MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
核心问题是什么?
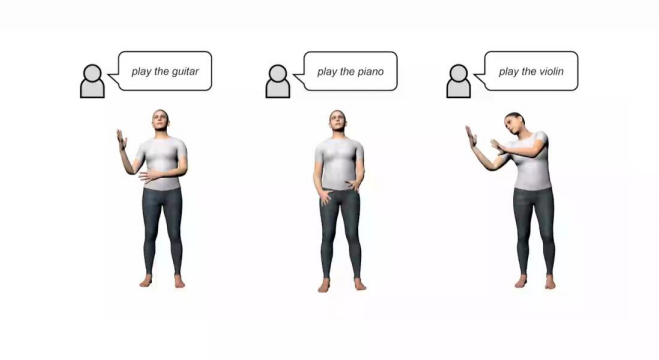
直接基于自然语言生成人体运动
现有方法及局限性
如何根据多样化文本输入实现细腻且精细的运动生成仍具挑战性。
本文方法及优势
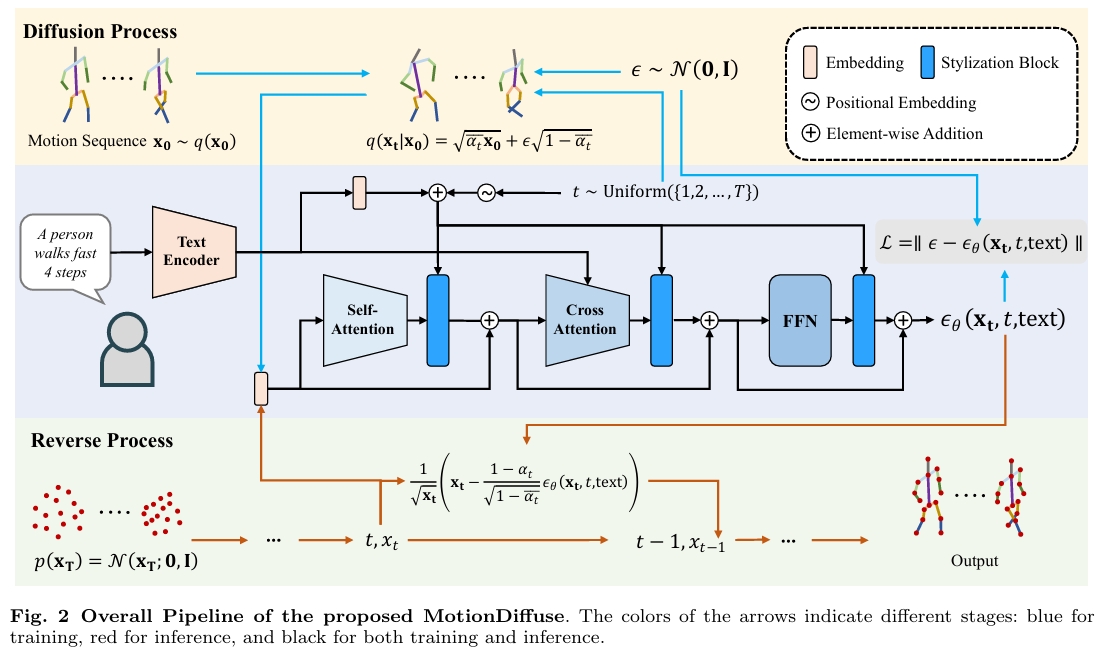
MotionDiffuse——首个基于扩散模型的文本驱动运动生成框架,其展现出超越现有方法的三大特性:
1)概率性映射。通过注入变异的多步去噪过程生成运动,取代确定性语言-运动映射;
2)真实合成。擅长复杂数据分布建模并生成生动运动序列;
3)多级操控。支持身体部位的细粒度指令响应,以及基于时变文本提示的任意长度运动合成。
实验表明MotionDiffuse在文本驱动运动生成和动作条件运动生成方面显著优于现有SoTA方法。定性分析进一步证明框架在综合运动生成方面的强大可控性。项目主页:https://mingyuan-zhang.github.io/projects/MotionDiffuse.html
方法
实验
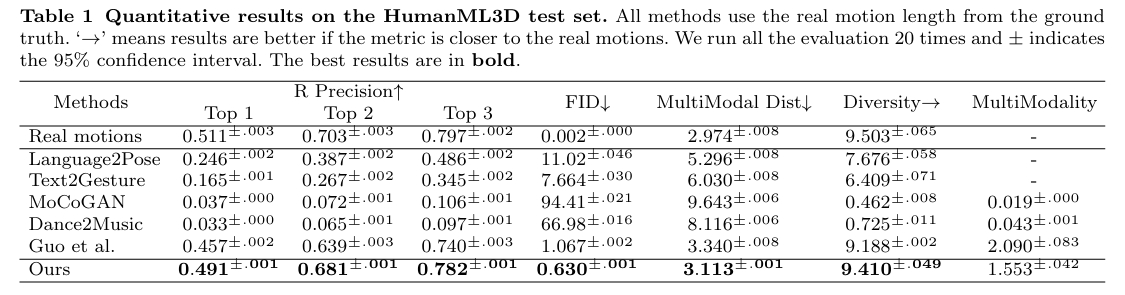
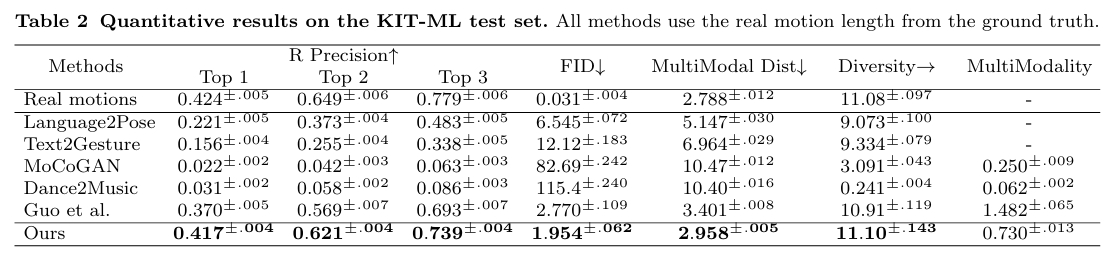
KIT-ML, HumanML3D
效果SOTA