回归问题是指找到一根直线/曲线最大程度的拟合样本点。
不同的回归算法对“拟合”有不同的理解。
例如线性回归算法定义“拟合”为:所有样本点到直线的MSE最小
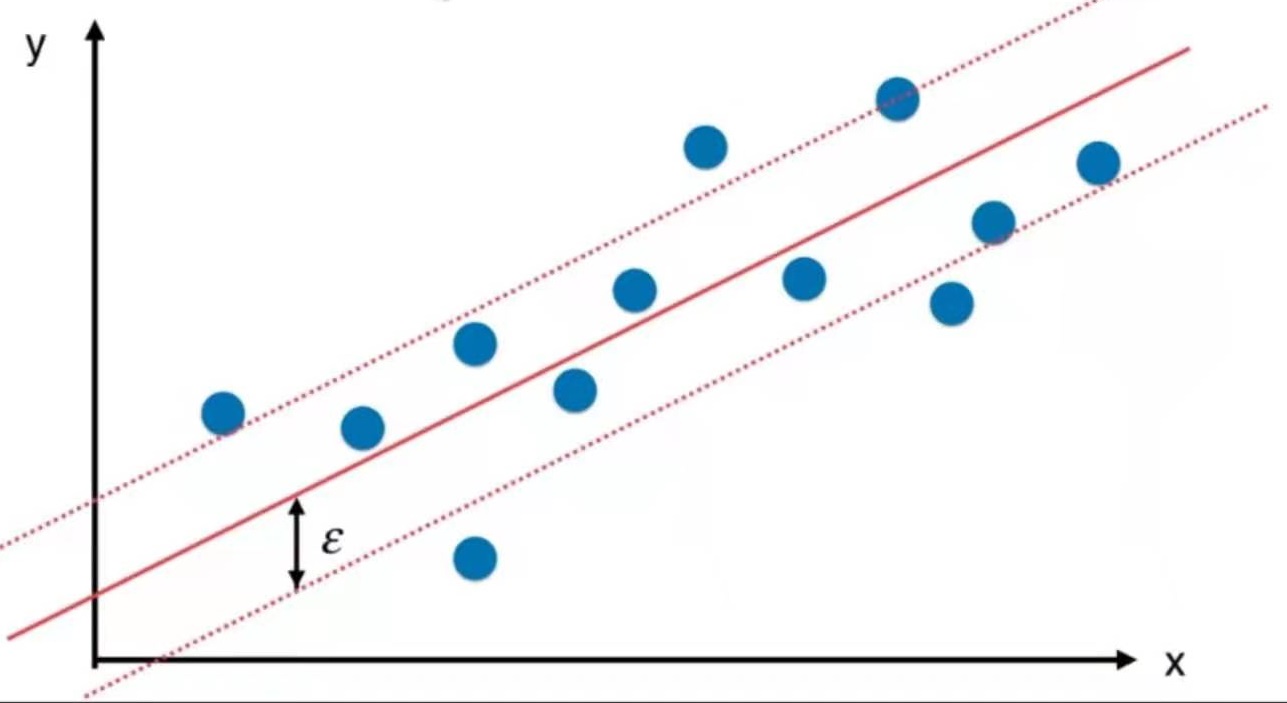
而SVM将“拟合”定义为:尽可能多的点被包含在margin范围内,取margin中间的直线。(与解决分类问题相反的思路)
margin的距离为超参数
代码实现
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
x = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()
dt_reg.fit(X_train, y_train)
dt_reg.score(X_test, y_test) # 0.6872676909790005
dt_reg.score(X_train, y_train) # 1.0
训练数据集上预测的准确率是100%,而在测试数据集上效果不好。 决策树非常容易产生过拟合现象,要消除过拟合就要使用12-5中介绍的参数。