AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
研究背景与问题
目的
-
T2I -> T2V。
本框架核心是一个即插即用的运动模块,该模块只需训练一次即可无缝集成于同源基础T2I模型衍生的任何个性化模型中。 -
MotionLoRA,这是AnimateDiff的轻量级微调技术,可使预训练运动模块以较低训练和数据收集成本适应新运动模式(如不同镜头类型)。
✅ (1) 用同一个 patten 生成 noise,得到的 image 可能更有一致性。
✅ (2) 中间帧的特征保持一致。
P99
主要方法
方法核心在于从视频数据中学习可迁移的运动先验,这些先验无需特定调优即可应用于个性化T2I模型。
推断流程
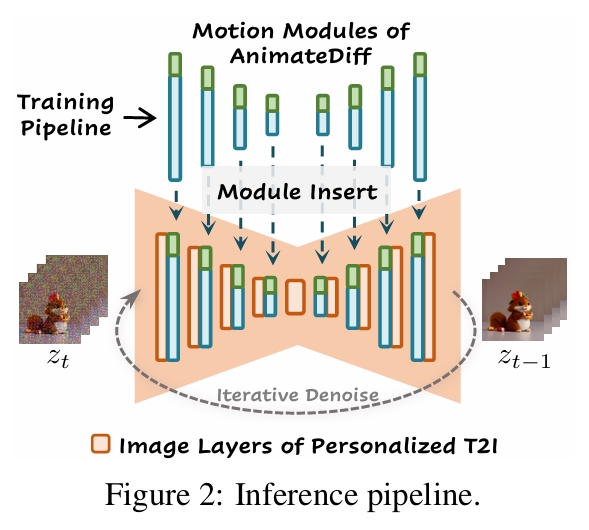
在推理阶段,运动模块(蓝色)及可选的MotionLoRA(绿色)可直接插入个性化T2I构成动画生成器,通过迭代去噪过程生成动画。
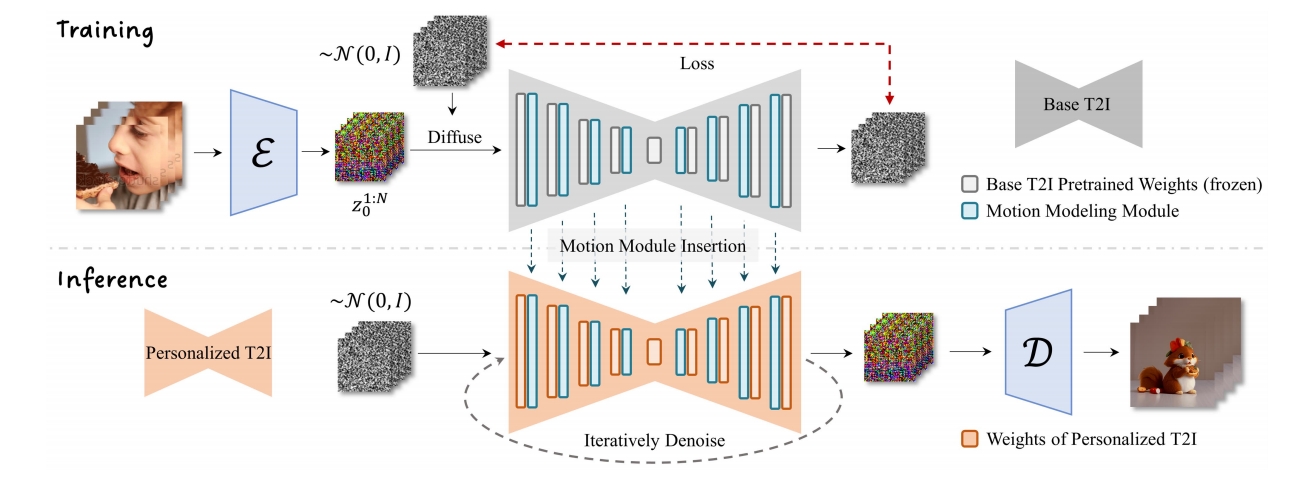
训练流程
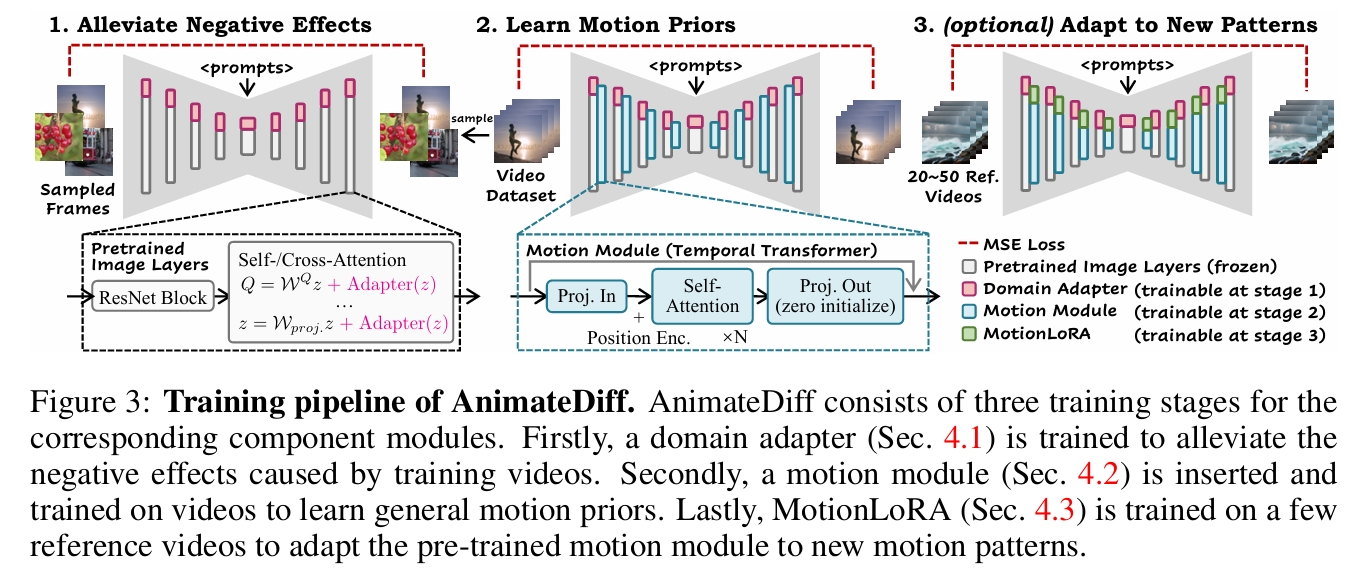
- 领域适配器(4.1节):仅在训练中使用,用于缓解基础T2I预训练数据与视频训练数据间的视觉分布差异;
