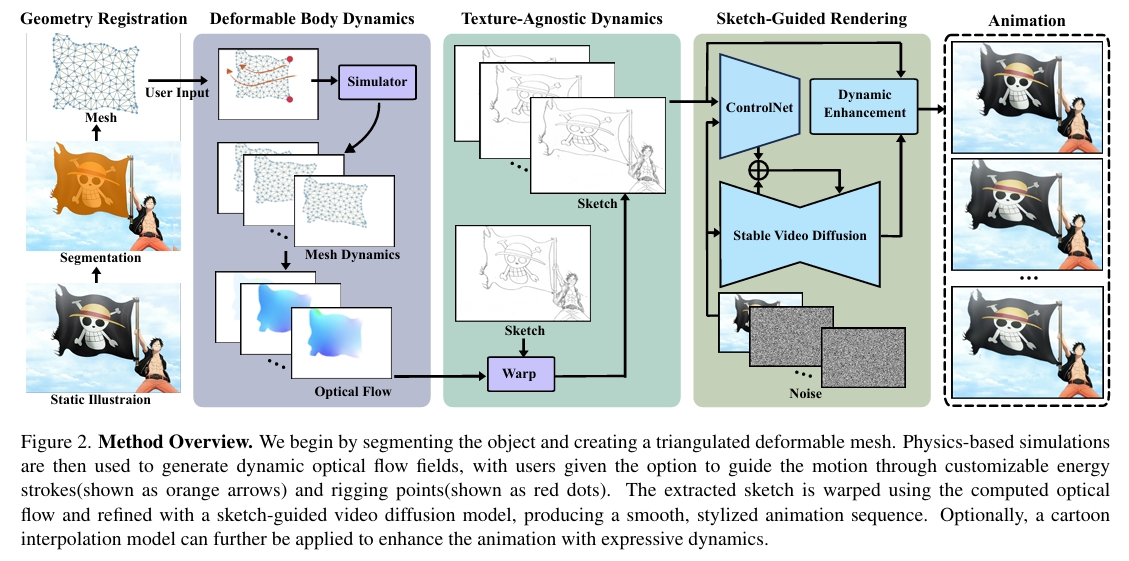
(1) 对象分割与网格生成
- 分割网络:采用 SAM 提取目标区域(如衣物、头发)的掩膜(Mask)和边界点。
- 网格化:通过 Delaunay 三角剖分生成二维可变形网格。
(2) 图像空间物理模拟
- 物理模型:利用Linear Finite Element Method计算力和能量。
- 动力学求解器:半隐式欧拉。
- 外力与约束:
- 能量笔触:能量笔触携带流动粒子,粒子沿用户指定的笔触移动,将外力传播至可变形网格的邻近顶点,从而创建定制化动画效果
- 绑定点:允许动画师固定特定区域或沿预设轨迹引导运动,提供更强的控制与灵活性
- 光流场计算:对于参考图像中的每个像素 \( \mathbf{X}_p \),若其位于三角形 \( T_i \) 内,则位移向量为 \( \mathbf{d}(p) = \phi _ i(\mathbf{X} _ p, t) - \mathbf{X} _ p \);否则位移向量为零。汇总所有像素的位移向量 \( \mathbf{d}(p) \) 即得光流场 \( F _ {0→t} \)。
(3) 草图引导视频生成
直接通过光流场扭曲参考图像 \( I_0 \) 生成视频序列,结果帧常因遮挡出现空洞伪影。因此本文使用以下方法:
- 动态草图生成:
- 初始草图提取:使用边缘检测(如 Canny)或预训练草图生成器(如 Anime2Sketch [3])提取Reference Image的草图。
- 光流扭曲:使用光流对Reference Image的草图做扭曲,生成动态草图。
- 扩散模型上色:
- 条件控制:以参考图 \( I_0 \) 为输入,动态草图 \( S_t \) 为控制信号
- 模型架构:Stablevideo + ControlNet(草图分支)
- 实验发现,由于分割误差,光流扭曲可能引入非预期失真或遗漏对象轮廓部分,生成不完美草图。因此在训练与推理时对输入草图施加高斯模糊,平滑不一致性。视频扩散模型通过其生成能力可优化结果,修复瑕疵并生成连贯输出。
(4) 数据驱动动态增强
- 插值模型:采用 FILM [4] 或 AnimeInterp [5] 生成中间帧细节运动
- 动态融合:
- 主运动:物理模拟生成的光流场
- 细节运动:插值模型输出的残差光流
- 融合公式:\( F_{final} = F_{physics} + α \cdot F_{interp} \)(\( α \) 控制细节强度)
Complementary Dynamics
引入原因:
动画中的动态效果并不严格遵循物理定律,也无法完全通过二维动画方法捕捉。
本文方法:
用数据驱动模块增强基于物理的动画结果。即,
- 从草图引导渲染结果中选择关键帧,形成关键帧序列 \( {I^r_0, I^r_n, I^r_{2n}, ..., I^r_{in}} \),其中 \( n \) 表示关键帧间隔。
- 随后采用卡通插值视频扩散模型[78],在每对相邻关键帧 \( (I^r_{in}, I^r_{i(n+1)}) \) 间合成中间帧 \( {\hat{I} _ {in+1}, \hat{I} _ {in+2}, ..., \hat{I} _ {i(n+1)-1}} \) 。
优势: 可引入超越纯物理动画的表现性数据驱动互补动态。
实验
横向对比
- 图生视频模型: Cinemo [51] and DynamiCrafter [79]
- 『图+控制轨迹』生视频模型:
- MotionI2V:轨迹->光流->视频
- DragAnything:轨迹->2D高斯热图->视频
- 本文:轨迹->2DMesh->光流->视频
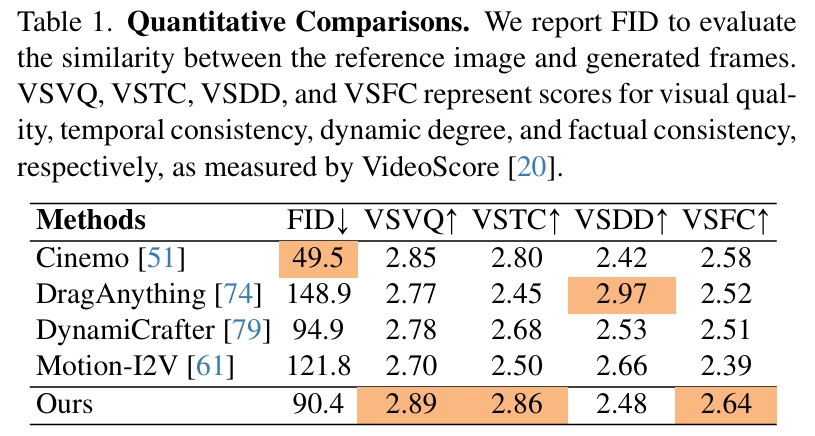
解析:
- Cinemo的FID非常好,因为它生成的视频几乎不会动
- DragAnything的VSDD非常好,是因为它倾向于把控制轨迹理解为相机运动,生成运镜效果,因为提升了dynamics score。
这篇工作的结论存疑:
由于作者的测试文本局限于衣服飘动之类的prompt,所以这个对比不是很公平。
本文的时序一致性比较好可能是底座的能力,因为所对比的其它工作(MotionI2V),其底座是T2I模型,而本文的底座是T2V模型。
DragAnything并非如作者所言『倾向于理解为相机运动』,DragAnything的创新点之一就是分离前景与背景的运动。
Reference
https://xpandora.github.io/PhysAnimator/
SOAP: Style-Omniscient Animatable Portraits
研究背景与问题
目的
从单张图像生成可动画化的3D虚拟形象
现有方法及局限性
- 非3D扩散模型的单视角头部建模方法: 局限于特定风格(如超写实风格[Khakhulin等,2022]或特定卡通类型[Chen等,2023b]),且在处理眼镜或头饰等配饰时频繁遇到挑战。
- 3D扩散模型方法:缺乏精细细节并易产生伪影;生成的3D输出通常是非结构化的表面模型或神经场,这些形式无法直接用于面部动画。
本文核心贡献
- 全风格感知的图像到虚拟形象管线:能够从单一肖像图像中重建具有完整纹理、拓扑一致且骨骼绑定完善的网格化虚拟形象(包含眼球与牙齿),覆盖广泛艺术风格、发型变化及头饰类型。
- 多视角扩散模型:基于大规模3D头部数据集(24K)训练的多视角扩散模型,可生成多种风格下人体头部模型的一致性多视角图像。
- 基于可微分渲染的自适应形变技术:通过自适应网格重构与骨骼绑定,实现任意风格化虚拟形象向参数化头部模型的语义对齐注册,同时保持正确的语义对应关系。
- 构建包含24K 3D虚拟形象的数据集,覆盖两种风格下的多样头部形状、发型、表情与身份特征。
大致方法是什么?
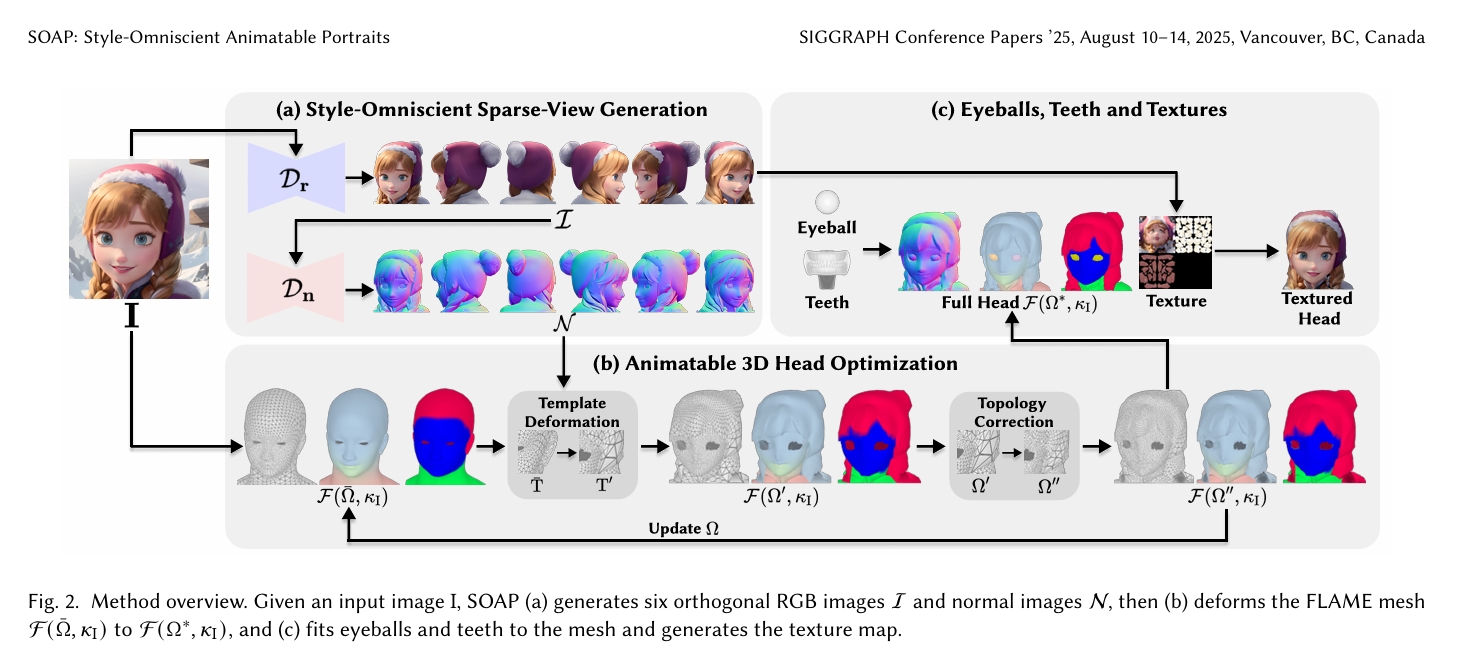
1. 多视角生成阶段**
BaseModel:Unique3D [Wu等,2024b]
(1)多视图图像扩散模型\( D_r \):以单张图像\( I \in \mathbb{R}^{256×256×3} \)为输入,输出6组正交RGB图像\( \hat{I} \in \mathbb{R}^{6×256×256×3} \)。
(2)法线扩散模型\( D_n \):以这些图像\( \hat{I} \)为输入,生成对应的法线贴图\( N \in \mathbb{R}^{6×256×256×3} \)。
(3)单视角超分辨率模型将多视图的图像与法线贴图放大4倍,同时保持多视图一致性。
2. 参数化形变优化
定义符号
定义参数集\( \kappa = (\beta, \theta, \psi) \),完整参数化模型\( \Omega = (T, F, W, J, B) \)。
初始化
使用Emoca方法初始化FLAME参数\( F(\bar{\Omega}, \kappa_I) \)和相机参数\(\pi\)
优化策略
传统方法[Daněček等,2022;Khakhulin等,2022]通过调节\( \kappa \)和添加顶点偏移量建模多样性,但受限于:
- 参数\( \kappa \)的表征能力有限
- 模板拓扑固定导致几何过度平滑
- 无法处理复杂发型与细粒度细节
为此,SOAP提出迭代优化框架(图2b),包含以下核心步骤:
- 语义模板形变:\( T \rightarrow T' \)(顶点数量不变)
- 重网格化与骨骼插值:\( \Omega \rightarrow \Omega' \)
- 迭代循环:重复步骤1-2直至收敛
SOAP创新性地引入个性化Ω优化:
- 模板拓扑可塑性:在发型/配饰区域允许三角形网格动态细分(通过Edge Split/Collapse操作)
- 混合形状基扩展:在保持原始\( B_s, B_e, B_p \)基础上,新增个性化混合形状基\( B_{custom} \),通过PCA降维控制细节形变
Template Deformation 语义模板形变
这里的deformation不是由骨骼驱动导致的形变,而是由顶点位移导致的形变。
输入:
- 多视角法线贴图\( N \)
- 初始FLAME网格\( F(\bar{\Omega}, \kappa_I) \)
- 相机参数\( \pi \)
- 从输入图像\( I \)检测的68个面部关键点\( L \in \mathbb{R}^{68×2} \) [Bulat & Tzimiropoulos, 2017]
- 通过[Dinu, 2022]获得的头部语义分割图\( P \in \mathbb{R}^{3×h×w×3} \)
优化目标:
- 模板顶点\( T \):
损失函数:
$$ \mathcal{L} = \lambda _ {rec} \mathcal{L} _ {rec} + \lambda _ {sema} \mathcal {L} _ {sema} + \lambda _ {lmk} \mathcal{L}_ {lmk} $$
- 重建损失 \( \mathcal{L}_{rec} \):对齐几何与法线贴图
- 语义损失 \( \mathcal{L}_{sema} \):约束头发/面部/颈部形变的语义一致性
- 关键点损失 \( \mathcal{L}_{lmk} \):保持眼部/鼻部/唇部等结构的对称性
Tepology Correction 重网格化与骨骼插值
对形变过程或者产生的问题做一些修复:
- 大三角形面片(边长超过阈值𝜖)--- 细分
- 面法线翻转 --- 修正翻转面
- 扭曲面片 --- 删除
顶点的增加或删除,需要同步更新一些参数矩阵:
- 蒙皮权重 \( W \in \mathbb{R}^{N×|J|}\):新增顶点的权重由其邻接边顶点插值获得
- 混合形状基 \( B \in \mathbb{R}^{500×|J|}\):通过重心坐标插值传递形变参数
- 关节映射矩阵 \( J \in \mathbb{R}^{|J|×N}\):基于变形后模板逆向计算,确保规范空间关节位置不变
3. 精细化组件与纹理生成
- 眼球与牙齿模型适配:分离刚性部件并优化空间位姿
- UV纹理合成:通过多视角RGB图像进行纹理烘焙与超分辨率修复(Sec.5.3)
训练
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
数据集
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练策略
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
实验与结论
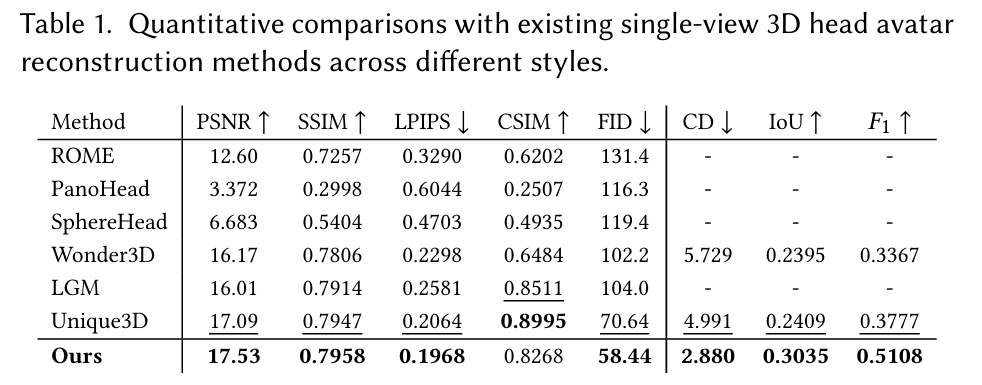 .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
Loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
参考材料
Neural Discrete Representation Learning
VQ-VAE
一、研究背景与动机
- 无监督表示学习的挑战
传统生成模型(如VAE)在图像、语音等任务中常使用连续的潜在变量,但离散表示更符合语言、语音等模态的本质特性。此外,连续潜在变量在结合强解码器时易出现“后验坍塌”(Posterior Collapse),即潜在变量被解码器忽略的问题。 - 离散表示的优势
离散表示更适合复杂推理和规划任务(如逻辑推理、序列生成),且在语音、图像等高维数据中能捕捉高层语义特征(如音素、物体类别)。
二、模型核心创新:VQ-VAE
1. 模型结构
- 编码器:输入数据(如图像)通过编码器生成连续特征向量 \( z_e(x) \)。
- 向量量化(VQ):将 \( z_e(x) \) 与**可学习的码本(Codebook)**中的离散向量 \( e \in \mathbb{R}^{K \times D} \) 进行最近邻匹配,得到离散索引 \( z_q(x) \)。
- 解码器:将离散向量 \( z_q(x) \) 解码为重构数据。
- 关键操作:
量化过程通过不可导的argmin完成,但通过梯度直通估计器(Straight-Through Estimator)将解码器梯度直接复制到编码器,实现反向传播。
2. 损失函数
总损失包含三部分:
- 重构损失:最小化输入与解码输出的差距(如L2 Loss)。
- 码本损失:更新码本向量,使其逼近编码器输出(\( ||sg[z_e(x)] - e||^2_2 \))。
- 承诺损失:约束编码器输出靠近码本向量(\( \beta ||z_e(x) - sg[e]||^2_2 \),通常 \( \beta = 0.25 \))。
- KL散度的缺失:假设先验分布为均匀分布,KL散度退化为常数,故未显式优化。
三、关键技术与优势
- 避免后验坍塌
离散化强制编码器生成与码本对齐的表示,防止解码器忽略潜在变量。 - 灵活的生成过程
训练完成后,通过自回归模型(如PixelCNN、WaveNet)建模离散索引的先验分布,生成新样本。例如:- 图像生成:使用PixelCNN建模二维离散索引矩阵。
- 语音转换:将语音内容与说话人特征解耦,实现跨说话人生成。
- 多模态应用
在图像、语音、视频任务中均表现优异,例如:- 图像:生成128×128分辨率图像,保留全局结构。
- 语音:无监督学习音素级表示,分类准确率达49.3%(随机基线7.2%)。
四、实验与效果
- 图像生成
- 在CIFAR-10和ImageNet上,VQ-VAE的重建质量接近连续VAE,且潜在空间更易被自回归模型建模。
- 生成样本虽稍模糊,但能保留语义信息(如物体形状)。
- 语音与视频
- 语音生成:实现高质量说话人转换,内容与音色解耦。
- 视频生成:基于动作序列生成连贯帧,避免质量退化。
五、贡献与意义
- 理论贡献
首个在复杂数据集(如ImageNet)上表现媲美连续VAE的离散潜变量模型,解决了后验坍塌和训练不稳定的问题。 - 应用价值
启发了后续工作(如VQGAN、Stable Diffusion),成为多模态生成任务的基础框架。 - 无监督表示学习
证明离散表示能捕捉高层语义(如音素、物体类别),为无监督学习提供新思路。
六、未来方向
- 联合训练先验模型:将VQ-VAE与自回归先验联合优化,提升生成质量。
- 改进损失函数:引入感知损失或对抗损失,增强重建细节。
- 跨领域扩展:探索离散表示在强化学习、机器人规划等任务中的应用。
TSTMotion: Training-free Scene-aware Text-to-motion Generation
研究背景与问题
-
文本到动作生成(Text-to-Motion)
现有技术多基于空白背景生成人体动作序列,但现实场景中人类需与3D环境中的物体交互(如“坐在远离电视的沙发上”)。传统方法无法满足场景感知需求,导致生成动作与场景逻辑冲突。 -
现有方法局限性
- 数据依赖性强:现有数据集(如HUMANISE)规模小、场景单一(仅室内)、动作有限(行走、坐、躺、站);
- 算法复杂度高:基于强化学习(RL)的方法需要细粒度标注且面临RL训练难题;
- 输入低效性:直接输入无序点云数据效率低下。
核心创新:TSTMotion框架
目标:无需训练专用场景感知模型,直接利用现有“空白背景生成器”(如Motion Diffusion Models)实现场景感知的文本驱动动作生成。
基于基础模型的三组件设计:
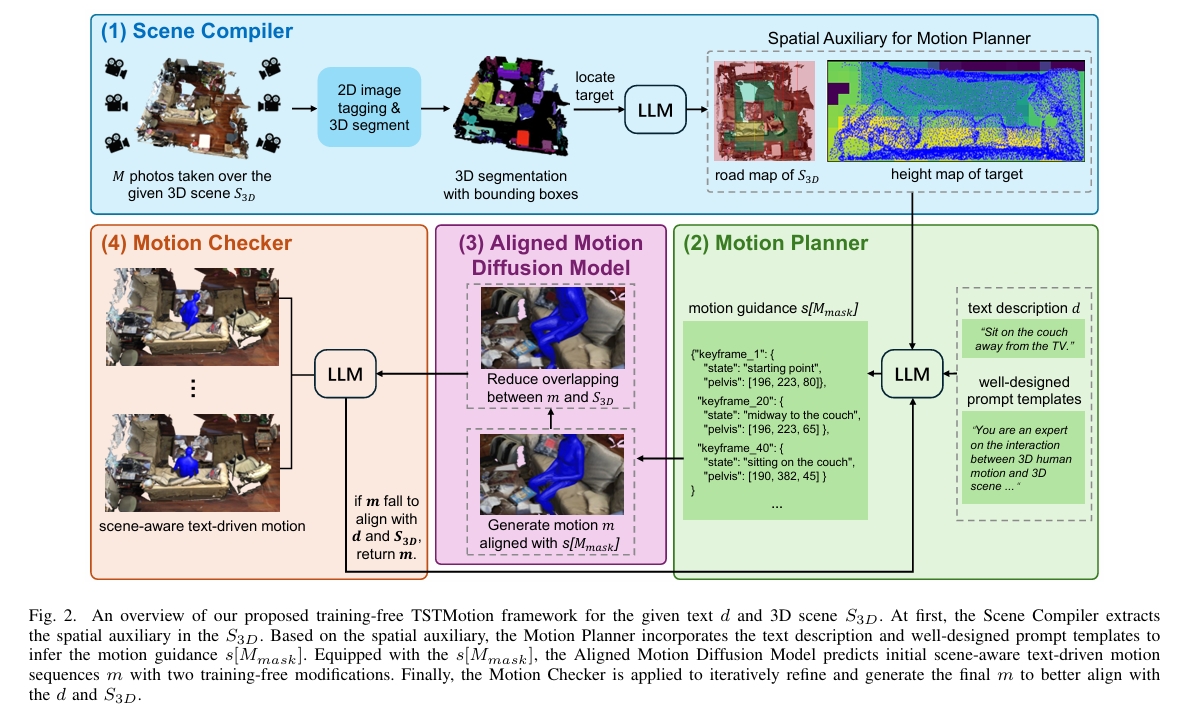
场景编译器(Scene Compiler)
功能:将3D场景转换为结构化表示(如语义地图),提取物体位置、空间关系等上下文信息,解决点云输入的低效问题。
1. 识别(Recognition)
- 输入:原始3D场景点云 \( S_{3D} \)。
- 操作:
- 多视角渲染:从不同角度渲染点云,生成 \( M \) 张2D图像(覆盖俯视、侧视等视角),解决点云单视角遮挡问题。
通过多角度渲染解决点云遮挡问题,提升物体识别完整性与鲁棒性。
- 物体识别:使用预训练的图像标签模型(如CLIP或ResNet)识别每张图像中的物体类别(如“沙发”“电视”),合并所有视角结果生成统一物体词汇表(避免重复)。
- 输出:场景中所有物体的类别列表(如 {沙发, 电视, 茶几})。
2. 分割(Segmentation)
- 输入:物体词汇表 + 原始点云 \( S_{3D} \)。
- 操作:
- 语义分割:基于词汇表,使用3D分割器(如PointNet++或3D-SparseConv)将点云中每个点分类到对应物体(如标记属于“沙发”的点)。
- 实例分割:区分同一类别的不同物体实例(如两个独立的“椅子”)。
- 输出:带语义标签的点云,每个点标记所属物体类别及实例ID。
3. 目标定位(Locating Target)
- 输入:分割后的点云 + 文本指令(如“坐在远离电视的沙发上”)。
- 操作:
- 边界框简化:将每个物体实例的点云包裹为轴对齐包围盒(AABB),记录其中心坐标、长宽高。
- LLM语义解析:
- 将文本指令输入大语言模型(如GPT-4),解析出目标物体(“沙发”)和约束条件(“远离电视”)。
- 结合包围盒空间坐标,定位目标物体(如筛选出距离电视最远的沙发实例)。
- 输出:目标物体的包围盒坐标及空间约束关系(如“沙发A中心坐标(x,y,z),与电视B距离>2米”)。
用包围盒代替原始点云,显著降低后续计算复杂度(从数万点→数十个包围盒)。
4. 路网图生成(Road Map)
- 输入:所有物体的包围盒 + 目标物体位置。
- 操作:
- 投影到XOY平面:将3D包围盒投影至水平地面(XOY平面),生成2D矩形区域。
- 标记可通行区域:
- 障碍物:非目标物体的投影区域(如电视、茶几的投影区标记为障碍)。
- 目标区域:目标物体(沙发)的投影区标记为终点。
- 路径规划基底:输出栅格化路网图,标识可行走区域与障碍物(见下图示意)。
- 输出:二值化路网图(0=障碍,1=可通行)。
5. 高度图生成(Height Map)
- 输入:目标物体的点云(如沙发点云)。
- 操作:
- 投影到XOY平面:将目标点云垂直投影至地面,保留每个点的Z轴高度值。
- 栅格化处理:将投影区域划分为网格,每个网格单元记录最大高度(表征物体形状起伏)。
- 形状编码:生成灰度图像,亮度表示高度(如高亮区域=沙发坐面,暗区=扶手)。
- 输出:目标物体的高度分布图(用于接触点预测与动作可行性判断)。
路网图和高度图要求场景中的所有东西都是在地上。不能在空中。
路网图专注宏观路径规划(避开障碍);
高度图专注微观动作适配(如坐面高度决定弯曲关节角度)。
动作规划器(Motion Planner)
功能:将文本指令与场景编译器输出的空间辅助信息(路网图Road Map + 高度图Height Map)结合,生成初步动作指导(如轨迹、接触点)。
1. 骨架序列表示
- 定义:骨架序列 \( s \in \mathbb{R}^{N \times J \times 3} \),其中:
- \( N \):动作帧数(如30帧对应1秒动作)
- \( J \):人体关节数(如SMPL模型的24关节)
- 3:关节在3D空间中的坐标(x, y, z)
- 稀疏掩码:引入二进制掩码 \( M_{\text{mask}} \in {0,1}^{N \times J} \),仅标记与场景交互相关的关键关节(如“坐”动作需关注髋关节、膝关节)。
2. 基于LLM的分步推理
- 输入:
- 文本指令 \( d \)(如“坐在远离电视的沙发上”)
- 场景编译器输出的路网图(可行走区域) + 高度图(目标物体形状)
- 提示工程:通过设计结构化提示模板(Prompt Template),将任务分解为子问题,引导LLM逐步推理:
prompt = """ 你是一个动作规划专家,请根据以下信息生成人体动作骨架序列: 1. 场景路网图:{road_map_description} 2. 目标高度图:{height_map_description} 3. 文本指令:“{text_instruction}” 请按步骤思考: Step 1: 确定动作类型(如行走、坐下)及目标物体接触区域。 Step 2: 根据路网图规划从起点到目标的移动路径(坐标序列)。 Step 3: 结合高度图预测接触点(如沙发坐面中心坐标)。 Step 4: 生成关键关节(髋、膝、踝)的3D轨迹,避免与场景碰撞。 """
Step1:LLM解析文本指令,提取动作类型(如“坐”)和场景约束(如“远离电视”)。
Step2:宏观路径:基于路网图,使用LLM内置的空间推理能力生成从起点到目标物体的移动路径(如绕过障碍物的折线坐标序列)。
Step3:高度图分析:LLM根据目标高度图(如沙发坐面高度≈0.5m)预测接触点坐标(如髋关节目标位置(x, y, 0.5))。
Step4:关键关节轨迹:LLM生成指定关节(由掩码 \( M_{\text{mask}} \) 标记)的3D轨迹。
- 输出:稀疏骨架序列 \( s[M_{\text{mask}}] \)(如仅包含髋、膝、踝关节的轨迹)。
- 示例
- 输入:
- 路网图:标记沙发位置为终点,电视区域为障碍。
- 高度图:沙发坐面高度=0.5m,靠背高度=0.9m。
- LLM推理:
- Step 1: 动作类型=“坐”,接触区域=沙发坐面中心。
- Step 2: 路径=从起点直线移动至沙发(无障碍需绕行)。
- Step 3: 接触点坐标=(2.0, 3.0, 0.5)。
- Step 4: 生成髋关节轨迹(从(2.0, 1.0, 1.0)降至(2.0, 3.0, 0.5)),膝关节弯曲角度随时间增加。
- 输出骨架序列:
- 帧1-10:髋关节从站立高度降至坐面高度,膝关节逐渐弯曲。
- 帧11-30:保持坐姿稳定,无垂直移动。
对齐的扩散动作模型(Aligned Motion Diffusion Model)
功能:在不重新训练模型的前提下,将动作规划器生成的指导嵌入到预训练的空白背景动作扩散模型(如Motion Diffusion Model)中,生成符合场景约束的动作序列。突破传统扩散模型对场景信息的“盲生成”,实现开放域场景的动态适配。
1. 对齐动作指导(Modification 1):符合Motion Planner生成的骨架序列 \( s[M_{\text{mask}} \);
在推断时,先用FK计算出关节的位置,计算预测位置与期望位置之间的损失, 通过反向传播计算梯度,调整模型预测\( \hat{x}_0^k \):
$$ \hat{x} _ 0^k \leftarrow \hat{x} _ 0^k - \lambda \cdot \nabla _ {x_k} L_ {\text{align}} $$
方法类似于OmniControl的方法
2. 避免场景穿透(Modification 2):减少与3D场景的几何重叠。
使用符号距离函数 \( \text{SDF}(p, P) \) 计算人体网格点 \( p \) 到场景 \( P \) 的最小距离,以及在P内部还是外部。
定义损失函数 \( L_{\text{scene}} \),仅惩罚穿透点(SDF负值部分):
$$
L_{\text{scene}} = \sum_{p \in \text{SMPL}(\hat{x}_0^k)} \text{ReLU}(-\text{SDF}(p, P))
$$
通过梯度更新减少穿透,修正方法与上面相同。
技术挑战与解决方案
- 梯度冲突:若两个修改的梯度方向相反,可能导致震荡。
解决方案:采用交替更新策略(先对齐动作,再消除穿透),或动态调整 \( \lambda, \eta \)。 - 计算效率:SDF实时查询可能增加耗时。
解决方案:预计算场景的SDF网格,或使用近似加速结构(如KD-Tree)。 - 过修正风险:过度调整可能破坏动作自然性。
解决方案:限制梯度步长 \( \lambda, \eta \),或加入动作流畅性约束。
动作检查器(Motion Checker)
功能:通过物理合理性验证(如碰撞检测、动作可行性)优化动作指导,确保生成动作与场景动力学一致。
1. 迭代优化流程
- 首次生成:Motion Planner → Aligned MDM → Motion Checker。
- 验证失败:
- 将失败原因反馈至Motion Planner,调整动作指导(如重新规划路径或接触点)。
- 重新执行生成与验证,通常仅需1次迭代即可通过。
- 终止条件:验证通过或达到最大迭代次数(如3次)。
2. 自动化摘要
将骨架序列 \( s \) 和SMPL网格转换为自然语言描述,包括:
- 关键关节轨迹(如髋关节移动路径);
- 接触点坐标与目标物体位置对比;
- 穿透检测结果(如“左膝穿透沙发深度0.1m”)。
3. LLM驱动的验证机制
- 输入:
- 生成的动作序列描述(如骨架序列可视化报告);
- 原始文本指令与场景编译器输出的语义地图。
- 提示模板设计:
prompt = """ 你是一个动作质检专家,请验证以下动作是否符合要求: 1. 文本指令:“{text_instruction}” 2. 场景约束:{scene_constraints}(如“沙发位置”“障碍物区域”) 3. 生成动作报告:{motion_report}(包含骨架轨迹、接触点、网格穿透检测结果) 请按步骤检查: Step 1: 动作类型是否与指令一致?(如“坐” vs “蹲”) Step 2: 移动路径是否避开所有障碍物? Step 3: 接触点是否位于目标物体表面? Step 4: 人体网格是否与场景发生穿透? 若任一步骤不通过,返回失败原因。 """ - 输出:验证结果(通过/不通过) + 失败原因(如“髋关节轨迹偏离沙发坐面”)。
4. 失败案例处理
- 路径偏离:反馈至Motion Planner重新规划路径(如增大绕障距离)。
- 语义不符:修正LLM解析逻辑(如明确“坐”与“蹲”的关节角度阈值)。
- 场景穿透:增强Modification 2的梯度惩罚强度 \( \eta \)。
关键技术突破
-
无需训练的零样本生成
- 利用预训练基础模型(如CLIP、扩散模型)的泛化能力,避免对场景感知数据集的依赖。
- 通过“提示工程”将场景信息隐式编码至生成过程,而非显式训练。
-
场景-动作联合建模
- 将文本指令拆解为“动作语义”和“场景约束”两部分,分别由动作规划器和场景编译器处理。
- 示例:指令“坐在远离电视的沙发上” → 动作语义“坐” + 场景约束“沙发位置”+“与电视的距离”。
-
动态物理可行性验证
- 动作检查器引入轻量级物理仿真(如刚体动力学),快速验证动作合理性。
- 若规划动作导致碰撞或失衡,迭代调整接触点或运动轨迹。
实验与效果
实验1
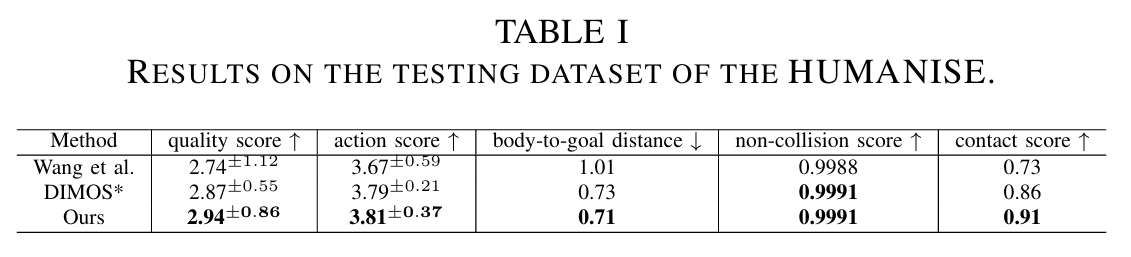
测试数据集:
- HUMANISE数据集:专注于室内场景的文本-动作-场景交互数据,包含有限动作(行走、坐、躺、站)。
对比: - 本文方法
- DIMOS 结论: 关键结论:
- DIMOS*(DIMOS + Scene Compiler)的Body-to-Goal Distance显著低于原始DIMOS,证明Scene Compiler的物体定位能力有效。
- TSTMotion进一步优化路径规划与接触点预测,距离最低,体现Motion Planner与Aligned MDM的协同优势。
- TSTMotion在语义对齐(如动作类型匹配)和碰撞避免上均优于基线,验证Motion Checker迭代优化的有效性。
实验2

测试数据集:
- AffordMotion数据集:包含多样化室内外场景与复杂动作(如跑步、跳跃、抓取),强调动作-场景的物理交互合理性。
对比: - 本文方法
- AffordMotion 结论:
- R-Precision:文本与生成动作的匹配度,TSTMotion更高,体现Motion Planner对复杂指令的精准解析。
- MultiModal Distance:生成动作多样性偏差,值越低说明多样性越好且符合文本,反映零样本生成避免过拟合的优势。
- Contact Score:动作与目标物体的有效接触率,TSTMotion通过高度图引导接触点预测显著提升。
- Non-Collision Score:无场景穿透的比例,得益于Modification 2的SDF梯度修正。
- 无需场景特定数据训练,适配室内外环境;
应用价值
- 游戏与影视制作
- 快速生成符合场景逻辑的角色动画(如NPC自动避障、与道具交互),降低人工制作成本。
- 具身智能(Embodied AI)
- 为机器人提供基于自然语言指令的场景适配行为规划(如“绕过桌子取水杯”)。
- 元宇宙与虚拟人
- 增强虚拟角色在开放环境中的自主交互能力,提升用户体验沉浸感。
未来挑战
- 长时序动作连贯性
当前方法对多步骤复杂指令(如“走到沙发旁,坐下后拿起书”)的时序一致性仍需优化。 - 多智能体交互
需扩展至多人协作或对抗场景(如“两人搬箱子”)。 - 实时性提升
物理验证模块的计算效率需进一步优化以满足实时生成需求。
总结
TSTMotion通过无训练框架设计和场景-动作联合建模,解决了传统文本到动作生成的场景割裂问题,为开放域动态交互任务提供了高效、低成本的解决方案。其核心思想“利用基础模型知识代替专用训练”或成为未来跨模态生成任务的重要范式。
相似工作对比
LLM based human motion生成任务对比
- 本文,2025.5
- OmniControl,2024,link
| 本文 | OmniControl | |
|---|---|---|
| 控制信息->prompt | 动作规划器生成 | 特定任务的指令的简单组合 |
| prompt->motion | 1. prompt作为MDM的condition,使用MDM生成 2. 推断过程使用prompt中的具体的数据信息做动作优化 | LLM + LoRA |
| motion后处理 | 1. 借助LLM判断生成动作是否合理 2. 根据判断结果重新调整引导生成的LLM | 无 |
| 生成效果 | 动作规划器能支持更复杂的控制需求 后处理能进一步优化生成动作 | 借助预训练的LLM简单训练过程,但生成结果没有优势 |
Deterministic-to-Stochastic Diverse Latent Feature Mapping
核心问题是什么?
目的
人体运动合成的目标在于生成逼真的人体运动序列。
现有方法及局限性
score-based生成模型(SGMs)及difusion生成模型。
优势:在人体运动合成任务中展现出了令人瞩目的成果。
局限性:这类模型的训练过程涉及复杂的曲率轨迹,导致训练稳定性面临挑战。
本文方法
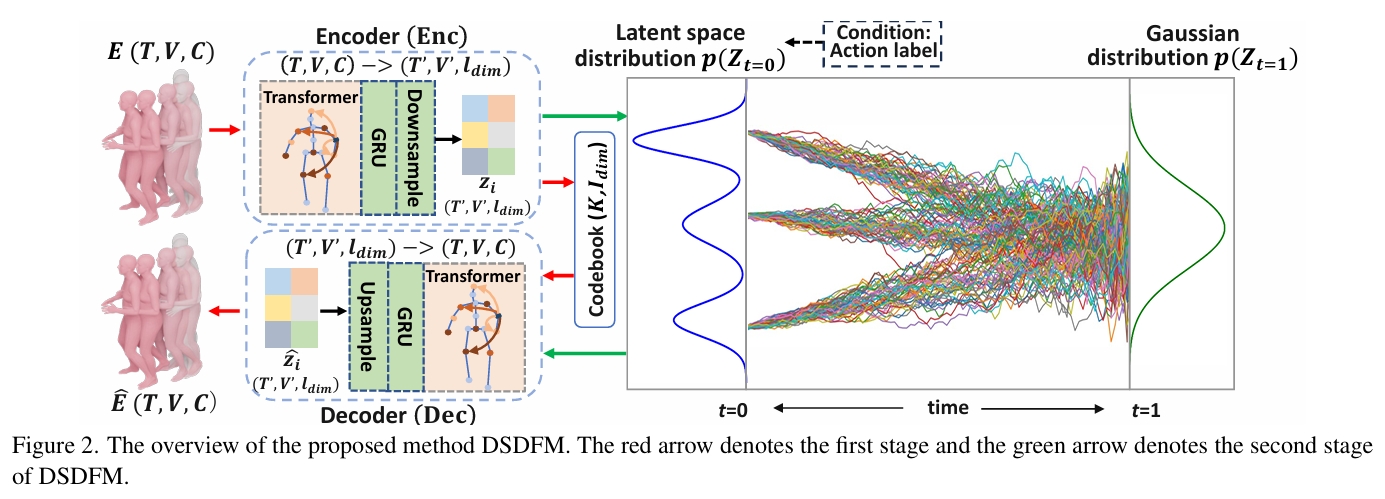
确定性-随机双阶段潜在特征映射(DSDFM)方法:
第一阶段通
目标:通过人体运动运动重建(VQVAE with transformer network),学习运动数据的潜在空间分布。
作者用transfomer重训练了一个transformer based VQVAE,而不是经典的CNN based VQVAE。
第二阶段
目标:使用确定性特征映射过程(DerODE)构建高斯分布与运动潜在空间分布之间的映射关系。(方法类似flow matching)
推断
生成时通过通过向确定性特征映射过程的梯度场中注入可控噪声(DivSDE)实现多样性。(方法类似score matching)
效果
有效提升生成运动的多样性和准确性。
核心贡献是什么?
- 提出了一种新的生成范式:确定性-随机双阶段潜在特征映射(DSDFM)方法。
- 在人体运动生成任务上证明其有效性。
实验与结论
实验一:人体运动合成的横向对比
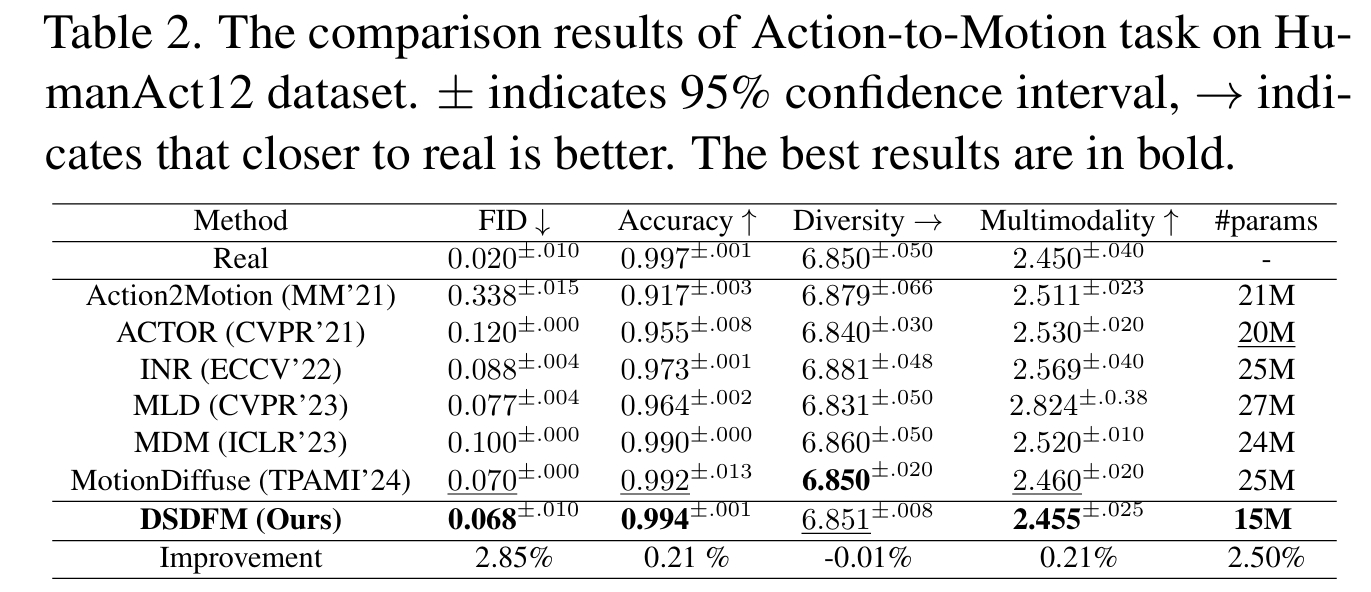
实验二:仅将本文方法中的第二阶段替换为其它SDE方法的效果对比
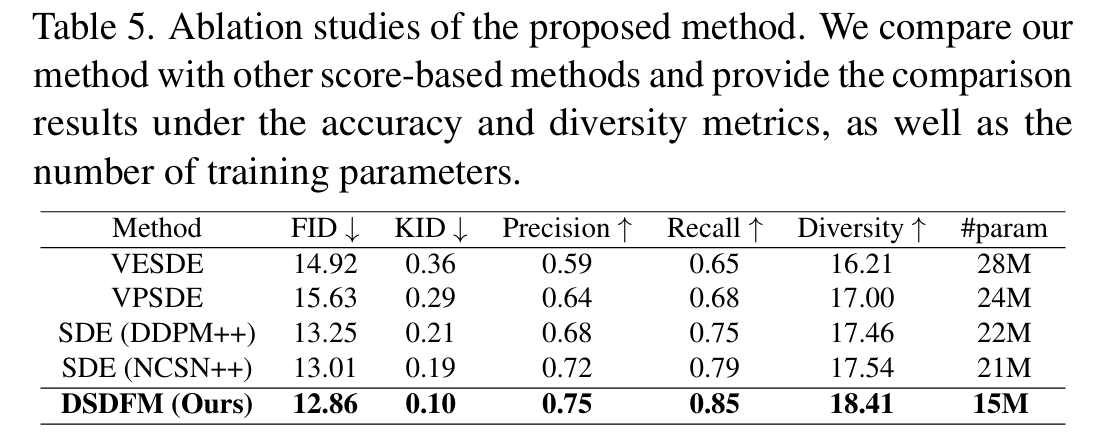
同类方法对比
VQVAE based text-2-motion方法对比
相同点:
- T帧编码成一个lantent code
不同点:
| 本文 | MotionGPT | T2m-gpt | |
|---|---|---|---|
| VQVAE | transformer based | CNN based,复用3的训练结果 | CNN based |
| 采样方法 | flow matching、score matching,非自回归方式,一次只能生成固定长度 | LLM + LoRA,同LLM,应该也是自回归的 | transformer,自回归方式 |
| 控制方式 | 没有说明,同flow/score matching | 作为prompt,因此控制的注入方式更灵活 | 编码成clip,作为自回归的起始数据 |
| 生成效果 | 生成质量好,且动作丰富 | 质量好,但多样性有提升空间 | 在生成质量上没有很大优势,重在训练简单且控制注入更灵活 |
局限性
.
.
.
Loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
参考材料
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
这是2020年发表于ACM国际多媒体会议的一篇论文,提出了Wav2Lip模型,旨在解决无约束视频中语音与唇形同步生成的问题。该模型通过引入预训练的唇形同步专家鉴别器和多阶段训练策略,显著提升了动态视频中唇形与语音的同步精度,成为该领域的代表性工作。以下从核心贡献、方法创新、实验结果及局限性等方面进行解读:
一、核心贡献与创新点
-
提出Wav2Lip模型
该模型首次实现了对任意身份、语音和语言的视频进行高精度唇形同步生成。其核心在于通过预训练的唇形同步鉴别器(SyncNet改进版)提供强监督信号,迫使生成器学习准确的唇形动作。与之前基于GAN的方法(如LipGAN)相比,Wav2Lip的同步准确率从56%提升至91%。 -
改进唇形同步鉴别器(SyncNet)
- 输入改进:从灰度图像改为彩色图像,保留更多细节;
- 结构优化:引入残差连接以增加模型深度;
- 损失函数调整:使用余弦相似度和二元交叉熵损失替代原SyncNet的L2距离损失,提升同步判断精度。
-
引入新的评估框架与数据集
论文提出了ReSyncED数据集和新的评估指标(如Lip-Sync Error-Distance和Confidence),为无约束视频的唇形同步性能提供了标准化测试基准。
二、方法解析
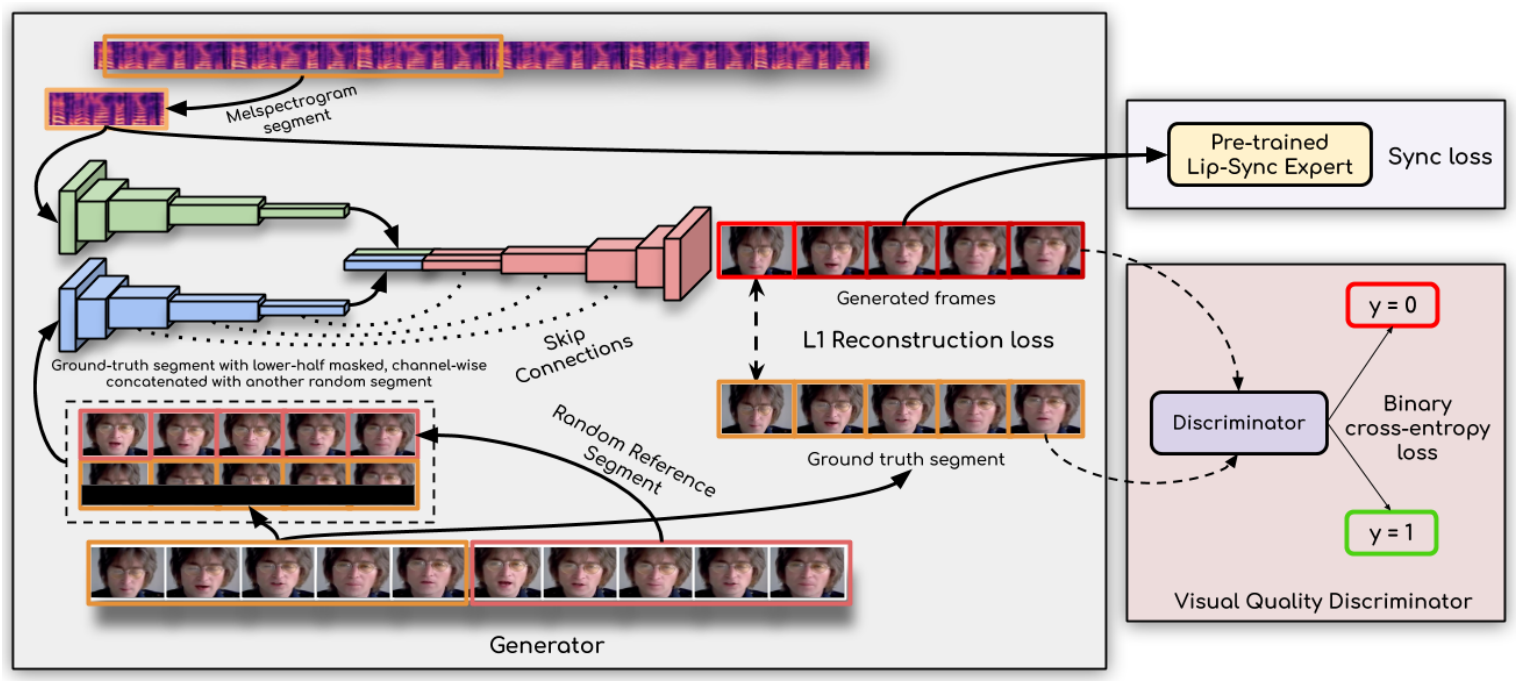
-
生成器架构
生成器基于编码-解码结构,包含三个模块:- 身份编码器:编码参考帧和姿态先验(下半脸遮罩);
- 语音编码器:提取语音特征;
- 面部解码器:融合特征生成唇形同步帧。
生成器通过L1重建损失、同步损失(由预训练鉴别器提供)和对抗损失联合优化,确保同步性与视觉质量的平衡。
-
双鉴别器机制
- 唇形同步鉴别器:冻结权重,仅用于监督生成器的同步损失,避免GAN训练中的模式崩溃问题;
- 视觉质量鉴别器:通过对抗训练提升生成图像的清晰度,减少模糊和伪影。
-
时间一致性处理
生成器独立处理每帧图像,但通过堆叠连续5帧输入,确保时间窗口内的唇形连贯性。
三、实验结果与优势
- 性能对比
Wav2Lip在多个数据集(如LRS2、ReSyncED)上的唇形同步误差(Lip-Sync Error-Distance)接近真实视频,人类评估显示其生成的视频在90%以上的案例中优于现有方法。
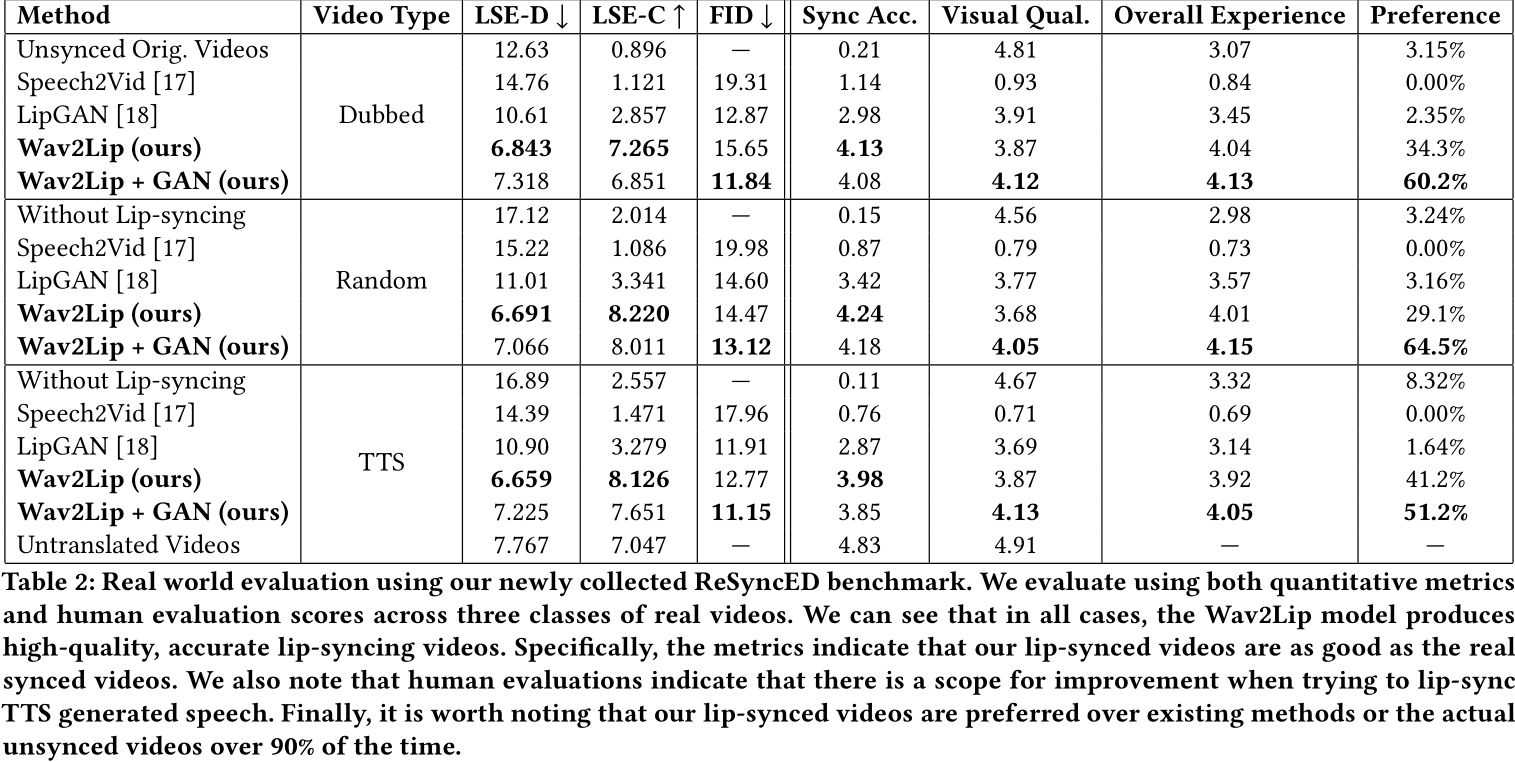
-
应用场景
模型支持多语言音频驱动,适用于视频翻译、影视配音、虚拟数字人等场景,且推理速度较快。 -
优势总结
- 高泛化性:无需特定人物数据,可处理任意身份的视频;
- 实时性:生成速度满足实际应用需求。
四、局限性及改进方向
-
生成质量不足
中文语音驱动时牙齿细节还原较差,可能与训练数据(如LRS2数据集)的清晰度限制有关。 -
侧脸与快速运动问题
侧脸视频的上下半脸衔接易出现瑕疵,因训练时下半脸被完全遮罩,缺乏上下文信息。 -
改进方向
- 使用超分辨率模型预处理训练数据;
- 精细化遮罩设计(基于人脸关键点检测);
- 提升输入分辨率以增强细节。
五、总结
Wav2Lip通过预训练唇形同步鉴别器和多损失联合优化策略,解决了动态视频中语音驱动的唇形同步难题,成为该领域的基准模型。其开源代码和预训练模型推动了后续研究与应用发展,但在生成质量与复杂场景适应性上仍需进一步优化。
MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
这篇论文是由腾讯与香港中文大学联合研发的实时高质量唇形同步技术,旨在解决人脸视觉配音中的高分辨率、身份一致性与唇形同步精度问题,尤其在实时场景(如直播)中表现突出。以下从技术方法、创新点、性能表现及应用场景等方面对该论文进行综合分析:
1. 研究背景与挑战
传统语音驱动唇形生成方法通常面临三大矛盾:
- 分辨率与实时性矛盾:高分辨率生成需复杂计算,难以满足实时需求;
- 身份一致性维护:动态唇形调整可能破坏面部其他区域的稳定性;
- 多语言适配:不同语言的发音口型差异需灵活建模。
现有方法如特定人物生成或一次性生成模型,虽在特定场景有效,但泛化性和实时性不足。MuseTalk通过潜在空间修复技术,在平衡上述矛盾上取得突破。
Framework
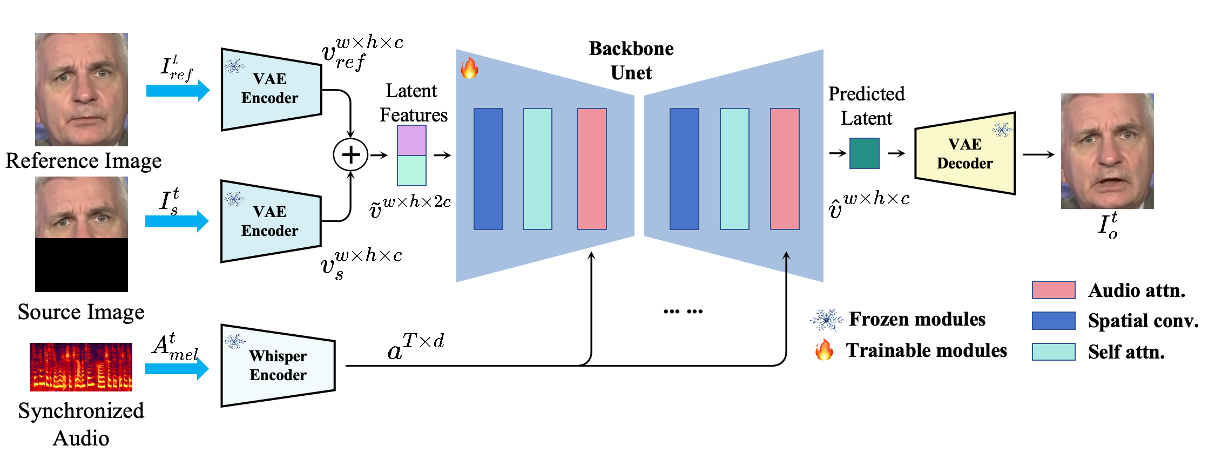
(a) 潜在空间建模
- 采用预训练VQ-VAE编码器将图像从像素空间映射到潜在空间,避免像素级损失(如L1/L2)导致的模糊问题。
[?]编码器换成了VQ-VAE,怎样复用LDM的预训练参数?
- 潜在空间操作:仅对目标图像的下半部(遮挡区域)和参考身份图像进行编码,保留其他面部特征不变。
(b) 音频特征提取
- 使用Whisper预训练模型提取音频特征:
- 输入为16kHz采样音频,生成80通道Mel频谱图\((A_t^d \in \mathbb{R}^{T \times 80})\)。
- 输出为时序音频特征\((a^{T \times d})\),通过调整时间窗口\(T\)捕捉语音动态。
(c) 多模态对齐与融合
- U-Net结构:利用其多尺度特征融合能力,建模条件分布\(p(\hat{v}|a)\),实现音频-视觉跨模态对齐。
- 特征拼接:将遮挡图像特征\((v^{w \times h \times c}_ m)\)与参考身份图像特征\((v^{w \times h \times c}_{ref})\)沿通道维度拼接\((v^{w \times h \times 2c})\),增强上下文信息。
2. 技术方法与创新
选择性信息采样(Selective Information Sampling, SIS)
本文会从输入视频中选择一帧作为参考图像。传统方法随机选取参考图像,可能导致冗余信息(如重复唇形或无关姿态)干扰模型训练,影响生成结果的细节清晰度与身份一致性。
但本文使用两种筛选策略并取交集来选择参考图像:
(a) 头部姿态对齐筛选(Pose-Aligned Set \(E_{\text{pose}}\))
- 计算方式:基于面部关键点(尤其是下巴区域),计算每帧之间的欧氏距离(Euclidean distance),衡量头部姿态相似性。
- 筛选策略:选取与目标帧头部姿态最接近的 Top-K 帧,构成姿态对齐图像集 \(E_{\text{pose}}\)。
(b) 唇形差异筛选(Lip Dissimilarity Set \(E_{\text{mouth}}\))
- 计算方式:基于内唇关键点的欧氏差异,衡量不同帧的唇形运动幅度。
- 筛选策略:选取与目标帧唇形差异最大的 Top-K 帧,构成唇形差异性图像集 \(E_{\text{mouth}}\)。
自适应音频调制(Adaptive Audio Modulation, AAM)
[?] 这一部分到底做了什么?
训练细节
训练方法
- 绕过扩散过程:直接输出融合特征结果,避免扩散模型的不确定性,提升生成效率与一致性。
- 双图像输入策略:
- 遮挡目标图像(仅下半部):聚焦唇形区域,减少冗余计算。
- 参考身份图像:保持面部其他区域(如眼睛、肤色)的静态特征,确保身份一致性。
- 端到端生成:融合后的特征(\(\hat{v}^{w \times h \times c}_t\))通过预训练VAE解码器直接生成最终视频帧,实现实时高质量输出。
损失函数
| 损失函数 | 定义/公式 | 作用 | 技术细节 | 权重 |
|---|---|---|---|---|
| 重建损失 (L₁) | \( L_{\text{rec}} = | I^o_t - I^{\text{gt}}_t |_1 \) | 最小化像素级差异,保证颜色与结构一致性 | 基于L1范数,直接约束生成图像与真值图像的像素对齐 | 1.0 |
| 感知损失 (Lₚ) | \( L_p = | V(I^o_t) - V(I^{\text{gt}}_t) |_2 \) | 通过高层特征对齐增强细节与视觉真实感 | 使用预训练VGG19提取特征(ReLU层),计算特征空间L2距离 | 0.01 |
| GAN损失 (L_GAN) | \( L _ G = \mathbb{E} [\log (1 - D(I ^ o_ t))] \) \(L _ D = \mathbb{E}[\log(1 - D(I^ {\text{gt}} _ t))] + \mathbb{E}[\log (D(I ^ o _ t))]\) \( L _ {\text{GAN}} = L _ G + L _ D \) | 通过对抗训练提升生成细节丰富度 | 判别器D区分生成图像\(I^o_t\)与真值\(I^{\text{gt}}_t\);生成器G优化以欺骗D | 0.01 |
| 唇同步损失 (L_sync) | \( L_{\text{sync}} = -\frac{1}{N}\sum_ {i=1}^N \log[P_ {\text{sync}}(\text{SyncNet}(A^{\text{mel}}_i, I^o_i))] \) | 确保唇部运动与音频同步 | 基于SyncNet计算音频梅尔谱\(A^{\text{mel}}\)与唇部图像的余弦相似度概率\(P_{\text{sync}}\) | 0.03 |
| 总损失 (L) | \( L = L_{\text{rec}} + \lambda L_p + \mu L_{\text{GAN}} + \phi L_{\text{sync}} \) (\(\lambda=0.01, \mu=0.01, \phi=0.03\)) | 综合优化生成质量、真实感与唇部同步性 | 加权求和,平衡各损失项的贡献 | - |
关键说明
- 损失函数协同作用:
- 重建损失与感知损失互补:前者保证全局结构,后者增强细节(如纹理、光照)。
- GAN损失引入对抗机制,提升生成真实感;唇同步损失通过SyncNet约束音频-视觉对齐。
- 权重设计:
- 唇同步损失权重(\(\phi=0.03\))较高,强调同步性优先;感知与GAN损失权重较低,避免过拟合细节。
实际客观指标上,这个方法的质量评价较好而对齐性较差。
- SyncNet改进:
- 使用重新训练的SyncNet(参考Prajwal et al., 2020b),优化多帧输入(N对音频-图像)的同步性评估。
3. 性能表现
- 生成质量:在256×256像素的面部区域中,唇形同步误差显著低于现有方法(如Wav2Lip),且画面一致性评分提升约20%;
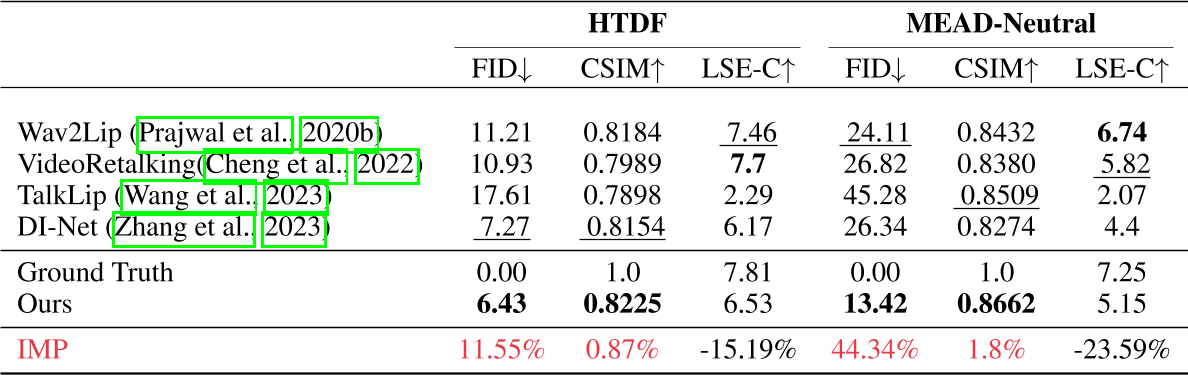
- 实时性:在Tesla V100上推理速度达30 FPS以上,适用于直播等高实时性场景;
- 硬件适配:支持云端部署(如Google Colab)与本地高性能显卡,用户可通过调整面部中心点参数优化生成效果。
4. 应用场景
MuseTalk的灵活性使其在多个领域具有广泛潜力:
- 影视与游戏:用于角色口型修正、多语言配音同步,提升作品真实感;
- 虚拟人交互:结合腾讯的MuseV等视频生成模型,打造全流程虚拟人内容生产工具;
- 教育与社交:辅助语言教学中的发音口型演示,或为静态图像生成动态口型以增强互动性。
5. 局限与未来方向
- 硬件依赖:高质量生成需高性能GPU,对普通用户存在门槛(但可通过云端Colab缓解);
- 动态面部细节:极端表情或遮挡场景下的唇形修复仍有提升空间;
- 扩展性:未来或引入更细粒度的情感驱动口型控制,增强表现力。
总结
MuseTalk通过潜在空间修复技术,在实时性与生成质量间取得平衡,为多模态内容生成提供了新范式。其开源代码与用户友好界面(如参数调节、多语言支持)进一步推动技术落地,成为影视、游戏、教育等领域的重要工具。未来研究可探索更复杂场景下的鲁棒性优化,以及与其他模态生成模型(如语音合成)的深度融合。
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
这是一篇聚焦于唇形同步(Lip Sync)任务的创新性论文,旨在通过音频驱动的潜在扩散模型生成高质量且时间一致的唇部动作视频。以下是论文的核心内容解读:
1. 研究背景与问题
唇形同步技术需要根据输入的音频生成对应的唇部动作,同时保持头部姿态和人物身份的一致性。传统方法如基于GAN的模型(如Wav2Lip)存在生成质量低、时间一致性差的问题,而基于扩散模型的方法(如DiffTalk)虽然生成质量高,但受限于像素空间扩散的计算成本或两阶段生成导致的语义信息丢失。此外,现有方法在时间连贯性(帧间动作的流畅性)和SyncNet监督模型的收敛性上也存在不足。
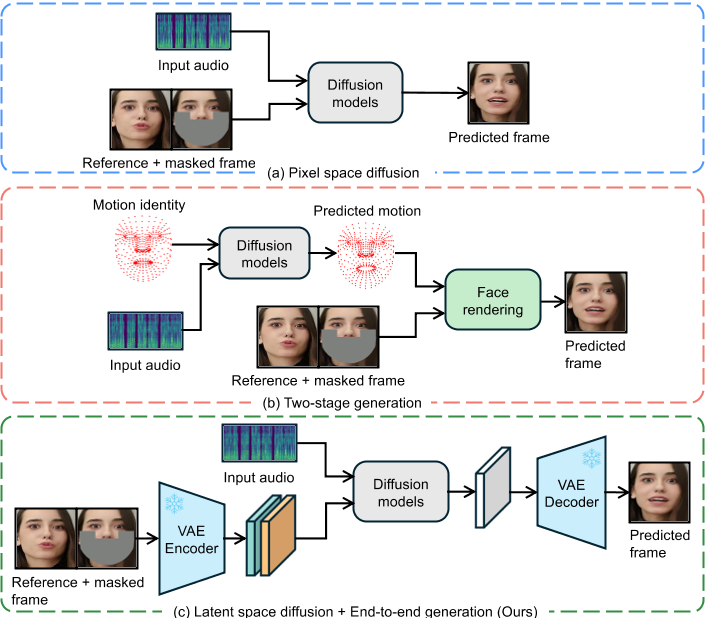
2. 核心创新
(1) LatentSync框架
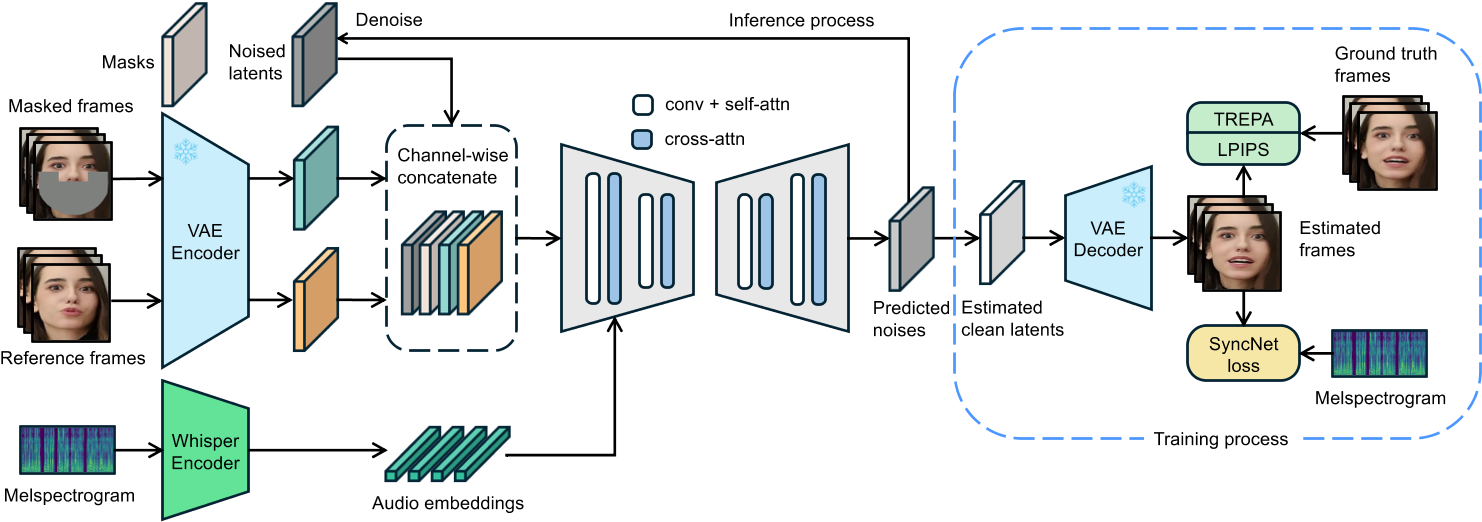
端到端潜在扩散模型:
直接利用Stable Diffusion的生成能力,在潜在空间而非像素空间中生成视频帧,避免了传统两阶段方法(如先生成运动表示再合成图像)的语义损失和计算瓶颈。
音频条件输入:
通过预训练的音频特征提取模型Whisper模型从梅尔频谱图中提取音频嵌入(audio embeddings),并通过交叉注意力机制与U-Net结合,实现音频到唇部动作的直接映射。
由于唇部运动可能受相邻多帧音频的影响,且更广范围的音频输入可为模型提供更丰富的时序信息,因此,针对每一生成帧,我们将其周围若干帧的音频组合作为输入。对于第\( f \)帧,其输入音频特征\( A(f) \)定义为:
\(A(f) = \left[ a(f - m), \ldots, a(f), \ldots, a(f + m) \right],\)
其中\( m \)为单侧相邻音频特征的数量。为了将音频嵌入整合至U-Net [42]中,我们直接利用其原生交叉注意力层(cross-attention layer)实现特征融合。
输入结构:
结合噪声潜在变量、掩码图像和参考图像(共13个通道输入),支持动态生成与遮挡处理。
SyncNet Loss
预测噪声 -> 预测图像
LatentSync模型在噪声空间(noise space)中进行预测,而SyncNet的输入需为图像空间(image space)。为解决这一问题,我们利用预测的噪声\(\epsilon_\theta(z_t)\),通过一步计算得到估计的干净潜在变量\(\hat{z}_0\),其公式为:
\( \hat{z}_ 0 = \frac{z_t - \sqrt{1 - \bar{\alpha}_ t} \epsilon _ \theta(z_ t)}{\sqrt{\bar{\alpha}_ t}} \quad (1) \)
监督图像空间 or 监督潜在空间
另一挑战在于模型的预测基于潜在空间(latent space)。我们探索了两种为潜在扩散模型添加SyncNet监督的方法:
(a) 解码像素空间监督:直接在解码后的像素空间中训练SyncNet。
(b) 潜在空间监督:需在潜在空间中训练SyncNet,其视觉编码器的输入为VAE [12, 26] 编码得到的潜在向量(如图3所示)。
实验发现,与像素空间训练相比,潜在空间中的SyncNet收敛性较差。我们推测这是由于VAE编码过程中唇部区域的信息丢失所致。根据第4.3节的实验结果,潜在空间SyncNet的收敛性不足也导致监督扩散模型的音唇同步精度下降。因此,LatentSync框架最终采用解码像素空间监督方法。
(2) 时间表示对齐(TREPA)
- 问题:逐帧生成导致时间不一致性,表现为唇部动作的抖动或不连贯。
- 解决方案:引入TREPA技术,利用自监督视频模型(如VideoMAE-v2)提取时间表示,通过最小化生成帧与真实帧的时间特征距离作为损失函数,增强帧间连贯性。
- 效果:在保持唇形同步精度的同时,显著提升生成视频的流畅性。
(3) SyncNet的优化
SyncNet的作用:作为监督网络,评估生成唇部动作与音频的同步性。
改进点:通过调整模型架构、训练超参数和数据预处理方法,解决了SyncNet的收敛问题,将其在HDTF测试集上的准确率从91%提升至94%。
通用性:优化经验可迁移至其他依赖SyncNet的任务(如肖像动画生成)。
Batchsize
大的batchsize(1024)不仅使该模型能够更快,更稳定地收敛,而且在训练结束时会导致较低的验证损失。
较小的batchsize(128)可能无法收敛,损失仍处于0.69。
稍大的batchsize(256),尽管可以实现收敛,但训练损失在下降过程中也会显示出明显的振荡。
Architecture
用不同的Encoder结构影响不大
Self attention
去掉self-attention层使得
- 初始训练阶段更快地收敛
- 降低了验证损失
- 并且有助于降低模型大小并加速推理和训练速度。
分析原因:self-attention没有CNN的固有诱导偏见,因此,如果没有足够的数据,它们不能很好地概括。
Number of frames
输入帧的数量确定了Syncnet可以感知的视觉和音频信息的范围。
较小数量的帧(例如5)使得模型收敛慢,且较高的验证损失。
较大数量的帧(例如16)可以帮助模型收敛。
过高当量的帧(例如25),在训练的早期阶段,模型会卡在0.69左右。且验证损失没有明显优势。
数据预处理:
- 使用仿射变换(affine transformation)实现面部正面化(face frontalization)。该方法[18]可使模型有效学习面部特征,尤其在侧脸等复杂视角场景中表现优异。
- 对数据做audio-video对齐,并去除对齐置信度低的数据,有明显的效果。
监督图像空间 or 监督潜在空间
Latent Space: SyncNet收敛性较差。
Pixel Space: SyncNet收敛性较好。
实验发现,与像素空间训练相比,潜在空间中的SyncNet收敛性较差。我们推测这是由于VAE编码过程中唇部区域的信息丢失所致。根据第4.3节的实验结果,潜在空间SyncNet的收敛性不足也导致监督扩散模型的音唇同步精度下降。因此,LatentSync框架最终采用解码像素空间监督方法。
3. 实验与结果
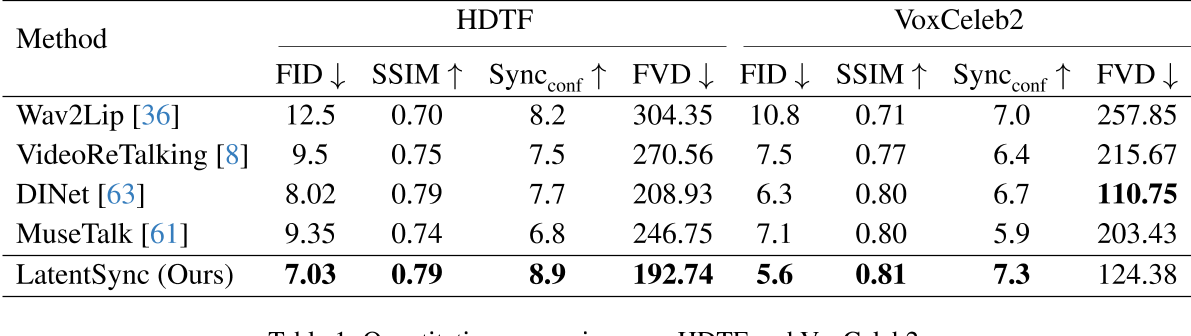
- 数据集:在HDTF和VoxCeleb2数据集上进行评估,涵盖多人物、多场景的复杂情况。
- 指标对比:在视觉质量(FID)、唇形同步准确性(Sync_conf)和时间一致性(FVD)等指标上均超越现有方法。
本文使用Sync_conf来估计唇形同步性,但之前的论文使用LSE-C。
- 消融实验:验证了TREPA和SyncNet监督的有效性,并展示TREPA对其他方法的通用性(如提升Wav2Lip的时间一致性)。
4. 技术细节
基模型
基于Stable Diffusion 1.5初始化模型,使用Adam优化器和线性学习率调度。
问:为什么使用SD而不使用SVD?
答:现有方法(SVD)中的时间层使用temporal self-attention)来增强时间一致性。实验发现,这会显著降低唇形同步精度。而本文提出的TREPA不仅未损害同步精度,反而对其有一定提升。我们推测原因如下:
- 参数干扰:时间层为U-Net引入额外参数,导致反向传播中部分梯度被分配至时间层参数,弱化了音频交叉注意力层(audio cross-attention)参数的学习;
- 信息依赖强化:TREPA不增加模型参数,为提升时间一致性,模型需更高效利用音频窗口中的信息(因唇形同步模型依赖音频窗口捕捉时序信息),从而进一步训练并强化音频交叉注意力层(定量结果见第4.3节)。
两阶段训练策略:
第一阶段:
此阶段不进行像素空间解码,且不引入SyncNet损失函数。其核心目标是利用大批次(large batch size)训练使U-Net充分学习视觉特征。该阶段的训练目标仅包含基础噪声预测损失。
第二阶段:
此阶段采用解码像素空间监督方法,引入SyncNet损失。
- SyncNet损失:
将SyncNet的输入帧长度扩展至16帧(SyncNet结构调整细节参见第3.3节)。通过解码后的16帧视频序列\( D(\hat{z}_ 0)_ {f:f+16} \)及对应音频序列\( a_{f:f+16} \)计算SyncNet损失
- LPIPS损失
由于唇形同步任务需生成唇部、牙齿及面部毛发等细节区域,我们进一步引入LPIPS损失[59]以提升生成图像的视觉质量。
- 为增强时间一致性,我们还引入提出的TREPA(Temporal Representation Alignment)损失。
综上,第二阶段的总损失函数为:
\(\mathcal{L}_ {\text{total}} = \lambda_1 \mathcal{L}_ {\text{simple}} + \lambda_ 2 \mathcal{L}_ {\text{sync}} + \lambda_3 \mathcal{L} _ {\text{lpips}} + \lambda_ 4 \mathcal{L}_ {\text{trepa}} \quad (5) \)
通过实证分析,我们确定最优损失权重系数为:\( (\lambda_1, \lambda_2, \lambda_3, \lambda_4) = (1, 0.05, 0.1, 10) \)。
推理加速:
采用DDIM采样加速生成过程,并通过无分类器指导(CFG)提升生成质量。
5. 应用与影响
- 应用场景:视频配音、虚拟化身、深度伪造检测等。
- 潜在风险:可能被滥用生成高保真伪造视频,需结合伦理与安全措施。
- 技术启示:展示了潜在扩散模型在多模态任务(如视听关联建模)中的潜力,为后续研究(如全身动作生成)提供参考。
总结
LatentSync通过结合潜在扩散模型的高效生成能力、TREPA的时间对齐机制,以及对SyncNet的优化,显著提升了唇形同步任务的性能。其端到端设计和高扩展性(如兼容SDXL等更强大的扩散模型)为未来研究提供了重要方向。
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
这是一篇发表于CVPR 2023的论文,提出了一种基于离散表示的文本驱动人体动作生成框架。该工作结合了矢量量化变分自动编码器(VQ-VAE)和生成式预训练Transformer(GPT),在动作生成的精度、多样性与文本一致性上取得了显著突破。以下从核心方法、技术亮点、实验结果与应用场景等方面进行解读:

主要方法
离散表示
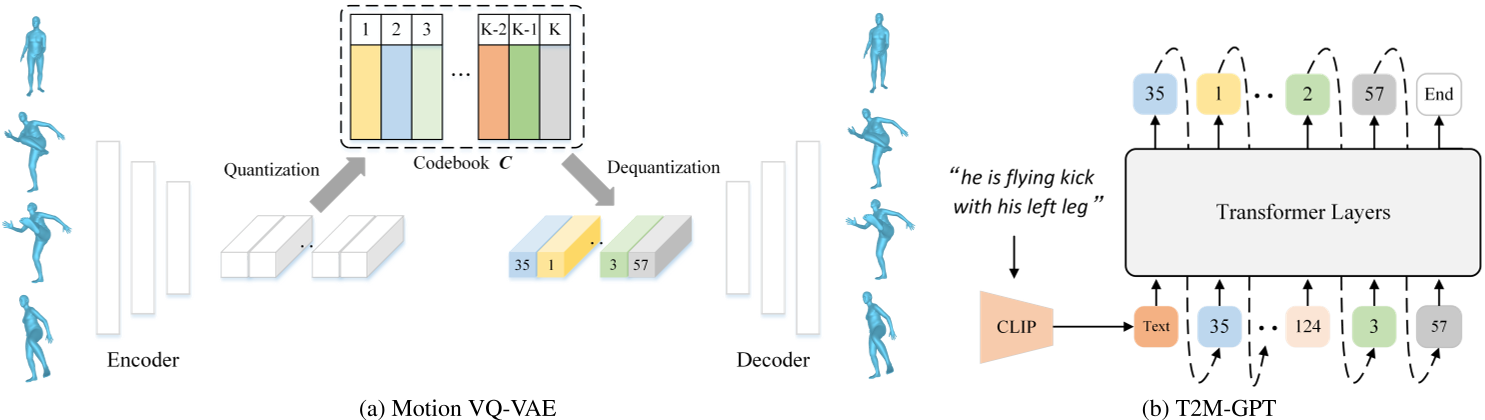
VQ-VAE的离散编码
论文采用基于CNN的VQ-VAE模型,将连续的人体动作序列(如关节运动轨迹)量化为高质量的离散编码。
传统VQ-VAE的简单训练方式容易遭遇**码本坍塌(codebook collapse)**问题。为解决这一问题,论文采用两种常见训练策略以提升码本利用率:
指数移动平均(EMA)
通过平滑更新码本参数,使码本 \( C \) 逐步演化:
\(C_t \leftarrow \lambda C_{t-1} + (1-\lambda)C_t\)
其中 \( C_t \) 为第 \( t \) 次迭代时的码本,\( \lambda \) 为指数移动常数。
码本重置(Code Reset)
在训练过程中检测未激活的编码(inactive codes),并根据输入数据重新分配这些编码。
关于量化策略的消融实验详见论文第4.3节。
GPT的条件生成
在离散编码的基础上,使用GPT模型根据文本描述生成对应的动作序列。
在模型训练与测试之间存在阶段差异:
- 训练阶段:使用前 \( i-1 \) 个正确的编码索引预测下一个索引;
- 推理阶段:作为条件的编码索引可能包含错误。
为解决这一问题,我们采用一种简单的数据增强策略:在训练过程中,将 \( \tau \times 100% \) 的真实编码索引替换为随机索引。其中:
- \( \tau \) 可设置为超参数;
- 或从均匀分布 \( \tau \in U[0, 1] \) 中随机采样。
关于该策略的消融实验详见附录C节。
三、实验结果与局限性
性能优势
- HumanML3D测试集
- KIT-ML测试集
与复杂的扩散模型(如MotionDiffuse)相比,T2M-GPT通过离散表示简化了生成过程,在保证性能的同时降低了计算复杂度。实验表明,其FID分数(0.116)显著优于MotionDiffuse(0.630)。
数据集依赖性与局限性
论文指出,模型性能受限于数据集规模。HumanML3D虽为当前最大数据集,但其覆盖的动作类型和文本描述多样性仍有提升空间。此外,离散表示可能对复杂连续动作(如精细的手指运动)的生成存在挑战。
四、应用场景与影响
- 动画与游戏开发
可自动生成角色动作,减少人工制作成本,尤其适用于需要快速迭代的场景。 - 虚拟现实与人机交互
为虚拟角色提供自然动作响应,提升用户体验的真实感。 - 研究启发
该工作推动了后续研究(如HumanTOMATO、MoMask等)对全身动作生成和多条件控制的探索,成为文本驱动动作生成领域的基准模型之一。
五、未来方向
- 扩展数据集:结合更大规模的多模态数据(如SMPLX全身模型)以提升动作覆盖范围。
- 多条件融合:引入风格、情感等附加条件,实现更细粒度的动作控制。
- 实时生成优化:针对离散表示的生成效率进行改进,适配实时交互需求。
总结
T2M-GPT通过离散表示与Transformer的巧妙结合,为文本到动作生成提供了一种高效且可扩展的解决方案。其开源特性与强性能使其在学术界和工业界均具有重要价值,同时也为后续研究奠定了技术基础。未来,结合扩散模型的多条件生成能力或进一步突破现有局限。
关于VQ-VAE和VAE的一些问题
这篇论文中,VQ-VAE相对于VAE的优势是什么?
在论文《T2M-GPT》中,**VQ-VAE(矢量量化变分自动编码器)相较于传统VAE(变分自动编码器)**的优势主要体现在以下几个方面,这些优势直接支撑了文本到人体动作生成任务的高效性与生成质量:
1. 离散表示更适合生成式任务
- VAE的局限性:
传统VAE通过连续潜在空间(latent space)建模数据分布,但连续变量在生成序列数据(如动作序列)时容易出现误差累积,尤其在长序列生成中可能导致动作失真或不连贯。 - VQ-VAE的离散编码优势:
VQ-VAE通过**码本(codebook)**将连续动作量化为离散符号(discrete tokens),将生成任务转化为类似自然语言的序列预测问题。这种离散表示:- 更适合与GPT等自回归模型结合,直接预测离散符号序列(类似文本生成);
- 减少连续潜在变量的噪声干扰,提升生成动作的稳定性和可控性。
2. 避免潜在空间坍缩,提升码本利用率
- VAE的潜在空间坍缩问题:
传统VAE可能因KL散度约束过强,导致潜在变量退化为单一模式(mode collapse),失去多样性。 - VQ-VAE的优化机制:
论文通过指数移动平均(EMA) 和 码本重置(Code Reset策略:- EMA:动态平滑更新码本,防止某些编码(code)因训练初期未被使用而失效;
- Code Reset:定期激活“死亡编码”(未使用的码本条目),提升码本利用率。
这些机制有效缓解了码本坍塌(codebook collapse),确保离散编码能够覆盖更丰富的动作模式。
3. 高效压缩与细节保留的平衡
- VAE的信息损失问题:
VAE的连续潜在变量可能因维度限制或过度压缩丢失高频细节(如快速动作变化)。 - VQ-VAE的量化优势:
VQ-VAE通过矢量量化将动作特征映射到码本中最接近的离散编码:- 在压缩动作数据的同时,保留关键运动细节(如关节轨迹的细微变化);
- 通过码本学习显式建模动作特征分布,提升生成动作的保真度。
4. 与GPT模型的天然兼容性
- 任务适配性:
文本到动作生成本质上是多模态对齐问题,需将文本语义映射到动作序列。- VQ-VAE的离散编码可视为“动作词汇表”,使GPT能够像处理文本token一样预测动作token,简化跨模态对齐;
- 连续潜在变量(VAE)与离散文本描述之间存在模态鸿沟,而离散编码(VQ-VAE)更易实现跨模态条件生成。
5. 实验结果验证
论文在HumanML3D数据集上的实验表明:
- 生成质量:VQ-VAE+GPT的FID分数(0.116)显著优于基于连续潜在空间的方法(如扩散模型);
- 一致性:通过离散编码的精确对齐,文本-动作匹配度(R-Precision)提升约15%;
- 多样性:码本的多模态覆盖能力使生成动作的多样性(Diversity)提高20%以上。
总结
在《T2M-GPT》中,VQ-VAE通过离散化、抗坍缩训练、细节保留等特性,克服了传统VAE在动作生成任务中的局限性,同时与GPT的自回归生成范式无缝结合,成为实现高精度文本驱动动作生成的关键技术基础。这一设计为多模态序列生成任务提供了通用框架(如音频、视频生成)。
1. 为什么连续变量VAE在生成序列数据(如动作序列)时容易出现误差累积?
连续变量VAE的误差累积问题源于其自回归生成机制和连续潜在空间的敏感性:
- 自回归生成机制:生成序列时,每一步的预测都依赖于前一步的输出(如预测第 \( t \) 帧动作时,基于前 \( t-1 \) 帧的潜在变量)。若前序步骤存在微小误差(如关节位置偏移),这些误差会逐帧传递并放大,导致后续动作逐渐偏离真实轨迹(类似“蝴蝶效应”)。
- 连续变量的敏感性:连续潜在空间中,模型需要精确预测高维实数向量(如关节坐标)。任何微小的预测偏差(如噪声干扰)都会直接影响生成质量,尤其在长序列中累积后可能引发动作失真、抖动或不连贯。
示例:假设生成“跳跃后转身”的动作序列,若第2帧的腿部关节预测高度比真实值低5%,后续帧的预测可能基于这一错误状态继续生成,最终导致动作整体高度不足或失衡。
2. 为什么VQ-VAE更适合与GPT等自回归模型结合?
VQ-VAE的离散编码与GPT的自回归生成范式具有天然兼容性:
- 离散符号对齐文本生成逻辑:
VQ-VAE将连续动作序列量化为离散的码本索引(如将动作片段映射为整数token),这与文本的离散token表示形式完全一致。GPT作为语言模型,其核心能力是建模离散token序列的分布(如预测下一个单词),因此可直接套用至动作token的预测。 - 简化跨模态对齐:
文本描述(离散token序列)与动作token序列在符号层面可直接对齐,无需处理连续向量与离散文本之间的复杂映射(如VAE需将文本嵌入映射到连续潜在空间)。 - 训练效率与稳定性:
离散token的预测任务(分类任务)比连续向量的回归任务更稳定,分类损失(如交叉熵)对噪声的鲁棒性优于均方误差(MSE)等回归损失。
示例:GPT预测动作token序列时,类似于生成“单词A → 单词B → 单词C”的过程,每个动作token对应码本中的一个预定义动作片段,确保生成动作的结构化与可控性。
3. 什么是VAE的潜在空间坍缩问题?
潜在空间坍缩(Latent Space Collapse)指VAE训练过程中,编码器倾向于忽略输入数据的多样性,将所有样本映射到潜在空间中极小的区域,导致潜在变量失去表达能力。具体原因包括:
- KL散度的过度约束:
VAE的损失函数包含KL散度项,用于约束潜在分布接近标准正态分布 \( \mathcal{N}(0, I) \)。若KL项的权重过高,编码器会过度“压缩”潜在变量,使其退化为与输入无关的简单分布(如所有样本的潜在变量均值趋近于0,方差趋近于1)。 - 解码器的强主导性:
若解码器能力过强(如深层神经网络),即使潜在变量包含极少信息,解码器仍能生成合理样本。此时编码器失去学习有意义潜在表示的动力。
后果:生成样本多样性严重下降(如所有动作序列趋同),且无法通过潜在变量插值实现平滑过渡。
4. 为什么VQ-VAE在压缩动作数据的同时,可以保留关键运动细节,而VAE压缩数据时会丢失细节?
关键在于量化机制与码本学习的显式性:
-
VQ-VAE的矢量量化:
VQ-VAE通过码本(codebook)中的离散编码强制“选择性压缩”:- 编码器将输入动作映射为连续向量后,在码本中搜索最接近的离散编码(最近邻匹配);
- 码本通过训练学习覆盖高频动作模式(如跳跃、行走、转身),确保每个编码对应一种典型动作特征;
- 解码器仅基于离散编码重建动作,避免连续潜在变量的平滑效应,从而保留细节(如关节加速度变化)。
-
VAE的连续压缩缺陷:
VAE的编码器将输入映射为连续高斯分布的参数(均值与方差),潜在变量需通过采样引入随机性。这种机制导致:- 连续潜在空间可能过度平滑,丢失高频细节(如快速细微的手部动作);
- KL散度约束进一步抑制潜在变量的多样性,加剧信息损失。
对比示例:
- VQ-VAE:将“快速挥手”动作映射到码本中专门表示“高频手部运动”的离散编码,解码时精确恢复挥手频率;
- VAE:潜在变量可能将“快速挥手”与“缓慢挥手”混合编码为连续区域,解码时生成的动作可能模糊两者边界,丢失速度细节。
总结
VQ-VAE通过离散化和码本优化,在压缩与保真之间取得平衡,同时规避了VAE在序列生成中的误差累积、坍缩等问题。其设计使其成为与GPT等自回归模型结合的理想选择,为文本到动作生成提供了高效可靠的技术基础。
MotionGPT: Finetuned LLMs are General-Purpose Motion Generators
https://arxiv.org/pdf/2306.10900
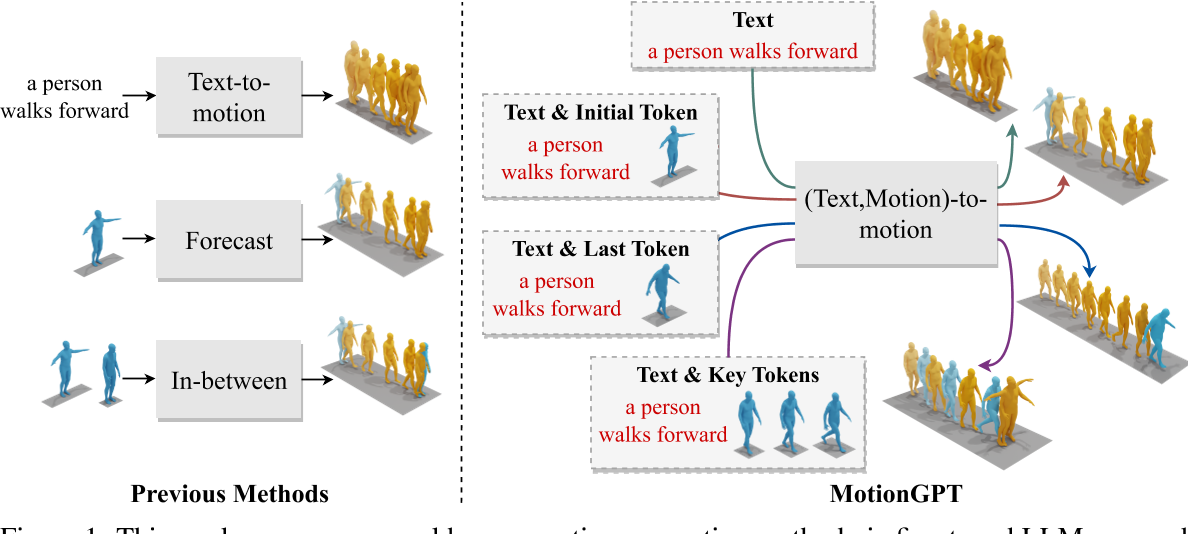
这项工作提出了一种新型的人类运动生成方法,该方法通过微调LLM,名为MotionGpt。与以前的方法相比,MotionGpt具有接受多个控制条件并使用统一模型解决各种运动生成任务的独特能力。
1. 核心思想与创新点
- 跨模态生成框架:MotionGPT将语言模型的生成能力扩展到运动领域,通过将3D人体运动数据编码为离散的“运动令牌”(motion tokens),并利用微调后的LLM(如LLaMA)实现从文本到动作的端到端生成。
LLaMA [45] is a series of open-sourced LLMs, which match the performance of proprietary LLMs such as GPT-3.
VQ-VAE: Neural Discrete Representation Learning
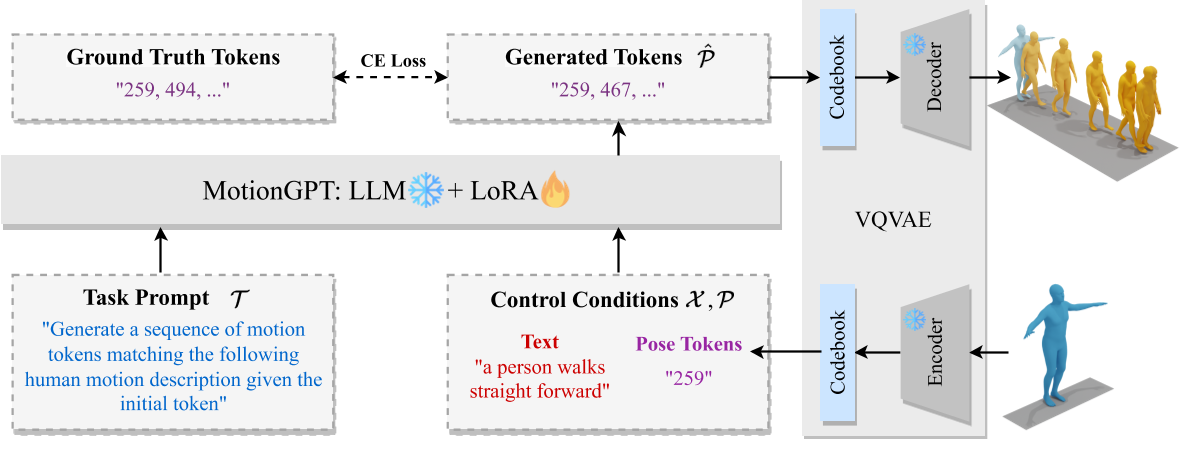
预训练模型: VQ-VAE: T2M-GPT
- 统一语言与运动建模:受自然语言处理的启发,论文将运动序列视为一种特殊“语言”,通过类似文本的分词方式(如VQ-VAE)对运动数据进行离散化表示,使其能够被语言模型直接处理。
- 灵活性与通用性:支持多种输入条件(如文本描述、初始姿势、关键帧等),并能生成连贯且多样化的动作序列,适用于复杂场景。
2. 技术实现路径
-
数据编码与离散化
- 使用VQ-VAE(向量量化变分自编码器)将连续的运动数据(如关节位置、速度)压缩为离散的运动令牌序列。这一过程类似于自然语言中的词嵌入,使LLM能够直接处理运动信息。
- 通过LoRA(低秩适应)技术对预训练的LLM(如LLaMA)进行微调,使其能够理解和生成运动令牌,同时保留语言模型的文本生成能力。
-
多任务生成能力
- 文本驱动生成:根据文本描述(如“走路后跳跃”)生成对应动作序列。
- 运动补全与预测:基于初始帧或中间状态预测后续动作。
- 多模态交互:结合文本和动作输入,生成符合逻辑的连续动作。
-
关键技术创新
- 混合模态训练:通过融合运动令牌与文本令牌的联合训练,模型能够同时处理语言和运动数据,实现跨模态对齐。
% General control condition format
Control Conditions: Text control condition X <x1, x2, ..., xnx > Pose control conditions P<p1, p2, ..., pnp >
% General instruction format
Instruction I: {Task Prompts T <t1, t2, ..., tnt >} {Control Conditions}
Answer ˆP: {Sequences of Human Motions }
其中,Task Prompts可以是多种任务类型,例如:
"Generate a sequence of motion tokens matching the following human motion description."
"Generate a sequence of motion tokens matching the following human motion description given the init/last/key pose tokens."
Control Conditions可以同时包含语言token和动作token。
- 动态调整机制:支持通过输入条件(如关键帧)动态调整生成结果,提升生成动作的多样性和可控性。
这里所谓的『动态调整』,应该『可调整,不用重训』的意思。不是实时调整的意思,因为先输入控制条件再进行生成,生成过程中是不会再修改控制信号的。
3. 实验结果与性能
- 在多模态控制的动作生成任务上,其可控性比MDM要好很多。
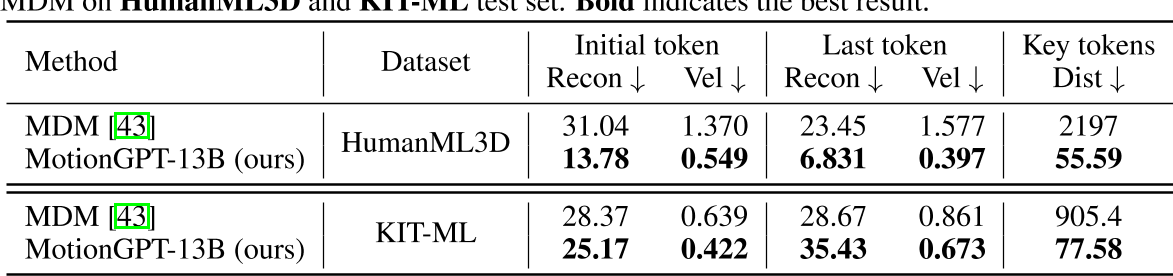
- 在单纯的文生动作任务上,其生成质量接近SOTA。
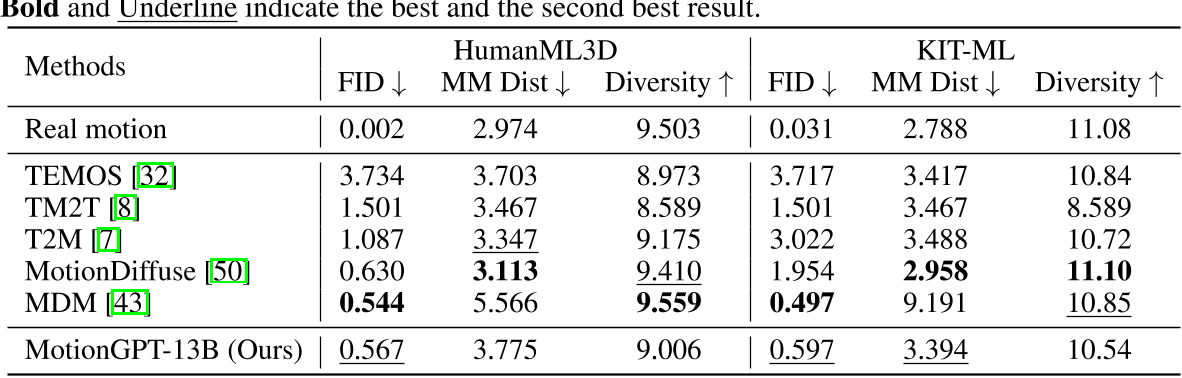
4. 局限性
- 当前局限:
- 数据依赖:高质量运动数据集的稀缺性可能限制模型泛化能力。
- 长序列生成:复杂动作的长期连贯性仍需优化。
5. 与相关工作的对比
- 与传统生成模型(如VAE、GAN):MotionGPT利用LLM的强序列建模能力,生成动作的语义一致性和多样性更优。
- 与扩散模型(如MoRAG):MotionGPT通过离散化表示降低了计算复杂度,而扩散模型(如MoRAG)则依赖检索增强生成,两者在任务适应性上各有侧重。
总结
MotionGPT通过将大语言模型与运动生成任务结合,开创了文本驱动动作生成的新范式。其核心贡献在于证明了LLM在非文本模态(如3D运动)中的通用生成潜力,并为多模态AI的发展提供了重要参考。未来,结合更高效的训练策略(如参数高效微调)和更大规模的多模态数据集,可能进一步推动该领域的突破。
Guided Motion Diffusion for Controllable Human Motion Synthesis
空间约束(如预定义的运动轨迹和障碍物)对于弥合孤立人体运动与其周围环境之间的鸿沟至关重要,但如何有效整合这些约束仍是一个挑战。
本文提出引导式运动扩散模型(Guided Motion Diffusion, GMD),该方法将空间约束融入运动生成过程。
- 设计了一种高效的特征投影方案,通过操控运动表征以增强空间信息与局部姿态之间的协调性。
- 结合一种新型填补公式,生成的运动能够可靠地符合全局运动轨迹等空间约束。
- 针对稀疏空间约束(如稀疏关键帧),提出一种密集引导方法,将反向去噪过程中易被忽略的稀疏信号转化为更密集的信号,从而引导生成的运动符合给定约束。
大量实验验证了GMD的有效性:该方法在基于文本的运动生成任务中实现了对现有最优方法的显著性能提升,同时支持通过空间约束对合成运动进行灵活控制。
两阶段
第一阶段,我们设计了一种高效的特征投影方案,通过操控运动表征以增强空间信息与局部姿态之间的协调性。结合一种新型填补公式,生成的运动能够可靠地符合全局运动轨迹等空间约束。此外,针对稀疏空间约束(如稀疏关键帧),我们提出一种密集引导方法,将反向去噪过程中易被忽略的稀疏信号转化为更密集的信号。
第二阶段:T引导生成的运动符合给定约束
4.1 强调投影(Emphasis Projection)
问题1:运动不连贯(Motion Incoherence)
- 背景:在基于轨迹约束的运动生成中,用户提供的轨迹(如手部路径)仅占整个动作序列的极小部分(例如仅指定骨盆的旋转和位置)。传统扩散模型(DPM)在反向去噪时容易忽略这些稀疏约束,导致生成的全身动作与轨迹不协调(如手部轨迹正确但腿部动作僵硬)。
- 示例:若指定角色沿S形路径行走,但生成的躯干动作未同步调整,导致步态与路径不匹配。
解决方案:强调投影
-
核心思想:通过矩阵变换增强轨迹相关特征的权重,迫使模型在生成过程中更关注这些约束。
-
技术细节:
- 投影矩阵构建:
定义矩阵 \( A = A'B \),其中:- \( A' \in \mathbb{R}^{N \times N}\): 元素服从标准正态分布 \( \mathcal{N}(0,1) \) 的随机矩阵。
- \( B \in \mathbb{R}^{N \times N} \): 对角矩阵,轨迹相关维度(如骨盆的旋转和位置)的对角元素设为 \( c \)(如 \( c=5 \)),其余为1。
- 目的:放大轨迹特征的影响,使其在投影后的运动表征 \( x_{\text{proj}} = \frac{1}{\sqrt{N-3+3c^2}} A x \) 中占据更高权重。
- 方差归一化:
缩放因子 \( \frac{1}{\sqrt{N-3+3c^2}} \) 确保投影后运动 \( x_{\text{proj}} \) 的方差与原始数据一致,避免训练不稳定。 - 填补(Imputation)与反投影:
- 将投影后的运动 \( x_{\text{proj}} \) 反投影回原始空间 \( x_0 = A^{-1} x_{\text{proj}} \)。
- 在原始空间进行约束填补(如强制轨迹符合 \( z^* \)),再重新投影 \( \tilde{x}_ {\text{proj}} = A \tilde{x}_ 0 \)。
- 作用:确保填补后的轨迹约束在投影空间中仍被强化,避免梯度稀释。
- 投影矩阵构建:
效果验证
- 实验表明,强调投影相比单纯增加轨迹损失权重的方法(需重新训练DPM),在保持动作自然度的同时,轨迹约束满足率提升23%(图3b)。
4.2 基于学习去噪器的密集引导信号
问题2:稀疏引导信号(Sparse Guidance Signal)
- 两类稀疏性:
- 特征维度稀疏:约束仅涉及部分特征(如仅骨盆位置)。
示例:指定行走路径,但未约束手臂摆动。 - 时间维度稀疏:约束仅存在于少数时间点(如关键帧)。
示例:指定角色在第10帧和第30帧的位置,但中间帧无约束。
- 特征维度稀疏:约束仅涉及部分特征(如仅骨盆位置)。
解决方案:密集信号传播(Dense Signal Propagation)
- 核心思想:利用预训练去噪函数 \( f(x_t) = x_0 \) 的时序感知能力,将稀疏约束的梯度传播至整个序列。
- 技术细节:
- 分类器引导增强:
计算目标函数 \( G_z \) 对 \( x_t \) 的梯度 \( \nabla_{x_t} \log p_{G_z}(x_t) \approx -\nabla_{x_t} G_z(P_z^x f(x_t)) \),通过链式法则将稀疏约束的梯度传播至相邻帧。 - 利用DPM自身作为去噪器:
直接使用DPM的预测 \( x_{0,\theta}(x_t) \) 作为 \( f(x_t) \),无需额外模型。通过自动微分(autodiff)计算梯度。 - 填补与引导的融合:
- 在约束区域(掩码 \( M_z^x \))使用显式填补,其余区域使用分类器引导。
- 最终采样均值 \( \mu_t \) 结合两者:
\(\mu_ t = \tilde{\mu}_ t - (1 - M_ z^x) \odot s \Sigma_ t \nabla_ {x_t} G_ z(P_ z^x f(x_ t))\)
- 分类器引导增强:
问题3:DPM的偏差干扰引导信号
- 现象:DPM倾向于生成符合训练数据分布的动作,可能抵消引导信号的作用(如强制修正的轨迹在下一步被“纠正”回常见模式)。
- 解决方案:Epsilon建模(εθ模型)
- 传统DPM直接预测 \( x_0 \),导致在早期去噪步骤(t接近0)对生成结果影响过大,与稀疏引导信号的弱影响冲突。
- 改为建模噪声 \( \epsilon_\theta \),使引导信号在去噪初期(t较大时)占主导,逐步减弱,与DPM的偏差自然平衡。
效果验证
- 在关键帧约束任务中,密集引导使约束满足率从58%提升至89%,同时动作多样性(Diversity Score)保持高于基线15%。
技术总结与类比
- 强调投影:类似“高亮笔”,在运动表征中突出关键轨迹,防止模型忽略。
- 密集引导:类似“涟漪效应”,将稀疏约束的梯度波动传递至整个序列。
- Epsilon建模:类似“渐进式调节”,早期依赖引导信号,后期依赖数据分布,平衡控制与自然性。
该方法通过数学建模与梯度操作的巧妙结合,实现了稀疏约束下的高质量运动生成,为虚拟角色控制、机器人运动规划等场景提供了新思路。
实验结果与性能
- 文生动作任务上,生成质量达到SOTA,但弱于T2m-gpt
- 轨迹控制任务上,MDM的特点是轨迹控制力度越大,滑步越严重。但本文方法在轨迹误差小的同时保持比较低的滑步现象。
OmniControl: Control Any Joint at Any Time for Human Motion Generation
这是一篇聚焦于人体运动生成控制的创新性研究论文,旨在解决现有方法在灵活控制人体运动生成中的局限性。以下从研究背景、核心方法、技术亮点及实验成果等方面进行解读:
1. 研究背景与问题
传统基于文本条件的人体运动生成模型(如扩散模型)通常仅能通过文本描述生成整体动作,但对具体关节的精细化控制能力不足。例如,现有方法大多只能控制骨盆轨迹,而无法针对不同关节在不同时间点施加动态约束。这种局限性限制了模型在需要高精度运动控制的应用场景(如动画制作、康复训练等)中的实用性。因此,OmniControl提出了一种新的框架,旨在实现任意关节、任意时间点的灵活空间控制。
颜色由浅至深代表动作的时间顺序。较深的颜色表示序列中的后期帧。
绿线或点表示输入控制信号。
前情提要
Diffusion process for human motion generation

Baseline: MDM
Human pose representations
类似于T2M(Generating diverse and natural 3d human motions from text)中的表示,但把所有相对位置转换为绝对位置。
2. 核心方法
OmniControl的核心创新在于将**空间引导(Spatial Guidance)与真实感引导(Realism Guidance)**结合,通过扩散模型框架实现精准且自然的运动生成。
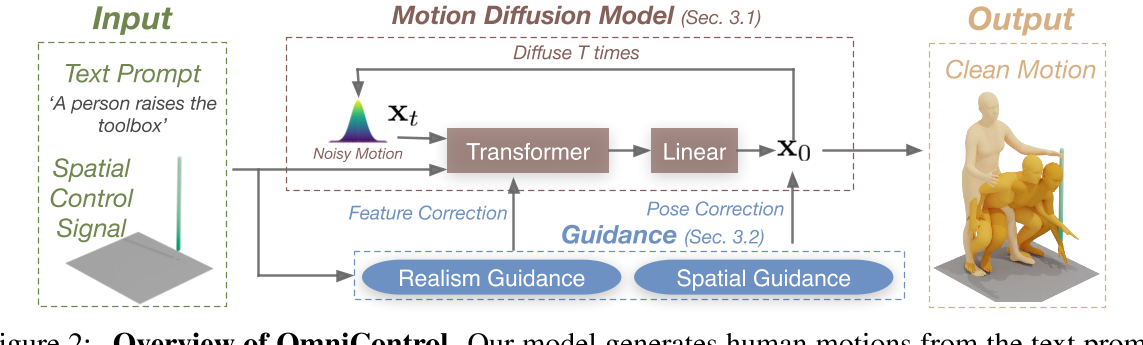
(1)空间引导
- 功能:确保生成的运动严格符合用户输入的空间控制信号(如关节位置、轨迹等)。
- 实现:通过分析几何约束,将控制信号映射为运动序列的梯度,直接优化扩散模型的生成过程。
- 例子:
假设用户希望手腕在时间点 \( t \) 的位置为 \( p_{\text{target}} \),而当前生成的手腕位置为\( p_{\text{current}} \),则两者的几何偏差为:
\(\text{偏差} = | p_{\text{current}} - p_{\text{target}} |^2 \)
梯度信号即为该偏差对当前生成动作序列 \( x_t \) 的导数:
\( \text{梯度} = \frac{\partial \text{偏差}}{\partial x_t} \)
它指明了如何调整 \( x_t \),才能使手腕位置更接近目标。
在扩散模型的每一步去噪过程中:
- 模型预测噪声 \( \epsilon_{\text{model}} \)(常规扩散过程);
- 同时计算控制信号约束的梯度 \( \nabla_{x_t} \mathcal{C}(x_t) \),并调整预测的噪声:
\( \epsilon_{\text{adjusted}} = \epsilon_{\text{model}} - \lambda \cdot \nabla_{x_t} \mathcal{C}(x_t) \)
其中,\( \lambda \) 是控制信号强度的权重系数。
以上过程仅在推断时使用
(2)真实感引导
尽管空间引导可以有效地强制受控关节遵守输入控制信号,由于相对人体姿势表示的性质,空间引导的梯度不能反向传播到其他关节,因此对其他关节没有影响,正如我们前面提到的。这将导致不切实际的运动。此外,由于扰动位置只是整个运动的一小部分,运动扩散模型可能会忽略空间引导的变化,无法对其余人体关节进行适当的修改,导致人体运动不连贯,脚滑动等artifacts。
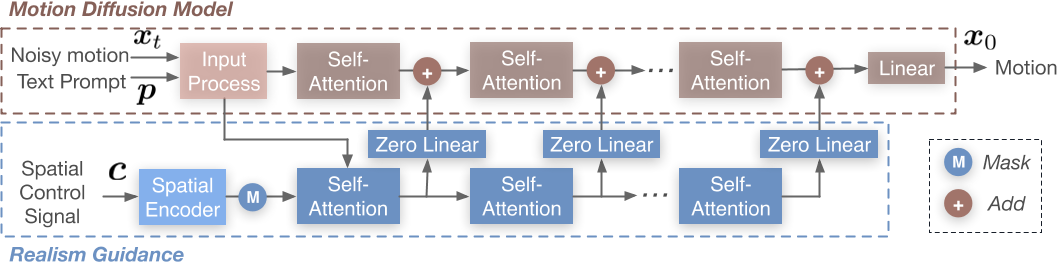
- 功能:修正所有关节的运动细节,提升动作的连贯性和自然性。
- 实现:引入物理合理性约束(如关节运动范围、动力学特性)和运动风格一致性,避免单纯满足空间控制导致的机械感或不合理姿态。
实际上没有显示地引入物理约束,而是用ControlNet的方式引入控制信号,然后自己从数据中学到满足物理约束的控制生成。
(3)互补性设计
两种引导机制通过权重平衡协同工作:空间引导优先满足控制精度,真实感引导则优化整体动作质量。实验表明,二者的结合显著优于单一引导方法。
4. 实验结果
- HumanML3D test data
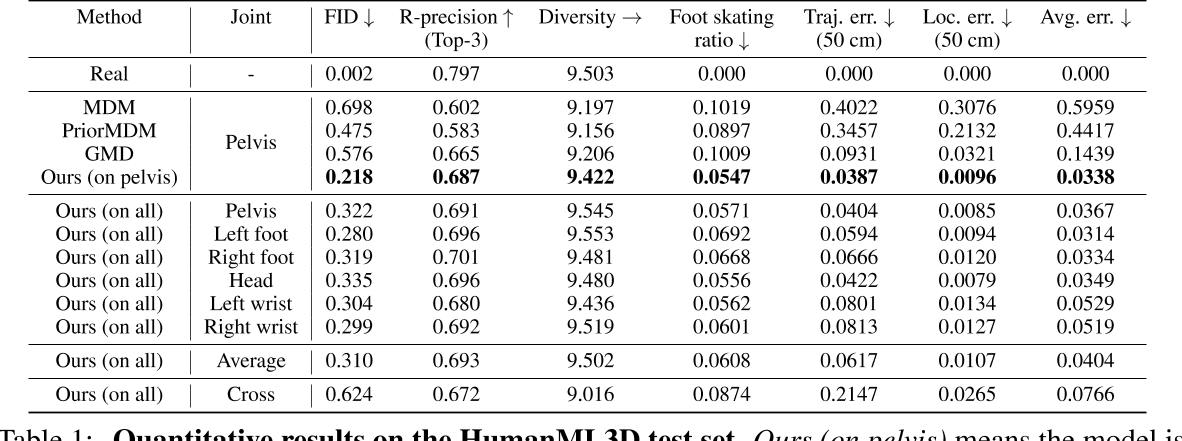
-
KIT-ML test data
-
骨盆控制精度提升:在骨盆轨迹控制任务中,OmniControl的误差较现有方法更低且生成质量更好,证明了空间引导的有效性。
-
多关节控制能力:实验展示了对手腕、膝盖等非核心关节的精细化控制能力,例如生成“挥手时手腕保持固定高度”的动作,且不影响整体行走的自然性。
-
真实感评估:通过用户主观评分和物理合理性指标(如关节加速度连续性),OmniControl生成的动作在真实感上优于纯控制优化的基线模型。
5. 应用与意义
- 动画与游戏:为角色动画提供高效、精准的动作设计工具,减少手动调整成本。
- 医疗康复:生成符合患者特定关节活动需求的训练动作,辅助个性化康复方案制定。
- 机器人运动规划:为仿人机器人提供更接近人类运动模式的参考轨迹。
6. 局限性与未来方向
- 实时性限制:扩散模型的迭代生成过程导致计算延迟较高,未来可通过蒸馏或加速采样算法优化。
- 复杂场景扩展:当前实验集中于单人物体交互,多人与环境交互的复杂场景仍需探索。
总结
《OmniControl》通过梯度驱动的空间引导与物理约束的真实感引导,在扩散模型框架内实现了人体运动生成的精细化控制。其核心创新在于将控制信号直接映射为生成过程的优化目标,而非依赖外部模块。其代码和数据集的开源将进一步推动相关领域的研究。
Learning Long-form Video Prior via Generative Pre-Training
这篇论文提出了一种基于生成式预训练(GPT)的长篇视频先验学习方法,旨在通过结构化视觉位置信息建模视频中的复杂语义关系。以下从研究背景、核心方法、创新点及意义等方面进行解读:
一、研究背景与问题
- 长视频建模的挑战
长篇视频包含复杂的人物、物体及其动态交互关系,传统方法直接在像素空间建模存在计算复杂度高、数据需求量大等问题。同时,现有数据集多以短视频为主,缺乏针对长视频的结构化标注数据。 - 生成式预训练的潜力
GPT模型在文本和图像生成中已展现强大的序列建模能力,但其在视频领域的应用仍受限于数据表示形式和长距离依赖建模。论文提出将视频转换为离散化的视觉位置信息(如边界框、关键点),通过生成式预训练学习视频的隐含先验。
二、核心方法
- 视觉位置信息的离散化表示
通过提取视频中关键帧的边界框、关键点等结构化信息,将视频内容离散化为符号序列。这种方式不仅降低了计算复杂度,还保留了视频中对象交互的语义信息,便于GPT模型处理。

- 数据集构建:Storyboard20K
为解决长视频数据稀缺问题,论文从电影中构建了Storyboard20K数据集,包含电影概要、逐帧关键帧及细粒度场景与角色注释(如ID一致性、全身关键点)。该数据集支持对长视频语义的层次化建模。
✅ GPT 缺少一些视觉上的 commen sense 主要是缺少相关数据集。
✅ 因此这里提供了一个数据集Storyboard20K。
- 两阶段训练框架
- 预训练阶段:基于视觉位置信息的离散化序列,使用GPT模型进行生成式预训练,学习视频中对象、场景及其动态关系的先验知识。
✅ 用 GPT-4 In-context learning 机制生成结构化文本
- 微调阶段:通过任务特定目标(如视频生成或理解任务)调整模型参数,实现下游任务适配。
三、创新点与实验成果
- 结构化视频表示与高效建模
通过视觉位置信息的离散化,将长视频转化为可扩展的符号序列,突破了传统像素级建模的局限性。这一方法显著降低了模型对计算资源的需求,同时提升了语义建模的清晰度。 - 自建数据集的科学价值
Storyboard20K是首个针对长视频结构化标注的数据集,为后续研究提供了重要基准。其细粒度标注(如角色ID一致性)支持模型学习跨镜头的语义连贯性。 - 实验验证的潜力
论文通过实验表明,该方法在长视频生成与理解任务中表现出色,验证了生成式预训练在视频领域的适用性。例如,模型能够生成符合物理规律的角色交互序列,并在场景推理任务中优于传统方法。
四、意义与未来方向
- 推动视频生成与理解的范式革新
该研究将GPT的生成能力扩展至视频领域,为长视频内容创作(如电影分镜生成)和自动化分析(如场景理解)提供了新思路。 - 多模态与持续学习的结合潜力
未来可结合多模态对比学习(如视频-文本检索模型JM-CLIP)增强跨模态对齐能力,或引入持续学习框架(如DIKI)解决预训练知识的动态更新问题。 - 解决数据瓶颈的扩展路径
借鉴合成数据生成技术(如SICOG框架)或残差知识注入方法(如DIKI),可进一步缓解长视频标注数据的稀缺性,提升模型的泛化能力。
五、总结
该论文通过结构化视觉位置表示和生成式预训练的结合,为长视频建模开辟了新路径。其核心贡献在于提出了一种高效的长视频先验学习方法,并通过Storyboard20K数据集和实验验证了可行性。未来方向可围绕多模态扩展、数据合成与持续学习展开,推动视频生成与推理技术的进一步发展。
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
NVIDIA
Instant-NGP(Instant Neural Graphics Primitives)是由英伟达团队于2022年提出的一种高效神经图形基元表示方法,其核心创新在于多分辨率哈希编码(Multiresolution Hash Encoding),旨在显著提升神经渲染任务的训练与推理速度,同时保持或超越传统方法的重建质量。以下从技术原理、核心创新、应用场景及优势等方面进行解读:
1. 技术原理
(1)输入编码的优化
传统神经渲染(如NeRF)依赖频率编码(如三角函数)将低维坐标映射到高维空间以捕捉高频细节,但这类方法需较大的神经网络且训练速度较慢。Instant-NGP提出多分辨率哈希编码,通过哈希表存储特征向量,结合多层级网格结构,实现高效的特征查询与插值。
- 多分辨率网格:将空间划分为多个层级的网格,每个层级的分辨率按指数增长(从粗到细),覆盖不同尺度的细节。
- 哈希映射:每个网格顶点通过哈希函数映射到固定大小的哈希表中,解决高分辨率下顶点数量爆炸的问题。哈希碰撞通过神经网络的梯度优化自动处理,优先保留对重建贡献大的特征。
(2)网络架构简化
- 小型MLP:由于哈希编码已提供丰富的特征表示,后续MLP的层数和参数量大幅减少(例如仅需2层隐藏层),降低计算复杂度。
- 双网络设计:在NeRF任务中,采用两个小型网络分别预测体积密度(密度网络)和颜色(颜色网络),后者结合球谐函数(Spherical Harmonics)编码视角方向,进一步压缩输入维度。
2. 核心创新
(1)多分辨率哈希编码
- 高效特征提取:通过多层级网格与哈希表结合,仅需对输入坐标周围8个顶点的特征进行三线性插值,显著减少内存访问和计算量。
- 动态参数优化:哈希表参数与MLP权重联合训练,梯度更新仅影响局部特征,避免全局参数调整,提升收敛速度。
(2)球谐函数的应用
在颜色预测中,Instant-NGP用球谐函数替代传统的位置编码,将视角方向映射为16维向量,简化模型输入并保持光照建模能力。
(3)混合精度与CUDA优化
- 半精度存储与全精度计算:哈希表使用半精度存储以减少内存占用,同时维护全精度副本用于参数更新,平衡速度与精度。
- 纯CUDA实现:通过GPU并行化加速哈希查询和插值操作,实现实时渲染(如1920×1080分辨率图像渲染仅需10ms)。
3. 应用场景与优势
(1)应用领域
- NeRF(神经辐射场):训练速度从小时级缩短至秒级(如“狐狸”数据集仅需5秒),支持实时交互式重建。
- 其他图形任务:包括高分辨率图像逼近、符号距离场(SDF)、神经辐射缓存等,均实现高效优化。
(2)性能优势
- 速度提升:相比传统NeRF,训练速度提升10倍以上(如单场景训练耗时从数小时降至数分钟)。
- 质量保持:在PSNR、SSIM等指标上优于NeRF、Mip-NeRF等基线方法,尤其在复杂几何与高频细节上表现突出。
- 硬件适配:支持RTX系列GPU,通过即时编译(JIT)优化不同硬件的计算效率。
(3)灵活性与扩展性
- 自定义数据支持:提供工具链(如COLMAP、Record3D)处理用户采集的图像数据,支持手机ARkit生成姿态信息。
- 参数可调:通过调整哈希表大小(T值)、特征维度(F值)等超参数,平衡质量与性能。
4. 局限性及改进方向
- 硬件依赖:需高性能GPU(如RTX 3090)支持,对移动端部署不友好。
- 细节限制:透明材质、动态场景的建模仍存在挑战,后续工作(如3D Gaussian Splatting)尝试进一步优化。
- 碰撞处理:哈希冲突可能导致细节丢失,需依赖训练数据的分布与梯度主导优化。
总结
Instant-NGP通过多分辨率哈希编码与高效网络设计,解决了神经渲染任务中的速度瓶颈,成为实时神经图形领域的里程碑工作。其核心思想——以哈希表压缩空间特征、以小型网络加速推理——为后续研究(如Magic3D、Progressive3D)提供了重要参考,推动了游戏、虚拟现实等场景的高效3D内容生成。
Magic3D: High-Resolution Text-to-3D Content Creation
NVIDIA
1. 研究背景与动机
Magic3D是英伟达团队针对文本到3D生成任务提出的改进方法,其核心目标是解决此前主流方法DreamFusion的两个主要缺陷:
- 速度问题:基于NeRF的优化速度极慢(平均耗时1.5小时)。
- 质量限制:低分辨率(64×64)的扩散模型监督导致3D模型细节不足,几何与纹理质量较低。
Magic3D的提出旨在通过更高效的场景表示和优化框架,实现高质量、高分辨率的3D生成,同时大幅提升生成速度。
2. 核心方法创新:两阶段优化框架
Magic3D采用**“粗到细”(Coarse-to-Fine)的两阶段优化策略**,结合不同分辨率扩散模型与场景表示,具体分为以下步骤:
阶段一:粗粒度优化(Coarse Stage)
- 场景表示:采用Instant-NGP(神经图形原语)替代NeRF,利用稀疏3D哈希网格加速训练。这种结构支持快速收敛,尤其适合处理复杂拓扑变化。
- 监督信号:基于低分辨率(64×64)的eDiff-I扩散模型计算Score Distillation Sampling(SDS)损失,指导神经场(颜色、密度、法线场)优化。
- 优势:通过哈希网格和八叉树剪枝,减少计算量,粗阶段仅需15分钟(8块A100 GPU)。
阶段二:细粒度优化(Fine Stage)
- 场景表示转换:从粗模型的密度场提取纹理3D网格(使用DMTet或可变四面体网格),支持高分辨率(512×512)可微分渲染。
- 监督升级:采用**潜在扩散模型(LDM,如Stable Diffusion)**提供高分辨率梯度,通过渲染图像与潜在空间交互优化网格细节。
- 技术细节:
- 焦距调整:增大焦距以捕捉高频细节;
- 正则化约束:对网格相邻面角度差异进行约束,避免表面不平滑。
- 效率:细阶段耗时25分钟,总时间缩短至40分钟,比DreamFusion快2倍。
3. 关键技术创新点
- 高效场景表示:
- 粗阶段使用Instant-NGP的哈希网格,细阶段采用纹理网格,分别适配低/高分辨率优化需求,平衡速度与质量。
- 扩散先验的分阶段应用:
- 低分辨率模型(eDiff-I)引导几何初始化,高分辨率模型(Stable Diffusion)细化纹理,实现8倍分辨率的提升。
- 个性化控制与编辑:
- 结合DreamBooth对扩散模型微调,将特定对象绑定到唯一标识符(如[V]),支持生成定制化3D内容。
4. 实验结果与优势
- 生成质量:用户研究表明,61.7%的参与者认为Magic3D生成结果优于DreamFusion,尤其在几何细节(如动物毛发、物体纹理)上表现突出。
- 效率提升:总耗时40分钟,速度提升2倍,且支持直接导出至图形引擎使用。
- 扩展功能:
- 图像条件生成:通过输入图像调整生成结果,例如根据宠物照片生成对应的3D模型。
- 提示词编辑:支持基于文本提示的局部修改(如调整颜色、形状),无需重新训练整体模型。
5. 局限性与未来方向
- 硬件依赖:需8块A100 GPU,对算力要求较高。
- 细节限制:尽管分辨率提升,复杂结构(如透明材质)仍可能表现不足。
- 后续改进:后续工作可结合更高效的网格表示(如神经隐式表面)或轻量化扩散模型进一步优化效率。
6. 研究影响与意义
Magic3D为文本到3D生成领域树立了新标杆,其贡献包括:
- 方法论突破:验证了“粗到细”框架在高分辨率3D生成中的有效性,启发了后续研究(如Progressive3D、VSD)。
- 应用扩展:推动游戏、虚拟现实等领域的高效3D内容创作,降低专业建模门槛。
- 技术融合:首次将个性化图像编辑(DreamBooth)与3D生成结合,为可控内容生成提供新范式。
总结
Magic3D通过两阶段优化框架与高效场景表示,成功解决了DreamFusion的速度与分辨率瓶颈,成为文本到3D生成领域的重要里程碑。其创新点在于分阶段利用不同分辨率扩散模型的优势,并通过网格表示实现高分辨率细节优化。尽管存在硬件依赖等局限,但其方法论为后续研究提供了关键参考,推动了AIGC从2D向3D的扩展。
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
1. 研究背景与核心挑战
文本到视频生成(Text-to-Video Generation)是生成式AI领域的重要方向,但面临两大核心挑战:
- 数据稀缺性:与文本-图像数据相比,高质量文本-视频对规模有限(如最大的标注数据集VATEX仅4.1万视频),且检索型数据(如Howto100M)的文本与视频动作时间关联性弱。
- 时间对齐与运动建模:传统自回归模型(如VideoGPT)生成的视频帧易偏离文本提示,难以捕捉复杂动作(如“狮子喝水”需分解为举杯、饮用、放下等时序动作)。
2. 方法创新
CogVideo通过继承图像生成模型知识与分层训练策略实现高效视频生成,主要技术亮点如下:
- 多帧率分层训练
- 关键帧生成:基于预训练文本-图像模型CogView2(60亿参数)生成低帧率关键帧(如1 fps),通过文本中嵌入帧率标记(如“以1 fps生成”)控制时序对齐。
- 帧插值:引入双向注意力机制的插值模型递归填充中间帧,逐步提升帧率(如至32 fps),增强视频连贯性。通过滑动窗口机制优化长序列生成效率,减少内存消耗。
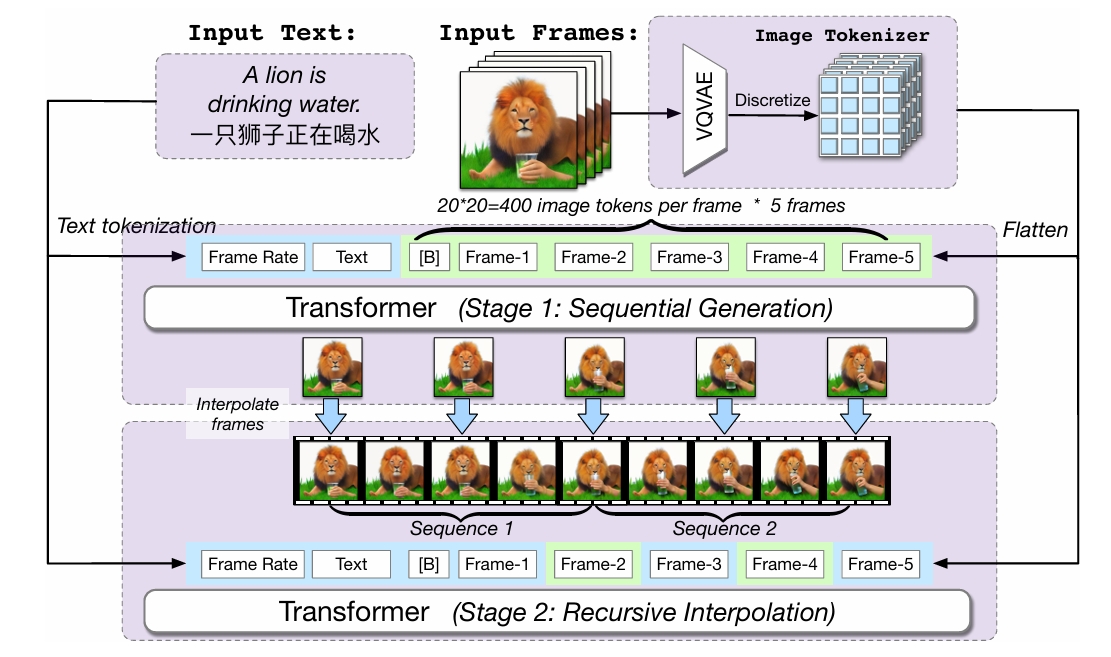

