TRACE: Learning 3D Gaussian Physical Dynamics from Multi-view Videos
核心问题是什么?
输入:动态多视角视频,及每个视角的相机参数,无需其它任何人工标注
输出:
- 建模三维场景的几何、外观
- 估计场景中对象的物理信息
- 基于物理信息预测续写视频
现有方法及局限性
现有工作通常通过将基于物理的损失作为软约束或将简单物理模型集成到神经网络中来实现,但往往难以学习复杂的运动物理规律,或者需要额外的标注(如物体类型或遮罩)。
本文方法及优势
我们提出了一个名为 TRACE 的新框架来建模复杂动态三维场景的运动物理规律:
- 将每个三维点建模为空间中具有大小和方向的刚性粒子
- 直接为每个粒子学习一个平动-旋转动力学系统,显式地估算出一整套物理参数来控制粒子随时间的运动。
在三个现有动态数据集和一个新创建的具有挑战性的合成数据集上进行的大量实验表明,我们的方法在未来帧外推任务中相对于基线模型具有卓越的性能。我们框架的一个优良特性是,只需对学习到的物理参数进行聚类,即可轻松分割多个物体或部件。我们的数据集和代码可在 https://github.com/vLAR-group/TRACE 获取。
主要方法
输入:具有已知相机位姿和内参的动态多视角RGB视频
三维场景表示模块旨在学习一组三维高斯核,用于在规范空间中表示三维场景的几何和外观
辅助变形场旨在根据当前训练时间t预测每个高斯核的位移和畸变
平动-旋转动力学系统旨在为每个三维刚性粒子学习一组物理参数,以控制其随时间变化的运动动力学
Canonical 3D Gaussians
准备
输入:t=0时刻的N个视角的图像、N个视角的相机参数
假设每个高斯核的不透明度 σ 和颜色 c 不会随时间更新
三维高斯核 G₀的表征:
- 三维位置 x₀
- 由四元数 r₀ 和缩放 s₀ 导出的协方差矩阵
- 不透明度 σ
- 由球谐函数计算的颜色 c 初始化:随机初始化或SfM初始化
优化过程
将高斯核投影到相机空间
将投影后的高斯核渲染到图像空间
通过 3DGS 中使用的 ℓ₁ 损失和 ℓₛₛᵢₘ 损失优化所有核参数

辅助变形场
它是一个基于 MLP 的网络。
输入是规范位置 x₀ 和时间 t。
输出是几何变化量 (δx, δr, δs),用于将规范高斯核 G₀ 扭曲到时间 t 的状态 Gₜ。
xₜ = x₀ + δx,
rₜ = r₀ ◦ δr,
sₜ = s₀ ⊙ δs,
σ, c(保持不变)
平动-旋转动力学系统
将复杂场景离散化为刚性粒子(即高斯核),并聚焦于学习每个粒子的独立动力学。
依据经典力学,将每个粒子的运动分解为绕一个运动的旋转中心进行的转动,同时该旋转中心自身也在平动。
模块输出: 为每个粒子学习两组物理参数 参数组 #1 - 旋转中心参数: 包括:
- 中心位置 P_c ∈ R³,
- 中心速度 v_c ∈ R³,
- 中心加速度 a_c ∈ R³(在世界坐标系下)。
旋转中心可以是任意位置,不一定是粒子所在的位置
参数组 #2 - 刚性粒子旋转参数: 包括:
- 刚性粒子相对于其旋转中心 P_c 的旋转矢量 w_p ∈ R³,
- 刚性粒子的角加速度 ϵ_p ∈ R³。
通过两组参数,得出粒子的合成速度为:
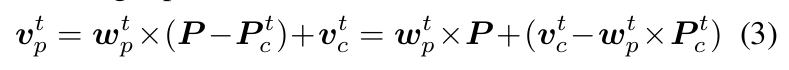
由于在网络推断的过程中 P_c 和 V_c 难以解耦,把 P_c 和 V_c 合并成 \(\bar v_c^t\)
因此MLP的实际输入输出为:

仅需在某个特定时间 t 学习一次这个完整的平动-旋转动力学系统,随后该粒子的未来运动将由学习到的动力学系统根据力学定律来支配。