Locomotion
任务:实时控制虚拟角色进行高效、真实、可控且自适应的行走、奔跑、跳跃等基础位移运动。
mindmap
Locomotion
多
更多的动作类型
适配不同地形(平地、楼梯、斜坡)
适配不同角色
二足/四足
不同体型
不同的动作
不同的风格
更多的应用场景
路径引导
风格控制
动作类型切换
动作插帧
实时运动输入(如动捕、VR 追踪数据)
快
满足交互式场景的帧率要求
快速地数据准备
好
动作具有物理真实感
运动轨迹、肢体姿态、步态节奏符合生物力学规律
无穿模、僵硬、浮空等失真现象
动作具有生物真实感
还原人类 / 生物自然运动特征
符合用户控制
支持用户高层指令(速度、方向、动作风格、启停)的精准响应
实现细粒度运动调节
稳定性
具备外力扰动下的稳定性
省
计算开销低
更少的数据
更少的人工参与
更少的预处理
在适配不同泛化性问题时,无需重新设计运动逻辑

直接使用“下一帧参考动画”作为角色动作数据的方法称为基于运动学的方法。 由力/力矩产生的“下一帧动画”作为角色动作数据的方法称为基于动力学的方法。
mindmap
Locomotion
基于运动学
数据库匹配
状态机
动作匹配
监督学习
基于相位
不基于相位
生成模型
基于当前帧的生成 + <br>结合控制目标的策略
diffusion
基于动力学
目标优化
策略优化
基于运动学的方法:直接控制每个关节的动画数据,不考虑其物理合理性,其效果上限受制于数据。
基于动力学的方法:不直接提供动画数据,而是提供关节受力,让每个关节在力的作用下运动。
说明:
- 轨迹跟踪:下一帧参考动画 → 下一帧动画
- 轨迹优化:下一帧参考动画 → PD控制目标
实际的动力学算出过程,不一定会显式地出现每个步骤,可能是几个步骤统一到一个步骤中的。
基于匹配的方法
graph TD
A[当前帧 frame] --> B{是否匹配?}
B -- N --> C[下一帧 frame]
B -- Y --> D[提取特征]
D --> E[当前特征]
F[获取数据] --> D
G["(5) 角色状态"] --> D
D --> H[最近邻搜索]
H --> I[当前帧 frame]
J[控制目标] --> H
H --> K["(3) 下一帧动作"]
L["(6) 角色的动作数据集"] --> M[提取特征]
M --> N[特征集]
| ID | Year | Title | 特点 |
|---|---|---|---|
| - | - | Motion Field | - |
| - | - | Motion Graph | Baseline,以 clip 为单位 (1) 只在一个 clip 结束时重新匹配 (2) 寻找最像的 clip,并用插值衔接 |
| - | - | Motion Matching | 以 frame 为单位 (1) 每帧或几帧重新匹配,响应更快 (2) 寻找最近匹配的帧,并用 blend 衔接 |
| - | 2020 | Learned Motion Matching | 基于数据集,把 (1)(2)(3) 替换成了网络模块,消除了在线搜索时对数据库的依赖 |
| P47 | Ⓐ | (风格迁移) | 让 (5) 和 (6) 分别是不同的角色,并增加将运动内容与运动风格解耦的模块。在运动空间进行最近邻匹配,在匹配空间中融入目标风格,实现在线风格迁移的效果。 |
Motion Graph / Motion Matching / Motion Field
flowchart LR
A([当前帧frame]) --> B("是否重新匹配(1)")
B -->|"N"|C([当前帧frame])
C --> D["(3)取下一帧动作"]
D --> E([下一帧frame])
E --> A
F --> G(["(5)角色状态"])
H([控制目标])
G --> I["(4)提取特征"]
H --> I
I --> N([当前特征])
N -->J["(2)最近邻搜索"]
J -->C
B --> F["(5)取数据"]
K(["(6)角色的动作数据集"])
K --> L["(4)<br>提取特征"]
L --> M(["特征集"])
M --> J
K --> D
| ID | Year | Title | 特点 |
|---|---|---|---|
| Motion Field | |||
| Motion Graph | Baseline,以clip为单位 (1) 只在一个clip结束时重新匹配自己 (2) 寻找最适配的clip,并用拖帧衔接。 | ||
| Motion Matching | 以frame为单位 (1) 每帧或几帧重新匹配,响应更快 (2) 寻找最匹配的帧,并用blend 做衔接。 | ||
