20250914骨骼动作离散表示
核心问题定义
用一句话说清楚:这个技术主要想解决动画/仿真领域的什么经典痛点或瓶颈?
角色骨骼动作生成是为了解决连续动作表示解码出的动作质量不同的痛点。
技术解析
它是什么
用直观的语言描述这项技术的核心思想
用离散编码来描述动作序列。
[TODO] 把下面表格中的图下载下来,换成本地链接
| 生成模型 | 特点 | 结构 | 链接 |
|---|---|---|---|
| AE | 降维、聚类,但latent仍是复杂分布,不能直接sample | 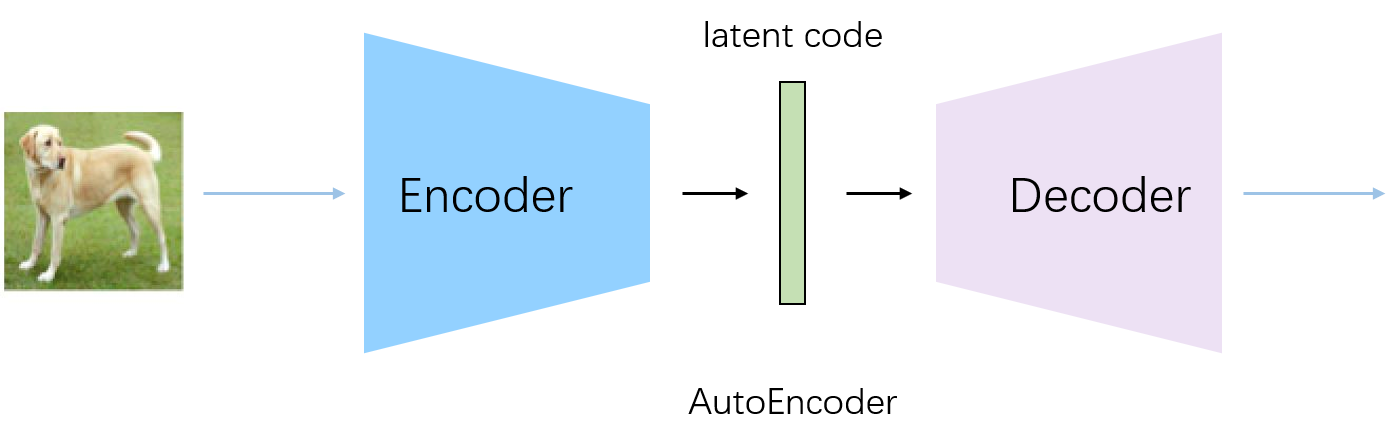 | |
| VAE | 降维、聚类,latent为std normal,可以直接sample | 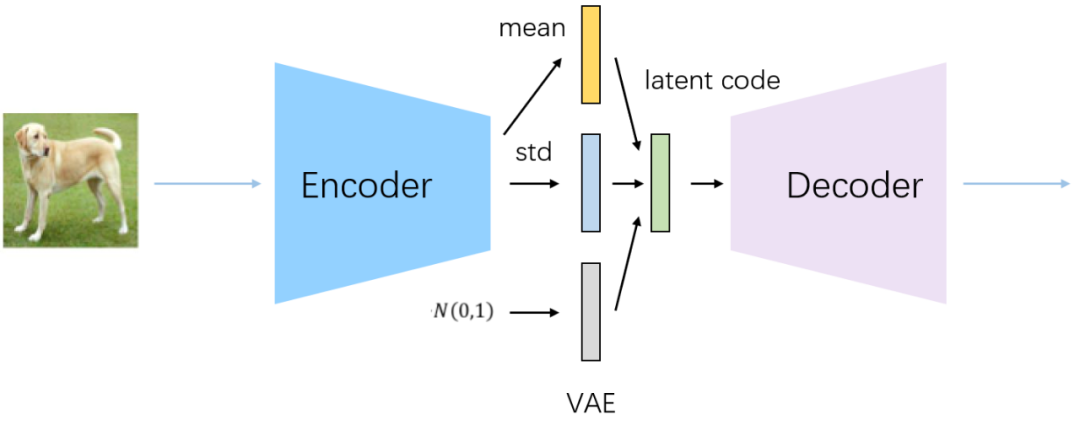 | |
| VQ-VAE | 离散AE(用于降维、聚类)。其分布为整个码本 但码本的使用率不可能到100%(Perplexity不会打满),因此不能直接采样。还需要结合其它生成模型。 例如图像生成中使用PixelCNN(用于sample) | 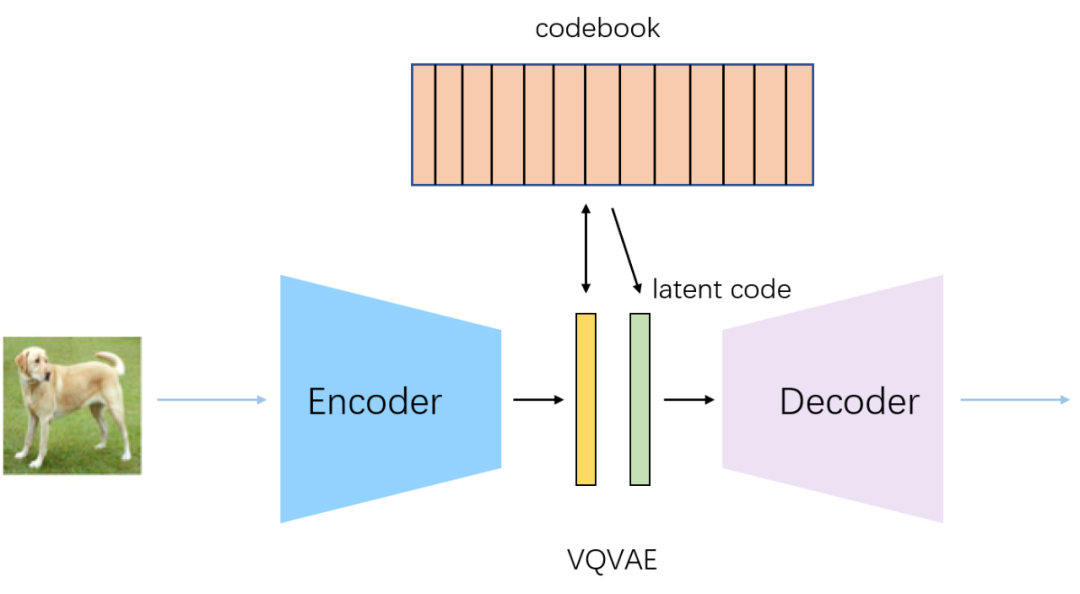 | |
| GAN |
VQ-VAE及其变体将动作编码为离散标记,本质上将运动生成问题从回归任务转化为分类任务。然而受限于码本结构,VQ-VAE倾向于存储已知动作而非泛化到新动作。虽然这些模型在训练数据分布内能精确生成和重建动作,却难以处理分布外运动导致信息损失和动作感知失真。
关键论文
关键论文/算法:找到1-2篇最具代表性的开创性论文或关键改进论文。不必深究数学细节,但要看懂其核心架构图和主要贡献。
- 基于离散表示的文生动作
虽然离散表示擅长精确存储训练数据,但最早使用离散动作表示,是为了像处理语言一样地处理动作。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 2022.8.4 | TM2T: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. | 文生3D全身动作,实现同文本生成多个差异化动作,并避免产生无意义的静止姿态序列。 | 首次提出离散量化的运动表示 互惠生成方法通过同时训练文本→运动和运动→文本任务,显著提升了语义对齐能力。 | 控制条件:文本(NMT Encoder) 生成方式:自回归 表示方式:离散表示(同VQ-VAE,但没有使用这个词) 生成模型:离散分布采样(NMT Decoder) |
