TSTMotion: Training-free Scene-aware Text-to-motion Generation
研究背景与问题
-
文本到动作生成(Text-to-Motion)
现有技术多基于空白背景生成人体动作序列,但现实场景中人类需与3D环境中的物体交互(如“坐在远离电视的沙发上”)。传统方法无法满足场景感知需求,导致生成动作与场景逻辑冲突。 -
现有方法局限性
- 数据依赖性强:现有数据集(如HUMANISE)规模小、场景单一(仅室内)、动作有限(行走、坐、躺、站);
- 算法复杂度高:基于强化学习(RL)的方法需要细粒度标注且面临RL训练难题;
- 输入低效性:直接输入无序点云数据效率低下。
核心创新:TSTMotion框架
目标:无需训练专用场景感知模型,直接利用现有“空白背景生成器”(如Motion Diffusion Models)实现场景感知的文本驱动动作生成。
基于基础模型的三组件设计:
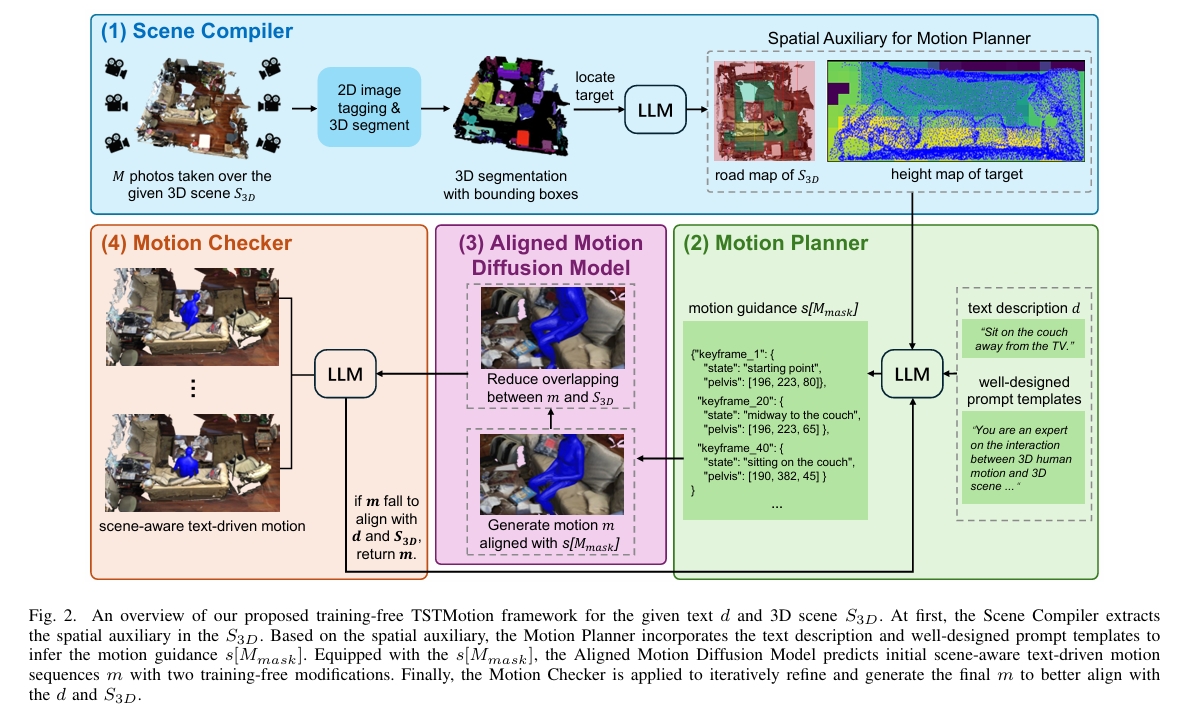
场景编译器(Scene Compiler)
功能:将3D场景转换为结构化表示(如语义地图),提取物体位置、空间关系等上下文信息,解决点云输入的低效问题。
1. 识别(Recognition)
- 输入:原始3D场景点云 \( S_{3D} \)。
- 操作:
- 多视角渲染:从不同角度渲染点云,生成 \( M \) 张2D图像(覆盖俯视、侧视等视角),解决点云单视角遮挡问题。
通过多角度渲染解决点云遮挡问题,提升物体识别完整性与鲁棒性。
- 物体识别:使用预训练的图像标签模型(如CLIP或ResNet)识别每张图像中的物体类别(如“沙发”“电视”),合并所有视角结果生成统一物体词汇表(避免重复)。
- 输出:场景中所有物体的类别列表(如 {沙发, 电视, 茶几})。
2. 分割(Segmentation)
- 输入:物体词汇表 + 原始点云 \( S_{3D} \)。
- 操作:
- 语义分割:基于词汇表,使用3D分割器(如PointNet++或3D-SparseConv)将点云中每个点分类到对应物体(如标记属于“沙发”的点)。
- 实例分割:区分同一类别的不同物体实例(如两个独立的“椅子”)。
- 输出:带语义标签的点云,每个点标记所属物体类别及实例ID。
3. 目标定位(Locating Target)
- 输入:分割后的点云 + 文本指令(如“坐在远离电视的沙发上”)。
- 操作:
- 边界框简化:将每个物体实例的点云包裹为轴对齐包围盒(AABB),记录其中心坐标、长宽高。
- LLM语义解析:
- 将文本指令输入大语言模型(如GPT-4),解析出目标物体(“沙发”)和约束条件(“远离电视”)。
- 结合包围盒空间坐标,定位目标物体(如筛选出距离电视最远的沙发实例)。
- 输出:目标物体的包围盒坐标及空间约束关系(如“沙发A中心坐标(x,y,z),与电视B距离>2米”)。
用包围盒代替原始点云,显著降低后续计算复杂度(从数万点→数十个包围盒)。
4. 路网图生成(Road Map)
- 输入:所有物体的包围盒 + 目标物体位置。
- 操作:
- 投影到XOY平面:将3D包围盒投影至水平地面(XOY平面),生成2D矩形区域。
- 标记可通行区域:
- 障碍物:非目标物体的投影区域(如电视、茶几的投影区标记为障碍)。
- 目标区域:目标物体(沙发)的投影区标记为终点。
- 路径规划基底:输出栅格化路网图,标识可行走区域与障碍物(见下图示意)。
- 输出:二值化路网图(0=障碍,1=可通行)。
5. 高度图生成(Height Map)
- 输入:目标物体的点云(如沙发点云)。
- 操作:
- 投影到XOY平面:将目标点云垂直投影至地面,保留每个点的Z轴高度值。
- 栅格化处理:将投影区域划分为网格,每个网格单元记录最大高度(表征物体形状起伏)。
- 形状编码:生成灰度图像,亮度表示高度(如高亮区域=沙发坐面,暗区=扶手)。
- 输出:目标物体的高度分布图(用于接触点预测与动作可行性判断)。
路网图和高度图要求场景中的所有东西都是在地上。不能在空中。
路网图专注宏观路径规划(避开障碍);
高度图专注微观动作适配(如坐面高度决定弯曲关节角度)。
动作规划器(Motion Planner)
功能:将文本指令与场景编译器输出的空间辅助信息(路网图Road Map + 高度图Height Map)结合,生成初步动作指导(如轨迹、接触点)。
1. 骨架序列表示
- 定义:骨架序列 \( s \in \mathbb{R}^{N \times J \times 3} \),其中:
- \( N \):动作帧数(如30帧对应1秒动作)
- \( J \):人体关节数(如SMPL模型的24关节)
- 3:关节在3D空间中的坐标(x, y, z)
- 稀疏掩码:引入二进制掩码 \( M_{\text{mask}} \in {0,1}^{N \times J} \),仅标记与场景交互相关的关键关节(如“坐”动作需关注髋关节、膝关节)。
2. 基于LLM的分步推理
- 输入:
- 文本指令 \( d \)(如“坐在远离电视的沙发上”)
- 场景编译器输出的路网图(可行走区域) + 高度图(目标物体形状)
- 提示工程:通过设计结构化提示模板(Prompt Template),将任务分解为子问题,引导LLM逐步推理:
prompt = """ 你是一个动作规划专家,请根据以下信息生成人体动作骨架序列: 1. 场景路网图:{road_map_description} 2. 目标高度图:{height_map_description} 3. 文本指令:“{text_instruction}” 请按步骤思考: Step 1: 确定动作类型(如行走、坐下)及目标物体接触区域。 Step 2: 根据路网图规划从起点到目标的移动路径(坐标序列)。 Step 3: 结合高度图预测接触点(如沙发坐面中心坐标)。 Step 4: 生成关键关节(髋、膝、踝)的3D轨迹,避免与场景碰撞。 """
Step1:LLM解析文本指令,提取动作类型(如“坐”)和场景约束(如“远离电视”)。
Step2:宏观路径:基于路网图,使用LLM内置的空间推理能力生成从起点到目标物体的移动路径(如绕过障碍物的折线坐标序列)。
