NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
NUWA-XL是微软亚洲研究院联合中科院提出的超长视频生成模型,其核心目标是通过创新的架构设计解决传统方法在长视频生成中的效率、连贯性和质量瓶颈。以下从技术背景、方法创新、实验效果及意义等方面进行解读:
一、技术背景与挑战
-
传统方法的局限性
现有长视频生成模型多采用“Autoregressive over X”架构(如Phenaki、NUWA-Infinity),即在短视频片段上训练,通过滑动窗口自回归生成更长的视频。然而,这种方法存在两大问题:- 训练-推理差距(Train-Inference Gap):模型在训练时仅接触短视频片段,无法学习长视频的全局时序信息,导致生成视频的中间片段质量下降、情节逻辑断裂。
- 顺序生成的低效性:自回归生成无法并行推理,导致生成时间随视频长度线性增长。例如,生成1024帧需7.5分钟。
-
实际应用需求
影视、动画等场景需生成数十分钟至数小时的连贯视频,而现有模型仅支持3-5秒的短视频生成,无法满足需求。
二、方法创新:Diffusion over Diffusion架构
NUWA-XL提出“扩散模型中的扩散”分层架构,通过**全局扩散模型(Global Diffusion)和局部扩散模型(Local Diffusion)**的协同,实现从粗到细的并行生成。

-
全局扩散模型
基于输入的文本描述(如16句提示),生成视频的关键帧序列(类似动画制作中的分镜),确保全局时序连贯性与情节一致性。例如,输入16句描述可生成11分钟动画的关键帧。 -
局部扩散模型
在关键帧之间递归填充中间帧,通过多层级扩散逐步细化内容。例如,首层局部扩散生成L²帧,后续层级以指数级扩展帧数,最终生成O(L^m)长度的视频。
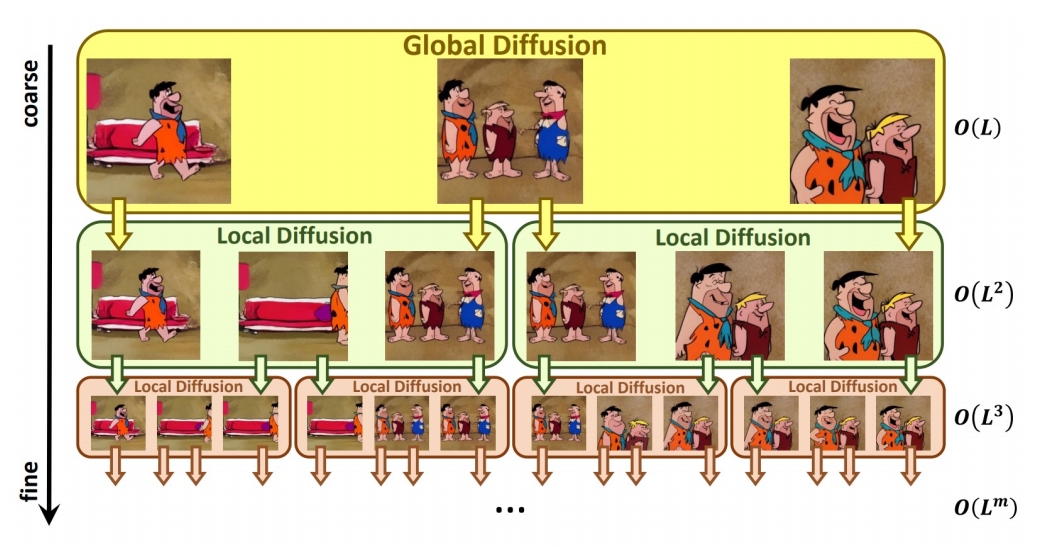
✅ 递归的 Local Diffusion
| Global diffusion model | Local diffusion model | |
|---|---|---|
| 文生图 | 关键帧插帧 | |
| 输入 | L text prompts | 2 text prompts + 2 keyframes |
| 输出 | L keyframes | L keyframes |