T2m-gpt首次证明了『离散表示+自回归生成框架』能够实现文生动作任务,且生成动作的质量非常高。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 88 | 2023.9.24 | T2m-gpt: Generating human motion from textual descriptions with discrete representations | 基于VQ-VAE与GPT的文生人体运动框架 | 1. 基于VQ-VAE的离散运动表示 2. VQ-VAE + Transformer(GPT)的文生动作框架** 3. 生成质量(FID)有明显提升 | 控制条件:文本(CLIP) 生成方式:自回归 表示方式:离散表示(VQ-VAE) 生成模型:离散分布采样(GPT) 其它:Transformer,开源 | link |
MoMask则首次提出了『离散表示 + 掩码语言模型生成框架』的文生动作模型。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 2023 | MoMask: Generative Masked Modeling of 3D Human Motions | VQ-VAE + Bert Style的文生动作新框架 | VQ-VAE + 分层码本结构;掩码预测生成粗糙运动,残差层逐步细化 首个离散运动表示+掩码语言模型的文生动作框架 | 控制条件:文本(CLIP) 生成方式:Bert Style 表示方式:离散表示(VQ-VAE + 残差细化) 生成模型:掩码语言模型 |
也有VQ-VAE结合其它生成框架的尝试,例如结合离散扩散模型、score matching等。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 2023 | Text-to-Motion Synthesis using Discrete Diffusion Model | 扩散模型计算成本较高,且生成的运动可能与输入文本对齐度不足。 | 结合离散潜在空间与扩散模型,学习表达性条件概率映射以实现运动合成。 1. 学习离散运动表达 2. 应用离散去噪扩散概率模型(D3PM)学习运动标记的条件概率分布。 3. 训练过程中进一步采用离散无分类器引导技术,通过合适的引导尺度实现运动与对应文本描述的对齐。 | 控制条件:文本 生成方式:非自回归 表示方式:离散表示(VQ-VAE) 生成模型:离散去噪扩散概率模型(D3PM) 其它:MoDDM |
此后的基于离散表示的动作生成研究主要有这些方向:
- 进一步提升动作质量
- 提升多样性/随机性
- 控制能力,例如更好地理解文本、支持长文本、其它控制方式等
- 进一步提升动作质量
