Linear Quadratic Regulator (LQR)
✅ LQR 是控制领域一类经典问题,它对原控制问题做了一些特定的约束。因为简化了问题。
$$ \min _{\mathbf{x} _{0:T}, \mathbf{u} _{0:T-1}} J(\mathbf{x}, \mathbf{u}) \quad \text{s.t.} \quad \mathbf{x} _{t+1} = f(\mathbf{x} _t, \mathbf{u} _t) $$
| 假设 | 一般问题 | LQR问题的数学形式 |
|---|---|---|
| 动力学 | 非线性:\(f(x,u)\) 是任意非线性函数 | 线性动力学 \(x _{t+1} = A _t x _t + B _t u _t\) |
| 目标函数 | 任意形式:\(J(x,u)\) 可能非凸、非二次 | 二次目标函数 \(J = x _T^T Q _T x _T + \sum (x _t^T Q _t x _t + u _t^T R _t u _t)\) |
| 效果 | 很难直接求解,需要数值方法 | 状态转移是线性的,代价是状态和控制的二次函数。问题有闭式解(解析解),无需数值迭代! |
LQR 的标准形式
目标函数:
$$ \min s ^T _T Q _T s _T+\sum _{t=0}^{T} s ^T _t Q _t s _t + a ^T _t R _t a _t $$
约束条件(动力学方程):
$$ s _{t+1}=A _t s _t+B _t a _t \quad \text{for } 0\le t <T $$
其中:
- \(s _t\):状态向量(state)
- \(a _t\):控制输入(action/control)
- \(A _t, B _t\):线性化后的系统矩阵
- \(Q _t, R _t\):代价权重矩阵
从轨迹优化到 LQR
如何从一般问题得到 LQR 形式
核心思想:在当前轨迹附近局部近似
一般轨迹优化问题
↓
在当前轨迹 (x̄, ū) 附近线性化
↓
δx_{t+1} = A·δx_t + B·δu_t (线性化动力学)
↓
J ≈ δx^T Q δx + δu^T R δu (二次近似)
↓
LQR 问题(有闭式解)
1. 动力学线性化
在标称轨迹 \((\bar{x}, \bar{u})\) 附近做一阶泰勒展开:
$$ f(x,u) \approx f(\bar{x},\bar{u}) + \underbrace{\frac{\partial f}{\partial x}}\ _{A}(x-\bar{x}) + \underbrace{\frac{\partial f}{\partial u}}\ _{B}(u-\bar{u}) $$
定义偏差变量:\(\delta x = x - \bar{x}, \quad \delta u = u - \bar{u}\)
得到线性化动力学:
$$ \delta x _{t+1} = A _t \delta x _t + B _t \delta u _t $$
其中 \(A _t = \frac{\partial f}{\partial x}| _{(\bar{x} _t,\bar{u} _t)}, \quad B _t = \frac{\partial f}{\partial u}| _{(\bar{x} _t,\bar{u} _t)}\)
2. 目标函数二次化
对目标函数做二阶泰勒展开(忽略常数项和一阶项):
$$ J \approx \frac{1}{2}\delta x ^T Q \delta x + \frac{1}{2}\delta u ^T R \delta u $$
其中 \(Q = \frac{\partial ^2 J}{\partial x ^2}, \quad R = \frac{\partial ^2 J}{\partial u ^2}\)
3. 求解 LQR
得到标准 LQR 问题:
