P67
T2I -> T2V
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2025 | Wan. Wan-AI/Wan2.1-T2V-14B | https://huggingface.co/Wan-AI/Wan2.1-T2V-14B | |||
| 2025 | CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer | ||||
| 2024 | Hunyuanvideo: A systematic framework for large video generative models | ||||
| 81 | 2024 | CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers | 1. 使用预训练T2I模型CogView2 2. 先生成1 fps关键帧再递归向中间插帧 3. 引入temporal channel,并以混合因子\(\alpha\)与spatial channel混合 | CogView2(60亿参数), Transformer Based | link |
| 107 | 2023 | Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators | link | ||
| 58 | 2023 | ModelScope Text-to-Video Technical Report | link | ||
| 2023 | ZeroScope | ✅ ZeroScope 在 ModelScope 上 finetune,使用了非常小但质量非常高的数据,得到了高分辨率的生成效果。 | |||
| 50 | 2023 | Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets | Scaling latent video diffusion models to large datasets Data Processing and Annotation | link | |
| 2023 | Wang et al., “LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models,” | Joint image-video finetuning with curriculum learning ✅ 提供了一套高质量数据集,生成的视频质量也更好(训练集很重要)。 | 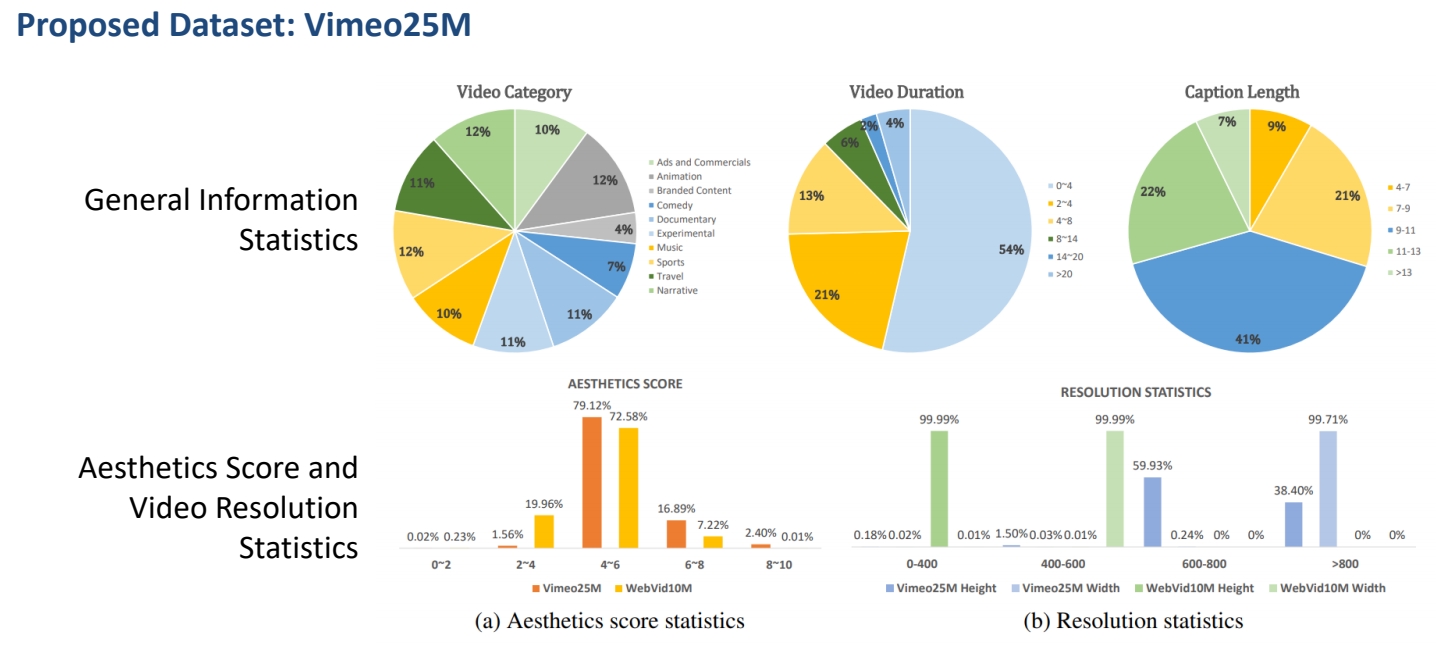 | ||
| 2023 | Chen et al., “VideoCrafter1: Open Diffusion Models for High-Quality Video Generation,” | LDM | 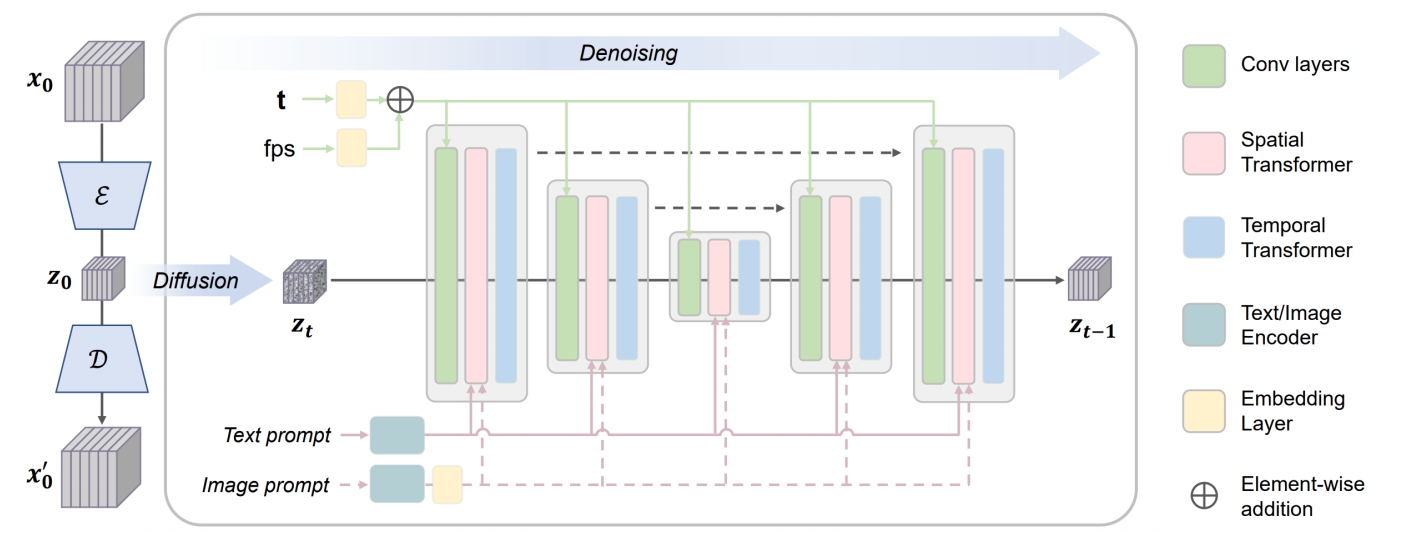 |
T2V -> Improved Text-2-Video
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 105 | 2025.5.27 | Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation | 1. 使用LLM分析视频生成的预期效果,用于引导生成 2. LLM对生成结果的评价也作为模型训练的Loss项 3. 基于Wan大模型的LoRA微调 | 数据集, LLM, LoRA, 数据集,物理 | link |
P74
其它相关工作
| " Robot dancing in times square,” arXiv 2023. | " Clown fish swimming through the coral reef,” arXiv 2023. | " Melting ice cream dripping down the cone,” arXiv 2023. | " Hyper-realistic photo of an abandoned industrial site during a storm,” arXiv 2023. |
 |  |  |  |
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/