3.1 Tuning-based
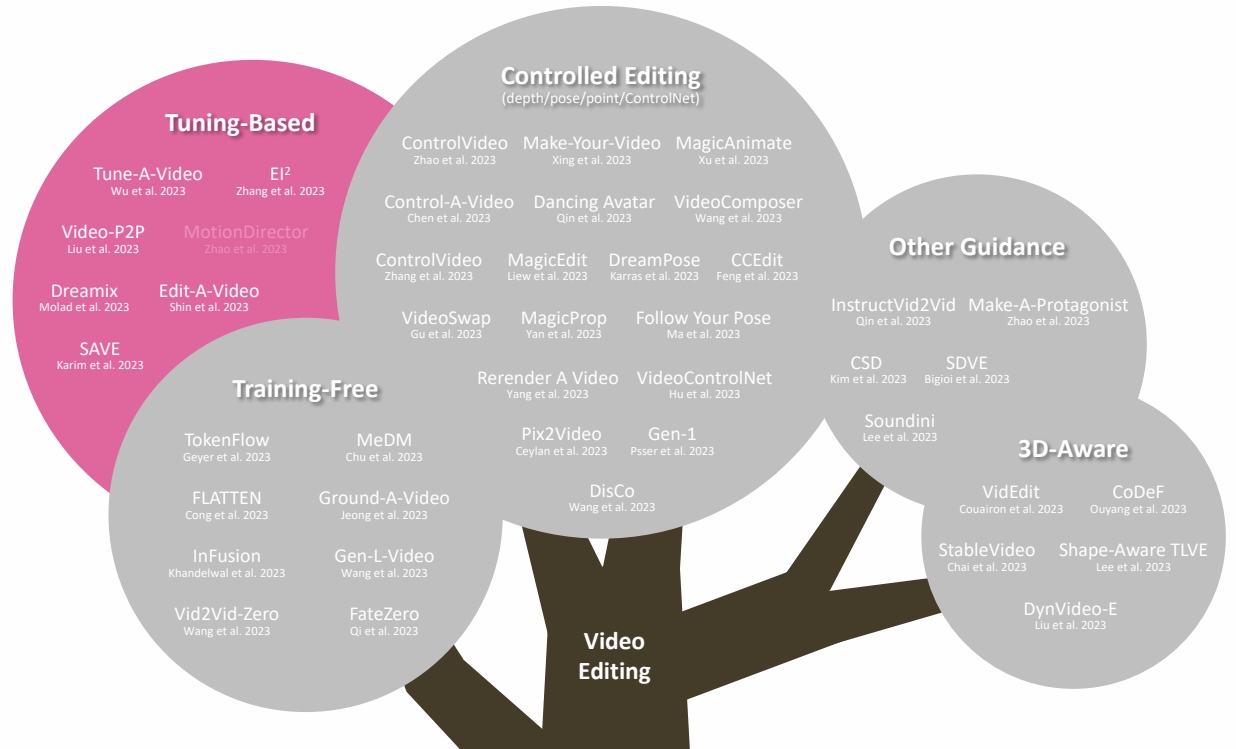
One-Shot Tuned Video Editing
Compared to training-free editing methods:
- Cons: still need 1 video for training
- Pros: supports significant shape change
P149
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 118 | 2023 | Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation | |||
| 119 | 2023 | Dreamix: Video Diffusion Models are General Video Editors | |||
| 2023 | Towards Consistent Video Editing with Text-to-Image rDiffusion Models | Modify self-attention for better temporal consistency | |||
| 2023 | Video-P2P: Video Editing with Cross-attention Control | Improve input-output semantic consistency of video editing via shared embedding optimization and cross-attention control。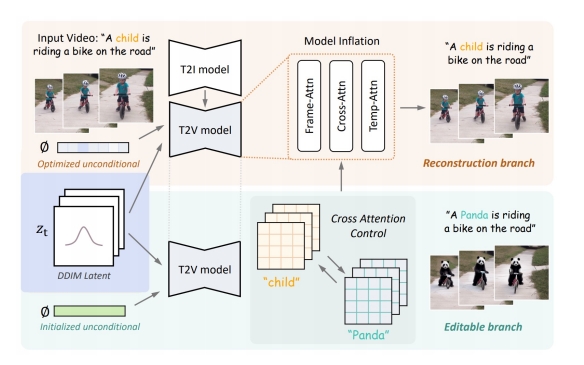 | attention控制 |
P166
Multiple-Shot Tuned
Video Editing: Text Conditioned
P167
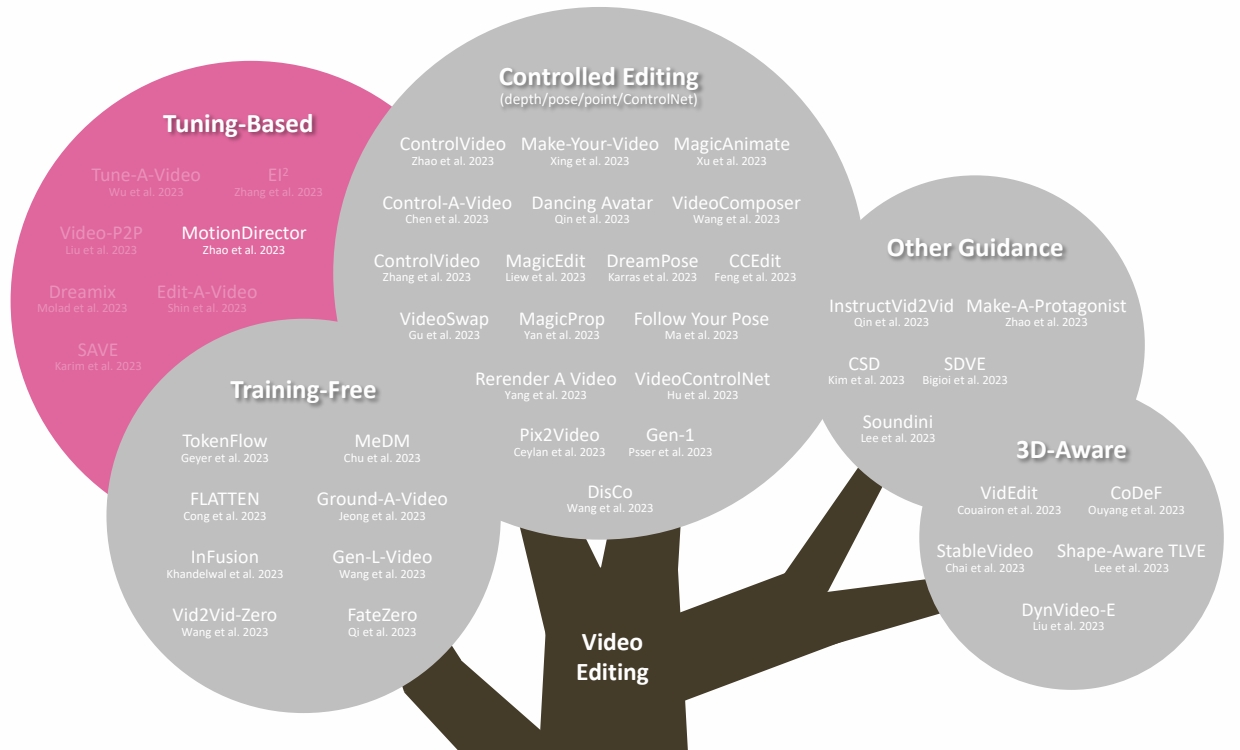
| ID | Year | Name | Note | Tags | Link |
|---|---|---|---|---|---|
