P36
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 57 | 2023.9 | Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation | 直接在像素空间实现时序扩散模型,结合修复(inpainting)与超分辨率技术生成高分辨率视频 | link | |
| 2023.8 | I2vgen-xl: High-quality image-to-video | 提出级联网络,通过分离内容与运动因素提升模型性能,并利用静态图像作为引导增强数据对齐。 | |||
| 48 | 2023.4 | Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models | 首次将潜在扩散模型(LDM)范式引入视频生成,在潜在空间中加入时序维度 T2I(LDM) -> T2V(SVD) Cascaded generation | Video LDM | link |
| 59 | 2023 | AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning | 1. T2I + Transformer = T2V 2. MotionLoRA实现不同风格的视频运动 | link | |
| 2023 | Chen et al., “GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation,” | Transformer-based diffusion for text-to-video generation ✅Transformer-based architecture extended from DiT (class-conditioned transformer-based LDM) ✅Train T2I \(\to \) insert temporal self-attn \(\to \) joint image-video finetuning (motion-free guidance) | 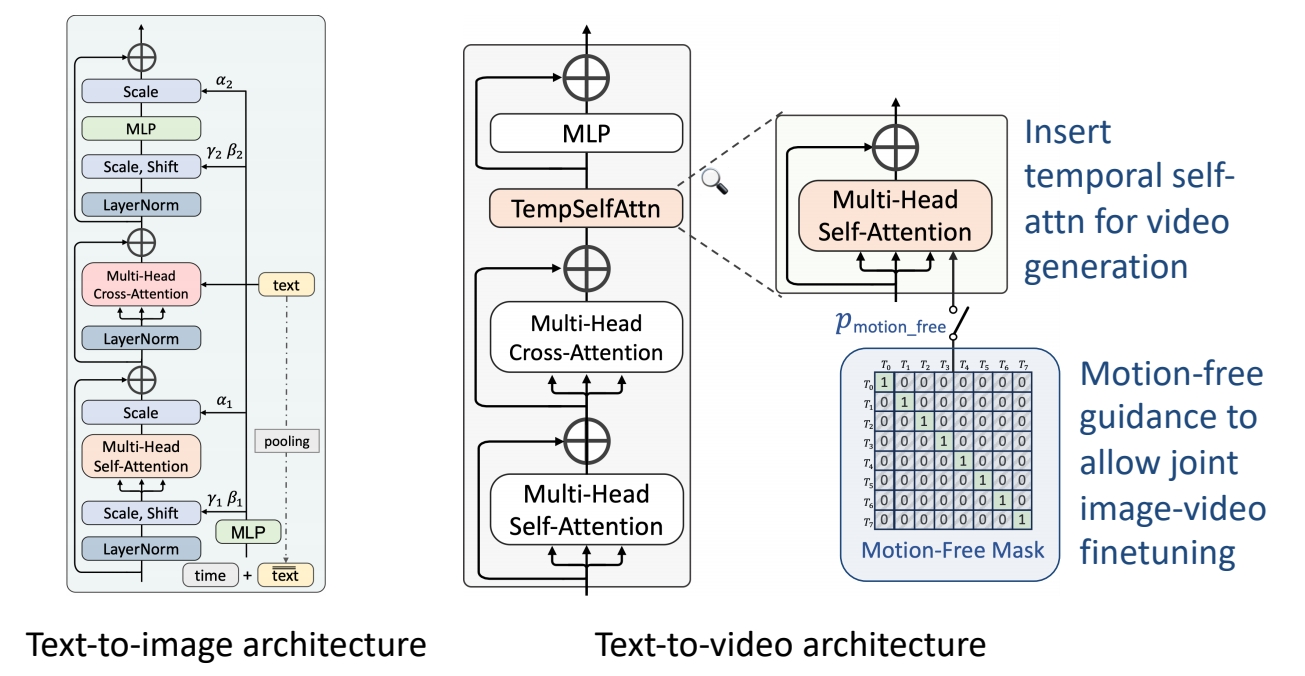 | ||
| 2023 | Gupta et al., “Photorealistic Video Generation with Diffusion Models,” | Transformer-based diffusion for text-to-video generation ✅Transformer-based denoising diffusion backbone ✅Joint image-video training via unified image/video latent space (created by a joint 3D encoder with causal 3D conv layers, allowing the first frame of a video to be tokenized independently) ✅Window attention to reduce computing/memory costs ✅Cascaded pipeline for high-quality generation | 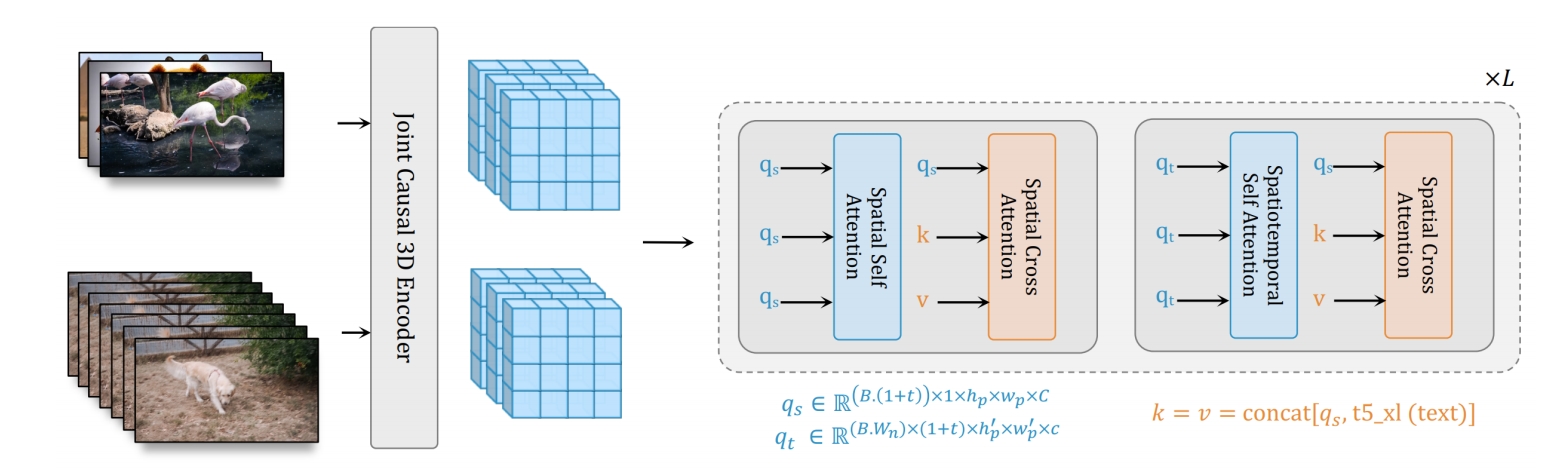 | ||
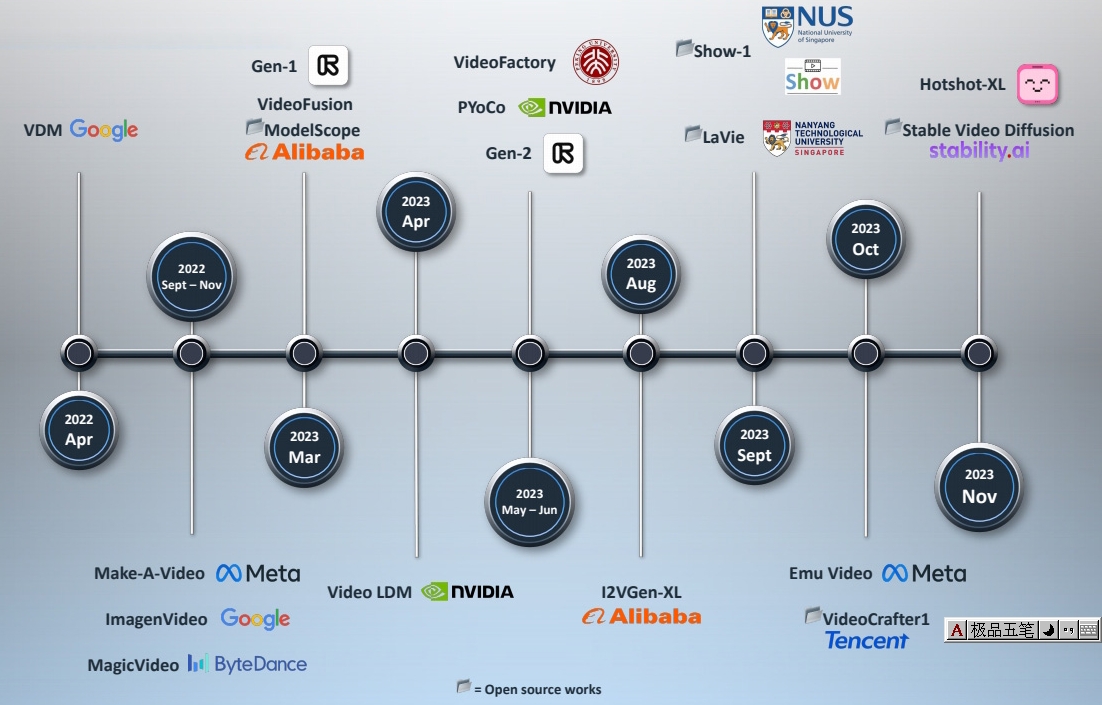
