P72
Sampling-based Policy Optimization
✅ 基于采样的方法。
-
Iterative methods
Goal: find the optimal policy \(\pi (s;\theta )\) that minimize the objective \(J(\theta )=\sum_{t=0}^{}h(s_t,a_t) \)- Initialize policy parmeters \(\pi (x;\theta )\)
- Repeat:
- Propose a set of candidate parameters {\(\theta _i \)} according to \(\theta \)
- Simulate the agent under the control of each \( \pi ( \theta _i)\)
- Evaluate the objective function \( J (\theta_i )\) on the simulated state-action sequences
- Update the estimation of \(\theta \) based on {\( J (\theta_i )\)}
-
Example: CMA-ES 把 \( \theta\) 建模为高斯分布,每次更新高斯分布的均值和方差。
P73
Example: Locomotion Controller with Linear Policy
🔎 [Liu et al. 2012 – Terrain Runner]
P74
Stage 1a: Open-loop Policy
Find open-loop control using SAMCON
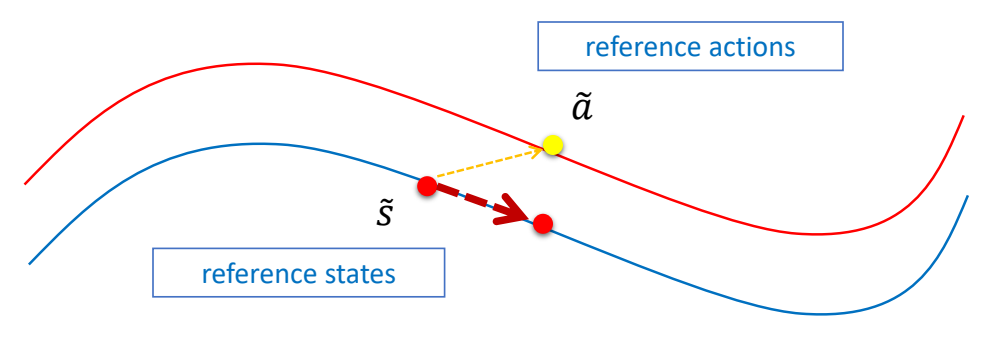
✅ 使用开环轨迹优化得到开环控制轨迹。
P76
Stage 1b: Linear Feedback Policy
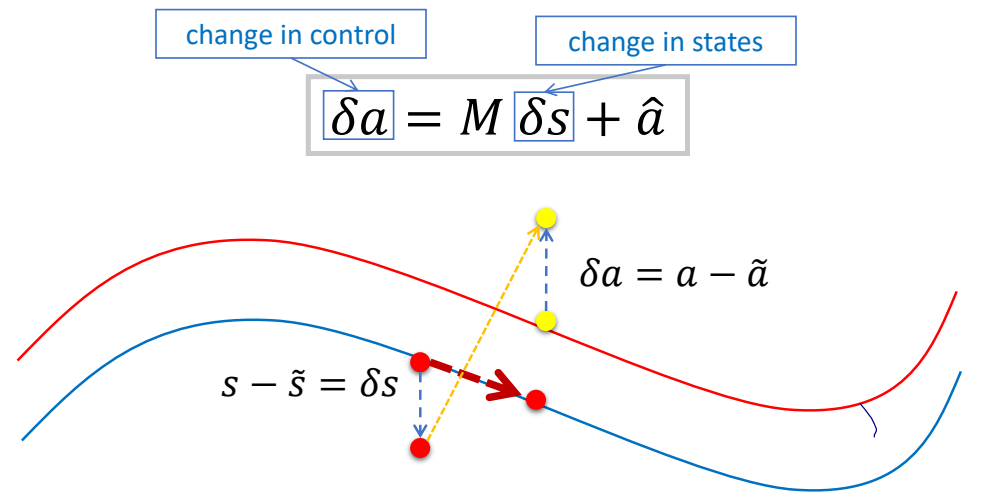
✅ 使用反馈控制更新控制信号。由于假设了线性关系,根据偏离 offset 可直接得到调整 offset.
