六、优化方法分类概览
轨迹优化方法可以从多个维度进行分类,详细的对比和分类请参见:方法对比与分类。
简要总结:
| 维度 | 分类 | 代表方法 |
|---|---|---|
| 优化时机 | 离线 vs. 在线 | CMA-ES/iLQR/DDP vs. MPC/SAMCON |
| 求解方法 | 解析法 vs. 数值法 vs. 学习法 | LQR vs. iLQR/DDP/CMA-ES vs. DeepMimic/AMP |
| 梯度需求 | 基于梯度 vs. 无梯度 | iLQR/DDP vs. CMA-ES/SAMCON |
七、与 DeepMimic/AMP 的关系
| 维度 | 轨迹优化 | DeepMimic/AMP |
|---|---|---|
| 输出 | 单一轨迹 \(\mathbf{x}_{0:T}\) | 策略 \(\pi(\mathbf{a} |
| 计算时机 | 离线优化(每任务一次) | 训练一次,在线推理 |
| 泛化能力 | 无(仅适用于该轨迹) | 有(可处理新情况) |
| 计算成本 | 高(分钟级) | 低(毫秒级推理) |
| 适用场景 | 特定动作生成 | 通用角色控制 |
关系:
- 轨迹优化结果可作为 RL 的参考轨迹
- RL 可学习模仿轨迹优化的行为
八、关键要点总结
-
优化变量:状态轨迹 \(\mathbf{x}{0:T}\) + 控制轨迹 \(\mathbf{u}{0:T-1}\)
-
目标函数:
- 终端代价 \(J_T(\mathbf{x}_T)\)
- 运行代价 \(\sum J_t(\mathbf{x}_t, \mathbf{u}_t)\)
- 常见项:跟踪误差、控制 effort、平滑项
-
约束条件:
- 动力学约束(运动方程)
- 接触约束(不穿透、摩擦锥)
- 控制/状态限制
-
方法选择建议:
- 线性系统 → LQR
