MotionShot: Adaptive Motion Transfer across Arbitrary Objects for Text-to-Video Generation
核心问题是什么?
文本到视频生成,且参考对象(动作信息来自图像)与目标对象(外观信息来自文本)外观或结构差异显著

现有方法及局限性
现有的方法在这种情况下,难以实现运动的平滑迁移。
本文方法及优势
MotionShot——一个无需训练的框架,能够以细粒度方式解析参考-目标对象的对应关系,在保持外观连贯性的同时实现高保真运动迁移。
- 首先通过语义特征匹配确保参考与目标对象的高层对齐
- 继而通过参考到目标的形状重定向实现底层形态对齐。
通过时序注意力机制编码运动,我们的方法能连贯地跨对象迁移运动,即使存在显著的外观与结构差异,大量实验已验证其有效性。项目页面详见:https://motionshot.github.io/。
主要方法
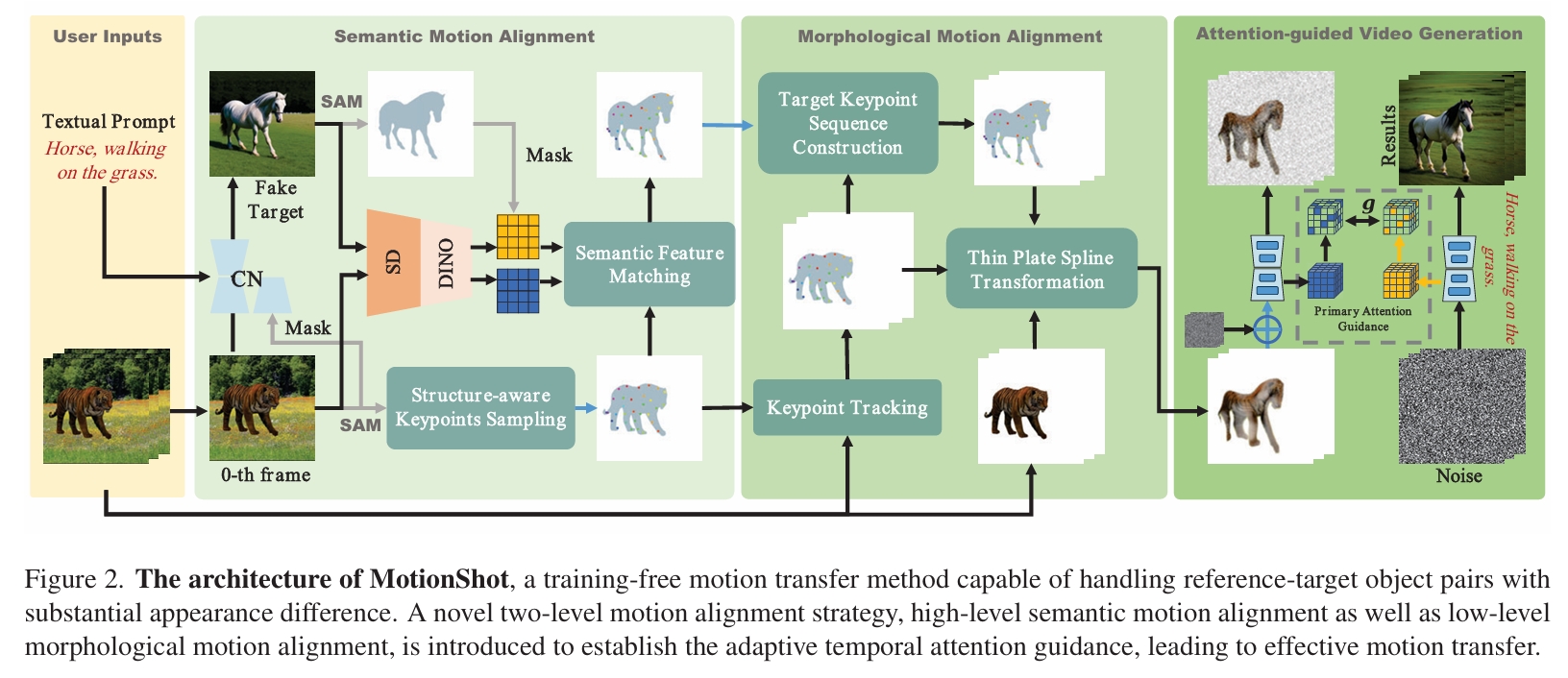
通过对Source Image(动作信息来源)做Warp,得到与『目标对象做特定动作』大致相似的图像做为condition,引导最终的生成。
源和目标虽然差距比较大,但在生理结构上仍具体语义相似性。作者利用这种相似性实现大致轮廓上迁移。
DINO:用于提取外观特征。
Semantic Feature Matching:用于识别生理结构上相似部位的匹配。
Thin Plate Spline Transformation:利用相似性实现轮廓迁移。
实验
Base Model: AnimateDiff