判断机器学习算法的性能

改进:训练和测试数据集的分离,train test split
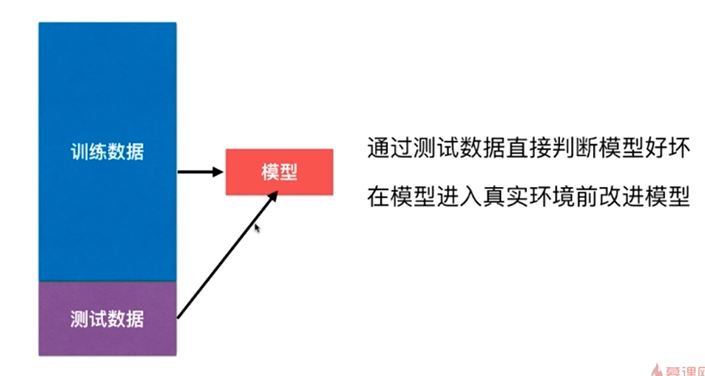
但这种方式也有它的问题,后面其它小节会讲到
准备iris数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X.shape为(150, 4),y.shape为(150,)
train_test_split
注意1:本例中训练数据集的为如下:

因此按顺序取前多少个样本不会有很好的效果,要先对数据乱序化
注意2:本例中X和y是分离的,但它们不能分别乱序化。乱序化的同时要保证样本和标签是对应的。
在Notebook实现
shuffle_indexes = np.random.permutation(len(X))
test_ratio = 0.2
test_size = int(len(x) * test_ratio)
test_indexes = shuffle_indexes[:test_size]
train_indexes = shuffle_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
将train_test_split封装成函数
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将X和y按照test_ratio分割成X_train,X_test,y_train,y_test"""
assert X.shape[0] == y.shape[0], "the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, "test_ration must be valid"
if seed:
np.random.seed(seed)
shuffle_indexes = np.random.permutation(len(X))
test_size = int(len(x) * test_ratio)
test_indexes = shuffle_indexes[:test_size]
train_indexes = shuffle_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
KNN结合train_test_split计算分类准确度
X_train, X_test, y_train, y_test = train_test_split(X, y)
my_Knn_clf = kNNClassifier(k = 3) # kNNClassifier在上一节实现
my_Knn_clf.fit(X_train, y_train)
y_predict = my_Knn_clf.predict(X_test)
accuracy = sum(y_predict == y_test) / len(y_test)
sklearn中的train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)