Image-2-Video
- 把用户控制(稀疏轨迹等)转为运动表征(光流等)
- 用运动表征驱动图像
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 51 | 2023 | Motion-Conditioned Diffusion Model for Controllable Video Synthesis | ✅ 用户提供的稀疏运动轨迹 -> dense光流 ✅ dense光流(condition) + Image -> 视频 | Two-stage, 自回归生成 | link |
| 44 | 2024 | Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling | ✅ 用户提供的控制信号(condition)+ Image -> dense光流 ✅ dense光流(condition) + Image -> 视频 | Two-stage,轨迹控制 | link |
| 2024 | Physmotion: Physicsgrounded dynamics from a single image. | 轨迹控制 | |||
| 2023 | LFDM (Ni et al.) “Conditional Image-to-Video Generation with Latent Flow Diffusion Models,” | ✅视频->光流 + Mask ✅ 光流+Mask+图像 ->视频 | 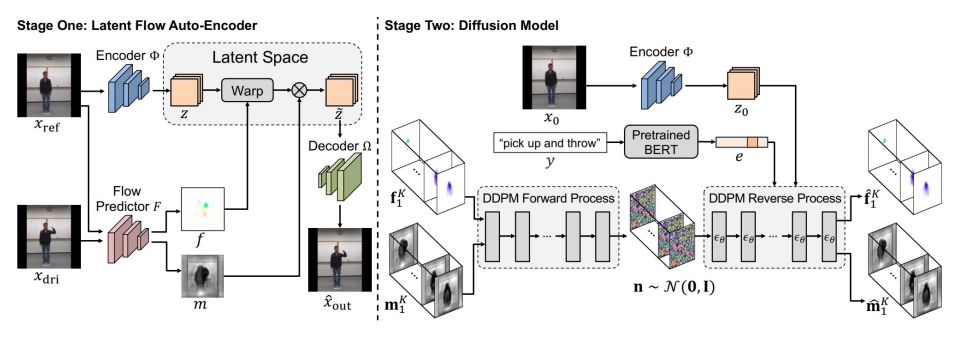 | ||
| 2024 | Generative Image Dynamics (Li et al.) “Generative Image Dynamics,” | 图像(无condition) -> SV ✅ SV + 力 -> 光流 ✅ 光流 + Image -> 视频 | 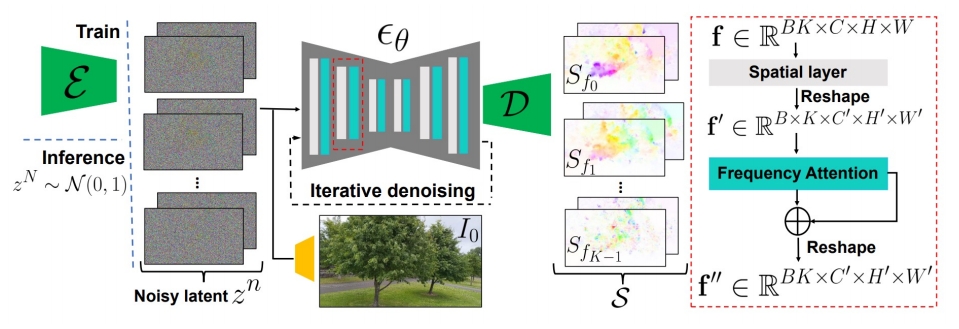 | ||
| 2023 | LaMD: Latent Motion Diffusion for Video Generation | 视频 -> 图像特征 + 运动特征 ✅ 运动特征+图像特征->视频 | | ||
