1.
Introduction
2.
第四章:K近邻算法
2.1.
4-1 K近邻算法基础
2.2.
4-2 scikit-learn中的机器学习算法的封装
2.3.
4-3 训练数据集,测试数据集
2.4.
4-4 分类准确度
2.5.
4-5 超参数
2.6.
4-6 网格搜索
2.7.
4-7 数据归一化 Feature Scaling
2.8.
4-8 scikit-learn中的Scaler
2.9.
4-9 更多有关K近邻算法的思考
3.
第五章:线性回归法
3.1.
5-1 简单线性回归
3.2.
5-2 最小二乘法
3.3.
5-3 简单线性回归的实现
3.4.
5-4 参数计算向量化
3.5.
5-5 衡量线性回归算法的指标
3.6.
5-6 最好的衡量线性回归法的指标 R Squared
3.7.
5-7 简单线性回归和正规方程解
3.8.
5-8 实现多元线性回归
3.9.
5-9 scikit-learn中的回归算法
3.10.
5-10 线性回归的可解释性和更多思考
4.
第六章:梯度下降法
4.1.
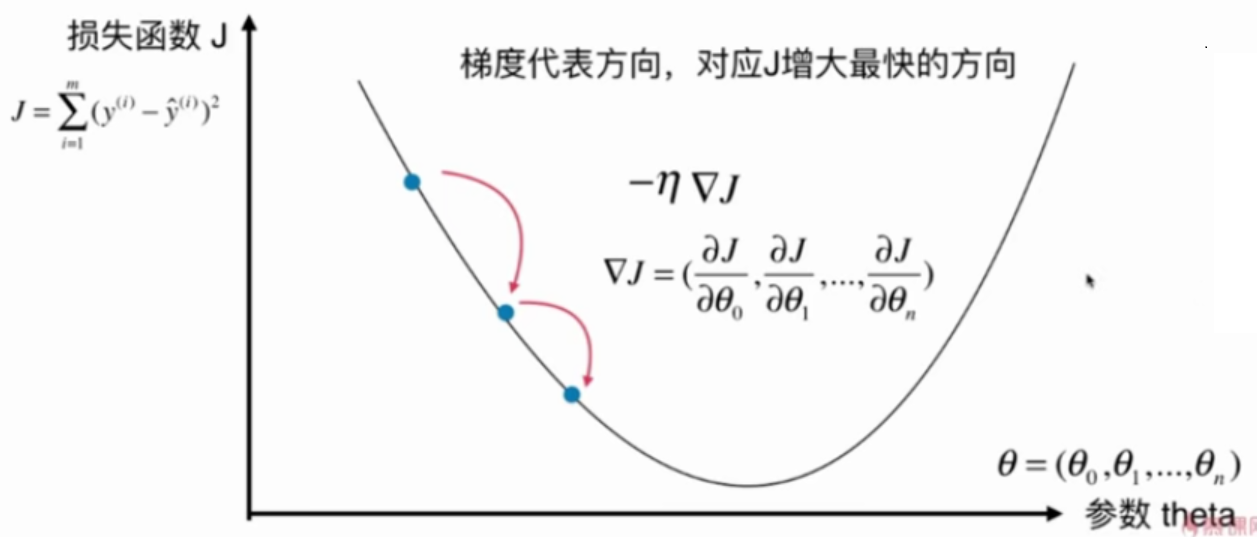
6-1 什么是梯度下降法
4.2.
6-2 模拟实现梯度下降法
4.3.
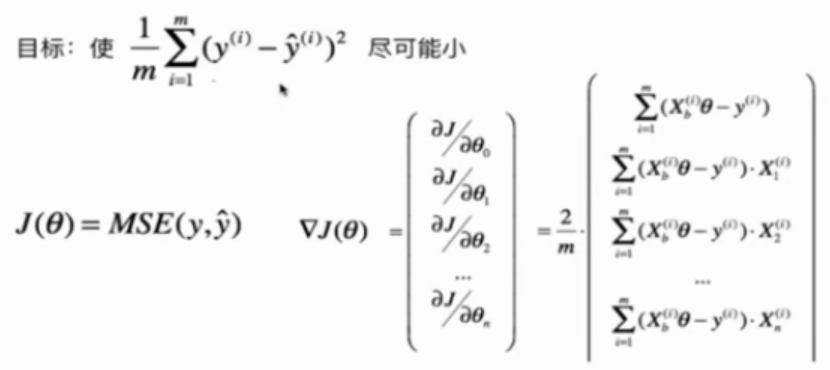
6-3 多元线性回归中的梯度下降法
4.4.
