
问题:发生了过拟合成不自知
解决方法:train test split

训练数据集:训练模型
测试数据集:调整超参数
问题:针对特定测试数据集过拟合?
解决方法:训练 - 验证 - 测试
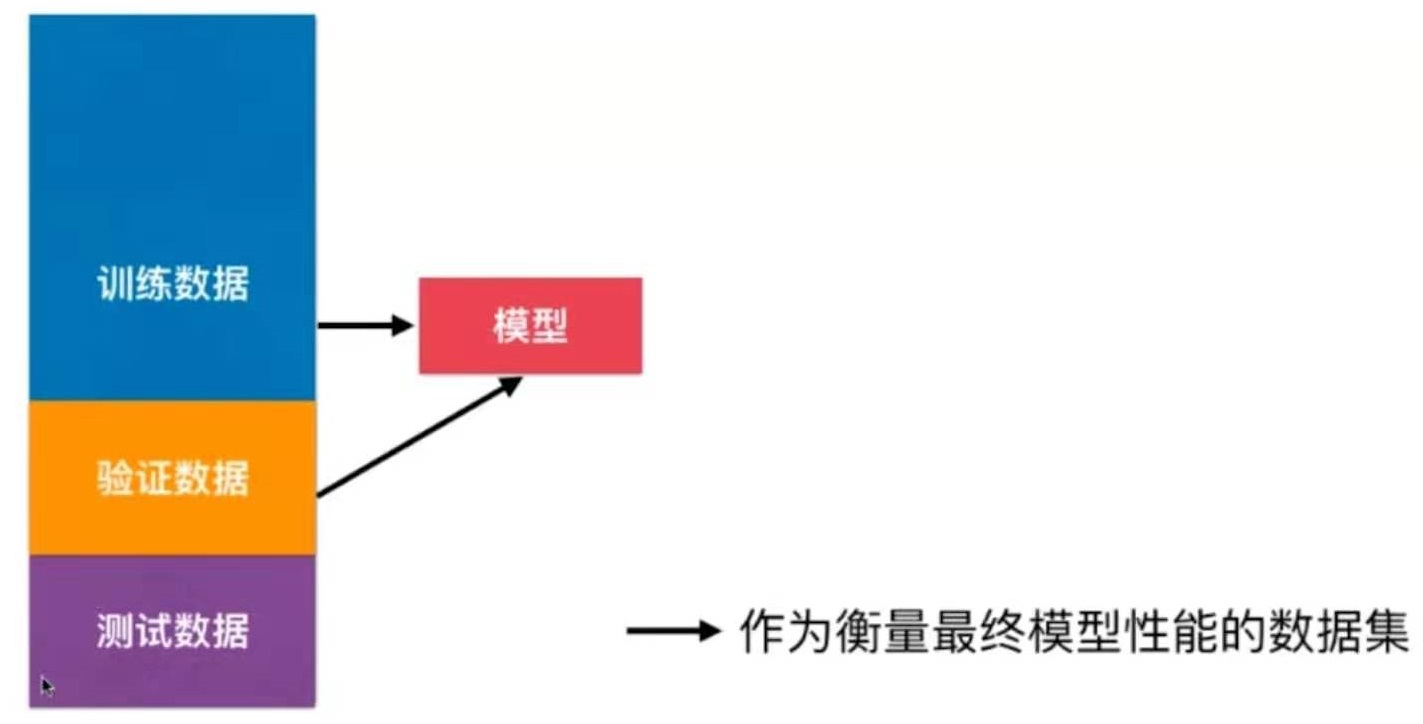
训练数据集:训练模型
验证数据集:调整超参数
测试数据集:不参数模型创建,作为衡量最终模型性能的数据集
问题:随机?一旦验证数据集有异常数据,就会导致模型不准确
解决方法:交叉验证
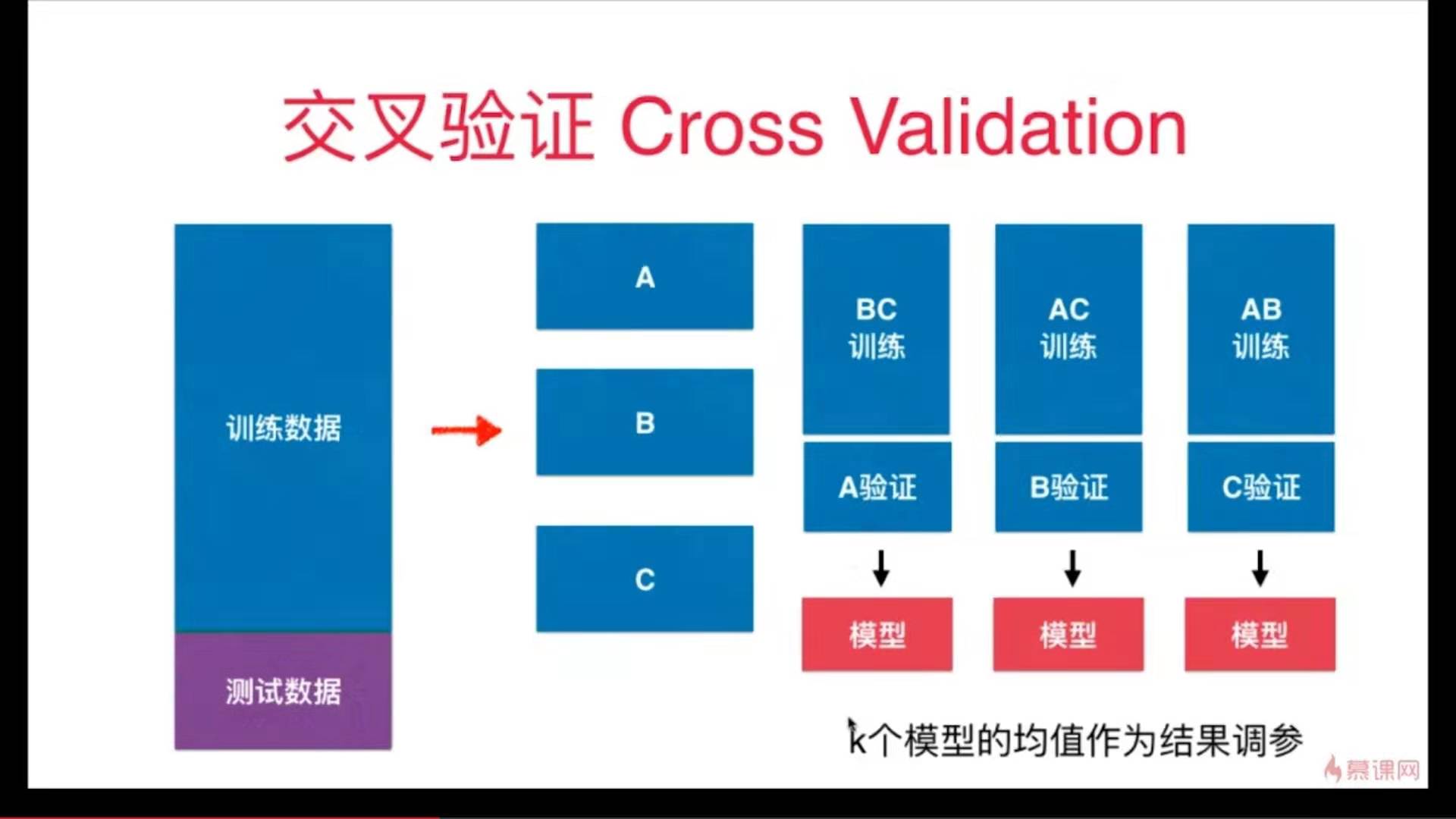
代码实现
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
测试train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
best_score, best_k, best_p = 0,0,0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_score, best_k, best_p = score, k, p
print("best k = ", best_k)
print("best p = ", best_p)
print("best score = ", best_score)
输出结果:
best k = 3
best p = 4
best score = 0.9860917941585535
使用交叉验证
from sklearn.model_selection import cross_val_score
knn_clf = KNeighborsClassifier()
cross_val_score(knn_clf, X_train, y_train)
输出结果:
array([0.98895028, 0.97777778, 0.96629213])
from sklearn.neighbors import KNeighborsClassifier
best_score, best_k, best_p = 0,0,0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p, cv=3)
scores = cross_val_score(knn_clf, X_train, y_train)