- 运动模块(4.2节):学习通用运动先验;
- MotionLoRA(4.3节,通用动画场景可选):将预训练运动模块适配至新运动模式。
领域适配器(Domain Adapter)
由于公开视频训练数据集(如WebVid)的视觉质量远低于图像数据集(如LAION-Aesthetic),导致基础T2I的高质量图像域与视频训练域存在显著差异。
为消除域差异对运动模块学习的干扰,在基础T2I中加入领域适配器(LoRA层)。
[?]为什么仅在训练阶段使用?
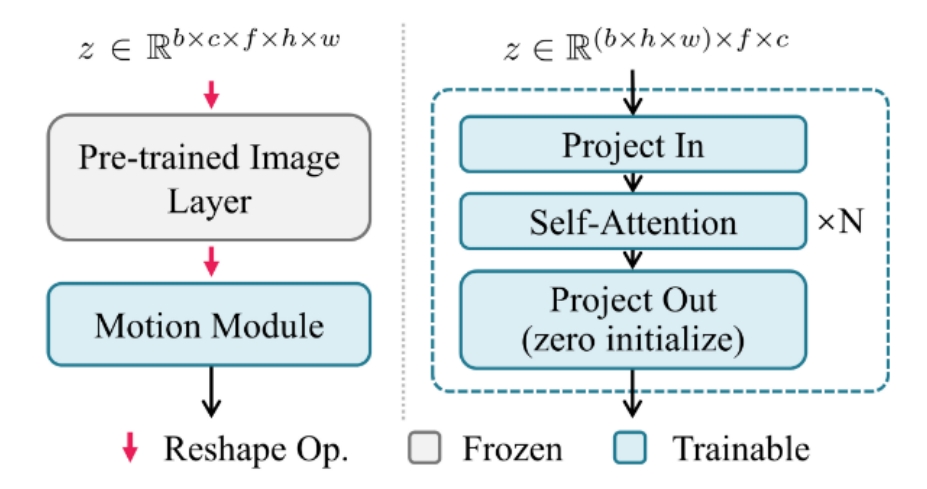
通过运动模块学习运动先验
使用Transformer(self attention + positioanl embedding)实现T2I->T2V
通过MotionLoRA适配新运动模式
目的:以少量参考视频和训练迭代量适配新运动模式(如镜头变焦/平移/旋转)
在运动模块的自注意力层添加LoRA层,并在新运动模式的参考视频上训练这些层。
训练
基模型:SD1.5 数据集:WebVid-10M, resized at 256x256
✅ 在低分辨率数据上训练,但结果可以泛化到高分辨率。
实验
横向对比
- Text2Video-Zero
- Tune-a-Video
- 本文方法