稳态误差问题(Steady-State Error)
✅ 本章定位:理解 PD 控制中稳态误差的产生原因、表现形式和解决方案。
一、什么是稳态误差
定义
稳态误差(Steady-State Error) 是指系统达到稳定状态后,实际输出与期望目标之间仍然存在的误差。
$$ e_{ss} = \lim_{t \to \infty} (q_{\text{des}}(t) - q_{\text{curr}}(t)) $$
PD 控制的稳态误差问题
PD 控制公式:
$$ \tau = k_p (\theta_{\text{des}} - \theta_{\text{curr}}) + k_d (\dot{\theta}{\text{des}} - \dot{\theta}{\text{curr}}) $$
核心问题:
- PD 控制需要误差才能产生力矩
- 当误差为零时,输出力矩也为零
- 但在有外力(如重力)的情况下,需要非零力矩才能维持平衡
二、直观例子:受重力影响的机械臂
问题演示
目标角度
↓
┌───┴───┐
│ 臂 │ ← 当前角度(受重力影响下垂)
└───┬───┘
↓
重力
现象:
- 机械臂永远无法精确达到目标角度
- 总会有一定的下垂误差
- 这个误差就是稳态误差
为什么会这样?
| 状态 | 误差 | PD 输出力矩 | 效果 |
|---|---|---|---|
| 达到目标角度 | \(e = 0\) | \(\tau = 0\) | 重力会让臂下垂 |
| 有下垂误差 | \(e > 0\) | \(\tau > 0\) | 产生力矩抵抗重力 |
| 平衡状态 | \(e_{ss} > 0\) | \(\tau = \tau_{\text{gravity}}\) | 力矩平衡重力 |
结论:稳态误差是 PD 控制器为了产生抵抗外力的力矩所必须的。
三、在角色动画中的表现
Motion Falls Behind Reference
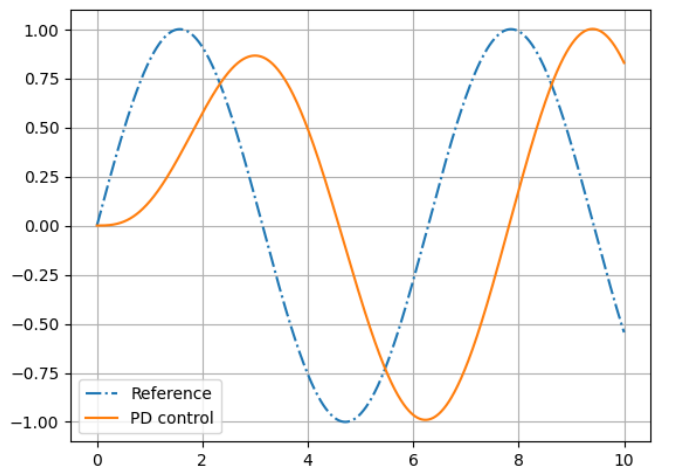
现象:
- 角色的实际运动总是滞后于参考轨迹
- 就像角色在"追赶"参考动作,但永远追不上
原因分析
$$ \tau = k_p (q_{\text{des}} - q_{\text{curr}}) + k_d (\dot{q}{\text{des}} - \dot{q}{\text{curr}}) $$
| 项 | 说明 |
|---|---|
| \(k_p (q_{\text{des}} - q_{\text{curr}})\) | 比例项,需要误差才能产生力 |
| \(k_d (\dot{q}{\text{des}} - \dot{q}{\text{curr}})\) | 微分项,只在速度变化时有效 |
问题:
- 需要 \(q_{\text{des}} - q_{\text{curr}} > 0\) 才能产生力矩
- 所以角色永远无法精确达到目标位置
四、稳态误差与欠驱动问题的关系
两个问题的根本原因
✅ 前面两个问题的根本原因是相同的:需要有误差才能计算 force,有了 force 才能控制。
| 问题 | 表现形式 | 本质原因 |
|---|---|---|
| 稳态误差 | 动作滞后于参考轨迹 | 需要误差才能产生力矩 |
| 欠驱动问题 | 无法直接控制质心位置 | 关节力矩合力为零 |
共同点
- 都源于 PD 控制的被动性
- 都需要外力/误差才能产生控制效果
- 都不能精确跟踪任意轨迹
五、解决方案
方案 1:增大 \(k_p\)
思路:用更大的增益来减小误差
$$ \tau = k_p \cdot e + k_d \cdot \dot{e} $$
效果:
- \(k_p\) 越大,稳态误差越小
- 但 \(k_p\) 过大会有问题
局限性:
| 问题 | 原因 |
|---|---|
| 数值不稳定 | 高增益需要非常小的时间步长 |
| 动作僵硬 | 关节过于"紧绷",失去自然感 |
| 计算成本高 | 需要更高的仿真频率(1000-2000Hz) |
典型设置:
对于 50kg 角色:k_p = 200, k_d = 20
轻量角色:需要更小的增益
动态动作:需要更大的增益
方案 2:隐式欧拉(Stable PD)
核心思想:使用隐式积分来提高数值稳定性。