| 2023 | Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models | PYoCo (Ge et al.) Generate video frames starting from similar noise patterns | 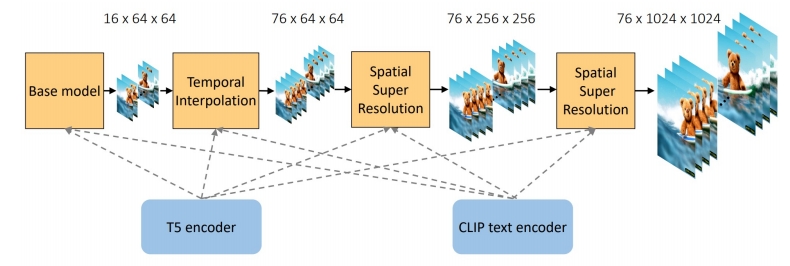 | ||
| 2023 | Animate-a-story: Storytelling with retrieval-augmented video generation | 深度控制 |
More Works 闭源
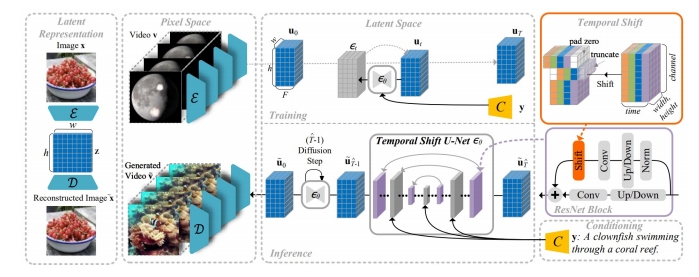 | Latent Shift (An et al.) Shift latent features for better temporal coherence “Latent-Shift: Latent Diffusion with Temporal Shift for Efficient Text-to-Video Generation,” arXiv 2023. |
 | Video Factory (Wang et al.) Modify attention mechanism for better temporal coherence “VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation,” arXiv 2023. |
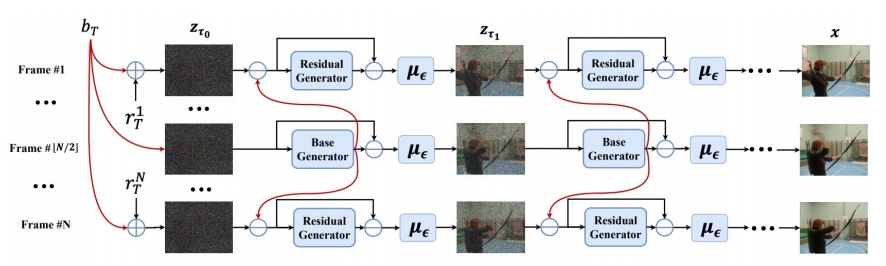 | VideoFusion (Lorem et al.) Decompose noise into shared “base” and individual “residuals” “VideoFusion: ecomposed Diffusion Models for High-Quality Video Generation,” CVPR 2023. |
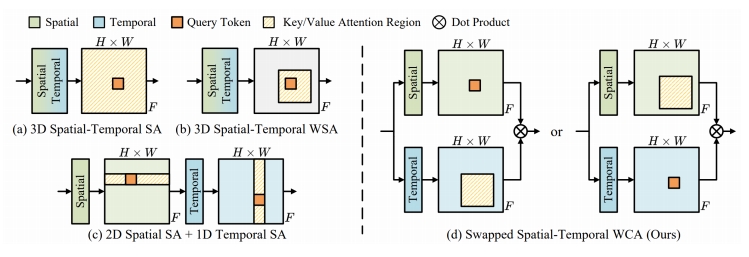