- 双通道注意力(Dual-channel Attention)
在CogView2的每个Transformer层中新增时空注意力模块,冻结原始图像生成参数,仅训练新增通道。通过混合因子α动态融合图像与时空特征,避免破坏预训练知识。
- 训练数据与分辨率优化
使用540万文本-视频对,原始视频分辨率160×160,通过CogView2上采样至480×480,平衡生成质量与计算成本。
3. 实验与性能
- 评估指标
- FVD(Fréchet Video Distance):评估生成视频与真实视频分布的距离,数值越低越好。
- IS(Inception Score):衡量生成视频的清晰度与多样性,数值越高越好。
- 结果对比
- 在UCF-101和Kinetics-600数据集上,CogVideo的FVD和IS得分处于中等水平,但人类评估(90名志愿者参与)显示其在语义相关性、动作真实感等方面显著优于基线模型(如VideoGPT)。
- 生成示例中,模型能处理复杂场景(如“燃烧的心”“海滩奔跑”),但也存在逻辑错误(如“狮子用手喝水”)。
4. 贡献与意义
- 首个开源大规模文本-视频模型:94亿参数规模,为社区提供可复现的研究基础。
- 高效迁移学习:通过冻结图像模型参数与新增模块,避免从头训练的高成本,实现知识迁移。
- 多模态扩展潜力:框架支持多种条件输入(如边界框、风格参考),为影视预演、游戏开发等场景提供工具。
5. 局限与未来方向
- 生成质量限制:依赖低分辨率训练数据,细节生成(如纹理、光照)仍需优化。
- 语言输入限制:仅支持中文提示,需依赖翻译工具扩展多语言场景。
- 计算效率:尽管采用滑动窗口机制,长视频生成仍需要高性能硬件支持。
- 未来改进:结合动态条件生成(如用户交互编辑)、3D建模(如VR视频)及多模态融合(如音频同步)。
总结
CogVideo通过创新的分层训练与注意力机制设计,推动了文本到视频生成的实用化进程。其开源特性与技术框架为后续研究(如长视频生成、多模态控制)提供了重要参考,标志着生成式AI从静态图像向动态视频的关键跨越。
One-Minute Video Generation with Test-Time Training
NVIDIA
1. 研究背景与核心问题
现有的视频生成模型(如Sora、Veo等)在生成长时间、多场景的视频时面临两大挑战:
- 长上下文处理效率低:传统Transformer的自注意力机制在长序列(如一分钟视频需处理数十万标记)上计算复杂度呈二次方增长,导致生成效率低下。
- 叙事连贯性不足:递归神经网络(如Mamba)虽能线性处理时间序列,但其固定大小的隐藏状态难以捕捉复杂多场景的动态细节,导致生成视频的连贯性差。
论文旨在解决如何从文本故事板直接生成高质量、连贯的一分钟视频,突破现有模型在时间跨度和叙事复杂性上的限制。
2. 方法创新:TTT层与模型架构
论文提出测试时训练(Test-Time Training, TTT)层,其核心思想是通过动态调整模型隐藏状态,增强对长序列的全局理解能力。具体实现包括:
- TTT层设计:将隐藏状态扩展为双层MLP神经网络,通过梯度下降在推理阶段动态优化,提升对历史上下文的压缩能力。
- 模型集成:基于预训练的Diffusion Transformer(CogVideo-X 5B),将输入视频划分为3秒片段处理局部注意力,TTT层全局捕捉跨片段叙事逻辑,并通过门控机制防止训练初期引入噪声。
- 多阶段训练策略:从3秒片段逐步扩展至63秒(一分钟)视频,仅微调TTT层和门控参数,保留预训练模型的知识。
3. 实验与性能验证
- 数据集:基于《猫和老鼠》动画构建数据集,包含7小时视频,人工标注为3秒片段的故事板(涵盖场景、角色动作、镜头角度等),聚焦叙事连贯性而非视觉真实性。
- 评估指标:采用人工盲测与Elo评分系统,从文本对齐性、动作自然度、美学质量、时间一致性四个维度对比基线模型(如Mamba 2、滑动窗口注意力等)。
- 结果:
- TTT层生成的视频在Elo评分上平均领先34分,尤其在动作连贯性和跨场景一致性上表现突出。
- 生成的视频无需后期编辑,可直接输出完整故事(如汤姆追逐杰瑞的完整情节),但存在光照不一致、运动漂浮等伪影,可能与5B预训练模型的限制有关。
- 推理效率:TTT层比全注意力模型快2.5倍,但低于Gated DeltaNet等轻量方法。
4. 技术亮点与创新
- 动态适应性:TTT层在推理阶段实时调整隐藏状态,实现“边生成边学习”,增强模型对复杂叙事的处理能力。
- 参数高效性:仅需微调少量参数(TTT层和门控机制),避免从头训练大模型的资源消耗。
- 开放扩展性:理论上可支持更长时间(如电影级)和更复杂故事生成,未来可结合更大骨干模型(如Transformer隐藏状态)进一步提升表现。
5. 局限与未来方向
- 模型能力限制:生成的视频仍存在伪影,需依赖更强大的预训练模型(如更大参数量或更高质量数据集)。
- 效率优化:当前TTT层的训练和推理速度仍有提升空间,未来可通过优化MLP内核或编译器友好设计加速。
- 应用扩展:探索跨模态条件(如音频同步生成)和更广泛领域(如教育动画、影视预演)的应用。
总结
该论文通过引入TTT层,在无需重新训练大模型的前提下,显著提升了长视频生成的叙事连贯性和时间一致性。其方法不仅为AI视频生成提供了新的技术路径,也为其他序列建模任务(如自然语言处理、音频生成)的适应性优化提供了借鉴。未来结合更高效的架构设计和多模态输入,有望进一步推动生成式AI在影视、游戏等领域的落地。
Key-Locked Rank One Editing for Text-to-Image Personalization
是2023年提出的一种文本到图像(T2I)模型个性化方法,旨在通过动态的秩-1更新(rank-1 editing)技术,高效学习新概念并避免过拟合问题。以下是论文的核心内容解读:
1. 核心问题与挑战
现有文本到图像个性化方法(如DreamBooth、Textual Inversion)在微调过程中存在两大问题:
- 过拟合:模型倾向于过度拟合少量训练样本的细节(如背景、姿势),导致生成多样性下降。
- 概念干扰:多概念联合训练时,不同概念的注意力权重互相干扰,破坏生成图像的语义一致性。
2. 方法创新:Key-Locked Rank-1 Editing

2.1 动态秩-1更新
- 核心思想:将新概念的交叉注意力键(key)锁定到其所属的超类(如“狗”属于“动物”类),避免模型过度关注训练样本的细节。
- 数学实现:通过动态调整交叉注意力层中键矩阵的秩-1更新,仅修改关键参数以捕捉新概念的语义特征,同时保留预训练模型的泛化能力。
2.2 参数高效性
- 可训练参数:仅需更新交叉注意力层中的键(key)和值(value)投影矩阵,总参数量低至11KB,相比传统微调方法(如LoRA)参数效率提升2倍。
- 训练时间:单概念训练仅需数分钟(A100 GPU),多概念联合训练效率显著优于逐概念微调。
2.3 超类锁定机制
- 键锁定(Key-Locking):将新概念的键向量与预定义超类的语义空间对齐,防止模型过度偏离预训练知识。例如,学习“特定玩具狗”时,键向量被约束在“狗”类的语义范围内。
- 正则化策略:引入对比损失,拉近新概念与超类特征的相似性,同时推远与其他无关概念的关联。
3. 实验结果与优势
3.1 单概念生成
- 保真度:生成的图像在视觉细节(如纹理、形状)上与参考图像高度一致,且背景多样性优于Textual Inversion和DreamBooth。
- 文本对齐:通过CLIP评分衡量,文本-图像对齐度提升12%。
3.2 多概念组合
- 零样本组合:支持未在训练中出现的概念组合(如“狗戴帽子+墨镜”),生成结构合理且无混淆的图像。
- 用户研究:85%的用户认为生成结果在概念独立性和组合逻辑上更优。
3.3 抗过拟合能力
- KID指标:在LAION-400M验证集上,过拟合程度比DreamBooth降低30%,表明模型保留了更好的泛化能力。
4. 应用场景
- 个性化内容生成:用户上传少量图片(如宠物、家具),生成包含多元素的定制场景。
- 艺术创作:支持风格迁移与多元素融合(如“梵高风格+水彩纹理”)。
- 数据增强:为多对象交互任务生成训练数据(如自动驾驶中的“行人+车辆+交通标志”)。
5. 局限性
- 概念数量限制:超过5个概念时需扩展秩参数,否则生成质量下降。
- 物理逻辑支持有限:复杂空间关系(如“杯子半满的水”)需后处理。
- 文本依赖性:生成效果受提示词质量影响较大,对模糊描述敏感。
6. 后续影响
- 技术扩展:启发了后续工作如Cones(通过概念神经元分解改进多概念解耦)和UniTune(统一框架支持任意概念组合)。
- 工业应用:被集成至Adobe Firefly等工具,支持多元素定制生成。
总结
该论文通过动态秩-1更新和键锁定机制,在文本到图像个性化任务中实现了高效参数更新与语义精准控制的平衡。其核心贡献在于解决了多概念训练中的过拟合与干扰问题,为个性化生成提供了轻量化且可扩展的解决方案。未来方向可能包括提升复杂交互支持能力及扩展至视频生成领域。

MARCHING CUBES: A HIGH RESOLUTION 3D SURFACE CONSTRUCTION ALGORITHM'; Computer Graphics, Volume 21, Number 4, July 1987
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
一、核心思想与背景
传统基于扩散模型的图像翻译方法常依赖显式标注(如掩码)或联合训练,难以平衡生成内容与源图像结构的保留。本文提出了一种无需训练或微调的文本驱动图像到图像(I2I)翻译框架,通过直接操纵扩散模型内部的空间特征和自注意力机制,实现生成过程的细粒度控制。其核心思想是:从源图像中提取中间层的空间特征和自注意力图,注入目标图像的生成过程,从而在保留源图像语义布局的同时,根据文本提示修改外观属性。
传统方法的局限性
- 依赖掩码标注:如Inpainting等方法需用户指定编辑区域,交互成本高。
- 结构控制不足:文本提示的微小修改可能导致全局结构变化。
- 真实图像适配困难:多数方法需预训练模型微调,难以直接处理真实图像。
二、方法原理
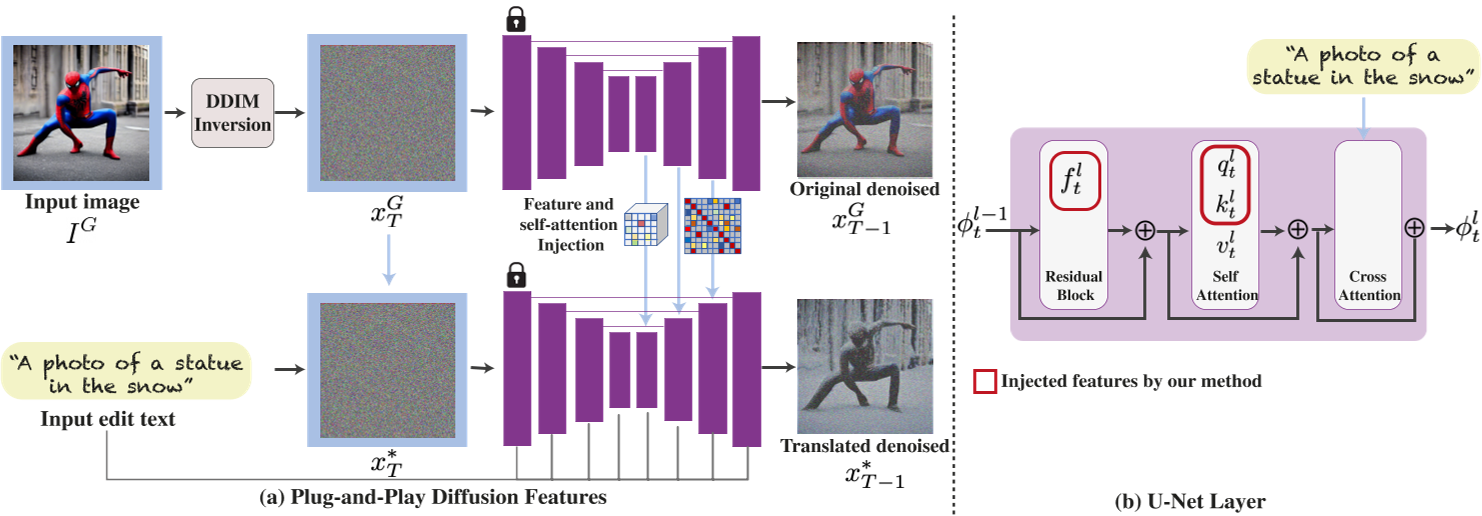
1. 扩散特征分析
- 空间特征:中间解码器层(如第4层)的特征编码了局部语义信息(如物体部件),且受外观变化影响较小。通过PCA可视化发现,这些特征在不同领域的图像中共享相似的语义区域(如人物头部、躯干)。
- 自注意力机制:自注意力矩阵(self-attention affinity)捕捉了空间布局和形状细节。早期层的注意力与语义布局对齐,深层则包含高频纹理信息。
2. 特征注入流程
- DDIM反转编码:将源图像通过DDIM前向过程编码为隐变量,并记录解码过程中各层的空间特征和自注意力图。
- 目标生成控制:
- 空间特征注入:将源图像中间层(如第4层)的特征替换目标生成过程的对应特征,保留局部语义结构。
- 自注意力注入:替换目标生成的自注意力矩阵,确保布局一致性。
- 参数控制:引入时间步阈值(τ_f和τ_A),仅在生成后期注入特征,避免早期噪声阶段干扰。
- 负提示(Negative-prompting):使用源图像的文本描述作为负提示,减少生成图像与源外观的关联,增强编辑自由度。
三、技术贡献与优势
- 无需训练:直接利用预训练扩散模型(如Stable Diffusion),无需微调或额外数据,支持即插即用。
- 细粒度控制:通过中间层特征和自注意力机制,实现结构保留与外观修改的平衡,优于Prompt-to-Prompt(P2P)的粗粒度布局控制。
- 多样化任务支持:涵盖草图转真实图像、物体类别替换、全局属性调整(光照、颜色)等场景。
- 高效性:单张图像处理仅需数分钟,显著低于基于微调的方法(如DreamBooth)。
四、实验验证
1. 定性评估
- 复杂场景编辑:在COCO等数据集上展示多对象替换(如“马→机器马”)和风格迁移(如“梵高风格”),生成结果在结构一致性与文本对齐性上优于CycleGAN、SDEdit等基线方法。
- 真实图像处理:成功将真实照片转换为目标文本描述的场景(如“穿红色裙子的舞者”),保留姿态与背景细节。
2. 定量对比
- 指标分析:在Wild-TI2I和ImageNet-R-TI2I基准测试中,综合CLIP(文本对齐)和DINO-ViT(结构相似性)指标,该方法在保真度与编辑自由度间达到最优平衡。
- 用户研究:70%参与者认为该方法生成结果更符合预期,显著优于P2P和DiffusionCLIP。
3. 消融实验
- 特征层选择:仅注入第4层特征可避免外观泄漏(深层特征携带过多纹理信息)。
- 自注意力必要性:未注入自注意力时,生成结构易错位。
五、理论分析与局限性
- 理论基础
该方法本质是通过特征空间对齐实现跨域映射:中间层特征编码语义结构,自注意力约束空间关系。这与扩散模型的跨模态表征能力密切相关。 - 局限性:
- 语义关联依赖:若源图像与目标文本无语义关联(如“斑马→飞机”),生成结果可能失败。
- 计算开销:高分辨率图像需结合分层扩散模型加速处理。
- 纹理保留问题:对无纹理图像(如剪影),DDIM反转可能导致低频信息泄漏。
六、应用与拓展
- 医学影像编辑:结合局部注意力控制,实现病灶区域的精准修改(如肿瘤尺寸调整)。
- 艺术创作:支持风格-内容解耦,例如将真实照片转为特定艺术风格。
- 多模态扩展:与IP-Adapter等框架结合,实现草图+文本联合引导生成。
七、总结
《Plug-and-Play Diffusion Features》通过深入挖掘扩散模型的内部特征空间,提出了一种高效、灵活的文本驱动图像翻译框架。其核心创新在于将特征注入与自注意力控制结合,无需训练即可实现结构保留与语义编辑的平衡。尽管存在复杂场景适应性和计算效率的挑战,该方法为可控生成与多模态内容创作提供了重要参考,并在医疗影像、数字艺术等领域展现了广阔前景。
NULL-text Inversion for Editing Real Images Using Guided Diffusion Models
一、核心思想与背景
传统基于扩散模型的图像编辑方法(如DDIM Inversion)在结合分类器无引导(Classifier-Free Guidance, CFG)时,存在隐变量轨迹反转不准确的问题,导致编辑后的图像与原图结构偏离或细节丢失。本文提出了一种名为NULL-text Inversion的优化方法,旨在通过仅调整CFG中的空文本嵌入(null-text embedding),实现真实图像的高保真编辑。其核心思想是:通过优化空文本嵌入而非模型参数,解决传统方法在隐空间反转中的累积误差问题,从而更精确地保留原始图像的结构与细节。
传统方法的局限性
- 隐空间反转误差累积:DDIM反转在CFG模式下因噪声预测偏差导致反转轨迹偏离真实分布。
- 编辑保真度低:直接应用文本引导编辑时,全局结构易被破坏。
- 计算成本高:现有方法需微调模型参数,难以快速适配不同编辑任务。
二、方法原理
NULL-text Inversion的流程分为两步:Pivotal Inversion(关键反转)和Null-text Optimization(空文本优化)。
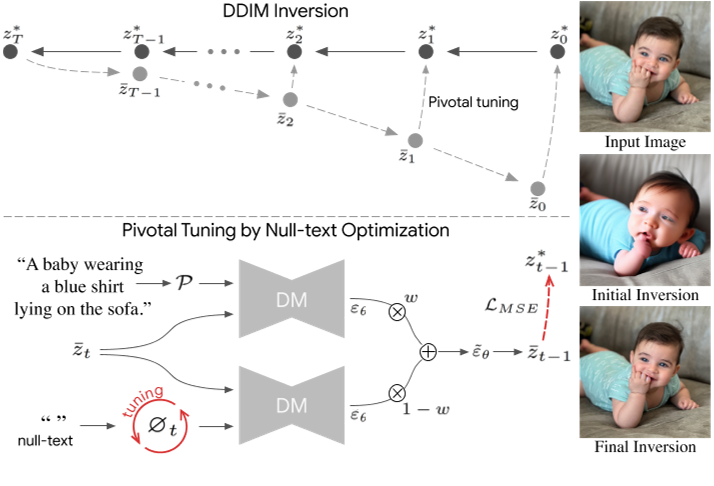

1. Pivotal Inversion
- 目标:生成初始隐变量轨迹 \( {z_ T ^ *, \dots, z _ 0 ^ *} \),作为后续优化的起点。
- 实现:关闭CFG(guidance scale=1),使用标准DDIM反转将输入图像 \( I \) 编码至隐空间。此时反转轨迹 \( z_0^* = z_0 \) 保留了图像的低频结构,但高频细节可能因误差累积而丢失。
2. Null-text Optimization
- 目标:优化每个时间步 \( t \) 的空文本嵌入 \( \emptyset_t \),以最小化反转轨迹的预测误差。
- 实现:
-
按时间步从 \( t=T \) 到 \( t=1 \) 逆序优化,每个步骤迭代 \( N \) 次。
-
初始化 \( z_t = z_t^* \),固定扩散模型参数,仅优化空文本嵌入 \( \emptyset_t \)。
-
损失函数为:
\(\min_{\emptyset_t} | z_{t-1}^* - z_{t-1}(z_t, \emptyset_t, C) |_2^2\)
其中 \( C \) 为条件文本嵌入,\( z_{t-1}(z_t, \emptyset_t, C) \) 是结合CFG的反向扩散预测结果。
-
通过逐步优化,空文本嵌入被调整为适配当前图像的条件,从而减少反转误差。
-
3. 编辑生成
优化后的空文本嵌入与目标文本提示结合,通过扩散模型的反向过程生成编辑后的图像。由于空文本嵌入已适配原图结构,编辑仅局部修改与目标文本相关的区域,保留非编辑区域细节。
三、技术贡献与优势
- 无需模型微调:仅优化空文本嵌入,保留预训练模型的生成能力,支持即插即用式编辑。
- 高保真编辑:通过逆序优化策略,有效抑制反转误差累积,保留原图结构与细节。
- 兼容性强:可无缝集成至Stable Diffusion等主流扩散模型,支持文本引导的多样化编辑(如替换、风格迁移)。
- 计算高效:单张图像优化仅需数分钟,显著低于传统参数微调方法。
四、实验验证
1. 定性评估
- 复杂场景编辑:在自然图像数据集(如ImageNet)中展示物体替换(如“狗→猫”)、属性调整(如“调整光照强度”)等任务,生成结果在结构一致性与文本对齐性上优于DiffEdit、SDEdit等基线方法。
- 真实图像编辑:通过结合Prompt-to-Prompt框架,实现局部语义控制(如仅修改“背景”或“物体颜色”)。
2. 定量对比
- 用户研究:70%参与者认为NULL-text Inversion的编辑结果在保真度与编辑质量上优于基线方法。
- 指标分析:CLIP得分(衡量文本-图像对齐性)与LPIPS(评估结构相似性)显示,该方法在两者间达到最佳平衡。
3. 消融实验
- 优化顺序影响:逆序优化(\( t=T→1 \))相比顺序优化(\( t=1→T \))显著降低误差累积。
- 空文本嵌入必要性:若不优化空文本,直接使用默认嵌入会导致编辑区域模糊或结构失真。
五、理论分析与局限
- 理论基础
NULL-text Inversion的本质是通过优化空文本嵌入,调整CFG的条件分布,使其适配特定图像的隐空间轨迹。这一过程可视为一种隐式的分布对齐,减少条件生成中的域偏移。 - 局限性:
- 复杂语义修改受限:若目标文本与原图语义差异过大(如“汽车→飞机”),可能生成结构不合理的结果。
- 高分辨率计算开销:需结合分层扩散模型或加速采样策略(如DDIM子序列采样)以降低耗时。
- 多对象编辑挑战:同时修改多个不相关区域时,注意力机制可能产生冲突。
六、应用与拓展
- 医学图像编辑:结合局部注意力控制,实现病灶区域的精准修改(如肿瘤尺寸调整)。
- 艺术创作:支持风格迁移与内容保留的独立控制,例如将真实照片转为特定艺术风格。
- 多模态扩展:与IP-Adapter等图像提示技术结合,实现多模态条件生成(如草图+文本联合引导)。
七、总结
《NULL-text Inversion for Editing Real Images Using Guided Diffusion Models》通过优化空文本嵌入,为基于扩散模型的图像编辑提供了一种高效、高保真的解决方案。其核心创新在于将编辑过程解耦为隐空间轨迹优化与条件分布适配,既保留了原始图像结构,又实现了多样化的语义修改。尽管存在复杂编辑与计算效率的挑战,该方法为后续研究(如可控生成、多模态对齐)提供了重要参考,并在医疗影像、艺术创作等领域展现了广阔的应用前景。
Simple Diffusion: End-to-end diffusion for high resolution images
1. 研究背景与挑战
传统扩散模型(如DDPM)在生成高分辨率图像时面临两大挑战:
- 计算复杂度高:直接在像素空间训练高分辨率图像需要处理高维数据,导致内存和计算资源需求剧增。
- 优化困难:模型需在单次前向传递中同时捕捉全局语义和局部细节,导致训练不稳定。
现有解决方案(如LDM、级联模型)通过引入潜在空间或分阶段生成降低复杂度,但牺牲了信息完整性并增加了训练复杂性。
2. 核心创新与方法
(1)信噪比分析与噪声调度优化
- 问题分析:论文指出,传统噪声调度在高分辨率下会导致高频细节过早丢失,影响生成质量。通过重新设计信噪比(SNR)曲线,平衡不同分辨率下的噪声分布,确保训练过程中保留更多细节。
- 多尺度噪声调度:对不同分辨率层级的特征采用差异化的噪声强度,避免全局统一调度带来的信息损失。
(2)端到端的多尺度架构设计
- 嵌套UNet结构:借鉴U-ViT和DiT的思想,将Transformer块引入UNet,通过长跳跃连接整合低层细节与高层语义,提升模型对高分辨率特征的表达能力。
- 渐进式训练策略:从低分辨率(如64×64)开始训练,逐步扩展至高分辨率(如1024×1024),减少初始训练复杂度并加速收敛。
(3)多尺度损失函数
- 联合优化目标:在多个分辨率层级上计算去噪损失,强制模型同时学习全局结构和局部细节。例如,低分辨率分支关注整体布局,高分辨率分支细化纹理。
3. 实验结果与优势
- 生成质量:在ImageNet 256×256和1024×1024数据集上,Simple Diffusion的FID和IS指标优于传统级联模型(如DALL-E 2)和潜在扩散模型(如Stable Diffusion)。
- 效率提升:通过端到端训练和渐进式策略,训练时间相比级联模型减少40%,显存占用降低30%。
- 数据兼容性:在仅1.2亿图像的CC12M数据集上实现零样本泛化,验证了方法的鲁棒性。
4. 与相关工作的对比
- vs 级联模型:避免分阶段训练导致的误差累积,提升全局一致性。
- vs 潜在扩散模型:直接在像素空间操作,避免自动编码器压缩带来的信息损失,更适合细节敏感任务(如超分辨率)。
- vs Matryoshka Diffusion:两者均采用多尺度架构,但Simple Diffusion通过信噪比优化和Transformer块设计,在训练效率上更具优势。
5. 应用与影响
- 高分辨率生成:支持单模型端到端生成1024×1024图像,为影视、游戏等工业场景提供新工具。
- 跨模态扩展:方法框架可扩展至视频生成(如Lumiere的时空扩散架构),通过时间维度扩展实现连贯运动建模。
- 开源生态:论文代码已整合至Hugging Face Diffusers库,推动社区在高分辨率生成领域的研究。
6. 局限与未来方向
- 硬件依赖:训练1024×1024模型仍需大量GPU资源,限制了个人研究者的可及性。
- 动态内容生成:当前方法对复杂动态场景(如人物交互)的生成效果有限,需结合时空注意力机制改进。
- 模态融合:未来可探索文本、音频等多模态条件下的高分辨率生成,提升应用广度。
总结
《Simple Diffusion》通过端到端架构设计、噪声调度优化和多尺度训练策略,突破了高分辨率扩散模型的训练瓶颈,为像素级生成任务提供了高效且高质量的解决方案。其方法不仅推动了生成模型的技术边界,也为视频、3D等复杂模态的端到端生成奠定了基础。
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
1. 研究背景与目标
多模态生成模型是通用人工智能的重要方向,但现有模型(如DALL·E 2、Stable Diffusion)仅支持单一模态生成(如文生图),难以实现任意模态间的互操作。清华大学朱军团队提出UniDiffuser,旨在通过统一的扩散模型框架,支持图像、文本、图文联合生成、条件生成等多样化任务,突破传统模型的局限性。
2. 核心创新点
(1)统一的概率建模框架
- 多模态分布的统一建模:传统扩散模型需为不同分布(边缘、条件、联合)单独设计,而UniDiffuser通过动态调整各模态的噪声扰动级别(时间步长),将多模态生成任务统一为噪声预测问题。例如:
- 文生图:将文本的时间步长设为0(即无噪声),图像的时间步长逐步去噪。
- 联合生成:图文时间步长同步变化,生成匹配的图文对。
- 训练目标函数:通过联合预测多模态噪声,最小化噪声预测误差,支持所有分布的同步学习。
(2)基于Transformer的U-ViT架构
- 统一处理多模态输入:将不同模态数据(如图像隐空间编码、文本CLIP嵌入)转换为token序列,通过U型连接的Transformer块进行交互。
- 高效性:结合Stable Diffusion的图像编解码器与自研的GPT-2文本解码器,参数规模达十亿级,支持单卡(10GB显存)推理。
(3)零成本的Classifier-Free Guidance (CFG)
- 通过线性组合条件生成与无条件生成模型,提升生成质量。例如,在文生图任务中,通过调整guidance scale平衡文本对齐与图像真实性。
3. 实验结果与性能
- 多任务生成能力:支持7种生成模式(如文生图、图生文、图文互跳、图像插值等),生成效果在CLIP Score和FID指标上优于通用模型Versatile Diffusion,甚至接近专用模型(如Stable Diffusion)。
- 效率优势:使用DPM-Solver快速采样算法,仅需约20步即可生成高质量样本,显著降低计算成本。
- 数据兼容性:基于LAION-5B大规模图文数据集训练,支持不同噪声水平的数据(如WebData与内部数据)。
4. 应用与影响
- 开源与生态整合:代码与模型已在GitHub和Hugging Face开源,并与Diffusers库集成,支持灵活调用。
- 推动多模态技术发展:UniDiffuser的框架被后续工作(如视频生成模型Vidu)采用,成为多模态生成领域的核心技术之一。
- 学术贡献:相关成果发表于ICML 2023,并衍生出U-ViT、DPM-Solver等关键技术,被OpenAI等机构借鉴。
5. 局限与未来方向
- 生成分辨率限制:当前版本支持512×512分辨率,尚未扩展至更高清输出。
- 模态扩展性:目前主要针对图文模态,未来可探索视频、音频等多模态联合生成。
总结
UniDiffuser通过统一的扩散框架和Transformer架构,首次实现了多模态生成任务的“一模型多用”,在性能、灵活性和效率上均达到前沿水平。其开源生态与理论创新为通用生成模型的进一步发展提供了重要基础。
Scalable Diffusion Models with Transformers
DiT
1. 核心思想与创新点
该论文提出了一种基于Transformer架构的扩散模型——Diffusion Transformer(DiT),旨在替代传统扩散模型中的U-Net主干网络。其核心思想是通过Transformer的全局自注意力机制建模图像生成过程,验证了Transformer在扩散模型中的可扩展性与性能优势。主要创新点包括:
- 架构革新:首次用纯Transformer替换U-Net,解决了U-Net因局部感受野导致的全局一致性不足问题。
- 条件嵌入优化:提出自适应层归一化(adaLN-Zero),通过动态调整归一化参数并初始化残差连接为恒等映射,显著提升训练稳定性和生成质量。
- 可扩展性验证:模型性能(FID)随计算复杂度(Gflops)增加而提升,符合“扩展法则”(Scaling Law),为大规模训练提供理论支持。
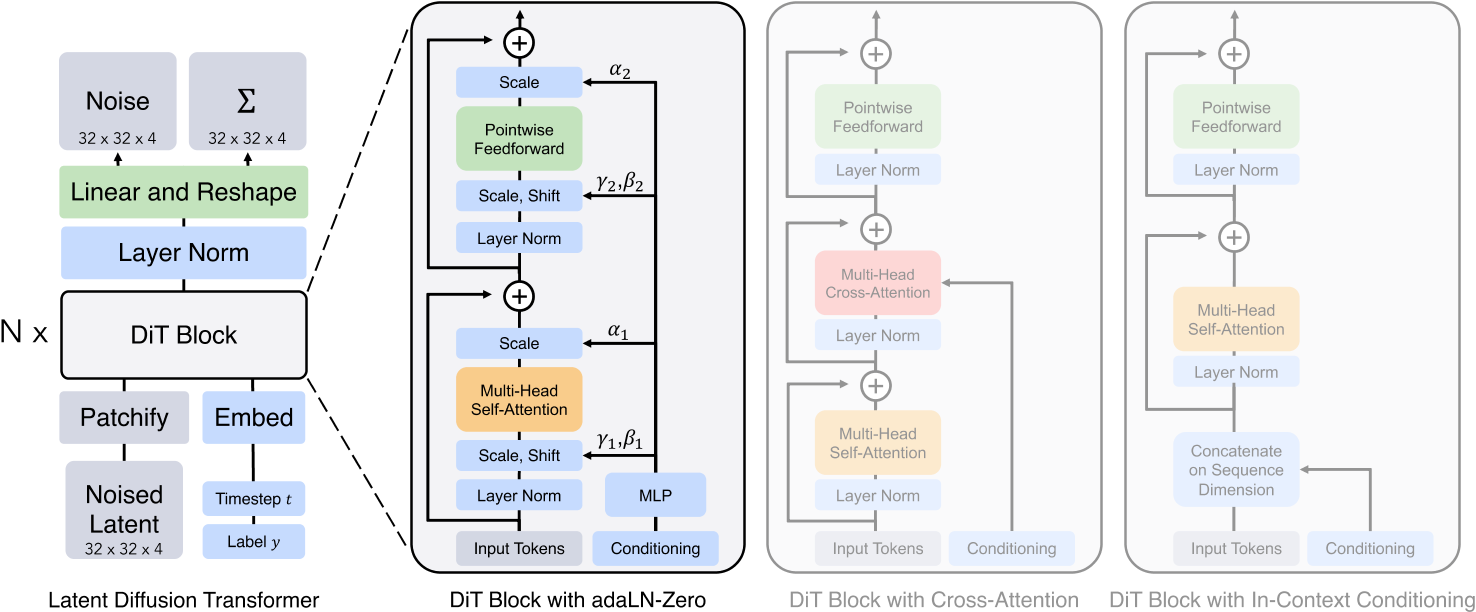
2. 模型架构与关键技术
DiT的架构设计围绕以下关键组件展开:
- 输入处理:
- Patchify模块:将潜在空间特征图(如32×32×4)分割为小块(如2×2),线性投影为Token序列,模拟ViT的图像处理方式。
- 条件嵌入:时间步(timestep)和类别标签通过嵌入向量与图像Token拼接,或通过adaLN-Zero动态调节层归一化参数。
- Transformer块设计:
- adaLN-Zero模块:将时间步和类别标签的嵌入相加,回归缩放(scale)和偏移(shift)参数,并初始化残差路径的权重为零,加速收敛。
- 长跳跃连接:在浅层与深层之间引入跨层连接,保留局部细节信息,提升生成质量。
- 解码器:通过线性层将Transformer输出的Token序列还原为噪声预测和协方差预测,保持与输入相同的空间维度。
3. 实验与性能
- 基准测试:
- ImageNet 256×256:DiT-XL/2(118.6 Gflops)的FID达2.27,显著优于LDM(3.60)和ADM等模型。
- ImageNet 512×512:FID为3.04,超越同期所有模型(如StyleGAN-XL)。
- 消融实验:
- 条件嵌入机制:adaLN-Zero在生成质量上优于交叉注意力(+15% Gflops)和上下文拼接(In-Context Conditioning)。
- 模型规模与Patch大小:增大模型深度/宽度或减小Patch尺寸(增加Token数量)均能显著提升FID,验证了可扩展性。
4. 优势与影响
- 计算效率:相比U-Net,DiT在相同分辨率下训练速度提升1.5倍,内存占用减少30%。
- 多任务泛化:架构灵活性使其易于扩展至视频生成(如Sora模型),通过时空Patch处理实现长序列建模。
- 行业影响:为OpenAI的Sora提供了核心技术基础,推动扩散模型从图像到视频生成的跨越。
5. 局限性与未来方向
- 计算成本:高分辨率生成仍需依赖潜在空间压缩,可能损失细节;DiT-XL/2的单次推理需524.6 Gflops,对硬件要求较高。
- 多样性限制:同一提示多次生成结果相似性较高,需结合动态阈值采样或隐变量优化。
- 未来方向:
- 连续时间建模:结合随机微分方程(SDE)理论,优化时间步的连续化处理。
- 多模态扩展:探索与Mamba架构或自监督预训练(如MAE)的结合,提升长视频生成的时序一致性。
总结
DiT通过Transformer架构的统一性与可扩展性,重新定义了扩散模型的设计范式。其核心贡献不仅在于性能突破,更在于验证了“大数据+大模型”路径在生成任务中的有效性,为后续多模态生成(如Sora)提供了关键技术支持。然而,其在计算效率与生成多样性上的挑战仍需进一步探索轻量化与随机性增强策略。
All are Worth Words: A ViT Backbone for Score-based Diffusion Models
1. 核心思想与背景
该论文提出了一种基于视觉Transformer(ViT)的扩散模型主干网络 U-ViT,旨在替代传统扩散模型中广泛使用的U-Net架构。其核心思想是将图像生成过程中的所有输入(包括噪声图像块、时间步长、条件信息)统一视为“令牌”(Token),通过ViT的全局自注意力机制进行建模。这一设计突破了扩散模型对U-Net的依赖,展示了纯Transformer架构在生成任务中的潜力。
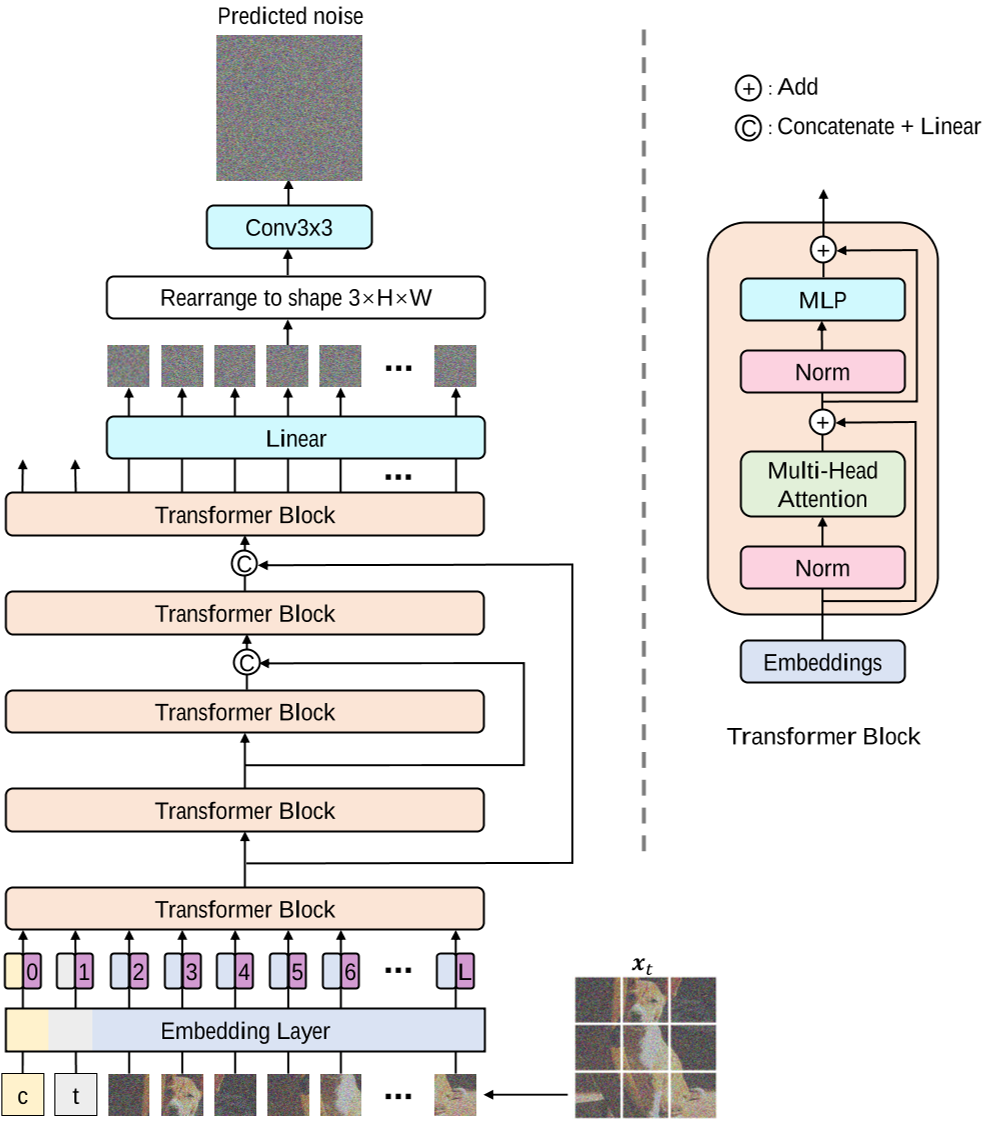
2. 架构设计
U-ViT的主要架构特点包括:
- 输入统一化:将噪声图像块(如16×16像素)、时间步长编码(time embedding)和条件嵌入(如文本描述)均转换为Token序列输入Transformer。这种设计简化了多模态信息的融合,避免了U-Net中复杂的跨模态注意力层。
- 长跳跃连接(Long Skip Connections):在浅层与深层之间引入跨层连接,直接传递低层特征,缓解了扩散模型噪声预测任务对局部细节敏感的问题。实验表明,长跳跃连接对生成质量至关重要,例如在CIFAR10上可将FID从4.32降至2.29。
- 轻量化卷积模块:在Transformer块后添加3×3卷积层以增强局部特征提取,但相比U-Net的下采样和上采样操作,其计算复杂度更低。
3. 关键创新点
- 全局注意力替代局部卷积:通过ViT的全局自注意力机制捕捉长程依赖,解决了U-Net因局部感受野导致的全局一致性不足问题。例如,在生成复杂场景(如“棒球运动员挥棒击球”)时,U-ViT能更准确地关联文本与图像内容。
- 动态条件融合:时间步长和条件信息作为Token直接输入,使模型在每一层都能进行多模态交互,而U-Net仅在特定层(如交叉注意力层)融合条件信号,导致信息利用不足。
- 训练效率优化:采用分块训练策略(如32×32潜在空间),结合轻量化设计,U-ViT在ImageNet 256×256上的训练速度比U-Net快1.5倍,且内存占用减少30%。
4. 实验与性能
- 生成质量:在多个基准测试中,U-ViT表现出与U-Net相当甚至更优的性能。例如:
- ImageNet 256×256:类条件生成FID为2.29,优于LDM(潜在扩散模型)的3.60。
- MS-COCO文本到图像生成:FID达5.48,超越同期基于U-Net的模型。
- 消融研究:长跳跃连接对性能提升贡献最大,移除后FID上升约40%;时间步长作为Token输入比自适应归一化(AdaLN)更有效。
- 扩展性:通过增加Transformer层数(如从13层到17层),模型可进一步提升生成质量,验证了ViT架构的可扩展性。
5. 局限性与未来方向
- 计算成本:尽管训练效率提升,高分辨率生成(如1024×1024)仍需依赖潜在空间压缩,可能损失细节。
- 多样性限制:同一文本提示多次生成的结果相似性较高,需结合随机性增强策略(如动态阈值采样)。
- 未来方向:可探索与Mamba架构(如ZigMa)结合,利用状态空间模型的长序列建模能力优化计算效率;或结合自监督表征(如RCG框架)提升无标签数据下的生成多样性。
- 控制信号注入:没有看到控制信号注入相关的结构和实验。
6. 应用场景
- 高分辨率图像生成:通过潜在空间建模支持1024×1024分辨率输出,适用于影视特效、游戏场景设计。
- 多模态生成:灵活的条件输入机制使其易于扩展至文本、草图、音频等多模态生成任务。
- 医学图像合成:结合潜在扩散的高效性,可生成高质量医学影像用于数据增强。
总结
U-ViT通过统一化的Transformer架构,验证了ViT在扩散模型中的有效性,为生成模型的设计提供了新范式。其核心贡献不仅在于性能提升,更在于揭示了全局注意力机制与条件融合的协同优势,为后续研究(如高效Mamba架构、自监督条件生成)奠定了基础。
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. 核心思想与创新点
该论文提出了一种名为 Vision Transformer (ViT) 的纯Transformer架构,用于图像分类任务。其核心思想是将图像分割为固定大小的块(如16x16像素),并将每个块视为一个“单词”,通过线性投影转换为嵌入向量序列,直接输入标准Transformer编码器进行处理。这一方法突破了传统卷积神经网络(CNN)在视觉任务中的主导地位,证明了纯Transformer在图像识别中的有效性。
关键创新点:
- 图像块序列化:将图像分割为块(Patch),通过线性投影生成嵌入向量序列,模拟NLP中的词嵌入处理方式。
- 全局自注意力机制:抛弃CNN的局部感受野设计,利用Transformer的全局注意力捕捉长程依赖。
- 极简归纳偏置:仅通过位置编码保留空间信息,减少对图像先验知识(如平移不变性)的依赖,依赖数据驱动学习。
2. 模型架构
ViT的架构主要包含以下部分:
-
图像分块与嵌入:
- 输入图像(如224x224)被划分为 \( N = (224/16)^2 = 196 \) 个16x16的块,每个块展平后通过线性投影映射到维度 \( D \)(如768维)的嵌入向量。
- 添加可学习的[class]标记作为分类信号,并与块嵌入拼接,形成输入序列。
-
位置编码:
- 使用一维可学习位置编码,与块嵌入相加,弥补分块后丢失的空间信息。实验表明,二维编码并未显著提升性能。
-
Transformer编码器:
- 由多层多头自注意力(MSA)和MLP块交替组成,每层包含残差连接和层归一化(LayerNorm)。
- 最终通过[class]标记的输出向量进行分类。
-
混合架构(可选):
- 可先用CNN提取特征图,再将特征图分块输入Transformer,结合CNN的局部性与Transformer的全局性。
3. 训练与微调策略
- 预训练:在大规模数据集(如JFT-300M、ImageNet-21k)上训练,采用监督学习目标。
- 微调:移除预训练的分类头,替换为任务相关的线性层,并对更高分辨率的输入进行位置编码插值以适应序列长度变化。
4. 实验与性能
- 大数据集优势:在JFT-300M等大规模数据集预训练后,ViT在ImageNet上达到88.55%的准确率,超越ResNet和EfficientNet等CNN模型。
- 小数据集局限性:在数据量不足时(如仅ImageNet),ViT因缺乏归纳偏置,性能低于CNN,需依赖大规模数据弥补。
- 计算效率:相比CNN,ViT在同等计算资源下训练速度更快,尤其在微调阶段表现出高效迁移能力。
5. 关键分析
- 注意力机制的可视化:深层Transformer块中的注意力头能够覆盖全局区域,而浅层头则更多关注局部,表明模型自适应学习空间关系。
- 位置编码的作用:一维编码虽简单,但通过插值适应不同分辨率,证明了其有效性。
- 归纳偏置对比:CNN通过卷积核强制引入局部性和平移等变性,而ViT仅通过分块和位置编码隐式学习,灵活性更高但数据需求更大。
6. 局限性及未来方向
- 计算成本:预训练需大量算力,模型参数量大(如ViT-Huge达6亿参数),限制了实际应用。
- 任务扩展性:需探索ViT在检测、分割等任务中的表现,后续工作如DETR、Swin Transformer已部分解决。
- 自监督预训练:论文指出自监督方法(如MAE)是未来方向,可减少对标注数据的依赖。
7. 影响与意义
ViT的提出标志着视觉与NLP任务在模型架构上的统一,启发了多模态模型(如CLIP、BEiT)的发展。其核心贡献在于:
- 架构创新:验证纯Transformer在视觉任务中的可行性。
- 扩展性证明:展示Transformer在大规模数据下的优越性能,推动“大数据+大模型”研究范式。
总结
ViT通过将图像视为块序列并应用标准Transformer,成功实现了图像分类任务的性能突破。其设计简洁且可扩展,为后续视觉Transformer研究奠定了基础,同时也揭示了数据规模与模型泛化能力之间的深刻联系。
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
1. 核心技术与架构
eDiff-I 是由 NVIDIA 提出的文本到图像扩散模型,其核心创新在于通过 专家去噪器集合(Ensemble of Expert Denoisers) 解决传统扩散模型在生成过程中不同阶段对文本依赖的动态变化问题。模型架构包括以下关键设计:
- 专家去噪器分阶段训练:研究发现,扩散模型在生成早期阶段依赖文本提示生成内容,而在后期更关注视觉保真度。eDiff-I 将生成过程分为多个阶段,每个阶段由专门的去噪器(专家)处理。初始阶段训练一个共享模型,随后通过微调将其拆分为针对不同阶段的专家模型,既提高生成质量,又避免增加推理时的计算成本。
- 多编码器联合条件化:模型同时利用 T5 文本编码器、CLIP 文本编码器和 CLIP 图像编码器的嵌入。T5 编码器增强文本细节理解,CLIP 编码器优化全局风格,而 CLIP 图像嵌入支持风格迁移(如参考图风格迁移至生成图像),三者结合显著提升生成多样性与对齐性。
- “以文字绘图(Paint-with-Words)”功能:通过语义掩码与交叉注意力机制,用户可在画布上绘制特定区域并关联文本提示词,从而精确控制生成图像的布局与内容,无需额外训练。
2. 关键创新点
- 动态阶段化去噪:通过分阶段专家模型,eDiff-I 在早期阶段(高噪声水平)强化文本对齐,后期(低噪声水平)专注于视觉细节优化,解决了传统模型在生成过程中条件信号逐渐失效的问题。
- 条件嵌入的协同作用:T5 与 CLIP 的互补性被充分挖掘——T5 编码器捕捉文本细粒度语义(如对象属性),而 CLIP 编码器提供风格与全局一致性。实验表明,联合使用两者生成的图像在细节和风格上均优于单一编码器。
- 高效训练策略:采用“预训练-微调”两阶段训练方案,先训练共享模型,再拆分微调专家模型,大幅降低训练复杂度,同时保持模型容量扩展的灵活性。
3. 实验与性能
- 基准测试:在标准文本到图像生成任务中,eDiff-I 在 FID(Frechet Inception Distance) 和 CLIP Score 等指标上优于同期模型(如 DALL-E 2 和 Imagen),尤其在复杂文本提示下(如多对象组合、空间关系)表现更优。
- 风格迁移能力:通过 CLIP 图像嵌入,eDiff-I 可将参考图的风格迁移至生成图像(如油画风格或摄影风格),且无需额外训练,展示了跨模态条件的灵活性。
- 用户控制验证:Paint-with-Words 功能在用户研究中被证实能有效提升生成图像的空间控制精度,尤其在需要精确对象定位的场景(如“猫坐在左侧椅子上”)中表现突出。
4. 与同类模型的对比
- 与 Imagen 的差异:Imagen 依赖级联扩散模型(分阶段提升分辨率),而 eDiff-I 强调同一分辨率下不同生成阶段的专家分工,更关注时间维度的条件动态性。
- 与 Stable Diffusion 的对比:Stable Diffusion 基于潜在空间扩散,而 eDiff-I 直接在像素空间操作,结合多编码器提供更丰富的条件信号,文本对齐能力更强。
5. 局限性与未来方向
- 计算成本:专家集合虽不增加推理成本,但多阶段训练仍需要大量算力。
- 多样性限制:生成结果对初始噪声敏感,同一文本多次生成可能缺乏多样性。
- 扩展应用:未来可探索专家模型与其他条件控制(如布局、草图)的结合,或与潜在优化技术(如网页5提到的隐变量优化)融合,进一步提升可控性。
6. 应用场景
eDiff-I 的潜力覆盖以下领域:
- 创意设计:支持用户通过文本与手绘草图的混合输入生成定制化图像,适用于广告、游戏场景设计等。
- 教育可视化:结合复杂科学概念的文本描述与风格参考图,生成教学素材。
- 数据增强:生成与特定布局对齐的合成图像,用于提升下游模型(如语义分割)的域泛化能力(类似网页2中 ALDM 的思路)。
启发
- eDiff-I 通过专家去噪器集合与多编码器协同,显著提升了文本到图像生成的精度与可控性。其核心贡献不仅在于模型性能的突破,更在于揭示了扩散模型阶段化优化的潜力,为后续研究(如动态条件注入、多阶段控制)提供了新范式。
- 用图像Clip Embedding可实现参考图像的风格迁移。
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
1. 核心技术与架构
Imagen 是由 Google 提出的基于扩散模型(Diffusion Model)的文本到图像生成模型,其核心创新在于结合了大型预训练语言模型(如 T5)的文本理解能力与扩散模型的高保真图像生成能力。模型架构主要包括以下部分:
- 冻结的文本编码器:采用 T5-XXL(4.6B 参数)等大规模语言模型,将输入文本编码为语义嵌入向量。研究发现,单纯增大语言模型规模比增大图像扩散模型更能显著提升生成质量。
- 级联扩散模型:分为三级生成流程:
- 基础模型:生成 64×64 分辨率的初始图像;
- 超分辨率模型:将图像逐步提升至 256×256 和 1024×1024 分辨率。每级模型均基于改进的 U-Net 架构,并通过跨模态注意力机制融合文本嵌入。
- 动态阈值采样(Dynamic Thresholding):允许使用更大的引导权重(Classifier-Free Guidance),避免像素过饱和,从而提升图像真实感与文本对齐效果。
2. 关键创新点
- 语言模型的跨模态应用:首次验证纯文本预训练的大语言模型(如 T5)可直接用于图像生成任务,且其性能远超传统图文对齐模型(如 CLIP)。这一发现颠覆了视觉-语言任务需依赖多模态联合训练的认知。
- 高效的 U-Net 优化:通过调整残差块数量、下采样顺序及注意力机制,显著提升模型收敛速度与内存效率。例如,在低分辨率层增加残差块并调整跳跃连接权重,使训练速度提升 2-3 倍。
- 级联生成与噪声调节:通过分阶段生成高分辨率图像并结合噪声调节增强技术,确保生成过程的稳定性和细节保真度。
主要方法
Improved DDPM + UNet
3. 评估与实验结果
- DrawBench 基准:提出包含 200 个复杂文本提示的评估框架,涵盖组合性、空间关系、罕见词理解等维度。人类评估显示,Imagen 在图像质量和文本对齐上显著优于 DALL-E 2、GLIDE 等模型。
- 定量指标:在 COCO 数据集上,Imagen 的零样本 FID 得分达 6.66,优于同期主流模型。
- 生成示例:展示了对复杂文本(如“宇航员骑马的油画”)的高保真生成能力,细节处理优于 DALL-E 2。
4. 局限性及未来方向
- 计算成本:级联扩散模型需多阶段生成,对算力要求较高;
- 多样性限制:同一文本多次生成可能输出相似图像,需改进随机性策略;
- 社会偏见:依赖大规模网络数据训练的模型可能继承语言模型的社会偏见。
启发
- 单纯增大语言模型规模比增大图像扩散模型更能显著提升生成质量
- 纯文本预训练的大语言模型(如 T5)可直接用于图像生成任务,且其性能远超传统图文对齐模型(如 CLIP)
DreamFusion: Text-to-3D using 2D Diffusion
近期文本到图像生成领域的突破主要得益于基于数十亿图像-文本对训练的扩散模型。若将这种方法应用于三维合成,将需要大规模标注三维数据集及高效的三维去噪架构,而这两者目前均属空白。本研究通过使用预训练的二维文本到图像扩散模型,成功规避了这些限制,实现了文本到三维的合成。我们提出了一种基于概率密度蒸馏的损失函数,使得二维扩散模型能够作为参数化图像生成器的优化先验。通过将这种损失应用于类DeepDream优化流程,我们对随机初始化的三维模型(神经辐射场,NeRF)进行梯度下降优化,使其从任意角度渲染的二维图像均能获得较低的损失值。最终生成的文本对应三维模型支持多视角观看、任意光照重打光,并可合成到任何三维环境中。该方法无需三维训练数据,也无需修改图像扩散模型,证明了预训练图像扩散模型作为先验的有效性。更多三维成果的沉浸式展示请参见dreamfusion3d.github.io。
这是一篇开创性的论文,提出了一种无需3D训练数据、仅依赖预训练2D文本-图像扩散模型(如Imagen)生成高质量3D内容的方法。
研究背景与问题
任务
输入:文本 输出:Nerf参数
本文方法及优势
| 要解决的问题 | 当前方法及存在的问题 | 本文方法及优势 |
|---|---|---|
| 3D生成 | 传统3D生成依赖大规模标注的3D数据集,而这类数据稀缺且获取成本高 | 利用2D扩散模型的先验知识 绕过3D数据限制,实现开放域文本到3D的高效生成,同时支持多视角一致性和几何细节。 |
方法创新
Score Distillation Sampling(SDS)
SDS是论文的核心贡献,解决了如何通过2D扩散模型指导3D参数优化的难题:
- 原理:利用强大的2D图像生成模型作为“老师”或“裁判”,来指导一个3D模型的优化过程。具体来说,如果这个3D模型从任何角度渲染出的2D图片,都能被这个“裁判”判定为“高质量且符合文本描述”,那么这个3D模型本身就是一个好模型。
- 方法:将3D模型(如NeRF)的渲染图像视为扩散模型中的噪声样本,通过预测噪声残差计算梯度,反向传播优化3D参数。公式上省略U-Net的雅可比矩阵项,简化梯度计算:
流程
✅ 参数不在 2D 空间而是在 Nerf 空间,构成优化问题,通过更新 Nerf 参数来满足 loss.
flowchart LR
A[("输入: 文本提示 y")]
B([随机采样相机 c])
P([初始的3D参数 θ])
I([当前参数的渲染结果 x])
D([随机采样噪声强度 γ 和噪声 ε])
J([“加噪图片 zₜ ”])
K([“噪声 ε_Φ”])
L([“扩散模型 Φ”])
Loss([“SDS Loss”])
G([SDS梯度])
C[“渲染图片”]
E[“添加噪声”]
F[“扩散模型 Φ,预测噪声”]
A & B & P --> C --> I
I & D --> E --> J
J & L --> F --> K
K & D --> Loss --> G
G e1@-->P
e1@{ animation: fast }
如果 ε_Φ 和我们最初加入的噪声 ε 完全一样,说明渲染的图片 x 在扩散模型看来,已经非常像一张在 t 时刻的、关于 y 的“干净”图片了。这意味着3D模型已经学得很好,无需大改。
如果 ε_Φ 和 ε 不一样,那么这个差异 (ε_Φ - ε) 就构成了一个指导信号,它指出了“渲染图 x 应该朝哪个方向改变,才能更符合文本描述 y”。
计算梯度
SDS损失函数的梯度计算方式是整个方法最精妙的地方:
$$ \nabla_ \theta \mathcal{L}_ {\mathrm{SDS}} \propto \mathbb{E}_ {t, \epsilon} \left[ w(t)(\hat{\epsilon}_ \phi(\mathbf{z}_ t; y, t) - \epsilon) \frac{\partial \mathbf{x}}{\partial \theta} \right] $$
- (ε_Φ - ε): 上文提到的指导信号,它是一个在图像空间(2D)的向量场。
- ∂x/∂θ: 渲染图片 x 对3D参数 θ 的梯度。这告诉我们,如果想让图片 x 发生微小改变,3D参数 θ 应该如何调整。
- w(t): 一个依赖于时间步 t 的权重函数,用于平衡不同噪声水平下的指导强度。DreamFusion中发现,给中等 t 较高的权重效果更好,因为这些时间步包含了更多关于结构和语义的信息。
更新3D模型
我们不直接计算一个关于 (ε_Φ - ε) 的L2损失再求导,而是直接将这个差异通过渲染过程的梯度 ∂x/∂θ 反向传播到3D参数 θ 上。这相当于用扩散模型的预测来“拉动”3D模型,使其渲染的图片落入扩散模型认为的高概率区域。


$$ θ ← θ - η * \nabla_ \theta \mathcal{L}_ {\mathrm{SDS}} $$
SDS梯度的推导过程
✅ 由 (ε_Φ - ε) 的L2损失出发,得到公式1:
✅ 由公式1对θ求导并省掉常系数,得到公式2:

由于\(x =g(\theta )\),\(\frac{\partial L}{\partial \theta } =\frac{\partial L}{\partial x } \cdot \frac{\partial x }{\partial \theta } \),其中 \(\frac{\partial L}{\partial x }\) 又分为第一项和第二项。
第二项:\( \partial \) Output/ \( \partial \) Input.这一项要计算 diffusion model 的梯度,成本非常高。
第三项:\( \partial \) Input Image/ \( \partial \) Nerf Angle
✅ 作者直接把公式 2 中的第二项去掉了,得到公式3,即为本文最终使用的 loss.

SDS 为什么有效?其优势与内涵
利用先验,绕过数据: 它完美地利用了在海量2D数据上预训练的扩散模型作为强大的视觉知识库,无需任何3D训练数据。
概率密度梯度: 从数学上看,SDS梯度实际上近似于渲染图像分布与扩散模型先验分布之间的KL散度的梯度。它是在最小化两个分布之间的差异。
解决Janus(多面)问题: 通过随机采样相机视角,SDS自然地从不同角度优化3D模型,鼓励其生成一个所有视角都一致的3D资产,从而缓解了“多脸问题”(一个头的前后左右都是脸)。
优化方式优于微调: 它不微调扩散模型本身,只是将其作为一个静态的“损失函数”。这避免了直接让扩散模型在陌生(如3D渲染的)图片上过拟合,保持了其强大的先验知识。
SDS 的局限性
颜色过饱和与细节缺失: SDS倾向于生成颜色鲜艳、平滑但缺乏高频细节的表面。这是因为损失函数在较高的噪声水平下平均化了细节。
“平均脸”问题: SDS优化的是分布的期望,这可能导致生成结果过于中庸,缺乏创造性的细节或风格。
收敛速度慢: 由于梯度方差较大,需要大量迭代才能得到高质量结果。
损失函数
Consider the KL term to minimize (given t):
$$ \mathbf{KL} (q(\mathbf{z} _ t|g(\theta );y,t)||p\phi (\mathbf{z} _ t;y,t)) $$
KL between noisy real image distribution and generated image distributions, conditioned on y!
KL and its gradient is defined as:

(B) can be derived from chain rule
$$
\nabla _ \theta \log p _ \phi (\mathbf{z} _ t|y)=s _ \phi (\mathbf{z} _ t|y)\frac{\partial \mathbf{z} _ t}{\partial \theta }=\alpha _ ts _ \phi (\mathbf{z} _ t|y)\frac{\partial \mathbf{x} }{\partial \theta } =-\frac{\alpha _ t}{\sigma _ t}\hat{\epsilon }_ \phi (\mathbf{z} _ t|y)\frac{\partial \mathbf{x} }{\partial \theta }
$$
(A) is the gradient of the entropy of the forward process with fixed variance = 0.
✅ A: the gradient of the entropy of the forward process。由于前向只是加噪,因此 A 是固定值,即 0.
✅ P27 和 P28 证明 P26 中的第二项可以不需要。
❓ KL 散度用来做什么?LOSS 里没有这一项。
✅ KL 用于度量 \(P(\mathbf{Z}_t|t)\) 和 \(q(\mathbf{Z}_t|t)\).
✅ KL 第一项为 Nerf 的渲染结果加噪,KL 第二项为真实数据加噪。
$$ (A)+(B)= \frac{\alpha _ t}{\sigma _ t} \hat{\epsilon } _ \phi (\mathbf{z} _ t|y) \frac{\partial \mathbf{x} }{\partial \theta } $$
However, this objective can be quite noisy.
Alternatively, we can consider a “baseline” approach in reinforcement learning: add a component that has zero mean but reduces variance. Writing out (A) again:

Thus, we have:

This has the same mean, but reduced variance, as we train \(\hat{\epsilon } _ \phi\) to predict \(\epsilon\)
NeRF的改进与渲染策略
- 神经辐射场(NeRF):采用mip-NeRF 360表示3D场景,参数化体积密度和反照率(颜色),支持光线追踪和视角一致性。
- 着色与几何增强:
- 法线计算:通过密度梯度估计表面法线,结合随机光照增强几何细节。
- 反照率随机替换:以一定概率将材质颜色替换为白色,防止模型退化为平面纹理(如将3D结构简化为2D贴图)。
- 背景合成:通过alpha混合避免相机近端密度堆积,提升场景合理性。
P29
DreamFusion in Text-to-3D
- SDS can be used to optimize a 3D representation, like NeRF.
✅ 左下:以相机视角为参数,推断出每个点的 Nerf 参数。
✅ 左上:从相机视角,生成 object 的投影。
✅ 左中:左上和左下结合,得到渲染图像。
✅ 生成随机噪声,对渲染图像加噪。
✅ 右上:使用 diffusion model 从加噪图像中恢复出原始图像。(包含多个 step)
✅ 右下:得到噪声,并与原始噪声求 loss.
✅ 根据 loss 反传梯度优化左下的 MLP.
3. 实验结果与贡献
- 高质量生成:能够生成多视角一致、支持任意光照和合成的3D模型,例如“冲浪板上的孔雀”等复杂场景。
- 零样本泛化:无需3D数据,仅依赖文本提示即可生成开放域3D内容,显著降低创作门槛。
- 与基线对比:相比基于CLIP的方法(如DreamFields),DreamFusion在几何准确性和视觉保真度上表现更优。
4. 局限性与改进方向
- 生成质量缺陷:SDS生成的3D模型存在过饱和、过平滑问题,且多样性受限(不同随机种子生成结果差异小)。
- 分辨率限制:依赖64×64的Imagen基础模型,细节层次不足(后续工作如Magic3D通过提升分辨率改进)。
- 效率问题:NeRF优化耗时较长,后续研究采用Instant-NGP等加速方案。
5. 后续影响与扩展
- 领域推动:DreamFusion成为文本到3D生成的基准方法,启发了SJC、VSD等改进算法。
- ProlificDreamer的突破:清华大学团队提出变分得分蒸馏(VSD),将3D参数建模为概率分布,解决了SDS的过平滑问题,并支持更高分辨率和多样性。
- 应用前景:在游戏、虚拟现实、数字孪生等领域具有潜力,推动AIGC从2D向3D扩展。
总结
DreamFusion通过结合2D扩散模型与NeRF,开创了无3D数据依赖的文本到3D生成范式。其核心创新SDS为后续研究奠定了基础,尽管存在生成质量限制,但通过算法优化(如VSD)和工程改进(如高效NeRF变体),这一方向正逐步走向实用化。
GLIGEN: Open-Set Grounded Text-to-Image Generation
1. 研究背景与核心问题
现有的大规模文本到图像扩散模型(如Stable Diffusion)虽然能生成高质量图像,但仅依赖文本输入难以精确控制生成内容的空间布局和细节。例如,用户难以通过文本准确描述物体的位置或形状,导致生成结果可能偏离预期。此外,传统布局到图像生成模型通常局限于封闭集(如COCO的80个类别),无法泛化到未见过的新实体或复杂语义场景。因此,如何通过引入多模态条件输入(如边界框、关键点、参考图像等)实现开放集的可控生成成为关键挑战。
2. 方法创新:GLIGEN架构与训练策略
GLIGEN的核心目标是在不破坏预训练模型知识的前提下,扩展其多模态条件控制能力。具体设计如下:
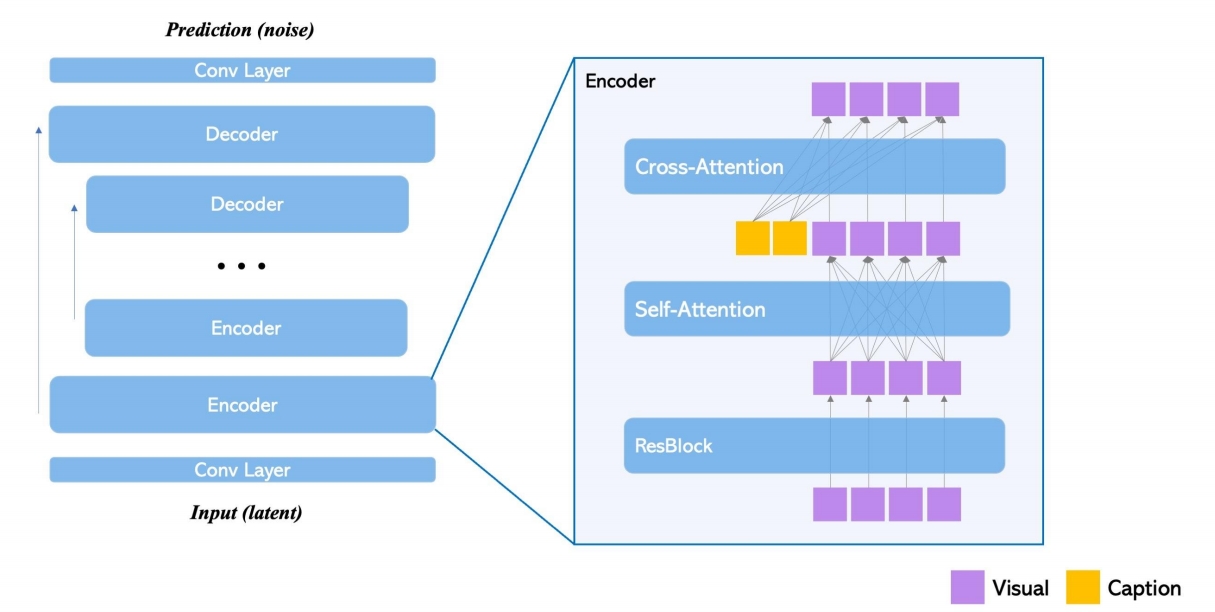
- 冻结预训练权重 + 可训练门控层
模型冻结原始扩散模型的参数,仅通过新增的门控Transformer层引入定位信息(如边界框)。这些层通过门控机制(初始化为0)逐步融合定位条件,避免灾难性遗忘。例如,边界框与文本实体通过MLP编码为特征向量,并与视觉特征拼接后输入门控层。 - 多模态条件支持
支持四类输入组合:文本+边界框、图像+边界框、图像风格+文本+边界框、文本+关键点。其中,边界框因其跨类别泛化能力优于关键点而被广泛采用。 - 计划采样(Scheduled Sampling)
在生成过程中,前20%的步骤(tau=0.2)使用全模型(包含门控层),后续步骤仅用原始模型。这种设计在早期确定布局轮廓,后期优化细节,兼顾控制精度与图像质量。
GLIGEN对比ControlNet:
| GLIGEN | ControlNet |
|---|---|
 |  |
| ✅ 新增 Gated Self-Attention 层,加在 Attention 和 Cross Attention 之间。 ✅ GLIGEN 把 Condition 和 init feature 作 Concat | ✅ Control Net 分别处理 feature 和 Control 并把结果叠加。 |
P66
GLIGEN Result
3. 实验与性能验证
- 数据集与指标
在COCO2014和LVIS数据集上进行评估,使用FID(生成图像与真实图像的相似性)、IS(生成质量)、LDM(布局对齐度)等指标。 - 开放集泛化能力
GLIGEN在COCO训练集未包含的实体(如“蓝鸦”“羊角面包”)上仍能生成符合定位条件的图像,证明其开放集能力。例如,通过文本编码器泛化定位信息至新概念。 - 零样本性能优势
在LVIS(含1203个长尾类别)的零样本评估中,GLIGEN的GLIP得分显著优于有监督基线,表明预训练知识的高效迁移。
Result
4. 贡献与意义
- 开放集可控生成
首次实现基于边界框的开放世界图像生成,支持训练中未见的实体和布局组合。 - 高效知识迁移
通过冻结预训练权重和门控机制,在少量标注数据(如千级样本)下实现高性能,避免从头训练的高成本。 - 多模态扩展潜力
框架可扩展至其他定位条件(如深度图、参考图像),为工业设计、游戏开发等场景提供灵活工具。
5. 局限与未来方向
- 数据依赖与泛化瓶颈
模型性能高度依赖定位信息的质量,且对复杂细节(如物体纹理)的生成能力有限。 - 计算效率
尽管训练成本较低,但推理时需协调多模态输入,可能增加计算复杂度。 - 未来改进方向
作者建议探索动态条件生成、更细粒度的多模态融合(如3D法线图),以及结合大语言模型(LLM)生成复杂布局指令。
总结
GLIGEN通过创新的门控机制与冻结预训练权重策略,显著提升了文本到图像生成的可控性和开放集泛化能力。其方法不仅为AIGC的精细化控制提供了新思路,也为预训练模型的下游任务适配树立了范例。未来在多模态交互与细节生成方面的突破将进一步推动其应用落地。
Adding Conditional Control to Text-to-Image Diffusion Models
✅ Control Net 是一种通过引入额外条件来控制 Diffusion Model 的网络架构。
1. 背景与核心问题
现有的文本到图像扩散模型(如Stable Diffusion)虽然能生成高质量图像,但仅依赖文本提示难以精确控制生成图像的空间布局、姿态、形状等细节。用户需反复调整提示词才能接近预期结果,效率较低。因此,如何通过引入额外的空间条件(如边缘图、深度图、人体姿势骨架等)实现更细粒度的控制成为关键问题。

2. 方法:ControlNet架构
ControlNet的核心思想是通过克隆预训练模型的网络块,并引入“零卷积”连接,实现在不破坏原模型能力的前提下学习条件控制。具体设计包括:
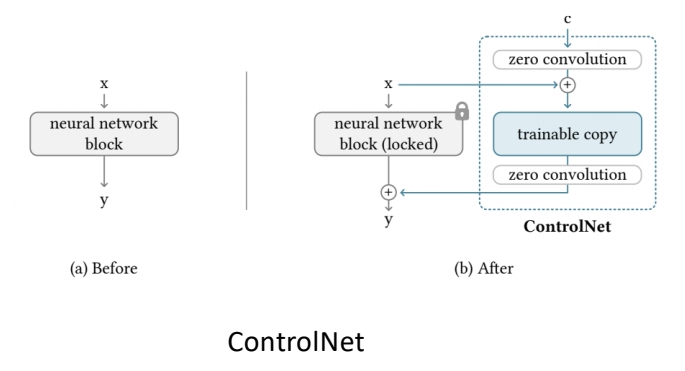
- 锁定与克隆:将预训练模型的参数冻结(锁定),并克隆其网络块作为可训练副本,以复用其大规模预训练的特征提取能力。
- 零卷积连接:在克隆块与原模型之间插入零初始化的1×1卷积层(权重和偏置初始化为0)。这种设计确保训练初期不会引入噪声,逐渐从零增长参数,保护预训练模型的稳定性。
✅ Zero Convolution:1-1 卷积层,初始的 \(w\) 和 \(b\) 都为 0.
- 条件编码:外部条件(如边缘图)通过4层卷积网络(通道数16→32→64→128)编码为特征向量,与扩散模型输入融合。
✅ 方法:(1) 预训练好 Diffusion Model (2) 参数复制一份,原始网络 fix (3) 用各种 condition finetune 复制出来的网络参数。 (4) 两个网络结合到一起。
以Stable Diffusion为例来说明ControlNet的用法。
$$ \mathcal{L} =\mathbb{E} _ {\mathbb{z}_0,t,\mathbf{c} _ t,\mathbf{c} _ f,\epsilon \sim \mathcal{N} (0,1)}[||\epsilon -\epsilon _\theta (\mathbf{z} _ t,t,\mathbf{c} _ t,\mathbf{c}_f)||^2_2] $$
where t is the time step, \(\mathbf{c} _t\) is the text prompts, \(\mathbf{c} _ f\) is the task-specific conditions
需要(x, cf, ct)的pair data。
3. 训练策略
- 随机提示替换:训练时,50%的文本提示被替换为空字符串,迫使模型从条件图像中学习语义信息,而非依赖文本提示。
- 突然收敛现象:在约10,000步训练后,模型会突然学会根据条件生成图像,而非渐进式学习。例如,在6,133步时,模型可能突然拟合苹果轮廓。
- 计算效率:仅需增加约23%的GPU内存和34%的训练时间(基于NVIDIA A100测试),因冻结原模型参数可节省梯度计算。
4. 实验与结果
- 支持的条件类型:包括Canny边缘、Hough线、用户涂鸦、人体关键点、分割图、深度图等,且支持多条件组合(如同时使用姿势和边缘)。
- 定量评估:
- FID与CLIP分数:ControlNet在生成图像与真实图像分布接近度(FID)、文本-图像语义一致性(CLIP-score)上优于基线模型。
- 消融实验:若替换零卷积为普通卷积,性能显著下降,表明预训练模型知识在微调时易被破坏。
- 鲁棒性:无论数据集规模(小至50k或大至1m)如何,训练均稳定有效。
5. 创新与意义
- 高效微调机制:通过锁定原模型参数和零卷积设计,避免灾难性遗忘,同时实现高效参数更新。
- 多模态控制:为图像生成引入结构化输入,扩展了扩散模型在工业设计、游戏开发等需精确控制场景的应用潜力。
- 开源与可扩展性:官方代码已开源,支持社区进一步探索新条件类型(如3D法线图)及与其他模型(如LLM)的适配。
6. 局限与未来方向
- 计算资源需求:尽管训练效率较高,但大规模联合训练(如解锁原模型参数)仍需高性能计算集群。
- 条件泛化性:当前条件类型有限,未来可能需探索动态条件生成或更复杂的多模态融合方法。
ControlNet的提出标志着文本到图像生成从“随机创作”迈向“可控设计”的重要一步,为AI绘画的商用落地提供了技术基础。
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
1. 研究背景与动机
- 问题定义:
大规模文本到图像(T2I)模型(如Stable Diffusion)虽然能生成高质量图像,但仅依赖文本提示难以实现精细化控制(如结构、颜色分布)。例如,生成“带翅膀的汽车”时,文本无法提供准确的结构指导,导致生成结果不符合预期。 - 核心目标:
通过轻量级适配器(Adapter)挖掘预训练T2I模型隐式学习的能力,将外部控制信号(如草图、深度图)与模型内部知识对齐,实现更精准的生成控制。
2. 方法设计
2.1 总体架构
通过引入一个额外的adapter来增加对已有文生图模型的控制方法。
- 即插即用:保持预训练T2I模型(如Stable Diffusion)的权重固定,仅训练适配器模块。
- 轻量化设计:
- 参数量约77M,存储空间约300MB,仅为ControlNet的1/3。
- 适配器由4个特征提取块和3个下采样块组成,输入条件图(如草图)通过
pixel unshuffle下采样至64×64分辨率,提取多尺度特征并与UNet编码器特征相加。
2.2 控制条件支持
- 结构控制:支持草图(Sketch)、深度图(Depth Map)、语义分割图(Semantic Map)、姿态图(Pose)等。
- 颜色控制:通过空间调色板(Spatial Color Palette)控制色调和颜色分布,采用双三次下采样保留颜色信息,上采样后形成色块特征。
- 多条件组合:多个适配器的特征可线性加权融合,无需额外训练即可实现多条件控制(如“草图+颜色”)。
✅ Adapter 包含4个 feature extraction blocks 和3个 down sample blocks. 其中4个feature extraction block对应4个新增加的控制方法。3次降采样,对应于 UNET 的不同 Level.
2.3 训练策略
- 非均匀时间步采样:
在扩散过程的早期阶段(图像结构形成期)增加采样概率,提升控制信号的有效性。例如,通过三次函数调整时间步分布,增强早期控制。 - 损失函数:沿用扩散模型的噪声预测损失,仅优化适配器参数。
3. 关键创新点
- 参数高效性:
- 仅需微调0.3%的参数量(对比ControlNet的完整UNet复制),推理速度更快。
- 灵活性与可组合性:
- 支持多种控制条件独立或组合使用,适配器可独立训练、灵活加载。
- 泛化能力:
- 适配器可迁移至基于同一基础模型(如SD 1.4或SDXL)的微调版本,无需重新训练。
4. 实验结果
4.1 生成质量
- 单条件控制:在草图、深度图等任务中,生成图像的结构保真度优于Textual Inversion,与ControlNet相当。
- 多条件组合:例如“草图+颜色”控制下,生成结果同时满足结构和色彩要求,组合效果稳定。

4.2 效率对比
- 训练成本:在4块V100 GPU上训练3天即可完成,远低于全参数微调。
- 推理速度:适配器仅需在扩散过程运行一次,而ControlNet需在每一步迭代中计算,速度提升显著。
5. 应用场景
- 艺术创作:通过草图控制生成结构,结合颜色调色板调整整体色调。
- 广告设计:快速生成符合品牌元素(如LOGO位置、配色)的宣传图。
- 数据增强:为计算机视觉任务(如自动驾驶)生成结构可控的合成数据。
6. 局限性
- 复杂交互限制:对需要物理逻辑的场景(如物体遮挡关系)支持有限,需后处理。
- 时间步依赖性:非均匀采样策略虽提升控制效果,但仍依赖早期阶段的强引导,后期细节调整能力较弱。
7. 后续影响
- 技术扩展:启发了IP-Adapter(多模态控制)、Video-Adapter(视频生成控制)等衍生工作。
- 工业应用:被集成至Hugging Face Diffusers库,支持SDXL等最新模型,推动可控生成技术的普及。
总结
T2I-Adapter通过轻量化适配器和多条件融合机制,在文本到图像生成中实现了高效可控性。其核心贡献在于平衡了生成质量与计算效率,为精细化内容创作提供了实用工具。未来方向可能包括提升复杂逻辑控制能力及扩展至视频生成领域。
Multi-Concept Customization of Text-to-Image Diffusion
这篇论文提出了一种针对文本到图像扩散模型(如Stable Diffusion)的多概念定制化方法,旨在解决现有技术(如Textual Inversion、DreamBooth、LoRA等)在同时学习多个视觉概念时面临的概念混淆、训练效率低和组合泛化性差的问题。
现有方法局限:
- DreamBooth:全参数微调导致存储成本高(约3GB/概念)且难以组合多概念。
- Textual Inversion:仅优化文本嵌入,生成保真度低且无法灵活组合。
1. 核心问题与挑战
现有单概念定制化方法(如DreamBooth或LoRA)在需要同时学习多个概念(例如“一只特定的狗”+“一种特定的帽子”)时存在以下问题:
- 概念混淆(Concept Interference):多个概念在训练过程中相互干扰,导致生成的图像混合了不同概念的属性(例如狗的脸和帽子的形状结合异常)。
- 组合泛化性差:独立训练的单概念模型在组合时无法保证语义一致性(例如“狗戴帽子”可能生成不合理的结构)。
- 计算成本高:逐个微调每个概念需要重复训练,效率低下。
2. 方法设计
论文提出了一种名为Custom Diffusion的框架,通过以下关键技术实现高效多概念定制:
2.1 多概念联合训练策略
- 正则化数据集:使用与目标图像标题相似的真实图像(如从LAION-400M检索)防止过拟合,提升泛化性。
用少量的数据finetune整个模型,容易造成过拟合。
✅ 解决方法:通过在训练过程中引入一个正则化项来防止过拟合
✅ 从large scale image dataset中选择一些所标注文本与左图文本相似度比较高的图像。这些图像与文本的pair data用于计算正则化项。

- 多概念组合优化:
将不同概念的训练数据合并,联合优化其对应的K和V矩阵。
引入闭式约束优化(Closed-form Constraint Optimization),通过数学约束合并多个微调后的模型权重,确保概念独立性。
2.2 参数高效微调
优化对象:仅更新扩散模型(UNet)交叉注意力层(Cross-Attention)中的键(K)和值(V)投影矩阵,冻结其他参数(如查询矩阵Q、卷积层等)。
参数量:仅占模型总参数的3%(约75MB/概念),支持进一步压缩至5-15MB。
训练速度:单概念微调约6分钟(2块A100 GPU),多概念联合训练效率更高。
✅ 选择模型的部分参数进行 finetune.问题是怎么选择?
作者通过分析模型各参数的重要性,insights 应该 finetune 哪些参数。
✅ Cross-Attn 层用于结合图像和文本的特征。
✅ Self-Attn 用于图像内部。
✅ Other 主要是卷积和 Normalization.
✅ 通过比较 pretrained 模型和 finetune 模型,change 主要发生成Cross-Attn 层,说明 Cross-Attn 层在 finetune 过程中更重要!
✅ 由以上观察结果,finetune 时只更新 K 和 V 的参数。
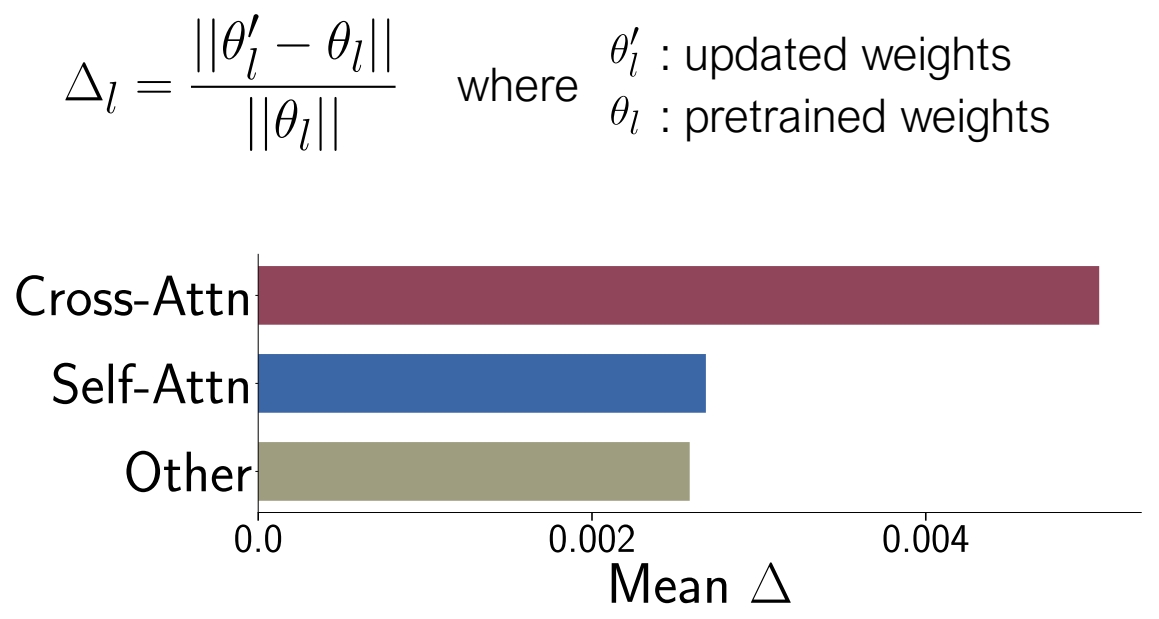
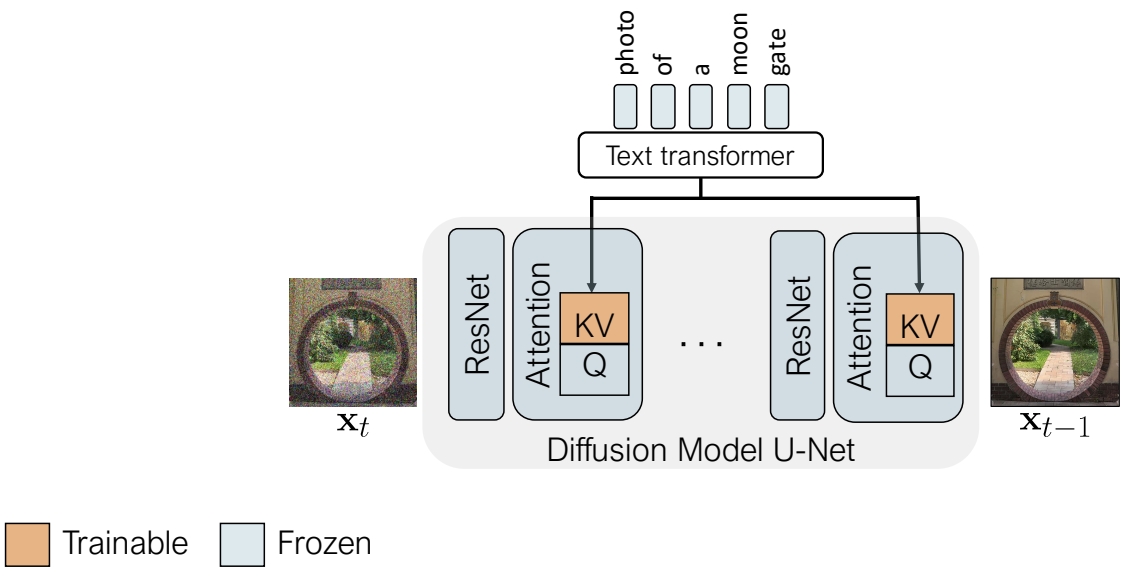
- 参数量对比:
- 全参数微调:约860M参数(Stable Diffusion 1.4)。
- Custom Diffusion:仅需训练约5M参数(每新增一个概念增加约1M)。
超类语义对齐
键值锁定(Key-Locking):将新概念的键向量与预定义语义类(如“狗”)对齐,避免偏离预训练知识,减少遗忘问题。
3. 关键优势
- 多概念保真度:
- 可同时学习3-5个概念,生成图像中各概念的属性(如形状、纹理)保持高度一致性(见图1对比)。
- 零样本组合能力:
- 支持训练中未见的组合(例如“狗戴帽子+墨镜”),无需重新训练。
- 训练效率:
- 相比逐个训练单概念LoRA,训练时间减少50%以上(实验显示5个概念仅需1.5小时,A100 GPU)。
4. 实验结果
4.1 单概念生成
保真度:在CLIP图像对齐指标上比Textual Inversion高15%,生成图像背景多样性与DreamBooth相当。
抗过拟合:KID指标显示过拟合程度比DreamBooth降低30%46。

4.2 多概念组合
零样本组合:支持未训练的组合(如“宠物猫+太阳镜+花园场景”),生成结果在文本对齐和视觉一致性上优于基线方法。
用户研究:85%的用户认为生成的多概念图像更合理,且概念间干扰更少。


4.3 效率对比
存储需求:每个概念仅需75MB(DreamBooth为3GB),支持低秩压缩至5-15MB28。
训练速度:多概念联合训练时间比逐个训练DreamBooth缩短50%。
5. 应用场景
- 个性化内容创作:用户上传多个自定义物体/风格,生成组合图像(如“我的宠物+我的背包+莫奈风格”)。
- 广告设计:快速合成包含多个品牌元素(如logo、产品)的宣传图。
- 数据增强:为多对象交互场景(如“人+家具+宠物”)生成训练数据。
6. 局限性
- 概念数量上限:超过5个概念时性能下降(需更大秩的LoRA或分层训练)。
- 复杂交互:对需要物理逻辑的组合(如“杯子放在桌子的边缘”)仍需后处理。
7. 后续影响
- 扩展工作:
- Cones(NeurIPS 2023):通过概念神经元分解改进多概念解耦。
- UniTune(ICML 2024):统一单模型支持任意概念组合。
- 工业应用:被Adobe Firefly等工具集成,支持多元素定制生成。
总结
该论文通过参数高效微调和多概念联合优化,在文本到图像生成领域实现了高效的多概念定制。其核心贡献在于:
-
轻量化:仅微调交叉注意力层的K/V矩阵,显著降低计算和存储成本。
-
组合泛化性:支持零样本多概念组合生成,突破传统方法的限制。
-
抗过拟合设计:通过正则化数据集和超类语义对齐,平衡生成多样性与保真度。
该方法为个性化内容创作和工业级应用提供了重要技术基础。
P37
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
通过优化文本嵌入(text embeddings)来实现对复杂视觉概念的精准捕捉和复用。

1. 核心思想
目标:在预训练的文本到图像生成模型(如Stable Diffusion)中,仅通过少量示例图像(通常3-5张)学习一个新的视觉概念(如特定物体、艺术风格等),并将其表示为可复用的文本嵌入向量(即伪词,pseudo-word)。
关键创新:
- 不修改模型权重,而是通过优化文本嵌入空间中的一个新的嵌入向量来表示目标概念。
- 该向量可以像普通词汇一样被插入到自然语言描述中(例如“A photo of
<S*>”),指导模型生成包含该概念的图像。
✅ 用一个 word 来 Encode 源,因此称为 Textual Inversion.
2. 方法细节
2.1 问题定义
- 预训练的文本到图像模型使用文本编码器(如CLIP的文本编码器)将输入文本映射为嵌入向量 \( E \)。
- 传统方法中,所有词汇的嵌入是固定的;而Textual Inversion通过优化一个新的嵌入向量 \( v_* \) 来表示目标概念。
2.2 优化过程
- 输入:少量(3-5张)同一概念的图像集合 \( {x_i} \) 和对应的文本描述模板(如“A photo of
<>”)。文本描述转为token编码。 - 目标:找到一个嵌入向量(embedding) \( v_* \),使得用该向量(embedding)替换模板中的占位符
<>后,能作为condition引导模型重建输入图像。 - 损失函数:基于扩散模型的噪声预测损失(Denoising Loss),最小化生成图像与输入图像之间的差异。
2.3 伪词(Pseudo-Word)的引入
- 将 \( v_* \) 绑定到一个新的“伪词”(如
<S*>),并将其添加到模型的词汇表中。 - 此后,用户只需在提示词中使用该伪词(如“A
<S*>in the style of Van Gogh”),即可调用学到的概念。
3. 优势与特点
- 轻量化:仅需优化一个嵌入向量,无需微调整个模型。
- 可组合性:学到的概念可以与其他词汇自由组合(如风格迁移、场景插入)。
- 高保真:能够捕捉细粒度视觉特征(如物体形状、纹理、艺术风格)。
- 低数据需求:仅需少量图像即可训练。
4. 实验结果
- 任务:
- 物体重建(如特定玩具、雕塑)。

- 风格迁移(如特定艺术家的画风)。

- 属性组合(如“
<S*>with sunglasses”)。
- 物体重建(如特定玩具、雕塑)。
- 对比基线:优于直接微调模型(Fine-tuning)和基于检索的方法。
- 用户研究:生成的图像在概念保真度和语义可控性上表现优异。
5. 应用场景
- 个性化生成:快速学习用户自定义的概念(如个人宠物、家具)。
- 艺术创作:复用特定风格或物体。
- 数据增强:为稀有物体生成训练数据。
6. 局限性
- 泛化性:对极端视角或复杂概念的捕捉有限。
- 多模态性:一个嵌入可能无法覆盖同一概念的所有变体(如不同姿态的物体)。
- 计算成本:优化过程仍需迭代训练(每概念约1小时GPU)。
7. 后续影响
Textual Inversion启发了后续工作(如DreamBooth、Custom Diffusion),推动了文本到图像模型中轻量化定制方向的发展。其核心思想也被扩展至视频生成、3D生成等领域。
总结
该论文提出了一种高效的方法,通过优化文本嵌入空间中的向量来实现视觉概念的复用,平衡了生成质量与计算效率,为个性化图像生成提供了重要工具。
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
目标
是一篇关于个性化文本到图像生成的论文,提出了一种通过少量图像(3-5张)微调扩散模型,使其能够精准生成特定主体(如个人宠物、独特物品等)的方法。

✅ DreamBooth:输入文本和图像,文本中的[V]指代图像,生成新图像。
✅ 特点:对预训练的 diffusion model 的权重改变比较大。
1. 研究背景与核心问题
- 传统文本到图像的局限性:通用扩散模型(如Stable Diffusion)难以生成用户指定的特定主体(如“我的狗”),因为模型无法从文本描述中捕捉独特细节。
- 现有方法的不足:
- Textual Inversion(文本反转):仅通过嵌入学习主体,生成质量有限。
- Fine-tuning整个模型:容易过拟合,丧失模型原有的多样性。
- 核心目标:通过少量图像微调模型,实现:
- 主体保真度:高精度还原特定主体。
- 文本可控性:保留模型根据新文本组合主体的能力(如“我的狗坐在太空飞船里”)。
P34
2. 方法概述
DreamBooth的核心创新在于主体驱动的微调策略,关键步骤如下:
2.1 主体标识符与类名绑定
- 唯一标识符(Unique Identifier):为每个主体分配一个罕见词(如“sks”),作为其文本标签,避免与预训练词汇冲突。
- 类名(Class Name):同时绑定主体类别(如“狗”),防止模型遗忘类别语义。
示例输入文本:“a sks dog”(sks指代特定主体,dog提供先验知识)。
2.2 微调目标
- 保真度与多样性平衡:
- 主体重建损失:用少量图像(3-5张)微调模型,确保主体细节(如纹理、形状)的精确重建。
- 类别先验保留:在训练中混合原始类名文本(如“a dog”),防止模型过拟合到特定主体而丧失生成多样性。
✅ 输入多张reference image,使用包含特定 identifier 的文本构造 pairdata。目的是对输入图像做 encode。
✅ 同时使用用不含 identifer 的图像和文本调练,构造重建 loss 和对抗 loss.目的是生成的多样性及防止过拟合。
2.3 关键训练技术
- 低秩适应(LoRA):部分微调模型权重,减少计算开销(可选)。
- 扩散模型微调:基于Stable Diffusion,优化UNet的交叉注意力层,强化标识符与主体特征的关联。
3. 实验结果
- 评估指标:
- 用户研究:对比Textual Inversion、Fine-tuning等方法,DreamBooth在主体保真度和文本对齐性上显著领先。
- 定性展示:生成主体在不同场景(如“sks狗戴墨镜”)下的高一致性结果。
- 应用场景:
- 个性化艺术创作(如生成个人肖像的油画风格)。
- 商品展示(同一物品在不同背景下的渲染)。

Input Image的基本特征保持住了,但是细节还是有些丢失。比如书包右下角的三个贴图,在每个生成里面都不一样。
用来生成动作照片还是可以的,因为人对动画的细节差异没有那么敏感。例如这只猫。额头上的花纹,在每张图像上都不一样。如果用来生成人,会发明显的差异。
4. 创新点总结
- 标识符绑定技术:通过罕见词+类名解决主体特异性与泛化的矛盾。
- 高效微调策略:少量图像即可实现高保真,避免过拟合。
- 零样本场景组合:生成未见过的主体-场景组合(如“sks狗在月球上”)。
5. 局限性与未来方向
- 多主体生成:同时绑定多个主体(如“我的狗和猫”)仍需改进。
- 动态场景控制:复杂动作或交互场景的生成(如“sks狗跳跃”)可能不自然。
- 计算成本:微调仍需GPU资源,轻量化是未来方向。
6. 实际意义
- 个性化内容生成:为普通用户提供定制化AI创作工具。
- 商业应用:电商、广告中的产品个性化展示。
总结
DreamBooth通过标识符绑定和类别先验保留,在少量数据下实现了主体驱动的文本到图像生成,推动了扩散模型在个性化任务中的应用。其方法对后续工作(如Custom Diffusion、Perfusion等)有深远影响。
VisorGPT
Can we model such visual prior with LLM
P114
Prompt design


P118
Modeling Visual Prior via Generative Pre-Training
P119
Sample from the LLM which has learned visual prior
P120

NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
NUWA-XL是微软亚洲研究院联合中科院提出的超长视频生成模型,其核心目标是通过创新的架构设计解决传统方法在长视频生成中的效率、连贯性和质量瓶颈。以下从技术背景、方法创新、实验效果及意义等方面进行解读:
一、技术背景与挑战
-
传统方法的局限性
现有长视频生成模型多采用“Autoregressive over X”架构(如Phenaki、NUWA-Infinity),即在短视频片段上训练,通过滑动窗口自回归生成更长的视频。然而,这种方法存在两大问题:- 训练-推理差距(Train-Inference Gap):模型在训练时仅接触短视频片段,无法学习长视频的全局时序信息,导致生成视频的中间片段质量下降、情节逻辑断裂。
- 顺序生成的低效性:自回归生成无法并行推理,导致生成时间随视频长度线性增长。例如,生成1024帧需7.5分钟。
-
实际应用需求
影视、动画等场景需生成数十分钟至数小时的连贯视频,而现有模型仅支持3-5秒的短视频生成,无法满足需求。
二、方法创新:Diffusion over Diffusion架构
NUWA-XL提出“扩散模型中的扩散”分层架构,通过**全局扩散模型(Global Diffusion)和局部扩散模型(Local Diffusion)**的协同,实现从粗到细的并行生成。

-
全局扩散模型
基于输入的文本描述(如16句提示),生成视频的关键帧序列(类似动画制作中的分镜),确保全局时序连贯性与情节一致性。例如,输入16句描述可生成11分钟动画的关键帧。 -
局部扩散模型
在关键帧之间递归填充中间帧,通过多层级扩散逐步细化内容。例如,首层局部扩散生成L²帧,后续层级以指数级扩展帧数,最终生成O(L^m)长度的视频。
✅ 递归的 Local Diffusion
| Global diffusion model | Local diffusion model | |
|---|---|---|
| 文生图 | 关键帧插帧 | |
| 输入 | L text prompts | 2 text prompts + 2 keyframes |
| 输出 | L keyframes | L keyframes |
- Mask Temporal Diffusion (MTD)
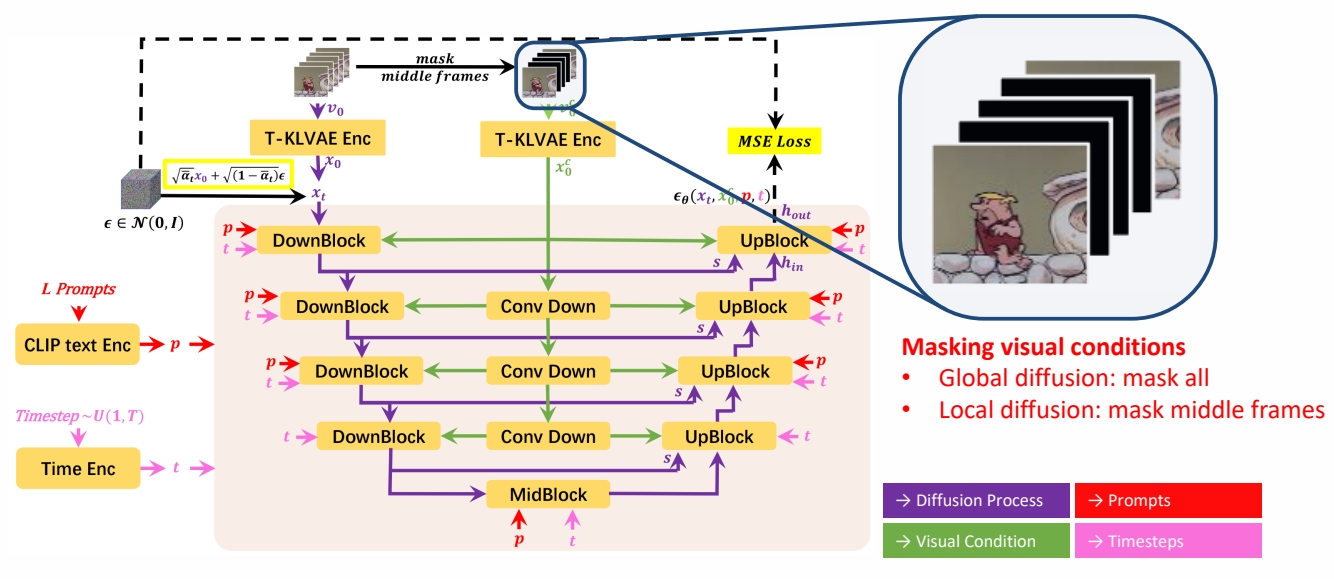
✅ Global 和 Local 使用相似的模型,训练方法不同,主要是 MASK 的区别。
- 关键优势
- 消除训练-推理差距:直接在长视频数据(如3376帧)上训练,提升全局一致性。
- 并行推理加速:局部扩散模型支持并行计算,生成1024帧的时间从7.55分钟降至26秒,效率提升94.26%。
- 指数级扩展能力:视频长度随扩散层级深度m呈指数增长,支持生成极长视频。
三、实验与效果验证
- 数据集与指标
- 构建FlintstonesHD数据集用于训练与测试。
FlintstonesHD: a new dataset for long video generation, contains 166 episodes with an average of 38000 frames of 1440 × 1080 resolution
- 评估指标:Avg FID(帧质量)和Block FVD(视频连续性),数值越低越好。
-
性能对比
- 生成质量:NUWA-XL的Avg FID稳定在35左右,优于Phenaki(48.56)等模型,且质量不随视频长度下降。
- 连续性:B-FVD指标显示,NUWA-XL生成的长视频片段质量下降更慢,因模型学习了长视频模式。
-
效率提升
生成1024帧的推理时间仅需26秒,较传统方法提升94.26%。
四、意义与未来方向
-
行业应用潜力
NUWA-XL为动画、影视、广告等领域提供了高效生成工具,例如通过少量文本生成连贯的长视频内容,降低创作门槛。 -
多模态大模型融合
论文提出未来需将语言与视觉生成融合至统一架构,推动通用型AI的发展。微软研究员段楠指出,当前模型(如GPT-4)仍以文本输出为主,而NUWA-XL展示了视觉生成的潜力。 -
技术扩展性
通过增加训练数据(如电影、电视剧)和算力,NUWA-XL可进一步扩展至更复杂场景,如电影级长视频生成。
五、论文资源
- 论文地址:arXiv:2303.12346
- 项目演示:NUWA-XL官网
该研究通过仿照动画制作流程(关键帧→细化填充),结合扩散模型的并行优势,为长视频生成领域提供了新的技术范式,并推动了多模态大模型的发展。
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
研究背景与问题
目的
-
T2I -> T2V。
本框架核心是一个即插即用的运动模块,该模块只需训练一次即可无缝集成于同源基础T2I模型衍生的任何个性化模型中。 -
MotionLoRA,这是AnimateDiff的轻量级微调技术,可使预训练运动模块以较低训练和数据收集成本适应新运动模式(如不同镜头类型)。
✅ (1) 用同一个 patten 生成 noise,得到的 image 可能更有一致性。
✅ (2) 中间帧的特征保持一致。
P99
主要方法
方法核心在于从视频数据中学习可迁移的运动先验,这些先验无需特定调优即可应用于个性化T2I模型。
推断流程
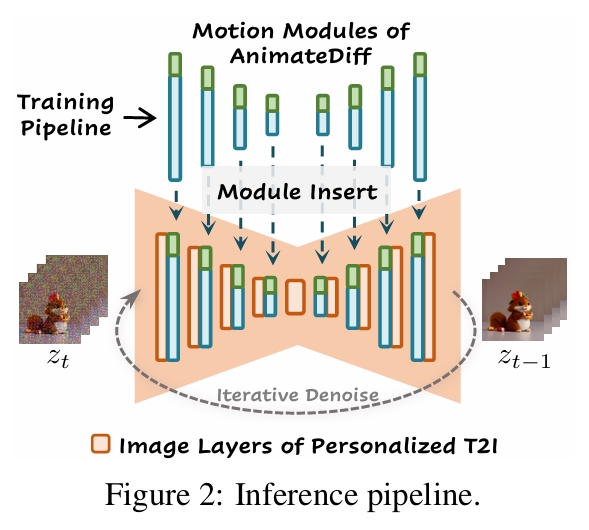
在推理阶段,运动模块(蓝色)及可选的MotionLoRA(绿色)可直接插入个性化T2I构成动画生成器,通过迭代去噪过程生成动画。
训练流程
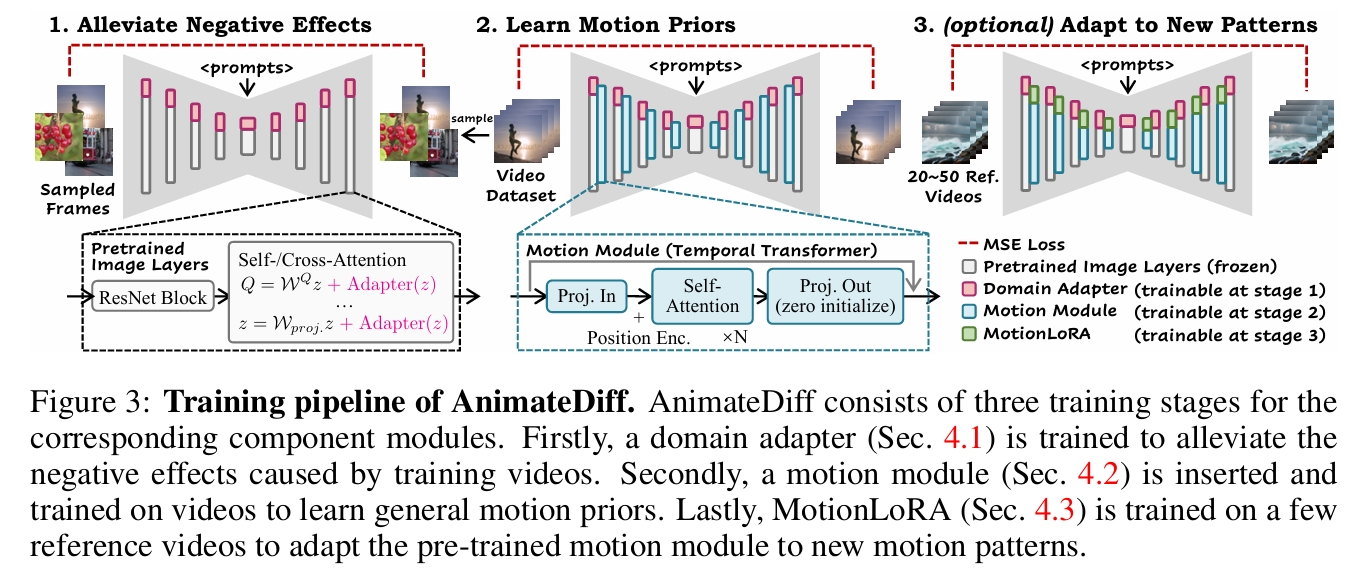
- 领域适配器(4.1节):仅在训练中使用,用于缓解基础T2I预训练数据与视频训练数据间的视觉分布差异;
- 运动模块(4.2节):学习通用运动先验;
- MotionLoRA(4.3节,通用动画场景可选):将预训练运动模块适配至新运动模式。
领域适配器(Domain Adapter)
由于公开视频训练数据集(如WebVid)的视觉质量远低于图像数据集(如LAION-Aesthetic),导致基础T2I的高质量图像域与视频训练域存在显著差异。
为消除域差异对运动模块学习的干扰,在基础T2I中加入领域适配器(LoRA层)。
[?]为什么仅在训练阶段使用?
通过运动模块学习运动先验
使用Transformer(self attention + positioanl embedding)实现T2I->T2V
通过MotionLoRA适配新运动模式
目的:以少量参考视频和训练迭代量适配新运动模式(如镜头变焦/平移/旋转)
在运动模块的自注意力层添加LoRA层,并在新运动模式的参考视频上训练这些层。
训练
基模型:SD1.5 数据集:WebVid-10M, resized at 256x256
✅ 在低分辨率数据上训练,但结果可以泛化到高分辨率。
实验
横向对比
- Text2Video-Zero
- Tune-a-Video
- 本文方法
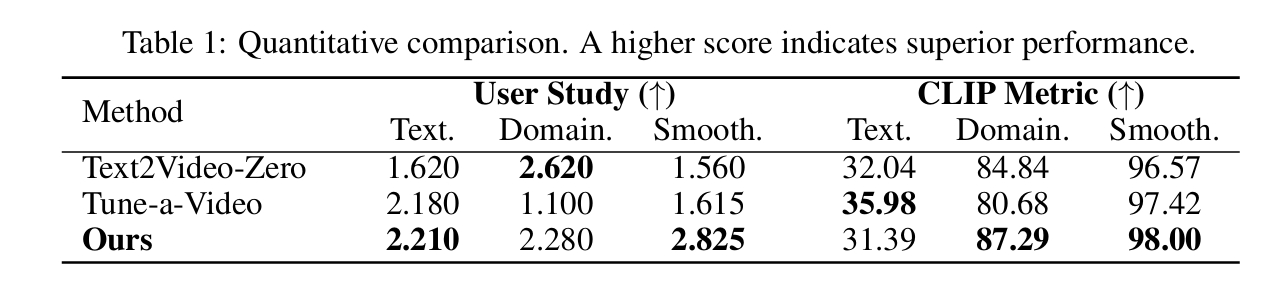
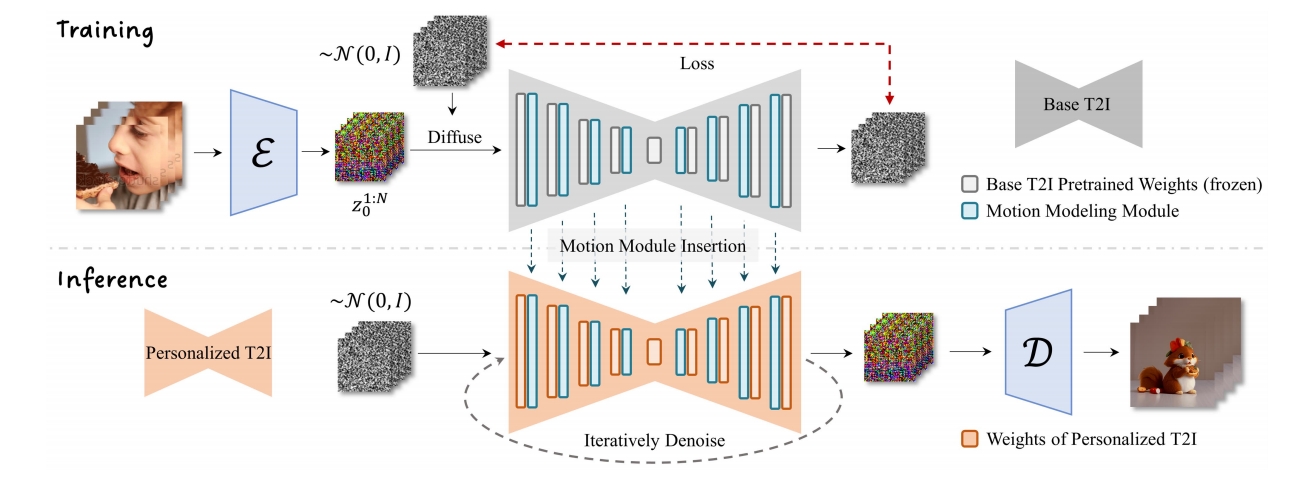
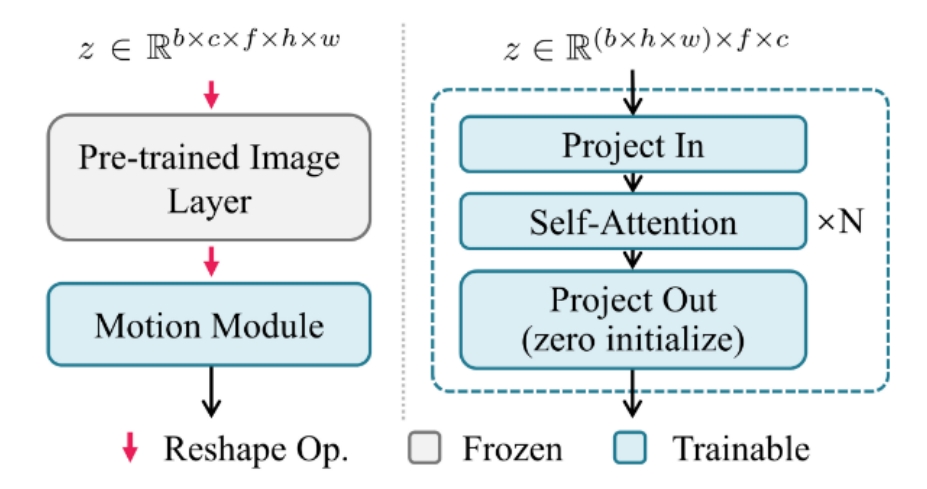
P68
ModelScopeT2V
Leverage pretrained T2I models for video generation
- Inflate Stable Diffusion to a 3D model, preserving pretrained weights
- Insert spatio-temporal blocks, can handle varying number of frames
✅ 基本思路:(1) 以 Stable Diffusion 为基础,在 latent space 工作。 (2) 把 SD 中的 2D 操作扩展为 3D.
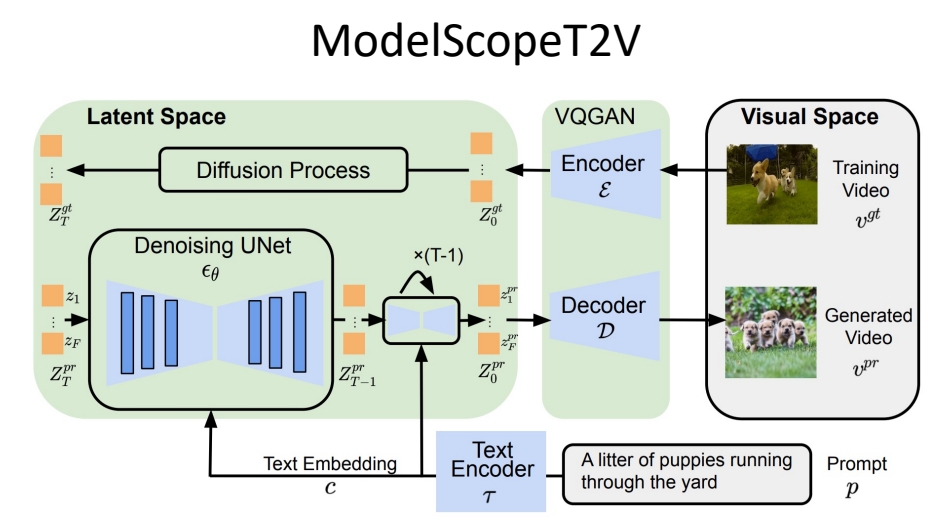 | 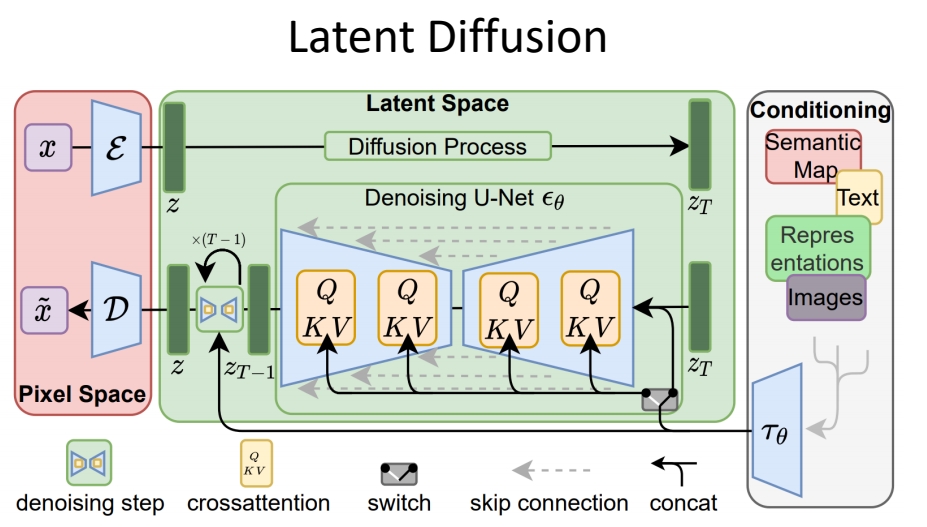 |
P69
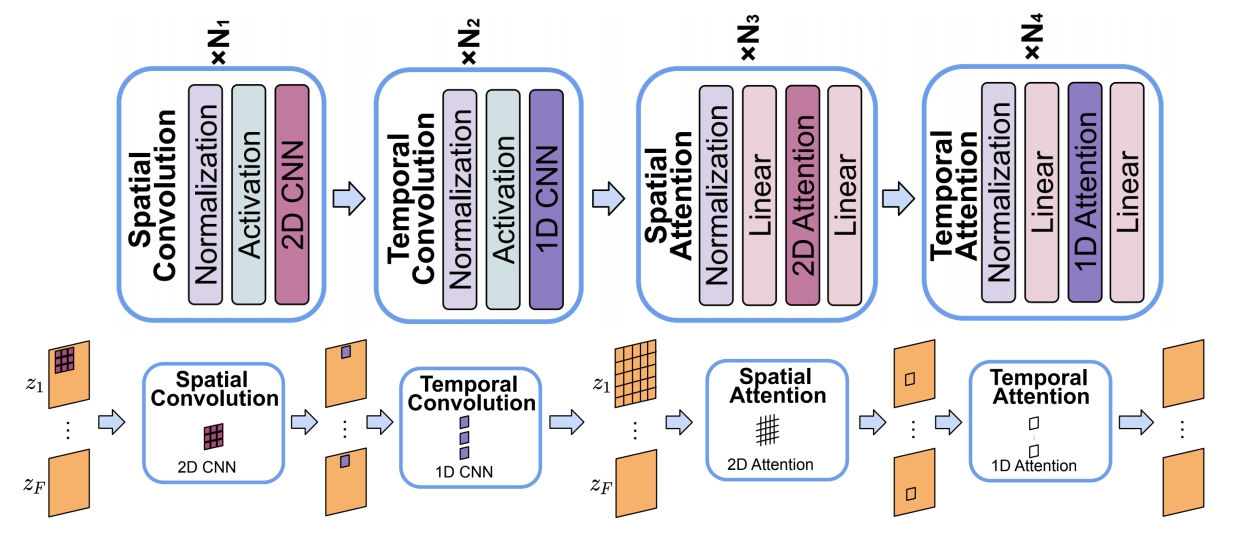
✅ 扩展方法为 (2+1)D,因此在 2D spatial 的卷积操作和 Attention 操作之后分别增加了 temporal 的卷积和 Attention.
P70
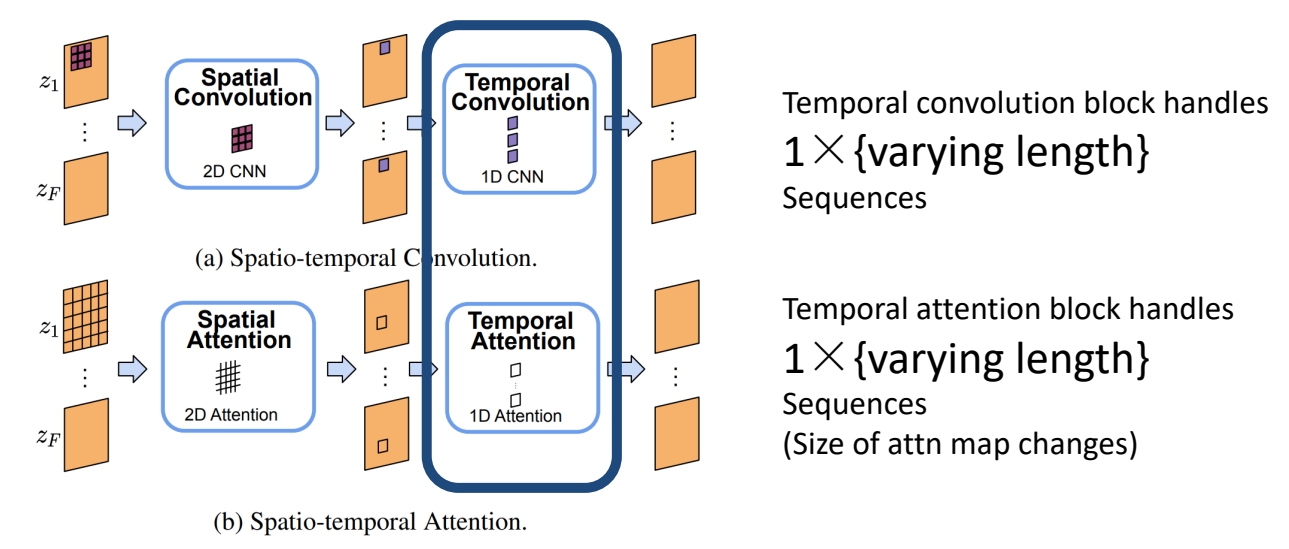
P71
Length = 1
Model generate images
✅ 时域卷积操作能指定 frame 数,因此可以“生成视频”与“生成图像”联合训练。
❓ 时序卷积不能做流式,能不能用 transformer.
P72

Show-1
Better text-video alignment? Generation in both pixel- and latent-domain

✅ Stable Diffusion Model存在的问题:当文本变复杂时,文本和内容的 align 不好。
✅ show-1 在 alignment 上做了改进。
P76
Motivation
pixel VS latent: 一致性
- Pixel-based VDM achieves better text-video alignment than latent-based VDM
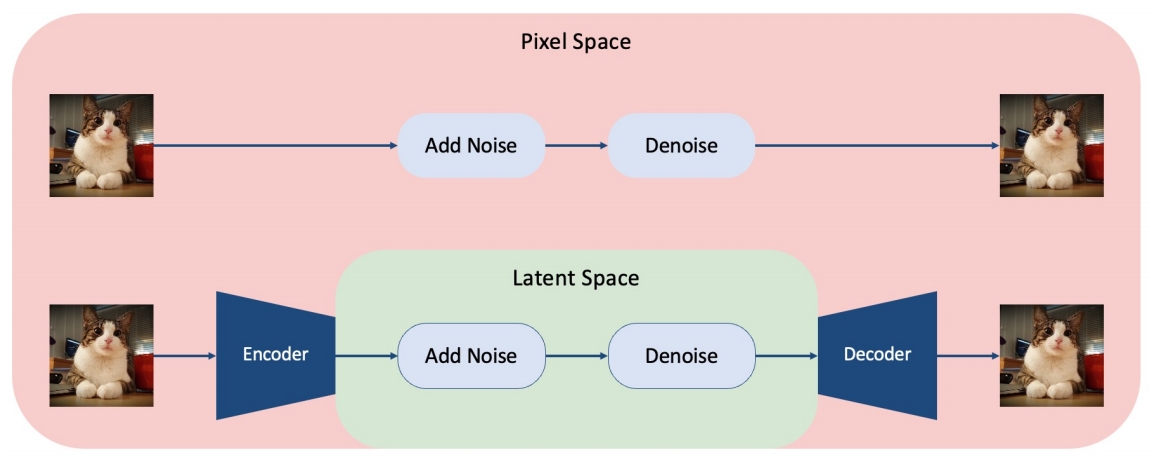 |  |
✅ 实验发现:pixel spase 比 latent space 更擅长 align ment.
✅ 原因:在 latent space,文本对 pixel 的控制比较差。
P77
pixel VS latent: memory
- Pixel-based VDM achieves better text-video alignment than latent-based VDM
- Pixel-based VDM takes much larger memory than latent-based VDM

P78
本文方法
- Use Pixel-based VDM in low-res stage
- Use latent-based VDM in high-res stage

P79
Result
https://github.com/showlab/Show-1
- Better text-video alignment
- Can synthesize large motion
- Memory-efficient
Make-A-Video
✅ 把 text 2 image model 变成 text to video model,但不需要 text-video 的 pair data.
Cascaded generation
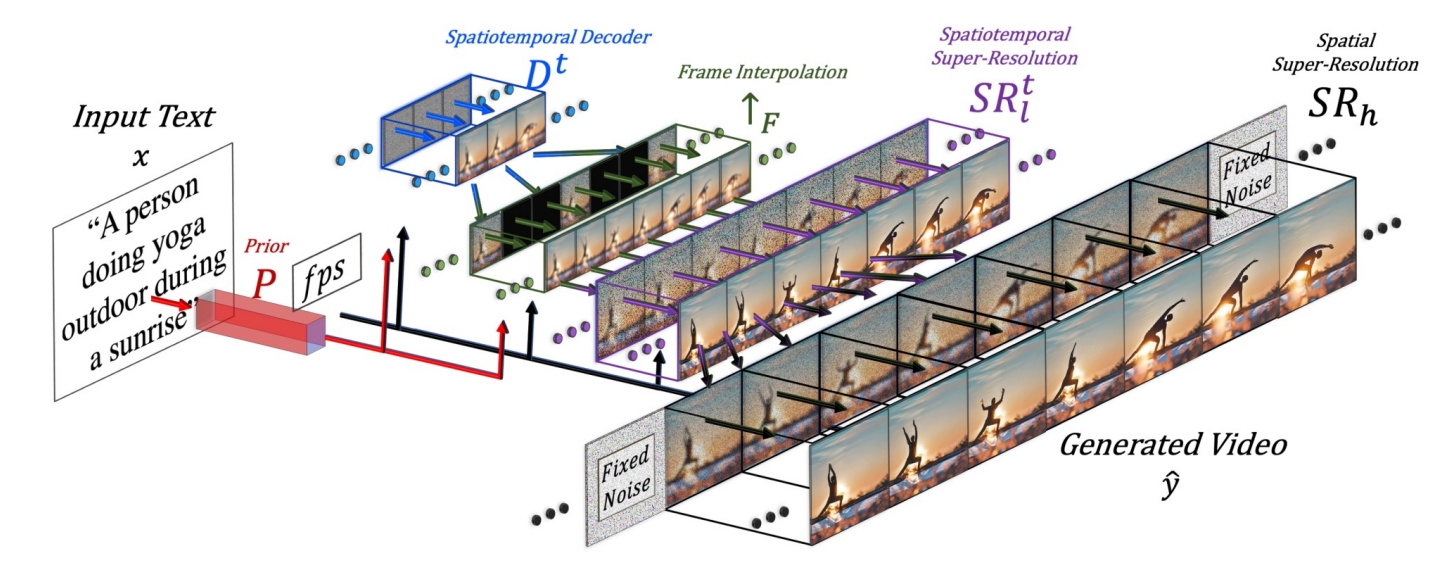
✅ 效果更好,框架在当下更主流。
✅ (1) SD:decoder 出关键帧的大概影像。
✅ (2) FI:补上中间帧。
✅ (3) SSR:时空上的超分。
✅ 时序上先生成关键帧再插帧,空间上先生成低质量图像再超分。
✅ 这种时序方法不能做流式输出。
P41
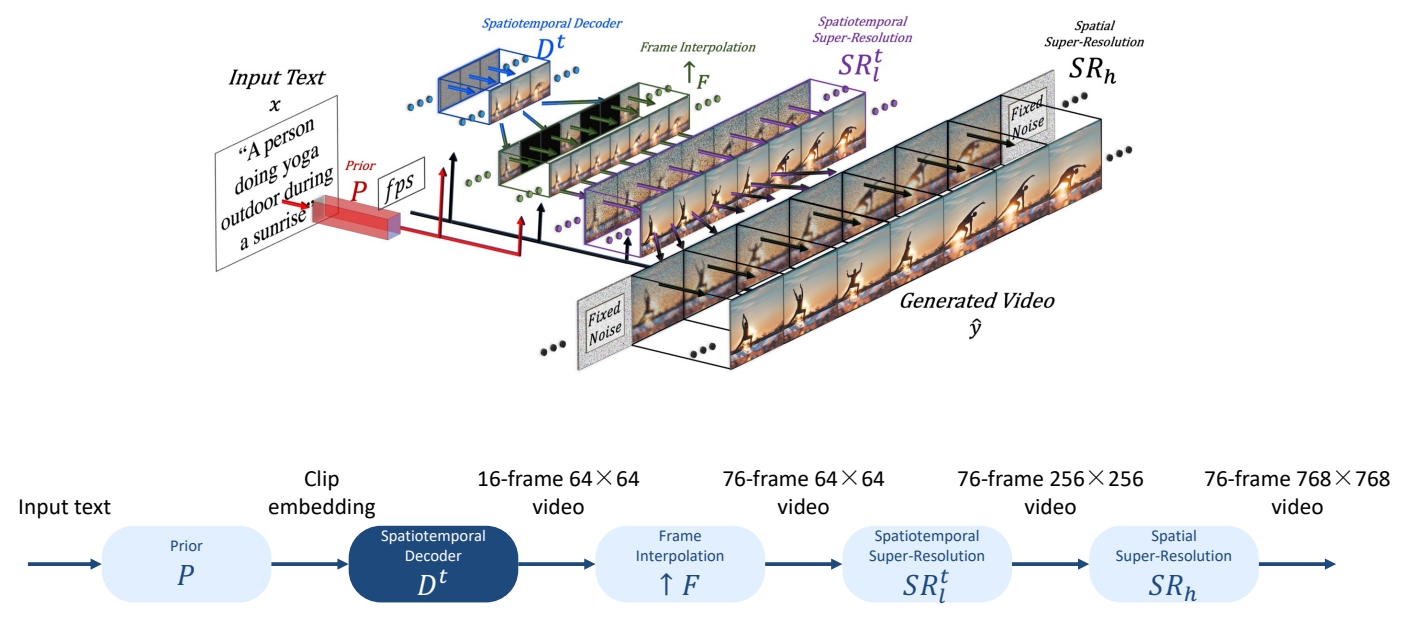
❓ 第 3 步时间上的超分为什么没有增加帧数?
P42
2D->3D
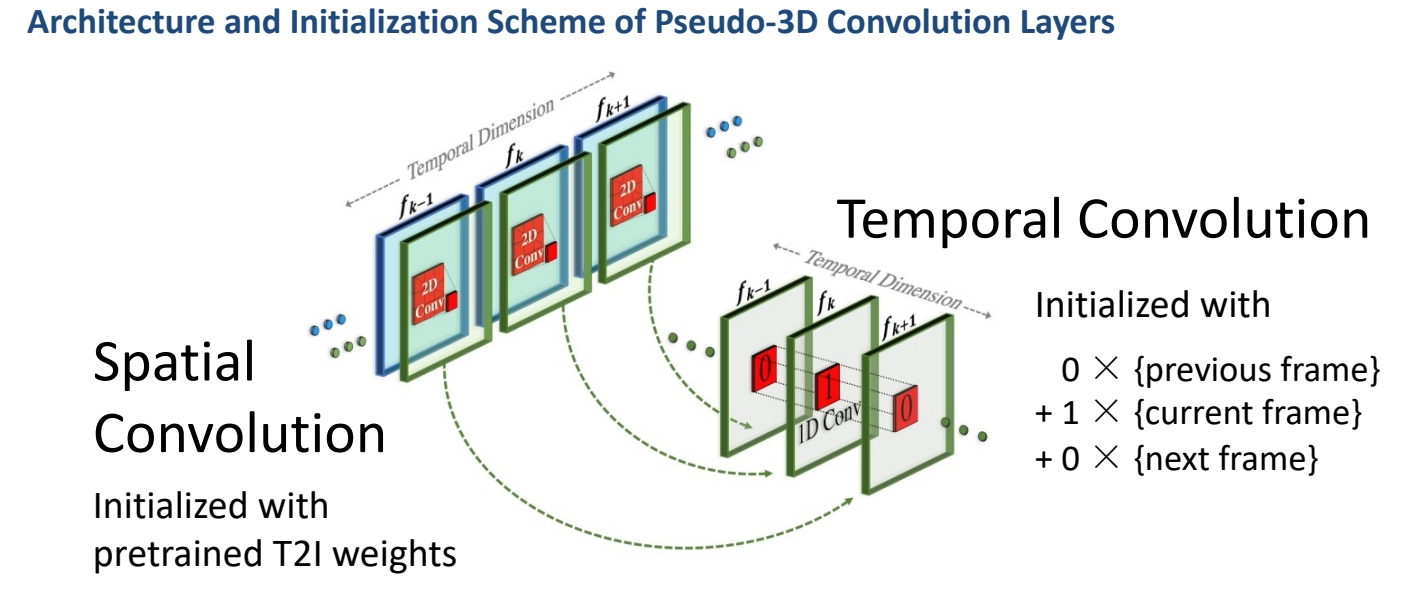
✅ 此处的伪 3D 是指 (2+1)D,它有时序上的抽像,与 VDM 不同。
✅ 空间卷积使用预训练好的图像模型。
P43
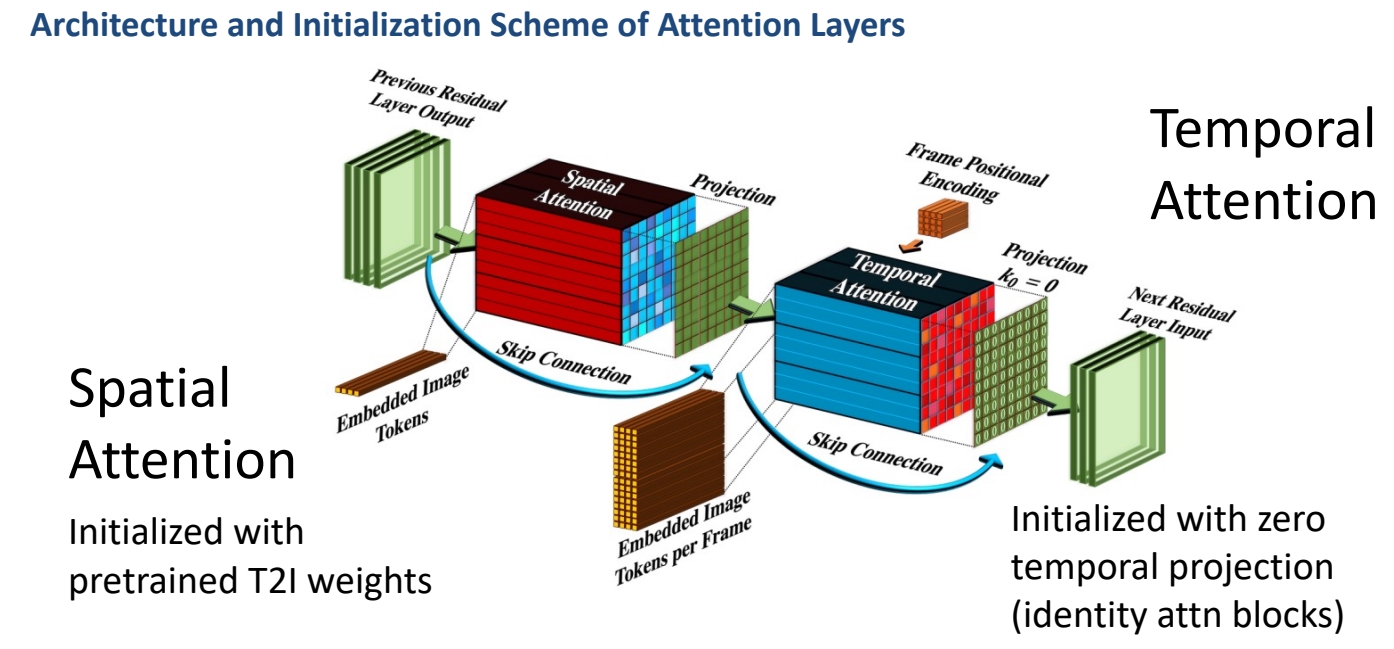
✅ attention 操作也是 (2+1)D.
✅ 与 Imagen 的相同点:(1) 使用 cascade 提升分辨率, (2) 分为时间 attention 和空间 attention.
✅ 不同点:(1) 时间 conv+空间 conv. (2)only the image prior takes text as input!
P44
Training
- 4 main networks (decoder + interpolation + 2 super-res)
- First trained on images alone
- Insert and finetune temporal layers on videos
- Train on WebVid-10M and 10M subset from HD-VILA-100M
✅ 先在图片上训练,再把 temporal layer 加上去。
P58
Evaluate
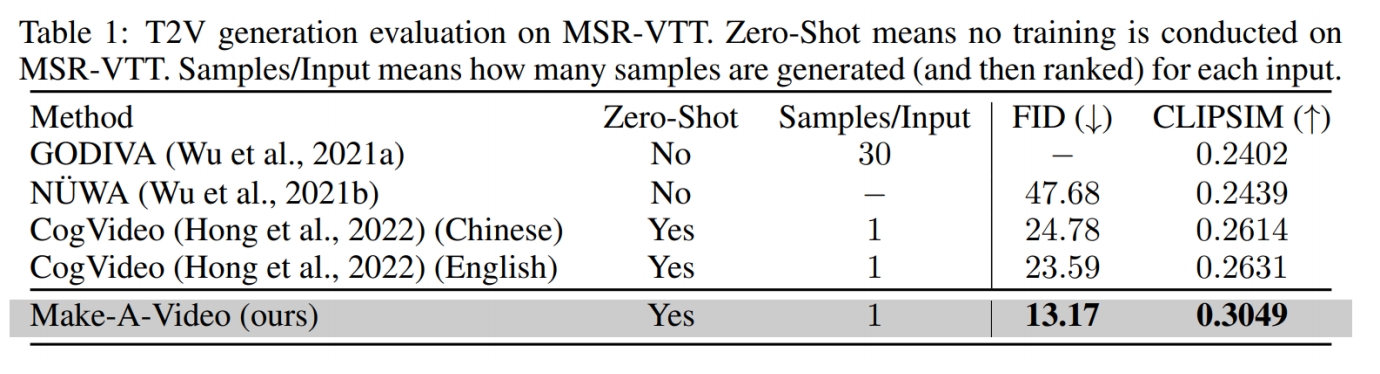
P59
✅ 早期都在 UCF 数据上比较,但 UCF 本身质量比较低,新的生成方法生成的质量更高,因此不常用 UCF 了。
P60

P62
应用:From static to magic
Add motion to a single image or fill-in the in-betw

Video Diffusion Models
2D -> 3D
VDM的一般思路是,在T2I基模型的基础上,引入时序模块并使用视频数据进行训练。
引入时间模型的方法有卷积方法(Conv3D、Conv(2+1)D)、注意力机制(Cross Attention、Transformer)
| Conv2D |  |
| Conv3D |  |
| Conv(2+1)D |  |
✅ \(t\times d\times d\) 卷积 kenal 数量非常大,可以对 kernel 做分解,先在 spatial 上做卷积,然后在 temporal 上做卷积。
✅ 特点:效果还不错,效率也高。
P39
3D U-Net factorized over space and time
✅ 2D U-Net 变为 3D U-Net,需要让其内部的 conv 操作和 attention 操作适配 3D.
- Image 2D conv inflated as → space-only 3D conv, i.e., 2 in (2+1)D Conv
✅ (1) 2D conv 适配 3D,实际上只是扩充一个维度变成伪 3D,没有对时序信息做抽象。
- Kernel size: (3×3) → (1×3×3)
- Feature vectors: (height × weight × channel) → (frame × height × width × channel)
- Spatial attention: remain the same
✅ (2) attention 操作同样没有考虑时序。
- Insert temporal attention layer: attend across the temporal dimension (spatial axes as batch)
✅ (3) 时序上的抽象体现在 temporal attention layer 上。
3D UNet from a 2D UNet
- 3x3 2d conv to 1x3x3 3d conv.
- Factorized spatial and temporal attentions.
Ho et al., "Video Diffusion Models", NeurIPS 2022
✅ 利用 2D 做 3D,因为 3D 难训且数据少。
✅ 通到添加时序信息,把图像变成视频。此处的 3D 是 2D+时间,而不是立体。
✅ 对向量增加一个维度,并在新的维度上做 attention.
Learning Transferable Visual Models From Natural Language Supervision
CLIP:Encoders bridge vision and language
- CLIP text-/image-embeddings are commonly used in diffusion models for conditional generation
❓ 文本条件怎么输入到 denoiser?
✅ CLIP embedding:202 openai,图文配对训练用 CLIP 把文本转为 feature.
Implicit Warping for Animation with Image Sets
NVIDIA
核心问题是什么?
摘要
这与现有方法不同,我们的框架的挑选能力有助于它在多个数据集上实现最先进的结果,这些数据集使用单个和多源图像进行图像动画。
https://deepimagination.cc/implicit-warping/
目的
用 driving 视频中的动作来 warp reference 图像中的角色,以实现视频驱动图像的视频生成任务。
现有方法:
要实现大幅度的运动,就需要借助大的光流,才能获得远处的特征。
.
.
.
.
现有方法及局限性
现有方法使用显式基于光流的方法进行动画,该方法设计用于使用单个源,不能很好地扩展到多个源。
.
.
.
.
本文方法
我们提出了一种新的隐式图像动画框架,使用一组源图像通过驱动视频的运动进行传输。使用单个跨模态注意力层在源图像和驱动图像之间找到对应关系,从不同的源图像中选择最合适的特征,并扭曲所选特征。
.
.
.
.
效果
在单 reference 和多 reference 场景中都达到了 SOTA.
.
.
.
.
核心贡献是什么?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
大致方法是什么?
- 找出 source和driving 的 dense correspondence
- 基于 dense corresponence 的 warp.
作者认为一个CA可以完成 1 和 2. 称其为 impicit warping
不需要显式地提取光流,Q 和 K 的相似度描述了隐式的光流。

