An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. 核心思想与创新点
该论文提出了一种名为 Vision Transformer (ViT) 的纯Transformer架构,用于图像分类任务。其核心思想是将图像分割为固定大小的块(如16x16像素),并将每个块视为一个“单词”,通过线性投影转换为嵌入向量序列,直接输入标准Transformer编码器进行处理。这一方法突破了传统卷积神经网络(CNN)在视觉任务中的主导地位,证明了纯Transformer在图像识别中的有效性。
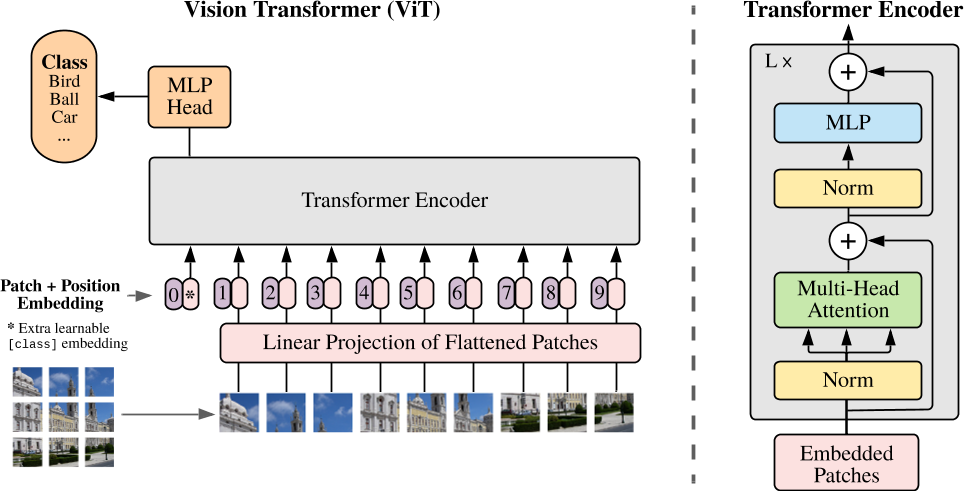
关键创新点:
- 图像块序列化:将图像分割为块(Patch),通过线性投影生成嵌入向量序列,模拟NLP中的词嵌入处理方式。
- 全局自注意力机制:抛弃CNN的局部感受野设计,利用Transformer的全局注意力捕捉长程依赖。
- 极简归纳偏置:仅通过位置编码保留空间信息,减少对图像先验知识(如平移不变性)的依赖,依赖数据驱动学习。
2. 模型架构
ViT的架构主要包含以下部分:
-
图像分块与嵌入:
- 输入图像(如224x224)被划分为 \( N = (224/16)^2 = 196 \) 个16x16的块,每个块展平后通过线性投影映射到维度 \( D \)(如768维)的嵌入向量。
- 添加可学习的[class]标记作为分类信号,并与块嵌入拼接,形成输入序列。
-
位置编码:
- 使用一维可学习位置编码,与块嵌入相加,弥补分块后丢失的空间信息。实验表明,二维编码并未显著提升性能。
-
Transformer编码器:
- 由多层多头自注意力(MSA)和MLP块交替组成,每层包含残差连接和层归一化(LayerNorm)。
- 最终通过[class]标记的输出向量进行分类。
-
混合架构(可选):
- 可先用CNN提取特征图,再将特征图分块输入Transformer,结合CNN的局部性与Transformer的全局性。
3. 训练与微调策略
- 预训练:在大规模数据集(如JFT-300M、ImageNet-21k)上训练,采用监督学习目标。
- 微调:移除预训练的分类头,替换为任务相关的线性层,并对更高分辨率的输入进行位置编码插值以适应序列长度变化。
4. 实验与性能
- 大数据集优势:在JFT-300M等大规模数据集预训练后,ViT在ImageNet上达到88.55%的准确率,超越ResNet和EfficientNet等CNN模型。
- 小数据集局限性:在数据量不足时(如仅ImageNet),ViT因缺乏归纳偏置,性能低于CNN,需依赖大规模数据弥补。
- 计算效率:相比CNN,ViT在同等计算资源下训练速度更快,尤其在微调阶段表现出高效迁移能力。
5. 关键分析
- 注意力机制的可视化:深层Transformer块中的注意力头能够覆盖全局区域,而浅层头则更多关注局部,表明模型自适应学习空间关系。
- 位置编码的作用:一维编码虽简单,但通过插值适应不同分辨率,证明了其有效性。
- 归纳偏置对比:CNN通过卷积核强制引入局部性和平移等变性,而ViT仅通过分块和位置编码隐式学习,灵活性更高但数据需求更大。
6. 局限性及未来方向
- 计算成本:预训练需大量算力,模型参数量大(如ViT-Huge达6亿参数),限制了实际应用。
- 任务扩展性:需探索ViT在检测、分割等任务中的表现,后续工作如DETR、Swin Transformer已部分解决。
- 自监督预训练:论文指出自监督方法(如MAE)是未来方向,可减少对标注数据的依赖。
7. 影响与意义
ViT的提出标志着视觉与NLP任务在模型架构上的统一,启发了多模态模型(如CLIP、BEiT)的发展。其核心贡献在于:
- 架构创新:验证纯Transformer在视觉任务中的可行性。
- 扩展性证明:展示Transformer在大规模数据下的优越性能,推动“大数据+大模型”研究范式。
总结
ViT通过将图像视为块序列并应用标准Transformer,成功实现了图像分类任务的性能突破。其设计简洁且可扩展,为后续视觉Transformer研究奠定了基础,同时也揭示了数据规模与模型泛化能力之间的深刻联系。