P126
2.6 Long video generation
长视频生成主要有这样一些难点:
- 长视频生成的复杂性
- 训练与推理差距:模型在训练时仅接触短视频,无法学习长视频的全局时序模式,导致生成内容逻辑断裂。
- 顺序生成的低效性:自回归生成需逐帧顺序处理,生成时间随视频长度线性增长,无法满足实际应用需求。
- 保持内容的一致性:长篇视频包含复杂的人物、物体及其动态交互关系。
- 数据稀缺性
高质量的长视频标注数据(如逐帧注释)获取成本极高,现有数据集(如短视频库)难以支持长视频先验的学习。
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2025.6.2 | DiffuseSlide: Training-Free High Frame Rate Video Generation Diffusion | 基于预训练扩散模型的高帧率视频生成新方法 | link | ||
| 2025.6.1 | FlowMo: Variance-Based Flow Guidance for Coherent Motion in Video Generation | 无训练引导方法增加视频生成的连续性 | link | ||
| 80 | 2025 | One-Minute Video Generation with Test-Time Training | 1. 引入TTT层,通过TTT层动态调整模型隐藏状态,增强对长序列的全局理解能力。 2. 通过门控机制防止TTT层训练初期引入噪声。 3. 多阶段训练策略:从3秒片段逐步扩展至63秒,仅微调TTT层和门控参数,保留预训练模型的知识。 | Test Time Training, RNN, | link |
| 41 | 2024 | STORYDIFFUSION: CONSISTENT SELF-ATTENTION FOR LONG-RANGE IMAGE AND VIDEO GENERATION | 先生成一致的关键帧,再插帧成中间图像 | link | |
| 60 | 2023 | NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation | diffusion over diffusion的递归架构实现长视频生成和并行生成 | coarse-to-fine, 数据集 | link |
| 2025 | Ouroboros-Diffusion: Exploring Consistent Content Generation in Tuning-free Long Video Diffusion | ||||
| 2022 | Latent Video Diffusion Models for High-Fidelity Long Video Generation (He et al.) Generate long videos via autoregressive generation & interpolation | 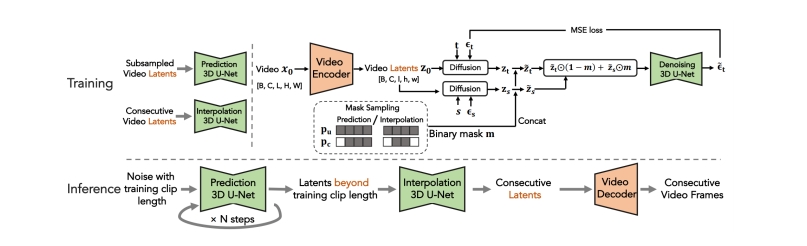 | |||
| 2023 | VidRD (Gu et al.) Autoregressive long video generation “Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation,” arXiv 2023. | 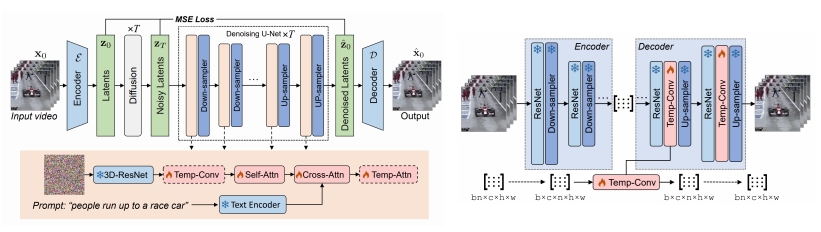 | |||
| 2023 | VideoGen (Li et al.) Cascaded pipeline for long video generation “VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation,” arXiv 2023. |  |
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/