轨迹优化
✅ 本章定位:理解如何通过优化方法生成物理可行的目标轨迹,供 PD 控制器跟踪。
在控制系统中的位置
flowchart TD
subgraph "高层:任务规划"
A["做什么动作?<br/>有限状态机、行为树"]
end
subgraph "中层:轨迹生成 (本章)"
B["如何生成目标动作?<br/>轨迹优化、DeepMimic、AMP"]
end
subgraph "底层:执行控制"
C["如何计算关节力矩?<br/>PD 控制"]
end
subgraph "仿真器"
D["物理仿真<br/>Mv̇ + C = f + Jᵀλ"]
end
A -->|动作指令 | B
B -->|目标状态 q*, q̇* | C
C -->|关节力矩 τ | D
D -->|当前状态 q, q̇ | C
轨迹优化的输入输出:
- 输入:参考轨迹 ((q^{\text{ref}}, \dot{q}^{\text{ref}})) + (可选)当前状态
- 输出:目标轨迹 ((q^, \dot{q}^)) + 控制轨迹 ((\tau^*)) → 送入 PD 控制器
与 PD 控制的关系:
- 轨迹优化输出目标轨迹 ((q^, \dot{q}^)) → PD 控制的目标
- 轨迹优化输出控制轨迹 ((\tau^*)) → PD 控制的前馈项
- PD 控制计算力矩:(\tau = \tau^* + k_p(q^* - q) + k_d(\dot{q}^* - \dot{q}))
轨迹优化的输入来源
轨迹优化需要参考轨迹作为输入,参考轨迹主要有三类来源:
| 输入来源 | 说明 | 特点 |
|---|---|---|
| 动作捕捉(Mocap) | 从真实演员捕捉的运动数据 | 真实自然,但可能物理不可行 |
| 运动学方法生成 | Motion Matching、PFNN、扩散模型等 | 数据驱动、实时生成,但无物理约束 |
| 动画师制作 | 手工关键帧动画 | 艺术可控,但耗时、可能不符合物理 |
轨迹优化的作用:
- 对上述输入进行物理修正
- 使其满足动力学约束(运动方程、接触约束等)
- 输出物理可行的目标轨迹供 PD 控制跟踪
flowchart LR
Input["输入:<br/>Mocap / 运动学方法 / 关键帧"] --> Opt["轨迹优化<br/>(物理修正)"]
Opt --> PD["PD 控制"]
PD --> Sim["物理仿真"]
✅ 本章聚焦轨迹优化:理解如何通过优化方法对参考轨迹进行物理修正。
四种轨迹的关系
轨迹优化涉及四种轨迹,它们的关系如下:
| 概念 | 符号 | 是什么 | 优化前/后 | 角色 |
|---|---|---|---|---|
| 参考轨迹 | ((q^{\text{ref}}, \dot{q}^{\text{ref}})) | 动捕/运动学方法/动画师提供的原始轨迹 | 优化前 | 轨迹优化的输入 |
| 状态轨迹 | ((q, \dot{q})) | 角色在每一帧的实际状态(位置 + 速度) | 通用术语 | 可指任何轨迹 |
| 目标轨迹 | ((q^, \dot{q}^)) | 轨迹优化后得到的物理可行轨迹 | 优化后 | 轨迹优化的输出 → PD 控制的目标 |
| 控制轨迹 | ((\tau)) | 每一帧的关节力矩序列 | 优化后 | 轨迹优化的输出 → PD 控制的前馈项 |
完整流程
参考轨迹 (q^ref, q̇^ref) ← 来自动捕/运动学方法/动画师
↓
轨迹优化(物理修正)
↓
├──→ 目标轨迹 (q*, q̇*) → 送给 PD 控制器作为目标
└──→ 控制轨迹 (τ*) → 送给 PD 控制器作为前馈项
关键对比
| 参考轨迹 | 目标轨迹 | 控制轨迹 | |
|---|---|---|---|
| 是什么 | "期望的动作" | "修正后的可行动作" | "产生动作需要的力" |
| 物理可行性 | ❌ 可能不可行 | ✅ 可行 | ✅ 可行 |
| 送给谁 | 轨迹优化 | PD 控制器 | PD 控制器(前馈) |
| 类比 | 设计师的设计图 | 工程师的施工图 | 施工用的材料清单 |
为什么需要轨迹优化
直接用 PD 控制跟踪动捕数据会有很大问题:
| 问题 | 原因 | 表现 |
|---|---|---|
| 稳态误差 | PD 控制需要误差才能产生力矩 | 动作滞后于参考轨迹 |
| 相位漂移 | 运动轨迹与原轨迹之间存在相位差 | 动作节奏不匹配 |
| 欠驱动问题 | 人形角色缺少对根节点的直接控制 | 质心位置无法直接控制 |
✅ 深入学习:欠驱动系统问题 - 详细讲解欠驱动系统的挑战和解决方案。
轨迹优化的作用:
- 在 mocap 基础上添加修正量,使其物理可行
- 引入轨迹优化之后,控制本质上变成了设计 target state
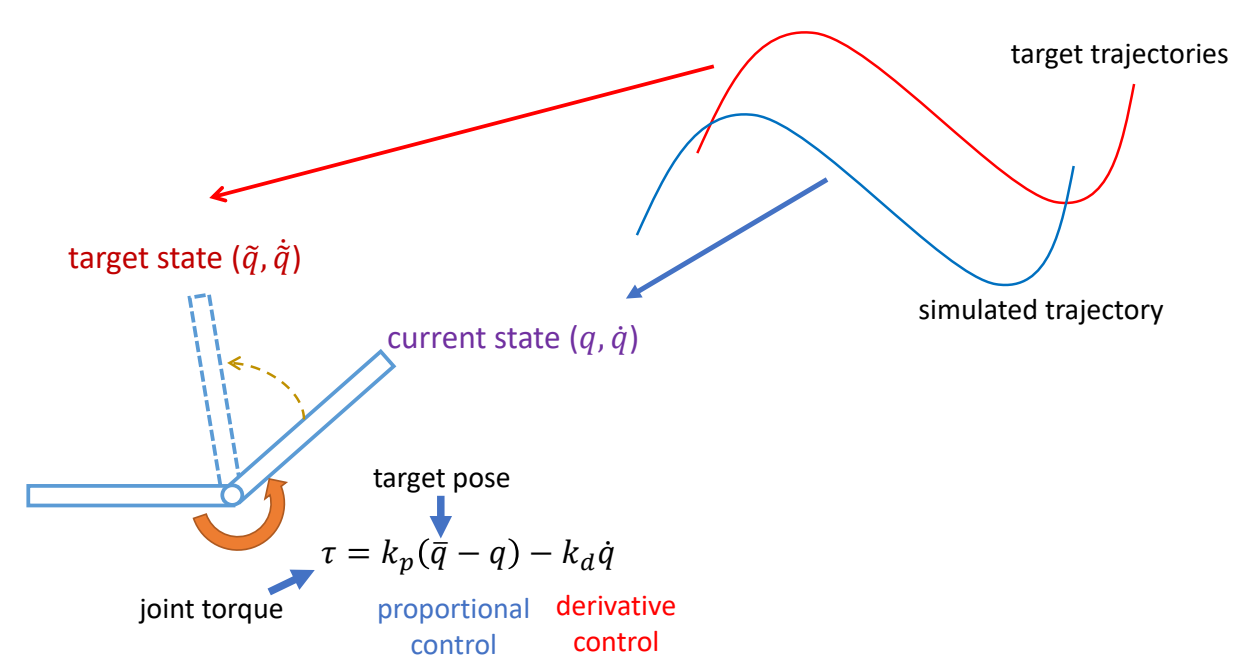
📖 数学形式化描述:详见 数学形式化描述 - 轨迹优化问题的完整数学描述。
本文出自 CaterpillarStudyGroup,转载请注明出处。 https://caterpillarstudygroup.github.io/GAMES105_mdbook/