$$ \min _{\delta u} \frac{1}{2}\delta x ^T Q \delta x + \frac{1}{2}\delta u ^T R \delta u \quad \text{s.t.} \quad \delta x _{t+1} = A \delta x + B \delta u $$
最优解:
$$ \delta u ^* = -K \delta x $$
其中 \(K\) 通过 Riccati 方程求解。
4. 迭代直到收敛(iLQR 思想)
✅ 详细内容见:iLQR
| 步骤 | 操作 |
|---|---|
| 1 | 猜测初始轨迹 \((\bar{x}, \bar{u})\) |
| 2 | 线性化动力学:计算 \(A, B\) |
| 3 | 二次化目标:计算 \(Q, R\) |
| 4 | 求解 LQR:得到 \(\delta u ^* = -K \delta x\) |
| 5 | 更新轨迹:\(x \leftarrow \bar{x} + \delta x, u \leftarrow \bar{u} + \delta u\) |
| 6 | 重复 2-5 直到收敛 |
关键理解:
- LQR 本身只适用于线性系统
- 但通过迭代线性化,可以用 LQR 求解非线性问题(iLQR)
- 因此 LQR 是理解 iLQR、DDP 等高级方法的基础
简单例子:方块跟踪正弦曲线
问题描述
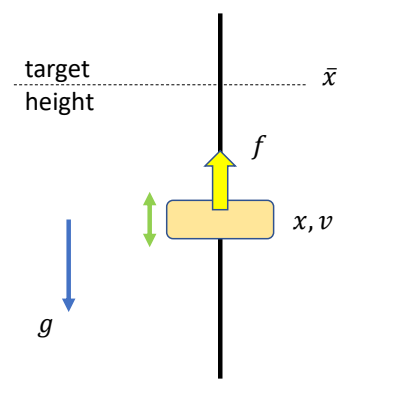
计算一条目标轨迹 \(\tilde{x}(t)\),使得仿真轨迹 \(x(t)\) 是正弦曲线。
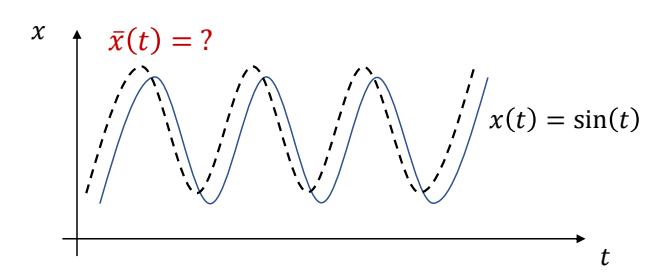
✅ 目标函数是关于优化对象 \(x _n\) 的二次函数。
$$ \min _{(x _n,v _n,\tilde{x} _n)} \sum _{n=0}^{N} (\sin (t _n)-x _n)^2+\sum _{n=0}^{N}\tilde{x} ^2 _n $$
✅ 运动学方程中的 \(x _{n+1}\)、\(v _{n+1}\) 与上一帧状态 \(x _n\)、\(v _n\) 是线性关系。
$$ \begin{aligned} s.t. \quad \quad v _ {n+1} & = v _ n + h(k _p ( \tilde{x} _ n - x _ n) - k _ dv _ n ) \\ x _ {n+1} & = x _ n + hv _ {n+1} \end{aligned} $$
✅ 这是一个典型的 LQR 问题。
动态规划(Dynamic Programming)
LQR 问题使用动态规划方法求解。这部分解释三个核心概念:
1. 什么是动态规划问题?为什么要用动态规划?
动态规划(Dynamic Programming, DP) 是一种求解多阶段决策问题的方法,适用于可以将问题分解为多个 sequential steps 的场景。
为什么 LQR 要用动态规划?
| 原因 | 说明 |
|---|---|
| 问题结构匹配 | LQR 是多阶段决策问题:每个时间步都要选择控制输入 \(a_t\) |
| 全局最优分解 | 动态规划将"找最优轨迹"这个全局问题分解为"每步选最优控制"的局部问题 |
| 高效求解 | 通过逆向递推,可以一次性求出所有时间步的最优策略,无需迭代 |
直观类比:
从 A 点开车到 B 点,如何选择路线?
方法 1:枚举所有可能路线,比较总长度 → 计算量爆炸
方法 2:动态规划 —— 从终点往回推,每个路口选择"到终点最短"的方向 → 高效
在 LQR 中:
- 目标:找到控制序列 \(a_{0:T}\),使总代价最小
- 方法:从最后一步 \(T\) 往前推,每一步求解局部最优
- 结果:得到最优反馈策略 \(a_t^* = -K_t s_t\)
2. 什么是最优子结构?为什么 LQR 具有最优子结构?
