P139
✅ 用文生图模型生成 appearance, dynamics 来自于 reference video.
P141
✅ 当前帧只与上帧和前一帧做 attention,大大减少计算量。
✅ 在所有帧上做 attention 开销比较大。
✅ 解决方法:前一帧与第一帧。
❓ 怎么保证生成动作与原视频动作的一致性呢?
P142
✅ 对要编辑的视频,先 DDIM Inversion,得到 inverfed noise,这是保留了原视频 pattern 的 noise.
✅ 用这个 noise 作为 init noise,还原出的视频跟原视频有比较好的结构化保留。
✅ 解法方法
P144
多生成任务
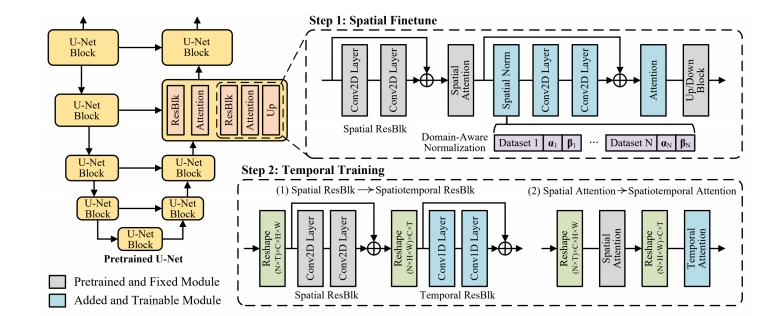 | MovieFactory (Zhu et al.) “MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images,” arXiv 2023. |
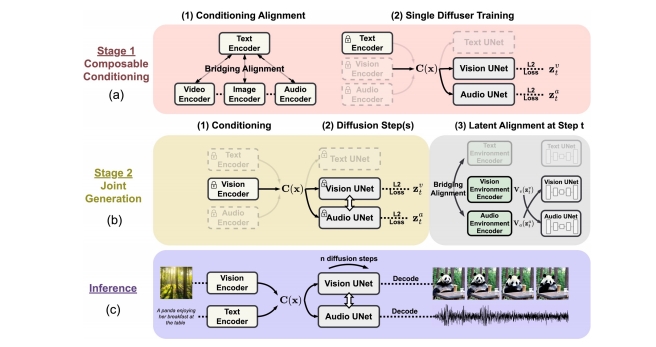 | CoDi (Tang et al.) “Any-to-Any Generation via Composable Diffusion,” NeurIPS 2023. |
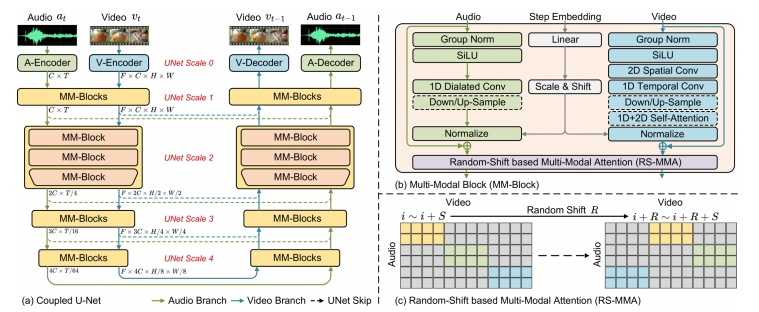 | MM-Diffusion (Ruan et al.) “MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation,” CVPR 2023. |
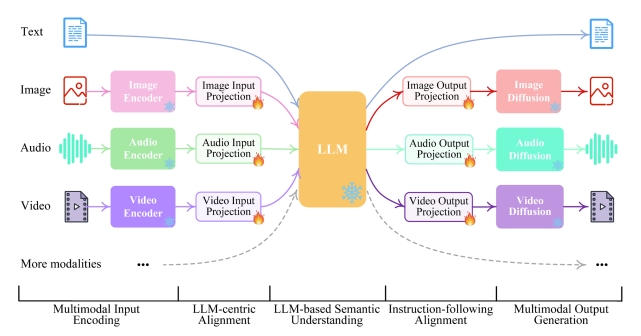 | NExT-GPT (Wu et al.) “NExT-GPT: Any-to-Any Multimodal LLM,” arXiv 2023. |
✅ 在物体改变比较大的情况下,diffusion 比其它生成方法效果更好。
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/