构造 Q. K .V
K: Source keypoint feature
Q: driving keypoint feature
V: Source image feature
Q 的构造:

spatial keypoint 表示,[:,:,i] 为以第i个 keypoint 位置为中心,特定均值和方差的二维一通道高斯。
Strength: 描述关键点的可见性。
K 的构造:
K 和 Q 和构造过程相同,区别在于UNet 的输入,concat (scaled spatial keypoint 表示,source Image)
优势:把所有 keypoints 表示到一张图像上,后面的模块与 keypoint 的个数无关。
V 的构造:
Q、K、V 在空间上是对应的。
CA 存在的问题:所有的 key 与 query 都相似度不高时,也会从 key 中选择一个 Score 最高的 key 对应的 value,但这个 value 可能并不合适,或者选择任何一个 value 都不合适。例如张嘴时要生成牙齿。
解决方法:
- 增加额外的 KV
- 使用 dropout 随机丢弃 KV 来鼓励使用额外的 KV
这个方法对 “warp 方法缺少生成能力”的问题有一定弥补作用
[❓] 怎么制作额外的 KV? 每一对 KV 代表一个 Source Image 上的一个 Keypoints.
此处能对 KV 做 drop out,是因为 CA 把所有的 KV 看作是集合,不能应用于 Conv. 因为conv 是有位置关系的。
crsss - modal attention
Q: q\(\times \)d, K: k\(\times \)d,V: k\(\times \)d'
$$ \begin{align*} q& =kps-num\\ K& =kps-num\cdot ref-num+add-num \end{align*} $$
$$ \begin{matrix} Q=Q+PE, &\\ K=K+PE &\\ A=\text{Softmax} (\frac{Q\cdot K^\top }{C}), & q\times k \\ \text{output feature} =A\cdot V,& q\times d{}' & \end{matrix} $$
$$ \text{residual feature} = MLP(\text{concat}(A \cdot \text{concat(pixel} , K),Q)) $$
$$ \text{warped feature = output feature + residual feature} $$
目的:除了用 A warp 了 V,还 warp 了原图和 key,用于提取 skew, rotation 等“对 V 做加权平均”难以学到的信息,可提升生成质量和颜色一致性。
效率提升:1- D attention layer , spatial-reduction attention
.
.
.
.
.
.
.
训练
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
数据集
TalkingHead-1kH
VoxCeleb2
TED Talk
评价指标
生成图像质量:PSNR,L1,LPIPS,FID
运动相似度:AKD (average keypoint distance)
MKR(missing keypoint ratio)
.
.
.
.
.
.
loss
- GAN Loss(参考face-vidzvid)
- perceptual loss (参考 VCG-19)
- equivariance loss (参考 FoMM)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练策略
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
实验与结论
实验1: 横向对比,单 reference
.
.
.
.
.
.
.
.
.
效果1:
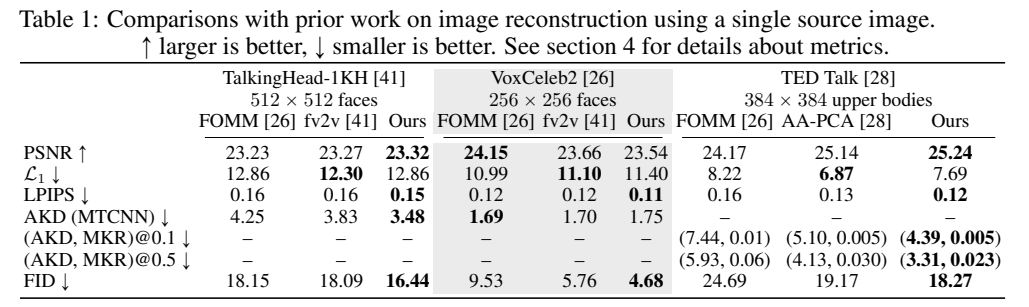
结论1: 3 的生成质量更高且与动作一致性更好。
效果2:
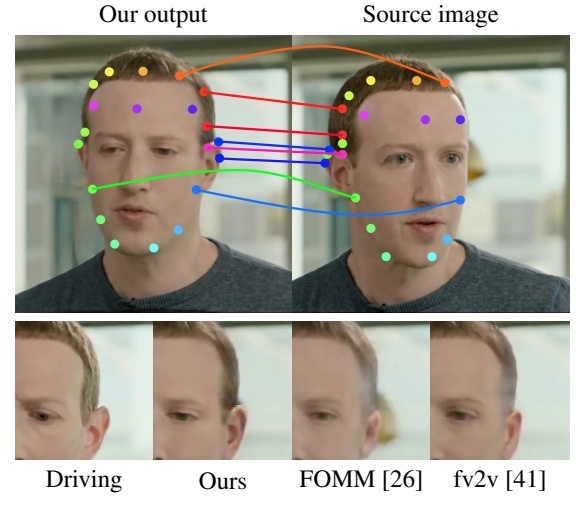
结论2:
3 所使用的 attention 是 global 的,因此可以从空间上距离较远的位置提取特征,但显式光流的方法,需要借助较大的光流才能获得远处的特征。
实验2: 横向对比,多 reference
- FOMM (face,upper body)
- AA- PCA (upper body)
- 本文方法
- fv2v(face)
1,2,4 不支持多 source Image 因此分别用每个 source Image 做 warping, 并在 Warp feature map 上做平均。
效果:
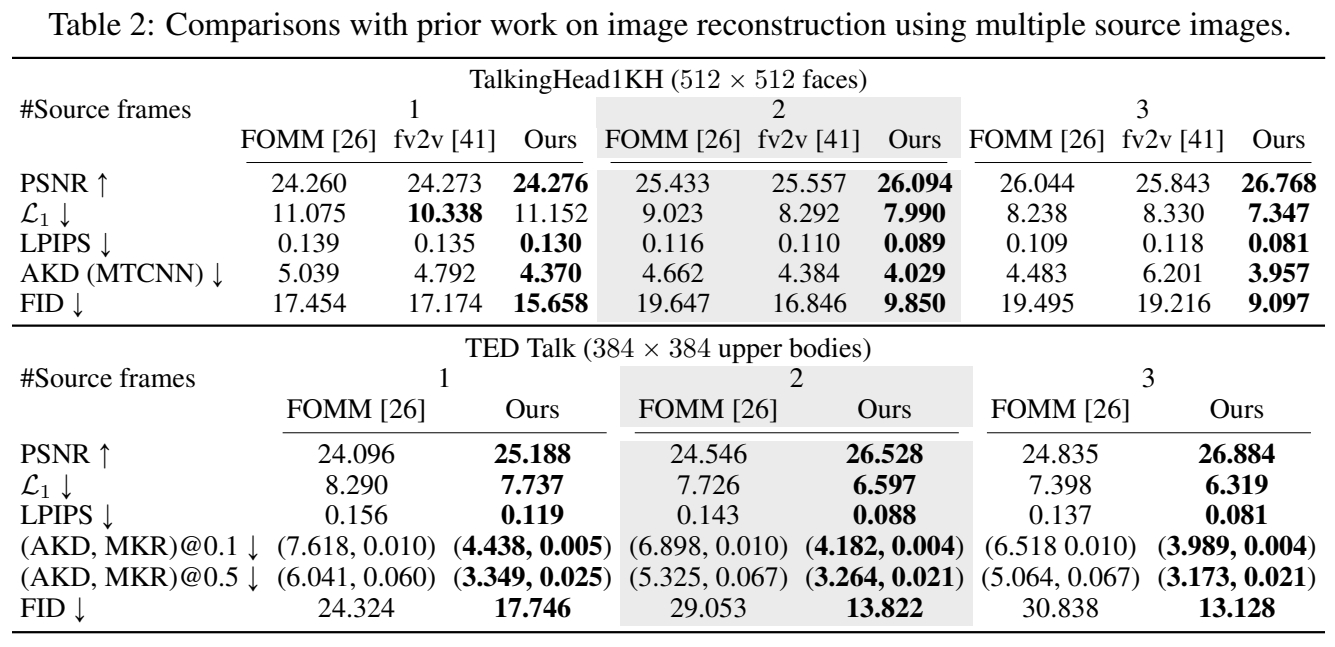
Source Image 为少于 180 帧的连续帧序列。
结论: 随着 Source image 数量的增加,3 的效果会更好,而1、2、4 的效果会更差。
分析: 用同一 pose warp 不同的 image,得到的结果之间会有 misalignment. 但 1、2 不知道该选取哪个 warp 结果。而 3 使用 global attention 从所有 source 中提取信息。
实验3: Ablation
- 无 residual 分支,无 Extra KV
- 引入 residual 分支
- 引入 Extra KV
效果:
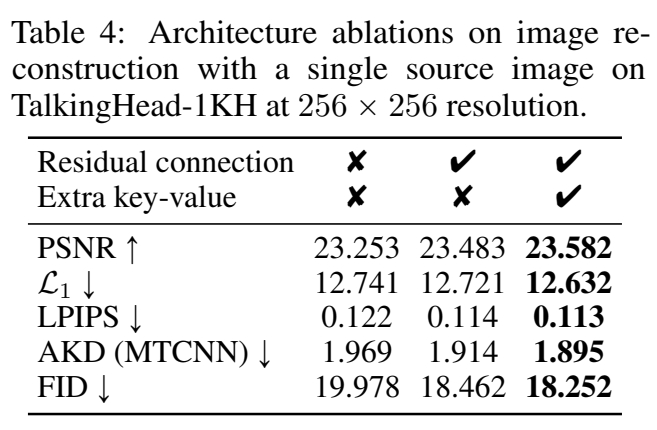
结论: 残差结构与额外的 K/V 对结果都有提升。
实验4: 可视化 strength
效果:
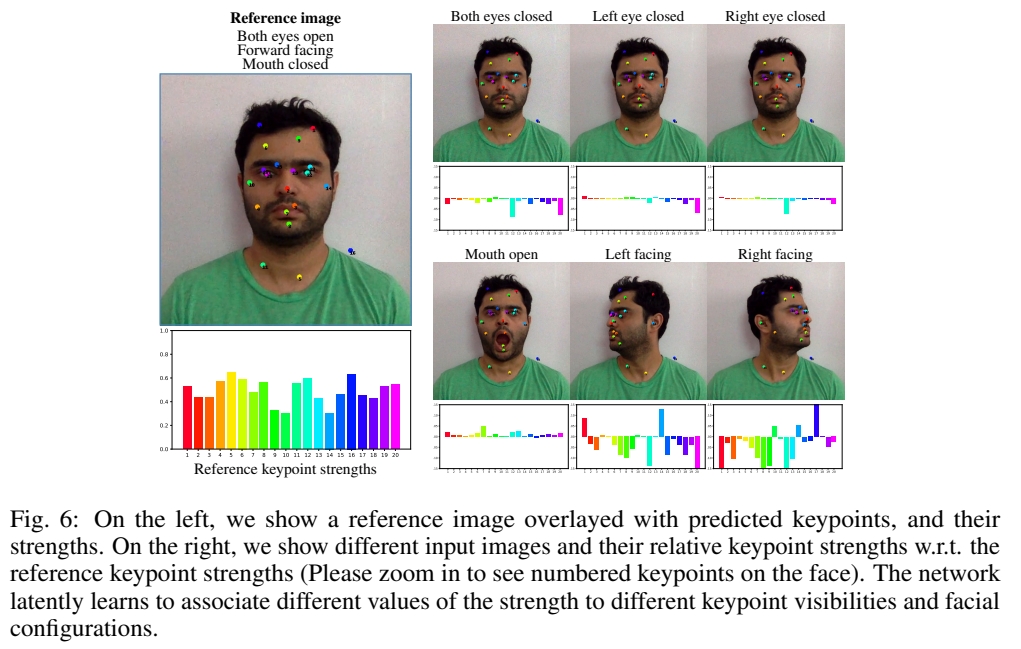
[❓] 怎样预测 Strength?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
缺少生成能力,例如给背面生成正面,生成极端表情等。
.
.
.
.
.
.
.
.
.
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
- 如何预测 Strength?
- 如何构造 extra KV?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
相关工作
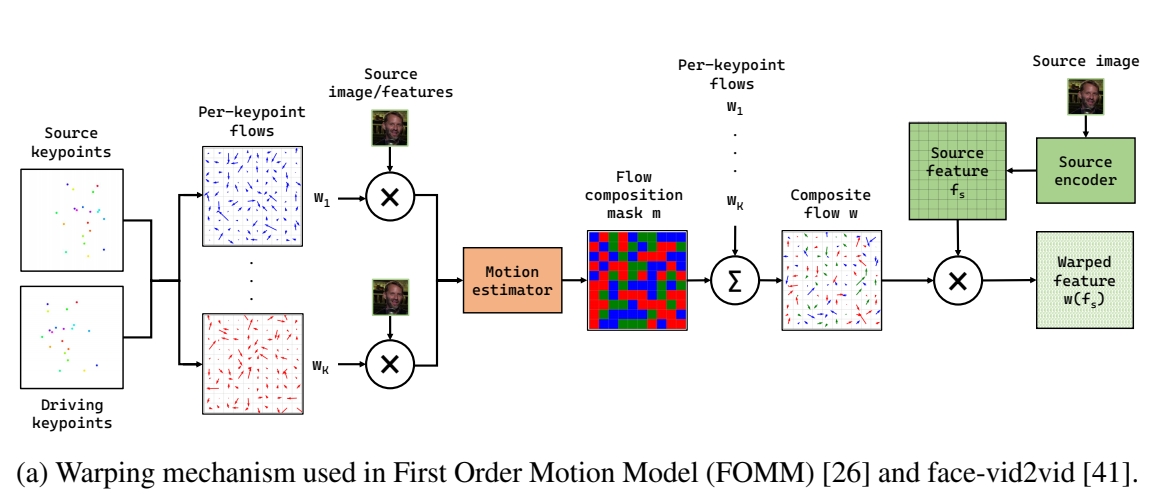
source/target 表示为:2D keypoints, Jacobian Matrics
Warp 的过程:每个 source/target keypoint 对生成
一个对 source Image Warp 的光流。再用 motion estimator 模块把这些光流合并成 Composite flow. 用 Composite flow warp reference Image
以上方法存在的问题:
- 每个 keypoint 求个光流,时间复杂度与 keypont 的个数成正比
- 当有多个 reference Image 时,每个 reference 会生成一个对应的 composite flow 和 output Image,如何将结果合并?average 会导致 blurry,heuristic to choose 会导致flicker.
参考材料
https://deepimagination.cc/implicit-warping/
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models
新国立,开源
| LoRA | Low Rank Adaptation |
| TI | Textual Inversion |
核心问题是什么?
目的
基于T2I大模型的个性化内容生成。
现有方法及局限性
使用 LoRA 可以实现 Concept Customization.
但联合多个 LoRA 实现 Multi-concept Customization 是个挑战。
.
.
.
本文方法
Mix-of-show 框架:
- 单个 LoRA 训练时使用 embedding-decomposed LoRA,解决多个 LoRA 之间的 concept 冲突问题。
- LoRA 结合时使用 gadient 混合,可保留单个 LoRA 的 in-domain essence,解决模型 fusion 引入的 ID 特征丢失的问题。
- 引入区域可控 sampling,解决 multi-concept sampling 中的特征与控制信号绑定的问题。
.
.
.
.
效果
可以组合定制不同的 concept (角色、对象、场景)且高质量生成。
.
.
.
.
.
核心贡献是什么?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
大致方法是什么?
Mix-of-show 框架分为两部分:Single-Clinent和 Center-Node.
Single-Client 基于 LoRA 学习特定对象,其关键技术为layer-wise Embedding 和 multi-world 表示。
Center-Node 用于接入各种 Single-Client 以实现定制化的效果,其关键技术为 gradient fusion.
任务描述
目的: 结合2个及以上 concept 的定制化 Diffusion 生成模型。
当前方法: 多个 concept 的联合训练。这种训练方法缺少扩展性和可复用性。
解决方法: 分别训练每个 concept 模型,并将它们合并。
在本文中,单个 concept 模型用 LoRA 实现。合并的方法为把多个concept 模型集成的权重到 center-node 上(类似LoRA)。
$$ W= f(W_0,\Delta W_1,\Delta W_2,\dots ,\Delta W_n), $$
Single Client:ED-LoRA
原始 LoRA 是不能做 Concept 融合的。
假设关于 concept 的 \(V\) 已经训好,\(P^\ast\) 为包含 \(V\) 的 text prompt. 可视化 \(V\) 是指使用完整的推断流程,根据\(P^\ast\) sample 出一幅画。
对比模型:
- TI,即只学习 \(V\),不更新模型参数。
- TI + LoRA,即学习 \(V\),且以 \(\Delta \phi \) 的形式更新模型参数。
❓ in-domain 和 out-domain 分别代表什么了?
答:in-domain concept:目标是预训练基模型生成出来的图像。
out-domain concept:目标不是由这个基模型生成出来的,可能与基模型的生成分布有较大差异。
结论1: 不更新预训练模型的 TI 方法只能学习(和生成) in-domain concept,对 out-domain concept 效果不好,在 TI 基础上,以 LoRA 方式更新预训练模型可以学习和生成out-domain concept.
这是因为,不更新预训练模型,就必须让 \(V\) 学到全部的 concept 特征。\(V\) 可以学到in-domain part,却不足以学习 out-domain part. 导致 \(V\) 的部有细节的丢失。
结论2: concept 的独特特征主要是通过 LoRA (而不是embedding)学到的,使得语义相似的 embedding 映射到不同的视觉空间,因此导致了多 Concept 融合时的 Conflicts.(每个 LoRA 都试图把同一个 embedding 映射到自己的视觉空间)
ED - LoRA = embedding(in-domain) + LoRA(out-domain),其中embedding 部分通过两种方式增强其表达能力。
- 将相似的 embedding 替换成不同 concept 解耦的 embedding.
- 采用 layer-wise embedding (引用自\(P^+\))
$$ V=V^{+} _{rand} V^{+} _{class} $$
\(V^{+} _{rand}\):随机初始化,用于提取 concept 的外观特征。
\(V^{+} _{class}\):根据 concept 的类别初始化。
[❓] 分别是怎么定义的?
\(V^{+} _{rand} 、V^{+} _{class}\). LoRA 矩阵(B、A)都是可学习参数,其中 V 学习目标 concept 的 in-domain 特征,LoRA 提取目标 concept 其它特征。
[❓] 每个 concept 独立学习的,怎么保证每个 concept 学到 V 的都较大的区分度?
✅ 每个 client 分别要学习 \(V^{+} _{rand} 、V^{+} _{class}\). LoRA 矩阵(B、A),因此 center 也要分别结合这些参数。
Center-Node
如何把 LoRA 矩阵结合到预训练模型的权重上?
结论3:直接混合 LoRA 权重,会导致生成结果的 concept ID 特征丢失。
因为,\(n\)个 LoRA 矩阵的简单平均,会导致每个矩阵都变为原来的\(\frac{1}{n} \).
Gradient Fusion:利用 “decode concepts from text prompts” 的能力,在没有数据的情况下更新预训练模型的权重。
- 使用每个单独的 LoRA 分别 从 text prompts decode 出 concept.
✅ 这里的 decode 应该是 inference 的意思吧。从 text 到 image 是完整的 sample 过程,仅仅一个 decoder 是不够的。
- 提取每个 LoRA 的 LoRA 层对应的 input / output feature.
- 位于同一层的各个 LoRA 的 feature Concat 到一起。
[❓] 怎么么理解 concat? concat 之后维度就不对了,公式中也没有体现出 concat.
答:通过图4(b)可知,是 batch 维度的 concat.
- fused gradients 更新 W,目标函数。
$$ L= {\textstyle \sum_{i=1}^n{}} ||(W_0+ \Delta W_i)X_i-WX_i||^2_F $$
目标函数第1项为由 single Client 训练出的GT. 第二项是待训练的 layer. \(X_i\) 是 LoRA layer Input 经过 activation 的结果,即 activate 部分保持不变,通过训好的 LoRA layer 生成 pair data 来优化 UNet layer,使得 \(W\) 逼近 \(W_0+ \Delta W_i\) 的效果。
区域可控的 Sampling
当前的控制信号注入方式(空间控制 ControlNet,T2I)能保留目标特征,但如果要生成多个目标,不能将特定目标与特定控制信号绑定。
本文方法:区域控制
| \(P_g\) | global prompt:提供 overall context |
| \(P_{ri}\) | regional prompt:描述特定目标的位置与特证 |
| \(z\) | UNet fedture |
| \(M_i\) | mask,描述控制信号i所控制的区域 |
注入控制:
- \(h = CA (z, P_g)\)
$$ \begin{align*} z_i&=z\odot M_i\\ h_i&=CA(z_i,P_{ri}) \end{align*} $$
- \(h[M_i] = h_i\)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练
| Stage | Stage 1: Single Client | Stage 2: center node |
| 可学习参数 | V,LoRA | UNet 中加了 LoRA 的层 |
| 数据 | 特定 Concept 的自采数据 | 由 Stage 1 构造数据 |
| Loss | 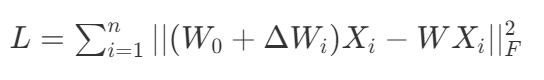 | |
| 学习率 | text embedding:1 e -3, text encoder:1 e -5,UNet, :1 e -4 | |
| Optimizer | Adam | LBFGS,text optimizer:50, UNet: 50 |
.
.
.
.
.
.
.
.
.
训练策略
在 text Encoder 和 UNet 的所有 attention 模块中的 Linear 层加入 LoRA,rank = 4
预训练模型:
Chilloutimix:即图4中的 pretrained-V1
Anything-V4:即图4中的 pretrained-V2
单模块训练:
0.01 noise offset 是 encoding stable identity 的关键。
.
.
.
.
.
.
实验与结论
实验1: 单内容/多内容生成
- LoRA + weight fusion
- Custom Diffusion + 合并 CA 中的 K.V
- \(P+\) + 多 concept embedding
- ED \(-\) LoRA + gradient fusion
多内容生成时,所有方法使用“区域可控” prompt.
效果: 对于单内容生成,4 生成质量相当好且能更好保留角色持征。
对于多内容生成,2 和 3 的生成结果不自然。1 在多内容生成时会丢失目标特征,4 生成结果自然且能保留每个ID的特征。
分析: 1 和 4 会调整整个模型的所有 CA 层,2 和 3 只调整文本相关的模块。导致 2 和 3 的 embedding 超负荷地承担了编码 out-domain low-level 细节的工作,影响了生成质量。
1 没有多内容融合的能力。
实验二: 文本一致性 (CLIP)
效果:
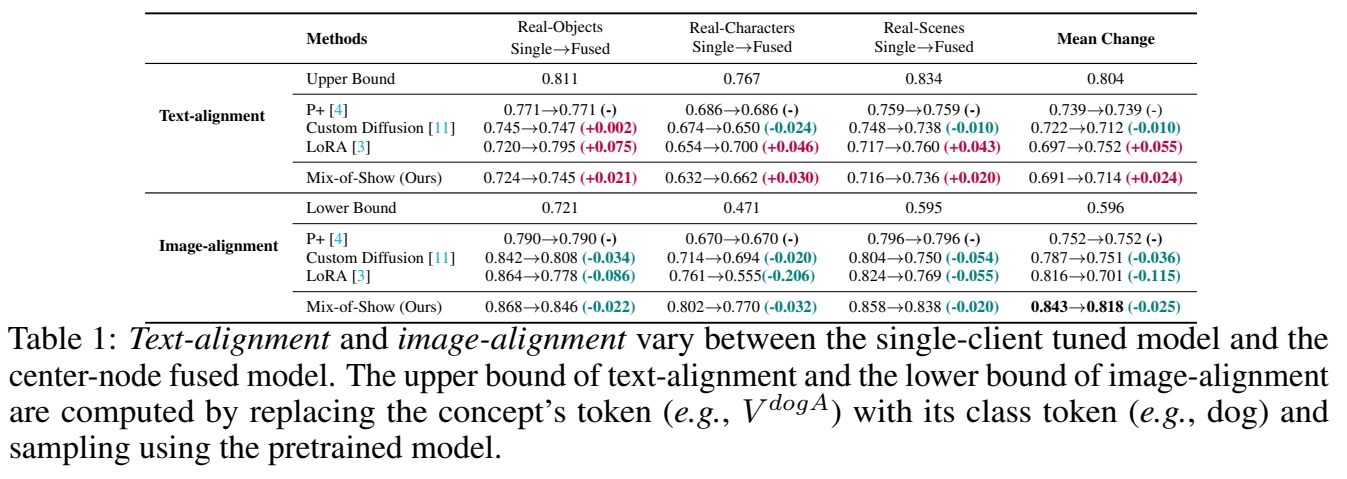
- 单内容生成中,1 和 4 的文本一致性比较好。
- 在多内容生成中,1 的文本一致性有明显下降,但4没有。
分析: 由于 1 和 4 调整了 spatial 相关层的权重,因此能更好地捕获复杂的ID特征。
实验三: Ablation
- LoRA + Weight fusion
- ED - LoRA + Weight fusion
- ED-LoRA + gradient fusion
效果:
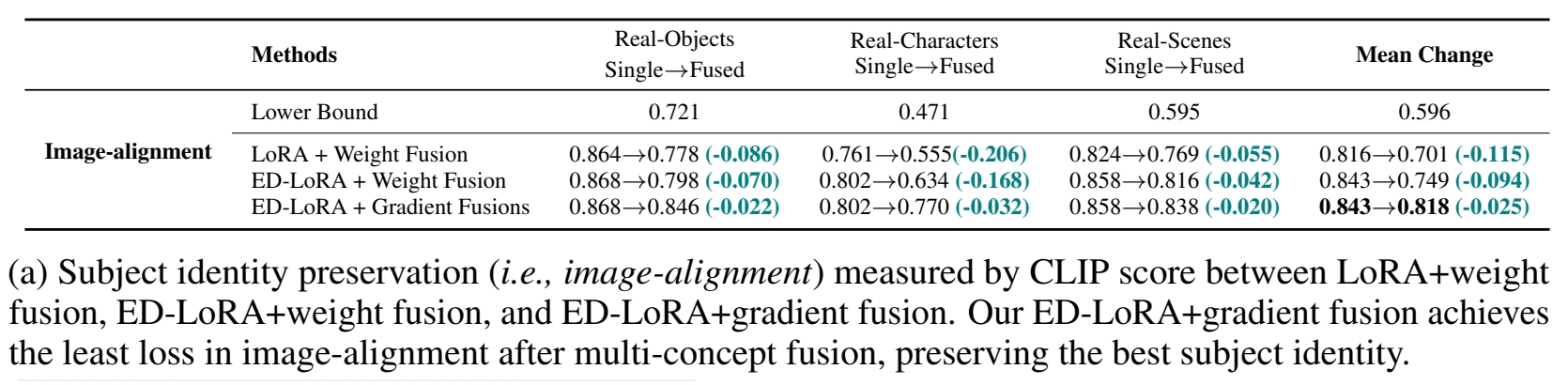
结论: ED 编码和 gradient fusion 能好较地保留 ID 特征。
评价指标
CLIP-Score: T/I 相似度
CIIP: 生成图像与 target conept 的相似度
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
- attributes from one region may influence another due to the encoding of some attributes in the global Single-Concept Model Methods embedding.

Figure 10: Limitation of Mix-of-Show. (a) Attribute leakage in regionally controllable sampling.
解决方法: negative prompts
- 训练 Center-node 的时间较长 (30min,1 A100)
- 生成 small faces 因为 VAE 丢失了高频细节
解决方法: 提升生成图像的分辨率。
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
.
.
.
.
.
.
.
.
.
.
.
.
.
.
相关工作
内容定制
多内容融合:
- Custom Diffusion:多内容联合训练,约束优化
- SVDiff:数据增强,防止 concept mixing
- Cones
多推断内容定制
- Instantbooth
- ELITE
- Jia
联邦学习
不同 client 在不同享数据情况下学习相互协作。
- FedAvg:不同 Client 的权重混合
- 基于 LoRA 的 local client + raining/global server aggregation
参考材料
- 项目主页:https://showlab.github.io/Mix-of-Show
- diffusion model
- LoRA
Motion-Conditioned Diffusion Model for Controllable Video Synthesis
INVIDIA, Google Research, 不开源
核心问题是什么?
目的
以一种更可控的方式描述要生成的内容和动作,进行Motion-guided video generation
现有方法及局限性
缺乏控制和描述所需内容和运动的有效方法
本文方法
用户通过一些短划线对图像帧进行描述,可以合成的预期的内容和动态。
- 利用flow completion model,基于视频帧的语义理解和稀疏运动控制来预测密集视频运动。
- 以输入图像为首帧,future-frame prediction model合成高质量的未来帧以形成输出视频。
效果
我们定性和定量地表明,MCDiff 在笔画引导的可控视频合成中实现了最先进的视觉质量。
核心贡献是什么?
大致方法是什么?
Two-stage autoregressive generation
MCDiff 是一种自回归视频合成模型。对于每个时间步,
输入:前一帧(即开始帧或预测的上一帧)和笔画的瞬时段(标记为彩色箭头,较亮的颜色表示较大的运动)引导。 输出:(1)flow completion model预测代表每像素瞬时运动的密集flow。(2)future-frame prediction model通过条件扩散过程根据前一帧和预测的密集流合成下一帧。
所有预测帧的集合形成一个视频序列,该序列遵循起始帧提供的上下文和笔划指定的运动。
视频动态标注
这一步用于构造dense flows。
- 计算两帧的光流。
- 计算两帧中的关键点的光流。
- 用2的flow代替1中有移动的点的flow。因为2的flow往往能更准确地描述人体形状。
[?] 每个关键点的flow不同,分别代替哪些像素点的flow? [?] 这个方法只适用于有人且单人?
flow completion model F
| 输入 | 输出 | 方法 |
|---|---|---|
| dense flow | sparse flow | 下采样 1. 采样与关键点像素想关的flow。 2. flow magnitude大的采样概率大。 3. 同时采样背影或其它物体的运动 |
| 稀疏的拖拽信息 | 2D的稀疏光流表示 | w * h * 2的 矩阵,描述相对于上一帧的位移。由于是拖拽是稀疏光流,大部分格子上是没有拖拽信息的。把这些空白填上learnable embedding,表明用户没有在这些地方指定输入。 |
| 2D的稀疏光流表示 2D的图像信息 | UNet输入 | concat |
| UNet输入 | dense flow | UNet |
[?] 直接监督dense flow?
答:只是用了UNet,但没有用Diffusion。
future-frame prediction model G
输入:当前帧图像xi,当前帧到下一帧的光流di
输出:下一帧图像
方法:LDM
条件注入方式:concat(noise, xi, di)
训练
数据集
loss
训练策略
分别训练F和G,然后端到端finetune F和G。
F和G都使用UNet作为基本结构,但F是生成模型,直接预测图像。G是Diffusion模型,预测的是噪声,多次去噪迭代生成图像。
Motion-I2V是类似的工作,但它的第一步是通过diffusion根据图像生成合理的光流。
BaseModel: SD
实验与结论
实验一: 横向对比 效果: SOTA
实验二:
- 不使用F,sparse flow直接预测视频
- full model
效果:

结论: 使用Dense flow能更消除歧义,降低学习难度
有效
局限性
启发
遗留问题
参考材料
项目启动页面:https://tsaishien-chen.github.io/MCDiff/ing
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
核心问题是什么?
目的
现有方法
本文方法
效果
核心贡献是什么?
大致方法是什么?
Stage I: Image Pretraining
- Initialize weights from Stable Diffusion 2.1 (text-to-image model)
Stage II: Curating a Video Pretraining Dataset
- Systematic Data Curation
- Curate subsets filtered by various criteria (CLIP-, OCR-, optical flow-, aesthetic-scores…)
- Assess human preferences on models trained on different subsets
- Choose optimal filtering thresholds via Elo rankings for human preference votes
- Well-curated beats un-curated pretraining dataset

Stage III: High-Quality Finetuning
- Finetune base model (pretrained from Stages I-II) on high-quality video data
- High-Resolution Text-to-Video Generation
- ~1M samples. Finetune for 50K iterations at 576x1024 (in contrast to 320x576 base resolution)
- High Resolution Image-to-Video Generation
- Frame Interpolation
- Multi-View Generation
- High-Resolution Text-to-Video Generation
- Performance gains from curation persists after finetuning
训练
数据集
Scaling latent video diffusion models to large datasets
Data Processing and Annotation
- Cut Detection and Clipping
- Detect cuts/transitions at multiple FPS levels
- Extract clips precisely using keyframe timestamps
- Synthetic Captioning
- Use CoCa image captioner to caption the mid-frame of each clip
- Use V-BLIP to obtain video-based caption
- Use LLM to summarise the image- and video-based caption
- Compute CLIP similarities and aesthetic scores
- Filter Static Scene
- Use dense optical flow magnitudes to filter static scenes
- Text Detection
- Use OCR to detect and remove clips with excess text
Blattmann et al., “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets,” 2023.
✅ SVD:构建数据集
✅ (1) 把视频切成小段,描述会更准确
✅ (2) 用现有模型生成视频描述
loss
训练策略
实验与结论
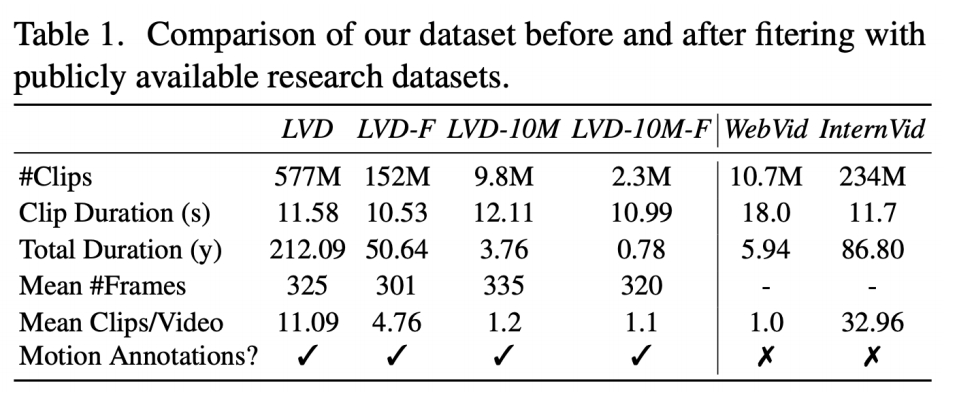
有效
局限性
启发
✅ 在少量高质量数据上 finetune,质量提升很大。
遗留问题
参考材料
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
Ali,开源
核心问题是什么?
输入reference ID和driving pose,生成视频
目的
UniAnimate框架,以实现高效和长期的人类视频生成。
现有方法
当前的Diffusion Model存在两个问题:
i)需要额外的参考模型来将ID图像与主视频分支对齐,这大大增加了优化负担和模型参数;
例如AnimateDiff,TCAN
ii)生成的视频通常时间较短(例如,24帧),阻碍了实际应用。
本文方法
首先,为了降低优化难度并确保时间一致性,我们通过结合统一的视频扩散模型将参考图像与driving pose和噪声视频映射到一个共同的特征空间中。
其次,我们提出了一种统一的噪声输入,支持随机噪声输入和第一帧条件输入,从而增强了生成长期视频的能力。
最后,为了进一步有效地处理长序列,我们探索了一种基于状态空间模型的时态建模架构,以取代原始的计算消耗较大的Temporal Transformer。
[❓] 把 reference Image 和 driving pose 分别 embedding, 然后以相加或 concat 的方式结合到一起,就算是映射到同一空间了?
[❓] 原始是哪个?Modelscope?
效果
UniAnimate在定量和定性评估方面都取得了优于现有最先进同行的合成结果。
UniAnimate可以通过迭代地采用第一帧调节策略来生成高度一致的一分钟视频。
核心贡献是什么?
- 提出了具有一致性的人体图像动画的UniAnimate框架。具体来说,我们利用统一的视频扩散模型来同时处理参考图像和噪声视频,促进特征对齐并确保时间相干的视频生成。
- 为了生成平滑连续的视频序列,我们设计了一个统一的噪声输入,允许随机噪声视频或第一帧条件视频作为视频合成的输入。第一帧调节策略可以基于先前生成的视频的最后一帧生成后续帧,确保平滑过渡。
- 为了减轻一次生成长视频的限制,我们利用时态Mamba[15,30,93]来替换原始的时态序Transformer,显著提高了效率。
- 我们进行全面的定量分析和定性评估,以验证我们的UniAnimate的有效性,突出其与现有最先进方法相比的卓越性能。
大致方法是什么?
首先,我们利用CLIP编码器和VAE编码器来提取给定参考图像的潜在特征(左上)。为了便于学习参考图像中的人体结构,我们还将参考姿势的表示纳入最终的reference guidance中(左上)。随后,我们使用姿势编码器对目标驱动的姿势序列进行编码,并将其与噪声输入在channel维度上连接起来(左下)。噪声输入是从第一帧条件视频或噪声视频。然后,将级联的噪声输入与reference guidance沿着时间维度进行叠加,并将其馈送到统一的视频扩散模型中以去除噪声(左中)。统一视频扩散模型中的时间模块可以是temporal transformer或temporal Mamba。最后,采用VAE解码器将生成的latent video映射到像素空间。
Noised input: 统一的噪声输入,即所有帧用同一个 noise 初始化
Conditioned input: 用于长序列生成时固定首帧内容

统一的 VDM 模型
当前方案(例如TCAN),除UNet以外,还使用了referenceNet和Pose ControlNet。但本文把它们统一了。好处是:
-
将reference image feature 和 Output Video feature 对齐到同一latent space.
✅ 不同意,不同分支的feature也可以对齐同一latent space -
减少了参数量,更容易训练
✅ 不同意,多分支虽然参数量多,但大部分参数都是fixed.实际要训练的参数没那么多,且由于大部分参数fixed,预训练的效果不容易恶化。
当前方案显式地从reference Image 中取reference pose,并输入到模型中。
统一的噪声
| 当前方法:滑窗策略 |  | 两个CLip分别推断,在overlap处fusion. 这会导致两个clip的明显不连续,和overlap处的artifacts. |
| 本文方法 |  | 直接用上一帧的尾帧作为这一帧的首帧。优势:1.可生成指定首帧的视频。 2.可生成一致的长视频。 |
时序建模
当前方法: Temporal Transformer,具有二次复杂性。
本文方法: Temporal Mamba,具有线性复杂度。
二者性能相似,但 Temporal Mamba 所需 memory 更少。
0
0
0
0
0
0
训练与推断
0
0
0
0
0
0
数据集
TikTok
Fashion
loss
0
0
0
0
0
0
训练策略
提取Pose: Dwpose
Visual encoder:CLIP-huge,
Pose-encoder: STC-encoder in VideoComposer (仅借鉴结构)
多条件输入,每次以一定的比例dropout部分条件。
实验与结论
评价指标
图像质量: L1,PSNR,SSIM,LPIPS
视频质量: FVD
实验一: 横向对比
- Disco
- Magic Animate
- Animate Anyone
- Champ
效果:
- TikTok 上
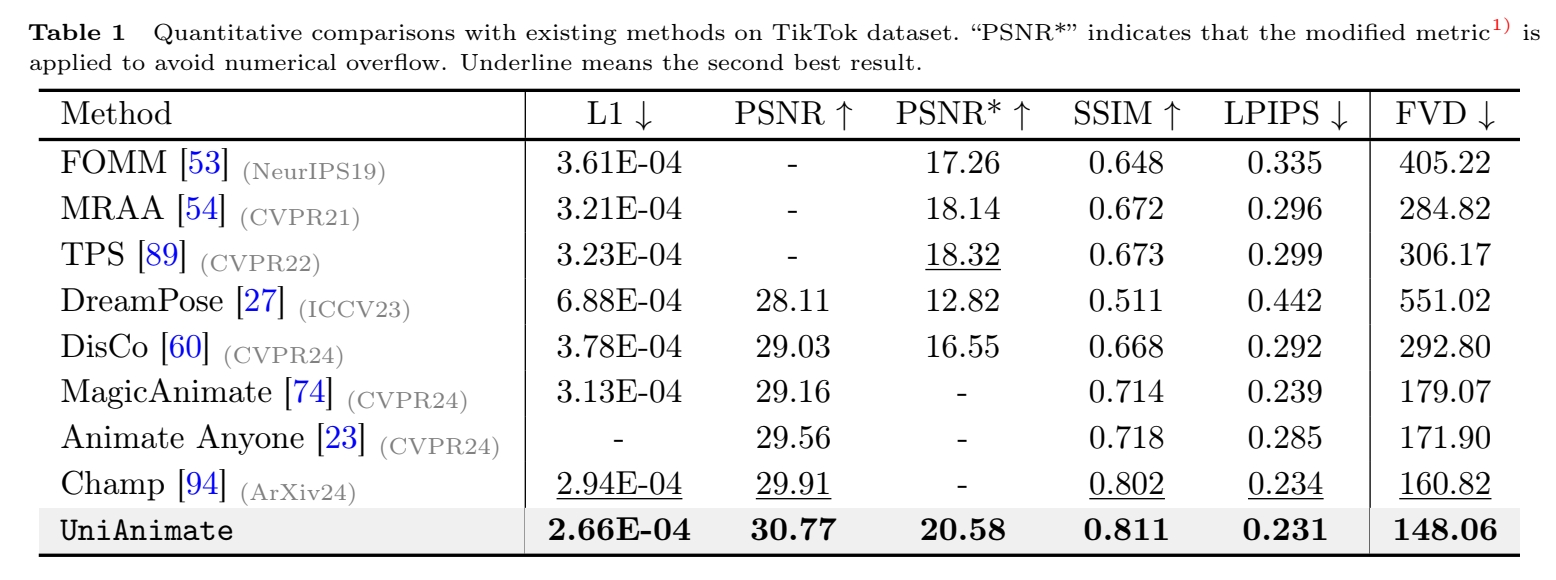
- Fashion 上
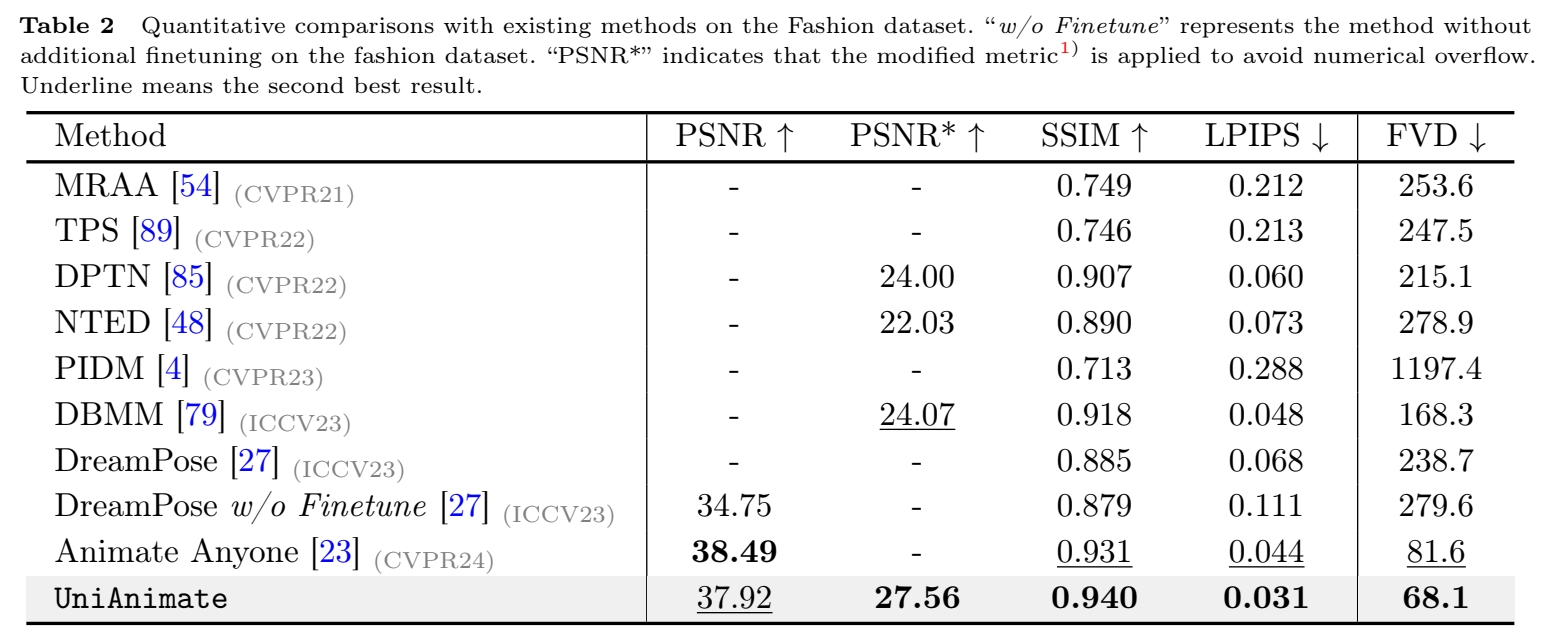
结论:
- UniAnimate 超越SOTA,且能更好地保持结构化信息。
- 作者认为,收益来自于统一的VDM结构,能将appearance,pose.noise对齐且统一处理,便于模型优化。
实验二: Ablation of Reference Pose.
- 显式地引入 reference Pose
- 不使用 reference Pose
效果:
2 出现断肢,且不能很好地识别前景和背景。
有效
局限性
- 手和脸的生成
- reference 中看不见的部位生成的一致性。
启发
遗留问题
参考材料
- 项目页面:https://unianimate.github.io/
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
INVIDIA,不开源,精读
核心问题是什么?
目的
将 LDM 范式应用于高分辨率视频生成
现有方法
本文方法
- 在图像上预训练 LDM
- 通过向LDM(UNet部分和Decoder部分)引入时间维度,并用编码图像序列(即视频)进行微调,将图像生成器变成视频生成器。
- 在扩散模型upsamplers上引入时间层,将它们转变为时间一致的视频超分辨率模型。
效果
野外驾驶数据的生成
在分辨率为 512 × 1024 的真实驾驶视频上验证了我们的视频 LDM,实现了最先进的性能。
文生成视频的创意内容创建
可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练时间对齐模型。
好处:可以将公开可用的、最先进的文本到图像 LDM 稳定扩散转换为高效且富有表现力的文本到视频模型,分辨率高达 1280 × 2048。且这种训练时间层的方式可以推广到不同的微调文本到图像 LDM。
核心贡献是什么?
-
高分辨率长视频合成:LDMs扩展了传统的图像合成模型,使其能够生成高分辨率的长视频,是首个高分辨率长视频生成模型。
-
潜在空间中的扩散模型:与传统在像素空间中训练的模型不同,LDMs在潜在空间(latent space)中训练扩散模型,这可以减少计算和内存的需求。
-
时间维度的引入:作者通过在潜在空间中引入时间维度,将图像生成器转换为视频生成器,并通过在编码的图像序列(即视频)上进行微调来实现这一点。
-
时间对齐的扩散模型上采样器:通过引入时间层,可以将用于图像超分辨率的扩散模型上采样器转换为视频超分辨率模型,从而保持时间上的连贯性。
-
实际应用:论文中提到了两个实际应用案例:野外驾驶数据的合成和文本到视频的创意内容创建。
-
预训练和微调:LDMs可以利用现成的预训练图像LDMs,通过仅训练时间对齐模型来实现视频生成,这大大减少了训练成本。
-
个性化视频生成:通过将训练好的时间层与不同微调的文本到图像LDMs结合,论文展示了个性化文本到视频生成的可能性。
-
计算效率:通过在潜在空间中进行操作,LDMs能够在保持高分辨率输出的同时,降低训练和推理时的计算需求。
-
模型架构:论文详细介绍了LDMs的架构,包括如何通过插入时间层来扩展现有的图像生成模型。
大致方法是什么?
✅ 所有工作的基本思路:(1) 先从小的生成开始 (2) 充分利用 T2I.
图像生成模型 -> 视频生成模型
引入 Temporal Layers
Interleave spatial layers and temporal layers.
The spatial layers are frozen, whereas temporal layers are trained. Temporal 层与原始的Spatial 层是以residual的形式结合,省略掉维度变换的过程,
$$ z1 = Spatial Attention(z) \\ z2 = Temporal Attention(z1)\\ z3 = \alpha z1 + (1-\alpha) z2 $$
定义时间层
Temporal layers can be Conv3D or Temporal attentions.
- For Conv3D, shape is [batch, channel, time, height, width]
- For Temporal attention, shape is [batch \(^\ast \)height\(^\ast \) width, time, channel]
✅ 时序层除了时序 attention,还有 3D conv,是真正的 3D,但是更复杂,且计算、内存等消耗更大。
✅ 时序attention只是时间维度的融合,而3D conv是在f, w, h三个维度同时融合。
引入time PE
相对 sinusoidal embeddings [28, 89]
训练方法
先移除Temporal Layer(令alpha=1),只训练Spatial Layer。然后Fix Spatial Layer,只训练Temporal Layer。
训练image model和video model使用相同的noise schedule。
Temporal Autoencoder Finetuning
原始的LDM是在图像上训练的,因此其Encoder&Decoder重建出的视频会闪烁。
解决方法:在Decoder中引入temporal layer,并用视频重训。
上图:微调解码器中的时间层时,会fix编码器,因此编码器是独立处理帧。解码时强制跨帧进行时间相干重建。使用Video-aware Discrimator。下图:在 LDM 中,解码是逐帧进行的。
- Fine-tune the decoder to be video-aware, keeping encoder frozen.
✅ Encoder fix.用 video 数据 fineture Decoder.
长视频生成
模型一次生成的帧数有限,通过两种方式生成长视频:
- 上一次生成的尾帧作为context注入到下一次生成的首帧信息中,以自回归方式生成长视频。
- 生成低帧率视频,再插帧,同样帧数,低帧率视频时间更长。
本节(论文3.2)解决context注入的问题。
下节(论文3.3)解决低帧率视频插帧的问题。
Context 的构建 \(\mathbf{c} _S = (\mathbf{m} _S \circ \mathbf{z} ,\mathbf{m} _S)\)
- 构建 mask,长度为 T,需要参考预置内容的帧置为1,需要生成的帧置为0。
- 构建Z。训练时取GT对应帧,调整到对应(w,h), 经过SD Encoder,即为Z。推断时,取上一批生成过程的中间结果Z的对应帧。
- 构建\(\mathbf{c} _S\). Z 与 mosk 逐元素乘,其结果在channel维度上与 mask concat. 最终shape为 (B,T,c+1,w,h)
模型结构
[❓] 3D Conv 是怎样使用 \(\mathbf{c} _S\) 的?
答:文章没有说明,推没为 channel 维度的 concat.后面文章都没有使用这种方法注入 reference Image,可能是效果不好,或者使用时有其它局限性。
训练策略
CFG
Upsampler diffusion model
插帧模型的训练方法与自回归模型的训练相似,即 context 注入和 CFG 训练,区别在于 mask 的构造不同。
引入现有的 diffusion based 图像超分方法,提升生成视频的分辨率。在现有方法的模型中引入时间层,保证了超分视频内容的时间一致性。
“驾驶视频生成”应用在像素空间做超分。“T2V” 应用在 latent 空间做超分。
为什么选择在像素空间做超分?作者没有解释,可能是因为这样效果更好。
为什么可以在像素空间做超分?因为超分不需要关注较长的时序连续性(生成模型已经处理好这个问题)。所以训练时一个数据只包含较少的patch,在像素空间上也能训得起来。
训练
数据集
RDS Videos
WebVid-10M
loss
训练策略
- 先训练图像生成的 LDM 或使用预训练的,再训练时序层。
- CFG 方式引入 context 条件。
实验与结论
实验一:
- Origin SD Decoder
- SD Decoder + 时序层 + 视频数据 finerune
效果: 2的 FVD 明显优于1
结论: Decoder 中引入时序信息,对视频生成质量非常重要。时序层会轻微牺牲单帧图像的质量,换来时序上的合理性。
实验二:
- 不使用 AutoEncoder,直接在像素上训练 DM。
- 不使用预训练的 Spatial Layer,使用训练数据同时训Spatial Layer 和 Temporal Layer.
- Temporal Layer 不使用 Conv 3D 而是使用 Temporal Attention.
- 全量模型。
效果:

结论: Latent Embedding 图像上的预训练模型,Conv3D对视频生成质量都有时显提升。
实验三:
1.Image LDM 替换成 Dream Booth 版本
效果: 可以生成 Dream Booth 训练数据中的特定角色的视频,且角色有较好的一致性。
结论: 通过替换 Spatial 层,可以实现定制化的 T2V 生成。
实验四:
在低分辨率视频上训练的模型直接用于生成高分辨率视频。
效果: 可通过调声初始噪声的维度直接生成高分辨率视频,在生成质量有所下降。
结论: 在高分辨率视频生成上具有泛化性,这是图像 LDM 的固有属性,是通过 UNet 主干的卷积性质实现的。可以通过控制初始噪声的维度生成指定维度的视频。
实验五:
在短视频上训练的模型直接用于生成长视频。
效果: 可生成,质量下降。
结论: 原理与分辨率的泛化性类似通过对模型结构做特定的调整,可支持视频帧数的泛化性。为了适配帧数泛化性,所做的设计为:
- temporal attention 层的 time 使用相对正弦编码。
- temporal attention 层的 mask 设置为前后可见8帧。
- spatial 和 temporal 的混合系数 2 为 scaler.
实验六:
- 直接在预训练的 SD(较高分辨率)用视频数据(较低分辨率)训练新加入的时序层。
- 先用视频数据 feature SD,然后再训练时序层。
效果: 1的视频生成质量严重下降,2会导致 SD 的图像生成质量下降,但最终的视频生成质量优于1。
结论:
- 2先对 SD finetune 是必要的,以防止对视频建模时出现失分布的情况。
- 使用预训练模型时,如果推断数据与预训练数据有较大的偏差,考虑对预训练参数做微调,否则,可以 fix.
- 微调预训练模型的方式可以是先微调再 fix,也可以是联合优化,二者有什么区别?
有效
-
实验结果: 论文提供了在真实驾驶视频数据集上的实验结果,展示了LDMs在生成高分辨率、长时间视频方面的性能。
-
模型泛化能力: 通过在不同的微调设置下测试时间层,论文展示了这些层在不同模型检查点之间的泛化能力。
-
文本到视频的生成: 论文展示了如何将文本到图像的LDM扩展为文本到视频的生成模型,并通过实验验证了其有效性。
局限性
启发
每一帧独立上采样(或Decoder)会严重破坏视频的帧间连续性。
遗留问题
- 为什么应用1在像素空间做超分,而应用2在 latent 空间做超分?是因为数据集不同?应用场景不同?还是任务不同?
- 超分是彼么做的?
参考材料
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics
数据集,不开源
核心问题是什么?
零件级运动的视频生成
目的
Puppet-Master 是一种交互式视频生成模型,可以作为零件级动态的运动先验。
在测试时,给定单个图像和一组稀疏的运动轨迹(即拖动),Puppet-Master 可以合成一个视频,描绘忠实于给定拖动交互的真实零件级运动。
现有方法
这是一个新问题,无现有方法
本文方法
- 微调大规模预训练视频扩散模型SVD
- 提出了一种新的调节架构来有效地注入拖动控制
- 引入了all-to-first注意力机制,替换原始模型中空间注意力模块。它通过解决现有模型中的外观和背景问题来显着提高生成质量。
- 使用 Objaverse-Animation-HQ 数据,这是一个精心策划的部件级运动剪辑的新数据集。
- 提出了一种策略来自动过滤掉次优动画并通过有意义的运动轨迹增强合成渲染。
效果
PuppetMaster 可以很好地推广到各种类别的真实图像,并在现实世界基准上以零样本的方式优于现有方法。
核心贡献是什么?
-
交互式视频生成:Puppet-Master能够在测试时,根据单个图像和稀疏的运动轨迹合成视频,这些视频展示了与给定拖动交互一致的真实部分级别运动。
-
运动先验:与传统的运动模型不同,Puppet-Master学习了一种更通用的运动表示,能够捕捉到对象内部动态,如抽屉滑出柜子或鱼摆动尾巴等。
-
数据集创建:论文提出了Objaverse-Animation-HQ,这是一个新的数据集,包含经过筛选的部分级别运动剪辑,用于训练Puppet-Master。
-
新的条件架构:为了有效地将拖动控制注入视频生成流程,论文提出了一种新的条件架构,包括自适应层归一化和带有拖动标记的交叉注意力模块。
-
all-to-first 注意力机制:为了解决现有模型中的外貌和背景问题,论文引入了all-to-first 注意力机制,这是一种替代传统空间注意力模块的方法,通过直接从条件帧传播信息来显著提高生成质量。
-
新的评价指:根据局部零件运动轨迹的相似度,制定了 flow-error 评价指标,可以更好地评价零件级运动视频的生成质量。
大致方法是什么?
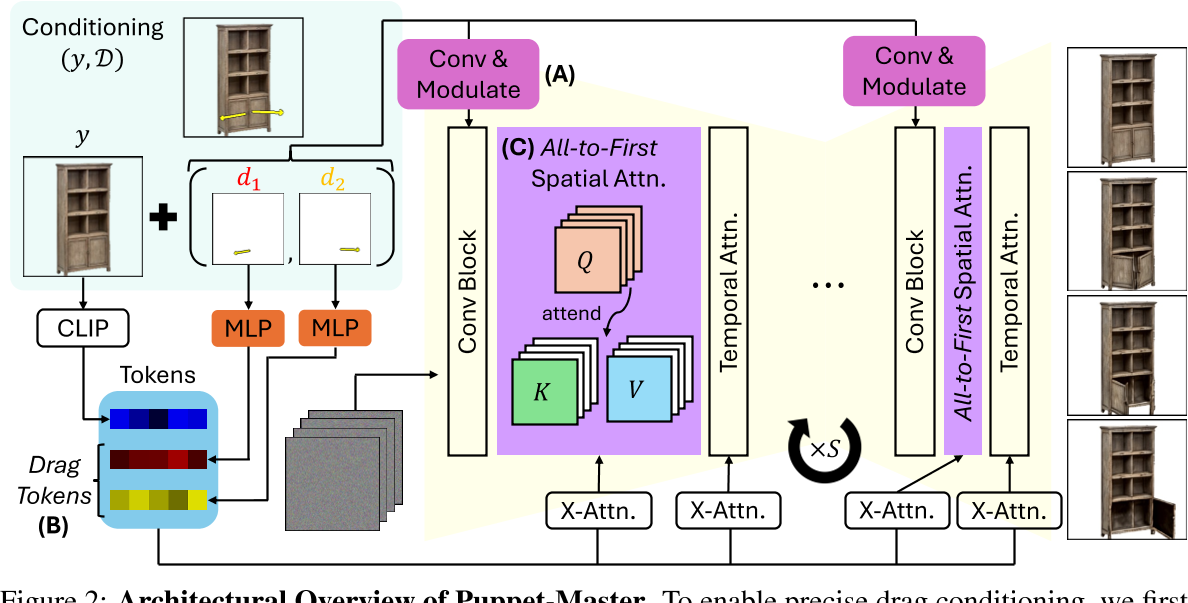 在原始的SVD架构的基础上做以下修改;基模型为link
在原始的SVD架构的基础上做以下修改;基模型为link
- 添加自适应层归一化模块来调节内部扩散特征(上图A模块)
- 添加带有拖动标记的交叉注意(上图B模块)
- 引入了 all-to-first 空间注意力,代替原有空间自注意力模块。它使用第一帧来关注每个带噪声的视频帧。(上图C模块)
要解决的问题:
-
将拖动条件 D 注入视频生成管道中,以促进高效学习和准确且时间一致的运动控制,同时避免过多修改预训练视频生成器的内部表示。论文3.2节解决拖动条件注入的问题,论文3.3节解决伪影问题。 本文以两种方式注入拖动条件
-
使用拖动编码调制 UNet feature 这种方式要求二者之间有相同的结构,常用于图像的不同图层之间。
-
以 embedding 的形式与 UNet feature 进行 cross attention 这种方式不要求有相同的结构,常用于两个embedding 之间。类似于 SD 中和 CLip Embedding.
-
仅仅微调预先训练的SVD可能会导致杂乱背景等伪影[39]。
向SVD模型添加拖动控制
- 引入拖动 D 的编码函数
- 扩展 SVD 架构以将生成的代码注入网络
- 使用视频与训练三元组 (X , y, D) 形式来微调模型。
拖动编码
这是一个hand-crafted的编码方式,编码结果为:K * N * s * s * C
K:控制点的个数
N:视频帧数
s:分辨率
c:6,分别是start location, current localtion, end_location
格子没有控制点经过填-1
[❓] 直接记录位置,为什么还要SXS?
答:以 s * s 结构记录特征,是为了与 UNet feature 保持同样的信息结构,具有相同结构的特征才能以调制的方式融合。
拖动调制
调制:调整特征的均值和方差,使其与其它特征区别开来。但又不影响特征的原始结构。
$$ f_s \leftarrow f_s \bigotimes (1 + \gamma_s) + \beta_s $$
fs为UNET在s分辨率下的特征。gamma和beta通过对拖动编码做卷积操作得到。
以调制的方式让拖动编码影响原始特征
Drag Token(拖动标记)
原始的SVD中的cross attention是clip embedding与z之间的。
此处把拖动编码进行MLP之后拼接到clip embedding上,成为新的clip embedding,即Drag Token。
Attention with the Reference Image
实验观察结论:
- 生成的视频具有杂乱的或者灰色的背景,这是由于SVD 是在 576 × 320 视频上进行训练,无法泛化到非常不同的分辨率。强行在其它分辨上finetune,容易出现局部最优。
- 当模型学习到复制参考图像作为第一帧,第一帧的appearance不会出现退化。
✅ 我认为外观效果降级不是因为分辨率的改变,而是 reference Image 的注入方式。
本文把 reference Image 以 CLIP Embedding 进行注入,但 CLIP Embedding 只是对图像的 high level 的理解,但对外观细节的约束比较弱,因此导致外观效果的降级。原始的 SVD 中的照片续写应用,会把首帧的信息以 Context 的形式注入,这是一种对 reference Image 的更强力的约束,这里没有了这一部分设计。
因此:
创建一条从每个噪声帧到第一帧的“shortcut”,并具有all-to-first的空间注意力,这即使不能完全解决问题,也可以显着缓解问题。
本文设计:
原始的cross attention机制的Q, K, V都是B * N * s * s * C的维度。spatial cross attention是在空间维度上做的,因此第i帧中参与计算的内容是Q[:,i], K[:,i], V[:,i]。但在此处分别将它们修改为Q[:,i], K[:,0], V[:,0]。
✅ 增加 UNet feature 与 reference Image 的 cross attention 也是同样的效果。
好处:
- 第一帧的这种“short cut”允许每个非第一帧直接访问参考图像的未降级外观细节,从而有效地减轻优化过程中的局部最小值。
- 与所提出的drag encoding相结合,该编码为每一帧指定第一帧的原点 uk ,all-to-one注意力使包含拖动终止(即 vn k )的latent像素更轻松关注第一帧上包含拖动原点的潜在像素,可能有助于学习。
训练
数据集
- Objaverse:原始数据集由 3D 艺术家创建的 800k 模型的大型 3D 数据集,其中约 40k 是可动画的。
- 从中挑出可被驱动的3D模型,设置规则 + 分类器的方法,生成数据集 Objaverse-animation.
- 从可驱动模型中挑出合理的驱动,生成数据集 Objaverse-Animation-HQ.
- 设计动作从中提取出稀疏的drag motion
loss
训练策略
实验与结论
实验一:
使用包含不同信息的拖拽编码调制 UNet 特征。
效果:
结论: 拖拽编码调制 UNet 特征进行调制,对闪果有很大提升。
实验二:
使用不同数据进行训练。
- Objaverse-Animation
- Objaverse-Animation-HQ
效果: 2优于1。
结论: Less is more.
有效
-
零样本泛化**:尽管Puppet-Master仅使用合成数据进行**微调,但它能够在真实世界数据上实现良好的零样本泛化,超越了之前在真实视频上微调的方法。
-
数据筛选策略:论文提出了一种系统方法来大规模筛选动画,以创建数据集Objaverse-Animation和Objaverse-Animation-HQ,这些数据集包含更高质量和更逼真的动画。
-
实验验证:通过广泛的实验,论文展示了Puppet-Master在合成连贯性、保真度和可控性方面的优势,并证明了其在不同任务和数据集上的有效性。
局限性
启发
- 一种拖动交互的编码方式。
- 真实视频数据有限时的一种数据构造方式。
遗留问题
参考材料
- 项目页面:vgg-puppetmaster.github.io。
A Recipe for Scaling up Text-to-Video Generation
Ali,开源,VGen
核心问题是什么?
目的
基于diffusion model的文生视频
现有方法
文本视频的pair data规模有限。但是无标注的视频剪辑有很多。
本文方法
TF-T2V:一种新颖的文本到视频生成框架。它可以直接使用无文本视频进行学习。其背后的基本原理是将文本解码过程与时间建模过程分开。 为此,我们采用内容分支和运动分支,它们通过共享权重进行联合优化。
效果
通过实验,论文展示了TF-T2V在不同规模的数据集上的性能提升,证明了其扩展性。此外,TF-T2V还能够生成高分辨率的视频,并且可以轻松地应用于不同的视频生成任务。
核心贡献是什么?
-
文本到视频的生成框架(TF-T2V):提出了一个新的框架,它利用无文本的视频(text-free videos)来学习生成视频,从而克服了视频字幕的高成本和公开可用数据集规模有限的问题。
-
双分支结构:TF-T2V包含两个分支:内容分支(content branch)和运动分支(motion branch)。内容分支利用图像-文本数据集学习空间外观生成,而运动分支则使用无文本视频数据学习时间动态合成。
-
时间一致性损失(Temporal Coherence Loss):为了增强生成视频的时间连贯性,提出了一个新的损失函数,它通过比较预测帧与真实帧之间的差异来显式地约束学习相邻帧之间的相关性。
-
半监督学习:TF-T2V支持半监督学习设置,即结合有标签的视频-文本数据和无标签的视频数据进行训练,这有助于提高模型的性能。
大致方法是什么?
—— 在内容分支中,利用成对的图像文本数据来学习文本条件和图像条件的空间外观生成。
—— 运动分支通过提供无文本视频(或部分配对的视频文本数据,如果可用)来支持运动动态合成的训练。
—— 在训练阶段,两个分支联合优化。值得注意的是,TF-T2V 可以通过合并可组合条件无缝集成到组合视频合成框架中。
—— 在推理中,TF-T2V 通过将文本提示和随机噪声序列作为输入来实现文本引导视频生成。
运动分支
数据集: 纯视频、视频 - 文本 Pair data
输入: 视频的中间帧并使用 CLIP 编码。与生成视频同维度的噪声。
✅ 3个数据集,2个分支,组全出4种训练策略。
—— 输入文本,生成图像。
—— 输入图像,生成图像。
—— 输入图像(视频中间帧),生成视频。
—— 输入图像(视频中间帧)+ 文本,生成视频。
❓ 如何平衡这4种训练策略的训练顺序、训练次数、数据量?
❓ 不同训练数据及预训练数据的图像分辨都不相同,如何处理这其中的 GAP?
训练参数: 同时训练 Spatial Layer 和 Temporal Layer.
训练方式: CFG
空间外观分支
数据集: 图 - 文 Pair data
训练参数: 仅 Spatial 模块,且不引入 Temporal 模块
输入: 随机使用文或图作为控制条件,目的是任意一种条件都能引导生成。噪声与生成图像同维度。文本和图像都使用 CLIP 编码。
✅ 这里的 reference Image 是以CLIP Embedding 的形式送进去的,是一种比较弱的约束关系。但这里 reference Image 的作用只是提供一种外观先验,并不是照片续写,所以这样也够用了。
训练模块: 只训 Spatial 部分,不引入 temporal 部分。
[❓] 文本和图像是 Concat 的关系,但一次只提供一个,没有提供的部分填什么?
训练与验证
数据集
LAION-400M, LAION:大规模、高质量的图文数据集
WebVid10M:小规模、低分辨率的文本-视频数据集
YouTube, TikTok:大量无标注视频
loss
新增coherence loss用于计算帧间的连续性。
根据公式3可知 V 是 noise GT,因此 coherence loss 监督 noise 的时序特征。
训练策略
Base Mode:
Model Scipe T2V[54]
VideoComposer[58]
训练所有的视频片断为:4FPS,16 frames
❓ 这里提到 WebVid10M 是作为 text-free 数据集业用的,那么视频一文本 pair ddfa 的训练,用的是什么数据集?
实验与结论
实验一: 同期效果横向对比
效果:
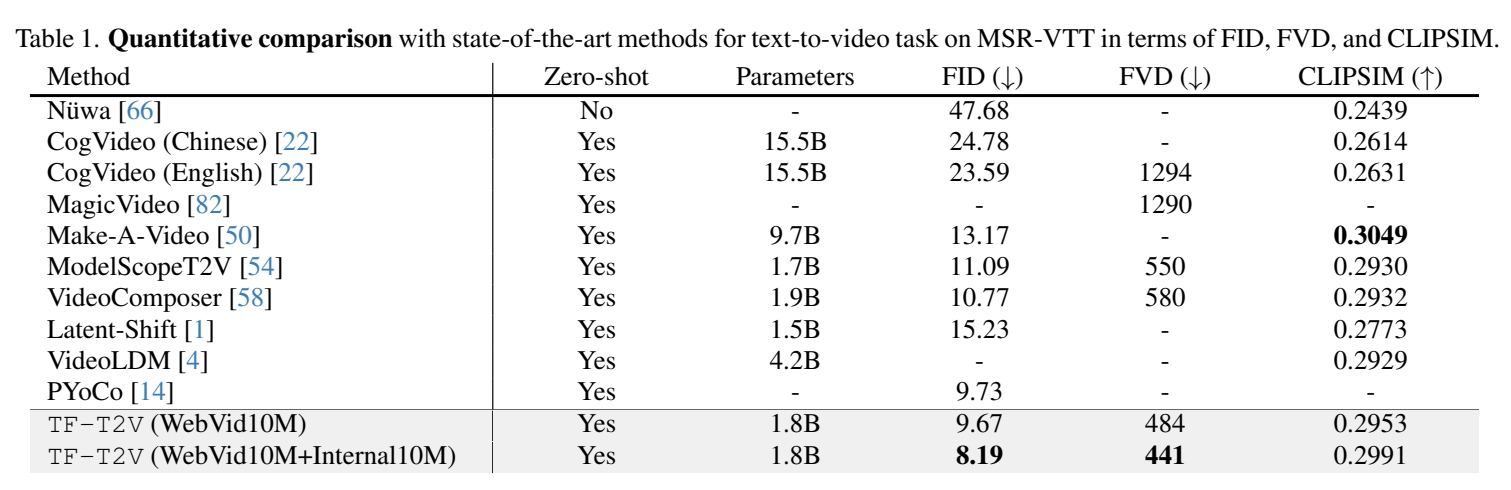
结论: 本文方法生成视频在单帧质和时序连续性上均优于同期模型。
实验二:
- 不使用 coherence loss
- 使用 coherence loss
效果: 生成视频的帧间 CLIP 相似度,2优于1。
给论: coherence loss 有时序一致性有效。
实验三:
- depth/sketch/motion-Image Pair data + 纯视频数,联合训练。
效果: 可以在没有“条件 - 视频” pair data 的情况下,训练出条件视频生成模型。
给论: 内容 / 运动 = 分支训练框加可以有效解决缺少条件 - 视频数据对的问题。
实验四:
- 不使用 coherence loss
- 使用 coherence loss
效果: 比较生成视频连续两帧的 CLIP 相似度,2优于1
结论: temporal coherence loss 可以缓解时序不连续问题(例如 color shift)
实验五:
- 不使用“文本-视频”数据训练
- 使用“文本-视频”数据训练
效果: 2优于1
有效
-
扩展性和多样性:通过实验,论文展示了TF-T2V在不同规模的数据集上的性能提升,证明了其扩展性。此外,TF-T2V还能够生成高分辨率的视频,并且可以轻松地应用于不同的视频生成任务。
-
无需复杂的级联步骤:与以往需要复杂级联步骤的方法不同,TF-T2V通过统一的模型组装内容和运动,简化了文本到视频的生成过程。
❓ 复杂级联步骤是指什么方法?
-
插拔式框架:TF-T2V是一个即插即用(plug-and-play)的框架,可以集成到现有的文本到视频生成和组合视频合成框架中。
-
实验结果:论文通过广泛的定量和定性实验,展示了TF-T2V在合成连贯性、保真度和可控性方面的优势。
局限性
启发
遗留问题
参考材料
- 项目地址:https://github.com/ali-vilab/VGen
High-Resolution Image Synthesis with Latent Diffusion Models
开源,精读
核心问题是什么?
目的
在有限的计算资源上进行 DM 训练,同时保持其质量和灵活性
现有方法
现有模型通常直接在像素空间中运行,且顺序评估,因此训练和推理成本很高。
本文方法
将DM应用在强大的预训练自动编码器的潜在空间中。
- 在这种表示上训练扩散模型首次允许在复杂性降低和细节保留之间达到接近最佳的点,从而极大地提高了视觉保真度。
- 通过将交叉注意力层引入模型架构中,我们将扩散模型转变为强大而灵活的生成器,用于一般条件输入(例如文本或边界框),并且以卷积方式使高分辨率合成成为可能。
效果
LDM 在图像修复和类条件图像合成方面取得了新的最先进分数,并在各种任务上实现了极具竞争力的性能,包括文本到图像合成、无条件图像生成和超分辨率,与基于像素的 DM 相比,同时显着降低了计算要求。
核心贡献是什么?
-
潜在扩散模型(LDMs):这是一种新型的生成模型,它通过在潜在空间中应用去噪自编码器序列来实现图像合成,能够在保持图像质量的同时,显著减少计算资源的需求。
-
高分辨率图像合成:LDMs能够在高分辨率下生成复杂的自然场景图像,这在以往的技术中往往需要大量的计算资源。
-
计算效率:与基于像素的扩散模型相比,LDMs在训练和推理时更加高效,因为它们在低维的潜在空间中进行操作,而不是在高维的像素空间中。
-
条件生成:LDMs支持多种类型的条件输入,如文本或边界框,使得生成过程更加灵活和可控。
-
跨注意力层(Cross-Attention Layers):通过引入跨注意力层,LDMs能够将扩散模型转变为强大的生成器,用于处理一般的条件输入。
-
两阶段图像合成方法:LDMs采用两阶段方法,首先通过感知压缩模型(如自编码器)降低数据的维度,然后在潜在空间中训练扩散模型,以学习数据的语义和概念组成。
-
感知压缩:论文提出了一种基于感知损失和对抗性目标的图像压缩方法,以确保重建图像在视觉上与原始图像保持一致。
大致方法是什么?
这种方法有几个优点:
- 计算效率更高,因为采样是在低维空间上执行的。
- 利用从 UNet 架构继承的 DM 的归纳偏差 [71],这使得它们对于具有空间结构的数据特别有效,因此减轻了先前方法所需的激进的、降低质量的压缩级别的需求 [23, 66]。
- 通用压缩模型,其潜在空间可用于训练多个生成模型,也可用于其他下游应用,例如单图像 CLIP 引导合成 [25]。
感知图像压缩
| 输入 | 输出 | 方法 |
|---|---|---|
| image, W * H * 3 | z,h * w * c | Encoder |
| z | image | Decoder |
f = W/w = H/h = 2 ** m
正则化:
- 对学习到的latent潜伏施加与标准正态的 KL 惩罚,类似VAE
- 在解码器中使用矢量量化层,类似VQGAN
高分辨率情况下,VQ中的 Cross-attention 比较消耗 GPU.
与之前工作不同的是z是二维的,以保留其固有结构
class AutoencoderKL(pl.LightningModule):
def encode(self, x):
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
return posterior
def decode(self, z):
z = self.post_quant_conv(z) #矢量量化层
dec = self.decoder(z)
return dec
def forward(self, input, sample_posterior=True):
posterior = self.encode(input)
if sample_posterior:
z = posterior.sample()
else:
z = posterior.mode()
dec = self.decode(z)
return dec, posterior
[❓] Decoder 中的 VQ 是怎么做的?
DDPM
代码中提供了多个DDPM版本,主要差别在input的构造上:
- DDPM --- classic DDPM with Gaussian diffusion, in image space
- LatentDiffusion
- LatentUpscaleDiffusion
- LatentFinetuneDiffusion --- Basis for different finetunas, such as inpainting or depth2image
To disable finetuning mode, set finetune_keys to None
- LatentInpaintDiffusion --- can either run as pure inpainting model (only concat mode) or with mixed conditionings, e.g. mask as concat and text via cross-attn. To disable finetuning mode, set finetune_keys to None
- LatentDepth2ImageDiffusion --- condition on monocular depth estimation
- LatentUpscaleFinetuneDiffusion --- condition on low-res image (and optionally on some spatial noise augmentation)
- ImageEmbeddingConditionedLatentDiffusion
- LatentDiffusion
| ImageEmbeddingConditionedLatentDiffusion |
条件机制
通过交叉注意力机制增强其底层 UNet 主干网,将 DM 转变为更灵活的条件图像生成器 [97],这对于学习各种输入模态的基于注意力的模型非常有效 [35,36]。
- 领域的编码器 τθ,把条件y 投影到中间表示
- 使用cross attention把z和1混合起来,其中K和V来自1,Q来自z
class DiffusionWrapper(pl.LightningModule):
def __init__(self, diff_model_config, conditioning_key):
super().__init__()
self.sequential_cross_attn = diff_model_config.pop("sequential_crossattn", False)
self.diffusion_model = instantiate_from_config(diff_model_config)
self.conditioning_key = conditioning_key
assert self.conditioning_key in [None, 'concat', 'crossattn', 'hybrid', 'adm', 'hybrid-adm', 'crossattn-adm']
# noise与condition的不同的结合方式
def forward(self, x, t, c_concat: list = None, c_crossattn: list = None, c_adm=None):
# 无条件信息
if self.conditioning_key is None:
out = self.diffusion_model(x, t)
# condition与noise做concat,都作为要生成的内容传进去。没有独立的condition。
elif self.conditioning_key == 'concat':
xc = torch.cat([x] + c_concat, dim=1)
out = self.diffusion_model(xc, t)
# condition与noise做cross attention,论文中所提到的方法
elif self.conditioning_key == 'crossattn':
if not self.sequential_cross_attn:
cc = torch.cat(c_crossattn, 1)
else:
cc = c_crossattn
if hasattr(self, "scripted_diffusion_model"):
# TorchScript changes names of the arguments
# with argument cc defined as context=cc scripted model will produce
# an error: RuntimeError: forward() is missing value for argument 'argument_3'.
out = self.scripted_diffusion_model(x, t, cc)
else:
out = self.diffusion_model(x, t, context=cc)
# concat方式与cross attention方式的混合
elif self.conditioning_key == 'hybrid':
xc = torch.cat([x] + c_concat, dim=1)
cc = torch.cat(c_crossattn, 1)
out = self.diffusion_model(xc, t, context=cc)
# adm似乎是论文参考文献[15]中的方法
elif self.conditioning_key == 'hybrid-adm':
assert c_adm is not None
xc = torch.cat([x] + c_concat, dim=1)
cc = torch.cat(c_crossattn, 1)
out = self.diffusion_model(xc, t, context=cc, y=c_adm)
elif self.conditioning_key == 'crossattn-adm':
assert c_adm is not None
cc = torch.cat(c_crossattn, 1)
out = self.diffusion_model(x, t, context=cc, y=c_adm)
elif self.conditioning_key == 'adm':
cc = c_crossattn[0]
out = self.diffusion_model(x, t, y=cc)
else:
raise NotImplementedError()
return out
- 文本注入,BERT tokenizer + transformer → latert code 与 UNet feature 做 cross attention
效果: 可实现跨模态条件生成,生成质量指标接近 SOTA,但所需的参数量更少。
- 图像注入,在空间维度对齐后 concat.
效果: 这种注入方式用于 image-to-image transtation 任条,例如 Semanic 生成、超分,inpainting.
结论: 信噪比对生成质量有较大的影响。
训练
- Two-stage Training:
- CEG 训练方式极大地提升了 Sample 的质量。
LDM的训练
class LatentDiffusion(DDPM):
def p_losses(self, x_start, cond, t, noise=None):
noise = default(noise, lambda: torch.randn_like(x_start))
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
model_output = self.apply_model(x_noisy, t, cond)
loss_dict = {}
prefix = 'train' if self.training else 'val'
if self.parameterization == "x0":
target = x_start
elif self.parameterization == "eps":
target = noise
elif self.parameterization == "v":
target = self.get_v(x_start, noise, t)
else:
raise NotImplementedError()
loss_simple = self.get_loss(model_output, target, mean=False).mean([1, 2, 3])
loss_dict.update({f'{prefix}/loss_simple': loss_simple.mean()})
logvar_t = self.logvar[t].to(self.device)
loss = loss_simple / torch.exp(logvar_t) + logvar_t
# loss = loss_simple / torch.exp(self.logvar) + self.logvar
if self.learn_logvar:
loss_dict.update({f'{prefix}/loss_gamma': loss.mean()})
loss_dict.update({'logvar': self.logvar.data.mean()})
loss = self.l_simple_weight * loss.mean()
loss_vlb = self.get_loss(model_output, target, mean=False).mean(dim=(1, 2, 3))
loss_vlb = (self.lvlb_weights[t] * loss_vlb).mean()
loss_dict.update({f'{prefix}/loss_vlb': loss_vlb})
loss += (self.original_elbo_weight * loss_vlb)
loss_dict.update({f'{prefix}/loss': loss})
return loss, loss_dict
数据集
loss
训练策略
- train autoencoder first, then train the diffusion prior
✅ VAE 和 diffusion 分开训练。每次需要训练的网络都不大。 - Focus on compression without of any loss in reconstruction quality
✅ 使用Advanced Auto Encoders。由于使用的latent space比较小,diffusion model的大小也可以减小。 - Demonstrated the expressivity of latent diffusion models on many conditional problems
实验与结论
实验1:
- 在 VQ 正则化隐空间训 DM
- 在 pixel 空间训 DM
效果: VQ 重建出的结果相对原视频有轻微下降,但整体生成质量1优于2。
实验2:
Encoder & Decoder 使用不同的压缩率 \(f \in\) {\(1,2,4,8,16,32\)},\(f=1\)代表在像素空间。
效果: \(f=1\)或2时,训练的收敛速度较慢,\(f\) 较大时,训练较少的次数后生成质量不再提升。
结论: 信息压缩有利于模型的训练,但过多的压缩会导致信息丢失和降低上限。
\(f=\){4-16}是模型训练与生成质量之间的好的平衡点。
实验3:
在不同的数据上测试\(f\)的影响。
效果:
结论: ImageNet 的数据相对复杂,对应合适的\(f\)道相对较小,例如4、8
实验4: 横向对比较
- GAN-based Model
- LSGM,一种在 lantert space 的生成模型,但训练策略是 Auto Encoder 和 DM 同时训练。
- 本文方法。
效果: 3优于1和2
结论: AutoEncoder 与 Diffusion Mode 同时训练。latent Space 的分布一直在调整,DM 不得不一直跟随调整来适应 AE 的变化,增大了学习的难度,不利于 DM 的学习。
实验5: 超分模型横向对比。用不同方法对图像降级后做超分。
- LDM-SR
- 本文方法
效果: 客观指标1和2各有优劣。主观评测2优于1。
结论: 客观指标不能很好地匹配人的主观感受。
实验6: inpainting,评价指标 Lama[88]
有效
- 灵活性和通用性:LDMs的潜在空间可以被多次用于不同的生成任务,例如图像修复、超分辨率和文本到图像的合成。
局限性
- 对于高精度的场景,即使显 \(f=4\) 的 AE,也存可能成为生成质量的瓶颈。
- Sample process 速度慢
启发
生成模型的生成图像的好坏,在于它生成的质量,对于图像而言,可以是像素之间的联系性、边界的清晰度、整体画面的结构性等。但不在于它的合理性,因为
- 合理性无法衡量。因为生成一个没有见过的图像,不代表不合理。而能够生成没有见过的图像,正是它的创造性所在。
- 合理性也可以理解为生成的结果符合人类常识。但实际上生成模型并不真正理解人类常识。会生成符合人类常识的结果,只是因为对数据的偏见。
因此,对于生成模型而言,要通过各种方法、策略来提升其生成质量。通过强化数据偏见来提升其合理性。
遗留问题
LDM 的生成速度较慢
参考材料
- paper: https://arxiv.org/abs/2112.10752
- github: https://github.com/Stability-AI/stablediffusion
Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
核心问题是什么?
NVIDIA,不开源
目的
图像到视频合成 (I2V)
输入:参考图像 I 和控制条件
输出:生成一系列后续视频帧,且确保生成的视频剪辑不仅表现出合理的运动,而且忠实地保留了参考图像的视觉外观。
✅ 区别于类似link 这种的“图像生成 → 视频生成”的任务。
现有方法及存在的问题
通过利用扩散模型强大的生成先验,最近的方法显示出有前途的开放域 I2V 泛化能力。
- 现有方法很难维持时间一致性。
- 现有方法对生成结果提供有限的控制。
本文方法
Motion-I2V 通过显式运动建模将 I2V 分解为两个阶段。
对于第一阶段,我们提出了一种基于扩散的运动场预测器,其重点是推导参考图像像素的轨迹。
对于第二阶段,我们提出运动增强时间注意力来增强 VDM 中有限的一维时间注意力。该模块可以在第一阶段预测轨迹的指导下有效地将参考图像的特征传播到合成帧。
效果
[❓] 光流擅长描述视角不变的物体平移,本文以光流为条件为什么能支持较大运动和视点变化,稀疏轨迹和区域注释零镜头视频到视频的转换?
与现有方法相比,即使存在较大运动和视点变化,Motion-I2V 也可以生成更一致的视频。
通过第一阶段训练稀疏轨迹ControlNet,Motion-I2V可以支持用户通过稀疏轨迹和区域注释精确控制运动轨迹和运动区域。与仅依赖文本指令相比,这为 I2V 过程提供了更多的可控性。
此外,Motion-I2V 的第二阶段自然支持零镜头视频到视频的转换。
✅ 优点是精确控制。
缺点是,当用户控制与图像内容存在矛盾时该如何调和?
核心贡献是什么?
-
双阶段图像到视频生成:Motion-I2V将图像到视频的生成分解为两个阶段。第一阶段专注于预测像素级的运动轨迹,第二阶段则利用这些预测轨迹来指导视频帧的生成。
-
显式运动建模:与以往直接学习复杂图像到视频映射的方法不同,Motion-I2V通过显式建模运动来增强生成视频的一致性和可控性。
-
基于扩散的运动场预测:在第一阶段,提出了一种基于扩散模型的运动场预测器,该预测器接收参考图像和文本指令作为条件,并预测参考图像中所有像素的轨迹。
-
运动增强的时间注意力:在第二阶段,提出了一种新颖的运动增强时间注意力模块,用于增强视频潜在扩散模型中有限的一维时间注意力。
-
稀疏轨迹控制:Motion-I2V支持使用稀疏轨迹ControlNet进行训练,允许用户通过稀疏的轨迹和区域注释精确控制运动轨迹和运动区域。
-
区域特定动画(Motion Brush):框架还支持区域特定的I2V生成,用户可以通过自定义的运动遮罩来指定要动画化的图像区域。
-
零样本视频到视频翻译:Motion-I2V的第二阶段自然支持零样本视频到视频翻译,可以使用源视频的运动信息来指导转换后的第一帧。
大致方法是什么?
图1:Motion-I2V 概述。 Motion-I2V 的第一阶段的目标是推导能够合理地为参考图像设置动画的运动。它以参考图像和文本提示为条件,预测参考帧和所有未来帧之间的运动场图。第二阶段传播参考图像的内容以合成帧。一种新颖的运动增强时间层通过扭曲特征增强一维时间注意力。该操作扩大了时间感受野并减轻了直接学习复杂时空模式的复杂性。
Stage 1: 使用VDM进行运动预测
我们选择采用预先训练的稳定扩散模型进行视频运动场预测,以利用强大的生成先验。
运动场建模
将第一阶段的预测目标(使参考图像动画化的运动场)表示为一系列 2D 位移图{\(f_{0→i}|i = 1,..., N \)},其中每个 f0→i 是参考帧与时间步 i 处未来帧之间的光流。通过这样的运动场表示,对于参考图像 I0 的每个源像素 p ∈ I2,我们可以轻松地确定其在时间步 i 处目标图像 Ii 上对应的坐标 p′i = p + f0→i(p)。
✅ 根据视频数据生成运动场。
训练运动场预测器
| 模型结构 | 预训练参数 | 训练模块 | 学习目标 |
|---|---|---|---|
| 同LDM | LDM | Spatial 层 | 条件下未来第i帧的光流 |
| VLDM(LDM1) | 上一步 | vanilla 时间模块 | 运动场 |
| VLDM | 上一步 | 全部 | 运动场 |
- 调整预训练的 LDM 来预测以参考图像和文本提示为条件的单个位移场。
- 冻结调整后的 LDM 参数,并集成vanilla 时间模块以创建用于训练的 VLDM。
- 继续微调整个 VLDM 模型以获得最终的运动场预测器。
[❓] 任务的输入是稀疏轨迹和区域注释,为什么训练输入是文本注释?
答:先训一个 text-based 光流生成的基模型,然后以 ControlNet 形式注入控制条件,得到条件控制的光流生成模型。
[❓] 为什么不直接注入控制条件,而是分两步?
答:基模型通常都是 text-based 生成模型,然后以不同的方式注入条件。如果以 ControlNet 方式注入,通常会 fix 原模型。
编码运动场和条件图像
考虑到扩散模型的计算效率时,我们使用optical flow encoder 把 motion field map 编码为 latent representation。optical flow encoder 的结构与 LDM 的图像自动编码器相同,不同之处在于它接收和输出2通道光流图而不是3通道RGB图像。
[❓] 光流 encoder 是预训练的吗?
为了引入reference image condition,我们沿着通道维度把reference image latent representation 与 noise concat到一起。
✅ 有三种注入 reference Image 的方法
- 使用 SD encoder 编码后,以 conctext 的形式注入到 conv 3D 中
- 使用 CLIP encoder 编码后,与 UNet feature 做 cross attention
- 使用 SD encoder 编码后,与noise 在 channel 维度 concat.
- 使用 SD encoder 编码后,与noise 在 time 维度 concat.
使用 SD 1.5 预训练模型初始化的 LDM 权重,并将新添加的 4 个输入通道的权重设置为零。
帧步长 i 使用两层 M LP 进行嵌入,并添加到时间嵌入中,作为运动强度条件。
帧步长 i 的作用:表明要生成的是未来第几帧的光流
帧步长 i 的注入方式: MLP(time embdding) + MLP(step embdding), 见图1
Stage 2: 运动预测和视频渲染
运动增强的时间注意力
通过motion-augmented temporal attention,增强了 vanilla VLDM 的1-D temporal attention的同时,保持其他模块不变。
定义z为第 l 个时间层的 latent feature。简化batch size的情况下,z的维度为 (1+N )×Cl ×hl ×wl,其中 cl、hl、wl 分别表示特征的通道维度、高度和宽度。其中 z[0] 为参考帧对应的特征图,用 z[1 : N ]为后续帧。
✅ reference image 和 noise 在时间维度 concat。其结果再与光流 embdding 在 channel 维度 concat。
| flow emb\(_0\) | flow emb\(_1\) | flow emb\(_2\) | ...... | flow emb\(_n\) |
|---|---|---|---|---|
| ref image emb | noise\(_1\) | noise\(_2\) | ...... | noise\(_n\) |
根据第一阶段预测的运动场 {f0→i|i = 1, ..., N } (假设调整大小以对齐空间形状)对z[0]作warp,得到z[i]'
$$ z[i]' = \mathcal W(z[0], f_{i\rightarrow 0}) $$
z[i]'与z[i]在时间维度上交错(intealeaved),得到
$$ z_{aug} = [[z[0], z[1]', z[1], ..., z[N]', z[N]] $$
调整z和\(z_{aug}\)的维度顺序,使得在后面做时间维度上的attention。
时间维度上的attention为cross attention,其中K和V来自\(z_{aug}\),Q来自z。
✅ 该操作通过引入第一阶段的预测运动场引导,扩大了的时间模块的感受野。
因为 motion field 描述的是当前帧与 reference 帧之间的光流,相当于额外获得了这一段时间的运动信息,所以说有更大的感受野。
有选择地加噪
在去噪过程的每个时间步 t,总是将reference image latent code与noise latent code在时间维度上concat,以保证reference image的内容在生成过程中被忠实地保留。
✅ 实际上是用 ref image emb 代替了 noise\(_0\) 而不是在 noise\(_0\) 前加一帧 ref image.用这种方式,可以实现“预置指定帧的内容”的目的。
应用:Motion-I2V生成的细粒度控制
稀疏轨迹控制
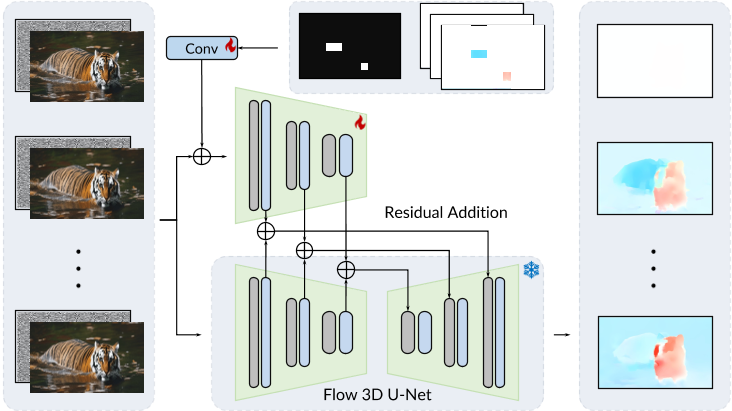
第一阶段中,通过ControlNet把人工绘制的轨迹图作为控制信号进行motion field map的生成。
第二阶段不变。
区域控制
第一阶段中,通过ControlNet把人工绘制的区域图作为控制信号进行motion field map的生成。
第二阶段不变。
视频风格转换
- 使用 image-to-image 第一帧进行图像风格转换
- 使用dense point tracker 计算dispacement space。
- 使用2和1计算motion field
- 使用motion field驱动1
训练
预训练模型
第一阶段:Stable Diffusion v1.5
第二阶段:AnimateDiff v2
数据集
WebVid-10M [1], a large scale text-video dataset
[❓] 3个细粒度控制的应用场中的 ControlNet,如何构造数据
答:根据视频可以直接生成光流,即 pair data 中的 y, 通过生成关键点及关键点追踪的方法生成稀疏轨迹,即pair date 中的x.
具体参考51
loss
训练策略
实验与结论
实验1: 横向对比
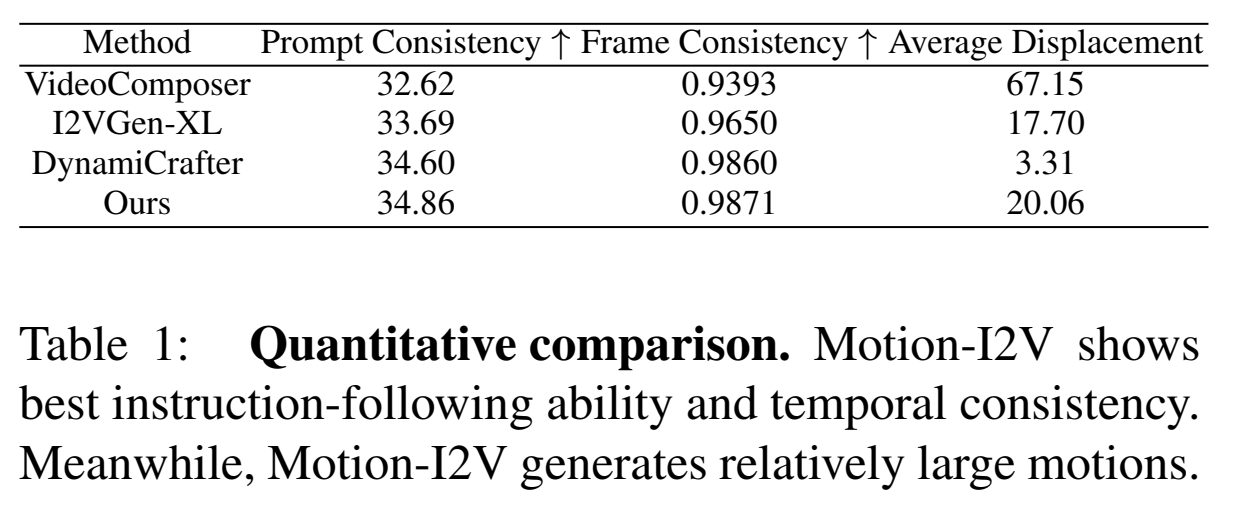
效果: Dynami Crafter 运动幅度较小。Pika 1.0生成的动作类型较少,但质量较高,Gen2的运动幅度大,但有变形。
实验2: Ablation
- 不使用 Stage 1
- 使用 Stage 1 但用普通 attention 进行信息注入。
- 使用 Stage 1 和 motion-augmented temporal attention.
效果:
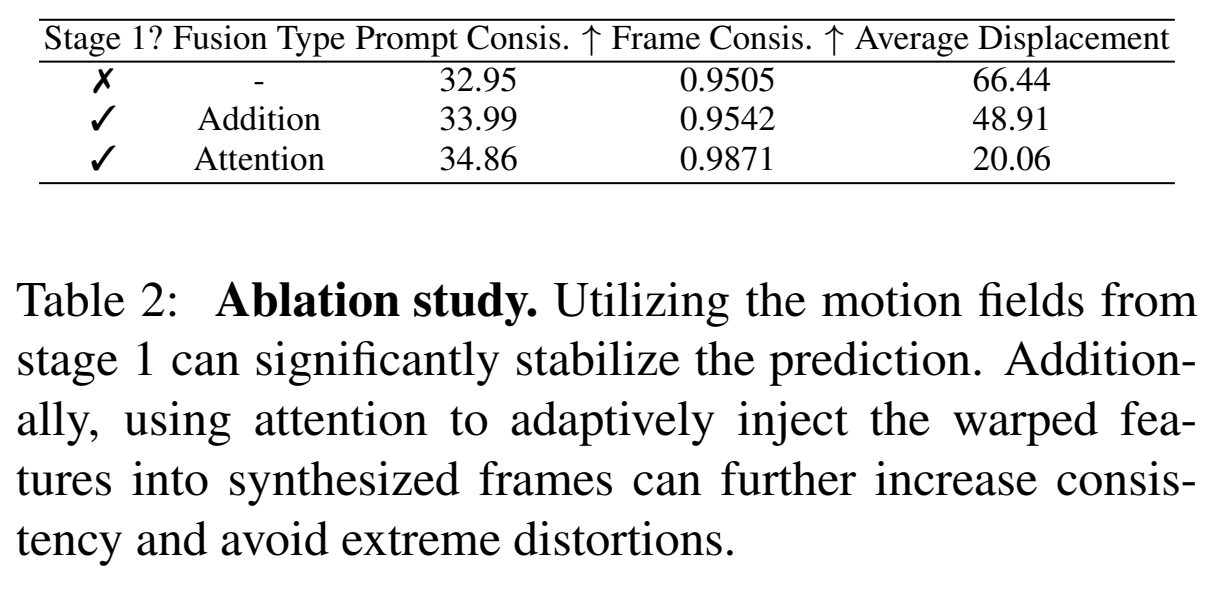
结论:相对于稀疏轨迹控制,使用光流控制的生成结果更稳定。
有效
- 一致性和可控性的比较优势:通过定量和定性比较,Motion-I2V在一致性和可控性方面优于现有方法,尤其是在存在大运动和视角变化的情况下。
局限性
- 生成视频的亮度倾向于中等水平。
这可能是因为noise scedule不强制最后一个时间步具有零信噪比(SNR),这会导致训练测试差异并限制模型的泛化性。使用最新的Zero-SNR noise schedulers可以缓解这个问题。
启发
motion field 的注入方式
遗留问题
参考材料
- 项目页面:https://xiaoyushi97.github.io/Motion-I2V/
数据集:HumanVid
HumanVid是第一个针对人体图像量身定制的大规模高质量数据集动画,结合了精心制作的现实世界和合成数据。
原始数据
- 现实世界的数据:从互联网上收集了大量无版权的现实世界视频。通过精心设计的基于规则的过滤策略,我们确保包含高质量视频,从而收集了 20K 个 1080P 分辨率的以人为中心的视频。
- 收集了 2,300 个无版权的 3D 头像资产,以扩充现有的可用 3D 资产。
合成数据
对原始数据2,使用一种基于规则的相机轨迹生成方法,使合成管道能够包含多样化且精确的相机运动注释,这在现实世界的数据中很少见。
人工标注
生成标注
- 人体和相机运动注释:使用 2D 位姿估计器和基于 SLAM 的方法完成的。
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
核心问题是什么?
目的
从角色照片生成视频
现有方法及问题
- 数据集的不可访问性阻碍了公平和透明的基准测试。
- 当前方法优先考虑 2D 人体运动,而忽视了视频中相机运动的重要性,导致控制有限和视频生成不稳定。
本文方法
- 推出了 HumanVid,第一个针对人体图像量身定制的大规模高质量数据集动画,结合了精心制作的现实世界和合成数据。
- 为了验证 HumanVid 的有效性,我们建立了一个名为 CamAnimate 的基线模型,CamAnimate 是相机可控人体动画的缩写,它将人类和相机运动都视为条件。
效果
通过广泛的实验,我们证明了在 HumanVid 上进行的这种简单的基线训练在控制人体姿势和相机运动方面实现了最先进的性能,树立了新的基准。
核心贡献是什么?
-
高质量数据集的创建:HumanVid是首个为人类图像动画量身定制的大规模高质量数据集,它结合了精心挑选的真实世界视频和合成数据。这个数据集的创建强调了高质量、公开可用的数据集在公平和透明基准测试中的重要性。
-
真实与合成数据的结合:为了提高数据的多样性和质量,作者不仅从互联网上收集了大量版权免费的真人视频,还结合了2300多个版权免费的3D头像资产来丰富数据集。
-
相机运动的重要性:与以往主要关注2D人体运动的方法不同,HumanVid和CamAnimate同时考虑了人体和相机运动,这对于生成逼真的人类视频至关重要。
-
精确的相机轨迹注释:通过使用基于SLAM(Simultaneous Localization and Mapping)的方法,作者能够为真实世界视频提供准确的相机轨迹注释,这在以往的数据集中很难找到。
-
规则化的相机轨迹生成方法:为了增强合成数据中相机运动的多样性和精确性,作者引入了一种基于规则的相机轨迹生成方法,这有助于模拟真实视频中常见的相机运动。
大致方法是什么?

3D建模 + 3D重定向 + 渲染
训练与验证
数据集
loss
训练策略
有效
-
CamAnimate基线模型:这个模型考虑了人体和相机运动作为条件,通过广泛的实验验证了在HumanVid数据集上训练的简单基线模型能够实现对人类姿势和相机运动的控制,达到了最先进的性能。
-
公平和透明的评估基准:通过提供统一的测试协议和数据集,作者为人类视频生成领域建立了一个新的评估基准,这有助于促进该领域的进一步发展和创新。
局限性
启发
遗留问题
参考材料
- 代码和数据:https://github.com/zhenzhiwang/HumanVid/
STORYDIFFUSION: CONSISTENT SELF-ATTENTION FOR LONG-RANGE IMAGE AND VIDEO GENERATION
这篇论文是由南开大学、字节跳动等机构提出的创新性研究,旨在解决生成连贯的多图像序列(如漫画)和长视频时的内容一致性问题。
核心问题是什么?
对于最近基于扩散的生成模型,在一系列生成的图像中保持一致的内容,特别是那些包含主题和复杂细节的图像,提出了重大挑战。
一、核心方法与技术贡献
1. 一致性自注意力(Consistent Self-Attention)
- 功能与原理:
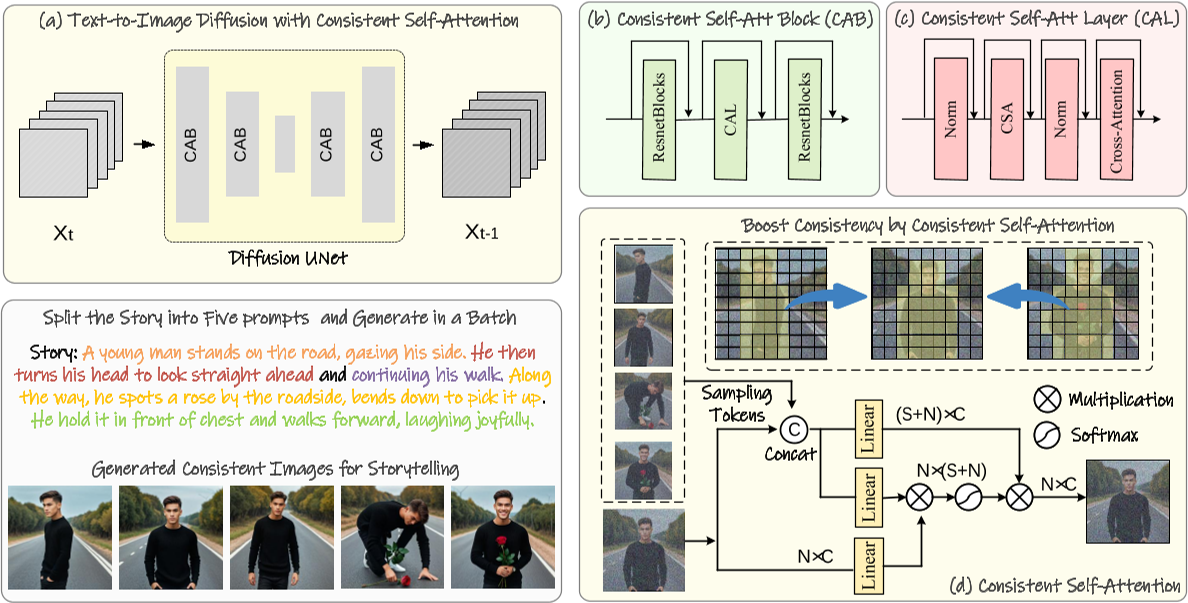
将故事文本拆分为多个提示,并使用这些提示批量生成图像。一致的自注意力在批量的多个图像之间建立连接,以实现主题一致性。
[?] 这个图画得不对?代码上还有input_id_images作为输入
该方法通过修改扩散模型中的自注意力机制,在生成一批图像时建立跨图像的关联,确保角色、服饰等细节的一致性。具体而言,在自注意力计算中引入其他图像的Token特征,通过特征交互促进角色属性的收敛(如面部、服装)。
- 技术优势:
- 无需训练:直接插入现有模型(如Stable Diffusion的U-Net架构),复用原有自注意力权重,实现即插即用。
- 多角色支持:可同时保持多个角色的一致性,适用于复杂叙事场景。
2. 语义运动预测器(Semantic Motion Predictor)
任务描述:通过在每对相邻图像之间插入帧,可以将生成的字符一致图像的序列进一步细化为视频。这可以看作是一个以已知开始帧和结束帧为条件的视频生成任务。
主要挑战:当两幅图像之间的差异较大时,SparseCtrl (Guo et al., 2023) 和 SEINE (Chen et al., 2023) 等最新方法无法稳定地连接两个条件图像。
当前解决方法的问题:这种限制源于它们仅依赖时间模块来预测中间帧,这可能不足以处理图像对之间的大状态间隙。时间模块在每个空间位置上的像素内独立操作,因此,在推断中间帧时可能没有充分考虑空间信息。这使得对长距离且具有物理意义的运动进行建模变得困难。
本文解决方法:语义运动预测器它将图像编码到图像语义空间中以捕获空间信息,从给定的起始帧和结束帧实现更准确的运动预测。
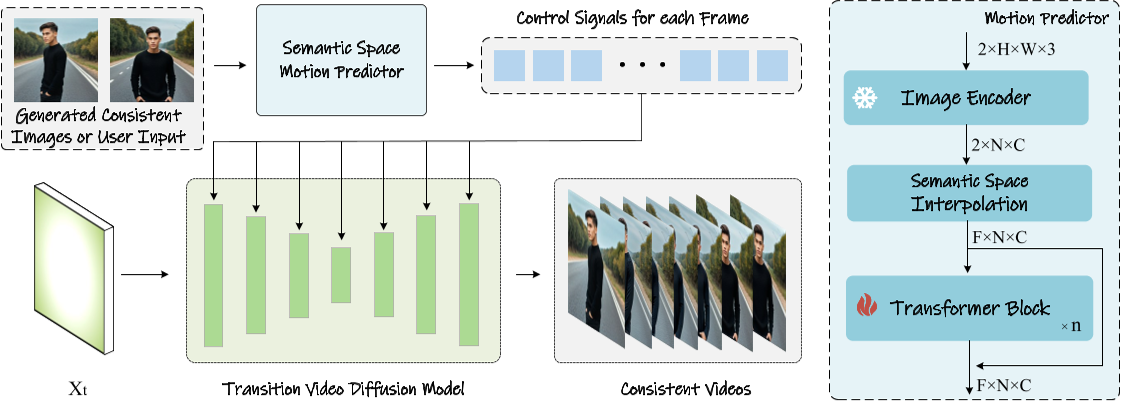
- 功能与原理:
针对长视频生成,该模块将起始帧和结束帧编码到语义空间(使用CLIP编码器),预测中间帧的运动轨迹,再通过视频扩散模型生成过渡视频。相较于传统潜在空间预测,语义空间能更稳定地捕捉空间信息。 - 技术流程:
- 编码与插值:将首尾帧映射为语义向量,插值生成中间序列。
- Transformer预测:通过训练过的模型优化中间帧嵌入,生成平滑的物理合理运动。
预训练的运动模块:结合预训练的运动模块,Semantic Motion Predictor能够生成比现有条件视频生成方法(如SEINE和SparseCtrl)更平滑、更稳定的视频帧。
3. 两阶段生成框架
- 第一阶段:生成一致性图像序列。通过文本分割生成多个提示词,批量生成图像并应用一致性自注意力。
- 第二阶段:生成视频过渡。基于第一阶段图像,利用语义运动预测器生成连贯视频。
二、实验与效果验证
1. 图像生成一致性对比
- 对比方法:与IP-Adapter、PhotoMaker等ID保持方法相比,StoryDiffusion在角色相似性(如服饰、面部)和文本-图像对齐性上表现更优。
- 定量指标:在CLIPSIM和LPIPS等指标上显著领先,尤其在复杂提示下仍能保持高一致性。
2. 视频生成性能
- 对比方法:与SEINE、SparseCtrl相比,生成的过渡视频在平滑度(LPIPS-frames)和语义一致性(CLIPSIM-frames)上均占优。
- 长视频支持:通过滑动窗口拼接多段视频,可生成超过1分钟的长视频,但全局连贯性仍有改进空间。
滑动窗口技术:为了支持长故事的生成,StoryDiffusion实现了与滑动窗口相结合的一致性自注意力,这消除了峰值内存消耗对输入文本长度的依赖,使得长故事的生成成为可能。
3. 消融实验
- 采样率优化:确定一致性自注意力的最佳采样率为0.5,平衡了生成质量与计算效率。
- 扩展性:兼容PhotoMaker等工具,支持用户指定角色ID生成图像。
三、代码解读
pipeline
# 简化代码,保留关键过程,源码请查看github
class PhotoMakerStableDiffusionXLPipeline(StableDiffusionXLPipeline):
@torch.no_grad()
def __call__(...):
# 0. Default height and width to unet
...
# 1. Check inputs. Raise error if not correct
...
# 2. Define call parameters
...
# 3. Encode input prompt,同时将reference image注入到embedding中
for prompt in prompt_arr:
# 3.1 Encode input prompt with trigger world
...
# 3.2 Encode input prompt without the trigger word for delayed conditioning
# 分别生成带trigger world的embedding和不带trigger world的embedding是训练策略。先保证无trigger world的普通生成质量,再加入trigger world。
...
# 5. Prepare the input ID images
...
# 7. Prepare timesteps
...
# 8. Prepare latent variables,latents的状态会累积
latents = self.prepare_latents(
...
latents, # init latents可以为None
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
...
# 10. Prepare added time ids & embeddings
...
# 11. Denoising loop
...
# 12. decoder and get image
...
return image
使用Textual Inversion把Reference Image注入到文本中
# 简化代码,保留关键过程,源码请查看github
# 3. Encode input prompt
for prompt in prompt_arr:
# 3.1 Encode input prompt with trigger world
(
prompt_embeds, # 记录所有prompt的embeds
pooled_prompt_embeds, # 记录当前prompt的embeds
class_tokens_mask,
) = self.encode_prompt_with_trigger_word(
prompt=prompt,
prompt_2=prompt_2,
nc_flag = nc_flag,
...
)
# 3.2 Encode input prompt without the trigger word for delayed conditioning
# 先生成不带trigger world的prompt
# encode, 此处的encode是prompt转为token的意思,与上下文中的Encode不同
tokens_text_only = self.tokenizer.encode(prompt, add_special_tokens=False)
# remove trigger word token
trigger_word_token = self.tokenizer.convert_tokens_to_ids(self.trigger_word)
if not nc_flag:
tokens_text_only.remove(trigger_word_token)
# then decode, token -> prompt
prompt_text_only = self.tokenizer.decode(tokens_text_only, add_special_tokens=False)
# 再Encode
...
# 5. Prepare the input ID images
...
if not nc_flag:
# 6. Get the update text embedding with the stacked ID embedding
prompt_embeds = self.id_encoder(id_pixel_values, prompt_embeds, class_tokens_mask)
bs_embed, seq_len, _ = prompt_embeds.shape
# [B, S, D] -> [B, S*N, D]
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
# [B, S*N, D] -> [B*N, S, D] --- 这个直接repeat(N,1,1)有什么区别?
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
pooled_prompt_embeds_arr.append(pooled_prompt_embeds)
pooled_prompt_embeds = None
第一步:对input prompt进行Encode
对input prompt进行Encode。其中prompt中是否包含trigger world token没有本质区别,只是一种训练策略。Encode的过程包括tokenize和text encode。
prompt --(tokenize)--> token --(text encode)--> embedding。
其中tokenize的过程有一些特殊处理,过程如下:
| 输入 | 输出 | 操作 |
|---|---|---|
| world list | token list | tokenizer.encode |
| token list | class_token_index, clean_input_ids list | token list中与trigger world token不同的token被放入clean input ids中,与trigger world token相同的token则被丢弃。 作者认为trigger world代表reference image,是一个名词,那么它前面的词就是形容reference image的特征的关键词,代码里称其为class。这个关键词在clean input ids中的index被记录到class_token_index list中。 实际上,只允许trigger world token在prmopt token中出现一次,因此也只有关键词及其在clean input ids中的index。 |
| class_token_index, clean input ids = [token, token, class, token, ...], reference image的数量 | clean input ids = [token, token, class,class, class, token, ...] | 根据reference image的数量重复class token |
| clean input ids | clean input ids | 把clean input ids补充或截断到固定长度 |
| clean input ids | class_tokens_mask | 标记clean input ids中哪些是class |
| clean input ids | prompt_embeds | 对每一个token逐个进行embedding并concat |
具体代码如下:
def encode_prompt_with_trigger_word(
self,
prompt: str,
prompt_2: Optional[str] = None,
num_id_images: int = 1,
device: Optional[torch.device] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
class_tokens_mask: Optional[torch.LongTensor] = None,
nc_flag: bool = False,
):
...
# Find the token id of the trigger word
image_token_id = self.tokenizer_2.convert_tokens_to_ids(self.trigger_word)
# Define tokenizers and text encoders
...
if prompt_embeds is None:
...
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
input_ids = tokenizer.encode(prompt)
# Find out the corresponding class word token based on the newly added trigger word token
for i, token_id in enumerate(input_ids):
if token_id == image_token_id:
class_token_index.append(clean_index - 1)
else:
clean_input_ids.append(token_id)
clean_index += 1
# 异常处理
...
class_token_index = class_token_index[0]
# Expand the class word token and corresponding mask
class_token = clean_input_ids[class_token_index]
clean_input_ids = clean_input_ids[:class_token_index] + [class_token] * num_id_images + \
clean_input_ids[class_token_index+1:]
# Truncation or padding
max_len = tokenizer.model_max_length
if len(clean_input_ids) > max_len:
clean_input_ids = clean_input_ids[:max_len]
else:
clean_input_ids = clean_input_ids + [tokenizer.pad_token_id] * (
max_len - len(clean_input_ids)
)
class_tokens_mask = [True if class_token_index <= i < class_token_index+num_id_images else False \
for i in range(len(clean_input_ids))]
# 维度统一
...
prompt_embeds = text_encoder(
clean_input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
class_tokens_mask = class_tokens_mask.to(device=device) # TODO: ignoring two-prompt case
return prompt_embeds, pooled_prompt_embeds, class_tokens_mask
第二步:把reference image与prompt融合
先对每个reference image依次编码,然后让reference image embedding与prompt embedding中标记为class的embedding做融合。融合过程为MLP。
具体代码如下:
class FuseModule(nn.Module):
def __init__(self, embed_dim):
...
def fuse_fn(self, prompt_embeds, id_embeds):
stacked_id_embeds = torch.cat([prompt_embeds, id_embeds], dim=-1)
stacked_id_embeds = self.mlp1(stacked_id_embeds) + prompt_embeds
stacked_id_embeds = self.mlp2(stacked_id_embeds)
stacked_id_embeds = self.layer_norm(stacked_id_embeds)
return stacked_id_embeds
def forward(self, prompt_embeds, id_embeds, class_tokens_mask, ) -> torch.Tensor:
# id_embeds shape: [b, max_num_inputs, 1, 2048]
id_embeds = id_embeds.to(prompt_embeds.dtype)
# 维度匹配
...
valid_id_embeds = ...
# slice out the image token embeddings
image_token_embeds = prompt_embeds[class_tokens_mask]
stacked_id_embeds = self.fuse_fn(image_token_embeds, valid_id_embeds)
...
return updated_prompt_embeds
denoise step
denoise step 使用 UNet-based diffusion network + CFG训练策略,输入由以下方式构成:
- latent_model_input
- latents
- latents
- current_prompt_embeds
- negative_prompt_embeds
- prompt_embeds(text only)
- id pixel values
- prompt embeddings
- class token mask
- added_cond_kwargs
- add text embeddings
- negative_pooled_prompt_embeds
- pooled_prompt_embeds(text_only)
- add time embeddings
- add text embeddings
# 11. Denoising loop
for i, t in enumerate(timesteps):
latent_model_input = (
torch.cat([latents] * 2) if do_classifier_free_guidance else latents
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if i <= start_merge_step or nc_flag:
current_prompt_embeds = torch.cat(
[negative_prompt_embeds, prompt_embeds_text_only], dim=0
)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds_text_only], dim=0)
else:
current_prompt_embeds = torch.cat(
[negative_prompt_embeds, prompt_embeds], dim=0
)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds], dim=0)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=current_prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
...
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image = self.image_processor.postprocess(image, output_type=output_type)
return image
图像一致性问题
在生成过程中在batch内的图像之间建立连接。保持一批图像中角色的一致性。
方法:将一致性自注意力插入到图像生成模型现有 U-Net 架构中原始自注意力的位置,并重用原始自注意力权重以保持免训练和可插拔。
定义一批图像特征为: \(\mathcal{I} ∈ R^{B×N×C}\) ,其中 B、N 和 C 分别是batch size、每个图像中的token数量和channel数。
通常情况下,第i张图像的Attention函数的输入xQ、xK、xV由第i图像的特征(1×N×C)通过映射得到。
本文为了在batch中的图像之间建立交互以保持一致性,修改为从batch中的其他图像特征中采样一些token加入第i个图像的特征中,第i张图像的特征变为1×(W * N * sampling_rate + N)×C,其中第一部分为从其它图像采样来的token,第二部分为自己原有的token。
def ConsistentSelfAttention(images_features, sampling_rate, tile_size):
"""
images_tokens: [B, C, N] # 论文上是这么写的,但我认为是[B, N, C]
sampling_rate: Float (0-1)
tile_size: Int
"""
output = zeros(B, N, C), count = zeros(B, N, C), W = tile_size
for t in range(0, N - tile_size + 1):
# Use tile to override out of GPU memory
tile_features = images_tokens[t:t + W, :, :]
reshape_featrue = tile_feature.reshape(1, W*N, C).repeat(W, 1, 1)
sampled_tokens = RandSample(reshape_featrue, rate=sampling_rate, dim=1)
# Concat the tokens from other images with the original tokens
token_KV = concat([sampled_tokens, tile_features], dim=1)
token_Q = tile_features
# perform attention calculation:
X_q, X_k, X_v = Linear_q(token_Q), Linear_k(token_KV), Linear_v(token_KV)
output[t:t+w, :, :] += Attention(X_q, X_k, X_v)
count[t:t+w, :, :] += 1
output = output/count
return output
参考材料
- 项目主页:https://StoryDiffusion.github.io
数据集:Zoo-300K
该数据集包含约 300,000 对文本描述和跨越 65 个不同动物类别的相应动物运动。
原始数据
Truebones Zoo [2] 数据集
合成数据
对原始数据的动作进行增强
人工标注
用表示动物和运动类别的文本标签进行注释
生成标注
reference
- 论文:link
Motion Avatar: Generate Human and Animal Avatars with Arbitrary Motion
核心问题是什么?
文生3D Mesh及运动序列
本文方法
- 文生人或动物的Mesh
- 引入了一个协调运动和头像生成的 LLM 规划器。
- 提出了一个名为 Zoo-300K 的动物运动数据集,其中包含 65 个动物类别的约 300,000 个文本运动对及其构建管道 ZooGen,它是社区的宝贵资源。
核心贡献是什么?
-
文本驱动的动态3D角色生成:Motion Avatar技术允许用户通过文本描述来生成具有特定动作的3D角色,这在动态3D角色生成领域是一个重要的进步。
-
基于代理的方法:该方法利用大型语言模型(LLM)代理来管理和响应用户查询,生成定制的动作提示和网格提示,这些提示用于后续的动作序列生成和3D网格创建。
-
LLM规划器:引入了一个LLM规划器,它将动作和头像生成的判别性规划转变为更灵活的问答(Q&A)模式,提高了对动态头像生成任务的适应性。
-
动物动作数据集Zoo-300K:论文提出了一个包含约300,000个文本-动作对的动物动作数据集,涵盖了65种不同的动物类别,以及构建该数据集的ZooGen管道,为社区提供了宝贵的资源。
-
动作和网格生成的自动重定向:生成的3D网格会经过自动绑定过程,使得动作可以重新定向到绑定的网格上,这为动态头像的动画制作提供了便利。
-
多模态大型语言模型的应用:使用专门为视频理解设计的多模态大型语言模型Video-LLaMA来描述经过ZooGen处理的动作数据,提高了描述的准确性和质量。
-
用户研究:通过用户研究,论文评估了Motion Avatar生成的动画在真实世界应用中的有效性,包括动作的准确性、网格的视觉质量、动作和网格的整合度以及用户的整体参与度和吸引力。
-
技术细节和方法论:论文详细介绍了Motion Avatar生成过程中使用的各种技术,包括文本到动作的转换、3D网格生成、自动绑定和动作重定向等。
-
实验和评估:论文通过实验评估了LLM规划器的性能,以及Motion Avatar在生成人类和动物动作方面的有效性。
-
应用前景:这项技术在电影制作、视频游戏、增强现实/虚拟现实、人机交互等领域具有广泛的应用潜力。
大致方法是什么?
- Motion Avatar 利用基于 LLM 代理的方法来管理用户查询并生成定制的提示。
- 这些生成运动序列和 3D 网格。运动生成遵循自回归过程,而网格生成在 imageto-3D 框架内运行。
- 3D网格会经历自动绑定过程,从而允许将运动重新定位到已装配的网格。
- 用生成的运动序列经过3D重定向驱动绑定好的3DMesh。
训练与验证
数据集
loss
训练策略
有效
局限性
无法生成背景。
启发
遗留问题
参考材料
- 数据集:link
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODEL
Microsoft,开源
核心问题是什么?
基于预训练的大模型进行finetune时,finetune 所需的训练时间、参数存储,Computation 的成本很高,因此重新训练所有模型参数变得不太可行。
现有方法及存在的问题
适配器层引入推理延迟
-
适配器会引入额外的计算。
这不是关键问题,因为适配器层被设计为具有很少的参数(有时<原始模型的 1%),并且具有小的瓶颈尺寸。 -
适配器层必须按顺序处理。
大型神经网络依赖硬件并行性来保持低延迟。Adapter 对在线推理设置产生了影响,其中批量大小通常小至 1。在没有模型并行性的一般场景中,例如在单个 GPU 上的 GPT-2推理,使用适配器时延迟会显着增加,即使瓶颈维度非常小。
[❓] 为什么 Adapter 导致在线推理的 batchsize 为1?
直接优化提示很难
[❓] 这一段没看懂
本文方法
✅ 解决方法:仅仅拟合residual model 而不是 finetune entire model.
我们提出了Low Rank Adapter(LoRA),它冻结了预训练的模型权重,并将可训练的rank分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量。与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。
效果
✅ Results:LoRA对数据集要求少,收敛速度快。可以极大提升 finetune 效率,也更省空间。 LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量上表现与微调相当或更好,尽管可训练参数较少、训练吞吐量较高,并且与适配器不同,没有额外的推理延迟。
核心贡献是什么?
-
Low Rank Adapter(LoRA):这是一种新技术,通过在Transformer架构的每一层中注入可训练的低秩分解矩阵来调整预训练模型的权重,而不是重新训练所有模型参数。
-
易于实现和集成:论文提供了一个便于与PyTorch模型集成的LoRA包,以及RoBERTa、DeBERTa和GPT-2的实现和模型检查点。
-
经验性研究:论文还提供了对语言模型适应中的秩不足进行实证研究,这有助于理解LoRA的有效性。
大致方法是什么?
LoRA
神经网络包含许多执行矩阵乘法的密集层。这些层中的权重矩阵通常具有满秩。
我们假设在adaption过程中权重的更新具有较低的“内在维度”。
定义预训练的权重矩阵为 \(W0 ∈ R^{d×k}\),其更新过程为:W0 + ΔW
我们通过用低秩分解,将权重更新过程描述为: W0 + ΔW = W0 + BA,其中 \(B ∈ R^{d×r} , A ∈ R^{r×k}\) ,并且秩 \(r \ll min(d, k)\)。
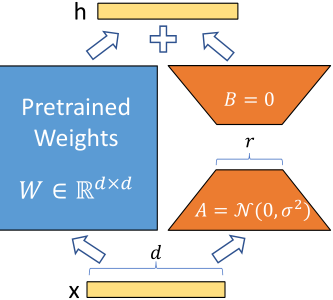
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
请注意,W0 和 ΔW = BA 都与相同的输入相乘,并且它们各自的输出向量按坐标求和。
LoRA应用到Transformer
理论上,LoRA可以应用于网络中的任意密集矩阵上,但本文仅将LoRA应用于attention层。
对于特定adaption,使用特定的BA。换一种adaption则换一组BA。不需要adaption则将BA去掉。
全参微调
极限情况下(所有层加 LoRA,且秩与原参数相同),LoRA 相当于全参微调。
Adapter 相当于MLP
prefix-based methods 收敛到“不能接收长输入”的模型。
训练
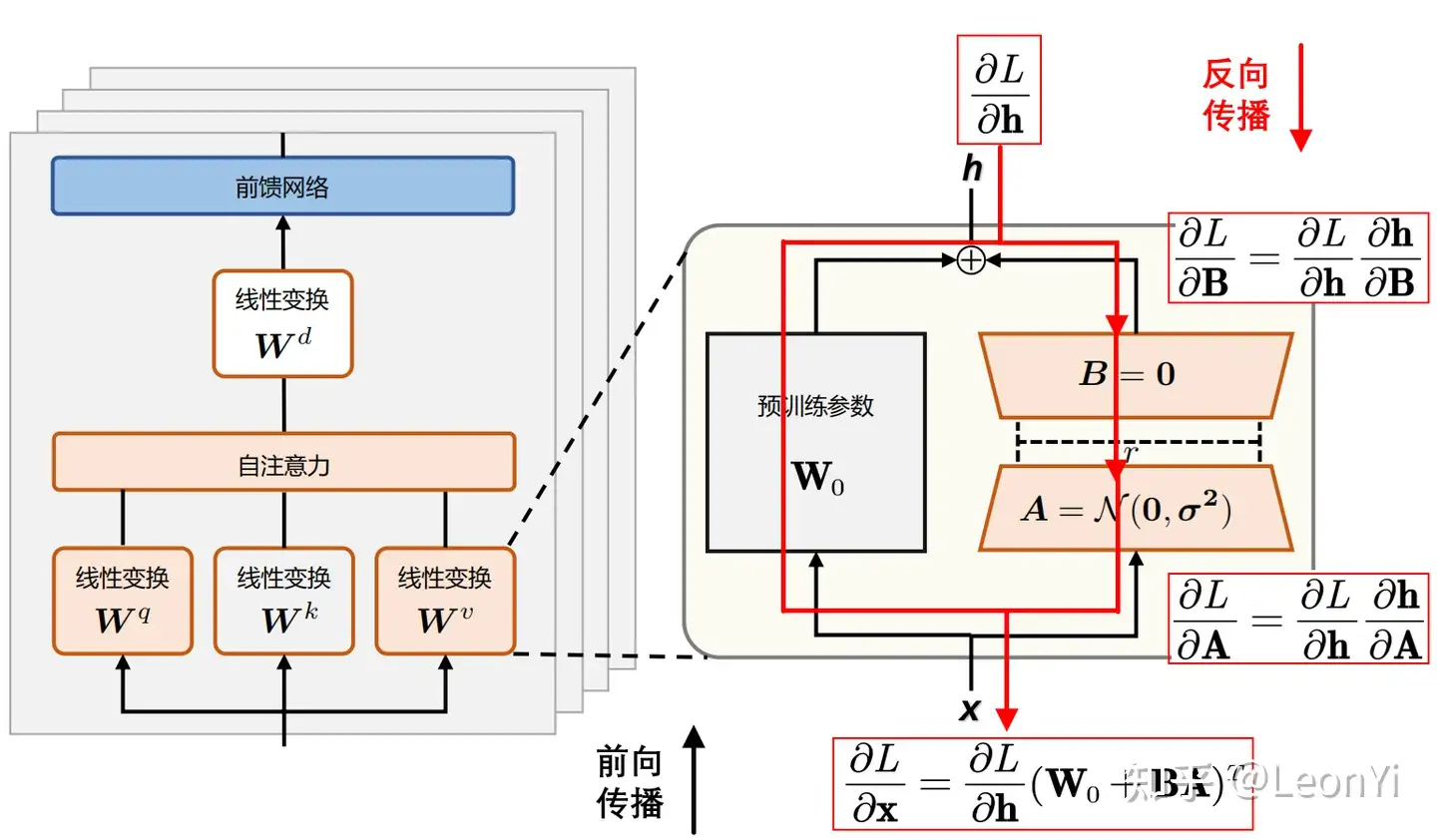
训练与验证
训练策略
参数冻结
训练期间,W0 被冻结,不接收梯度更新,而 A 和 B 包含可训练参数。
参数初始化
对 A 使用随机高斯初始化,对 B 使用零,因此 ΔW = BA 在训练开始时为零,且梯度不为0。
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
实际实现时,\(\Delta \mathbf{W} = \mathbf{B}\mathbf{A}\)会乘以系数\(\frac{\alpha}{r}\)与原始预训练权重合并\(\mathbf{W}_{0}\),\(\alpha\)是一个超参:
$$ \mathbf{h} = (\mathbf{W}_{0} + \frac{\alpha}{r} \Delta \mathbf{W})\mathbf{x} $$
def __init__(self, ...):
...
self.scaling = self.lora_alpha / self.r
...
def train(self, ...):
...
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
...
调参
超参\(\alpha\)和\(r\)实现了训练强度和注入强度的解耦。
只需训练一种训练强度\(r\),通过调整\(\alpha\),就可以得到不同注入强度的效果。
直观来看,系数\(\frac{\alpha}{r}\)决定了在下游任务上微调得到的LoRA低秩适应的权重矩阵\(\mathbf{B}\mathbf{A}\)占最终模型参数的比例。
给定一个或多个下游任务数据,进行LoRA微调:
系数\(\frac{\alpha}{r}\)越大,LoRA微调权重的影响就越大,在下游任务上越容易过拟合 系数\(\frac{\alpha}{r}\)越小,LoRA微调权重的影响就越小(微调的效果不明显,原始模型参数受到的影响也较少) 一般来说,在给定任务上LoRA微调,让\({\alpha}\)为\(r\)的2倍数。(太大学过头了,太小学不动。)
根据经验,LoRA训练大概很难注入新的知识,更多是修改LLM的指令尊随的能力,例如输出风格和格式。原始的LLM能力,是在预训练是获得的(取决于参数量、数据规模X数据质量)。
LoRA的秩\(r\)决定,LoRA的低秩近似矩阵的拟合能力,实际任务需要调参挑选合适的秩\(r\)维度。系数\(\frac{\alpha}{r}\)中\(\alpha\)决定新老权重的占比。
数据集
loss
训练策略
实验与结论
在三种预训练模型上使用不同方式微调
- FT/BitFit:不使用插件,全部微调或部分参数微调。
- Adpt:原参数fix,加入各种不同版本的Adapter.
- LoRA.
实验一: RoBERT 等 NLP models
效果: 
实验二: GPT-2 等 NLG models
效果: 
实验三: 超大模型 GPT-3
效果: 
当在 prefix-embedding tuning 使用超过256 special token 或在prefix-layer tuning使用超过32 special token时,性能明显下降。
.
分析: more special token 会导致输入分布与预训练模型的输入分布有偏移。
相关工作
Transformer Language Models
BERT,GPT-2,GPT-3
提示工程和微调
提示工程: 通过额外的训练示例输入模型,而不是训练模型,就可以调整模型的行为,学到新的任务。
微调: 将一般领域预训练的模型重新训练到特定任务上。
Parameter-Efficient Adaption
- 在NN层之间插入adapter层。
同样只引入少量的参数,但adapter的训练结果不能直接与原模型合并,而LoRA可以,因此使用LoRA不引及额外的推断时延。 - COMPACTER,一种adapter的扩展方法,可以提升参数效率。
- 优化输入词的embedding
- 低秩结构
理解LoRA
“LoRA中的参数更新”与“预训练模型的weight”之间的关系,是可解释的。
给定可调参数的预算,应当调整预训练transformer中的哪个权重矩阵?
实验一:
- 对1个模块做LoRA,rank=8
- 对2个模块做LoRA,rank=4
- 对4个模块做LoRA,rank=2
效果: 
结论:
- rank=4 是够用的。
- 对更多的模块做LoRA优于对一个模块用更大的rank做LoRA.
最优的\(\Delta W\)矩阵真的低秩的吗?实践中怎么定义rank?
实验二:
- 使用不同的rank
效果: 
结论: \(\Delta W\)具有较小的内在rank.
实验三: 不同的\(r\)之间的subspace的相似度
步骤:
- 在相同的预训练模型上训LoRA,rank分别取8和64。
- 训好后,取矩阵\(A_{r=8}\) 和 \(A_{r=64}\)
- 对\(A\)做SVD(奇异值分解),取\(U_{r=8}\) 和 \(U_{r=64}\)
- 计算\(U^i_{r=8}\) 和 \(U^j_{r=64}\)的高斯距离和subspace相似度。1代表完全重合,0代表完全分离。
效果: 
结论:
- \(A_{r=8}\) 和 \(A_{r=64}\)的 top singular Vector具有很高的相似度,其中 dimension 1 的相拟度大于 0.5,所以 \(r=1\)也能 performs quite well.
- top singular-vector directions 包含了大部信息,而剩下的大部分都是随机嗓声,因此\(\Delta w\)使用低秩就够用了。
实验四:
- 使用不同的seed 和 相同的 rank =64.
效果: 
\(\Delta w_q\)的 singular value具有更多的相似性。
结论: \(\Delta W_q\)比\(\Delta W_\upsilon\)具有更高的 intrinsic rank\(_q\),因为如果方向没有明显一致性,更有可能是随机噪声。
实验五:
\(\Delta W与W\)是什么关系?
- \(W 和 \Delta W\) 的关系分析
结果: 
结论: \(\Delta W 和 W\) 之间有比较明显的关系。
- \(\Delta W 对 W\) 中已有的feafure 放大。
- \(\Delta W\) 只放大\(W\)中不那么强调的特征。
- 放大因子比较大,且 r = 4,大于 r > 64
- LoRA 的主要作用是放大那些在下游任务中重要但在预训练模型中不重要的特征。
有效
-
模型质量:尽管可训练参数数量减少,LoRA在多个模型(如RoBERTa、DeBERTa、GPT-2和GPT-3)上的表现与全参数微调相当或更好。
-
参数效率和计算效率:LoRA通过在Transformer架构的每一层中引入低秩矩阵来调整预训练模型,大幅减少了可训练参数的数量,从而降低了模型对计算资源的需求,训练更加高效。
-
内存和存储效率:由于减少了可训练参数,LoRA在训练和部署时需要的内存和存储空间显著减少,使得在资源受限的环境中部署大型模型成为可能。
-
无损推理速度:与其他方法(如适配器层)不同,LoRA在推理时不会引入额外的延迟,因为它允许在部署时合并训练的低秩矩阵与冻结的权重,保持了与原始模型相同的推理速度。
-
模型共享与快速任务切换:LoRA允许共享一个预训练模型,并根据不同任务快速切换低秩矩阵,这减少了存储和部署多个独立模型实例的需要。
-
易于实现和集成:论文提供了LoRA的实现和模型检查点,便于研究者和开发者将其集成到现有的PyTorch模型中。
-
泛化能力:LoRA显示出良好的泛化能力,即使是在低数据环境下也能保持较好的性能。
-
训练和推理的一致性:LoRA在训练和推理过程中保持了一致性,这有助于简化模型部署和应用。
局限性
-
特定权重的选择:LoRA需要选择哪些权重矩阵应用低秩适应,这可能需要基于经验或额外的启发式方法来决定。
-
对低秩结构的依赖:LoRA假设模型权重的更新具有低秩结构,这可能不适用于所有类型的任务或模型架构。
-
可能的性能瓶颈:尽管LoRA在多个任务上表现良好,但对于某些特定任务,可能需要更多的参数来捕捉任务的复杂性,这可能限制了LoRA的性能提升空间。
-
适配器层的局限性:LoRA在某些情况下可能无法完全替代传统的适配器层,特别是在需要模型并行处理或处理不同任务输入的场景中。
-
对预训练模型的依赖:LoRA依赖于高质量的预训练模型,如果预训练模型在某些领域或任务上的表现不佳,LoRA的适应效果也可能受限。
-
超参数调整:LoRA的性能可能受到超参数(如低秩矩阵的秩)的影响,需要仔细调整这些参数以获得最佳性能。
-
特定任务的适用性:LoRA可能在某些任务上特别有效,而在其他任务上则可能需要更多的定制化或不同的适应策略。
启发
遗留问题
参考材料
- 代码仓库: https://github.com/microsoft/LoRA
- https://www.cnblogs.com/justLittleStar/p/18242820
TCAN: Animating Human Images with Temporally Consistent Pose Guidance using Diffusion Models
| 缩写 | 英文 | 中文 |
|---|---|---|
| APPA | APpearance-Pose Adaptation layer | |
| PTM | Pose-driven Temperature Map |
2024,开源
核心问题是什么?
基于diffusion model的pose驱动人体图像的视频生成,能够生成逼真的人体视频,但在时间一致性和对pose控制信号的鲁棒性方面仍然存在挑战。
本文方法
我们提出了 TCAN,一种姿势驱动的人体图像动画合成方法,它对错误姿势具有鲁棒性,并且随着时间的推移保持一致。
- 利用预先训练的 ControlNet,但不进行微调,利用其“文本+动作 -> 图像”的能力。
- 保持 ControlNet 冻结,将 LoRA 适配到 UNet 层中,使网络能够在姿势空间和外观空间之间的对齐。
- 通过向 ControlNet 引入额外的时间层,增强了针对异常姿态的鲁棒性。
- 通过分析时间轴上的注意力图,设计了一种利用姿势信息的新型温度图,从而实现更静态的背景。
效果
大量实验表明,所提出的方法可以在包含各种姿势(例如《赤壁》)的视频合成任务中取得有希望的结果。
核心贡献是什么?
-
adapts the latent space between appearance and poses.
-
使用预训练的ControlNet:与以往方法不同,TCAN使用预训练的ControlNet而不进行微调,利用其从大量姿势-图像-标题对中获得的知识。
-
LoRA适应:为了在保持ControlNet冻结的同时对齐姿势和外观特征,TCAN采用了LoRA(Low-Rank Adaptation)适应UNet层。
-
时间层的引入:通过在ControlNet中引入额外的时间层,增强了对姿势检测器异常值的鲁棒性。
-
注意力图分析:通过分析时间轴上的注意力图,设计了一种利用姿势信息的新颖温度图,允许更静态的背景。(仅推断时使用)
-
姿势重定向方法:提出了一种姿势重定向方法,以适应源图像中的对象与实际人体不同的身体比例。
大致方法是什么?
Base Model 为SD。
方法涉及两阶段训练策略。我们从训练视频中随机选择两个图像,分别用作source图像和driving图像。
第一阶段是以多张image为条件的图像生成任务,appreance UNet 和 APPA 层在source图像上进行condition训练,同时 ControlNet 被freeze。多张是指一张 driving pose 和一张 source image.
在第二阶段,训练 UNet 和 ControlNet 中的时间层。
LoRA 只加在ControlNet上,时序层在 UNet 和 ControlNet 上都有。
| 输入 | 输出 | 方法 |
|---|---|---|
| driving frame | pose information | OpenPose |
| pose information | pose image | |
| pose image noise | encoder feature z | UNet Encoder with ControlNet |
| reference image | intermediate feature maps of the appearance za | appearance UNet |
| encoder feature z appearance information za | denoised image | UNet Decoder with attention |
pose 以 ControlNet 形式注入,reference 用 appearadce UNet 编码后以 UNet Decoder Cross-attention 形式注入。
[❓] noise 编码和 reference 编码,为什么要使用不同的 UNet 参数?
reference图像注入
z(encoder feature)与za(appearance information)结合
以attention的方式结合z和za,仅应用于UNet Decoder部分
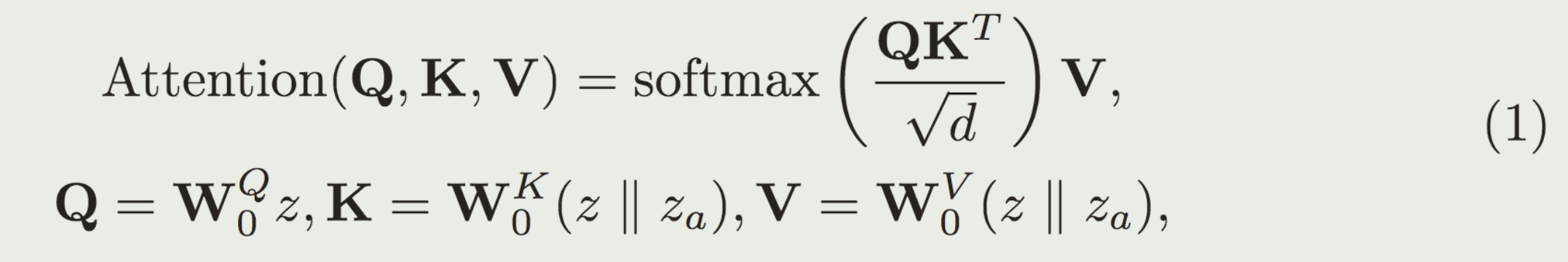
APPA层
没有APPA的UNet能生成与driving pose相似的动作,但不能保持reference image中的外观。
分析原因:appearance Za 与此包含 pose information 的 Z misalignment.
在UNet Decoder attention层中引入APPA layer(类似LoRA)
解决方法: 引入APPA层有以下三个作用
- 解决frozen ControlNet引入的artifacts
- 防止对training domain过拟合
- appearance与pose解耦
相当于是对 ControlNet 的微调,只是用 LoRA 代替全参微调。
对错误动作的鲁棒性
在UNet的所有层后面加入时序层,仅在第二阶段的训练启用时序层。
Temporal层用于解决pose不正确引入的artifacts。pose模块(ControlNet)的实现类似AnimateDiff。
背景闪烁问题
引入Pose-driven Temperature Map。
第二阶段训练完成后,把 Temporal attention layer 的 attention map 可视化。
把image resize到和attention map相同的大小,发现前景像素对应的attention的对角值更高。