P78
Stage 1b: Reduced-order Closed-loop Policy
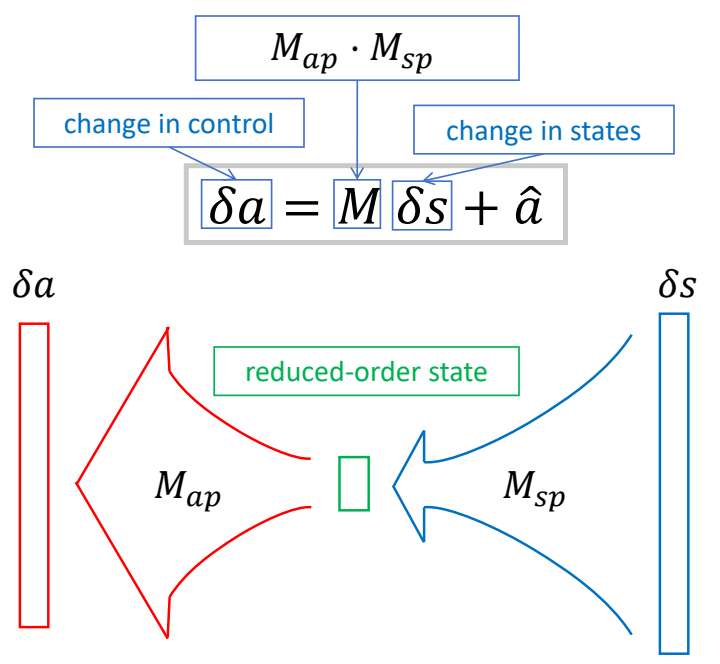
✅ 把 \(M\) 分解为两个矩阵,\(M_{AXB} = M_{AXC}\cdot M_{CXB}\) 如果 \(C\) 比较小,可以明显减少矩阵的参数量。
✅ 好处:(1) 减少参数,减化优化过程。(2) 抹掉状态里不需要的信息。
P79
一些工程上的 trick
Manually-selected States: s
- Running: 12 dimensions
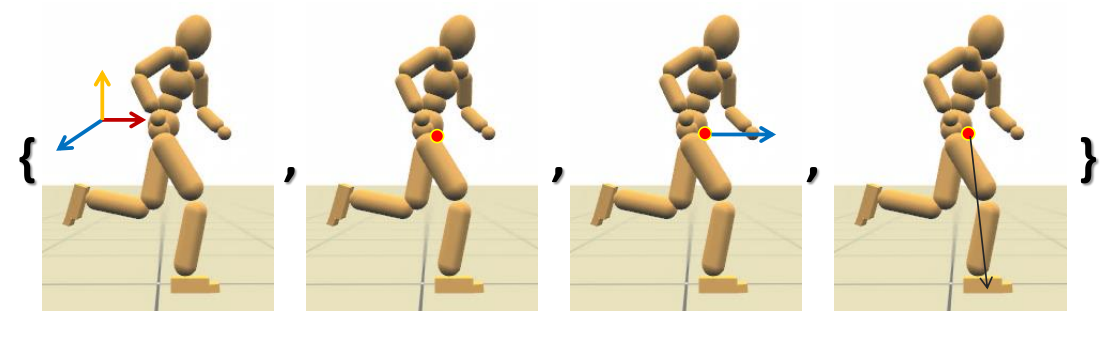
✅ (1)根结点旋转(2)质心位置(3)质心速度(4)支撑脚位置
P80
Manually-selected Controls: a
- for all skills: 9 dimensions
✅ 仅对少数关节加反馈。
P81
Optimization
$$ \delta a=M\delta s+\hat{a} $$
- Optimize \(M\)
- CMA, Covariance Matrix Adaption ([Hansen 2006])
- For the running task:
- #optimization variables: \(12 ^\ast 9 = 108 / (12^\ast 3+3 ^\ast 9) = 63\)
- 12 minutes on 24 cores
本文出自CaterpillarStudyGroup,转载请注明出处。
https://caterpillarstudygroup.github.io/GAMES105_mdbook/