- 平滑非线性 → iLQR/DDP
- 接触频繁/不可微 → CMA-ES
- 实时控制 → MPC/SAMCON
- 需要泛化 → DeepMimic/AMP
📚 深入学习:
P3
Recap
| feedforward | feedback |
|---|---|
 |  |
 |  |
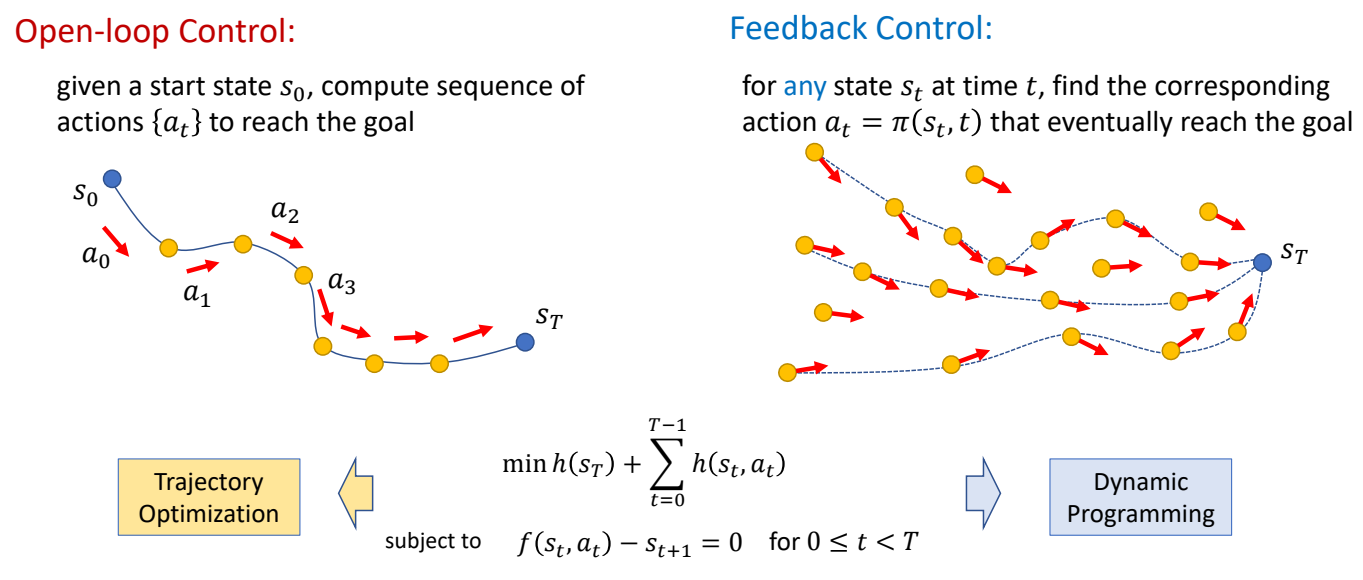
✅ 开环控制:只考虑初始状态。 ✅ 前馈控制:考虑初始状态和干挠。 ✅ 前馈控制优化的是轨迹。 ✅ 反馈控制优化的是控制策略,控制策略是一个函数,根据当前状态优化轨迹。
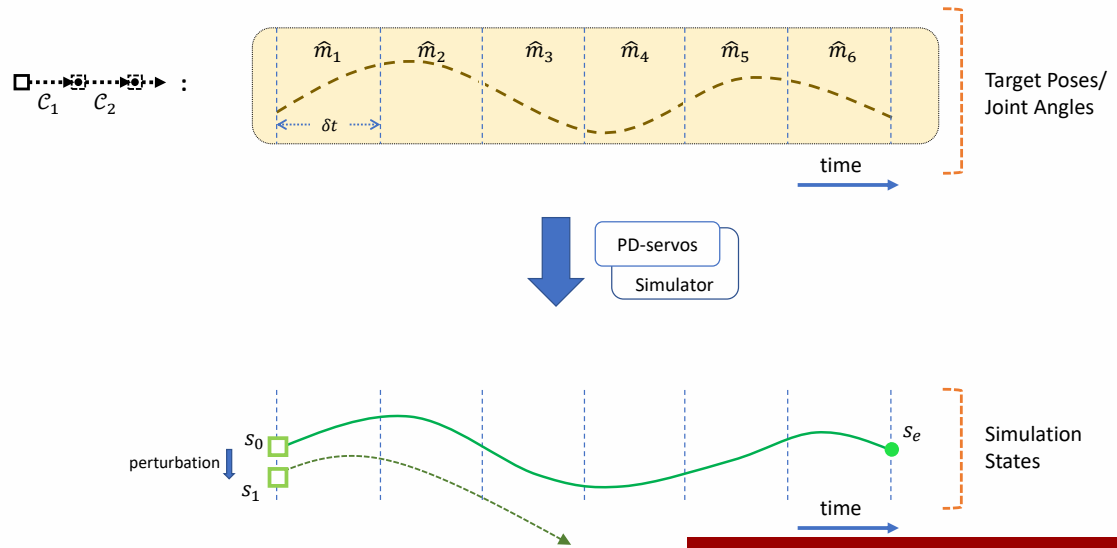
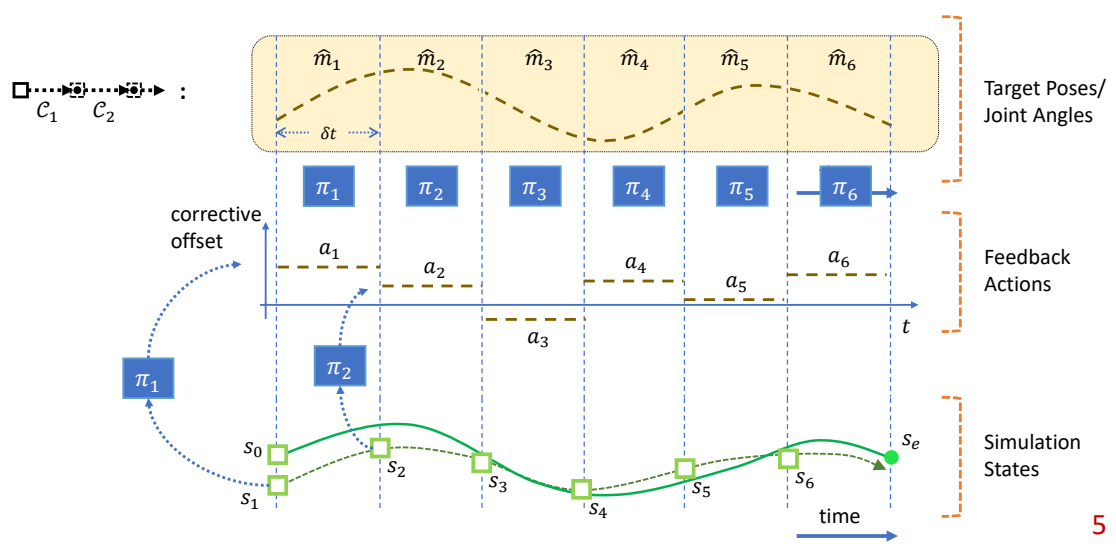
P9
✅ Feedback 类似构造一个场,把任何状态推到目标状态。
P10
开环控制
问题描述
$$ \begin{matrix} \min_{x} f(x)\ 𝑠.𝑡. g(x)=0 \end{matrix} $$

P12
把硬约束转化为软约束
$$ \min_{x} f(x)+ wg(x) $$
(^*) The solution (x^\ast) may not satisfy the constraint
P16
Lagrange Multiplier - 把约束条件转化为优化
✅ 拉格朗日乘子法。
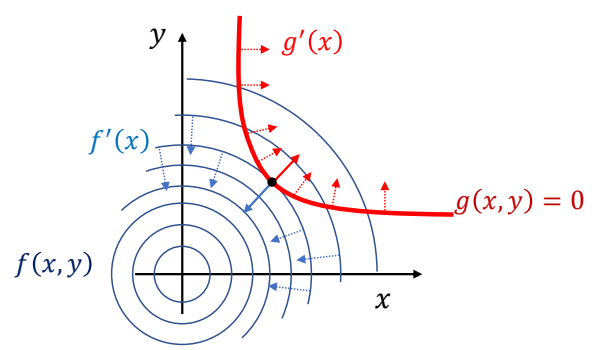
✅ 通过观察可知,极值点位于({f}'(x)) 与 (g) 的切线垂直,即 ({f}' (x)) 与 ({g}' (x)) 平行。(充分非必要条件。)
因此:

Lagrange function
$$ L(x,\lambda )=f(x)+\lambda ^Tg(x) $$
✅ 把约束条件转化为优化。
