P108
2.5 Storyboard
P113
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 84 | 2024 | Learning Long-form Video Prior via Generative Pre-Training | 利用GPT生成长视频内容的结构化信息,用于帮助下游的视频生成/理解任务。 | 结构化信息,数据集 | dataset link |
| 61 | 2023 | Xie et al., “VisorGPT: Learning Visual Prior via Generative Pre-Training,” | A “diffusion over diffusion” architecture for very long video generation | link | |
| 2023 | Lin et al., “VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning,” | Use storyboard as condition to generate video ✅ Control Net,把文本转为 Pixel 图片。 | 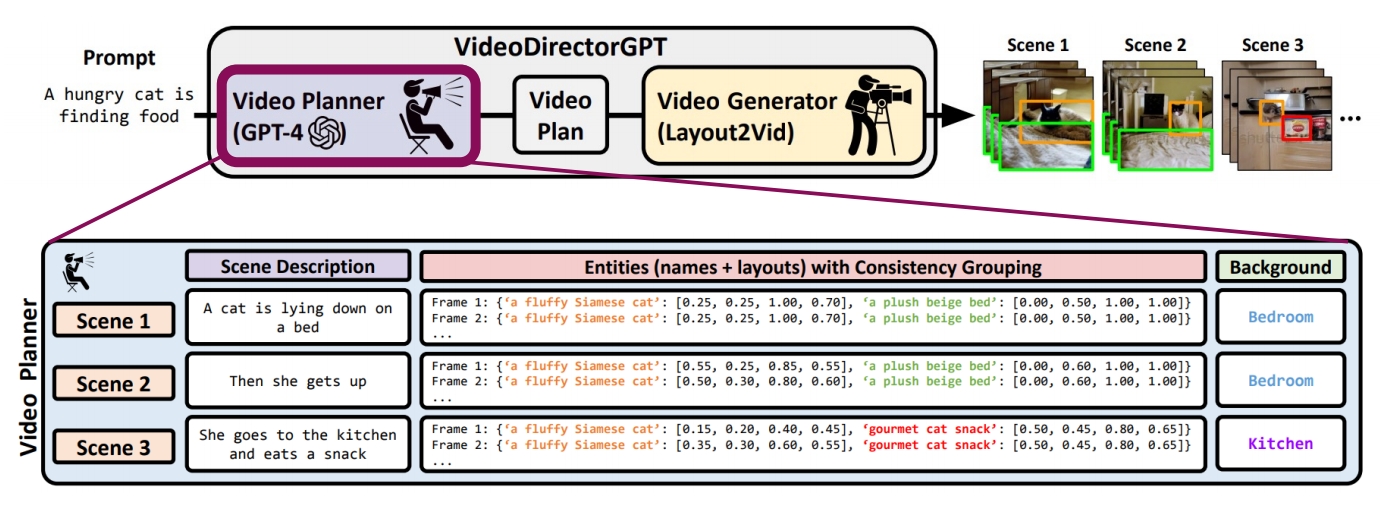 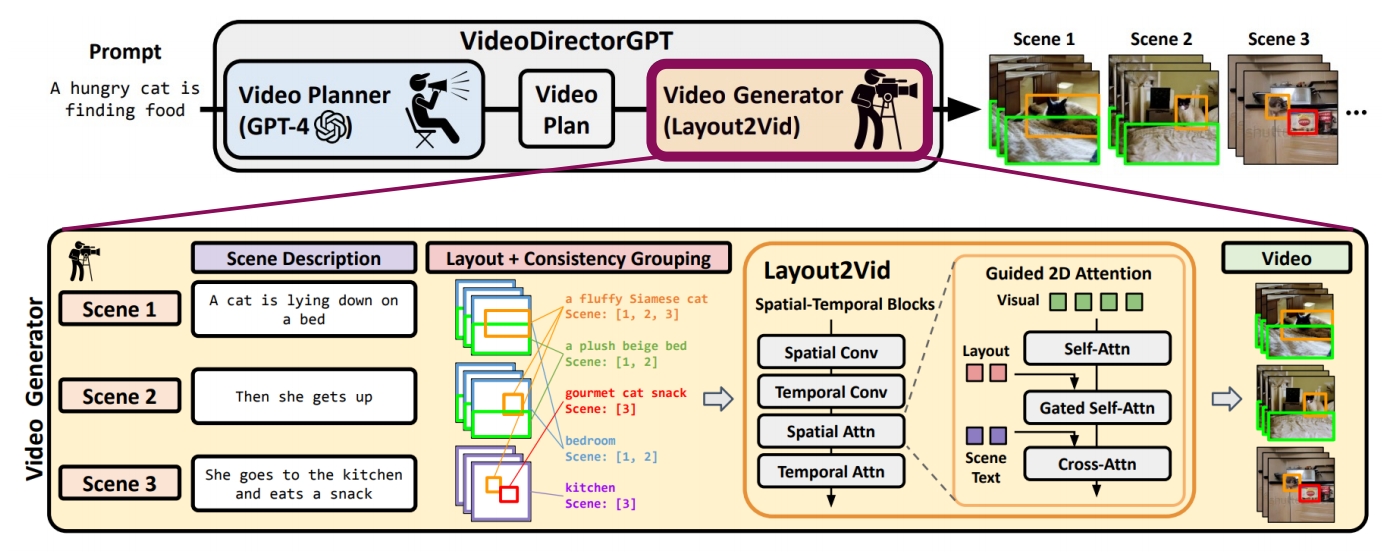 |
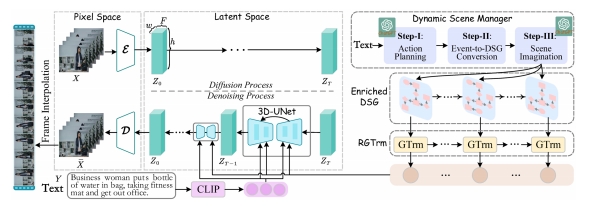 | Dysen-VDM (Fei et al.) Storyboard through scene graphs “Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models,” arXiv 2023. |