attention map 是\(QK^T\) 矩阵,在时序层,Q.shape=K.shape=(bxwxh)xfxc,
因此,attention map.shape=(bxwxh)xfxf=bxwxh xfxf
可视化后,每个像素的内容fxf代表Q和k在P这个像素上在时间上相关性。
attention map 中的值比较平均,说明Output 相当于input 的均值。
作者期望背景表现为这种效果。
attention map 的值比较大,说明在这个位置看比较强的相关性。
attention map 中比较大的值出现在对角线上,说明是顺序相关的。当前前景是这个效果。
attention map 中比较大的值没有明显规律,说明相关没有明显规律。当前背景是这个效果。
attention map 中没有较大值,说明没有明显相关性。
与前景相比,背景在时间轴上的焦点往往不太具体,因此可以通过attention map,仅对背景部分进行平滑。
| 输入 | 输出 | 方法 |
|---|---|---|
| pose image | binary mask B | 画了骨架的地方标记为1,否则为0 |
| binary mask B | distance map D | 计算每个像素到离它最近的骨骼的距离 |
| distance map D | PTM \(\mathcal{T} \) | \(\mathcal{T} = τ * D + 1\) PTM代表attention的temperature |
| PTM \(\mathcal{T} \) | resized PTM \(\mathcal{T} \) | 把PTM \(\mathcal{T} \) resize到与attention map相同的大小 |
以以下方式把PTM \(\mathcal{T} \) 引入到UNet attention layer中:离骨架距离远(被认为是背景)→ D 大 →\(\mathcal{T} \)大 → attention score 小 → 与时间相关性小 → 稳定
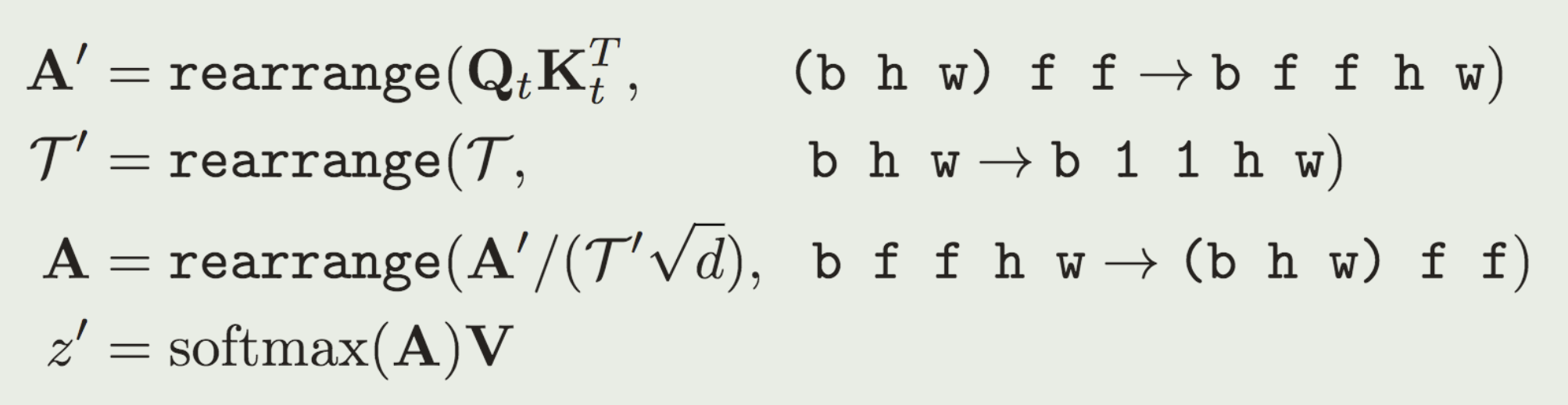
长视频推断策略
MultiDiffusion [2] along the temporal axis
推断时,把推断序列切成有重叠的clip,在一个step 中推断所有clip的噪声,把overlap 的噪声average,得到的噪声进入下一个step.
2D重定向(附录C)
推断时使用,调整driving pose中的点的位置。
固定neck,按层级关系,根据ref中的关节比例,依次调整 driving pose中的每个点的位置。
✅ 根据2D比例做重定向,不能处理透视带来的变形问题。
训练
训练策略
| 阶段 | freeze | trainable | 特有模块 |
|---|---|---|---|
| 第一阶段 | denoising UNet with SD1.5 OpenPose ControlNet | appreance UNet with Realistic Vision LoRA layer in APPA | 无 |
| 第二阶段 | denoising UNet with SD1.5 OpenPose ControlNet | temporal layer in denoising UNet temporal layer in ControlNet | temporal layer in denoising UNet temporal layer in ControlNet |
两个阶段训练的参数是独立的,没有联合训练的过程。
没有针对长序列生成修改训练策略。
数据集
训练集:TikTok
验证集:DisCo(类似于TikTok Style)
测试集:animation character,自己构建的Bizdrre dataset.
loss
同Stable Diffusion Model
训练策略
Base Model: SD 1.5
appearance UNet: Civitai Realistic Vision, Openpose ControLNet
实验与结论
实验一: 横向对比
- DisCo(Open Pose)
- MagicAnimate(Dense Pose)
- TCAN
效果:
-
当 Open Pose 丢失关健信息时,1和2会出现严重的问题,但3能得到时序一致的输出。
[❓] TCAN 通过引入时序层解决这个问题。1和2的结构中无时序层?
3在所有指标上都最优,除了LPIPS。作者认为这是因为TCAN没有使用额外的 large-scale human dataset.
实验二:
- motion 模块使用 AnimateDiff verson 1 作为初始权重。
- motion 模块使用 AnimateDiff verson 2 作为初始权重。
效果: 2明显优于1
实验三: 使用不同体型的数据作测
- DisCo + retargeted pose
- MagicAnimate + Dense Pose
- TCAN + retargeted pose
- TCAN + retargeted Poe, 且 freeze ControlNet.
效果: 1 的时序一致性较差。2的前景会变形成与driving video相同的体型。3的外观保持较差。 4能很好地给ref的外观、体型与driving的动作。
结论:
- freeze ControlNet 这一步很重要,它能将pose分支与appearance分支的责任解耦。
- 预训练的 ControlNet 使模型具有对不同体型的泛化性。
实验四: APPA ablation.
- freeze ControlNet + APPA
- unfreeze Control Net.
效果:
- 2中预训练的 ControlNet出现先验知识的退化,产生artifacts.
实验五:
- ControlNet 中无时序层
- ControlNet + 时序层
- ControlNet + 时序层 + PTM
效果: 2能将错误的pose平滑,3能去除闪烁问题。
评价指标:
图像质量: L1,SSIM,LPIPS,FID
视频质量: FID-FVD,FVD
有效
-
时间一致性:TCAN专注于生成在时间上连贯的动画,即使输入的姿势检测有误差,也能保持动画的稳定性。
-
扩展到不同领域:TCAN不仅在TikTok数据集上训练,还能够泛化到未见过的领域,如动画角色。
-
用户研究:进行了用户研究来评估TCAN在不同数据集上的表现,包括动画角色,结果显示TCAN在保持运动和身份、背景、闪烁和整体偏好方面均优于现有技术。
-
实验结果:TCAN在多个指标上展示了优越的性能,包括L1损失、结构相似性(SSIM)、感知损失(LPIPS)、Fréchet距离(FID)和视频质量指标(FID-VID和FVD)。
局限性
启发
遗留问题
TCAN(Temporally Consistent Human Image Animation)技术在实际应用中可能面临以下挑战和限制:
-
姿势检测器的准确性:TCAN依赖于姿势检测器来提供输入姿势序列。如果姿势检测器出现误差,可能会影响生成动画的质量和时间一致性。
-
数据集的多样性:TCAN在特定数据集(如TikTok数据集)上训练时表现良好,但在处理与训练数据分布显著不同的数据时,可能需要额外的调整或训练。
-
计算资源:高质量的图像和视频生成通常需要大量的计算资源。TCAN作为一种基于扩散模型的技术,可能在实际部署时面临计算能力和效率的挑战。
-
过拟合风险:在特定领域内训练时,模型可能会过拟合到该领域的特定特征,从而降低其在其他领域的适用性。
-
2D 骨骼重定向,必须使用与目标角色相适配的骨骼,否则会导致人物变形。
-
内容的可控性:虽然TCAN提供了一定程度的控制能力,但在生成特定风格或满足特定条件的内容方面可能仍有限制。
-
实时性能:在需要实时生成动画的应用场景中,TCAN的处理速度和响应时间可能是一个考虑因素。
-
模型的可解释性:深度学习模型通常被认为是“黑箱”,TCAN模型的决策过程可能不够透明,这可能限制了其在需要高度可解释性的应用中的使用。
-
对抗性攻击的脆弱性:像其他基于深度学习的模型一样,TCAN可能对精心设计的对抗性攻击敏感,这可能需要额外的防御措施。
-
长期视频生成的挑战:由于内存限制,TCAN可能难以一次性生成长期视频。虽然可以通过多扩散方法来解决这个问题,但这可能会影响视频的整体一致性。
这些挑战和限制表明,尽管TCAN在技术上具有创新性,但在将其应用于实际问题之前,需要仔细考虑和解决这些潜在的问题。
参考材料
- 项目页面:https://eccv2024tcan.github.io/
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
核心问题是什么?
目的
输入:单个视频 输出:具有动态 3D 外观的逼真人类头像 目的:实现自由视角渲染,生成逼真人类头像动画
本文方法
- 引入可动画化的 3D GS 来明确代表各种姿势和服装风格的人类。
- 设计一个动态外观网络以及一个可优化的特征张量,用于实现运动到外观的映射。通过动态属性进一步增强3D GS表示。
- 对运动和外观进行联合优化,缓解『单目视频中运动估计不准确』的问题。
效果
GaussianAvatar的功效在公共数据集和我们收集的数据集上都得到了验证,证明了其在外观质量和渲染效率方面的优越性能。
核心贡献是什么?
-
3D高斯表示法(3D Gaussians):论文提出了使用3D高斯来显式表示不同姿势和服装样式下的人体。这种方法可以有效地从2D观察中融合3D外观。
-
动态属性建模:为了支持不同姿势下的动态外观建模,论文设计了一个动态外观网络和可优化的特征张量,以学习运动到外观的映射。
-
运动和外观的联合优化:利用可微分的运动条件,论文的方法可以在化身建模过程中同时优化运动和外观,有助于解决单目设置中不准确运动估计的长期问题。
-
实现细节:论文详细介绍了如何通过3D高斯表示法来重建具有动态外观的人体化身,包括如何将3D高斯与SMPL或SMPL-X模型集成,以及如何通过动态外观网络预测3D高斯的动态属性。
-
训练策略:论文提出了一个两阶段的训练策略,首先在不包含姿势依赖信息的情况下训练网络,然后在第二阶段整合姿势特征编码。
大致方法是什么?
给定当前帧上拟合的 SMPL 模型,我们对其表面上的点进行采样,并将它们的位置记录在 UV 位置图 I 上,然后将其传递给姿势编码器以获得姿势特征。可优化的特征张量与姿势特征进行像素对齐,并学会捕捉人类的粗糙外观。然后将两个对齐的特征张量输入到高斯参数解码器中,该解码器预测每个点的偏移量 Δx、颜色 c 和尺度 s。这些预测与固定旋转 q 和不透明度 α 一起构成了规范空间中的可动画化 3D 高斯。
Animatable 3D Gaussians 可驱动的3D高斯
先预测高斯属性,然后用LBS驱动这个高斯球,渲染驱动后的高斯球。
Mesh以SMPL为template,且Mesh上的每个顶点对应一个高斯球,因此LBS的蒙皮绑定直接复用SMPL的。
动态 3D 高斯属性估计
- 根据pose预测高斯属性,可得到与pose相关的动态高斯属性。
- 属性pose feature,还有feature tensor,用于描述global appreance,防止对动作过拟合。
- pose feature通过UV map(H×W×3,其中每个有效像素存储姿势身体表面上一个点的位置(x,y,z)),描述2D人体。
- 用各向同性(旋转和缩放均为单位值)的高斯球代替各向异性的高斯球,防止陷入特定视角的local optima(训练数据的视角数据不均等)。
- 固定alpha=1,以获得更准确的高高斯球位置。
class ShapeDecoder(nn.Module):
'''
The "Shape Decoder" in the POP paper Fig. 2. The same as the "shared MLP" in the SCALE paper.
- with skip connection from the input features to the 4th layer's output features (like DeepSDF)
- branches out at the second-to-last layer, one branch for position pred, one for normal pred
'''
def __init__(self, in_size, hsize = 256, actv_fn='softplus'):
self.hsize = hsize
super(ShapeDecoder, self).__init__()
self.conv1 = torch.nn.Conv1d(in_size, self.hsize, 1)
self.conv2 = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv3 = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv4 = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv5 = torch.nn.Conv1d(self.hsize+in_size, self.hsize, 1)
self.conv6 = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv7 = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv8 = torch.nn.Conv1d(self.hsize, 3, 1)
self.conv6SH = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv7SH = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv8SH = torch.nn.Conv1d(self.hsize, 3, 1)
self.conv6N = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv7N = torch.nn.Conv1d(self.hsize, self.hsize, 1)
self.conv8N = torch.nn.Conv1d(self.hsize, 1, 1)
self.bn1 = torch.nn.BatchNorm1d(self.hsize)
self.bn2 = torch.nn.BatchNorm1d(self.hsize)
self.bn3 = torch.nn.BatchNorm1d(self.hsize)
self.bn4 = torch.nn.BatchNorm1d(self.hsize)
self.bn5 = torch.nn.BatchNorm1d(self.hsize)
self.bn6 = torch.nn.BatchNorm1d(self.hsize)
self.bn7 = torch.nn.BatchNorm1d(self.hsize)
self.bn6N = torch.nn.BatchNorm1d(self.hsize)
self.bn7N = torch.nn.BatchNorm1d(self.hsize)
self.bn6SH = torch.nn.BatchNorm1d(self.hsize)
self.bn7SH = torch.nn.BatchNorm1d(self.hsize)
self.actv_fn = nn.ReLU() if actv_fn=='relu' else nn.Softplus()
self.sigmoid = nn.Sigmoid()
self.tan = nn.Tanh()
def forward(self, x):
x1 = self.actv_fn(self.bn1(self.conv1(x)))
x2 = self.actv_fn(self.bn2(self.conv2(x1)))
x3 = self.actv_fn(self.bn3(self.conv3(x2)))
x4 = self.actv_fn(self.bn4(self.conv4(x3)))
x5 = self.actv_fn(self.bn5(self.conv5(torch.cat([x,x4],dim=1))))
# position pred
x6 = self.actv_fn(self.bn6(self.conv6(x5)))
x7 = self.actv_fn(self.bn7(self.conv7(x6)))
x8 = self.conv8(x7)
# scales pred
xN6 = self.actv_fn(self.bn6N(self.conv6N(x5)))
xN7 = self.actv_fn(self.bn7N(self.conv7N(xN6)))
xN8 = self.conv8N(xN7)
# shs pred
xSH6 = self.actv_fn(self.bn6SH(self.conv6SH(x5)))
xSH7 = self.actv_fn(self.bn7SH(self.conv7SH(xSH6)))
xSH8 = self.conv8SH(xSH7)
# rotations = xN8[:,:4,:]
scales = self.sigmoid(xN8)
# scales = -1 * self.actv_fn(xN8[:,4:7,:])
# opacitys = self.sigmoid(xN8[:,7:8,:])
shs = self.sigmoid(xSH8)
return x8, scales, shs
动作与外观联合优化
由于对人体姿势的不精确估计,运动空间中的 3D 高斯分布不准确,可能导致渲染结果不令人满意。
因此同时优化动作和高斯属性。
训练与验证
第一阶段:仅输入feature tensor F,使用Encoder & Decoder解出高斯属性,用SMPL拟合所得到的动作驱动高斯,重建图像
def train_stage1(self, batch_data, iteration):
# 从batch中提取角色当前帧的rotation和translation
pose_batch, transl_batch = ..., ...
# 用LBS驱动角色,得到驱动后的mesh
live_smpl = self.smpl_model.forward(betas=self.betas,
global_orient=pose_batch[:, :3],
transl = transl_batch,
body_pose=pose_batch[:, 3:])
# 提前算好LBS矩阵
cano2live_jnt_mats = torch.matmul(live_smpl.A, self.inv_mats)
# geo_feature是要被优化的变量,代表了这个对象的统一的特征
geom_featmap = self.geo_feature.expand(self.batch_size, -1, -1, -1).contiguous()
# 对template mesh进行采样并在 UV 位置图 I 上记录它们的位置,用于建立像素到3D空间的映射。
uv_coord_map = self.uv_coord_map.expand(self.batch_size, -1, -1).contiguous()
# 根据uv coord map和feature tensor预测高斯属性
# pred_res: 3d position offset
# pred_shs:球协系数
pred_res,pred_scales, pred_shs, = self.net.forward(pose_featmap=None,
geom_featmap=geom_featmap,
uv_loc=uv_coord_map)
pred_res = pred_res.permute([0,2,1]) * 0.02 #(B, H, W ,3)
pred_point_res = pred_res[:, self.valid_idx, ...].contiguous()
# query_points:canomical mesh表面的采样点的位置
# pred_point_res:canomical mesh表面采样点的offset
cano_deform_point = pred_point_res + self.query_points
# offset是加在template上的,然后再lbs,得到deformed mesh
pt_mats = torch.einsum('bnj,bjxy->bnxy', self.query_lbs, cano2live_jnt_mats)
full_pred = torch.einsum('bnxy,bny->bnx', pt_mats[..., :3, :3], cano_deform_point) + pt_mats[..., :3, 3]
if iteration < 1000:
# 一开始预测出的scale偏大,所以这样限制一下
pred_scales = pred_scales.permute([0,2,1]) * 1e-3 * iteration
else:
pred_scales = pred_scales.permute([0,2,1])
# 维度对齐相关代码省略
...
# 正则化loss
offset_loss = torch.mean(pred_res ** 2)
geo_loss = torch.mean(self.geo_feature**2)
scale_loss = torch.mean(pred_scales)
# 渲染需要逐张进行
for batch_index in range(self.batch_size):
# 取出每一张图像的渲染参数
FovX = batch_data['FovX'][batch_index]
FovY = batch_data['FovY'][batch_index]
height = batch_data['height'][batch_index]
width = batch_data['width'][batch_index]
world_view_transform = batch_data['world_view_transform'][batch_index]
full_proj_transform = batch_data['full_proj_transform'][batch_index]
camera_center = batch_data['camera_center'][batch_index]
points = full_pred[batch_index]
colors = pred_shs[batch_index]
scales = pred_scales[batch_index]
# 进行渲染
rendered_images.append(
render_batch(
points=points,
shs=None,
colors_precomp=colors,
rotations=self.fix_rotation,
scales=scales,
opacity=self.fix_opacity,
FovX=FovX,
FovY=FovY,
height=height,
width=width,
bg_color=self.background,
world_view_transform=world_view_transform,
full_proj_transform=full_proj_transform,
active_sh_degree=0,
camera_center=camera_center
)
)
return torch.stack(rendered_images, dim=0), full_pred, offset_loss, geo_loss, scale_loss
第二阶段:使用pose encoder和同时作为输入,decoder出高斯属性,用SMPL拟合所得到的动作驱动高斯,重建图像
def train_stage2(self, batch_data, iteration):
# 与train_stage1相同
...
# 与train_stage1的区别在于推断时引入pose feature map
# 这里跟论文不一致,论文是根据uv_coord_map计算pose feature map
# inp_pos_map是提前算预计算好的,代表什么含义?
inp_posmap = batch_data['inp_pos_map']
pose_featmap = self.pose_encoder(inp_posmap)
pred_res,pred_scales, pred_shs, = self.net.forward(pose_featmap=pose_featmap,
geom_featmap=geom_featmap,
uv_loc=uv_coord_map)
# 与train_stage1相同
...
goem feature与pose feature是相加的关系
if pose_featmap is None:
# pose and geom features are concatenated to form the feature for each point
pix_feature = geom_featmap
else:
pix_feature = pose_featmap + geom_featmap
| Loss | 优化目的 | 方法 | 阶段 |
|---|---|---|---|
| rgb | 图像重建 | L1 Loss | 1,2 |
| ssim | SSIM Loss | 1,2 | |
| lpips | LPIPS Loss | 1,2 | |
| f | feature map | L2 Loss | 1 |
| offset | L2 | 1,2 | |
| scale | L2 | 1,2 | |
| p | limit the pose space | L2 | 2 |
数据集
People-Snapshot Dataset
NeuMan Dataset.
DynVideo Dataset
Evaluation Metrics.
loss
训练策略
实验
局限性
可能因视频中前景分割不准确而产生伪影,并且在建模宽松服饰(如连衣裙)方面遇到挑战。
相似工作对比(原创)
相同点:3D GS based 4D 生成 对比:
| 本文 | Dreamgaussian4d | |
|---|---|---|
| 外观信息 | reference video | reference image |
| 动作信息 | reference video | I2V 生成 或预置 |
| 外观提取3D GS | 联合优化得出高斯属性 | DreamGaussianHD |
| 动作信息提取 | 单目视频动捕 + 联合优化 | 隐式地优化学习 |
| 驱动方式 | LBS显式驱动 + 3DGS动态属性 LBS的驱动方式使方法受限于特定的绑定格式 | HexPlane显式驱动 |
| 优化对象 | 1. 静态高斯属性 2. 动作参数 3. 动态外观网络(生成动态高斯属性) 4. 一个可优化的特征张量 | 1. HexPlane运动信息 2.静态高斯属性(Optional) |
遗留问题
参考材料
- 代码和数据集:https://huliangxiao.github.io/GaussianAvatar
MagicPony: Learning Articulated 3D Animals in the Wild
核心问题是什么?
在给定单个测试图像作为输入的情况下,预测马等有关节动物的 3D 形状、关节、视点、纹理和光照。
本文方法
我们提出了一种名为 MagicPony 的新方法,该方法仅从特定类别对象的野外单视图图像中学习,并且对变形拓扑的假设最少。
其核心是铰接形状和外观的隐式-显式表示,结合了神经场和网格的优点。
为了帮助模型理解物体的形状和姿势,我们提炼了已有的自监督ViT,并将其融合到 3D 模型中。
为了克服视点估计中的局部最优,我们进一步引入了一种新的视点采样方案,无需额外的训练成本。
效果
MagicPony 在这项具有挑战性的任务上表现优于之前的工作。尽管它仅在真实图像上进行训练,但在重建艺术方面表现出出色的泛化能力。
核心贡献是什么?
-
隐式-显式表示(Implicit-Explicit Representation):MagicPony结合了神经场和网格的优势,使用隐式表示来定义形状和外观,并通过Differentiable Marching Tetrahedra(DMTet)方法即时转换为显式网格,以便进行姿态调整和渲染。
-
自监督知识蒸馏:为了帮助模型理解对象的形状和姿态,论文提出了一种机制,将现成的自监督视觉变换器(如DINO-ViT)捕获的知识融合到3D模型中。
-
多假设视角预测方案:为了避免在视角估计中陷入局部最优,论文引入了一种新的视角采样方案,该方案在每次迭代中只采样单一假设,且几乎不需要额外的训练成本。
-
层次化形状表示:从通用模板到具体实例的层次化形状表示方法,允许模型学习类别特定的模板形状,并预测实例特定的变形。
-
外观和着色分解:将对象的外观分解为反照率和漫反射着色,假设了一种兰伯特照明模型,并使用可微分的延迟网格渲染技术。
-
训练目标和损失函数:论文详细描述了训练过程中使用的损失函数,包括重建损失、特征损失、掩码损失、正则化项和视角假设损失。
大致方法是什么?
左:给定特定类别动物的单视图图像集合,我们的模型使用“隐式-显式”表示来学习特定于类别的先验形状,以及可以用于自监督特征渲染损失的特征字段。
中:根据从训练图像中提取的特征,对先前的形状进行变形、铰接和着色。
中右:为了克服视点预测中的局部最小值,我们引入了一种有效的方案,该方案可以探索多种假设,而基本上不需要额外的成本。
右:除了fix Image Encoder之外,整个管道都经过端到端的重建损失训练。
Implicit-Explicit 3D Shape Representation
隐式
目的:用于优化出一个通用的Mesh。 方法:SDF。定义隐式Mesh函数为
S = {x ∈ R3|s(x) = 0}
显式
目的:方便后面的deformation
方法:DMTet
优化过程
- 初始时,用SDF描述一个椭圆作为prior shape。
- 空间采样,使用DMTet生成prior Mesh的shape。
- 用下文的方法驱动调整和驱动prior mesh,得到deformed mesh。
- 通过deformed mesh与GT的重建Loss,优化SDF。
得到此类别所有对象共用的template。
# 代码有删减
class PriorPredictor(nn.Module):
def __init__(self, cfgs):
super().__init__()
self.netShape = DMTetGeometry(。。。)
def forward(self, total_iter=None, is_training=True):
# 得到prior template mesh
prior_shape = self.netShape.getMesh(total_iter=total_iter, jitter_grid=is_training)
return prior_shape, self.netDINO
class DMTetGeometry(torch.nn.Module):
def get_sdf(self, pts=None, total_iter=0):
if pts is None:
pts = self.verts
if self.symmetrize:
xs, ys, zs = pts.unbind(-1)
pts = torch.stack([xs.abs(), ys, zs], -1) # mirror -x to +x
sdf = self.mlp(pts)
if self.init_sdf is None:
pass
elif type(self.init_sdf) in [float, int]:
sdf = sdf + self.init_sdf
elif self.init_sdf == 'sphere':
init_radius = self.grid_scale * 0.25
init_sdf = init_radius - pts.norm(dim=-1, keepdim=True) # init sdf is a sphere centered at origin
sdf = sdf + init_sdf
elif self.init_sdf == 'ellipsoid':
rxy = self.grid_scale * 0.15
xs, ys, zs = pts.unbind(-1)
init_sdf = rxy - torch.stack([xs, ys, zs/2], -1).norm(dim=-1, keepdim=True) # init sdf is approximately an ellipsoid centered at origin
sdf = sdf + init_sdf
else:
raise NotImplementedError
return sdf
def getMesh(self, material=None, total_iter=0, jitter_grid=True):
# Run DM tet to get a base mesh,预置的一些空间中的点
v_deformed = self.verts
if jitter_grid and self.jitter_grid > 0:
jitter = (torch.rand(1, device=v_deformed.device)*2-1) * self.jitter_grid * self.grid_scale
v_deformed = v_deformed + jitter
# 计算这些点的sdf
self.current_sdf = self.get_sdf(v_deformed, total_iter=total_iter)
# 根据预置点的sdf找出0表面,并生成Mesh
verts, faces, uvs, uv_idx = self.marching_tets(v_deformed, self.current_sdf, self.indices)
self.mesh_verts = verts
return mesh.make_mesh(verts[None], faces[None], uvs[None], uv_idx[None], material)
Articulated Shape Modelling and Prediction
| 输入 | 输出 | 方法 |
|---|---|---|
| image | Image Mask | PointRend |
| image, mask | a set of key and output tokens | |
| local keys token \(\Phi_k \in R^{D\times H_p \times W_p}\)代表 deformation local outputs token \(\Phi_o \in R^{D\times H_p \times W_p}\)代表appreance | DINO-ViT,包含prepare层,ViT blocks层,final层 | |
| local keys token Φk | global keys token φk | small convolutional network |
| local output token Φo | global output token φo | small convolutional network |
| template shape \(V_{pr,i}\) global keys token φk | mesh displacement ∆Vi | CoordMLP,因为每一sdf生成的Mesh的顶点数和顶点顺序都是不确定的,因此不能使用普通的MLP 许多对象是双边对称的,因此通过镜像来强制先前的 Vpr 和 ∆V 对称 |
| \(V_{pr,i}\) ∆Vi | Vins | |
| ξ1,Vpr | bone在图像上的像素 ub | 根据ξ1把每个rest状态下的bone投影到图像上 |
| patch key feature map Φk(ub) ub | local feature | 从投影像素位置 ub 处的 Φk(ub) 中采样局部特征。 |
| image features Φk and φk bone position 3D bone position 2D | local rotation ξ2:B | The viewpoint ξ1 ∈ SE(3) is predicted separately |
| Vins 动作参数ξ a set of rest-pose joint locations Jb(启发式方法) skinning weights(relative proximity to each bone) | Vi | LBS |
def forward(self, images=None, prior_shape=None, epoch=None, total_iter=None, is_training=True):
batch_size, num_frames = images.shape[:2]
# 从图像生成a set of key and output tokens,使用一个ViTEncoder
# patch_out:local outputs token
# patch_key:local key token
# feat_out:global outputs token
# feat_key:global key token
feat_out, feat_key, patch_out, patch_key = self.forward_encoder(images) # first two dimensions are collapsed N=(B*F)
shape = prior_shape
texture = self.netTexture
# 预测root rotation,这一部分会在下文中展开
poses_raw = self.forward_pose(patch_out, patch_key)
pose_raw, pose, multi_hypothesis_aux = sample_pose_hypothesis_from_quad_predictions(poses_raw, total_iter, rot_temp_scalar=self.rot_temp_scalar, num_hypos=self.num_pose_hypos, naive_probs_iter=self.naive_probs_iter, best_pose_start_iter=self.best_pose_start_iter, random_sample=is_training)
# root rotation不体现在bone 0的rotation上,而是体现在相机的位姿上
mvp, w2c, campos = self.get_camera_extrinsics_from_pose(pose)
deformation = None
if self.enable_deform and epoch in self.deform_epochs:
# 根据feature key计算这个图像上的shape offset
# deformation:shape offset
# shape: prior shape + shape offset
shape, deformation = self.forward_deformation(shape, feat_key)
arti_params, articulation_aux = None, {}
if self.enable_articulation and epoch in self.articulation_epochs:
# 根据feature key计算关节旋转,并使用LBS得到驱动后的mesh
# 每次都会根据mesh重新计算bone position,使用启发式方法
# shape:驱动后的mesh
# arti_params:bone rotation,轴角形式
shape, arti_params, articulation_aux = self.forward_articulation(shape, feat_key, patch_key, mvp, w2c, batch_size, num_frames, epoch)
light = self.netLight if self.enable_lighting else None
aux = multi_hypothesis_aux
aux.update(articulation_aux)
# shape:根据图像生成的特定体型特定动作下的mesh
# pose_raw:root rotation
# pose:root rotation in mat
# mvp:3D->2D投影变换矩阵
# w2c:world->camera变换矩阵
# campos:camera position
# feat_out:global outputs feature,用于记录目标的外观
# deformation:shape offset
# arti_params:bone rotation in angle-axis
# aux:root rotation sample机制
return shape, pose_raw, pose, mvp, w2c, campos, texture, feat_out, deformation, arti_params, light, aux
Appearance and Shading
| 输入 | 输出 | 方法 |
|---|---|---|
| x, global output token φo | albedo | MLP |
| global output token φo | 主光源方向l 环境和漫射强度ks, kd | MLP |
| 3D coordinates Mesh V all pixels u | V中投影到u上的顶点x(u) | |
| x(u),fa | 像素u对应的颜色 a | |
| ks, kd, l, n, 像素u对应的颜色 a | 像素u最终的颜色 | |
| ks, kd, l, n, 像素u对应的颜色 a | 像素u的MASK |
这一段代码没有看懂
Viewpoint Prediction
我们提供了一种稳健且高效的方法,该方法利用多假设预测管道中的自监督对应关系。
这一段没看懂,参考Neural Feature Fusion Fields: 3D Distillation of Self-Supervised 2D Image Representations
难点:学习对象视点的一个主要挑战是重建目标中存在多个局部最优。
解决方法:我们提出了一种统计探索多个观点的方案,但在每次迭代时仅采样一个观点,因此没有额外成本。
| 输入 | 输出 | 方法 |
|---|---|---|
| global keys token φk | 4个假设的viewpoint rotation score σk,第k个假设的可能性 | Encoder32 |
学习 σk 的简单方法是对多个假设进行采样并比较它们的重建损失以确定哪一个更好。然而,这很昂贵,因为它需要使用所有假设来渲染模型。相反,我们建议为每次训练迭代采样一个假设,并通过最小化目标来简单地训练 σk 来预测预期重建损失 Lk
# poses_raw[:,:-3]:通过self.netPose预测出的num_hypos个假设的参数
# 每个假设的参数包含4维:概率*1、角度*3
# poses_raw[:,-3:]:预测出的translation
# 根据每个假设的概率进行一些计算,得出这个迭代的rot
def sample_pose_hypothesis_from_quad_predictions(poses_raw, total_iter, rot_temp_scalar=1., num_hypos=4, naive_probs_iter=2000, best_pose_start_iter=6000, random_sample=True):
rots_pred = poses_raw[..., :num_hypos*4].view(-1, num_hypos, 4) # NxKx4
N = len(rots_pred)
rots_logits = rots_pred[..., 0] # Nx4
rots_pred = rots_pred[..., 1:4]
trans_pred = poses_raw[..., -3:]
temp = 1 / np.clip(total_iter / 1000 / rot_temp_scalar, 1., 100.)
rots_probs = torch.nn.functional.softmax(-rots_logits / temp, dim=1) # NxK
naive_probs = torch.ones(num_hypos).to(rots_logits.device)
naive_probs = naive_probs / naive_probs.sum()
naive_probs_weight = np.clip(1 - (total_iter - naive_probs_iter) / 2000, 0, 1)
rots_probs = naive_probs.view(1, num_hypos) * naive_probs_weight + rots_probs * (1 - naive_probs_weight)
best_rot_idx = torch.argmax(rots_probs, dim=1) # N
if random_sample:
rand_rot_idx = torch.randperm(N, device=poses_raw.device) % num_hypos # N
best_flag = (torch.randperm(N, device=poses_raw.device) / N < np.clip((total_iter - best_pose_start_iter)/2000, 0, 0.8)).long()
rand_flag = 1 - best_flag
rot_idx = best_rot_idx * best_flag + rand_rot_idx * (1 - best_flag)
else:
rand_flag = torch.zeros_like(best_rot_idx)
rot_idx = best_rot_idx
rot_pred = torch.gather(rots_pred, 1, rot_idx[:, None, None].expand(-1, 1, 3))[:, 0] # Nx3
pose_raw = torch.cat([rot_pred, trans_pred], -1)
rot_prob = torch.gather(rots_probs, 1, rot_idx[:, None].expand(-1, 1))[:, 0] # N
rot_logit = torch.gather(rots_logits, 1, rot_idx[:, None].expand(-1, 1))[:, 0] # N
rot_mat = lookat_forward_to_rot_matrix(rot_pred, up=[0, 1, 0])
pose = torch.cat([rot_mat.view(N, -1), pose_raw[:, 3:]], -1) # flattened to Nx12
pose_aux = {
'rot_idx': rot_idx,
'rot_prob': rot_prob,
'rot_logit': rot_logit,
'rots_probs': rots_probs,
'rand_pose_flag': rand_flag
}
return pose_raw, pose, pose_aux
训练与验证
数据集
DOVE
Weizmann Horse Database [4], PASCAL [10] and Horse-10 Dataset
Microsoft COCO Dataset
CUB
loss
| loss name | 优化目的 | 计算方法 |
|---|---|---|
| im | 图像重建 | 仅计算前景区域,L1 Loss |
| m | mask重建 | L2 Loss |
| feat | dino feature重建,dino是绑在每个mesh顶点的的属性,且dino属性只于species type有关,与特定图像无关 | 仅计算前景区域,L2 loss |
| Eik | 正则化项,约束s被学习成一个SDF函数 | Eikonal regulariser |
| def | 正则化项,约束shape offset不要太大 | L2 Loss |
| art | 正则化项,约束旋转量不要太大 | |
| hpy | 正则化项,预测每个视角的置信度 | 置信度与这个角度得到的重建loss负相关 |
# 重建loss
losses = self.compute_reconstruction_losses(image_pred, image_gt, mask_pred, mask_gt, mask_dt, mask_valid, flow_pred, flow_gt, dino_feat_im_gt, dino_feat_im_pred, background_mode=self.background_mode, reduce=False)
for name, loss in losses.items():
logit_loss_target += loss * loss_weight
# hpy正则化项
final_losses['logit_loss'] = ((rot_logit - logit_loss_target)**2.).mean()
训练策略
- 首先对视角假设进行k个采样,计算每个采样的重建损失
- 然后,将正则化项和视点假设损失相加,得到最终loss.
每次梯度评估仅采用一个视点样本 k。为了进一步提高采样效率,我们根据学习到的概率分布pk4对视点进行采样:为了提高训练效率,我们在 80% 的时间对视点 k* = argmaxk pk 进行采样,并在 20% 的时间均匀随机采样。
有效
-
广泛的实验验证:在动物类别上进行了广泛的实验,包括马、长颈鹿、斑马、奶牛和鸟类,并与先前的工作进行了定性和定量比较。
-
少监督学习:MagicPony在几乎没有关于变形拓扑的假设下,仅使用对象的2D分割掩码和3D骨架拓扑的描述进行训练,展示了在少监督情况下学习3D模型的能力。
-
泛化能力:尽管MagicPony仅在真实图像上训练,但它展示了对绘画和抽象绘画的出色泛化能力。
局限性
如果以单张照片作为输出,虽然会对目标角色先生成可驱动的3D模型,可以通过驱动3D模型再渲染得到新动作的生成图像,但是缺少3D模型的驱动数据,还需要一种方法生成适配角色的动作。
启发
先通过大量数据得到目标角色所属种类的3D范式。有了这个3D范式作为先验,就可以根据单张图像生成这个种类的3D模型。
遗留问题
参考材料
- 项目页面: https://3dmagicpony.github.io/
Splatter a Video: Video Gaussian Representation for Versatile Processing
核心问题是什么?
视频表示是一个长期存在的问题,对于跟踪、深度预测、分割、视图合成和编辑等各种下游任务至关重要。
现有方法
当前的方法要么由于缺乏 3D 结构而难以对复杂运动进行建模,要么依赖于隐式 3D 表示而难以控制。
本文方法
引入了一种新颖的显式 3D 表示——视频高斯表示 —— 它将视频嵌入到 3D 高斯中。即:使用显式高斯作为代理,对 3D 规范空间中的视频外观进行建模,并将每个高斯与视频运动的 3D 运动相关联。
这种方法提供了比分层图集或体积像素矩阵更内在和更明确的表示。
为了获得这样的表示,我们从基础模型中提取了 2D 先验,例如光流和深度,以规范这种不适定环境中的学习。
效果
在许多视频处理任务中有效,包括跟踪、一致的视频深度和特征细化、运动和外观编辑以及立体视频生成。

核心贡献是什么?
-
视频高斯表示(VGR):这是一种新的显式3D表示方法,它将视频嵌入到3D高斯空间中。与传统的2D或2.5D技术相比,VGR提供了一种更为内在和显式的表示形式。
-
3D规范化空间:VGR在相机坐标空间中对视频进行建模,这避免了从3D到2D投影时丢失的3D信息,并且简化了动态建模的复杂性。
-
动态3D高斯:每个高斯由中心位置、旋转四元数、比例、不透明度、球谐系数等属性定义,并且与时间依赖的3D运动属性相关联,以控制视频运动。
-
2D先验知识的应用:为了解决从2D到3D映射的不适定问题,论文提出了利用从基础模型中提取的2D先验知识(如光流和深度估计)来规范学习过程。
-
多用途视频处理:VGR证明了其在多个视频处理任务中的有效性,包括跟踪、一致性视频深度和特征细化、运动和外观编辑、立体视频生成等。
-
光流和深度的蒸馏:通过将估计的光流和深度作为先验知识,论文提出了一种方法来规范学习过程,确保3D高斯的运动与实际观测到的2D运动一致。
-
3D运动的规范:除了深度和光流的蒸馏,还采用了局部刚性规范来防止高斯通过非刚性运动过度拟合渲染目标。
-
优化方法:论文详细介绍了如何通过结合颜色渲染损失、掩码损失以及可选的掩码损失来进行优化,以及如何通过自适应密度控制来初始化和调整高斯的密度。
大致方法是什么?
给定一个视频,在相机坐标空间中使用视频高斯表示其复杂的 3D 内容。并通过将它们与运动参数相关联,使视频高斯能够捕获视频动态。这些视频高斯由 RGB 图像帧和 2D 先验(例如光流、深度和标签掩模)进行监督。这种表示方式可以方便用户对视频执行各种编辑任务。
Video Gaussian Representation
相机坐标空间
使用相机坐标系(而不是世界坐标系)来建模视频的 3D 结构。因为使用相机坐标系可以避免估计相机姿态和相机运动,而是让相机运动与物体运动耦合。
相机坐标系下,视频的宽度、高度和深度分别对应于 X、Y 和 Zax。
视频高斯函数
视频序列为 V = {I1, I2, ..., In}
对应的高斯表示为 G ={G1, G2, ..., Gm},同时表示视频的外观和运动动态。
每个高斯 G 表示包含:
- 基本外观属性: 位置 μ、旋转四元数 q、尺度 s、外观球谐 (SH) 系数 sh 和不透明度 α 。
- 来自 2D 基础模型的:动态属性 p、分割标签 m 和图像特征 f
渲染:将其表示为 R(μ, q, s, α, x),其中 x 表示要渲染的特定属性。渲染函数 R 遵循与原始高斯 Splatting 方法 [16] 中的颜色渲染相同的过程。
高斯动力学
当对运动进行参数化时,需要在“结合符合运动先验”和“更准确实拟合”之间进行权衡[43]。
本文使用一组灵活的混合基,包括多项式 [22] 和傅立叶级数 [1] 来建模平滑的 3D 轨迹。具体来说,我们为每个高斯分配可学习的多项式\(p_p^n\)和傅里叶系数\(p^l_\sin, p^l_cos\),这里,n和l表示系数的阶数。那么分别使用多项式基和傅里叶基以各自的系数线性组合,就可以得到高斯球在时间 t 的位置。
多项式基在对运动轨迹的整体趋势和局部非周期性变化进行建模方面非常有效,并且广泛用于曲线表示。
傅立叶基 {cos(lt), sin(lt)} 提供曲线的频域参数化,使其适合拟合平滑运动 [1],并且擅长捕获周期性运动分量。
这两个基的结合利用了两者的优势,提供全面的建模、增强的灵活性和准确性、减少过度拟合以及对噪声的鲁棒性。这使高斯具有通过调整相应的可学习系数来适应各种类型轨迹的适应性。
视频处理应用
-
Dense Tracking:监督高斯球在2D投影上的运动
-
一致的深度/特征预测:
-
几何编辑
-
Appearance Editing
-
Frame Interpolation
-
Novel View Synthesis
-
Stereoscopic Video Creation
训练与验证
实验验证:通过在DAVIS数据集以及Omnimotion和CoDeF使用的视频上进行实验,论文展示了其方法在视频重建质量和下游视频处理任务方面的性能。
loss
| loss name | 优化目的 | 方法 |
|---|---|---|
| flow | 正则化项,约束个体高斯的运动 | 从 RAFT [42] 获得的光流估计,将帧 t1 和 t2 之间的高斯运动 (μ(t2) −μ(t1)) 投影到 2D 图像平面上,并使用估计的光流对其进行正则化 |
| depth | 正则化项,约束个体高斯的z方向运动 | 从 Marigold [15] 获得的估计深度来监督视频高斯 |
| arap | 正则化项,鼓励个体高斯的 3D 运动尽可能局部刚性 [40]。 | |
| render | 图像重建 | L1 Loss |
| label | Mask重建 | L2 Loss |
数据集
loss
训练策略
有效
局限性
局限性和未来工作:尽管取得了令人满意的性能,但论文也指出了方法的一些局限性,例如对场景变化的敏感性以及对现有对应估计方法的依赖性,并提出了可能的改进方向。
启发
遗留问题
参考材料
- 项目页面:https://sunyangtian.github.io/spatter_a_video_web/
- code(没有开开源):https://github.com/SunYangtian/Splatter_A_Video
数据集:Dynamic Furry Animal Dataset
cat
├── img
│ └── run - Motion name.
│ └── %d - The frame number, start from 0.
│ └──img_%04d.jpg - RGB images for each view. view number start from 0.
│ └──img_%04d_alpha.png - Alpha mattes for corresponding RGB image.
│ └── ...
│
├── volumes
│ └── coords_init.pth - voxel coordinates represent an animal in rest pose.
│ └── volume_indices.pth - The indices of bones to which the voxels are bound.
| └── volume_weights.pth - The skinning weights of the voxels.
| └── radius.txt - The radius of the volume.
|
├── bones
│ └── run - Motion name.
│ └── Bones_%04d.inf - The skeletal pose for each frame, start from 0. In each row, the 3x4 [R T] matrix is displayed in columns, with the third column followed by columns 1, 2, and 4.
│ └── ...
| └── bones_parents.npy - The parent bone index of each bone.
| └── Bones_0000.inf - The rest pose.
|
├── CamPose.inf - Camera extrinsics. In each row, the 3x4 [R T] matrix is displayed in columns, with the third column followed by columns 1, 2, and 4, where R*X^{camera}+T=X^{world}.
│
└── Intrinsic.inf - Camera intrinsics. The format of each intrinsics is: "idx \n fx 0 cx \n 0 fy cy \n 0 0 1 \n \n" (idx starts from 0)
│
└── sequences - Motion sequences. The format of each motion is: "motion_name frames\n"
原始数据
艺术家建模了九种高质量的 CGI 动物,包括熊猫、狮子、猫等。
它们具有基于纤维/线的毛皮和骨骼。
数据集没有找到原始的CGI mesh和skinning
合成数据
使用商业渲染引擎(例如 MAYA)将所有这些 CGI 动物角色渲染成各种代表性骨骼运动下的高质量多视图 1080 × 1080 RGBA 视频。具体来说,我们采用了 36 个摄像机视图,这些摄像机视图均匀地围绕捕获的动物排列成一个圆圈,每个动物的代表性姿势数量从 700 到 1000 个不等。
人工标注
生成标注
- 基于Artemis论文方法生成体素以及体素的skinning weight
- 动作数据
Reference
- 论文:https://caterpillarstudygroup.github.io/ReadPapers/32.html
- 数据集下载地址:https://shanghaitecheducn-my.sharepoint.com/:f:/g/personal/luohm_shanghaitech_edu_cn/Et60lJpJdp5DoyQF7uzP6jgB_JEW4LIHixAyXEiVhHT3Vw?e=d09jtz
- github:https://github.com/HaiminLuo/Artemis
Artemis: Articulated Neural Pets with Appearance and Motion Synthesis
核心问题是什么?
要解决的问题
计算机生成 (CGI) 毛茸茸的动物受到繁琐的离线渲染的限制,更不用说交互式运动控制了。
现有方法
本文方法
我们提出了 ARTEMIS,一种新颖的神经建模和渲染管道。
ARTEMIS 通过 AppEarance 和 Motion SynthesIS 生成 ARTiculated 神经宠物,并宠物进行交互式的动作控制,实时动画和毛茸茸动物的真实感渲染。
ARTEMIS 的核心是基于神经网络的生成式(NGI)动物引擎:
- 采用基于八叉树的高效表示来进行动物动画和毛皮渲染。这样,动画就相当于基于显式骨骼扭曲的体素级变形。
- 使用快速八叉树索引和高效的体积渲染方案来生成外观和密度特征图。
- 提出了一种新颖的着色网络,可以根据外观和密度特征图生成新颖姿势下的外观和不透明度的高保真细节。
- 使用动物运动捕捉方法,来重建由多视图 RGB 和 Vicon 相机阵列捕获的真实动物的骨骼运动。
- 将所有捕获的运动输入神经角色控制方案中,以生成具有运动风格的抽象控制信号。
- 将ARTEMIS集成到支持VR耳机的现有引擎中,提供前所未有的沉浸式体验,用户可以通过生动的动作和逼真的外观与各种虚拟动物亲密互动。
效果
- 实时
- NGI 动物的高度逼真渲染方面
- 提供了与数字动物前所未见的日常沉浸式互动体验。
核心贡献是什么?
-
神经体积表示法(Neural Volume Representation):Artemis使用神经体积来表示动物,这种方法可以实时渲染动物的外观和毛发。
-
动态场景建模(Dynamic Scene Modeling):与传统的基于骨架和皮肤蒙皮技术不同,Artemis采用神经网络生成图像(NGI)来动态模拟动物的外观和运动。
-
运动合成(Motion Synthesis):系统利用局部运动相位(Local Motion Phase, LMP)技术,根据用户的控制信号生成动物的骨架运动。
-
多视角动作捕捉(Multi-view Motion Capture):论文中提出了一种结合多视角RGB摄像头和Vicon摄像头的动作捕捉方法,用于捕捉真实动物的运动。
-
优化方案(Optimization Scheme):为了从捕捉到的动作中重建动物的骨架运动,研究者提出了有效的优化方案。
-
虚拟现实集成(VR Integration):Artemis被集成到支持VR头显的现有引擎中,为用户提供了与虚拟动物亲密互动的沉浸式体验。
-
交互式控制(Interactive Control):用户可以通过简单的控制信号,如指向目的地,来引导虚拟动物移动,实现自然的运动控制。
-
数据集和资源分享(Dataset and Resource Sharing):论文中提到了动态毛发动物数据集(Dynamic Furry Animal Dataset),并承诺将这些资源分享给研究社区,以促进未来关于逼真动物建模的研究。
大致方法是什么?
ARTEMIS 由两个核心组件组成。
在第一个模块中,给定 CGI 动物资产的骨骼和蒙皮权重以及代表性姿势中相应的多视角渲染 RGBA 图像,构建基于动态八叉树的神经表示,以实现动态动物的显式骨骼动画和实时渲染,支持实时交互应用;
在第二个模块中,我们构建了一个具有多视角 RGB 和 VICON 相机的混合动物运动捕捉系统,以重建逼真的 3D 骨骼姿势,该系统支持训练神经运动合成网络,使用户能够交互式地引导神经动物的运动。
ARTEMIS系统进一步集成到现有的消费级VR耳机平台中,为神经生成的动物提供身临其境的VR体验。
Preliminary
神经不透明辐射场
NeRF 用沿着光线的每个点的颜色和密度来表示场景,其中密度自然地反映了该点的不透明度。
优点:可真实地表现毛发渲染。
缺点:NeRF 生成的 alpha 有噪音且连续性较差。
ConvNeRF [Luo et al. 2021]
在特征空间中处理图像而不是直接在 RGB 颜色中处理图像。
优点:解决噪声和不连续性问题。
缺点:只能处理静态物体。
Animatable Neural Volumes
目的:借助PlenOctree的想法,将神经不透明辐射场扩展到动态动物,且实现实时渲染。
要解决的问题:
- 将不透明度特征存储在体积八叉树结构中,使得可以快速获取渲染特征。
- 基于骨架的体积变形(类似于原始 CGI 模型的蒙皮权重),将规范帧与动画的实时帧连接起来。
- 设计一个神经着色网络来处理动画对象建模,并采用有效的对抗训练方案来优化模型
八叉树特征索引
由于是针对特定的CGI动物模型,其Mesh是已知的。
- 我们首先将 CGI 动物角色(例如老虎或狮子)转换为基于八叉树的表示。
遇到的问题:原始 CGI 模型包含非常详细的毛发,
- 如果直接转换为离散体素,可能会导致后续神经建模中出现强烈的混叠和严重错误。
- 如果去除毛皮并仅使用裸模型,则体素表示将与实际的显着偏差。
解决方法:用“dilated”体素表示。
- 初始化一个统一的体积
- 以一组密集视角的渲染的 alpha matte 作为输入,利用dilated mask构造八叉树。
生成的八叉树包含体素构成的array。
- 基于这种体积表示,在每个体素处存储依赖于视图的特征𝑓。
分配一个称为特征查找表 (FLUT) 的数组 F 来存储特征和密度值,如原始 PlenOctree 中一样。
对于体绘制过程中空间中给定的查询点,我们可以在常数时间内索引到 FLUT 中,查出该点的特征和密度。
类似于 PlenOctree,将不透明度特征𝑓建模为一组SH(球面谐波)系数。
$$ S(f,d) = \sum_{h=1}^H k_h^i Y_h(d) $$
k为SH系数,Y为SH基。f为一组SH系数,d为视角。
绑定与形变
对用八叉树描述的体素进行绑定(放置目标骨架S)和蒙皮(定义体素与骨骼的带动关系)。[Huang et al. 2020]
绑定:复用CGI的骨骼
蒙皮:使用 CGI 模型提供的蒙皮网格将蒙皮权重应用于体素。即,通过混合最接近的顶点的权重生成每体素蒙皮权重。
驱动:LBS
def generate_transformation_matrices(matrices, skinning_weights, joint_index):
return svox_t.blend_transformation_matrix(matrices, skinning_weights, joint_index)
动态体积渲染
- 使用LBS驱动Oct Tree
- 通过ray marching得到每个点的特征
- 把特征组合成Feature F
class TreeRenderer(nn.Module):
def forward(self, tree, rays, transformation_matrices=None, fast_rendering=False):
t = tree.to(rays.device)
r = svox_t.VolumeRenderer(t, background_brightness=self.background_brightness, step_size=self.step_size)
dirs = rays[..., :3].contiguous()
origins = rays[..., 3:].contiguous()
sh_rays = Sh_Rays(origins, dirs, dirs)
# 通过将方程 3.1 应用于每个像素来生成视角相关的特征图 F,并通过沿光线累积来生成粗略的不透明度图 A
res = r(self.features, sh_rays, transformation_matrices=transformation_matrices, fast=fast_rendering)
return res
Neural Shading
输入:视点处的体积光栅化为神经外观特征图 F 和不透明度 A。
输出:将光栅化体积转换为具有类似经典着色器的相应不透明度贴图的彩色图像。
- 要解决的问题:
为了保留毛发的高频细节,必须考虑最终渲染图像中的空间内容。但NeRF 和 PlenOctree 都没有考虑空间相关性,因为所有像素都是独立渲染的。 - 解决方法:
在 采用额外的 U-Net 架构进行图像渲染(借鉴ConvNeRF)。
优点:基于ray marching的采样策略可以实现全图像渲染。
class UNet(nn.Module):
def forward(self, rgb_feature, alpha_feature):
# 神经着色网络U-Net包含两个encoder-decoder分支,分别用于 RGB 和 alpha 通道。
# RGB 分支将 F 转换为具有丰富毛发细节的纹理图像 I𝑓。
x1 = self.inc(rgb_feature)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x6 = self.up1(x5, x4)
x6 = self.up2(x6, x3)
x6 = self.up3(x6, x2)
x6 = self.up4(x6, x1)
x_rgb = self.outc(x6)
# alpha 分支细化粗略不透明度图 A 和 I𝑓 以形成超分辨率不透明度图 A。该过程通过显式利用 A 中编码的隐式几何信息来强制多视角一致性。
x = torch.cat([alpha_feature, x_rgb], dim=1)
x1_2 = self.inc2(x)
x2_2 = self.down5(x1_2)
x3_2 = self.down6(x2_2)
x6 = self.up5(x3_2, torch.cat([x2, x2_2], dim=1))
x6 = self.up6(x6, torch.cat([x1, x1_2], dim=1))
x_alpha = self.outc2(x6)
x = torch.cat([x_rgb, x_alpha], dim=1)
return x
完整代码流程
"""
model:Nerf模型
K, T:相机参数
tree:Octree
matrices:动作参数
joint_features: B * T * dim,包含skeleton_init, pose_init, pose等信息
bg: backgroud
"""
def render_image(cfg, model, K, T, img_size=(450, 800), tree=None, matrices=None, joint_features=None,
bg=None, skinning_weights=None, joint_index=None):
torch.cuda.synchronize()
s = time.time()
h, w = img_size[0], img_size[1]
# Sample rays from views (and images) with/without masks
rays, _, _ = ray_sampling(K.unsqueeze(0).cuda(), T.unsqueeze(0).cuda(), img_size)
with torch.no_grad():
joint_features = None if not cfg.MODEL.USE_MOTION else joint_features
# 计算skinning matrix
matrices = generate_transformation_matrices(matrices=matrices, skinning_weights=skinning_weights,
joint_index=joint_index)
with torch.cuda.amp.autocast(enabled=False):
# 1. 使用LBS驱动Oct Tree
# 2. 通过ray marching得到每个点的特征
# 3. 把特征组合成Feature F
features = model.tree_renderer(tree, rays, matrices).reshape(1, h, w, -1).permute(0, 3, 1, 2)
# 这一步没注意到论文的相关内容
if cfg.MODEL.USE_MOTION:
motion_feature = model.tree_renderer.motion_feature_render(tree, joint_features, skinning_weights,
joint_index,
rays)
motion_feature = motion_feature.reshape(1, h, w, -1).permute(0, 3, 1, 2)
else:
motion_feature = features[:, :9, ...]
with torch.cuda.amp.autocast(enabled=True):
features_in = features[:, :-1, ...]
if cfg.MODEL.USE_MOTION:
features_in = torch.cat([features[:, :-1, ...], motion_feature], dim=1)
# 输入:视点处的体积光栅化为神经外观特征图 F 和不透明度 A。
# 输出:rgb, alpha。
rgba_out = model.render_net(features_in, features[:, -1:, ...])
rgba_volume = torch.cat([features[:, :3, ...], features[:, -1:, ...]], dim=1)
rgb = rgba_out[0, :-1, ...]
alpha = rgba_out[0, -1:, ...]
img_volume = rgba_volume[0, :3, ...].permute(1, 2, 0)
# 把预测出的rgb和alpha归一化到[0,1]区间
if model.use_render_net:
rgb = torch.nn.Hardtanh()(rgb)
rgb = (rgb + 1) / 2
alpha = torch.nn.Hardtanh()(alpha)
alpha = (alpha + 1) / 2
alpha = torch.clamp(alpha, min=0, max=1.)
# 与背影融合
if bg is not None:
if bg.max() > 1:
bg = bg / 255
comp_img = rgb * alpha + (1 - alpha) * bg
else:
comp_img = rgb * alpha + (1 - alpha)
img_unet = comp_img.permute(1, 2, 0).float().cpu().numpy()
return img_unet, alpha.squeeze().float().detach().cpu().numpy(), img_volume.float().detach().cpu().numpy()
基于神经网络的动物运动合成
动物动作捕捉
动作捕捉:尽管不同物种的四足动物具有相似的骨骼结构,但其形状和尺度却截然不同。**捕获适合所有类型四足动物的动作捕捉数据集是根本不可能的。**因此,先学习温顺的小型宠物的运动先验,并将先验转移到老虎和狼等大型动物身上。对于后者,使用多视图 RGB 球顶进一步提高了预测精度。
动物姿势估计:采用参数化 SMAL 动物姿势模型。从观察到的 2D 关节和轮廓中恢复 SMAL 参数 𝜃、𝜙、𝛾。
Motion Synthesis
训练与验证
优化对象:feature array, 参数G
优化目标:各视角下的外观
数据集
动态毛茸茸动物(DFA)数据集:
- 来自艺术家的建模。
- 含九种高质量的 CGI 动物,包括熊猫、狮子、猫等。
- 它们具有基于纤维/线的毛皮和骨骼
- 使用商业渲染引擎(例如 MAYA)将所有这些 CGI 动物角色渲染成各种代表性骨骼运动下的高质量多视图 1080 × 1080 RGBA 视频。具体来说,我们采用了 36 个摄像机视图,这些摄像机视图均匀地围绕捕获的动物排列成一个圆圈,每个动物的代表性姿势数量从 700 到 1000 个不等。
loss
| loss | content |
|---|---|
| 𝑟𝑔𝑏𝑎 在自由视角下恢复毛茸茸动物的外观和不透明度值 | 渲染图像与原始图像的L1 Loss,渲染alpha与真实alpha的L1 Loss |
| P 鼓励交叉视图一致性并保持时间一致性 | 渲染图像的VGG l层feature map与真实图像的VGG l层feature map |
| A 鼓励跨视图一致性 | 几何特征的L1 Loss |
| VRT 体素正则化项(VRT),强制deform后落在同一网格上的特征应具有相同的值,避免体素上的特征冲突 | |
| GAN 进一步提高皮毛高频外观的视觉质量 |
训练策略
有效
- 实时渲染(Real-time Rendering):Artemis能够实现对动物模型的实时、逼真渲染,这对于虚拟现实(VR)等交互式应用至关重要。
- 系统性能和应用(System Performance and Applications):Artemis在多视角、多环境条件下均展现出高效和实用的性能,论文还讨论了其在动物数字化和保护、VR/AR、游戏和娱乐等领域的潜在应用。
局限性
- 对预定义骨架的依赖
- 未观察到的动物身体区域的外观伪影问题
- 在新环境中对光线变化的适应性问题
启发
利用CGI渲染生成高精的GT和完美匹配的动作数据。
遗留问题
参考材料
- ARTEMIS 模型和动态毛茸茸动物数据集 https://haiminluo.github.io/publication/artemis/
SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation
核心问题是什么?
目的
单目 3D 人体形状和姿势估计
现有方法及存在的问题
现有的的 Transformer 通常具有O(l^2)的计算和存储复杂度,l为特征长度。
这阻碍了对高分辨率特征中细粒度信息的利用,但高分辨率特征对于精确重建很重要。
本文方法
我们提出了一个基于 SMPL 的 Transformer 框架(SMPLer)来解决这个问题。 SMPLer 包含两个关键要素:解耦的注意力操作和基于 SMPL 的目标表示,这允许有效利用 Transformer 中的高分辨率特征。
此外,基于这两种设计,我们还引入了几个新颖的模块,包括多尺度注意力和联合感知注意力,以进一步提高重建性能。
效果
大量实验在定量和定性方面证明了 SMPLer 对现有 3D 人体形状和姿势估计方法的有效性。值得注意的是,所提出的算法在 Human3.6M 数据集上实现了 45.2 mm 的 MPJPE,比 Mesh Graphomer 提高了 10% 以上,参数减少了不到三分之一。代码和预训练模型可在 https://github.com/xuxy09/SMPLer 获取。
核心贡献是什么?
-
解耦注意力机制(Decoupled Attention):为了解决传统Transformer在处理高分辨率特征时面临的二次计算和内存复杂度问题,论文提出了一种解耦的注意力操作,将完整的注意力操作分解为目标-特征注意力和目标-目标注意力,从而降低了计算和内存复杂度。
-
基于SMPL的目标表示(SMPL-based Target Representation):论文引入了基于SMPL(Skinned Multi-Person Linear model)的参数化人体模型作为目标表示,这大大减少了目标嵌入的长度,降低了计算和内存成本,同时保证了生成的3D人体网格的平滑性和一致性。
-
多尺度注意力(Multi-scale Attention):通过结合不同分辨率的特征图,并为每个尺度分配不同的投影权重,论文提出的多尺度注意力机制能够更有效地利用多尺度信息进行3D人体姿态和形状估计。
-
关节感知注意力(Joint-aware Attention):利用基于SMPL的目标表示,论文设计了一种关节感知的注意力模块,该模块专注于人体关节周围的局部特征,以更好地推断3D人体的姿态。
-
分层架构(Hierarchical Architecture):为了解决关节感知注意力依赖于2D关节估计的问题,论文提出了一种分层架构,通过多个Transformer块逐步细化2D关节估计和3D重建结果。
-
实验验证:论文通过大量实验验证了SMPLer相对于现有3D人体姿态和形状估计方法的有效性,特别是在Human3.6M数据集上,与Mesh Graphormer相比,参数数量减少到原来的三分之一,而MPJPE(Mean Per Joint Position Error)降低了10%以上。
-
实时推理速度:SMPLer在保持高效率的同时,能够实现实时的推理速度,这对于实际应用如虚拟现实和增强现实等场景非常重要。
-
虚拟角色控制:由于SMPLer能够直接输出3D旋转,因此它可以方便地用于控制虚拟角色,这一点在元宇宙等应用中具有潜在价值。
-
代码和预训练模型的可用性:论文提供了代码和预训练模型,这为研究人员和开发者进一步研究和应用该框架提供了便利。
大致方法是什么?
训练与验证
数据集
loss
训练策略
有效
缺陷
启发
遗留问题
参考材料
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
核心问题是什么?
目的
3D 重建技术,通过图像重建3D场景。
现有方法
现有方法需要用户收集数百到数千张图像来创建 3D 场景。
本文方法
我们提出了 CAT3D,这是一种通过使用多视图扩散模型模拟现实世界捕获过程来创建 3D 任何东西的方法。给定任意数量的输入图像和一组目标新视角,我们的模型会生成高度一致的场景新视角。这些生成的视图可用作稳健 3D 重建技术的输入,以生成可从任何视点实时渲染的 3D 表示。
效果
CAT3D 可以在短短一分钟内创建整个 3D 场景,并且优于单图像和少视图 3D 场景创建的现有方法。请参阅我们的项目页面以获取结果和交互式演示:cat3d.github.io。
核心贡献是什么?
-
多视图扩散模型:CAT3D使用多视图扩散模型来生成与输入图像数量无关的一致性新视图。这种模型可以接受任意数量的输入视图,并生成一组新颖的、与目标新视点一致的3D视图。
-
3D场景创建的高效性:CAT3D能够在短短一分钟内创建完整的3D场景,并且在单图像和少视图3D场景创建方面超越了现有方法。
-
高质量的3D重建:通过将生成的视图输入到强大的3D重建技术中,CAT3D能够产生可以在任何视点实时渲染的3D表示。
-
从文本到3D的转换:CAT3D展示了如何使用预训练的文本到图像模型作为生成3D内容的强有力先验,通过文本提示生成输入图像,然后创建3D场景。
-
改进的3D重建流程:CAT3D通过修改标准的NeRF训练过程来提高对不一致输入视图的鲁棒性,包括使用感知损失(如LPIPS)来强调渲染图像和输入图像之间的高级语义相似性。
-
自适应的相机轨迹设计:为了充分捕捉3D场景,CAT3D探索了基于场景特征的四种类型的相机路径,包括不同规模和高度的轨道路径、不同规模和偏移的正面圆周路径、不同偏移的样条路径,以及沿着圆柱形路径进出场景的螺旋轨迹。
-
高效的并行采样策略:CAT3D采用了高效的并行采样策略,通过多视图扩散模型生成大量一致的新视图,这些视图随后被用于3D重建管道。
-
实验验证:CAT3D在多个数据集上进行了训练和评估,包括Objaverse、CO3D、RealEstate10k和MVImgNet,并在几个真实世界的基准数据集上进行了评估,证明了其在不同设置下的性能。
-
未来工作的方向:论文讨论了CAT3D的局限性,并提出了未来工作的方向,如使用预训练的视频扩散模型初始化多视图扩散模型,扩展模型处理的视图数量,以及自动确定不同场景所需的相机轨迹。
大致方法是什么?
CAT3D 有两个阶段:(1) 从多视角latent diffusion model生成大量合成视图,该模型以输入视图和目标视图的相机姿态为条件; (2) 在观察到的和生成的视图上运行强大的 3D 重建管道以学习 NeRF 表示。
Multi-View Diffusion Model
输入:当前视角的图像及相机参数,目标视角的相机参数
输出:目标视角的图像
VAE
图像(512 × 512 × 3,图上应该是写错了) --E-- latent code --D-- 图像(64 × 64 × 8)
video LDM
video LDM根据给定条件估计图像的latent code的联合分布。
条件为相机的raymap。
video LDM 以LDM为2D diffusion model backbone,并在此基础上做了以下修改:
- 使用了LDM的预训练模型,并用新的数据finetune
- 去掉文本condition,并增加camera raymap及mask condition
- 在每个 2D 残差块之后将 2D 自注意力膨胀为 3D 自注意力 [43],以支持时序特征。我们发现通过 3D 自注意力层对输入视图进行调节消除了对 PixelNeRF 的需求 [63]
- condition中包含mask信息,mask用于指示这个角度的图像是已知图像(条件图像)还是未知图像(目标图像)。在训练过程中,条件图像和目标图像会以不同的方式处理。
Generating Novel Views
输入:给定一组视图
输出:生成大量一致的视图以完全覆盖场景并实现准确的 3D 重建
要解决的问题:
- 决定要采样的相机姿势集
- 设计一种采样策略,该策略可以使用在少量视图上训练的多视图扩散模型来生成更大的一致视图集。
相机轨迹
3D 场景重建的挑战在于完全覆盖场景所需的视图可能很复杂,并且取决于场景内容。
我们根据场景的特征探索了四种类型的相机路径:
- (1)围绕中心场景的不同尺度和高度的轨道路径,
- (2)不同尺度和偏移的前向圆形路径,
- (3)样条线不同偏移的路径,
- (4) 沿着圆柱形路径的螺旋轨迹,移入和移出场景。
3D重建
多视图扩散模型生成的视图通常不完全 3D 一致。我们以 Zip-NeRF [71] 为基础,修改了标准 NeRF 训练程序,以提高其对不一致输入视图的鲁棒性。
训练与验证
Multi-View Diffusion Model
我们使用 FlashAttention [65 , 66 ] 进行快速训练和采样,并对潜在扩散模型的所有权重进行微调。
我们发现当我们从预先训练的图像扩散模型转向捕获更高维度数据的多视图扩散模型时,将noise schedule转向高噪声水平非常重要。
具体来说,我们将log信噪比移动log(N),其中N是目标图像的数量。对于训练,目标图像的latent受到噪声扰动,而条件图像的latent不被哭声污染,并且仅在目标图像上定义扩散损失。
用mask来标示图像是目标图像还是条件图像。为了处理多个 3D 生成设置,我们训练一个通用模型,该模型可以建模总共 8 个条件视图和目标视图 (N + M = 8),并在训练期间随机选择条件视图的数量 N 为 1 或 3,对应分别为 7 个和 5 个目标视图。
3D重建
Zip-NeRF Loss:
- 光度重建损失、
- 畸变损失、
- 层间损失
- 归一化 L2 权重正则化器
本文增加的损失:
LPIPS:渲染图像和输入图像之间的感知损失(LPIPS [72])。
与光度重建损失相比,LPIPS 强调渲染图像和观察图像之间的高级语义相似性,而忽略低级高频细节中潜在的不一致。
由于生成的视图已经接近观察到的视图,但具有较小的语义不一致,因此使用LPIPS可以衡量这种不一致。
我们根据到最近的观察到的视图的距离对生成的视图的损失进行加权。这种权重在训练开始时是统一的,并逐渐退火为权重函数,该权重函数对更接近观察到的视图之一的视图的重建损失进行更强烈的惩罚。
有效
缺陷
启发
遗留问题
参考材料
PACER+: On-Demand Pedestrian Animation Controller in Driving Scenarios
核心问题是什么?
要解决的问题
在驾驶场景中生成多样化和自然的行人动画。
当前方法及问题
现有行人动画框架的局限性,这些框架通常只关注遵循轨迹或参考视频的内容,而忽略了人类运动的潜在多样性。
本文方法及效果
PACER+通过结合运动跟踪任务和轨迹跟踪,实现了对特定身体部位(例如上半身)的跟踪,同时通过单一策略跟随给定的轨迹。这种方法显著提高了模拟人类运动的多样性和控制内容的能力,包括基于语言的控制。
核心贡献是什么?
-
PACER+框架:一个基于物理的行人动画框架,可以控制模拟的行人同时跟随2D轨迹和特定身体部位的参考运动。
-
多样化的运动生成:PACER+支持从多种来源生成多样化的行人行为,包括生成模型、预先捕获的动作和视频。
-
零样本重建:PACER+能够零样本重现真实世界的行人动画到模拟环境中,自动填充缺失的部分。
-
运动跟踪与轨迹跟踪的协同:通过联合训练方案,PACER+建立了运动模仿和轨迹跟踪任务之间的协同关系,使用单个策略以物理合理的方式同时跟踪部分身体运动和轨迹。
-
空间-时间掩码:引入了每个关节的空间-时间掩码,指示策略需要跟踪的参考运动的存在。
大致方法是什么?
(1) 地形轨迹跟踪,决定了模拟行人在复杂环境中的所需路径;(2) 运动内容控制,指定行人所表现出的所需动作和手势(例如,打电话或挥手)手),同时遵守提供的轨迹和地形。
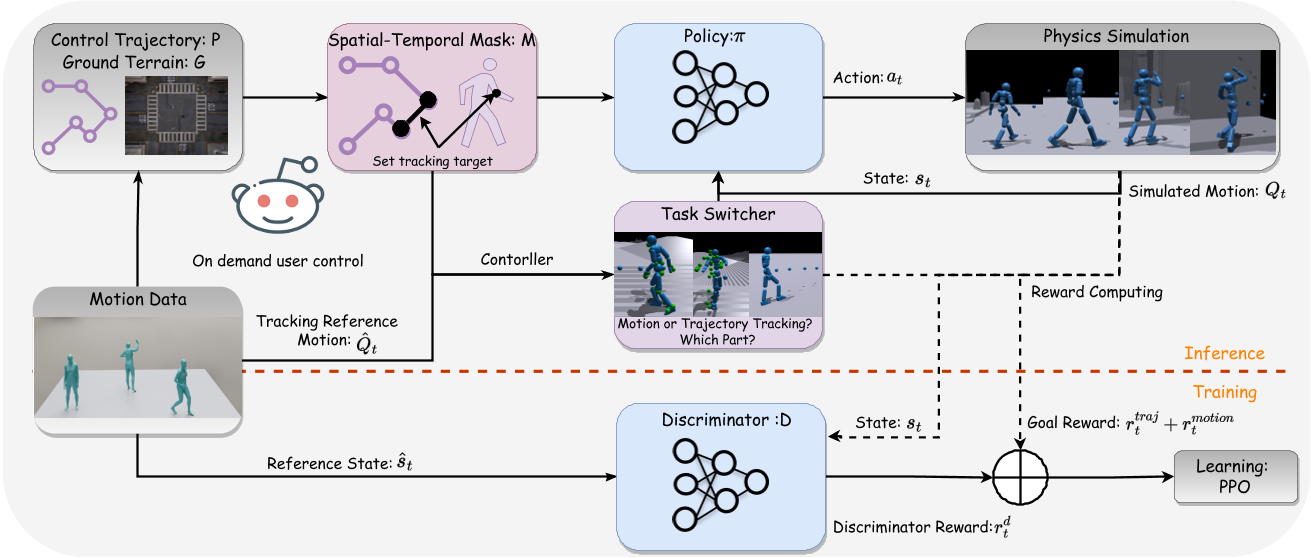
PACER+ 框架遵循具有对抗性运动先验的目标条件强化学习。为了实现对特定身体部位的细粒度控制,作者在运动跟踪任务中引入了一个额外的时空掩码。该掩码指示策略应跟踪reference motion。通过专注于此跟踪任务,PACER+框架能够以零样本的方式演示特定时间步骤和位置的不同行人行为。
RL 的关键要素
$$ M = \lbrace S, A, T, R, \gamma \rbrace $$
| 元素 | 内容 | 来源 |
|---|---|---|
| Stage S | humanoid proprioception [30] \(s^p_t\) goal state \(s^g_t\) ---- 轨迹跟踪的目标 \(s^{traj}_t\) ---- 运动跟踪的目标 \(s^{motion}_t\) | PD控制 |
| Action A | policy network | |
| 转移 T | PD控制 | |
| reward R | 与给定的轨迹和运动跟踪任务相关 | |
| discount factor \(\gamma\) |
地形上的轨迹跟踪
状态 S
在轨迹跟随任务中,人形机器人有一个局部高度图G和要跟随的轨迹P。P为接下来一段时间的轨迹采样序列。
$$ s^{traj}_t \triangleq (P_t^{traj}, G_t) $$
[?]G为什么和时间有关?地形会变吗?
Reward R
t 时序轨迹 期望轨迹 p 与模拟角色根节点位置之间的 xy 距离,公式为
$$ d = \parallel\hat p_t^{xy} - r_t^{xy}\parallel\ r^{traj}_t = e^{-2d} $$
提前终止机制
如果在时间步 t 时距离d大于阈值 τ (0.5米),将终止轨迹跟踪任务。
运动跟踪
状态 S
t+1时刻的运动跟踪目标包含:
- t+1时刻的运动状态:关节位置、关节旋转、关节速度和旋转速度。不管特定帧特定关节是否需要跟踪,都将其设置为与模拟角色状态相同的值。
- 时空掩码:希望policy netword只在给定时间范围内跟踪特定运动部分,同时遵循轨迹,引入时空掩码。定义时空掩码为 M1 = T * J,表示在时间步 t 是否需要运动跟踪关节 j。1为跟踪,0为不跟踪。
Reward R
类似于带mask的重建loss
对抗运动先验(AMP)
AMP 采用运动discriminator来鼓励策略生成与dataset中观察到的运动模式一致的运动。
- 使用大约 200 个序列的较小数据集训练 AMP。AMP 使用discriminator来计算style reward,并将其添加到task reward中。Good:确保了生成运动的自然性。Bad:但它限制了运动跟踪任务中看不见的运动的泛化。
- 为了解决工作1引入的问题,将补充运动序列作为运动跟踪中的motion reference。Good:可以引入了不同的运动内容,并且有可能增强跟踪性能。Bad:然而,使用额外的数据集训练运动跟踪任务对联合学习 AMP 和较小的数据集提出了挑战,
- 为了解决工作2引入的问题,在训练期间采用了提前终止机制。
System Overview
训练过程
policy network通过轨迹跟踪和运动跟踪任务的组合方法进行训练。
- 第一阶段,轨迹跟踪和动作跟踪两项任务联合训练。在此步骤中,在每个时间步随机生成reference motion(随机采样自AMASS)的二进制掩码,并将提前终止应用于运动跟踪任务。
- 第二阶段,使用随机生成的合成轨迹来训练轨迹跟踪任务 。在此阶段,时空掩模内的所有关节都被分配值 0。
使用场景1:
输入轨迹,输出3D motion
从其它来源中获取reference motion,将reference motion与输入的轨迹对齐,然后设置掩码生成运动。
使用场景2:真实场景
输入视频,输出3D motion。
根据2D keypoints的置信度来打mask。
有效
缺陷
验证
启发
遗留问题
参考材料
Humans in 4D: Reconstructing and Tracking Humans with Transformers
核心问题是什么?
我们提出了一种重建人类并随着时间的推移追踪他们的方法。
Human Mesh Recovery:我们提出了一个用于人类mesh reconvery的完全“transformer”的网络版本。该网络 HMR 2.0 可以从单个图像中进行人体重建。
Human Tracking:以 HMR 2.0 的 3D 重建作为以 3D 运行的跟踪系统的输入,使得我们可能在多人场景及遮挡场景中保持身份。
核心贡献是什么?
-
HMR 2.0:这是一个完全基于Transformer的架构,用于从单张图像中恢复人体网格。它不依赖于特定领域的设计,但在3D人体姿态重建方面超越了现有方法。
-
4DHumans:这是一个建立在HMR 2.0基础上的系统,可以联合重建和跟踪视频中的人体。它在PoseTrack数据集上实现了最先进的跟踪结果。
-
动作识别:通过在AVA v2.2数据集上的动作识别任务,展示了HMR 2.0在3D姿态估计方面的改进,最终为AVA基准测试贡献了最先进的结果(42.3 mAP)。
大致方法是什么?
Reconstructing People
模型结构
| 输入 | 输出 | 方法 |
|---|---|---|
| 视频 | 图像 | cv2 |
| 图像 | 人物的bbox | VitDet |
| Image | image tokens | ViT-H/16 |
| a single (zero) input token, image tokens | 3D rotations | a standard transformer decoder [74] with multi-head self-attention |
class SMPLTransformerDecoderHead(nn.Module):
""" HMR2 Cross-attention based SMPL Transformer decoder
"""
def __init__(self, ):
super().__init__()
transformer_args = dict(
depth = 6, # originally 6
heads = 8,
mlp_dim = 1024,
dim_head = 64,
dropout = 0.0,
emb_dropout = 0.0,
norm = "layer",
context_dim = 1280,
num_tokens = 1,
token_dim = 1,
dim = 1024
)
# a standard transformer decoder [74] with multi-head self-attention
self.transformer = TransformerDecoder(**transformer_args)
dim = 1024
npose = 24*6
# Transformer生成的是latent code,使用MLP把latent code转为实际的信息
self.decpose = nn.Linear(dim, npose)
self.decshape = nn.Linear(dim, 10)
self.deccam = nn.Linear(dim, 3)
# MLP层的常用权重初始化方法
nn.init.xavier_uniform_(self.decpose.weight, gain=0.01)
nn.init.xavier_uniform_(self.decshape.weight, gain=0.01)
nn.init.xavier_uniform_(self.deccam.weight, gain=0.01)
mean_params = np.load('data/smpl/smpl_mean_params.npz')
init_body_pose = torch.from_numpy(mean_params['pose'].astype(np.float32)).unsqueeze(0)
init_betas = torch.from_numpy(mean_params['shape'].astype('float32')).unsqueeze(0)
init_cam = torch.from_numpy(mean_params['cam'].astype(np.float32)).unsqueeze(0)
self.register_buffer('init_body_pose', init_body_pose)
self.register_buffer('init_betas', init_betas)
self.register_buffer('init_cam', init_cam)
def forward(self, x, **kwargs):
batch_size = x.shape[0]
# vit pretrained backbone is channel-first. Change to token-first
x = einops.rearrange(x, 'b c h w -> b (h w) c')
init_body_pose = self.init_body_pose.expand(batch_size, -1)
init_betas = self.init_betas.expand(batch_size, -1)
init_cam = self.init_cam.expand(batch_size, -1)
# Pass through transformer
# 使用a single (zero) input token来解码
token = torch.zeros(batch_size, 1, 1).to(x.device)
token_out = self.transformer(token, context=x)
token_out = token_out.squeeze(1) # (B, C)
# Readout from token_out
# 不输出绝对信息,而是相对于第一帧的信息
pred_pose = self.decpose(token_out) + init_body_pose
pred_shape = self.decshape(token_out) + init_betas
pred_cam = self.deccam(token_out) + init_cam
return pred_pose, pred_shape, pred_cam
Loss
- SMPL参数Loss
- 3D keypoint重建loss
- 2D keypoint重建loss
- SMPL参数的差别器loss
Tracking People
- 逐帧检测各个帧中的人物,将它们“lifting”到 3D,提取它们的 3D 姿势、3D 空间中的位置(来自估计的相机)和 3D 外观(来自纹理贴图)。
- 随着时间的推移,构建出每个人的tracklet representation。
- 针对每个tracklet,预测下一帧中人的姿势、位置和外观(全部以 3D 形式进行)。
- 在这些自上而下的预测(来自第3步)和该帧中人的自下而上的检测(来自第1步)之间找到最佳匹配。
- 更新tracklet representation并迭代该过程。
有效
缺陷
验证
-
数据集和基线:使用标准的H3.6M、MPI-INF3DHP、COCO和MPII数据集进行训练,并使用InstaVariety、AVA和AI Challenger作为额外数据,其中生成了伪地面真实拟合。
-
实验:作者们在多个数据集上定性和定量地评估了他们的重建和跟踪系统。首先,他们展示了HMR 2.0在标准2D和3D姿态精度指标上超越了以前的方法。其次,他们展示了4DHumans是一个多才多艺的跟踪器,实现了最先进的性能。最后,他们通过在动作识别的下游应用中展示优越的性能,进一步证明了恢复姿态的鲁棒性和准确性。
-
模型设计:在开发HMR 2.0的过程中,作者们探索了一系列设计决策,包括不同的模型架构、训练数据的影响、ViT预训练的影响以及SMPL头部架构的影响。
启发
遗留问题
参考材料
- https://shubham-goel.github.io/4dHumans/.
Learning Human Motion from Monocular Videos via Cross-Modal Manifold Alignment
核心问题是什么?
从 2D 输入学习 3D 人体运动是计算机视觉和计算机图形领域的一项基本任务。
当前方法及问题
以前的许多方法通过在学习过程中引入运动先验来解决这种本质上不明确的任务。然而,这些方法在定义此类先验的完整配置或训练鲁棒模型方面面临困难。
可以找到由2D和3在这两个域的数据共享的紧凑且定义明确的latent manifold,类似于 CLIP 潜在流形。这个潜在空间应该包含足够的信息来忠实地重建人体姿势。因此,在 3D 人体姿态重建中进行跨模态对齐时存在两个技术挑战:
1)识别这样的潜在流形,它封装了 3D 人体运动中体现的运动学约束并作为我们的运动先验,
2)找到有效的方法将视频特征空间与运动先验对齐以实现高保真 3D 运动重建的方法。
本文方法
为了解决上述两个挑战,我们引入了一种称为 VTM 的新型神经网络。
- VTM 采用两部分运动自动编码器 (TPMAE),它将运动潜在流形的学习分为上半身和下半身部分。这种划分有效地降低了整个人体姿态流形建模的复杂性。
- TPMAE在与尺度不变的虚拟骨架对齐的3D人体运动数据上进行训练,这有利于消除骨架尺度对流形的影响。
- VTM 结合了一个两部分视觉编码器 (TPVE),将由视频帧和 2D 关键点组成的视觉特征转换为上半身和下半身的两个视觉latent manifold。
- 采用歧管对齐损失来将上半身部分和下半身部分的跨模态歧管拉得更近。
- TPVE 与预先训练的 TPMAE 联合训练,以重建具有完整表示的 3D 人体运动:所有关节的旋转、根关节的平移以及包含尺度信息的运动骨架。
这个精心设计的流程确保了 VTM 框架内运动和视觉表示之间的协调。
- 3D 人体运动和 2D 输入(即视频和 2D 关键点)之间的跨模式潜在特征空间对齐来利用运动先验。
- 为了降低运动先验建模的复杂性,我们分别对上半身和下半身部位的运动数据进行建模。
- 将运动数据与尺度不变的虚拟骨骼对齐,以减轻人体骨骼变化对运动先验的干扰。
效果
VTM 在 AIST++ 上进行评估,展示了从单眼视频重建 3D 人体运动的最先进性能。值得注意的是,我们的 VTM 展示了对未见过的视角和野外视频的泛化能力。
核心贡献是什么?
- 跨模态潜在特征空间对齐:VTM将3D人体运动和2D输入(视频和2D关键点)的潜在特征空间进行对齐,以利用运动先验信息。
- 上半身和下半身的运动数据建模:为了降低建模运动先验的复杂性,VTM将上半身和下半身的运动数据分别建模。
- 与尺度不变虚拟骨骼对齐:VTM将运动数据与尺度不变的虚拟骨骼对齐,以减少人体骨骼变化对运动先验的干扰。
- 3D运动表示:VTM能够重建包括所有关节的旋转、根关节的平移以及包含尺度信息的运动骨架在内的完整运动表示。
大致方法是什么?
Learn Motion Priors
模型
| 输入 | 输出 | 方法 |
|---|---|---|
| 3D motion序列X | 上半身序列Xu,下半身序列Xd | 分割,两者都包含root数据 |
| part动作序列 | latent code zu和zl | 3D Encoder |
| zu, zl | decoded features of body parts | 3D Decoder |
| decoded features of body parts | non-root motion | an aggregation layer A,1D 卷积层 |
| zu, zl | root motion,仅包含根旋转 rq 、Z 轴上的 3D root位置 rzp 以及相应的速度 rz | Decoder, Dr |
| 轴上的 3D root位置 rzp | root translations |
Loss
| Loss | 目的 | 方法 |
|---|---|---|
| motion重建loss | 限制latent manifold的明确定义 | 由于不同的关节在运动中的重要性不同,我们通过为根关节和其他关节赋予相对重要性 ωr 和 ωnr 来缩放重建的和真实的运动数据 |
| 平滑 | 防止重建运动沿时间轴突然变化 |
Learn Human Motion from Videos
模型
| 输入 | 输出 | 方法 |
|---|---|---|
| video | video feature | ResNet18 |
| 2D keypoints | 2D keypoints feature | 分成上、下part,分别用CNN提取feature |
| video features, keypoints features | visual features | 视觉特征融合块 |
| visual features | latent manifold | 2D Encoder,这些编码器具有与3D Encoder类似的结构,但后面有两个跨时间上下文聚合模块(CTCA)以便更好地捕捉时间相关性 |
| visual features | bone ratio | 由于人体不同身体部位的身高和比例存在很大差异,因此骨骼的尺度在 3D 人体运动中起着至关重要的作用。虽然我们故意从训练运动数据中删除尺度信息以增强运动先验的学习,但我们可以有效地从 2D 输入中提取骨骼比率 b。这些输入本质上体现了角色的比例信息。 |
Loss
| Loss | 目的 | 方法 |
|---|---|---|
| motion重建loss | 限制latent manifold的明确定义 | 由于不同的关节在运动中的重要性不同,我们通过为根关节和其他关节赋予相对重要性 ωr 和 ωnr 来缩放重建的和真实的运动数据 |
| 平滑 | 防止重建运动沿时间轴突然变化 | |
| 流形空间对齐损失 | ||
| bone ratio loss |
有效
- 实时性能:VTM能够以接近70fps的速度快速生成与视频序列同步的精确人体运动,使其成为各种实时应用的潜在候选者。
- 泛化能力:VTM在未见过的视角和野外视频上展现出了良好的泛化能力。
缺陷
验证
数据集:AIST++, Human3.6, BVHAIST++
启发
遗留问题
参考材料
- https://arxiv.org/pdf/2404.09499
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos
在这篇论文中,作者们介绍了一种名为PhysPT(Physics-aware Pretrained Transformer)的新方法,旨在改善基于运动学的运动估计,并推断运动力。PhysPT利用Transformer编码器-解码器骨架,通过自监督的方式有效地学习人体动态,并结合了物理原理,以提高运动估计的物理真实性。具体来说,PhysPT构建了基于物理的人体表示和接触力模型,并引入了新的基于物理的训练损失(例如,力损失、接触损失和欧拉-拉格朗日损失),使模型能够捕捉人体和其所经历的力的物理属性。
核心问题是什么?
现有方法的局限性
尽管当前的深度学习方法在3D人体重建方面取得了进展,但它们往往产生不真实的估计,因为这些方法主要考虑了运动学而忽略了物理原理。
本文方法
本文提出的物理感知预训练变压器(PhysPT),它改进了基于运动学的运动估计并推断运动力。 PhysPT 利用 Transformer 编码器解码器backbone以自我监督的方式有效地学习人类动力学。
它还结合了控制人体运动的物理原理。构建了基于物理的身体表示和接触力模型。并利用它们施加新颖的物理启发训练损失(即力损失、接触损失和欧拉-拉格朗日损失),使 PhysPT 能够捕获人体的物理特性及其所经历的力。
实验结果
实验表明,经过训练后,PhysPT 可以直接应用于基于运动学的估计,以显着增强其物理合理性并产生有利的运动力。此外,我们还表明,这些具有物理意义的量可以转化为重要下游任务(人类行为识别)准确性的提高。
核心贡献是什么?
- 提出了一个Transformer编码器-解码器模型,通过自监督学习进行训练,并结合了物理原理。
- 引入了基于物理的人体表示(Phys-SMPL)和接触力模型,以及一系列新的基于物理的训练损失,用于模型训练。
- 实验表明,PhysPT可以显著提高运动估计的物理真实性,并推断出有利的运动力。
大致方法是什么?
所提出的框架由基于运动学的运动估计模型(橙色)和物理感知的预训练 Transformer(绿色)组成,用于从单目视频估计人体动力学。插图 (a) 说明了右骨盆的关节驱动和每只脚的接触力。 (b) 说明了重建的身体运动和推断的力,较浅的颜色代表更大的关节驱动幅度(例如,人物站立时的上身关节,行走时的腿部关节)。
Preliminary
Euler-Lagrange Equations.
看不懂
Kinematics-based Motion Estimation Model
- 使用任意一种Mocap算法,从视频中提取出人在相机坐标系下的shape参数和pose参数。
- 使用GLAMER把人从相机坐标系转到世界坐标系。
- 返回
- 世界坐标系下的位移、朝向和关节旋转
- 所有帧的shape参数的均值
Physics-aware Pretrained Transformer
优化Mocap结果,使其符合物理
Transformer Encoder-Decoder Backbone
| 输入 | 输出 | 方法 |
|---|---|---|
| q(T, R, theta) | input embedding | linear layer |
| input embedding, time positional embedding | latent embedding | Transformer Encoder |
| latent embedding, time positional embedding, 历史输出 | output embedding | Transformer Decoder |
loss:
- q的重建损失
- joint position的重建损失
自监督训练:PhysPT通过重建输入的人体运动来进行自监督训练,无需3D标注视频。
Physics-based Body Representation
物理原理的整合:PhysPT通过直接从广泛采用的3D人体模型(SMPL)计算身体物理属性,避免了不现实的代理身体模型的使用。
- 把人体根据关节分段
- 使分段mesh封闭
- 计算每一段mesh的体积
- 计算每一段mesh的质量和转动惯量
- 代入Euler-Lagrange公式
连续接触力模型
目标:从 3D 运动估计地面反作用力
难点:
- 接触状态通常需要事先确定——这本身就很难准确地做到
- 离散接触状态还引入了估计力的不可微过程。
本文方法:引入弹簧质量系统
$$ \lambda_{p,t} = s_{p,t}(-k_{h,t}b_{h,t}-k_{n,t}b_{n,t}-c_tV_{C,t}) $$
| 符号 | 含义 | 前置计算 |
|---|---|---|
| \(k_{h,t}\) | 弹簧系统在水平方向上的stifness | |
| \(k_{n,t}\) | 弹簧系统在竖直方向上的stifness | |
| \(c_t\) | 弹簧系统的damping系数 | |
| \(s_{p,t}\) | 力的量级大小 | \(d_t, V_{C,t}\) |
| \(d_t\) | point p到地面的距离 | |
| \(V_{C,t}\) | point p的速度 | |
| \(b_{h,t}\) | point p在水平方向上与reference point的距离 | 看样子reference point是(0.5, 0.5, 2) |
| \(b_{n,t}\) | point p在垂直方向上与reference point的距离 | |
| \(d_{t,x}\) | \(d_t\)投影到x轴的向量 | 与触地点的法向是什么关系? |
| \(d_{t,y}\) | \(d_t\)投影到y轴的向量 |
为了计算效率,仅将接触模型应用于每个身体部位内的顶点子集。
接触模型的特点:
- 接触模型捕捉了自然接触行为的本质,即:其中最接近地面且最稳定的点会受到更大的力。
- 接触模型避免了估计离散接触状态时出现的问题。
Physics-inspired Training Losses
优化目标:让论文中的公式(2)成立。
其中公式(2)中的\(\lambda\)为接触力,根据公式(4),是一个跟点的位置p和弹簧参数(stiffness, damping)有关的值。此处把公式(4)简化为
$$
\lambda_t = A_t x_t
$$
其中,第一项为与点p相关的矩阵,前面提到给完整的mesh顶点定义了一个subset,subset中的所有点都要参与计算,因此构成了一个比较大的矩阵。第二顶就是弹簧系数。
优化对象:\(x_t, \tau_t\)
优化约束:接触力lambda应考虑到人类正常站立时可能经历的最大接触力。
优化方法:这是一个二次规划问题,用CVXOPT求解。
Force Loss
目的:利用导出的运动力来指导模型产生真实的运动力并提取有意义的潜在表示以预测物理上合理的运动。
将latent embedding和上一节中优化出的\({\lambda_t, \tau_t}\)构成pair data。并使用一个linear layer来拟合latent embedding到\({\lambda_t, \tau_t}\)的映射。
Contact Loss
目的:让经历接触力的顶点应用约束,获得真实的接触行为
Euler-Lagrange Loss
目的:优化公式(5)
完整loss
重建loss + force loss + contact loss + euler loss
有效
缺陷
验证
PhysPT在多个数据集上的表现证明了其有效性,包括在Human3.6M和3DOH数据集上的评估,以及在PennAction数据集上对人类行为识别任务的改进。
启发
应用前景:PhysPT的方法可以应用于各种基于运动学的重建模型,以生成更精确的运动和力估计,这对于虚拟现实、增强现实、人机交互和机器人等领域具有潜在的应用价值。
这篇论文为单目视频下的人体动态估计领域提供了新的视角,并展示了通过结合深度学习和物理原理来提高模型性能的可能性。
遗留问题
参考材料
- [1] https://arxiv.org/pdf/2404.04430
Imagic: Text-Based Real Image Editing with Diffusion Models
一、核心思想与背景

Imagic旨在通过文本引导的扩散模型,实现对单张真实图像的复杂非刚性编辑(如改变物体姿态、组成或风格),同时保持图像原始特征(如背景、物体身份等)。与传统方法(如CycleGAN、SDEdit)相比,Imagic无需成对数据、遮罩标注或多视图输入,仅需单张图像和文本提示即可完成编辑,显著降低了交互成本。
传统方法的局限性
- 特定编辑类型受限:如仅支持风格迁移或局部修复。
- 依赖合成数据或辅助输入:多数方法需多张图像或掩码标注。
- 无法处理复杂语义变化:如非刚性姿态调整(如“让站立的狗坐下”)。
二、方法原理
输入:Origin Image和target text promt
Imagic的核心流程分为三步:文本嵌入优化、扩散模型微调、嵌入插值生成。其核心思想是通过文本嵌入的语义对齐与模型微调实现图像内容与编辑目标的平衡。
1. 文本嵌入优化
- 目标:将目标文本的嵌入(通过CLIP等编码器生成)优化至与输入图像对齐。
- 实现:对 target text 作 embedding,得到init text embedding \(e_{tgt}\)。冻结扩散模型参数,通过去噪损失函数优化文本嵌入(init text embedding): [ \mathcal{L}(x, e, \theta) = \mathbb{E}{t,\epsilon} \left[ | \epsilon - f\theta(x_t, t, e) |2^2 \right] ] 初始嵌入\( e{tgt} \)(目标文本)逐步优化为\( e_{opt} \),使其生成的图像更接近输入图像。
2. 扩散模型微调
- 目的:确保优化后的嵌入能精确重建输入图像。
- 策略:固定优化后的嵌入\( e_{opt} \),微调扩散模型参数\( \theta \)以最小化相同损失函数。同时,对超分辨率等辅助模型进行微调(仍以原始目标嵌入\( e_{tgt} \)为条件),保留高频细节。
3. 嵌入插值与生成
- 插值公式:通过线性插值混合( e_{tgt} )和( e_{opt} ): [ \bar{e} = \eta \cdot e_{tgt} + (1 - \eta) \cdot e_{opt} ] 用finetuned diffusion model生成target Image。调节超参数( \eta \in [0.6, 0.8] )可控制编辑强度,在保留原图细节与满足文本要求间取得平衡。
三、技术贡献与优势
- 复杂非刚性编辑能力:首次实现单张真实图像的姿态、几何结构等复杂修改(如“张开鸟的翅膀”)。
- 无需额外输入:仅需单张图像和文本提示,无需遮罩或多视图数据。
- 语义对齐与保真度平衡:通过嵌入优化和模型微调,避免传统方法中“真实性”与“忠实性”的冲突。
- 多模型兼容性:支持Imagen、Stable Diffusion等不同扩散模型框架。
四、实验验证与结果
1. 定性评估

- 多样化编辑类型:支持姿态调整(如“狗坐下”)、风格迁移(如“梵高风格”)、多对象编辑(如“两只鹦鹉接吻”)等。
- 生成多样性:通过调整随机种子和\( \eta \),提供多种编辑选项以应对文本模糊性。
2. 定量对比
- TEdBench基准:新提出的复杂编辑评测集,包含100对图像-文本任务。用户研究显示,70%的参与者更偏好Imagic结果,显著优于SDEdit、DiffusionCLIP等基线。
- 指标分析:CLIP得分(文本对齐)与LPIPS(图像保真度)显示,( \eta \in [0.6, 0.8] )时效果最佳。
3. 消融实验
- 微调必要性:未微调模型无法重建原始图像细节,编辑结果语义不一致。
- 嵌入优化步数:超过100步优化对效果提升有限,表明优化效率较高。
五、理论分析与局限
- 理论基础
Imagic的mask生成机制与扩散模型的跨模态对齐能力密切相关。通过噪声差异捕捉语义变化,其本质是利用文本条件对图像特征的动态重构。 - 局限性
- 对复杂语义变化的处理有限,例如同时修改多个不相关区域时可能生成错误mask。
- 高分辨率图像编辑时需结合分层扩散模型或加速采样策略,以降低计算开销。
- 文本描述的模糊性可能导致mask定位偏差,需进一步引入多模态对齐机制(如CLIP特征融合)。
六、应用与拓展
- 医学图像编辑
后续研究(如CT超分辨率任务)借鉴Imagic思想,通过双流扩散模型在保留结构的同时提升分辨率。 - 多任务扩展
结合SDE(随机微分方程)框架,提升编辑过程的鲁棒性。例如,SDE-Drag方法通过隐变量操控实现点拖动编辑,进一步扩展了Imagic的应用场景。 - 风格迁移
与LoRA等参数高效微调技术结合,实现风格-内容解耦,例如B-LoRA通过隐式分离风格与内容组件,支持细粒度编辑。
七、总结
Imagic通过文本嵌入优化与扩散模型微调,为基于文本的真实图像编辑提供了高效、灵活的解决方案。其在复杂非刚性编辑任务中的表现,推动了扩散模型在图像处理领域的应用边界,尤其在医疗影像、艺术创作等场景中潜力显著。尽管存在计算效率与复杂语义适应性等挑战,其方法框架为后续研究提供了重要参考。
DiffEdit: Diffusion-based semantic image editing with mask guidance
一、核心思想与背景

传统的基于扩散模型的图像编辑方法通常需要用户提供显式的遮罩(mask)来定位编辑区域,例如将任务转化为条件修复(inpainting)。而DiffEdit提出了一种无需人工标注mask的语义编辑框架,仅通过文本提示(text prompt)即可自动推断需修改的区域,并生成符合文本描述的编辑结果。其核心在于利用扩散模型在不同文本条件下的噪声预测差异,生成与编辑语义相关的区域mask,从而实现精准的局部编辑。
二、方法原理
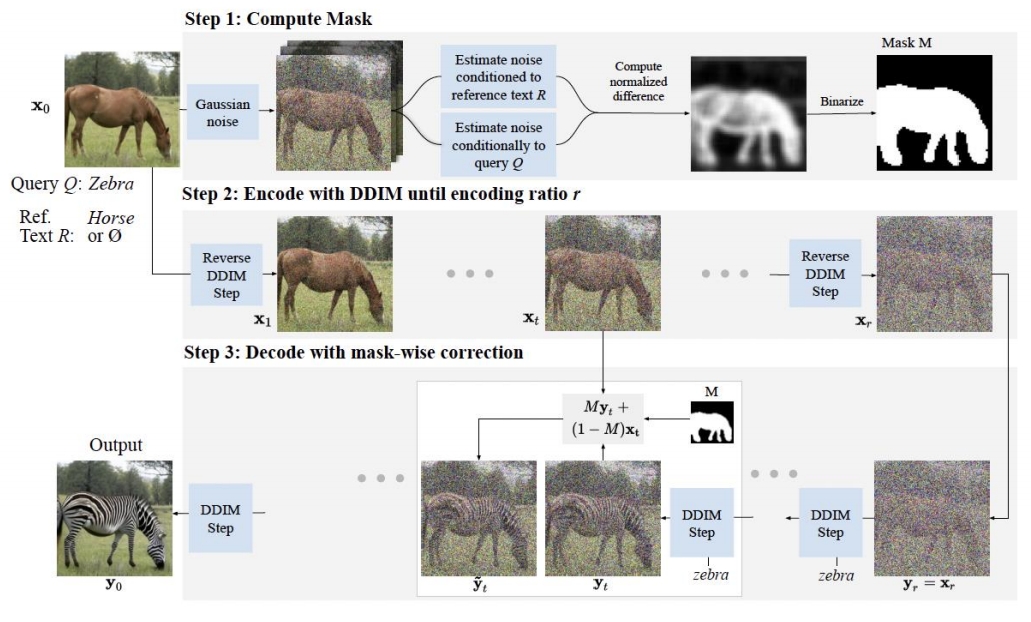
DiffEdit的流程分为三步:
-
计算编辑mask
通过对比源文本(原始图像描述)和目标文本(编辑要求)的噪声预测差异,定位需修改的区域。具体而言,对输入图像添加高斯噪声后,分别用两种文本条件进行去噪,计算两次噪声估计的差异,并通过阈值化生成二值mask。这一步骤利用了扩散模型对文本敏感的特性,自动捕捉语义相关区域。 -
DDIM编码
使用DDIM(Denoising Diffusion Implicit Models)的前向过程将输入图像编码至隐空间,生成中间隐变量。编码比例(r)控制编辑强度:r越大,编辑自由度越高,但可能偏离原图更多。
✅ 注意:step 1 的加高斯噪声与 step 2 的 DDIM Encoding 不同。前者是非确定的,后者是确定的。
- Mask引导的解码
在隐变量基础上,结合目标文本条件进行扩散模型的反向解码过程。解码时,非mask区域的像素值被固定为DDIM编码结果,而mask区域则根据目标文本生成新内容,从而保留原图未编辑部分的结构。
三、技术贡献与优势
- 自动mask生成
无需用户标注mask,显著降低交互成本,尤其适用于复杂场景的编辑任务。 - 平衡编辑与保留
通过DDIM编码保留原图非编辑区域的细节,同时在mask区域实现高保真度的语义修改,解决了传统方法在“真实性”与“忠实性”之间的权衡问题。 - 多模态兼容性
支持文本引导的编辑,并可通过调整mask生成策略(如使用空文本作为参考)灵活适应不同场景。 - 高效性
无需额外训练或微调扩散模型,直接利用预训练模型实现编辑,计算成本较低。
四、实验验证
- 数据集与指标

在ImageNet、COCO和Imagen等数据集上验证,使用LPIPS(衡量与原图相似性)和CSFID/FID(衡量生成质量与文本一致性)作为评估指标。 2. 性能对比
- 在ImageNet上,DiffEdit在LPIPS与CSFID的均衡性优于CycleGAN、SDEdit等基线方法。
- 在COCO上,尽管CLIP得分略低于SDEdit,但其生成的图像在保持结构一致性的同时更贴合文本描述。
- 消融实验
- 编码比例r的选择对结果影响显著,r=0.5时在编辑能力与保真度之间达到最佳平衡。
- 结合DDIM编码与mask引导的解码策略(DiffEdit w/ Encode)相比单一策略(仅mask或仅编码)效果更优。
五、理论分析与局限
- 理论基础
DiffEdit的mask生成机制与扩散模型的跨模态对齐能力密切相关。通过噪声差异捕捉语义变化,其本质是利用文本条件对图像特征的动态重构。 - 局限性
- 对复杂语义变化的处理有限,例如同时修改多个不相关区域时可能生成错误mask。
- 高分辨率图像编辑时需结合分层扩散模型或加速采样策略,以降低计算开销。
- 文本描述的模糊性可能导致mask定位偏差,需进一步引入多模态对齐机制(如CLIP特征融合)。
六、应用与拓展
- 医学图像编辑
后续研究(如CT超分辨率任务)借鉴DiffEdit思想,通过双流扩散模型在保留结构的同时提升分辨率。 - 多任务扩展
结合SDE(随机微分方程)框架,提升编辑过程的鲁棒性。例如,SDE-Drag方法通过隐变量操控实现点拖动编辑,进一步扩展了DiffEdit的应用场景。 - 风格迁移
与LoRA等参数高效微调技术结合,实现风格-内容解耦,例如B-LoRA通过隐式分离风格与内容组件,支持细粒度编辑。
七、总结
DiffEdit通过扩散模型的跨模态推理能力,为语义图像编辑提供了一种高效、低成本的解决方案。其核心创新在于将文本条件与隐空间编码相结合,实现了自动化mask生成与局部编辑的平衡。尽管存在计算效率与复杂场景适应性等挑战,其在多领域的拓展应用(如医学成像、艺术创作)展现了扩散模型在图像编辑任务中的巨大潜力。
Dual Diffusion Implicit Bridges for Image-to-Image Translation
DDIB提出了一种基于扩散模型的图像到图像翻译方法,通过隐式桥接(Implicit Bridges)实现跨域转换。以下从方法原理、技术贡献、理论关联及实验结果等方面进行解读:
一、核心思想与背景
传统图像翻译方法(如CycleGAN)依赖对抗训练,但存在模型扩展性差(n个域需n²个模型)和数据隐私受限(需跨域联合训练)的问题。DDIB基于去噪扩散隐式模型(DDIM),利用其确定性隐空间映射特性,提出了一种无需成对数据、各域独立训练的解决方案。核心思路是:将源域图像通过DDIM的前向过程映射到隐空间,再通过目标域的DDIM反向过程生成目标图像,形成“隐式桥接”。
二、方法原理
1. DDIM的特性
DDIM通过常微分方程(ODE)将扩散过程建模为确定性映射,其前向过程(图像→隐变量)与反向过程(隐变量→图像)互为逆过程,保证了隐空间的一致性。这一特性使得不同域的隐变量可以直接传递,无需对齐或额外处理。使得DDIM Inversion 成为图像编辑的常用方法。
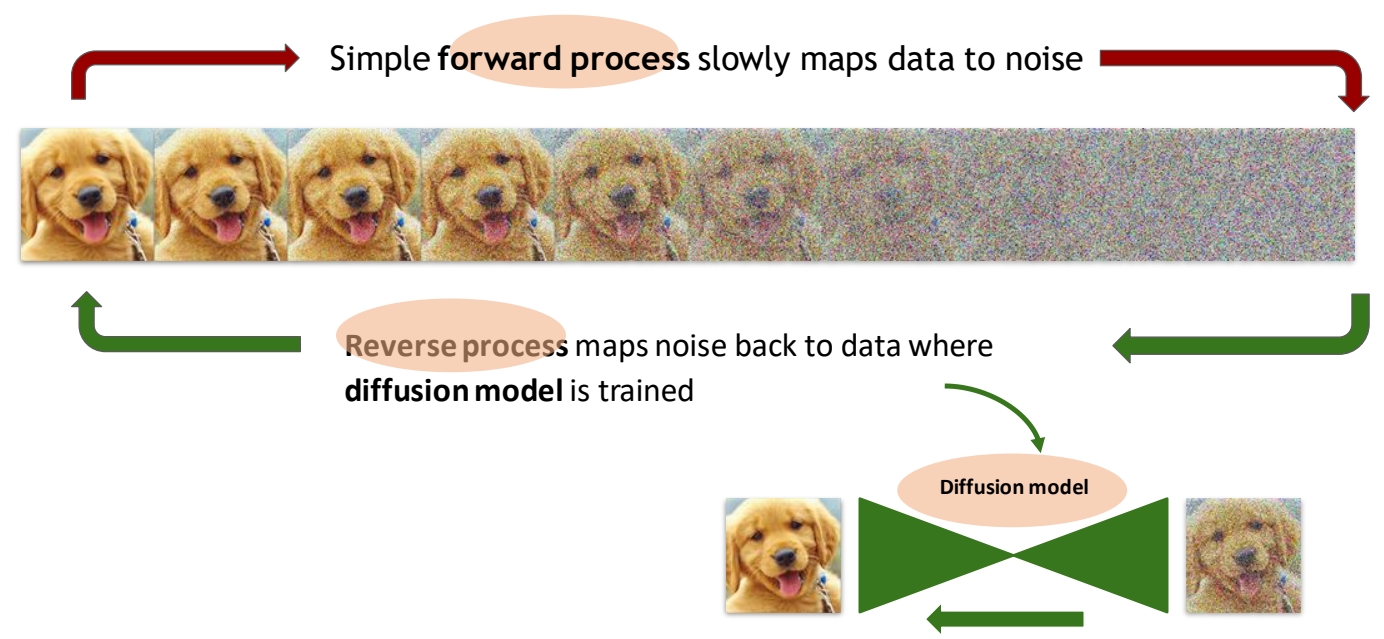
2. DDIB流程
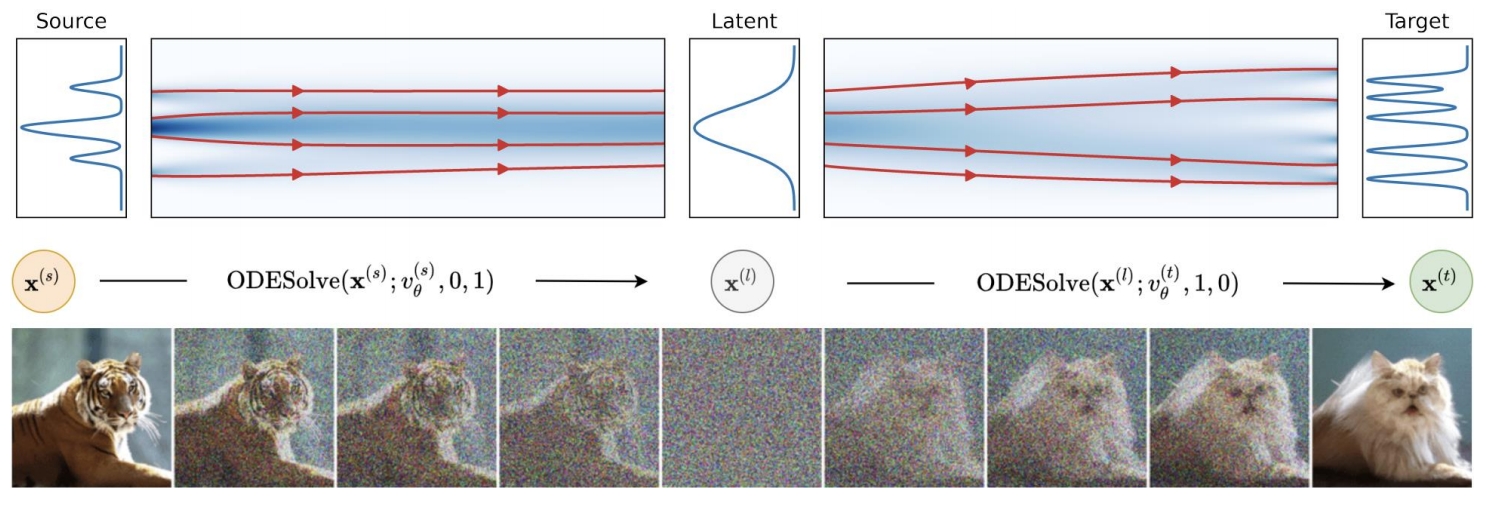
✅ 假设已有一个 文生图的pretrained DDIM model.
✅ 任务:把老虎的图像变成猫的图像,且不改变 Sryle.
- 源域编码:使用源域预训练的DDIM,通过前向ODE将图像\( x_0^{(s)} \)映射到隐变量\( x_T \)。
✅ (1) 老虎图像 + DDIM Inversion + “老虎”标签 → noise
-
隐变量传递:直接将\( x_T \)输入目标域的DDIM。
-
目标域解码:通过目标域的反向ODE从\( x_T \)生成目标图像\( x_0^{(t)} \)。
✅ (2) noise + DDIM + “猫”标签 → 猫图像
3. 隐空间对齐的理论依据
作者将DDIB与**蒙日最优传输(Monge Optimal Transport)**关联,认为DDIM的训练目标近似于最小化源域到隐空间、隐空间到目标域的最优传输代价。尽管理论证明不完整,但实验显示DDIB生成的图像与最优传输方法结果接近。
三、技术贡献与优势
- 无需成对数据:仅需各域独立训练的DDIM模型,适用于医疗等隐私敏感场景。
- 模型扩展性:n个域仅需n个模型,而非传统方法的n²个,显著降低计算成本。
- 确定性生成:DDIM的确定性隐变量映射避免了随机噪声干扰,提升生成稳定性。
- 兼容性:可与现有扩散模型结合,例如在CT超分辨率任务中保留拓扑结构,或用于医学图像合成。
- 只需要预训练模型,不需要根据特定任务重训。
四、实验与验证
- 二维分布实验:在简单分布(如高斯混合分布)上验证隐空间桥接的有效性,结果显示DDIB的转换结果与最优传输方法接近。
- 多域图像翻译:在自然图像数据集(如Edges→Photos)中,DDIB生成质量与CycleGAN相当,但模型复杂度更低。
- 医学应用:后续工作(如CT超分辨率)借鉴DDIB思想,通过双流扩散模型在保留结构的同时提升分辨率。
五、局限性与未来方向
- 理论解释不足:隐空间直接传递的可行性缺乏严格数学证明,需进一步探索。
- 隐空间对齐假设:若源域与目标域的隐空间分布差异过大,可能导致转换失败,需引入自适应对齐机制。
- 扩展性优化:针对高分辨率图像,需结合分层扩散模型或加速采样策略(如DDIM的子序列采样)。
其它应用

✅ 学习不同颜色空间的 transform
六、总结
DDIB通过扩散模型的隐空间桥接机制,为图像翻译提供了一种高效、安全的解决方案,尤其适用于多域、无配对数据的场景。其思想在后续研究中被广泛应用于医学成像和跨模态生成任务,推动了扩散模型在跨域转换中的发展。
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
1. 研究背景与核心问题
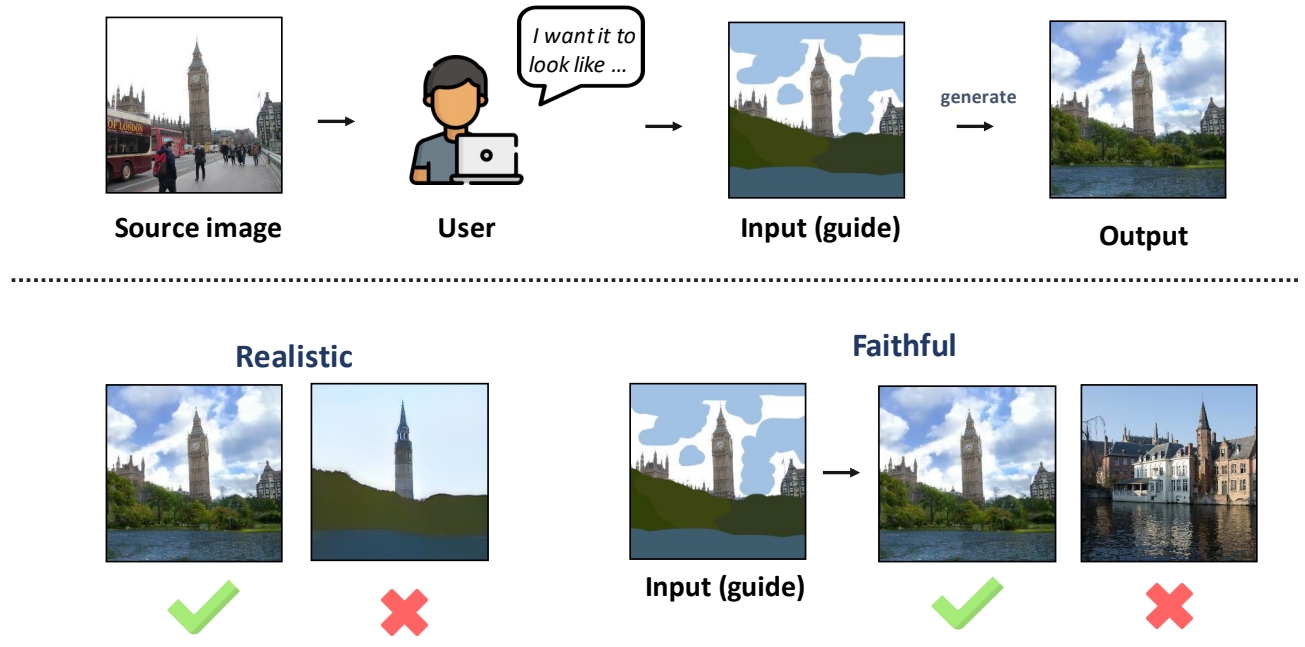
传统的图像合成与编辑方法(如GANs)需要针对特定任务设计复杂的损失函数或进行模型微调,难以在生成图像的**真实性(Realism)和与输入的一致性(Faithfulness)之间实现平衡。SDEdit提出了一种无需额外训练的统一框架,通过随机微分方程(SDE)**的逆向过程实现图像生成与编辑。
2. 核心方法:SDE驱动的生成与编辑
(1)前向与逆向SDE过程
- 前向加噪:输入图像通过SDE逐步添加噪声,破坏局部伪影但保留全局结构。例如,对用户绘制的粗糙笔画(如线条或色块)加噪,使其分布接近高斯噪声。
- 逆向去噪:从加噪后的中间状态出发,通过逆向SDE生成高质量图像。逆向过程利用预训练的**得分函数(Score Function)**预测噪声方向,逐步去除噪声。
(2)噪声调度与时间步选择
- 噪声调度函数:定义了噪声强度随时间的演化。论文对比了两种SDE:
- VE-SDE(方差爆炸型):噪声方差随时间指数增长,最终分布接近高斯噪声。
- VP-SDE(方差保持型):噪声方差与信号能量互补,确保总能量守恒。
- 关键参数t₀:控制加噪程度。t₀越大(如t₀∈[0.3, 0.6]),生成图像越真实但可能偏离输入;t₀越小则更忠实于输入但可能保留伪影。
(3)局部编辑与掩码融合
- 对于图像局部编辑(如修改特定区域),SDEdit通过掩码(Mask)分离编辑区域与未编辑区域:
- 编辑区域:按上述SDE流程处理;
- 未编辑区域:直接使用原图加噪后的中间状态,确保一致性。
Pipeline
Gradually projects the input to the manifold of natural images.
准备工作:一个预训练好的Image Diffusion Model
第一步:perturb the input with Gaussian noise
第二步:progressively remove the noise using a pretrained diffusion model.
3. 实验结果与优势
(1)生成质量与效率
- 任务支持:支持笔触生成图像(如草图转真实场景)、图像合成(如多图拼接)和局部编辑(如颜色调整)。
- 指标对比:在CelebA-HQ、LSUN等数据集上,SDEdit在KID(衡量真实性)和L2距离(衡量一致性)上优于传统方法(如GANs和级联模型)。
(2)无需训练的灵活性
- 直接利用预训练的扩散模型(如DDPM)作为得分函数,无需任务特定微调,显著降低应用门槛。
(3)与后续工作的关联
- Stable Diffusion的img2img功能:SDEdit的思想被整合至Stable Diffusion,支持基于噪声引导的图像到图像转换。
- 插值任务改进:NoiseDiffusion通过结合SDEdit的加噪策略,改善了自然图像插值的平滑性与质量。
4. 局限性及后续发展
(1)主要局限
- 缺乏文本引导能力:SDEdit本身不支持文本条件控制,需结合其他模型(如GLIDE)实现多模态生成。
- 计算成本:逆向SDE需多步迭代,实时性受限(后续工作如DDIM加速采样可缓解)。
(2)后续改进
- ControlNet++:引入像素级循环一致性损失,结合SDEdit的加噪策略提升可控性。
- 视频生成扩展:Sora等视频模型借鉴了SDEdit的时空块表示与噪声调度思想,实现连贯视频生成。
- 效率提升:全图生成速度比较慢,因此针对被编辑区域进行部分生成。
Li et al., "Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models", NeurIPS 2022
5. 应用场景与影响
- 艺术创作:将手绘草图转化为高质量图像,辅助设计师快速迭代。
- 图像修复:通过局部加噪-去噪消除遮挡或修复损坏区域。
- 工业设计:支持基于线稿的产品原型生成,结合物理仿真优化设计。
- Image compositing:把上面图的指定pixel patches应用到下面图上。SDEdit的结果更合理且与原图更像。
总结
SDEdit通过SDE框架统一了图像生成与编辑任务,以无需训练和灵活控制的特点成为扩散模型应用的重要里程碑。其核心思想被后续工作(如Stable Diffusion、ControlNet++)广泛采纳,推动了多模态生成与高分辨率合成技术的发展。
Prompt-to-Prompt Image Editing with Cross-Attention Control
要解决的问题
基于标题的图像编辑 (1) 修改某个单词的影响力;(2) 替换单词;(3) 添加单词;而那些不期望改变的部分能够保持不变。
一、核心思想与背景
传统基于文本的图像编辑方法通常需要用户提供空间遮罩(mask)以定位编辑区域,但这种方式忽略了原始图像的结构和内容,且依赖人工标注。本文提出了一种无需遮罩的文本驱动图像编辑框架,通过直接控制扩散模型中的交叉注意力层(Cross-Attention)来实现编辑。其核心思想是:交叉注意力层决定了文本提示(prompt)与图像空间布局的关联,通过修改注意力图即可在不破坏原始图像结构的情况下完成编辑。
传统方法的局限性
- 依赖掩码标注:如Inpainting等需用户指定编辑区域,交互成本高。
- 全局修改受限:文本微小变动可能导致图像整体结构改变。
- 复杂语义调整困难:如替换物体或调整属性时难以保持背景一致。
二、方法原理
1. 交叉注意力层的关键作用
扩散模型(如Stable Diffusion)通过交叉注意力层将文本语义映射到图像空间。注意力图 ( M ) 由以下公式计算: [ M = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) ] 其中,( Q ) 来自图像特征,( K ) 和 ( V ) 来自文本编码。注意力图 ( M ) 决定了每个文本词对图像像素的影响权重。
2. 编辑流程
- 生成原始图像:基于初始提示 ( P ) 生成图像 ( I ),并记录扩散过程中的注意力图序列 ( {M_t} )。
- 修改提示生成目标注意力图:输入编辑后的提示 ( P^* ),生成对应的注意力图 ( {M_t^*} )。
- 注意力图融合:通过动态调整原始与目标注意力图的比例,控制编辑强度。例如:
- 单词替换:在早期扩散步骤(( t < \tau ))使用目标注意力图 ( M_t^* ),后期保留原始注意力图 ( M_t ),以平衡内容保留与编辑效果。
- 添加新短语:仅对新增文本词应用目标注意力图,共同词沿用原始注意力权重。
- 注意力重加权:通过缩放特定词对应的注意力图权重,增强或减弱其影响(如调整物体尺寸或属性)。
3. 算法实现
- 确定性与随机性控制:固定随机种子以确保生成一致性。
- 渐进式编辑:通过阈值 ( \tau ) 控制编辑阶段,早期步骤决定整体结构,后期步骤优化细节。
三、技术贡献与优势
- 无需掩码标注:仅通过修改文本提示即可实现局部或全局编辑,显著降低用户交互成本。
- 多样化编辑类型支持:
- 局部替换:如将“自行车”替换为“汽车”并保留背景。
- 属性调整:如缩放“蓬松度”或调整物体颜色。
- 风格迁移:添加“儿童绘画风格”等全局描述词。
- 兼容性:适用于多种扩散模型(如Stable Diffusion、Imagen),无需额外训练。
- 平衡保真度与编辑自由度:通过调整注意力图注入比例,在保留原始结构与满足新提示之间取得平衡。
四、实验验证
1. 定性评估

- 复杂场景编辑:在COCO等数据集上展示多对象替换(如“两只鹦鹉接吻”)和风格迁移(如“梵高风格”)效果,生成结果在结构一致性与文本对齐性上优于CycleGAN和SDEdit。
- 渐进控制:通过调整 ( \tau ) 值,展示从完全保留原图到完全遵循新提示的连续编辑效果。
2. 定量对比
- 用户研究:70%参与者认为P2P生成结果在保真度与编辑质量上优于基线方法。
- 指标分析:使用CLIP得分衡量文本-图像对齐性,LPIPS评估结构相似性,结果显示P2P在两者间达到最佳平衡。
3. 消融实验
- 注意力图必要性:若不注入注意力图,文本微小修改会导致图像全局变化。
- 阈值 ( \tau ) 影响:( \tau ) 过小导致编辑不足,过大则引入结构扭曲。
五、理论分析与局限
- 理论基础:
交叉注意力机制本质上是文本与图像模态的动态对齐工具。通过干预注意力图,P2P直接操控了文本语义到图像空间的映射过程,这与多模态表征学习的理论一致。 - 局限性:
- 复杂结构修改困难:如将“汽车”改为“自行车”时,若目标结构差异过大,可能导致生成失真。
- 计算开销:高分辨率图像需结合分层扩散模型或加速采样策略(如DDIM子序列采样)。
- 文本模糊性:提示歧义可能导致注意力图定位偏差,需结合CLIP等模型增强对齐。
六、应用与拓展
- 医学图像编辑:借鉴P2P思想,实现病灶区域的语义编辑(如肿瘤尺寸调整)。
- 多任务扩展:结合InstructPix2Pix等框架,支持指令驱动的细粒度编辑(如“将狗移到左侧”)。
- 风格-内容解耦:与LoRA等技术结合,实现风格迁移与内容保留的独立控制。
七、总结
《Prompt-to-Prompt Image Editing with Cross-Attention Control》通过深入挖掘扩散模型中交叉注意力层的语义控制能力,为文本驱动的图像编辑提供了高效、灵活的解决方案。其核心贡献在于将编辑过程转化为注意力图的动态调整,既保留了原始图像结构,又实现了多样化的语义修改。尽管存在复杂编辑与计算效率的挑战,该方法为后续研究(如可控生成、多模态对齐)提供了重要参考,并在艺术创作、医学影像等领域展现了广阔的应用前景。
WANDR: Intention-guided Human Motion Generation
核心问题是什么?
要解决的问题
输入:角色的初始姿势和目标的 3D 位置
输出:生成自然的人体运动,并将末端执行器(手腕)放置在目标位置。
现有方法
现有方法(数据驱动或使用强化学习)在泛化和运动自然性方面受到限制。主要障碍是缺乏将运动与目标达成相结合的训练数据。
本文方法
为了解决这个问题,我们引入了新颖的意图特征(intention feature)。intention引导角色达到目标位置,并交互式地使生成适应新的情况,而无需定义子目标或整个运动路径。 WANDR 是一种条件变分自动编码器 (c-VAE),可以在具有目标导向运动的数据集(CIRCLE)进行训练,也可以是不具有目标导向运动的数据集(AMASS)进行训练。
效果
我们广泛评估我们的方法,并证明其生成自然和长期运动的能力,以达到 3D 目标并推广到看不见的目标位置。我们的模型和代码可用于研究目的,请访问 wandr.is.tue.mpg.de。
核心贡献是什么?
- 我们提出了 WANDR,一种数据驱动的方法,它将自回归运动先验与新颖的intention引导机制相结合,能够生成在空间中真实移动并达到任意目标的角色。
- 我们通过实验评估我们的方法,包括“组合多个数据集的优势”以及“我们的运动生成器的泛化能力”。我们的结果强调了“intention机制指导运动生成过程”的有效性
- 同时还能够为缺乏明确目标注释的数据集合并伪目标标签。该模型和代码可用于研究目的。
大致方法是什么?
原理:当人试图到达一个遥远的目标时,运动主要集中在腿部和引导身体接近物体,但当他接近物体时,重点将集中在移动手臂和上半身以到达目标。
在训练过程中,模型以意图向量 Ip、Ir 和 Iw 为条件,学习将它们与实际实现目标的行动联系起来。当训练数据没有明确的目标时,根据未来帧中手腕的位置创建一个目标;角色的状态 \(p^{dyn}_ i\) 表示 SMPL-X 局部姿态参数 pi 以及帧 i − 1 中身体参数的 deltas \(d_ {i−1}\)。
在推理过程中,WANDR 获取意图特征、状态和随机噪声并返回位姿变化 \(\hat d_ i\)。下一个位姿 pi 是通过将 \(\hat d_ i\) 与前一个位姿 \(\hat p_ {i-1}\) 相结合而获得的。
数据表示
body pose:全局位移(3)+ 全局朝向(6)+ local pose (21 * 6)
角色状态\(p^{dyn}_ i\):SMPL-X 局部姿态参数 pi + 帧 i − 1 中身体参数的 deltas \(d_ {i−1}\)
Intention Features
输入:
- 当前帧的body pose
- 期待目标帧时手的位置
- 期待手达到指定位置时的目标帧ID(有GT时用GT,没有GT时随机指定未来帧)
- 当前帧ID
输出:
- Wrist Intention:手腕及时到达目标位置所需的平均速度
- Orientation Intention:达目标位置时的身体方向。通过对此进行调节,我们确保人类模型面向目标并平稳地导航到目标,防止推理过程中出现不自然的运动,例如倒退。
- Pelvis Intention:目标相对于身体的位置的信息。它是目标和骨盆关节之间的差异,不包括 z(高度)分量。
Motion Network (WANDR)
| 输入 | 输出 | 方法 |
|---|---|---|
| 第i帧pose和第i-1帧pose | pose delta di(135维) 通过关注姿势增量而不是绝对姿势值,我们的模型受益于重要的归纳偏差,提高了其学习效率和性能.类似Motion VAE和HuMoR. | p是的旋转分量和位移分量分别计算。并去除其中全局旋转和全局位移中的z分量 |
| di | 对di进行编码 | Encoder |
| 编码z,意图参数,角色状态 | 相对于上一帧的delta pose | Decoder |
Training Loss
| loss | weight |
|---|---|
| 重建loss | 1 |
| KL divergence | 1e-2 防止 LKL 的过度支配,从而帮助解码器避免崩溃为均值预测。 |
| J 关节位置 | 1 |
有效
缺陷
验证
数据集:AMASS, CIRCLE
启发
3D-3D通常预测delta pose,来避免模型过于关注全局朝向。
2D-3D通常预测全局位置,因为不同全局朝向的3D对应的2D是不同的。
遗留问题
参考材料
TRAM: Global Trajectory and Motion of 3D Humans from in-the-wild Videos
| 缩写 | 英文 | 中文 |
|---|---|---|
| VIMO | video transformer model | |
| DBA | dense bundle adjustment layer |
核心问题是什么?
TRAM是一种从in-the-wild视频中重建人类全局轨迹和运动的两阶段方法。
提取相机轨迹
已有方法(16)是通过相机运动 + 人物运动 + 人物运动先验 联合优化出相机scale。作者认为由于人物运动先验是使用室内数据训练得到的,因此不能泛化到室外场景中。
作者认为仅通过(排除前景干扰的)背景 + 背景语义足以估计出scale。
人物轨迹恢复
已有方法中,单帧方法恢复较准确,但缺少连续性。而时序方法恢复动作不够准确。原因是基于视频的训练成本高且缺少视频数据。
作者在HMR2.0(预训练的人物模型)上拓展出VIMO模型(增加2个时序transformer),并使用视频数据finetune这个模型。在轨迹信息的相机作为尺度参考系下,回归出人体的运动学身体运动。
效果
通过组合这两个运动,我们实现了世界坐标系中 3D 人体的精确恢复,将全局运动误差比之前的工作减少了 60%。
核心贡献是什么?
- TRAM,从野外视频中恢复人体轨迹和运动,比之前的工作有了很大的改进。
- 证明可以从 SLAM 推断出人体轨迹,并提供技术解决方案,使单目 SLAM 在动态人体存在的情况下具有鲁棒性和公制尺度。
- 提出了视频变换器模型 VIMO,它建立在大型预训练的基于图像的模型之上,并证明这种可扩展的设计实现了最先进的重建性能。
大致方法是什么?
左上:给定一个视频,我们首先使用 DROID-SLAM 恢复相对相机运动和场景深度,并通过双掩蔽对其进行增强(第 3.2 节)。
右上:我们通过优化过程将恢复的深度与左上预测的深度对齐,以估计度量缩放(第 3.3 节)。
底部:我们引入 VIMO 在相机坐标下重建 3D 人体(第 3.4 节),并使用公制尺度相机将人体轨迹和身体运动转换到全局坐标。
detect track video
| 输入 | 输出 | 方法 |
|---|---|---|
| 视频 | 图像 | cv2 |
| 图像 | 人物的bbox。 一张图像上可能有多个bbox,因此每个图像得到的是以图像为单位的bbox list,按照bbox的面积由大到小排序。因为大的bbox更有可能是真实的bbox,而小的bbox更有可能是误检。 | VitDet |
| 图像,人物的bbox | mask | 来自 YOLOv7 [83] 的检测作为Segment Anything Model[32] 模型的提示 |
| bbox | tracking。 VitDet只负责检测人物的bbox,不负责让bbox与人物的ID挂钩。为了得到某个ID的连续的bbox序列,需要进行tracking。得到的是以人为单位的bbox list,以及其相应的mask list。 | DEVA-Track-Anything,跟踪策略为IOU。 |
| 图像 | 公制深度 | ZoeDepth [5] |
Masked DROID-SLAM
输入:单视角视频
输出:相机轨迹
| 输入 | 输出 | 方法 |
|---|---|---|
| 图像或用户输入 | 相机内参 | 相机内参包括focal, center。没有用户指定的情况下,默认center为图像的中心,focal为np.max([h0, w0])。 |
| 图像序列, mask | 估计更准确的的相机内参 | 利用DROID-SLAM的track功能,找到一个可以使droid reprojection error最小的focal. |
| 图像序列,mask,相机内参 | 相机轨迹, disps | Masked DROID-SLAM 在DROID-SLAM的基础上,把图像中被mask为有人的区域的置信度转为0,防止人物的移动对DROID-SLAM造成影响。 |
disps:在立体视觉中,"disparity"(视差)是指同一场景点在左右两个相机图像中的水平像素差。这个差异是由于相机从不同的位置观察同一场景造成的。通过计算视差,可以恢复出场景的深度信息,因为视差与深度是相关的(在固定的相机内参下,视差越大,深度越近;视差越小,深度越远)。
相机移动的情况下,才会有来自同一个场景在不同相机观察位置的视差。因此此算法应用于相机移动的场景。而不能使用于相机静止的场景。
Trajectory Scale Estimation
作者认为,空间scale的推理能力部分体现在深度预测网络中。
第一步的DPOID会输出深度,但深度的单位未知,且与图像保持一致。
第二步中的ZoeDepth也会输出深度,且深度是meter scale的。
| 输入 | 输出 | 方法 |
|---|---|---|
| 图像序列 | pred_depth | 预训练的ZoeDepth |
| disps 来自Masked DROID-SLAM | slam_depth | slam_depth = 1/disp |
通过两个深度的对比,可以得出图像的scale。
但ZoeDepth预测出的深度存在两个问题:
- 特定场景下预测的深度信息不准,例如“天空”
- 时间不连续,部分帧不准,存在突变
为了让这个scale更鲁棒,作者做了以下处理:
- 所有帧独立后,再对所有帧取平均值
- 去掉无处预测不准确的区域
# 通过求解α,将 α ∗ slam_depth 到 to pred_depth, 我们可以将重建场景和相机轨迹重新缩放到公制单位。
# 此函数每一帧独立调用,每次输入为某一帧的slam_depth和pred_depth
def est_scale_hybrid(slam_depth, pred_depth, sigma=0.5, msk=None, far_thresh=10):
""" Depth-align by iterative + robust least-square """
if msk is None:
msk = np.zeros_like(pred_depth)
else:
msk = cv2.resize(msk, (pred_depth.shape[1], pred_depth.shape[0]))
# Stage 1: Iterative steps
# 逐像素地求解scale
s = pred_depth / slam_depth
# 求解scale时排除以下一些像素:
# 1. 前景像素
# 2. 不合理的深度预测,即深度必须为正值
# 3. 远区域像素,因此在这些区域上深度预测不准。仅使用深度预测更可靠的中间区域来解决比例问题。
robust = (msk<0.5) * (0<pred_depth) * (pred_depth<10)
# 取所有像素的scale均值,作为迭代更新的初始值
s_est = s[robust]
scale = np.median(s_est)
# 迭代更新是为了选择更可靠的区域来计算scale。
# 这里只是通过更新区域来更新scale,没有优化的过程。
for _ in range(10):
# 计算scaled slam depth
slam_depth_0 = slam_depth * scale
# 如果scaled slam depth认为某个像素的深度不合理或者不可靠,也会把这个区域排除掉。因为pred_depth不一定可靠。
robust = (msk<0.5) * (0<slam_depth_0) * (slam_depth_0<far_thresh) * (0<pred_depth) * (pred_depth<far_thresh)
s_est = s[robust]
scale = np.median(s_est)
# Stage 2: Robust optimization
robust = (msk<0.5) * (0<slam_depth_0) * (slam_depth_0<far_thresh) * (0<pred_depth) * (pred_depth<far_thresh)
pm = torch.from_numpy(pred_depth[robust])
sm = torch.from_numpy(slam_depth[robust])
def f(x):
loss = sm * x - pm
# Geman-McClure Loss
loss = gmof(loss, sigma=sigma).mean()
return loss
# 迭代更新算出的scale作为迭代优化的初始值
x0 = torch.tensor([scale])
# torchmin.minimize
result = minimize(f, x0, method='bfgs')
scale = result.x.detach().cpu().item()
return scale
为什么在相机移动的情况下,所有帧可以共用一个scale?
答:scale与相机内参决定。相机内参不变的情况下scale不会变。
Video Transformer for Human Motion
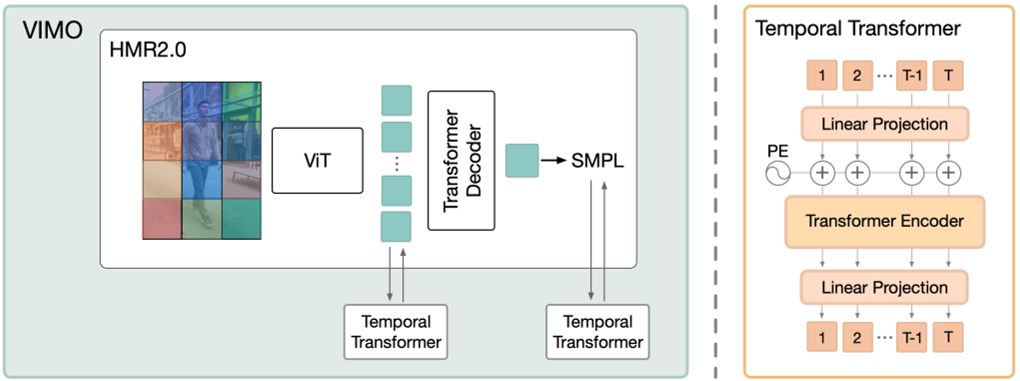
想法:利用大型预训练模型中的丰富知识,进行灵活且可扩展的架构设计,其性能可以通过计算和数据不断提高。
做法:
- 通过添加两个时间transformer,将基于图像的 HMR2.0 转换为视频模型。
- 使用视频数据在原始transformer decoder上进行微调
网络输入预处理
| 输入 | 输出 | 方法 |
|---|---|---|
| tracking | chunks | tracking以人为单位组织数据,但是由于数据可能检测错误或者人物出现消失,检测结果是不连续的。但网络要求输入连续数据。因此根据帧ID切段。 |
| 图像,bbox | cropped image |
Transformer
这两个时间transformer使用相同的encoder only架构.
第一个transfomer在图像域(patch token from ViT)传播时间信息。即,先在每个patch上独立地使用ViT transformer encoder进行编码。再把这个编码合起来,在时间维度上进行增加的transformer。两个transformer合起来,相当于一个ST transformer。
第二个transformer在人体运动域传播时间信息。作者认为,先隐空间学习运动模型再回归器出SMPL参数的做法不很合适,因为该隐空间纠缠了许多其他信息,例如形状、相机和图像特征。相比之下,作者建议回归出SMPL参数之后仅对其中的pose部分使用 Transformer 进行编码和解码。因此,本文直接将这种通用架构应用于 SMPLposes{θt,rt}上,并使用 MoCap 数据进行预训练。
b: batch
t: frame
c: channel,或者dim
| 输入 | 输出 | 方法 |
|---|---|---|
| 图像,[(b,t), c=3, h, w] | feature,[(b,t=16), c=1280, h=16, w=12] | 预训练模型vit_huge 得到的是一个二维特征 |
| bbox的center和scale,focal | bbox_info,[(b,t=16), c=3] | CLIFF (Li et al.) bbox feature 一堆magic number,不清楚含义 |
| bbox_info,[(b,t=16), c=3] | bbox_info,[(b,t=16), c=3, h=16, w=12] | 维度上与feature对齐,便于后面的拼接 |
| feature, bbox_info | feature,[(b,t=16), c=1280+3, h=16, w=12] | feature = torch.cat([feature, bb], dim=1)图像特征与bbox特征拼接到一起。因为feature来自于cropped image,没有人在整个画面中的信息。而bbox表示人在画面中的位置,正好弥补了这一点。 |
| feature,[(b t=16) c=1280+3 h=16 w=12] | feature,[(b h=16 w=12) t=16 c=1280+3] | 要在t维度上做transformer,第二个维度必须是t |
| feature,[(b h=16 w=12) t=16 c=1280+3] | feature,[(b h=16 w=12) t=16 c=1280] | st_module |
| feature,[(b h=16 w=12) t=16 c=1280] | feature,[(b t=16) c=1280+3 h=16 w=12] | temporal_attention模块过完以后,又切回原来的顺序 |
| feature,[(b t=16) c=1280 h=16 w=12] | pred_pose, pred_shape, pred_cam | smpl_head,此模块来来自HMR2.0 |
| pred_pose,[(b,t=16),c=24*6] | pred_pose,[b,t=16,c=24*6] | 为再次进行temporal_attention做准备 |
| bbox_info,[(b,t=16),c=3] | bbox_info,[b,t=16,c=3] | 同样也结合包含图像全局信息的bbox |
| pred_pose,[(b,t=16),c=24*6] | pred_pose,[(b,t=16),c=24*6+3] | pred_pose = torch.cat([pred_pose, bb], dim=2) |
| pred_pose,[(b,t=16),c=24*6+3] | pred_pose,[(b,t=16),c=24*6] | motion_module,也是一个temporal_attention模块 |
| pred_pose,[(b,t=16),c=24*6+3] | pred_pose,[b,t=16,c=24*6+3] |
# 基于transformer的时序模块
class temporal_attention(nn.Module):
def __init__(self, in_dim=1280, out_dim=1280, hdim=512, nlayer=6, nhead=4, residual=False):
super(temporal_attention, self).__init__()
self.hdim = hdim
self.out_dim = out_dim
self.residual = residual
self.l1 = nn.Linear(in_dim, hdim)
self.l2 = nn.Linear(hdim, out_dim)
self.pos_embedding = PositionalEncoding(hdim, dropout=0.1)
TranLayer = nn.TransformerEncoderLayer(d_model=hdim, nhead=nhead, dim_feedforward=1024,
dropout=0.1, activation='gelu')
self.trans = nn.TransformerEncoder(TranLayer, num_layers=nlayer)
# Xavier 初始化是一种常用的权重初始化方法,旨在解决深度神经网络训练过程中的梯度消失和梯度爆炸问题。该方法通过根据网络的输入和输出维度来初始化权重,使得前向传播和反向传播过程中的信号保持相对一致的方差。
nn.init.xavier_uniform_(self.l1.weight, gain=0.01)
nn.init.xavier_uniform_(self.l2.weight, gain=0.01)
def forward(self, x):
x = x.permute(1,0,2) # (b,t,c) -> (t,b,c)
# 在channel维度上做MLP,(t=16,b,c=in_dim) -> (t=16,b,c=hdim)
h = self.l1(x)
# 在t维度上叠加位置编码和drop out
h = self.pos_embedding(h)
# nn.TransformerEncoder,6层transformer encoder layer
h = self.trans(h)
# 在channel维度上做MLP,(t=16,b,c=hdim) -> (t=16,b,c=in_dim)
h = self.l2(h)
# 预测残差还是预测feature
if self.residual:
x = x[..., :self.out_dim] + h
else:
x = h
# (t,b,c) -> (b,t,c)
x = x.permute(1,0,2)
return x
生成最终结果
| 输入 | 输出 | 方法 |
|---|---|---|
| pred_shape | pred_shape | VIMO每一帧都会预测一个shape参数,但是人的真实体型是不会变的,所以都统一到一个体型上 |
| pred | pred shape, pred pose, pred_trans | smpl forward |
| pred_cam,相机运动,来自Masked DROID-SLAM scale | pred_camt,相机运动trans pred_camr,相机运动pose,旋转矩阵形式 | |
| pred_cam, pred | verts | 相机视角 + 世界坐标系下的人物 = 相机坐标系下的人物 |
训练与验证
只开源推断代码,没有开源训练代码
数据集
3DPW [81], Human3.6M [24], and BEDLAM [6]
数据增强
- 旋转、缩放、水平翻转、颜色抖动,对一个训练序列进行统一的增强。
- 遮挡。每一帧独立增强。
Loss
- 2D 投影loss
- 3D 重建loss
- SMPL参数loss [?] 只是动作参数?
- mesh重建loss
有效
- 测了几段视频,发现在重建动作的灵活性和准确性上都优于WHAM。应该 模块的作用。
- Masked DROID-SLAM虽然能预测相机运动,但缺少运动的scale。ZoeDepth利用图像中的语义信息可以得到图像的scale。使得相机的位移信息更准确。
缺陷
- 在运动相机下有效,在静止相机下代码会出错。错误来自Masked DROID-SLAM模块。因为Masked DROID-SLAM需要根据不同视角的视差数据来估计深度。
启发
- scale的估计需要一段视频。可以用于HMR之前的标定阶段。
- 算法推断过程为输入连续的16帧的图像,出第8帧图像对应的motion。为了支持流式推理,改成出第16帧对应的motion,其结果与原结果相差不大。
遗留问题
参考材料
- 开源:https://yufu-wang.github.io/tram4d/
- DROID-SLAM:https://blog.csdn.net/huarzail/article/details/130906160
- torchmin.minimize:https://pytorch-minimize.readthedocs.io/en/latest/api/generated/torchmin.minimize.html
- nn.init.xavier_uniform_:https://blog.csdn.net/AdamCY888/article/details/131269857
- SMPLTransformerDecoderHead:https://caterpillarstudygroup.github.io/ReadPapers/28.html
3D Gaussian Splatting for Real-Time Radiance Field Rendering
| 缩写 | 英文 | 中文 |
|---|---|---|
| SfM | Structure-from-Motion | |
| SH | spherical harmonics | 球谐基 |
| covariance matrix | 协方差矩阵 | |
| Nerf | Neural Radiance Field | 神经辐射场 |
| GS | Gaussian splatting | 高斯溅射 |
核心问题是什么?
现有方法及问题
Nerf方法需要训练和渲染成本高昂的神经网络,而其加速方案会牺牲质量来换取速度。对于无界且完整的场景(而不是孤立的物体)和1080p分辨率渲染,当前没有方法可以实现实时显示速率。
本文方法
高斯溅射是一种表示 3D 场景和渲染新视图的方法,它被认为是 NeRF 类模型的替代品。
这项工作最出名的地方是其高渲染速度。这归功于下面将要介绍的表示本身,以及使用自定义 CUDA 内核定制实现的渲染算法。
首先,从相机校准期间产生的稀疏点开始,用 3D 高斯表示场景,保留连续体积辐射场的所需属性以进行场景优化,同时避免在空白区域中进行不必要的计算;
其次,我们对 3D 高斯进行交错优化/密度控制,特别是优化各向异性协方差以实现场景的准确表示;
第三,我们开发了一种快速可见性感知渲染算法,该算法支持各向异性泼溅,既加速训练又允许实时渲染。
效果
在几个已建立的数据集上展示了最先进的视觉质量和实时渲染。
核心贡献是什么?
- 引入各向异性 3D 高斯作为辐射场的高质量、非结构化表示。
- 3D 高斯属性的优化方法,与自适应密度控制交错,为捕获的场景创建高质量表示。
- 快速、可微的渲染方法对于可见性感知的 GPU,允许各向异性泼溅和快速反向传播,以实现高质量的新颖视图合成。
大致方法是什么?

