PhysAnimator: Physics-Guided Generative Cartoon Animation
研究背景与问题
从静态动漫插图中生成物理合理且具有动漫风格动画
现有方法局限性
传统工具:依赖分层输入(如分离的线稿与色彩层),无法处理复杂真实插图(如带噪纹理、细节密集的动漫图像)。
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2020 | Autocomplete animated sculpting | 基于关键帧的雕刻系统,通过直观笔刷界面自动补全用户编辑 | |||
| 2018 | A mixed-initiative interface for animating static pictures. | 针对带纹理的动漫图像,将插图分割为不同对象的图层,并允许用户提供涂鸦作为轨迹引导 | |||
| 2015 | Autocomplete hand-drawn animations | 将局部相似性技术扩展至全局相似性,实现基于前帧的自动草图补全。 |
数据驱动模型:光流预测缺乏物理约束,导致运动伪影(如不自然的扭曲、断裂),且难以控制外力交互(如自定义风场)。
核心创新点:
- 物理模拟与生成模型融合:结合物理引擎的准确性(确保运动合理性)与生成模型的创造性(保持艺术风格),突破传统动画制作范式
- 图像空间变形技术:直接在提取的网格几何体上进行物理计算,避免复杂的三维重建过程
- 艺术控制增强机制:通过能量笔触和绑定点支持实现物理模拟与艺术表现的平衡
关键技术路线:
物理模拟层:
- 可变形体建模:将插图中的对象(如头发、衣物)抽象为可变形网格,通过连续介质力学方程(如弹性力学)计算形变。
- 外力交互:能量笔触(Energy Strokes)允许用户以绘画方式定义外力场(如风力方向与强度),增强艺术控制。
生成增强层:
- 光流引导草图生成:利用物理模拟输出的光流场扭曲初始草图,生成动态线稿序列,规避纹理干扰。
- 扩散模型上色:以参考插图为风格基准,通过条件扩散模型(如Stable Diffusion Video)为动态线稿添加色彩与细节,保持风格一致性。
- 数据驱动插值:针对物理模拟未覆盖的细节(如发丝末端颤动),使用基于学习的插值模型补充次要动态。
主要贡献
- 基于物理模拟与数据驱动的视频生成
- 图像空间可变形体模拟技术,将动漫对象建模为可变形网格
- 草图引导的视频扩散模型将模拟动态渲染为高质量帧
主要方法
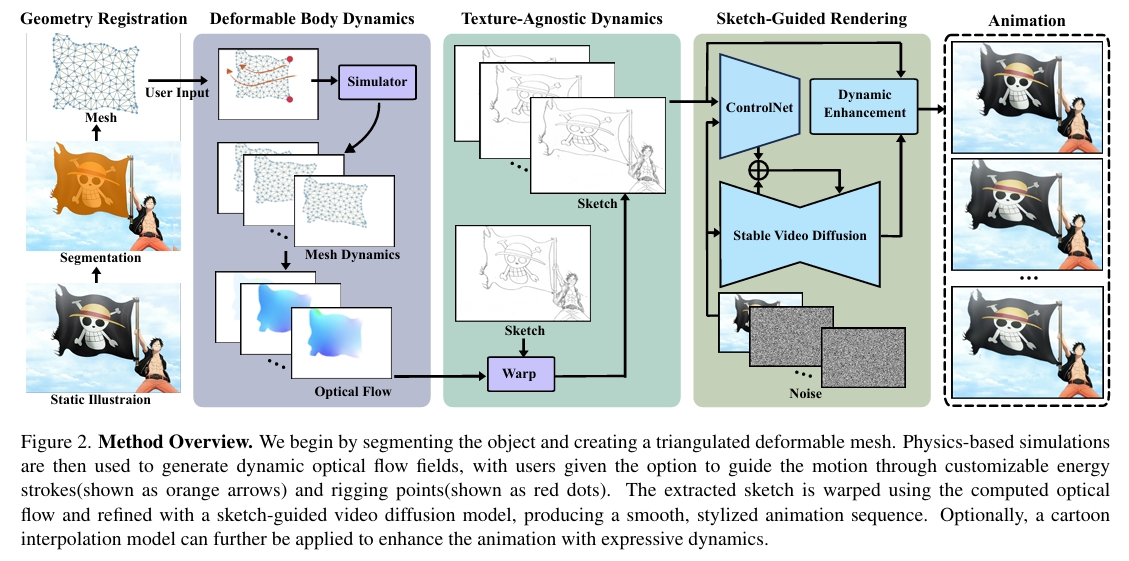
(1) 对象分割与网格生成
- 分割网络:采用 SAM 提取目标区域(如衣物、头发)的掩膜(Mask)和边界点。
- 网格化:通过 Delaunay 三角剖分生成二维可变形网格。
(2) 图像空间物理模拟
- 物理模型:利用Linear Finite Element Method计算力和能量。
- 动力学求解器:半隐式欧拉。
- 外力与约束:
- 能量笔触:能量笔触携带流动粒子,粒子沿用户指定的笔触移动,将外力传播至可变形网格的邻近顶点,从而创建定制化动画效果
- 绑定点:允许动画师固定特定区域或沿预设轨迹引导运动,提供更强的控制与灵活性
- 光流场计算:对于参考图像中的每个像素 \( \mathbf{X}_p \),若其位于三角形 \( T_i \) 内,则位移向量为 \( \mathbf{d}(p) = \phi _ i(\mathbf{X} _ p, t) - \mathbf{X} _ p \);否则位移向量为零。汇总所有像素的位移向量 \( \mathbf{d}(p) \) 即得光流场 \( F _ {0→t} \)。
