Architecture
P5
U-Net Based Diffusion Architecture
U-Net Architecture
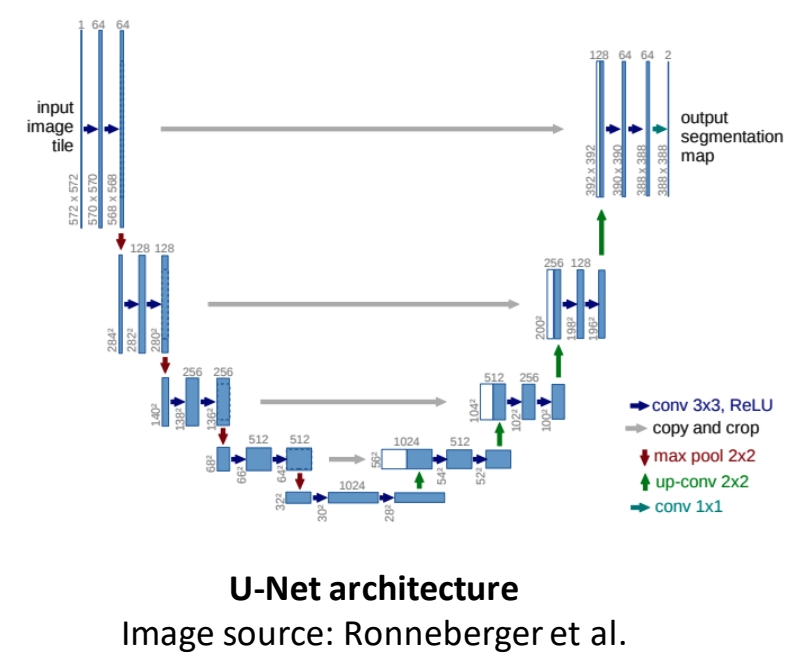
✅ U-Net的是Large Scale Image Diffusion Model中最常用的backbone。
🔎 Ronneberger et al., “U-Net: Convolutional Networks for Biomedical Image Segmentation”, MICCAI 2015
Pipeline
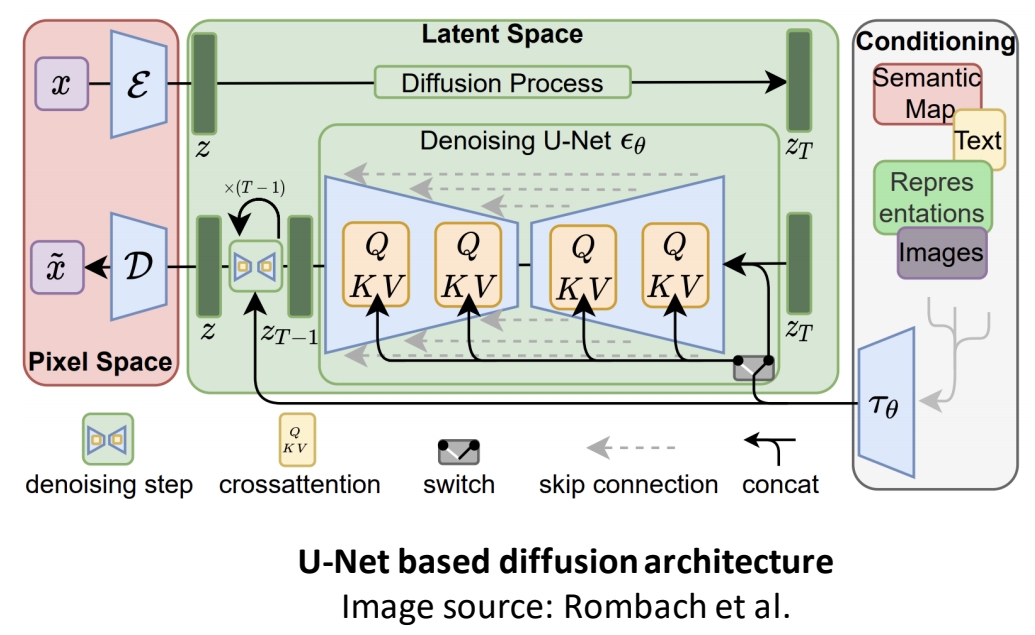
✅ 包含Input、U-Net backbone、Condition。
✅ Condition 通常用 Concat 或 Cross attention 的方式与 Content 相结合。
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 45 | 2022 | High-Resolution Image Synthesis with Latent Diffusion Models | 常被称为Stable Diffusion 或 LDM,是diffusion方法做图像生成最经典工作(没有之一) ✅ (1):在 latent space 上工作 ✅ (2):引入多种 condition. | UNet, latent space | link |
| 69 | 2022 | Photorealistic text-to-image diffusion models with deep language understanding | 1. 用纯文本预训练的大语言模型(如 T5)而不是传统图文对齐模型(CLIP) 2. 用4级超分而不是latent space | Imagen, UNet, T5, Google, pixel space | link |
| 70 | 2022 | ediffi: Text-to-image diffusion models with an ensemble of expert denoiser | 1. T5, Clip混合引导 2. 第二阶段基于第一阶段对时间步分段微调,解决传统扩散模型在生成过程中不同阶段对文本依赖的动态变化问题。 3. 部分区域关联文本条件 | NVIDIA, eDiff-I, UNet, pixel space | link |
P7
Transformer Architecture