标准 PD(显式欧拉): $$ \tau_{\text{int}} = -K_p(q^n + \dot{q}^n \Delta t - \bar{q}^{n+1}) - K_d(\dot{q}^n + \ddot{q}^n \Delta t) $$
Stable PD(隐式欧拉):
- 使用下一时刻的状态计算力矩
- 允许更大的 \(k_p\) 和更大的时间步长
- 可以在 60-120Hz 下稳定运行
效果对比:
| 方法 | 时间步长 | 频率 | 稳定性 |
|---|---|---|---|
| 标准 PD | 0.5-1ms | 1000-2000Hz | 高增益不稳定 |
| Stable PD | 1/60-1/120s | 60-120Hz | 高增益稳定 |
方案 3:前馈补偿(Feedforward Compensation)
核心思想:预先计算需要抵消的外力,直接加到控制输出中。
$$ \tau = \underbrace{k_p e + k_d \dot{e}}{\text{反馈}} + \underbrace{\tau{\text{feedforward}}}_{\text{前馈}} $$
前馈力矩计算: $$ \tau_{\text{feedforward}} = M(q)\ddot{q}_{\text{des}} + C(q, \dot{q}) + G(q) $$
其中:
- \(M(q)\):质量矩阵
- \(C(q, \dot{q})\):科里奥利力/离心力
- \(G(q)\):重力项
效果:
- 前馈项负责抵消已知外力
- 反馈项只负责跟踪误差
- 可以显著减小稳态误差
方案 4:添加积分项(PID 控制)
核心思想:累积历史误差,即使当前误差为零也能产生力矩。
$$ \tau = k_p e + k_d \dot{e} + k_i \int e , dt $$
积分项的作用:
- 累积过去的误差
- 即使 \(e = 0\),积分项仍可能非零
- 可以产生持续力矩抵抗重力
局限性:
- 在角色动画中很少使用
- 积分饱和问题
- 可能导致振荡
六、相关工作
Wampler et al. - Stable PD
$$ \tau_{\text{int}} = -K_p(q^n + \dot{q}^n \Delta t - \bar{q}^{n+1}) - K_d(\dot{q}^n + \ddot{q}^n \Delta t) $$
贡献:
- 使用隐式欧拉积分
- 允许更大的时间步长
- 提高数值稳定性
Mixture of Simulation and Mocap
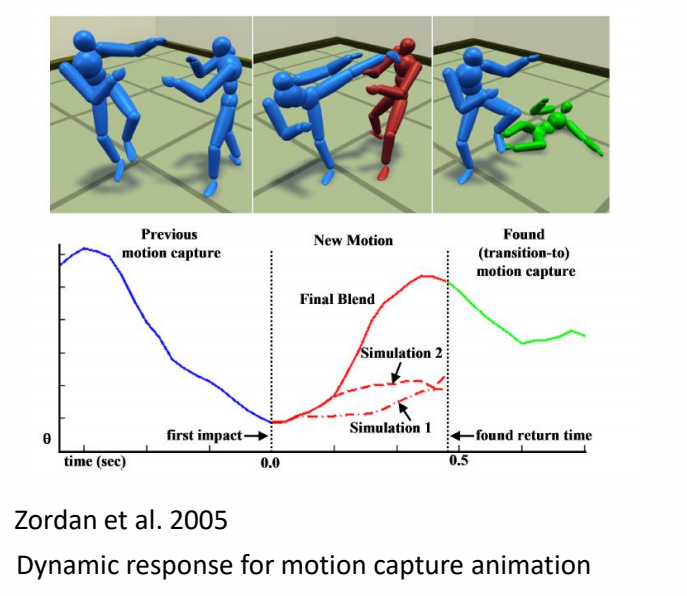
核心思想:关键帧与仿真的混合
- 用 mocap 提供目标轨迹
- 用仿真保证物理可行性
- 通过轨迹优化减小稳态误差
七、稳态误差 vs. 欠驱动问题
虽然两个问题都源于 PD 控制的局限性,但它们是不同的问题:
| 维度 | 稳态误差 | 欠驱动问题 |
|---|---|---|
| 本质 | 控制器设计问题 | 系统结构问题 |
| 原因 | 需要误差才能产生力矩 | 无法直接控制所有自由度 |
| 表现 | 动作滞后 | 质心不可控 |
| 解决 | 增大 \(k_p\)、前馈补偿 | 净外力、动量控制 |
| 是否可消除 | 可以(用前馈) | 不可以(系统特性) |
八、关键要点总结
-
稳态误差是 PD 控制的固有特性
- 需要误差才能产生力矩
- 有外力时必然存在稳态误差
-
在角色动画中的表现
- 动作滞后于参考轨迹
- Motion falls behind reference
-
解决方案
- 增大 \(k_p\):简单但有上限
- Stable PD:提高数值稳定性
- 前馈补偿:最有效,但需要模型
- PID:少用,可能振荡
-
与欠驱动问题的区别
- 稳态误差:控制器设计问题
- 欠驱动:系统结构问题
✅ 与前向/后向动力学的关系:
- 前向动力学:给定力求运动(仿真器)
- 后向动力学:给定运动求力(控制器)
- 稳态误差是后向动力学中的问题
📚 深入学习:
- Controlling Characters - PD 控制在角色上的应用
- 欠驱动系统问题 - PD 控制的另一个挑战
- 轨迹优化 - 通过优化目标轨迹来减小误差
本文出自 CaterpillarStudyGroup,转载请注明出处。 https://caterpillarstudygroup.github.io/GAMES105_mdbook/