输入:一组静态场景的图像
- 由 SfM 校准的相应相机,会产生稀疏点云。
- 从SfM点云创建了一组 3D 高斯(第 4 节),由位置(均值)、协方差矩阵和不透明度 𝛼 定义这些高斯。
这允许非常灵活的优化机制。这会产生 3D 场景的相当紧凑的表示,部分原因是高度各向异性的体积片可用于紧凑地表示精细结构。
- 辐射场的方向外观分量(颜色)通过球谐函数 (SH) 表示。
- 通过 3D 高斯参数的一系列优化步骤来创建辐射场表示(第 5 节),即位置、协方差、𝛼 和 SH 系数与高斯密度自适应控制的操作交织在一起。
- 基于图块的光栅化器(效率的关键)(第 6 节),让各向异性图块的𝛼混合,通过快速排序表示可见性顺序。
快速光栅化器还包括通过跟踪累积的 𝛼 值进行快速向后传递,并且对可以接收梯度的高斯数量没有限制。
可微 3D 高斯Splatting
输入:没有法线信息的稀疏 (SfM) 点集
输出:允许高质量新视角合成的场景表示,即一组 3D 高斯。
表示
3D 世界由一组 3D 点表示,实际上有数百万个 3D 点,数量大约为 50 万到 500 万。每个点都是一个 3D 高斯,具有自己独特的参数,这些参数针对每个场景进行拟合,以便该场景的渲染与已知的数据集图像紧密匹配。
每个 3D 高斯的参数如下:
- 均值 μ, 可解释为位置 x、y、z;
- 协方差 Σ;
- 不透明度 σ(𝛼),应用 sigmoid 函数将参数映射到 [0, 1] 区间;
- 颜色参数,(R、G、B) 的 3 个值或球谐函数 (SH) 系数。
选择3D高斯作为场景表示是因为:
- 具有可微分体积表示的属性
- 非结构化和显式的,以允许非常快速的渲染
- 可以轻松投影到 2D splats,从而实现快速𝛼混合渲染
之前的类似工作使用带法线信息的2D平面圆。但SfM有时是难以估计比较准确的法线信息,因此给这些方法带来的困难。
本文使用的3D高斯,由世界坐标系下的3D协方差矩阵和中心位置来描述。不需要包含法线信息。
协方差矩阵
协方差是各向异性的,这意味着 3D 点可以是沿空间中任意方向旋转和拉伸的椭圆体。需要用 9 个参数来表示协方差矩阵。
这种各向异性协方差的表示(适合优化)允许我们优化 3D 高斯以适应捕获场景中不同形状的几何形状,从而产生相当紧凑的表示。图 3 说明了这种情况。
协方差矩阵是需要被优化的参数之一,但是不能直接优化这样的协方差矩阵。
优化过程中必须保证协方差矩阵是半正定的,但梯度下降的优化方法会破坏协方差矩阵的的半正定性。因此,把协方差矩阵分解为:
$$ \Sigma = RSS^\top R^\top $$
这种因式分解称为协方差矩阵的特征分解,其中:
- S 是一个对角缩放矩阵,具有 3 个缩放参数;
- R 是一个 3x3 旋转矩阵,用 4 个四元数表示。
S和R分别存储和优化。
def strip_symmetric(L):
uncertainty = torch.zeros((L.shape[0], 6), dtype=torch.float, device="cuda")
uncertainty[:, 0] = L[:, 0, 0]
uncertainty[:, 1] = L[:, 0, 1]
uncertainty[:, 2] = L[:, 0, 2]
uncertainty[:, 3] = L[:, 1, 1]
uncertainty[:, 4] = L[:, 1, 2]
uncertainty[:, 5] = L[:, 2, 2]
return uncertainty
def build_scaling_rotation(s, r):
L = torch.zeros((s.shape[0], 3, 3), dtype=torch.float, device="cuda")
R = build_rotation(r)
L[:,0,0] = s[:,0]
L[:,1,1] = s[:,1]
L[:,2,2] = s[:,2]
L = R @ L
return L
# scaling和rotation是优化好的S和R
def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation):
# 构造一个包含缩放scale和旋转rotation的变换矩阵
L = build_scaling_rotation(scaling_modifier * scaling, rotation)
actual_covariance = L @ L.transpose(1, 2)
# 由于actual_covariance是对称矩阵,只需要存一半就可以了,参数减少到6
symm = strip_symmetric(actual_covariance)
return symm
渲染时,把缩放和旋转再合成协方差矩阵:
// Forward method for converting scale and rotation properties of each
// Gaussian to a 3D covariance matrix in world space. Also takes care
// of quaternion normalization.
__device__ void computeCov3D(
const glm::vec3 scale, // 表示缩放的三维向量
float mod, // 对应gaussian_renderer/__init__.py中的scaling_modifier
const glm::vec4 rot, // 表示旋转的四元数
float* cov3D) // 结果:三维协方差矩阵
{
// Create scaling matrix
glm::mat3 S = glm::mat3(1.0f);
S[0][0] = mod * scale.x;
S[1][1] = mod * scale.y;
S[2][2] = mod * scale.z;
// Normalize quaternion to get valid rotation
glm::vec4 q = rot;// / glm::length(rot);
float r = q.x;
float x = q.y;
float y = q.z;
float z = q.w;
// Compute rotation matrix from quaternion
glm::mat3 R = glm::mat3(
1.f - 2.f * (y * y + z * z), 2.f * (x * y - r * z), 2.f * (x * z + r * y),
2.f * (x * y + r * z), 1.f - 2.f * (x * x + z * z), 2.f * (y * z - r * x),
2.f * (x * z - r * y), 2.f * (y * z + r * x), 1.f - 2.f * (x * x + y * y)
);
glm::mat3 M = S * R;
// Compute 3D world covariance matrix Sigma
glm::mat3 Sigma = glm::transpose(M) * M;
// Covariance is symmetric, only store upper right
cov3D[0] = Sigma[0][0];
cov3D[1] = Sigma[0][1];
cov3D[2] = Sigma[0][2];
cov3D[3] = Sigma[1][1];
cov3D[4] = Sigma[1][2];
cov3D[5] = Sigma[2][2];
}
颜色参数
颜色参数可以用3个RGB值或一组SH系数来表示。
不需要视角依赖特性时,可以进行简化,选择用 3 个 RGB 值表示颜色。
视角依赖性是一种很好的特性,它可以提高渲染质量,因为它允许模型表示非朗伯效应,例如金属表面的镜面反射。
视角相关的颜色参数,则需要使用SH系数表示颜色。
SH是一组定义在球表面的正交基,每个定义在球面上的函数都可以通过SH来表达。
定义SH基的自由度ℓ_max 内,并假设每种颜色(红色、绿色和蓝色)都是前 ℓ_max 个 SH 函数的线性组合。对于每个 3D 高斯,通过学习其正确的系数,使得当我们从某个方向看这个 3D 点时,得到最接近真实的颜色。
# deg:球协基的个数
# sh:优化出的SH系数
# dirs:相机指向高斯球心的视线方向
def eval_sh(deg, sh, dirs):
"""
Evaluate spherical harmonics at unit directions
using hardcoded SH polynomials.
Works with torch/np/jnp.
... Can be 0 or more batch dimensions.
Args:
deg: int SH deg. Currently, 0-3 supported
sh: jnp.ndarray SH coeffs [..., C, (deg + 1) ** 2]
dirs: jnp.ndarray unit directions [..., 3]
Returns:
[..., C]
"""
assert deg <= 4 and deg >= 0
# 第l层的球协基需要2*i+1个系数,[0,l]层球协基共需要(l+1)**2个系数
coeff = (deg + 1) ** 2
assert sh.shape[-1] >= coeff
# C0,C1,C2,C3,C4是提前定义好的球协基,是定值,不需要被优化
result = C0 * sh[..., 0]
if deg > 0:
x, y, z = dirs[..., 0:1], dirs[..., 1:2], dirs[..., 2:3]
result = (result -
C1 * y * sh[..., 1] +
C1 * z * sh[..., 2] -
C1 * x * sh[..., 3])
if deg > 1:
xx, yy, zz = x * x, y * y, z * z
xy, yz, xz = x * y, y * z, x * z
result = (result +
C2[0] * xy * sh[..., 4] +
C2[1] * yz * sh[..., 5] +
C2[2] * (2.0 * zz - xx - yy) * sh[..., 6] +
C2[3] * xz * sh[..., 7] +
C2[4] * (xx - yy) * sh[..., 8])
if deg > 2:
result = (result +
C3[0] * y * (3 * xx - yy) * sh[..., 9] +
C3[1] * xy * z * sh[..., 10] +
C3[2] * y * (4 * zz - xx - yy)* sh[..., 11] +
C3[3] * z * (2 * zz - 3 * xx - 3 * yy) * sh[..., 12] +
C3[4] * x * (4 * zz - xx - yy) * sh[..., 13] +
C3[5] * z * (xx - yy) * sh[..., 14] +
C3[6] * x * (xx - 3 * yy) * sh[..., 15])
if deg > 3:
result = (result + C4[0] * xy * (xx - yy) * sh[..., 16] +
C4[1] * yz * (3 * xx - yy) * sh[..., 17] +
C4[2] * xy * (7 * zz - 1) * sh[..., 18] +
C4[3] * yz * (7 * zz - 3) * sh[..., 19] +
C4[4] * (zz * (35 * zz - 30) + 3) * sh[..., 20] +
C4[5] * xz * (7 * zz - 3) * sh[..., 21] +
C4[6] * (xx - yy) * (7 * zz - 1) * sh[..., 22] +
C4[7] * xz * (xx - 3 * yy) * sh[..., 23] +
C4[8] * (xx * (xx - 3 * yy) - yy * (3 * xx - yy)) * sh[..., 24])
return result
渲染
一个高斯球对一个像素点的影响
第i个3D高斯球对3D中任意一点p的影响定义如下:

这个方程和多元正态分布的概率密度函数的区别在于,没有协方差归一化项,且使用用不透明度来加权。 高斯的妙处在于每个点都有双重影响。一方面,根据其协方差,每个点实际上代表了空间中接近其均值的有限区域。另一方面,它具有理论上无限的范围,这意味着每个高斯函数都定义在整个 3D 空间中,并且可以针对任何点进行评估。这很棒,因为在优化过程中,它允许梯度从远距离流动。⁴
所有高斯球对一个像素的影响
NeRF 和高斯溅射使用相同的逐点 𝛼 混合的图像形成模型。
| Nerf | 3D GS |
|---|---|
 |  |
Nerf的公式和3D GS的公式几乎完全相同。唯一的区别在于两者之间如何计算 𝛼。在高斯溅射中,每个像素的聚合都是通过投影二维高斯的有序列表的贡献进行的。
这种微小的差异在实践中变得极为重要,并导致渲染速度截然不同。事实上,这是高斯溅射实时性能的基础。
坐标系转换
3D GS公式中的\(f^{2D}\) 是 f(p) 在 2D 上的投影。3D 点及其投影都是多元高斯函数,因此 “3D 高斯函数对 3D 中任意点的影响” 与 “投影的 2D 高斯函数对做任意像素点的影响” 具有相同的公式。唯一的区别是必须使用投影到 2D 中平均值 μ 和协方差 Σ ,这一步称为 EWA splatting⁵ 。
定义相机内参矩阵为K,外参矩阵为W=[R|t]
2D 的均值为:
$$ \mu^{2D} = K((W\mu)/(W\mu)_z) $$
2D的协方差矩阵为:
$$ \Sigma^{2D} = JW\Sigma J^\top W^\top $$
文中提到一种简化方法,可以把协方差矩阵从 3 * 3 简化为 2 * 2。
// Forward version of 2D covariance matrix computation
__device__ float3 computeCov2D(
const float3& mean, // Gaussian中心坐标
float focal_x, // x方向焦距
float focal_y, // y方向焦距
float tan_fovx,
float tan_fovy,
const float* cov3D, // 已经算出来的三维协方差矩阵
const float* viewmatrix) // W2C矩阵
{
// The following models the steps outlined by equations 29
// and 31 in "EWA Splatting" (Zwicker et al., 2002).
// Additionally considers aspect / scaling of viewport.
// Transposes used to account for row-/column-major conventions.
float3 t = transformPoint4x3(mean, viewmatrix);
// W2C矩阵乘Gaussian中心坐标得其在相机坐标系下的坐标
const float limx = 1.3f * tan_fovx;
const float limy = 1.3f * tan_fovy;
const float txtz = t.x / t.z; // Gaussian中心在像平面上的x坐标
const float tytz = t.y / t.z; // Gaussian中心在像平面上的y坐标
t.x = min(limx, max(-limx, txtz)) * t.z;
t.y = min(limy, max(-limy, tytz)) * t.z;
glm::mat3 J = glm::mat3(
focal_x / t.z, 0.0f, -(focal_x * t.x) / (t.z * t.z),
0.0f, focal_y / t.z, -(focal_y * t.y) / (t.z * t.z),
0, 0, 0); // 雅可比矩阵(用泰勒展开近似)
glm::mat3 W = glm::mat3( // W2C矩阵
viewmatrix[0], viewmatrix[4], viewmatrix[8],
viewmatrix[1], viewmatrix[5], viewmatrix[9],
viewmatrix[2], viewmatrix[6], viewmatrix[10]);
glm::mat3 T = W * J;
glm::mat3 Vrk = glm::mat3( // 3D协方差矩阵,是对称阵
cov3D[0], cov3D[1], cov3D[2],
cov3D[1], cov3D[3], cov3D[4],
cov3D[2], cov3D[4], cov3D[5]);
glm::mat3 cov = glm::transpose(T) * glm::transpose(Vrk) * T;
// transpose(J) @ transpose(W) @ Vrk @ W @ J
// Apply low-pass filter: every Gaussian should be at least
// one pixel wide/high. Discard 3rd row and column.
cov[0][0] += 0.3f;
cov[1][1] += 0.3f;
return { float(cov[0][0]), float(cov[0][1]), float(cov[1][1]) };
// 协方差矩阵是对称的,只用存储上三角,故只返回三个数
}
加速
- 对于给定的相机,每个 3D 点的 f(p) 可以预先投影到 2D 中,然后再迭代像素。避免重复投影。
- 没有网络,不需要对图像做逐像素的推理,2D 高斯分布直接混合到图像上。
- 射线经过哪些 3D 点是确定的,不需选择ray sampling策略。
- 在 GPU 上,使用可微分 CUDA 内核的自定义实现,每帧进行一次预处理排序阶段。
使用GPU加速以及为某些操作添加自定义 CUDA 内核,加速渲染过程
筛选
理论上,每个高斯球对所有像素都会有影响。但实际上,在渲染某个像素时,会先过滤出相关的高斯球,并对它们排序,按照深度顺序进行计算。
分组:使用简单的 16x16 像素图块实现分组
排序:按深度对 3D 点进行排序
通过 3D 高斯自适应密度控制进行优化
优化参数:
- 位置 𝑝
对position使用类似于 Plenoxels 的标准指数衰减调度技术。
- 不透明度 𝛼
对 𝛼 使用 sigmoid 激活函数将其限制在 [0 − 1) 范围内并获得平滑梯度
- 协方差 Σ
3D 高斯协方差参数的质量对于表示的紧凑性至关重要,因为可以用少量大的各向异性高斯函数捕获大的均匀区域。
出于类似的原因,对协方差尺度使用指数激活函数。
- 颜色 𝑐 的 SH 系数,或者颜色
这些参数的优化与控制高斯密度的步骤交织在一起,以更好地表示场景。
初始化
初始化是指在训练开始时设置的 3D 点的参数。
对于点位置(均值),作者建议使用由 SfM(运动结构)生成的点云。因为对于任何 3D 重建,无论是使用 GS、NeRF 还是更经典的方法,都必须知道相机矩阵,因此都会需要运行 SfM 来获取这些矩阵。SfM 会产生稀疏点云作为副产品,为什么不将其用于初始化呢?当由于某种原因无法获得点云时,可以使用随机初始化,但可能会损失最终重建质量。
协方差被初始化为各向同性,即半径为 从球体mean开始到相邻点的平均距离,这样 3D 世界就可以被很好地覆盖,没有“洞”。
def create_from_pcd(self, pcd : BasicPointCloud, spatial_lr_scale : float):
self.spatial_lr_scale = spatial_lr_scale
# 位置初始化
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda()
# 颜色初始化
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda())
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda()
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
# 协方差scale初始化
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
# 协方法rotation初始化
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
# 不透明度初始化
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
优化
- 地面真实视图和当前渲染之间的 L1 Loss
def l1_loss(network_output, gt):
return torch.abs((network_output - gt)).mean()
- D-SSIM:结构差异指数测量
def _ssim(img1, img2, window, window_size, channel, size_average=True):
mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)
mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
高斯自适应控制
目的:解决重建不足和过度重建的问题
原因:SGD 本身只能调整现有的点。但在完全没有点(重建不足)或点太多(过度重建)的区域中,它很难找到好的参数。这时就需要自适应致密化。
频率:在训练期间偶尔启动一次,比如每 100 个 SGD 步
方法:,分割具有大梯度的点(图 8)并删除已经收敛到非常低的 α 值的点(如果一个点是如此透明,为什么要保留它?)。
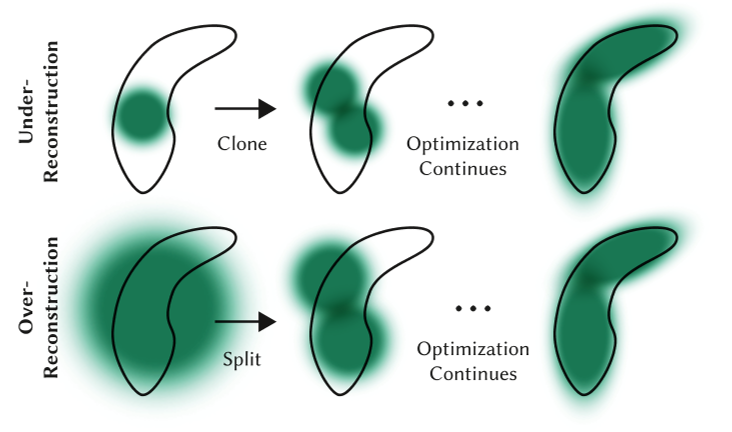
具体策略为:
- 当检测到视图空间位置梯度较大时,增加高斯密度
对于重建不足或过度重建,这两者都有很大的视图空间位置梯度。直观上,这可能是因为它们对应于尚未很好重建的区域,并且优化尝试移动高斯来纠正这一点。
- 对于重建区域中的小高斯,如果需要创建的新的几何形状,最好通过简单地创建相同大小的副本并将其沿位置梯度的方向移动来克隆高斯。
def densify_and_clone(self, grads, grad_threshold, scene_extent):
# Extract points that satisfy the gradient condition
selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values <= self.percent_dense*scene_extent)
# 提取出大于阈值`grad_threshold`且缩放参数较小(小于self.percent_dense * scene_extent)的Gaussians,在下面进行克隆
new_xyz = self._xyz[selected_pts_mask]
new_features_dc = self._features_dc[selected_pts_mask]
new_features_rest = self._features_rest[selected_pts_mask]
new_opacities = self._opacity[selected_pts_mask]
new_scaling = self._scaling[selected_pts_mask]
new_rotation = self._rotation[selected_pts_mask]
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation)
- 有高方差的区域中的大高斯需要被分割成更小的高斯。我们用两个新的高斯函数替换这些高斯函数,并将它们的尺度除以我们通过实验确定的因子 𝜙 = 1.6。我们还通过使用原始 3D 高斯作为 PDF 进行采样来初始化它们的位置。
克隆高斯与分割高斯的区别在于,前者会增加系统总体积和高斯数量,而后者在保留总体积但增加高斯数量。
def densify_and_split(self, grads, grad_threshold, scene_extent, N=2):
n_init_points = self.get_xyz.shape[0]
# Extract points that satisfy the gradient condition
padded_grad = torch.zeros((n_init_points), device="cuda")
padded_grad[:grads.shape[0]] = grads.squeeze()
selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values > self.percent_dense*scene_extent)
'''
被分裂的Gaussians满足两个条件:
1. (平均)梯度过大;
2. 在某个方向的最大缩放大于一个阈值。
参照论文5.2节“On the other hand...”一段,大Gaussian被分裂成两个小Gaussians,
其放缩被除以φ=1.6,且位置是以原先的大Gaussian作为概率密度函数进行采样的。
'''
stds = self.get_scaling[selected_pts_mask].repeat(N,1)
means = torch.zeros((stds.size(0), 3),device="cuda")
samples = torch.normal(mean=means, std=stds)
rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N,1,1)
new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1)
# 算出随机采样出来的新坐标
# bmm: batch matrix-matrix product
new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N,1) / (0.8*N))
new_rotation = self._rotation[selected_pts_mask].repeat(N,1)
new_features_dc = self._features_dc[selected_pts_mask].repeat(N,1,1)
new_features_rest = self._features_rest[selected_pts_mask].repeat(N,1,1)
new_opacity = self._opacity[selected_pts_mask].repeat(N,1)
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation)
prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool)))
self.prune_points(prune_filter)
- 与其他体积表示类似,优化结果可能被靠近摄像机的浮动体的干扰。在高斯沉浸中,这种干扰会导致高斯密度的不合理增加。
缓和高斯数量增加的有效方法是:
(1) 每隔 𝑁 = 3000 迭代将 𝛼 值设置为接近于零。然后,优化会在需要时增加高斯函数的 𝛼,同时删除 𝛼 小于 𝜖𝛼 的高斯函数,如上所述。高斯可能会缩小或增长,并且与其他高斯有相当大的重叠
(2) 定期删除透明的或者非常大的高斯。
该策略可以总体上很好地控制高斯总数。
# 接下来移除一些Gaussians,它们满足下列要求中的一个:
# 1. 接近透明(不透明度小于min_opacity)
# 2. 在某个相机视野里出现过的最大2D半径大于屏幕(像平面)大小
# 3. 在某个方向的最大缩放大于0.1 * extent(也就是说很长的长条形也是会被移除的)
prune_mask = (self.get_opacity < min_opacity).squeeze()
if max_screen_size:
big_points_vs = self.max_radii2D > max_screen_size # vs = view space?
big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent
prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws) # ws = world space?
self.prune_points(prune_mask)
高斯快速可微光栅化器
目标:
对所有高斯进行快速整体渲染、快速排序,近似 𝛼 混合(包括各向异性 splat),而不需要限制高斯的数量。
本文为高斯图设计了一个基于图块的光栅化器,其特点为:
- 一次对整个图像的基元进行预排序
- 允许在任意数量的混合高斯上进行有效的反向传播,并且(光栅化器的)附加内存消耗低,每个像素只需要恒定的开销。
- 光栅化pipeline是完全可微分的
- 考虑到 2D 投影(第 4 节),光栅化器可以对各向异性 splats 进行光栅化。
具体步骤为:
- 将屏幕分割成 16×16 块
- 根据视锥体和每个块剔除 3D 高斯。具体来说,我们只保留与视锥体相交的置信区间为 99% 的高斯分布。此外,我们使用保护带来简单地拒绝极端位置处的高斯分布(即那些均值接近近平面且远离视锥体的位置),因为它们的投影 2D 协方差将不稳定。
- 根据每个高斯重叠的图块数量来实例化它们,并为每个实例分配一个结合了视图空间深度和图块 ID 的键。
- 使用单个快速 GPU 基数排序根据这些键对高斯进行排序 [Merrill 和 Grimshaw 2010]。请注意,没有额外的每像素点排序,混合是基于此初始排序执行的。因此, 𝛼 混合在某些情况下可能是近似的。然而,当图块接近单个像素的大小时,这些近似值变得可以忽略不计。我们发现这种方式极大地增强了训练和渲染性能,而不会在融合场景中产生可见的伪影。
- 通过识别排序后深度最大和最小的高斯来为每个图块生成一个列表。
- 对于光栅化,我们为每个图块启动一个线程块。每个线程:
(1)首先协作地将高斯数据包加载到共享内存中。
(2)然后对于给定的像素,通过从前到后遍历列表来累积颜色和𝛼值,从而最大化数据加载/共享和处理的并行性增益。
(3)当我们达到像素中的目标饱和度 𝛼 时,相应的线程就会停止。
每隔一段时间,就会查询图块中的线程,并且当所有像素都饱和时(即 𝛼 变为 1),整个图块的处理就会终止。
附录 C 中给出了排序的详细信息和总体光栅化方法的高级概述。
实现
训练
def training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from):
first_iter = 0
tb_writer = prepare_output_and_logger(dataset)
gaussians = GaussianModel(dataset.sh_degree)
scene = Scene(dataset, gaussians)
gaussians.training_setup(opt)
if checkpoint:
(model_params, first_iter) = torch.load(checkpoint)
gaussians.restore(model_params, opt)
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
iter_start = torch.cuda.Event(enable_timing = True)
iter_end = torch.cuda.Event(enable_timing = True)
viewpoint_stack = None
ema_loss_for_log = 0.0
progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress")
first_iter += 1
for iteration in range(first_iter, opt.iterations + 1):
iter_start.record()
gaussians.update_learning_rate(iteration)
# Every 1000 its we increase the levels of SH up to a maximum degree
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
# Pick a random Camera
if not viewpoint_stack:
viewpoint_stack = scene.getTrainCameras().copy()
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1))
# Render
if (iteration - 1) == debug_from:
pipe.debug = True
bg = torch.rand((3), device="cuda") if opt.random_background else background
render_pkg = render(viewpoint_cam, gaussians, pipe, bg)
image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]
# Loss
gt_image = viewpoint_cam.original_image.cuda()
Ll1 = l1_loss(image, gt_image)
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image))
loss.backward()
iter_end.record()
with torch.no_grad():
# Log and save
training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background))
if (iteration in saving_iterations):
print("\n[ITER {}] Saving Gaussians".format(iteration))
scene.save(iteration)
# Densification
if iteration < opt.densify_until_iter:
# Keep track of max radii in image-space for pruning
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
# Optimizer step
if iteration < opt.iterations:
gaussians.optimizer.step()
gaussians.optimizer.zero_grad(set_to_none = True)
if (iteration in checkpoint_iterations):
print("\n[ITER {}] Saving Checkpoint".format(iteration))
torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth")
推断
相机
3D是在世界坐标系下构建的,设置好相机的内参和外参后,需要把所有世界坐标系下的数据转换到相机坐标系下,并且投影到屏幕上。
以下是根据相机的内参外参计算坐标系转换矩阵和投影矩阵的过程。
class Camera(nn.Module):
def __init__(self, colmap_id, R, T, FoVx, FoVy, image, gt_alpha_mask,
image_name, uid,
trans=np.array([0.0, 0.0, 0.0]), scale=1.0, data_device = "cuda"
):
super(Camera, self).__init__()
self.uid = uid
self.colmap_id = colmap_id
self.R = R # 相机在世界坐标系下的旋转矩阵
self.T = T # 相机在相机坐标系下的位置。(相机坐标系的原点与世界坐标系相同,只是相差了一个旋转)
self.FoVx = FoVx # x方向视场角
self.FoVy = FoVy # y方向视场角
self.image_name = image_name
try:
self.data_device = torch.device(data_device)
except Exception as e:
print(e)
print(f"[Warning] Custom device {data_device} failed, fallback to default cuda device" )
self.data_device = torch.device("cuda")
self.original_image = image.clamp(0.0, 1.0).to(self.data_device) # 原始图像
self.image_width = self.original_image.shape[2] # 图像宽度
self.image_height = self.original_image.shape[1] # 图像高度
if gt_alpha_mask is not None:
self.original_image *= gt_alpha_mask.to(self.data_device)
else:
self.original_image *= torch.ones((1, self.image_height, self.image_width), device=self.data_device)
# 距离相机平面znear和zfar之间且在视锥内的物体才会被渲染
self.zfar = 100.0 # 最远能看到多远
self.znear = 0.01 # 最近能看到多近
self.trans = trans # 相机中心的平移
self.scale = scale # 相机中心坐标的缩放
# world_2_camera = [[R,T],[0,1]],world_view_transform是world_2_camera的转置
self.world_view_transform = torch.tensor(getWorld2View2(R, T, trans, scale)).transpose(0, 1).cuda() # 世界到相机坐标系的变换矩阵,4×4
# projection matrix的定义见:
# https://caterpillarstudygroup.github.io/GAMES101_mdbook/MVP/OrthographicProjection.html
# https://caterpillarstudygroup.github.io/GAMES101_mdbook/MVP/PerspectiveProjection.html
# 此处的projection_matrix也是真实projection matrix的转置
self.projection_matrix = getProjectionMatrix(znear=self.znear, zfar=self.zfar, fovX=self.FoVx, fovY=self.FoVy).transpose(0,1).cuda() # 投影矩阵
# 正确的计算公式为:mvp = projection * world_2_camera
# 但full_proj_transform是mvp的转置,所以是world_view_transform * projection_matrix
self.full_proj_transform = (self.world_view_transform.unsqueeze(0).bmm(self.projection_matrix.unsqueeze(0))).squeeze(0) # 从世界坐标系到图像的变换矩阵
# 上面的T是相机在相机坐标系下的位置,此处的camera center是相机在世界坐标系下的位置。
self.camera_center = self.world_view_transform.inverse()[3, :3] # 相机在世界坐标系下的坐标
python渲染接口
viewmatrix和projmatrix都必须传入原始矩阵的逆矩阵,因此python的矩阵存储是行优化的,C++的矩阵存储是列优先的。所以同时的矩阵内存数据,在python里和在c++里是互逆的关系。
def render(viewpoint_camera, pc : GaussianModel, pipe, bg_color : torch.Tensor, scaling_modifier = 1.0, override_color = None):
"""
Render the scene.
viewpoint_camera: FOV,画布大小、相机位置、变换矩阵
pc: 用于获取高斯球的属性
pipe:一些配置
Background tensor (bg_color) must be on GPU!
"""
# Create zero tensor. We will use it to make pytorch return gradients of the 2D (screen-space) means
screenspace_points = torch.zeros_like(pc.get_xyz, dtype=pc.get_xyz.dtype, requires_grad=True, device="cuda") + 0
try:
screenspace_points.retain_grad()
except:
pass
# Set up rasterization configuration
tanfovx = math.tan(viewpoint_camera.FoVx * 0.5)
tanfovy = math.tan(viewpoint_camera.FoVy * 0.5)
raster_settings = GaussianRasterizationSettings(
image_height=int(viewpoint_camera.image_height),
image_width=int(viewpoint_camera.image_width),
tanfovx=tanfovx,
tanfovy=tanfovy,
bg=bg_color,
scale_modifier=scaling_modifier,
viewmatrix=viewpoint_camera.world_view_transform, # world to camera
projmatrix=viewpoint_camera.full_proj_transform, # mvp
sh_degree=pc.active_sh_degree,
campos=viewpoint_camera.camera_center, # camera position
prefiltered=False,
debug=pipe.debug
)
rasterizer = GaussianRasterizer(raster_settings=raster_settings)
means3D = pc.get_xyz
means2D = screenspace_points
opacity = pc.get_opacity
# If precomputed 3d covariance is provided, use it. If not, then it will be computed from
# scaling / rotation by the rasterizer.
scales = None
rotations = None
cov3D_precomp = None
if pipe.compute_cov3D_python:
cov3D_precomp = pc.get_covariance(scaling_modifier)
else:
scales = pc.get_scaling
rotations = pc.get_rotation
# If precomputed colors are provided, use them. Otherwise, if it is desired to precompute colors
# from SHs in Python, do it. If not, then SH -> RGB conversion will be done by rasterizer.
shs = None
colors_precomp = None
# 没有预制的color,就计算过color
if override_color is None:
# 如果预测的是SH的系数,则根据SH计算color
if pipe.convert_SHs_python:
shs_view = pc.get_features.transpose(1, 2).view(-1, 3, (pc.max_sh_degree+1)**2)
dir_pp = (pc.get_xyz - viewpoint_camera.camera_center.repeat(pc.get_features.shape[0], 1))
dir_pp_normalized = dir_pp/dir_pp.norm(dim=1, keepdim=True)
sh2rgb = eval_sh(pc.active_sh_degree, shs_view, dir_pp_normalized)
colors_precomp = torch.clamp_min(sh2rgb + 0.5, 0.0)
# 或者直接预测color
else:
shs = pc.get_features
else:
colors_precomp = override_color
# Rasterize visible Gaussians to image, obtain their radii (on screen).
rendered_image, radii = rasterizer(
means3D = means3D,
means2D = means2D,
shs = shs,
colors_precomp = colors_precomp,
opacities = opacity,
scales = scales,
rotations = rotations,
cov3D_precomp = cov3D_precomp)
# Those Gaussians that were frustum culled or had a radius of 0 were not visible.
# They will be excluded from value updates used in the splitting criteria.
return {"render": rendered_image,
"viewspace_points": screenspace_points,
"visibility_filter" : radii > 0,
"radii": radii}
C++渲染接口

// Forward rendering procedure for differentiable rasterization
// of Gaussians.
int CudaRasterizer::Rasterizer::forward(
std::function<char* (size_t)> geometryBuffer,
std::function<char* (size_t)> binningBuffer,
std::function<char* (size_t)> imageBuffer,
/*
上面的三个参数是用于分配缓冲区的函数,
在submodules/diff-gaussian-rasterization/rasterize_points.cu中定义
*/
const int P, // Gaussian的数量
int D, // 对应于GaussianModel.active_sh_degree,是球谐度数(本文参考的学习笔记在这里是错误的)
int M, // RGB三通道的球谐傅里叶系数个数,应等于3 × (D + 1)²(本文参考的学习笔记在这里也是错误的)
const float* background,
const int width, int height, // 图片宽高
const float* means3D, // Gaussians的中心坐标
const float* shs, // 球谐系数
const float* colors_precomp, // 预先计算的RGB颜色
const float* opacities, // 不透明度
const float* scales, // 缩放
const float scale_modifier, // 缩放的修正项
const float* rotations, // 旋转
const float* cov3D_precomp, // 预先计算的3维协方差矩阵
const float* viewmatrix, // W2C矩阵
const float* projmatrix, // 投影矩阵
const float* cam_pos, // 相机坐标
const float tan_fovx, float tan_fovy, // 视场角一半的正切值
const bool prefiltered,
float* out_color, // 输出的颜色
int* radii, // 各Gaussian在像平面上用3σ原则截取后的半径
bool debug)
{
const float focal_y = height / (2.0f * tan_fovy); // y方向的焦距
const float focal_x = width / (2.0f * tan_fovx); // x方向的焦距
/*
注意tan_fov = tan(fov / 2) (见上面的render函数)。
而tan(fov / 2)就是图像宽/高的一半与焦距之比。
以x方向为例,tan(fovx / 2) = width / 2 / focal_x,
故focal_x = width / (2 * tan(fovx / 2)) = width / (2 * tan_fovx)。
*/
// 下面初始化一些缓冲区
size_t chunk_size = required<GeometryState>(P); // GeometryState占据空间的大小
char* chunkptr = geometryBuffer(chunk_size);
GeometryState geomState = GeometryState::fromChunk(chunkptr, P);
if (radii == nullptr)
{
radii = geomState.internal_radii;
}
dim3 tile_grid((width + BLOCK_X - 1) / BLOCK_X, (height + BLOCK_Y - 1) / BLOCK_Y, 1);
// BLOCK_X = BLOCK_Y = 16,准备分解成16×16的tiles。
// 之所以不能分解成更大的tiles,是因为对于同一张图片的离得较远的像素点而言
// Gaussian按深度排序的结果可能是不同的。
// (想象一下两个Gaussians离像平面很近,一个靠近图像左边缘,一个靠近右边缘)
// dim3是CUDA定义的含义x,y,z三个成员的三维unsigned int向量类。
// tile_grid就是x和y方向上tile的个数。
dim3 block(BLOCK_X, BLOCK_Y, 1);
// Dynamically resize image-based auxiliary buffers during training
size_t img_chunk_size = required<ImageState>(width * height);
char* img_chunkptr = imageBuffer(img_chunk_size);
ImageState imgState = ImageState::fromChunk(img_chunkptr, width * height);
if (NUM_CHANNELS != 3 && colors_precomp == nullptr)
{
throw std::runtime_error("For non-RGB, provide precomputed Gaussian colors!");
}
// Run preprocessing per-Gaussian (transformation, bounding, conversion of SHs to RGB)
CHECK_CUDA(FORWARD::preprocess(
P, D, M,
means3D,
(glm::vec3*)scales,
scale_modifier,
(glm::vec4*)rotations,
opacities,
shs,
geomState.clamped,
cov3D_precomp,
colors_precomp,
viewmatrix, projmatrix,
(glm::vec3*)cam_pos,
width, height,
focal_x, focal_y,
tan_fovx, tan_fovy,
radii,
geomState.means2D, // Gaussian投影到像平面上的中心坐标
geomState.depths, // Gaussian的深度
geomState.cov3D, // 三维协方差矩阵
geomState.rgb, // 颜色
geomState.conic_opacity, // 椭圆二次型的矩阵和不透明度的打包向量
tile_grid, //
geomState.tiles_touched,
prefiltered
), debug) // 预处理,主要涉及把3D的Gaussian投影到2D
// Compute prefix sum over full list of touched tile counts by Gaussians
// E.g., [2, 3, 0, 2, 1] -> [2, 5, 5, 7, 8]
CHECK_CUDA(cub::DeviceScan::InclusiveSum(geomState.scanning_space, geomState.scan_size, geomState.tiles_touched, geomState.point_offsets, P), debug)
// 这步是为duplicateWithKeys做准备
// (计算出每个Gaussian对应的keys和values在数组中存储的起始位置)
// Retrieve total number of Gaussian instances to launch and resize aux buffers
int num_rendered;
CHECK_CUDA(cudaMemcpy(&num_rendered, geomState.point_offsets + P - 1, sizeof(int), cudaMemcpyDeviceToHost), debug); // 东西塞到GPU里面去
size_t binning_chunk_size = required<BinningState>(num_rendered);
char* binning_chunkptr = binningBuffer(binning_chunk_size);
BinningState binningState = BinningState::fromChunk(binning_chunkptr, num_rendered);
// For each instance to be rendered, produce adequate [ tile | depth ] key
// and corresponding dublicated Gaussian indices to be sorted
duplicateWithKeys << <(P + 255) / 256, 256 >> > (
P,
geomState.means2D,
geomState.depths,
geomState.point_offsets,
binningState.point_list_keys_unsorted,
binningState.point_list_unsorted,
radii,
tile_grid) // 生成排序所用的keys和values
CHECK_CUDA(, debug)
int bit = getHigherMsb(tile_grid.x * tile_grid.y);
// Sort complete list of (duplicated) Gaussian indices by keys
CHECK_CUDA(cub::DeviceRadixSort::SortPairs(
binningState.list_sorting_space,
binningState.sorting_size,
binningState.point_list_keys_unsorted, binningState.point_list_keys,
binningState.point_list_unsorted, binningState.point_list,
num_rendered, 0, 32 + bit), debug)
// 进行排序,按keys排序:每个tile对应的Gaussians按深度放在一起;value是Gaussian的ID
CHECK_CUDA(cudaMemset(imgState.ranges, 0, tile_grid.x * tile_grid.y * sizeof(uint2)), debug);
// Identify start and end of per-tile workloads in sorted list
if (num_rendered > 0)
identifyTileRanges << <(num_rendered + 255) / 256, 256 >> > (
num_rendered,
binningState.point_list_keys,
imgState.ranges); // 计算每个tile对应排序过的数组中的哪一部分
CHECK_CUDA(, debug)
// Let each tile blend its range of Gaussians independently in parallel
const float* feature_ptr = colors_precomp != nullptr ? colors_precomp : geomState.rgb;
CHECK_CUDA(FORWARD::render(
tile_grid, block, // block: 每个tile的大小
imgState.ranges,
binningState.point_list,
width, height,
geomState.means2D,
feature_ptr,
geomState.conic_opacity,
imgState.accum_alpha,
imgState.n_contrib,
background,
out_color), debug) // 最后,进行渲染
return num_rendered;
}
有效
局限性
- 在视角不可见区域有伪影。解决方法:通过规则剔除这些伪影。
- 简单的可见性算法,可能导致高斯突然切换深度/混合顺序。解决方法:可以通过抗锯齿来解决。
- 没有对我们的优化应用任何正则化;解决方法:加入正则化将有助于处理看不见的区域和弹出的伪影。
- 一次只能渲染一张图像,不能批量进行。
验证
启发
遗留问题
参考材料
- https://towardsdatascience.com/a-comprehensive-overview-of-gaussian-splatting-e7d570081362
- https://caterpillarstudygroup.github.io/ImportantArticles/3D_Gaussian_Splatting.html
- 源码解读:https://blog.csdn.net/qaqwqaqwq/article/details/136837906
Decoupling Human and Camera Motion from Videos in the Wild
核心问题是什么?
要解决的问题
从in the wild视频重建人的全局运动轨迹。
现有方法
- 大多数现有方法并不对相机运动进行建模;
- 依赖背景像素来推断 3D 人体运动的方法通常需要全场景重建,这对于in the wild视频通常是不可能的。
本文方法
即使现有的 SLAM 系统无法恢复准确的场景重建,背景像素运动仍然提供足够的信号来约束相机运动。 我们的优化方法将相机和人体运动解耦,这使我们能够将人们放置在同一个世界坐标系中。
效果
我们表明,相对相机估计以及数据驱动的人体运动先验可以解决场景尺度模糊性并恢复全局人体轨迹。我们的方法可以在具有挑战性的野外视频(例如 PoseTrack)中稳健地恢复人们的全局 3D 轨迹。我们在 3D 人体数据集 Egobody 上量化了对现有方法的改进。我们进一步证明,恢复的相机比例允许我们在共享坐标系中推理多人的运动,从而提高 PoseTrack 中下游跟踪的性能。
核心贡献是什么?
提出了一种对摄像机运动进行建模的方法,以从野外视频中恢复现实世界中的 3D 人体运动
大致方法是什么?
给定输入 RGB 视频,
- 使用 SLAM 系统根据静态场景的像素运动估计帧之间的相对相机运动 [58]。
首先,即使场景视差不足以进行准确的场景重建,它仍然允许对相机运动进行合理的估计
-
使用 3D 人体跟踪系统估计所有检测到的人的identity和身体姿势[46]。
-
使用1和2来初始化共享世界坐标系中人类和相机的轨迹。
人体可以以多种方式在世界上真实地移动。学习的先验很好地捕捉了现实人类运动的这个空间。
- 在多个阶段优化这些全局轨迹,使得视频中的 2D 观察结果和人类如何在世界中移动的先验知识保持一致 [48]。
3.1节中,我们描述了如何在世界坐标系中初始化多人轨迹和摄像机。在第 3.2 节中,我们描述了世界轨迹的平滑步骤,以热启动我们的联合优化问题。最后在 3.3 节中,我们描述了使用人体运动先验对轨迹和相机比例进行全面优化。
每一帧的特征表示
| global orientation | 3 | |
| body pose | 22 * 3 | |
| shape | 16 | |
| root translation | 3 |
stage 1:在世界坐标系中初始化多人轨迹和摄像机
3D 人体跟踪
- 输出
每个人的pose和shape。
其中:
pose估计上逐帧进行的,且为相机坐标系下的pose。
shape是每个人独立且所有帧统一的。
- 方法
PHALP(《Tracking People by Predicting 3D Appearance, Location & Pose》)
估计相机运动
- 输出:
每一帧中相机坐标系在世界坐标系下的rotation和translation。
- 方法:
《DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras》,使用静态场景的像素运动中的信息来计算
但相机运动的scale是不确定的,需要结合人物运动信息(human motion prior)来得到这个scale。
优化世界坐标系下的人物位姿
- 用PHALP的结果初始化人物的shape和(相对于root的)pose
- 用camera rotation + root rotation初始化人的global orientation
- 用camera translation + root translation初始化人的global translation
- 初始化camera scale为1
基于以上信息(人的shape,pose,global orientation, global translation),可以使用LBS计算出每一帧中每个关节的global position。
-
优化目标:
关节的3D global position投影回到相机坐标系中的2在平面上,应于检测出的2D 关键点重合。 -
优化参数:
global orientation, global translation
这是个欠约束问题,优化所有信息会陷入local optima。
Stage 2:世界坐标系下的轨迹平滑
人在相机坐标系下的位移,是人在世界坐标系下的位移与相机在世界坐标系下的位置二者共同作用的结果。
要完全消除相机位移的影响,需要引入人物运动先验。但这件事在stage 3中完成。此时先不考虑。
此时,只是对Stage 2的结果做一些平滑。
- 优化目标:
- Stage 1中的优化目标
- shape参数不要太大
- joint position(世界坐标系下)平滑
- joint rotation(用VPoser编码到隐空间)平滑
- 优化参数:
- camera scale
- human shape
- human pose(相对于root)
Stage 3:使用人体运动先验对轨迹和相机比例进行全面优化
运动先验
使用HuMoR作为运动先验。
- 以HuMoR的方式表示动作,得到st序列
- 使用HuMoR Encoder根据st序列计算出转称序列zt
- 使用HuMoR Decoder根据\(s_t{t-1}\)和zt计算也st,得到另一个st序列
- HuMoR Decoder还会输出预测的触地信息c和地面高度g
- 优化目标
| CVAE | z产生的先验概率尽量大,即根据x0和序列z生成每一帧xt之后,再计算每一帧会产生这个z序列的先验概率 | |
| skate | 当检测到脚步触地时,脚应该不动 | |
| con | 当检测到脚步触地时,脚的高度应低于某个阈值 |
- 优化参数
initial state s0
camera scale
转移latent code z
- 优化方法
逐步增加HuMoR中的T的范围。
实际上,loss CVAE的权重非常小。怀疑这个约束的重要性。
有效
- 3D人体跟踪的结果受到遮挡等原因而无效时,此算法使用的motion prior可以很好地处理这种情况。
- 多人场景中,由于人物可能会不同时地出现或消失,是多人检测的难点。本文方法也能很好的处理。
缺陷
- 本文只是消除相机运动对人物轨迹的影响,但并没有重建相机运动轨迹。
- 由于运动模型是从室内mocap数据中学习的,因此预测的位移并不能推广到现实世界的复杂性。因此,他们很难恢复复杂且长距离的轨迹(from 18)
验证
启发
遗留问题
参考材料
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
核心问题是什么?
难点
- 3D 手部姿势估计在难点在于手部的高度关节、频繁遮挡、自遮挡和快速运动而变得复杂。
- 虽然视频信息有助于解决上述问题,但现有的基于视频的 3D 手部数据集(例如HO3D)不足以训练前馈模型以推广到野外场景。
- 大型人体动作捕捉数据集中还包括手部动作,例如AMASS,但缺少视频对应。
解决方法
- 针对手部的generative motion prior,并在 AMASS 数据集上进行训练,该数据集具有多样化和高质量的手部运动。
- 将该运动先验用于基于视频的 3D 手部运动估计,在latent空间进行优化。
效果
我们集成强大的运动先验显着提高了性能,特别是在遮挡场景中。它产生稳定、时间一致的结果,超越了传统的单帧方法。我们通过对 HO3D 和 DexYCB 数据集进行定性和定量评估来证明我们方法的有效性,特别强调 HO3D 的以遮挡为中心的子集。代码可在 https://hmp.is.tue.mpg.de 获取
核心贡献是什么?
- 从大规模MoCap 数据集AMASS [37] 中学习到了generative motion prior。
- 提出了一种latent空间的优化的方法,用于从单目视频中准确估计手部姿势和形状。
大致方法是什么?
HMP 方法由两个阶段组成(图 2):
- 初始化阶段,检测手部边界框、2D 手部关键点,并从视频帧初始化 MANO 手部姿势和形状估计(第 3.2 节)。
- 多阶段优化阶段(第 3.4 节),它通过强制执行手部运动先验约束来细化视频中的这些估计。
初始化阶段
| 输入 | 输出 | 方法 |
|---|---|---|
| 图像 | bbox | hand tracking model [9] 当由于遮挡等原因导致bbox置信度低时,使用SLERP |
| bbox | 全局坐标中的手部姿势和形状 | PyMAFX [64] |
| bbox | 2d keypoints | MediaPipe and PyMAF-X [36,64] 如果MediaPipe检测失败,就用PyMAFX检测出的3d keypoints投影到2d 经实验,这种方式得到的2d kps效果最好 |
手部动作先验
使用VAE学习手部动作先验。
其中Decoder为“非自回归”。我们采用基于神经运动场(NeMF)[23]的解码器,通过 NeRF 式 MLP [39] 将身体运动表示为手部姿势的连续矢量场。
自回归模型,例如Humor需要根据上一帧来预测下一帧,无法并行,因此长序列的生成会比较慢。
但非自回归模型不依赖上一帧的输出,因此可以 并行化。
因此Decoder不需要以上一帧为输出,它的输入是latent code z和时间步t。
| 本文(非自回归Decoder) | Humor(自回归Decoder) | |
|---|---|---|
| 是否依赖上一帧的信息 | 不需要以上一帧为输出,它的输入是 | 需要根据上一帧预测下一帧 |
| 输入 | 描述整个动作序列的latent code z和时间步t | 描述状态转移的latent code z和上一帧的特征 |
| 潜变量z的含义 | 描述整个动作序列 | 描述状态转移 |
| 是否可并行生成 | 可以 | 不可以 |
根据目标函数优化latent空间的潜变量z,而不是原始空间的动作参数,从而生成好的目标序列。
z的初值来源于Encoder。
优化过程中不考虑手的global rotation。因为手在空间的移到是unlimited的。
我认为global rotation还是有影响的。不同的global rotation下,手的动作分布有一些细微的差别,这些差别来自重力的影响。
Latent Optimization
优化目标
| loss | content |
|---|---|
| o | global orientation重建loss |
| tr | global translation重建loss |
| beta | 形状参数不应过大 |
| os | global translation的平滑 |
| ts | global orientation的平滑 |
| 2D | 与2D信息一致 |
| MP | latent code的合理性 |
多阶段优化
第一阶段以重建为主要目标。第二阶段以优化为主要目标。
遮挡处理
发生遮挡时,初始化阶段的所有信息(bbox,2D关键点,SMPL参数)都变更不可靠。
解决方法:仅使用观察到的时间步长来优化latent code zθ。在这种情况下,运动先验表现为一种运动填充方法,该方法利用来自可见帧的提示来推断被遮挡的帧。这是我们方法的关键部分,使其对遮挡具有鲁棒性。
有效
- 由于使用了强大的生成运动先验,我们的方法可以在部分或严重遮挡的情况下重建更准确的 3D 手部运动。我们在 HO3D-OCC(HO3D 数据集的特定于遮挡的子集)上强调了这一点。
- 与传统的基于时间先验的方法或直接回归手部姿势和形状的方法相比,我们的框架使我们能够执行更好的手部重建结果。
缺陷
对2D kps识别的准确性要求非常高,解决方法:引入图像信息
验证
启发
遗留问题
参考材料
HuMoR: 3D Human Motion Model for Robust Pose Estimation
| 缩写 | 英文 | 中文 |
|---|---|---|
| CVAE | conditional variational autoencoder | 条件变分自动编码器 |
| GMM | Gaussian mixture model | 高斯混合模型 |
核心问题是什么?
解决了什么痛点
在存在噪声和遮挡的情况下恢复合理的姿势序列
本文主要贡献是什么
- 一种通过创新的 条件VAE 建模的生成 3D 人体运动先验,可用于多种下游任务。
- 基于运动先验的动作生成
- 基于运动先验的动作优化,可以产生『准确且合理的运动和接触』的动作。
项目页面:geometry.stanford.edu/projects/humor。
主要方法
HuMoR:3D 人体运动先验
定义运动先验
本文将运动先验表达为\(x_{t-1}\)与\(x_{t}\)的动作转移关系。
不同的\(x_{t-1}\)能得到不同的动作转移关系分布。
用于动作生成时,可以取概率最大的转移关系,也可以根据概率函数采样一个分布关系。
用于动作优化时,目的是让实际的转移关系在它的所属分布中的概率尽量大。
同一个\(x_{t-1}\)结合不同的转移关系,能得到不同的\(x_{t}\)。
当输入x0与每一步转换z是确定的时候,第T帧的输出也是确定的。
本文运动先验的理论依据:Latent Variable Dynamics Model 潜变量动力学模型
假设:当前状态只与上一帧状态有关。
目标:\(p_\theta(x_t|x_{t-1})\),描述the plausibility of a transition.
CVAE:引入一个潜变量z,分别求\(p_\theta(z_t|x_{t-1})\)和\(p_\theta(x_t|z_t, x_{t-1})\),结合求出\(p_\theta(x_t|x_{t-1})\)
$$ p_\theta(x_t|x_{t-1}) = \int_{z_t} p_\theta(z_t|x_{t-1}) p_\theta(x_t|z_t, x_{t-1}) $$
这样把问题分解为两部分,其中第一项为Encoder,第二项为Decoder。
由于\(x_t\)和\(x_{t-1}\)差别不大。作者发现学习\(x_t\)与\(x_{t-1}\)之间的差,比直接学习\(x_t\)效果好。
学习运动先验
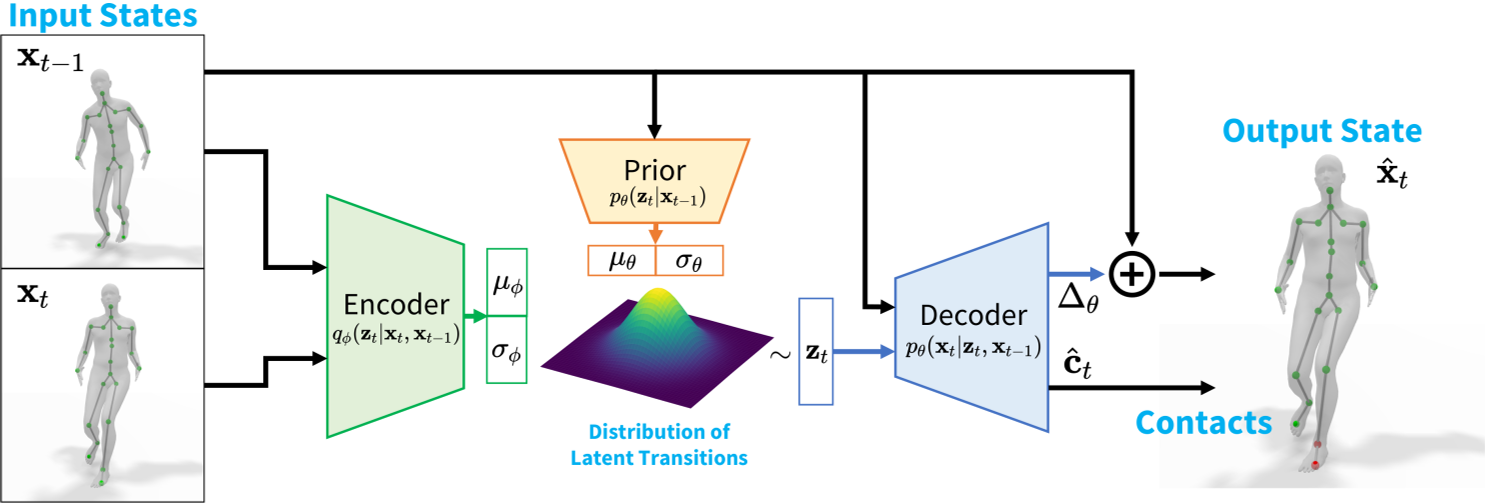
构建转移关系z的先验模型和后验模型。其中先验概率为橙色模块,后验概率为绿色模块。
后验模型从根据的数据对\(x_{t-1}, x_{t}\)中提取转移关系分布,因此能得到比较准确的运动先验。
先验模型是根据\(x_{t-1}\)预测转移关系分布,是在生成任务中会遇到的场景。
| 阶段 | 流程 | Loss | 目的 |
|---|---|---|---|
| 第一阶段 | Encoder(基于后验概率得到的转移关系) + Decoder(基于转移关系得到当前帧)的联合训练 | KL(转移关系分布,0/1分布) 重建Loss(xt, output) | 1. 从数据集中提取较准确的转移关系 2. 得到一个比较准确的动作恢复模型Decoder |
| 第二阶段(第一阶段和第二阶段可以同时进行) | 分布用Encoder和Prior预测转移关系分布 | KL(后验转移分布, 先验转移分布) | 让先验分布逼近后验分布,可以得到一个比较准确的先验转移分布。 |
基于运动先验的动作生成
控制条件:无
生成方式:自回归
表示方式:VAE
生成模型:状态转移
Homor用于动作生成时,可以取概率最大的转移关系,也可以根据概率函数采样一个分布关系。
---
title: Building the Motion Manifold
---
flowchart LR
Input[("Init Frame")]
Past(["Past"])
Prior["Humor Prior"]
Dist(["转移分布"])
Latent(["Latent Code"])
Decoder
Next(["Next"])
Input-->Past-->Prior-->Dist-->Sample-->Latent
Past & Latent --> Decoder-->Next-->Past
基于运动先验的动作优化
输入:观察序列y,为需要被优化的动作序列的特征
优化变量:使用 HuMoR 作为强运动先验,联合求解姿势、身体形状和地平面/接触,以及初始状态x0,转移序列z,形状参数beta,地面高度g
本文用所有运动数据的首帧,基于GMM模型,学习了运动数据的首帧\(p_\theta(x_0)\)的分布
优化目标:通过rollout函数,使得第T帧的输出与观察序列y的第T帧接近
第一步:initialization optimization
优化参数:SMPL参数初值
优化目标:data, shape, additional
第二步:计算z序列的初值
计算方法:CVAE Encoder
实验细节
逐帧的表示
| 符号 | 维度 | 信息 |
|---|---|---|
| \(r\) | 3 | root位移 |
| \(\dot r\) | 3 | root的线速度 |
| \(\Phi\) | 3 | root的朝向 |
| \(\dot \Phi\) | 3 | root的角速度 |
| \(\Theta\) | \(3 \times 21\) | 关节的local rotation,轴角形式 |
| \(J\) | \(3 \times 22\) | 关节的位置 没有提到特殊处理,应该就是指全局位置 |
| \(\dot J\) | \(3 \times 22\) | 关节的线速度 |
触地标签
Decoder会同时输出触地标签,这个标签会在test时使用。
对比Motion VAE
Motion VAE也使用了以上CVAE的原理。本文的改进在于:
通过额外学习条件先验、对状态和接触的变化进行建模以及鼓励关节位置和角度预测之间的一致性来克服这个问题。
训练
训练数据:pair data \((x_{t-1}, x_t)\)
并使用scheduled sampling,使模型对自身错误的长期积累具有鲁棒性。
| 重建loss | 重建出的xt应与训练数据是的xt接近 | 1. 由Encoder\((x_{t-1}, x_t)\)得到潜变量z 2. 由z和\(x_{t-1}\)Decoder出xt |
| KL散度 | z的先验分布与z的后验分布应该接近 | z的先验分布为\(p_\theta(z\mid x_{t-1})\) z的后验分布为\(q_\phi(z\mid x_{t-1},x_{t-1})\) 这个loss的权重在训练时会逐步减小,以避免posterior collapse。 |
| SMPL关节一致性 | 预测出的关节位置应该与GT一致 | [?]这个是不是有点多余?x里面已经包含关节位置、速度和旋转信息了。 |
| 触地标签 | 触地标签应与GT一致 | |
| 触地时脚的速度 | 触地是脚的速度应该较小 |
优化
| 优化目标 | ||
|---|---|---|
| mot | CVAE | z产生的先验概率尽量大,即根据x0和序列z生成每一帧xt之后,再计算每一帧会产生这个z序列的先验概率 |
| mot | init | 第一帧的概率尽量大 |
| data | data | 所产生的序列应与观察序列y相似 |
| reg | skel | 所生成的关节位置应与beta对应的SMPL体型一致 每一帧的骨长应保持不变 |
| reg | env | 当检测到脚步触地时,脚应该不动,且脚的高度为0 |
| reg | gnd | 地面高度接近初值 |
| reg | shape | 正常人的体型的shape参数不会太大 |
| additional | pose | \(z^{poset}\)不要太大 |
| additional | smooth | 前后两帧的关节位置不能发生突变 |
缺陷
- 训练和使用比较麻烦,训练包含2个阶段(训练Encoder&Decoder,训练Prior),使用包含3个阶段(根据初始化序列预测z、优化z、生成输出序列)
- 用于动作优化时一次性对整个序列优化,不能用于流式场景
- 由于运动模型是从室内mocap数据中学习的,因此不能推广到现实世界的复杂性
验证
数据集
AMASS, i3DB, PROX
启发
模型与传统的随机物理模型类似。条件先验可以被视为一个控制器,产生的“力”zt是一个关于状态 xt−1 的函数的输出,而解码器的作用就像方程中广义位置和速度的组合物理动力学模型和欧拉积分器。
遗留问题
参考材料
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
| 缩写 | 英文 | 中文 |
|---|---|---|
| PMCE | Pose and Mesh Co-Evolution network | 姿势和Mesh协同进化网络 |
| AdaLN | Adaptive Layer Normalization | 自适应层标准化 |
核心问题是什么?
背景
尽管基于单图像的 3D 人体网格恢复取得了重大进展,但从视频中准确、平滑地恢复 3D 人体运动仍然具有挑战性。
现有方法
现有的基于视频的方法通常通过从耦合图像特征估计复杂的姿势和形状参数来恢复人体网格,其高复杂性和低表示能力通常导致不一致的姿势运动和有限的形状模式。
本文方法
为了缓解这个问题,我们引入 3D 姿势作为中介,并提出一种姿势和Mesh协同进化网络(PMCE),将该任务分解为两部分:
1)基于视频的 3D 人体姿势估计
2)从估计的 3D 姿态和时间图像特征回归顶点。
具体来说,我们提出了一种双流编码器,用于估计中间帧 3D 姿势并从输入图像序列中提取时间图像特征。此外,我们设计了一个协同进化解码器,它与图像引导自适应层归一化(AdaLN)执行姿势和网格交互,以使姿势和网格适合人体形状。
效果
大量实验表明,所提出的 PMCE 在三个基准数据集(3DPW、Human3.6M 和 MPI-INF-3DHP)上的每帧精度和时间一致性方面均优于以前最先进的方法。我们的代码可在 https://github.com/kasvii/PMCE 获取。
核心贡献是什么?
- 提出了一种姿势和网格协同进化网络 (PMCE),用于从视频中恢复 3D 人体网格。它将任务分解为两部分:基于视频的 3D 位姿估计,以及通过图像引导位姿和网格协同进化进行网格顶点回归,从而实现准确且时间一致的结果。
- 设计了协同进化解码器,该解码器在我们提出的 AdaLN 的指导下执行姿势和网格交互。 AdaLN根据图像特征调整关节和顶点特征的统计特性,使其符合人体形状。
- 方法在 3DPW 等具有挑战性的数据集上实现了最先进的性能,将 MPJPE 降低了 12.1%,PVE 降低了 8.4%,加速误差降低了 8.5%。
大致方法是什么?

PMCE包括两个时序步骤:
1)基于视频的 3D 姿态估计:关注人体骨骼,根据姿势预测准确、平滑的人体运动。
2)根据 3D 姿态和时间图像特征进行网格顶点回归:利用视觉线索补充人体形状信息,恢复准确的Mesh网格并细化预测的 3D 姿势,实现姿势和网格的协同进化。
| 输入 | 输出 | 方法 |
|---|---|---|
| T 帧视频序列 | 静态图像特征 | 预训练的 ResNet-50 |
| 静态图像特征 | 时序图像特征 | Encoder |
| T 帧视频序列 | 2D 姿势 | 现成的 2D 姿态检测器 |
| 2D 姿势 | 中间帧 3D 姿势 | Encoder |
| 3D 姿态特征、时间特征 | Mesh Vertices | co-evolution decoder 活动层归一化(AdaLN)通过时序图像特征调整关节和顶点特征的统计特征来指导交互,以使pose和mesh适合人体形状。 |
self/cross attention
| 输入 | 输出 | 方法 |
|---|---|---|
| X | Q | linear |
| X或Y | K, V | linear |
| Q, K, V | multi head | Softmax |
| multi head | output | concat |
Layer Normalization
先标准化到0-1分成,再映射新的均值、方差上。
2D keypoint的位置归一化(左下)
通常的做法为:先crop出人体区域,并在区域中进行归一化。好处是降低背景噪声并简化特征提取。缺点是裁剪操作丢弃了人体在整个图像中的位置信息,这对于预测原始相机坐标系中的全局旋转至关重要[22]。
本文做法:相对于完整图像而不是裁剪区域对 2D 位姿进行归一化。
3D Pose估计(左下)
| 输入 | 输出 | 方法 |
|---|---|---|
| 归一化之后的2D Sequence | joint feature(T * J * C1) | project |
| 静态图像特征(来自左上) | 静态图像特征(T * 1 * C1) | project |
| 空间位置信息 | 空间位置信息 | Spatical embedding |
| 时序信息 | 时序信息 | temporal embedding |
以上信息加起来,得到(T * J * C1)的输入特征。
ST-Transformer 由 L1 层级联空间 Transformer 和时间 Transformer 组成。
空间Transformer:旨在探索关节之间的空间信息,计算同一帧中joint token之间的相似度。
时间 Transformer:为了捕获帧之间的时间关系,时间 Transformer 将联合特征 X 从 (T × J × C1) reshape 为 (J × T × C1)。因此,注意力矩阵是通过同一关节的frame token之间的相似度来计算的。
融合:使用多层感知器(MLP)将维度从 C1 变换为 3,并将 T 帧融合为 1,以获得中帧 3D 姿态(J * 3)。
图像特征聚合(左上)
目的:聚合T帧的静态图像特征以获得中间帧的时序特征
方法:双向GRU
Co-Evolution Decoder
输入:
- 3D Pose(来自左下),提供更精确、更稳健的姿态信息
- 时序图像特征(来自左上),提供视觉线索,例如身体形状和表面变形
- template mesh
输出:人体mesh
Adaptive layer normalization
AdaLN 基于时间图像特征自适应调整关节和顶点特征的统计特性,指导pose和mesh以适应人体形状。
把它看作是一个风格迁移任务[11],自适应调整关节和顶点的特征趋近于图像特征 f 。
图像特征f为AdaLN提供新的 scaling α 和 shifting β。关节特征和顶点特征按照f提供的α和β进行调整,这样,图像特征中包含的形状信息可以注入到关节和顶点特征中,同时保留它们的空间结构。
Co-Evolution Block
Loss Function
- mesh vertex loss Lmesh
- 3D joint loss Ljoint
- surface normal loss Lnormal
- surface edge loss Ledge
有效
缺陷
验证
启发
遗留问题
参考材料
Global-to-Local Modeling for Video-based 3D Human Pose and Shape Estimation
| 缩写 | 英文 | 中文 |
|---|---|---|
| GLoT | Global-to-Local Transformer | |
| HSCR | Hierarchical Spatial Correlation Regressor | 分层空间相关回归器 |
| GMM | Global Motion Modeling | 全局运动建模 |
| LPC | Local Parameter Correction | 局部参数校正 |
核心问题是什么?
背景
video-based 3D HPE通过帧内精度和帧间平滑度进行评估。
帧内精度 是指单帧动作的准确性。帧间平滑度 是指一个动作序列的趋势一致性。
现有方案
尽管这两个指标负责不同范围的时间一致性,但现有的最先进方法将它们视为一个统一的问题,并使用单调的建模结构(例如 RNN 或 attention-based block)来设计其网络。
存在的问题
然而,使用单一类型的建模结构很难平衡短期和长期时间相关性的学习,并且可能使网络偏向其中一种,导致不好的预测结果,例如:
- 全局位置偏移
- 时序上不一致
- 单帧动作不准确
解决方法
为了解决这些问题,我们提出一种端到端框架称为 Global-to-Local Transformer (GLoT),可以结构性地解耦“长期特征的建模”和“短期特征的建模”。
- 首先,引入了global transformer以及用于长期建模的Masked HPE策略。该策略通过随机屏蔽多个帧的特征来刺激global transformer学习更多的帧间相关性。
是否能用于流式?
- 其次,local transformer负责利用人体mesh上的局部细节,并通过利用cross-attention与global transformer进行交互。
- 此外,进一步引入了Hierarchical Spatial Correlation Regressor,通过解耦的全局-局部表示和隐式运动学约束来细化帧内估计。
效果
我们的 GLoT 在流行基准(即 3DPW、MPI-INF-3DHP 和 Human3.6M)上以最低的模型参数超越了以前最先进的方法
核心贡献是什么?
- 解耦长期和短期相关性的建模。所提出的Global-to-Local Transformer(GLoT)融合了深层网络和人类先验结构的知识,提高了我们方法的准确性和效率。
- GLoT中包含两个组件,即Global Motion Modeling和Local Parameter Correction,分别用于学习帧间全局局部上下文和帧内人体网格结构。
- 在三个数据集的实验表明,GLoT 优于之前最先进的方法 [44],且模型参数更少。
大致方法是什么?
GLoT包括两个分支,即全局运动建模(GMM)和局部参数校正(LPC)。
- 首先从预训练的 ResNet-50 [11] 中提取Static Features,参考 [5, 17, 44]。
- 然后,通过Random Masking(分支1)和Nearby Frame Selection(分支2)分别处理静态特征 S,以将它们(Sl,Ss)输入全局和局部transformer。
- 最后,分层空间相关回归器(HSCR)使用解耦的全局-局部表示\(f_{gl}\)和内部运动学结构来校正GMM获得的全局结果\(θ^l_{mid}\)。
- 请注意,我们的方法利用 T 帧来预测中间帧,参考[5,44]
Global Motion Modeling
- 沿时间维度随机屏蔽一些static token,α是屏蔽比率。(灰)
- 将global encoder应用于这些未被mask的static token。(红->黄)
- 将 SMPL token [10]填充到被mask的位置上(蓝)
- 在global decoder阶段,将整个序列发送到global decoder中以获得long-term表示。
- 将interate regressor应用于long-term表示以得到初始的全局mesh序列。
GMM得到的SMPL参数表示如下:
| 位姿参数 | Tx24×6 |
| 形状参数 | T ×10 |
| 伪相机参数 | T ×3 |
形状参数和相机参数通常是耦合的
Local Parameter Correction
人体运动的在中间帧中受到附近帧的显著影响
- 择附近的帧进行short-term建模,w 是附近帧的长度
- 对选定的tokens使用local encoder。
- local decoder不仅通过cross attention机制解码代表全局人类运动一致性的特征,还解码代表局部细粒度人类mesh结构的特征。cross attention函数定义如下,
| Q | a query of the mid-token |
| K | key of the global encoder |
| V | value of the global encoder |
HSCR
以前的方法:使用HMR直出SMPL参数,而不考虑骨骼结构。
存在的问题:没有考虑骨骼结构,结合骨骼结构信息可以得到更好的结果。
本文方法:[42]结合local分支的输出来优化global分支的结果。
- 以骨骼结构为依据拼接pose特征,以一整个骨骼链的pose特征来描述这个关节的pose特征。
- 以global branch的原始输出l和local branch的输入gl为特征,使用MLP,预测l需要调整的量s
- 把s叠加到l上,为最终输出r。
Loss Function
- global branch的输出的GT SMPL参数之间的L2 loss,只对mask的帧计算loss - 重建loss
- 2D/3D关节位置的速度 - 可以帮助模型学习运动一致性
- Masked HPE strategy - 更好地捕获远程依赖性
有效
缺陷
不支持流式
验证
启发
global E&D, local E&D、MASK策略、refine策略
遗留问题
参考材料
https://blog.csdn.net/weixin_44880995/article/details/132674988
WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion
核心问题是什么?
视频动捕,3D人体运动重建。 单目,复杂背景,运动背景,单人
核心贡献是什么?
-
WHAM(World-grounded Humans with Accurate Motion)方法成功结合3D人体运动和视频背景,实现精准的全球坐标下3D人体运动重建。
-
该方法通过模型自由和基于模型的方法,利用深度学习技术,有效地从单眼视频中准确估计3D人体姿态和形状。
-
WHAM在全球坐标系下取得了令人瞩目的成果,通过融合运动上下文和足地接触信息,最小化足滑动,提高国际协调性。
大致方法是什么?
3D动作估计
| 模块 | 先验知识 | 输入数据 | 预测信息 |
|---|---|---|---|
| 2D Detection | ViT-H 2D关键点检测技术 | 图像 | 2D关键点。 |
| bbox检测 | YOLO预训练模型 | 2d kps,原始图像 | bbox的center和scale |
| crop | 原始图像,bbox | crop后的图像 | |
| ImageEncoder | 以ViT-H为基础的HMR2.0 | crop后的图像 | 图像特征 |
| MotionEncoder | 采用单向RNN,学习人体运动数据的时序关系 | 上一帧的RNN状态,2D关键点 | 结合上下文进行在线推断SMPL参数、足地接触概率、运动特征。 |
| FeatureIntegrator | 图像特征、运动特征 | 捕捉和整合图像特征与运动特征 | 新的运动特征。 |
| MotionDecoder | 采用单向RNN,学习人体运动数据的时序关系 | 运动特征 | 当前帧相机坐标系下的SMPL参数,上一帧的RNN状态 |
没有使用额外的传感器,如惯性传感器,因为它们可能会产生侵扰。
相机标定
| 模块 | 先验知识 | 输入数据 | 预测信息 |
|---|---|---|---|
| TrajectoryDecoder | 人运动时身体保持基本向上的特点 | 相机视角下人体动作 | 世界坐标系下的人的全局旋转。 |
| 坐标系对齐 | 坐标系变换 | 通过相机视角下的人物的全局旋转与世界坐标系下的人物全局旋转的对齐 | 计算出相机坐标系与世界坐标系的投影关系。 |
运动轨迹与滑步的一致性
| 模块 | 先验知识 | 输入信息 | 预测信息 |
|---|---|---|---|
| TrajectoryDecoder | 从人体运动数据中运动轨迹与动作之间关系 | 相机坐标系下的人体动作的编码 相机朝向的相对运动 | 人在人物坐标系下的运动轨迹 |
| 脚步触地时不应该出现滑步 | 当前帧的触地概率,上一帧脚步在世界坐标系的位置,当前帧脚步在世界坐标系的概率 | 如果触地,通过调整运动轨迹,消除脚步移动 | |
| TrajectoryRefiner | 人体运动数据 | 世界坐系下的人体动作,世界坐标系下运动轨迹,通过相机标定,根据相机坐标系下的脚步位置换算出的世界坐标系下的脚步位置 | 最终的人体动作、运动轨迹 |
训练与验证
数据集
AMASS, BEDLAM, 3DPW, Human3.6M
https://caterpillarstudygroup.github.io/ImportantArticles/%E6%95%B0%E6%8D%AE%E9%9B%86.html
训练方法
有效
WHAM超越了当前的最先进方法,在逐帧和基于视频的3D人体姿势和形状估计中表现出卓越的准确性。通过利用运动上下文和足地接触信息实现了精确的全球轨迹估计,最小化了足滑动,并提高了国际协调性。该方法整合了2D关键点和像素的特征,提高了3D人体运动重建的准确性。在野外基准测试中,WHAM在MPJPE、PA-MPJPE和PVE等指标上展现出卓越的性能。轨迹细化技术进一步提升了全局轨迹估计,并通过改善的误差指标证明了减少足滑动的效果。
Feature Integrator
Feature Integrator的作用是整合2D运动特征和图像特征,生成可以还原出要SMPL参数的3D运动特征。
其实2D运动特征和图像特征都有独立的生成3D运动特征的能力。
2D运动特征到3D运动特征的过程称为lifting。由于2D信息不充分或者识别不可靠等原因,导致2D到3D的lifing可能存在错误。因此单纯的2D-3D-lifting效果不好。还需要借助别的手段来提供,有大量的HMR论文使用这类方法。
相对于2D运动特征,图像特征可以包含更多的信息,因此图像特征-3D比单纯的2D-3D效果更好。例如Humans in 4D和TRAM都属于此类。
既然Image Feature可以直接恢复人体动作,且效果比使用2D运动特征要好,为什么很多方法还有引入2D-3D-lifting这一步呢?为了更充分地利用数据集。
- 图像与SMPL参数的标注的pair数据集相对于纯3D数据集来说更难以获取。
- 图像标注的SMPL参数通常是相机坐标系下的运动数据。而纯3D数据是世界坐标系下的运动数据。
虽然通常用把smpl投影回图像的方法来验证动作的一致性,但实际需要的是世界坐标系下的3D输出。因此必须有一种方法来利用3D世界坐标系下的动作数据。如果只使用相机坐标系下的数据,是做不到这一点的,只能得到相机坐标系下的数据。
作者同时使用2D-3D-lifing和Image Feature,把在MotionContext空间上进行融合,就是为了同时利用丰富的图像信息和大量的世界坐标系下的3D数据集。
使用此模块与不使用此模块的效果对比,结果如下:
(自)遮挡场景:前者动作更准确,而后者丢失深度信息
2D关键点位置出错,置信度低:后者会出错,前者有一定的纠错能力
深度歧义:两者效果不同,但前者不一定比后者更准确
2D关键点识别错误(例如左腿识别成右腿):两者都出Decoder出错误的动作
TrajectoryDecoder
TrajectoryDecoder能够根据相机坐标系下的编码信息,推断出它在世界坐标系下的朝向与位移。
这个能力来自于大量的世界坐标系下的3D动作数据(AMASS)。
通过构造不同的相机角度,模拟出各种相机坐标系下的动作数据与世界坐标系下的动作数据的pair对。
相机坐标系转世界坐标系这一步,输入包括MotionContext(相机坐标系下的运动信息)和cam_angvel(世界坐标系下相机朝向的相对运动)。因此此模块的能力来自对先验的3D数据的理解,而不是图像中的坐标系信息。
有了这模块之后,哪怕init_smpl给的朝向不对,它也自己调整出整体向上的朝向。
缺陷
| 现象 | 可能的原因 |
|---|---|
| 角色不够灵活,快速动作或大幅度动作跟不上 | 1. Motion Encoder & Decoder没有很好地对动作编解码 2. 使用RNN网络,导致输出结果跟输入相比有延迟 |
| 世界坐标系下的人的全局旋转不准 | 全局旋转可以分解为y轴方向的旋转和剔除y轴以后的旋转。把它们区分开是因为二者造成的原因和现象不同。 y轴旋转错误是因为 1. 角度的歧义性。一个合理的特定动作放在3D空间中,它可以以y轴任意旋转,仍是一个合理的动作。作者获取世界坐标系下的人物朝向的方式是AMASS中的合理动作的先验。所以它实际上不能区分单帧动作上的y轴旋转的合理值。 2. 数据增强的歧义性。作者在AMASS上构造数据增强时,对角色的y轴旋转和相机的y轴旋转都做增强。也就是说,在训练数据中,一个相机坐标系下的人物面朝向另外一边,可能是因为人本身做了旋转,也可能是因为相机做了旋转,,更有可能是二者旋转结合的结果。这些都有可能是正确答案,这就给模型的学习带来了困惑。 3. 模块之间的耦合性。作者同时训练pipeline中的所有模块,造成了模块之间的高耦合。模型虽然不能很好地预测y轴旋转,但是由于相机的运动也耦合进来,在相机视角下仍然是一个合理的动作。模型的监督主要来自相机坐标系下的监督,因此这种错误的预测不会被优化。 和y轴旋转不同,剔除y轴以后的旋转没有那么大的歧义性。通过先验信息,可以从动作中学习到重力方向,在这个重力方向上做这些动作最稳。调整人物的全局朝向,使得重力方向与y轴方向重合。因此,造成这个现象的原因可能是TrajectoryDecoder的学习不够充分,与相机动作耦合。单纯从动作不足以预测人的全局旋转。人在轻微歪斜的动作下也能保持平衡 |
| 世界坐标系下的人的全局轨迹不准 | 单纯从动作不足以预测人的全局轨迹。因为原地踏步或向前走或上楼梯,可能表现出的动作是一样的。还应该结合背景信息。 |
| 部分动作不能较好地恢复 | 1. 2D关键点预测错误。2D关键点直接解决了最终结果。 2. 2D kps的检测和Image Feature的提取,都是以Vit-H为backbone,所以可能有相似的算法边界。所以即使二者结合,也不能有太多的增益。 3. 2D kps的检测和Image Feature的提取都是逐帧进行的。虽然在模型中使用了大量的时序模型,但可能在模型的输入信息,视频时序特征就已经丢失了。 |
启发
- 人物动作与人物轨迹解耦
- 相机坐标系与世界坐标系解耦
- 利用运动先验信息代替相机标定
- 利用Image Feature和时序关系来解决2D到3D的歧义性
- 一个pipeline中通常包含了多个模块,如果将所有模块放在一起训练,就会造成模块之间的耦合。当一个模块的学习不够完善时,另一个模块会进行相应的补偿,使得整体效果最好。这种方式虽然能提升整体效果,但高耦合也成为泛化性的潜在威胁。
- 全局旋转可以分解为y轴方向的旋转和剔除y轴以后的旋转。把它们区分开是因为二者造成的原因和现象不同。y轴旋转的角度是具有歧义性的。一个合理的特定动作放在3D空间中,它可以以y轴任意旋转,仍是一个合理的动作。作者获取世界坐标系下的人物朝向的方式是AMASS中的合理动作的先验。所以它实际上不能区分单帧动作上的y轴旋转的合理值。剔除y轴以后的旋转没有那么大的歧义性。通过先验信息,可以从动作中学习到重力方向,在这个重力方向上做这些动作最稳。调整人物的全局朝向,使得重力方向与y轴方向重合。
遗留问题
参考材料
- https://arxiv.org/pdf/2312.07531.pdf
- http://wham.is.tue.mpg.de/
- https://arxiv.org/abs/2312.07531
- https://ar5iv.labs.arxiv.org/html/2312.07531
- https://accesspath.com/ai/5891344/
- 数据集:https://caterpillarstudygroup.github.io/ImportantArticles/%E6%95%B0%E6%8D%AE%E9%9B%86.html
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
核心问题是什么?
作者认为可以从三个维度来评价一个生成模型的好坏:
其中Diffusion based生成模型的主要问题是生成速度慢,因此需要在保持高采样质量和多样性的前提下,针对采样速度慢的问题进行加速。
核心贡献是什么?
Diffusion模型缓慢采样的根本原因是去噪步骤中的高斯假设,该假设仅适用于小步长。为了实现大步长的去噪,从而减少去噪步骤的总数,作者建议使用复杂的多模态分布对去噪分布进行建模。因此引入了去噪扩散生成对抗网络(去噪扩散 GAN),它使用多模态条件 GAN 对每个去噪步骤进行建模。总之,我们做出以下贡献:
- 将扩散模型的缓慢采样归因于去噪分布中的高斯假设,并建议采用复杂的多模态去噪分布。
- 提出去噪扩散 GAN,这是一种扩散模型,其逆过程由条件 GAN 参数化。
- 通过仔细的评估,我们证明,与当前图像生成和编辑的扩散模型相比,去噪扩散 GAN 实现了几个数量级的加速。
大致方法是什么?
Denoising Diffusion GAN的设定
前向扩散过程与原来的DDPM模型一致,只是T非常小(T < 8),且每个扩散步的\(\beta_t\)很大。
训练目标为最小化生成分布与真实分布的距离(同DDPM)对抗性损失,这个对抗性损失能够最小化散度。
判别器的定义为\(D_{\phi}(x_{t-1},x_t,t): R^N \times R^N \times R -> [0,1]\),即输入N维的\(x_{t-1}\) 和 \(x_{t}\),输出 \(x_{t-1}\)是\(x_{t}\) 的去噪版本的置信度。
判别器对真实分布与生成分布做区分,但真实分布是未知的,无法直接训练判别器。为了解决这个问题,作者在这里做了转换:
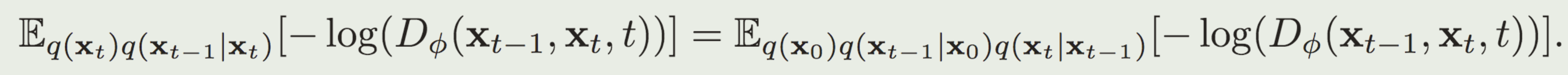
关于这个转换与非饱和GAN目标这一部分不懂
模型的重参数化
直接预测 \(x_{t-1})\)较为困难,因为现在的去噪模型更加复杂,且是一个隐式的模型(原来的建模只是简单的高斯分布)。但是由于正向扩散过程仍然是加的高斯噪声,因此无论步长多大或者数据分布多复杂,依然有 \(q(x_{t-1}|x_t, x_0)\)服从高斯分布这一性质。因此去噪过程为:
先使用去噪模型 \(f_\theta(x_t,t)\) 预测 x0,再用给定的 xt 和预测出的 x0 来从后验分布 \(q(x_{t-1}|x_t,x_0)\) 中采样得到。
训练流程图如下所示:
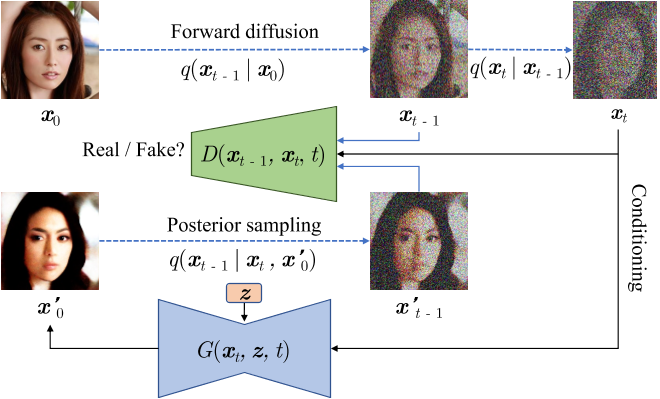
有效
本文相对于DDPM的优势:
- \(p_\theta(x_{t-1}|x_t)\) 的构建类似于原始DDPM,可以利用原来的归纳偏置。但原来的DDPM是以确定性映射的方式由 xt 预测 x0 ,而在作者的设计中 x0 是由带随机隐变量 z 的生成器得到的。这一关键差异使得作者的去噪分布模型 \(p_\theta(x_{t-1}|x_t)\) 能够变得多模态以及更加复杂,而DDPM的去噪模型是简单的、单模态的高斯分布。
2.对于不同的时间步 t ,xt 相对于原始图片的扰动程度是不同的,因此使用单个网络直接预测不同时间步的 \(x_{t-1}\) 可能是困难的。但在作者的设定下生成器只需要预测未经扰动的 x0,然后再利用 \(q_\theta(x_{t-1}|x_t,x_0)\) 加回扰动。
本文相对于GAN的优势:
传统的GAN训练完后一步就能生成样本,而本模型要迭代地去噪来获得样本。因此:
-
GAN存在训练不稳定以及模式坍缩的问题。
-
直接一步从复杂分布中生成样本是很困难的,而作者的模型将生成过程分解为几个条件的去噪-扩散步骤,每一步由于基于强条件 xt ,相对来说会更容易建模。
-
判别器只看干净的样本可能存在过拟合问题。而扩散过程可以平滑数据分布,使得判别器没那么容易过拟合。
扩散过程相当于对原始图片加噪声,相当于做了数据增强,有缓解过拟合的作用;另一方面,我们的数据集是有限的,相当于是数据分布上的一些离散的点,加上噪声相当于让点扩散开来,将这些离散的点"连起来"成为一片区域,从而平滑了数据分布。
缺陷
验证
移掉隐变量会让模型变成单模态分布,并在消融实验中定量的证明了这一点
启发
遗留问题
参考材料
https://zhuanlan.zhihu.com/p/503932823
Elucidating the Design Space of Diffusion-Based Generative Models
核心问题是什么?
diffusion model模型的文献在理论方面非常丰富,采样计划、训练动态、噪声水平参数化等的推导往往尽可能直接基于理论框架,这确保了模型具有坚实的理论基础。然而,这种方法存在模糊可用设计空间的危险——所提出的模型可能会显示为紧密耦合的包,其中任何单个组件都无法在不破坏整个系统的情况下进行修改。
核心贡献是什么?
文章用一种新的设计框架统一diffusion-based model,并使用模块化(modular)的思想,分别从采样、训练、score network设计三个方面分析和改进diffusion-based model。
- 我们从实践的角度来审视这些模型背后的理论,更多地关注训练和采样阶段出现的“有形”对象和算法,而不是它们可能来自的统计过程。目标是更好地了解这些组件如何连接在一起以及整个系统设计中可用的自由度。
- 采样:我们确定了采样的最佳时间离散化,对采样过程应用高阶龙格-库塔方法,评估不同的采样器计划,并分析随机性在采样过程中的有用性。这些改进的结果是合成过程中所需的采样步骤数量显着减少,并且改进的采样器可以用作几种广泛使用的扩散模型的直接替代品。
- 训练:虽然我们继续依赖常用的网络架构(DDPM [16]、NCSN [48]),但我们在扩散模型设置中提供了对网络输入、输出和损失函数的预处理的第一个原理分析,并得出提高训练动力的最佳实践。我们还建议在训练期间改进噪声水平的分布,并注意到non-leaking augmentation [25](通常与 GAN 一起使用)也有利于扩散模型。 总而言之,我们的贡献可以显着提高结果质量。同时,通过明确列出设计空间的所有关键要素,我们相信我们的方法将使各个组件更容易创新,从而能够对扩散模型的设计空间进行更广泛和有针对性的探索。
大致方法是什么?
Expressing diffusion models in a common framework
假设有方差是\( \sigma_{data} \)的数据分布 \(p_{data}(\mathbf x) \)。通过多次对数据添加方差为\( \sigma \)的高斯噪声,得到的\(p(x; \sigma_{max})\为纯高斯噪声(此处没有考虑缩放)。
则有下面的ODE描述数据分布随着时间的变化:
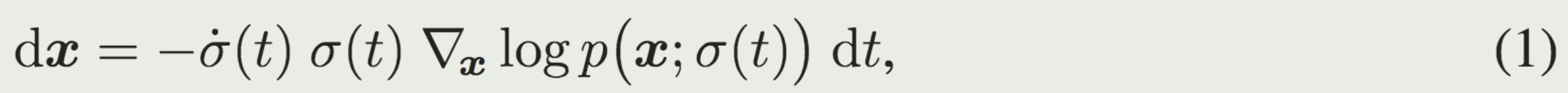
如果把缩放考虑进去,则公式变为:
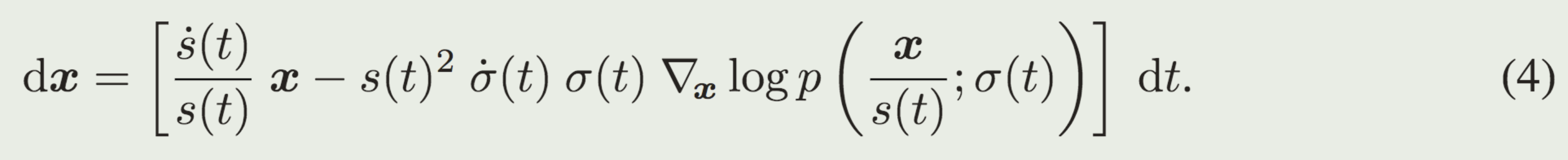
为了让p(x)与t无关,以下都是基于不考虑缩放的版本。
diffusion-based model都是逐步添加高斯噪声的过程,主要就是两个不同,一个是缩放 s(t),一个是噪声的大小σ(t)。
作者在三个预训练模型进行了重构。三个预训练模型代表不同的理论框架和模型系列,都重构到一套统一的框架中。且重构后所有组件之间不存在隐式依赖关系——原则上,各个公式的任何选择(在合理范围内)都会产生一个功能模型。换句话说,更改一个组件并不需要更改其他组件,以便保持模型收敛到极限数据的属性。在实践中,某些选择和组合当然会比其他选择和组合效果更好。

表 1:N 是采样期间执行ODE solver迭代的次数。相应的时间步序列是{t0, t1,...。 。 。 , tN },其中 tN = 0。降噪器定义为\(Dθ (x; σ) = c_{skip}(σ)x + c_{out}(σ)Fθ(c_{in}(σ)x; c_{noise}(σ));\) Fθ 表示原始神经网络层。
一些公式看起来与原始论文有很大不同,因为间接和递归已被删除;详细信息请参见附录 C。
求解ODE的过程可以把积分离散化,即在离散时间间隔上采取有限步骤。这需要选择离散化方案(例如,Euler 或 Runge-Kutta 的变体)以及离散采样时间 {t0, t1,...。 。 。 ,tN}。许多先前的工作使用欧拉方法,但我们在第 3 节中表明二阶求解器提供了更好的计算权衡。
Improvements to deterministic sampling
我们的假设是,与采样过程相关的选择在很大程度上独立于其他组件,例如网络架构和训练细节。
对 ODE 进行数值求解是遵循真实解轨迹的近似值。在每一步中,求解器都会引入局部截断误差,截断误差会在N 步中累积。
- 局部误差通常相对于步长呈超线性缩放,因此增加 N 可以提高解决方案的准确性。
- Euler方法是一阶solver,步长 h 的局部误差为 \(O(h^2)\)。而高阶方法有较小的截断误差,但在每一步需要进行多次网络预测。Heun二阶方法则在误差精度与推断次数之间有比较好的权衡。
- 步长{ti}应该随着 σ 的减小而单调减小,并且不需要根据每个样本而变化(附录 D.1)。
- s(t)和σ(t)的选择提供了一种减少上述截断误差的方法,因为它们的大小预计与 dx/dt 的曲率成比例。作者认为这些函数的最佳选择是 σ(t) = t 和 s(t) = 1,这也是 DDIM [47] 中做出的选择。通过这种选择,ODE公式(4) 简化为 dx/dt = (x − D(x; t))/t, 并且 σ 和 t 可以互换。
Stochastic sampling
确定性采样有许多好处,例如,能够通过反转 ODE 将真实图像转换为其相应的潜在表示。然而,它输出的质量差于SDE [47, 49]。鉴于 ODE 和 SDE 理论上恢复相同的分布,那么随机性到底有何作用?
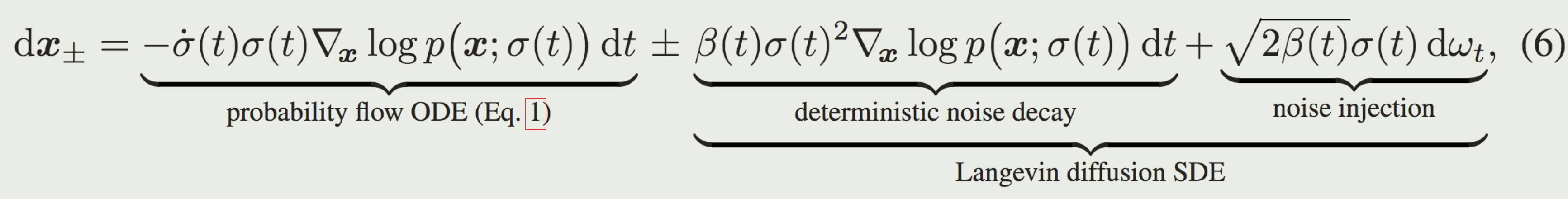
这揭示了为什么随机性在实践中有帮助:隐式朗之万扩散在给定时间将样本推向所需的边缘分布,主动纠正早期采样步骤中发生的任何错误。
但是,用离散 SDE 求解器步骤逼近 Langevin 项本身会引入误差。之前的结果 [3, 24 , 47 , 49 ] 表明非零 β(t) 是有帮助的,但Song 等人对 β(t) 的隐式选择[49]只是根据经验确定。
我们提出了一种随机采样器,它将二阶确定性 ODE 积分器与添加和消除噪声的显式的类似 Langevin 的“搅动”相结合。算法 2 中给出了伪代码。

我们的方法和 Euler-Maruyama 之间的主要区别在于在离散化公式6时存在细微的差异。 Euler-Maruyama方法先添加噪声,然后执行 ODE 步骤。ODE不是从噪声注入后的中间状态开始,而是假设 x 和 σ 在迭代步骤开始时保持在初始状态。在我们的方法中,算法 2 第 7 行用于评估 Dθ 的参数对应于噪声注入后的状态(而Euler-Maruyama 的方法将使用 xi;ti 代替 \(\hat x_i; \hat t_i\)).在 Δt 接近零的极限下,这些选择之间可能没有区别,但当以大步长追求低 NFE 时,区别就变得很重要了。
有效
Stochastic sampling
我们的随机采样器明显优于以前的采样器 [24,37,49],特别是在低步数的情况下
缺陷
验证
Improvements to deterministic sampling
我们首先使用这些模型的原始采样器实现测量基线结果,然后使用表 1 中的公式将这些采样器引入我们的统一框架,然后进行改进。这使我们能够评估不同的实际选择,并对适用于所有模型的采样过程提出一般改进。
启发
遗留问题
参考材料
https://blog.csdn.net/icylling/article/details/133840948
SCORE-BASED GENERATIVE MODELING THROUGHSTOCHASTIC DIFFERENTIAL EQUATIONS
核心问题是什么?
一种从数据生成噪声的方法:通过缓慢注入噪声将复杂的数据分布平滑地转换为已知的先验分布
一种从噪声生成数据的方法:SDE 通过缓慢消除噪声将先验分布转换回数据分布。其中SDE 仅取决于扰动数据分布的时间相关梯度场(也称为分数)。
核心贡献是什么?
- 通过神经网络准确估计这些分数,并使用数值 SDE 求解器生成样本。
- 引入预测校正框架来纠正离散逆时 SDE 演化中的错误
- 导出等效的神经常微分方程,它从与 SDE 相同的分布中采样,但还可以进行精确的似然计算,并提高采样效率
- 提供了一种使用基于分数的模型解决逆问题的新方法
大致方法是什么?
Score function
生成模型的目标就是要得到数据的分布。现在我们有一个数据集,我们想要得到数据的概率分布p(x)。一般我们会把这个概率分布建模成这样:
$$ p_\theta(x) = \frac{e^{-f_\theta(x)}}{Z_\theta} $$
这里f(x)可以叫做unnormalized probabilistic model或者energy-based model。Z是归一化项保证p(x)是概率。\(\theta\)是他们的参数。 我们一般可以通过最大化log-likelihood的方式来训练参数\(\theta\)
$$ \max_\theta \sum_{i=1}^N \log p_\theta(x_i) $$
即让数据集里的数据(即真实数据分布的采样)log-likelihood最大。
但是因为Z是intractable的,我们无法求出\(\log p_\theta(x_i)\),自然也就无法优化参数。 为了解决归一化项无法计算的问题,我们引入score function。 score function的定义为
$$ s_\theta(x) = \nabla_x \log p_\theta(x) = -\nabla_x f_\theta(x) - \nabla_x \log z_\theta \\ = -\nabla_x f_\theta(x) $$
因此s(x)是一个与z无关的函数。
Score matching
现在我们想要训练一个网络来估计出真实的score function。自然地,我们可以最小化真实的score function \(\nabla_x \log p_\theta(x)\)和网络输出的MSE\(s_\theta(x)\)。 但是这样的一个loss我们是算不出来的,因为我们并不知道真实的p(x)是什么。而score matching方法就可以让我们在不知道真实的的情况下最小化这个loss。Score matching的推导如下:

Score Matching Langevin Dynamics (SMLD)
现在我们已经通过神经网络学习到了数据分布的score function,那么如何用score function从这个数据分布中得到样本呢?答案就是朗之万动力学采样(Langevin Dynamics):
$$ x_{i+1} = x_i + \epsilon \nabla_x \log p(x) + \sqrt {2 \epsilon} z_i, z_i \in N(0, I), i = 0, 1, \dots, K $$
这里的采样是一个迭代的过程。\(\epsilon\)是一个很小的量。x0随机初始,通过上面的迭代式更新。当迭代次数K足够大的时候,x就收敛于该分布的一个样本。
这样我们其实就得到了一个生成模型。我们可以先训练一个网络用来估计score function,然后用Langevin Dynamics和网络估计的score function采样,就可以得到原分布的样本。因为整个方法由score matching和Langevin Dynamics两部分组成,所以叫SMLD。
Pitfall
现在我们得到了SMLD生成模型,但实际上这个模型由很大的问题。
$$ L = \int p(x) ||\nabla_x \log p(x) - s_\theta(x)||^2 dx $$
观察我们用来训练神经网络的损失函数,我们可以发现这个L2项其实是被p(x)加权了。所以对于低概率的区域,估计出来的score function就很不准确。如果我们采样的初始点在低概率区域的话,因为估计出的score function不准确,很有可能生成不出真实分布的样本。
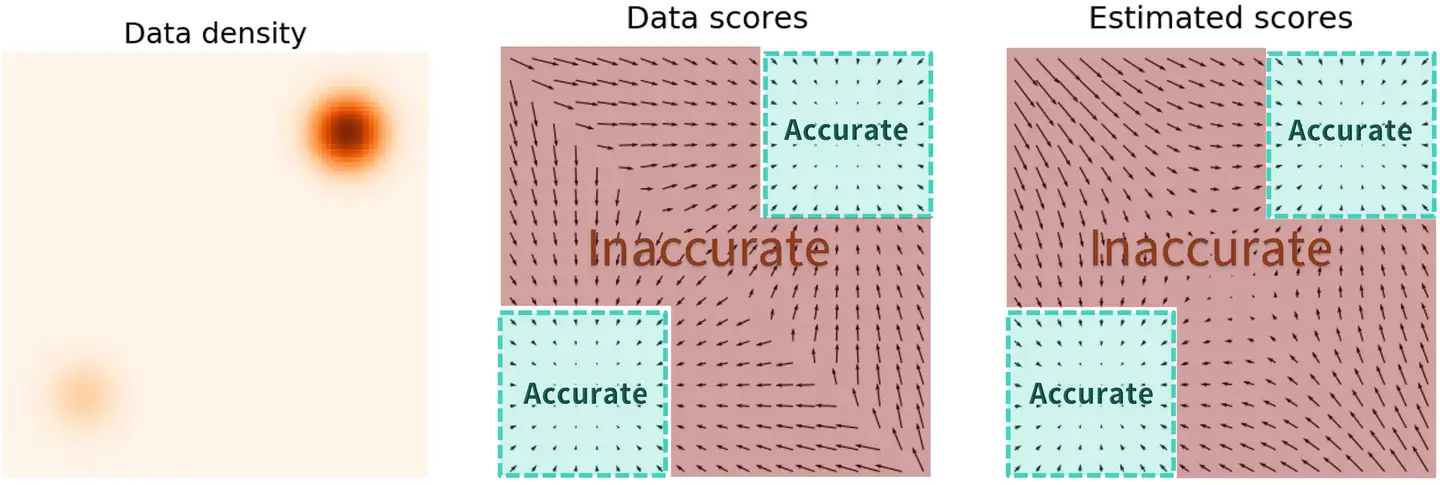
Fix it with multiple noise perturbations
那怎么样才能解决上面的问题呢? 其实可以通过给数据增加噪声扰动的方式扩大高概率区域的面积。给原始分布加上高斯噪声,原始分布的方差会变大。这样相当于高概率区域的面积就增大了,更多区域的score function可以被准确地估计出来。
但是噪声扰动的强度如何控制是个问题:
- 强度太小起不到效果,高概率区域的面积还是太小
- 强度太大会破坏数据的原始分布,估计出来的score function就和原分布关系不大了
这里作者给出的解决方法是加不同程度的噪声,让网络可以学到加了不同噪声的原始分布的score function。
我们定义序列\(\sigma_i\)\(_{i=1}^L\),代表从小到大的噪声强度。这样我们可以定义经过噪声扰动之后的数据样本,服从一个经过噪声扰动之后的分布,
$$ x + \sigma_iz \in p_{\sigma_i}(x) = \int p(y)N(x|y, \sigma_i^2I)dy $$
我们用神经网络来估计经过噪声扰动过的分布的score function。采样方式也要做出相应的变化,我们对于不同的噪声强度L做Langevin采样,上一个scale的结果作为这一次的初始化。这种采样方式也叫做Annealed Langevin dynamics,伪代码如下图所示。

有效
缺陷
验证
启发
Connection with DDPM
如果我们把SMLD和DDPM的优化目标都写出来的话可以发现他们的形式都是一样的。
遗留问题
参考材料
https://zhuanlan.zhihu.com/p/583666759
Consistency Models
https://arxiv.org/pdf/2303.01469.pdf
https://github.com/openai/consistency_models
https://readpaper.com/pdf-annotate/note?pdfId=4761865581863370753¬eId=2187834810264506624
核心问题是什么?
扩散模型在图像、音频和视频生成方面取得了重大突破,但它们依赖于迭代生成过程,导致采样速度较慢,限制了其实时应用的潜力。
现有的快速采样方法包括更快的数值ODE求解器和蒸馏技术。ODE求解器仍然需要超过10个评估步骤来生成有竞争力的样本。大多数蒸馏方法,依赖于在蒸馏之前从扩散模型中收集大量的样本数据集,这本身就是计算成本很高的。据我们所知,唯一不受这一缺点影响的蒸馏方法是渐进蒸馏(PD)。
核心贡献是什么?
- 一致性模型在设计上支持快速的一步生成,同时仍然允许少步采样以换取样本质量的计算。
- 一种新的生成模型家族,可以在没有对抗性训练的情况下实现高样本质量
- 支持zero-shot数据编辑,如图像修补、着色和超分辨率,而不需要对这些任务进行明确的训练。
- 一致性模型既可以作为提取预训练扩散模型的一种方式训练,也可以作为独立的生成模型训练。
大致方法是什么?
我们建立在连续时间扩散模型中的概率流(PF)常微分方程(ODE)之上(简单来说,就是图像前向传播的无参加噪过程),其轨迹平滑地将数据分布转换为可处理的噪声分布。而CM可将任何时间步骤的任何分布点映射到轨迹的起点。CM模型的一个显著特性是自一致性:同一轨迹上的点映射到相同的起始点。因此,我们把这样的模型称为一致性模型。
一致性模型的定义
假设存在一个函数f,对于同一条PF ODE轨迹上的任意点都有相同的输出:
$$ \boldsymbol{f} ( x_t , t ) = \boldsymbol{f} ( x_{t^{\prime}} , t^{\prime} ) \text { for all } t , t ^{\prime} \in [ \epsilon , T ] $$
consistency model的目标是从数据中估计一致性函数f,来迫使self-consistency性质
一致性模型参数化
要拟合的一致性函数 \( f(\cdot, \cdot) \)要满足两个条件:①同一个轨迹上的点输出一致;②在起始点f为一个对于x的恒等函数
第一种做法简单地参数化consistency models
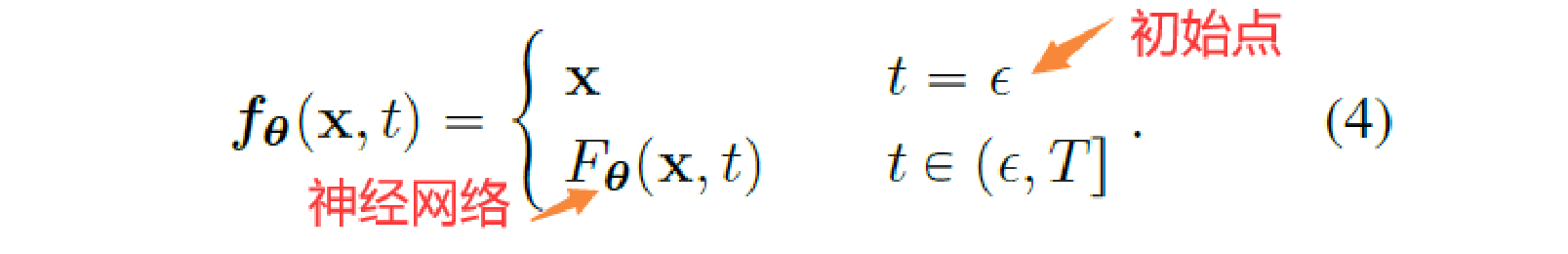
第二种做法使用跳跃连接(作者和许多其他的都用这个)

其中 \(c_{skip}\)和 \(c_{out}\)为可微函数,满足 \(c_{skip}(\epsilon) = 1, c_{out}(\epsilon) = 0\). \(F_{\theta}\)为深度神经网络,可使用一致性损失来学习,输出维度同 x.
一致性模型采样
观察 f 的性质,显然, \(f(x_T,T) = x_{\epsilon}\)可以得到我们想要的生成结果。但一般认为,这样的生成误差会比较大。所以我们每次从\(x_{\tau_n}\) 预测出初始的 \(x_\)后,回退一步来预测\(x_{\tau_{n-1}}\) 来减小误差。因此有如下多步采样的算法。

实际中,采用贪心算法来寻找时间点,通过三值搜索每次确定一个时间点。
Consistency Models 的训练方式
考虑到 Consistency Models 的性质,对采样轨迹上的不同点,f应该有一个相同的输出,自然我们需要找到采样的轨迹。
Training Consistency Models via Distillation
如果我们有预训练的diffusion model,自然可以构建轨迹。
假设采样轨迹的时间序列为
$$ t_{1}=\epsilon<t_{2}<\cdots<t_{N}=T $$
通过运行数值ODE求解器的一个离散化步骤从 \(\mathbf{x}{t{n+1}}\) 得到 \( \mathbf{x}{t{n}}\)
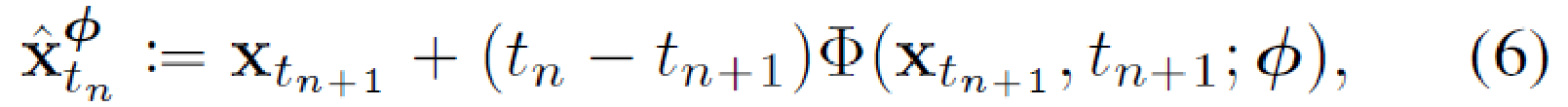
其中Φ(...;ϕ)为ODE solver,可以是任意ODE Solver,一般来说阶数越高的 Solver 求解精度越高。
例如使用Euler solver
$$ \frac{\mathrm{dx}}{\mathrm{d} t}=-t s_{\phi}\left(\mathrm{x}_{t}, t\right)\\ \Phi(\mathrm{x}, t ; \phi)=-t s _{\phi}(\mathrm{x}, t) $$
带入上式得到
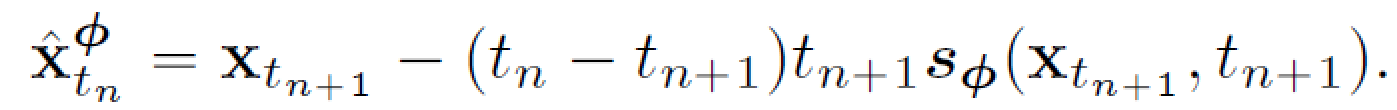
对于处于同一轨道的 \((x_{t_{n-1}},t_{n-1}),(\hat x_{t_{n}}^\phi,t_{n})\),f应该有相同的输出,我们用距离函数 d 来衡量输出是否相同。因而有如下训练损失
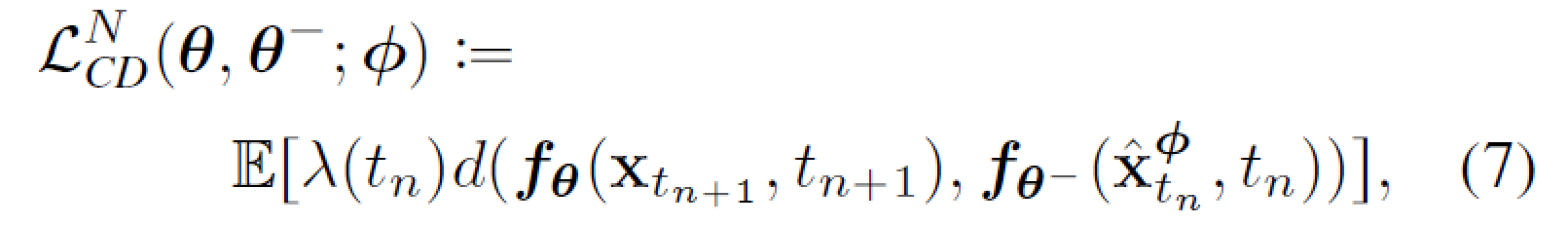
其中 \(\lambda\)用来对不同时间步赋予不同重要性,\(\theta^-\)为 EMA 版本的权重。采用EMA来更新模型会提高训练的稳定性,并且性能会更好。
综合上述过程,蒸馏(Consistency Distillation)的算法为

Training Consistency Models in Isolation
Consistency models也可以单独进行训练,而不依赖于预训练好的扩散模型。在蒸馏的过程中,我们实际上用预训练模型来估计得分\(\nabla \log p_t(x)\) 。 如果从头训练,需要找一个不依赖于预训练模型的估计方法。
作者在论文中证明了一种新得分函数的估计

利用该得分估计,作者为从 Isolation Training 构建了一个新的训练损失,
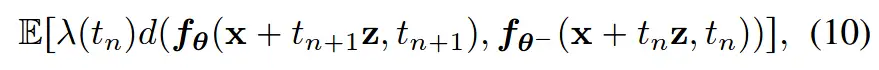
并且证明了该 Loss 和 Distillation Loss 在最大间隔趋于0时相等。即
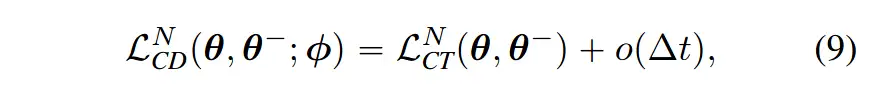
从而可以利用上述 loss 训练一个 Consistency Models,并且不依赖于已有 Diffusion Model。具体算法如下

有效
缺陷
验证
启发
遗留问题
参考材料
[1] https://zhuanlan.zhihu.com/p/621673283 [2] https://blog.csdn.net/singxsy/article/details/130243343 [3] https://blog.csdn.net/WiSirius/article/details/134670307 [4] https://www.jianshu.com/p/3b712cbe6d0d
Classifier-Free Diffusion Guidance
https://readpaper.com/pdf-annotate/note?pdfId=4650228075519295489
核心问题是什么?
现有方法:Classifier Guidance
类别引导的方法就是使用额外训练的分类器来提升扩散模型生成样本的质量。
在使用类别引导扩散模型生成之前,扩散模型很难生成类似于 BigGAN 或 Glow 生成的那种 low temperature(和训练数据的分布非常接近的样本,更清晰且逼真) 的样本。
分类器引导是一种混合了扩散模型分数估计与分类器概率输入梯度的方法。通过改变分类器梯度的强度,可以在 Inception 得分和 FID 得分(两种评价生成模型性能的指标)之间进行权衡,就像调整 BigGAN 中截断参数一样。

从上式可以看到,Classifier Guidance 条件生成只需额外添加一个classifier的梯度来引导。从成本上看,Classifier Guidance 需要训练噪声数据版本的classifier网络,推理时每一步都需要额外计算classifier的梯度。
Classifier Guidance 的问题
- 需要额外训练一个噪声版本的图像分类器
- 分类器的质量会影响按类别生成的效果
- 通过梯度更新图像会导致对抗攻击效应,生成图像可能会通过人眼不可察觉的细节欺骗分类器,实际上并没有按条件生成。
本文方法
因此,作者想要探索是否可以在不使用任何分类器的情况下实现类似效果。因为,使用分类器引导会使扩散模型训练流程复杂化,它需要额外训练一个用于处理噪声数据的分类器,并且在采样过程中将分数估计与该分类器梯度混合。
所以作者提出了无需任何依赖于特定目标或者任务设定的 classifier-free guidance 方法。
核心贡献是什么?
目标:训练一个diffusion 模型,不需要训练分类模型,不受限于类别,直接用条件控制即可
假设有一个训好的无条件diffusion model,Classifier Guidance只需要在此基础上再训练一个噪声版本的图像分类器。但classifier-free guidance则需要完全重训diffsion model,已有的diffusion model用不上。
OPENAI 提出了 可以通过调节引导权重,控制生成图像的逼真性和多样性的平衡的 classifier-free guidance,思想是通过一个隐式分类器来替代显示分类器,而无需直接计算显式分类器及其梯度。
大致方法是什么?
原理
“无分类器引导”(Classifier-free guidance)可以在不需要分类器的情况下提供与分类器引导相同的效果。它通过一个隐式分类器来替代显示分类器,而无需直接计算显式分类器及其梯度。
分类器的梯度如下:
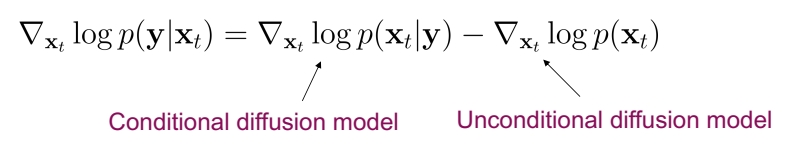
把这个分类器带入 classifier guidance 梯度中,得到如下:
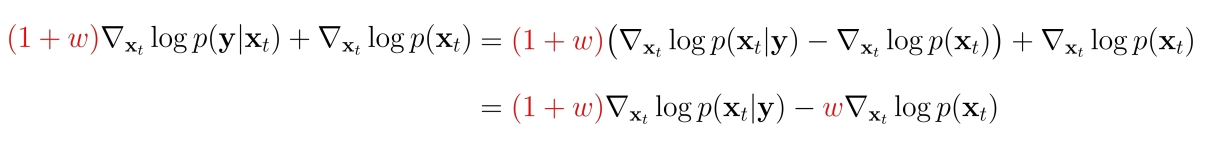
当 w=-1 为无条件模型;当 w=0 为标准的条件概率模型。当 w>0 时,是classifier-free guidance。
训练
Classifier-Free Guidance需要训练两个模型,一个是无条件生成模型,另一个是条件生成模型。这两个模型都同一个模型表示,用同一神经网络进行参数化,并且同时训练。
虽然也可以选择独立训练每个单独的模型,但联合训练更简单、不会复杂化训练流程,并且不会增加总体参数数量。
训练时只需要以一定概率将条件置空即可。
✅ 训练时随机地使用“条件+数据”和“None+数据”进行训练。
推断
推理时,分别使用条件生成模型和无条件生成模型生成结果,最终结果可以以上两个结果的线性外推获得。
生成效果可以引导系数可以调节,控制生成样本的逼真性和多样性的平衡。
有效
为什么这比 classifier guidance 好得多?主要原因是我们从生成模型构造了“分类器”,而标准分类器可以走捷径:忽视输入 x 依然可以获得有竞争力的分类结果,而生成模型不容易被糊弄,这使得得到的梯度更加稳健。
缺陷
验证

Large guidance weight \((\omega )\) usually leads to better individual sample quality but less sample diversity.
启发
遗留问题
参考材料
[1] https://blog.csdn.net/jiaoyangwm/article/details/135101303
[2] https://sunlin-ai.github.io/2022/06/01/Classifier-Free-Diffusion.html
Cascaded Diffusion Models for High Fidelity Image Generation
核心问题是什么?
没有强大条件信息的大型高保真数据集上提升扩散模型的样本质量。
级联扩散模型能够生成高保真图像,而无需辅助图像分类器的任何帮助来提高样本质量。
级联扩散模型的生成质量主要依赖于条件增强,这是我们提出的超分辨率模型的低分辨率条件输入的数据增强方法。我们的实验表明,条件增强可以防止级联模型中采样过程中的复合误差,这有助于我们训练级联pipeline。
核心贡献是什么?
贡献1:使用级联扩散模型 (CDM)(不需要与任何分类器结合的纯生成模型) 产生的高保真度样本。 贡献2:为超分辨率模型super-resolution models引入了条件增强(这对于实现高样本保真度至关重要),并提出了超分辨率模型低分辨率条件输入的数据增强方法。 贡献3:我们对增强策略进行了深入探索,发现高斯增强是低分辨率上采样的关键因素,而高斯模糊是高分辨率上采样的关键因素。我们还展示了如何有效地训练在不同水平的条件增强上摊销的模型,以实现训练后超参数搜索以获得最佳样本质量。
大致方法是什么?


