PD 控制
✅ 本章定位:理解如何设计和应用 PD 控制器,将目标状态转换为关节力矩。
在控制系统中的位置
flowchart TD
subgraph "高层:任务规划"
A["做什么动作?<br/>有限状态机、行为树"]
end
subgraph "中层:轨迹生成/策略学习"
B["如何生成目标动作?<br/>轨迹优化、DeepMimic、AMP"]
end
subgraph "底层:执行控制 (本章)"
C["如何计算关节力矩?<br/>PD 控制"]
end
subgraph "仿真器"
D["物理仿真<br/>Mv̇ + C = f + Jᵀλ"]
end
A -->|动作指令 | B
B -->|目标状态 q*, q̇* | C
C -->|关节力矩 τ | D
D -->|当前状态 q, q̇ | C
D -->|新状态 | A
| 层次 | 功能 | 典型方法 |
|---|---|---|
| 高层 | 任务规划:决定做什么动作 | 有限状态机、行为树 |
| 中层 | 轨迹生成:输出目标状态 \(q^, \dot{q}^\) | 轨迹优化、DeepMimic、AMP |
| 底层 | 执行控制:计算关节力矩 \(\tau\) | PD 控制 |
PD 控制的输入输出:
- 输入:目标状态 \(q^, \dot{q}^\) + 当前状态 \(q, \dot{q}\)
- 输出:关节力矩 \(\tau\) → 送入仿真器
与仿真器的关系
| 模块 | 输入 | 输出 | 核心问题 |
|---|---|---|---|
| 控制器 | 目标状态/轨迹 + 当前状态 | 关节力矩 τ | 如何生成力矩让角色达到目标? |
| 仿真器 | 关节力矩 τ + 外力 | 新状态 | 给定力矩,角色会如何运动? |
分工说明:
- 控制器是「逆向问题」:从目标反推力矩
- 仿真器是「前向问题」:从力矩推算运动
✅ 详细讲解见 角色物理仿真基础
本章内容导航
| 文件 | 内容 |
|---|---|
| 关节力矩 | 什么是关节力矩 - 物理定义与数学推导 - 为什么需要关节力矩(vs. 外力) - 在运动方程中的位置 |
| Proportional-Derivative Control | PD 控制理论基础 - 简化例子:物体上下移动 - P 控制、PD 控制、PID 控制 - Stable PD(隐式欧拉) |
| Controlling Characters | PD 在角色上的应用 - 参数调优(\(k_p\)、\(k_d\)) - 欠驱动问题与净外力 - 稳态误差问题 |
| Static Balance | 静态平衡专题 - 支撑面与质心 - PD 控制策略 - Jacobian Transpose Control |
本章重点问题
-
PD 参数如何调优?
- \(k_p\) 太小:无法达到目标
- \(k_p\) 太大:角色僵硬
- \(k_d\) 太小:振荡
- \(k_d\) 太大:响应慢
-
欠驱动系统如何处理?
- 人形角色是欠驱动系统(无法直接控制质心位置)
- 解决方案:净外力(root force/torque)
-
稳态误差如何解决?
- PD 控制需要误差才能产生力
- 解决方案:增大 \(k_p\) 或使用前馈补偿
-
如何保证数值稳定性?
- 高增益需要小时间步长
- 解决方案:隐式欧拉(Stable PD)
补充概念
Fully-Actuated vs. Underactuated
在上一节中,\(f\) 与 \(V\) 的自由度可能是不同的。\(f\) 是关节数\( × 3\),\(V\) 是刚体数\( × 3\)。
 |  |
| If #actuators ≥ #dofs, the system is fully-actuated | If #actuators < #dofs, the system is underactuated |
| For any \([x,v,\dot{v} ]\), there exists an \(f\) that produces the motion | For many \([x,v,\dot{v} ]\) , there is no such \(f\) that produces the motion |
| ✅ 可以精确控制机械臂到达目标状态。 | ✅ 不借助外力情况,人无法控制 Hips 的状态(位置)。 |
✅ #actuators:\(f \) 和 \(\tau \) 的自由度。 ✅ #dofs:角色状态的自由度。 ✅ 避免让角色掉入无法控制的状态。
✅ 深入学习:欠驱动系统问题 - 详细讲解人形角色为什么是欠驱动系统以及解决方案。
Feedforward vs. Feedback
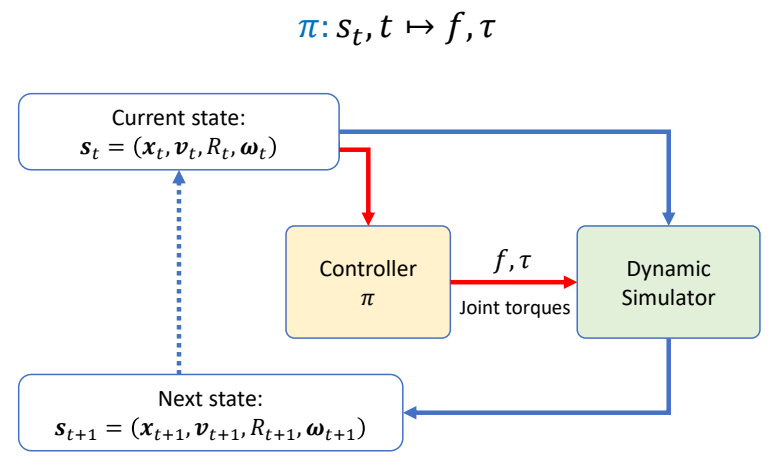
驱动角色运动的控制器是通过优化目标函数产生的。
| Feedforward control | Feedback control |
|---|---|
| \(f,\tau =\pi (t)\) | \(f,\tau =\pi (s_t,t)\) |
| Apply predefined control signals without considering the current state of the system | Adjust control signals based on the current state of the system |
| Assuming unchanging system. | Certain perturbations are expected. |
| Perturbations may lead to unpredicted results ✅ 如果角色受到挠动而偏离了原计划,无法修正回来。 | The feedback signal will be used to improves the performance at the next state. |