| - | 2020 | Learned Motion Matching | 基于数据集,把 (1)(2)(3)(4) 替换成了网络模块,消除了在线推理时对数据库的依赖。 |
| 209 | 2023.10.16 | MOCHA: Real-Time Motion Characterization via Context Matching | 让 (5) 和 (6) 分别是不同的角色,并增加将运动内容与运动风格解耦的模块。 在运动空间进行最近邻匹配,在匹配结果中融入目标风格,实现在线风格迁移的效果。 |
通过检索、拼接、插值实现运动生成,是工业界长期主流方案。
优势:
- 实现简单:基于准备好的数据库,即可以与角色进行实时控制
- 可控性高
缺点:
- 依赖特定角色的海量数据
- 最近邻搜索成本高
- 内存占用大
- 对不同地形泛化性差
- 随着数据集规模增大,扩展性较差
基于监督学习的方法
非相位方法
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 2018.10.4 | Recurrent Transition Networks for Character Locomotion | 传统方法(如运动图、高斯过程模型)存在泛化性差、仅适配单一动作类型、运行时计算成本高等问题。 基于深度学习的“从当前状态到目标状态的定向过渡生成”处于研究空白 | 1. 改进型 LSTM:传统 LSTM 仅依赖历史状态,RTN 在门控计算中加入未来上下文特征(目标 + 偏移),使生成过程始终朝向目标状态,避免无约束漂移; 2. 隐藏状态初始化:摒弃 “零向量初始化” 或 “全局共享初始状态”,通过 MLP 学习输入首帧与最优初始隐藏状态的映射,让 LSTM 从初始阶段就捕捉运动特征,提升生成质量; 3. ResNet 风格解码器:输出当前帧与下一帧的偏移量,而非直接输出姿态,减少生成帧与输入上下文的间隙,提升过渡流畅性。 | link |
基于相位的方法
flowchart LR
C([NN2])-->A
D([NN3]) -->A
E([NN4]) -->A
B([NN1]) -->A[专家混合]
A-->F([混合专家模型])
F-->G[模型推理]
H(["控制目标<br>(轨迹、标签)"])-->G
J([当前状态])-->G
G -->K([相位变化量])-->P([相位])-->O([当前相位])
G -->L([触地信息])-->R[IK]-->N
G -->Q([未来轨迹])-->N
G -->M([下一帧状态])-->N([动作输出])-->J
O -->A
优势:
- 能对用户输入做出稳定实时的响应。
局限性:
- 依赖精心的设计
- 用高度可变的运动数据进行训练,会产生平均化的结果。
- 难以泛化到数据以外的动作。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 212 | 2023.8.24 | Motion In-Betweening with Phase Manifolds | 首次将周期自编码学习的相位流形引入角色补间动画 | 1. 将复杂的人体运动分解到频域,用相位 + 振幅编码运动的周期性和时序规律。 2. 相位提取:DeepPhase. 3. 双向控制:角色坐标系 + 目标坐标系。 4. 用户控制:轨迹控制、动作类型控制。 | 多:超长动作插帧 快:实时动作插帧 好:可进行路径、风格控制 | |
| 211 | 2022.1.12 | Real-Time Style Modelling of Human Locomotion via Feature-Wise Transformations and Local Motion Phases | 将相位方法引入到风格迁移任务中。 | 1. 发布了 100 style 数据集 2. 扩展相位提取方式,对于非接触运动也能提取相位:对同一类数据使用 PCA 提取主成分,取第一主成分的系数。若存在周期性,用 sin 函数拟合系数。 3. 注入风格:输入风格 clip,输出 alpha 和 beta,用于调制主网络的隐藏层。训练时,先训练主网络,再接入 FiLM,并 finetune FiLM。推断时,不需要 FiLM,使用预置风格的 alpha 和 beta,也可以用插值得到 alpha 和 beta。 | 多:具有风格迁移能力。动作泛化到非接触的周期动作。 快:实时的风格切换。 好:连续的风格参数,风格切换无跳变。 | |