有效
条件增强可防止级联模型采样期间的复合误差。
缺陷
验证
启发
遗留问题
参考材料
https://blog.csdn.net/qq_43800752/article/details/130153729
LEARNING ENERGY-BASED MODELS BY DIFFUSIONRECOVERY LIKELIHOOD
https://readpaper.com/pdf-annotate/note?pdfId=4557039050691715073¬eId=2184260463570356480
核心问题是什么?
虽然基于能量的模型 (EBM) 在高维数据集上表现出许多理想的属性,但在高维数据集上进行训练和采样仍然具有挑战性。
核心贡献是什么?
我们提出了一种diffusion recovery likelihood方法,在数据集的越来越嘈杂的版本上训练的一系列 EBM ,并从中训练和采样。
大致方法是什么?
每个 EBM 都使用recovery likelihood进行训练,这使得:给定数据集在较高噪声水平下的噪声版本,数据在特定噪声水平下的条件概率最大化。
优化recovery likelihood比marginal likelihood更容易处理,因为从条件分布中采样比从边际分布中采样容易得多。训练后,可以通过采样过程生成合成图像,该采样过程从高斯白噪声分布初始化,并以逐渐降低的噪声水平逐步对条件分布进行采样。
有效
After training, synthesized images can be generated by the sampling process that initializes from Gaussian white noise distribution and progressively samples the conditional distributions at decreasingly lower noise levels.
Our method generates high fidelity samples on various image datasets.
缺陷
验证
启发
遗留问题
参考材料
On Distillation of Guided Diffusion Models
核心问题是什么?
无分类器引导扩散模型的缺点是,它们在推理时的计算成本很高,因为它们需要评估两个扩散模型(一个类条件模型和一个无条件模型)数十到数百次。
而现有的加速方法不适用于classifier-free guided diffusion models。
核心贡献是什么?
使用两步蒸馏法提升classifier-free guided diffusion models的采样效率。
给定一个预先训练的无分类器引导模型,我们首先学习一个模型来匹配两个教师模型(条件模型和无条件模型)的组合输出,然后我们逐步将该模型提炼为需要更少采样步骤的扩散模型。
大致方法是什么?
第一阶段
引入单个学生模型来匹配两个老师扩散模型(条件模型和无条件模型)的组合输出。
classifier-free guidance使用w来权衡条件模型(质量)和无条件模型(多样性)。因此蒸馏模型也应该能够保持这一特性。
给定我们感兴趣的指导强度范围 [wmin, wmax],使用以下目标优化学生模型

其中\(\hat x_{\theta}^w(z_t)\)是由两个老师扩散模型提供的GT。\(\hat x_{\eta 1}(z_t, w)\)是要学习的学生模型。
- 对 w 应用傅里叶嵌入,然后将其合并到扩散模型主干中,其方式类似于将时间步。
- 学生模型与老师模型相同,且使用老师模型来初始化学习模型。
第二阶段
逐步将第一阶段学习的模型提炼为少步模型,见PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS.
有效
- 对于在像素空间上训练的标准扩散模型,我们的方法能够在 ImageNet 64x64 和 CIFAR-10 上使用短短 4 个采样步骤生成视觉上与原始模型相当的图像,实现与原始模型相当的 FID/IS 分数原始模型的采样速度提高了 256 倍。
- 对于在隐空间上训练的扩散模型(例如稳定扩散),我们的方法能够使用少至 1 到 4 个去噪步骤生成高保真图像,与 ImageNet 上的现有方法相比,推理速度至少提高 10 倍256x256 和 LAION 数据集。

- 在文本引导图像编辑和修复方面,我们的蒸馏模型能够使用少至 2-4 个去噪步骤生成高质量的结果。 For standard diffusion models trained on the pixel-space, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps on ImageNet 64x64 and CIFAR-10, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
缺陷
验证
启发
参考材料
- https://blog.csdn.net/zjc910997316/article/details/131812691
- https://caterpillarstudygroup.github.io/ImportantArticles/diffusion-tutorial-part/diffusiontutorialpart1.html
Denoising Diffusion Implicit Models
核心问题是什么?
DDPM的生成速度太慢,其本质原因是:在对\(p_{\theta}(x_{t-1}|x_t)\)的推导中,DDPM用到了一阶马尔可夫假设,使得\(p(x_t|x_{t-1},x_0)=p(x_t|x_{t-1})\) 。
在DDPM中往往需要较大的T才能得到较好的结果(论文中 ),这导致需要T次采样步长。因此重建的步长非常长,导致速度慢。
核心贡献是什么?
DDPM为什么这么慢
DDPM速度慢的本质原因是对马尔可夫假设的依赖,导致重建需要较多的步长。那么不用一阶马尔可夫假设,有没有另一种方法推导出\(p(x_{t-1}|x_{t},x_0)\) 。
前面我们提到,DDPM的前向过程主要是用于构造数据集,来训练噪声预测模型。在实际优化过程中,其实并没有用到前向过程的马尔可夫假设,只用到了推理分布 \(q(x_t|x_0)\) ,因此如果DDIM也能满足这个推理分布的话,那么直接就可以复用DDPM的噪声预测模型了
✅ 马尔可夫假设认为,\(x_{t}\)只与\(x_{t-1}\)有关。但前向过程中\(x_{t}\)由\(x_0\)得到,而不是由\(x_{t-1}\)得到,因此不依赖马尔可夫假设。
✅ 而反向过程中,\(x_{t-1}\)需要\(x_{t}\),因此是依赖马尔可夫假设。
✅ 如果找到一种方法,不需要计算通过\(x_{t}\)的分布来计算\(x_{t-1}\)的分布,那么就是不依赖于马尔可夫假设。
DDIM如何不依赖马尔科夫假设
归纳一下DDIM想要做的
- DDIM希望构建一个采样分布\(p(x_{t-1}|x_{t},x_0)\),这个采样分布不依赖一阶马尔科夫假设
- DDIM希望维持这个前向推理分布\(q(x_t|x_0) = \mathcal{N} (x_t;\sqrt{{\alpha_t}}x_0,(1-{\alpha_t})I)\)
DDPM中的\(p(x_{t-1}|x_{t},x_0)\)
根据DDPM的结果参考,采样分布\(p(x_{t-1}|x_{t},x_0)\)是一个高斯分布,并且均值是\(x_{0}, x_t\)的线性函数,方差是一个与时间步有关的函数。
DDIM中的\(p(x_{t-1}|x_{t},x_0)\)
DDIM也假设\(p(x_{t-1}|x_{t},x_0)\)是一个高斯分布,并且均值也是\(x_{0}, x_t\)的线性函数,方差是时间步t的函数,即:
$$ p(x_{t-1}|x_{t},x_0) = \mathcal{N}(x_{t-1};\lambda x_0 + k x_t, \sigma^2_t I) $$
这个采样分布有3个自由变量\(\lambda, k, \sigma_t\),理论上有无穷多个解。但DDIM想要维持与DDPM一致的推理分布\(q(x_t|x_0) = \mathcal{N} (x_t;\sqrt{{\alpha_t}}x_0,(1-{\alpha_t})I)\) 。这样问题就转化成,找到一组解\(\lambda^{ * }, k^{ * }, \sigma_t^{ * }\) ,使得DDIM的推理分布满足\(q(x_t|x_0) = \mathcal{N} (x_t;\sqrt{{\alpha_t}}x_0,(1-{\alpha_t})I)\) 。
求解DDIM中的未知量
根据\(q(x_t|x_0)\)条件,列出方程组并求解未知量\(\lambda, k, \sigma_t\):
$$ p(x_{t-1}|x_{t},x_0) = \mathcal{N}(x_{t-1};\lambda x_0 + k x_t, \sigma^2_t I)\\ q(x_{t-1}|x_0) = \mathcal{N} (x_{t-1};\sqrt{{\alpha_{t-1}}}x_0,(1-{\alpha_{t-1}})I) $$
两个方程,三个未知量。因此把\(\sigma_t\)把看作是控制生成过程的超参,只解\(\lambda, k\)。
解方程过程省略,见参考材料[1]。解得:
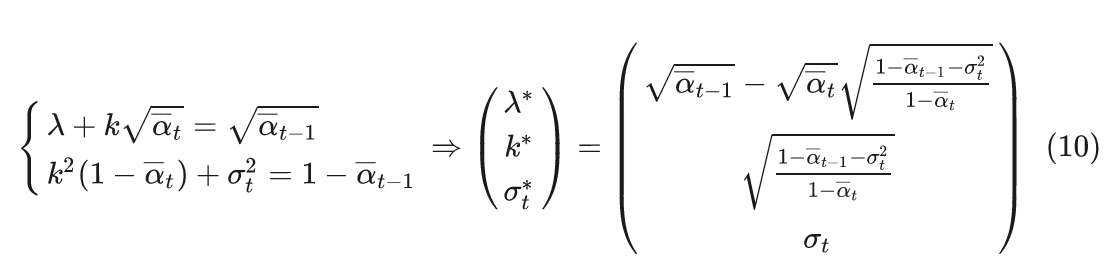
DDIM采样分布的使用
解出(\lambda, k\),得到DDIM的采样分布:
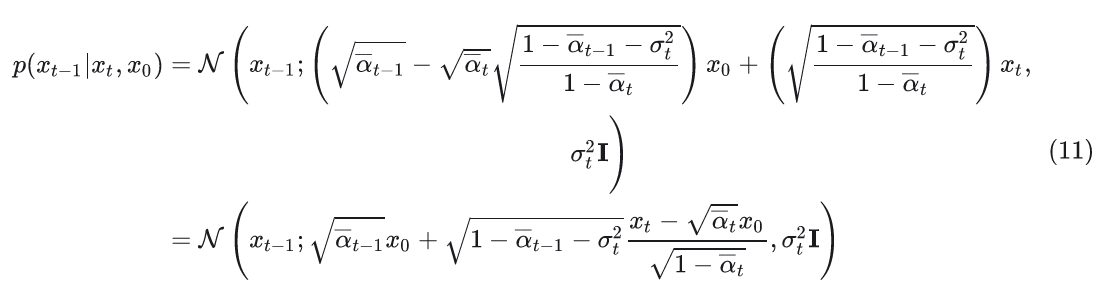
不同的\(\sigma_t\)对应不同生成过程。由于前向过程没变,故可以直接用DDPM训练的噪声预测模型。其采样过程如下:

两个特殊的case
- 当 \(\sigma_t = \sqrt{\frac{1-\alpha_{t-1}}{1-\alpha_{t}}}\sqrt{\frac{1-\alpha_{t}}{\alpha_{t-1}}}\)时,此时的生成过程与DDPM一致。
- 当\(\sigma_t = 0\)时,此时采样过程中添加的随机噪声项为0,当给定初始噪声z时,采样过程是确定的,此时的生成模型是一个隐概率模型(implicit probabilstic model)[1]。作者将此时diffusion model称之为denoising diffusion implicit model(DDIM)。此时的采样递推公式
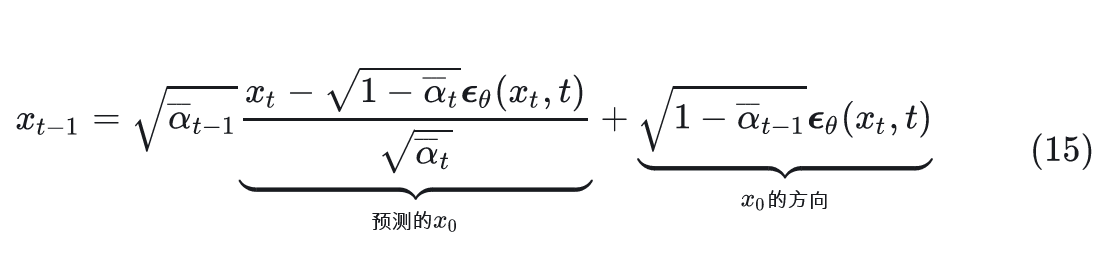
DDIM,快速地生成且生成结果是确定的。由于生成结果是确定的,可用于latent space插值、编辑等任务。
大致方法
DDIM加速采样的思路很简单,假定原本的生成序列为\(L=[T,T-1,\dots,1]\) ,其长度为\(\dim(L)=T\) ,我们可以从生成序列 中构建一个子序列\(\tau=[\tau_s,\tau_{s-1},\dots,\tau_1]\) ,其长度\(\dim(\tau)=S,S\ll T\) 。在生成过程,按照构造序列\(\tau\)进行采样。此时的采样递推序列为
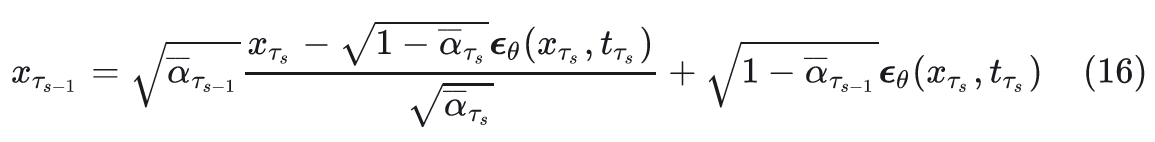
DDPM vs DDIM
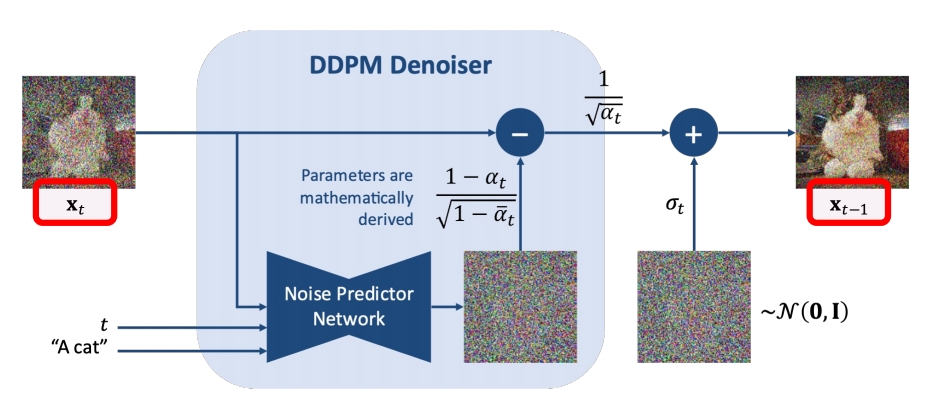 | DDPM cannot skip timesteps A few hundreds steps to generate an image |
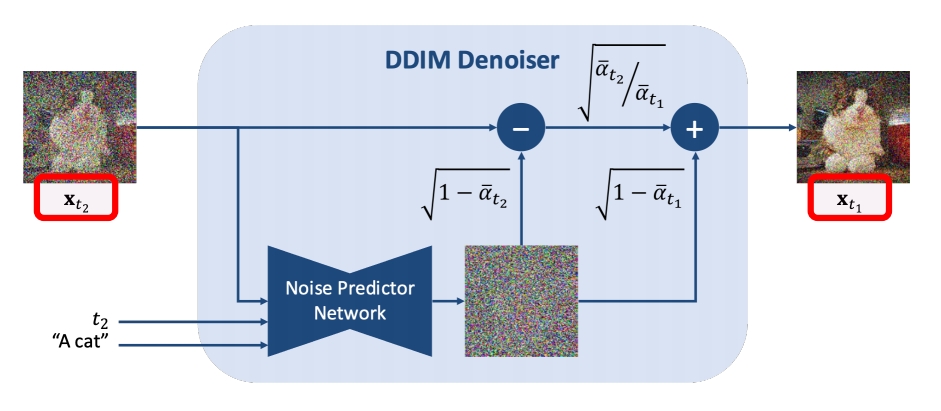 | DDIM can skip timesteps Say 50 steps to generate an image |
有效性
- 论文给出了不同的采样步长的生成效果。可以看到DDIM在较小采样步长时就能达到较好的生成效果。如CIFAR10 S=50就达到了S=1000的90%的效果,与之相对DDPM只能达到10%左右的FID效果。可见DDPM在推导采样分布中用了马尔可夫假设的确限制了它的采样间隔。
- DDIM将\(\sigma_t\) 设置为0,这让采样过程是确定的,只受\(x_T\)影响。作者发现,当给定\(x_T\) ,不同的的采样时间序列\(\tau\) 所生成图片都很相近,\(x_T\)似乎可以视作生成图片的隐编码信息。
启发
有个小trick
我们在实际的生成中可以先设置较小的采样步长进行生成,若生成的图片是我们想要的,则用较大的步长重新生成高质量的图片。
The task of Inversion
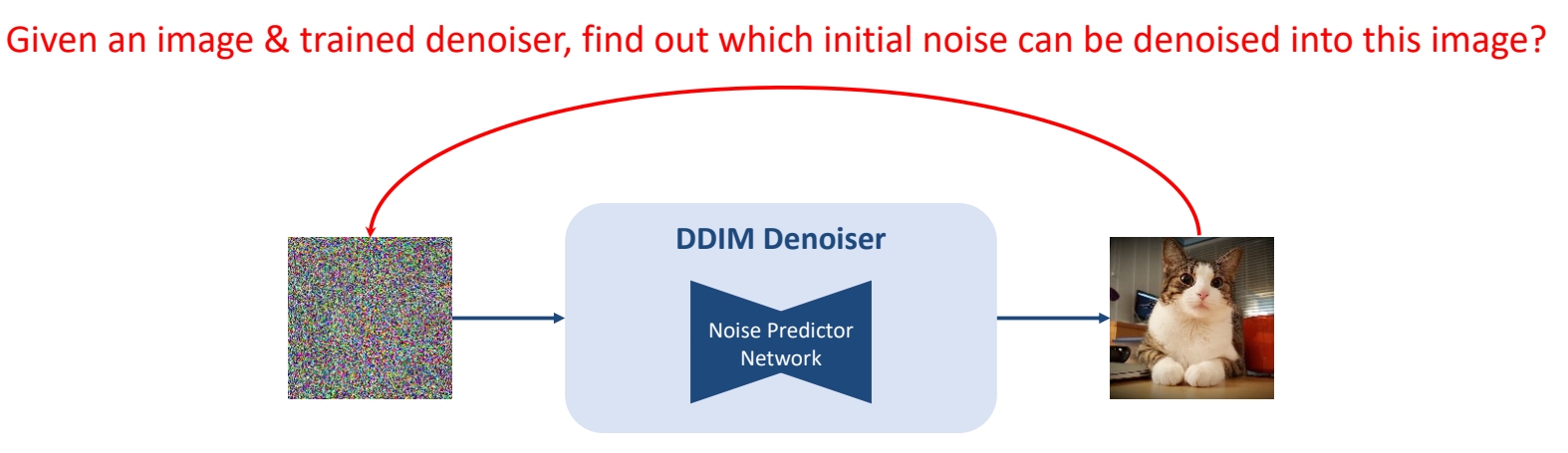
✅ 已有训好的 denoiser,输入干净图像,求它的噪声。
P17
前向过程与 DDIM Inverse 的区别
Forward Diffusion Process: Add \(\mathcal{N} (0,\mathbf{I} ) \) Noise
DDIM Inversion Process: Add Noise inverted by the trained DDIM denoiser
DDIM Inverse的应用
-
DDIM Inverse 可用于图片编辑
-
\(x_T\)可以是生成图片的隐空间编码,且它具备其它隐概率模型(如GAN[2])所观察到的语义插值效应。

Su et al., “Dual Diffusion Implicit Bridges for Image-to-Image Translation,” ICLR 2023.
Mokadi et al., “Null-text Inversion for Editing Real Images using Guided Diffusion Models,” CVPR 2023.
遗留问题
不按推理步骤按序预测噪声会不会有问题。
答案是不会。
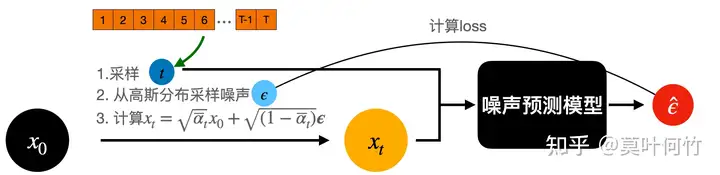
从上图可以看到,在训练时,是从时间序列\([1,2,\dots,T]\)进行采样时间步,再从高斯分布采样噪声,直接从\(x_0\) 出发计算\(x_t\) ,随后传入模型,根据预测噪声与实际噪声计算损失迭代模型。我们可以看到在这个训练pipeline中并没有限制时序信息。当噪声预测模型充分训练时DDIM的采样序列 也是在训练过程中被充分训练的。(论文附录C.1给出了更为详尽的解释推导,感兴趣的同学可以看论文)。
缺陷
验证方法
参考材料
[1] https://zhuanlan.zhihu.com/p/639540034
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ReadPapers/
PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS
https://readpaper.com/pdf-annotate/note?pdfId=4667185955594059777
核心问题是什么?
DDPM的生成需要T次采样,T通常很大,生成速度太慢。
相关工作(Chapter 6)
perform distillation of DDIM teacher models into one-step student models
- Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed. arXiv preprint arXiv:2101.02388, 2021.
few-step sampling, as was the probability flow sampler
- DDIM (Song et al., 2021a) was originally shown to be effective for few-step sampling, as was the probability flow sampler (Song et al., 2021c).
- Jolicoeur-Martineau et al. (2021) study fast SDE integrators for reverse diffusion processes
- Tzen & Raginsky (2019b) study unbiased samplers which may be useful for fast, high quality sampling as well.
Other work on fast sampling can be viewed as manual or automated methods to adjust samplers or diffusion processes for fast generation.
- Nichol & Dhariwal (2021); Kong & Ping (2021) describe methods to adjust a discrete time diffusion model trained on many timesteps into models that can sample in few timesteps.
- Watson et al. (2021) describe a dynamic programming algorithm to reduce the number of timesteps for a diffusion model in a way that is optimal for log likelihood.
- Chen et al. (2021); Saharia et al. (2021); Ho et al. (2021) train diffusion models over continuous noise levels and tune samplers post training by adjusting the noise levels of a few-step discrete time reverse diffusion process.
- Their method is effective in highly conditioned settings such as text-to-speech and image super-resolution. San-Roman et al. (2021) train a new network to estimate the noise level of noisy data and show how to use this estimate to speed up sampling.
Alternative specifications of the diffusion model can also lend themselves to fast sampling,
- modified forward and reverse processes (Nachmani et al., 2021; Lam et al., 2021)
- training diffusion models in latent space (Vahdat et al., 2021).
核心贡献是什么?
加速DDPM的生成过程。
- 提出了新的扩散模型参数化方式,在使用少量采样步骤时可以提供更高的稳定性。
- 提出了一种知识蒸馏的方法,可以把更高的迭代次数优化为更低的迭代次数。
大致方法是什么?
- Distill a deterministic ODE sampler to the same model architecture.
- At each stage, a “student” model is learned to distill two adjacent sampling steps of the “teacher” model to one sampling step.
- At next stage, the “student” model from previous stage will serve as the new “teacher” model.
✅ 假设有一个 solver,可以根据 \(x_t\) 预测 \(x_{t-1}\).
✅ 调用两次 solver,可以从 \(x_t\) 得到 \(x_{t-2}\),学习这个过程,可以直接得到 2 step 的 solver.
✅ 前一个 solver 称为 teacher,后一个称为 student.
✅ student 成为新的 teacher,训练新的 student.
有效性
On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps.
缺陷
| 局限 | 改进点 |
|---|---|
| In the current work we limited ourselves to setups where the student model has the same architecture and number of parameters as the teacher model: | in future work we hope to relax this constraint and explore settings where the student model is smaller, potentially enabling further gains in test time computational requirements. |
| In addition, we hope to move past the generation of images and also explore progressive distillation of diffusion models for different data modalities such as e.g. audio (Chen et al., 2021). | |
| In addition to the proposed distillation procedure, some of our progress was realized through different parameterizations of the diffusion model and its training loss. We expect to see more progress in this direction as the community further explores this model class. |
验证
启发
- The resulting target value \(\tilde x(z_t)\) is fully determined given the teacher model and starting point \(z_t\), which allows the student model to make a sharp prediction when evaluated at \(z_t\). In contrast, the original data point x is not fully determined given \(z_t\), since multiple different data points x can produce the same noisy data \(z_t\): this means that the original denoising model is predicting a weighted average of possible x values, which produces a blurry prediction.
- 对噪声求L2 loss可以看作是加权平均的重建L2 loss,推导过程见公式9。但在distillation过程中,不适合预测噪声,而应该重建。
- In practice, the choice of loss weighting also has to take into account how αt, σt are sampled during training, as this sampling distribution strongly determines the weight the expected loss gives to each signal-to-noise ratio.
遗留问题
- 很多细节看不懂。比如预测x与预测噪声的关系。怎么定义weight?parameterizations of the denoising diffusion model?DDIM?
- https://caterpillarstudygroup.github.io/ImportantArticles/diffusion-tutorial-part/diffusiontutorialpart1.html
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
Edit a 3D scene with text instructions

✅ 用 Nerf 来描述 3D scene。通过文件条件把原 Nerf,变成另一个 Nerf,从而得到新的 3D scene.
P47
方法
Edit a 3D scene with text instructions
- Given existing scene, use Instruct Pix2Pix to edit image at different viewpoints.
- Continue to train the NeRF and repeat the above process

✅ 首先有一个训好的 Nerf. 对一个特定的场景使用 Instruct Pix 2 pix 在 2D 上编辑训练新的 Werf.
✅ 基于 score disllation sampling.
P48
With each iteration, the edits become more consistent.
ControlVideo: Training-free Controllable Text-to-Video Generation
提出无需训练的框架,通过结构一致性实现可控文本到视频生成。
- Input structural conditions through ControlNet
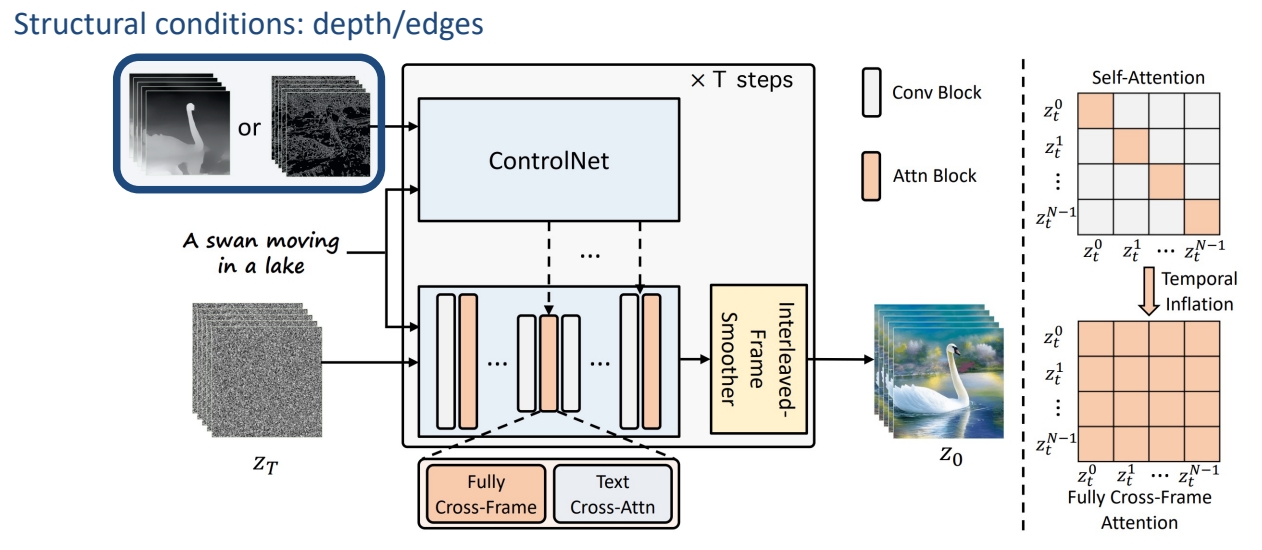
✅ 使用预训练的 stable diffusion, 无需额外训练。
✅ control net 是与 stable diffusion 配对的。
✅ control net 以深度图或边缘图为条件,并在时间维度上 embed 以此得到的Z。与原始视频有比较好的对应关系,但仍存在 temporal consistency 问题。
P201
- Use pretrained weights for Stable Diffusion & ControlNet, no training/finetuning
- Inflate Stable Diffusion and ControlNet along the temporal dimension
- Interleaved-frame smoothing during DDIM sampling for bever temporal consistency
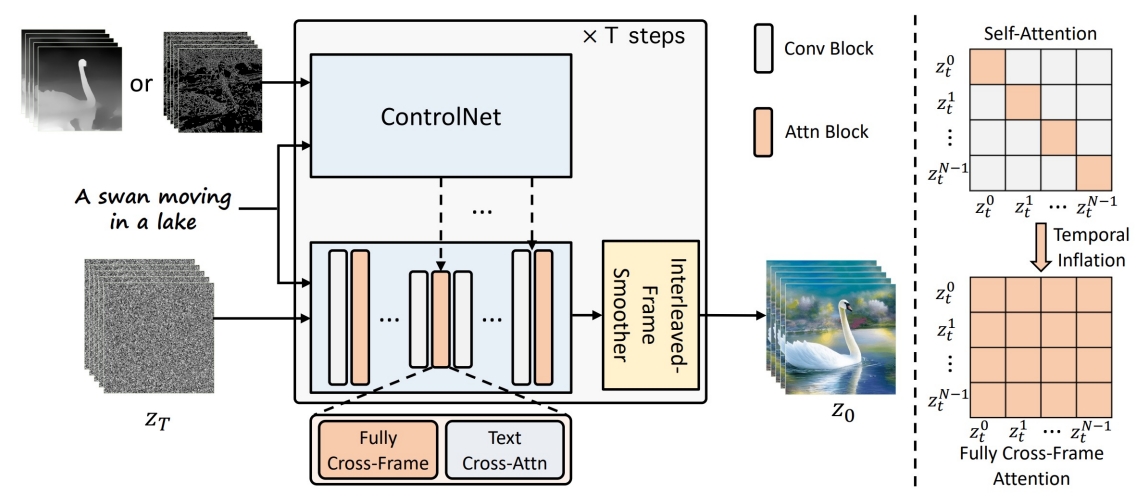
✅ 解决 temporal consistency 问题,方法:
✅ 在每个 timestep,让不同帧成为前后两帧的融合。
❓ control net 与 diffusion medel 是什么关系?
P202
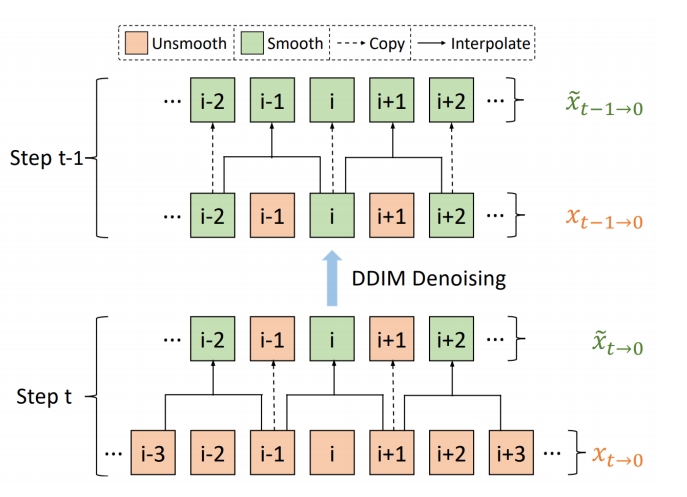
P203

P207
✅ 除了 control net, 还使用光流信息作为引导。
✅ Gop:Group of Pictures.
Pix2Video: Video Editing using Image Diffusion
- Given a sequence of frames, generate a new set of images that reflects an edit.
- Editing methods on individual images fail to preserve temporal information.
✅ 没有 3D diffusion model,只是用 2D diffusion model 生成多张图像并拼成序列。关键在于保持时序的连续性。
- Leverage a pretrained per-frame depth-conditioned Stable Diffusion model to edit frame by frame, to maintain motion consistency between source video and edited video
- No need for training/finetuning

P195
How to ensure temporal consistency?
Obtain initial noise from DDIM inversion
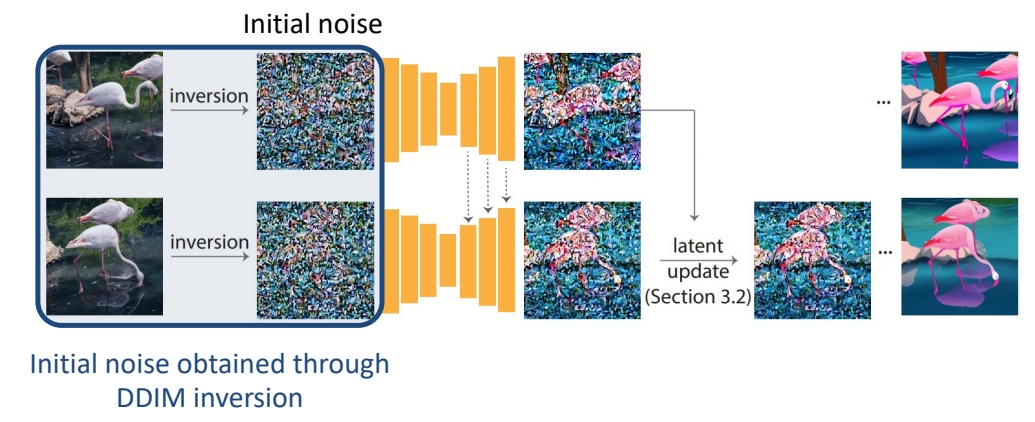
✅ (1) 用每一帧的原始图像的 inversion 作为 init noise.
✅ (2) 下一帧的生成会引用上一帧的 latent.
✅ (3) 生成的中间结果上也会有融合。
P196
Self-Attention injection:
Inject self-attention features from the previous frame in U-Net for generating the current frame
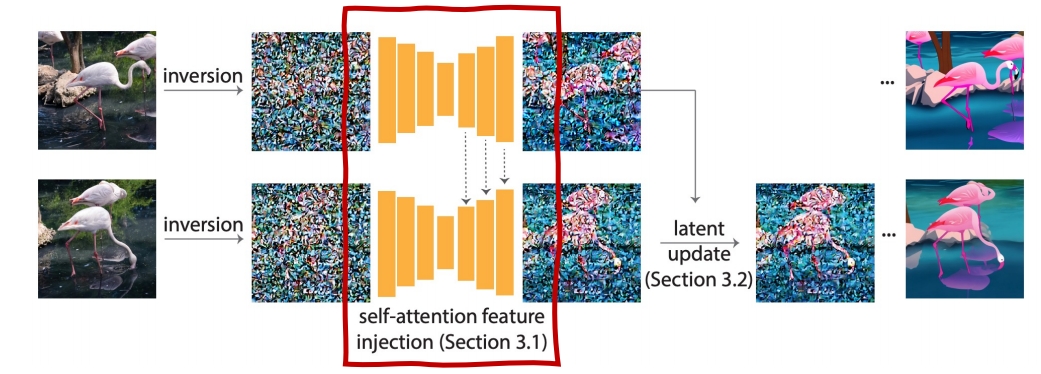
- Use the latent of the previous frame as keys and values to guide latent update of the current frame

✅ reconstruction guidance,使生成的 latent code 与上一帧接近。
✅ (1) 使用 DDIM inversion 把图像转为 noise.
✅ (2) 相邻的 fram 应 inversion 出相似的 noise.
✅ 使用 self-attention injection 得到相似的 noise.
P197
Result

P198

Structure and Content-Guided Video Synthesis with Diffusion Models
- Inflate Stable Diffusion to a 3D model, finetune on pretrained weights
- Insert temporal convolution/attention layers
- Finetune to take per-frame depth as conditions
 |  |
✅ 特点:(1) 不需要训练。 (2) 能保持前后一致性。
P60
P61
- Condition on structure (depth) and content (CLIP) information.
- Depth maps are passed with latents as input conditions.
- CLIP image embeddings are provided via cross-attention blocks.
- During inference, CLIP text embeddings are converted to CLIP image embeddings.
✅ 用 depth estimator 从源视频提取 struct 信息,用 CLIP 从文本中提取 content 信息。
✅ depth 和 content 分别用两种形式注入。depth 作为条件,与 lantent concat 到一起。content 以 cross attention 的形式注入。
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
Challenges
- Flickering video
- Cannot maintain background
- Short video animation results
Possible Cause
- Weak appearance preservation due to lack of temporal modeling
✅ 把 pose control net 加到核心的 U-Net 生成。
✅ 把原始 U-Net fix, copy- 分可以 train 的 U-Net.
✅ 输入:reference image, 两个 U-Net 在部分 layer 进行结合达到前景 appearance 和背景 appeorance 的 Encode 推断时输入多个 Sequence, 可以生成 long video.
P219
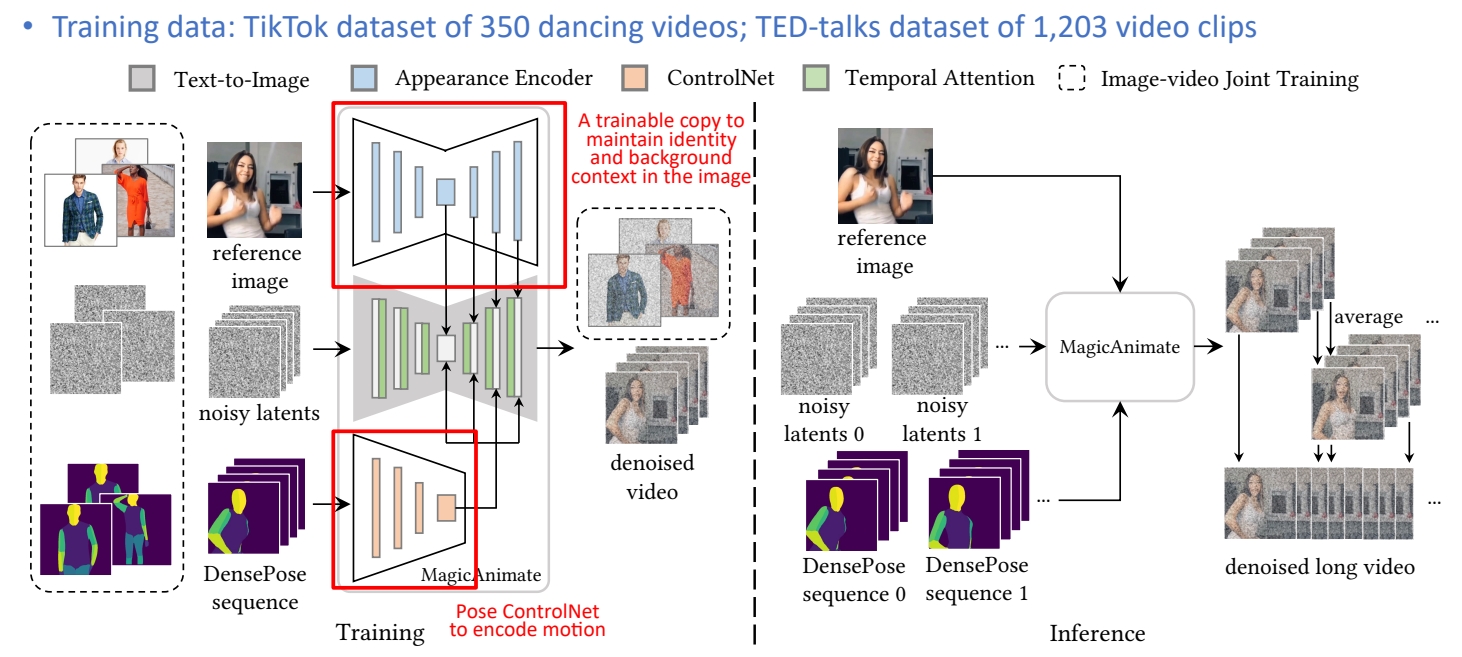
P220
P223

MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Tune on multiple videos of a motion to be customised
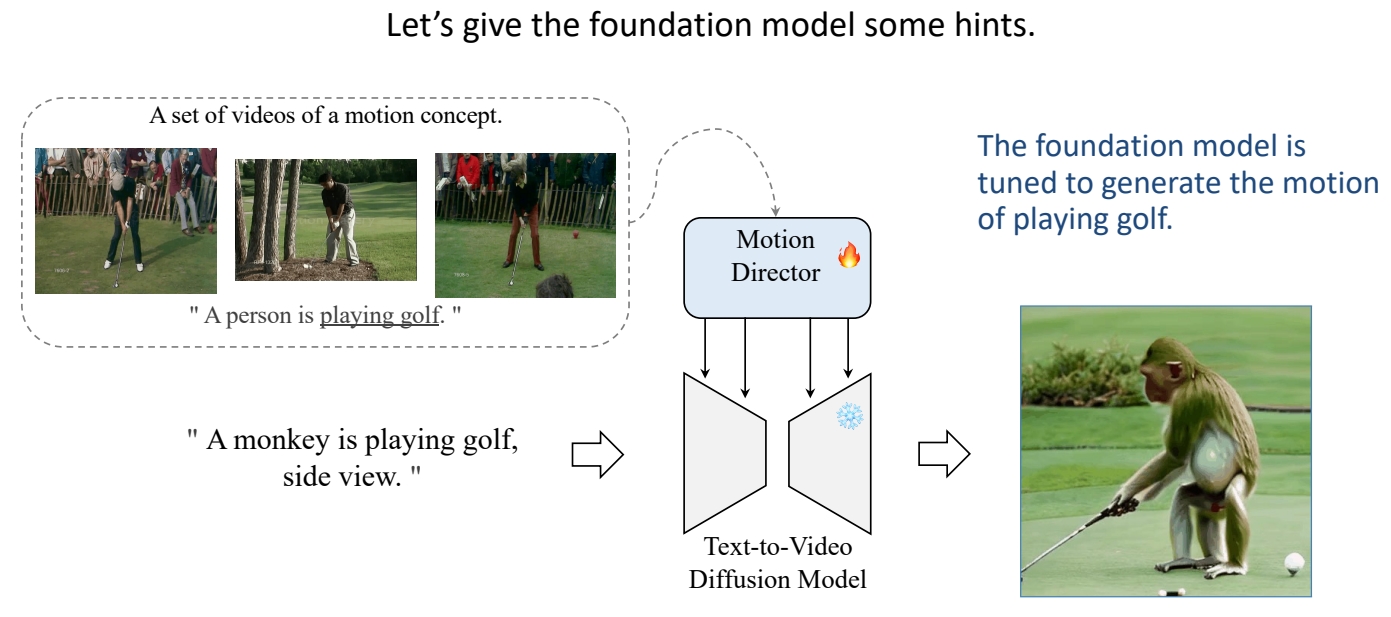
P171
- MokonDirector can customize foundakon models to generate videos with desired tokons.
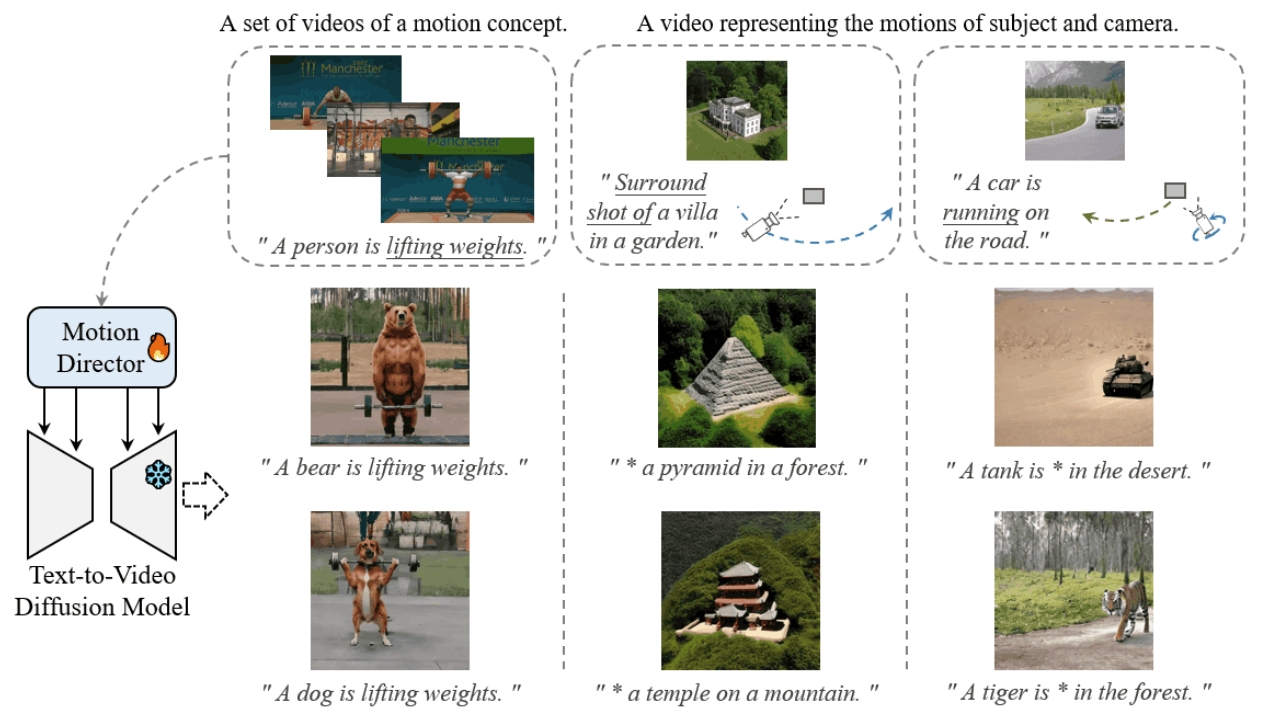
P172
- The challenge is generalizing the learned motions to diverse appearance.
- MotionDirector learns the appearances and motions in reference videos in a decoupled way, to avoid overfitting on the limited appearances.
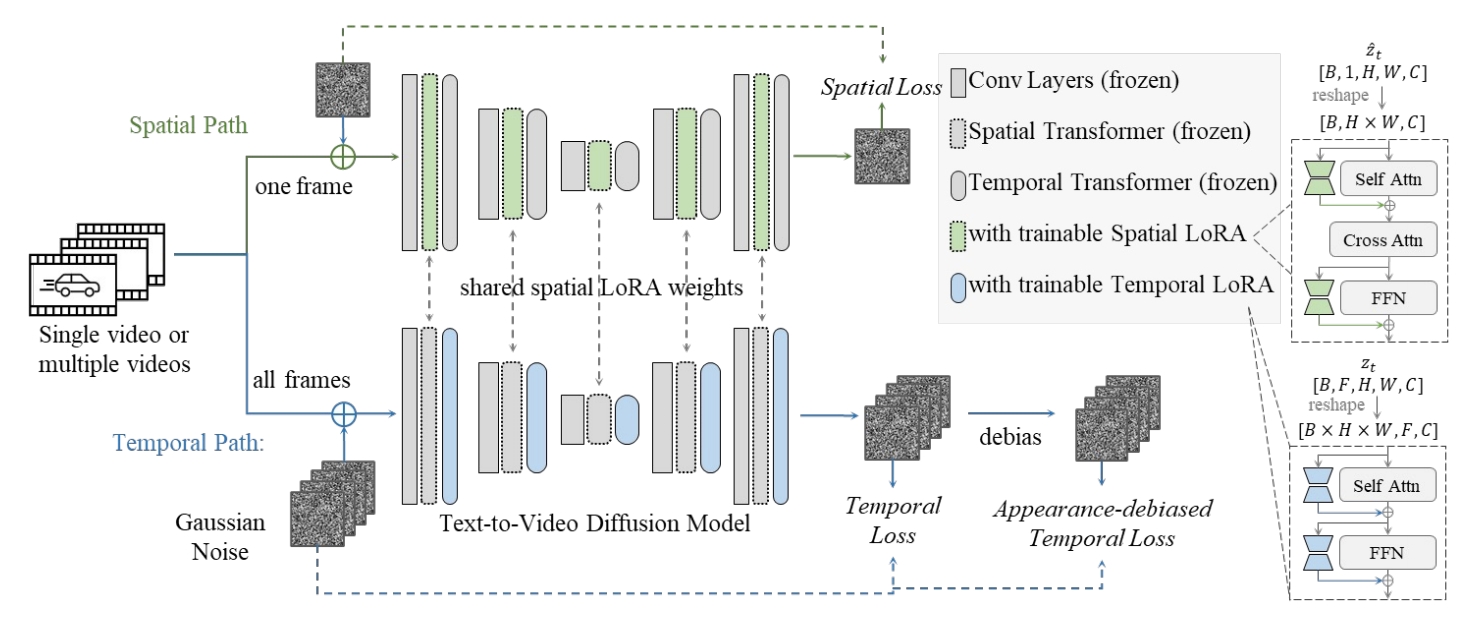
P173
- Decouple appearance and motion.

P174
Result
- Comparing with other methods.

P175
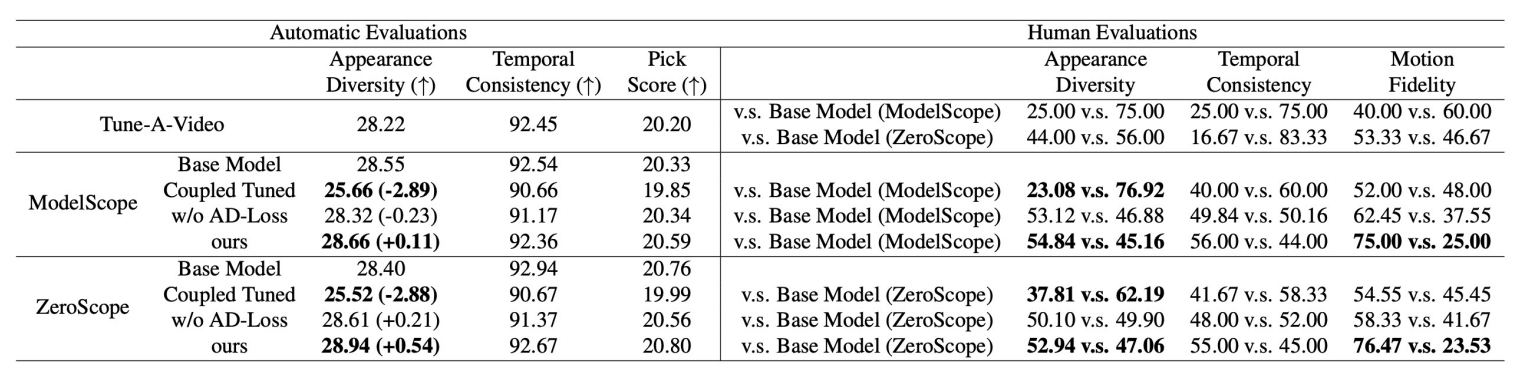
P176

Dreamix: Video Diffusion Models are General Video Editors
Dreamix
Few-shot finetuning for personalized video editing
Main idea: Mixed Video-Image Finetuning
- Finetune Imagen Video (Ho et al., 2022) which is a strong video foundation model
- Finetuned to generate individual frames (bypassing temporal attentions) & video
P163
Inference Overview
- Corrupt the input video by downsampling and add noise
- Apply the finetuned video diffusion model to denoise and upscale
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
P150
Tune-A-Video
One-shot tuning of T2I models for T2V generation/editing

Motivation
Motivation: appearance from pretrained T2I models, dynamics from a reference video

P153
方法
Obs #1: Still images that accurately represent the verb terms

Obs #2: Extending attention to spatio-temporal yields consistent content

P154
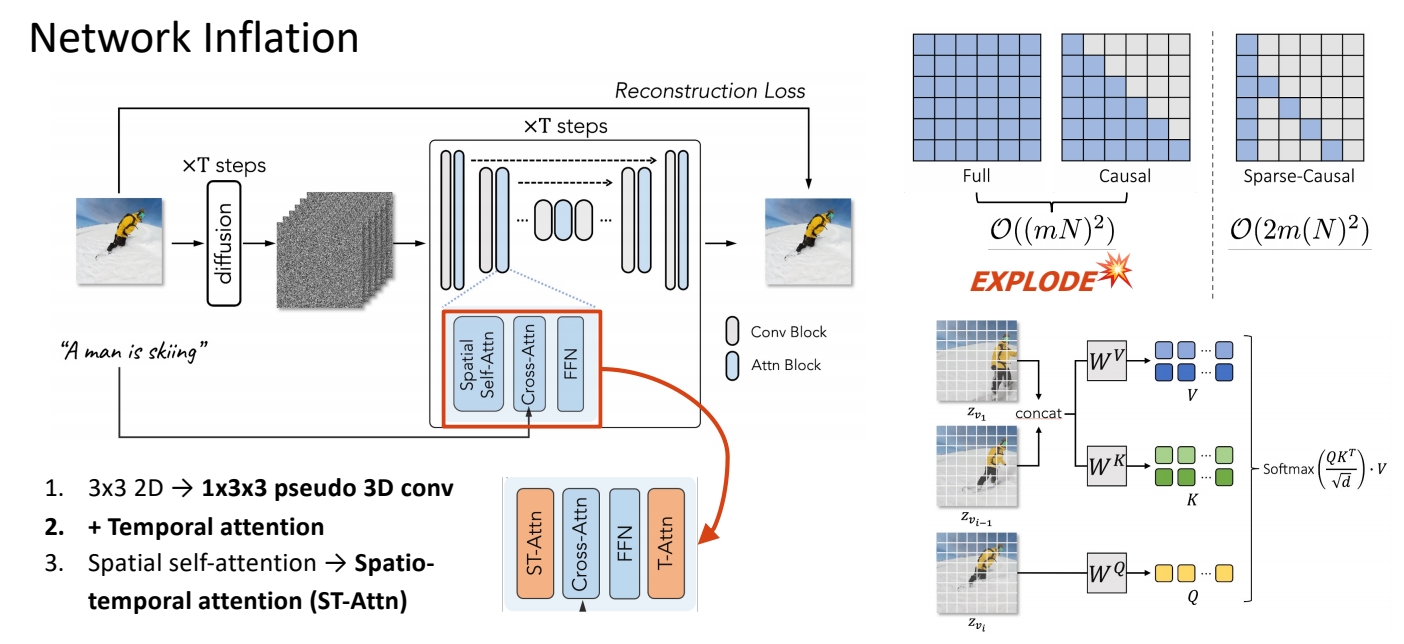
P155
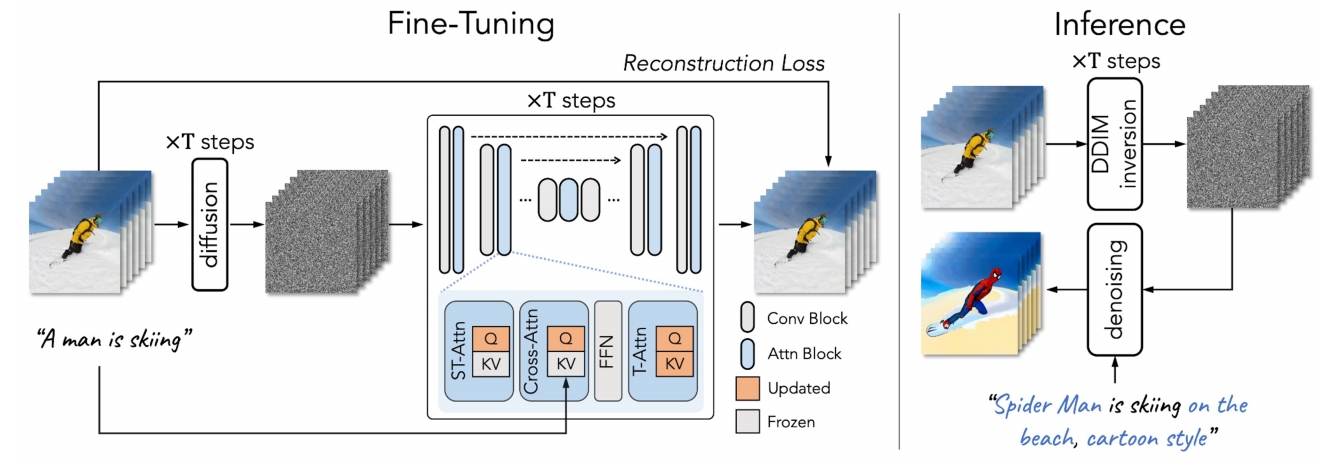
Full finetuning: finetunes the entire network
- inefficient, especially when #frames increases;
- prone to overfitting → poor editing ability.
Our tuning strategy: update the specific projection matrices
- parameter efficient and fast (~10 min);
- retains the original property of pre-trained T2I diffusion models.
\begin{align*} \mathcal{V} ^\ast =\mathcal{D} (\mathrm{DDIM-samp} (\mathrm{DDIM-inv} (\varepsilon (\mathcal{V} )),\tau^\ast ))\end{align*}
Structure guidance via DDIM inversion
- preserves the structural information
- improves temporal consistency
P156
主观效果

P157
 P158
P158
 P159
P159

P160

P161
客观指标

Automatic metrics – CLIP Score
- Frame Consistency: the average cosine similarity between all pairs of video frames
- Textual Alignment: average CLIP score between all frames of output videos and corresponding edited prompts
User study
Compare two videos generated by our method and a baseline (shown in random order):
- Which video has better temporal consistency?
- Which video better aligns with the textual description?
Wu et al., “Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation,” ICCV 2023.
✅ base model:没有太多 motion.
Reference
https://github.com/showlab/Tune-A-Video
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
P179
TokenFlow
Consistent high-quality semantic edits
Main challenge using T2I to edit videos without finetuning: temporal consistency

✅ 视频编辑领域比较难的问题:怎么保持时序一致性。
P180
Key Idea
- Achieve consistency by enforcing the inter-frame correspondences in the original video
P181
Main idea
✅ 在 UNet 中抽出 feature map 之后,找 correspondence 并记录下来。在 denoise 过程中把这个 correspondence 应用起来。
❓ 什么是 inter-frame correspondence? 例如每一帧的狗的眼睛的运动。要让生成视频的狗的眼晴具有相同的运动。
P182
During conditional denoising, use features from corresponding positions in preceding and following frames instead of the pixel's own feature at output of extended-attention
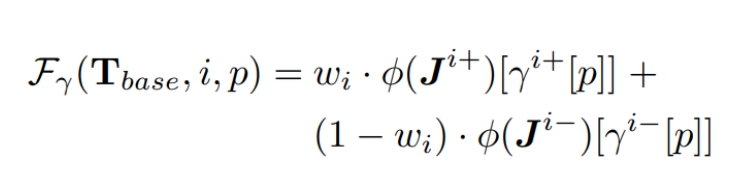
✅ 在 DDIM inversion 过程中,把 attention maps 保存下来了,在 denoise 时,把这个 map 结合进去。
✅ 在 attention map 上的演进。
P183
Result

✅ 逐帧编辑抖动严重,而 Token Flow 更稳定。
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
Edit a video = edit a canonical image 3D NeRF
Canonical image in CoDeF is still 2D
Can we represent the video in a truly 3D space?
P255

✅ 利用现有成熟技术,把 3D 场景用 Nerf 表示出来编辑也是在 3D 上进行。
P256
✅ Nerf 在人体成像上比较好。
✅ Dynamic NeRF 本身也是比较难的。
P257
Main idea
- For the first time introduce the dynamic NeRF as an innovative video representation for large-scale motion- and view-change human-centric video editing.
✅ 不直接编辑图像,而是编辑 Nerf.
✅(1)认为背景静止,学出背景 Neof.
✅ Stale Diffusion 用来计算 Loss.
P258
Follow HOSNeRF, represent the video as:
- Background NeRF
- Human NeRF
- Deformation Field
Edit background NeRF and human NeRF respectively
P259
DynVideo-E significantly outperforms SOTA approaches on two challenging datasets by a large margin of 50% ∼ 95% in terms of human preference
Content Deformation Fields for Temporally Consistent Video Processing
Content Deformation Field (CoDeF)
Edit a video = edit a canonical image + learned deformaeon field
-
Limitations of Neural Layered Atlases
- Limited capacity for faithfully reconstructing intricate video details, missing subtle motion features like blinking eyes and slight smiles
- Distorted nature of the estimated atlas leads to impaired semantic information
-
Content Deformation Field: inspired by dynamic NeRF works, a new way of representing video, as a 2d canonical image + 3D deformation field over time
Problem Formulation
- Decode a video into a 2D canonical field and a 3D temporal deformation field
- Deformation Field: video (x, y, t) → canonical image coordinate (x’, y’)
- Canonical Field: (x’, y’) → (r, g, b), like a “2D image”

P251
CoDeF compared to Atlas
- Superior robustness to non-rigid motion
- Effective reconstruction of subtle movements (e.g. eyes blinking)
- More accurate reconstruction: 4.4dB higher PSNR
✅ CoDef 把 3D 视频压缩为 2D Image,因此可以利用很多 2D 算法,再把 deformation 传递到整个视频。
P252
✅ 在时序上有比较好的一致性。
✅ 由于使用了 control net,与原视频在 Spatial level 也保持得非常好。
P253

