GLIGEN: Open-Set Grounded Text-to-Image Generation
1. 研究背景与核心问题
现有的大规模文本到图像扩散模型(如Stable Diffusion)虽然能生成高质量图像,但仅依赖文本输入难以精确控制生成内容的空间布局和细节。例如,用户难以通过文本准确描述物体的位置或形状,导致生成结果可能偏离预期。此外,传统布局到图像生成模型通常局限于封闭集(如COCO的80个类别),无法泛化到未见过的新实体或复杂语义场景。因此,如何通过引入多模态条件输入(如边界框、关键点、参考图像等)实现开放集的可控生成成为关键挑战。
2. 方法创新:GLIGEN架构与训练策略
GLIGEN的核心目标是在不破坏预训练模型知识的前提下,扩展其多模态条件控制能力。具体设计如下:
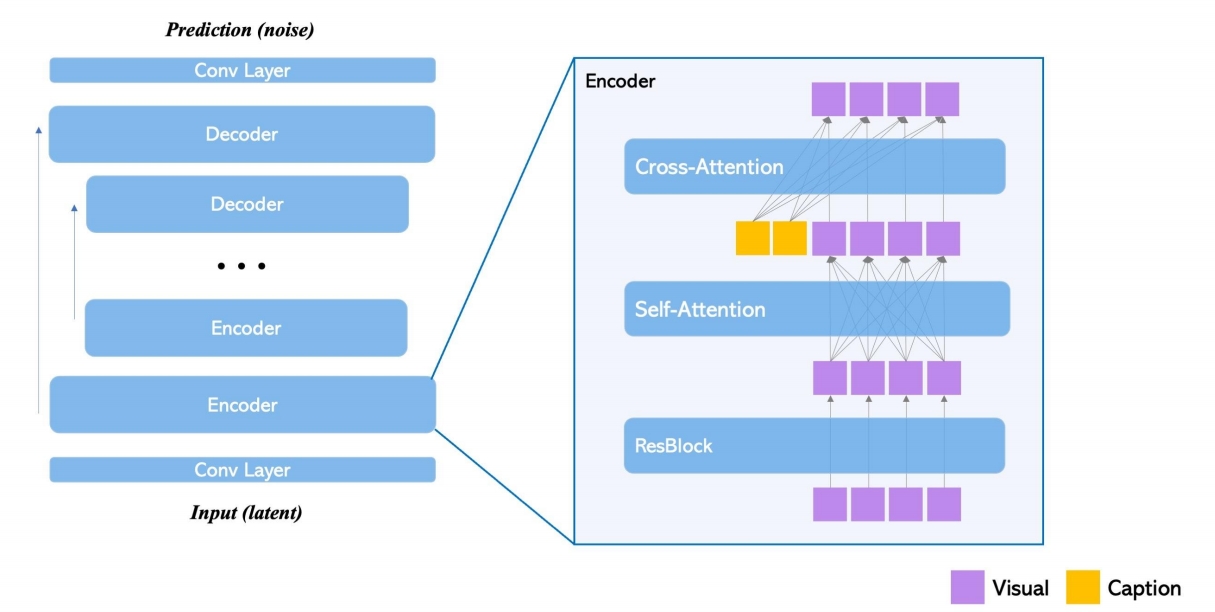
- 冻结预训练权重 + 可训练门控层
模型冻结原始扩散模型的参数,仅通过新增的门控Transformer层引入定位信息(如边界框)。这些层通过门控机制(初始化为0)逐步融合定位条件,避免灾难性遗忘。例如,边界框与文本实体通过MLP编码为特征向量,并与视觉特征拼接后输入门控层。 - 多模态条件支持
支持四类输入组合:文本+边界框、图像+边界框、图像风格+文本+边界框、文本+关键点。其中,边界框因其跨类别泛化能力优于关键点而被广泛采用。 - 计划采样(Scheduled Sampling)
在生成过程中,前20%的步骤(tau=0.2)使用全模型(包含门控层),后续步骤仅用原始模型。这种设计在早期确定布局轮廓,后期优化细节,兼顾控制精度与图像质量。
GLIGEN对比ControlNet:
| GLIGEN | ControlNet |
|---|---|
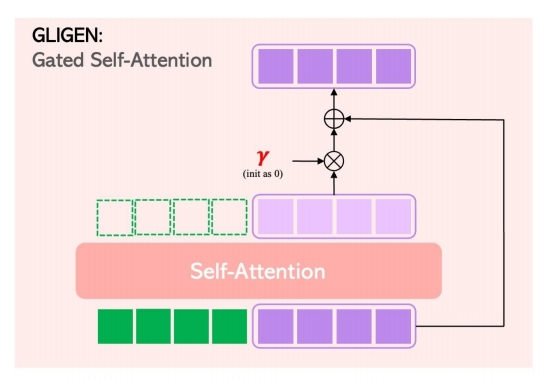 | 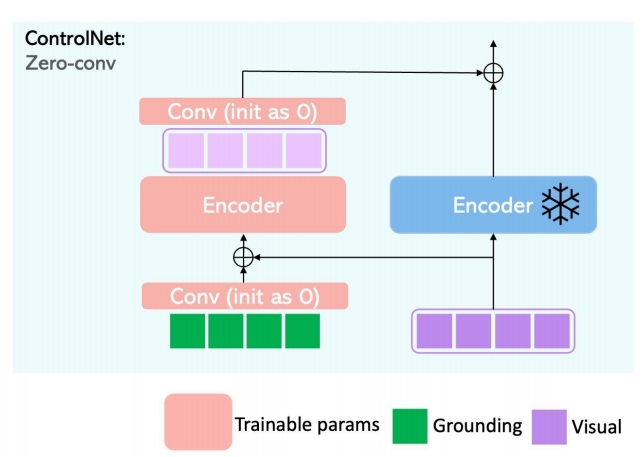 |