score = np.min(scores)
if score > best_score:
best_score, best_k, best_p = score, k, p
print("best k = ", best_k)
print("best p = ", best_p)
print("best score = ", best_score)
输出结果:
best k = 2
best p = 2
best score = 0.9823599874006478
train_test_split和交叉验证结果对比:
两种方法得到的best_k和best_p,通常认为使用交叉验证得到参数更可靠。
因为方法一得到的结果很有可能只是过拟合了那一组测试数据。
方法二的分数低于方法一,因为它没有过拟合某一组数据。
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=2, p=2)
best_knn_clf.fit(X_train, y_train)
best_knn_clf.score(X_test, y_test)
输出结果:0.980528511821975
Note:这个算法最终的分类准确度不是上面的0.9823,而是这里的0.9805
回顾网格搜索
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'weights':['distance'],
'n_neighbors': [i for i in range(2, 11)],
'p': [i for i in range(1, 6)]
}
]
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid, cv=3)
grid_search.fit(X_train, y_train)
输入:grid_search.best_score_
输出:0.9823747680890538
输入:grid_search.best_params_
输出:{'n_neighbors': 2, 'p': 2, 'weights': 'distance'}
输入:
best_knn_clf = grid_search.best_estimator_
best_knn_clf.score(X_test, y_test)
输出:0.980528511821975
使用网络搜索与使用交叉验证得到的结果相同。