| 2022.11 | Imagen Video: High Definition Video Generation with Diffusion Models | 提出级联扩散模型以生成高清视频,并尝试将文本到图像(text-to-image)范式迁移至视频生成 级联扩散模型实现高清生成,质量与分辨率提升 ✅ 先在 image 上做 cascade 生成 ✅ 视频是在图像上增加时间维度的超分 ✅ 每次的超分都是独立的 diffusion model? 7 cascade models in total. 1 Base model (16x40x24) 3 Temporal super-resolution models. 3 Spatial super-resolution models. ✅ 通过 7 次 cascade,逐步提升顺率和像素的分辨率,每一步的训练对上一步是依赖的。 | Cascade | 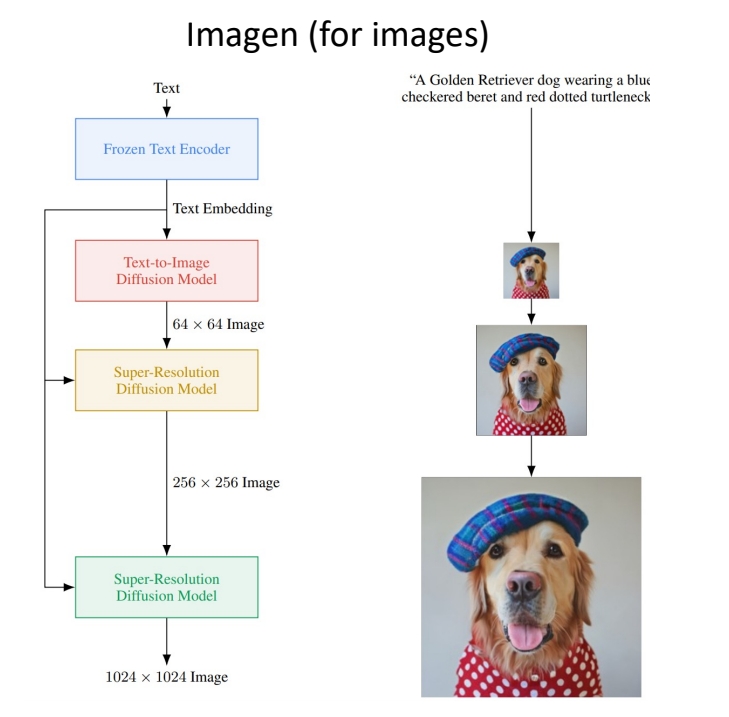 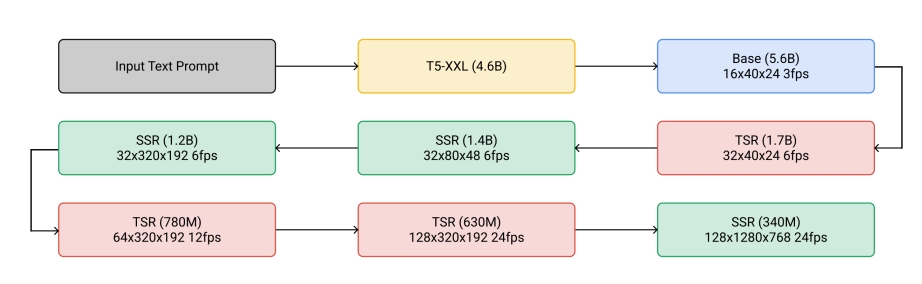 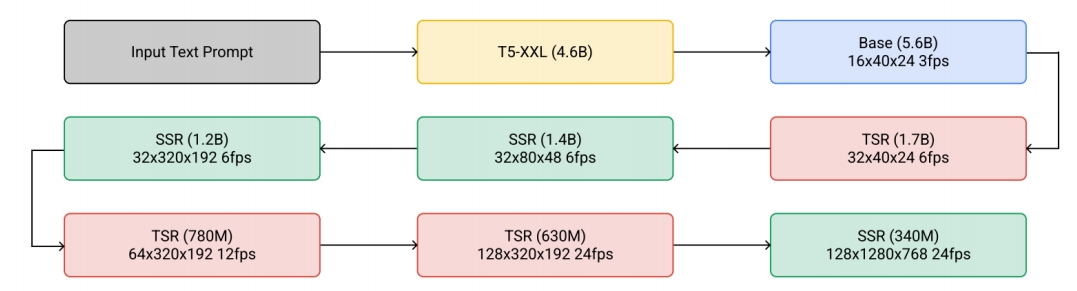 | |
| 56 | 2022.9 | Make-A-Video: Text-to-Video Generation without Text-Video Data | link | ||
| 55 | 2022.4 | Video Diffusion Models | 首次采用3D U-Net结构的扩散模型预测并生成视频序列 引入conv(2+1)D,temporal attention | link |
More Works
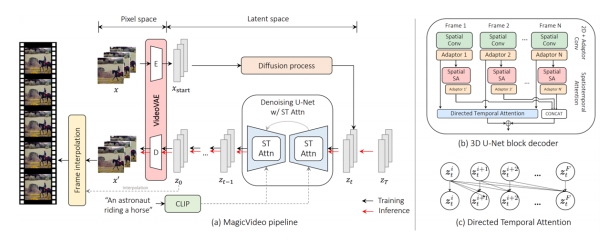 | MagicVideo (Zhou et al.) Insert causal attention to Stable Diffusion for better temporal coherence “MagicVideo: Efficient Video Generation With Latent Diffusion Models,” arXiv 2022. |