P18
Lagrange Multiplier
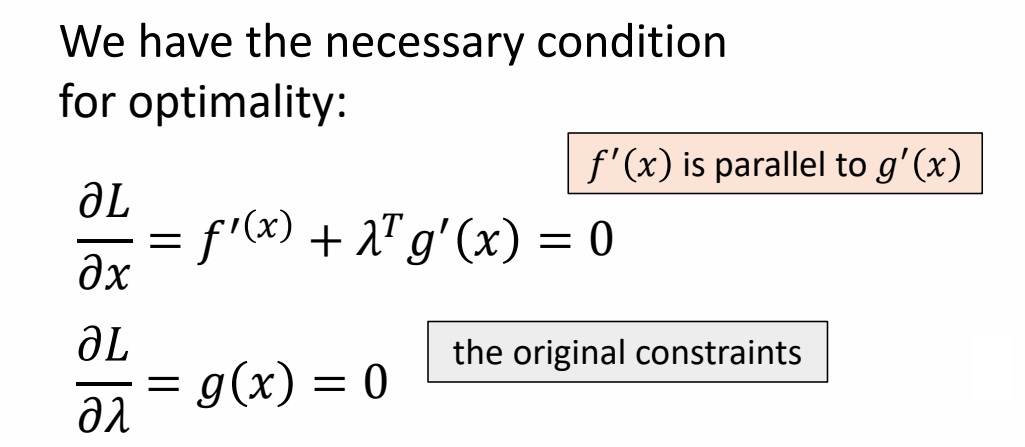
✅ 这是一个优化问题,通过梯度下降找到极值点。
P20
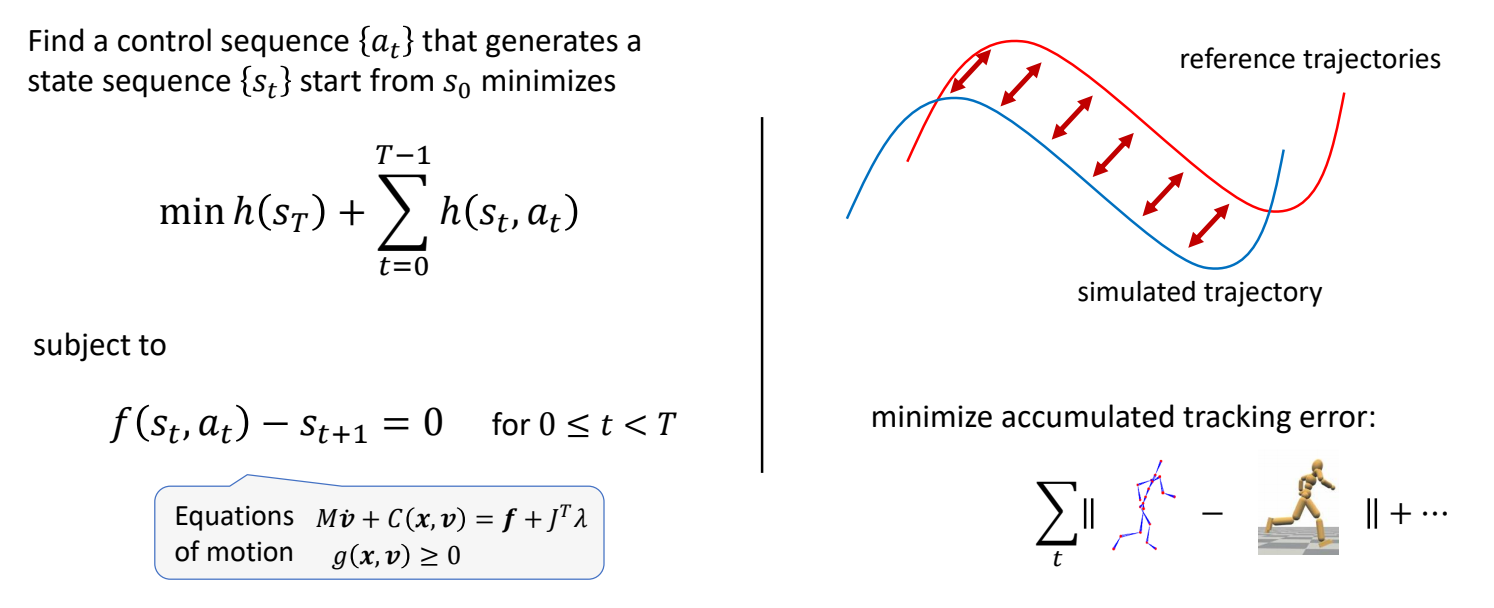
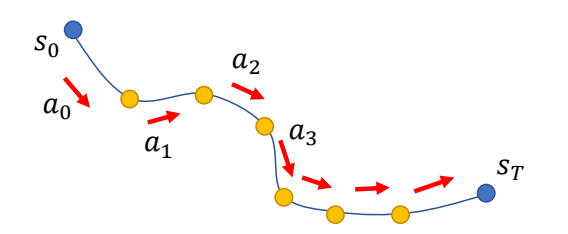
Solving Trajectory Optimization Problem
定义带约束的优化问题
Find a control sequence {(a_t)} that generates a state sequence {(s_t)} start from (s_o) minimizes
$$ \min h (s_r)+\sum _{t=0}^{T-1} h(s_t,a_t) $$
✅ 因为把时间离散化,此处用求和不用积分。
subject to
$$ \begin{matrix} f(s_t,a_t)-s_{t+1}=0\ \text{ for } 0 \le t < T \end{matrix} $$
✅ 运动学方程,作为约束
转化为优化问题
The Lagrange function
$$ L(s,a,\lambda ) = h(s _ T)+ \sum _ {t=0} ^ {T-1} h(s _t,a _t) + \lambda _ {t+1}^T(f(s _t,a _t) - s _ {t+1}) $$
P27
求解拉格朗日方程
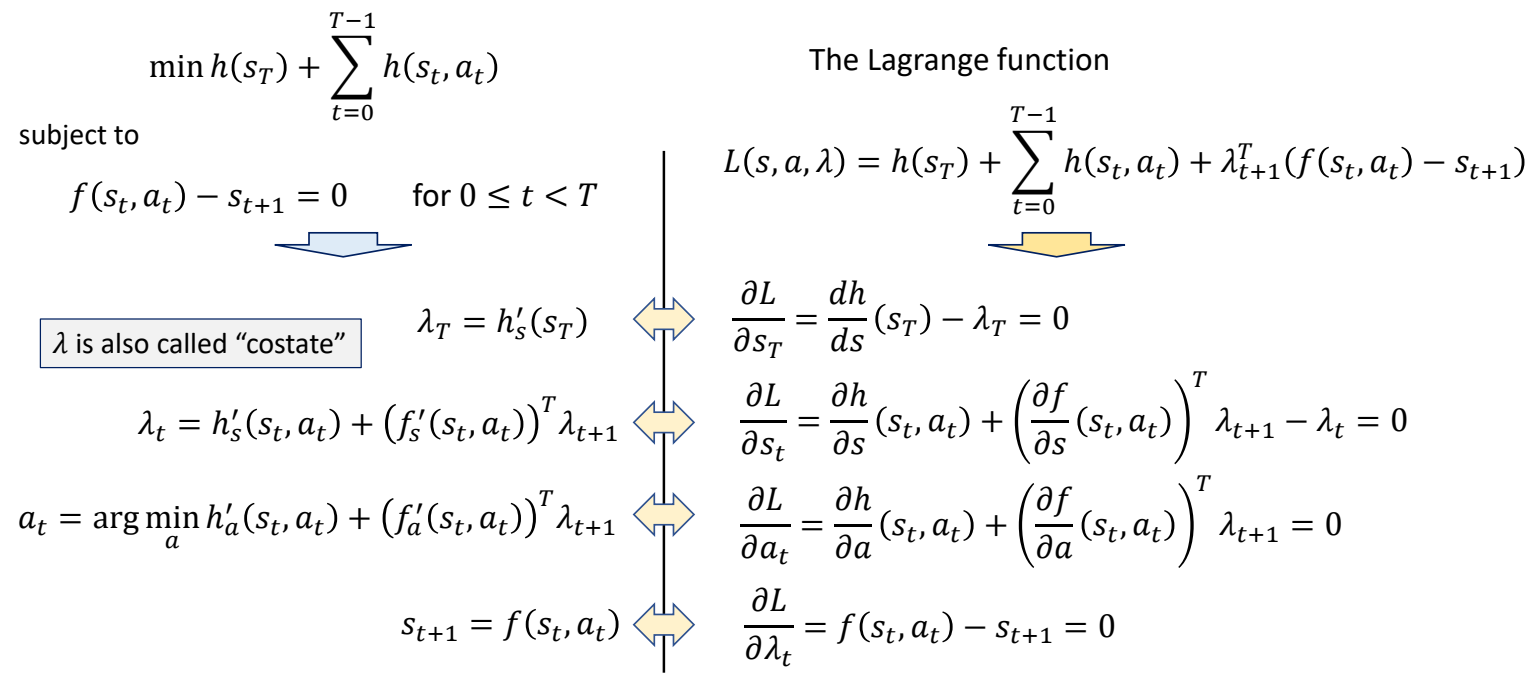
✅ 拉格朗日方程,对每个变量求导,并令导数为零。因此得到右边方程组。 ✅ 右边方程组进一步整理,得到左边。 ✅ (\lambda ) 类似于逆向仿真。 ✅ 公式 3:通过转为优化问题求 (a).
P30