最优子结构的定义
Bellman 最优性原理:最优策略具有这样的性质——无论初始状态和初始决策是什么,剩余的决策对于由第一个决策产生的状态而言,必须构成最优策略。
用数学语言表达:
$$ V(s) = \min_{a} \left[ h(s, a) + V(f(s, a)) \right] $$
其中:
- \(V(s)\):从状态 \(s\) 到终点的最小总代价(Value Function)
- \(h(s, a)\):当前步的即时代价
- \(f(s, a)\):状态转移函数
- \(V(f(s, a))\):从下一状态到终点的最小代价
为什么 LQR 具有最优子结构?
LQR 问题满足最优子结构的两个关键条件:
| 条件 | LQR 中的体现 |
|---|---|
| 无后效性 | 下一状态 \(s_{t+1}\) 只取决于当前状态 \(s_t\) 和控制 \(a_t\),与历史无关 |
| 代价可分解 | 总代价是各步代价之和:\(J = \sum (s_t^T Q_t s_t + a_t^T R_t a_t)\) |
直观理解:
时刻: 0 → 1 → 2 → ... → t → t+1 → ... → T
│ │ │
└─────────┴──────────────┘
未来决策只取决于当前状态 s_t
与之前如何到达 s_t 无关
这意味着:
- 在时刻 \(t\),只需要考虑"从 \(s_t\) 到终点"的最优策略
- 不需要关心"是如何到达 \(s_t\) 的"
- 因此可以从终点 \(T\) 开始,一步步往前推导最优策略
3. 什么是 Value Function?
Value Function 的定义
Value Function(值函数) \(V(s)\) 表示:
从状态 \(s\) 出发,使用最优策略到达终点所需的最小总代价。
$$ V(s) = \min_{a_{0:T}} J(s, a_{0:T}) $$
在 LQR 中,Value Function 具有二次形式:
$$ V_t(s) = s^T P_t s $$
其中 \(P_t\) 是对称矩阵,表示"从时刻 \(t\) 的状态 \(s\) 到终点的代价权重"。
Value Function 的物理意义
| 概念 | 说明 |
|---|---|
| 状态价值 | \(V(s)\) 越小,表示从 \(s\) 出发越"有利"(离目标越近) |
| 未来代价的封装 | \(V(s_t)\) 包含了"从 \(s_t\) 到终点"的所有未来代价 |
| 递推的关键 | 通过 \(V_{t+1}\) 可以推导 \(V_t\),实现逆向动态规划 |
Value Function 的递推关系
根据 Bellman 方程:
$$ V_t(s_t) = \min_{a_t} \left[ \underbrace{s_t^T Q_t s_t + a_t^T R_t a_t}{\text{即时代价}} + \underbrace{V{t+1}(s_{t+1})}_{\text{未来代价}} \right] $$
代入 \(s_{t+1} = A_t s_t + B_t a_t\) 和 \(V_{t+1}(s) = s^T P_{t+1} s\):
$$ V_t(s_t) = \min_{a_t} \left[ s_t^T Q_t s_t + a_t^T R_t a_t + (A_t s_t + B_t a_t)^T P_{t+1} (A_t s_t + B_t a_t) \right] $$
通过求导找到最优 \(a_t^*\),代回得到 \(V_t(s) = s^T P_t s\) 的递推公式(Riccati 方程)。
动态规划求解流程总结
逆向动态规划(Backward Pass)
初始化:P_T = Q_T (终点的 Value Function)
对 t = T-1, T-2, ..., 0:
1. 写出 V_t(s) = min [即时代价 + V_{t+1}(s_{t+1})]
2. 对 a_t 求导,得到最优控制 a_t^* = -K_t s_t
3. 代回 V_t,得到 P_t 的递推公式(Riccati 方程)
4. 存储 K_t 和 P_t
结果:
- 所有时间步的反馈增益 {K_0, K_1, ..., K_{T-1}}
- 所有时间步的 Value Function 矩阵 {P_0, P_1, ..., P_T}
正向执行(Forward Pass):
$$ \text{对每个 } t: \quad a_t = -K_t s_t $$
最后一步的推导
考虑最后一步(从 \(T-1\) 到 \(T\)):
$$ V _{T-1}(s _{T-1}) = \min _{a _{T-1}} \left[ s _{T-1}^T Q _{T-1} s _{T-1} + a _{T-1}^T R _{T-1} a _{T-1} + V _T(s _T) \right] $$
代入 \(s _T = A _{T-1} s _{T-1} + B _{T-1} a _{T-1}\) 和 \(V _T(s _T) = s _T^T P _T s _T\):
