P23
由于缺少3D数据,把2D T2I Base Model作为先验来实现3D生成。
SDS
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 82 | 2023 | Magic3D: High-Resolution Text-to-3D Content Creation | 在68的基础上: 1. 采用**“粗到细”(Coarse-to-Fine)的两阶段优化策略,,结合不同分辨率扩散模型与场景表示,coarse阶段速度更快,Fine阶段提升细节 2. Coarse阶段采用Instant-NGP + eDiff-I,快速收敛,且适合处理复杂拓扑变化。 3. Fine阶段使用DMTet + LDM | SDS, Coarse-to-Fine | link |
| 2023 | Wang et al.,"Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation", | Alternative to SDS | |||
| 2023 | Wang et al., "ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation", | Alternative to SDS |
P31
Alternative to SDS: Score Jacobian Chaining
A different formulation, motivated from approximating 3D score.

In principle, the diffusion model is the noisy 2D score (over clean images),
but in practice, the diffusion model suffers from out-of-distribution (OOD) issues!
For diffusion model on noisy images, the non-noisy images are OOD!
✅ 2D sample, 3D score
P32
Score Jacobian Chaining
SJC approximates noisy score with “Perturb-and-Average Scoring”, which is not present in SDS.
- Use score model on multiple noise-perturbed data, then average it.
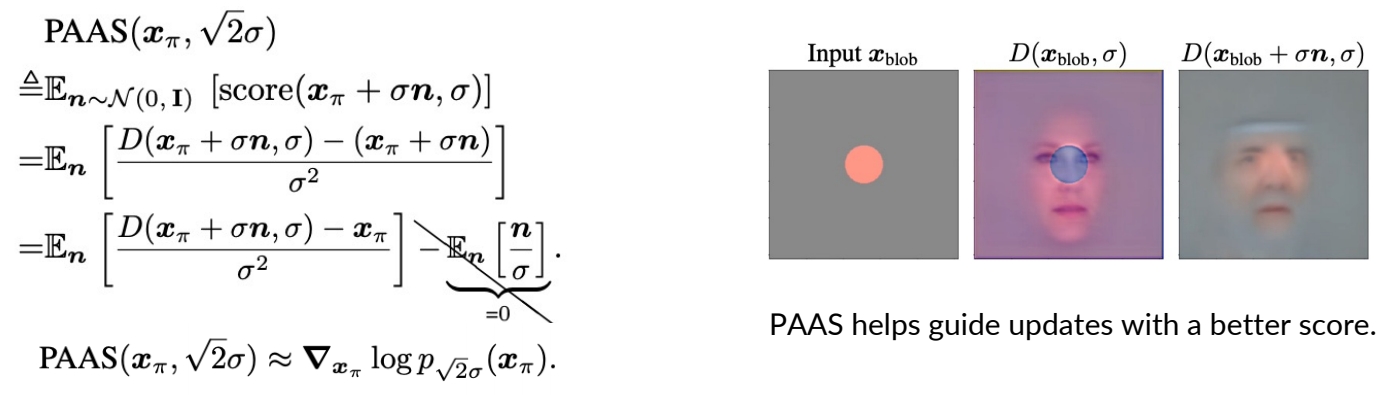
✅ 通过这种方法来近似 clean image 的输出,解决 clean image 的 OOD 问题。
P33
SJC and SDS
SJC is a competitive alternative to SDS.

P34
Alternative to SDS: ProlificDreamer
- SDS-based method often set classifier-guidance weight to 100, which limits the “diversity” of the generated samples.
- ProlificDreamer reduces this to 7.5, leading to diverse samples.

P35
ProlificDreamer and Variational Score Distillation
Instead of maximizing the likelihood under diffusion model, VSD minimizes the KL divergence via variational inference.
$$ \begin{matrix} \min_{\mu } D _ {\mathrm{KL} }(q^\mu _ 0(\mathbf{x} _ 0|y)||p _ 0(\mathbf{x} _ 0|y)). \\ \quad \mu \quad \text{is the distribution of NeRFs} . \end{matrix} $$
Suppose is a \(\theta _ \tau \sim \mu \) NeRF sample, then VSD simulates this ODE:
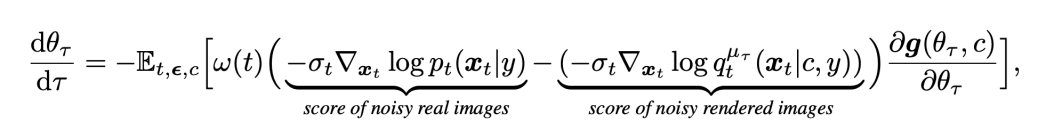
- Diffusion model can be used to approximate score of noisy real images.
- How about noisy rendered images? sss
✅ 第一项由 diffusion model 得到,在此处当作 GT.
P36
- Learn another diffusion model to approximate the score of noisy rendered images!
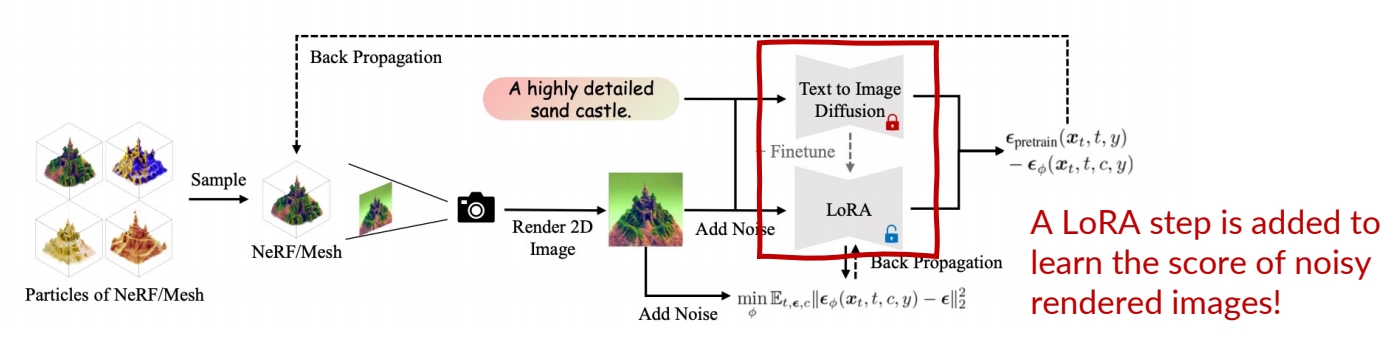
✅ 使用 LoRA 近第二项。
P37
Why does VSD work in practice?
-
The valid text-to-image NeRFs form a distribution with infinite possibilities!
-
In SDS, epsilon is the score of noisy “dirac distribution” over finite renders, which converges to the true score with infinite renders!
-
In VSD, the LoRA model aims to represent the (true) score of noisy distribution over infinite number of renders!
-
If the generated NeRF distribution is only one point and LoRA overfits perfectly, then VSD = SDS!
-
But LoRA has good generalization (and learns from a trajectory of NeRFs), so closer to the true score!
-
This is analogous to
- Representing the dataset score via mixture of Gaussians on the dataset (SDS), versus
- Representing the dataset score via the LoRA UNet (VSD)
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/