Magic3D: High-Resolution Text-to-3D Content Creation
NVIDIA
1. 研究背景与动机
Magic3D是英伟达团队针对文本到3D生成任务提出的改进方法,其核心目标是解决此前主流方法DreamFusion的两个主要缺陷:
- 速度问题:基于NeRF的优化速度极慢(平均耗时1.5小时)。
- 质量限制:低分辨率(64×64)的扩散模型监督导致3D模型细节不足,几何与纹理质量较低。
Magic3D的提出旨在通过更高效的场景表示和优化框架,实现高质量、高分辨率的3D生成,同时大幅提升生成速度。
2. 核心方法创新:两阶段优化框架
Magic3D采用**“粗到细”(Coarse-to-Fine)的两阶段优化策略**,结合不同分辨率扩散模型与场景表示,具体分为以下步骤:
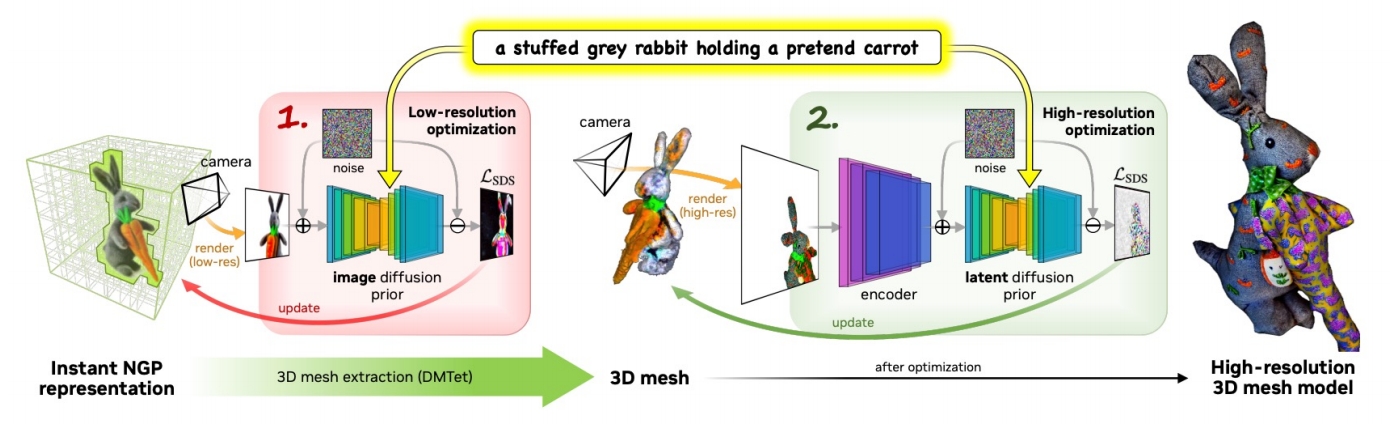
阶段一:粗粒度优化(Coarse Stage)
- 场景表示:采用Instant-NGP(神经图形原语)替代NeRF,利用稀疏3D哈希网格加速训练。这种结构支持快速收敛,尤其适合处理复杂拓扑变化。
- 监督信号:基于低分辨率(64×64)的eDiff-I扩散模型计算Score Distillation Sampling(SDS)损失,指导神经场(颜色、密度、法线场)优化。
- 优势:通过哈希网格和八叉树剪枝,减少计算量,粗阶段仅需15分钟(8块A100 GPU)。
阶段二:细粒度优化(Fine Stage)
- 场景表示转换:从粗模型的密度场提取纹理3D网格(使用DMTet或可变四面体网格),支持高分辨率(512×512)可微分渲染。
- 监督升级:采用**潜在扩散模型(LDM,如Stable Diffusion)**提供高分辨率梯度,通过渲染图像与潜在空间交互优化网格细节。
- 技术细节:
- 焦距调整:增大焦距以捕捉高频细节;
- 正则化约束:对网格相邻面角度差异进行约束,避免表面不平滑。
- 效率:细阶段耗时25分钟,总时间缩短至40分钟,比DreamFusion快2倍。
3. 关键技术创新点
- 高效场景表示:
- 粗阶段使用Instant-NGP的哈希网格,细阶段采用纹理网格,分别适配低/高分辨率优化需求,平衡速度与质量。
- 扩散先验的分阶段应用:
- 低分辨率模型(eDiff-I)引导几何初始化,高分辨率模型(Stable Diffusion)细化纹理,实现8倍分辨率的提升。
- 个性化控制与编辑:
- 结合DreamBooth对扩散模型微调,将特定对象绑定到唯一标识符(如[V]),支持生成定制化3D内容。
4. 实验结果与优势
- 生成质量:用户研究表明,61.7%的参与者认为Magic3D生成结果优于DreamFusion,尤其在几何细节(如动物毛发、物体纹理)上表现突出。
- 效率提升:总耗时40分钟,速度提升2倍,且支持直接导出至图形引擎使用。
- 扩展功能:
- 图像条件生成:通过输入图像调整生成结果,例如根据宠物照片生成对应的3D模型。
- 提示词编辑:支持基于文本提示的局部修改(如调整颜色、形状),无需重新训练整体模型。
5. 局限性与未来方向
- 硬件依赖:需8块A100 GPU,对算力要求较高。
- 细节限制:尽管分辨率提升,复杂结构(如透明材质)仍可能表现不足。
- 后续改进:后续工作可结合更高效的网格表示(如神经隐式表面)或轻量化扩散模型进一步优化效率。
6. 研究影响与意义
Magic3D为文本到3D生成领域树立了新标杆,其贡献包括:
- 方法论突破:验证了“粗到细”框架在高分辨率3D生成中的有效性,启发了后续研究(如Progressive3D、VSD)。
- 应用扩展:推动游戏、虚拟现实等领域的高效3D内容创作,降低专业建模门槛。
- 技术融合:首次将个性化图像编辑(DreamBooth)与3D生成结合,为可控内容生成提供新范式。
总结
Magic3D通过两阶段优化框架与高效场景表示,成功解决了DreamFusion的速度与分辨率瓶颈,成为文本到3D生成领域的重要里程碑。其创新点在于分阶段利用不同分辨率扩散模型的优势,并通过网格表示实现高分辨率细节优化。尽管存在硬件依赖等局限,但其方法论为后续研究提供了关键参考,推动了AIGC从2D向3D的扩展。