3.3 Controlled Edifng (depth/pose/point/ControlNet)
✅ 已有一段视频,通过 guidance 或文本描述,修改视频。
P189
P190
Depth Control
Depth estimating network
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2022 | Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer | ✅ 深变信息 Encode 成 latent code, 与 noise concat 到一起。 | |||
| 122 | 2023 | Structure and Content-Guided Video Synthesis with Diffusion Models | Transfer the style of a video using text prompts given a “driving video”,以多种形式在预训练图像扩散模型中融入时序混合层进行扩展 |  | Gen-1, Framewise, depth-guided |
| 123 | 2023 | Pix2Video: Video Editing using Image Diffusion | Framewise depth-guided video editing |
P199
ControlNet / Multiple Control
也是control net 形式,但用到更多控制条件。
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 124 | 2023 | ControlVideo: Training-free Controllable Text-to-Video Generation | |||
| 2023 | VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet | Optical flow-guided video editing; I, P, B frames in video compression ✅ 内容一致性,适用于 style transfer, 但需要对物体有较大编辑力度时不适用(例如编辑物体形状)。 | 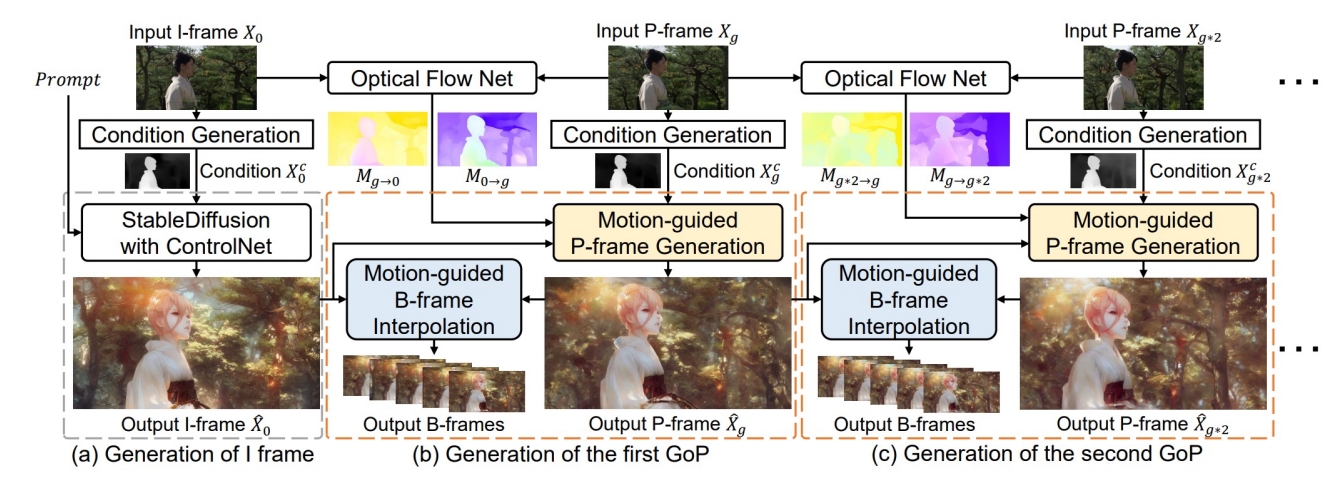 | ||
| 2023 | CCEdit: Creative and Controllable Video Editing via Diffusion Models | 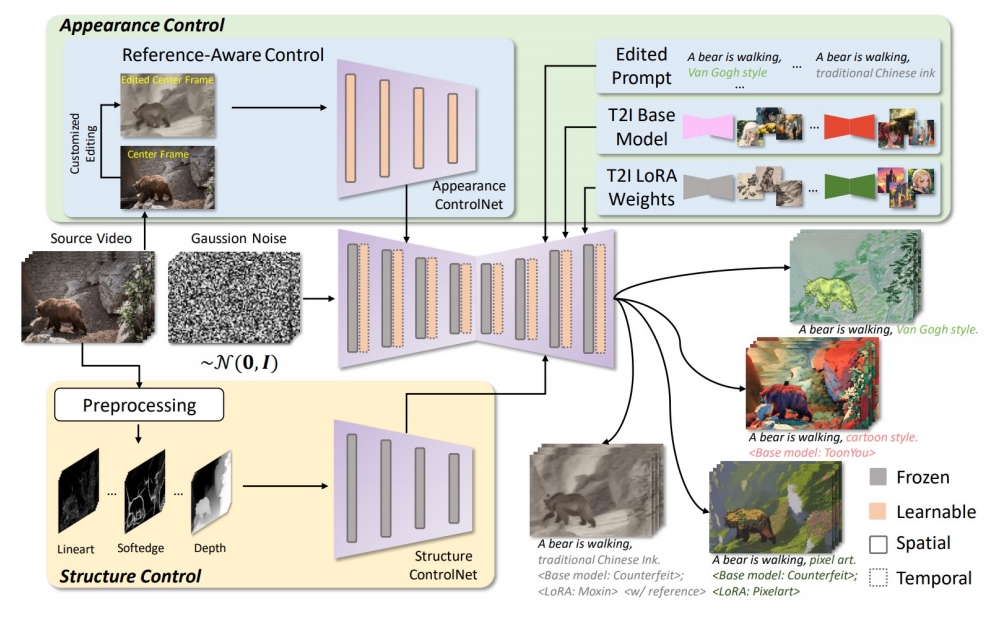 | |||
| 2023 | VideoComposer: Compositional Video Synthesis with Motion Controllability | Image-, sketch-, motion-, depth-, mask-controlled video editing ✅ 每个 condition 进来,都过一个 STC-Encoder, 然后把不同 condition fuse 到一起,输入到 U-Net. Spako-Temporal Condikon encoder (STC-encoder): a unified input interface for condikons | 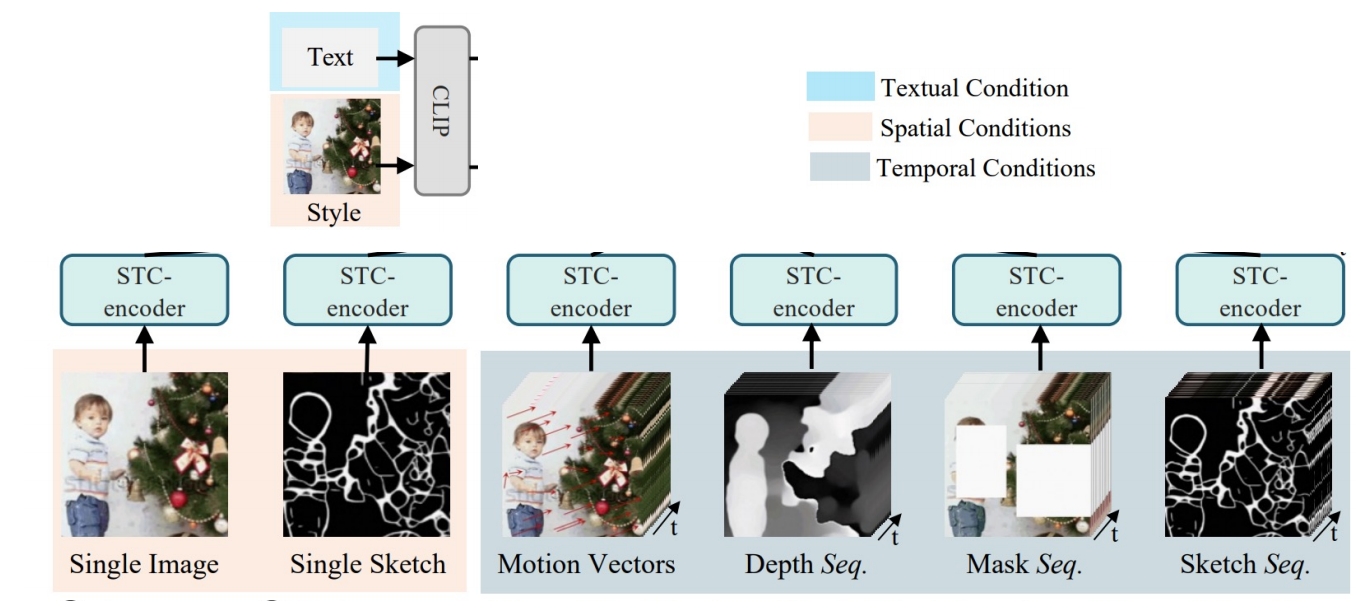 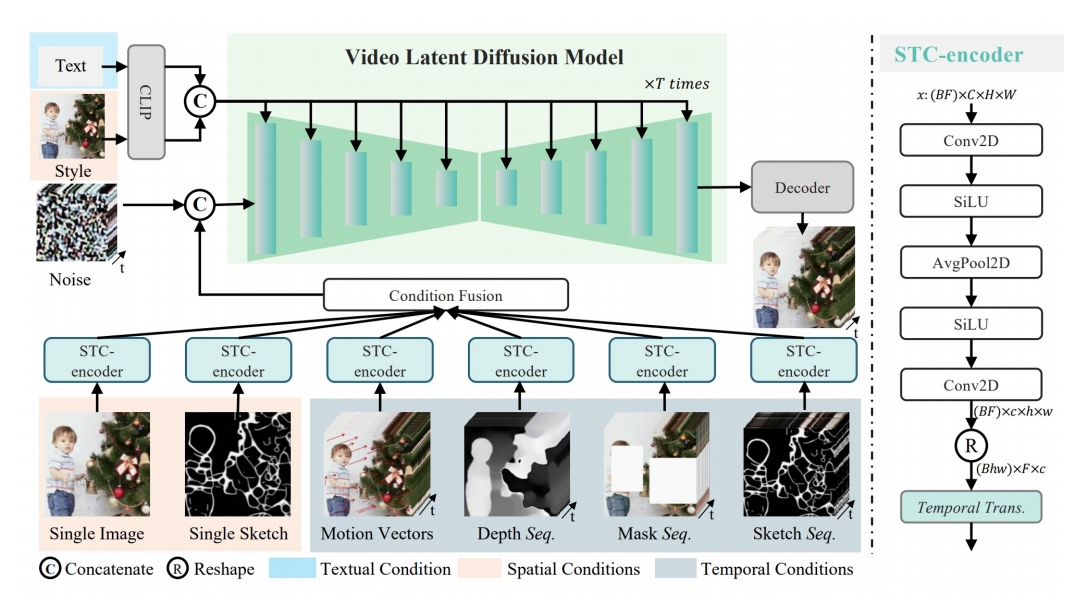 | ||
