ReadPapers
1.
Introduction
2.
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
3.
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
4.
Feature-Based Locomotion Controllers
5.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
6.
ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters
7.
Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion
8.
UniPhys Unified Planner and Controller with Diffusion for Flexible
9.
Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead
10.
PDP: Physics-Based Character Animation via Diffusion Policy
11.
DiffuseLoco: Real-Time Legged Locomotion Control with Diffusion from Offline Datasets
12.
Perpetual Humanoid Control for Real-time Simulated Avatars
13.
Calm: Conditional Adversarial Latent Models for Directable Virtual Characters
14.
Universal humanoid motion representations for physics-based control
15.
DReCon: data-driven responsive control of physics-based characters
16.
PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
17.
TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
18.
SAM 3: Segment Anything with Concepts
19.
CLOSD: CLOSING THE LOOP BETWEEN SIMULATION AND DIFFUSION FOR MULTI-TASK CHARACTER CONTROL
20.
MotionPersona: Characteristics-aware Locomotion Control
21.
Diffuse-CLoC Guided Diffusion for Physics-based Character Look-ahead
22.
Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion
23.
UniPhys: Unified Planner and Controller with Diffusion for Flexible
24.
Maskedmimic: Unified physics-based character control through masked motion
25.
Regional Time Stepping for SPH
26.
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
27.
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
28.
ParticleGS: Particle-Based Dynamics Modeling of 3D Gaussians for Prior-free Motion Extrapolation
29.
Animate3d: Animating any 3d model with multi-view video diffusion
30.
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
31.
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
32.
PIG: Physically-based Multi-Material Interaction with 3D Gaussians
33.
EnliveningGS: Active Locomotion of 3DGS
34.
SplineGS: Learning Smooth Trajectories in Gaussian Splatting for Dynamic Scene Reconstruction
35.
PAMD: Plausibility-Aware Motion Diffusion Model for Long Dance Generation
36.
PMG: Progressive Motion Generation via Sparse Anchor Postures Curriculum Learning
37.
LengthAware Motion Synthesis via Latent Diffusion
38.
IKMo: Image-Keyframed Motion Generation with Trajectory-Pose Conditioned Motion Diffusion Model
39.
UniMoGen: Universal Motion Generation
40.
AMD: Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
41.
Flame: Free-form language-based motion synthesis & editing
42.
Human Motion Diffusion as a Generative Prior
43.
Text-driven Human Motion Generation with Motion Masked Diffusion Model
44.
ReMoDiffuse: RetrievalAugmented Motion Diffusion Model
45.
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
46.
ReAlign: Bilingual Text-to-Motion Generation via Step-Aware Reward-Guided Alignment
47.
Absolute Coordinates Make Motion Generation Easy
48.
Seamless Human Motion Composition with Blended Positional Encodings
49.
FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
50.
Fg-T2M: Fine-Grained Text-Driven Human Motion Generation via Diffusion Model
51.
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
52.
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
53.
EMDM: Efficient Motion Diffusion Model for Fast and High-Quality Motion Generation
54.
Motion Mamba: Efficient and Long Sequence Motion Generation
55.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
56.
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
57.
AttT2M:Text-Driven Human Motion Generation with Multi-Perspective Attention Mechanism
58.
BAD: Bidirectional Auto-Regressive Diffusion for Text-to-Motion Generation
59.
MMM: Generative Masked Motion Model
60.
Priority-Centric Human Motion Generation in Discrete Latent Space
61.
AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond
62.
MotionGPT: Human Motion as a Foreign Language
63.
Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation
64.
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting
65.
Incorporating Physics Principles for Precise Human Motion Prediction
66.
PIMNet: Physics-infused Neural Network for Human Motion Prediction
67.
PhysDiff: Physics-Guided Human Motion Diffusion Model
68.
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
69.
Riemannian Motion Generation: A Unified Framework for Human Motion Representation and Generation via Riemannian Flow Matching
70.
GaussiAnimate: Rethinking Gaussian Splatting for Articulated Models via Skeleton-Aware Representation
71.
SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
72.
FIT: A Large-Scale Dataset for Fit-Aware Virtual Try-On
73.
Geometric Neural Distance Fields for Learning Human Motion Priors
74.
Character Controllers Using Motion VAEs
75.
Improving Human Motion Plausibility with Body Momentum
76.
MoGlow: Probabilistic and controllable motion synthesis using normalising flows
77.
Modi: Unconditional motion synthesis from diverse data
78.
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
79.
A deep learning framework for character motion synthesis and editing
80.
Multi-Object Sketch Animation with Grouping and Motion Trajectory Priors
81.
TRACE: Learning 3D Gaussian Physical Dynamics from Multi-view Videos
82.
X-MoGen: Unified Motion Generation across Humans and Animals
83.
Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
84.
MotionShot: Adaptive Motion Transfer across Arbitrary Objects for Text-to-Video Generation
85.
Drop: Dynamics responses from human motion prior and projective dynamics
86.
POMP: Physics-constrainable Motion Generative Model through Phase Manifolds
87.