| 120 | 2023 | MotionDirector: Motion Customization of Text-to-Video Diffusion Models |
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/ImportantArticles/
✅ 在一个视频上训练后可以对视频进行编辑。
✅ 训练过程:(1) 对模型的时域模块 finetune.
✅ (2) 对图像打乱后用图像 finetune.
✅ 把视频和图片进行 mix finetune.
✅ 图片 finetune 会把 tenmporal 模块 fix 住。
✅ 需要训练的模型,且针对一个模型进行训练。
✅ 基本泛式:输入:一段视频,一个文生图模型,一个文本提示词。输出:基于定制化的文生图得到文生视频。
✅ 不在大规模上训练,只在一个视频上训练,只需十分钟。
✅ 推断过程:(1) 把视频 dounsample,维度变小。
✅ (2) 加入噪声作为初始噪声,类似于 DDIM Inversion.
✅ (3) 用 diffusion model 生成。
✅ (4) 上采样。
✅ 如果有更多 reference vedio 是不是能学得更好。
✅ (1) 用几段视频学习 concept.
✅ (2) 把 concept 接入到 diffusion model 中。
✅ 通过多段视频学习 motion concept.
✅ 不仅学 motion,还可以学 camera motion,camera motion,物体轨迹。
✅ 怎么把一个 concept 应用到不同的物体上。
✅ 怎样只学 motion 而不被物体的 appearance 影响,能不能 decouple.
✅ 分支1:spatial path,灰色为 spatial LoRA,学习外表信息。
✅ 分支2:temporal path,蓝色为 temporal LoRA,这个 path 用于学习 motion.
✅ debias:去掉 appreance 对 loss 的影响。
✅ temporal LORA 学习时使用但不修改 spatial LORA 的 Weight.
✅ 应用:(1) 也可以用于 one shot
✅ (2) 可以用于 appreace 和 motion 的组合
✅ (3) 可以用于 Image Animation