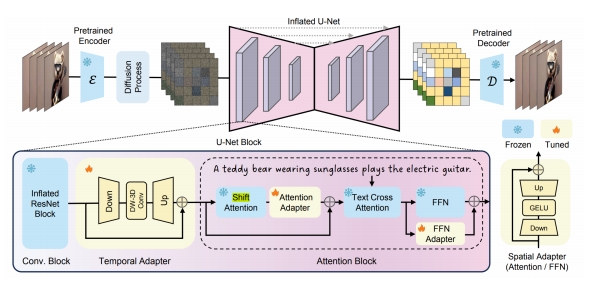 | Simple Diffusion Adapter (Xing et al.) Insert lightweight adapters to T2I models, shift latents, and finetune adapters on videos “SimDA: Simple Diffusion Adapter for Efficient Video Generation,” arXiv 2023. |
 | Dual-Stream Diffusion Net (Liu et al.) Leverage multiple T2I networks for T2V “Dual-Stream Diffusion Net for Text-to-Video Generation,” arXiv 2023. |
| MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation,2024 |
Traning Free
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 84 | 2025.5.14 | Generating time-consistent dynamics with discriminator-guided image diffusion models | 1. 训练一个时序一致性判别器,用判别器引导T2I模型生成时序一致性的模型。 | 图像生成+时间一致性判别器=视频生成 | link |
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/