Dreamgaussian4d: Generative 4d gaussian splatting
88.
Drive Any Mesh: 4D Latent Diffusion for Mesh Deformation from Video
89.
AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation
90.
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
91.
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
92.
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
93.
Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation
94.
Generating time-consistent dynamics with discriminator-guided image diffusion models
95.
GENMO:AGENeralist Model for Human MOtion
96.
HGM3: HIERARCHICAL GENERATIVE MASKED MOTION MODELING WITH HARD TOKEN MINING
97.
Towards Robust and Controllable Text-to-Motion via Masked Autoregressive Diffusion
98.
MoCLIP: Motion-Aware Fine-Tuning and Distillation of CLIP for Human Motion Generation
99.
FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
100.
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
101.
DragAnything: Motion Control for Anything using Entity Representation
102.
PhysAnimator: Physics-Guided Generative Cartoon Animation
103.
SOAP: Style-Omniscient Animatable Portraits
104.
Neural Discrete Representation Learning
105.
TSTMotion: Training-free Scene-aware Text-to-motion Generation
106.
Deterministic-to-Stochastic Diverse Latent Feature Mapping for Human Motion Synthesis
107.
A lip sync expert is all you need for speech to lip generation in the wild
108.
MUSETALK: REAL-TIME HIGH QUALITY LIP SYN-CHRONIZATION WITH LATENT SPACE INPAINTING
109.
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
110.
T2m-gpt: Generating human motion from textual descriptions with discrete representations
111.
Motiongpt: Finetuned llms are general-purpose motion generators
112.
Guided Motion Diffusion for Controllable Human Motion Synthesis
113.
OmniControl: Control Any Joint at Any Time for Human Motion Generation
114.
Learning Long-form Video Prior via Generative Pre-Training
115.
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
116.
Magic3D: High-Resolution Text-to-3D Content Creation
117.
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
118.
One-Minute Video Generation with Test-Time Training
119.
Key-Locked Rank One Editing for Text-to-Image Personalization
120.
MARCHING CUBES: A HIGH RESOLUTION 3D SURFACE CONSTRUCTION ALGORITHM
121.
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
122.
NULL-text Inversion for Editing Real Images Using Guided Diffusion Models
123.
simple diffusion: End-to-end diffusion for high resolution images
124.
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
125.
Scalable Diffusion Models with Transformers
126.
All are Worth Words: a ViT Backbone for Score-based Diffusion Models
127.
An image is worth 16x16 words: Transformers for image recognition at scale
128.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
129.
Photorealistic text-to-image diffusion models with deep language understanding||Imagen
130.
DreamFusion: Text-to-3D using 2D Diffusion
131.
GLIGEN: Open-Set Grounded Text-to-Image Generation
132.
Adding Conditional Control to Text-to-Image Diffusion Models
133.
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
134.
Multi-Concept Customization of Text-to-Image Diffusion
135.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
136.
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
137.
VisorGPT: Learning Visual Prior via Generative Pre-Training
138.
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
139.
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
140.
ModelScope Text-to-Video Technical Report
141.
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
142.
Make-A-Video: Text-to-Video Generation without Text-Video Data
143.
Video Diffusion Models
144.
Learning Transferable Visual Models From Natural Language Supervision
145.
Implicit Warping for Animation with Image Sets
146.
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models
147.
Motion-Conditioned Diffusion Model for Controllable Video Synthesis
148.
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
149.
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
150.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
151.
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics
152.
A Recipe for Scaling up Text-to-Video Generation
153.
High-Resolution Image Synthesis with Latent Diffusion Models
154.
Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
155.
数据集:HumanVid
156.
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
157.
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
158.
数据集:Zoo-300K
159.
Motion Avatar: Generate Human and Animal Avatars with Arbitrary Motion
160.
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
161.
TCAN: Animating Human Images with Temporally Consistent Pose Guidance using Diffusion Models
162.
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
163.
MagicPony: Learning Articulated 3D Animals in the Wild
164.
Splatter a Video: Video Gaussian Representation for Versatile Processing
165.
数据集:Dynamic Furry Animal Dataset
166.
Artemis: Articulated Neural Pets with Appearance and Motion Synthesis
167.
SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation
168.
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
169.
PACER+: On-Demand Pedestrian Animation Controller in Driving Scenarios
170.
Humans in 4D: Reconstructing and Tracking Humans with Transformers
171.
Learning Human Motion from Monocular Videos via Cross-Modal Manifold Alignment
172.
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos
173.
Imagic: Text-Based Real Image Editing with Diffusion Models
174.
DiffEdit: Diffusion-based semantic image editing with mask guidance
175.
Dual diffusion implicit bridges for image-to-image translation
176.
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
177.
Prompt-to-Prompt Image Editing with Cross-Attention Control
178.
WANDR: Intention-guided Human Motion Generation
179.
TRAM: Global Trajectory and Motion of 3D Humans from in-the-wild Videos
180.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
181.
Decoupling Human and Camera Motion from Videos in the Wild
182.