Pontryagin's Maximum Principle for discrete systems

✅ 方程组整理得到左边,称为 PMP 条件。是开环控制最优的必要条件。
P32
Optimal Control
Open-loop Control: given a start state (s_0), compute sequence of actions {(a_t)} to reach the goal
Shooting method directly applies PMP. However, it does not scale well to complicated problems such as motion control… (
) Need to be combined with collocation method, multiple shooting, etc. for those problems. (
) Or use derivative-free approaches.
✅ 对于复杂函数,表现比较差,还需要借助其它方法。
闭环控制
P34 P49
The Bellman Equation
Mathematically, an optimal value function (V(s)) can be defined recursively as:
$$ V(s)=\min_{a} (h(s,a)+V(f(s,a))) $$
✅ h 代表 s 状态下执行一步 a 的代价。f 代表 s 状态下执行一步 a 之后的状态。
If we know this value function, the optimal policy can be computed as
$$ \pi (s)=\arg \min_{a} (h(s,a)+V(f(s,a))) $$
✅ pi 代表一种策略,根据当前状态 s 找到最优的下一步 a。 ✅ This arg max can be easily computed for discrete control problems. But there are not always closed-forms solution for continuous control problems.
or
$$ \begin{matrix} \pi (s)=\arg \min_{a} Q(s,a)\ \text{where} \quad \quad Q(s,a)=h(s,a)+V(f(s,a)) \end{matrix} $$
Q-function 称为 State-action value function Learning (V(s)) and/or (Q(s,a)) is the core of optimal control / reinforcement learning methods
✅ 强化学习最主要的目的是学习 (V) 函数和 (Q) 函数,如果 (a) 是有限状态,遍历即可。但在角色动画里,(a) 是连续状态。
动态规划推导(逆向归纳法)
✅ 由于存在最优子结构(optimal substructure),可以从最后一步往前推导:
- 每一步只需要考虑从当前状态到终点的最优解
- 最后一个状态的 Value 计算与 \(a\) 无关
- 计算完最后一步,再计算倒数第二步,依次往前推
Value Function 的形式
假设从时刻 \(t\) 到终点的最优代价(Value Function)具有二次形式:
$$ V _t(s) = s ^T P _t s $$
其中 \(P _t\) 是对称矩阵。
本文出自 CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/GAMES105_mdbook/