(3) 草图引导视频生成
直接通过光流场扭曲参考图像 \( I_0 \) 生成视频序列,结果帧常因遮挡出现空洞伪影。因此本文使用以下方法:
- 动态草图生成:
- 初始草图提取:使用边缘检测(如 Canny)或预训练草图生成器(如 Anime2Sketch [3])提取Reference Image的草图。
- 光流扭曲:使用光流对Reference Image的草图做扭曲,生成动态草图。
- 扩散模型上色:
- 条件控制:以参考图 \( I_0 \) 为输入,动态草图 \( S_t \) 为控制信号
- 模型架构:Stablevideo + ControlNet(草图分支)
- 实验发现,由于分割误差,光流扭曲可能引入非预期失真或遗漏对象轮廓部分,生成不完美草图。因此在训练与推理时对输入草图施加高斯模糊,平滑不一致性。视频扩散模型通过其生成能力可优化结果,修复瑕疵并生成连贯输出。
(4) 数据驱动动态增强
- 插值模型:采用 FILM [4] 或 AnimeInterp [5] 生成中间帧细节运动
- 动态融合:
- 主运动:物理模拟生成的光流场
- 细节运动:插值模型输出的残差光流
- 融合公式:\( F_{final} = F_{physics} + α \cdot F_{interp} \)(\( α \) 控制细节强度)
Complementary Dynamics
引入原因:
动画中的动态效果并不严格遵循物理定律,也无法完全通过二维动画方法捕捉。
本文方法:
用数据驱动模块增强基于物理的动画结果。即,
- 从草图引导渲染结果中选择关键帧,形成关键帧序列 \( {I^r_0, I^r_n, I^r_{2n}, ..., I^r_{in}} \),其中 \( n \) 表示关键帧间隔。
- 随后采用卡通插值视频扩散模型[78],在每对相邻关键帧 \( (I^r_{in}, I^r_{i(n+1)}) \) 间合成中间帧 \( {\hat{I} _ {in+1}, \hat{I} _ {in+2}, ..., \hat{I} _ {i(n+1)-1}} \) 。
优势: 可引入超越纯物理动画的表现性数据驱动互补动态。
实验
横向对比
- 图生视频模型: Cinemo [51] and DynamiCrafter [79]
- 『图+控制轨迹』生视频模型:
- MotionI2V:轨迹->光流->视频
- DragAnything:轨迹->2D高斯热图->视频
- 本文:轨迹->2DMesh->光流->视频
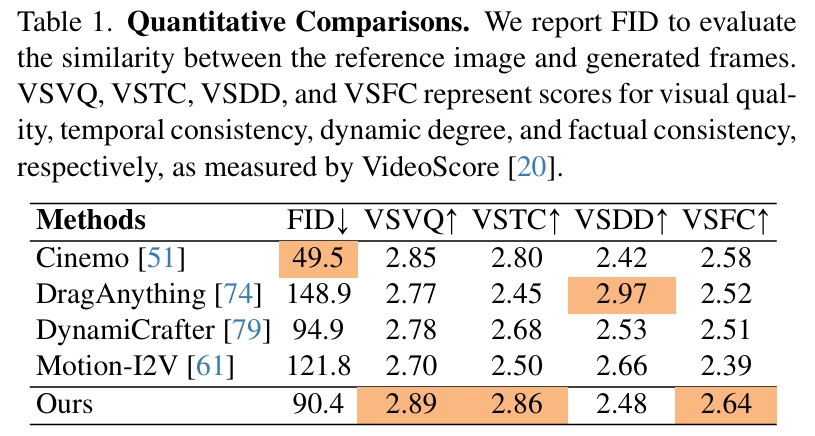
解析:
- Cinemo的FID非常好,因为它生成的视频几乎不会动
- DragAnything的VSDD非常好,是因为它倾向于把控制轨迹理解为相机运动,生成运镜效果,因为提升了dynamics score。
这篇工作的结论存疑:
由于作者的测试文本局限于衣服飘动之类的prompt,所以这个对比不是很公平。
本文的时序一致性比较好可能是底座的能力,因为所对比的其它工作(MotionI2V),其底座是T2I模型,而本文的底座是T2V模型。
DragAnything并非如作者所言『倾向于理解为相机运动』,DragAnything的创新点之一就是分离前景与背景的运动。
Reference
https://xpandora.github.io/PhysAnimator/