$$ V _{T-1}(s _{T-1}) = \min _{a _{T-1}} \left[ s _{T-1}^T Q _{T-1} s _{T-1} + a _{T-1}^T R _{T-1} a _{T-1} + (A _{T-1} s _{T-1} + B _{T-1} a _{T-1})^T P _T (A _{T-1} s _{T-1} + B _{T-1} a _{T-1}) \right] $$
求解最优控制
对 \(a _{T-1}\) 求导并令导数为零:
$$ \frac{\partial V _{T-1}}{\partial a _{T-1}} = 2 R _{T-1} a _{T-1} + 2 B _{T-1}^T P _T (A _{T-1} s _{T-1} + B _{T-1} a _{T-1}) = 0 $$
整理得:
$$ (R _{T-1} + B _{T-1}^T P _T B _{T-1}) a _{T-1} = -B _{T-1}^T P _T A _{T-1} s _{T-1} $$
解得最优控制:
$$ a _{T-1}^* = -(R _{T-1} + B _{T-1}^T P _T B _{T-1})^{-1} B _{T-1}^T P _T A _{T-1} s _{T-1} $$
最优控制律的一般形式
$$ a _t^* = -K _t s _t $$
其中反馈增益矩阵 \(K _t\) 为:
$$ K _t = (R _t + B _t^T P _{t+1} B _t)^{-1} B _t^T P _{t+1} A _t $$
✅ 结论:最优策略是当前状态的线性函数,\(K\) 是线性反馈系数。
求解 Value Function
将最优控制 \(a _t^* = -K _t s _t\) 代回 Value Function:
$$ V _{t}(s _t) = s _t^T (Q _t + K _t^T R _t K _t + (A _t - B _t K _t)^T P _{t+1} (A _t - B _t K _t)) s _t $$
因此:
$$ P _t = Q _t + K _t^T R _t K _t + (A _t - B _t K _t)^T P _{t+1} (A _t - B _t K _t) $$
或者展开为更常见的形式(离散代数 Riccati 方程):
$$ P _t = Q _t + A _t^T P _{t+1} A _t - A _t^T P _{t+1} B _t (R _t + B _t^T P _{t+1} B _t)^{-1} B _t^T P _{t+1} A _t $$
✅ \(V(s _{T-1})\) 和 \(V(s _T)\) 的形式基本一致,只是 \(P\) 的表示不同。
逆向递推算法
从终点往起点递推计算 \(P _t\) 和 \(K _t\):
| 步骤 | 计算 |
|---|---|
| 初始化 | \(P _T = Q _T\)(终端代价) |
| 对 \(t = T-1, T-2, \dots, 0\) | |
| 1. 计算反馈增益 | \(K _t = (R _t + B _t^T P _{t+1} B _t)^{-1} B _t^T P _{t+1} A _t\) |
| 2. 更新 P 矩阵 | \(P _t = Q _t + K _t^T R _t K _t + (A _t - B _t K _t)^T P _{t+1} (A _t - B _t K _t)\) |
| 3. 存储 | \(K _t, P _t\) |
Solution 总结
- LQR is a special class of optimal control problems with
- Linear dynamic function
- Quadratic objective function
- Solution of LQR is a linear feedback policy
$$ a _t^* = -K _t s _t $$

离线计算:从 \(T\) 到 \(0\) 逆向递推,计算所有 \(K _t\)
在线执行:对每个时间步,应用 \(a _t = -K _t s _t\)
更复杂的情况
如何处理非线性问题?
- How to deal with
- Nonlinear dynamic function?
- Non-quadratic objective function?
✅ 人体运动涉及到角度旋转,因此是非线性的。
解决方案:
| 方法 | 核心思想 |
|---|---|
| iLQR | 迭代线性化 + LQR 求解 |
| DDP | 二阶泰勒展开 + 动态规划 |
| CMA-ES | 无导数优化(不需要线性化) |
这些方法将在后续章节介绍。
本文出自 CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/GAMES105_mdbook/