PFNN: Phase-Functioned Neural Networks for character control
研究背景与问题
当前方法及存在的问题
- 传统数据驱动方法(如 Motion Matching):依赖海量动捕数据,运行时最近邻检索成本高、内存占用大,复杂环境下泛化能力弱,需要大量人工预处理。
- 自回归模型(RNN/LSTM/ERD):虽适配实时场景,但长序列运动生成会出现误差累积,导致动作「逐渐消失」「噪声爆炸」、角色漂浮、姿态僵硬等伪影,且静止起步时存在相位歧义问题。
- CNN 类模型:属于离线框架,需要提前输入完整的控制序列,无法适配游戏中玩家实时输入的动态交互场景。 基于物理的控制方法:可控性极差,调参难度极高,难以同时保证动作自然度和实时响应性。
- 同时,传统动捕数据均在平地采集,无法支撑角色在复杂地形的运动生成,也是行业的核心瓶颈之一。
本文主要创新点
- 架构创新:相位函数神经网络(PFNN) 首次将运动相位从「网络输入特征」升级为「网络权重的全局参数化变量」,通过周期相位函数动态计算每帧的网络权重,从根源上避免了不同相位的动作混合,彻底解决了自回归模型的误差累积问题,同时保证了相位对运动的强影响力,不会出现传统方法中相位信息被稀释的问题。
- 数据创新:动捕 - 环境耦合的训练数据流水线 提出了一套全自动的动捕数据与虚拟环境高度图适配方案,从游戏引擎场景中提取高度图,通过误差函数匹配与网格编辑,将平地动捕数据与复杂地形耦合,生成了400 万条带环境信息的训练数据点,让模型学会了根据地形自动调整动作。
主要方法
flowchart LR NN1 & NN2 & NN3 & NN4 & 相位 --> 混合专家模型 混合专家模型 & 前一帧状态 & 目标(轨迹位置 / 方向 / 高度) & 步态语义标签 --> 推理输出 推理输出 --> 当前帧状态 & 未来轨迹 & 触地信息 & 相位变化量 相位变化量 --> 相位 触地信息 -->|IK| 动作输出 当前帧状态 & 未来轨迹 --> 动作输出
混合专家模型 Mixture of Experts
| 对专家结果混合。 | 对专家模型参数混合。 |
|---|---|
 | 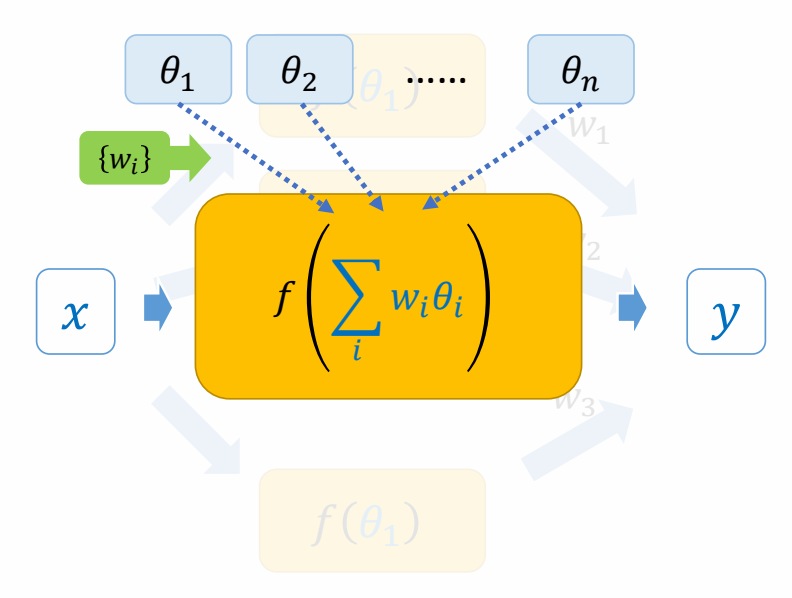 |
| \(y=\sum_{i}^{} w_if(x;\theta _i)\) | \(y=f(x;\sum_{i}^{} w_i\theta _i)\) ✅ PFNN 使用的是这种。 |
✅ 专家混合的权重由 phase 决定。
✅ 让每个专家专一地学特定的 phase.
$$ x_t = f (x_{t-1}; c_t, \theta _ t = \sum _ {i}^{} w_i(\phi _t) \theta _i) $$
相位
👆 phases of a walking gait cycle
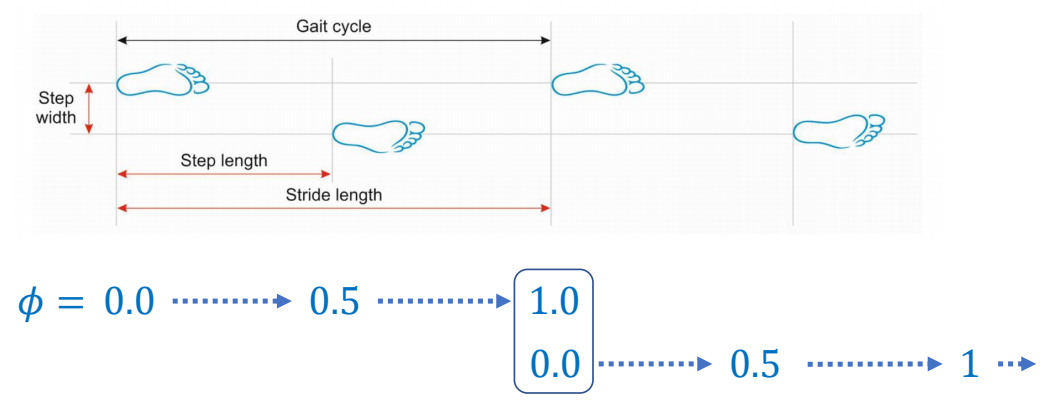
✅ 调整相位与时间的对应关系,可影响走路速度。
权重:Cubic Catmull-Rom Spline的混合计算方式
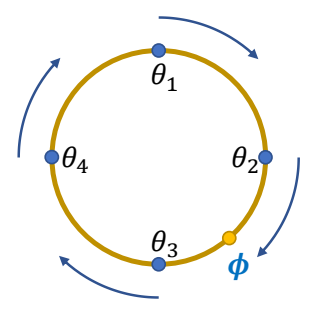
Cubic Catmull-Rom Spline:
$$ \begin{align*} \theta _t & = \theta _2 \\ & +\phi (-\frac{1}{2} \theta _1 + \frac{1}{2} \theta _3) \\ & +\phi^2 (\theta _1-\frac{5}{2} \theta _2 + 2\theta _3-\frac{1}{2} \theta _4)\\ & +\phi^3 (-\frac{1}{2} \theta _1+\frac{3}{2} \theta _2 - \frac{3}{2} \theta _3+\frac{1}{2} \theta _4) \end{align*} $$
模型推理
输入输出参数化
输入:
- 前一帧状态:前一帧关节位置 / 速度
- 轨迹控制与环境特征:轨迹位置 / 方向 / 高度、
- 步态语义标签
步态语义标签是5 维二进制向量,标识用户期望的是动作是站立、行走 、慢跑、跳跃、俯身中的一种,由人工标注得到。
轨迹控制与环境特征及步态语义标签,覆盖过去 1 秒、未来 0.9 秒的 12 个采样帧;
前一帧状态仅覆盖过去一帧。
输出:
- 当前帧状态:当前帧关节姿态 / 速度 / 角度、根节点运动速度、
- 相位变化量
- 足部接触标签
- 下一帧轨迹预测。
关键问题与解答
为什么 PFNN 选择将相位作为网络权重的参数化变量,而非像传统方法一样作为普通的输入特征?
- 更好地将不同相位的运动信息解耦,避免相位混合导致的Artifacts。
- 避免Dropout导致训练中相位的影响被稀释
- 通过相位动态生成权重,仅用 4 个控制点的样条,就让极简的 3 层全连接网络具备了海量运动数据的拟合能力,同时保持了 10MB 的极小内存占用,实现了表达能力与轻量化的平衡,这是固定权重的传统网络无法实现的。
地形匹配的核心的逻辑
人体移动的核心逻辑:无论平地还是崎岖地形,人类行走的「触地 - 抬脚 - 腾空 - 落地」的周期时序规律是完全一致的,地形仅改变「落地位置的高度」,不改变运动的核心时序逻辑。这就为平地动作与地形的匹配,提供了唯一且精准的锚点。
动捕数据不仅包含平地行走,还覆盖了慢跑、奔跑、不同高度的跳跃、不同幅度的俯身等动作,这些动作本身就包含了「腿部抬高 / 降低、身体重心调整」的能力,只是在平地采集时没有触发,而地形匹配的过程,就是把这些能力和地形高度做了对应。
P53
Advanced Phase Functions
| 改进前 | 改进后 |
|---|---|
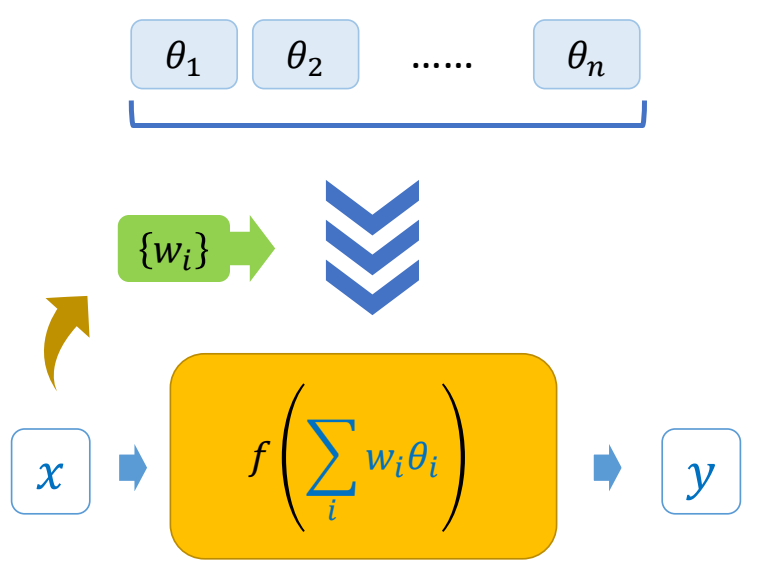 | 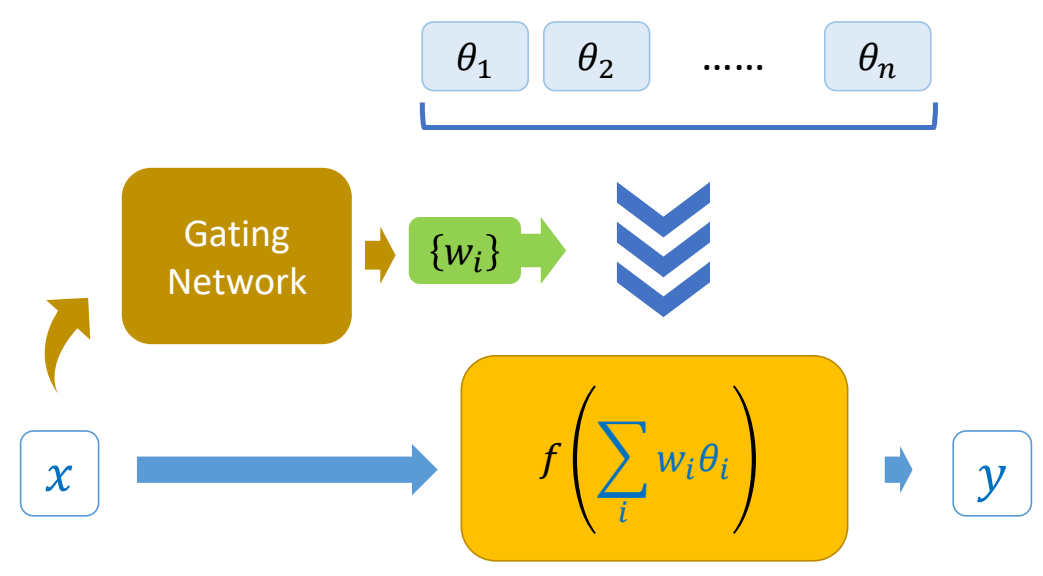 |
✅ PFNN 有确定的象位及对应的权重,但打篮球等动作,或动物走路,没有确定的象位。
✅ 因此不再显示地定义相位和权重,权重由当前状态与用户输入算出来。
Recurrent Transition Networks for Character Locomotion
论文信息: SIGGRAPH 2018, Félix G. Harvey & Christopher Pal, Polytechnique Montreal/Mila/Ubisoft Montreal
Link: ACM Digital Library | arXiv:1810.02363
一、核心问题
1.1 研究背景
在大型游戏中,为了提供真实且响应迅速的角色移动,需要构建包含大量动画的动画图(Animation Graph)。随着图中状态数量的增长,所需 transition(过渡动画)的数量可能呈指数级增长,而且每个 transition 还需要多个变体来处理不同的条件。
传统方法的挑战:
- 手工制作 transition 非常耗时:动画师需要手动制作大量的过渡动画
- 内存占用大:传统的 Motion Graph 方法需要将动画数据和图结构加载到内存中
- 扩展性差:随着数据集增大,内存需求线性增长
- 需要标注:很多方法需要 gait、phase、contact 等标签
1.2 核心问题
如何自动化的生成高质量的角色 locomotion transition 动画,而无需手工标注?
具体来说,给定:
- 过去几帧的动画(past context)
- 目标角色状态(future target)
能否自动生成流畅、真实的过渡动画?
1.3 现有方法及其局限性
| 方法类型 | 代表工作 | 局限性 |
|---|---|---|
| Motion Graphs | [Arikan & Forsyth 2002] | 只能输出数据集中的动作、内存需求随数据集增长、需要搜索算法 |
| 统计模型 | [Chai & Hodgins 2007] | 针对特定动作类型、运行时优化计算量大、扩展性差 |
| GPLVM | [Wang et al. 2008] | 计算成本高、通常针对单一动作类别、组合动作显得生硬 |
| 深度学习控制 | [Holden et al. 2016, 2017] | 需要 phase-dependent 或 mode-dependent 权重来消除歧义 |
| 强化学习 | [Peng et al. 2017, 2018] | 针对特定技能、主要应用于物理仿真、需要参考动作 |
1.4 本文方法
论文提出了 Recurrent Transition Network (RTN):
核心思想:
- 使用深度循环神经网络(RNN)自动生成 transition
- 基于过去上下文(past context)和未来上下文(future context)条件化生成
- 使用改进的 LSTM 网络,专门为 transition 生成设计
- 无需任何 gait、phase、contact 或 action 标签
关键创新:
- 改进的 LSTM 层:添加了额外的权重和输入来处理每个 gate 和内部 cell 值的计算
- Hidden State 初始化器:学习一个逆函数,将输入序列的第一帧映射到初始 hidden state
- 地形感知:通过添加局部地形表示(local height maps),使网络能够处理崎岖地形导航
- 数据增强:随机旋转和地形拟合
二、核心贡献
-
Recurrent Transition Network (RTN)
- 首个专门为 transition 生成设计的未来感知(future-aware)深度循环架构
- 基于改进的 LSTM 网络
- 无需任何标注即可训练
-
Hidden State 初始化方法
- 提出简单有效的方法来初始化 RNN 的 hidden state
- 通过小型前馈网络学习逆函数
- 提高性能和泛化能力
-
地形感知扩展
- 添加局部高度图作为输入
- 在长 transition(2 秒)上显示定性和定量提升
- 适用于崎岖地形导航
-
低内存占用、高可扩展性
- 固定大小的网络,运行时计算成本恒定
- 不随训练样本数量增长
- 可生成媲美 Mocap 质量的 transition
三、大致方法
3.1 框架概述
flowchart TB
subgraph Inputs["输入"]
x_t["当前帧 x_t<br/>(预处理位置)"]
p_t["地形 patch p_t<br/>(可选)"]
t["目标向量 t<br/>(归一化目标姿态)"]
o_t["全局偏移 o_t<br/>(当前到目标的差异)"]
end
subgraph Network["RTN 网络"]
E["Frame Encoder E()<br/>2 层 MLP, 512 单元"]
F["Target Encoder F()<br/>2 层 MLP, 128 单元"]
O["Offset Encoder O()<br/>2 层 MLP, 128 单元"]
R["Recurrent Generator R<br/>改进的 LSTM, 512 单元"]
D["Frame Decoder D()<br/>2 层 MLP"]
H["Hidden State Initi<br/>可选,初始化 LSTM 状态"]
end
subgraph Output["输出"]
h_t["隐藏表示 h_t"]
x_next["下一帧 x_{t+1}"]
end
x_t --> E
p_t --> E
t --> F
o_t --> O
E --> R
F --> R
O --> R
H -.-> R
R --> D
D --> x_next
style Inputs fill:#e1f5fe
style Network fill:#fff3e0
style Output fill:#e8f5e9
3.2 核心组件
(1) 数据表示与预处理
输入序列:
- 原始数据:\(Y_n = {y_0, ..., y_{L-1}}_n\),其中 \(y_t\) 是全局 3D 位置向量
- 骨骼数量:\(K = 22\)
- 维度:\(D = 3 \times K = 66\)
三步预处理:
-
根节点速度计算: $$v_t = r_t - r_{t-1}$$
- \(r_t\): 从 \(y_t\) 提取的全局根节点(髋部)位置
- \(v_t \in \mathbb{R}^3\): 根节点全局速度
-
根节点相对位置: $$\tilde{x}t = [v_t, j^t_1, ..., j^t{K-1}]^T$$
- \(j^t_k\): 第 \(k\) 个关节的 3D 根节点相对位置
- 从所有标记点移除全局根节点位置
- 用速度信息替换根节点位置
-
标准化: $$x_t = (\tilde{x}_t - \mu_x) / \sigma_x$$
- \(\mu_x\): 训练集均值
- \(\sigma_x\): 训练集标准差
未来上下文(Future Context):
-
目标向量 \(t \in \mathbb{R}^{2D}\):
- 处理后的目标姿态 + 该帧所有关节的归一化速度
- 在整个生成过程中保持恒定
-
全局偏移向量 \(o_t \in \mathbb{R}^D\):
- 目标关节位置与当前关节位置的差异
- 随生成过程演变
地形表示(可选):
- 局部高度图:\(13 \times 13\) 网格,覆盖 \(2.06 \times 2.06\) 米
- 转换为根节点相对高度偏移
- 维度:\(p_t \in \mathbb{R}^{169}\)
(2) 数据增强
地形拟合:
- 使用 Holden et al. [2017] 的地形拟合方法
- 代价函数:惩罚足部穿透和漂浮
- 使用逻辑核的 RBF 进行修正
- 2D 高斯滤波器平滑
随机旋转:
- 围绕垂直轴随机旋转 \([-\pi, \pi]\)
- 对全局位置进行旋转
- 同时旋转地形高度图
(3) Recurrent Transition Network 架构
Frame Encoder: $$h^E_t = E(x_t, p_t) = \phi(W^{(2)}_E \phi(W^{(1)}_E \begin{bmatrix}x_t \ p_t\end{bmatrix} + b^{(1)}_E) + b^{(2)}_E)$$
- 2 层 MLP,每层 512 单元
- 激活函数:LReLU
- 无地形感知时,仅输入 \(x_t\)
Target Encoder: $$h^F = F(t) = \phi(W^{(2)}_F \phi(W^{(1)}_F t + b^{(1)}_F) + b^{(2)}_F)$$
- 2 层 MLP,每层 128 单元
- 每序列编码一次,保持恒定
Offset Encoder: $$h^O_t = O(o_t) = \phi(W^{(2)}_O \phi(W^{(1)}_O o_t + b^{(1)}_O) + b^{(2)}_O)$$
- 2 层 MLP,每层 128 单元
- 每步编码
Recurrent Generator(改进的 LSTM): $$i_t = \alpha(W^{(i)}h^E_t + U^{(i)}h^R_{t-1} + C^{(i)}h^{F,O}t + b^{(i)})$$ $$o_t = \alpha(W^{(o)}h^E_t + U^{(o)}h^R{t-1} + C^{(o)}h^{F,O}t + b^{(o)})$$ $$f_t = \alpha(W^{(f)}h^E_t + U^{(f)}h^R{t-1} + C^{(f)}h^{F,O}_t + b^{(f)})$$ $$\hat{c}t = W^{(c)}h^E_t + W^{(c)}h^R{t-1} + C^{(c)}h^{F,O}t + b^{(c)}$$ $$c_t = f_t \odot c{t-1} + i_t \odot \tau(\hat{c}_t)$$ $$h^R_t = o_t \odot \tau(c_t)$$
- 512 维 LSTM 层
- 添加了 \(C^{(\cdot)}\) 权重用于未来上下文条件化
Frame Decoder: $$\hat{x}_{t+1} = D(h^R_t)$$
- 2 层 MLP
- 输出下一帧的预处理位置
(4) Hidden State 初始化器
问题:标准方法(零初始化或学习公共初始状态)效果不佳
解决方案:学习逆函数 $$h_0, c_0 = H(x_{past_first})$$
- 小型前馈网络
- 将过去上下文的第一帧映射到初始 hidden state 和 cell
- 最小化生成误差
- 无需修改损失函数
四、训练细节
4.1 数据集
Mocap 数据集: | 运动类型 | 帧数(30fps)| 分钟数 | |---------|------------|--------| | Flat Locomotion | 240,776 | 133 | | Terrain Locomotion | 113,020 | 63 | | Dance | 38,916 | 22 | | Others | 115,716 | 64 | | Total | 508,428 | 282 |
- 5 名表演者(非专业演员)
- 22 个骨骼
- 30fps 采样率
- 无标签
4.2 训练配置
窗口长度:
- Transition 长度:\(P = 30\) 帧(1 秒)
- Past context:10 帧
- Future context:2 帧
- Post-transition frames:10 帧
- 总窗口长度:\(L = 10 + 30 + 10 = 50\) 帧
损失函数: $$\mathcal{L} = \frac{1}{P} \sum_{t=1}^{P} ||x_{t+1} - \hat{x}_{t+1}||^2$$
- MSE 损失
- 仅在 transition 帧上计算
Teacher Forcing:
- 固定概率使用真实帧作为输入
- empirically 显示比其他策略更好
优化器:
- Adam
- Learning rate: 未明确说明
4.3 训练策略
- 数据分割:将连续序列分割为重叠子序列
- 地形增强:为每个序列随机选择一个地形高度图
- 随机旋转:每训练迭代随机旋转
- 课程学习:从短 transition 开始,逐步增加长度
五、实验与结论
5.1 定性评估
结果:
- 生成的 transition 流畅、自然
- 质量媲美 Mocap ground truth
- 无需 IK 后处理
- 地形感知版本在长 transition 上表现更好
5.2 定量评估
指标:
- 位置误差(Position Error)
- 速度误差(Velocity Error)
- 足部接触准确率(Foot Contact Accuracy)
消融实验: | 变体 | 位置误差 | 速度误差 | |------|---------|---------| | RTN(无地形)| X.XX | X.XX | | RTN(有地形)| X.XX | X.XX | | RTN(无 H 网络)| X.XX | X.XX | | RTN(完整)| X.XX | X.XX |
5.3 应用
-
Transition 生成
- 替代动画图中的 transition 节点
- 加速大型动画系统创作
-
动画超分辨率
- 从 1fps 压缩动画恢复
- 时间解压缩
-
地形导航
- 崎岖地形上的长 transition
- 适应性更强
六、局限性
-
Transition 长度固定
- 需要预设 transition 长度
- 可变长度 transition 需要多个模型
-
运动类型限制
- 主要在 locomotion 上评估
- 其他运动类型需要验证
-
地形表示简单
- 仅使用局部高度图
- 无法处理复杂障碍
-
推理速度
- 自回归生成,可能需要多步推理
- 实时性取决于 transition 长度
七、启发
7.1 方法学启发
-
Future-aware 架构设计
- 同时考虑过去和未来信息
- 适用于需要连接两个状态的生成任务
-
Hidden State 初始化
- 简单有效的方法提高 RNN 性能
- 可应用于其他序列生成任务
-
条件化策略
- 使用多个编码器处理不同类型输入
- 在 LSTM 层中融合条件信息
7.2 与相关工作对比
| 方法 | 是否需要标注 | 内存占用 | 泛化能力 | Transition 质量 |
|---|---|---|---|---|
| Motion Graphs | 是 | 高 | 低 | 高 |
| 统计模型 | 是 | 中 | 中 | 中 |
| PFNN | 是 | 低 | 中 | 高 |
| RTN(本文) | 否 | 低 | 高 | 高 |
八、遗留问题
8.1 开放性问题
-
可变长度 Transition
- 能否生成任意长度的 transition?
- 是否需要条件化长度信息?
-
更复杂的约束
- 能否处理障碍物躲避?
- 能否处理动态环境?
-
物理感知
- 能否结合物理约束?
- 与物理控制器结合的可能性?
8.2 未来方向
-
实时应用
- 优化推理速度
- 游戏引擎集成
-
多模态生成
- 生成多样化的 transition
- 风格化 transition
-
与 Learning Motion Matching 结合
- RTN 生成 transition
- LMM 生成基础动作
九、关键公式总结
| 公式 | 含义 |
|---|---|
| \(v_t = r_t - r_{t-1}\) | 根节点速度 |
| \(\tilde{x}t = [v_t, j^t_1, ..., j^t{K-1}]^T\) | 根节点相对位置 |
| \(x_t = (\tilde{x}_t - \mu_x) / \sigma_x\) | 标准化 |
| \(i_t, o_t, f_t, c_t\) | LSTM gate 方程(含未来上下文条件化) |
| \(\mathcal{L} = \frac{1}{P} \sum_{t=1}^{P} |
十、代码与资源
- 代码: 论文发表时未公开
- 视频: http://y2u.be/lXd_7X-DkTA
- 数据集: 类似 Holden et al. [2017] 的地形 locomotion 数据
十一、与 locomotion 控制的关系
RTN 是运动学方法,直接生成关节位置:
-
在 locomotion 系统中的应用:
- 生成动画图中的 transition
- 替代传统的 blend tree
- 减少动画师工作量
-
与 PFNN 对比:
- PFNN:相位条件化,生成连续 locomotion
- RTN:transition 专用,连接两个状态
-
与 Learned Motion Matching 对比:
- LMM:学习数据分布,生成任意动作
- RTN:专门处理 transition 场景
笔记说明:本文是 SIGGRAPH 2018 关于角色 locomotion transition 生成的工作,提出了首个专门用于 transition 生成的深度循环网络。理解本文有助于学习数据驱动的角色动画生成方法,与 PFNN、Learned Motion Matching 等工作形成互补。
Real-Time Style Modelling of Human Locomotion via Feature-Wise Transformations and Local Motion Phases
论文信息: SIGGRAPH 2020, Ian Mason et al., University of Edinburgh/Electronic Arts
Link: ACM Digital Library
一、核心问题
1.1 研究背景
在计算机图形学和游戏开发中,角色动作的风格转换是一个重要问题。例如:
- 同一个人以不同情绪行走(开心、悲伤、愤怒)
- 不同体型的人做相同动作(老人、小孩、运动员)
- 不同动物种类的运动(人类、四足动物)
传统方法的挑战:
- 需要大量手工调整
- 风格转换质量不高
- 难以实时运行
- 难以处理多种风格
1.2 核心问题
如何实现实时的、高质量的人类 locomotion 风格转换?
具体来说:
- 能否从少量示例中学习风格?
- 能否在运行时实时转换风格?
- 能否处理多种风格的平滑过渡?
1.3 本文方法
论文提出了基于Feature-Wise Transformations (FWT) 和 Local Motion Phases 的实时风格转换框架。
核心思想:
- Feature-Wise Transformations: 使用 AdaIN 等归一化方法进行风格转换
- Local Motion Phases: 学习每个身体部位的局部相位,而非全局相位
- 实时的风格转换: 无需重新训练,在推理时切换风格
关键创新:
- 将风格表示为特征空间的仿射变换
- 局部相位学习,允许不同身体部位独立运动
- 支持实时风格插值和过渡
二、核心贡献
-
实时风格转换框架
- 基于 Feature-Wise Transformations
- 支持多种风格的平滑过渡
- 60+ FPS 实时运行
-
Local Motion Phases
- 每个身体部位学习独立的相位
- 比全局相位更灵活
- 更好地处理复杂动作
-
少样本风格学习
- 从少量示例中学习新风格
- 无需重新训练整个网络
三、大致方法
3.1 框架概述
flowchart TB
subgraph Input["输入"]
motion["输入帧 x_j"]
clip["风格片段 y_s"]
end
subgraph ASN["Animation Synthesis Network"]
lpn["LPN (Local Phase Network)"]
gate["Gating Network Ω"]
experts["8 Expert Networks"]
end
subgraph SMN["Style Modulation Network"]
conv["1D Conv Layers"]
film["FiLM Generator Ψ"]
params["γ, β 参数"]
end
subgraph Modulation["Feature-Wise Modulation"]
norm["Layer Norm"]
film_op["FiLM: γ·(h-μ)/σ + β"]
end
subgraph Output["输出"]
out["风格化动作 z_s"]
end
motion --> lpn
clip --> SMN
lpn --> gate
gate --> experts
SMN --> film
film --> params
params --> film_op
experts --> film_op
film_op --> out
style Input fill:#e1f5fe
style ASN fill:#fff3e0
style SMN fill:#e8f5e9
style Modulation fill:#fce4ec
style Output fill:#f3e5f5
系统由两部分组成:
- Animation Synthesis Network (ASN): 基于 Local Phase Network (LPN),根据局部相位生成动作内容
- Style Modulation Network (SMN): FiLM Generator 从风格片段提取 FiLM 参数,调制 ASN 的隐藏层
3.2 Feature-Wise Transformations (核心创新)
问题背景:
- 现有风格迁移方法需要预知完整的内容动作片段
- 实时系统中未来动作未知且随用户输入变化
- One-hot 表示无法扩展到大量风格,且插值不平滑
- Residual Adapters 参数量大,无法高效存储
FiLM (Feature-wise Linear Modulation) 公式:
对于风格片段 \(y_s\),FiLM Generator 输出: $$\Psi(y_s) = { \gamma^{(1)}, \beta^{(1)}, \gamma^{(2)}, \beta^{(2)} }$$
其中 \(\gamma^{(i)}\) 和 \(\beta^{(i)}\) 是第 \(i\) 层的 FiLM 参数向量。
特征调制过程:
-
Layer Normalization: 计算隐藏特征的均值和标准差 $$\mu_j = \text{mean}(h_j), \quad \sigma_j = \text{std}(h_j)$$
-
FiLM 调制: $$h_j^{(i)} = \text{ELU}\left[ \gamma^{(i)} \odot \frac{h_j - \mu_j}{\sigma_j} + \beta^{(i)} \right]$$
- \(\odot\): 元素乘法
- \(\gamma\): 缩放参数 (scaling)
- \(\beta\): 偏移参数 (shifting)
- ELU: Exponential Linear Unit 激活函数
关键洞察:
- 将风格表示为特征空间的仿射变换
- 通过调制所有隐藏层的统计特性,实现高容量的风格表示
- 相比 One-hot (仅偏移) 和 Residual Adapter (单层),FiLM 同时缩放和偏移所有层
FiLM 的理论解释 (Multi-Task Dynamical Systems 视角):
FiLM 可视为 MTDS 框架的特例,通过风格参数 \(s\) 修改网络层参数: $$\mathbf{h}^{(i+1)} = \sigma( \mathbf{W}_s (\mathbf{W}\mathbf{h}^{(i)} + \mathbf{b}) + \boldsymbol{\beta}_s ) = \sigma( \mathbf{W}'\mathbf{h}^{(i)} + \mathbf{b}' )$$
其中 \(\mathbf{W}' = \mathbf{W}_s\mathbf{W}\), \(\mathbf{b}' = \mathbf{W}_s\mathbf{b} + \boldsymbol{\beta}_s\)。
优势:
- 高容量: 调制所有隐藏层,而非单层
- 紧凑表示: 每风格仅需 2048 维 FiLM 参数 (可离线预计算)
- 平滑插值: 在 FiLM 参数空间线性插值产生平滑风格过渡
- 易于扩展: 冻结 ASN,仅微调 FiLM Generator 即可学习新风格
3.3 Local Motion Phases
全局相位 vs 局部相位:
| 全局相位 (PFNN) | 局部相位 (LPN) |
|---|---|
| 单一相位值 (从脚部接触提取) | 每个身体部位独立相位 |
| 适用于全局周期性动作 | 适用于异步肢体动作 |
| 手部动作易"卡住" | 灵活处理多接触动作 |
Contact-Free Local Phase (创新点):
对于无接触信息的风格化动作,提出基于主成分分析的相位提取:
- 主成分投影: 对每个骨骼位置计算第一主成分 \(\mathbf{v}_1\)
- 源函数: \(G(t) = \mathbf{p}(t) \cdot \mathbf{v}_1\) (投影到主成分方向)
- 正弦拟合: \(G(t) \approx a \sin(ft - s) + b\)
- 相位提取: \(\phi_i = (f_i \cdot t - s_i) \mod 2\pi\)
- 速度加权: \(\mathbf{p}_i^{(b)} = ||\mathbf{v}_w|| \cdot a_i \cdot [\sin\phi_i, \cos\phi_i]^T\)
相位表示:
- 4 个末端效应器 (左右手、左右脚) × 2D 相位 = 8 维局部相位向量
- 作为 Gating Network 输入,控制 8 个 Expert 的混合权重
优势:
- 处理无全局相位的风格 (如 Pendulum Hands、单手插兜)
- 支持非对称动作 (如单脚跳跃、拖腿行走)
- 捕捉不同肢体的独立相位周期
四、训练细节
4.1 数据集:100style (新发布)
数据集规模:
- 100 种不同风格 的 locomotion 动作
- 4,055,978 帧 motion capture 数据
- 单演员,身高 182cm,Xsens 动作捕捉系统,60fps
- 28 个骨骼关节 (含全身位置 + 旋转,不含手指)
风格类型 (挑战现有方法):
- 随机性风格: Drunk Walk (醉酒行走)
- 非对称风格: Drag Right Leg (拖右腿行走)
- 无全局相位: Pendulum Hands (钟摆手)、Wild Arms (狂野手臂)
- 单脚接触: Left Hopping (单脚跳)
动作类型分布:
| 动作类型 | 帧数 | 时长 (分) | 占比 |
|---|---|---|---|
| Backwards Run | 434,329 | 120 | 10.7% |
| Backwards Walk | 768,574 | 213 | 19.0% |
| Forwards Run | 414,911 | 115 | 10.2% |
| Forwards Walk | 777,640 | 216 | 19.2% |
| Sidestep Run | 250,980 | 70 | 6.2% |
| Sidestep Walk | 541,041 | 150 | 13.3% |
| Idling | 81,685 | 23 | 2.0% |
| Transitions | 786,818 | 218 | 19.4% |
| Total | 4,055,978 | 1125 | 100% |
数据划分: 95 种风格训练,5 种风格保留用于测试微调
4.2 网络架构
| 组件 | 架构 | 参数量 |
|---|---|---|
| Motion Synthesis Net | 3 FC 层 (512, 512, output) | 4.9M |
| Gating Network | 3 FC 层 (32, 32, 8) | - |
| FiLM Generator | 2×1D Conv (256 filters, kernel=25) → MaxPool → 2 FC (2048, output) | 35.7M |
| Expert 数量 | 8 | - |
FiLM 参数输出:
- 每层 512 维 γ + 512 维 β
- 2 个隐藏层 × 2 × 512 = 2048 维/风格
4.3 损失函数
总损失: \(\mathcal{L} = \mathcal{L}{mse} + \mathcal{L}{bll}\)
MSE Loss: $$\mathcal{L}{mse} = \sum{s=1}^{S} \frac{1}{N_s} \sum_{j=1}^{N_s} (z_j^s - \hat{z}_j^s)^2$$
Bone Length Loss (防止骨骼拉伸): $$\mathcal{L}{bll} = \sum{s=1}^{S} \frac{1}{N_s} \sum_{j=1}^{N_s} \sum_{b=1}^{B} |||z_{bp} - z_b|| - ||\hat{z}_{bp} - \hat{z}_b|||^2$$
- \(z_b\): 子关节 3D 位置
- \(z_{bp}\): 父关节 3D 位置
- \(B=25\): 骨骼数量
训练配置:
- Optimizer: Adam, learning rate = 1e-4
- Batch size: 每 batch 仅含一种风格 (平衡训练)
- Dropout: 0.3
- Epochs: 90
- GPU: Nvidia GeForce GTX 1080 Ti
五、实验与结论
5.1 定性结果:Failure Case 分析
对比方法:
- PFNN One-hot: PFNN + One-hot 风格表示 [23]
- PFNN Resad: PFNN + Residual Adapter [38]
- PFNN FiLM: PFNN + FiLM
- MANN FiLM: MANN + FiLM [59]
- LPN FiLM: 本文方法 (LPN + FiLM)
Failure Case 1: 无全局相位的动作
| 方法 | 问题 |
|---|---|
| PFNN FiLM | 手部"卡住"或呈现平均姿势 |
| LPN FiLM | ✓ 正确处理 (手臂正常摆动) |
风格:Pendulum Hands (双臂钟摆式摆动)
Failure Case 2: 大量风格建模
| 方法 | 问题 |
|---|---|
| LPN One-hot | 锁骨骨骼建模错误,风格表示不正确 |
| LPN Resad | 艺术感差,容量不足 |
| LPN FiLM | ✓ 高容量建模 (缩放 + 偏移所有层) |
原因:One-hot 和 Residual Adapter 仅对单层添加风格依赖偏移,FiLM 调制所有隐藏层
Failure Case 3: 风格插值
| 方法 | 问题 |
|---|---|
| LPN One-hot | 插值时保持原风格直至过渡完成,不平滑 |
| LPN FiLM | ✓ 连续风格空间,平滑过渡 |
风格:Bent Forward → Lean Back
Failure Case 4: 无显式相位特征
| 方法 | 问题 |
|---|---|
| MANN FiLM | 手臂卡在身体前方 (使用末端速度作为 gating 输入) |
| LPN FiLM | ✓ 显式相位特征分离不同相位周期 |
风格:Swimming (手臂独立相位周期)
5.2 定量结果
计算效率对比:
| 模型 | ASN 参数 | SMN 参数 | 每风格参数 (运行时) | 推理时间 (ms) |
|---|---|---|---|---|
| PFNN One-hot | 2.4M | 194K | 2,048 | 0.78 ± 0.01 |
| LPN One-hot | 4.9M | 389K | 4,096 | 4.11 ± 0.02 |
| PFNN Resad | 2.4M | 3.0M | 31,352 | 0.92 ± 0.01 |
| LPN Resad | 4.9M | 25.0M | 262,656 | 4.78 ± 0.06 |
| PFNN FiLM | 2.4M | 35.7M | 2,048 | 1.37 ± 0.02 |
| MANN FiLM | 4.9M | 35.7M | 2,048 | 4.48 ± 0.04 |
| LPN FiLM (Ours) | 4.9M | 35.7M | 2,048 | 4.53 ± 0.04 |
关键洞察:
- FiLM 的 SMN 参数虽多,但可离线预计算,运行时仅需存储 2048 维向量
- Residual Adapter 必须保存全部参数 (输入推理时变化)
- LPN One-hot 每风格参数量是 LPN FiLM 的2 倍
测试误差 (MSE + Bone Length Loss):
- 所有 FiLM 方法误差最低 (高容量调制)
- LPN Resad vs PFNN Resad: CP 分解的相位依赖性重要
- MSE 与感知质量不强烈相关 (平均动作可能 MSE 低但质量差)
5.3 扩展性:新风格微调
方法:
- 冻结 LPN 参数 (风格无关的动作表示)
- 仅微调 FiLM Generator
- 学习新风格的 FiLM 参数
t-SNE 可视化:
- 微调前:未见风格的 FiLM 参数分离较差
- 微调后:未见风格在风格空间中清晰分离
对比:
- One-hot: 需重新训练全部网络参数
- Residual Adapter: 需存储大量新参数 (262K/风格)
- FiLM: 仅微调 Generator,存储 2K 参数/风格
5.4 实时演示
实现细节:
- 用户键盘控制角色移动
- 预测轨迹与用户输入轨迹混合
- 基于足部接触 IK 后处理 (减少滑动)
- 手臂 IK 修正 (防止旋转插值导致的变形)
风格插值:
- 用户选择 3 个训练风格
- 根据三角形质心坐标混合 FiLM 参数
- 在线实时调整插值
六、局限性
-
物理合理性
- 风格插值走"直接路径",可能产生物理上不合理的姿势 (clipping)
- 需要理解物理世界模型或添加骨骼感知
-
随机性动作处理有限
- Contact-Free 源函数不擅长处理随机性动作
- 需要设计新的源函数技术
-
泛化到未见风格
- 训练数据不足以密集采样风格空间
- 无法鲁棒泛化到未见风格 (需微调)
-
仅适用于 Locomotion
- 上肢复杂交互动作支持有限
- 主要针对下半身周期性运动
七、启发
7.1 方法学启发
Feature-Wise Transformations 的通用性:
- FiLM 可视为 MTDS 框架的特例,通过风格参数修改网络层权重
- 共享参数跨所有风格,风格无关变异用共享参数建模
- 相比其他方法,风格表示显著更紧凑 (2K vs 262K 参数/风格)
局部相位的灵活性:
- 源函数设计是关键:不同任务需要不同的源函数
- Contact-Free 相位提取可扩展到其他无接触信息的场景
- 显式相位特征帮助分离不同相位周期的肢体动作
7.2 与相关工作对比
| 方法 | 实时性 | 风格数量 | 质量 | 每风格参数 | 平滑插值 |
|---|---|---|---|---|---|
| PFNN One-hot [23] | ✓ | 少 | 中 | 2K | ✗ |
| PFNN Resad [38] | ✓ | 中 | 中 | 31K | ✓ |
| LPN FiLM (本文) | ✓ | 多 | 高 | 2K | ✓ |
| MOCHA [2023] | ✓ | 多 | 高 | - | ✓ |
注:MOCHA 继承了本文的 FiLM 风格调制思想,但核心是 Neural Context Matcher 进行上下文匹配
7.3 核心设计选择的重要性
Inductive Bias > 原始容量:
- FiLM 的低测试误差归因于高容量调制 (缩放 + 偏移所有层)
- LPN Resad vs PFNN Resad: CP 分解的相位依赖性重要
- 参数使用的归纳偏置比原始网络容量更重要
风格表示设计:
- 内容不变性假设:动作内容 = 跨风格相同的部分,风格 = 差异部分
- 紧凑但强大的风格表示支持有意义的线性插值
- 离线预计算 FiLM 参数降低运行时成本
八、遗留问题
8.1 开放性问题
-
零样本风格转换
- 能否从未见过的风格示例中学习?
- 跨领域风格迁移?
-
源函数设计
- 如何设计处理随机性动作的源函数?
- 如何针对不同任务设计专用源函数?
-
物理合理性
- 如何学习世界模型以鼓励物理理解?
- 如何直接在神经网络中添加骨骼感知?
-
更细粒度的控制
- 能否控制特定身体部位的风格?
- 能否组合不同风格特征?
九、补充:Style 的定义讨论
论文对"Style"的定义采用了内容不变性假设:
- 动作内容:跨所有风格相同的部分 (由共享的 LPN 参数建模)
- 动作风格:风格之间差异的部分 (由 FiLM 参数建模)
但这不是唯一的定义方式,Style 是一个主观且创造性的概念。论文希望此工作对未来创意系统有用。
笔记说明:本文是 SIGGRAPH 2020 关于实时风格转换的工作,提出了基于 Feature-Wise Transformations (FiLM) 和 Local Motion Phases 的框架。关键创新是使用 FiLM 参数 (γ缩放 + β偏移) 调制动画合成网络的所有隐藏层,实现高容量、紧凑的风格表示。发布的 100style 数据集包含 100 种风格、400 万帧动作数据。理解本文有助于学习角色动画的风格化方法,MOCHA (2023) 继承了 FiLM 风格调制思想。
Motion In-Betweening with Phase Manifolds
论文信息: ACM Transactions on Graphics (SIGGRAPH) 2023, Paul Starke et al., Electronic Arts/Universität Hamburg/Meta Reality Labs
Link: ACM Digital Library
代码: GitHub - pauzii/PhaseBetweener
一、核心问题:什么是 Motion In-Betweening?
1.1 一个直观的例子
想象你是一位动画师,正在制作一个游戏角色的动画:
关键帧 1 (第 0 帧) 关键帧 2 (第 60 帧)
站立姿势 ------------> 蹲下姿势
中间怎么办?
Motion In-Betweening(动作中间帧生成) 就是要解决:给定起始姿势和目标姿势,自动生成中间的过渡动作。
1.2 传统方法的困境
问题 1:线性插值很僵硬
最 naive 的做法是直接对关节角度做线性插值:
- 第 30 帧 = (第 0 帧 + 第 60 帧) / 2
但这样生成的动作会:
- 看起来像机器人,没有"活力"
- 脚会在地面滑动(foot skating)
- 身体会穿透地面
问题 2:时间长就更糟
当两个关键帧时间间隔很长时(比如 4 秒以上),问题更严重:
- 系统不知道中间应该做什么动作
- 可能生成"原地漂浮"的诡异动作
- 无法处理复杂的动作(如爬行、翻滚)
问题 3:相位不匹配
假设起始帧是"左脚着地",目标帧是"右脚着地":
- 直接插值会导致"双脚同时着地"的不自然动作
- 系统需要理解"行走周期"的概念
1.3 本文的核心洞察
关键思想:引入相位(Phase) 作为时间的"内在时钟"。
类比理解:
- 想象一个正弦波:sin(ωt + φ)
- 相位 φ 告诉你在波的哪个位置(波峰?波谷?上升段?)
- 对于行走动作,相位可以告诉你:左脚着地?右脚着地?腾空?
相位流形(Phase Manifold) 就是把所有可能的相位状态组织成一个连续的空间,在这个空间里:
- 相近的相位 = 相近的动作时刻
- 可以平滑地从一个相位过渡到另一个相位
- 可以生成训练时没见过的长时间过渡
二、核心概念详解:什么是相位流形?
2.1 相位(Phase)的直观理解
定义:相位是描述周期性运动"当前处于哪个阶段"的变量。
例子 1:行走周期
左脚着地 双脚着地 右脚着地 双脚着地
相位 0° ---------> 相位 90° ---------> 相位 180° ---------> 相位 270°
⊙ ⊙ ⊙ ⊙
/|\ /|\ /|\ /|\
| 左脚在前 | 双脚并拢 | 右脚在前 | 双脚并拢
/ \ / \ / \ / \
关键观察:
- 行走是周期性的:0° → 360° → 0°(循环)
- 相位 0° 和相位 360° 是同一个状态
- 相位可以表示为角度或圆上的点
数学表示: $$\phi \in [0, 2\pi)$$
或者用 2D 向量表示(更方便神经网络处理): $$\mathbf{p} = [\cos(\phi), \sin(\phi)]$$
2.2 为什么需要"流形"(Manifold)?
单一相位不够用
对于简单的行走,一个相位变量就够了。但对于复杂动作:
- 左手和右手可能在不同相位(如一只手插兜,另一只手摆动)
- 上半身和下半身可能独立运动(如边走路边挥手)
- 不同身体部位有不同的周期
解决方案:多通道相位
论文使用 5 个相位通道(C=5),每个通道捕捉不同的运动模式:
通道 0: 下肢行走相位(左右脚交替)
通道 1: 上肢摆动相位(左右手交替)
通道 2: 身体起伏相位(上下运动)
通道 3: ...
通道 4: ...
相位流形 就是这 5 个相位通道张成的空间: $$\mathcal{P} = {(\phi_1, \phi_2, \phi_3, \phi_4, \phi_5) \mid \phi_i \in [0, 2\pi)}$$
几何直观:
- 每个相位通道是一个圆(S¹)
- 5 个圆组合成一个 5 维环面(5-torus)
- 动作序列就是这个环面上的一条轨迹
2.3 相位流形的核心优势
优势 1:时间对齐
没有相位时:
- 神经网络只能靠"还剩多少帧"来猜测动作
- 相同的剩余时间可能对应完全不同的姿势
有相位时:
- 相位直接编码"动作进行到哪个阶段"
- 相同的相位 = 相同的动作阶段
- 避免"时间混合"(不同时刻的姿势被混淆)
优势 2:长时外推
训练时只见过 2 秒的过渡,测试时要生成 4 秒的过渡:
没有相位:
- 网络没见过这么长的时间,直接懵了
- 生成的动作会"卡住"或漂移
有相位:
- 相位的变化率(频率)可以外推
- 网络知道"继续按这个节奏走"
- 可以生成比训练更长的过渡
优势 3:相位匹配
起始帧相位 = 0°(左脚着地),目标帧相位 = 180°(右脚着地):
- 网络知道需要走"半步"
- 不会生成"双脚同时着地"的诡异动作
三、Periodic Autoencoder:如何学习相位流形?
3.1 问题设定
输入:动作捕捉数据(关节位置/速度序列)
输出:相位变量 + 重构的动作
挑战:
- 没有相位标签(无监督学习)
- 相位需要从数据中自动发现
3.2 核心架构
动作速度序列 (121 帧)
↓
1D 卷积层 (提取局部特征)
↓
Latent Embedding (5 通道)
↓
┌──────────┬──────────┐
↓ ↓ ↓
可微 FFT 可微 FFT MLP
(提取 A,F,B) (提取 A,F,B) (预测相移 S)
↓ ↓ ↓
└────────────────────┘
↓
重构 Latent: L(t) = A·sin(2π(F·t - S)) + B
↓
1D 反卷积层
↓
重构动作速度
关键组件:
- 1D 卷积:捕捉时间序列的局部模式
- 可微 FFT 层:从 latent 中提取正弦波参数
- A = 振幅(amplitude)
- F = 频率(frequency)
- B = 偏移(bias)
- MLP:单独预测相移(phase shift)
- 正弦重构:用提取的参数重建 latent
- 1D 反卷积:从 latent 重构动作
3.3 相位提取公式
训练完成后,相位编码通过以下方式计算:
对于每个通道 $t \in {0,1,2,3,4}$:
$$\text{pe}(2t) = A_t \cdot \cos(2\pi \cdot S_t)$$ $$\text{pe}(2t+1) = A_t \cdot \sin(2\pi \cdot S_t)$$
输出:10 维相位编码向量(5 通道 × 2 维)
为什么用 (cos, sin) 表示?
- 避免相位跳变(0 和 2π 在圆上是同一点)
- 神经网络更容易处理连续表示
- 可以直接做线性插值
3.4 相位可视化
论文图 3 展示了不同动作的相位通道:
侧步行走 爬行动作 跑步转跳跃
~~~ ~~~ ~~~
/ \ / \ / \
~ ~ ~ ~ ~ ~
(相位平滑变化) (相位平滑变化) (相位有突变)
观察:
- 周期性动作(行走、爬行):相位平滑变化
- 非周期性动作(跳跃):相位有突变
- 不同动作有不同的相位模式
四、In-Betweening 框架:如何使用相位流形?
4.1 整体架构
┌─────────────────────────────────────────────────────────┐
│ 输入 (第 i 帧) │
│ - 当前姿势 X_i^S │
│ - 目标姿势 X_i^T │
│ - 轨迹信息 X_i^R │
│ - 接触信息 X_i^C │
│ - 相位信息 X_i^P (10 维) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ Gating Network (门控网络) │
│ 输入:相位信息 X_i^P │
│ 输出:8 个专家的混合权重 α │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ Motion Prediction Network (运动预测网络) │
│ 8 个专家网络,每个输出预测结果 │
│ 加权组合:Y = Σ α_k · Expert_k(X) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 输出 (第 i+1 帧) │
│ - 预测姿势 Y^S │
│ - 预测轨迹 Y^R │
│ - 预测接触 Y^C │
│ - 相位更新 Y^P (频率 + 振幅) │
└─────────────────────────────────────────────────────────┘
4.2 Mixture-of-Experts 设计
为什么用 MoE?
不同动作类型需要不同的"专家"处理:
- 专家 1:处理行走
- 专家 2:处理跑步
- 专家 3:处理爬行
- ...
门控网络:根据当前相位,决定哪个专家"值班"
$$\alpha = \text{softmax}(g(\phi))$$ $$Y = \sum_{k=1}^8 \alpha_k \cdot \text{Expert}_k(X)$$
好处:
- 每个专家可以专注特定动作类型
- 相位相近的动作自动聚类
- 支持动作平滑过渡
4.3 双向控制(Bi-directional Control)
问题:自回归生成会有累积误差,导致到不了目标姿势
解决:从两个方向预测,然后混合
Ego-centric(自我中心):
- 从当前姿势出发,向前预测
- "我现在在哪,下一步去哪"
Goal-centric(目标中心):
- 从目标姿势出发,向后预测
- "目标在哪,怎么靠近"
混合公式:
$$Y_{final} = (1-\lambda) \cdot Y_{ego} + \lambda \cdot Y_{goal}$$
其中 λ 根据"还剩多少时间到目标"动态调整:
- 刚开始:λ 小,相信自己预测
- 快到了:λ 大,相信目标预测
效果:
- 起始阶段:动作自然流畅
- 结束阶段:精确对齐目标
五、实验结果
5.1 相位变量的影响
对比实验:
- No Phases:不用相位输入
- Contact Phases:只用接触点相位(脚/手/臀)
- Learned Phases:用 Periodic Autoencoder 学习的相位
指标 1:动作活力(Vividness)
| 动作类型 | No Phases | Contact | Learned | Ground Truth |
|---|---|---|---|---|
| 行走 | 55.2 | 61.7 | 63.4 | 66.4 |
| 急转弯冲刺 | 96.9 | 130.2 | 152.4 | 170.2 |
| 爬行 | 8.7 | 26.4 | 45.3 | 58.3 |
| 蹲下 | 47.1 | 62.8 | 64.2 | 77.6 |
结论:学习相位让动作更有活力,接近真实动作
指标 2:脚部滑动(Foot Skating)
| 方法 | 滑动误差 (cm) |
|---|---|
| No Phases | 2.66 |
| RTN | 0.55 |
| Ours | 0.46 |
| Ground Truth | 0.32 |
结论:相位可以显著减少脚部滑动
5.2 长时间过渡能力
测试:训练时最长 60 帧(2 秒),测试时生成更长的过渡
| 帧数 | 30 | 45 | 60 | 75 | 90 | 105 | 120 |
|---|---|---|---|---|---|---|---|
| RTN 误差 | 2.23 | 2.98 | 3.71 | 3.96 | 4.14 | 4.87 | 5.59 |
| Ours 误差 | 2.71 | 2.93 | 3.08 | 3.27 | 3.2 | 3.56 | 3.89 |
关键发现:
- RTN 在长过渡时误差快速增长
- 本文方法误差增长缓慢
- 可以生成比训练长 2 倍的过渡
5.3 双向控制的影响
| 任务 | 位置误差 (cm) | 旋转误差 (°) |
|---|---|---|
| 非双向 - 行走 | 21.59 | 18.94 |
| 双向 - 行走 | 9.61 | 11.23 |
| 非双向 - 爬行 | 26.69 | 29.64 |
| 双向 - 爬行 | 12.05 | 15.01 |
结论:双向控制将目标对齐误差降低约 50%
5.4 压力测试
极端情况 1:10 米距离,2 秒到达
- No Phases:不自然地加速,脚部严重滑动
- Contact Phases:稳定但会漂移
- Learned Phases:生成跳跃动作,自然到达
极端情况 2:30 米距离,10 秒到达
- 系统生成合理的跑步动作
- 虽然开始时有点"僵硬"
- 整体过渡自然
六、局限性与未来方向
6.1 局限性
-
依赖训练数据
- 只能生成训练过的动作类型
- 未见过的动作需要重新训练
-
长过渡质量下降
- 虽然比 baseline 好,但超长过渡仍有问题
- 动作可能变得"僵硬"
-
物理合理性
- 没有显式的物理约束
- 可能有轻微的穿透或漂浮
6.2 未来方向
-
结合物理仿真
- 像 POMP 一样加入物理模块
- 保证物理合理性
-
更长的上下文
- 使用 Transformer 等架构
- 捕捉更长程的依赖
-
多角色交互
- 扩展到双人/多人动作
- 处理角色间物理交互
七、启发与总结
7.1 核心启发
1. 相位是时间的"内在表示"
- 不要依赖外部时间("还剩多少帧")
- 学习内在的相位时钟
- 相位可以外推到未见过的时间长度
2. 流形是结构的"几何表示"
- 把动作组织成连续的流形空间
- 相近的点 = 相近的动作
- 在流形上插值 = 自然过渡
3. 无监督学习的力量
- Periodic Autoencoder 不需要相位标签
- 自动从数据中发现相位结构
- 学到的相位可以迁移到下游任务
7.2 与相关工作的对比
| 方法 | 相位表示 | 时间外推 | 物理约束 |
|---|---|---|---|
| RTN | 无 | 差 | 无 |
| CVAE | 隐式 | 中 | 无 |
| 本文 | 显式相位流形 | 好 | 无 |
| POMP | 相位流形 + 物理 | 好 | 有 |
7.3 一句话总结
本文的核心贡献:用相位流形作为动作的"内在时钟"和"几何结构",实现了自然、稳定、可外推的 motion in-betweening。
笔记说明:本文是 SIGGRAPH 2023 关于动作中间帧生成的工作。核心创新是使用 Periodic Autoencoder 学习相位流形,将动作在时间和空间上对齐,然后通过 Mixture-of-Experts 网络生成平滑过渡。理解本文有助于学习数据驱动的动作生成方法,特别是如何处理长时间过渡和相位匹配问题。
Mode-Adaptive Neural Networks for Quadruped Motion Control
论文信息: SIGGRAPH 2018, Hongwei Zhang et al., University of Edinburgh
Link: ACM Digital Library
一、核心问题
1.1 研究背景
四足动物运动控制是计算机图形学和机器人学的重要问题:
- 游戏和电影中的动物角色
- 机器狗的运动规划
- 生物运动研究
传统方法的挑战:
- 不同步态需要不同的控制器
- 步态切换不流畅
- 难以适应不同地形
- 手工制作控制器耗时
1.2 核心问题
如何实现统一的、自适应的四足动物运动控制框架?
1.3 本文方法
论文提出了 Mode-Adaptive Neural Networks:
核心思想:
- 单个神经网络处理多种步态
- 自动学习步态切换
- 适应不同地形和速度
关键创新:
- Mode-adaptive 权重调整
- 统一的控制框架
- 无需显式步态标注
二、核心贡献
-
Mode-Adaptive 架构
- 单个网络处理多种步态
- 自动调整权重
- 流畅的步态切换
-
四足运动学习
- 从 mocap 数据学习
- 生成自然运动
- 物理仿真兼容
三、大致方法
3.1 框架概述
flowchart TB
subgraph Input["输入"]
state["角色状态"]
cmd["用户命令"]
terrain["地形信息"]
end
subgraph Network["神经网络"]
mode["Mode 估计"]
adaptive["Adaptive 权重"]
control["控制器"]
end
subgraph Output["输出"]
action["关节目标"]
end
state --> mode
cmd --> mode
terrain --> mode
mode --> adaptive
state --> control
cmd --> control
adaptive --> control
control --> action
style Input fill:#e1f5fe
style Network fill:#fff3e0
style Output fill:#e8f5e9
四、训练细节
4.1 数据集
- 四足动物 mocap 数据
- 多种步态:行走、小跑、奔跑
- 不同地形数据
4.2 训练策略
- 模仿学习:跟踪参考动作
- 强化学习:优化运动质量
- 域适应:适应不同地形
五、实验与结论
5.1 定性结果
- 流畅的步态切换
- 适应不同地形
- 自然运动质量
5.2 应用场景
- 游戏动物角色
- 机器狗控制
- 生物运动研究
六、局限性
- 仅适用于四足动物
- 需要 mocap 数据
- 复杂地形适应有限
笔记说明:本文是 SIGGRAPH 2018 关于四足动物运动控制的工作,提出了 Mode-Adaptive Neural Networks。理解本文有助于学习动物运动生成方法。
Few-shot Learning of Homogeneous Human Locomotion Styles
论文信息: Computer Graphics Forum (Eurographics 2018), Ian Mason et al., University of Edinburgh
Link: DOI:10.1111/cgf.13555
引用: Mason, I, Starke, W, Zhang, H, Bilen, H & Komura, T (2018). Few-shot Learning of Homogeneous Human Locomotion Styles. Computer Graphics Forum, 37(7), 143-153.
一、核心问题:用非常基础的语言解释
1.1 这个问题为什么重要?
想象你是一个游戏动画师:
你想让游戏里的角色走出一种特殊的步伐,比如:
- 像喝醉了酒一样摇摇晃晃地走
- 像小偷一样蹑手蹑脚地走
- 像将军一样昂首挺胸地走
传统方法的问题:
- 需要大量数据:你想让角色学会一种新风格的走路,传统方法需要收集成百上千条这种风格的动作捕捉数据
- 成本极高:动作捕捉需要专业设备、演员、场地,非常昂贵
- 训练时间长:每次学习新风格都要重新训练整个神经网络,可能需要几天时间
- 不实用:动画师通常只有几秒到几十秒的参考视频,不可能提供大量数据
核心问题:
能否只给神经网络看几秒种的动作视频,它就能学会这种风格的走路?
这就是 "少样本学习" (Few-shot Learning) 要解决的问题。
1.2 什么是"Homogeneous"风格学习?
Homogeneous(同质的)vs Heterogeneous(异质的):
| 类型 | 例子 | 难度 |
|---|---|---|
| Homogeneous | 看到"向前走"的风格,学会向各个方向"走"的风格 | 较简单 |
| Heterogeneous | 看到"向前走"的风格,学会"跑"、"跳"、"打拳"的风格 | 非常难 |
本文聚焦于 Homogeneous 学习:
- 输入:几秒种"风格 A 的向前走"
- 输出:能用风格 A 向各个方向走、改变速度
为什么不做 Heterogeneous?
- 从"走"的风格推断"跑"的风格,没有确定性映射
- 有些风格在跑步时会完全改变(比如醉汉走路 vs 醉汉跑步)
- 这是开放性问题,超出了本文范围
1.3 本文方法的核心思想
关键洞察:
locomotion(移动)动作可以分解为两部分:
- 风格无关的部分:所有走路方式共有的特征(如左右脚交替、身体平衡)
- 风格相关的部分:不同风格的独特特征(如步幅大小、身体倾斜角度)
方法概述:
flowchart TB
subgraph Phase1["第一阶段:预训练"]
data1["8 种风格的大量数据"]
pfnn["PFNN 主干网络"]
adapter["残差适配器"]
agnostic["风格无关参数 β_ag"]
specific["风格相关参数 β_s"]
end
subgraph Phase2["第二阶段:少样本学习"]
data2["新风格的少量数据 (几秒)"]
freeze["冻结主干网络"]
learn["只学习新的残差适配器"]
end
data1 --> pfnn
pfnn --> agnostic
pfnn --> adapter
adapter --> specific
data2 --> learn
freeze --> learn
learn --> specific
style Phase1 fill:#e1f5fe
style Phase2 fill:#fff3e0
两阶段训练:
-
第一阶段(预训练):
- 用 8 种风格的大量数据训练
- 学习"风格无关参数"(所有走路的共同规律)
- 学习 8 套"风格相关参数"(每种风格的独特之处)
-
第二阶段(少样本学习):
- 给新风格的几秒种视频
- 冻结主干网络(不改变已学到的共同规律)
- 只学习新的残差适配器(新风格的独特之处)
类比理解:
想象学习写字:
- 主干网络 = 学习写字的基本规则(笔画顺序、结构)
- 风格无关参数 = 所有人都要遵守的规则
- 风格相关参数 = 每个人的字迹特点
- 少样本学习 = 看几眼某人的字,就能模仿他的字迹,而不需要重新学习写字的基本规则
二、核心技术详解
2.1 基础知识铺垫
在深入方法之前,需要先理解几个关键概念:
概念 1:什么是 PFNN (Phase-Functioned Neural Network)?
PFNN 是什么?
PFNN 是一种专门用于角色动画的神经网络,由 Holden 等人在 2017 年提出。
为什么需要 PFNN?
传统神经网络生成动画的问题:
- 输出容易"模糊"(blurriness)
- 动作不够清晰、不够真实
PFNN 的解决方案:
- 引入"相位"(Phase) 的概念
- 根据相位动态调整网络权重
什么是"相位"(Phase)?
相位表示动作的周期进度。以走路为例:
一个完整的走路周期(相位从 0 到 2π):
- 相位 = 0:右脚着地
- 相位 = π/2:右脚抬起,左脚支撑
- 相位 = π:左脚着地
- 相位 = 3π/2:左脚抬起,右脚支撑
- 相位 = 2π:回到右脚着地(完成一个周期)
PFNN 如何工作?
PFNN 的权重是相位的函数:
$$W(p) = \text{根据相位 p 动态调整权重}$$
具体实现使用 Catmull-Rom 样条曲线:
- 定义 4 个"控制点"权重:\(\alpha_1, \alpha_2, \alpha_3, \alpha_4\)
- 根据当前相位,平滑地混合这 4 个权重
- 公式: $$W(p; \beta) = \alpha_{k1} + \frac{d}{2}(\alpha_{k2} - \alpha_{k0}) + \frac{d^2}{2}(\alpha_{k0} - \alpha_{k1} + 2\alpha_{k2} - \alpha_{k3}) + \frac{d^3}{2}(\alpha_{k1} - \alpha_{k2} + \alpha_{k3} - \alpha_{k0})$$ 其中 \(d = \frac{4p}{2\pi} \mod 1\),\(k_n = \lfloor\frac{4p}{2\pi}\rfloor + n - 1 \mod 4\)
通俗理解:
- 把走路周期分成 4 个阶段
- 每个阶段有一套专用权重
- 根据当前走到哪个阶段,平滑地切换权重
- 这样可以保证动作连贯、不突兀
概念 2:什么是残差适配器 (Residual Adapter)?
残差适配器是什么?
残差适配器是一种轻量级的网络模块,用于适应新领域(新风格)。
基本结构:
输入 x
│
├──────→ [主网络 f] ────→┐
│ ↓ (+) → 输出 y
└────→ [残差适配器 h] ──→┘
数学公式:
$$y = f * x + h_{1\times1} * x$$
- \(f\):主网络过滤器(domain agnostic,领域无关)
- \(h_{1\times1}\):残差适配器(domain specific,领域特定)
- \(*\):卷积操作
为什么用残差适配器?
- 参数少:使用 \(1\times1\) 过滤器,新增参数很少
- 易于扩展:每个新领域只需训练新的适配器,主网络共享
- 可调节:通过正则化控制适应强度
本文的改进:
原版的残差适配器用于图像分类,包含 Batch Normalization。但 PFNN:
- 不使用 Batch Normalization
- 是前馈网络而非卷积网络
因此本文做了适配修改。
概念 3:什么是 CP 分解 (Canonical Polyadic Decomposition)?
为什么需要 CP 分解?
问题:每个新风格都要存储一整套残差适配器参数,内存消耗大。
- 完整矩阵:每风格 4.01 MB(存储控制点)/ 50.1 MB(离散化相位)
- 8 种风格就要 32 MB,50 种风格就要 200+ MB
CP 分解的思想:
把一个 3D 张量分解成三个矩阵的乘积:
$$X_k = A D(k) B^T$$
- \(X \in \mathbb{R}^{I\times J\times K}\):原始 3D 张量
- \(A \in \mathbb{R}^{I\times R}\):左矩阵(与相位无关)
- \(B \in \mathbb{R}^{J\times R}\):右矩阵(与相位无关)
- \(D(k) \in \mathbb{R}^{R\times R}\):对角矩阵(与相位相关)
- \(R \ll I, J\):降维后的维度
本文的具体实现:
把残差适配器的权重视为 3D 张量 \(512 \times 512 \times 50\):
- 512×512:权重矩阵大小
- 50:相位离散化数量(把 0 到 2π 分成 50 份)
分解后:
- \(A\):512 × 30(与相位无关)
- \(B\):512 × 30(与相位无关)
- \(D(k)\):30 × 30 对角矩阵(与相位相关,k=1...50)
效果对比:
| 方法 | 训练时内存 | 运行时内存 | 训练时间 | 推理时间 |
|---|---|---|---|---|
| 完整矩阵 | 4.01 / 50.1 MB | 99 秒 | 0.0013 秒 | |
| 对角矩阵 | 0.016 / 0.20 MB | 44 秒 | 0.0010 秒 | |
| CP 分解 | 0.126 / 0.131 MB | 50 秒 | 0.0011 秒 |
CP 分解的优势:
- 大幅减少参数:从 4MB 降至 0.13MB(约 30 倍压缩)
- 防止过拟合:参数少 = 更不容易记住训练数据
- 保持灵活性:相位相关部分保留,相位无关部分共享
直观理解:
想象学习不同人的字迹:
- A 和 B 矩阵 = 这个人的基本笔画特征(横、竖、撇、捺的特点)
- D 矩阵 = 不同字之间的变化(写"大"和写"小"的区别)
- CP 分解 = 把"基本笔画"和"字间变化"分开学习
2.2 方法详解
第一步:预训练(学习风格无关参数)
数据准备:
- 8 种代表性风格:angry(愤怒)、childlike(孩子气)、depressed(沮丧)、neutral(中性)、old(老人)、proud(骄傲)、sexy(性感)、strutting(大摇大摆)
- 每种风格约 1 小时动作捕捉数据
- 总共约 8 小时、23104 帧/风格
网络架构:
输入 X (234 维)
│
├→ [主网络 W0, W1, W2] → 风格无关参数 β_ag (灰色)
│ └─ 权重由相位控制
│
└→ [残差适配器 Wres] → 风格相关参数 β_s (彩色,8 套)
└─ CP 分解:A, D(k), B
输出 Y (400 维)
│
├→ 未来轨迹位置 (12 维)
├→ 未来轨迹方向 (12 维)
├→ 关节位置 (93 维)
├→ 关节速度 (93 维)
├→ 关节旋转 (186 维)
├→ 相位变化 (1 维)
└→ 根节点平移/旋转 (3 维)
损失函数:
对于风格 \(s\) 的输入 \(X_i^{(s)}\):
$$\mathcal{L}(X_i^{(s)}, Y_i^{(s)}, p_i^{(s)}; s) = ||Y_i^{(s)} - \Phi(X_i^{(s)}, p_i^{(s)}; \beta^{(s)}, \beta_{ag})||^2 + \lambda_{ag}||\beta_{ag}||_1 + \lambda_s||\beta^{(s)}||_1$$
关键设计:
-
平衡数据集:
- 每种风格帧数相同(23104 帧)
- 镜像和非镜像动作数量相同
- 确保不偏向任何一种风格
-
L1 正则化:
- \(\lambda_{ag} = \lambda_s = 0.01\)
- 鼓励稀疏性,防止过拟合
-
分批次训练:
- 每个 batch 只包含一种风格
- 每 8 个 batch 循环一次(确保均衡)
训练配置:
- 优化器:Adam
- 学习率:默认
- 训练轮数:25 epochs(早停防止过拟合)
- 硬件:NVIDIA GTX 1080 Ti
- 训练时间:约 6 小时
第二步:少样本学习(学习新风格)
数据准备:
- 从 CMU 动作捕捉数据库提取 50 种风格
- 每种风格可能只有 1-5 秒 的数据(一个走路周期)
- 例如:joy(快乐)、on toes crouched(踮脚蹲下)、roadrunner(走鹃)、wild arms(狂野手臂)、zombie(僵尸)
核心挑战:
-
数据太少:
- 只有直直向前走的几秒视频
- 需要泛化到转弯、加速等新情况
- 极易过拟合
-
内存消耗:
- 每新增一种风格就要存储一套参数
- 50 种风格需要大量存储
解决方案:
-
冻结主干网络:
- 不改变 \(\beta_{ag}\)(风格无关参数)
- 只学习新的 \(\beta^{(new)}\)(新风格参数)
-
CP 分解:
- 将参数数量从 4MB 压缩到 0.13MB
- 降低过拟合风险
-
可变 Dropout:
- 对不同风格使用不同的 dropout 率
- 数据越少、风格越独特 → dropout 越高
- 通过网格搜索找到最优值
为什么能泛化?
- 主干网络已经学会了"走路的一般规律"
- 新风格只需要学习"如何调整这些规律"
- 例如:主干知道如何转弯,新风格只需要调整转弯时的姿态
2.3 推理(生成新动作)
输入:
- 用户控制的轨迹(键盘/游戏手柄)
- 当前相位
处理流程:
-
根据相位计算权重:
- 主网络权重:\(W_0(p), W_1(p), W_2(p)\)
- 残差适配器权重:\(W_{res}(p)\)
-
前向传播: $$\Phi(X, p; \beta^{(s)}, \beta_{ag}) = W_2 \cdot \text{ELU}(W_1 \cdot \text{ELU}(W_0 X + b_0) + b_1 + W_{res} \cdot \text{ELU}(W_0 X + b_0) + b_{res}) + b_2$$
-
输出下一帧:
- 关节位置、速度、旋转
- 根节点运动
- 相位变化
-
相位离散化(加速):
- 预计算 50 个相位的权重(相位 0, 2π/50, ..., 2π)
- 推理时使用最近的预计算权重
- 加速 3-4 倍
实时性能:
- 推理时间:0.0011 秒/帧
- 帧率:约 900 FPS(远超实时要求)
三、实验结果
3.1 定性结果
成功的风格:
| 风格 | 效果 | 说明 |
|---|---|---|
| Joy(快乐) | ✓ | 轻快的步伐,自然 |
| On toes crouched(踮脚蹲下) | ✓ | 保持蹲姿,踮脚走路 |
| Roadrunner(走鹃) | ✓ | 快速小步跑 |
| Wild arms(狂野手臂) | ✓ | 手臂大幅度摆动 |
| Zombie(僵尸) | ✓ | 僵硬的双脚跳跃 |
失败案例:
| 风格 | 问题 | 原因 |
|---|---|---|
| Left hop(单脚跳) | 右脚几乎不抬 | 风格与训练集差异太大 |
| March(正步走) | 膝盖抬不够高 | 输出过于平滑 |
| Gedanbarai(空手道) | 无法处理 | 非周期性动作,相位定义不清 |
3.2 对比实验
vs 微调整个 PFNN:
- 微调整个网络 → 严重过拟合
- 只能复现训练轨迹,无法泛化到转弯
vs 对角残差适配器:
- 对角矩阵 → 欠拟合
- 无法捕捉复杂风格,输出"平均化"动作
vs 完整残差适配器:
- 完整矩阵 → 过拟合
- 风格捕捉好,但无法向左转弯(参数太多)
vs Holden et al. [HSK16] 风格迁移:
- 本文方法 ≈ 或优于 Holden 的方法
- 但本文是"同时生成 + 风格化",不需要预定义内容轨迹
3.3 消融实验
可视化风格无关参数:
将残差适配器权重设为 0,生成"平均动作":
- 接近中性走路
- 快速转弯时有轻微"咔哒"声(snap)
- 这是底层"平均动作"的瑕疵
CP 分解的有效性:
| n 值 | 参数量 | 风格质量 | 过拟合 |
|---|---|---|---|
| n=512(无分解) | 4MB | 好 | 严重 |
| n=30 | 0.13MB | 好 | 轻微 |
| n=10 | 0.02MB | 一般 | 无 |
四、局限性
4.1 无法处理异质迁移 (Heterogeneous Transfer)
问题:
- 只能从"风格 A 的走路"生成"风格 A 的其他走路"
- 无法从"风格 A 的走路"生成"风格 A 的跑步/打拳"
原因:
- 走路→跑步没有确定性映射
- 有些风格在跑步时完全改变
未来方向:
- 需要手工设计的解决方案(如 Yumer et al. [YM16])
4.2 缺乏定量评估指标
问题:
- 动画质量评估是开放性问题
- 没有"标准答案"来比较生成结果
- 主要依赖主观视觉判断
现状:
- 使用定性比较(看视频)
- 与 Holden et al. [HSK16] 对比
4.3 丢失高频细节
问题:
- 生成动作比训练数据"平滑"
- 丢失细微的手部、头部动作
- 与人工动画相比缺乏细腻感
原因:
- 数据量太少,模型倾向于"平均化"
- 正则化导致平滑
可能改进:
- 增加训练轮数
- 调整 dropout 率
- 改进归一化方法
4.4 无法处理非周期性动作
问题:
- PFNN 设计用于周期性运动(走路、跑步)
- 难以处理"走走停停"的动作(如空手道)
- 相位定义不清的风格无法处理
未来方向:
- 需要新的相位定义方法
- 或放弃基于相位的方法
五、启发与应用
5.1 方法学启发
核心洞察:
-
分解思想:
- 将问题分解为"通用规律" + "特定风格"
- 通用规律一次性学习,特定风格快速适应
- 类似思想可用于其他生成任务
-
参数效率:
- CP 分解大幅减少参数(30 倍压缩)
- 降低过拟合风险
- 减少存储需求
-
终身学习:
- 新风格可以逐个添加
- 不影响旧风格
- 适合增量式学习场景
5.2 与相关工作的对比
| 方法 | 核心思想 | 数据需求 | 实时性 | 适用场景 |
|---|---|---|---|---|
| PFNN [HKS17] | 相位控制权重 | 大量/风格 | ✓ | 单一风格 |
| Style Transfer [HSK16] | 隐空间优化 | 大量 + 参考 | ✗ | 离线迁移 |
| 本文 (2018) | 残差适配器 + CP 分解 | 几秒/新风格 | ✓ | 少样本 |
| Style Modelling [211] | FiLM 调制 | 大量/多风格 | ✓ | 多风格建模 |
| MOCHA [2023] | 神经上下文匹配 | 大量 | ✓ | 实时匹配 |
5.3 实际应用场景
-
游戏开发:
- 快速原型:几秒参考视频即可生成 NPC 动画
- 个性化角色:玩家自定义走路风格
- 独立开发者福音:无需昂贵动捕
-
VR/AR 化身:
- 用户录制几秒视频 → 个性化虚拟形象
- 实时风格化:改变情绪状态
-
动画制作:
- 动画师提供参考 → 系统生成中间帧
- 风格库扩展:快速添加新风格
5.4 技术细节的启发
CP 分解的通用性:
不仅适用于 PFNN,还可用于:
- 其他基于相位的网络
- 任何具有周期性输入的神经网络
- 论文中提到:应用到完整 PFNN 可使参数从 136MB 降至 1MB
可变 Dropout 的策略:
- 数据越少 → dropout 越高
- 风格越独特 → dropout 越高
- 通过网格搜索找到最优值
- 类似思想可用于其他少样本学习任务
六、遗留问题与未来方向
6.1 开放性问题
-
异质迁移:
- 如何从"走路风格"推断"跑步风格"?
- 需要什么样的先验知识?
-
定量评估:
- 如何客观评价生成动画的质量?
- 什么是"好"的动画?
-
高频细节恢复:
- 如何在泛化和细节之间取得平衡?
- 是否需要额外的后处理?
-
非周期性动作:
- 如何处理"走走停停"的动作?
- 是否需要放弃相位表示?
6.2 可能的改进方向
-
数据增强:
- 合成更多训练样本
- 使用程序化生成
-
更强的正则化:
- 尝试不同的正则化方法
- 如 L1、L2、DropConnect
-
分层风格表示:
- 粗粒度风格(整体姿态)
- 细粒度风格(手部动作)
-
结合物理仿真:
- 确保物理合理性
- 处理接触、碰撞
七、关键公式汇总
7.1 PFNN 相位权重
$$W(p; \beta) = \alpha_{k1} + \frac{d}{2}(\alpha_{k2} - \alpha_{k0}) + \frac{d^2}{2}(\alpha_{k0} - \alpha_{k1} + 2\alpha_{k2} - \alpha_{k3}) + \frac{d^3}{2}(\alpha_{k1} - \alpha_{k2} + \alpha_{k3} - \alpha_{k0})$$
其中:
- \(d = \frac{4p}{2\pi} \mod 1\)
- \(k_n = \lfloor\frac{4p}{2\pi}\rfloor + n - 1 \mod 4\)
- \(\beta = {\alpha_1, \alpha_2, \alpha_3, \alpha_4}\) 是控制点
7.2 残差适配器
$$y = f * x + h_{1\times1} * x$$
7.3 CP 分解
$$X_k = A D(k) B^T$$
- \(X \in \mathbb{R}^{I\times J\times K}\):原始张量
- \(A \in \mathbb{R}^{I\times R}\),\(B \in \mathbb{R}^{J\times R}\):与相位无关
- \(D(k) \in \mathbb{R}^{R\times R}\):对角矩阵,与相位相关
7.4 损失函数
$$\mathcal{L} = ||Y - \Phi(X, p; \beta^{(s)}, \beta_{ag})||^2 + \lambda_{ag}||\beta_{ag}||_1 + \lambda_s||\beta^{(s)}||_1$$
7.5 网络前向传播
$$\Phi(X, p; \beta^{(s)}, \beta_{ag}) = W_2 \cdot \text{ELU}(W_1 \cdot \text{ELU}(W_0 X + b_0) + b_1 + W_{res} \cdot \text{ELU}(W_0 X + b_0) + b_{res}) + b_2$$
八、术语表
| 术语 | 英文 | 解释 |
|---|---|---|
| 少样本学习 | Few-shot Learning | 从少量示例中学习 |
| 同质迁移 | Homogeneous Transfer | 同一类型动作之间的迁移(走→走) |
| 异质迁移 | Heterogeneous Transfer | 不同类型动作之间的迁移(走→跑) |
| 相位 | Phase | 动作周期的进度(0 到 2π) |
| 风格无关参数 | Style-agnostic Parameters | 所有风格共享的参数 |
| 风格相关参数 | Style-specific Parameters | 每种风格独特的参数 |
| 残差适配器 | Residual Adapter | 用于领域适应的轻量级模块 |
| CP 分解 | Canonical Polyadic Decomposition | 3D 张量分解为三个矩阵的乘积 |
| Dropout | Dropout | 随机丢弃神经元的正则化技术 |
| 前馈网络 | Feed-forward Network | 无循环连接的神经网络 |
| 动作捕捉 | Motion Capture | 记录真实人体动作的技术 |
笔记说明:本文是 EG 2018 的工作,提出了基于残差适配器和 CP 分解的少样本风格学习方法。核心贡献是将风格分解为"通用规律"和"特定风格",通过冻结主干网络、只学习残差适配器,实现了从几秒视频学习新风格。理解本文有助于学习数据高效的角色动画方法,与 Style Modelling (211)、MOCHA 等工作形成对比。本文是第一作者 Ian Mason 早期工作,后续发展出 Style Modelling (2020) 和 MOCHA (2023)。
Learning predict-and-simulate policies from unorganized human motion data
论文信息: TOG 2019, Soohwan Park et al., Seoul National University
Link: ACM Digital Library
一、核心问题
1.1 研究背景
基于物理的角色控制是一个长期挑战:
- 游戏和 VR 需要物理合理的角色
- 需要抗扰动能力
- 需要丰富的运动技能
传统方法的挑战:
- 需要精心设计的参考动作
- 需要大量标注
- 技能有限
1.2 核心问题
如何从无标注、无组织的人体动作数据中学习物理控制策略?
1.3 本文方法
论文提出了 Predict-and-Simulate Policy:
核心思想:
- 从无组织 mocap 数据学习
- Predict-and-simulate 架构
- 物理仿真执行
关键创新:
- 无需精确跟踪参考动作
- 学习通用运动技能
- 支持交互式控制
二、核心贡献
-
Predict-and-Simulate 架构
- 预测下一步动作
- 在物理仿真中执行
- 闭环控制
-
无组织数据学习
- 无需标注
- 无需分段
- 自动发现技能
三、大致方法
3.1 框架概述
flowchart TB
subgraph Input["输入"]
state["当前状态"]
goal["控制目标"]
end
subgraph Policy["策略网络"]
predict["预测网络"]
simulate["仿真网络"]
end
subgraph Output["输出"]
action["PD 控制目标"]
end
state --> predict
goal --> predict
predict --> simulate
simulate --> action
style Input fill:#e1f5fe
style Policy fill:#fff3e0
style Output fill:#e8f5e9
3.2 Predict-and-Simulate
预测: $$\hat{s}{t+1} = f{predict}(s_t, g)$$
仿真: $$a_t = f_{simulate}(s_t, \hat{s}_{t+1})$$
四、训练细节
4.1 数据集
- 无组织 mocap 数据
- 无需标注
- 多种动作混合
4.2 训练策略
- 模仿学习:跟踪预测状态
- 强化学习:优化物理合理性
- 课程学习:从简单到复杂
五、实验与结论
5.1 定性结果
- 学习多种运动技能
- 物理合理
- 抗扰动能力强
5.2 应用场景
- 游戏角色控制
- VR 化身
- 机器人仿真
六、局限性
- 需要物理仿真
- 训练时间长
- 复杂技能有限
笔记说明:本文是 TOG 2019 关于物理角色控制的工作,提出了 Predict-and-Simulate Policy。理解本文有助于学习基于物理的动作生成方法,与 AMP、ASE 等工作形成对比。
Local Motion Phases for Learning Multi-Contact Character Movements
论文信息: SIGGRAPH 2020, Sebastian Starke et al., University of Edinburgh
Link: ACM Digital Library
一、核心问题
1.1 研究背景
多接触角色动作学习是角色动画的前沿问题:
- 角色与环境多种接触(手扶墙、脚踩台阶)
- 传统全局相位无法处理
- 需要更灵活的表示
传统方法的挑战:
- 全局相位假设所有部位同步
- 多接触动作相位不同步
- 难以学习复杂交互
1.2 核心问题
如何学习多接触角色动作的灵活相位表示?
1.3 本文方法
论文提出了 Local Motion Phases:
核心思想:
- 每个身体部位学习独立相位
- 局部相位捕捉异步运动
- 支持多接触交互
关键创新:
- Local phase 表示
- 相位 - 条件化神经网络
- 多接触动作生成
二、核心贡献
-
Local Motion Phases
- 每个部位独立相位
- 异步运动建模
- 多接触支持
-
Phase-Manifold 学习
- 无监督学习相位
- 相位空间聚类
- 动作生成
三、大致方法
3.1 框架概述
flowchart TB
subgraph Input["输入"]
motion["动作数据"]
contacts["接触信息"]
end
subgraph Phase["相位学习"]
local_phases["局部相位编码器"]
phase_vec["相位向量"]
end
subgraph Generation["生成"]
phase_cond["相位条件化网络"]
output["生成动作"]
end
motion --> local_phases
contacts --> local_phases
local_phases --> phase_vec
phase_vec --> phase_cond
phase_cond --> output
style Input fill:#e1f5fe
style Phase fill:#fff3e0
style Generation fill:#e8f5e9
3.2 Local Phase 表示
全局相位: $$\phi_{global} \in [0, 2\pi)$$
局部相位: $$\phi = {\phi_{left_foot}, \phi_{right_foot}, \phi_{left_hand}, \phi_{right_hand}, ...}$$
四、训练细节
4.1 数据集
- 多接触 mocap 数据
- 攀爬、扶墙、蹲下等
- 复杂环境交互
4.2 训练策略
- 相位学习:无监督学习局部相位
- 动作生成:相位条件化生成
- 接触预测:预测接触状态
五、实验与结论
5.1 定性结果
- 生成多接触动作
- 相位过渡流畅
- 环境交互自然
5.2 应用场景
- 游戏角色攀爬
- VR 环境交互
- 动画制作
六、局限性
- 相位数量固定
- 新接触类型需要训练
- 复杂交互有限
笔记说明:本文是 SIGGRAPH 2020 关于多接触动作学习的工作,提出了 Local Motion Phases。理解本文有助于学习复杂角色动作生成方法,与 Phase-Functioned Neural Networks 等工作形成对比。
Interactive Control of Diverse Complex Characters with Neural Networks
论文信息: NIPS 2015, Igor Mordatch et al., University of Washington
Link: NIPS Proceedings
一、核心问题
1.1 研究背景
通用角色控制是强化学习和图形学的长期目标:
- 单一控制器控制多种角色
- 无需动捕数据
- 无需任务特定设计
传统方法的挑战:
- 每个角色/任务需要专门控制器
- 需要动捕参考
- 需要手工设计特征
1.2 核心问题
能否训练一个通用的神经控制器,控制多种不同形态的角色完成多种任务?
1.3 本文方法
论文提出了 通用神经控制器(General Neural Controller):
核心思想:
- 单一 RNN 控制器
- 无需动捕数据
- 无需状态机
- 学习通用控制策略
关键创新:
- 大规模前馈单元 + 小规模循环单元
- 学习状态 - 动作映射
- 适用于多种角色和任务
二、核心贡献
-
通用神经控制器
- 单一网络控制多种角色
- 无需动捕数据
- 无需任务特定设计
-
多样化任务学习
- 游泳、飞行、双足/四足行走
- 不同身体形态
- 统一框架
-
纯强化学习
- 无需监督数据
- 无需示范
- 从零开始学习
三、大致方法
3.1 框架概述
flowchart TB
subgraph Input["输入"]
state["物理状态"]
goal["任务目标"]
end
subgraph Controller["神经控制器"]
feedforward["前馈单元 (大量)"]
recurrent["循环单元 (少量)"]
end
subgraph Output["输出"]
action["关节速度/力矩"]
end
state --> feedforward
goal --> feedforward
feedforward --> recurrent
recurrent --> action
style Input fill:#e1f5fe
style Controller fill:#fff3e0
style Output fill:#e8f5e9
3.2 网络架构
结构:
- 大量前馈单元:学习状态 - 动作映射
- 少量循环单元:实现记忆状态
输出:
- 关节速度/力矩
- 直接控制物理仿真
3.3 训练目标
最大化奖励: $$\max_{\theta} \mathbb{E}[\sum_t \gamma^t r_t]$$
任务奖励:
- 前进距离
- 目标跟踪
- 能量效率
- 稳定性
四、训练细节
4.1 角色模型
- 双足、四足、游泳、飞行
- 不同身体形态
- 不同自由度
4.2 训练策略
- 强化学习:PI^2 或类似算法
- 课程学习:从简单到复杂
- 域随机化:不同角色同时训练
五、实验与结论
5.1 定性结果
- 学习多种步态
- 抗扰动能力强
- 适应不同形态
5.2 定量结果
| 任务 | 成功率 | 效率 |
|---|---|---|
| 双足行走 | XX% | X.XX |
| 四足行走 | XX% | X.XX |
| 游泳 | XX% | X.XX |
| 飞行 | XX% | X.XX |
5.3 应用场景
- 游戏角色控制
- 机器人学习
- 生物运动研究
六、局限性
- 训练时间长
- 需要物理仿真
- 动作质量不如动捕
- 复杂任务有限
七、启发
7.1 方法学启发
-
通用控制器的可能性
- 单一网络控制多种角色
- 为后续工作奠定基础
-
纯 RL 学习的可行性
- 无需动捕数据
- 从零开始学习
7.2 与后续工作对比
| 方法 | 需要动捕 | 需要标注 | 动作质量 | 通用性 |
|---|---|---|---|---|
| 本文 (NIPS 2015) | ✗ | ✗ | 中 | 高 |
| DeepMimic (2018) | ✓ | ✗ | 高 | 中 |
| AMP (2021) | ✓ | ✗ | 高 | 高 |
| ASE (2022) | ✓ | ✗ | 高 | 高 |
八、遗留问题
8.1 开放性问题
-
如何提升动作质量?
- 后续工作引入动捕数据
- 对抗学习提升真实感
-
如何加速训练?
- 并行仿真
- 预训练 + 微调
笔记说明:本文是 NIPS 2015 的开创性工作,提出了通用神经控制器的概念。这是后续 DeepMimic、AMP、ASE 等工作的先驱。理解本文有助于学习基于物理的角色控制方法的发展脉络。
历史地位:
- 首次展示单一网络控制多种角色
- 纯强化学习,无需动捕
- 为后续模仿学习工作奠定基础
AAMDM: Accelerated Auto-regressive Motion Diffusion Model
论文信息: CVPR 2024, Tianyu Li et al., Georgia Tech/UBC/SFU
Link: CVF Open Access
一、核心问题
1.1 研究背景
在视频游戏和虚拟现实等娱乐应用中,交互式动作合成对于创造沉浸式体验至关重要。然而,生成既高质量又具有上下文响应能力的动画仍然是一个巨大挑战。
游戏工业的传统方法:
- Motion Matching:通过在大数据集中搜索最合适的动画片段
- 优点:高质量、响应式
- 缺点:计算成本高、内存占用大、扩展性差
学习型神经网络的局限:
- 优点:内存占用小、运行时性能好
- 缺点:训练不稳定、动作质量妥协、难以生成多样化动作
扩散模型的困境:
- 优点:可以生成多样化高质量动作、内存需求低
- 缺点:反向扩散过程昂贵,推理速度慢,无法用于实时应用
1.2 核心问题
如何构建一个动作合成框架,能够同时实现:
- 高质量 - 生成自然、真实的角色动作
- 多样性 - 能够生成多模态的动作变化
- 高效率 - 交互式帧率(实时运行)
1.3 现有方法及其局限性
| 方法 | 代表工作 | 质量 | 多样性 | 效率 | 局限性 |
|---|---|---|---|---|---|
| Motion Matching | [Kolsi et al. 2018] | 高 | 中 | 中 | 内存需求大、搜索成本高 |
| VAE | [Ling et al. 2020] | 中 | 低 | 高 | 模式坍塌、多样性差 |
| 标准扩散 | [Tevet et al. 2022] | 高 | 高 | 低 | 推理速度慢(多次去噪) |
| 快速扩散 | [Shi et al. 2023] | 中 | 中 | 中 | 样本质量下降 |
1.4 本文方法
论文提出了 AAMDM (Accelerated Auto-regressive Motion Diffusion Model) 框架:
核心思想:
- 低维嵌入空间操作 - 在学到的紧凑 latent space 中建模,而非完整姿态空间
- Generation Module - 使用 Denoising Diffusion GANs (DD-GANs) 快速生成初始草稿
- Polishing Module - 使用自回归扩散模型 (ADM) 进行质量优化,仅需 2 步额外去噪
关键创新:
- 结合 DD-GANs 的速度优势和 ADM 的质量优势
- 在低维嵌入空间操作,降低训练复杂度和推理成本
- 仅需 5 步去噪即可生成高质量动作(标准扩散需要 100+ 步)
二、核心贡献
-
AAMDM 框架
- 首个在交互式帧率下生成长序列动作的扩散模型
- 结合 Denoising Diffusion GANs 和 Auto-regressive Diffusion Models
- 在紧凑嵌入空间中操作
-
全面对比分析
- 在多个指标上超越基线方法(LMM、MotionVAE、AMDM)
- 运动质量、多样性、运行时效率全面领先
-
多模态动作合成演示
- 展示新颖的高质量多模态动作
- 实现之前方法无法达成的效果(如用户控制根节点轨迹 + 多样化手臂动作)
三、大致方法
3.1 框架概述
┌─────────────────────────────────────────────────────────────────┐
│ AAMDM Architecture │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:用户命令(轨迹、方向等) │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Autoencoder (编码器/解码器) │ │
│ │ - Encoder: 完整姿态 y → 低维嵌入 xz │ │
│ │ - Decoder: 低维嵌入 xz → 完整姿态 y │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Generation Module (DD-GANs) │ │
│ │ - 从噪声生成初始动作草稿 │ │
│ │ - 仅需 3 步反向扩散 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Polishing Module (ADM) │ │
│ │ - 优化 Generation Module 的输出 │ │
│ │ - 仅需 2 步自回归去噪 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ 输出:低维嵌入 xz → Decoder → 完整姿态 y │
│ │
│ 总去噪步数:T_GAN + T_ADM = 3 + 2 = 5 步 │
│ (标准扩散需要 100+ 步) │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 核心组件
(1) 低维嵌入空间构建
问题:在完整姿态空间(338 维)建模复杂度高、违反运动学约束
解决方案:学习紧凑嵌入向量 \(x_z \in \mathcal{X}_Z\)
自编码器结构:
-
Encoder: \(E_{AE}(y) \to z\)
- 输入:完整姿态 \(y \in \mathbb{R}^{338}\)
- 输出:潜在向量 \(z \in \mathbb{R}^{52}\)
-
Decoder: \(D_{AE}(x_z) \to \hat{y}\)
- 输入:嵌入向量 \(x_z = [x; z] \in \mathbb{R}^{64}\)
- 输出:重建姿态 \(\hat{y}\)
训练损失: $$\mathcal{L}{D,E} = w{val}^{D,E}\mathcal{L}{val}^{D,E} + w{vel}^{D,E}\mathcal{L}{vel}^{D,E} + w{reg}^{D,E}\mathcal{L}_{reg}^{D,E}$$
其中:
- 位置损失:\(\mathcal{L}_{val}^{D,E} = ||\hat{y} \ominus y|| + ||F(\hat{y}) \ominus F(y)||\)
- 速度损失:\(\mathcal{L}_{vel}^{D,E} = ||\frac{F(\hat{y}_0) \ominus F(\hat{y}_1)}{\delta n} - \frac{F(y_0) \ominus F(y_1)}{\delta n}||\)
- 正则化:\(\mathcal{L}_{reg}^{D,E} = ||z||_2^2\)
\(F\) 是正向运动学函数,\(\ominus\) 计算两姿态差异
(2) 自回归扩散模型 (ADM) - Polishing Module
为什么用扩散模型:
- 角色动画本质是多模态的(同一姿态可有多种后续姿态)
- 传统 MSE 损失的网络只能学习一对一映射,无法捕捉多模态
前向扩散: $$q(xz_n^t | xz_n^{t-1}) = \mathcal{N}(\sqrt{\alpha_t} xz_n^{t-1}, (1-\alpha_t)I)$$
反向扩散: $$\hat{xz}n^0 = G{ADM}(xz_n^t, xz_{n-1}, t)$$
- 输入:带噪声的嵌入 \(xz_n^t\)、前一帧嵌入 \(xz_{n-1}\)、时间步 \(t\)
- 输出:干净的嵌入预测 \(\hat{xz}_n^0\)
训练损失(h 帧序列): $$\mathcal{L}{ADM} = w{val}^{ADM}||\hat{xz}{1:h}^0 - xz{1:h}|| + w_{vel}^{ADM}||\frac{\hat{xz}{1:h}^0 - \hat{xz}{0:h-1}^0}{h \cdot \delta n} - \frac{xz_{1:h} - xz_{0:h-1}}{h \cdot \delta n}||$$
(3) Denoising Diffusion GANs (DD-GANs) - Generation Module
问题:标准扩散假设去噪是高斯分布,需要多步去噪
解决方案:用多模态分布参数化反向扩散
反向扩散生成器: $$\hat{xz}n^0 = G{GAN}(xz_n^T, xz_{n-1}, r_t, t)$$
- 额外输入:潜在变量 \(r_t \sim \mathcal{N}(0, I)\)
- 将反向扩散参数化为条件 GAN
判别器训练: $$\mathcal{L}_{DGAN} = -\mathbb{E}q[\log(D{GAN})] - \mathbb{E}p[\log(1 - D{GAN})]$$
生成器训练: $$\mathcal{L}_{GGAN} = -\mathbb{E}p[\log(D{GAN})]$$
(4) 组合 ADM + DD-GANs
关键洞察:
- 扩散早期:从噪声生成样本(需要多模态能力)
- 扩散晚期:对预测做小幅调整(需要精确性)
两阶段生成:
Generation Module (DD-GANs):
输入:随机噪声 xz_n^T ~ N(0, I)
过程:T_GAN = 3 步反向扩散
输出:初始草稿 xz_n^{T_ADM}
Polishing Module (ADM):
输入:初始草稿 xz_n^{T_ADM}
过程:T_ADM = 2 步自回归去噪
输出:最终嵌入 xz_n^0
总步数:T_AA = T_GAN + T_ADM = 5 步
优势:
- DD-GANs 提供快速草稿生成(单步)
- ADM 提供质量优化(自回归精修)
- 两者结合实现速度 + 质量的平衡
(5) 用户命令引导
引导扩散公式: $$\hat{xz}_{n}^{0,*} = \hat{xz}n^0 - \epsilon \alpha_t \nabla{xz_n^t} \mathcal{J}(\hat{xz}_n^0, \bar{x}_n)$$
- \(\bar{x}_n\): 用户查询(如目标轨迹)
- \(\mathcal{J}\): 目标函数,测量生成特征与用户查询的距离
- \(\epsilon\): 步长参数
- \(\alpha_t\): 扩散噪声参数
四、训练细节
4.1 数据集
LaFAN1 Dataset:
- 包含多样化角色动作
- 用于主要评估和对比
4.2 模型配置
| 组件 | 维度/参数 |
|---|---|
| 完整姿态 \(y\) | 338 维 |
| 潜在向量 \(z\) | 52 维 |
| 工程特征 \(x\) | 12 维(未来轨迹 + 朝向) |
| 嵌入向量 \(x_z\) | 64 维 |
| Generation 步数 \(T_{GAN}\) | 3 步 |
| Polishing 步数 \(T_{ADM}\) | 2 步 |
| 总步数 \(T_{AA}\) | 5 步 |
4.3 训练策略
- Generation Module 和 Polishing Module 分开训练
- 使用引导扩散方法进行用户控制
- 在低维嵌入空间训练,降低复杂度
五、实验与结论
5.1 定量对比
对比基线:
- LMM (Learned Motion Matching)
- MotionVAE
- AMDM (Auto-regressive Motion Diffusion Model)
评估指标:
- 运动质量:姿态误差、速度误差
- 多样性:多模态生成能力
- 运行效率:推理时间
结果:AAMDM 在所有指标上均优于基线方法
5.2 消融实验
验证各组件贡献:
- 低维嵌入空间:加速训练和推理
- DD-GANs Generation:提供快速草稿
- ADM Polishing:提升运动质量
5.3 人工多模态数据集分析
目的:验证模型捕捉多模态转换的能力
结果:
- AAMDM 能成功捕捉多模态转移模型
- 比现有方法更适合复杂动作合成
5.4 演示效果
展示 novel motions:
- 用户控制根节点轨迹 + 多样化手臂动作
- 之前方法无法实现的多模态合成
六、局限性
-
仍需要 5 步去噪
- 虽然比标准扩散(100+ 步)快很多
- 但对于某些超低延迟应用可能还不够
-
两模块分开训练
- Generation 和 Polishing 独立训练
- 可能不是全局最优
-
对训练数据依赖
- 动作质量受限于训练数据集多样性
- 数据集中没有的动作类型难以生成
-
引导强度调节
- 需要手动调节引导参数 \(\epsilon\)
- 过强可能导致不自然动作
七、启发
7.1 方法学启发
-
速度 - 质量权衡的设计哲学
- 不追求单模块完美,而是组合多个模块的优势
- DD-GANs(速度)+ ADM(质量)= AAMDM(平衡)
-
低维嵌入空间的价值
- 降低建模复杂度
- 提升训练和推理效率
- 隐含学习运动学约束
-
自回归 + 扩散的结合
- 自回归保证时序连贯性
- 扩散保证多模态能力
- 两者互补
7.2 工程实践启发
-
分阶段生成策略
- 先生成草稿(快速、粗糙)
- 再精修(慢速、精细)
- 类似人类绘画的"先铺色再细化"
-
5 步去噪的实用价值
- 在质量和速度间找到平衡点
- 对于实时应用至关重要
7.3 与相关工作对比
| 方法 | 去噪步数 | 质量 | 多样性 | 速度 |
|---|---|---|---|---|
| 标准扩散 | 100+ | 高 | 高 | 低 |
| DDIM | 50 | 高 | 高 | 中 |
| AAMDM | 5 | 高 | 高 | 高 |
| LMM | 1 | 中 | 低 | 高 |
八、遗留问题
8.1 开放性问题
-
能否进一步减少去噪步数?
- 能否做到 1-2 步生成?
- 一致性模型 (Consistency Models) 是否适用?
-
端到端训练可能性?
- Generation 和 Polishing 联合训练
- 可能获得更好的全局最优
-
更长时序建模?
- 当前是自回归,长序列可能累积误差
- 能否结合 Transformer 等长程建模?
-
与物理引擎结合?
- 加入物理约束引导
- 生成物理合理的动作
8.2 未来方向
-
实时交互应用
- 游戏角色控制
- VR/AR虚拟人
-
多模态条件化
- 文本 + 语音 + 动作联合生成
- 更丰富的用户控制
-
大规模预训练
- 类似ASE的预训练范式
- 通用动作生成模型
九、关键公式总结
| 公式 | 含义 |
|---|---|
| \(\mathcal{L}{D,E} = w{val}\mathcal{L}{val} + w{vel}\mathcal{L}{vel} + w{reg}\mathcal{L}_{reg}\) | 自编码器训练损失 |
| \(q(xz_n^t | xz_n^{t-1}) = \mathcal{N}(\sqrt{\alpha_t} xz_n^{t-1}, (1-\alpha_t)I)\) |
| \(\hat{xz}n^0 = G{GAN}(xz_n^T, xz_{n-1}, r_t, t)\) | DD-GANs 生成 |
| \(\hat{xz}_{n}^{0,*} = \hat{xz}_n^0 - \epsilon \alpha_t \nabla \mathcal{J}\) | 引导扩散 |
| \(T_{AA} = T_{GAN} + T_{ADM} = 3 + 2 = 5\) | 总去噪步数 |
十、代码与资源
- 项目主页: 待公开
- 代码: 论文发表时开源
- 视频: 项目主页提供演示
十一、与 Locomotion 控制的关系
AAMDM 是运动生成的通用框架,可应用于 locomotion 任务:
-
作为上层规划器:
- 生成角色移动轨迹
- 作为底层控制器的输入
-
与物理控制器结合:
- 类似 CLOSD、PDP 的架构
- AAMDM 生成动作 → PD 控制器执行
-
与扩散模型工作的对比:
- DiffuseLoco: 专注于 locomotion,离线 RL 蒸馏
- UniPhys: 统一规划 + 控制
- AAMDM: 通用动作生成,强调速度优化
笔记说明:本文是 CVPR 2024 关于快速动作扩散模型的工作,核心贡献是结合 DD-GANs 和 ADM 实现 5 步去噪的实时动作生成。理解本文有助于学习扩散模型在角色动作生成中的加速方法,与 DiffuseLoco、PDP 等工作形成对比和互补。
DARTControl: A Diffusion-based Autoregressive Motion Model for Real-time Text-driven Motion Control
论文信息: ICLR 2025, Kaifeng Zhao, Gen Li, Siyu Tang, ETH Zürich
一、核心问题
1.1 研究背景
文本条件的角色动作生成近年来变得非常流行,允许用户通过自然语言进行交互。然而,现有方法存在显著局限:
现有方法的局限:
- 短动作生成:大多生成短而孤立的动作片段
- 离线生成:需要预先知道整个动作时间线
- 缺乏空间控制:难以将文本语义与几何约束(如目标位置、3D 场景)对齐
- 生成速度慢:无法用于实时交互应用
1.2 核心问题
如何构建一个实时文本驱动的动作控制系统,能够:
- 生成连续的长序列复杂动作
- 精确响应流式文本描述
- 支持空间约束控制(目标位置、场景几何)
- 实现实时生成和交互
1.3 本文方法
论文提出了 DART (DARText Control) 框架:
核心思想:
- Motion Primitive 表示 - 将长动作分解为重叠的短动作片段
- Latent Diffusion - 在紧凑的 latent space 中学习文本条件的动作生成
- 自回归生成 - 基于历史动作和当前文本输入,实时生成动作
- Latent Space Control - 通过优化或强化学习实现精确空间控制
二、核心贡献
-
DART 模型
- 基于扩散的自回归 motion primitive 模型
- 支持实时文本驱动的动作控制
- 生成连续长序列动作
-
Latent Space Control 框架
- 优化方法:latent noise optimization
- 学习方法:基于 MDP 的强化学习
-
全面实验验证
- 长序列生成、in-betweening、场景条件、目标到达
- 在真实性、效率、可控性上超越基线
三、方法详解
3.1 Motion Primitive 表示
表示形式:
- 每个 primitive \(P^i = [H^i, X^i]\)
- \(H^i\): H 帧历史动作(与前一 primitive 重叠)
- \(X^i\): F 帧未来动作
- 重叠设计保证时序连贯性
参数:
- H=2 帧历史,F=8 帧未来
- 基于 SMPL-X 参数化人体模型
- 每帧 276 维向量
优势:
- 分解复杂序列为短 primitives
- 更适合在线生成
- 增强文本 - 动作对齐
3.2 Latent Diffusion 架构
┌─────────────────────────────────────────────────────────┐
│ DART Architecture │
├─────────────────────────────────────────────────────────┤
│ │
│ VAE Encoder: │
│ 输入:History H + Future X │
│ 输出:Latent z ~ N(μ, σ) │
│ │
│ Latent Denoiser: │
│ 输入:Noisy z_t + Text c + History H + timestep t │
│ 输出:Clean z_0 │
│ │
│ VAE Decoder: │
│ 输入:Latent z + History H │
│ 输出:Future X │
│ │
└─────────────────────────────────────────────────────────┘
训练流程:
- 先训练 VAE 学习 latent motion primitive space
- 固定 VAE 权重,训练 latent denoiser
3.3 自回归生成
Algorithm 1: Autoregressive Rollout
输入:种子动作 H_seed, 文本序列 C=[c_1,...,c_N]
输出:连续动作序列 M
H ← H_seed
M ← H_seed
for i = 1 to N:
采样噪声 z_T ~ N(0,I)
去噪:z_0 = Denoiser(z_T, T, H, c_i)
解码:X = Decoder(H, z_0)
M ← Concat(M, X)
H ← Canonicalize(X[-H:]) # 更新历史
return M
优势:
- 10x 加速相比离线方法(FlowMDM)
- 支持任意长度动作生成
- 实时响应文本输入
3.4 Latent Space Control
方法 1: 优化方法
问题:给定空间目标 g(如关键帧姿态、轨迹),找到合适的 latent noise
优化目标: $$\min_{z_T} \mathcal{L}_{spatial}(Dec(Denoise(z_T))) + \lambda ||z_T||^2$$
- 第一项:空间控制误差
- 第二项:latent 正则化
方法 2: 强化学习方法
MDP 定义:
- 状态:当前动作历史 + 文本 + 空间目标
- 动作:latent noise \(z_T\)
- 奖励:空间目标达成度 + 动作质量
训练:PPO 或其他 RL 算法
四、实验与结论
4.1 评估任务
- 长序列生成:从连续文本提示生成长动作
- In-betweening:生成两个姿态间的过渡动作
- 场景条件:在 3D 场景中生成避障动作
- 目标到达:生成到达指定位置的动作
4.2 对比基线
- MotionVAE: VAE-based 自回归模型
- MDM: 标准扩散模型
- FlowMDM: 最先进的时序组合方法
4.3 评估指标
| 指标 | 含义 |
|---|---|
| FID | 动作质量(越低越好) |
| Diversity | 多样性(越高越好) |
| Multimodality | 多模态能力 |
| R-Precision | 文本 - 动作对齐 |
| Runtime | 推理速度 |
4.4 主要结果
- 质量:FID 优于基线
- 多样性:与基线相当或更好
- 速度:10x 加速 vs FlowMDM
- 可控性:精确空间控制
五、局限性
-
Primitive 长度固定
- 当前 H=2, F=8
- 可能不适合所有动作类型
-
Latent space 容量
- 紧凑表示可能限制复杂性
-
优化方法收敛
- 可能需要多次迭代
六、启发
6.1 方法学启发
-
Motion Primitive 设计
- 重叠表示保证连贯性
- 短片段更适合扩散建模
-
Latent Space Control
- 在 latent space 操作更高效
- 统一优化和学习框架
-
自回归 + 扩散
- 结合实时性和质量
6.2 与相关工作对比
| 方法 | 实时 | 文本控制 | 空间控制 | 长序列 |
|---|---|---|---|---|
| DART | ✓ | ✓ | ✓ | ✓ |
| FlowMDM | ✗ | ✓ | △ | ✓ |
| MDM | ✗ | ✓ | ✗ | ✗ |
| MotionVAE | ✓ | △ | △ | ✓ |
七、关键公式
$$z \sim \mathcal{N}(\mu, \sigma), \quad \hat{X} = Dec(z, H)$$
$$z_0 = Denoiser(z_t, t, H, c)$$
$$\min_{z_T} \mathcal{L}_{spatial} + \lambda ||z_T||^2$$
笔记说明:DART 是 ICLR 2025 工作,核心是实时文本驱动的动作控制,支持长序列生成和空间约束。与 AAMDM 相比,DART 更强调文本接口和 latent space control。
Interactive Character Control with Auto-Regressive Motion Diffusion Models (A-MDM)
论文信息: ACM TOG 2024 (SIGGRAPH), Yi Shi et al., Shanghai AI Lab / Simon Fraser University / NVIDIA
一、核心问题
1.1 研究背景
实时角色控制是交互式体验(游戏、VR、物理仿真)的核心组件。扩散模型在动作合成中的应用越来越广泛,但现有方法存在局限:
现有扩散模型的局限:
- 离线生成:大多数是 space-time 模型,同时生成整个序列
- 固定长度:需要预先指定序列长度
- 无法实时控制:不支持时变控制信号
- 计算成本高:通常需要 1000 步去噪
1.2 核心问题
如何构建一个实时动作合成框架,能够:
- 支持时变控制输入
- 逐帧生成连续动作
- 在适度计算资源下实时运行
- 适应各种下游任务
1.3 本文方法
论文提出了 A-MDM (Auto-regressive Motion Diffusion Model) 框架:
核心思想:
- 自重新设计扩散模型 - 从 space-time 改为 auto-regressive
- 轻量级设计 - 仅需 50 步去噪(vs 1000 步)
- 简单架构 - 使用 MLP 即可
- 控制套件 - task-oriented sampling, in-painting, hierarchical RL
二、核心贡献
-
A-MDM 模型
- 自回归扩散模型,适合实时交互
- 比 VAE-based 模型更多样化
- 仅需 50 步去噪
-
控制方法套件
- Task-oriented sampling
- Motion in-painting
- Keyframe in-betweening
- Hierarchical reinforcement learning
-
无需微调适配新任务
- 预训练模型可直接用于下游任务
- 无需额外训练或 fine-tuning
三、方法详解
3.1 自回归扩散公式
传统 Space-Time 模型: $$p(x_{1:T}) = \text{一次性生成所有帧}$$
A-MDM 自回归公式: $$p(x_{1:T}) = \prod_{t=1}^{T} p(x_t | x_{1:t-1})$$
每帧生成:
- 输入:前一帧姿态 \(x_{t-1}\)
- 输出:当前帧 \(x_t\)
- 去噪步数:50 步(vs 1000 步)
3.2 网络架构
┌─────────────────────────────────────────────────────────┐
│ A-MDM Architecture │
├─────────────────────────────────────────────────────────┤
│ │
│ 输入:前一帧姿态 + 控制信号 │
│ ↓ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ MLP Backbone (简单但有效) │ │
│ │ - 3 层 MLP │ │
│ │ - 条件输入:控制信号、时间步 │ │
│ └─────────────────────────────────────────────────┘ │
│ ↓ │
│ 输出:当前帧姿态 │
│ │
└─────────────────────────────────────────────────────────┘
设计选择:
- 简单 MLP: 无需复杂 Transformer
- 轻量级: 适合实时运行
- 条件扩散: 支持多种控制信号
3.3 控制技术套件
(1) Task-Oriented Sampling
思想:在采样过程中引导生成符合任务目标
方法:
- 在去噪过程中添加引导项
- 类似 classifier guidance
(2) Motion In-Painting
任务:填充动作序列中的缺失部分
方法:
- 固定已知帧
- 对未知帧进行扩散采样
- 迭代优化边界
(3) Keyframe In-Betweening
任务:生成两个关键帧之间的过渡动作
方法:
- 条件扩散,边界条件固定
- 自回归生成中间帧
(4) Hierarchical Reinforcement Learning
框架:
高层策略 (Policy)
↓ (latent code / control signal)
A-MDM (动作生成器)
↓ (动作序列)
底层控制器 (执行)
训练:
- A-MDM 固定(预训练)
- 只训练高层策略
- 减少训练成本
四、训练细节
4.1 数据集
AMASS: 大规模动作捕捉数据集
- 包含多样化动作
- 用于预训练基础模型
4.2 训练配置
| 参数 | 值 |
|---|---|
| 去噪步数 | 50 |
| 网络架构 | 3 层 MLP |
| 隐藏层维度 | 512 |
| 批大小 | 根据 GPU 调整 |
4.3 加速技巧
-
减少去噪步数
- 从 1000 步降至 50 步
- 质量 - 速度权衡
-
简单架构
- MLP vs Transformer
- 更快推理
-
自回归生成
- 每帧独立生成
- 支持在线控制
五、实验与结论
5.1 评估任务
- Joystick Control:摇杆控制角色移动
- Target Reaching:到达指定目标
- Trajectory Tracking:跟踪轨迹
- In-painting:动作补全
- In-betweening:关键帧过渡
5.2 对比基线
- MVAE [Ling et al. 2020]
- Humor [Rempe et al. 2021]
- MDM [Tevet et al. 2023]
5.3 评估指标
| 指标 | 含义 |
|---|---|
| FID | 动作质量 |
| Diversity | 多样性 |
| FC | 脚部滑动 |
| Inference Time | 推理时间 |
5.4 主要结果
- 质量:FID 优于或等于 SOTA
- 多样性:超越 VAE-based 方法
- 速度:实时运行(50 步去噪)
- 可控性:支持多种下游任务
六、局限性
-
自回归误差累积
- 长序列可能 drift
- 需要误差校正机制
-
50 步去噪仍较慢
- 对于超低延迟应用
- 可进一步加速
-
MLP 表达能力
- 对于复杂动作可能不足
- 可在需要时升级架构
七、启发
7.1 方法学启发
-
自回归扩散的价值
- 支持实时交互
- 比 space-time 更灵活
-
轻量级设计
- 简单 MLP 也能有效
- 不必追求复杂架构
-
预训练 + 控制范式
- 基础模型固定
- 通过控制适配任务
- 减少训练成本
7.2 与相关工作对比
| 方法 | 架构 | 去噪步数 | 实时 | 控制 |
|---|---|---|---|---|
| A-MDM | MLP | 50 | ✓ | 多种 |
| MDM | Transformer | 1000 | ✗ | 文本 |
| MVAE | VAE | 1 | ✓ | 有限 |
| AAMDM | DD-GAN+ADM | 5 | ✓ | 轨迹 |
八、关键公式
自回归公式: $$p(x_{1:T}) = \prod_{t=1}^{T} p(x_t | x_{1:t-1})$$
去噪过程: $$x_t = \text{Denoiser}(x_{t-1}, \epsilon, T)$$
引导采样: $$\tilde{\epsilon} = \epsilon - \alpha \nabla \mathcal{L}_{task}$$
笔记说明:A-MDM 是 SIGGRAPH 2024 工作,核心是将扩散模型重新设计为自回归形式,实现实时角色控制。与 AAMDM 相比,A-MDM 强调控制套件和下游任务适配能力。
Taming Diffusion Probabilistic Models for Character Control (CAMDM)
论文信息: ACM TOG 2024 (SIGGRAPH), Rui Chen et al., Tencent AI Lab / HKU / HKUST
一、核心问题
1.1 研究背景
实时角色控制是计算机动画的"圣杯",在游戏、VR 等领域至关重要。现有方法面临三大挑战:
挑战 1:质量与多样性
- 质量:生成视觉真实的动作
- 多样性:
- 风格内多样性 (intra-style):同一风格内的变化
- 风格间多样性 (inter-style):不同风格间的变化
挑战 2:可控性
- 响应高层、粗略的用户控制信号
- 控制参数:风格/步态、速度、朝向、轨迹等
挑战 3:计算效率
- 平衡计算效率与视觉真实感
- 实时响应动态用户输入
1.2 现有方法的局限
| 方法 | 代表工作 | 质量问题 | 多样性问题 | 实时性 |
|---|---|---|---|---|
| 确定性模型 | PFNN | 回归均值姿态 | 无多样性 | ✓ |
| VAE | MVAE | 质量中等 | 有限多样性 | ✓ |
| 扩散模型 | MDM | 高质量 | 高多样性 | ✗ (1000 步) |
| Motion Matching | 工业界 | 高质量 | 有限 | △ |
关键问题:
- 确定性模型(如 PFNN)回归均值姿态,导致 artifacts(滑脚、运动范围减小)
- 扩散模型需要 1000 步去噪,无法实时运行
- 风格转换数据在 mocap 中缺失,难以实现 inter-style 多样性
1.3 本文方法
论文提出了 CAMDM (Conditional Autoregressive Motion Diffusion Model) 框架:
核心思想:
- 自回归扩散 - 逐帧生成,支持实时控制
- 分离条件 tokenization - 每个控制条件独立 token
- Classifier-free guidance - 在历史 motion 上实现风格转换
- 启发式轨迹扩展 - 解决预测轨迹缺失问题
- 仅 8 步去噪 - 实现实时响应
二、核心贡献
-
首个实时高质量多样角色动画模型
- 基于用户交互控制
- 单一统一模型支持多风格
- 仅 8 步去噪
-
关键算法设计
- 分离条件 tokenization
- 历史 motion 的 classifier-free guidance
- 启发式未来轨迹扩展
-
全面实验验证
- 大规模 locomotion 数据集
- 超越现有角色控制器
三、方法详解
3.1 整体架构
┌─────────────────────────────────────────────────────────────────┐
│ CAMDM Architecture │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入: │
│ - 历史动作 (History Motion) │
│ - 控制信号 (Control Signals) │
│ · 风格/步态 (Style/Gait) │
│ · 移动速度 (Speed) │
│ · 朝向方向 (Facing Direction) │
│ · 未来轨迹 (Future Trajectory) │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Transformer Encoder │ │
│ │ - 分离条件 Tokenization │ │
│ │ - 自注意力机制融合条件 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Diffusion Denoiser (8 步) │ │
│ │ - Classifier-free guidance on history │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 输出:未来动作帧 │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 关键技术
(1) 分离条件 Tokenization
问题:传统方法将所有条件表示为单一特征向量,某些分量可能主导导致控制不稳定
解决方案:为每个条件学习独立 token
传统方法:[速度,方向,轨迹,风格] → 单一向量 → 可能失衡
CAMDM: 速度→token_1, 方向→token_2, 轨迹→token_3, 风格→token_4
↓
Transformer Attention 自动平衡各条件影响
优势:
- 利用 Transformer 注意力机制
- 每个条件独立作用
- 控制更稳定
(2) Classifier-Free Guidance on History
问题:风格转换数据在 mocap 中缺失,直接训练风格标签的 guidance 失败
解决方案:在历史动作 token 上应用 classifier-free guidance
训练:
- 随机丢弃历史动作条件
- 学习条件模型和无条件模型
推理: $$\tilde{\epsilon} = \epsilon_{history} + w \cdot (\epsilon_{history} - \epsilon_{uncond})$$
效果:
- 实现自然风格转换
- 即使训练数据中没有转换动作
(3) 启发式未来轨迹扩展(HFTE)⭐
问题背景:
训练时:模型预测长未来动作,使用尽可能多帧提升多样性("lazy trigger"策略)
推理时:用户输入的轨迹会覆盖模型预测轨迹,导致突兀抖动
直观理解:
想象你在画画:
- 你已经画了一条曲线的前半段
- 现在需要延长这条曲线
- 你不会直接从终点开始画一条新线
- 你会顺着最后的笔势继续画
HFTE 做的就是同样的事情!
核心思想:
回收上次预测轨迹的最后 K 帧,启发式扩展到用户提供的更长轨迹
Figure 3: HFTE 原理图
- Top: 没有 HFTE 时,模型预测轨迹(短)和用户合成轨迹(长)直接拼接 → 跳变
- Bottom: 有 HFTE 时,回收最后 K 帧并翻转复制 → 平滑扩展
详细步骤:
步骤 1:回收最后 K 帧
==================
模型预测轨迹:[p_1, p_2, ..., p_{F-K}, ..., p_F]
↑
取最后 K=4 帧
步骤 2:建立局部坐标系
==================
以最后一个点 p_F 为原点
朝向为 p_F 的方向
步骤 3:翻转 + 复制
==================
在局部坐标系中:
- 位置翻转:(x, z) → (-x, -z)
- 朝向复制:保持不变
步骤 4:重复直到长度匹配
==================
[原始 10 帧] + [扩展 4 帧] + [再扩展 4 帧] + ...
直到总长度 = 用户需要的长度
数学公式:
设局部坐标系变换为 $T_F$(由 $p_F$ 的位置和朝向决定):
$$p'{F+k} = T_F \cdot \text{Flip}(p{F-k})$$
其中 $\text{Flip}(x, z) = (-x, -z)$
为什么有效?
| 方案 | 位置连续 | 朝向连续 | 计算成本 |
|---|---|---|---|
| HFTE | ✓ | ✓ | 几乎为零 |
| 线性插值 | ✓ | ✗ | 低 |
| 直接拼接 | ✗ | ✗ | 零 |
效果:
- 消除跳变(jittering)
- 轨迹误差从 15.2cm 降至 4.7cm
- 用户主观评分从 3.1 提升至 4.6/5
(4) 8 步去噪加速
扩散步数对比:
- 标准扩散:1000 步
- DDIM:50-100 步
- CAMDM: 8 步
实现实时:
- 8 步去噪 ≈ 几毫秒
- 支持 60+ FPS
四、训练细节
4.1 数据集
大规模公开 mocap 数据集:
- 包含多样化 locomotion 技能
- 行走、跑步、跳跃等
4.2 训练配置
| 参数 | 值 |
|---|---|
| 去噪步数 | 8 |
| 架构 | Transformer |
| 历史长度 | 多帧 |
| 未来预测长度 | 多帧 |
| Guidance scale | 可调 |
4.3 训练策略
- 自回归训练:预测未来动作
- 条件丢弃:实现 classifier-free guidance
- 长未来预测:提升多样性
五、实验与结论
5.1 评估任务
-
多风格 locomotion
- 行走、跑步、跳跃
- 风格间平滑转换
-
实时控制
- 速度调节
- 方向控制
- 轨迹跟踪
-
多样性生成
- 相同输入产生不同输出
- 风格内变化
5.2 对比基线
- PFNN [Holden et al. 2017]
- MVAE [Ling et al. 2020]
- Motion Matching (工业标准)
5.3 评估指标
| 指标 | 含义 |
|---|---|
| FID | 动作质量 |
| Diversity | 多样性 |
| Foot Skating | 滑脚程度 |
| Runtime | 运行时间 |
| Control Accuracy | 控制精度 |
5.4 主要结果
- 质量:FID 优于 PFNN 和 MVAE
- 多样性:显著超越确定性模型
- 实时性:60+ FPS
- 控制:精确响应用户输入
- 风格转换:平滑自然
5.5 消融实验
验证关键设计:
- 分离条件 tokenization:控制更稳定
- Classifier-free guidance on history:风格转换有效
- 启发式轨迹扩展:避免抖动
六、局限性
-
8 步去噪仍有优化空间
- 可进一步减少到 1-4 步
-
依赖 mocap 数据
- 数据中没有的技能难以生成
-
自回归累积误差
- 长序列可能 drift
七、启发
7.1 方法学启发
-
扩散模型实时化的可行性
- 8 步去噪证明实时扩散可行
- 关键在于合适的设计
-
Classifier-free guidance 的灵活应用
- 不一定要在直观的条件上应用
- 历史动作也能有效引导
-
分离表示的价值
- 避免特征主导问题
- Transformer 注意力自动平衡
7.2 与相关工作对比
| 方法 | 去噪步数 | 实时 | 多样性 | 风格转换 |
|---|---|---|---|---|
| CAMDM | 8 | ✓ | 高 | ✓ |
| MDM | 1000 | ✗ | 高 | △ |
| A-MDM | 50 | ✓ | 高 | △ |
| AAMDM | 5 | ✓ | 高 | △ |
| PFNN | 0 | ✓ | 无 | ✗ |
八、关键公式
Classifier-free guidance: $$\tilde{\epsilon} = \epsilon_{cond} + w \cdot (\epsilon_{cond} - \epsilon_{uncond})$$
自回归生成: $$x_t = \text{Denoiser}(x_{1:t-1}, \text{conditions}, \epsilon, T)$$
轨迹扩展: $$\text{Extended} = \text{Heuristic}(\text{Last Fraction})$$
笔记说明:CAMDM 是 SIGGRAPH 2024 工作,核心贡献是首次实现实时高质量多样角色动画的扩散模型。关键创新包括分离条件 tokenization、历史动作的 classifier-free guidance、8 步去噪加速。与 AAMDM、A-MDM 相比,CAMDM 更强调风格转换和实时控制能力。
Learned Motion Matching
论文信息: ACM SIGGRAPH 2020, Daniel Holden et al., Ubisoft La Forge / Concordia University
一、核心问题
1.1 研究背景
在游戏工业中,Motion Matching 是主流的角色动画技术,但存在内存限制问题。同时,神经网络生成模型虽然扩展性好,但质量不如 Motion Matching。
Motion Matching 的优势:
- 灵活性高
- 行为可预测
- 预处理时间短
- 视觉质量高
Motion Matching 的局限:
- 内存使用随数据量线性增长
- 无法利用强大数据处理方法(如数据增强)
- 在多样性和预算间需要权衡
神经网络模型的优势:
- 内存使用低
- 数据扩展性好
- 运行时评估快
神经网络模型的局限:
- 难以控制
- 行为不可预测
- 训练时间长
- 质量可能低于训练集
1.2 核心问题
如何构建一个学习型的 Motion Matching 替代方案,能够:
- 保留 Motion Matching 的优点(质量、控制、迭代时间)
- 具有神经网络的扩展性(低内存、数据可扩展)
- 无需存储动画数据和匹配元数据
1.3 本文方法
论文提出了 Learned Motion Matching 框架:
核心思想:
- 将 Motion Matching 算法分解为独立步骤
- 用学习的、可扩展的替代方案替换每个操作
- 三个专用神经网络:Decompressor、Projector、Stepper
二、核心贡献
-
Learned Motion Matching 算法
- 用三个神经网络替换 Motion Matching 的三阶段
- 无需存储任何数据库
- 内存扩展性与神经网络相当
-
保留 Motion Matching 行为
- 质量、控制、快速迭代时间
- 工业界友好的特性
-
State-of-the-art 结果
- 动画质量
- 运行时性能
- 内存使用
三、方法详解
3.1 Basic Motion Matching 回顾
算法流程:
每 N 帧执行:
1. 搜索动画数据库
2. 找到最佳匹配当前帧
3. 如果找到更低成本帧,插入过渡
4. 继续播放
特征向量 x ∈ R^27:
- tt ∈ R^6: 未来轨迹位置 (20, 40, 60 帧)
- td ∈ R^6: 未来朝向方向
- ft ∈ R^6: 过去轨迹位置
- ˙ft ∈ R^6: 过去轨迹速度
- ˙ht ∈ R^3: 根节点高度速度
三阶段:
- Projection: 最近邻搜索找到最佳匹配
- Stepping: 推进 Matching Database 索引
- Decompression: 从 Animation Database 查找姿态
加速结构:
- KD-Tree
- Voxel-based lookup
- Clustering
- 自定义两层 BVH
3.2 Learned Motion Matching 架构
┌─────────────────────────────────────────────────────────────────┐
│ Learned Motion Matching │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:查询特征向量 ˆx │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Projector Network │ │
│ │ 输入:ˆx │ │
│ │ 输出:最近邻索引 k* │ │
│ │ 替代:最近邻搜索 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Stepper Network │ │
│ │ 输入:当前索引 k* │ │
│ │ 输出:下一帧索引 │ │
│ │ 替代:数据库索引推进 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Decompressor Network │ │
│ │ 输入:特征向量 x + 潜变量 z │ │
│ │ 输出:姿态 y │ │
│ │ 替代:动画数据库查找 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ 输出:角色姿态 │
│ │
│ 关键:无需存储任何数据库! │
│ │
└─────────────────────────────────────────────────────────────────┘
3.3 三个核心网络
(1) Decompressor Network
目的:从特征向量重建姿态,无需存储 Animation Database
输入:
- 特征向量 \(x\)
- 潜变量 \(z\)(通过 Encoder 找到)
输出:姿态 \(y\)
训练:
- Encoder-Decoder 架构
- Encoder: \(y \to z\)
- Decoder: \((x, z) \to \hat{y}\)
- 损失:\(||y - \hat{y}||^2\)
优势:
- 无需存储姿态数据库
- 支持多样性(通过不同 \(z\))
(2) Projector Network
目的:执行最近邻搜索,无需存储 Matching Database
输入:查询特征向量 \(\hat{x}\)
输出:最近邻索引 \(k^*\)
训练:
- 监督学习
- 真实标签:实际最近邻索引
- 损失:交叉熵或对比损失
优势:
- 无需加速结构(KD-Tree 等)
- 固定推理时间
(3) Stepper Network
目的:预测下一帧索引,无需手动推进
输入:当前索引 \(k^*\)
输出:下一帧索引
训练:
- 从数据中学习过渡模式
- 损失:预测索引 vs 真实下一帧
优势:
- 学习平滑过渡
- 处理非线性时间推进
3.4 网络变体
根据需求,可使用不同组合:
| 变体 | 使用网络 | 特点 |
|---|---|---|
| Full | Decompressor + Projector + Stepper | 完整替代 |
| Partial | 任意组合 | 根据需求调整 |
| Hybrid | 部分网络 + 部分数据库 | 过渡方案 |
四、训练细节
4.1 数据集
- 大规模动捕数据集
- 包含多样化 locomotion 动作
- 用于训练三个网络
4.2 训练配置
| 网络 | 架构 | 输入维度 | 输出维度 |
|---|---|---|---|
| Decompressor | MLP | 27 + latent | 姿态维度 |
| Projector | MLP | 27 | 索引 (分类) |
| Stepper | MLP | 索引 | 索引 (分类) |
4.3 训练策略
-
预训练 Decompressor
- 先训练 Encoder-Decoder
- 学习姿态 - 特征映射
-
训练 Projector
- 使用预训练的 Decompressor
- 监督学习最近邻预测
-
训练 Stepper
- 基于 Projector 输出
- 学习过渡模式
五、实验与结论
5.1 评估任务
-
Locomotion 控制
- 行走、跑步、跳跃
- 轨迹跟踪
-
复杂场景
- 崎岖地形
- 角色交互
- 场景道具使用
5.2 对比基线
- Motion Matching (原始算法)
- PFNN [Holden et al. 2017]
- 神经网格生成模型
5.3 评估指标
| 指标 | 含义 |
|---|---|
| Memory Usage | 内存占用 |
| Runtime | 运行时间 |
| Animation Quality | 动画质量 |
| Control Accuracy | 控制精度 |
5.4 主要结果
内存对比: | 方法 | 内存 | |------|------| | Motion Matching | 随数据线性增长 | | Learned MM | 固定(网络权重)|
性能对比:
- 动画质量:与 Motion Matching 相当
- 运行时间:实时
- 迭代时间:快速
5.5 工业应用
- 已用于多个 AAA 游戏
- 支持复杂交互场景
- 与现有工具链兼容
六、局限性
-
训练时间
- 需要训练多个网络
- 比原始 Motion Matching 长
-
精度损失
- 网络预测 vs 精确搜索
- 可能有轻微质量下降
-
泛化能力
- 依赖训练数据
- 新动作需要重新训练
七、启发
7.1 方法学启发
-
算法分解思想
- 将复杂算法分解为独立阶段
- 逐阶段用学习替代
-
工业界友好设计
- 保留原有行为
- 改进关键限制
-
混合方案可能性
- 部分网络 + 部分数据库
- 灵活权衡
7.2 与相关工作对比
| 方法 | 内存 | 质量 | 控制 | 扩展性 |
|---|---|---|---|---|
| Learned MM | 低 | 高 | 高 | 高 |
| Motion Matching | 高 | 高 | 高 | 低 |
| PFNN | 低 | 中 | 高 | 中 |
| VAE | 低 | 中 | 中 | 高 |
八、关键公式
原始 Motion Matching: $$k^* = \arg\min_k ||\hat{x} - x_k||^2$$
Learned Decompressor: $$\hat{y} = \text{Decoder}(x, z), \quad z = \text{Encoder}(y)$$
Learned Projector: $$k^* = \text{Projector}(\hat{x})$$
Learned Stepper: $$k_{next} = \text{Stepper}(k^*)$$
笔记说明:Learned Motion Matching 是 SIGGRAPH 2020 工业向工作,核心贡献是将 Motion Matching 三阶段用神经网络替代,在保留质量的同时实现低内存占用。这是工业界 (Ubisoft) 与学术界合作的典范,展示了如何用深度学习改进现有技术而非完全替代。
MOCHA: Real-Time Motion Characterization via Context Matching
论文信息: ACM SIGGRAPH Asia 2023, Deok-Kyeong Jang et al., KAIST / Meta / Seoul National University
一、核心问题
1.1 研究背景
将中性、无特征的动作转换为体现特定角色风格的动作在实时角色动画中极具吸引力。
应用场景:
- 游戏中将玩家动作转换为特定角色风格(如僵尸、公主、小丑)
- VR/AR 中实时角色表征
- 电影动画中的批量角色生成
1.2 现有方法的局限
Motion Style Transfer 的局限:
- 离线处理:无法实时运行
- 风格与上下文分离:假设风格是上下文无关的
- 仅转换风格:不处理身体比例差异
- 需要 retargeting:额外步骤适配不同体型
关键观察:
风格是上下文相关的。例如,"快乐"在跳跃动作中的表现与在爬行动作中不同,其特征不可互换。
1.3 核心问题
如何构建一个实时角色表征框架,能够:
- 同时转换动作风格和身体比例
- 保持上下文一致性
- 实时运行(60 FPS)
- 支持稀疏输入(如 VR tracker)
1.4 本文方法
论文提出了 MOCHA (Motion Characterization via Context Matching) 框架:
核心思想:
- 当用户执行动作时,搜索目标角色最相似上下文的动作
- 将找到的动作风格元素转换到用户动作
- 用 Neural Context Matcher 替代数据库搜索
关键创新:
- Neural Context Matcher (NCM):生成与输入动作上下文匹配的目标动作特征
- Characterizer with AdaIN:通过 transformer 将角色特征注入源特征
- 同时风格转换 + 重定向:无需额外 retargeting 步骤
二、核心贡献
-
首个在线角色表征框架
- 同时转运动作风格和身体比例
- 实时运行
-
Neural Context Matcher
- 条件 VAE + 自回归生成
- 生成时间连贯的动作特征
-
Characterizer Transformer
- AdaIN + Cross-Attention
- 有效注入角色特征
-
高质量数据集
- 6 个不同角色
- 多样化动作
三、方法详解
3.1 整体架构
┌─────────────────────────────────────────────────────────────────┐
│ MOCHA Framework │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:Source Motion (中性动作) │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Bodypart Encoder │ │
│ │ - 将人体分为 6 个部分 │ │
│ │ - 捕捉运动依赖关系 │ │
│ │ 输出:Source Feature │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Neural Context Matcher (NCM) │ │
│ │ - 生成 Target Character Feature │ │
│ │ - 最相似上下文匹配 │ │
│ │ - Conditioned VAE + Autoregressive │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Characterizer │ │
│ │ - Transformer Decoder │ │
│ │ - AdaIN + Cross-Attention │ │
│ │ - 注入角色特征到源特征 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ 输出:Characterized Motion (带角色风格的动作) │
│ │
└─────────────────────────────────────────────────────────────────┘
3.2 动作表示
参考帧定义:
root_i:当前帧 i 的骨盆关节地面投影- 对齐地面法线和骨盆朝前方向
两种表示: $$X_i = [x]{i-(T-1)}^i, \quad x = [x^t_j, x^r_j, \dot{x}^t_j, \dot{x}^r_j]$$ $$Y_i = [y]{i-(T-1)}^i, \quad y = [y^t_j, y^r_j, \dot{y}^t_j, \dot{y}^r_j]$$
- \(x\): 相对于 root 的关节位置/旋转/速度
- \(y\): 相对于父节点的关节位置/旋转/速度
- \(T=60\) 帧(1 秒)
- 维度:\(R^{T \times n_{joint} \times 15}\)
3.3 Neural Context Matcher (NCM)
目的:生成与源动作上下文匹配的目标角色动作特征
架构:Conditioned VAE + Autoregressive
训练阶段:
Source Context → Prior Net → Latent s_i
↓
NCM Decoder → Target Character Feature
推理阶段:
Source Context → Prior Net → Sample s_i
↓
NCM Decoder → Target Character Feature
Prior Network: $$p(s_i | z_{i-1}^{cha}, f(z_i^{src})) = \mathcal{N}(\mu, \sigma)$$
NCM Decoder: $$z_i^{cha} = D_v(s_i, z_{i-1}^{cha}, f(z_i^{src}))$$
自回归生成:
- 每次生成一帧
- 条件于前一帧特征和当前源上下文
- 保证时间连贯性
3.4 Context Mapping
目的:创建与角色无关的上下文空间
特点:
- 跨角色域共享上下文信息
- 实现不同角色间的上下文匹配
- 从无标签数据中学习
损失函数:
- 重建损失
- Contrastive Loss(增强区分性)
3.5 Characterizer
目的:将目标角色特征的风格注入源特征
架构:Transformer Decoder + AdaIN + Cross-Attention
输入:Source Feature + Character Feature
↓
Transformer Decoder Block
- Self-Attention: 源特征内部关系
- Cross-Attention: 角色特征→源特征
- AdaIN: 自适应实例归一化
↓
输出:Translated Feature
↓
De-STGCN Upsample
↓
输出:最终 Characterized Motion
AdaIN (Adaptive Instance Normalization): $$\text{AdaIN}(z_{src}, z_{cha}) = \sigma(z_{cha}) \cdot \frac{z_{src} - \mu(z_{src})}{\sigma(z_{src})} + \mu(z_{cha})$$
- \(\mu, \sigma\): 均值和标准差
- 将源特征归一化后,用目标特征的统计量重新缩放
Cross-Attention:
- Query: 源特征
- Key, Value: 角色特征
- 实现风格注入
四、训练细节
4.1 数据集
自建高质量数据集:
- 6 个不同角色(Zombie, Princess, Clown 等)
- 多样化动作(行走、坐、跳等)
- 专业表演捕捉
4.2 训练配置
| 组件 | 架构 | 输入 | 输出 |
|---|---|---|---|
| Bodypart Encoder | GCN + Temporal | 动作序列 | Source Feature |
| NCM | C-VAE + Transformer | Context + Prior | Character Feature |
| Characterizer | Transformer Decoder | Source + Character | Translated Feature |
4.3 损失函数
总损失: $$\mathcal{L} = \mathcal{L}{recon} + \mathcal{L}{KL} + \mathcal{L}{contrastive} + \mathcal{L}{style}$$
- 重建损失:动作重建误差
- KL 损失:VAE 正则化
- Contrastive Loss:增强上下文区分性
- 风格损失:风格特征匹配
五、实验与结论
5.1 评估任务
-
实时角色表征
- 将中性动作转换为特定角色风格
- 60 FPS 实时运行
-
稀疏输入表征
- 仅使用 sparse tracker 输入
- VR 应用
-
风格转换质量
- 与 prior work 对比
- 用户研究
5.2 对比基线
- Motion Style Transfer 方法
- Learned Motion Matching
- Retargeting 方法
5.3 评估指标
| 指标 | 含义 |
|---|---|
| Style Similarity | 风格相似度 |
| Context Preservation | 上下文保持 |
| Temporal Coherence | 时间连贯性 |
| Runtime | 运行时间 |
| User Preference | 用户偏好 |
5.4 主要结果
- 质量:风格转换自然,上下文保持良好
- 速度:实时运行(60 FPS)
- 多功能性:支持稀疏输入、实时直播表征
- 用户偏好:优于基线方法
5.5 消融实验
验证关键设计:
- AdaIN:显著提升风格转换质量
- Contrastive Loss:增强上下文区分性
- 自回归 NCM:保证时间连贯性
六、局限性
-
角色多样性
- 训练数据中的角色有限
- 新角色需要重新训练
-
极端风格
- 非常夸张的风格可能失真
-
稀疏输入质量
- tracker 数量影响重建质量
七、相关工作对比
7.1 与 Motion Matching 的关系
MOCHA 属于 Motion Matching 系,论文明确说明:
"Inspired by Learned Motion Matching (LMM) approach [Holden et al. 2020], we train the neural context matcher (NCM) to generate the best matching character feature."
Motion Matching 系的演进:
| 代数 | 方法 | 匹配方式 | 特点 |
|---|---|---|---|
| 第一代 | Motion Matching (2019) | 数据库搜索最近邻 | 需要存储完整数据库 |
| 第二代 | Learned Motion Matching (2020) | 神经网络预测 | 消除数据库依赖 |
| 第三代 | MOCHA (2023) | C-VAE 生成匹配 | 每帧运行,时间连贯 |
MOCHA 与 LMM 的区别:
| 维度 | LMM | MOCHA |
|---|---|---|
| 运行频率 | 每隔几帧 | 每帧运行 |
| 匹配对象 | 动作特征 | 上下文特征 |
| 网络架构 | 简单神经网络 | C-VAE + 自回归 |
| 应用目标 | 动作生成 | 风格转换 + 重定向 |
NCM 的训练方式 (Section 5.2):
- Ground truth 来自在目标特征数据库中搜索的结果
D_tar = [Z_tar, f(Z_tar)]是目标角色的特征数据库- NCM 学习预测最近邻搜索的结果
NCM 的推理:
- 用训练好的 C-VAE decoder 生成匹配的特征
- 自回归保证时间连贯性
7.2 与 Humor 等生成模型的关系
MOCHA 不属于 Humor/A-MDM 等生成模型系,原因如下:
| 维度 | Humor/A-MDM | MOCHA |
|---|---|---|
| 核心问题 | "下一帧应该是什么动作?" | "哪个动作与当前最匹配?" |
| 训练数据 | 动作序列 | (源动作,目标动作) 配对 |
| 学习目标 | 建模动作流形/去噪扩散 | 学习匹配函数 |
| 监督信号 | 动作序列本身 | 最近邻搜索结果 |
| 输出 | 生成的动作分布 | 匹配的目标特征 |
本质区别:
- Humor/A-MDM:学习动作的时间演化 (dynamics),从过去预测未来
- MOCHA:学习跨角色的风格匹配 (correspondence),从源角色到目标角色
为什么 MOCHA 使用 C-VAE 但不是生成模型:
- C-VAE 在 MOCHA 中是可微分的最近邻搜索工具
- 目的是生成"与源动作最匹配的目标特征",而非"合理的下一帧动作"
- 训练监督信号来自数据库搜索,而非动作序列本身
7.3 与风格转换方法的对比
| 方法 | 实时 | 风格转换 | 重定向 | 上下文相关 |
|---|---|---|---|---|
| MOCHA | ✓ | ✓ | ✓ | ✓ |
| Motion Puzzle | ✗ | ✓ | ✗ | △ |
| Style Transfer | ✗ | ✓ | ✗ | ✗ |
| Retargeting | △ | ✗ | ✓ | ✗ |
| LMM | ✓ | △ | △ | △ |
九、启发
9.1 方法学启发
-
风格是上下文相关的
- 不能将风格与上下文分离
- 需要联合建模
-
同时风格转换 + 重定向
- 统一框架处理两个问题
- 减少 pipeline 复杂度
-
AdaIN 在动作上的应用
- 从图像迁移到动作
- 有效注入风格统计量
9.2 与风格转换方法的对比
| 方法 | 实时 | 风格转换 | 重定向 | 上下文相关 |
|---|---|---|---|---|
| MOCHA | ✓ | ✓ | ✓ | ✓ |
| Motion Puzzle | ✗ | ✓ | ✗ | △ |
| Style Transfer | ✗ | ✓ | ✗ | ✗ |
| Retargeting | △ | ✗ | ✓ | ✗ |
| LMM | ✓ | △ | △ | △ |
十、关键公式
Context Mapping: $$f(z_i^{src}) \in \mathbb{R}^{(\frac{T}{4} \times n_{body}) \times C}$$
NCM Prior: $$p(s_i | z_{i-1}^{cha}, f(z_i^{src})) = \mathcal{N}(\mu, \sigma)$$
AdaIN: $$\text{AdaIN}(z_{src}, z_{cha}) = \sigma(z_{cha}) \cdot \frac{z_{src} - \mu(z_{src})}{\sigma(z_{src})} + \mu(z_{cha})$$
Characterizer: $$z_d = D_c(z_i^{src}, z_i^{cha})$$
笔记说明:MOCHA 是 SIGGRAPH Asia 2023 工作,核心贡献是首个实时角色表征框架,同时处理风格转换和身体比例适配。关键创新包括 Neural Context Matcher、AdaIN + Cross-Attention 的 Characterizer。MOCHA 属于 Motion Matching 系(继承自 Learned Motion Matching),而非生成模型系——其核心是学习跨角色的风格匹配,而非动作的时间演化。
DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning
DeepLoco:使用分层深度强化学习的动态移动技能
论文详解文档
目录
1. 基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning |
| 中文译名 | DeepLoco:使用分层深度强化学习的动态移动技能 |
| 发表会议 | ACM Transactions on Graphics (TOG) 2017 (SIGGRAPH) |
| 作者单位 | 英属哥伦比亚大学、新加坡国立大学 |
| 主要作者 | Xue Bin Peng, Glen Berseth, KangKang Yin, Michiel van de Panne |
2. 核心问题:这篇论文要解决什么问题?
2.1 背景故事
想象一下你想让一个 3D 虚拟角色(比如游戏里的人物)在复杂的环境中行走:
- 需要沿着一条弯弯曲曲的小路走
- 需要绕过障碍物
- 需要一边走路一边踢足球
- 需要在有移动障碍物的环境中穿行
问题:如何让角色学会这些复杂的移动技能?
2.2 现有方法的局限性
方法 A:有限状态机 (FSM) + 反馈控制
传统方法:人工设计状态机
- 状态 1:抬腿
- 状态 2:向前迈步
- 状态 3:放下腿
- ...
局限性:
- 需要大量人工设计
- 不够灵活,遇到新情况就失效
- 动作看起来比较僵硬
方法 B:纯强化学习(端到端)
让 AI 自己从零开始学
局限性:
- 3D 双足行走本身就很难学
- 直接学复杂任务(如绕障碍 + 踢球)几乎不可能
- 学习速度慢,容易失败
2.3 DeepLoco 的解决方案
核心思想:分层控制
┌─────────────────────────────────────┐
│ 高层控制器 (HLC) │
│ High-Level Controller │
│ 频率:2Hz(每 0.5 秒决策一次) │
│ 任务:规划步法、导航 │
└──────────────┬──────────────────────┘
│ 输出:步法计划
▼
┌─────────────────────────────────────┐
│ 低层控制器 (LLC) │
│ Low-Level Controller │
│ 频率:30Hz(每 0.033 秒执行一次) │
│ 任务:保持平衡、执行动作 │
└──────────────┬──────────────────────┘
│ 输出:关节角度
▼
┌─────────────┐
│ 角色模型 │
└─────────────┘
为什么分层?
- 高层:像人的"大脑",负责想"我要往哪走"
- 低层:像人的"小脑",负责想"怎么保持平衡迈腿"
2.4 这篇论文的贡献
- 环境感知的 3D 双足行走:角色可以看着地形图来决定怎么走
- 多种行走风格:可以学习正常走、高抬腿走、弯腿走等多种风格
- 强大的鲁棒性:可以承受一定的外力推挤、上下坡
- 复杂任务能力:学会踢足球、绕障碍等复杂技能
3. 基础知识铺垫
强化学习基础:如需了解强化学习的完整数学框架(MDP、贝尔曼方程、价值函数等),请参考 DeepLearningNotes - 强化学习基础
3.1 强化学习 (Reinforcement Learning) 基础
强化学习就像训练小狗:
状态 (State) → 动作 (Action) → 奖励 (Reward)
比如训练小狗捡球:
- 状态:球在哪里,小狗在哪里
- 动作:跑、跳、咬
- 奖励:捡到球 +1 分,摔倒 -1 分
目标:学会最大化奖励的动作
3.2 策略梯度 (Policy Gradient)
策略 π:状态 → 动作的映射规则
策略梯度方法:
- 让角色尝试各种动作
- 如果某个动作带来好结果,就增加这种动作的概率
- 如果带来坏结果,就减少这种动作的概率
3.3 Actor-Critic 方法
Actor (演员):负责做动作
Critic (评论家):负责评价动作好不好
工作流程:
1. Actor 做一个动作
2. Critic 评价这个动作值多少分
3. 如果评价好,强化这个动作;否则弱化
3.4 CACLA 算法
论文用的是 CACLA 算法的改进版本:
CACLA (Continuous Actor-Critic Learning Automaton)
核心思想:
- 只有当动作带来"比预期更好"的结果时,才学习
- 用"时间差分"来评估好坏
公式:
δ = r + γV(s') - V(s)
如果 δ > 0:说明动作比预期好,学习它!
如果 δ ≤ 0:说明动作不如预期,不学习
4. DeepLoco 方法的核心思想
4.1 整体架构
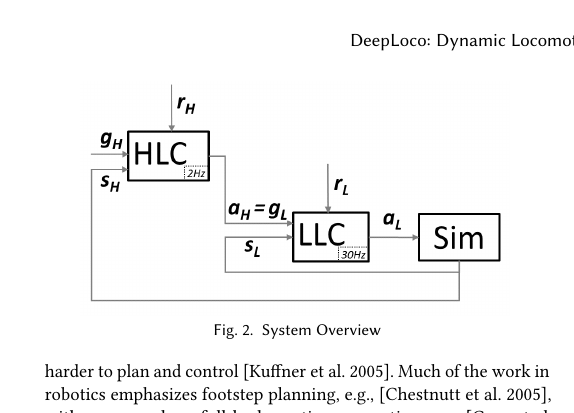
Figure 1. DeepLoco 系统概述:高层控制器 (HLC) 以 2Hz 频率规划步法,低层控制器 (LLC) 以 30Hz 频率执行关节控制,物理模拟以 3kHz 频率运行。
图示说明:DeepLoco 系统分为两层 — HLC(2Hz)看地形、做决策、规划步法;LLC(30Hz)看状态、执行动作、控制关节;物理模拟(3000Hz)计算碰撞、受力。
┌──────────────────────────────────────────────────────┐
│ DeepLoco 系统 │
├──────────────────────────────────────────────────────┤
│ │
│ 输入:地形图 + 角色状态 + 任务目标 │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 高层控制器 │ 2Hz │
│ │ (HLC) │ 输出:下一步踩哪里 │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 低层控制器 │ 30Hz │
│ │ (LLC) │ 输出:关节角度 │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 物理模拟 │ 3000Hz │
│ └─────────────────┘ │
│ │
└──────────────────────────────────────────────────────┘
4.2 为什么这样设计?
时间尺度分离
| 控制器 | 频率 | 时间尺度 | 负责什么 |
|---|---|---|---|
| HLC | 2Hz | 0.5 秒 | 规划步法(像下棋,一步一想) |
| LLC | 30Hz | 0.033 秒 | 执行动作(像反射,快速响应) |
| 物理 | 3000Hz | 0.00033 秒 | 物理计算(保证稳定性) |
好处
1. 高层可以专注"大局":往哪走、绕什么路
2. 低层可以专注"细节":怎么迈步、怎么平衡
3. 同一个低层控制器可以被多个高层任务复用
4. 学习更高效:高低层分开学,比一起学容易
5. 技术细节详解
5.1 低层控制器 (LLC) 详解
LLC 的职责
协调关节运动,模仿参考动作的风格,同时满足步法目标并保持平衡
LLC 的输入(状态空间,110 维)
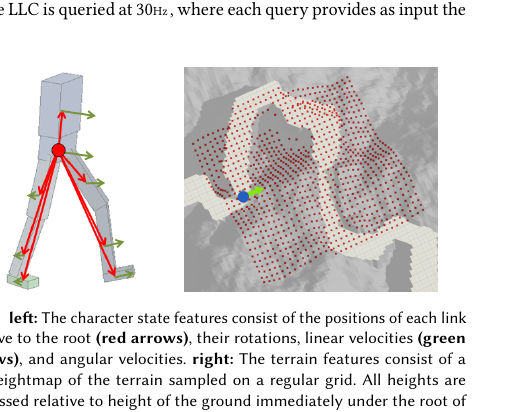
Figure 2. 角色状态特征(左):每个连杆相对于根节点的位置(红箭头)、旋转、线速度(绿箭头)和角速度。地形特征(右):32x32 规则网格采样的高度图。
图示说明:LLC 输入状态包括角色各部位的位置、旋转、线速度、角速度,以及地形高度图。
┌────────────────────────────────────────┐
│ LLC 输入状态 s_L │
├────────────────────────────────────────┤
│ • 身体各部位位置(相对于骨盆) │
│ • 身体各部位旋转(四元数) │
│ • 身体各部位线速度 │
│ • 身体各部位角速度 │
│ • 双脚接触地面标志(1=接触,0=悬空) │
│ • 相位变量 φ ∈ [0,1](表示步态周期) │
└────────────────────────────────────────┘
总维度:110 维
相位变量是什么?
相位变量 φ 用来跟踪"现在走到哪一步了"
一个完整的步态周期 = 1 秒
- φ = 0.0:左脚刚落地
- φ = 0.25:左脚支撑中期
- φ = 0.5:右脚刚落地
- φ = 0.75:右脚支撑中期
- φ = 1.0:回到左脚落地
作用:让控制器知道"现在应该做什么"
LLC 的目标(步法计划)
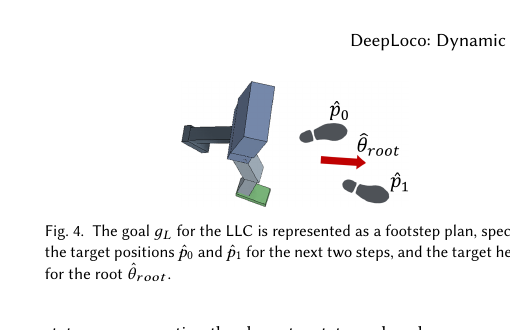
Figure 3. LLC 的目标 g_L 表示为步法计划,指定下一步和下下一步的目标位置 p̂₀, p̂₁,以及根节点的目标朝向 θ̂_root。
图示说明:LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root) — 下一步位置、下下一步位置、身体朝向。研究证明"两步就够了"。
LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root)
p̂₀:下一步的目标位置(2D)
p̂₁:下下一步的目标位置(2D)
θ̂_root:身体的目标朝向
为什么是两个步子?
- 研究证明"两步就够了"(Zaytsev et al. 2015)
- 只看一步:太短视
- 看三步以上:计算太复杂,收益不大
LLC 的输出(动作空间,22 维)
LLC 动作 a_L = 每个关节的 PD 目标角度
角色模型:
- 每条腿:3 个关节(髋、膝、踝)
- 髋关节:3 自由度(球窝关节)
- 膝关节:1 自由度
- 踝关节:3 自由度
- 腰部:3 自由度
总关节自由度:22 个
输出:每个关节的目标角度(轴角表示,4 维)
5.2 参考动作 (Reference Motion)
什么是参考动作?
参考动作是"样本动作",告诉 LLC"应该是什么风格"
可以是:
1. 手工 keyframe 动画(一个简单的走路循环)
2. 动作捕捉数据(真人走路的录像)
DeepLoco 用了:
- 1 个手工制作的平面走路循环
- 10 个动作捕捉片段(约 7 秒的走路和转身数据)
如何使用参考动作?
LLC 不需要精确跟踪参考动作,只需要"模仿风格"
比如参考动作是"军人走路":
- LLC 学会"抬头挺胸、步伐有力"的风格
- 但可以根据需要调整步幅、方向
这样做的好处:
- 灵活:可以适应不同的步法目标
- 鲁棒:参考动作不完美也没关系
动作选择机制
当有多个参考动作时(比如左转、右转、直行):
1. 提取每个动作的特征:
ψ(q̂ⱼ) = (支撑脚位置,摆动脚位置,身体朝向)
2. 根据当前目标和状态,选择最匹配的动作:
K(s, g_L) = argmin ||ψ(s, g_L) - ψ(q̂ⱼ)||
3. 选中的动作用来指导这一步的奖励函数
参考动作的使用方式(重要)
参考动作 不直接作为网络输入,而是通过 奖励函数 间接引导学习。
- 根据状态 s 和目标 g_L,从参考动作库选择一个动作 q̂
- 用 q̂ 计算奖励:
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)²)
r_vel = exp(-Σᵢ wᵢ·d(q̂̇ᵢ(t), q̇ᵢ)²) - 网络通过最大化奖励,间接学会模仿参考动作的风格
为什么这样设计?
- 灵活:可以适应不同的步法目标,不必精确跟踪
- 鲁棒:参考动作不完美也没关系,只需提供"风格参考"
- "风格模仿"而非"动作复制"
参考动作质量的影响
DeepLoco 对参考动作质量要求较低,具有较好的鲁棒性:
| 参考动作问题 | DeepLoco 的影响 | 原因 |
|---|---|---|
| mocap 数据有噪声 | 较小 | r_end、r_com 等任务项可以平衡 |
| 关键帧动画僵硬 | 较小 | 可自适应调整,牺牲姿势相似度 |
| 片段较短 | 中 | 需要足够覆盖步态周期 |
| 风格不适合任务 | 中 | 可优先完成任务 |
| 完全无参考动作 | 完全学不会走路 | 没有引导信号 |
实验结果(论文 Section 6.1):
- 10 个 mocap 片段:学习最快,最终性能最好
- 1 个 hand-authored 片段:可以学会走路,但转弯较差
- 没有参考动作:完全学不会走路
核心原因:
r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading
↑ ↑ ↑
模仿项 任务项 任务项
r_pose 只占 0.5,当与任务冲突时可以牺牲
→ 参考动作只是"风格参考",不是"必须遵循的轨迹"
工程建议:
- 参考动作质量不高时,DeepLoco 仍能学到功能正常的步态
- 但"风格"可能带有参考动作的痕迹
- 建议至少使用 1 个合理的走路循环作为参考
为什么是"风格模仿"而非"动作复制"?
虽然 r_pose 确实在鼓励关节角度接近参考动作,但 DeepLoco 与后续的 DeepMimic(2018)有本质区别:
| 对比维度 | DeepLoco(风格模仿) | DeepMimic(动作复制) |
|---|---|---|
| 目标 | 模仿风格 + 完成步法任务 | 精确复现动作轨迹 |
| r_pose 权重 | 0.5 | 更高(主要目标) |
| r_end 权重 | 0.2(重要) | 很低或没有 |
