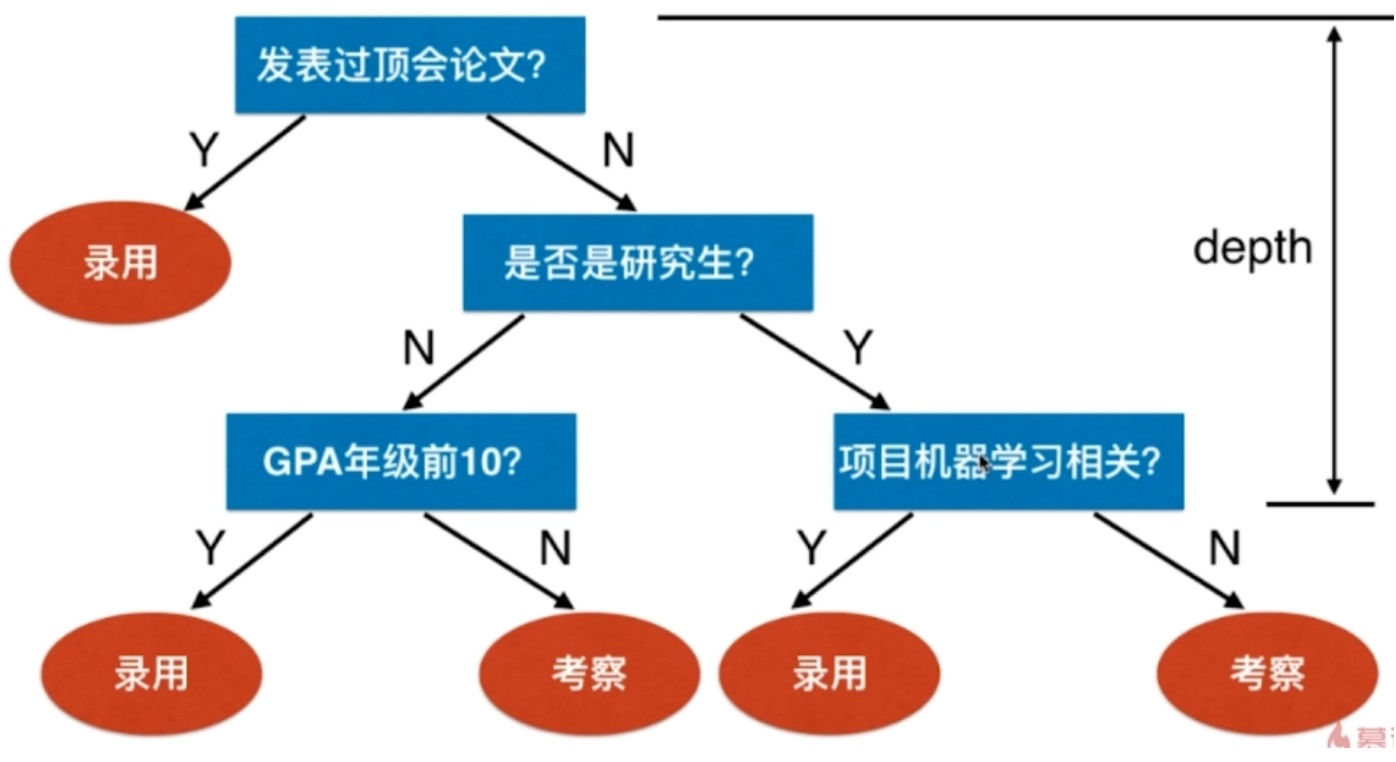
 假设上图是某公司招聘算法工程师的过程。
假设上图是某公司招聘算法工程师的过程。
图中的叶子节点代码决策,在寻找决策过程是形成了树是决策树。
这棵树的深度为3,因为最多经过3次判断就能做出决策。
使用sklearn中的决策树
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
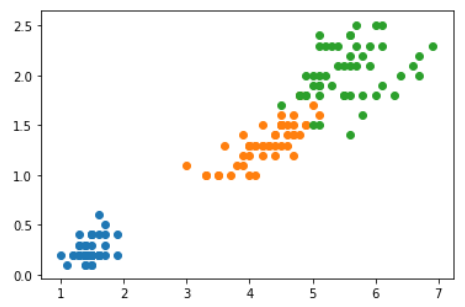
X = iris.data[:, 2:]
y = iris.target
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==2,0],X[y==2,1])
plt.show()
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') # entropy = 熵