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
183.
HuMoR: 3D Human Motion Model for Robust Pose Estimation
184.
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
185.
Global-to-Local Modeling for Video-based 3D Human Pose and Shape Estimation
186.
WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion
187.
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
188.
Elucidating the Design Space of Diffusion-Based Generative Models
189.
SCORE-BASED GENERATIVE MODELING THROUGHSTOCHASTIC DIFFERENTIAL EQUATIONS
190.
Consistency Models
191.
Classifier-Free Diffusion Guidance
192.
Cascaded Diffusion Models for High Fidelity Image Generation
193.
LEARNING ENERGY-BASED MODELS BY DIFFUSIONRECOVERY LIKELIHOOD
194.
On Distillation of Guided Diffusion Models
195.
Denoising Diffusion Implicit Models
196.
PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS
197.
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
198.
ControlVideo: Training-free Controllable Text-to-Video Generation
199.
Pix2Video: Video Editing using Image Diffusion
200.
Structure and Content-Guided Video Synthesis with Diffusion Models
201.
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
202.
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
203.
Dreamix: Video Diffusion Models are General Video Editors
204.
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
205.
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
206.
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
207.
Content Deformation Fields for Temporally Consistent Video Processing
208.
PFNN: Phase-Functioned Neural Networks
209.
Recurrent Transition Networks for Character Locomotion
210.
Real-Time Style Modelling of Human Locomotion
211.
Motion In-Betweening with Phase Manifolds
212.
Mode-Adaptive Neural Networks for Quadruped Motion Control
213.
Few-shot Learning of Homogeneous Human Locomotion Styles
214.
Learning predict-and-simulate policies from unorganized human motion data
215.
Local Motion Phases for Learning Multi-Contact Character Movements
216.
Interactive Control of Diverse Complex Characters with Neural Networks
217.
Accelerated Auto-regressive Motion Diffusion Model
218.
DARTControl: A Diffusion-based Autoregressive Motion Model for Real-time Text-driven Motion Control
219.
Interactive Character Control with Auto-Regressive Motion Diffusion Models
220.
Taming Diffusion Probabilistic Models for Character Control
221.
Learned Motion Matching
222.
MOCHA: Real-Time Motion Characterization via Context Matching
223.
DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning
224.
Benchmarking Deep Reinforcement Learning for Continuous Control
225.
SIMBICON: Simple Biped Locomotion Control
226.
RLOC: Terrain-Aware Legged Locomotion using Reinforcement Learning and Optimal Control
227.
Efficient Self-Supervised Data Collection for Offline Robot Learning
228.
Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
229.
Dataset Distillation for Offline Reinforcement Learning
230.
mimic-one: A Scalable Model Recipe for General Purpose Robot Dexterity
231.
4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
232.
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
233.
Smooth Skinning Decomposition with Rigid Bones
234.
Robust and Accurate Skeletal Rigging from Mesh Sequences
Light (default)
Rust
Coal
Navy
Ayu
ReadPapers
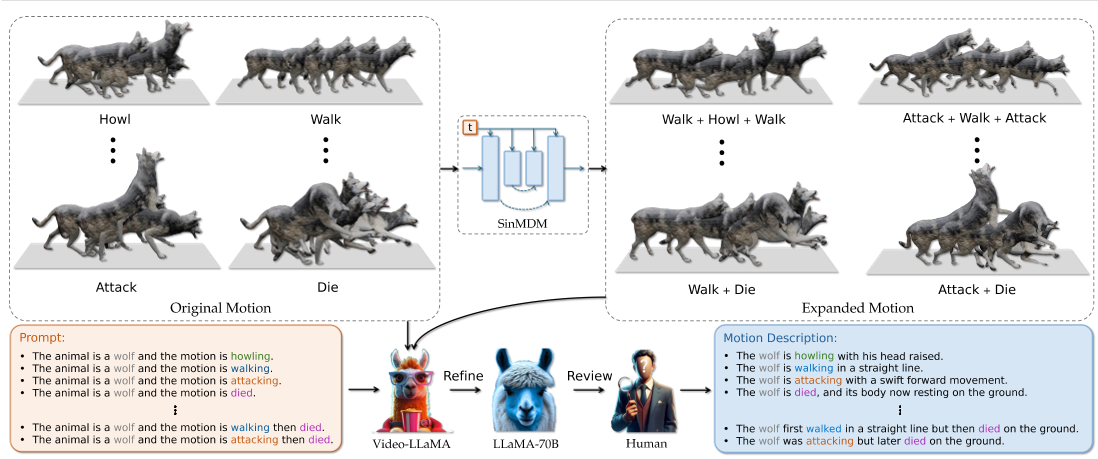
数据集:Zoo-300K
该数据集包含约 300,000 对文本描述和跨越 65 个不同动物类别的相应动物运动。
原始数据
Truebones Zoo [2] 数据集
合成数据
对原始数据的动作进行增强
人工标注
用表示动物和运动类别的文本标签进行注释
生成标注
reference
论文:
link