SOAP: Style-Omniscient Animatable Portraits
研究背景与问题
目的
从单张图像生成可动画化的3D虚拟形象
现有方法及局限性
- 非3D扩散模型的单视角头部建模方法: 局限于特定风格(如超写实风格[Khakhulin等,2022]或特定卡通类型[Chen等,2023b]),且在处理眼镜或头饰等配饰时频繁遇到挑战。
- 3D扩散模型方法:缺乏精细细节并易产生伪影;生成的3D输出通常是非结构化的表面模型或神经场,这些形式无法直接用于面部动画。
本文核心贡献
- 全风格感知的图像到虚拟形象管线:能够从单一肖像图像中重建具有完整纹理、拓扑一致且骨骼绑定完善的网格化虚拟形象(包含眼球与牙齿),覆盖广泛艺术风格、发型变化及头饰类型。
- 多视角扩散模型:基于大规模3D头部数据集(24K)训练的多视角扩散模型,可生成多种风格下人体头部模型的一致性多视角图像。
- 基于可微分渲染的自适应形变技术:通过自适应网格重构与骨骼绑定,实现任意风格化虚拟形象向参数化头部模型的语义对齐注册,同时保持正确的语义对应关系。
- 构建包含24K 3D虚拟形象的数据集,覆盖两种风格下的多样头部形状、发型、表情与身份特征。
大致方法是什么?
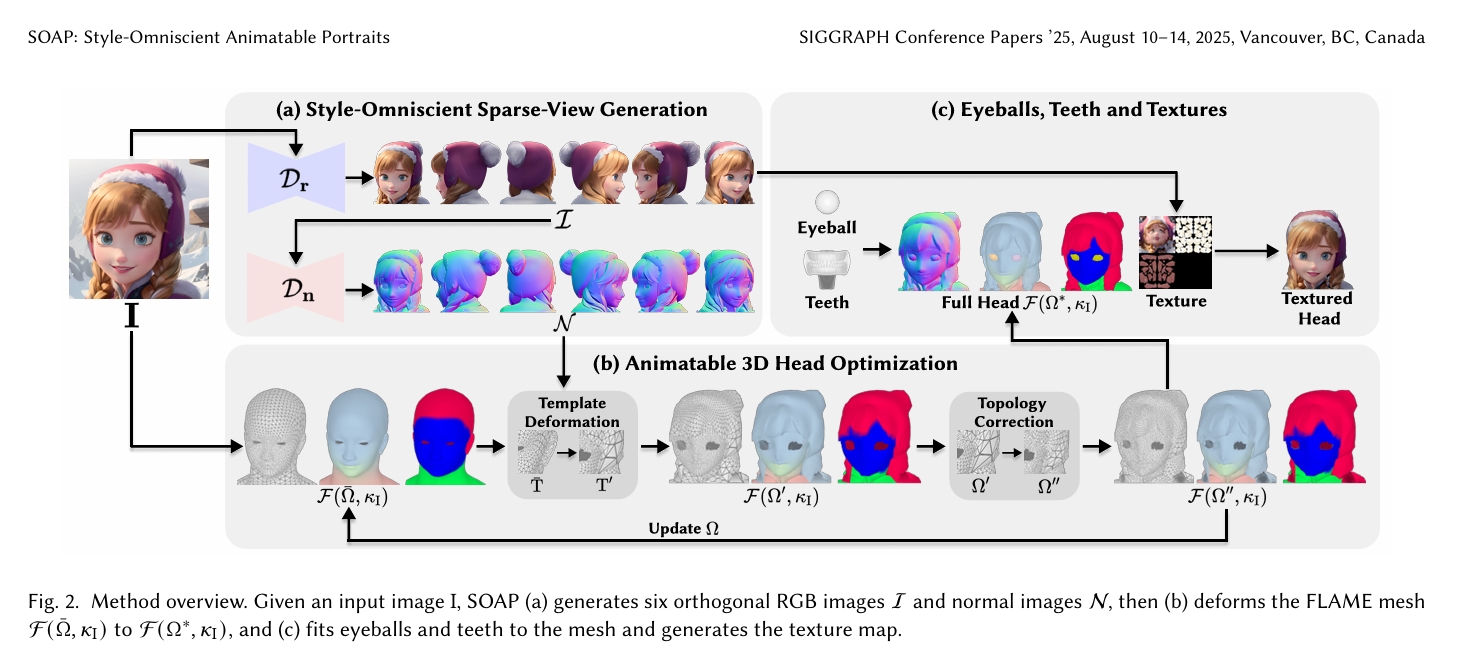
1. 多视角生成阶段**
BaseModel:Unique3D [Wu等,2024b]
(1)多视图图像扩散模型\( D_r \):以单张图像\( I \in \mathbb{R}^{256×256×3} \)为输入,输出6组正交RGB图像\( \hat{I} \in \mathbb{R}^{6×256×256×3} \)。
(2)法线扩散模型\( D_n \):以这些图像\( \hat{I} \)为输入,生成对应的法线贴图\( N \in \mathbb{R}^{6×256×256×3} \)。
(3)单视角超分辨率模型将多视图的图像与法线贴图放大4倍,同时保持多视图一致性。
2. 参数化形变优化
定义符号
定义参数集\( \kappa = (\beta, \theta, \psi) \),完整参数化模型\( \Omega = (T, F, W, J, B) \)。
初始化
使用Emoca方法初始化FLAME参数\( F(\bar{\Omega}, \kappa_I) \)和相机参数\(\pi\)
优化策略
传统方法[Daněček等,2022;Khakhulin等,2022]通过调节\( \kappa \)和添加顶点偏移量建模多样性,但受限于:
- 参数\( \kappa \)的表征能力有限
- 模板拓扑固定导致几何过度平滑
- 无法处理复杂发型与细粒度细节
为此,SOAP提出迭代优化框架(图2b),包含以下核心步骤:
- 语义模板形变:\( T \rightarrow T' \)(顶点数量不变)
- 重网格化与骨骼插值:\( \Omega \rightarrow \Omega' \)
- 迭代循环:重复步骤1-2直至收敛
SOAP创新性地引入个性化Ω优化:
- 模板拓扑可塑性:在发型/配饰区域允许三角形网格动态细分(通过Edge Split/Collapse操作)
- 混合形状基扩展:在保持原始\( B_s, B_e, B_p \)基础上,新增个性化混合形状基\( B_{custom} \),通过PCA降维控制细节形变
Template Deformation 语义模板形变