- Mask Temporal Diffusion (MTD)
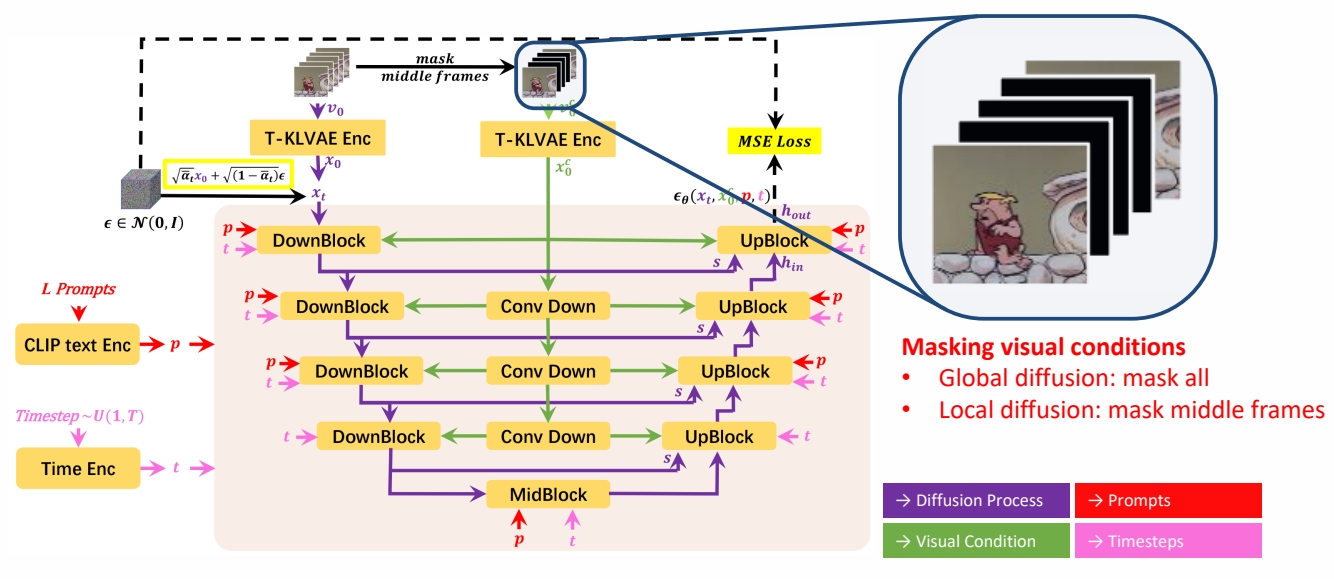
✅ Global 和 Local 使用相似的模型,训练方法不同,主要是 MASK 的区别。
- 关键优势
- 消除训练-推理差距:直接在长视频数据(如3376帧)上训练,提升全局一致性。
- 并行推理加速:局部扩散模型支持并行计算,生成1024帧的时间从7.55分钟降至26秒,效率提升94.26%。
- 指数级扩展能力:视频长度随扩散层级深度m呈指数增长,支持生成极长视频。
三、实验与效果验证
- 数据集与指标
- 构建FlintstonesHD数据集用于训练与测试。
FlintstonesHD: a new dataset for long video generation, contains 166 episodes with an average of 38000 frames of 1440 × 1080 resolution
- 评估指标:Avg FID(帧质量)和Block FVD(视频连续性),数值越低越好。
-
性能对比
- 生成质量:NUWA-XL的Avg FID稳定在35左右,优于Phenaki(48.56)等模型,且质量不随视频长度下降。
- 连续性:B-FVD指标显示,NUWA-XL生成的长视频片段质量下降更慢,因模型学习了长视频模式。
-
效率提升
生成1024帧的推理时间仅需26秒,较传统方法提升94.26%。
四、意义与未来方向
-
行业应用潜力
NUWA-XL为动画、影视、广告等领域提供了高效生成工具,例如通过少量文本生成连贯的长视频内容,降低创作门槛。 -
多模态大模型融合
论文提出未来需将语言与视觉生成融合至统一架构,推动通用型AI的发展。微软研究员段楠指出,当前模型(如GPT-4)仍以文本输出为主,而NUWA-XL展示了视觉生成的潜力。 -
技术扩展性
通过增加训练数据(如电影、电视剧)和算力,NUWA-XL可进一步扩展至更复杂场景,如电影级长视频生成。
五、论文资源
- 论文地址:arXiv:2303.12346
- 项目演示:NUWA-XL官网
该研究通过仿照动画制作流程(关键帧→细化填充),结合扩散模型的并行优势,为长视频生成领域提供了新的技术范式,并推动了多模态大模型的发展。