One-Minute Video Generation with Test-Time Training
NVIDIA
1. 研究背景与核心问题
现有的视频生成模型(如Sora、Veo等)在生成长时间、多场景的视频时面临两大挑战:
- 长上下文处理效率低:传统Transformer的自注意力机制在长序列(如一分钟视频需处理数十万标记)上计算复杂度呈二次方增长,导致生成效率低下。
- 叙事连贯性不足:递归神经网络(如Mamba)虽能线性处理时间序列,但其固定大小的隐藏状态难以捕捉复杂多场景的动态细节,导致生成视频的连贯性差。
论文旨在解决如何从文本故事板直接生成高质量、连贯的一分钟视频,突破现有模型在时间跨度和叙事复杂性上的限制。
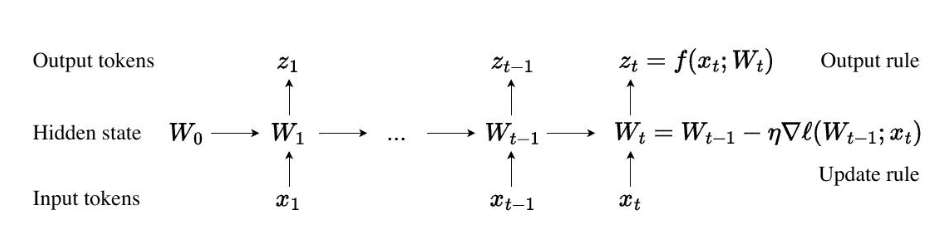
2. 方法创新:TTT层与模型架构
论文提出测试时训练(Test-Time Training, TTT)层,其核心思想是通过动态调整模型隐藏状态,增强对长序列的全局理解能力。具体实现包括:
- TTT层设计:将隐藏状态扩展为双层MLP神经网络,通过梯度下降在推理阶段动态优化,提升对历史上下文的压缩能力。
- 模型集成:基于预训练的Diffusion Transformer(CogVideo-X 5B),将输入视频划分为3秒片段处理局部注意力,TTT层全局捕捉跨片段叙事逻辑,并通过门控机制防止训练初期引入噪声。
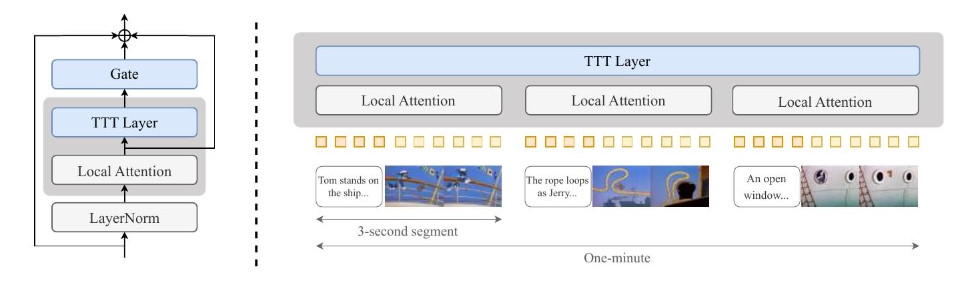
- 多阶段训练策略:从3秒片段逐步扩展至63秒(一分钟)视频,仅微调TTT层和门控参数,保留预训练模型的知识。
3. 实验与性能验证
- 数据集:基于《猫和老鼠》动画构建数据集,包含7小时视频,人工标注为3秒片段的故事板(涵盖场景、角色动作、镜头角度等),聚焦叙事连贯性而非视觉真实性。
- 评估指标:采用人工盲测与Elo评分系统,从文本对齐性、动作自然度、美学质量、时间一致性四个维度对比基线模型(如Mamba 2、滑动窗口注意力等)。
- 结果:
- TTT层生成的视频在Elo评分上平均领先34分,尤其在动作连贯性和跨场景一致性上表现突出。
- 生成的视频无需后期编辑,可直接输出完整故事(如汤姆追逐杰瑞的完整情节),但存在光照不一致、运动漂浮等伪影,可能与5B预训练模型的限制有关。
- 推理效率:TTT层比全注意力模型快2.5倍,但低于Gated DeltaNet等轻量方法。
4. 技术亮点与创新
- 动态适应性:TTT层在推理阶段实时调整隐藏状态,实现“边生成边学习”,增强模型对复杂叙事的处理能力。
- 参数高效性:仅需微调少量参数(TTT层和门控机制),避免从头训练大模型的资源消耗。
- 开放扩展性:理论上可支持更长时间(如电影级)和更复杂故事生成,未来可结合更大骨干模型(如Transformer隐藏状态)进一步提升表现。
5. 局限与未来方向
- 模型能力限制:生成的视频仍存在伪影,需依赖更强大的预训练模型(如更大参数量或更高质量数据集)。
- 效率优化:当前TTT层的训练和推理速度仍有提升空间,未来可通过优化MLP内核或编译器友好设计加速。
- 应用扩展:探索跨模态条件(如音频同步生成)和更广泛领域(如教育动画、影视预演)的应用。
总结
该论文通过引入TTT层,在无需重新训练大模型的前提下,显著提升了长视频生成的叙事连贯性和时间一致性。其方法不仅为AI视频生成提供了新的技术路径,也为其他序列建模任务(如自然语言处理、音频生成)的适应性优化提供了借鉴。未来结合更高效的架构设计和多模态输入,有望进一步推动生成式AI在影视、游戏等领域的落地。