| 211 | 2020.7.8 | Local Motion Phases for Learning Multi-Contact Character Movements | 1. PFNN 只用于周期性动作; PFNN 需要手动标注相位 | 1. 非周期动作=各个局部周期动作的叠加,因此给几个重要的关节独立的相位。 2. 自动提取相位的方法:定义接触为 1,再用 sin 函数拟合。 3. 一个权重估计网络,输入 n 个相位,输出 m 个权重参数。 4. 用户的控制信号过于稀疏,导致生成结果平均化。因此训练生成模型 GAN,根据稀疏控制信号生成细节控制信号。 | 多:泛化到非周期动作。 好:引入生成模型,避免动作趋于平均化。 省:无须人工标注。 | |
| 214 | 2018.10.1 | Few-shot Learning of Homogeneous Human Locomotion Styles | 小样本的学习策略 | 1. 数据准备:(1) 大量基本风格数据(2)少量特定风格数据 2. 模型准备:用 PFNN 实现通用模块,用 residual adapter 来实现 style 模块 3. 训练策略:数据(1)用于通用模块与 style 模块的解耦,数据 (2) 用于 finetune style 模块 4. 参数策略:将 adapter 矩阵分解为 X=ADB^T,进一步减少参数量。 | 多:泛化到不同风格。 快:少量样本即可迁移,训练快。 好:无过拟合,泛化性好。 少:省训练数据,少内存。 | |
| 213 | 2018.6.30 | Mode-Adaptive Neural Networks for Quadruped Motion Control | 传统数据驱动方法(运动图、运动匹配):需存储完整动作数据库,依赖手动分割、标注,搜索过程复杂,实时性差;CNN 存在输入输出映射模糊问题,RNN 长期预测易收敛到平均姿态(漂浮),PFNN 虽解决模糊问题,但依赖手动相位标注,无法适配非循环运动。 | 本文提出模式自适应神经网络(MANN),专为四足动物运动控制设计,核心通过"门控网络 + 运动预测网络"的双模块架构,从大规模非结构化动作捕捉(MOCAP)数据中自主学习运动模式,无需手动标注相位或步态标签;门控网络基于脚部关节速度、目标速度等特征动态加权多个专家网络输出,运动预测网络生成平滑连贯的下一帧运动,支持怠速、移动、跳跃、坐姿等多种循环与非循环运动,同时允许用户通过速度、方向、动作变量交互控制。 | PPT | |
| 113 | 2017.7.20 | Phase-functioned neural networks for character control | 1. Motion Matching 需要存储大量数据 2. 自回归方法存在误差积累 3. CNN方法不能实时 4. 物理方法不可控 5. 不能支持复杂地形 | 1. 混合专家模型,首次将运动相位从「网络输入特征」升级为「网络权重的全局参数化变量」2. 将平地动捕数据与复杂地形耦合,让模型学会了根据地形自动调整动作。 Baseline | PFNN 多:支持不同地形的泛化性 快:0.8ms/帧 好:1. 混合专家模型,解决相位混合引入的artifacts 2. IK后处理解决脚本问题 省:引入NN,不需要存储原始数据 | link |
基于生成的方法
生成 + 控制
(1) 无控制自回归生成模型
flowchart LR A([数据集])-->|"预训练"|C[先验模型] B([当前状态])--> C-->D([下一帧状态])
(2) 引入控制策略
flowchart LR A([控制目标])-->B([策略])--> D[先验模型]--> E([下一帧状态]) C([当前状态])--> D
flowchart LR A([当前状态])-->B[先验模型] B--> C([生成1])--> F B--> D([生成2])--> F B--> E([⋮])--> F B--> G([生成n])--> F F([选出下一帧])
| ID | Year | Title | 特点 |
|---|---|---|---|
| 136 | 2021.3.26 | Character Controllers Using Motion VAEs | 在给定足够丰富的运动捕捉片段集合的情况下,如何实现有目的性且逼真的人体运动 |
| 206 | 2024.8.16 | Interactive Character Control with Auto-Regressive Motion Diffusion Models (A-MDM) | A-MDM 136 中的 VAE 替换成了 MLP diffusion 并使用分层强化学习进行控制。 |
条件生成