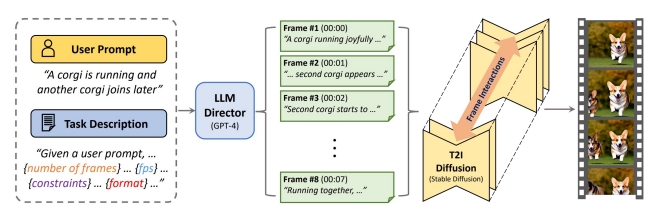 | DirectT2V (Hong et al.) Storyboard through bounding boxes “Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation,” arXiv 2023. |
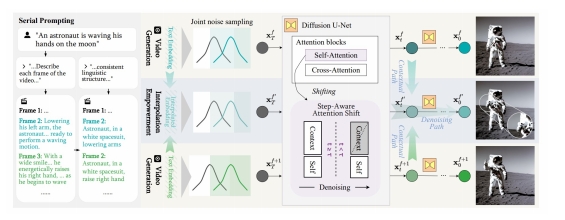 | Free-Bloom (Huang et al.) Storyboard through detailed text prompts “Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator,” NeurIPS 2023. |
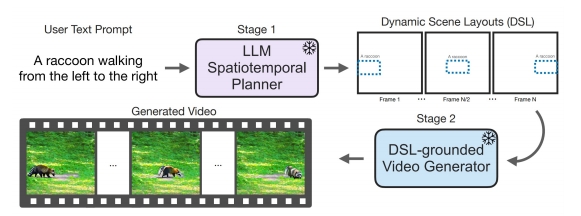 | LLM-Grounded Video Diffusion Models (Lian et al.) Storyboard through foreground bounding boxes “LLM-grounded Video Diffusion Models,” arXiv 2023. |
P104
✅ 生成电影级别的视频,而不是几秒钟的视频。
P106
✅ 文本 → 结构化的中间脚本 → 视频
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/