Step3:高度图分析:LLM根据目标高度图(如沙发坐面高度≈0.5m)预测接触点坐标(如髋关节目标位置(x, y, 0.5))。
Step4:关键关节轨迹:LLM生成指定关节(由掩码 \( M_{\text{mask}} \) 标记)的3D轨迹。
- 输出:稀疏骨架序列 \( s[M_{\text{mask}}] \)(如仅包含髋、膝、踝关节的轨迹)。
- 示例
- 输入:
- 路网图:标记沙发位置为终点,电视区域为障碍。
- 高度图:沙发坐面高度=0.5m,靠背高度=0.9m。
- LLM推理:
- Step 1: 动作类型=“坐”,接触区域=沙发坐面中心。
- Step 2: 路径=从起点直线移动至沙发(无障碍需绕行)。
- Step 3: 接触点坐标=(2.0, 3.0, 0.5)。
- Step 4: 生成髋关节轨迹(从(2.0, 1.0, 1.0)降至(2.0, 3.0, 0.5)),膝关节弯曲角度随时间增加。
- 输出骨架序列:
- 帧1-10:髋关节从站立高度降至坐面高度,膝关节逐渐弯曲。
- 帧11-30:保持坐姿稳定,无垂直移动。
对齐的扩散动作模型(Aligned Motion Diffusion Model)
功能:在不重新训练模型的前提下,将动作规划器生成的指导嵌入到预训练的空白背景动作扩散模型(如Motion Diffusion Model)中,生成符合场景约束的动作序列。突破传统扩散模型对场景信息的“盲生成”,实现开放域场景的动态适配。
1. 对齐动作指导(Modification 1):符合Motion Planner生成的骨架序列 \( s[M_{\text{mask}} \);
在推断时,先用FK计算出关节的位置,计算预测位置与期望位置之间的损失, 通过反向传播计算梯度,调整模型预测\( \hat{x}_0^k \):
$$ \hat{x} _ 0^k \leftarrow \hat{x} _ 0^k - \lambda \cdot \nabla _ {x_k} L_ {\text{align}} $$
方法类似于OmniControl的方法
2. 避免场景穿透(Modification 2):减少与3D场景的几何重叠。
使用符号距离函数 \( \text{SDF}(p, P) \) 计算人体网格点 \( p \) 到场景 \( P \) 的最小距离,以及在P内部还是外部。
定义损失函数 \( L_{\text{scene}} \),仅惩罚穿透点(SDF负值部分):
$$
L_{\text{scene}} = \sum_{p \in \text{SMPL}(\hat{x}_0^k)} \text{ReLU}(-\text{SDF}(p, P))
$$
通过梯度更新减少穿透,修正方法与上面相同。
技术挑战与解决方案
- 梯度冲突:若两个修改的梯度方向相反,可能导致震荡。
解决方案:采用交替更新策略(先对齐动作,再消除穿透),或动态调整 \( \lambda, \eta \)。 - 计算效率:SDF实时查询可能增加耗时。
解决方案:预计算场景的SDF网格,或使用近似加速结构(如KD-Tree)。 - 过修正风险:过度调整可能破坏动作自然性。
解决方案:限制梯度步长 \( \lambda, \eta \),或加入动作流畅性约束。