✅ Framwork (1) 在原模型中加入 temporal layers (2) fix 原模型,训练新的 layers (3) 把 lager 插入到目标 T2 I 模型中。
Sound2Video
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 2023 | The Power of Sound (TPoS): Audio Reactive Video Generation with Stable Diffusion | Text + Sound -> Video | 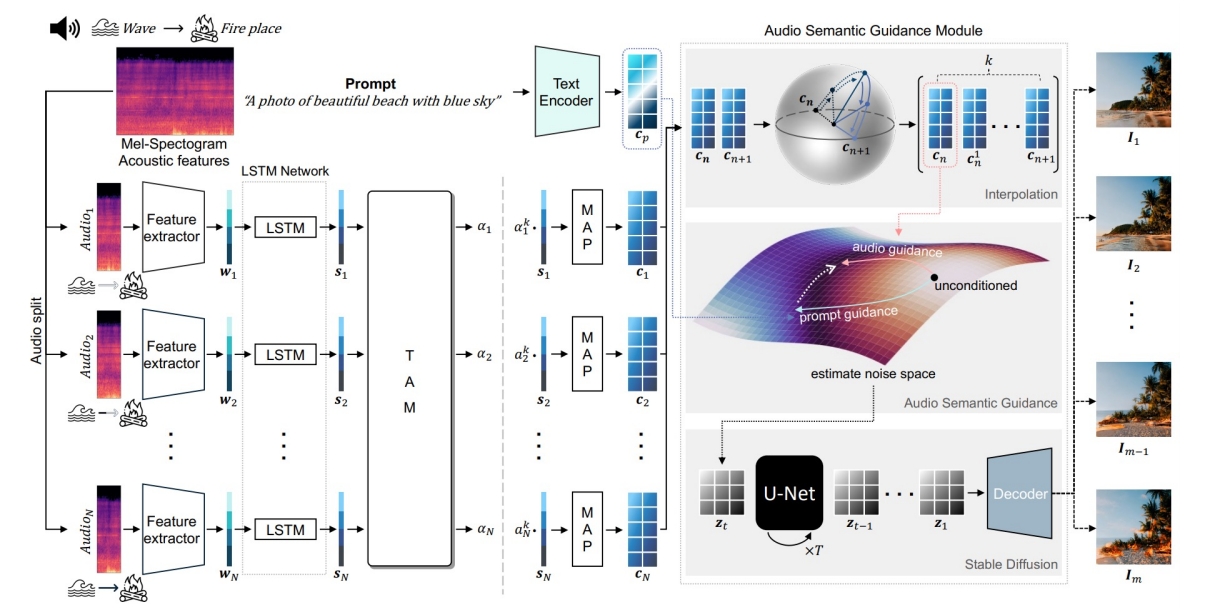 | ||
| 2023 | AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion | 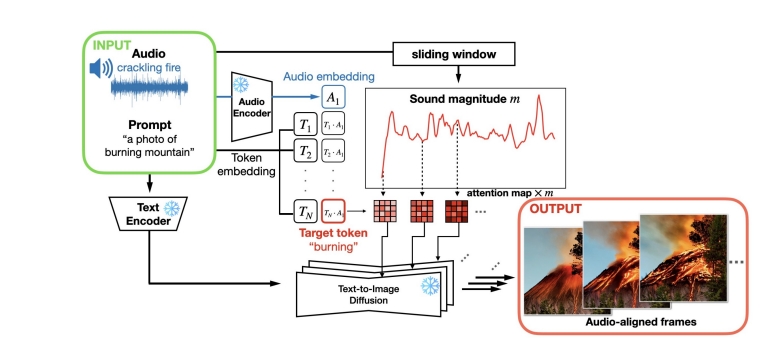 | |||
| 2023 | Generative Disco (Liu et al.) “Generative Disco: Text-to-Video Generation for Music Visualization, | 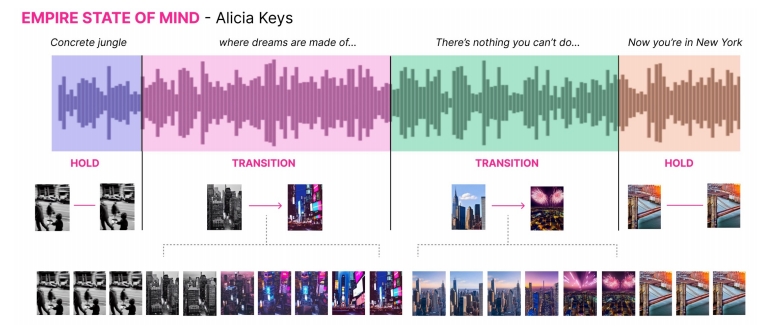 |
Bain Activity 2 Video
✅ 大脑信号控制生成。
Brain activity-guided video generation
- Task: human vision reconstruction via fMRI signal-guided video generation
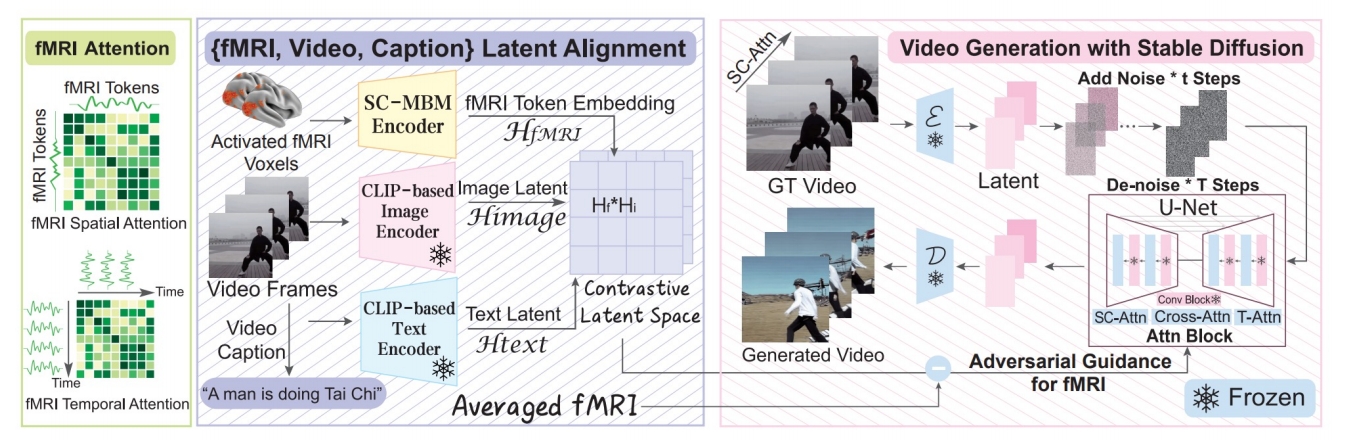
Chen et al., “Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity,” arXiv 2023.
✅ 用纯文本的形式把图片描述出来。
✅ 方法:准备好 pair data,对 GPT 做 fine-tune.
✅ 用结构化的中间表示生成图片。
✅ 先用 GPT 进行文本补全。
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/