在基础码本之上,增加残差码本,提升码本可表示的细节。代表论文为上面提到的MoMask。
HGM3则是在MoMask基础上的发展。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 102 | 2025.5.16 | HGM³: Hierarchical Generative Masked Motion Modeling with Hard Token Mining | 由于文本固有的歧义性以及人体运动动态的复杂性 | 1. 类似MoMask的残差VQ-VAE,但专门训练了一个网络来决定给哪些token掩码 2. 把文本编码成不同粒度的embedding,提升文本的整体把控与细节控制 | 控制条件:文本(Graph Reasoning) 生成方式:Bert Style 表示方式:离散表示(分层文本编码,每一层是残差VQ-VAE) 生成模型:残差VQ-VAE(类似于Diffusion的逐渐细化的生成模式) | link |
所需数据
它需要什么样的数据进行训练?(图像、3D模型、运动捕捉数据、仿真数据?)是监督学习、无监督还是自监督?
真实的3D骨骼动作数据
应用场景与案例
学术界
在Siggraph等顶会上,这项技术最常被用在哪些方面?找1-2个论文中的例子。
VQ-VAE是一种动作表示方式,可以用于任何与骨骼动作有关的场景。但目前调研中都是用于动作生成任务。但应该也可以用于其它任务。
工业界
是否有公司已经将其产品化?
无产品化。
电影/VFX:迪士尼、Weta等工作室如何用它?
游戏:哪些游戏引擎或大厂在探索它?
创业公司:是否有基于该技术的明星创业公司?
价值主张分析(战略家的核心思考)
效率提升:它能将某个环节的速度提升多少倍?能节省多少艺术家的人力成本?
相比于连续表示方式,无效率提升。
质量突破:它是否能实现传统方法无法达到的质量或逼真度?
相比于连续表示方式,质量有很大提升。
创新可能性:它是否开启了全新的创作范式或产品类型?(例如,实时虚拟制作、个性化内容生成)
它使得可以像处理语言一样地处理动作。
现状与挑战
当前局限性:这项技术目前最大的问题是什么?(计算成本高、训练慢、控制力不足、艺术导向性差?)
- 大多数网络适用于连续数据表示。要适配这种离散数据表示,需要一些额外的工程。
- 受限于码本结构,VQ-VAE倾向于存储已知动作而非泛化到新动作。虽然这些模型在训练数据分布内能精确生成和重建动作,却难以处理分布外运动导致信息损失和动作感知失真。
未来趋势:它的下一个突破点可能在哪里?
VQ-VAE使得可以像处理语言一样地处理动作,那么也能发展出类似于大语言模型的大动作模型,目前主要局限于有限的真实动作的数据量。