6-4 在线性回归模型中使用梯度下降法
4.5.
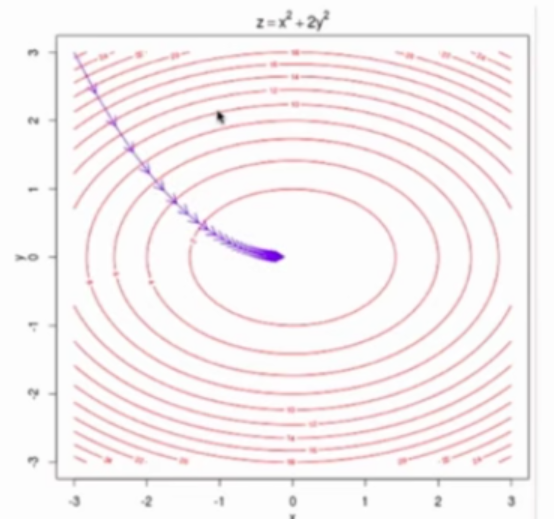
6-5 梯度下降的向量化
4.6.
6-6 随机梯度下降
4.7.
6-7 代码实现随机梯度下降
4.8.
6-8 调试梯度下降法
4.9.
6-9 有关梯度下降法的更多深入讨论
5.
第七章:PCA与梯度上升法
5.1.
7-1 什么是PCA
5.2.
7-2 使用梯度上升法求解主成分分析问题
5.3.
7-3 代码实现主成分分析问题
5.4.
7-4 求数据的前N个主成分
5.5.
7-5 高维数据向低维数据映射
5.6.
7-6 scikit learn中的PCA
5.7.
7-7 MNIST数据集
5.8.
7-8 使用PCA降噪
5.9.
7-9 人脸识别和特征脸(未完成)
6.
第八章:多项式回归与模型泛化
6.1.
8-1 什么是多项式回归
6.2.
8-2 scikit-learn中的多项式回归和pipeline
6.3.
8-3 过拟合和欠拟合
6.4.
8-4 为什么要训练数据集和测试数据集
6.5.
8-5 学习曲线
6.6.
8-6 验证数据集与交叉验证
6.7.
8-7 偏差方差权衡 Bias Variance Trade off
6.8.
8-8 模型正则化 Regularization
6.9.
8-9 LASSO Regularization
6.10.
8-10 L1,L2和弹性网络
7.
第九章:逻辑回归
7.1.
9-1 逻辑回归 Logistic Regression
7.2.
9-2 逻辑回归的损失函数
7.3.
9-3 逻辑回归算法损失函数的梯度
7.4.
9-4 实现逻辑回归算法
7.5.
9-5 决策边界
7.6.
9-6 在逻辑回归中使用多项式特征
7.7.
9-7 scikit-learn中的逻辑回归
7.8.
9-8 OvR与OvO
8.
第十章:评价分类结果
8.1.
10-1 准确度的陷阱和混淆矩阵
8.2.
10-2 精确率和召回率
8.3.
10-3 实现混淆矩阵、精准率、召回率
8.4.
10-4 F1 score
8.5.
10-5 Precision-Recall平衡
8.6.
10-6 precision-recall曲线
8.7.
10-7 ROC曲线
8.8.
10-8 多分类问题中的混淆矩阵
9.
第十一章:支撑向量机 SVM
9.1.
11-1 什么是支撑向量机
9.2.
11-2 支撑向量机的推导过程
9.3.
11-3 Soft Margin和SVM的正则化
9.4.
11-4 scikit-leran中的SVM
9.5.
11-5 SVM中使用多项式特征
9.6.
11-6 什么是核函数
9.7.
11-7 高斯核函数
9.8.
11-8 scikit-learn中的高斯核函数
9.9.
11-9 SVM思想解决回归问题
10.
第十二章:决策树
10.1.
12-1 什么是决策树
10.2.
12-2 信息熵
10.3.
12-3 使用信息寻找最优划分
10.4.
12-4 基尼系数
10.5.
12-5 CART和决策树中的超参数
10.6.
12-6 决策树解决回归问题
10.7.
12-7 决策树的局限性
11.
第十三章:集成学习和随机森林
11.1.
13-1 什么是集成学习
11.2.
13-2 soft voting
11.3.
13-3 bagging和pasting
11.4.
13-4 更多关于bagging的讨论
11.5.
13-5 随机森林和extra-trees
11.6.
13-6 ada boosting和gradiesnt boosting
11.7.
13-7 Stacking
Light (default)
Rust
Coal
Navy
Ayu
LYBStudy