3.4 3D-Aware
P243
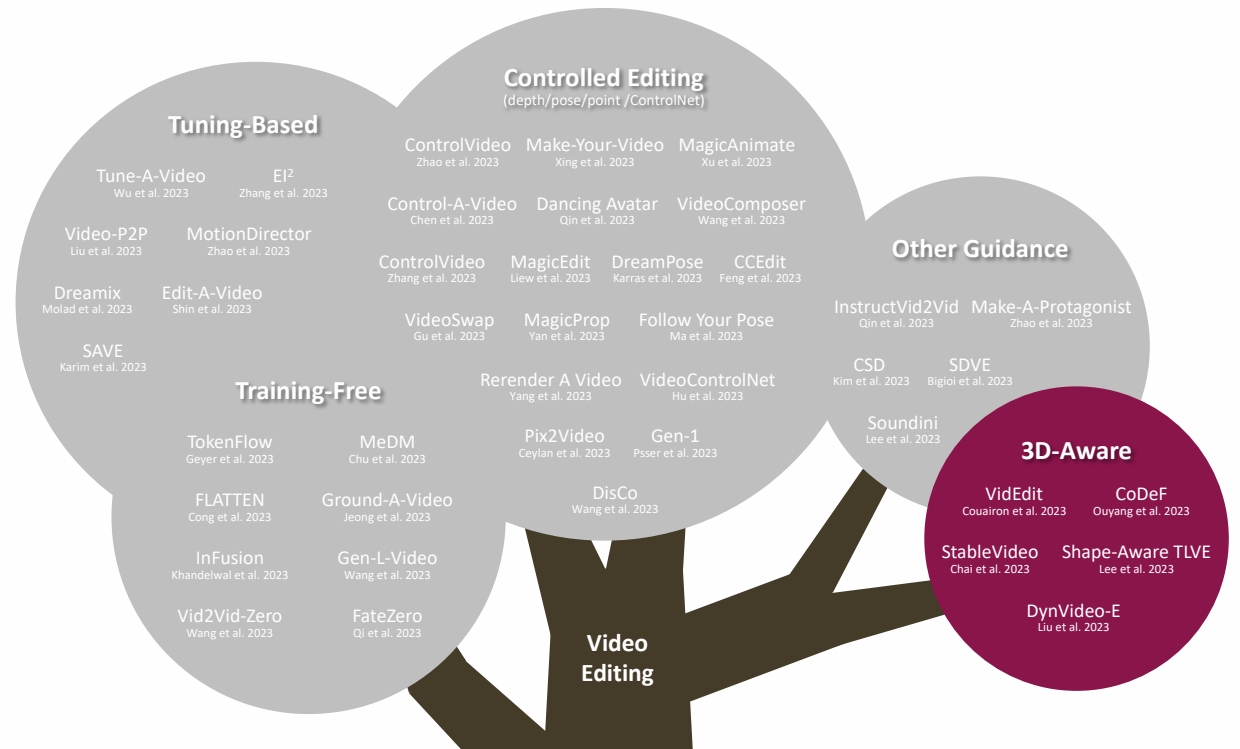
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2023 | Layered Neural Atlases for Consistent Video Editing | - Decompose a video into a foreground image + a background image - Edit the foreground/background image = edit the video ✅ 对背景进行编辑(图片编辑、风格迁移)再传播到不同帧上去。 | 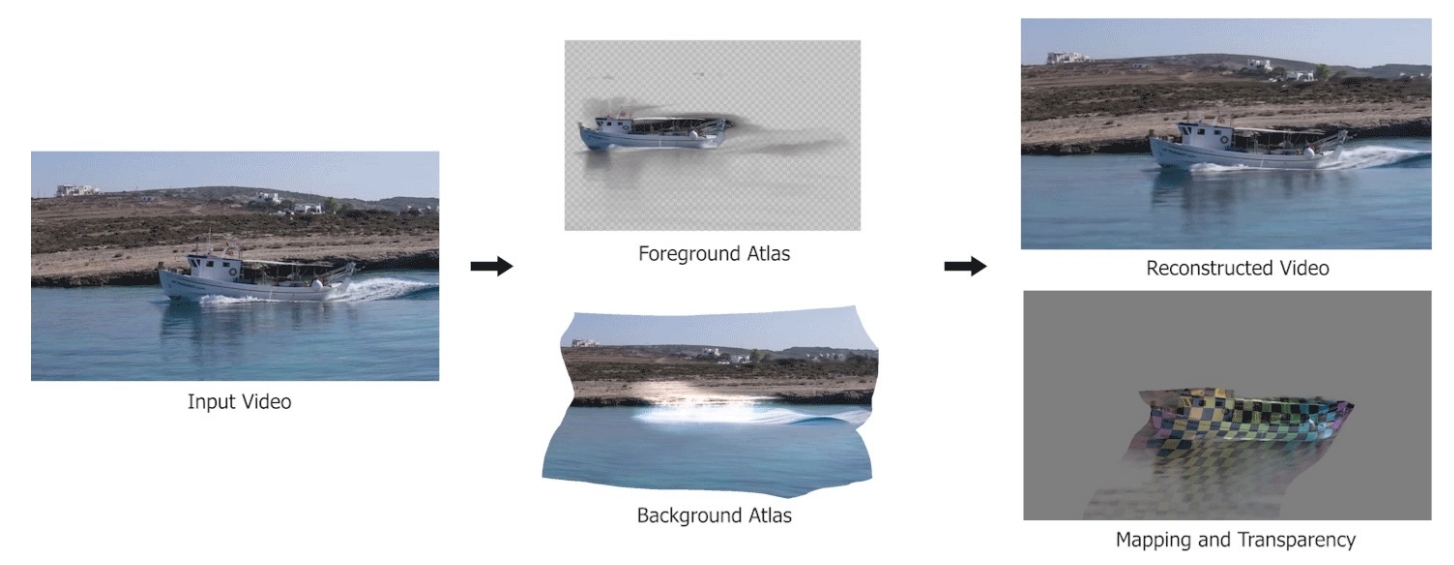  | ||
| 2023 | VidEdit: Zero-Shot and Spagally Aware Text-Driven Video Edigng | Atlas-based video editing - Decompose a video into a foreground image + a background image - Edit the foreground/background image = edit the video - Use diffusion to edit foreground/background atlas > ✅ 前景编辑: (1) 抠出第一帧前景并进行编辑得到 Partial Atlas. ✅ (2) Partial Atlas 作为下一帧的 condition 整体上是自回归的。 ✅ 所有 Partial 合起来得到一个整体。 ✅ 背景使用深度信息作为 cordition. |  | ||
| 2023 | Shape-aware Text-driven Layered Video Editing | Atlas-based video editing | 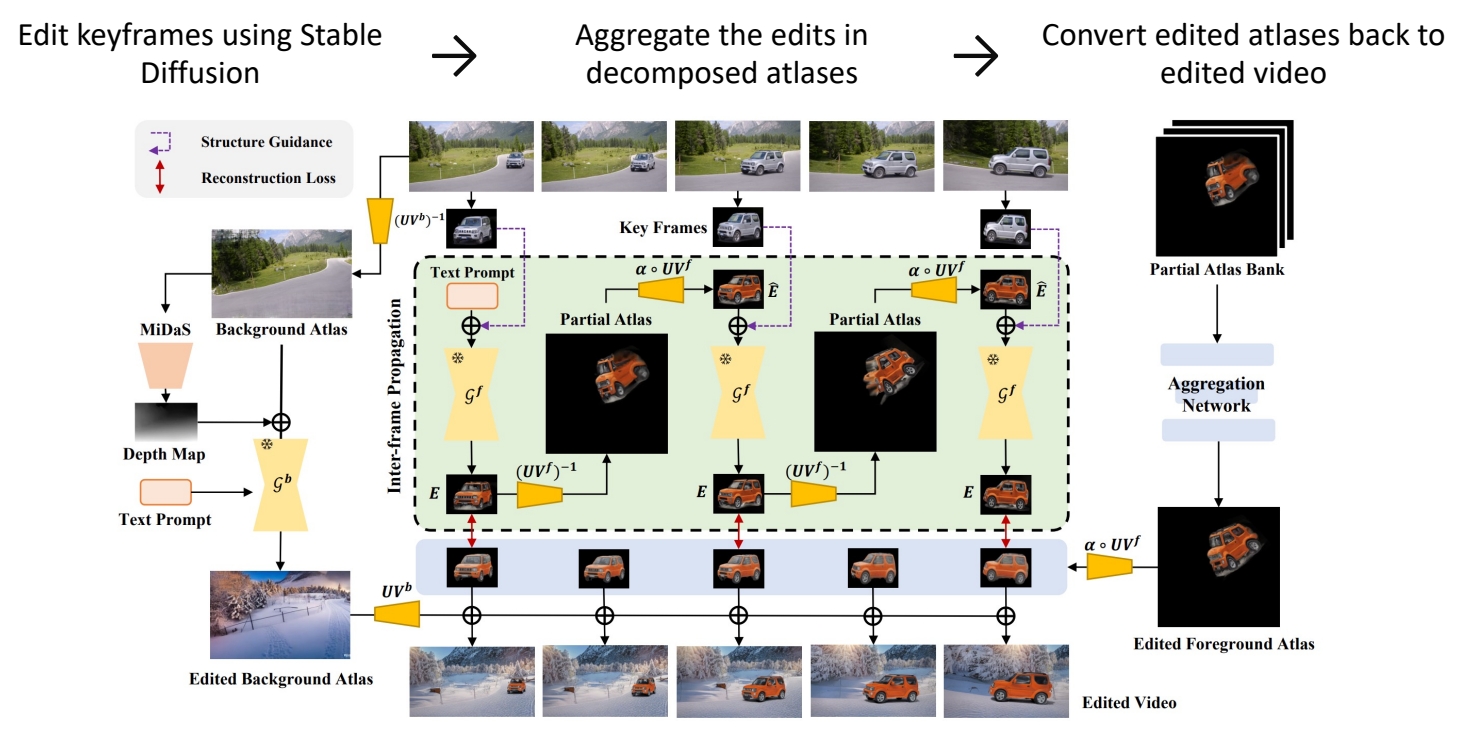 | ||
| 2023.11 | Stablevideo: Text-driven consistency-aware diffusion video editing | ✅ 给一个场景的多视角图片,基于 MLP 学习 3D 场景的隐式表达。 |  | ||
| 115 | 2023 | CoDeF: Content Deformation Fields for Temporally Consistent Video Processing | link | ||
| 2023 | HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video | ||||
| 116 | 2023 | DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing | link |
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/