动作检查器(Motion Checker)
功能:通过物理合理性验证(如碰撞检测、动作可行性)优化动作指导,确保生成动作与场景动力学一致。
1. 迭代优化流程
- 首次生成:Motion Planner → Aligned MDM → Motion Checker。
- 验证失败:
- 将失败原因反馈至Motion Planner,调整动作指导(如重新规划路径或接触点)。
- 重新执行生成与验证,通常仅需1次迭代即可通过。
- 终止条件:验证通过或达到最大迭代次数(如3次)。
2. 自动化摘要
将骨架序列 \( s \) 和SMPL网格转换为自然语言描述,包括:
- 关键关节轨迹(如髋关节移动路径);
- 接触点坐标与目标物体位置对比;
- 穿透检测结果(如“左膝穿透沙发深度0.1m”)。
3. LLM驱动的验证机制
- 输入:
- 生成的动作序列描述(如骨架序列可视化报告);
- 原始文本指令与场景编译器输出的语义地图。
- 提示模板设计:
prompt = """ 你是一个动作质检专家,请验证以下动作是否符合要求: 1. 文本指令:“{text_instruction}” 2. 场景约束:{scene_constraints}(如“沙发位置”“障碍物区域”) 3. 生成动作报告:{motion_report}(包含骨架轨迹、接触点、网格穿透检测结果) 请按步骤检查: Step 1: 动作类型是否与指令一致?(如“坐” vs “蹲”) Step 2: 移动路径是否避开所有障碍物? Step 3: 接触点是否位于目标物体表面? Step 4: 人体网格是否与场景发生穿透? 若任一步骤不通过,返回失败原因。 """ - 输出:验证结果(通过/不通过) + 失败原因(如“髋关节轨迹偏离沙发坐面”)。
4. 失败案例处理
- 路径偏离:反馈至Motion Planner重新规划路径(如增大绕障距离)。
- 语义不符:修正LLM解析逻辑(如明确“坐”与“蹲”的关节角度阈值)。
- 场景穿透:增强Modification 2的梯度惩罚强度 \( \eta \)。
关键技术突破
-
无需训练的零样本生成
- 利用预训练基础模型(如CLIP、扩散模型)的泛化能力,避免对场景感知数据集的依赖。
- 通过“提示工程”将场景信息隐式编码至生成过程,而非显式训练。
-
场景-动作联合建模
- 将文本指令拆解为“动作语义”和“场景约束”两部分,分别由动作规划器和场景编译器处理。
- 示例:指令“坐在远离电视的沙发上” → 动作语义“坐” + 场景约束“沙发位置”+“与电视的距离”。
-
动态物理可行性验证
- 动作检查器引入轻量级物理仿真(如刚体动力学),快速验证动作合理性。
- 若规划动作导致碰撞或失衡,迭代调整接触点或运动轨迹。
实验与效果
实验1
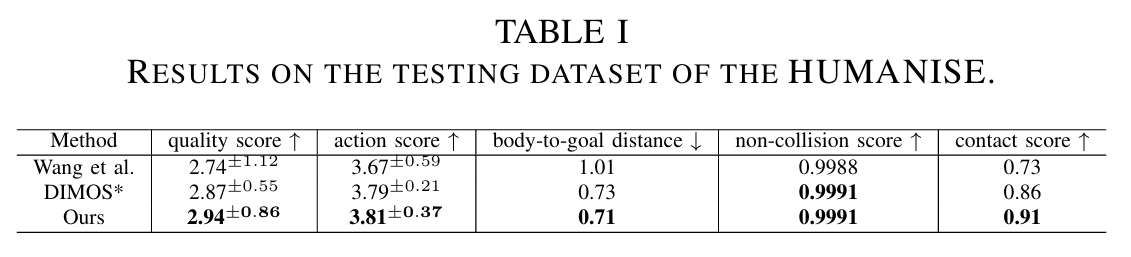
测试数据集:
- HUMANISE数据集:专注于室内场景的文本-动作-场景交互数据,包含有限动作(行走、坐、躺、站)。
对比: - 本文方法
- DIMOS 结论: 关键结论:
- DIMOS*(DIMOS + Scene Compiler)的Body-to-Goal Distance显著低于原始DIMOS,证明Scene Compiler的物体定位能力有效。
- TSTMotion进一步优化路径规划与接触点预测,距离最低,体现Motion Planner与Aligned MDM的协同优势。
- TSTMotion在语义对齐(如动作类型匹配)和碰撞避免上均优于基线,验证Motion Checker迭代优化的有效性。
实验2

测试数据集:
- AffordMotion数据集:包含多样化室内外场景与复杂动作(如跑步、跳跃、抓取),强调动作-场景的物理交互合理性。
对比: - 本文方法
- AffordMotion 结论:
- R-Precision:文本与生成动作的匹配度,TSTMotion更高,体现Motion Planner对复杂指令的精准解析。
- MultiModal Distance:生成动作多样性偏差,值越低说明多样性越好且符合文本,反映零样本生成避免过拟合的优势。
- Contact Score:动作与目标物体的有效接触率,TSTMotion通过高度图引导接触点预测显著提升。
- Non-Collision Score:无场景穿透的比例,得益于Modification 2的SDF梯度修正。
- 无需场景特定数据训练,适配室内外环境;
应用价值
- 游戏与影视制作
- 快速生成符合场景逻辑的角色动画(如NPC自动避障、与道具交互),降低人工制作成本。
- 具身智能(Embodied AI)
- 为机器人提供基于自然语言指令的场景适配行为规划(如“绕过桌子取水杯”)。
- 元宇宙与虚拟人
- 增强虚拟角色在开放环境中的自主交互能力,提升用户体验沉浸感。
未来挑战
- 长时序动作连贯性
当前方法对多步骤复杂指令(如“走到沙发旁,坐下后拿起书”)的时序一致性仍需优化。 - 多智能体交互
需扩展至多人协作或对抗场景(如“两人搬箱子”)。 - 实时性提升
物理验证模块的计算效率需进一步优化以满足实时生成需求。
总结
TSTMotion通过无训练框架设计和场景-动作联合建模,解决了传统文本到动作生成的场景割裂问题,为开放域动态交互任务提供了高效、低成本的解决方案。其核心思想“利用基础模型知识代替专用训练”或成为未来跨模态生成任务的重要范式。
相似工作对比
LLM based human motion生成任务对比
- 本文,2025.5
- OmniControl,2024,link
| 本文 | OmniControl | |
|---|---|---|
| 控制信息->prompt | 动作规划器生成 | 特定任务的指令的简单组合 |
| prompt->motion | 1. prompt作为MDM的condition,使用MDM生成 2. 推断过程使用prompt中的具体的数据信息做动作优化 | LLM + LoRA |
| motion后处理 | 1. 借助LLM判断生成动作是否合理 2. 根据判断结果重新调整引导生成的LLM | 无 |
| 生成效果 | 动作规划器能支持更复杂的控制需求 后处理能进一步优化生成动作 | 借助预训练的LLM简单训练过程,但生成结果没有优势 |