X-MoGen: Unified Motion Generation across Humans and Animals
核心问题是什么?
文生人类动作和动物动作

现有方法及局限性
- 分别建模人类与动物动作
- 联合跨物种方法具备统一表征与更强泛化性等关键优势,但由于物种间形态差异,常导致动作失真。
本文方法及优势
X-MoGen:首个覆盖人类与动物的统一跨物种文本驱动动作生成框架。
第一阶段:条件图变分自编码器学习规范T姿态先验,同时自编码器将动作编码至由形态学损失正则化的共享潜空间;
第二阶段:通过掩码动作建模生成基于文本描述的动作嵌入。
训练中采用形态一致性模块保障跨物种骨骼合理性。为支持统一建模,我们构建了包含115个物种、11.9万动作序列的大规模数据集UniMo4D,在共享骨骼拓扑下整合人/动物动作进行联合训练。UniMo4D上的大量实验表明,X-MoGen在已知/未知物种上均超越现有最优方法。
主要方法
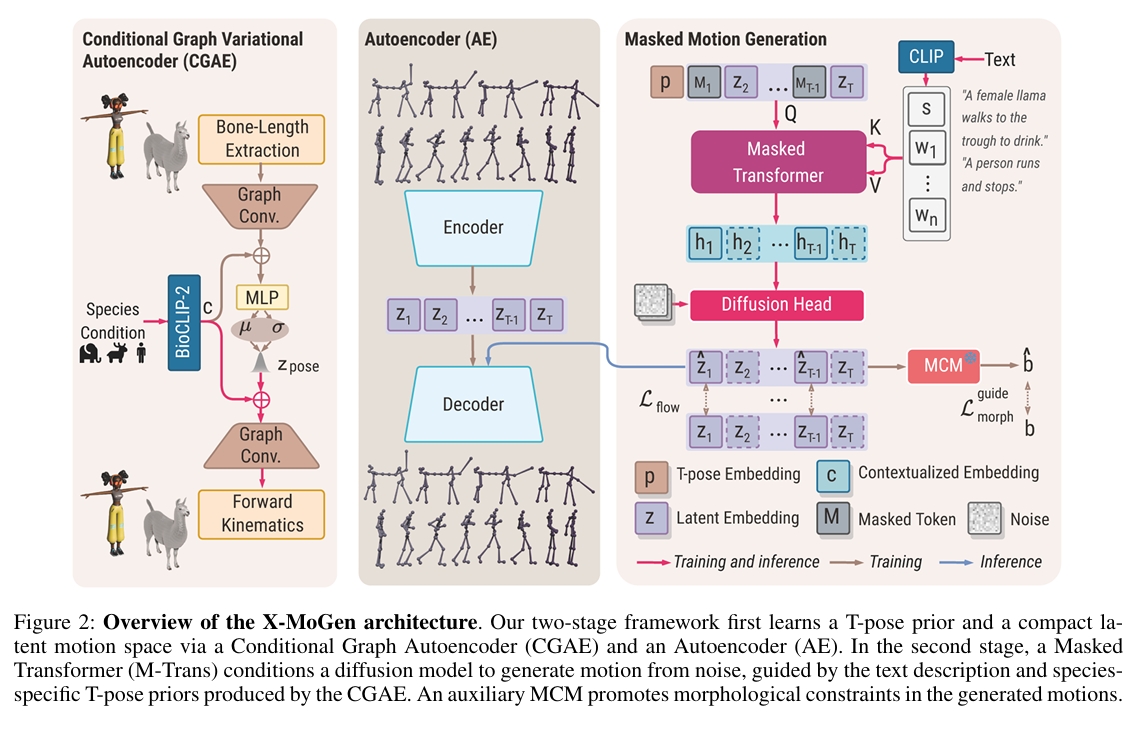
图2:X-MoGen架构概览 我们的两阶段框架首先通过条件图自编码器(CGAE) 和自编码器(AE) 学习T姿态先验与紧凑动作潜空间。第二阶段中,掩码Transformer(M-Trans) 引导扩散模型从噪声生成动作,该过程以文本描述及CGAE生成的物种特定T姿态先验为条件。辅助的形态一致性模块(MCM) 对生成动作施加形态学约束。
Stage 1: Feature Modeling
T-pose Modeling via CGAE
[?]
- 本文要求所有物理的骨骼拓扑是一一致的。只是长度的朝向的差异。
- CGAE中只编码了骨骼长度的信息,怎么约束朝向信息呢?
- CGAE中的BioCLIP-2部分只对一个物种信息编码,怎么实现跨物种的效果?
Motion Representation via AE
[?] 这里为什么是AE而不是VAE
Stage 2: Masked Motion Generation
Masked Motion Modeling
Diffusion-based Completion Head
[?]为什么需要输入T-pose Embedding?Latent Embedding足以恢复信息。 [?]蒙皮权重与Mesh的影响不考虑进去?
Morphological Consistency Module
- MCM是怎么做的?从哪里获取角度极限的信息?
- MCM是什么时候训练的?