| 2023 | Control-A-Video: Controllable Text-to-Video Generagon with Diffusion Models | 通过边缘图或深度图等序列化控制信号生成视频,并提出两种运动自适应噪声初始化策略 | 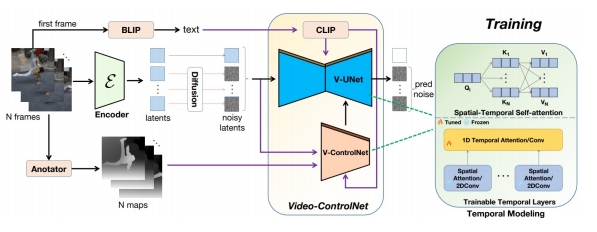 | ||
| 2024 | Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models. | 轨迹控制 | |||
| 2023 | MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation | 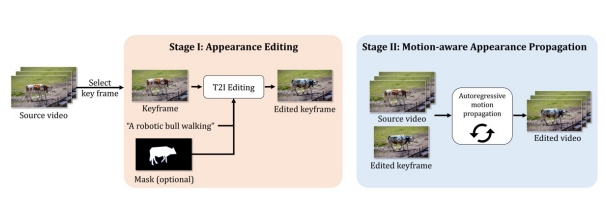 | |||
| 2023 | Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance | 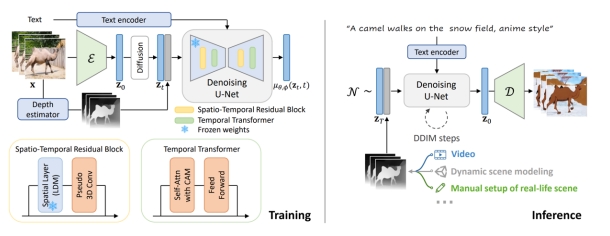 | |||
| 2023 | MagicEdit: High-Fidelity and Temporally Coherent Video Editing | 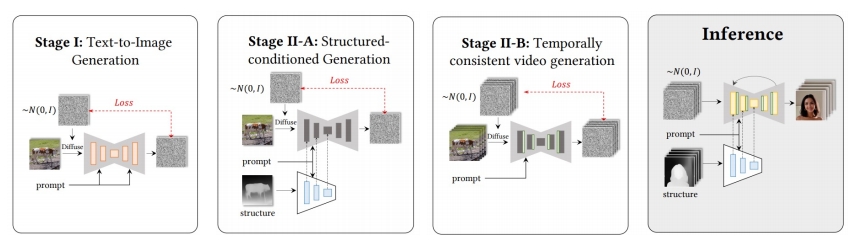 | |||
| 2023 | EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints | 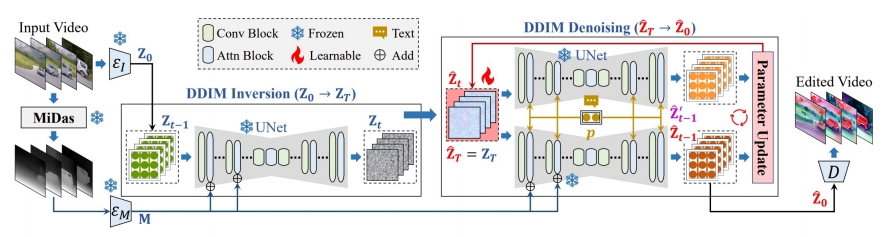 |
P225
Point-Control
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 98 | 2023 | VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence |
P226
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/