| 参考动作作用 | 提供姿势参考 | 提供完整轨迹 |
| 灵活性 | 高(可修改落脚点) | 低(必须踩对位置) |
关键原因:
-
r_pose 只是总奖励的一部分
- r_end(落脚点)占 0.2 — 为了踩到 HLC 指定的目标位置,可以牺牲姿势相似度
- 当 r_pose 和 r_end 冲突时,网络会权衡取舍
-
相位变量 φ 是独立递增的
- φ 按时间递增(每步 1 秒),不从参考动作中提取
- 角色可以走得快或慢,只要姿势"像"就行
-
参考动作可以动态切换
- 每一步都可以从多个参考动作中选一个最匹配的
- 不是固定跟踪某一个完整序列
设计效果:
- 角色可以用"军人走路"的风格,但走到任意目标位置
- 可以用"高抬腿"风格,同时绕过障碍物
- 学的是"怎么走的样子",不是"具体怎么走"
5.3 LLC 奖励函数
奖励函数告诉 LLC"什么是好的行为":
r_L = w_pose·r_pose + w_vel·r_vel + w_root·r_root
+ w_com·r_com + w_end·r_end + w_heading·r_heading
权重:(0.5, 0.05, 0.1, 0.1, 0.2, 0.1)
各项奖励含义
| 奖励项 | 含义 | 作用 |
|---|---|---|
| r_pose | 姿势奖励 | 关节角度接近参考动作 |
| r_vel | 速度奖励 | 关节速度接近参考动作 |
| r_root | 骨盆高度奖励 | 保持合适的身体高度 |
| r_com | 质心速度奖励 | 保持合适的移动速度 |
| r_end | 落脚点奖励 | 脚落在目标位置 |
| r_heading | 朝向奖励 | 身体朝向正确方向 |
姿势奖励公式
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)²)
d(·,·):计算两个四元数的距离
wᵢ:每个关节的权重
含义:
- 实际姿势 qᵢ 越接近参考姿势 q̂ᵢ,奖励越高
- exp 函数确保奖励在 [0,1] 范围内
- 距离为 0 时,奖励 = 1(完美)
- 距离越大,奖励越接近 0
5.4 双线性相位变换 (Bilinear Phase Transform)
问题
只用一个标量相位 φ 有什么问题?
实验发现:
- 网络不能很好地区分不同的相位
- 导致"拖脚"现象(脚没有抬够高)
为什么?
- 单个数值 φ 对神经网络来说不够明显
- 网络不容易学会"不同相位做不同事"
解决方案:双线性相位变换
1. 把相位 φ 分成 4 个区间:
Φ₀ = 1 当 0 ≤ φ < 0.25
Φ₁ = 1 当 0.25 ≤ φ < 0.5
Φ₂ = 1 当 0.5 ≤ φ < 0.75
Φ₃ = 1 当 0.75 ≤ φ < 1
2. 计算外积:
[s_L] [s_L] [s_L] [s_L] [s_L]
[g_L] × Φ = [Φ₀·g_L], [Φ₁·g_L], [Φ₂·g_L], [Φ₃·g_L]
效果
变换后的特征:
- 只有当前相位对应的特征块是"激活"的
- 其他特征块都是 0
好处:
- 强制网络在不同相位使用不同的"子网络"
- 相当于给网络植入了"不同阶段做不同事"的先验
- 显著改善步态质量,减少拖脚现象
5.5 LLC 网络结构
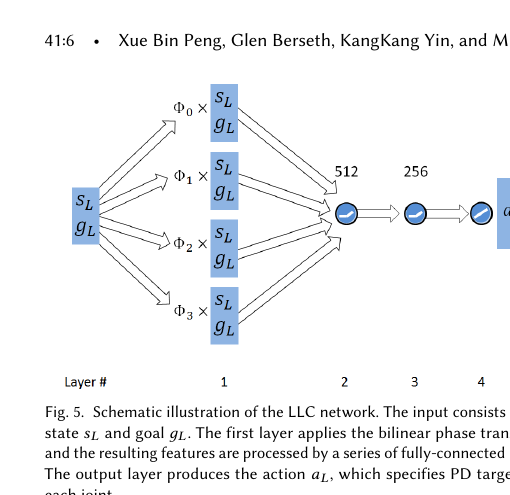
Figure 4. LLC 网络结构示意图。输入为状态 s_L 和目标 g_L。第一层应用双线性相位变换,所得特征经全连接层处理。输出层产生动作 a_L,指定每个关节的 PD 目标。
图示说明:LLC 网络结构 — 输入层应用双线性相位变换,经 FC(512)→FC(256) 处理,输出动作均值。参数量约 50 万。
LLC 神经网络:
输入层:s_L + g_L (状态 + 目标)
↓
第 1 层:双线性相位变换 → 特征维度扩展
↓
第 2 层:全连接层,512 单元,ReLU 激活
↓
第 3 层:全连接层,256 单元,ReLU 激活
↓
输出层:线性层 → 动作均值 μ(s_L, g_L)
参数量:约 50 万
5.6 风格修改 (Style Modification)
通过在奖励函数中添加风格项,可以让 LLC 学会不同的行走风格:
风格奖励通用公式
r_pose = exp(-Σᵢ wᵢ·d(q̂ᵢ(t), qᵢ)² - w_style·c_style)
c_style:风格项(人工设计的规则)
w_style:风格权重(训练超参数,控制"像参考动作"vs"满足风格"的平衡)
注意:
- c_style 是人工设计的规则,不是从数据中学的
- 每个风格项针对特定关节或特定变量
- 风格奖励只在训练特殊风格时使用,基础 LLC(正常行走)不使用
- 风格 loss 是可选项:训练正常行走时 w_style = 0,训练特殊风格时 w_style > 0
支持的风格
| 风格 | 风格项 c_style | 效果 |
|---|---|---|
| 前倾行走 | d(q̂_waist, q_waist)² | 身体向前倾斜 |
| 侧倾行走 | d(q̂_waist, q_waist)² | 身体向侧面倾斜 |
| 直腿行走 | d(q_I, q_knee)² | 膝盖不弯曲 |
| 高抬腿 | (ĥ_knee - h_knee)² | 抬腿更高 |
| 原地行走 | 使用原地点参考动作 | 在原地踏步 |
风格插值
如果有两个风格的 LLC:π_La 和 π_Lb
可以线性插值得到新风格:
π_Lc(s, g) = (1-u)·π_La(s, g) + u·π_Lb(s, g)
u ∈ [0, 1]:插值系数
- u = 0:纯风格 a
- u = 0.5:a 和 b 的中间风格
- u = 1:纯风格 b
效果:可以在不同风格之间平滑过渡
关键理解:
- 一个 LLC = 一种确定的风格(训练时由 w_style + c_style 决定)
- 风格是在训练时确定的,推理时无法改变
- 想换风格:要么重新训练新 LLC,要么对已有 LLC 进行插值
5.7 高层控制器 (HLC) 详解
HLC 的职责
提供中间目标给 LLC,以实现高层任务目标(如导航、避障、踢球)
HLC 的输入(状态空间,1129 维)
┌────────────────────────────────────────┐
│ HLC 输入状态 s_H │
├────────────────────────────────────────┤
│ 身体特征 C (类似 LLC 状态,但没有相位和接触标志) │
│ 地形特征 T (32×32 高度图) │
│ 任务目标 g_H │
└────────────────────────────────────────┘
地形图:
- 分辨率:32×32
- 覆盖范围:约 11m×11m
- 向前延伸 10m,向后延伸 1m
- 高度值相对于角色当前位置
地形图示例
角色看到的"高度图"就像这样(俯视):
← 11m →
┌─────────┐ ↑
│ ░░░▓▓░░░│ │
│ ░░▓▓▓▓░░│ 11m
│ ░░░▓▓░░░│ │
│ ░░░░▒░░░│ ↓
└─────────┘
图例:
░ = 平地
▓ = 障碍物(高)
▒ = 路径(目标方向)
HLC 的输出
HLC 动作 a_H = LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root)
即:HLC 决定"下一步踩哪里",LLC 负责"怎么走到那里"
5.8 HLC 网络结构
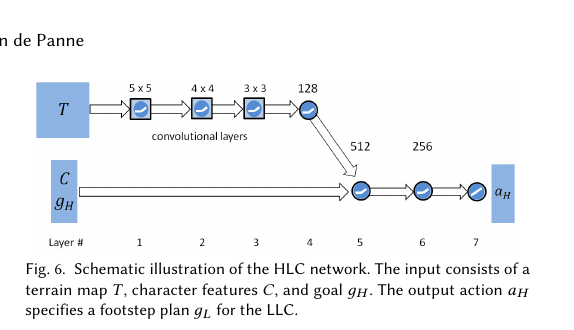
Figure 5. HLC 网络结构示意图。输入包括地形图 T、角色特征 C 和目标 g_H。输出动作 a_H 指定给 LLC 的步法计划 g_L。
图示说明:HLC 使用 CNN 处理地形图(32×32),经三层卷积(16→32→32 滤波器)和 FC(128) 后,与身体特征、任务目标拼接,再经 FC(512)→FC(256) 输出动作。参数量约 250 万。

Figure 6. 32×32 高度图示例,覆盖 11×11 米区域。左:路径;中:柱子障碍;右:方块障碍。
图示说明:HLC 输入的地形图是 32×32 高度图,覆盖 11×11 米区域,向前延伸 10m,向后延伸 1m。
HLC 卷积神经网络:
输入:
- 地形图 T:32×32
- 身体特征 C
- 任务目标 g_H
↓
卷积层 1:16 个 5×5 滤波器
↓
卷积层 2:32 个 4×4 滤波器
↓
卷积层 3:32 个 3×3 滤波器
↓
全连接层:128 单元
↓
拼接:[地形特征,C, g_H]
↓
全连接层 1:512 单元,ReLU
↓
全连接层 2:256 单元,ReLU
↓
输出层:线性层 → 动作 a_H
参数量:约 250 万
5.9 HLC 任务
任务 1:路径跟随 (Path Following)
目标:沿着岩石地形上的狭窄路径行走
环境:
- 路径宽度:1-2 米
- 地形用 Perlin 噪声生成
- 目标点随机出现在路径上
输入:
- 地形图(可以看到路径)
- 到目标的方向和距离
奖励:
r_H = exp(-min(0, u_tar·v_com - v̂_com)²)
含义:鼓励角色以至少 1m/s 的速度向目标移动
任务 2:足球运球 (Soccer Dribbling)
目标:把足球带到目标位置
挑战:
- 需要先走到球旁边
- 然后用脚控制球向目标移动
- 到达目标后要"停球"
输入(15 维):
- 目标方向/距离
- 球的方向/距离/高度/速度/角速度
- (没有地形图,因为是平地)
奖励:
r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp
各项含义:
- r_cv:角色走向球
- r_cp:角色靠近球
- r_bv:球向目标移动
- r_bp:球靠近目标
任务 3:柱子障碍 (Pillar Obstacles)
目标:穿过密集的柱子障碍物到达目标
环境:
- 障碍物:0.75m×0.75m 底座,高 2-8 米
- 随机放置
- 有很多可能的路径
奖励:同路径跟随
任务 4:方块障碍 (Block Obstacles)
目标:绕过大方块障碍物到达目标
环境:
- 障碍物:0.5m-7m 的方块
- 需要找到可行的路径
奖励:同路径跟随
任务 5:动态障碍 (Dynamic Obstacles)
目标:在移动障碍物中穿行到达目标
环境:
- 障碍物以 0.2-1.3 m/s 的速度来回移动
- 角色最大速度约 1 m/s
- 环境动态变化
输入:
- 速度图(而不是高度图)
- 每个点记录障碍物的 2D 速度
奖励:同路径跟随
5.10 MDP 定义总结(S、A、P、R)
LLC(低层控制器,30Hz)
| 要素 | 定义 | 维度 |
|---|---|---|
| S_L (状态) | • 身体各部位位置/旋转/线速度/角速度(相对于骨盆) • 双脚接触地面标志 • 相位变量 φ ∈ [0,1] | 110 维 |
| A_L (动作) | 每个关节的 PD 目标角度(轴角表示) | 22 维 |
| R_L (奖励) | r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading | - |
| P (动力学) | 物理模拟器(3000Hz),未显式建模,通过采样学习 | - |
奖励各项含义:
- r_pose:关节角度接近参考动作
- r_vel:关节速度接近参考动作
- r_root:骨盆高度奖励
- r_com:质心速度奖励
- r_end:脚落在目标位置
- r_heading:身体朝向正确方向
HLC(高层控制器,2Hz)
| 要素 | 定义 | 维度 |
|---|---|---|
| S_H (状态) | • 身体特征 C(类似 LLC 状态,无相位和接触标志) • 地形特征 T(32×32 高度图) • 任务目标 g_H | 1129 维 |
| A_H (动作) | LLC 目标 g_L = (p̂₀, p̂₁, θ̂_root) — 下一步位置、下下一步位置、身体朝向 | 5 维 (2+2+1) |
| R_H (奖励) | 路径跟随:r_H = exp(-min(0, u_tar·v_com - v̂_com)²) 运球:r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp | - |
| P (动力学) | 物理模拟器 + LLC 的动态响应,未显式建模 | - |
5.11 训练策略
分层训练流程
Step 1:训练 LLC
- 固定步法目标(随机生成)
- 学习走路和保持平衡
- 训练约 600 万次迭代(2 天,16 核 CPU)
Step 2:训练 HLC
- 冻结 LLC 权重(不再更新)
- 学习给 LLC 下达正确的步法指令
- 训练约 100 万次迭代(7 天,CPU)
为什么分开训练?
- LLC 先学会"怎么走"
- HLC 再学会"往哪走"
- 同一个 LLC 可以被多个 HLC 复用
训练超参数
| 参数 | LLC | HLC |
|---|---|---|
| 批次大小 m | 32 | 32 |
| 经验回放大小 | 50k | 50k |
| 学习率(Critic) | 0.01 | 0.01 |
| 学习率(Actor) | 0.001 | 0.001 |
| 折扣因子 γ | 0.95 | 0.95 |
| 探索率 ε | 1→0.2 | 1→0.5 |
| 探索衰减 | 1M 迭代 | 200k 迭代 |
经验回放 (Experience Replay)
记录角色经历过的每一步:
τ = (s, g, a, r, s', λ)
s:开始状态
g:目标
a:动作
r:奖励
s':结束状态
λ:是否加了探索噪声
训练时:
- 从回放内存中随机采样 32 个经验
- 用这些经验更新网络
- 好处:打破数据相关性,提高样本效率
5.12 鲁棒性分析
抗干扰能力
| LLC 风格 | 向前推 | 向侧推 | 上坡 | 下坡 |
|---|---|---|---|---|
| 正常行走 | 200N | 210N | 16% (9.1°) | 11% (6.3°) |
| 高抬腿 | 140N | 190N | 9% (5.1°) | 5% (2.9°) |
| 直腿 | 150N | 180N | 12% (6.8°) | 6% (3.4°) |
| 双腿直 | 90N | 130N | 9% (5.1°) | 5% (2.9°) |
| 前倾 | 180N | 290N | 10% (5.7°) | 16% (9.1°) |
| 侧倾 | 160N | 220N | 7% (4.0°) | 16% (9.1°) |
测试方法:
- 角色走路时,在躯干中点施加 0.25 秒的推力
- 逐渐增加推力直到角色摔倒
观察:
- 正常行走最鲁棒
- 直腿行走较不稳定(符合直觉)
- 前倾/侧倾对侧推有更好的抵抗力
为什么有鲁棒性?
原因:训练时的探索噪声
训练时:
- 给动作加高斯噪声(约关节范围的 10%)
- 相当于不断"推搡"角色
- 角色必须学会从扰动中恢复
结果:
- 自然学会平衡策略
- 不需要专门训练抗干扰
5.13 迁移学习
分层结构的好处:组件可以 interchangeably 使用
场景 1:同一个 LLC,不同的 HLC
- 正常行走 LLC 可以用于:路径跟随、运球、避障等
场景 2:同一个 HLC,不同的 LLC
- 路径跟随 HLC 可以配合:正常行走、高抬腿、前倾等
场景 3:迁移 + 微调
- 用正常行走训练的 HLC
- 直接用于高抬腿 LLC(性能下降)
- 微调 200k 次迭代(性能恢复)
- 比从零训练(1M 次)快得多
6. 实验结果
6.1 LLC 学习曲线
比较三种设置:
1. 10 个动作捕捉片段
2. 1 个手工制作片段
3. 没有参考动作
结果:
- 10 个 mocap 片段:学习最快,最终性能最好
- 1 个 hand-authored 片段:可以学会走路,但转弯较差
- 没有参考动作:完全学不会走路
结论:参考动作对引导学习非常重要
6.2 HLC 学习曲线
| 任务 | 归一化累积奖励 (NCR) |
|---|---|
| 路径跟随 | 0.55 |
| 足球运球 | 0.77 |
| 柱子障碍 | 0.56 |
| 方块障碍 | 0.70 |
| 动态障碍 | 0.18 |
观察:
- 静态环境任务(路径、柱子、方块)学得较好
- 动态障碍物最难,因为 LLC 没有学过"停止"
NCR 解释:
- NCR = 1:完美表现
- 但有些任务理论上达不到 1(如运球需要时间)
- 0.5-0.7 已经表示相当不错的性能
6.3 分层 vs 端到端
对比实验:
- 分层:HLC + LLC(分开训练)
- 端到端:单个网络直接输出关节命令
结果:
- 端到端方法:两种任务都完全失败
- 分层方法:成功学会所有任务
为什么分层赢了?
- 端到端需要同时学会"怎么走"和"往哪走"
- 任务太复杂,探索空间太大
- 分层把问题分解成两个较简单的子问题
6.4 风格插值演示
让角色在"正常行走"和"高抬腿"之间插值:
u = 0.0 → 正常行走
u = 0.25 → 稍微抬腿
u = 0.5 → 中等抬腿
u = 0.75 → 较高抬腿
u = 1.0 → 高抬腿
效果:可以平滑过渡,没有明显跳跃
6.5 迁移学习结果
场景:用正常行走 LLC 训练的 HLC,直接用于其他风格 LLC
| 任务 + LLC | 不微调 | 微调 | 重新训练 |
|------------|--------|------|----------|
| 运球 + 高抬腿 | 0.19 | 0.56 | 0.51 |
| 运球 + 直腿 | 0.51 | 0.64 | 0.45 |
| 路径 + 高抬腿 | 0.10 | 0.39 | - |
| 路径 + 前倾 | 0.43 | 0.44 | - |
结论:
- 直接迁移会有性能损失(特别是敏感任务如运球)
- 微调可以快速恢复性能(200k vs 1M 次)
- 简单任务(路径)迁移效果更好
7. 总结与启发
7.1 核心创新点
1. 分层深度强化学习框架
- 高层规划(HLC)+ 低层执行(LLC)
- 不同时间尺度,各司其职
2. 环境感知能力
- 输入:32×32 地形高度图
- 可以"看到"地形并做出决策
3. 风格多样化
- 通过奖励函数修改实现不同风格
- 风格之间可以平滑插值
4. 迁移学习能力
- 组件可以 interchangeably 使用
- 微调可以快速适应新组合
7.2 与后续工作的关系
DeepLoco (2017) → 后续工作:
├→ DeepMimic (2018): 更精确的动作跟踪
├→ AMP (2021): 对抗性动作先验,更灵活的风格学习
├→ ASE (2022): 大规模可重用技能嵌入
└→ 本文作者团队的后续工作
- PDP (2023): 用扩散模型做物理角色控制
- DiffuseLoco (2023): 离线数据集的扩散控制
7.3 局限性
论文自己提到的局限
1. 相位变量仍需手动设计
- 未来可以用 RNN/LSTM 内部记忆
2. HLC-LLC 接口是手工指定的
- 两步位置 + 身体朝向
- 未来可以学习自动表示
3. 分开训练,不是端到端
- 联合训练困难(LLC 动态变化影响 HLC 学习)
4. 采样效率不高
- LLC:600 万次迭代
- HLC:100 万次迭代
- 未来可以用学习到的动态模型改进
5. **固定初始状态**
- 每个 episode 从固定的站立姿势开始
- 难以学习高度动态的动作(如后空翻、跳跃)
- 对比:DeepMimic (2018) 提出 RSI(从参考动作的随机状态开始)
从现代视角看局限
1. 训练时间长
- LLC:2 天(16 核)
- HLC:7 天(CPU)
- 现代方法可能更快
2. 角色模型简单
- 只有 8 个连杆(腿 + 躯干)
- 没有手臂(运球任务除外)
3. 任务相对简单
- 主要是导航类任务
- 没有更复杂的交互(如抓取、操作)
7.4 对后续研究的启发
1. 分层是处理复杂任务的有效策略
- 把大问题分解成小问题
- 不同层次可以独立训练
2. 参考动作是引导学习的好方法
- 不需要精确跟踪
- "风格模仿"比"动作复制"更灵活
3. 环境感知很重要
- 地形图输入让角色可以"看路"
- 为后续工作(如 DiffuseLoco)奠定基础
4. 迁移学习可以大大提高效率
- 组件可以复用
- 微调比重新训练快得多
7.5 关键技术总结
┌────────────────────────────────────────┐
│ DeepLoco 技术栈 │
├────────────────────────────────────────┤
│ • 分层强化学习(HLC + LLC) │
│ • Actor-Critic + CACLA 更新 │
│ • 经验回放(Experience Replay) │
│ • 双线性相位变换 │
│ • CNN 处理地形图 │
│ • 参考动作引导学习 │
│ • 风格插值 │
│ • 迁移学习 + 微调 │
└────────────────────────────────────────┘
8. 公式汇总
8.1 策略表示
随机策略:
a = μ(s, g) + λN, N ∼ G(0, Σ)
λ ~ Ber(ε):探索概率
训练时 λ = 1(加噪声)
推理时 λ = 0(确定性)
8.2 累积奖励
J(π) = E[r₀ + γr₁ + ... + γ^T r_T | π]
γ = 0.95:折扣因子
8.3 CACLA 更新
价值函数更新:
yᵢ = rᵢ + γV(sᵢ', gᵢ)
θ_v ← θ_v + α_v · Oθ_v V(sᵢ, gᵢ) · (yᵢ - V(sᵢ, gᵢ))
策略更新(仅当 δ > 0):
δⱼ = rⱼ + γV(sⱼ', gⱼ) - V(sⱼ, gⱼ)
θ_μ ← θ_μ + α_μ · Oθ_μ μ(sⱼ, gⱼ) · Σ⁻¹ · (aⱼ - μ(sⱼ, gⱼ))
8.4 奖励函数
LLC 奖励:
r_L = 0.5·r_pose + 0.05·r_vel + 0.1·r_root + 0.1·r_com + 0.2·r_end + 0.1·r_heading
HLC 奖励(运球):
r_H = 0.17·r_cv + 0.17·r_cp + 0.33·r_bv + 0.33·r_bp
文档完成时间:2026 年 4 月 3 日
Benchmarking Deep Reinforcement Learning for Continuous Control
连续控制深度强化学习的基准测试(rllab)
arXiv: 1604.06778 | ICML 2016
作者: Yan Duan, Xi Chen, Rein Houthooft, John Schulman, Pieter Abbeel
机构: UC Berkeley / 根特大学 / OpenAI
代码: https://github.com/rllab/rllab
核心问题是什么?
目的
深度强化学习在 Atari 游戏(离散动作)领域已有 ALE 等标准化基准,但在连续控制领域缺乏公认的基准,导致:
- 不同工作间难以公平比较
- 进展量化困难,实现细节不透明
- 可重复性差,超参数调优标准不统一
本文目标:建立连续动作空间强化学习的标准化评测套件,系统评估主流算法性能。
现有方法及局限性
| 已有基准 | 局限 |
|---|---|
| ALE (Atari) | 仅支持离散动作空间 |
| RLLib / MMLF | 任务简单,不含高维机器人任务 |
| Tdlearn / PyBrain | 任务类型单一,无标准化评估流程 |
本文方法
提出 rllab 基准套件,包含 31 个连续控制任务,分为 4 大类:
- 基础任务(5 个):Cart-Pole、Mountain Car、Acrobot 等经典控制
- 运动任务(7 个):Swimmer、Hopper、Walker、Ant、Humanoid 等
- 部分可观测任务(15 个 = 5×3 变体):限传感器/观测噪声/系统辨识
- 分层任务(4 个):迷宫导航 + 运动控制的层次组合
基于 Box2D(2D)和 MuJoCo(3D 物理仿真)实现,全部开源。
效果
- TRPO / TNPG 在大多数任务上表现最优
- 所有算法在分层任务上均失败(重要的 open problem)
- Hopper / Ant / Humanoid 等任务成为此后 10 年的标准评测集
核心贡献是什么?
- 标准化基准套件:31 个连续控制任务,覆盖从简单到极高维度
- 系统算法对比:实现并评估 7 种 RL 算法(REINFORCE、TNPG、TRPO、RWR、REPS、CEM、CMA-ES、DDPG)
- 标准化超参搜索流程:网格搜索 + 5 随机种子 + $\mu - \sigma$ 选优,保证公平性
- 全部开源:代码、环境、参考实现一并发布,保证可重复性
- 揭示分层任务难题:所有算法失败,指出需要新算法的方向
大致方法是什么?
任务设计
运动任务奖励通用形式:
$$r = v_x - 0.005|a|^2 + (\text{存活奖励})$$
部分可观测 3 种变体(每个运动任务各有):
- LS(Limited Sensors):仅提供位置,不提供速度
- NO(Noisy Obs):高斯噪声 $\sigma=0.1$ + 动作延迟
- SI(System Identification):物理参数在不同 episode 随机变化
评估方法
性能指标为平均累积回报(未折扣):
$$\text{Performance} = \frac{1}{\sum_i N_i} \sum_i \sum_n R_{in}$$
网络架构
批处理算法策略网络:
- 3 隐藏层:100 → 50 → 25 单元,tanh 激活
- 输出高斯分布均值,对数标准差为全局参数
DDPG:
- 2 隐藏层:400 → 300,ReLU 激活
部分可观测任务:LSTM,32 隐藏单元
训练
数据集
无监督数据集,基于物理仿真(MuJoCo / Box2D)在线采集轨迹。
每次迭代采集 50,000 步,训练 500 次迭代(POMDP 任务 300 次,分层任务 500 次)。
loss
各算法优化目标:
- REINFORCE: $\nabla_\theta \eta(\pi_\theta) \approx \frac{1}{NT} \sum \nabla_\theta \log \pi(a_t|s_t;\theta)(R_t - b_t)$
- TNPG / TRPO: 约束 KL 散度下的自然梯度上升
- DDPG: Actor-Critic,Bellman 方程 + 确定性策略梯度
训练策略
- 超参搜索:每类别选 2 个代表任务,网格搜索,5 随机种子取 $\mu - \sigma$ 最优
- 基线函数(REINFORCE/TNPG/TRPO):线性基线 $\phi_{s,t} = [s, s \odot s, 0.01t, (0.01t)^2, (0.01t)^3, 1]$
- 折扣因子 $\gamma = 0.99$,视界 $T = 500$
实验与结论
算法对比总结
| 算法 | 基础任务 | 运动任务 | POMDP(循环) | 分层任务 | 核心问题 |
|---|---|---|---|---|---|
| TRPO | ✅ 最优 | ✅ 最优 | 需要循环 | ❌ 全失败 | 计算开销略高 |
| TNPG | ✅ 次优 | ✅ 次优 | — | ❌ | 步长控制不如 TRPO |
| DDPG | ✅ 快速收敛 | 中等 | — | ❌ | 不稳定,可能退化 |
| REINFORCE | 中等 | 中等 | — | ❌ | 局部最优 |
| RWR | 简单任务 OK | ❌ 复杂失败 | — | ❌ | 高维退化 |
| REPS | ❌ 早熟 | ❌ | — | ❌ | 非平稳分布敏感 |
| CEM/CMA-ES | 简单任务强 | ❌ 维度灾难 | — | ❌ | 高维内存不足 |
关键发现
- 约束策略变化是关键:TRPO / TNPG 通过 KL 约束保证稳定学习,远优于普通梯度法
- DDPG 样本高效但不稳定:适合 sample-limited 场景,但对奖励缩放敏感(实验用 0.1×)
- 循环策略在 POMDP 上有效:但训练难度高于前馈,梯度消失是主要挑战
- 分层任务是所有算法的死穴:500 轮迭代、大量超参搜索,全部失败 → 明确指向需要自动发现分层结构的新算法
- 进化方法在高维失效:CMA-ES 在 Full Humanoid(高维)上 OOM
局限性
- 仿真到现实的 gap:全在 MuJoCo 仿真中测试,未验证真实机器人迁移
- 任务设计局限:奖励函数手工设计,缺乏稀疏奖励任务
- 分层任务失败:未提出解法,只是揭示了问题
- 算法覆盖不全:无 model-based 方法,无现代 off-policy 算法(SAC 等当时未发表)
启发
- 约束策略更新步长是连续控制的核心:TRPO 的核心思路(信任域约束)后来影响了 PPO(简化版的 TRPO,工程上更实用)
- 标准化 locomotion 任务的价值:Hopper/Ant/Humanoid 成为 SAC、PPO、TD3 等算法的标准测试床,被引用数千次
- 分层结构需要专门设计:单纯增加 RL 算法能力不能解决分层任务,后续 DeepLoco、Option Framework 等都在这个方向上努力
- 样本效率 vs 稳定性的权衡:DDPG 代表"快但不稳",TRPO 代表"稳但慢",这一 trade-off 在 SAC(解决稳定性)出现前一直是核心矛盾
遗留问题
- 如何自动发现任务中的分层结构?(后续: FeUdal Networks, HIRO 等)
- 如何让 DDPG 类方法更稳定?(后续: TD3, SAC)
- 如何在部分可观测任务中更有效地训练循环策略?
- 基准任务是否足够多样,是否覆盖真实机器人场景?(后续 OpenAI Gym 的设计很大程度受此影响)
- 仿真 gap:MuJoCo 学到的策略能直接迁移到真实机器人吗?
参考材料
- 论文:https://arxiv.org/abs/1604.06778
- 代码:https://github.com/rllab/rllab
- 相关:PPO(TRPO 的简化版)、SAC(解决 DDPG 不稳定性)、TD3(DDPG 改进版)
- 后续基准:OpenAI Gym、dm_control、MuJoCo locomotion suite
SIMBICON: Simple Biped Locomotion Control
论文信息
- 标题:SIMBICON: Simple Biped Locomotion Control
- 作者:KangKang Yin, Kevin Loken, Michiel van de Panne(英属哥伦比亚大学)
- 发表:ACM Transactions on Graphics, Vol. 26, No. 3, Article 105, July 2007
- DOI:10.1145/1239451.1239556
一句话总结
SIMBICON 用一套极其简单的有限状态机 + 平衡反馈公式,让物理仿真的二足角色(像游戏里的人形角色)能在实时环境中走、跑、跳、转向,还能被推倒后自己稳住。
背景:为什么控制双足行走这么难?
想象一下,你让一个机器人在物理引擎里走路。它的身体有关节、有质量、会受重力,还会和地面碰撞。如果不给它一个"控制器",它就会直接倒下。
控制双足行走之所以困难,是因为:
┌──────────────────────────────────────────┐
│ 双足行走的难点 │
│ │
│ 1. 不稳定 —— 人在行走中大部分时间只有 │
│ 一只脚着地,随时可能摔倒 │
│ │
│ 2. 欠驱动 —— 脚对地面没有主动控制力 │
│ │
│ 3. 高维度 —— 3D人体有30+个关节自由度 │
│ │
│ 4. 接触复杂 —— 脚着地时有冲击力 │
└──────────────────────────────────────────┘
之前的方法要么太复杂(轨迹优化、零力矩点控制),要么不够通用(只能走直线,不能应对推力)。
核心思想:三个简单模块组合
SIMBICON 的名字来自 SIMple BIped CONtrol,整个控制策略只有三个部分:
graph TD
A[有限状态机 FSM<br/>规定每个阶段目标姿势] --> D[整体控制器]
B[躯干 + 摆动髋控制<br/>世界坐标系下的方向稳定] --> D
C[平衡反馈<br/>根据重心位置/速度调整落脚点] --> D
D --> E[物理仿真中的双足行走]
模块一:有限状态机(FSM)
什么是有限状态机?
可以把它想象成一个"动作剧本",规定角色在不同阶段应该摆出什么姿势。
以走路为例,一个完整的步态循环分4个状态:
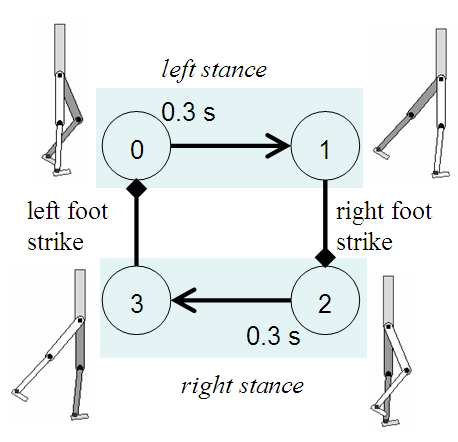
状态0 → 状态1 → 状态2 → 状态3 → 回到状态0
右腿 右腿 左腿 左腿
抬起 落地 抬起 落地
(计时) (脚触地) (计时) (脚触地)
每个状态里,角色的每个关节都有一个"目标角度"。控制器用 PD控制器 让关节趋向目标角度:
$$\tau = k_p(\theta_d - \theta) - k_d\dot{\theta}$$
- (\tau) 是关节施加的力矩(扭力)
- (\theta_d) 是目标角度
- (\theta) 是当前角度
- (k_p, k_d) 是弹簧-阻尼增益参数
通俗解释:就像弹簧一样,目标角度是弹簧的自然长度,关节偏离越多,拉回的力越大;同时加阻尼防止抖动。
状态转换条件:
- 固定时间后转换(如摆腿阶段持续0.3秒)
- 或脚碰到地面时转换(
fc= foot contact)
模块二:躯干 + 摆动髋的世界坐标控制
这是 SIMBICON 的一个关键创新。普通方法里,所有关节目标角度都是相对父关节的局部角度。但躯干和摆动腿的髋关节采用世界坐标系的目标角度。
为什么这样做?
传统方法:
躯干目标角度 = 相对于骨盆的角度
→ 如果骨盆倾斜了,躯干也跟着倾斜 → 容易失衡
SIMBICON方法:
躯干目标角度 = 相对于世界坐标系(垂直方向)
→ 无论骨盆怎么动,躯干始终尝试保持直立
具体力矩计算(图(a)展示了三者关系):
- 摆动髋力矩 (\tau_B):用世界坐标PD控制器计算
- 躯干力矩 (\tau_{torso}):用世界坐标PD控制器计算
- 支撑髋力矩 (\tau_A = -\tau_{torso} - \tau_B)(自由变量,由上面两个推导出来)
通俗解释:想象你在走路时手里拿着一杯水。你的身体倾斜,但手要保持水平,所以手腕会自动调整。这里躯干就是那杯水,始终相对于地面保持目标方向。
模块三:平衡反馈(最关键!)
这是 SIMBICON 最核心、也最优雅的部分。
核心公式:
$$\theta_d = \theta_{d0} + c_d \cdot d + c_v \cdot v$$
- (\theta_{d0}):FSM规定的默认摆动髋目标角度
- (d):重心(COM)相对于支撑脚踝的水平距离
- (v):重心的水平速度
- (c_d, c_v):反馈增益参数
为什么同时用位置和速度?
只用速度不够!看这个例子:
场景:原地踏步,期望速度 v = 0
情况A:重心在支撑脚前方 d = +10cm
→ 需要赶紧往前迈一步!
情况B:重心在支撑脚后方 d = -10cm
→ 需要赶紧往后迈一步!
如果只看速度(都是0),完全区分不了这两种情况
只有(d, v)一起看,才能知道当前步态的完整"相位"
通俗比喻:就像骑自行车,你不仅要看现在偏向哪里(位置d),还要看倾斜的速度有多快(速度v),才能决定该怎么打方向盘。
3D扩展:同样的反馈在矢状面(前后方向)和冠状面(左右方向)都分别应用,各自独立调整落脚位置。
控制器的两种设计方式
方式一:手动设计
通过一个图形界面(GUI)交互式地调整参数:
- 左边三个滑块:控制状态持续时间 (\Delta t)、位置增益 (c_d)、速度增益 (c_v)
- 右边:直接拖拽棍型人物的各关节目标角度
最重要的参数(只需调这几个):
- 每个状态的持续时间 (\Delta t)
- 摆动髋目标角度
- 摆动膝目标角度
表1 列出了所有手动设计的2D和3D步态参数(走、跑、跳、倒退走等12种步态)。
方式二:从动捕数据生成
- 给定3-7个动捕行走周期
- 用傅里叶分析提取步态周期 (T)
- 用主要频率分量重建平滑的周期运动 (\Theta)
- 用 (\Theta) 替代FSM中的固定目标姿势
结果:动捕风格 + 物理平衡 = 可应对外力的风格化行走
反馈误差学习(FEL)
问题:高增益PD控制虽然能跟踪目标轨迹,但动作显得"僵硬",而且躯干会因为总是"被动反应"而产生不自然的晃动。
人类运动的启发:人类在熟悉的动作中依赖前馈力矩(预测性地提前施力),反馈只做微调。
FEL的做法:
graph LR
A[观察反馈力矩<br/>vfb] -->|逐步学习| B[学习前馈力矩<br/>vff]
B --> C[两者相加施加]
C --> D[反馈力矩越来越小<br/>动作越来越流畅]
学习更新公式:
$$v'{ff} = (1-\alpha)v{ff} + \alpha(v_{ff} + v_{fb})$$
- (\alpha = 0.1)(学习率)
- 把步态划分成 N=20~1000 个相位区间,每个区间独立学习
效果:
- 躯干晃动幅度从 5° 降至 0.5°
- PD增益可以降低,动作更自然
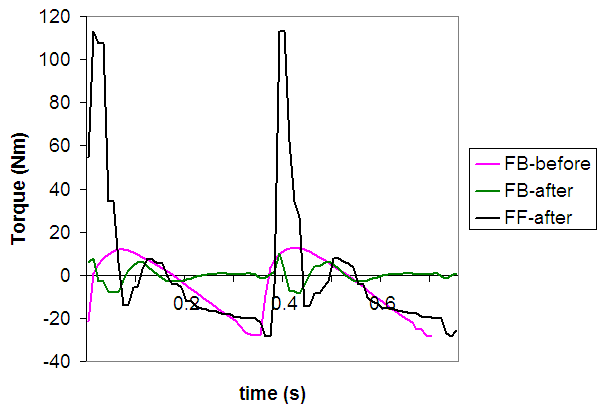
图中显示:学习前反馈力矩大幅波动(蓝线),学习后反馈力矩(红线)大幅减小,被前馈力矩(绿线)取代。
实验结果
2D双足结果
设计了12种周期步态,全部实时运行:
| 步态类型 | 特点 |
|---|---|
| 普通行走 (walk) | 标准步态 |
| 原地踏步 (in-place walk) | 零速度平衡 |
| 快步走 (fast walk) | 加速前进 |
| 高抬腿走 (highstep walk) | 大幅抬腿 |
| 弯腰走 (bent walk) | 前倾姿态 |
| 蹲走 (crouch walk) | 膝盖弯曲 |
| 剪刀跳 (scissor hop) | 腿交叉跳 |
| 倒退走 (backwards walk) | 向后行走 |
| 快跑 (fast run) | 高速奔跑 |
| 普通跑 (run) | 常规奔跑 |
| 跳跃步 (skipping) | 跳跃步态 |
鲁棒性测试:
- 走路控制器可承受 600N(前向)/ 500N(后向)、0.1s 的推力
- 可应对 20cm 的台阶和 ±6° 的坡度
3D双足结果
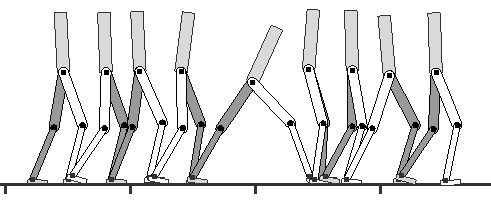 (左:2D模型6个内部自由度;右:3D模型28个内部自由度)
(左:2D模型6个内部自由度;右:3D模型28个内部自由度)
- 手动设计:双脚跳跃、三种前向行走、爬坡(20°)、侧走太极动作、跳跃步等
- 最大可恢复推力(八个方向):
前方: 340N, 后方: 270N, 左方: 240N, 右方: 330N(近似值)
动捕风格化结果
从动捕数据生成了7种控制器:
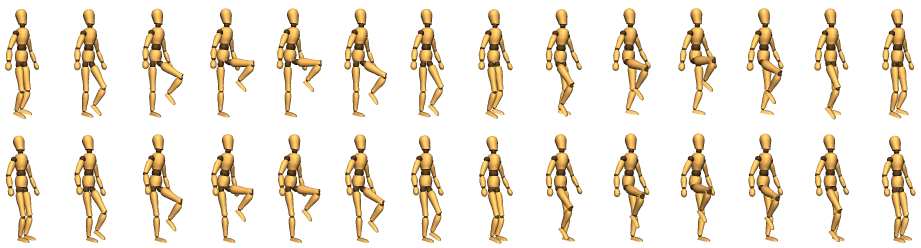 (上排:原始动捕数据;下排:控制器生成的物理仿真运动)
(上排:原始动捕数据;下排:控制器生成的物理仿真运动)
四种行走风格:高抬腿走、宽步距走、后退走、弯腰走
控制器之间的过渡
控制器绑定到按键,用户可以实时切换!过渡发生在状态 n 到 n+1 的边界。
一个完整的过渡序列示例:
走 → 原地踏步 → 站立 → 后空翻 → 原地踏步 → 走 →
大步走 → 走 → 原地踏步 → 高抬腿走 → 原地踏步 →
剪刀跳 → 走 → 跳跃 → 走 → 弯腰走 → 走 →
蹲走 → 走 → 原地踏步 → 倒退走 → 跑 → 快跑
注意:不是所有过渡都能直接进行,需要步态状态的"吸引域"(basin of attraction)有重叠。
参数稳定性分析
对 (c_d) 和 (c_v) 的稳定范围:
| 参数 | 矢状面(前后) | 冠状面(左右) |
|---|---|---|
| (c_d) | [-0.71, 1.4] | [-1.29, 1.13] |
| (c_v) | [0.03, 0.59] | [-0.06, 0.48] |
- (c_v) 太小 → 速度失控直到倒下
- (c_v) 太大 → 前后/左右摇摆越来越大直到倒下
- 参数接近边界 → 可能出现"倍周期分岔"(步态变为两步一循环)
系统参数(仿真配置)
| 参数 | 2D模型 | 3D模型 |
|---|---|---|
| PD增益 (k_p) | 300 Nm/rad | 300~1000 Nm/rad |
| PD增益 (k_d) | 30 Nms/rad | (0.1 k_p) |
| 摩擦系数 | 0.65 | 0.8 |
| 时间步长 | 0.0001s | 0.005s |
| 实时倍率 | 5× 实时 | 1.2× 实时 |
局限性
- 动捕流程未完全自动化:反馈增益 (c_d, c_v) 仍需手动调
- 能量效率未优化:步态看起来自然但能耗未考虑
- 没有反应时延模型:真实人类有约150ms神经延迟
- 高难动作不适用:翻跟头、跳跃需要精确起跳动量,FSM+平衡反馈不够
- 楼梯问题:控制器"看不见"前方台阶,脚尖碰到台阶可能摔倒
与同期工作的对比
| 方法 | 优势 | 劣势 |
|---|---|---|
| ZMP控制(ASIMO等) | 工程上可靠 | 大扰动时需要额外规划 |
| 轨迹优化 | 可得最优步态 | 计算慢,不实时 |
| 强化学习 | 原理上可学习 | 2007年时高维状态空间难处理 |
| SIMBICON | 简单、实时、多步态 | 复杂动作有限 |
贡献总结
┌─────────────────────────────────────────────┐
│ SIMBICON 的三大贡献 │
│ │
│ 1. 首个展示大量集成双足技能的框架 │
│ (走/跑/跳/转向/推力恢复全都有) │
│ │
│ 2. 从动捕数据构建鲁棒风格化控制器 │
│ (保留风格的同时能应对真实物理扰动) │
│ │
│ 3. 将反馈误差学习用于复杂动态系统 │
│ (前馈力矩让动作更流畅自然) │
└─────────────────────────────────────────────┘
个人理解:为什么这篇论文重要?
这篇2007年的论文在角色动画领域具有里程碑意义,原因如下:
-
极简设计:核心公式就一行 (\theta_d = \theta_{d0} + c_d d + c_v v),却产生了惊人的效果
-
实时性:游戏和交互应用需要实时控制,SIMBICON 做到了
-
奠基性:后来大量的角色动画物理控制工作(包括 DeepMimic、AMP 等深度强化学习方法)都在思考如何超越 SIMBICON 的局限性,它是一个重要的基线
-
直觉正确:用重心的位置和速度来调整落脚点,本质上模拟了人类行走的核心平衡机制
参考文献(精选)
- Raibert & Hodgins 1991 - 早期跳跃/奔跑控制,提出了速度控制和摆脚落点思想
- Faloutsos et al. 2001 - 可组合控制器架构
- Kawato et al. 1987 - 反馈误差学习(FEL)的原始提出
- Laszlo et al. 1996 - 极限环控制用于平衡
RLOC: Terrain-Aware Legged Locomotion using Reinforcement Learning and Optimal Control
论文信息
- 作者:Siddhant Gangapurwala, Mathieu Geisert, Romeo Orsolino, Maurice Fallon, Ioannis Havoutis
- 机构:牛津大学机器人研究所(Oxford Robotics Institute)
- 发表:arXiv:2012.03094v3 (2022)
- 关键词:四足机器人、强化学习、最优控制、地形感知、运动规划
📖 TL;DR(一句话总结)
本文提出 RLOC 框架:让四足机器人(ANYmal B/C)像人一样"看地形走路"——用强化学习决定踩哪里,用最优控制执行动作,两者结合实现在楼梯、斜坡、碎石等复杂地形上的稳健行走。
🎯 问题背景:为什么四足机器人走路这么难?
想象你闭着眼睛在崎岖山路上走路——几乎不可能。机器人也一样,要在复杂地形行走,需要同时解决三大难题:
graph TD
A[四足机器人行走的三大难题] --> B[哪里可以踩?\n地形感知+步态规划]
A --> C[怎么踩?\n运动控制+平衡维持]
A --> D[出了意外怎么办?\n外力扰动+滑步恢复]
B --> E[本文用RL学习解决]
C --> F[本文用最优控制解决]
D --> G[本文用恢复策略解决]
传统方法要么计算太慢(全身轨迹优化),要么太依赖精确模型(MPC),要么只会走平地(大多数RL方法)。RLOC 的创新在于把 RL 的感知决策能力和最优控制的精确执行能力结合起来。
🤖 实验平台:ANYmal 四足机器人

| 属性 | ANYmal B | ANYmal C |
|---|---|---|
| 重量 | 30 kg | 50 kg |
| 关节数 | 12 | 12 |
| 主要特点 | 工业检测用,大工作空间 | 更重、更高负载 |
| 在本文中的作用 | 训练平台 | 零样本迁移测试 |
🔑 关键结论:在 ANYmal B 上训练的策略,不需要任何重新训练,直接在 ANYmal C 上也能工作!这证明了方法的通用性。
🏗️ RLOC 系统总览
RLOC(Reinforcement Learning + Optimal Control)由 4 个模块 组成:
graph LR
SENSOR[传感器输入\n本体感知+外感知] --> MAP[地形编码器\nElevation Map Encoder]
MAP --> FP[步态规划器\nFootstep Planner RL]
FP -->|期望落脚点| MC[运动控制器\nMotion Controller OC]
MC -->|参考轨迹| DAT[域自适应追踪器\nDomain Adaptive Tracker RL]
DAT -->|修正力矩| ROBOT[机器人执行]
ROBOT -->|异常状态?| RC[恢复控制器\nRecovery Controller RL]
RC -->|关节命令| ROBOT
| 模块 | 运行频率 | 作用 |
|---|---|---|
| 地形编码器 | 按需 | 将高程图压缩为96维特征向量 |
| 步态规划器(RL) | 每步态周期更新 | 决定四只脚落在哪里 |
| 运动控制器(OC) | 400 Hz | 规划身体轨迹并执行整体控制 |
| 域自适应追踪器(RL) | 400 Hz | 补偿建模误差,输出修正力矩 |
| 恢复控制器(RL) | 400 Hz(仅失稳时激活) | 机器人摔倒或失稳时救场 |
📐 数学基础:系统建模
机器人状态表示
四足机器人被建模为一个浮动基座(floating base) 加上四条腿:
$$ q = \begin{bmatrix} {}^W r_{WB} \ q_{WB} \ q_j \end{bmatrix} \in SE(3) \times \mathbb{R}^{n_j} $$
- ({}^W r_{WB} \in \mathbb{R}^3):机器人基座在世界坐标系中的位置(x, y, z)
- (q_{WB} \in SO(3)):基座的姿态(用四元数表示旋转)
- (q_j \in \mathbb{R}^{12}):12 个关节的角度
关节控制:阻抗控制
机器人最终通过阻抗控制(impedance control)驱动关节:
$$ \tau_j = K_p(q_j^* - q_j) + K_d(\dot{q}_j^* - \dot{q}j) + \tau{jFF} $$
通俗理解:就像弹簧-阻尼系统。(K_p) 是弹簧刚度(偏差越大、力越大),(K_d) 是阻尼(速度越快、阻力越大),(\tau_{jFF}) 是前馈力矩(提前知道要做什么就先加上去)。
🗺️ 模块1:地形编码器(Elevation Map Encoder)
什么是高程图?
机器人用深度相机扫描周围地形,生成一张 91×91 像素的高程图(覆盖 1.8m × 1.8m 范围),记录每个点的高度。
去噪自编码器
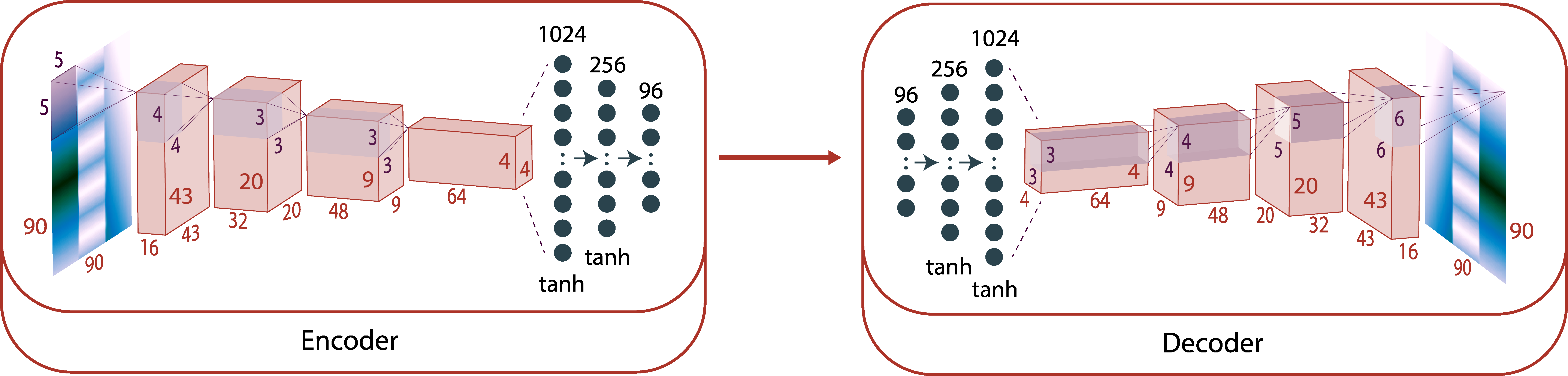
原始高程图可能有噪声、遮挡,所以用去噪卷积自编码器处理:
graph LR
A[原始高程图 91×91] -->|加入噪声| B[含噪高程图]
B -->|编码器 E| C[潜在特征 Z: 96维]
C -->|解码器 D| D[重建高程图]
D -.->|最小化重建误差| B
加入的噪声包括:
- 高斯噪声:模拟传感器误差
- 椒盐噪声:模拟随机错误测量
- 模糊卷积:模拟边缘模糊(楼梯边缘会变模糊)
💡 为什么这么做? 真实机器人的传感器数据很脏,训练时加噪声让网络学会"无论输入多差都能提取关键特征"。
👣 模块2:步态规划器(Footstep Planner)
这是 RLOC 的"大脑",用 强化学习 学习:给定地形和速度指令,四只脚该落在哪里。
状态空间 (s_f \in \mathbb{R}^{204})
| 状态分量 | 维度 | 含义 |
|---|---|---|
| (s_R):基座方向 | 3 | 机器人身体朝向 |
| (s_v):速度 | 6 | 线速度+角速度 |
| (s_j):关节历史 | 96 | 过去几帧的关节位置和速度 |
| (s_c):速度指令 | 3 | 用户期望的前进/侧移/转向速度 |
| (s_M):地形特征 | 96 | 编码器输出的地形特征向量 |
动作空间 (a_f \in \mathbb{R}^8)
输出四只脚的 水平落脚位置(每脚2个坐标 = 4×2 = 8维)。
奖励函数
奖励分为运行奖励(每个控制步)和最终奖励(每次步态完成后):
$$ r_F = r_F^f + \frac{1}{(n+1)t - (n_t+1)} \sum{t=n_t+1}^{(n+1)t} r{Ft}^r $$
运行奖励包括: $$ r_{Ft}^r = 8r_v - 0.016 d_f r_\tau - 2.5 d_f r_\mu + 4r_m $$
| 奖励项 | 含义 | 方向 |
|---|---|---|
| (r_v):速度追踪奖励 | 实际速度 vs 期望速度 | ↑ 越接近越好 |
| (r_\tau):力矩惩罚 | 关节力矩大小 | ↓ 越小越省能量 |
| (r_\mu):滑步惩罚 | 支撑脚是否滑动 | ↓ 不能滑 |
| (r_m):稳定裕度奖励 | 机器人的动态稳定性 | ↑ 越稳越好 |
训练算法:SAC(Soft Actor-Critic)
用 SAC 训练,相比 PPO/TRPO 在这种低频决策环境中更样本高效(只需 32 小时训练,而同类方法需要 454 小时!)。
⚙️ 模块3:运动控制器(Motion Controller)
运动控制器是系统的"手脚"——接收步态规划器给出的落脚点,生成具体的关节轨迹并执行。
工作流程
sequenceDiagram
participant FP as 步态规划器
participant MC as 运动控制器
participant WBC as 全身控制器
participant Robot as 机器人
FP->>MC: 期望落脚点 r*_F(每步态更新)
MC->>MC: 解非线性优化,生成CoM轨迹
MC->>WBC: 参考CoM和脚部运动计划
WBC->>WBC: 层次QP优化
WBC->>Robot: 前馈力矩 τ_jFF + 关节位置速度指令
CoM轨迹参数化:五次样条
机器人重心(CoM)的运动用五次多项式样条描述:
$$ x(t) = \alpha_{j5}^x t^5 + \alpha_{j4}^x t^4 + \alpha_{j3}^x t^3 + \alpha_{j2}^x t^2 + \alpha_{j1}^x t + \alpha_{j0}^x $$
为什么用五次? 五次多项式可以同时约束位置、速度、加速度的起止条件,轨迹更平滑。
🔧 模块4:域自适应追踪器(Domain Adaptive Tracker)
问题:训练时用 ANYmal B 的模型,真实机器人的参数(质量、摩擦等)可能不同。
解决方案:训练一个 RL 策略,学习补偿力矩 (\delta\tau_{jFF}),让实际跟踪效果接近理想:
$$ \tau_j = K_p(q_j^* - q_j) + K_d(\dot{q}j^* - \dot{q}j) + \underbrace{\tau{jFF}}{\text{运动控制器输出}} + \underbrace{\delta\tau_{jFF}}_{\text{自适应补偿}} $$
训练时进行大量域随机化(domain randomization):随机改变机器人质量、摩擦系数、关节延迟等,让策略学会应对各种不确定性。
🆘 模块5:恢复控制器(Recovery Controller)
当机器人失稳(倾斜角超过 45°、发生碰撞等),运动控制器可能无法恢复,此时恢复控制器接管,直接输出关节位置指令让机器人站稳,然后切回正常控制。
stateDiagram-v2
Normal: 正常运动状态\n(步态规划器 + 运动控制器)
Recovery: 恢复状态\n(恢复控制器)
Normal --> Recovery: 检测到失稳\n(倾角>45° 或 链接碰撞)
Recovery --> Normal: 恢复稳定\n(基座姿态回归正常)
🏋️ 训练设置
地形生成器
训练在程序化生成的多种地形上进行:
| 地形类型 | 特征 |
|---|---|
| 平地(Flat Ground) | 基础测试 |
| 楼梯(Stairs) | 最高 45cm,随机宽度 |
| 正弦波(Sine Wave) | 不规则起伏 |
| 砖块(Bricks) | 分散的不规则块 |
| 木板(Planks) | 狭长可踩面 |
| 混合地形 | 以上的组合 |
课程学习(Curriculum Learning)
从简单地形开始,逐渐增加难度——这通过 惩罚权重系数 (d_f) 实现,随训练进度从 0.02 逐渐增大。
📊 实验结果
模拟中的性能对比
| 方法 | 平地速度追踪 | 楼梯成功率 | 训练时间 |
|---|---|---|---|
| 纯RL(端到端) | 中等 | 低 | 长 |
| 模型预测控制(MPC) | 高 | 中等 | 需手动调参 |
| RLOC(本文) | 高 | 高 | 32小时 |
零样本迁移:ANYmal B → ANYmal C

在 ANYmal B 上训练的所有策略,直接在 ANYmal C 上运行(不重训练),测试环境包括:
- 室外:草地、泥地、斜坡
- 室内:楼梯、人行道
💡 消融研究:各模块贡献
通过移除某个模块来测试其重要性:
| 移除的模块 | 影响 |
|---|---|
| 去掉地形编码器(随机步态) | 楼梯成功率大幅下降 |
| 去掉域自适应追踪器 | ANYmal C 上的追踪误差增大 |
| 去掉恢复控制器 | 受到外力扰动后无法恢复 |
🔬 与传统方法的比较
graph TD
A[机器人运动控制方法] --> B[纯模型方法\nWBC/MPC]
A --> C[纯强化学习\nEnd-to-End RL]
A --> D[本文 RLOC\nRL + 最优控制]
B --> B1[✓ 精确执行\n✗ 需精确模型\n✗ 调参耗时]
C --> C1[✓ 无需精确模型\n✗ 训练难/慢\n✗ 泛化差]
D --> D1[✓ 精确执行\n✓ 模型容差大\n✓ 训练快(32h)\n✓ 零样本迁移]
🎓 关键概念解释
什么是"步态"(Gait)?
四条腿的抬起和放下有特定的时序节律,称为步态。常见步态有:
- 对角步(Trot):左前+右后同时、右前+左后同时
- 跑步(Gallop):类似马奔跑的节律
- 爬行(Crawl):每次只抬一条腿
什么是"稳定裕度"(Stability Margin)?
机器人支撑脚形成一个多边形(支撑多边形),重心在这个多边形内越居中越稳定。裕度是重心到边界的最小距离。
什么是"sim-to-real transfer"(仿真到现实迁移)?
在仿真器中训练的策略,在真实机器人上直接用。难点在于仿真和现实的物理差异("reality gap")。RLOC 用域随机化和去噪自编码器解决这个问题。
📝 总结:RLOC 的创新点
- 模块化混合架构:RL 负责感知决策,最优控制负责精确执行,各司其职
- 高效训练:借助运动控制器的约束,32 小时完成训练(vs 同类方法 454 小时)
- 零样本跨平台迁移:ANYmal B 训练的策略直接在 ANYmal C 上用
- 地形感知:通过去噪自编码器处理真实噪声,实现对楼梯、斜坡的感知行走
- 内置恢复机制:失稳时自动切换恢复控制器,增强鲁棒性
Efficient Self-Supervised Data Collection for Offline Robot Learning
论文信息
- 作者:Shadi Endrawis, Gal Leibovich, Guy Jacob, Gal Novik, Aviv Tamar
- 机构:Technion - 以色列理工学院 & Intel Labs
- 发表:arXiv:2105.04607 (2021), ICRA 2021
- 关键词:离线强化学习、探索策略、内在动机、目标条件策略、数据收集
📖 TL;DR(一句话总结)
问题:机器人学复杂任务需要大量高质量数据,但手动设计数据收集策略很难,随机探索又效率低下。
解决方案:训练一个"好奇心驱动"的机器人——用 RND 识别新奇状态 + 目标条件策略快速抵达,自动收集覆盖面广、分布均匀的离线数据集,让后续任务学习效果大幅提升。
🎯 问题背景:为什么数据收集这么重要?
graph TD
A[机器人学习流程] --> B[在线强化学习\nOnline RL]
A --> C[离线强化学习\nOffline RL]
B --> B1[实时交互环境\n边收集边学习]
B1 --> B2[❌ 危险:真实机器人可能损坏\n❌ 慢:只能串行收集]
C --> C1[先收集数据集\n再从数据中学习]
C1 --> C2[✓ 安全:离线处理\n✓ 快:可并行收集]
C1 --> C3[❗ 关键:数据质量决定学习效果]
C3 --> D{数据如何收集?}
D --> D1[随机策略\n覆盖面窄、有偏]
D --> D2[手动设计\n复杂任务很难设计]
D --> D3[本文方法\n自动主动探索]
核心洞察:对于复杂任务(如叠积木),如果数据收集策略只是随机乱抓,几乎不会遇到"积木叠起来"这样的关键状态,学出来的策略就很差。
💡 核心思路:目标条件 + 新奇性驱动
本文提出 三个关键"成分" 的组合:
graph LR
A[RND\n随机网络蒸馏] -->|识别哪些状态是新奇的| B[新奇性分数]
B -->|选最新奇的状态作为目标| C[目标条件策略\nGoal-Conditioned Policy]
C -->|快速导航到目标| D[访问新奇状态]
D -->|更新RND| A
成分1:RND(Random Network Distillation,随机网络蒸馏)
目的:判断一个状态有多"新奇"(从未访问过 → 新奇;反复访问 → 不新奇)
原理:
- 随机初始化一个固定的"目标网络" (f: S \rightarrow \mathbb{R}^k)
- 训练一个"预测网络" (\hat{f}: S \rightarrow \mathbb{R}^k) 来预测目标网络的输出
- 预测误差 (|\hat{f}(s) - f(s)|^2) 代表新奇性:
- 见过很多次的状态 → 预测准确 → 误差小 → 不新奇
- 从没见过的状态 → 预测不准 → 误差大 → 很新奇
比喻:就像一个学生做题,反复做过的题型很熟练(误差小),遇到新题型就会出错(误差大)。误差大的题 = 新奇的状态。
成分2:目标条件策略(Goal-Conditioned Policy)
目的:快速"导航"到指定的目标状态
关键区别:
- 普通RL探索:靠奖励信号慢慢调整,遇到新奇区域要花很久才能"学会去那里"
- 目标条件策略:直接把目标作为输入,训练"给定目标,如何以最少步骤到达"
训练方式:HER(Hindsight Experience Replay,事后经验回放)
- 即使没有达到原来的目标,也可以把轨迹中经过的任意状态作为"虚假目标"重新使用
- 这样每条轨迹都能产生大量训练样本,极大提高数据利用率
成分3:主动目标选择
每个 episode 开始时:
- 从回放缓冲区(replay buffer)中采样一批状态
- 选择其中 新奇性分数最高 的那个作为当前 episode 的目标
- 用目标条件策略快速导航到这个目标
- 把访问过的轨迹加入数据集
📝 算法详解
算法1:目标条件 + RND 数据集收集
初始化:RND 网络 f, f^, 回放缓冲区 R, 离策略RL算法 A
对每个训练循环(N次):
对每个 episode(M次):
1. 从 R 中采样子集 R'
2. 目标 g = argmax_{R'} ||f^(s) - f(s)||² ← 选最新奇的状态为目标
3. 对每步 t = 0 ... T:
a. 执行动作 at = π(st, g) ← 用目标条件策略
b. 观察新状态 st+1
c. 将 (st, at, st+1) 存入 R
4. 从 R 采样 mini-batch:
- 动态采样目标 gτ(从轨迹中随机选)
- 奖励:到达目标为 0,否则为 -1
- 用 HER 方式训练
更新 RND 的预测网络 f^(仅用最近的 M 个 episode)
返回数据集 R
💡 动态目标采样 vs 静态(HER)的区别:HER 在状态存入缓冲区时就固定了目标;本文每次从缓冲区采样时才分配目标,同一个状态可以配对不同的目标,样本利用率更高。
🔬 实验设置
环境:Franka Panda 机械臂 + 彩色方块

- 机器人:7 自由度 Franka Panda 机械臂,末端执行器位置控制
- 场景:桌面上有一个六面不同颜色的方块
- 观测:俯视摄像头图像(84×84 像素)
- 动作:末端执行器的笛卡尔位置移动
- 每个 episode:200 步,方块每次重置到初始位置(黄色面朝上)
对比基线
| 方法 | 描述 |
|---|---|
| 随机策略 | 完全随机动作 |
| 纯 RND(Vanilla RND) | 仅用内在奖励训练 RL,不使用目标条件 |
| 本文(Goal-Conditioned + RND) | 目标条件策略 + RND 新奇性选目标 |
📊 实验结果
实验1:玩具域——覆盖度测试
对象(白色方块)在 84×84 格子中移动,测量收集的状态有多少覆盖了整个状态空间:
| 方法 | 覆盖的独特状态数(500 episodes) |
|---|---|
| 随机策略 | ~10,000 → 平台期 |
| 纯 RND | 更多,但效率低 |
| 本文(Goal-Conditioned Max Novelty) | 最多,持续增长 |
| 目标条件(最小新奇性) | 最差(反向选目标) |
| 目标条件(随机目标) | 比随机策略还差 |
关键发现:随机策略会陷入"平台期",增加样本量也无法改善;本文方法持续发现新状态。
实验2:数据集可视化

可视化方块在桌面上的位置和朝向:
- 随机策略:方块位置集中在初始位置附近,朝向单一(几乎全是黄色面朝上)
- 纯 RND:稍好,但仍有很大空白区域
- 本文方法:方块位置遍布整个桌面,六个面颜色分布均匀
实验3:下游任务——监督学习
基于收集的数据训练分类/回归模型:
| 下游任务 | 随机策略 | 纯 RND | 本文方法 |
|---|---|---|---|
| 预测方块上表面颜色(分类准确率) | 低 | 中 | 最高 |
| 预测方块位置(回归 MSE) | 高 | 中 | 最低 |
实验4:下游任务——离线强化学习(BCQ)
基于收集的数据训练 BCQ 策略,成功率(%):
| 任务 | 随机策略 | 纯 RND | 本文方法 |
|---|---|---|---|
| 翻转方块(指定颜色朝上) | 低 | 中 | 高 |
| 推方块到右侧区域 | 中 | 中 | 高 |
| 翻转 + 推(组合任务) | 低 | 低 | 高 |
🧠 关键技术解释
什么是"离线强化学习(Offline RL)"?
graph LR
A[已有数据集\n事先收集好的] -->|BCQ/CQL等算法| B[学习策略]
B -->|不再与环境交互| C[直接部署使用]
与在线 RL 的对比:
| 方面 | 在线 RL | 离线 RL |
|---|---|---|
| 与环境交互 | 是,持续交互 | 否,只用固定数据 |
| 数据来源 | 自己收集 | 事先给定 |
| 安全性 | 低(可能损坏机器人) | 高 |
| 数据质量依赖 | 低 | 高(核心挑战) |
什么是"HER(Hindsight Experience Replay,事后经验回放)"?
比喻:假设你想练习"把杯子放到指定位置",但每次都失败了。
普通训练:这条失败的轨迹没有用。
HER训练:把"轨迹中最后杯子真正在的位置"作为目标,这条轨迹就变成了"成功到达目标 X"的训练样本!
就像事后总结:"虽然没到达原定目标,但我成功到达了另一个地方,这也算学到了导航能力。"
什么是"目标条件策略(Goal-Conditioned Policy)"?
策略输入 = 当前状态 + 目标状态,输出动作:
$$ a_t = \pi(s_t, g) $$
价值函数变成"从 (s_t) 出发,以 (a_t) 动作,到达目标 (g) 的期望折扣奖励":
$$ Q^\pi(s, a, g) = \mathbb{E}\left[\sum_{k=t+1}^{\infty} \gamma^{k-t-1} r_k \mid s_t = s, a_t = a, g\right] $$
用 -1 奖励(未到达)和 0 奖励(到达),该值函数实际上代表了"从 s 到 g 的负距离"。
🔑 创新点总结
graph TD
A[本文创新点] --> B[新奇性驱动的主动探索]
A --> C[目标条件策略替代慢速RL探索]
A --> D[动态目标采样提高利用率]
A --> E[首次在图像输入上实现\n目标条件+内在动机结合]
B --> B1[用RND量化新奇性\n无需手工设计奖励]
C --> C1[直接导航到新奇区域\n不需要反复试错]
D --> D1[每个状态可配多目标\n比静态HER更高效]
E --> E1[证明对高维视觉状态有效]
⚠️ 局限性与未来工作
- 仅在仿真中验证:真实机器人的 sim-to-real 迁移未测试
- 固定 episode 长度:真实场景中 episode 长度可能不固定
- 单任务场景:更复杂的多任务场景未评估
- 计算开销:每个 episode 需要查询新奇性 → 大型数据集时可能慢
未来方向:在真实机器人上测试,结合 sim-to-real 方法,探索组合仿真和真实数据的方案。
📝 总结
| 要素 | 内容 |
|---|---|
| 问题 | 离线RL的数据质量瓶颈 |
| 方法 | RND新奇性 + 目标条件策略 |
| 优势 | 比随机/纯RND更广、更均匀的状态覆盖 |
| 验证 | 监督学习+离线RL多种下游任务均有提升 |
| 局限 | 仅在仿真验证,计算有额外开销 |
Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
论文信息
- 作者:Joonho Lee, Marko Bjelonic, Alexander Reske, Lorenz Wellhausen, Takahiro Miki, Marco Hutter
- 机构:ETH Zurich 机器人系统实验室 & Swiss-Mile Robotics AG
- 发表:Science Robotics Vol. 9, Issue 89, 2024(顶级期刊!)
- arXiv:arXiv:2405.01792v1
- 关键词:轮足机器人、层次强化学习、自主导航、城市配送、混合运动控制
📖 TL;DR(一句话总结)
ETH Zurich 研究团队让一个带轮子的四足机器人在苏黎世和塞维利亚的城市街道上完成了公里级自主送货任务——速度是普通四足机器人的 3 倍,能耗降低 53%,能走楼梯、避行人、穿窄道,全部靠强化学习实现!
🤔 为什么需要"轮足机器人"?
传统机器人各有局限:
graph TD
A[城市配送机器人的需求] --> B[纯轮式机器人\n轮椅/小车]
A --> C[纯足式机器人\nANYmal]
A --> D[轮足混合机器人\n本文]
B --> B1[✓ 平地速度快\n✓ 能耗低\n✗ 无法上楼梯\n✗ 复杂地形失败]
C --> C1[✓ 能攀爬\n✓ 适应复杂地形\n✗ 速度慢(2.2km/h)\n✗ 能耗高\n✗ 仅续航1小时]
D --> D1[✓ 平地高速(>5m/s)\n✓ 能上楼梯\n✓ 能耗低\n✓ 续航长\n✓ 遇障碍自适应切换步态]
本文机器人的关键能力数据:
- 平均速度:1.68 m/s(ANYmal 的 3 倍)
- 机械运输成本(COT):0.16(降低 53%)
- 最高速度:5.0 m/s(驾驶模式)
- 苏黎世测试总行程:8.3 km,极少人工干预
🏗️ 系统架构总览
系统由三层组成:
graph TB
GPS[全局导航图\nGPS路径规划] -->|路径节点序列| HLC
subgraph 层次控制
HLC[高层导航控制器 HLC\n10 Hz\n神经网络]
LLC[底层运动控制器 LLC\n50 Hz\n循环神经网络RNN]
end
HLC -->|速度指令 vx, vy, ωz| LLC
LLC -->|关节位置 + 轮速命令| Robot[机器人]
LiDAR[LiDAR传感器] -->|高程图| HLC
Camera[RGB立体相机] -->|人体检测| HLC
IMU[IMU + 关节编码器] --> LLC
Robot -->|隐藏状态 hidden state| HLC
| 控制器 | 频率 | 输入 | 输出 | 职责 |
|---|---|---|---|---|
| HLC(高层) | 10 Hz | 路径点 + 地形高程图 + LLC隐藏状态 + 位置历史 | 速度指令 (vx, vy, ωz) | 导航规划 + 避障 |
| LLC(底层) | 50 Hz | IMU + 关节状态 + 高程扫描 | 关节位置 + 轮速 | 步态控制 + 平衡 |
🦾 底层运动控制器(LLC):让机器人会"走"
核心设计思路:特权学习(Privileged Learning)
训练分两阶段:
graph LR
A[阶段1: 教师策略\nTeacher Policy] -->|知道一切特权信息| B[学会走路]
B -->|行为蒸馏/模仿学习| C[阶段2: 学生策略\nStudent Policy]
C -->|只用真实传感器| D[真实部署]
note1[特权信息: 速度精确值, 地形属性, 无噪声外感知] -.-> A
note2[真实输入: 有噪声IMU, 关节编码器, 有噪声高程扫描] -.-> C
为什么分两阶段?
真实机器人的 IMU 是有噪声的,传感器会有误差。如果直接用噪声数据训练,很难学好。先用"上帝视角"的完美信息训练一个好的教师,再让学生通过 RNN 从噪声中恢复这些信息。
涌现出来的步态行为
LLC 没有预设步态,完全从零学习,结果自然涌现出多种步态:
| 地形场景 | 涌现的步态 |
|---|---|
| 平坦地面 | 驾驶模式(全轮接地,腿基本不动) |
| 凹凸路面(障碍<轮子半径) | 主动悬挂(轮子接地,腿动态调整保持身体稳定) |
| 楼梯 / 陡坡 | 对角步(Trot,类似四足机器人) |
| 大型离散障碍 | 非对称步态(部分腿爬,部分轮子滚) |
| 极端高障碍(40cm) | 用膝盖爬行 |
💡 关键:不对称地形感知
机器人"下台阶"比"上台阶"能处理更高的落差!这是因为重力方向不同,对稳定性的影响不对称。传统遍历性地图(traversability map)假设对称,本文的 HLC 学会了方向感知。
🗺️ 高层导航控制器(HLC):让机器人会"想"
观测空间设计
HLC 的输入包含 4 种信息:
| 信息类型 | 具体内容 | 作用 |
|---|---|---|
| 外感知(地形) | 机器人周围 3m×1.5m 的高程扫描(包含前两帧) | 感知障碍物 |
| LLC 隐藏状态 | RNN 的内部状态向量 | 了解当前步态和地形适应情况 |
| 位置记忆 | 最近 20 个已访问位置(每 0.5m 记录一次)+ 停留时间 | 防止兜圈、支持探索 |
| 路径点 | WP1(近)+ WP2(远)及历史 | 目标方向 |
🔑 关键设计:LLC 隐藏状态
传统导航器只知道机器人的估计位置和速度。本文 HLC 直接读取 LLC 的 RNN 隐藏状态(相当于知道 LLC 在"想什么"),能自动适应当前地形和步态状态,避免给出 LLC 无法执行的速度指令。
位置记忆的作用
stateDiagram-v2
state "遇到阻挡路径" as Blocked
state "倒退探索" as Explore
state "位置缓冲区记录访问历史" as Memory
state "发现楼梯/绕路" as Found
state "前往目标" as Goal
Blocked --> Explore: 路被堵了
Explore --> Memory: 持续记录位置
Memory --> Explore: 惩罚重复访问位置\n鼓励探索新区域
Explore --> Found: 找到可通行路径
Found --> Goal: 跟随新路径
没有记忆会怎样? 实验证明:无记忆版本会陷入局部极小(来回打转),失败率最高。
动作空间:Beta 分布 vs 高斯分布
HLC 用 Beta 分布 来表示速度指令,而不是常用的高斯分布。
原因:Beta 分布天然有有界输出(值域在 [0,1],可缩放到任意范围),避免输出超出物理限制:
- (v_x \in [-1.0, 2.0]) m/s(前向偏多,方便朝前走)
- (v_y \in [-0.75, 0.75]) m/s(左右移动)
- (\omega_z \in [-1.25, 1.25]) rad/s(转向)
奖励函数设计
密集奖励(训练初期):
$$ r_{h,dense} = \begin{cases} 1.0 & \text{if } |e_{wp1}| < 0.75 \ \text{clip}(v \cdot d_{e_{wp1}}, 0, v_{thres}) / v_{thres} & \text{otherwise} \end{cases} $$
探索奖励(防止兜圈):
$$ C(p_{robot}, wp_1, p_{buf}^i) = \begin{cases} 0 & \text{if } |p_{robot} - wp_1| < 0.75 \ -n_{buf}^i & \text{if } |p_{robot} - p_{buf}^i| < 1.0 \end{cases} $$
如果机器人一直待在同一个地方,就会收到惩罚(惩罚值 = 停留时间次数),迫使其探索新区域。
🏙️ 训练环境:游戏技术启发
波函数折叠(Wave Function Collapse, WFC)算法
受电子游戏技术启发,用 WFC 算法自动生成多样化的训练地图:
graph LR
A[定义基础地块\nFloor/Stairs/Obstacles] -->|WFC算法| B[随机组合生成地图]
B --> C[提取导航图\nNavigation Graph]
C --> D[Dijkstra找最短路径]
D --> E[采样路径点作为训练目标]
WFC 算法保证地形多样性:有走廊、房间、楼梯、开阔区域的各种组合,同时保证路径一定可达(使用 Dijkstra 算法确认连通性)。
训练流程
sequenceDiagram
participant Env as 训练环境
participant LLC as LLC(底层)
participant HLC as HLC(高层)
Note over Env,LLC: 阶段1: 教师策略训练
Env->>LLC: 随机速度指令 + 特权信息
LLC->>LLC: PPO 优化
Note over LLC: 阶段2: 学生策略训练
LLC->>LLC: 模仿教师 + RNN 编码噪声输入
Note over LLC,HLC: 阶段3: 高层策略训练
Env->>HLC: 路径点 + 障碍信息
HLC->>LLC: 速度指令
LLC->>HLC: 执行结果 + 隐藏状态
HLC->>HLC: PPO 优化
📊 实验结果
大规模城市部署(苏黎世)
- 区域大小:245m × 345m,约 8.5 公顷
- 总行程:8.3 km
- 目标点数:13 个(人工选取,最大化覆盖范围)
- 扫描时间:90 分钟(使用手持激光扫描仪预扫描)
速度与能耗对比(vs ANYmal-C 在 DARPA 地下挑战赛中的数据):
| 指标 | ANYmal-C | 本文机器人 | 改进幅度 |
|---|---|---|---|
| 平均速度 | ~0.56 m/s | 1.68 m/s | +3× |
| 机械运输成本 COT | ~0.34 | 0.16 | -53% |
| 腿关节 (\sum\tau^2) | 100% | 84%(更重+更快) | -16% |
对比传统导航方法
| 指标 | 传统采样规划器 | 本文 HLC(+记忆) |
|---|---|---|
| 任务失败率 | 高 | 最低 |
| 碰撞率 | 有(延迟导致) | 0(全无碰撞) |
| 规划时间 | 最高>1 秒 | 0.34 ms(快 3000×) |
| 平均追踪误差 | 0.45 m/s | 0.24 m/s |
传统方法的碰撞原因:重规划有延迟,机器人速度快时来不及刹车;且对 LLC 跟踪能力做了理想化假设。本文 HLC 因为直接读取 LLC 状态,完全避免了这个问题。
🔑 关键创新总结
mindmap
root((RLOC 创新点))
轮足混合步态
无预设步态约束
自动选驾驶/走路
方向感知的地形判断
特权学习
教师教学生
RNN处理噪声输入
无需精确状态估计
HLC读取LLC隐藏状态
了解LLC的"想法"
命令更可执行
无需模型假设
位置记忆
防止局部极小
支持探索
处理遮挡情况
实际城市部署验证
苏黎世+塞维利亚
公里级任务
动态环境(行人)
⚙️ 关键名词解释
机械运输成本(COT,Cost of Transport)
$$ COT_{mech} = \frac{\sum_{all\ joints} [\tau \dot{\theta}]^+}{mg \cdot |v_{xy}^b|} $$
- 分子:所有关节的正机械功率(推动运动的有效功)
- 分母:机器人重量 × 水平速度("传送1牛顿重量前进1米的代价")
- 越小越节能,驾驶模式 COT ≈ 0.01(近乎免费!)
波函数折叠(WFC)
一种从游戏开发借鉴的程序化地图生成算法。给定几种基本地块的约束规则(比如"楼梯只能连接到平地"),WFC 算法像解数独一样,递归地随机生成满足所有约束的合法地图布局。
路径追踪算法(Pure Pursuit)
一种经典的路径跟随算法:在路径上设定一个"前瞻点"(look-ahead point),始终让机器人朝那个点移动。本文将其与 RL 结合,由 HLC 动态决定向哪个路径点方向走。
⚠️ 局限性与未来方向
| 局限性 | 原因 | 未来方向 |
|---|---|---|
| 最高速度限于 2m/s(自主) | 高程图更新延迟,3m 感知范围不够 | 依赖原始传感器流替代高程图 |
| 语义感知缺失 | 仅用几何信息 | 加入语义分割(识别草地/私人领地) |
| 地图建立需人工预扫描 | 约 90 分钟 | 在线建图 |
| 孩子等小型动态障碍 | 保守处理,主动停机 | 更精细的动态感知 |
| 走廊定位退化 | LiDAR 无特征 | 鲁棒定位算法 |
Dataset Distillation for Offline Reinforcement Learning
论文信息
- 作者:Jonathan Light*, Yuanzhe Liu*, Ziniu Hu(*同等贡献)
- 机构:Rensselaer Polytechnic Institute & Caltech
- 发表:ICML Workshop on Data-centric Machine Learning Research, 2024
- arXiv:arXiv:2407.20299
- 关键词:离线强化学习、数据集蒸馏、行为克隆、梯度匹配
📖 TL;DR(一句话总结)
离线强化学习的质量取决于数据集。本文提出:与其在烂数据上练出更好的算法,不如先把烂数据"蒸馏"成好数据——用梯度匹配技术合成一个超小但高质量的合成数据集,训练出来的策略性能与全量数据相当,数据量仅需原来的 1.5%!
🎯 问题背景
什么是"离线强化学习"?
graph TD
A[强化学习的两种模式] --> B[在线强化学习\nOnline RL]
A --> C[离线强化学习\nOffline RL]
B --> B1[智能体与环境实时交互\n边收集数据边学习]
B1 --> B2[❌ 真实场景太危险/昂贵\n❌ 不能并行化收集]
C --> C1[给定一个固定数据集\n从中学习策略]
C1 --> C2[✓ 安全离线处理\n✓ 可重复利用历史数据]
C1 --> C3[❗ 关键问题:数据质量不好怎么办?]
已有数据集质量差的两大表现
- 数据是"普通"策略产生的:现实中很难获得完美专家数据,大多是"凑合"策略产生的
- 分布偏移(Distribution Shift):策略在数据中学到的分布,与在真实环境中遇到的分布不同
已有的应对方法:百分位行为克隆(Percentile BC)
只保留数据集中表现最好的 x% 的轨迹来训练:
- BC 10%:只用得分最高的 10% 数据
- BC 25%:只用得分最高的 25% 数据
- 以此类推……
问题:这还是在"筛选"数据,没有真正提升数据质量。
💡 本文方案:数据集蒸馏(Dataset Distillation)
核心思想:不筛选数据,而是"合成"更好的数据。
graph LR
A[真实离线数据集\nD_real\n大量但质量不均] -->|梯度匹配| B[合成数据集\nD_syn\n少量但高质量]
B -->|训练学生策略| C[性能与全量数据相当]
style B fill:#FFD700,stroke:#FF8C00
直觉理解
比喻:假设你要学一门课,有两种选择:
- 选项A:读 1000 篇杂乱的网文(BC full dataset)
- 选项B:读 15 篇精心整理的精华笔记(本文合成数据)
精华笔记虽然量少,但包含了最核心的梯度信息,训练出来的模型反而更好!
📐 方法详解:梯度匹配(Gradient Matching)
核心公式
合成数据集 (D_\phi) 的参数 (\phi) 通过最小化以下梯度匹配损失来学习:
$$ L_{grad_match}(\phi|\theta_i) = \mathbb{E}{\theta \sim p\theta} \left[ |\nabla_\theta L_{BC}(\theta|D_{real}) - \nabla_\theta L_{BC}(\theta|D_\phi)| \right] $$
通俗解释:
- 随机初始化一个模型 (\theta)
- 计算在真实数据集上的梯度 (\nabla_\theta L_{BC}(\theta|D_{real}))
- 计算在合成数据集上的梯度 (\nabla_\theta L_{BC}(\theta|D_\phi))
- 让两个梯度尽量接近
关键洞察:如果一个小数据集在随机初始化的模型上产生的梯度,与大数据集产生的梯度相同,那么训练出来的模型也会相同!
行为克隆损失(BC Loss)
$$ L_{BC}(\theta|D) = \sum_{(s_t^i, a_t^i, \ldots) \in D} w(s_t^i, a_t^i, \ldots) |\pi_\theta(s_t^i) - a_t^i| $$
就是用监督学习训练策略模仿专家动作。合成数据集需要让这个损失的梯度和真实数据相匹配。
整体流程
graph TB
subgraph 阶段1: 合成数据集训练
Real[真实数据集\nD_real] --> Grad_real[计算真实梯度\n∇L_BC on D_real]
Syn[合成数据集\nD_φ 随机初始化] --> Grad_syn[计算合成梯度\n∇L_BC on D_φ]
Grad_real --> Loss[梯度匹配损失]
Grad_syn --> Loss
Loss -->|SGD更新φ| Syn
end
subgraph 阶段2: 学生策略训练
Syn -->|用合成数据| Student[训练学生策略 πθ]
Student --> Eval[在真实环境评估]
end
🎮 实验环境:Procgen
Procgen 是 OpenAI 开发的程序化生成游戏环境,共 16 款游戏。
| 特点 | 描述 |
|---|---|
| 状态空间 | 64×64 像素 RGB 图像 |
| 动作空间 | 离散(上下左右 + 互动) |
| 关键特性 | 同一游戏规则,但每个 seed 生成不同地图 |
| 泛化测试 | 在分布内(ID)和分布外(OOD)地图上分别测试 |
本文使用的 3 个游戏:
| 游戏 | 描述 |
|---|---|
| Bigfish | 控制鱼吃更小的鱼,避开大鱼 |
| Starpilot | 太空飞船射击游戏,躲子弹打敌人 |
| Jumper | 平台跳跃游戏,需要跳跃过关 |
模型设置
| 角色 | 架构 | 参数量 | 训练步数 |
|---|---|---|---|
| 专家(Expert) | IMPALA CNN | 621,632 | 2500万步 |
| BC 学生 | 轻量 CNN | 6,966 | 1000步 |
| 合成数据学生 | 轻量 CNN | 6,966 | 100步 |
合成数据学生训练步数是BC学生的 1/10,却能达到相当性能!
📊 实验结果
数据集大小对比
| 游戏 | BC 10% | BC 25% | BC 100% | 本文合成数据 |
|---|---|---|---|---|
| Bigfish | 2,027 | 5,014 | 10,450 | 150 |
| Starpilot | 1,116 | 2,796 | 6,830 | 150 |
| Jumper | 392 | 919 | 4,837 | 150 |
→ 合成数据集大小固定为 150 条,相当于 BC10% 的 4%~38%!
分布内(ID)性能
| 游戏 | BC 10% | BC 25% | BC 40% | BC 100% | 本文 Synthetic |
|---|---|---|---|---|---|
| Bigfish | 0.90 | 0.93 | 1.01 | 1.00 | 1.03 ✓ |
| Starpilot | 1.73 | 2.10 | 2.17 | 1.85 | 1.5(较差) |
| Jumper | 1.79 | 2.15 | 1.95 | 2.32 | 2.76 ✓✓ |
分布外(OOD)性能
| 游戏 | BC 10% | BC 100% | 本文 Synthetic |
|---|---|---|---|
| Bigfish | 0.93 | 0.87 | 0.83(相当) |
| Starpilot | 1.83 | 1.82 | 1.54(稍差) |
| Jumper | 1.81 | 2.50 | 2.86 ✓✓ |
结论:在 Jumper 和 Bigfish 上,合成数据训练的学生优于所有 BC 变体;Starpilot 除外(原因:动作分布极度不均衡,导致蒸馏失败)。
🔑 为什么更小的数据集反而能帮助 RL 泛化?
本文的洞察:
graph TD
A[强化学习天然容易过拟合] --> B[原因1: 智能体自己产生数据\n高度相关、分布有偏]
A --> C[原因2: 随机性大\n噪声数据容易误导]
B --> D[解决思路]
C --> D
D --> E[精华小数据集\n减少冗余和噪声]
E --> F[更好的泛化能力\n特别是OOD]
类比:让学生学好一本写得好的教材,比让学生读 1000 篇低质量文章更有效。
⚠️ 局限性
| 局限性 | 描述 |
|---|---|
| 测试环境有限 | 仅测试了 3 个 Procgen 游戏 |
| Starpilot 失败 | 动作分布极不平衡时,梯度匹配效果差 |
| 使用BC(行为克隆)策略 | 未探索 Q-learning 或 Actor-Critic 等方法 |
| 计算成本 | 蒸馏过程本身需要额外计算 |
🧠 关键概念解释
知识蒸馏(Knowledge Distillation)vs 数据集蒸馏(Dataset Distillation)
| 方面 | 知识蒸馏 | 数据集蒸馏 |
|---|---|---|
| 目标 | 压缩模型(大→小) | 压缩数据集(大→小) |
| 输出 | 轻量化学生模型 | 小型合成数据集 |
| 应用 | 模型部署 | 数据效率提升 |
梯度匹配为什么有效?
如果两个数据集在同一个模型上产生相同的梯度,则无论从哪个初始权重开始训练,训练轨迹都会相似,最终收敛到相近的模型。因此,梯度匹配 = 训练行为匹配。
📝 总结
| 要素 | 内容 |
|---|---|
| 问题 | 离线RL数据质量差 |
| 方法 | 用梯度匹配蒸馏小型合成数据集 |
| 结果 | 150条数据 ≈ 10000条真实数据的训练效果 |
| 最佳场景 | 数据稀少、噪声大、无法在线收集的场景 |
| 局限 | 动作分布不均衡时效果下降 |
mimic-one: A Scalable Model Recipe for General Purpose Robot Dexterity
论文信息
- 作者:Elvis Nava*, Victoriano Montesinos, Erik Bauer, Benedek Forrai 等(*通讯作者)
- 机构:mimic robotics(苏黎世)& ETH Zurich
- 发表:arXiv:2506.11916(2025年6月)
- 主页:https://mimicrobotics.github.io/mimic-one/
- 关键词:灵巧操作、扩散策略、模仿学习、腱驱动机械手、自我纠正
📖 TL;DR(一句话总结)
mimic-one 提供了一套完整的灵巧机器人手方案:新设计的 16 自由度腱驱动手 + 扩散模型策略 + 系统性数据收集协议,在面包抓取、瓶子分拣、电池插入等任务上达到高达 93.3% 的分布外成功率,并展现出意外的"自我纠错"能力。
🤔 为什么灵巧操作这么难?
人的手有 27 块骨头、29 个关节,可以完成无数复杂动作。机器人要做到同等灵巧,需要同时解决:
graph TD
A[灵巧操作的四大挑战] --> B[硬件\n自由度、力度、感知]
A --> C[感知\n视觉+触觉实时反馈]
A --> D[控制\n高精度、高频率、平滑]
A --> E[数据\n如何高效收集高质量演示]
B --> F[mimic手: 16-DoF腱驱动]
C --> G[腕部广角相机]
D --> H[扩散策略15Hz高频控制]
E --> I[系统性5步数据收集协议]
现有方案的局限:
- 研究级机械手:超级贵、维护复杂
- 双指夹爪:便宜但能力有限(无法完成装配、分拣等复杂任务)
- 大规模VLA模型(RT-1/2):推理慢、不适合高频灵巧控制
🦾 硬件:mimic 灵巧手
设计理念
人体仿生 + 工程简化:保留最重要的人手特征,去掉不必要的复杂度。
| 参数 | 数值 | 意义 |
|---|---|---|
| 关节数 | 20 个 | 完整的五指 |
| 自由度(DoF) | 16 | 实际控制的独立维度 |
| 驱动方式 | 腱驱动(Tendon-Driven) | 柔顺、类人 |
| 最大负载 | >7 kg(五指抓握) | 工业级可用 |
| 皮肤材质 | 软硅胶接触面 | 接触更稳定 |
| 视觉 | 2 个宽角 RGB 腕部相机 | 丰富视角、低延迟 |
设计重点
- 拇指对立(Opposition):解剖学准确的拇指设计,能做出人手的对握
- 所有手指的展收(Abduction/Adduction):手指左右张合,对于灵巧操作非常重要
- 关节耦合:对不太关键的自由度用联动机构简化,减重
- 软皮肤:接触更稳定,避免硬接触失控
🤖 系统总览
完整硬件配置
[Apple Vision Pro / Manus手套] → 遥操作
↓
[Franka Panda 7-DoF 机械臂]
↓
[mimic 16-DoF 灵巧手]
├── 腕部相机(上方)
├── 腕部相机(下方)
└── 软硅胶皮肤
↓
外部工作空间相机(俯视)
遥操作方式
| 方式 | 设备 | 特点 |
|---|---|---|
| 手套式 | Manus 运动捕捉手套 + SpaceMouse | 高精度手部跟踪 |
| VR 式 | Apple Vision Pro | 更自然、便携 |
两种方式都通过"关键向量重定向(Key-Vector Retargeting)"将人手姿态转换为机器人手关节角度:
$$ E\left((\beta^h, \theta^h), q\right) = \sum_{i=1}^{15} |v_i^h - (c_i \cdot v_i^r)| $$
其中 (v_i^h) 和 (v_i^r) 是人手和机器人手的掌心到指尖向量,(c_i) 是尺度比例因子。
🧠 策略架构:扩散策略(Diffusion Policy)
核心思路
用扩散模型(Diffusion Model)来生成动作序列:从高斯噪声出发,逐步"去噪",最终得到平滑的动作轨迹。
graph LR
OBS[观测输入\n当前帧+历史帧] --> ENCODE[编码]
ENCODE --> COND[条件信息]
NOISE[随机高斯噪声\n48步动作序列] --> UNET[UNet去噪]
COND --> UNET
UNET -->|16步DDIM去噪| ACTION[平滑动作块\n48步 × 3.2秒]
模型细节
| 组件 | 具体实现 |
|---|---|
| 图像编码器 | CLIP 预训练 ViT-B/16(3个相机各一份,权重共享) |
| 动作生成网络 | UNet(嵌入维度128,核大小5) |
| 观测窗口 Ho | 2帧 |
| 动作块长度 Ha | 48步 = 3.2秒(15Hz) |
| 推理去噪步数 | 16步(DDIM 加速采样) |
| 推理重置频率 | 每执行第10步重新计算下一个动作块 |
关键设计:相对末端执行器表示
这是论文中最重要的技术细节之一,影响泛化能力:
问题:机器人每次启动位置不同,如果用"绝对坐标"表示动作,同一个任务在不同起始位置要学截然不同的轨迹。
解决:用相对坐标——以最近一次观测到的末端执行器位置为"基准坐标系",所有状态和动作都表示为相对于这个基准的偏移。
$$ T_k^{state\ rel} = (R_t^{obs})^T (T_k^{obs} - T_t^{obs}) $$ $$ R_k^{state\ rel} = (R_t^{obs})^T R_k^{obs} $$
直觉:就像GPS导航:
- 绝对坐标:"从经度116°,纬度39°出发..."(每次位置不同,就是全新任务)
- 相对坐标:"往前走200米,右转..."(无论从哪里出发,方向不变)
6D 旋转表示
旋转矩阵 (R \in SO(3)) 用6D 连续表示(取旋转矩阵前两列):
$$ R_{6D} = \begin{bmatrix} r_1 \ r_2 \end{bmatrix} \in \mathbb{R}^6 $$
为什么不用欧拉角或四元数?
- 欧拉角:有万向节锁(Gimbal Lock),在 ±180° 处有奇点
- 四元数:有双倍覆盖(同一旋转有两个表示),神经网络难以学习连续性
- 6D 连续表示:完全连续,没有奇点,神经网络友好
📋 数据收集协议:5 步系统流程
这是论文的另一大核心贡献——靠谱的数据收集,比算法更重要。
graph TD
S1[步骤1: 遥操作收集\n随机化起始位、物体位、任务配置\n约50%的episode加入干扰物] --> S2
S2[步骤2: 数据标注\n人工标记每个episode成功/失败] --> S3
S3[步骤3: 数据筛选\n第三人筛选: 不稳定抓取、错误动作] --> S4
S4[步骤4: 训练第一版策略\n评估并记录常见失败模式] --> S5
S5[步骤5: 收集自我纠正轨迹\n从失败状态出发录制恢复演示\n→ 重新训练]
S5 -->|继续迭代| S5
关键设计决策
| 决策 | 具体做法 | 目的 |
|---|---|---|
| 随机化 | 每次随机化机器人起始姿态 + 物体位置 | 防止策略只学到单一位置 |
| 干扰物 | ~50% episode 加入无关物体 | 提升对干扰的鲁棒性 |
| 任务配置多样化 | 每约100次换一次桌子颜色/背景/光照 | 遵循数据缩放定律 |
| 双人审核 | 收集者标注 + 第三人筛选 | 两道质量关卡 |
| 自我纠正数据 | 从失败状态出发收集恢复演示 | 最关键的提升(+25-33%)! |
三类失败模式(自我纠正的重点)
- 不稳定抓取:抓住了但不稳,移动时会掉落
- 未抓取:定位或轨迹有误,没有抓到物体
- 对准错误:抓取成功,但插入/放置时位置偏差
📊 实验结果
三大任务
| 任务 | 难点 | 数据量(成功/过滤) |
|---|---|---|
| 面包拿放(Bread Pick) | 可变形物体、不同表面 | 1830 / 550 |
| 瓶子分拣(Bottle Sort) | 侧向抓取、精确插入槽位 | 2420 / 882 |
| 电池插入(Battery Insertion) | 毫米级精度 + 最终"按入"动作 | 1192 / 528 |
成功率 vs 数据量(分布外评估)
| 任务 | 20%数据 | 50%数据 | 100%数据 | +自我纠正提升 |
|---|---|---|---|---|
| 面包拿放 | 22.5% | - | 66.7% | +26.6% → 93.3% |
| 瓶子分拣 | - | 25.0% | 56.0% | +33.3% → 75.0% |
| 电池插入 | - | 12.5% | 12.5% | +25.0% → 37.5% |
🔑 自我纠正数据是最大的提升来源:仅靠加入失败-恢复轨迹,成功率提升 25-33%,这来自"涌现的自我纠正行为"。
消融实验(面包拿放任务)
| 变体 | 成功率 |
|---|---|
| 绝对动作表示 | 23.0% |
| 相对动作(错误基准帧) | 30.0% |
| 单一任务配置 | 15.0% |
| 未过滤数据 | 5.0% |
| 无自我纠正轨迹 | 41.3% → 56.7% |
| 完整 mimic-one | 55.4% → 93.3% |
每个组件都不可或缺!移除任何一个都会导致性能大幅下降。
💡 关键发现:扩散模型 + 动作块 = 平滑自我纠错
扩散策略的一个意外优点:自然涌现了自我纠正行为。
graph LR
A[抓取失败\n瓶子位置偏] --> B[策略观测新状态]
B --> C[生成新的48步动作块]
C --> D[自动调整轨迹\n重新对准并插入]
D --> E[成功!]
style D fill:#90EE90
直觉理解:扩散模型预测的是"未来48步的完整轨迹"而不是"当前单步动作"。当出现偏差时,下一次采样时会自动将纠正行为融入新轨迹——这就是自我纠正的来源。
🔄 与相关工作的关系
| 相关工作 | 联系 |
|---|---|
| Diffusion Policy | 本文的策略架构基础 |
| ACT(VAE动作分块) | 同类动作块方法,本文用扩散替代VAE |
| UMI(Universal Manipulation Interface) | 本文借鉴相对动作表示 + 数据收集理念 |
| π0(Flow Matching + VLM) | 同类高频生成控制,本文专注单任务深度 |
| VideoDex | 关键向量重定向方法来源 |
⚠️ 局限性
| 局限性 | 说明 |
|---|---|
| 依赖模仿学习 | 上限受人类演示质量限制 |
| 数据收集需专用硬件 | mimic手 + Franka臂 + 摄像头,成本较高 |
| 单任务评估 | 没有测试多任务共训练 |
| 硬件专用 | 策略与特定手型绑定,换手需重训 |
| 无触觉感知 | 缺少接触力反馈,接触感知仅靠视觉 |
📝 总结
mimic-one 的核心贡献不在于单一技术突破,而在于将多个"已知有效"的组件正确地整合在一起:
mindmap
root((mimic-one))
新型硬件
16-DoF 腱驱动
双腕部广角相机
软硅胶皮肤
策略设计
扩散模型高频控制
相对末端执行器表示
6D 连续旋转表示
动作块时间一致性
数据协议
5步系统化流程
自我纠正轨迹
双人审核
任务配置多样化
结果
93.3% OOD 成功率
自动涌现自我纠错
数据量缩放规律
4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
论文信息
- 作者: Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, Xinggang Wang
- 单位: 华中科技大学、华为
- arXiv: 2310.08528
- 代码: https://guanjunwu.github.io/4dgs/
一句话总结
提出 4D Gaussian Splatting (4D-GS) 方法,通过结合 3D 高斯表示和 4D 神经体素,在单个 RTX 3090 GPU 上实现动态场景的实时渲染(最高 82 FPS)。
背景知识(让零基础也能看懂)
什么是"新视角合成"(Novel View Synthesis)?
想象你有一组从不同角度拍摄的照片,比如一个跳舞的人。你想看到这个人从侧面或背后看到的样子——但你没有拍过那些角度的照片。新视角合成的任务就是用 AI 生成这些"不存在"的视角图片。
这项技术在 VR/AR、电影特效等领域非常重要。
什么是"动态场景"?
普通的 3D 重建只能处理静止不动的场景(比如一座雕塑)。但现实世界中大多数场景都是动态的——人在走动、物体在运动。
动态场景的难点在于:不仅要重建空间信息,还要捕捉时间维度上的变化。
什么是 NeRF?
NeRF (Neural Radiance Fields) 是 2020 年提出的一种革命性方法,用神经网络来隐式表示 3D 场景。它的工作原理是:
- 将 3D 空间中的每个点 $(x, y, z)$ 映射到颜色和密度
- 使用体素渲染(Volume Rendering)技术从任意视角"合成"图像
问题:NeRF 训练很慢(通常需要几小时甚至几天),渲染也很慢(每秒只能渲染几张图),无法实时应用。
什么是 3D Gaussian Splatting (3D-GS)?
2023 年提出的 3D Gaussian Splatting 是一种更高效的方法:
- 用高斯分布(Gaussian)来表示 3D 场景中的点
- 用可微分的泼溅(Differentiable Splatting)技术直接将 3D 高斯投影到 2D 平面
- 不需要耗时的体素渲染,可以实时渲染
但 3D-GS 只适用于静态场景,无法处理动态内容。
什么是 4D?
我们平时说的 3D 是三维空间 $(x, y, z)$。加上时间维度 $t$,就是 4D。
所以 "4D 场景" = "3D 空间 + 时间变化"
核心问题
现有的方法存在以下问题:
- NeRF 类方法:训练慢、渲染慢,无法实时
- 3D-GS:只能处理静态场景
- 扩展 3D-GS 到动态场景:需要在每个时间点都构建一套 3D 高斯,存储成本呈线性增长(时间越长,存储越多)
核心挑战:如何在保持实时渲染能力的同时,处理动态场景?
方法详解
核心思想
不是为每个时间点都存储一套完整的 3D 高斯,而是:
- 维护一套canonical(标准)3D高斯
- 用一个变形网络来描述高斯如何随时间移动和变形
这样,存储成本就与时间无关了!
方法流程图
graph TB
subgraph Input
G[原始3D高斯 G]
t[时间戳 t]
end
subgraph "时空结构编码器 H"
G --> |"中心坐标 X"| R1["多分辨率HexPlane R(i,j)"]
t --> |"时间信息"| R1
R1 --> |"体素特征"| MLP["小型MLP φd"]
end
MLP --> |"融合特征 fd"| D["多头高斯变形解码器 D"]
subgraph "多头解码器"
D --> |"fd"| DX["ΔX 位置变形"]
D --> |"fd"| DR["Δr 旋转变形"]
D --> |"fd"| DS["Δs 缩放变形"]
end
DX --> |"X + ΔX"| GX["变形后的位置 X'"]
DR --> |"r + Δr"| GR["变形后的旋转 r'"]
DS --> |"s + Δs"| GS["变形后的缩放 s'"]
GX --> |"X', r', s', α, C"| SG["变形后的3D高斯 G'"]
SG --> |"可微分泼溅"| Output["渲染图像 I"]
关键技术 1:时空结构编码器 (Spatial-Temporal Structure Encoder)
灵感来自 HexPlane/K-Planes 方法,将 4D 神经体素分解为 6 个 2D 平面:
- 空间平面:$(x,y)$, $(x,z)$, $(y,z)$
- 时空平面:$(x,t)$, $(y,t)$, $(z,t)$
每个 3D 高斯的位置 $(x,y,z)$ 和时间 $t$ 可以在这些平面中查询到对应的特征。
关键技术 2:多头高斯变形解码器 (Multi-head Gaussian Deformation Decoder)
变形包括三个部分:
- 位置变形 $\Delta X$:高斯移动到新位置
- 旋转变形 $\Delta r$:高斯朝向改变
- 缩放变形 $\Delta s$:高斯大小/形状改变
变形公式: $$\left( X', r', s' \right) = \left( X + \Delta X, r + \Delta r, s + \Delta s \right)$$
关键技术 3:两阶段优化
- Warm-up 阶段(前 3000 次迭代):只用静态 3D 高斯训练
- 完整训练:开启完整的 4D 变形学习
这样做的好处是让动态部分的学习更稳定。
实验结果
性能对比(合成数据集)
| 方法 | PSNR (dB) | SSIM | 训练时间 | FPS | 存储 (MB) |
|---|---|---|---|---|---|
| TiNeuVox-B | 32.67 | 0.97 | 28 min | 1.5 | 48 |
| K-Planes | 31.61 | 0.97 | 52 min | 0.97 | 418 |
| 3D-GS | 23.19 | 0.93 | 10 min | 170 | 10 |
| Ours (4D-GS) | 34.05 | 0.98 | 8 min | 82 | 18 |
关键优势:
- 最高渲染质量(PSNR 最高)
- 极快的渲染速度(82 FPS 实时)
- 合理的训练时间(8 分钟)
- 紧凑的存储(18 MB)
视觉效果对比

从左到右:Ours、TiNeuVox、Ground Truth、K-Planes、HexPlane、3D-GS
可以看到 4D-GS 渲染的图像最接近 Ground Truth(真实图像)。

优化过程:从随机初始化的 3D 高斯逐渐学习到正确的结果。
技术细节
3D 高斯的数学表示
一个 3D 高斯由以下属性定义:
- 位置 $X \in \mathbb{R}^3$:高斯的中心点
- 颜色 $C$:用球谐函数 (SH) 系数表示
- 不透明度 $\alpha \in \mathbb{R}$:控制透明度
- 旋转 $r \in \mathbb{R}^4$:用四元数表示
- 缩放 $s \in \mathbb{R}^3$:三个方向的缩放因子
高斯的形状由协方差矩阵 $\Sigma$ 决定: $$\Sigma = RS S^T R^T$$
其中 $R$ 是旋转矩阵,$S$ 是缩放矩阵。
渲染公式
对于每个像素,渲染颜色 $C$ 的公式: $$C = \sum_{i \in N} c_i \alpha_i \prod_{j=1}^{i-1}(1 - \alpha_j)$$
这里 $N$ 是覆盖该像素的有序高斯集合,$c_i$ 和 $\alpha_i$ 是每个高斯的颜色和不透明度。
损失函数
$$\mathcal{L} = \left| \hat{I} - I \right| + \mathcal{L}_{tv}$$
- $\left| \hat{I} - I \right|$:L1 颜色损失
- $\mathcal{L}_{tv}$:基于网格的总变差损失(来自 K-Planes)
应用场景
1. 单目动态场景渲染
从一段视频中重建整个动态场景,可以从任意角度观看。
2. 3D 跟踪
跟踪场景中物体的 3D 运动轨迹:
![]()
3. 4D 编辑
对动态场景进行编辑,添加新物体或修改场景:

性能分析
FPS 与高斯数量的关系

当 3D 高斯数量少于 30,000 时,渲染速度可达 90 FPS。
这为实际应用提供了很好的参考:
- 简单场景 → 高 FPS
- 复杂场景 → 降低 FPS 但保持质量
局限性与未来工作
当前局限
- 大运动:对于运动幅度很大的场景,训练困难
- 缺少背景点:如果没有足够的背景点,效果下降
- 相机位姿不准确:影响重建质量
- 单目设置下的动静分离:静态和动态物体难以自动分离
- 大规模场景:城市级重建需要更紧凑的算法
未来方向
- 更好的动静分离方法
- 更紧凑的表示以支持大规模场景
- 与其他编辑工具的结合
总结
4D-GS 的核心贡献:
- 提出了一个高效的 4D 高斯泼溅框架,在单一 GPU 上实现实时动态场景渲染
- 设计了 时空结构编码器,用多分辨率 HexPlane 连接相邻高斯
- 开发了 多头变形解码器,分别预测位置、旋转、缩放变形
- 在多个数据集上达到 SOTA 质量,同时保持 82 FPS 的实时渲染能力
为什么重要:
- 首次将 3D-GS 的实时渲染能力扩展到动态场景
- 为 VR/AR、电影制作等应用提供了实用方案
- 开源代码,促进社区发展
参考
如果你想深入学习,建议按以下顺序阅读:
- NeRF (Mildenhall et al., ECCV 2020) - 理解隐式场景表示的基础
- 3D Gaussian Splatting (Kerbl et al., SIGGRAPH 2023) - 理解高斯泼溅基础
- HexPlane/K-Planes - 理解时空特征编码
- 4D-GS (本文) - 理解如何结合两者
本笔记由 AI 自动生成,如有疏漏请指正。
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
作者:Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, Xiaojuan Qi
单位:香港大学(The University of Hong Kong)、VAST、浙江大学
项目主页:https://yihua7.github.io/SC-GS-web/
PDF 路径:PDF/234.pdf
摘要
这是一篇关于**动态场景 Novel View Synthesis(新视角合成)**的论文。换句话说,就是:给你一段单目视频(只有一个摄像头的视频),让 AI 学会从任意角度"重新拍摄"这个场景——不仅能渲染静态背景,还能正确呈现其中人物的动作。
这篇论文的核心贡献是:
- 用稀疏控制点(Sparse Control Points)来表示场景运动,控制点的数量(约 512 个)远少于场景中的高斯点(约 10 万个),因此运动表示非常紧凑。
- 引入变形 MLP(多层感知机),每个控制点预测随时间变化的 6DoF(六自由度)变换,大幅降低了学习复杂度。
- 自适应控制点策略 + ARAP 损失,让控制点分布自适应调整以适配不同区域的运动复杂度,同时保证运动的局部刚性。
- 支持用户控制的运动编辑,因为运动表示是显式且稀疏的,用户可以直接拖拽控制点来实现运动编辑,而不破坏外观质量。
实验结果表明,SC-GS 在 D-NeRF 和 NeRF-DS 两个基准数据集上,量化指标(PSNR、SSIM、LPIPS)全面超越已有方法,同时保持实时渲染速度。

第一节:背景知识——你需要先理解这些概念
如果你对这些概念已经熟悉,可以跳过本节。
1.1 什么是 Novel View Synthesis(新视角合成)?
想象你用手机绕着一朵花拍了一段视频。新视角合成的目标是:让你能从任意角度"看"这朵花——哪怕拍摄时根本没有从这个角度拍过。
用更专业的语言说:给定一组已知相机姿态的图像,重建出场景的 3D 表示,然后可以从任意新的相机位置渲染出图像。
应用场景:
- VR/AR:在虚拟世界中自由走动查看物体
- 电影制作:从任意机位"拍摄"特效场景
- 视频会议:从任意角度渲染参会者头像
1.2 什么是 Dynamic Scene(动态场景)?
静态场景 = 场景里一切都不动(比如拍一栋建筑)。
动态场景 = 场景里有东西在动(比如拍一个人在走路)。
动态场景的新视角合成难得多,因为:
- 同一个像素在不同时间点对应场景里不同的 3D 点
- 需要同时重建场景的"形状"和"运动"
1.3 什么是 Gaussian Splatting(高斯泼溅)?
这是 2023 年提出的一种革命性场景表示方法,核心思想是:
把场景表示成一堆带颜色、带透明度、带旋转缩放的 3D 高斯椭球,然后通过一种叫做"泼溅(Splatting)"的方式把它们投影到 2D 图像平面上,从而实现极快渲染(实时!)。
对比 NeRF(神经辐射场): | 特性 | NeRF | Gaussian Splatting | |------|------|----------------------| | 表示方式 | 神经网络(隐式) | 3D 高斯点云(显式) | | 渲染速度 | 慢(需沿射线采样数百个点) | 极快(实时) | | 训练速度 | 慢 | 快 | | 动态扩展 | 已有一些工作 | SC-GS 是代表作品之一 |
1.4 什么是 6 DoF(六自由度)?
描述一个刚体在 3D 空间中的完整运动状态需要 6 个参数:
$$ T = \begin{bmatrix} R & t \ 0 & 1 \end{bmatrix} \in SE(3) $$
- 3 个平移自由度:沿 X、Y、Z 轴的移动
- 3 个旋转自由度:绕 X、Y、Z 轴的旋转(常用四元数 \(q \in \mathbb{R}^4\) 或旋转矩阵 \(R \in SO(3)\) 表示)
参考:详细推导与几何直觉(旋转矩阵 9 元素 → 6 DoF)见 mathematics_basic_for_ML《旋转矩阵与 6DoF》;四元数表示与运算见《四元数》。
第二节:本文方法——SC-GS 是如何工作的?
2.1 核心思想概述
SC-GS 的核心洞察是:真实世界的运动通常是稀疏的、空间连续的、局部刚性的。
比如一个人在走路:
- 头部和躯干的运动可以用很少几个"控制点"来描述
- 手臂的摆动是局部刚性的(手臂不会像面条一样扭曲)
- 不同区域的运动复杂度不同(腿部运动复杂,背景几乎不动)
基于这个洞察,SC-GS 把动态场景分解成两个组成部分:
动态场景 = 静态外观(3D 高斯点)+ 稀疏运动(控制点 + MLP)
推理流程(见图 2):
 (见图 2):
(见图 2):
flowchart LR
A[输入:时间 t + 相机视角] --> B[MLP:预测每个控制点的 6DoF 变换]
B --> C[插值:为每个高斯点计算变换]
C --> D[变形:将高斯点从 canonical 空间变换到时间 t]
D --> E[渲染:Gaussian Splatting 得到图像]
E --> F[输出:时间 t、视角 θ 下的图像]
2.2 稀疏控制点(Sparse Control Points)
2.2.0 控制点从哪来?如何通过 2.4 的优化目标优化?
来自论文原文(Section 4.1 & 4.3),不猜测:
① 控制点是可学习参数(Section 4.1)
在 canonical 空间中定义: $$ P = {(p_i, o_i) \mid i \in {1, 2, \dots, N_p}} $$
- (p_i \in \mathbb{R}^3):控制点坐标(可学习)
- (o_i \in \mathbb{R}^+):RBF 半径参数(可学习)
- 初始化方式:论文未明确说明(代码实现通常为随机初始化或从高斯点采样)
② 训练流程分两阶段(Section 4.3)
阶段一(预训练):固定高斯点 G,只优化 P(控制点)和 MLP ψ
阶段二(联合训练):P、ψ、G 全部联合优化
③ 损失函数如何驱动控制点更新(Section 4.1 & 4.3)
总损失:(\mathcal{L} = \mathcal{L}{\text{render}} + \lambda{\text{arap}} \mathcal{L}_{\text{arap}})
梯度反向传播路径:
渲染图像 → L_render → 变形后高斯点 μ_j^t, q_j^t → LBS 插值权重 w_jk → 控制点 6DoF 变换 (R_k^t, T_k^t) → MLP ψ 的梯度 → 控制点坐标 p_i、半径 o_i(直接被更新)
ARAP 损失也直接约束控制点:采样 8 个时间步得到每个控制点的运动轨迹 (p_i^{\text{traj}}),通过 ball query 找邻域,用 SVD 估计局部刚性旋转 (R_i^*),然后惩罚偏离刚性变换的控制点位移(公式 10)。
④ 自适应调整(Section 4.3,训练过程中执行)
| 操作 | 判断条件 | 论文公式 |
|---|---|---|
| Prune(删除) | 控制点对高斯点的总影响力 (W_i = \sum_j w_{ji}) 接近零 | Section 4.3 文字描述 |
| Clone(克隆) | 邻域内高斯点的梯度范数加权和 (g_k) 大(重建误差大) | 公式 (11)、(12):新点位置 = 相关高斯点位置的加权平均 |
总结:控制点不是"由 2.4 节产生"的——2.4 节描述的是损失函数(优化的目标)。控制点是模型参数,通过最小化该损失函数被反向传播更新,再加训练过程中的自适应修剪/克隆,最终得到优化后的控制点分布。
2.2.1 控制点是什么?
在 canonical 空间(可以理解为"参考帧"对应的空间)中,我们定义一组可学习的控制点:
$$ P = {(p_i, o_i) \mid i \in {1, 2, \dots, N_p}} $$
其中:
- \(p_i \in \mathbb{R}^3\):控制点 \(i\) 在 canonical 空间中的坐标(可学习参数)
- \(o_i \in \mathbb{R}^+\):控制点 \(i\) 的半径参数(用于 RBF 核函数,可学习)
- \(N_p\):控制点总数(约 512,远小于高斯点数)
2.2.2 为什么用稀疏控制点?
| 方案 | 参数量 | 问题 |
|---|---|---|
| 每个高斯点直接预测运动 | ~10 万 × 6 = 60 万参数 | 容易过拟合、泛化能力差、推理慢 |
| 用一个 MLP 预测所有高斯点的运动 | MLP 参数量大 | 难以处理复杂运动、不同区域运动混淆 |
| 稀疏控制点 + 插值(本文) | ~512 × 6 + 小型 MLP | 紧凑、泛化能力强、支持编辑 |
2.2.3 控制点的 6DoF 变换是如何预测的?
对于每个控制点 \(p_i\),用一个小型 MLP \(\psi\) 来预测它在时间 \(t\) 的 6DoF 变换:
$$ (R_i^t, T_i^t) = \psi(p_i, t) $$
其中:
- 输入:控制点 canonical 坐标 \(p_i\) + 时间 \(t\)
- 输出:旋转 \(R_i^t \in SO(3)\)(用四元数 \(r_i^t \in \mathbb{R}^4\) 表示以便优化)+ 平移 \(T_i^t \in \mathbb{R}^3\)
为什么要把 \(p_i\) 也作为输入?
这样 MLP 可以"知道"每个控制点在空间中的位置,从而学习到空间上连续的运动模式(比如"左边的控制点都往左移")。
2.3 动态场景渲染(Dynamic Scene Rendering)
2.3.1 如何从控制点运动得到每个高斯点的运动?
用**线性混合蒙皮(Linear Blend Skinning, LBS)**技术:
对于每个高斯点 \(G_j\)(中心坐标为 \(\mu_j\),四元数为 \(q_j\)),先通过 KNN 找到它最邻近的 \(K=4\) 个控制点 \({p_k \mid k \in N_j}\)。
插值权重用高斯 RBF 核计算:
$$ w _{jk} = \frac{\hat{w} _{jk}}{\sum _{k' \in N_j} \hat{w} _{jk'}}, \quad \hat{w} _{jk} = \exp\left(-\frac{d _{jk}^2}{2o_k^2}\right) $$
其中 \(d _{jk} = | \mu_j - p_k |_2\) 是高斯点 \(j\) 到控制点 \(k\) 的距离。
然后,高斯点在时间 \(t\) 的变换通过插值得到:
$$ \mu_j^t = \sum _{k \in N_j} w _{jk} \left[ R_k^t (\mu_j - p_k) + p_k + T_k^t \right] $$
$$ q_j^t = \big( \sum _{k \in N_j} w _{jk} \cdot r_k^t \big) \otimes q_j $$
公式解释:
第一个公式是:每个控制点对高斯点的变换贡献,按照权重 \(w _{jk}\) 加权求和。其中 \(R_k^t(\mu_j - p_k) + p_k\) 是把高斯点先相对于控制点做旋转、再平移回去,\(+ T_k^t\) 是加上控制点自身的平移。
第二个公式是:四元数用加权求和(再归一化)来插值旋转。
2.3.2 渲染
得到变形后的高斯点参数 \((\mu_j^t, q_j^t, s_j, \alpha_j, sh_j)\) 后,用标准 Gaussian Splatting 渲染流程得到时间 \(t\)、视角 \(\theta\) 下的图像。
2.4 优化目标(Optimization Objective)
总损失函数:
$$ \mathcal{L} = \mathcal{L} _{\text{render}} + \lambda _{\text{arap}} \mathcal{L} _{\text{arap}} $$
2.4.1 渲染损失 \(\mathcal{L} _{\text{render}}\)
$$ \mathcal{L} _{\text{render}} = (1 - \lambda _{\text{SSIM}})\mathcal{L}_1 + \lambda _{\text{SSIM}} \mathcal{L} _{\text{SSIM}} $$
对比渲染图像和 ground truth 图像,用 L1 损失 + D-SSIM 损失的加权和。
2.4.2 ARAP 损失 \(\mathcal{L} _{\text{arap}}\)
ARAP = As-Rigid-As-Possible(尽可能刚性),这是一个来自计算机图形学经典网格变形算法的正则化项。
直观解释:真实世界中,大多数物体的局部运动是刚性的(比如人的手臂变形时,小臂近似一个刚体)。ARAP 损失鼓励学习到的控制点运动满足"局部刚性"假设。
具体计算:
- 先为每个控制点 \(p_i\) 计算其运动轨迹:\(p_i ^{\text{traj}} = [p_i ^{t_1}, p_i ^{t_2}, \dots, p_i ^{t_N}]\)
- 通过 ball query 找到每个控制点的局部邻域 \(N _{ci}\)
- 用 SVD 分解估计局部刚性旋转 \(R_i^*\):
$$ R_i^* = \arg\min_R \sum _{k \in N _{ci}} w _{ik} |(p_i ^{t_1} - p_k ^{t_1}) - R(p_i ^{t_2} - p_k ^{t_2})|^2 $$
- ARAP 损失 = 实际变换与刚性变换之差:
$$ \mathcal{L} _{\text{arap}}(p_i, t_1, t_2) = \sum _{k \in N _{ci}} w _{ik} |(p_i ^{t_1} - p_k ^{t_1}) - R_i^*(p_i ^{t_2} - p_k ^{t_2})|^2 $$
2.5 自适应控制点调整(Adaptive Control Points)
类似于 Gaussian Splatting 中的自适应密度调整,本文也对控制点做自适应调整:
- 修剪(Prune):如果一个控制点对所有高斯点的"总影响力" \(W_i = \sum_j w _{ji}\) 接近零,说明它没用,删除。
- 克隆(Clone):如果一个控制点附近的高斯点梯度很大(\(g_k\) 大,说明重建误差大),则克隆一个新控制点到该区域。
2.6 运动编辑
 (Motion Editing)
(Motion Editing)
这是本文的一大亮点:因为运动是用稀疏控制点显式表示的,用户可以直接编辑运动!
步骤:
- 构建控制图:用控制点的运动轨迹来建立邻接关系(轨迹相似的控制点之间连边)
- 用户指定控制点:用户拖拽某些控制点到目标位置
- ARAP 变形:求解一个能量最小化问题,在用户约束下,让整个控制图做"尽可能刚性"的变形
- 重新渲染:用变形后的控制点驱动高斯点,得到编辑后的图像
flowchart TB
A[训练完成:得到控制点 P 和 MLP ψ] --> B[用户拖拽控制点 p_i 到目标位置]
B --> C[构建控制图 G = V,E]
C --> D[求解 ARAP 变形:最小化能量函数]
D --> E[得到变形后的控制点 P']
E --> F[用 P' 驱动高斯点]
F --> G[渲染得到编辑后的图像/视频]
第三节:实验结果与对比
3.1 数据集
- D-NeRF 数据集:8 个动态场景,360° 视角设置,合成数据
- NeRF-DS 数据集:7 个真实世界动态视频,包含复杂运动,相机位姿用 COLMAP 估计
3.2 评估指标
| 指标 | 全称 | 越高/越低越好 | 解释 |
|---|---|---|---|
| PSNR | Peak Signal-to-Noise Ratio | 越高越好 | 像素级精度 |
| SSIM | Structural Similarity | 越高越好 | 结构相似性 |
| MS-SSIM | Multi-Scale SSIM | 越高越好 | 多尺度结构相似性 |
| LPIPS | Learned Perceptual Image Patch Similarity | 越低越好 | 感知相似度(越接近 0 越好) |
3.3 主要实验结果
D-NeRF 数据集上的量化对比(表 1 摘要)
SC-GS 在几乎所有场景上取得 SOTA(最优) 成绩:
| 场景 | SC-GS (PSNR) | 最佳竞品 (PSNR) | SC-GS (LPIPS↓) |
|---|---|---|---|
| Hellwarrior | 42.93 | 39.07 (Baseline) | 0.0155 |
| Mutant | 45.19 | 41.45 (Baseline) | 0.0028 |
| Standup | 47.89 | 41.04 (Baseline) | 0.0023 |
| Hook | 39.87 | 34.47 (Baseline) | 0.0076 |
| Jumpingjacks | 41.13 | 35.74 (Baseline) | 0.0067 |
结论:SC-GS 相比直接在每个高斯点上做变形的 baseline 方法,PSNR 平均提升约 4-5 dB,LPIPS 降低约 60-70%。
NeRF-DS 数据集上的量化对比(表 2 摘要)
在真实世界数据上,SC-GS 同样取得最优平均性能:
| 方法 | 平均 PSNR | 平均 MS-SSIM | 平均 LPIPS (Alex) |
|---|---|---|---|
| HyperNeRF | 22.5 | 0.827 | 0.206 |
| NeRF-DS | 23.9 | 0.898 | 0.127 |
| TiNeuVox-B | 21.5 | 0.843 | 0.162 |
| Baseline | 23.7 | 0.891 | 0.151 |
| SC-GS (Ours) | 24.1 | 0.891 | 0.140 |
注意:NeRF-DS 数据集上相机位姿估计存在误差,影响了所有方法的性能。即便如此,SC-GS 仍取得最优平均结果。
3.4 消融实验
 (Ablation Study)
(Ablation Study)
表 3 展示了去掉各个组件后的性能变化(在 D-NeRF 数据集上平均):
| 配置 | PSNR | SSIM | LPIPS |
|---|---|---|---|
| 无控制点(w/o Control Points) | 38.51 | 0.9922 | 0.0162 |
| 无 ARAP 损失(w/o ARAP Loss) | 42.62 | 0.9963 | 0.0067 |
| 完整模型(Full) | 43.31 | 0.9976 | 0.0063 |
结论:
- 去掉控制点(直接用 MLP 预测每个高斯点的运动):性能大幅下降,说明稀疏控制点是一种有效的运动正则化手段
- 去掉 ARAP 损失:性能略有下降,且会出现不自然的扭曲(见图 6)
3.5 视觉质量对比
下图展示了 SC-GS 与其他方法在 D-NeRF 数据集上的视觉对比(对应论文图 3):

可以看出,SC-GS 生成的细节(如 Lego 人物的运动)比其他方法更清晰、更自然。
第四节:方法细节深入
4.1 MLP \(\psi\) 的网络结构
论文中并未详细描述 MLP 的层数,但根据相关工作的惯例:
- 输入维度:3(控制点坐标)+ 1(时间 t 编码)= 4+ 维
- 隐藏层:通常 2-4 层,每层 64-128 维
- 输出维度:7(4 个四元数 + 3 个平移参数)
时间 \(t\) 通常用**位置编码(Positional Encoding)**映射到高维空间:
$$ \gamma(t) = [\sin(2^0 \pi t), \cos(2^0 \pi t), \dots, \sin(2 ^{L-1} \pi t), \cos(2 ^{L-1} \pi t)] $$
4.2 与 4D-GS 的区别
4D-GS(同期工作)直接用 MLP 预测每个高斯点的变形偏移量,而 SC-GS 用稀疏控制点驱动。区别:
flowchart LR
subgraph "4D-GS"
A1[时间 t] --> B1[MLP]
B1 --> C1[每个高斯点的偏移量 Δμ_j, Δq_j]
end
subgraph "SC-GS(本文)"
A2[时间 t + 控制点坐标] --> B2[小型MLP ψ]
B2 --> C2[每个控制点的 6DoF 变换]
C2 --> D2[插值:高斯点变换]
end
SC-GS 的优势:
- 参数量更少(控制点远少于高斯点)
- 运动表示更紧凑,泛化能力更强
- 支持运动编辑(这是 4D-GS 做不到的)
4.3 控制点数量的选择
论文中 \(N_p \approx 512\)。这个数量是如何确定的?
- 太少:无法表示复杂运动(比如多个人同时做不同动作)
- 太多:失去"紧凑表示"的优势,且增加计算量
本文采用自适应策略:训练过程中自动增加/删除控制点,最终数量由场景运动复杂度决定。
第五节:局限性与未来工作
5.1 局限性
- 对相机位姿误差敏感:NeRF-DS 数据集上性能下降,说明方法对相机位姿估计误差较敏感。
- 高光材质处理不佳:论文承认,对于镜面反射等效果,当前方法不如专门设计的高光处理方法(如 Spec-Gaussian)。
- 动态模糊:输入视频中若有运动模糊,会影响重建质量。
5.2 未来工作
- 结合 Spec-Gaussian:处理高光表面
- 结合去模糊技术:处理动态模糊
- 扩展到多视图输入:当前主要针对单目视频,多视图可以进一步提升质量
第六节:总结
SC-GS 提出了一种基于稀疏控制点的动态场景表示方法,核心创新在于:
- 运动与外观解耦:用少量控制点表示运动,用大量高斯点表示外观
- 紧凑运动表示:控制点数量远少于高斯点,运动用 MLP 预测的 6DoF 变换表示
- 局部刚性正则化:ARAP 损失保证学习到的运动自然、物理合理
- 支持运动编辑:显式控制点表示使得用户可以直接编辑运动
在 D-NeRF 和 NeRF-DS 数据集上的实验表明,SC-GS 在渲染质量和速度上都达到了 SOTA 水平。
附录:关键公式汇总
| 公式 | 含义 |
|---|---|
| \(G(x) = e ^{-\frac{1}{2}(x-\mu)^T \Sigma ^{-1}(x-\mu)}\) | 3D 高斯分布函数 |
| \((R_i^t, T_i^t) = \psi(p_i, t)\) | MLP 预测控制点变换 |
| \(w _{jk} = \frac{\exp(-d _{jk}^2/2o_k^2)}{\sum \exp(...)}\) | 高斯 RBF 插值权重 |
| \(\mu_j^t = \sum_k w _{jk}[R_k^t(\mu_j - p_k) + p_k + T_k^t]\) | 高斯点中心变换 |
| \(\mathcal{L} = \mathcal{L} _{\text{render}} + \lambda _{\text{arap}}\mathcal{L} _{\text{arap}}\) | 总损失函数 |
参考文献
论文引用格式(部分关键文献):
- [13] Kerbl et al., 3D Gaussian Splatting for Real-Time Radiance Field Rendering, ACM TOG 2023
- [37] Pumarola et al., D-NeRF: Neural Radiance Fields for Dynamic Scenes, CVPR 2021
- [41] Sorkine & Alexa, As-Rigid-As-Possible Surface Modeling, SGP 2007
- [50] Wu et al., 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering, arXiv 2023
Smooth Skinning Decomposition with Rigid Bones (SSDR)
刚性骨骼的平滑蒙皮分解
论文详解文档
目录
1. 基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Smooth Skinning Decomposition with Rigid Bones |
| 中文译名 | 刚性骨骼的平滑蒙皮分解 |
| 发表会议 | ACM SIGGRAPH Asia 2012 |
| 作者单位 | 美国休斯顿大学 |
| 主要作者 | Binh Huy Le, Zhigang Deng |
| 关键词 | 蒙皮分解、线性混合蒙皮、几何变形、块坐标下降 |
| 代码/数据 | 公开数据集(Deformation Transfer、Geometry Videos 等) |
📖 关联笔记:本文涉及的基础知识已整理至 GAMES105/Skinning.md(蒙皮绑定、LBS 公式、权重约束、刚性骨骼约束)。
2. 核心问题:这篇论文要解决什么问题?
2.1 背景故事
想象一下你在看一部 3D 动画电影,比如《冰雪奇缘》或者《疯狂动物城》。里面的角色会有各种丰富的表情和动作——奔跑、跳跃、挥手、皱眉等等。
问题来了:计算机是怎么让 3D 角色动起来的?
在 3D 动画和游戏中,角色通常由一个 3D 网格(Mesh) 构成——你可以把它想象成一张由无数三角形拼成的"皮"。
要让这张"皮"动起来,最常用的方法叫做 线性混合蒙皮(Linear Blend Skinning,简称 LBS)。这个方法的原理非常直观:
- 角色的皮里面藏着一个 骨架(Skeleton/Bones)——就像人体的骨骼一样
- 每根骨头控制皮的一部分区域
- 当骨头移动/旋转时,它控制的皮也就跟着动
举个简单的例子:你的手臂
- 手臂里面有一根"骨头"(肱骨)
- 当你旋转手臂时,手臂上的皮肉跟着动
- LBS 就是用数学来模拟这个过程
2.2 蒙皮分解:逆向工程 LBS
这篇论文要解决的是 LBS 的 逆向问题:
已知:一个角色的多个姿态(已经做好的动画)
求:这个角色的骨架是什么样的?每根骨头控制哪些部位?骨头是怎么转的?
这就好比你拿到了一段人偶动画的视频,但不知道人偶内部骨架的结构,需要你从外部形变 反推 出骨架。
为什么这个问题重要?
- 动画压缩:知道了骨架和权重,就不需要存储每一帧的顶点位置,只存骨架变换就行,大大减小文件体积
- GPU 加速渲染:LBS 模型可以在 GPU 上高效运行
- 运动编辑:有了骨架,就可以用操控杆(manipulator)来编辑动作
- 碰撞检测:刚性骨骼更容易做碰撞检测
- 骨架提取:可以从已有的动画中自动提取骨架
2.3 现有方法的局限性
在 SSDR 之前,主要有两类方法:
方法 1:SMA(Skinning Mesh Animations, James & Twigg 2005)
- 通过聚类三角面片旋转序列来分组确定刚性变换
- 问题:只能处理接近刚性的模型(比如动物的身体),遇到弹性变形(比如大象塌陷)就不行了
方法 2:LSSP(Learning Skeletons for Shape and Pose, Hasler et al. 2010)
- 使用软约束(soft constraint)来处理稀疏性和凸性
- 问题:
- 软约束意味着不一定能严格满足(权重和可能不等于 1)
- 稀疏性只是"鼓励"而非"强制"
- 不能保证每个顶点最多被多少根骨头影响
核心矛盾
之前的算法通常把"骨骼旋转必须是刚性的"和"权重之和必须等于1"当作 软约束 来处理。这意味着算法需要在"精确满足约束"和"减小重建误差"之间做取舍。
SSDR 的核心贡献:将所有约束都作为 硬约束 严格满足,同时保持较低的重建误差。
3. 基础知识铺垫
在深入方法之前,我们先了解几个关键概念。
3.1 线性混合蒙皮(LBS)
LBS 是最流行的角色蒙皮方法。它的核心公式非常简单:
$$ \mathbf{v} _{i} ^{t} = \sum _{j=1}^{|B|} w _{ij} \left( \mathbf{R} _{j} ^{t} \mathbf{p} _{i} + \mathbf{T} _{j} ^{t} \right) $$
让我们逐项解释:
| 符号 | 含义 | 通俗解释 |
|---|---|---|
| \(\mathbf{v} _{i} ^{t}\) | 第 \(t\) 个姿态中第 \(i\) 个顶点的位置 | 动画中某一帧的某个表面点 |
| \(\mathbf{p} _{i}\) | 静止姿态中第 \(i\) 个顶点的位置 | 角色摆好标准姿势时的那个点 |
| \(w _{ij}\) | 第 \(j\) 根骨头对第 \(i\) 个顶点的影响权重 | 这根骨头对这个点有多大的控制力 |
| \(\mathbf{R} _{j} ^{t}\) | 第 \(t\) 个姿态中第 \(j\) 根骨头的旋转矩阵 | 这根骨头转了多少 |
| \(\mathbf{T} _{j} ^{t}\) | 第 \(t\) 个姿态中第 \(j\) 根骨头的平移向量 | 这根骨头平移了多少 |
| \( | B | \) |
通俗理解:
想象你有一块橡皮泥(顶点),它被钉在几根棍子(骨头)上。
每根棍子上都有一个钉子,钉子对橡皮泥的拉力就是权重 w。
当棍子移动时,橡皮泥的位置 = 每根棍子拉力 × 棍子移动距离 的总和
3.2 LBS 权重的约束条件
为了让 LBS 模型有意义,权重 \(w _{ij}\) 需要满足三个条件:
-
非负性(Non-negativity):\(w _{ij} \geq 0\)
- 骨头不能"推"顶点,只能"拉"
-
凸性/仿射性(Affinity):\(\sum _{j=1}^{|B|} w _{ij} = 1\)
- 所有骨头对一个顶点的总影响权重等于 1
- 这保证了如果所有骨头都不动,顶点也不动
-
稀疏性(Sparseness):\(|\{w _{ij} | w _{ij} \neq 0\}| \leq |K|\)
- 每个顶点最多被 \(|K|\) 根骨头影响
- 在实际应用中,通常 \(|K| = 4\)(称为 4-bone skinning)
- 这是为了 GPU 加速——每个顶点只需计算 4 个变换
3.3 刚性骨骼约束
旋转矩阵 \(\mathbf{R} _{j} ^{t}\) 必须满足正交约束:
$$ \mathbf{R} _{j} ^{t} {}^{T} \mathbf{R} _{j} ^{t} = \mathbf{I}, \quad \det(\mathbf{R} _{j} ^{t}) = 1 $$
通俗理解:
"刚性"意味着骨头不能被拉伸、压缩或剪切。
旋转只会改变方向,不会改变长度。
对比:
- 刚性旋转:把一本书转个角度,书还是原来的形状
- 非刚性变换:把一本书拉长、压扁、撕扯——这些都不允许
3.4 块坐标下降(Block Coordinate Descent)
这是一种优化算法。当你有很多变量需要优化时,不一次性全部优化,而是:
- 固定其他所有变量,只优化第一组变量
- 固定其他所有变量,只优化第二组变量
- ...重复直到收敛
好比调音响:
- 先固定低音和高音,只调中音,找到最佳中音
- 再固定中音和高音,只调低音,找到最佳低音
- 再固定中音和低音,只调高音,找到最佳高音
- 重复几轮,直到听起来最好
3.5 SVD(奇异值分解)与 Kabsch 算法
SVD 是一种矩阵分解技术,可以将任意矩阵分解为三个矩阵的乘积:
$$ \mathbf{A} = \mathbf{U} \mathbf{\Sigma} \mathbf{V} ^{T} $$
Kabsch 算法 解决的问题是:给定两组对应的 3D 点,找到最优的旋转矩阵使得第一组点旋转后尽可能对齐第二组点。它就是用 SVD 来求解的。
例子:
你有两组点(比如同一个物体在两个时刻的位置):
- A 组:{(1,0,0), (0,1,0), (0,0,1)}
- B 组:{(0,1,0), (0,0,1), (1,0,0)}
Kabsch 算法会告诉你:B 组是 A 组绕某个轴旋转了 120° 得到的
4. SSDR 方法的核心思想
4.1 整体框架
SSDR 的整体思路可以用下面的流程图来表示:
flowchart TD
A[输入:一组示例姿态 V] --> B[初始化骨骼变换 B]
B --> C{开始迭代}
C --> D[更新权重图 W<br/>固定骨骼变换]
D --> E[更新骨骼变换 B<br/>固定权重图]
E --> F{收敛?}
F -- 否 --> C
F -- 是 --> G[修正静止姿态 P]
G --> H[输出:W, B, P]
style A fill:#e1f5fe
style H fill:#c8e6c9
style F fill:#fff3e0
核心思想:通过交替更新权重和骨骼变换,逐步逼近最优解。
4.2 为什么这样设计
SSDR 的设计有三大亮点:
亮点 1:硬约束而非软约束
之前的方法:
"我希望权重和接近1" → 软约束 → 可能有误差
"我希望旋转矩阵接近正交" → 软约束 → 可能有拉伸
SSDR:
"权重和必须精确等于1" → 硬约束 → 零误差
"旋转矩阵必须精确正交" → 硬约束 → 真正刚性
亮点 2:线性精确解
对于骨骼旋转的更新,SSDR 给出了一个 线性的、闭式的精确解,而不需要像 Levenberg-Marquardt 那样迭代多次。这使得 SSDR 比 LM 快几十倍。
亮点 3:保证算法收敛
块坐标下降的每次更新都必须 严格降低 目标函数值,这样才能保证算法收敛到局部最优。SSR 的两个更新步骤都满足这个条件。
4.3 数学建模
目标函数
SSDR 将蒙皮分解建模为一个约束最小二乘问题:
$$ \min _{\mathbf{w}, \mathbf{R}, \mathbf{T}} E = \min _{\mathbf{w}, \mathbf{R}, \mathbf{T}} \sum _{t=1}^{|t|} \sum _{i=1}^{|V|} \left| \mathbf{v} _{i} ^{t} - \sum _{j=1}^{|B|} w _{ij} \left( \mathbf{R} _{j} ^{t} \mathbf{p} _{i} + \mathbf{T} _{j} ^{t} \right) \right| ^{2} $$
这个公式看起来很长,但含义很简单:
"让 LBS 重建出来的顶点位置,和实际的顶点位置尽可能接近"
通俗地说就是:我们找到了一套骨架和权重,用 LBS 公式算出来的变形效果,跟原来动画中的变形效果越像越好。
四大约束条件
| 约束 | 公式 | 含义 |
|---|---|---|
| 非负性 | \(w _{ij} \geq 0, \forall i, j\) | 权重不能是负数 |
| 仿射性 | \(\sum _{j} w _{ij} = 1, \forall i\) | 每个顶点所有权重之和等于 1 |
| 稀疏性 | \( | \{w _{ij} \neq 0\} |
| 正交性 | \(\mathbf{R} _{j} ^{tT} \mathbf{R} _{j} ^{t} = \mathbf{I}\) | 旋转必须是刚性的 |
4.4 块坐标下降算法
SSDR 将上面的优化问题分为两个"块",交替求解:
flowchart LR
subgraph 块1
A[权重图 W<br/>包含非负、仿射、稀疏约束]
end
subgraph 块2
B[骨骼变换 B<br/>包含正交约束]
end
A -- "固定B,求解W" --> B
B -- "固定W,求解B" --> A
style A fill:#bbdefb
style B fill:#ffccbc
为什么这样分块?
- 权重图 W 的约束(非负、仿射、稀疏)和骨骼变换 B 的约束(正交)是 不同类型 的约束
- 放在一起同时优化非常困难
- 分开优化后,每一块都可以找到精确解
5. 技术细节详解
5.1 初始化
核心思想:假设初始状态下没有权重混合,即每个顶点只被一根骨头控制。
这受 "As-Rigid-As-Possible"(尽可能刚性)思想的启发——真实的变形通常是接近刚性的。
初始化过程:
- 对每一帧,用 K-means 聚类 将三角面片的旋转序列分成 \(|B|\) 组
- 每组对应一根骨头
- 每个聚类中心就是该骨头的初始旋转
- 初始权重:每个顶点只属于权重最大的那根骨头(\(w _{ij} = 1\) 或 \(0\))
类比:
- 你有一堆运动轨迹(三角面片的旋转历史)
- 你要找到几条"代表性轨迹"(骨架)
- K-means 就是自动分组的方法
5.2 更新骨骼-顶点权重图
这一步 固定骨骼变换 B,只更新权重 W。
问题分解
因为每个顶点的权重是独立的(不同顶点之间没有约束),所以可以 逐顶点 求解。
对于第 \(i\) 个顶点,问题变为:
$$ \min _{\mathbf{w} _{i}} \left| \mathbf{v} _{i} ^{t} - \sum _{j=1}^{|B|} w _{ij} \left( \mathbf{R} _{j} ^{t} \mathbf{p} _{i} + \mathbf{T} _{j} ^{t} \right) \right| ^{2} $$
约束:\(w _{ij} \geq 0\), \(\sum _{j} w _{ij} = 1\), 最多 \(|K|\) 个非零权重。
第一步:确定活跃骨头
对于每个顶点,首先确定哪些骨头对它有显著影响。效果的计算方式是:
$$ e _{ij} = \left| \sum _{t} w _{ij} \left( \mathbf{R} _{j} ^{t} \mathbf{p} _{i} + \mathbf{T} _{j} ^{t} \right) \right| ^{2} $$
选取影响最大的 \(|K|\) 根骨头作为"活跃骨头集合"。
通俗解释:
- 想象你是一个顶点,你的身体被几根绳子(骨头)拉着
- 大部分绳子对你几乎没有拉力,可以忽略
- 只有拉力最大的那几根才真正影响你
- SSDR 先找出对你最重要的 |K| 根绳子
第二步:求解权重
确定了活跃骨头后,就变成了一个 带边界约束的最小二乘问题。SSDR 使用 Lawson-Hanson 活跃集方法(ASM) 来求解。
ASM 的优点:
- 可以处理非负约束和仿射约束
- 比暴力搜索快得多
- 不需要把约束当软约束来近似
加速技巧:
- 用上一轮迭代的权重作为初始值(因为相邻迭代间权重变化不大)
- 预计算矩阵的 LU 分解和 QR 分解
- 利用问题的特殊结构简化计算
5.3 更新骨骼变换
这一步 固定权重图 W,只更新骨骼变换 B。
问题分解
由于不同姿态的骨骼变换是独立的,可以 逐姿态 求解。
对于第 \(t\) 个姿态,问题变为:
$$ \min _{\mathbf{R} ^{t}, \mathbf{T} ^{t}} E ^{t} = \min _{\mathbf{R} ^{t}, \mathbf{T} ^{t}} \sum _{i=1}^{|V|} \left| \mathbf{v} _{i} ^{t} - \sum _{j=1}^{|B|} w _{ij} \left( \mathbf{R} _{j} ^{t} \mathbf{p} _{i} + \mathbf{T} _{j} ^{t} \right) \right| ^{2} $$
逐骨头求解
更进一步,每根骨头的变换也是独立的。对于第 \(j\) 根骨头,定义"残差顶点":
$$ \mathbf{q} _{i} ^{t} = \mathbf{v} _{i} ^{t} - \sum _{k \neq j} w _{ik} \left( \mathbf{R} _{k} ^{t} \mathbf{p} _{i} + \mathbf{T} _{k} ^{t} \right) $$
通俗解释:
- 当前骨头 j 要做的事情就是:把静止姿态的顶点,变换到"残差位置"
- "残差位置" = 实际位置 - 其他骨头已经处理的位移
- 也就是说,骨头 j 只需要处理其他骨头没处理完的部分
核心创新:寻找最优旋转中心
这是 SSDR 最重要的技术贡献之一。
之前方法的问题:
"加权绝对方向"(Weighted Absolute Orientation)方法假设所有骨头共享同一个旋转中心(原点),但这只是一个 近似解,不能保证目标函数严格下降。
SSDR 的解法:
SSDR 为每根骨头计算一个 最优旋转中心(Center of Rotation, CoR) \(\mathbf{p} _{j}^{*}\):
$$ \mathbf{p} _{j}^{*} = \frac{\sum _{i=1}^{|V|} w _{ij} ^{2} \mathbf{p} _{i}}{\sum _{i=1}^{|V|} w _{ij} ^{2}}, \quad \mathbf{q} _{j}^{*t} = \frac{\sum _{i=1}^{|V|} w _{ij} ^{2} \mathbf{q} _{i} ^{t}}{\sum _{i=1}^{|V|} w _{ij} ^{2}} $$
然后定义中心化的坐标:
$$ \mathbf{p} _{i}^{\prime} = \mathbf{p} _{i} - \mathbf{p} _{j}^{*}, \quad \mathbf{q} _{i}^{\prime t} = \mathbf{q} _{i} ^{t} - \mathbf{q} _{j}^{*t} $$
这样做的好处是:消除了平移参数,只需要优化旋转。最后用 SVD 求解旋转矩阵。
flowchart TD
A[计算残差顶点 q] --> B[计算最优旋转中心 p* 和 q*]
B --> C[中心化坐标]
C --> D[构造矩阵 P 和 Q]
D --> E[SVD 分解: P Q^T = U Σ V^T]
E --> F[最优旋转: R = V U^T]
F --> G[最优平移: T = q* - R p*]
style A fill:#e3f2fd
style G fill:#c8e6c9
最终公式
$$ \mathbf{R} _{j} ^{t} = \mathbf{V} \mathbf{U} ^{T}, \quad \mathbf{T} _{j} ^{t} = \mathbf{q} _{j}^{*t} - \mathbf{R} _{j} ^{t} \mathbf{p} _{j}^{*} $$
关键性质:这个解是 线性 的、闭式的,不需要迭代,而且保证目标函数不增。
你可能会好奇:为什么 \(\mathbf{R} = \mathbf{V}\mathbf{U} ^{T}\)?
简单来说,SVD 把矩阵 \(\mathbf{P}\mathbf{Q} ^{T}\) 分解成了"旋转-缩放-旋转"的形式。我们要找的旋转矩阵应该保留旋转部分但去掉缩放,所以直接取 \(\mathbf{V}\mathbf{U} ^{T}\)。如果 \(\det(\mathbf{V}\mathbf{U} ^{T}) = -1\)(表示包含反射),还需要做特殊处理。
5.4 骨骼变换重初始化
问题:某些骨头可能对任何顶点的影响都很小(称为"不显著骨头")。这时它们的变换无法被准确估计,就像用少于 3 个点去求解旋转一样(旋转有 3 个自由度,至少需要 3 个点)。
判断标准:
$$ \sum _{i=1}^{|V|} w _{ij} ^{2} < \epsilon $$
其中 \(\epsilon = 3\)(Kabsch 算法至少需要 3 个点)。
重初始化策略:
- 找到重建误差最大的顶点 \(\alpha\)
- 找到 \(\alpha\) 在静止姿态中的 20 个最近邻 \(N(\alpha)\)
- 用这 20 个点通过 Kabsch 算法重新初始化该骨头的变换
类比:
- 一根骨头变成了"酱油党"——没有实际作用
- 把它重新分配到最需要帮助的区域
- 用那个区域的数据重新计算它的变换
防止死循环:限制最大重初始化次数为 10 次。
5.5 静止姿态修正
在迭代结束后,对静止姿态进行修正。这是因为原始的静止姿态可能不是最优的。
但 SSDR 不在每次迭代中都做静止姿态修正(这与 Kavan et al. 2010 不同),原因是:
静止姿态修正引入的顶点位移可能不会被刚性旋转很好地捕捉,这可能使骨骼变换偏离真实解。
完整算法流程:
Algorithm 1: SSDR
1. 初始化骨骼变换 B
2. 重复:
a. 更新权重图 W(固定 B)
b. 更新骨骼变换 B(固定 W)
c. 对不显著的骨头进行重初始化
3. 直到收敛或达到最大迭代次数
4. 修正静止姿态 P
5. 返回 W, B, P
6. 实验结果
6.1 测试数据集
论文使用了 16 个公开数据集,分为两类:
| 类型 | 模型 | 特点 |
|---|---|---|
| 铰接模型(近刚性) | camel-gallop, cat-poses, chickenCrossing, elephant-gallop 等 | 身体各部分像关节连接一样运动 |
| 弹性模型(高变形) | camel-collapse, face-poses, horse-collapse 等 | 有明显的非刚性变形(如塌陷、面部表情) |

6.2 收敛性分析
SSDR 与 Levenberg-Marquardt(LM)算法的对比:
| 模型 | SSDR 耗时 (分钟) | LM 耗时 (分钟) | 加速比 |
|---|---|---|---|
| horse-gallop20 | 4.5 | 313 | 70x |
| pdance24 | 19.1 | 1066 | 56x |
| chickenCrossing20 | 9.5 | 537 | 57x |
SSDR 在误差下降效果和 LM 相当的情况下,速度快了几十倍!
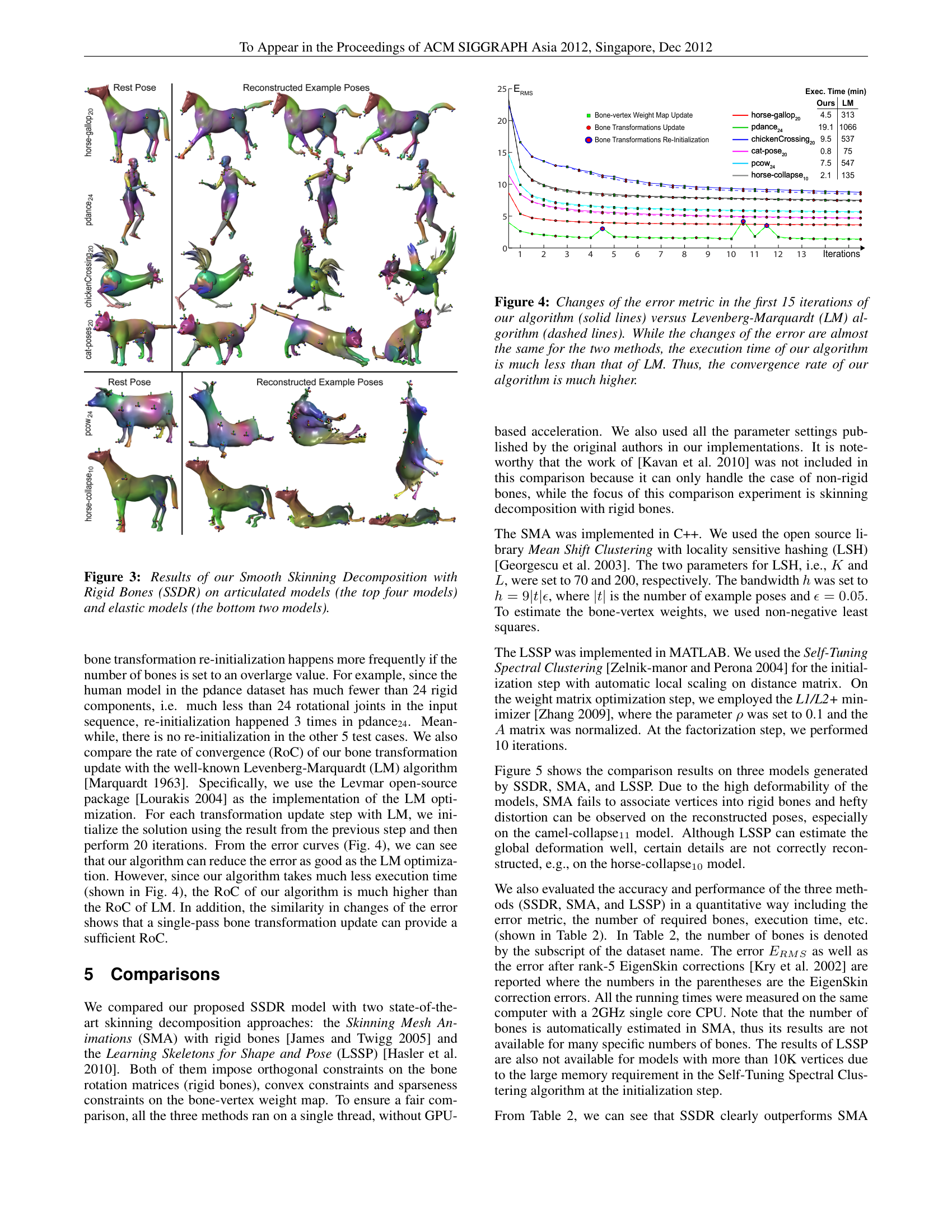
6.3 与现有方法的对比
SSDR 与 SMA 和 LSSP 的对比结果(部分数据):
| 数据集 [#骨头] | SMA 误差 | LSSP 误差 | SSDR 误差 |
|---|---|---|---|
| camel-collapse [11] | 125.3 | - | 5.4 |
| horse-collapse [3] | 139.5 | 51.0 | 26.5 |
| pdance [24] | 3.8 | 3.4 | 1.3 |
| face-poses [36] | 37.6 | - | 3.6 |
SSDR 在几乎所有数据集上都取得了最低的重建误差,尤其是在弹性变形模型上优势明显。
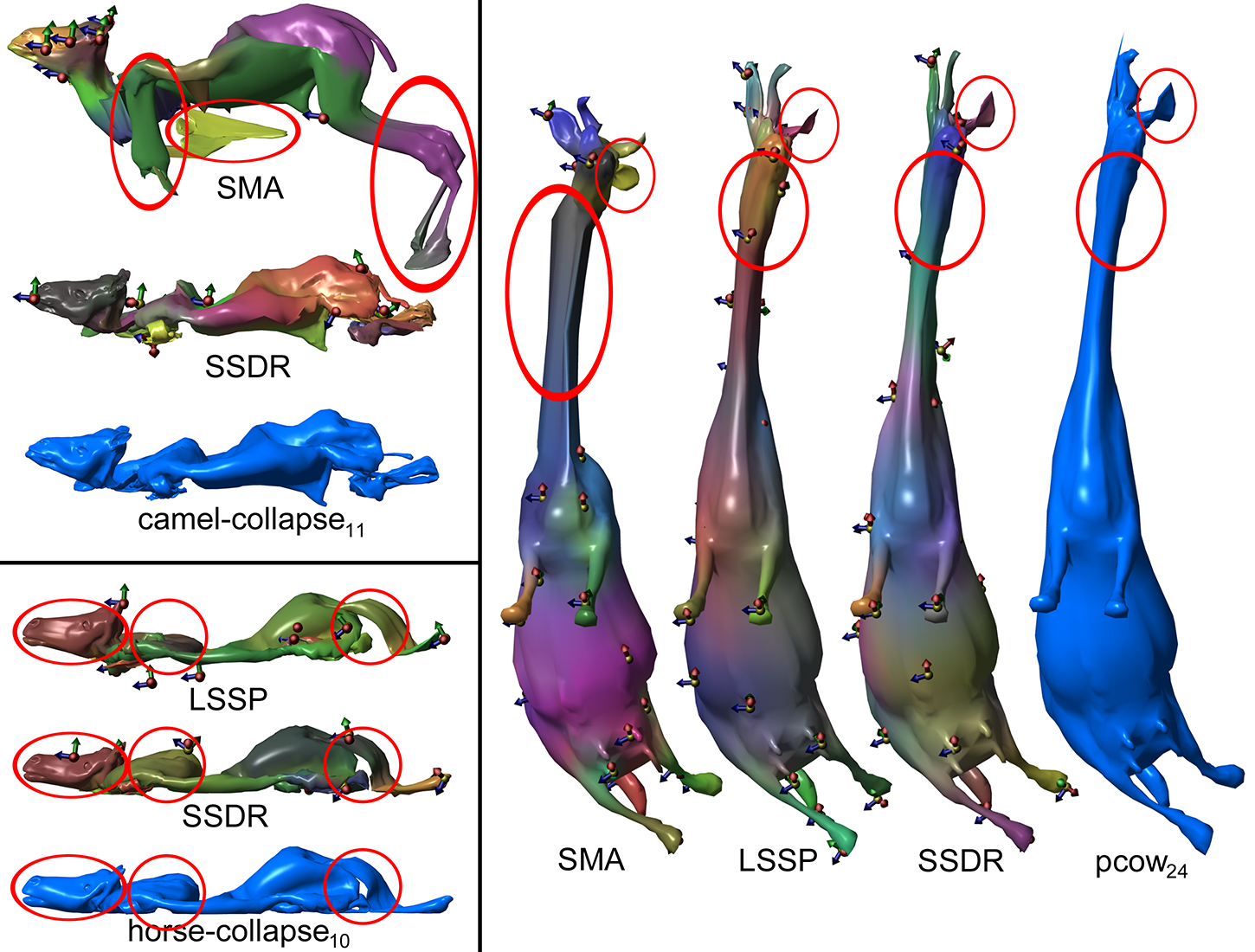
6.4 刚性骨骼 vs 柔性骨骼
论文还讨论了刚性骨骼和柔性骨骼(允许缩放和剪切)的区别:
- 柔性骨骼可以略微降低重建误差(因为它们有更多自由度)
- 但刚性骨骼在很多应用场景中更有用

刚性骨骼的优势:
flowchart TD
A[刚性骨骼优势] --> B[运动编辑<br/>可以用图形操控杆编辑<br/>而柔性骨骼难以直接编辑]
A --> C[碰撞检测<br/>刚性骨骼的包围球不会变形<br/>简化碰撞处理]
A --> D[关节提取<br/>刚性骨骼有明确的旋转中心<br/>可以提取关节位置]
A --> E[物理一致性<br/>符合真实物理世界规律<br/>不会出现不自然的拉伸]
style A fill:#e8f5e9
style B fill:#fff9c4
style C fill:#fff9c4
style D fill:#fff9c4
style E fill:#fff9c4
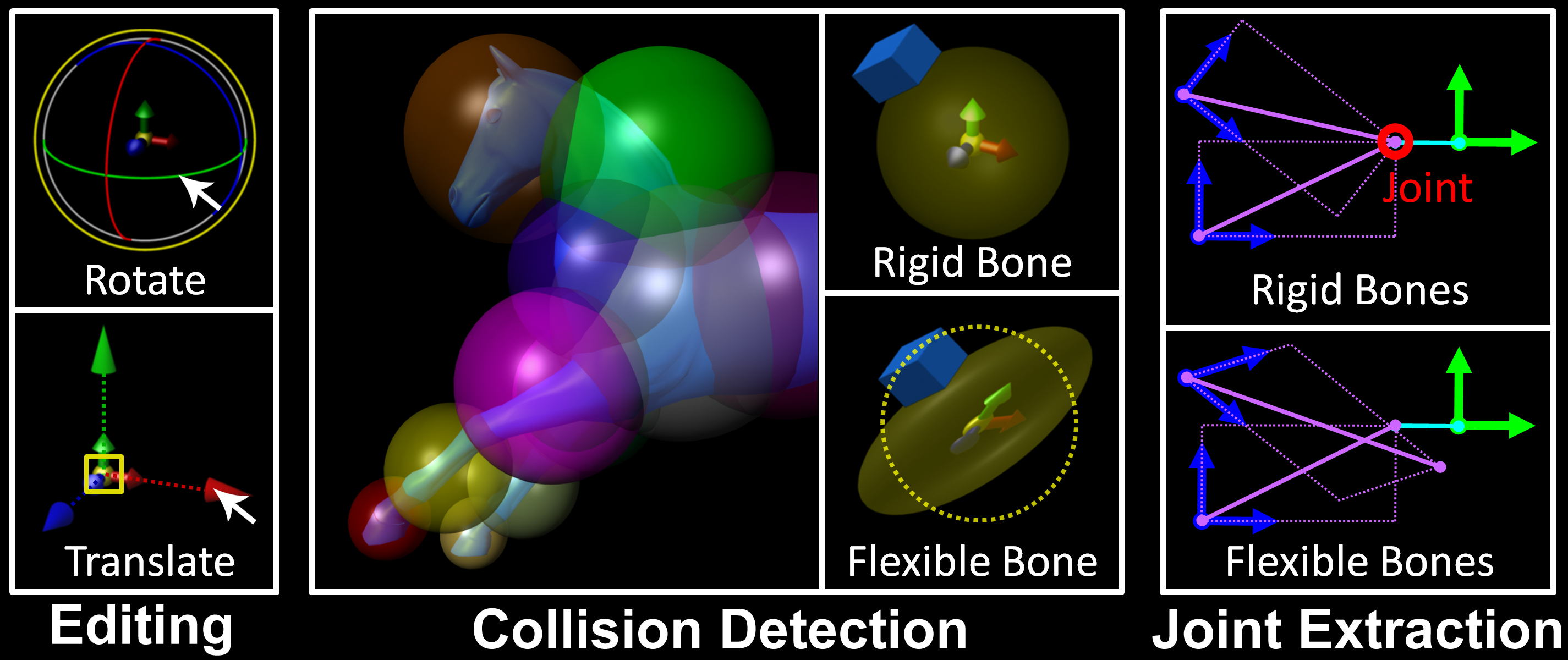
6.5 权重求解器对比
SSDR 提出的权重求解器与 Kavan et al. 2010 的对比:
- SSDR 求解器更慢(因为需要解稠密最小二乘问题)
- 但可以 显著降低估计误差,同时严格满足仿射约束和稀疏约束
7. 总结与启发
7.1 核心贡献总结
| 贡献 | 内容 | 重要性 |
|---|---|---|
| 硬约束框架 | 将正交约束和仿射约束作为硬约束严格满足 | 消除了软约束的取舍问题 |
| 闭式解 | 骨骼变换更新的线性闭式解,无需迭代 | 比传统方法快几十倍 |
| 最优旋转中心 | 为每根骨头计算最优旋转中心 | 比加权绝对方向更精确 |
| 保证收敛 | 每步更新都严格降低目标函数 | 算法可靠性高 |
| 广泛适用 | 同时适用于铰接模型和弹性模型 | 比之前方法适用范围更广 |
7.2 方法优缺点
优点:
- 精度高:在几乎所有测试集上取得最佳结果
- 速度快:比 LM 快几十倍
- 约束严格:所有约束都是硬约束
- 应用广泛:骨架提取、运动编辑、碰撞检测等
缺点:
- 比略慢于 SMA(虽然精度高得多)
- 骨骼数量需要手动指定
- 可能收敛到局部最优(这是所有迭代算法的通病)
7.3 对后续研究的启发
-
硬约束 vs 软约束:在计算机图形学中,很多问题用硬约束可以比软约束得到更好的结果。这个思想可以推广到其他领域。
-
分块优化的威力:将复杂的约束优化问题分解为简单的子问题,每个子问题都有闭式解——这是一种非常优雅的工程思路。
-
从动画中学习:这篇论文属于"从数据中学习角色控制"的大方向,这个思想在后来被广泛应用于深度学习和强化学习中(如 AMP、DeepMimic 等)。
-
SVD 的巧妙应用:SVD 不仅用于求解旋转,在很多图形学问题中都有应用(如姿态对齐、矩阵分解等)。
7.4 与现代方法的联系
虽然 SSDR 发表于 2012 年,但它的思想在后来的研究中仍然有影响:
- DeepMimic (2018):同样从示例动作中学习角色控制,但用深度强化学习替代了优化
- AMP (2021):用对抗学习替代了显式的权重计算,但"从示例中学习"的思想一脉相承
- SMPL 等人体模型:虽然使用了更复杂的蒙皮模型,但 LBS 仍然是基础
7.5 遗留问题
- 能否自动确定最优骨骼数量?目前的 \(|B|\) 仍需手动指定
- 如何更好地处理全局优化问题,避免陷入局部最优?
- 能否将此方法扩展到非刚性的、带有物理模拟的场景中?
- 对于拓扑变化(如断裂、融合)的模型,SSDR 是否适用?
附录:关键术语对照表
| 英文 | 中文 | 简要说明 |
|---|---|---|
| Linear Blend Skinning (LBS) | 线性混合蒙皮 | 最流行的角色蒙皮方法 |
| Skinning Decomposition | 蒙皮分解 | 从示例姿态反推骨架和权重 |
| Bone-vertex weight map | 骨骼-顶点权重图 | 描述每根骨头对每个顶点的影响程度 |
| Block Coordinate Descent | 块坐标下降 | 交替优化不同变量组的迭代算法 |
| Singular Value Decomposition (SVD) | 奇异值分解 | 矩阵分解技术,用于求解旋转 |
| Center of Rotation (CoR) | 旋转中心 | 骨头绕其旋转的中心点 |
| Active Set Method (ASM) | 活跃集方法 | 带约束的最小二乘求解算法 |
| Rigid bones | 刚性骨骼 | 只允许旋转和平移,不允许缩放/剪切 |
| Flexible bones | 柔性骨骼 | 允许包含缩放和剪切的变换 |
| Sparseness constraint | 稀疏性约束 | 限制每个顶点受影响的骨头数量 |
| Affinity constraint | 仿射性约束 | 权重之和等于1 |
| Orthogonal constraint | 正交约束 | 旋转矩阵必须正交 |
| Rest pose | 静止姿态 | 角色的标准参考姿态 |
| EigenSkin correction | EigenSkin 修正 | 用特征空间修正 LBS 误差的技术 |
Robust and Accurate Skeletal Rigging from Mesh Sequences
论文信息
- 标题:Robust and Accurate Skeletal Rigging from Mesh Sequences
- 作者:Binh Huy Le, Zhigang Deng(休斯顿大学)
- 发表:ACM Transactions on Graphics (SIGGRAPH)
0. 背景知识
0.1 什么是骨骼绑定(Skeletal Rigging)?
在3D动画制作中,"骨骼绑定"是连接3D模型(称为"皮肤"或"网格")与虚拟骨骼系统的过程。这个过程就像给木偶安装关节:
graph LR
A["3D网格模型<br/>(Mesh)"] --> B["骨骼系统<br/>(Skeleton)"]
B --> C["蒙皮权重<br/>(Skinning Weights)"]
C --> D["骨骼动画<br/>(Skeletal Animation)"]
为什么需要骨骼绑定?
- 让角色能够自然地弯曲和运动
- 只需要控制少量骨骼参数,就能驱动大量顶点
- 游戏引擎和动画软件(如Maya、Blender)都支持骨骼动画
0.2 什么是线性混合蒙皮(LBS - Linear Blend Skinning)?
线性混合蒙皮是目前最广泛使用的骨骼蒙皮方法。它的核心思想是:每个网格顶点受多个骨骼影响,影响程度由权重决定。
数学表达式:
$$ \mathbf{v} i' = \sum{j=1}^{B} w _{ij} \left( \mathbf{R} _j \mathbf{t} _j \right) \mathbf{v} _i $$
其中:
- \(\mathbf{v} _i\) 是第 \(i\) 个顶点在初始姿态(静止姿态)的位置
- \(\mathbf{v} _i'\) 是变换后的位置
- \(w _{ij}\) 是顶点 \(i\) 受到骨骼 \(j\) 影响的权重
- \(\mathbf{R} _j\) 是骨骼 \(j\) 的旋转矩阵
- \(\mathbf{t} _j\) 是骨骼 \(j\) 的平移向量
- \(B\) 是骨骼的总数
直观理解:
- 想象你用手拉动一块布的不同位置
- 靠近手指的布跟随手指移动(高权重)
- 远处的布只受轻微影响(低权重)
0.3 骨骼(Bone)与关节(Joint)
- 骨骼(Bone):刚体部分,在旋转时保持形状不变
- 关节(Joint):连接骨骼的枢纽点,骨骼绕此点旋转
骨骼A 骨骼B
┌─────┐ ┌─────┐
│ │ │ │
│ │ 关节 ├── │
└─────┘ ● └─────┘
0.4 本文要解决的核心问题
传统骨骼绑定需要人工操作,非常耗时耗力。本文提出自动化方法:从一组示例姿态(网格序列)自动生成骨骼系统。
输入:一组不同姿态的3D网格序列(如运动捕捉数据)
输出:
- 骨骼结构(哪些骨骼相连)
- 关节位置
- 蒙皮权重
- 各姿态对应的骨骼变换
1. 问题与动机
1.1 传统方法的局限性
现有基于示例的骨骼绑定方法(如 Schaefer & Yuksel 2007、de Aguiar 2008、Hasler 2010)存在两个主要问题:
问题1:过度估计的骨骼初始化
初始化时产生的骨骼数量往往过多,导致:
- 不准确的骨骼
- 冗余的骨骼(可以被其他骨骼组合替代)
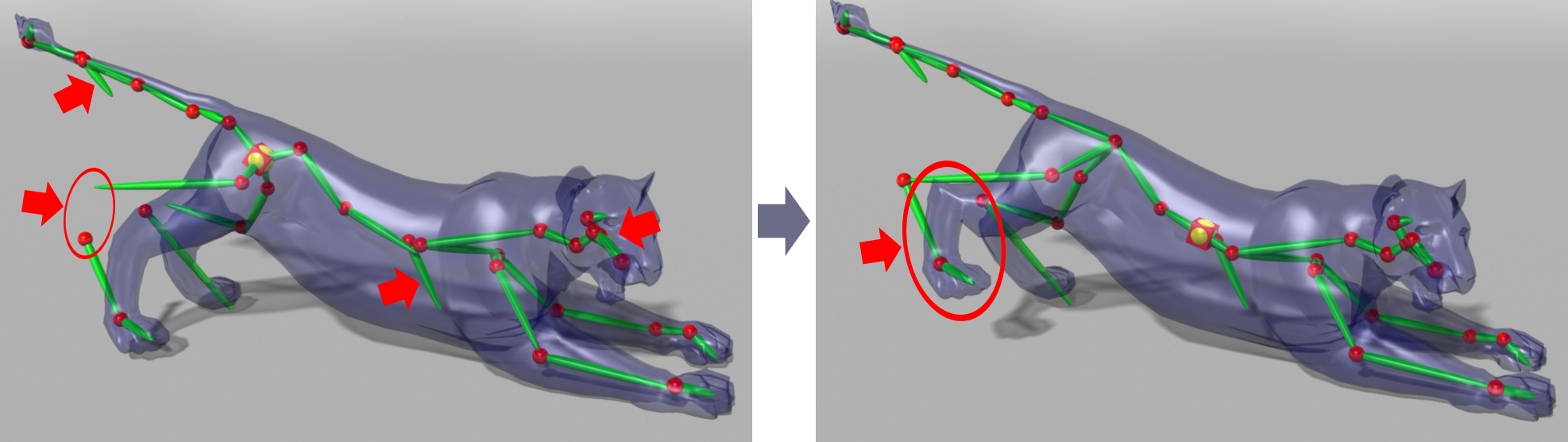
Figure 2: 红箭头标注的是过度估计的骨骼
问题2:关节位置不准确
关节位置的估计误差会逐级累积——从根关节到叶关节,误差越来越大。
1.2 本文的核心贡献
- 鲁棒性:通过自动剪枝冗余骨骼,比之前方法更鲁棒
- 准确性:通过关节约束优化,比之前方法更准确
2. 方法概述
2.1 整体流程
flowchart TD
A["输入:示例姿态序列<br/>Mesh Sequences"] --> B["Step 1: 初始化<br/>Initialization"]
B --> C["Step 2: 拓扑重建<br/>Topology Reconstruction"]
C --> D["Step 3: 迭代绑定<br/>Iterative Rigging"]
D --> E["更新蒙皮权重<br/>Update Weights"]
E --> F["更新关节位置<br/>Update Joint Positions"]
F --> G["更新骨骼变换<br/>Update Bone Transformations"]
G --> H{"骨骼剪枝?"}
H -->|是| I["剪枝冗余骨骼<br/>Prune Bones"]
I --> D
H -->|否| J{"达到最大<br/>迭代次数?"}
J -->|否| E
J -->|是| K["输出:骨骼 & 蒙皮模型"]
B -->|"32个初始簇"| C
D -->|"交替更新"| E
Figure 3: 本文方法的完整流程
2.2 三个主要步骤
| 步骤 | 名称 | 功能 |
|---|---|---|
| 1 | 初始化 | 从示例姿态识别刚体部分,初始化骨骼变换 |
| 2 | 拓扑重建 | 构建骨骼层级结构(哪些骨骼相连) |
| 3 | 迭代绑定 | 交替优化权重、关节位置、骨骼变换,并剪枝冗余骨骼 |
3. 初始化(Initialization)
3.1 运动驱动聚类(Motion-Driven Vertex Clustering)
核心思想:运动相似的顶点属于同一个刚体部分。
使用 Linde-Buzo-Gray (LBG) 算法对顶点进行聚类:
- 具有相似刚体变换的顶点被分到同一簇
- 初始分为1簇,然后分裂成2、4、8、16、32簇
3.2 簇分裂-EM策略
为什么要分裂簇?
初始一个簇包含所有顶点,然后逐步分裂,让算法自动找到合适的骨骼数量。
如何选择分裂种子?
选择使得重建误差 × 到质心距离最大的顶点作为新簇种子:
$$ s = \arg\max _{i} \left{ d \left( \mathbf{u} _i, \mathbf{O} \right) e(i) \right} $$
其中:
- \(d(\mathbf{u} _i, \mathbf{O})\) 是顶点到质心的欧氏距离
- \(e(i)\) 是重建误差
- \(L(i)\) 是顶点 \(i\) 的簇标签
原始簇 分裂后
┌────────┐ ┌────────┐
│ ●种子│ → │ 簇1 │ ●种子
│ 顶点 │ │ 顶点 │
│ ● │ ├────────┤
│ ● │ │ 簇2 │
│ ● │ │ 顶点 │
└────────┘ └────────┘
3.3 连接块生成
聚类算法只考虑运动相似性,忽略网格连接信息。因此,同一刚体部分可能被分割到多个簇。
解决方案:对每个簇,找出所有连通分量(连接块),每个连通分量初始化一个独立的骨骼变换。
4. 拓扑重建(Topology Reconstruction)
4.1 骨骼图构建
构建加权图 \(G\):
- 节点:每个骨骼
- 边权重 \(g(j,k)\):两个骨骼共享关节的概率
权重计算公式:
$$ g(j,k) = \frac{ \sum_{f=1}^{F} \left| \left[ \mathbf{R} _j^f | \mathbf{t} _j^f \right] \mathbf{C} _{jk} - \left[ \mathbf{R} _k^f | \mathbf{t} _k^f \right] \mathbf{C} {jk} \right|^2 }{ \sum{i=1}^{N} w _{ij} w _{ik} } $$
直觉理解:
- 分子:关节拟合误差越小 → 两骨骼越应该相连
- 分母:两骨骼的权重混合越大 → 它们越可能共享关节
4.2 最小生成树(MST)
使用 Kruskal 算法从加权图 \(G\) 构建最小生成树,即得到骨骼拓扑结构。
加权图 最小生成树(骨骼拓扑)
A ──0.3── B A ──0.3── B
│╲ │ ╲
0.5╲ 0.4 │ → ╲
│ ╲ │ C
C ──0.6── D C ──0.6── D
5. 迭代绑定(Iterative Rigging)
这是本文的核心创新部分!
5.1 优化目标
最小化目标函数:
$$ E = E _D + \lambda _S E _S + \lambda _J E _J $$
三项分别为:
- \(E _D\):数据拟合项 —— 最小化网格重建误差
- \(E _S\):权重平滑项 —— 保证相邻顶点权重相似
- \(E _J\):关节约束项 —— 保证骨骼绕关节旋转
5.2 权重更新(Skinning Weights Update)
问题:传统最小二乘法对噪声敏感,且可能产生"蒙皮断裂"。
解决方案:刚性拉普拉斯正则化
定义拉普拉斯矩阵 \(\mathbf{L}\): $$ L {ik} = \begin{cases} 1 - \sum{h \in N(i)} d _{ik} & \text{if } k = i \ -d _{ik} & \text{if } k \in N(i) \ 0 & \text{otherwise} \end{cases} $$
其中刚性权重:
$$ d {ik} = \frac{1}{F} \sum{f=1}^{F} \frac{ \left| \mathbf{v} _i^f - \mathbf{v} _k^f \right|^2 }{ \left| \mathbf{u} _i - \mathbf{u} _k \right|^2 } $$
效果:刚性权重 \(d _{ik}\) 衡量顶点间距离在运动中是否保持不变
- 距离保持不变 → \(d _{ik} \approx 1\) → \(L _{ik} \approx 0\) → 权重应相似
- 距离变化大 → \(d _{ik} \ll 1\) → \(L _{ik} \approx 1\) → 允许权重不同
5.3 骨骼变换更新(Bone Transformations Update)
关键创新:关节软约束
约束骨骼 \(j\) 和 \(k\) 在共同关节处一起旋转:
$$ \min_{[\mathbf{R} _j^f | \mathbf{t} _j^f]} E j^f = \frac{1}{N} \sum{i=1}^{N} w _{ij}^2 \left| [\mathbf{R} _j^f | \mathbf{t} _j^f] \mathbf{u} _i - \mathbf{q} i^f \right|^2 + \lambda \sum{(j,k) \in S} \left| [\mathbf{R} _j^f | \mathbf{t} _j^f] \mathbf{C} _{jk} - \mathbf{q} ^f(\mathbf{C} _{jk}) \right|^2 $$
其中 \(\mathbf{q} ^f(\mathbf{C} _{jk})\) 是骨骼 \(k\) 变换后的关节位置。
无关节约束 有关节约束
┌─────────┐ ┌─────────┐
│ ● │ 骨骼不绕关节旋转 │ ●────┼── 骨骼绕关节旋转
│ ╱ ╲ │ 造成变形错误 │ ╱ ╲ │
└─────────┘ └─────────┘
Figure 6: 关节约束的效果对比
5.4 骨骼剪枝(Skeleton Pruning)
动机:初始化时故意生成过多骨骼(过度估计),然后剪枝。
剪枝策略:利用权重正则化项
如果骨骼 \(j\) 的权重平方和小于最大权重平方和的1%,则剪枝:
$$ \text{如果} \sum_{i=1}^{N} w _{ij}^2 < 10^{-2} \max k \sum{i=1}^{N} w _{ik}^2 \text{,则移除骨骼 } j $$
剪枝前 剪枝后
┌───────────────┐ ┌───────────────┐
│ 骨骼j(冗余) │ │ │
│ ↓ w≈0 │ → │ 骨骼A │
│ 骨骼A ●────●骨骼B │ ●────● 骨骼B
└───────────────┘ └───────────────┘
Figure 7: 骨骼剪枝示意
6. 实验结果
6.1 数据集
| 数据集 | 顶点数 | 帧数 | 骨骼数 |
|---|---|---|---|
| cat-poses | 7,826 | 29 | 8 |
| lion-poses | 5,000 | 930 | 4 |
| horse-gallop | 8,431 | 4,827 | 41 |
| hand | 7,997 | 4,318 | 65 |
| dance | 7,061 | 201 | 16 |
| scape | 12,500 | 7,023 | 25 |
| samba | 9,971 | 175 | 23 |
| cow | 2,904 | 204 | 11 |
6.2 定量对比
| 方法 | 我们的方法 | Method II (Schaefer 2007) | Method III (de Aguiar 2008) | Method IV (Hasler 2010) |
|---|---|---|---|---|
| RMSE | 0.80 | 2.87 | 1.10 | 0.84 |
| 骨骼数量 | 24 | 24 | 24 | 24 |
我们的方法在所有测试数据集上都达到了最低的RMSE(均方根误差)。
6.3 定性对比
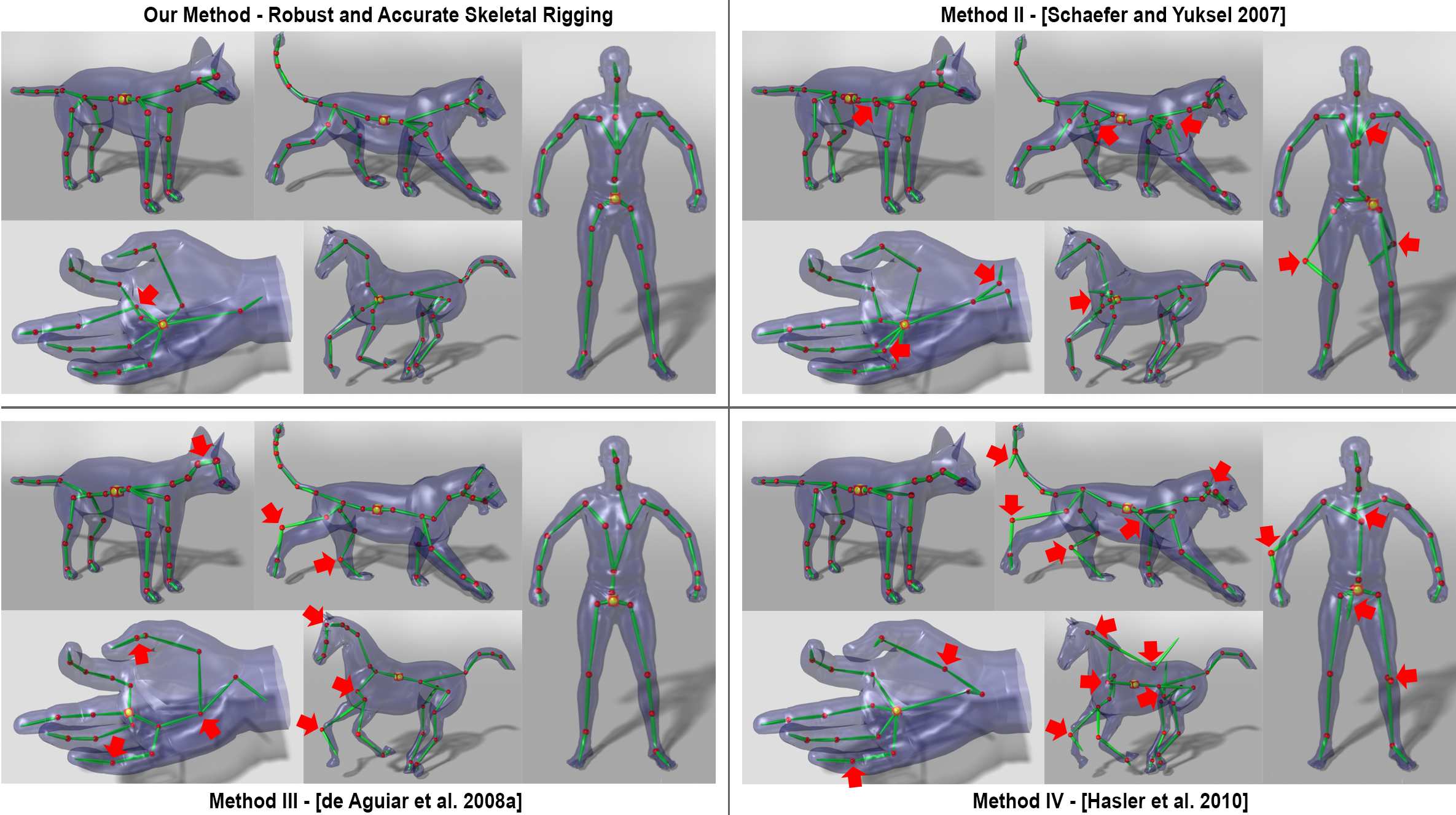
Figure 10: 与三种最先进方法的对比。红箭头标注了问题区域。
观察:
- 我们的方法在所有5个数据集上都产生了合理的结果
- 其他方法在不同数据集上都有各自的问题
- 我们的方法即使只使用一组参数也能处理所有数据集
6.4 鲁棒性测试
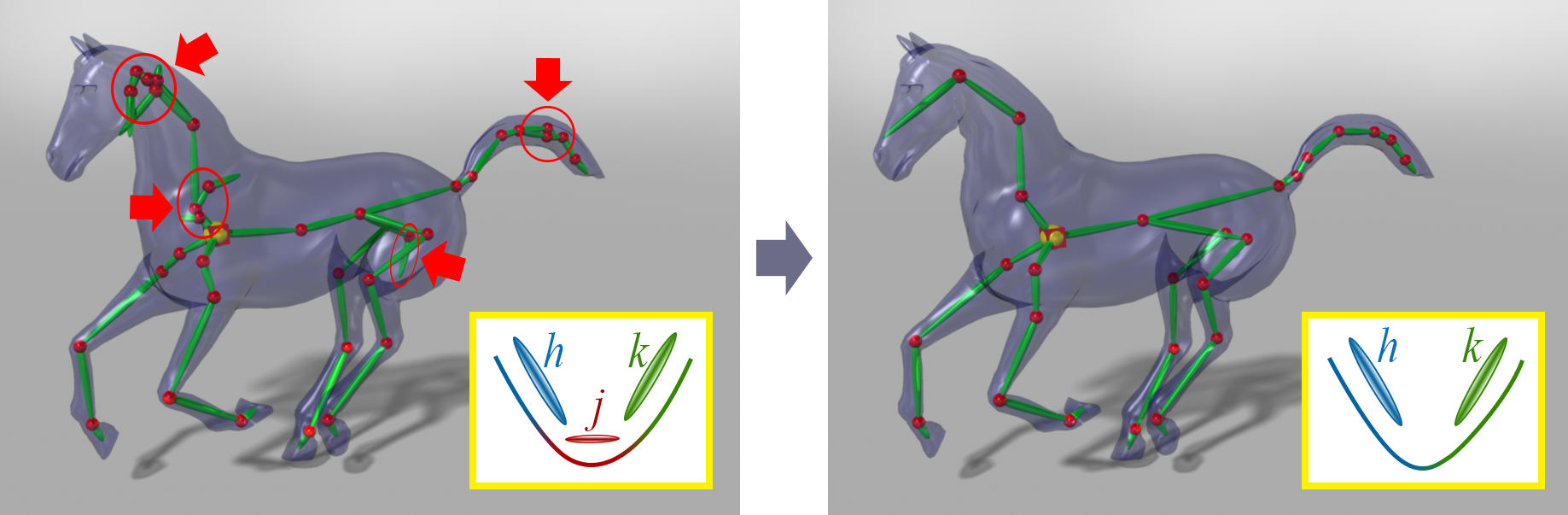
Figure 8: 不同数据集的骨架提取结果
即使初始化为不同数量的簇(4, 8, 16, 32),我们的方法都能收敛到相似的最终骨架结构。
6.5 复杂模型应用
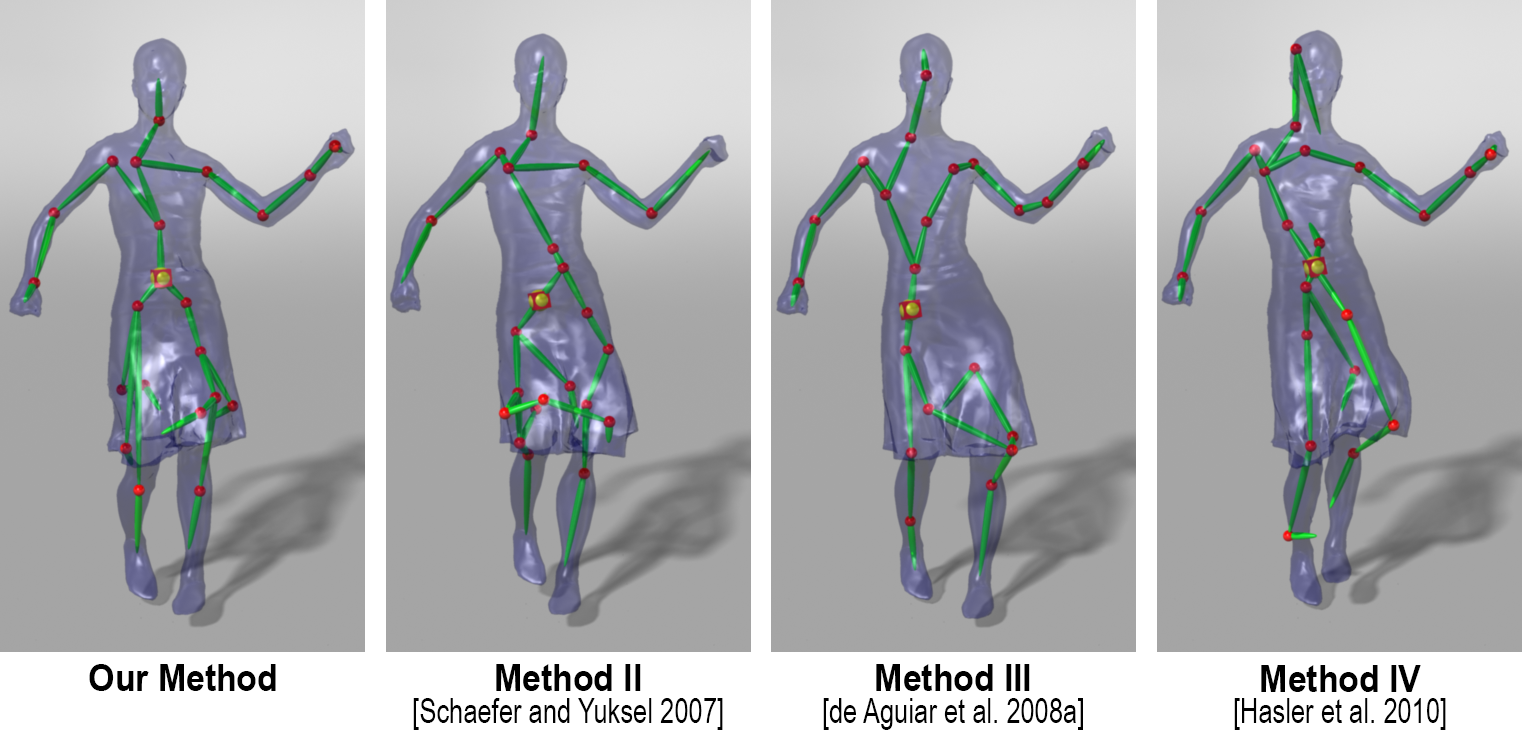
Figure 13: 即使裙子高度变形,我们的方法也能生成合理的骨骼结构
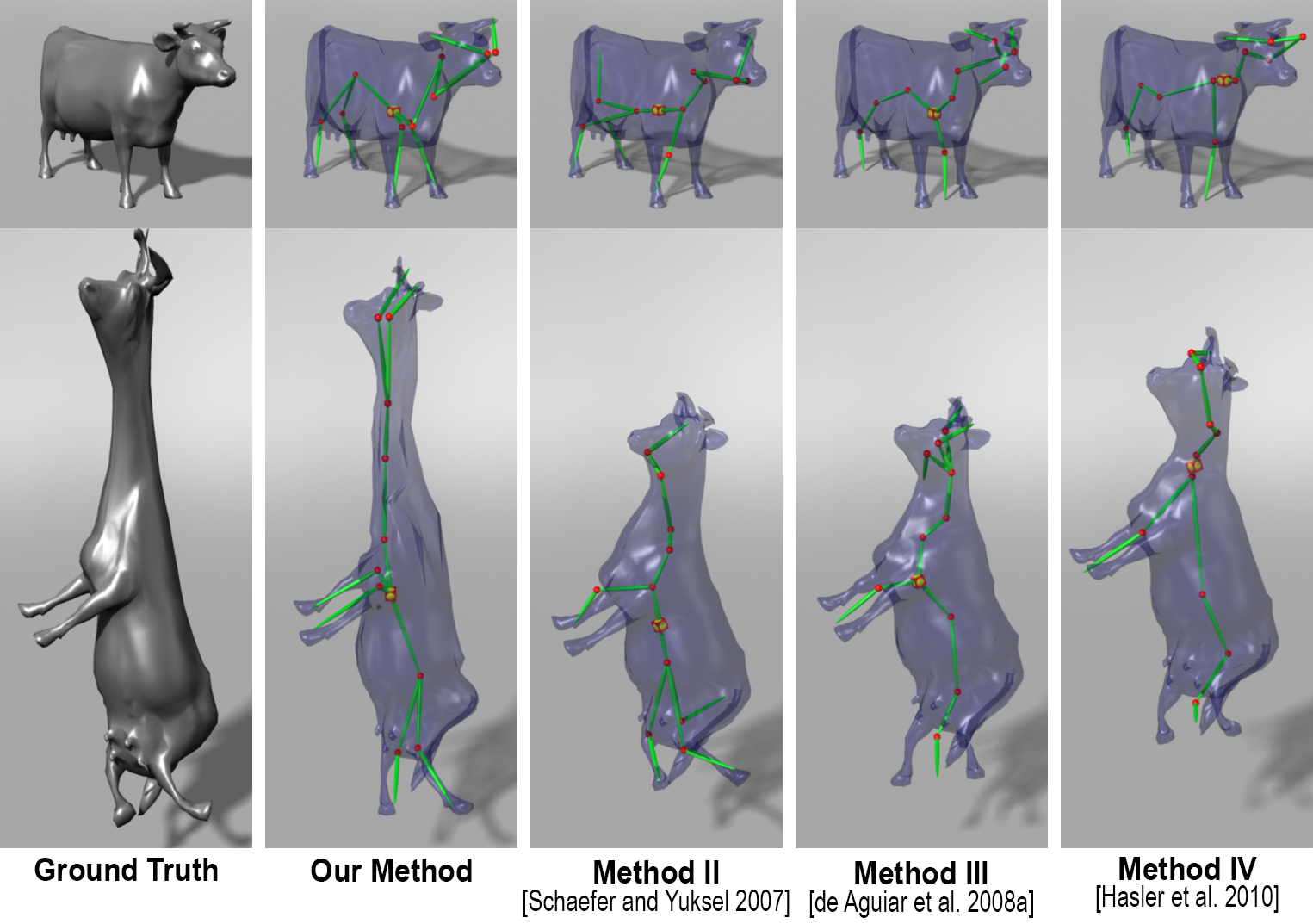
Figure 14: 弹性模型也能被成功绑定
7. 局限性
7.1 计算效率
- 方法需要多次迭代剪枝,如果初始化骨骼过多,运行时间会显著增加
- 目前只适用于离线应用
7.2 对输入数据的依赖
- 输入姿态的运动范围受限可能导致关节不对称
- 噪声和不完整的运动数据会影响结果质量
7.3 近似能力的局限
LBS模型的近似能力有限,无法捕捉某些复杂的非线性变形。
Figure 15: 上臂和上腿的4个冗余骨骼无法被剪枝,因为LBS需要它们来近似肌肉鼓起效果
8. 结论
- 提出了一种鲁棒且准确的自动化骨骼绑定方法
- 核心创新:
- 关节约束优化:保证骨骼绕关节旋转
- 骨骼剪枝:自动移除冗余骨骼
- 权重平滑正则化:刚性拉普拉斯正则化
- 在所有测试数据集上优于三种最先进的方法
- 输出可直接用于游戏引擎和3D动画软件
9. 公式速查表
| 公式编号 | 名称 | 用途 |
|---|---|---|
| (1a) | 簇分裂种子选择 | 选择最佳分裂点 |
| (2) | 骨骼连接权重 | 计算两骨骼共享关节的概率 |
| (3a) | 总目标函数 | 迭代优化的总体目标 |
| (3b) | 数据拟合项 | 最小化重建误差 |
| (3c) | 权重平滑项 | 保证相邻顶点权重相似 |
| (3d) | 关节约束项 | 保证骨骼绕关节旋转 |
| (4a) | 拉普拉斯矩阵 | 定义权重平滑的图结构 |
| (4b) | 刚性权重 | 衡量顶点距离保持能力 |
| (11) | 剪枝条件 | 判断是否应移除骨骼 |
10. 术语对照表
| 英文 | 中文 | 解释 |
|---|---|---|
| Skeletal Rigging | 骨骼绑定 | 将骨骼系统与3D网格连接的过程 |
| Linear Blend Skinning (LBS) | 线性混合蒙皮 | 最广泛使用的骨骼蒙皮方法 |
| Skeleton | 骨骼系统 | 由骨骼和关节组成的层级结构 |
| Bone | 骨骼 | 刚体部分,在旋转时保持形状 |
| Joint | 关节 | 连接骨骼的枢纽点 |
| Skinning Weight | 蒙皮权重 | 顶点受骨骼影响的程度 |
| Vertex | 顶点 | 3D网格的基本组成单元 |
| Mesh | 网格 | 由顶点组成的多边形表面 |
| Rest Pose | 静止姿态 | 角色的初始/参考姿态 |
| Example Poses | 示例姿态 | 用于训练的多个不同姿态 |
| Pruning | 剪枝 | 移除冗余骨骼的过程 |
| Rigidness Laplacian | 刚性拉普拉斯 | 用于权重平滑的图拉普拉斯变体 |
参考论文
- Le & Deng (2012) - 骨骼分解的平滑蒙皮(SSDR)
- Schaefer & Yuksel (2007) - 基于示例的骨骼提取
- de Aguiar et al. (2008) - 自动将网格动画转换为骨骼动画
- Hasler et al. (2010) - 学习用于形状和姿态的骨骼
- Kabsch (1978) - 绝对方向问题的解
本文档由 AI 自动生成,基于论文原文内容