定义:X是样本数据,每一行是一个数据,它有m个数据,每个数据有n个特征
$$
X =
\begin{bmatrix}
X_1^{(1)} && X_1^{(2)} && \cdots && X_1^{(n)} \
X_2^{(1)} && X_2^{(2)} && \cdots && X_2^{(n)} \
\cdots && \cdots && \cdots && \cdots \
X_m^{(1)} && X_m^{(2)} && \cdots && X_m^{(n)}
\end{bmatrix}
$$
$W_k$是求得的前k个主成分矩阵,每一行是一个主成分的单位方向,它有k个主成分方向,每个主成分的方向有n个维度
$$
X =
\begin{bmatrix}
W_k^{(1)} && W_1^{(2)} && \cdots && W_1^{(n)} \
W_2^{(1)} && W_2^{(2)} && \cdots && W_2^{(n)} \
\cdots && \cdots && \cdots && \cdots \
W_k^{(1)} && W_k^{(2)} && \cdots && W_k^{(n)}
\end{bmatrix}
$$
问:如何将样本X从N维转换成K维?
答:降维:把所有样本映射到K个主成分上
$$
X \cdot W_k^T = X_k
$$
还原:把降维后的数据还原到原坐标空间
$$
X_k \cdot W_k = X_m
$$
还原后的X与原X不同。
把PCA封装成类
import numpy as np
class PCA:
def __init__(self, n_components):
"""初始化PCA"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""获取数据集的前n个主成分"""
assert self.n_components <= X.shape[1], "n_components must not be greater than the feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
# 把向量单位化
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if(abs(f(w, X)) - abs(f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape = (self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X.shape[1])
eta = 0.001
w = first_component(X_pca, initial_w, eta)
self.components_[i, :] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""将给定的X,映射到各个主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""将给定的X反向映射回原来的特征空间"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
使用PCA降维
准备数据
import numpy as np
import matplotlib.pyplot as plt
X = np.empty((100,2))
X[:,0] = np.random.uniform(0., 100., size=100)
X[:,1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10., size=100)
训练模型1
pca = PCA(n_components=2)
pca.fit(X)
输入:pca.components_
输出:array([[ 0.75366776, 0.65725559], [-0.65723751, 0.75368352]])
训练模型2:降维
pca = PCA(n_components=1)
pca.fit(X)
X_reduction = pca.transform(X)
X_restore = pca.inverse_transform(X_reduction)
输入:X_reduction.shape
输出:(100, 1)
输入:X_restore.shape
输出:(100, 2)
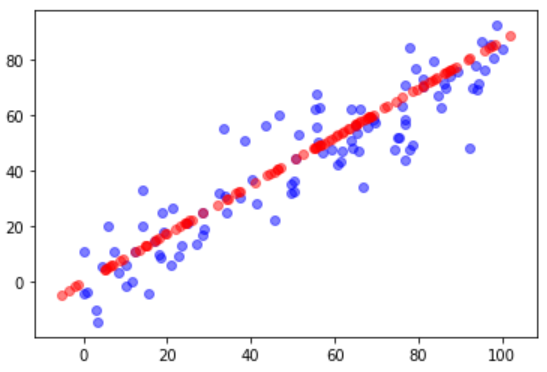
对比原始数据与降维再恢复后的数据
plt.scatter(X[:, 0], X[:, 1], color='b', alpha=0.5)
plt.scatter(X_restore[:, 0], X_restore[:, 1], color='r', alpha=0.5)
plt.show()