P31
P34
Problem Definition
Text-Guided Video Generation
输入:Text prompt(或其它控制信号)
输出:video
T2I -> T2V
✅ 由于已有一个开源的大数据文生图预训练模型Stale Diffusion Model。为了充分利用这个预训练模型,通常的做法是把这个文生图模型改造成文生视频模型。即,从 2D 输出变成 3D 输出。
动作信息来源:文本
外观信息来源:文本
T2I/T2V -> TI2V
直接从文本生成视频,很难对视频内容进行更细节的控制,因此演生出了Image-2-Video任务。I2V通常是通过在预训练T2I的基础上,引入reference image的注入和时序层来实现。也可以通过直接在预训练的T2V上增加reference image的注入来实现。
任务1:驱动图像
外观信息来源:图像
动作信息来源:无控制地续写、或文本
任务2:以视频为控制条件的视频生成
外观信息来源:文本
动作信息来源:视频
T2I/T2V/TI2V + 其它控制信号
选一个合适的(开源)预训练模型,在此基础上
- 注入自己的控制信号,例如图像、控制点、光流、拖拽等
- 构造特定的(相对于训练基模型来说)少量的训练数据
- 根据任务特性引入一些技巧
- 经过(相对于训练基模型来说)少量的训练 就得到了针对特定任务的垂域的视频生成模型。
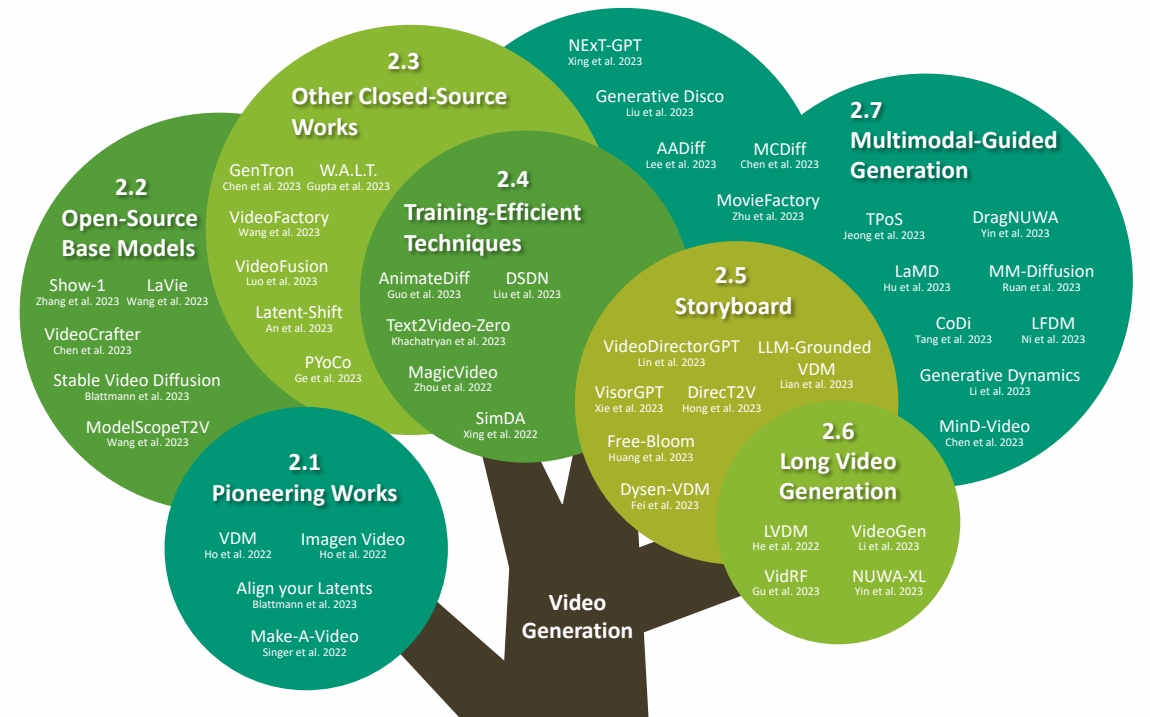
对于大多数社区玩家来说,只能获取到开源的预训练模型,因此要先了解可用的开源模型。
外观信息来源:图像
动作信息来源:文本、骨骼动作序列、物理规律、用户交互轨迹等
T2V -> Improved T2V
在预训练的T2V的基础上,通过一些微调手段,让它在某些方向更优,成为更强大的基模型
动作信息来源:文本
外观信息来源:文本
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/