flowchart LR A([当前状态])--> C B([控制目标])--> C C([条件])--> F[Diffusion]--> G([latent code]) --> H[Decoder]--> I([下一帧状态]) D([噪声])--> F E([t])-->F
- 难以在各种控制信号间进行泛化。
- 难以泛化到数据以外的动作。
- 支持多模态条件信号和任意损失引导。
- 能够实现更长期的目标和复杂任务。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 187 | 2025.5.30 | MotionPersona: Characteristics-aware Locomotion Control | 首个生成式角色控制器。实时交互 + 角色个性化 | 1. 输入:文本描述->CLIP->emb,SMPL beta,历史状态,未来轨迹,示例版本 (Optimal) 2. 模型:DiT 结构,每次 45 帧,单帧>60fps 3. 动作衔接:在噪声空间对生成的前 5 帧与最后一帧做平滑 4. 推理时基于对小样本对编码层和输出层微调(DreamBooth) 5. 数据集 | 多:个性化 快:实时推理 省:极少的定制化数据及微调时间 | |
| 205 | 2025.5.13 | DARTControl: A Diffusion-based Autoregressive Motion Model for Real-time Text-driven Motion Control | 自然语言的角色控制,条件为自然语言。 为了支持轨迹控制,额外引入控制方式,类似上文“生成 + 控制”方法。 | link | ||
| 204 | 2024.7.11 | AAMDM: Accelerated Auto-regressive Motion Diffusion Model | 使用 DDGAN 进行推断加速 | link | ||
| 177 | 2024.4.23 | Taming Diffusion Probabilistic Models for Character Control (CAMDM) | 这篇发表于 SIGGRAPH 2024 的论文聚焦基于扩散模型的实时角色控制,提出了条件自回归运动扩散模型(CAMDM),首次将运动扩散概率模型成功落地到实时交互式角色控制场景中。核心解决了传统扩散模型计算量大、可控性差、多样性不足的问题,实现了单模型支持多风格、实时响应用户控制、生成高质量且多样化的角色动画,同时能完成风格间的无缝过渡,是角色动画和运动生成领域的重要突破。 |
基于动力学的方法
核心特征:输出为关节力矩或 PD 控制目标,需要物理仿真器执行。
与运动学方法的区别:
| 维度 | 运动学方法 | 动力学方法 |
|---|---|---|
| 输出 | 关节姿态/速度 | 关节力矩/PD 控制目标 |
| 物理仿真 | 否 | 是 |
| 抗扰动能力 | 无 | 有 |
| 训练成本 | 低 | 高 |
| 实时性 | 高 | 中 |
mindmap
基于动力学的方法
参考学习
运动生成 + 运动模仿/sim2real
运动先验 + 下游控制
无参考的强化学习
设计规则作为先验
纯强化学习无先验
无参考的强化学习
优势:
(1) 能够生成新颖且符合物理规律的动作
(2) 数据依赖少
局限性:
(1) 开销问题
(2) 可扩展性问题
(3) 需要大量手工调优奖励函数,收敛速度慢,在步态切换、跳跃等复杂机动动作上难以实现稳定表现。
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 2007.7.29 | SIMBICON: simple biped locomotion control | ① 零力矩点(ZMP)方法依赖预计算轨迹,灵活性不足; ② 强化学习 / 策略搜索需设计复杂奖励函数,高维状态下难以收敛; ③ 数据驱动方法多为运动学建模,缺乏物理适应性。 | “有限状态机 + 全局坐标控制 + 质心反馈” 的极简组合,无需复杂动力学建模,实现实时、鲁棒的物理基双足运动生成 | link |
| ID | Paper | Note |
|---|---|---|
| 185 | Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion | 1. 单个循环策略同时学习站立、行走、奔跑及步态过渡,避免多策略架构的切换复杂度 2. 一种路由机制根据步态 ID 动态激活步态目标,核心解决不同步态的奖励目标冲突问题 3.让机器人自主学习符合人体生物力学的自然运动,摆脱对 MoCap 数据的依赖 4. 用于技能扩展的渐近式多阶段课程。 |
基于参考的学习,例如APM、模仿学习,动作空间还是来自于数据,物理只是一种动作合理化的方法。 优势:
- 物理的方法与数据的方法相结合,利用两种范式的优势,提升运动质量、多样性的泛化能力。
局限性: - 依赖高质量数据
- 存在数据角色与被驱动角色之间的形态不匹配
- 难以泛化到数据分布之外
运动先验 + 下游控制
类似于“生成 + 控制”
- 每个任务都需要单独训练策略
| ID | Year | Name | 解决了什么痛点 | 主要贡献是什么 | Tags | Link |
|---|---|---|---|---|---|---|
| 198 | 2022.5.12 | AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control | 模仿学习时,模仿目标需要精心设定,模仿效果的目标函数也难设定。 | 不模仿特定的动作,而是模仿目标动作的风格。通过对抗学习来判断模仿的风格像不像。 AMP 动作先验 = 对抗式判别器。 | link |
运动规划器 + 运动控制器 + 运动执行器(PD控制)
运动规划器:当前状态 + 控制目标 → 下一帧参考动画
运动控制器:下一帧参考动画 + 当前状态 → PD 控制目标
类似“可控生成 + 动作优化” 。
局限性:
- 规划器和控制器之间存在GAP,导致动作质量下降
- 控制策略难以准确跟踪规划的运动,需要微调,限制了其泛化能力
| ID | Paper | Note |
|---|---|---|
| 190 | DReCon: data-driven responsive control of physics-based characters | Motion Matching+RL 跟踪 +PD 执行 |
| 189 | PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers | 迭代数据扩增 |
| 188 | CLOSD: CLOSING THE LOOP BETWEEN SIMULATION AND DIFFUSION FOR MULTI-TASK CHARACTER CONTROL | Diffusion 规划器 +RL 跟踪器 |
(规划器, 控制器)+PD
由于规划器与控制器之间的 GAP,此文章开始尝试把它们统一到一个模型中
| ID | Paper | Note |
|---|---|---|
| 183 | Maskedmimic: Unified physics-based character control through masked motion | 掩码运动补全 |
| 192 | PDP: Physics-Based Character Animation via Diffusion Policy | RL 专家蒸馏 |
| 184 | UniPhys: Unified Planner and Controller with Diffusion for Flexible | 1. 把运动规划和控制整合到一个模型中,消除两个模型带来的 domaingap 2. 文本、目标、轨迹等多模态输入 3. Diffusion Forcing 范式进行训练,消除长期累计误差 4. 通过引导采样,无需 finetune,即可泛化到不同(包括没见过)的控制信号。 具体方法为行为克隆学习,先从动捕数据中提取状态 - 策略对,再用 diffusion 学习策略。 |
或者更直接一点,把PD也整合进一个模型,生成模型直接出力/力矩
| ID | Paper | Note |
|---|---|---|
| 186 | Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead | 直接生成力/力矩 |
控制 + 转移 + PD
与生成模型一样,数据也可以用于学状态转移,由RL来指导角色的控制性
| ID | Paper | Note |
|---|---|---|
| 191 | Universal Humanoid Motion Representations for Physics-Based Control | Prior+ 蒸馏 +RL |
运动执行器:
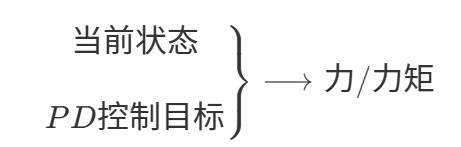
运动执行器可以是PD、PID等,图形学习里用的几乎都是PD。
所谓PD控制,实际不是控制器而是执行器。
PD控制器是传统方法,需要调 \(k_d\)、\(k_s\) 两个参数。用LQR可以计算出最能贴合目标的PD效果。
优点:
- 同“可控生成”
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/GAMES105_mdbook/