这里的deformation不是由骨骼驱动导致的形变,而是由顶点位移导致的形变。
输入:
- 多视角法线贴图\( N \)
- 初始FLAME网格\( F(\bar{\Omega}, \kappa_I) \)
- 相机参数\( \pi \)
- 从输入图像\( I \)检测的68个面部关键点\( L \in \mathbb{R}^{68×2} \) [Bulat & Tzimiropoulos, 2017]
- 通过[Dinu, 2022]获得的头部语义分割图\( P \in \mathbb{R}^{3×h×w×3} \)
优化目标:
- 模板顶点\( T \):
损失函数:
$$ \mathcal{L} = \lambda _ {rec} \mathcal{L} _ {rec} + \lambda _ {sema} \mathcal {L} _ {sema} + \lambda _ {lmk} \mathcal{L}_ {lmk} $$
- 重建损失 \( \mathcal{L}_{rec} \):对齐几何与法线贴图
- 语义损失 \( \mathcal{L}_{sema} \):约束头发/面部/颈部形变的语义一致性
- 关键点损失 \( \mathcal{L}_{lmk} \):保持眼部/鼻部/唇部等结构的对称性
Tepology Correction 重网格化与骨骼插值
对形变过程或者产生的问题做一些修复:
- 大三角形面片(边长超过阈值𝜖)--- 细分
- 面法线翻转 --- 修正翻转面
- 扭曲面片 --- 删除
顶点的增加或删除,需要同步更新一些参数矩阵:
- 蒙皮权重 \( W \in \mathbb{R}^{N×|J|}\):新增顶点的权重由其邻接边顶点插值获得
- 混合形状基 \( B \in \mathbb{R}^{500×|J|}\):通过重心坐标插值传递形变参数
- 关节映射矩阵 \( J \in \mathbb{R}^{|J|×N}\):基于变形后模板逆向计算,确保规范空间关节位置不变
3. 精细化组件与纹理生成
- 眼球与牙齿模型适配:分离刚性部件并优化空间位姿
- UV纹理合成:通过多视角RGB图像进行纹理烘焙与超分辨率修复(Sec.5.3)
训练
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
数据集
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
训练策略
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
实验与结论
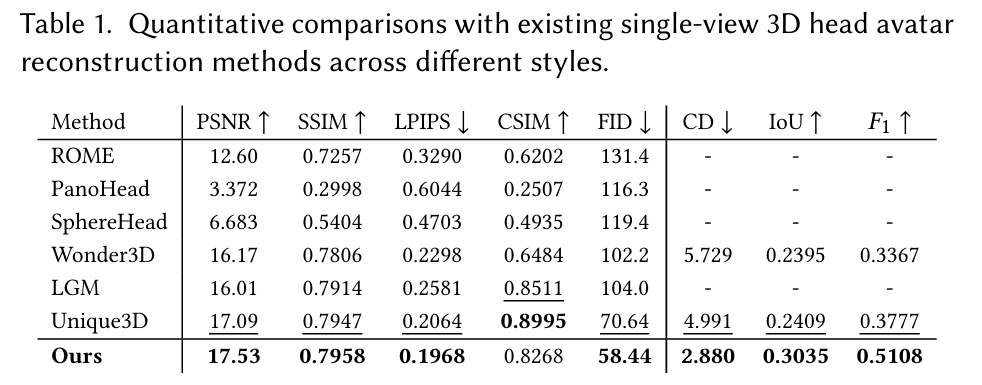 .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
Loss
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
有效
.
.
.
.
.
.
.
.
.
.
.
.
局限性
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
启发
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
遗留问题
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.