Character Controllers Using Motion VAEs

计算机动画的一个基本问题是,在给定足够丰富的运动捕捉片段集合的情况下,如何实现有目的性且逼真的人体运动。我们采用自回归条件变分自编码器(即运动VAE)来学习数据驱动的人体运动生成模型。经过学习的自编码器其潜在变量定义了运动的动作空间,从而控制运动随时间推移的演变。规划或控制算法随后可利用该动作空间来生成期望的运动。特别地,我们运用深度强化学习来训练能够实现目标导向运动的控制器。我们通过多项任务验证了该方法的有效性,进一步评估了系统设计的不同方案,并阐述了当前运动VAE存在的局限性。
构造先验
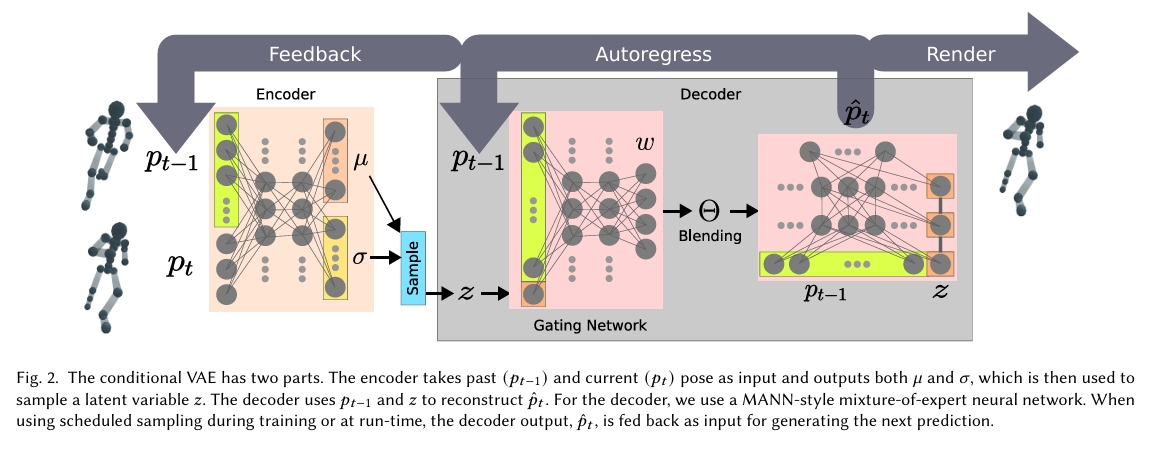
采用自回归条件变分自编码器(即运动VAE)来学习数据驱动的人体运动模型,作为后续生成模型的先验。
规避后验坍塌。
- 可以使用单帧姿态作为条件输入,也可采用连续历史姿态序列(即𝑝𝑡−𝑘...𝑝𝑡−1)作为条件。
实验结论:使用多帧条件能提升MVAE的重构质量,但会降低输出姿态的多样性。极端情况下,解码器可能学会忽略编码器输出,即出现后验坍塌问题。 - 后验坍塌问题是指,解码器忽略编码器输出,仅复现原始运动捕捉数据。
解决方法:
(1)使用较少的历史帧作为条件。实验表明,采用一至两帧连续姿态作为条件即可获得良好效果,但最优选择通常需综合考虑运动数据库的多样性与质量。
(2)将潜变量z输入专家网络的所有层级来强化其重要性。实证研究表明该技巧能有效降低后验坍塌的发生概率。
(3)其他影响后验坍塌概率的设计决策包括:解码器网络规模、KL散度损失的权重(在𝛽-VAE中)以及潜维度数量。
运动质量与泛化能力的平衡
- 平衡源自重构损失与KL散度损失的权重分配
(1)过度侧重运动质量时,系统仅会复现原始运动捕捉序列
(2)若过度强调运动泛化,则可能生成不符合物理规律的动作姿态
实验表明:当MVAE的重构损失与KL散度损失在收敛时保持同一数量级,即可作为衡量质量与泛化间适当平衡的有效指标。
自回归的预测失稳问题
问题原因:不断累积的重构误差会迅速导致模型进入状态空间中不可恢复的新区域
解决方法:计划采样技术
具体方法:为每个训练周期定义采样概率𝑝,当完成姿态预测后,以1−𝑝的概率将预测结果作为下一时间步的输入(而非使用训练数据中的真实姿态)。整个训练过程包含三个模式:监督学习模式(𝑝=1)、计划采样模式(𝑝值衰减)和自回归预测模式(𝑝=0)。
训练片断
使用T帧作为一个训练片断,T帧的切割方式有两种:
(1)任何帧都可被视为序列的起始或结束姿态,切割方法:运动片段被自由划分为等长子序
(2)需要固定起止姿态的特定运动,切割方法:通过填充序列至最长序列长度来处理变长输入
语言都是用第二种,动作通常用第一种。
基于先验的生成
随机生成
控制条件:无
生成方式:自回归
表示方式:连续表示(VAE)
生成模型:VAE
以单帧输入作为起始帧,随机采样下一帧,可以生成以下效果的运动:
- 当初始角色状态取自短跑周期的中间帧时,MVAE将持续重构短跑周期动作;
- 当初始状态为静止姿态(多数运动片段的起始通用姿态)时,角色可自然过渡到行走、奔跑、跳跃或静止等不同运动模式。
当随机行走在大量采样后仍无法实现运动过渡时,就意味着需要补充额外的运动捕捉数据(特别是过渡动作)
可控生成
控制条件:目标位置
生成方式:自回归
表示方式:连续表示(VAE)
生成模型:VAE
方法
在固定时间步长(𝐻)内执行多次蒙特卡洛推演(𝑁),从所有采样轨迹中选取最优路径的首个动作作为当前时间步的角色控制指令,该过程循环执行直至任务完成或终止。
效果
- 在简单运动任务(如目标追踪§6.1)中表现尚可。
- 当采用𝑁=200、𝐻=4参数时,角色通常能朝向目标移动并绕其盘旋,同时适应目标位置的突变(详见补充视频)。
局限性
- 难以引导角色抵达目标两英尺范围内。
- 对于更复杂的任务无法达成预期目标。
- 需要精细调参。
- 需要更高的运行时计算量。
动作先验与强化学习
[?] 这一部分没有看懂