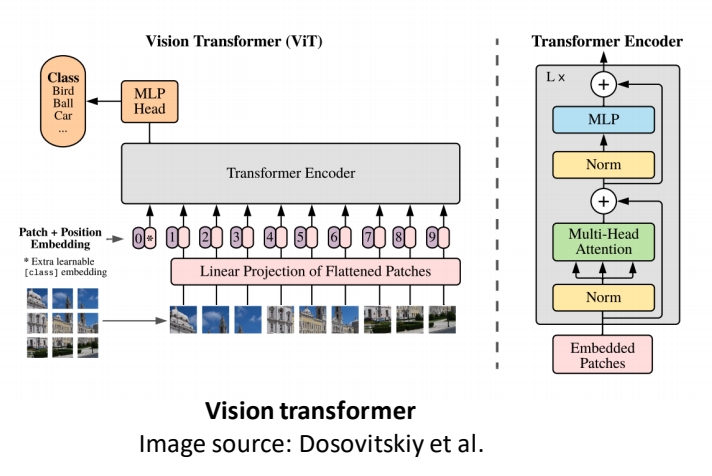
Vision Transformer(ViT)
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 71 | 2021 | Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale” | 分类任务。 基核心思想是将图像分割为固定大小的块(如16x16像素),并将每个块视为一个“单词”,通过线性投影转换为嵌入向量序列,直接输入标准Transformer编码器进行处理。 这一方法突破了传统卷积神经网络(CNN)在视觉任务中的主导地位,证明了纯Transformer在图像识别中的有效性。 | ViT | link |
Pipeline
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
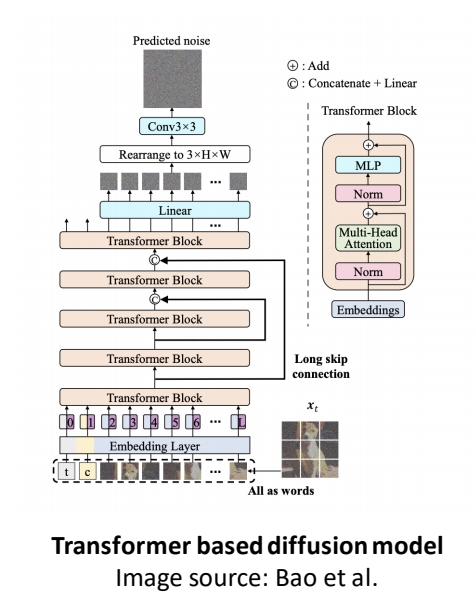
| 72 | 2022 | All are Worth Words: a ViT Backbone for Score-based Diffusion Models | 1. 基于transformer的diffusion网络 U-ViT,替代传统U-Net架构。 2. 将图像生成过程中的所有输入(包括噪声图像块、时间步长、条件信息)统一视为“令牌”(Token),通过ViT的全局自注意力机制进行建模。 3. 突破了diffusion对U-Net的依赖,展示了纯Transformer架构在生成任务中的潜力。 | U-ViT | link |
| 73 | 2022 | Scalable Diffusion Models with Transformers | 1. 以ViT为backbone的扩散模型——Diffusion Transformer(DiT),代表UNet backbone 2. 通过Transformer的全局自注意力机制建模图像生成过程,验证了Transformer在扩散模型中的可扩展性与性能优势。 | DiT, ViT | link |
其它
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2022 | DALL-E2 | 利用CLIP(Radford等,2021)联合特征空间优化文本-图像对齐度,解决"语义漂移"问题 | |||
| 2021 | GLIDE | 首次引入文本条件控制,并通过分类器引导(classifier guidance)机制提升生成效果 首次将条件控制(文本)与扩散过程结合,通过梯度调节实现语义精准映射 |