前面小节就针对二分类问题的,这一节把这些指标扩展到多分类问题。
加载手写数据集
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8,random_state=666)
使用逻辑回归训练模型
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
输出:0.93115438108484
计算精准率
y_predict = log_reg.predict(X_test)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict)
会报错,因为默认只能为二分类问题计算精准率
解决方法:

from sklearn.metrics import precision_score
precision_score(y_test, y_predict, average='micro')
输出:0.93115438108484
计算混淆矩阵并可视化
计算混淆矩阵
混淆矩阵天然支持多分类问题。
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_predict)
输出:

第i行第j列代表真值为i而预测值为j的样本数量。
对角线位置是预测正确的位置。
把矩阵可视化,可以直观地看到犯错误比较多的地方。
可视化
import matplotlib.pyplot as plt
cfm = confusion_matrix(y_test, y_predict)
plt.matshow(cfm, cmap=plt.cm.gray) # 映射成灰度值
plt.show()

越亮的地方代表数值越大。
图中对角线部分太亮,无法观察到我们关心的部分,改进如下:
row_sums = np.sum(cfm, axis=1)
err_matrix = cfm / row_sums
np.fill_diagonal(err_matrix, 0)
err_matrix

plt.matshow(err_matrix, cmap=plt.cm.gray)
plt.show()
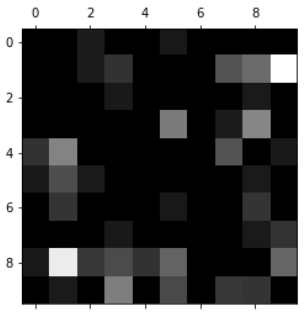 图中越亮的地方表示犯错越多的地方。
图中越亮的地方表示犯错越多的地方。
针对错误比较多的地方做算法的微调。