| ✅ 新增 Gated Self-Attention 层,加在 Attention 和 Cross Attention 之间。 ✅ GLIGEN 把 Condition 和 init feature 作 Concat | ✅ Control Net 分别处理 feature 和 Control 并把结果叠加。 |
P66
GLIGEN Result
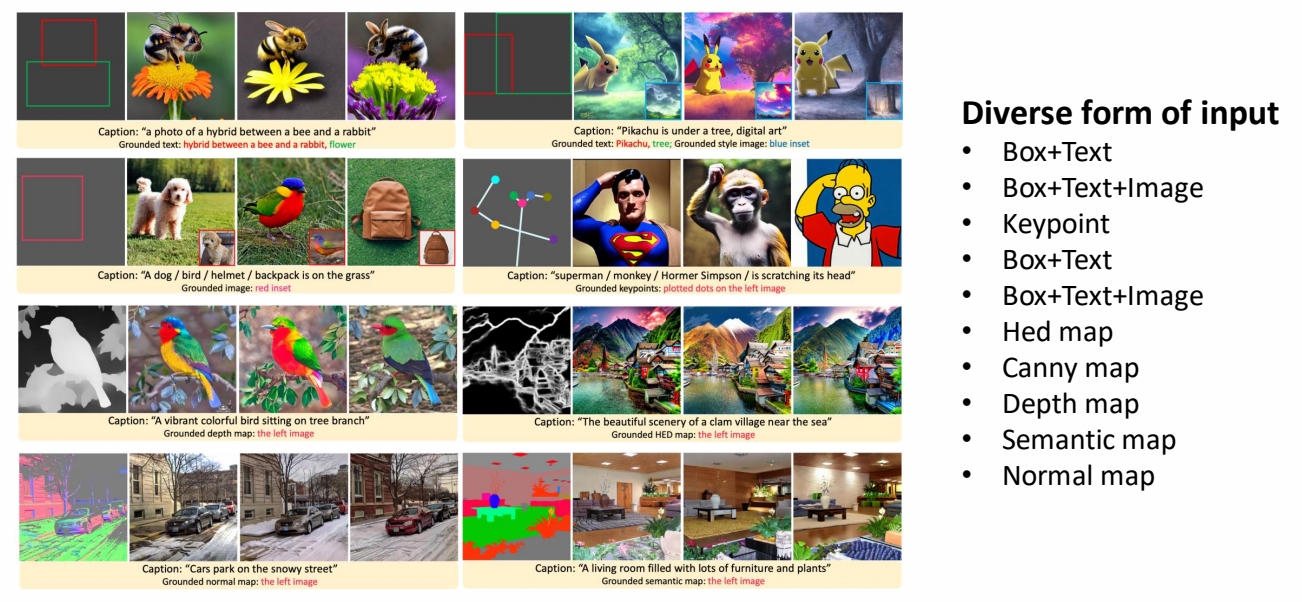
3. 实验与性能验证
- 数据集与指标
在COCO2014和LVIS数据集上进行评估,使用FID(生成图像与真实图像的相似性)、IS(生成质量)、LDM(布局对齐度)等指标。 - 开放集泛化能力
GLIGEN在COCO训练集未包含的实体(如“蓝鸦”“羊角面包”)上仍能生成符合定位条件的图像,证明其开放集能力。例如,通过文本编码器泛化定位信息至新概念。 - 零样本性能优势
在LVIS(含1203个长尾类别)的零样本评估中,GLIGEN的GLIP得分显著优于有监督基线,表明预训练知识的高效迁移。
Result
4. 贡献与意义
- 开放集可控生成
首次实现基于边界框的开放世界图像生成,支持训练中未见的实体和布局组合。 - 高效知识迁移
通过冻结预训练权重和门控机制,在少量标注数据(如千级样本)下实现高性能,避免从头训练的高成本。 - 多模态扩展潜力
框架可扩展至其他定位条件(如深度图、参考图像),为工业设计、游戏开发等场景提供灵活工具。
5. 局限与未来方向
- 数据依赖与泛化瓶颈
模型性能高度依赖定位信息的质量,且对复杂细节(如物体纹理)的生成能力有限。 - 计算效率
尽管训练成本较低,但推理时需协调多模态输入,可能增加计算复杂度。 - 未来改进方向
作者建议探索动态条件生成、更细粒度的多模态融合(如3D法线图),以及结合大语言模型(LLM)生成复杂布局指令。
总结
GLIGEN通过创新的门控机制与冻结预训练权重策略,显著提升了文本到图像生成的可控性和开放集泛化能力。其方法不仅为AIGC的精细化控制提供了新思路,也为预训练模型的下游任务适配树立了范例。未来在多模态交互与细节生成方面的突破将进一步推动其应用落地。