dt_clf.fit(X, y)
plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==2,0],X[y==2,1])
plt.show()
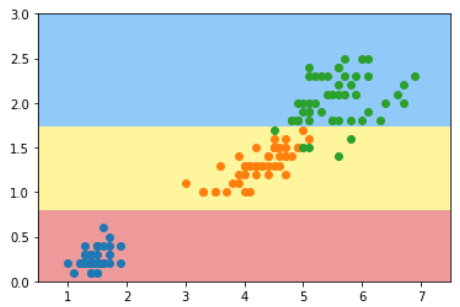
这个分类结果与视频中的分类结果不同
总结
决策树怎样做决策的
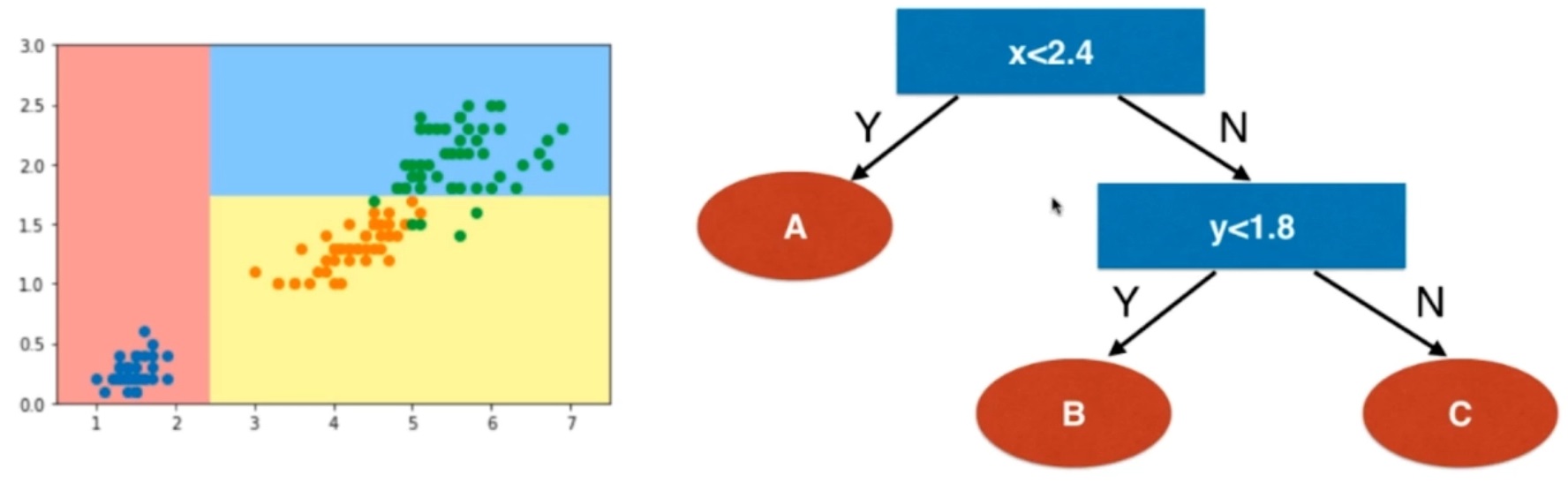 当属性是数值特征时,在每一个节点上,选择某一个维度上的数值,以它为域值将样本分成两类。
当属性是数值特征时,在每一个节点上,选择某一个维度上的数值,以它为域值将样本分成两类。
决策树的特点
- 是非参数学习算法
- 可以分类问题
- 天然可以解决多分类问题
- 也可以解决回归问题(用分类算法将样本归到某个叶子上,该叶子上所有样本的平均值即输出标记)
- 有非常好的可解释性
怎样创建决策树
- 每个结点在哪个维度做划分?
- 某个维度的哪个值上做划分?